
附录:教材各章习题答案
第1章统计与统计数据
1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5)
分类数据。
1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家庭”;
(2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。
1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物者
的月平均花费;(4)统计量;(5)推断统计方法。
1.5(略)。
1.6(略)。
第2章数据的图表展示
2.1(1)属于顺序数据。
(2)频数分布表如下
(4)帕累托图(略)。
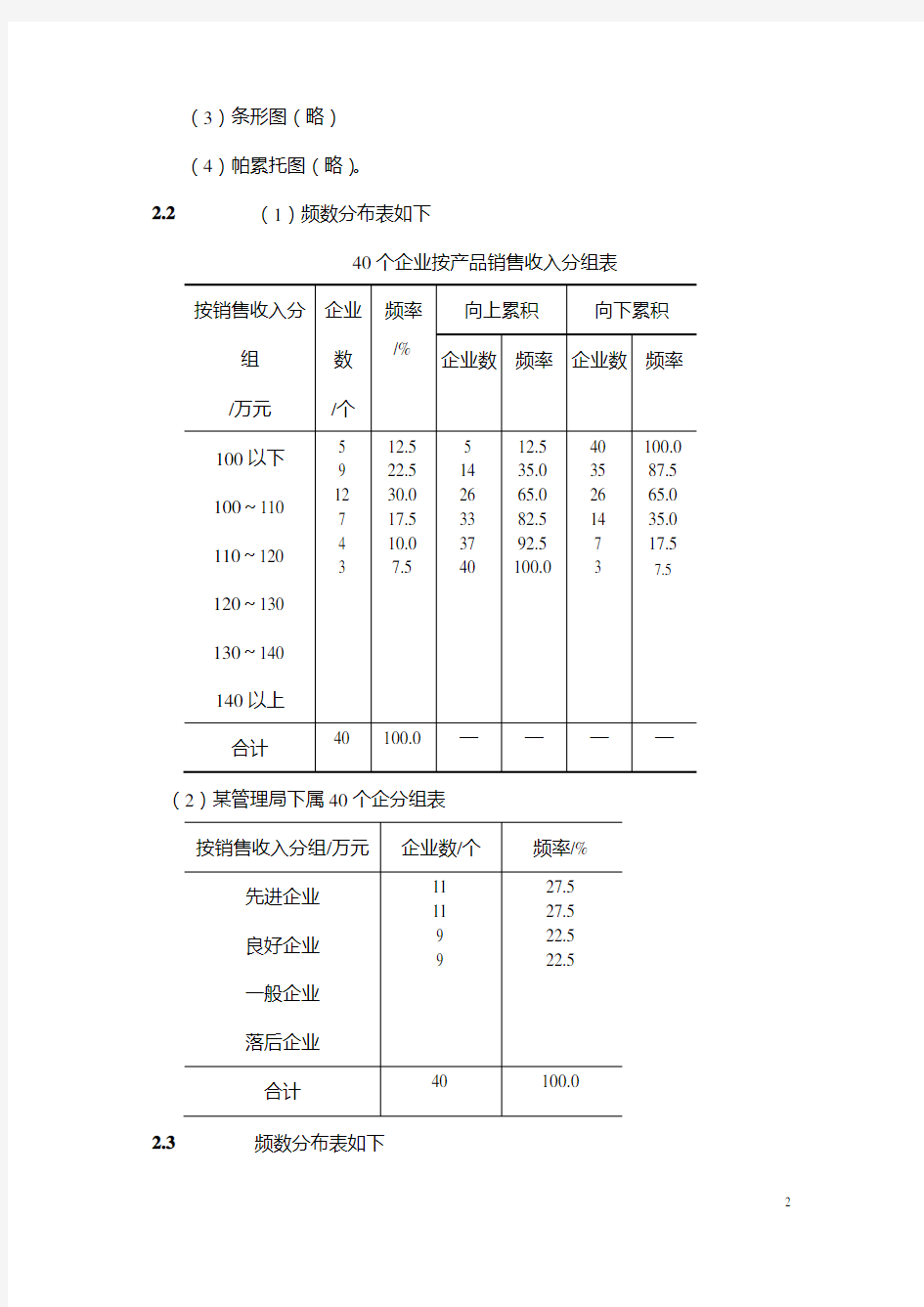
2.2(1)频数分布表如下
2.3
2.5(1)排序略。
(2)频数分布表如下
(4)茎叶图如下
2.6
(3)食品重量的分布基本上是对称的。
2.7
2.8(1)属于数值型数据。
2.9 (1)直方图(略)。
(2)自学考试人员年龄的分布为右偏。
布比A 班分散,
且平均成绩较A 班低。
2.11 (略)。 2.12 (略)。 2.13 (略)。 2.14 (略)。 2.15 箱线图如下:(特征请读者自己分析)
第3章 数据的概括性度量 3.1
(1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。 (3)2.4=s 。 (4)左偏分布。 3.2
(1)190=M ;23=e M 。
(2)5.5=L Q ;12=U Q 。 (3)24=x ;65.6=s 。 (4)08.1=SK ;77.0=K 。 (5)略。 3.3 (1)略。
(2)7=x ;71.0=s 。
(3)102.01=v ;274.02=v 。
(4)选方法一,因为离散程度小。 3.4 (1)x =274.1(万元);M e=272.5 。
(2)Q L =260.25;Q U =291.25。 (3)17.21=s (万元)。 3.5 甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原
因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。 3.6
(1)x =426.67(万元);48.116=s (万元)。
(2)203.0=SK ;688.0-=K 。
3.7 (1)(2)两位调查人员所得到的平均身高和标准差应该差不多相
同,因为均值和标准差的大小基本上不受样本大小的影响。
(3)具有较大样本的调查人员有更大的机会取到最高或最低者,因为样本越大,变化的范围就可能越大。 3.8 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于男生
体重的离散系数0.08。 (2) 男生:x =27.27(磅),27.2=s (磅); 女生:x =22.73(磅),27.2=s (磅); (3)68%;
(4)95%。 3.9
通过计算标准化值来判断,1=A z ,5.0=B z ,说明在A项测试中
该应试者比平均分数高
出1个标准差,而在B 项测试中只高出平均分数0.5个标准差,由于A 项测试的标准化值高于B 项测试,所以A 项测试比较理想。 3.10 通过标准化值来判断,各天的标准化值如下表
日期 周一 周二 周三 周四 周五 周六 周日 标准化值Z 3 -0.6 -0.2 0.4 -1.8 -2.2 0 周一和周六两天失去了控制。
