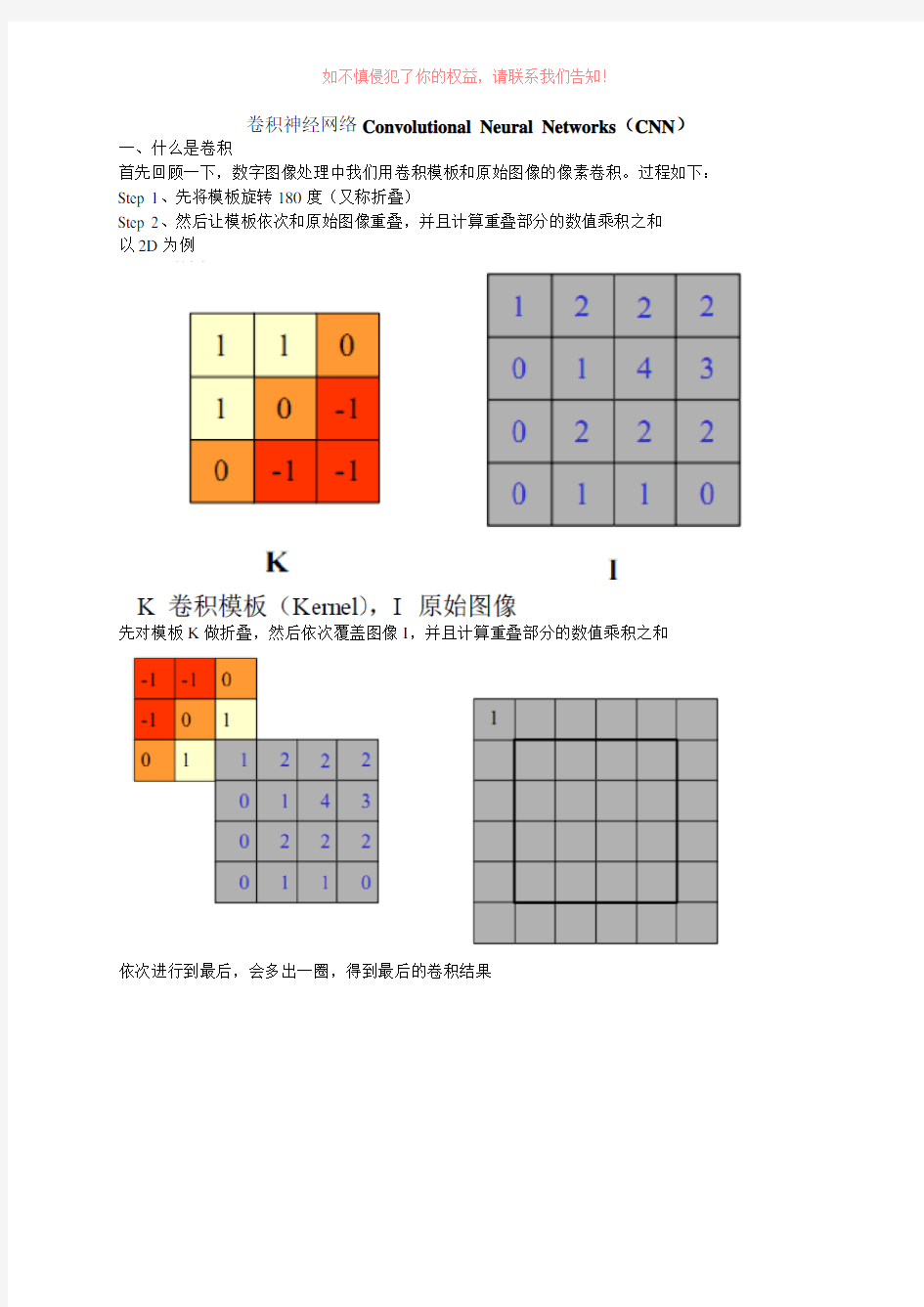

卷积神经网络Convolutional Neural Networks(CNN)一、什么是卷积
首先回顾一下,数字图像处理中我们用卷积模板和原始图像的像素卷积。过程如下:Step 1、先将模板旋转180度(又称折叠)
Step 2、然后让模板依次和原始图像重叠,并且计算重叠部分的数值乘积之和
以2D为例
先对模板K做折叠,然后依次覆盖图像I,并且计算重叠部分的数值乘积之和
依次进行到最后,会多出一圈,得到最后的卷积结果
卷积的意义(图像处理而言);对图像使用不同的卷积模板,对图像做不同的处理。比如平滑模板可以使图像模糊,并且可以减少噪声、锐化模板可以使图像的轮廓变得清晰。
二、卷积网络的结构
2.1 从BP网络到卷积网络
回想一下BP神经网络。BP网络每一层节点是一个线性的一维排列状态,层与层的网络节点之间是全连接的。这样设想一下,如果BP网络中层与层之间的节点连接不再是全连接,而是局部连接的。这样,就是一种最简单的一维卷积网络。如果我们把上述这个思路扩展到二维,这就是我们在大多数参考资料上看到的卷积神经网络。具体参看下图:
图1:全连接的2D 网络(BP网络)图2:局部连接的2D网络(卷积网络)
现在我们考虑单隐层结构,
上图左:全连接网络。如果我们有1000x1000像素的图像,有1百万个隐层神经元,每个隐层神经元都连接图像的每一个像素点,就有1000x1000x1000000=10^12个连接,也就是10^12个权值参数。上图右:局部连接网络,每一个节点与上层节点同位置附近10x10的窗口相连接,则1百万个隐层神经元就只有100w乘以100,即10^8个参数。其权值连接个数比原来减少了四个数量级。
因此,卷积网络降低了网络模型的复杂度,减少了权值的数量。该优点在网络的输入是多维图像时表现的更为明显,使图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程。
2.2 卷积网络的结构
卷积神经网络是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。卷积神经网络中的每一个特征提取层(C-层)都紧跟着一个用来求局部平均与二次提取的下采样层(S-层),这种特有的两次特征提取结构使网络在识别时对输入样本有较高的畸变容忍能力。
图3 经典的卷积神经网络结构图
原始图像的大小决定了输入向量的尺寸,隐层由C-层(特征提取层)和S-层(下采样层)组成,每层均包含多个平面。C1层神经元提取图像的局部特征,因此每个神经元都与前一层的局部感受野(也就是局部输入窗口)相连。C1层中各平面(由神经元构成)提取图像中不同的局部特征,如边缘特征,上下左右方向特征等,C1层中的输入是有由上一层局部窗口的数值和连接的权值的加权和(也就是卷积,后面会具体解释为什么是卷积),然后通过一个激活函数(如sigmoid 函数,反正切函数)得到C1层的输出,接下来S2层是下采样层,简单来书,由4个点下采样为1个点,也就是4个数的加权平均。换句话说,就是我们把2*2的像素缩小成为一个像素,某种意义上来说可以认识是图像处理中的模糊。然后按照这个C—S的结构继续构成隐层,当然这些隐层的连接都是局部相连的。同时有人会问了,例如S2和C3层具体要怎么连接呢,为什么会从6张变成16张特征图呢。C3层的特征图是由S2层图像的感受野和对应权值的卷积后,通过随机的组合而形成的,也就意味着S2层和C3层并不像C1层和S2层那样是一一对应的。但当我们感受野的大小和图像一样时,我们经过特征提取后就变成一个像素了,这里我们开始使用全连接(这样才能完整的把特征保留)。
2.3 为什么给这种局部连接命名为卷积网络
卷积网络第一个特点是连接权值远远小于BP网络的权值。卷积神经网络另外一个特性是权值共享。这样一来就更进一步减少了对网络权值的训练(毕竟权值是共享的,也就意味着有一些全是是相同的)。权值共享是指同一平面层的神经元权值相同。如何理解呢!看下图2,假设红色的点和黑色的点是C1层第一个特征图的2个不同神经元,感受窗口的大小是5*5的(意味着有25个连接),这2个神经元连接的权值是共享的(相同的)。这样一来,C1层中的每个神经元的输入值,都有由原始图像和这个相同的连接权值的加权和构成的,想想看,这个过程是不是和卷积的过程很像呢!没错,就是由这个得名的。同时这样一来,我们需要训练的权值就更少了,因为有很多都是相同的。
还没理解的话,接着看
C1层是一个卷积层(也就是上面说的特征提取层),由6个特征图Feature Map构成。特征图中每个神经元与输入中5*5的邻域相连。特征图的大小为28*28。C1层有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias[偏置]参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。
S2层是一个下采样层,有6个14*14的特征图。特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有12个可训练参数和5880个连接。
三、卷积网络的训练
我们想想卷积网络到底有什么那些参数需要训练呢。第一、卷积层中的卷积模板的权值。第二、下采样层的2个参数(每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置),第三、学习特征的组合(例如S2到C3的组合方式)
3.1 我们先回顾一下BP的反向传播算法
3.1.1、Feedforward Pass前向传播
在下面的推导中,我们采用平方误差代价函数。我们讨论的是多类问题,共c类,共N个训练样本。
这里表示第n个样本对应的标签的第k维。表示第n个样本对应的网络输出的第k个输出。对于多类问题,输出一般组织为“one-of-c”的形式,也就是只有该输入对应的类的输出节点输出为正,其他类的位或者节点为0或者负数,这个取决于你输出层的激活函数。sigmoid就是0,tanh 就是-1.
因为在全部训练集上的误差只是每个训练样本的误差的总和,所以这里我们先考虑对于一个样本的BP。对于第n个样本的误差,表示为:
传统的全连接神经网络中,我们需要根据BP规则计算代价函数E关于网络每一个权值的偏导数。我们用l来表示当前层,那么当前层的输出可以表示为:
输出激活函数f(.)可以有很多种,一般是sigmoid函数或者双曲线正切函数。sigmoid将输出压缩到[0, 1],所以最后的输出平均值一般趋于0 。所以如果将我们的训练数据归一化为零均值和方差