3.11
(1)离散系数,因为它消除了不同组数据水平高地的影响。
(2)成年组身高的离散系数:024.01.1722
.4==
s v ; 幼儿组身高的离散系数:032.03
.713
.2==
s v ; 由于幼儿组身高的离散系数大于成年组身高的离散系数,说明幼儿组身高的离散程度相对较大。 3.12
3.13 第4章 抽样与参数估计
4.1 (1)200。(2)5。(3)正态分布。(4))1100(2-χ。 4.2 (1)32。(2)0.91。 4.3 0.79。
4.4 (1))2,17(~225N x 。(2))1,17(~100N x 。
4.5 (1)1.41。(2)1.41,1.41,1.34。 4.6 (1)0.4。(2)0.024 。(3)正态分布。 4.7 (1)0.050,0.035,0.022,016。(2)当样本量增大时,样本比例的标准
差越来越小。 4.8 (1)14.2=x σ;(2)E =4.2;(3)(115.8,124.2)。
4.9 (87819,121301)。 4.10(1)81±1.97;(2)81±2.35;(3)81±3.10。 4.11(1)(24.11,2
5.89);(2)(113.17,12
6.03);(3)(3.136,3.702) 4.12(1)(8687,9113);(2)(8734,9066);(3)(8761,9039);(4)(8682,
9118)。
4.13(2.88,3.76);(2.80,3.84);(2.63,4.01)。 4.14(7.1,12.9)。 4.15(7.18,11.57)。 4.16(1)(148.9,150.1);(2)中心极限定理。 4.17(1)(100.9,123.7);(2)(0.017,0.183)。 4.18(1
5.63,1
6.55)。 4.19(10.36,16.76)。
4.20(1)(0.316,0.704);(2)(0.777,0.863);(3)(0.456,0.504)。 4.21(18.11%,27.89%);(17.17%,22.835)。 4.22167。
4.23(1)2522;(2)601;(3)268。 4.24(1)(51.37%,76.63%);(2)36。 4.25(1)(2.13,2.97);(2)(0.015,0.029);(3)(2
5.3,42.5)。 4.26(1)(0.33,0.87);(2)(1.25,3.33);(3)第一种排队方式更好。 4.27 48。 4.28 139。 第5章 假设检验
5.1 研究者想要寻找证据予以支持的假设是“新型弦线的平均抗拉强度相对于以
前提高了”,所以原假设与备择假设应为:1035:0≤μH ,1035:1>μH 。 5.2 π=“某一品种的小鸡因为同类相残而导致的死亡率”,04.0:0≥πH ,
04.0:1<πH 。
5.3 65:0=μH ,65:1≠μH 。
5.4 (1)第一类错误是该供应商提供的这批炸土豆片的平均重量的确大于等于
60克,但检验结果却提供证据支持店方倾向于认为其重量少于60克; (2)第二类错误是该供应商提供的这批炸土豆片的平均重量其实少于60克,但检验结果却没有提供足够的证据支持店方发现这一点,从而拒收这批产品;
(3)连锁店的顾客们自然看重第二类错误,而供应商更看重第一类错误。 5.5 (1)检验统计量n
s x z /μ-=
,在大样本情形下近似服从标准正态分布;
(2)如果05.0z z >,就拒绝0H ;
(3)检验统计量z =2.94>1.645,所以应该拒绝0H 。 5.6 z =3.11,拒绝0H 。 5.7 66.1=t ,不拒绝0H 。 5.8 39.2-=z ,拒绝0H 。 5.9 04.1=t ,不拒绝0H 5.1044.2=z ,拒绝0H 。
5.11z =1.93,不拒绝0H 。 5.12z =7.48,拒绝0H 。 5.132χ=20
6.22,拒绝0H 。 5.1442.2=F ,拒绝0H 。 第6章 方差分析
6.1 0215.86574.401.0=<=F F (或01.00409.0=>=-αvalue P ),不能拒绝原假
设。
6.2 579.48234.1501.0=>=F F (或01.000001.0=<=-αvalue P ),拒绝原假设。 6.3 4170.50984.1001.0=>=F F (或01.0000685.0=<=-αvalue P ),拒绝原假设。 6.4 6823.3755
7.1105.0=>=F F (或05.0000849.0=<=-αvalue P ),拒绝原假设。 6.5 8853.30684.1705.0=>=F F (或05.00003.0=<=-αvalue P ),拒绝原假设。
85.54.14304.44=>=-=-LSD x x B A ,拒绝原假设; 85.58.16.424.44=<=-=-LSD x x C A ,不能拒绝原假设; 85.56.126.4230=>=-=-LSD x x C B ,拒绝原假设。
6.6
554131.3478.105.0=<=F F (或05.0245946.0=>=-αvalue P ),不能拒绝原假设。
第7章 相关与回归分析
7.1 (1)散点图(略),产量与生产费用之间正的线性相关关系。
(2)920232.0=r 。
(3)检验统计量2281.24222.14=>=αt t ,拒绝原假设,相关系数显著。 7.2 (1)散点图(略)。
(2)8621.0=r 。
7.3 (1)0
?β表示当0=x 时y 的期望值。 (2)1?β表示x 每变动一个单位y 平均下降0.5个单位。 (3)7)(=y E 。 7.4 (1)%902=R 。
(2)1=e s 。 7.5 (1)散点图(略)。
(2)9489.0=r 。
(3)x y 00358.01181.0?+=。回归系数00358.0?1
=β表示运送距离每增加1公里,运送时间平均增加0.00358天。
7.6 (1) 散点图(略)。二者之间为高度的正线性相关关系。
(2)998128.0=r ,二者之间为高度的正线性相关关系。
(3)估计的回归方程为:x y 308683.06928.734?+=。回归系数308683.0?1
=β表示人均GDP 每增加1元,人均消费水平平均增加0.308683元。 (4)判定系数996259.02=R 。表明在人均消费水平的变差中,有99.6259%
是由人均GDP 决定的。
(5)检验统计量61.6692.1331=>=αF F ,拒绝原假设,线性关系显著。
(6)1078.22785000308683.06928.734?5000=?+=y (元)
。 (7)臵信区间:[1990.749,2565.464];预测区间:[1580.463,2975.750]。
7.7 (1) 散点图(略),二者之间为负的线性相关关系。
(2)估计的回归方程为:x y 7.41892.430?-=。回归系数7.4?1
-=β表示航班正点率每增加1%,顾客投诉次数平均下降4.7次。
(3)检验统计量3060.2959.42=>=αt t (P-Value=0.001108<05.0=α),
拒绝原假设,回归系数显著。
(4)1892.54807.41892.430?80=?-=y (次)。