为1,可以在梯度下降的过程中增加收敛性。对于归一化的数据集来说,双曲线正切函数也是不错的选择。
3.1.2、Backpropagation Pass反向传播
反向传播回来的误差可以看做是每个神经元的基的灵敏度sensitivities(灵敏度的意思就是我们的基b变化多少,误差会变化多少,也就是误差对基的变化率,也就是导数了),定义如下:(第二个等号是根据求导的链式法则得到的)
因为?u/?b=1,所以?E/?b=?E/?u=δ,也就是说bias基的灵敏度?E/?b=δ和误差E对一个节点全部输入u的导数?E/?u是相等的。这个导数就是让高层误差反向传播到底层的神来之笔。反向传播就是用下面这条关系式:(下面这条式子表达的就是第l层的灵敏度,就是)
公式(1)
这里的“?”表示每个元素相乘。输出层的神经元的灵敏度是不一样的:
最后,对每个神经元运用delta(即δ)规则进行权值更新。具体来说就是,对一个给定的神经元,得到它的输入,然后用这个神经元的delta(即δ)来进行缩放。用向量的形式表述就是,对于第l层,误差对于该层每一个权值(组合为矩阵)的导数是该层的输入(等于上一层的输出)与该层的灵敏度(该层每个神经元的δ组合成一个向量的形式)的叉乘。然后得到的偏导数乘以一个负学习率就是该层的神经元的权值的更新了:
公式(2)
对于bias基的更新表达式差不多。实际上,对于每一个权值(W)ij都有一个特定的学习率ηIj。
3.2 卷积神经网络
3.2.1、Convolution Layers 卷积层
我们现在关注网络中卷积层的BP更新。在一个卷积层,上一层的特征maps被一个可学习的卷积核进行卷积,然后通过一个激活函数,就可以得到输出特征map。每一个输出map可能是组合卷积多个输入maps的值:
这里M j表示选择的输入maps的集合,那么到底选择哪些输入maps呢?有选择一对的或者三个的。但下面我们会讨论如何去自动选择需要组合的特征maps。每一个输出map会给一个额外的偏置b,但是对于一个特定的输出map,卷积每个输入maps的卷积核是不一样的。也就是说,如果输出特征map j和输出特征map k都是从输入map i中卷积求和得到,那么对应的卷积核是不一样的。Computing the Gradients梯度计算
我们假定每个卷积层l都会接一个下采样层l+1 。对于BP来说,根据上文我们知道,要想求得层l的每个神经元对应的权值的权值更新,就需要先求层l的每一个神经节点的灵敏度δ(也就是权值更新的公式(2))。为了求这个灵敏度我们就需要先对下一层的节点(连接到当前层l的感兴趣节点的第l+1层的节点)的灵敏度求和(得到δl+1),然后乘以这些连接对应的权值(连接第l层感兴趣节点和第l+1层节点的权值)W。再乘以当前层l的该神经元节点的输入u的激活函数f的导数值(也就是那个灵敏度反向传播的公式(1)的δl的求解),这样就可以得到当前层l每个神经节点对应的灵敏度δl了。
然而,因为下采样的存在,采样层的一个像素(神经元节点)对应的灵敏度δ对应于卷积层(上一层)的输出map的一块像素(采样窗口大小)。因此,层l中的一个map的每个节点只与l+1层中相应map的一个节点连接。
为了有效计算层l的灵敏度,我们需要上采样upsample 这个下采样downsample层对应的灵敏度map(特征map中每个像素对应一个灵敏度,所以也组成一个map),这样才使得这个灵敏度map 大小与卷积层的map大小一致,然后再将层l的map的激活值的偏导数与从第l+1层的上采样得到的灵敏度map逐元素相乘(也就是公式(1))。
在下采样层map的权值都取一个相同值β,而且是一个常数。所以我们只需要将上一个步骤得到的结果乘以一个β就可以完成第l层灵敏度δ的计算。
我们可以对卷积层中每一个特征map j重复相同的计算过程。但很明显需要匹配相应的子采样层的map(参考公式(1)):
up(.)表示一个上采样操作。如果下采样的采样因子是n的话,它简单的将每个像素水平和垂直方向上拷贝n次。这样就可以恢复原来的大小了。实际上,这个函数可以用Kronecker乘积来实现:
好,到这里,对于一个给定的map,我们就可以计算得到其灵敏度map了。然后我们就可以通过简单的对层l中的灵敏度map中所有节点进行求和快速的计算bias基的梯度了:
公式(3)
最后,对卷积核的权值的梯度就可以用BP算法来计算了(公式(2))。另外,很多连接的权值是共享的,因此,对于一个给定的权值,我们需要对所有与该权值有联系(权值共享的连接)的连接对该点求梯度,然后对这些梯度进行求和,就像上面对bias基的梯度计算一样:
一、简介 卷积神经网络(Convolutional Neural Networks,简称CNN)是近年发展起来,并引起广泛重视的一种高效的识别方法。 1962年,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的局部互连网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络[1](Convolutional Neural Networks-简称CNN)7863。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。 Fukushima在1980年基于神经元间的局部连通性和图像的层次组织转换,为解决模式识别问题,提出的新识别机(Neocognitron)是卷积神经网络的第一个实现网络[2]。他指出,当在不同位置应用具有相同参数的神经元作为前一层的patches时,能够实现平移不变性1296。随着1986年BP算法以及T-C问题[3](即权值共享和池化)9508的提出,LeCun和其合作者遵循这一想法,使用误差梯度(the error gradient)设计和训练卷积神经网络,在一些模式识别任务中获得了最先进的性能[4][5]。在1998年,他们建立了一个多层人工神经网络,被称为LeNet-5[5],用于手写数字分类,这是第一个正式的卷积神经网络模型3579。类似于一般的神经网络,LeNet-5有多层,利用BP算法来训练参数。它可以获得原始图像的有效表示,使得直接从原始像素(几乎不经过预处理)中识别视觉模式成为可能。然而,由于当时大型训练数据和计算能力的缺乏,使得LeNet-5在面对更复杂的问题时,如大规模图像和视频分类,不能表现出良好的性能。 因此,在接下来近十年的时间里,卷积神经网络的相关研究趋于停滞,原因有两个:一是研究人员意识到多层神经网络在进行BP训练时的计算量极其之大,当时的硬件计算能力完全不可能实现;二是包括SVM在内的浅层机器学习算法也渐渐开始暂露头脚。直到2006年,Hinton终于一鸣惊人,在《科学》上发表文章,使得CNN再度觉醒,并取得长足发展。随后,更多的科研工作者对该网络进行了改进。其中,值得注意的是Krizhevsky等人提出的一个经典的CNN架构,相对于图像分类任务之前的方法,在性能方面表现出了显著的改善2674。他们方法的整体架构,即AlexNet[9](也叫ImageNet),与LeNet-5相似,但具有更深的结构。它包括8个学习层(5个卷积与池化层和3个全连接层),前边的几层划分到2个GPU上,(和ImageNet是同一个)并且它在卷积层使用ReLU作为非线性激活函数,在全连接层使用Dropout减少过拟合。该深度网络在ImageNet 大赛上夺冠,进一步掀起了CNN学习热潮。 一般地,CNN包括两种基本的计算,其一为特征提取,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。这两种操作形成了CNN的卷积层。此外,卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,即池化层,这种特有的两次特征提取结构减小了特征分辨率。
一文读懂卷积神经网络 自今年七月份以来,一直在实验室负责卷积神经网络(Convolutional Neural Network,CNN),期间配置和使用过theano和cuda-convnet、 cuda-convnet2。为了增进CNN的理解和使用,特写此博文,以其与人交流,互有增益。正文之前,先说几点自己对于CNN的感触。先明确一点就是,Deep Learning是全部深度学习算法的总称,CNN是深度学习算法在图像处理领域的一个应用。 第一点,在学习Deep learning和CNN之前,总以为它们是很了不得的知识,总以为它们能解决很多问题,学习了之后,才知道它们不过与其他机器学习算法如svm等相似,仍然可以把它当做一个分类器,仍然可以像使用一个黑盒子那样使用它。 第二点,Deep Learning强大的地方就是可以利用网络中间某一层的输出当做是数据的另一种表达,从而可以将其认为是经过网络学习到的特征。基于该特征,可以进行进一步的相似度比较等。 第三点,Deep Learning算法能够有效的关键其实是大规模的数据,这一点原因在于每个DL都有众多的参数,少量数据无法将参数训练充分。 接下来话不多说,直接奔入主题开始CNN之旅。 卷积神经网络简介(Convolutional Neural Networks,简称CNN) 卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。 一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个
一文读懂卷积神经网络CNN ★据说阿尔法狗战胜李世乭靠的是卷积神经网络算法,所以小编找到了一篇介绍该算法的文章,大家可以看一看。★ 自去年七月份以来,一直在实验室负责卷积神经网络(Convolutional Neural Network,CNN),期间配置和使用过theano和cuda-convnet、cuda-convnet2。为了增进CNN的理解和使用,特写此博文,以其与人交流,互有增益。正文之前,先说几点自己对于CNN的感触。先明确一点就是,Deep Learning是全部深度学习算法的总称,CNN是深度学习算法在图像处理领域的一个应用。第一点,在学习Deep learning 和CNN之前,总以为它们是很了不得的知识,总以为它们能解决很多问题,学习了之后,才知道它们不过与其他机器学习算法如svm等相似,仍然可以把它当做一个分类器,仍然可以像使用一个黑盒子那样使用它。第二点,Deep Learning强大的地方就是可以利用网络中间某一层的输出当做是数据的另一种表达,从而可以将其认为是经过网络学习到的特征。基于该特征,可以进行进一步的相似度比较等。第三点,Deep Learning算法能够有效的关键其实是大规模的数据,这一点原因在于每个DL都有众多的参数,少量数据无法将参数训练充分。接下来话不多说,直接奔入主题开始
CNN之旅。卷积神经网络简介(Convolutional Neural Networks,简称CNN)卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。20世纪60年代,Hubel 和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网 络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。K.Fukushima在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid 函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少
deepLearnToolbox-master是一个深度学习matlab包,里面含有很多机器学习算法,如卷积神经网络CNN,深度信念网络DBN,自动编码AutoEncoder(堆栈SAE,卷积CAE)的作者是Rasmus Berg Palm)代码下载:rasmusbergpalm/DeepLearnToolbox 这里我们介绍deepLearnToolbox-master中的CNN部分。 DeepLearnToolbox-master中CNN内的函数: 调用关系为: 该模型使用了mnist的数字作为训练样本,作为cnn的一个使用样例, 每个样本特征为一个28*28=的向量。 网络结构为: 让我们来看看各个函数: 一、Test_example_CNN: (1) 三、 (2) 四、 (2) 五、 (2) 五、 (2) 六、 (3) 一、Test_example_CNN: Test_example_CNN: 1设置CNN的基本参数规格,如卷积、降采样层的数量,卷积核的大小、降采样的降幅 2cnnsetup函数初始化卷积核、偏置等