(5)臵信区间:(37.660,70.619);预测区间:(7.572,100.707)。 7.8 Excel 输出的结果如下(解释与分析请读者自己完成)
Multiple R 0.7951 R Square 0.6322 Adjusted R Square 0.6117 标准误差
2.6858
观测值 20 方差分析
df
SS MS
F
Significance F 回归分析 1 223.1403 223.1403 30.9332
2.79889E-05
残差 18 129.8452 7.2136
总计 19 352.9855
Coefficients
标准误差
t Stat P-value Lower 95%
Upper 95%
Intercept 49.3177 3.8050 12.9612 0.0000 41.3236 57.3117 X Variable 1
0.2492
0.0448
5.5618
0.0000
0.1551
0.3434
7.9
(2)%60.868660.067
.16428662====
SST R 。表明汽车销售量的变差中有86.60%是由于广告费用的变动引起的。
(3)9306.08660.02===R r 。
(4)x y 420211.16891.363?+=。回归系数420211.1?1=β表示广告费用每增加一个单位,销售量平均增加1.420211个单位。
(5)Significance F =2.17E-09<05.0=α,线性关系显著。
7.10 x y
3029.26254.13?+=;%74.932=R ;8092.3=e s 。 7.11 (1)27。 (2)4.41。
(3)拒绝0H 。 (4)7746.0-=r 。 (5)拒绝0H 。
7.12 (1)05.18)(95.15≤≤y E 。
(2)349.19651.140≤≤y 。
7.13 x y
24.1529.46?+-=;045.685)(555.44140≤≤y E 。 7.14 21928.10497.003.25?x x y
+-=;预测28.586。
7.15 (略)。 7.16 (1)显著。 (2)显著。 (3)显著。
7.17 (1)16039.16377.88?x y
+=。 (2)213010.12902.22301.83?x x y
++=。 (3)不相同。方程(1)中的回归系数6039.1?1=β表示电视广告费用每增加1万元,月销售额平均增加 1.6039万元;方程(1)中的回归系数
2902.2?1=β表示在报纸广告费用不变的条件下,电视广告费用每增加1万元,月销售额平均增加2.2902万元。
(4)%91.912=R ;%66.882
=a R 。
(5)1β的P-Value=0.0007,2β的P-Value=0.0098,均小于05.0=α,两个回归系数均显著。
7.18 (1)216717.3273865.225910.0?x x y
++-= (2)回归系数3865.22?1=β表示降雨量每增加1毫mm ,小麦收获量平均增加22.3865kg/hm 2;回归系数6717.327?2=β表示温度每增加1C 0,小麦收获量平均增加327.6717kg/mh 2。 (3)可能存在。
7.19 (1)3211350.08210.08147.07005.148?x x x y
+++=。 (2)%75.892=R ;%83.872
=a R 。
(3)Significance F =3.88E-08<05.0=α,线性关系显著。 (4)1β的
P-Value=0.1311>05.0=α,不显著;2β的
P-Value=0.0013<05.0=α,显著;3β的P-Value=0.0571>05.0=α,不显著。 第8章 时间序列分析和预测 8.1 (1)时间序列图(略)。 (2)13.55%。
(3)1232.90(亿元)。 8.2 (1)时间序列图(略)。
(2)1421.2(公斤/公顷)。
(3)3.0=α时的预测值:18.13802001=F ,误差均方=291455; 5.0=α时的预测值:23.14072001=F ,误差均方=239123。5.0=α更合适。 8.3 (1)3期移动平均预测值=630.33(万元)。
(2)3.0=α时的预测值:95.56719=F ,误差均方=87514.7; 4.0=α时的
预测值:06.59119=F ,误差均方=62662.5;5.0=α时的预测值:
54.60619=F ,误差均方=50236。5.0=α更合适
(3)趋势方程t Y t 9288.2173.239?+=。估计标准误差6628.31=Y s 。 8.4 (1)趋势图(略)。
(2)趋势方程t t
Y 16077.178.145??=。2001年预测值=3336.89(亿元)。 8.5 (1)趋势图(略)。
(2)线性趋势方程t Y 9495.135202.69?+=,2000年预测值=585.65(万吨)。 8.6 线
性
趋
势
:
t
Y 6137.01613.374?-=;二次曲线:2
0337.08272.16442.381?t t Y +-=;
三
次
曲
线
:
320036.01601.00030.15617.372?t t t Y +-+=。 8.7 (1)原煤产量趋势图(略)。
(2)趋势方程20309.09674.05824.4?t t Y t -+=,预测值28.11?2001
=Y (亿吨)。 8.8 (1)图形(略)。
(2)移动平均法或指数平滑法。
(3)移动平均预测=72.49(万元);指数平滑法预测=72.5(万元)( 4.0=α)。 8.9 (1)略。
计算趋势:分离季节因素后的趋势方程为:t Y t
7064.16392.2043?+=。图形(略)
周期波动图(略)。 8.11各月季节指数如下
1月 2月 3月 4月
5月 6月 0.6744 0.6699 0.7432 0.7903 0.8061 0.8510 7月 8月 9月 10月 11月 12月 0.7552 0.3449 0.9619 1.1992 1.8662 2.3377
季节变动图(略)。
计算趋势:分离季节因素后的趋势方程为:t Y t
42449.0159.119?+=。图形(略)。
周期波动图(略)。 随机波动图(略)。 第9章 指数
9.1 (1)%80.110=v 。(2)%46.122=p I 。(3)%48.90=q I 。(4)13920元=26190元-12270元。 9.2 (1)111.72%。(2)111.60%。(3)100.10%。(4)15.3万元=15.1532
万元+0.1468万元。 9.3 (1)2.62%;8016元。(2)28.42%;124864元。(3)143.37%;132880
元。 9.4 (1)单位成本增长11.11%。(2)%11.111=p I ;%91.90=q I 。 9.5 结果如下表:
年份 缩减后的人均GDP
1990 1584.9 1991 1817.2 1992 2149.4 1993 2562.3 1994 3161.2 1995 4145.2 1996
5148.7
1997 5889.1
1998 6357.9
1999 6640.0
2000 7049.8 9.6%
I,下跌1.48%。
52
98
.