3cnntrain函数训练cnn,把训练数据分成batch,然后调用 cnnff完成训练的前向过程, cnnbp计算并传递神经网络的error,并计算梯度(权重的修改量) cnnapplygrads把计算出来的梯度加到原始模型上去 4cnntest函数,测试当前模型的准确率 该模型采用的数据为, 含有70000个手写数字样本其中60000作为训练样本,10000作为测试样本。 把数据转成相应的格式,并归一化。 设置网络结构及训练参数 初始化网络,对数据进行批训练,验证模型准确率 绘制均方误差曲线 二、 该函数你用于初始化CNN的参数。 设置各层的mapsize大小, 初始化卷积层的卷积核、bias 尾部单层感知机的参数设置 * bias统一设置为0 权重设置为:-1~1之间的随机数/sqrt(6/(输入神经元数量+输出神经元数量))
深度神经网络全面概述从基本概念到实际模型和硬件基础 深度神经网络(DNN)所代表的人工智能技术被认为是这一次技术变革的基石(之一)。近日,由 IEEE Fellow Joel Emer 领导的一个团队发布了一篇题为《深度神经网络的有效处理:教程和调研(Efficient Processing of Deep Neural Networks: A Tutorial and Survey)》的综述论文,从算法、模型、硬件和架构等多个角度对深度神经网络进行了较为全面的梳理和总结。鉴于该论文的篇幅较长,机器之心在此文中提炼了原论文的主干和部分重要内容。 目前,包括计算机视觉、语音识别和机器人在内的诸多人工智能应用已广泛使用了深度神经网络(deep neural networks,DNN)。DNN 在很多人工智能任务之中表现出了当前最佳的准确度,但同时也存在着计算复杂度高的问题。因此,那些能帮助 DNN 高效处理并提升效率和吞吐量,同时又无损于表现准确度或不会增加硬件成本的技术是在人工智能系统之中广泛部署 DNN 的关键。 论文地址: 本文旨在提供一个关于实现 DNN 的有效处理(efficient processing)的目标的最新进展的全面性教程和调查。特别地,本文还给出了一个 DNN 综述——讨论了支持 DNN 的多种平台和架构,并强调了最新的有效处理的技术的关键趋势,这些技术或者只是通过改善硬件设计或者同时改善硬件设计和网络算法以降低 DNN 计算成本。本文也会对帮助研究者和从业者快速上手 DNN 设计的开发资源做一个总结,并凸显重要的基准指标和设计考量以评估数量快速增长的 DNN 硬件设计,还包括学界和产业界共同推荐的算法联合设计。 读者将从本文中了解到以下概念:理解 DNN 的关键设计考量;通过基准和对比指标评估不同的 DNN 硬件实现;理解不同架构和平台之间的权衡;评估不同 DNN 有效处理技术的设计有效性;理解最新的实现趋势和机遇。 一、导语 深度神经网络(DNN)目前是许多人工智能应用的基础 [1]。由于 DNN 在语音识别 [2] 和图像识别 [3] 上的突破性应用,使用DNN 的应用量有了爆炸性的增长。这些 DNN 被部署到了从自动驾驶汽车 [4]、癌症检测 [5] 到复杂游戏 [6] 等各种应用中。在这许多领域中,DNN 能够超越人类的准确率。而 DNN 的出众表现源于它能使用统计学习方法从原始感官数据中提取高层特征,在大量的数据中获得输入空间的有效表征。这与之前使用手动提取特征或专家设计规则的方法不同。 然而 DNN 获得出众准确率的代价是高计算复杂性成本。虽然通用计算引擎(尤其是 GPU),已经成为许多 DNN 处理的砥柱,但提供对 DNN 计算更专门化的加速方法也越来越热门。本文的目标是提供对 DNN、理解 DNN 行为的各种工具、有效加速计算的各项技术的概述。 该论文的结构如下: Section II 给出了 DNN 为什么很重要的背景、历史和应用。 Section III 给出了 DNN 基础组件的概述,还有目前流行使用的 DNN 模型。 Section IV 描述了 DNN 研发所能用到的各种资源。 Section V 描述了处理 DNN 用到的各种硬件平台,以及在不影响准确率的情况下改进吞吐量(thoughtput)和能量的各种优化方法(即产生 bit-wise identical 结果)。 Section VI 讨论了混合信号回路和新的存储技术如何被用于近数据处理(near-data processing),从而解决 DNN 中数据流通时面临的吞吐量和能量消耗难题。 Section VII 描述了各种用来改进 DNN 吞吐量和能耗的联合算法和硬件优化,同时最小化对准确率的影响。 Section VIII 描述了对比 DNN 设计时应该考虑的关键标准。
卷积神经网络全面解析之代码注释 自己平时看了一些论文,但老感觉看完过后就会慢慢的淡忘,某一天重新拾起来的时候又好像没有看过一样。所以想习惯地把一些感觉有用的论文中的知识点总结整理一下,一方面在整理过程中,自己的理解也会更深,另一方面也方便未来自己的勘察。更好的还可以放到博客上面与大家交流。因为基础有限,所以对论文的一些理解可能不太正确,还望大家不吝指正交流. 下面是自己对代码的注释: cnnexamples.m [plain]view plain copy 1.clear all; close all; clc; 2.addpath('../data'); 3.addpath('../util'); 4.load mnist_uint8; 5. 6.train_x = double(reshape(train_x',28,28,60000))/255; 7.test_x = double(reshape(test_x',28,28,10000))/255; 8.train_y = double(train_y'); 9.test_y = double(test_y'); 10. 11.%% ex1 12.%will run 1 epoch in about 200 second and get around 11% error. 13.%With 100 epochs you'll get around 1.2% error 14. 15.c https://www.doczj.com/doc/0115528077.html,yers = { 16. struct('type', 'i') %input layer 17. struct('type', 'c', 'outputmaps', 6, 'kernelsize', 5) %convol ution layer 18. struct('type', 's', 'scale', 2) %sub sampling layer