p
第1章统计与统计数据
一、学习指导
统计学是处理和分析数据的方法和技术,它几乎被应用到所有的学科检验领域。本章首先介绍统计学的含义和应用领域,然后介绍统计数据的类型及其来源,最后介绍统计中常用
二、主要术语
1. 统计学:收集、处理、分析、解释数据并从数据中得出结论的科学。
2. 描述统计:研究数据收集、处理和描述的统计学分支。
3. 推断统计:研究如何利用样本数据来推断总体特征的统计学分支。
4. 分类数据:只能归于某一类别的非数字型数据。
5. 顺序数据:只能归于某一有序类别的非数字型数据。
6. 数值型数据:按数字尺度测量的观察值。
7. 观测数据:通过调查或观测而收集到的数据。
8. 实验数据:在实验中控制实验对象而收集到的数据。
9. 截面数据:在相同或近似相同的时间点上收集的数据。
10. 时间序列数据:在不同时间上收集到的数据。
11. 抽样调查:从总体中随机抽取一部分单位作为样本进行调查,并根据样本调查结果来推
断总体特征的数据收集方法。
12. 普查:为特定目的而专门组织的全面调查。
13. 总体:包含所研究的全部个体(数据)的集合。
14. 样本:从总体中抽取的一部分元素的集合。
15. 样本容量:也称样本量,是构成样本的元素数目。
16. 参数:用来描述总体特征的概括性数字度量。
17. 统计量:用来描述样本特征的概括性数字度量。
18. 变量:说明现象某种特征的概念。
19. 分类变量:说明事物类别的一个名称。
20. 顺序变量:说明事物有序类别的一个名称。
21. 数值型变量:说明事物数字特征的一个名称。
22. 离散型变量:只能取可数值的变量。
23. 连续型变量:可以在一个或多个区间中取任何值的变量。
四、习题答案
1. D
2. D
3. A
4. B
5. A
6. D
7. C
8. B
9. A
10.A
11.C、12.C
13.B
14.A
15.C
16.D
17.C
18.A
19.C
20.D
21.A
22.C
23.C
24.B
25.D
26.C
27.B
28.D
29.A
30.D
31.A
32.B
33.C
34.A
35.A
36.A
37.D
38.B
39.B
40.C
41.C
42.D
43.C
44.D
45.A
46.B
47.C
48.A
49.C
50.D
51.A
52.C
53.D
54.A
55.B
第2章数据的图表展示
一、学习指导
数据的图表展示是应用统计的基本技能。本章首先介绍数据的预处理方法,然后介绍不同类型数据的整理与图示方法,最后介绍图表的合理使用问题。本章各节的主要内容和学习要点如下表所示。
二、主要术语
24. 频数:落在某一特定类别(或组)中的数据个数。
25. 频数分布:数据在各类别(或组)中的分配。
26. 比例:一个样本(或总体)中各个部分的数据与全部数据之比。
27. 比率:样本(或总体)中各不同类别数值之间的比值。
28. 累积频数:将各有序类别或组的频数逐级累加起来得到的频数。
29. 数据分组:根据统计研究的需要,将原始数据按照某种标准划分成不同的组别。
30. 组距分组:将全部变量值依次划分为若干个区间,并将这一区间的变量值作为一组。
31. 组距:一个组的上限与下限的差。
32. 组中值:每一组的下限和上限之间的中点值,即组中值=(下限值+上限值)/2。
33. 直方图:用矩形的宽度和高度(即面积)来表示频数分布的图形。
34. 茎叶图:由“茎”和“叶”两部分组成的、反应原始数据分布的图形。
35. 箱线图:由一组数据的最大值、最小值、中位数和两个四分位数5个特征值绘制而成的、
反应原始数据分布的图形。
四、习题答案
1. C
2. A
3. B
4. C
5. D
6. B
7. C 8. B
9. B
10.C
11.A
12.B
13.B
14.C
15.C
16.B
17.D
18.D
19.C
20.B
21.C
22.D
23.D
24.B
25.D
26.B
27.B
28.D
29.D
30.C
31.B
32.C
33.C
34.A
35.B
第3章数据的概括性度量
一、学习指导
数据分布的特征可以从三个方面进行描述:一是分布的集中趋势,反映各数据向其中心值靠拢或聚集的程度;二是分布的离散程度,反映各数据远离其中心值的趋势;三是分布的形状,反映数据分布偏斜程度和峰度。本章将从数据的不同类型出发,分别介绍集中趋势测度值的计算方法、特点及其应用场合。本章各节的主要内容和学习要点如下表所示。
二、主要术语和公式
(一)主要术语
M表示。
1. 众数:一组数据中出现频数最多的变量值,用
o
M表示。
2. 中位数:一组数据排序后处于中间位置上的变量值,用
e
3. 四分位数:一组数据排序后处于25%和75%位置上的值。
4. 平均数:一组数据相加后除以数据的个数而得到的结果。
G表示。
5. 几何平均数:n个变量值乘积的n次方根,用
m
6. 异众比率:非众数组的频数占总频数的比率。
7. 四分位差:也称为内距或四分间距,上四分位数与下四分位数之差。
8. 极差:也称全距,一组数据的最大值与最小值之差。
9. 平均差:也称平均绝对离差,各变量值与其平均数离差绝对值的平均数。
10. 方差:各变量值与其平均数离差平方的平均数。
11. 标准差:方差的平方根。
12. 标准分数:变量值与其平均数的离差除以标准差后的值。
13. 离散系数:也称为变异系数,一组数据的标准差与其相应的平均数之比。
14. 偏态:数据分布的不对称性。
15. 偏态系数:对数据分布不对称性的度量值。
16. 峰态:数据分布的平峰或尖峰程度。
17. 峰态系数:对数据分布峰态的度量值。
(二)主要公式
统计学试题库含答案 Modified by JEEP on December 26th, 2020.
《统计学》试题库 第一章:统计基本理论和基本概念 一、填空题 1、统计是统计工作、统计学和统计资料的统一体,统计资料 是统计工作的成果,统计学是统计工作的经验总结和理论概括。 2、统计研究的具体方法主要有大量观察法、统计分组法、统计推断法和综合指标法。 3、统计工作可划分为设计、调查、整理和分析四个阶段。 4、随着研究目的的改变,总体和个体是可以相互转化的。 5、标志是说明个体特征的名称,指标是说明总体数量特征的概念及其数值。 6、可变的数量标志和所有的统计指标称为变量,变量的具体数值称为变量值。 7、变量按其数值变化是否连续分,可分为连续变量和离散变量,职工人 数、企业数属于离散变量;变量按所受影响因素不同分,可分为确定性变量和随机变量。 8、社会经济统计具有数量性、总体性、社会性、具体性等特点。 9、一个完整的统计指标应包括指标名称和指标数值两个基本部分。 10、统计标志按是否可用数值表示分为品质标志和数量标志;按在 各个单位上的具体表现是否相同分为可变标志和不变标志。 11、说明个体特征的名称叫标志,说明总体特征的名称叫指标。 12、数量指标用绝对数表示,质量指标用相对数或平均数表示。 13、在统计中,把可变的数量标志和统计指标统称为变量。 14、由于统计研究目的和任务的变更,原来的总体变成总体单位, 那么原来的指标就相应地变成标志,两者变动方向相同。 二、是非题 1、统计学和统计工作的研究对象是完全一致的。(×) 2、运用大量观察法,必须对研究对象的所有或足够多的单位进行观察调查。(√) 3、统计学是对统计实践活动的经验总结和理论概括。(√)
第三章节:数据的图表展示 (1) 第四章节:数据的概括性度量 (15) 第六章节:统计量及其抽样分布 (26) 第七章节:参数估计....................................................... (28) 第八章节:假设检验........................................................ (38) 第九章节:列联分析........................................................ (41) 第十章节:方差分析........................................................ (43) 3.1 为评价家电行业售后服务的质量,随机抽取了由100个家庭构成的一个样本。服务质量的等级分别表示为:A.好;B.较好;C一般;D.较差;E.差。