卷积神经网络全面解析之算法实现 前言 从理解卷积神经到实现它,前后花了一个月时间,现在也还有一些地方没有理解透彻,CNN还是有一定难度的,不是看哪个的博客和一两篇论文就明白了,主要还是靠自己去专研,阅读推荐列表在末尾的参考文献。目前实现的CNN在MINIT数据集上效果还不错,但是还有一些bug,因为最近比较忙,先把之前做的总结一下,以后再继续优化。 卷积神经网络CNN是Deep Learning的一个重要算法,在很多应用上表现出卓越的效果,[1]中对比多重算法在文档字符识别的效果,结论是CNN优于其他所有的算法。CNN 在手写体识别取得最好的效果,[2]将CNN应用在基于人脸的性别识别,效果也非常不错。前段时间我用BP神经网络对手机拍照图片的数字进行识别,效果还算不错,接近98%,但在汉字识别上表现不佳,于是想试试卷积神经网络。 1、CNN的整体网络结构 卷积神经网络是在BP神经网络的改进,与BP类似,都采用了前向传播计算输出值,反向传播调整权重和偏置;CNN与标准的BP最大的不同是:CNN中相邻层之间的神经单元并不是全连接,而是部分连接,也就是某个神经单元的感知区域来自于上层的部分神经单元,而不是像BP那样与所有的神经单元相连接。CNN的有三个重要的思想架构: ?局部区域感知 ?权重共享 ?空间或时间上的采样 局部区域感知能够发现数据的一些局部特征,比如图片上的一个角,一段弧,这些基本特征是构成动物视觉的基础[3];而BP中,所有的像素点是一堆混乱的点,相互之间的关系没有被挖掘。 CNN中每一层的由多个map组成,每个map由多个神经单元组成,同一个map的所有神经单元共用一个卷积核(即权重),卷积核往往代表一个特征,比如某个卷积和代表一段弧,那么把这个卷积核在整个图片上滚一下,卷积值较大的区域就很有可能是一段弧。注意卷积核其实就是权重,我们并不需要单独去计算一个卷积,而是一个固定大小的权重矩阵去图像上匹配时,这个操作与卷积类似,因此我们称为卷积神经网络,实际上,BP也可以看做一种特殊的卷积神经网络,只是这个卷积核就是某层的所有权重,即感知区域是整个图像。权重共享策略减少了需要训练的参数,使得训练出来的模型的泛华能力更强。 采样的目的主要是混淆特征的具体位置,因为某个特征找出来后,它的具体位置已经不重要了,我们只需要这个特征与其他的相对位置,比如一个“8”,当我们得到了上面一个"o"时,我们不需要知道它在图像的具体位置,只需要知道它下面又是一个“o”我们就可以知道是一个'8'了,因为图片中"8"在图片中偏左或者偏右都不影响我们认识它,这种混淆具体位置的策略能对变形和扭曲的图片进行识别。 CNN的这三个特点是其对输入数据在空间(主要针对图像数据)上和时间(主要针对时间序列数据,参考TDNN)上的扭曲有很强的鲁棒性。CNN一般采用卷积层与采样层交
卷积神经网络全面解析之代码详解 本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Convolutional Neural Networks (LeNet)。 一、CNN卷积神经网络原理简介 要讲明白卷积神经网络,估计得长篇大论,网上有很多博文已经写得很好了,所以本文就不重复了,如果你了解CNN,那可以往下看,本文主要是详细地解读CNN的实现代码。 CNN的最大特点就是稀疏连接(局部感受)和权值共享,如下面两图所示,左为稀疏连接,右为权值共享。稀疏连接和权值共享可以减少所要训练的参数,减少计算复杂度。 至于CNN的结构,以经典的LeNet5来说明:
这个图真是无处不在,一谈CNN,必说LeNet5,这图来自于这篇论文:Gradient-Based Learning Applied to Document Recognition,论文很长,第7页那里开始讲LeNet5这个结构,建议看看那部分。 我这里简单说一下,LeNet5这张图从左到右,先是input,这是输入层,即输入的图片。input-layer到C1这部分就是一个卷积层(convolution 运算),C1到S2是一个子采样层(pooling运算),关于卷积和子采样的具体过程可以参考下图: 然后,S2到C3又是卷积,C3到S4又是子采样,可以发现,卷积和子采样都是成对出现的,卷积后面一般跟着子采样。S4到C5之间是全连接的,这就相当于一个MLP的隐含层了(如果你不清楚MLP,参考《DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解》)。C5到F6同样是全连接,也是相当于一个MLP的隐含层。最后从F6到输出output,其实就是一个分类器,这一层就叫分类层。 ok,CNN的基本结构大概就是这样,由输入、卷积层、子采样层、全连接层、分类层、输出这些基本“构件”组成,一般根据具体的应用或者
1 卷积神经网络 卷积神经网络是深度学习的一种,已成为当前图像理解领域的研究热点它的权值共享网络结构使之更类似于生物神经网络,降低了网络模型的复杂度,减少了权值的数量。这个优点在网络的输入是多维图像时表现得更为明显, 图像可以直接作为网络的输入,避免了传统识别算法中复杂的特征提取和数据重建过程. 卷积网络是为识别二维形状而特殊设计的一个多层感知器,这种网络结构对平移、比例缩放以及其他形式的变形具有一定不变性. 在典型的CNN 中,开始几层通常是卷积层和下采样层的交替, 在靠近输出层的最后几层网络通常是全连接网络。卷积神经网络的训练过程主要是学习卷积层的卷积核参数和层间连接权重等网络参数, 预测过程主要是基于输入图像和网络参数计算类别标签。卷积神经网络的关键是:网络结构(含卷积层、下采样层、全连接层等) 和反向传播算法等。在本节中, 我们先介绍典型CNN 的网络结构和反向传播算法, 然后概述常用的其他CNN 网络结构和方法。神经网络参数的中文名称主要参考文献 [18] 卷积神经网络的结构和反向传播算法主要参考文献[17] 。 网络结构 卷积层 在卷积层, 上一层的特征图(Feature map) 被一个可学习的卷积核进行卷积, 然后通过一个激活函数(Activation function), 就可以得到输出特征图. 每个输出特征图可以组 合卷积多个特征图的值[17] : ()l l j j x f u = 1j l l l l j j ij j i M u x k b -∈= *+∑ 其中, l j u 称为卷积层l 的第j 个通道的净激活(Netactivation), 它通过对前一层输出 特征图1l j x -进行卷积求和与偏置后得到的, l j x 是卷积层l 的第j 个通道的输出。()f 称为激活函数, 通常可使用sigmoid 和tanh 等函数。j M 表示用于计算l j u 的输入特征图子集, l ij k 是卷积核矩阵, l j b 是对卷积后特征图的偏置。对于一个输出特征图l j x ,每个输入特征图1l j x -对应的卷积核l ij k 可能不同,“*”是卷积符号。 ; 下采样层 下采样层将每个输入特征图通过下面的公式下采样输出特征图[17]: ()l l j j x f u = 1()l l l l j j j j u down x b β-=+ 其中, l j u 称为下采样层l 的第j 通道的净激活, 它由前一层输出特征图1 l j x -进行下采样
卷积神经网络全面解析(2) 一、介绍 这个文档讨论的是CNNs的推导和实现。CNN架构的连接比权值要多很多,这实际上就隐含着实现了某种形式的规则化。这种特别的网络假定了我们希望通过数据驱动的方式学习到一些滤波器,作为提取输入的特征的一种方法。 本文中,我们先对训练全连接网络的经典BP算法做一个描述,然后推导2D CNN网络的卷积层和子采样层的BP权值更新方法。在推导过程中,我们更强调实现的效率,所以会给出一些Matlab代码。最后,我们转向讨论如何自动地学习组合前一层的特征maps,特别地,我们还学习特征maps的稀疏组合。 二、全连接的反向传播算法 典型的CNN中,开始几层都是卷积和下采样的交替,然后在最后一些层(靠近输出层的),都是全连接的一维网络。这时候我们已经将所有两维2D的特征maps转化为全连接的一维网络的输入。这样,当你准备好将最终的2D特征maps输入到1D网络中时,一个非常方便的方法就是把所有输出的特征maps连接成一个长的输入向量。然后我们
回到BP算法的讨论。(更详细的基础推导可以参考UFLDL中“反向传导算法”)。 2.1、Feedforward Pass前向传播 在下面的推导中,我们采用平方误差代价函数。我们讨论的是多类问题,共c类,共N个训练样本。 这里表示第n个样本对应的标签的第k维。表示第n个样本对应的网络输出的第k个输出。对于多类问题,输出一般组织为“one-of-c”的形式,也就是只有该输入对应的类的输出节点输出为正,其他类的位或者节点为0或者负数,这个取决于你输出层的激活函数。sigmoid就是0,tanh就是-1. 因为在全部训练集上的误差只是每个训练样本的误差的总和,所以这里我们先考虑对于一个样本的BP。对于第n个样本的误差,表示为: 传统的全连接神经网络中,我们需要根据BP规则计算代价函数E 关于网络每一个权值的偏导数。我们用l来表示当前层,那么当前层的输出可以表示为:
卷积神经网络CNN代码解析 deepLearnToolbox-master是一个深度学习matlab包,里面含有很多机器学习算法,如卷积神经网络CNN,深度信念网络DBN,自动编码AutoEncoder(堆栈SAE,卷积CAE)的作者是Rasmus Berg Palm (rasmusbergpalm@https://www.doczj.com/doc/0115528077.html,) 代码下载:https://https://www.doczj.com/doc/0115528077.html,/rasmusbergpalm/DeepLearnToolbox 这里我们介绍deepLearnToolbox-master中的CNN部分。 DeepLearnToolbox-master中CNN内的函数: 调用关系为: 该模型使用了mnist的数字mnist_uint8.mat作为训练样本,作为cnn的一个使用样例, 每个样本特征为一个28*28=的向量。
网络结构为: 让我们来看看各个函数: 一、Test_example_CNN: (2) 三、cnntrain.m (5) 四、cnnff.m (6) 五、cnnbp.m (7) 五、cnnapplygrads.m (10) 六、cnntest.m (11) 一、Test_example_CNN: Test_example_CNN: 1设置CNN的基本参数规格,如卷积、降采样层的数量,卷积核的大小、降采样的降幅 2 cnnsetup函数初始化卷积核、偏置等 3 cnntrain函数训练cnn,把训练数据分成batch,然后调用 3.1 cnnff 完成训练的前向过程,
3.2 cnnbp计算并传递神经网络的error,并计算梯度(权重的修改量) 3.3 cnnapplygrads 把计算出来的梯度加到原始模型上去 4 cnntest 函数,测试当前模型的准确率 该模型采用的数据为mnist_uint8.mat, 含有70000个手写数字样本其中60000作为训练样本,10000作为测试样本。把数据转成相应的格式,并归一化。 设置网络结构及训练参数 初始化网络,对数据进行批训练,验证模型准确率 绘制均方误差曲线 二、Cnnsetup.m 该函数你用于初始化CNN的参数。 设置各层的mapsize大小, 初始化卷积层的卷积核、bias 尾部单层感知机的参数设置 * bias统一设置为0
深度学习(卷积神经网络)一些问题总结 涉及问题: 1.每个图如何卷积: (1)一个图如何变成几个? (2)卷积核如何选择? 2.节点之间如何连接? 3.S2-C3如何进行分配? 4.16-120全连接如何连接? 5.最后output输出什么形式? ①各个层解释: 我们先要明确一点:每个层有多个Feature Map,每个Feature Map通过一种卷积滤波器提取输入的一种特征,然后每个Feature Map有多个神经元。 C1层是一个卷积层(为什么是卷积?卷积运算一个重要的特点就是,通过卷积运算,可以使原信号特征增强,并且降低噪音),由6个特征图Feature Map构成。特征图中每个神经元与输入中5*5的邻域相连。特征图的大小为28*28,这样能防止输入的连接掉到边界
之外(是为了BP反馈时的计算,不致梯度损失,个人见解)。C1有156个可训练参数(每个滤波器5*5=25个unit参数和一个bias参数,一共6个滤波器,共(5*5+1)*6=156个参数),共156*(28*28)=122,304个连接。 S2层是一个下采样层(为什么是下采样?利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息),有6个14*14的特征图。特征图中的每个单元与C1中相对应特征图的2*2邻域相连接。S2层每个单元的4个输入相加,乘以一个可训练参数,再加上一个可训练偏置。结果通过sigmoid函数计算。可训练系数和偏置控制着sigmoid函数的非线性程度。如果系数比较小,那么运算近似于线性运算,亚采样相当于模糊图像。如果系数比较大,根据偏置的大小亚采样可以被看成是有噪声的“或”运算或者有噪声的“与”运算。每个单元的2*2感受野并不重叠,因此S2中每个特征图的大小是C1中特征图大小的1/4(行和列各1/2)。S2层有12个可训练参数和5880个连接。 图:卷积和子采样过程:卷积过程包括:用一个可训练的滤波器f x去卷积一个输入的图像(第一阶段是输入的图像,后面的阶段就是卷积特征map了),然后加一个偏置b x,得到卷积层C x。子采样过程包括:每邻域四个像素求和变为一个像素,然后通过标量W x+1加权,再增加偏置b x+1,然后通过一个sigmoid激活函数,产生一个大概缩小四倍的特征映射图 S x+1。 所以从一个平面到下一个平面的映射可以看作是作卷积运算,S-层可看作是模糊滤波器,起到二次特征提取的作用。隐层与隐层之间空间分辨率递减,而每层所含的平面数递增,这样可用于检测更多的特征信息。 C3层也是一个卷积层,它同样通过5x5的卷积核去卷积层S2,然后得到的特征map 就只有10x10个神经元,但是它有16种不同的卷积核,所以就存在16个特征map了。这里需要注意的一点是:C3中的每个特征map是连接到S2中的所有6个或者几个特征map的,表示本层的特征map是上一层提取到的特征map的不同组合(这个做法也并不是唯一的)。(看到没有,这里是组合,就像之前聊到的人的视觉系统一样,底层的结构构成上层更抽象的结构,例如边缘构成形状或者目标的部分)。
卷积神经网络全面解析之代码详解
卷积神经网络全面解析之代码详解 本文介绍多层感知机算法,特别是详细解读其代码实现,基于python theano,代码来自:Convolutional Neural Networks (LeNet)。 一、CNN卷积神经网络原理简介 要讲明白卷积神经网络,估计得长篇大论,网上有很多博文已经写得很好了,所以本文就不重复了,如果你了解CNN,那可以往下看,本文主要是详细地解读CNN的实现代码。 CNN的最大特点就是稀疏连接(局部感受)和权值共享,如下面两图所示,左为稀疏连接,右为权值共享。稀疏连接和权值共享可以减少所要训练的参数,减少计算复杂度。 至于CNN的结构,以经典的LeNet5来说明:
这个图真是无处不在,一谈CNN,必说LeNet5,这图来自于这篇论文:Gradient-Based Learning Applied to Document Recognition,论文很长,第7页那里开始讲LeNet5这个结构,建议看看那部分。 我这里简单说一下,LeNet5这张图从左到右,先是input,这是输入层,即输入的图片。input-layer到C1这部分就是一个卷积层(convolution运算),C1到S2是一个子采样层(pooling运算),关于卷积和子采样的具体过程可以参考下图: 然后,S2到C3又是卷积,C3到S4又是子采样,可以发现,卷积和子采样都是成对出现的,卷积后面一般跟着子采样。S4到C5之间是全连接的,这就相当于一个MLP的隐含层了(如果你不清楚MLP,参考《DeepLearning tutorial(3)MLP多层感知机原理简介+代码详解》)。C5到F6同样是全连接,也是相当于一个MLP的隐含层。最后从F6到输出output,其实就是一个分类器,这一层就叫分类层。ok,CNN的基本结构大概就是这样,由输入、卷积层、子采样层、全连接层、分类层、输出这些基本“构件”组成,一般根据具体的应用或
第一点,在学习Deep learning和CNN之前,总以为它们是很了不得的知识,总以为它们能解决很多问题,学习了之后,才知道它们不过与其他机器学习算法如SVM等相似,仍然可以把它当作一个分类器,仍然可以像使用一个黑盒子那样使用它。 第二点,Deep Learning强大的地方就是可以利用网络中间某一层的输出当作是数据的另一种表达,从而可以将其认为是经过网络学习到的特征。基于该特征,可以进行进一步的相似度比较等。 第三点,Deep Learning算法能够有效的关键其实是大规模的数据,这一点原因在于每个DL都有众多的参数,少量数据无法将参数训练充分。 接下来话不多说,直接奔入主题开始CNN之旅。 卷积神经网络简介(Convolutional Neural Networks,简称CNN),卷积神经网络是近年发展起来,并引起广泛重视的一种高效识别方法。20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感和方向选择的神经元时发现其独特的网络结构可以有效地降低反馈神经网络的复杂性,继而提出了卷积神经网络(Convolutional Neural Networks-简称CNN)。现在,CNN已经成为众多科学领域的研究热点之一,特别是在模式分类领域,由于该网络避免了对图像的复杂前期预处理,可以直接输入原始图像,因而得到了更为广泛的应用。K.Fukushima 在1980年提出的新识别机是卷积神经网络的第一个实现网络。随后,更多的科研工作者对该网络进行了改进。其中,具有代表性的研究成果是Alexander和
Taylor提出的“改进认知机”,该方法综合了各种改进方法的优点并避免了耗时的误差反向传播。 一般地,CNN的基本结构包括两层,其一为特征提取层,每个神经元的输入与前一层的局部接受域相连,并提取该局部的特征。一旦该局部特征被提取后,它与其它特征间的位置关系也随之确定下来;其二是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射是一个平面,平面上所有神经元的权值相等。特征映射结构采用影响函数核小的sigmoid函数作为卷积网络的激活函数,使得特征映射具有位移不变性。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数。卷积神经网络中的每一个卷积层都紧跟着一个用来求局部平均与二次提取的计算层,这种特有的两次特征提取结构减小了特征分辨率。 CNN主要用来识别位移、缩放及其他形式扭曲不变性的二维图形。由于CNN 的特征检测层通过训练数据进行学习,所以在使用CNN时,避免了显示的特征抽取,而隐式地从训练数据中进行学习;再者由于同一特征映射面上的神经元权值相同,所以网络可以并行学习,这也是卷积网络相对于神经元彼此相连网络的一大优势。卷积神经网络以其局部权值共享的特殊结构在语音识别和图像处理方面有着独特的优越性,其布局更接近于实际的生物神经网络,权值共享降低了网络的复杂性,特别是多维输入向量的图像可以直接输入网络这一特点避免了特征提取和分类过程中数据重建的复杂度。 1、神经网络
卷积神经网络C N N代码解析m精编b HUA system office room 【HUA16H-TTMS2A-HUAS8Q8-HUAH1688】
卷积神经网络CNN代码解析 deepLearnToolbox-master是一个深度学习matlab包,里面含有很多机器学习算 法,如卷积神经网络CNN,深度信念网络DBN,自动编码AutoEncoder(堆栈SAE,卷积 CAE)的作者是 Rasmus Berg Palm 代码下载: 这里我们介绍deepLearnToolbox-master中的CNN部分。 DeepLearnToolbox-master中CNN内的函数: 调用关系为: 该模型使用了mnist的数字mnist_uint8.mat作为训练样本,作为cnn的一个使用样例, 每个样本特征为一个28*28=的向量。 网络结构为: 让我们来看看各个函数: 一、Test_example_CNN: (2) 三、cnntrain.m (5) 四、cnnff.m (6) 五、cnnbp.m (7)
五、cnnapplygrads.m (10) 六、cnntest.m (11) 一、Test_example_CNN: Test_example_CNN: 1设置CNN的基本参数规格,如卷积、降采样层的数量,卷积核的大小、降采样的降幅 2 cnnsetup函数初始化卷积核、偏置等 3 cnntrain函数训练cnn,把训练数据分成batch,然后调用 3.1 cnnff 完成训练的前向过程, 3.2 cnnbp计算并传递神经网络的error,并计算梯度(权重的修改量) 3.3 cnnapplygrads 把计算出来的梯度加到原始模型上去 4 cnntest 函数,测试当前模型的准确率 该模型采用的数据为mnist_uint8.mat, 含有70000个手写数字样本其中60000作为训练样本,10000作为测试样本。 把数据转成相应的格式,并归一化。 设置网络结构及训练参数 初始化网络,对数据进行批训练,验证模型准确率
CNN卷积神经网络 一、相关背景知识 通常神经认知机包含两类神经元,即承担特征抽取的S-元和抗变形的C-元。S-元中涉及两个重要参数,即感受野与阈值参数,前者确定输入连接的数目,后者则控制对特征子模式的反应程度。 二、卷积神经网络 2.1 网络结构 卷积神经网络(Convolutional Neural Network)是一个多层的神经网络,每层由多个二维平面组成,而每个平面由多个独立神经元组成。网络中包含一些简单元和复杂元,分别记为S-元和C-元。S-元聚合在一起组成S-面,S-面聚合在一起组成S-层,用U s表示。C-元、C-面和C-层(U s)之间存在类似的关系。网络的任一中间级由S-层与C-层串接而成。一般地,U s为特征提取层,每个神经元的输入与前一层的局部感受野相连,并提取该局部的特征,一旦该局部特征被提取后,它与其他特征间的位置关系也随之确定下来;U c是特征映射层,网络的每个计算层由多个特征映射组成,每个特征映射为一个平面,平面上所有神经元的权值相等。此外,由于一个映射面上的神经元共享权值,因而减少了网络自由参数的个数,降低了网络参数选择的复杂度。 图1是卷积神经网络的典型结构图。将原始图像直接输入到输入层(U c1),神经元提取图像的局部特征,因此每个神经元都与前一层的局部感受野相连。该图有4层网络结构,隐层由S-层和C-层组成。每层均包含多个平面,输入层直接映射到U s2层包含的多个平面上。每层中各平面的神经元提取图像中特定区域的局部特征,如边缘特征,方向特征等,在训练时不断修正S-层神经元的权值。同一平面上的神经元权值相同。S-层中每个神经元局部输入窗口的大小均为5x5,由于同一个平面上的神经元共享一个权值向量,所以从一个平面到下一个平面的映射可以看作是作卷积运算。 图1卷积神经网络结构图
卷积神经网络CNN从入门到精通 卷积神经网络算法的一个实现 前言 从理解卷积神经到实现它,前后花了一个月时间,现在也还有一些地方没有理解透彻,CNN还是有一定难度的,不是看哪个的博客和一两篇论文就明白了,主要还是靠自己去专研,阅读推荐列表在末尾的参考文献。目前实现的CNN在MINIT数据集上效果还不错,但是还有一些bug,因为最近比较忙,先把之前做的总结一下,以后再继续优化。 卷积神经网络CNN是Deep Learning的一个重要算法,在很多应用上表现出卓越的效果,[1]中对比多重算法在文档字符识别的效果,结论是CNN优于其他所有的算法。CNN在手写体识别取得最好的效果,[2]将CNN应用在基于人脸的性别识别,效果也非常不错。前段时间我用BP神经网络对手机拍照图片的数字进行识别,效果还算不错,接近98%,但在汉字识别上表现不佳,于是想试试卷积神经网络。 1、CNN的整体网络结构 卷积神经网络是在BP神经网络的改进,与BP类似,都采用了前向传播计算输出值,反向传播调整权重和偏置;CNN与标准的BP最大的不同是:CNN中相邻层之间的神经单元并不是全连接,而是部分连接,也就是某个神经单元的感知区域来自于上层的部分神经单元,而不是像BP那样与所有的神经单元相连接。CNN的有三个重要的思想架构: 局部区域感知 权重共享 空间或时间上的采样 局部区域感知能够发现数据的一些局部特征,比如图片上的一个角,一段弧,这些基本特征是构成动物视觉的基础[3];而BP中,所有的像素点是一堆混乱的点,相互之间的关系没有被挖掘。 CNN中每一层的由多个map组成,每个map由多个神经单元组成,同一个map 的所有神经单元共用一个卷积核(即权重),卷积核往往代表一个特征,比如某个卷积和代表一段弧,那么把这个卷积核在整个图片上滚一下,卷积值较大的区域就很有可能是一段弧。注意卷积核其实就是权重,我们并不需要单独去计算一个卷积,而是一个固定大小的权重矩阵去图像上匹配时,这个操作与卷积类似,因此我们称为卷积神经网络,实际上,BP也可以看做一种特殊的卷积神经网络,只是这个卷积核就是某层的所有权重,即感知区域是整个图像。权重共享策略减少了需要训练的参数,使得训练出来的模型的泛华能力更强。 采样的目的主要是混淆特征的具体位置,因为某个特征找出来后,它的具体位置已经不重要了,我们只需要这个特征与其他的相对位置,比如一个“8”,当我们得到了上面一个"o"时,我们不需要知道它在图像的具体位置,只需要知道它下面又是一个“o”我们就可以知道是一个'8'了,因为图片中"8"在图片中偏左或者偏右都不影响我们认识它,这种混淆具体位置的策略能对变形和扭曲的图片进行识别。 CNN的这三个特点是其对输入数据在空间(主要针对图像数据)上和时间(主要针对时间序列数据,参考TDNN)上的扭曲有很强的鲁棒性。CNN一般采用卷积层与