调查结果如下: B E C C A D C B A E D A C B C D E C E E A D B C C A E D C B B A C D E A B D D C C B C E D B C C B C D A C B C D E C E B B E C C A D C B A E B A C E E A B D D C A D B C C A E D C B C B C E D B C C B C 要求: (1)指出上面的数据属于什么类型。 顺序数据 (2)用Excel制作一张频数分布表。 用数据分析——直方图制作: 接收频率 E16 D17 C32 B21 A14 (3)绘制一张条形图,反映评价等级的分布。 用数据分析——直方图制作: (4)绘制评价等级的帕累托图。 逆序排序后,制作累计频数分布表:
《管理运筹学》第四版课后习题解析(上) 第2章 线性规划的图解法 1.解: (1)可行域为OABC 。 (2)等值线为图中虚线部分。 (3)由图2-1可知,最优解为B 点,最优解1x = 127,2157x =;最优目标函数值697 。 图2-1 2.解: (1)如图2-2所示,由图解法可知有唯一解12 0.2 0.6x x =??=?,函数值为3.6。 图2-2 (2)无可行解。 (3)无界解。 (4)无可行解。 (5)无穷多解。
(6)有唯一解 12203 8 3x x ?=????=?? ,函数值为923。 3.解: (1)标准形式 12123max 32000f x x s s s =++++ 1211221231212392303213229,,,,0 x x s x x s x x s x x s s s ++=++=++=≥ (2)标准形式 1212min 4600f x x s s =+++ 12112212121236210764,,,0 x x s x x s x x x x s s --=++=-=≥ (3)标准形式 1 2212min 2200f x x x s s ''''=-+++ 12 211 2212221 2212355702555032230,,,,0x x x s x x x x x x s x x x s s '''-+-+=''''-+=''''+--=''''≥ 4.解: 标准形式 1212max 10500z x x s s =+++ 1211221212349528,,,0 x x s x x s x x s s ++=++=≥ 松弛变量(0,0) 最优解为 1x =1,x 2=3/2。 5.解:
统计学试题库及答案 Document serial number【KKGB-LBS98YT-BS8CB-BSUT-BST108】
《统计学》试题库 知识点一:统计基本理论和基本概念 一、填空题 1、统计是、和的统一体,是统计工作的成果,是统计工作的经验总结和 理论概括。 2、统计研究的具体方法主要有、、和。 3、统计工作可划分为、、和四个阶段。 4、随着的改变,总体和是可以相互转化的。 5、标志是说明,指标是说明。 6、可变的数量标志和所有的统计指标称为,变量的具体数值称为。 7、变量按分,可分为连续变量和离散变量,职工人数、企业数属于变量;变量按分,可 分为确定性变量和随机变量。 8、社会经济统计具有、、、等特点。 9、一个完整的统计指标应包括和两个基本部分。 10、统计标志按是否可用数值表示分为和;按在各个单位上的具体表现是否相同分为 和。 11、说明特征的名称叫标志,说明特征的名称叫指标。 12、数量指标用表示,质量指标用或平均数表示。 13、在统计中,把可变的和统称为变量。 14、由于统计研究目的和任务的变更,原来的变成,那么原来的指标就相应地变成标志,两者 变动方向相同。 二、是非题 1、统计学和统计工作的研究对象是完全一致的。 2、运用大量观察法,必须对研究对象的所有单位进行观察调查。 3、统计学是对统计实践活动的经验总结和理论概括。 4、一般而言,指标总是依附在总体上,而总体单位则是标志的直接承担者。 5、数量指标是由数量标志汇总来的,质量指标是由品质标志汇总来的。 6、某同学计算机考试成绩80分,这是统计指标值。 7、统计资料就是统计调查中获得的各种数据。 8、指标都是用数值表示的,而标志则不能用数值表示。 9、质量指标是反映工作质量等内容的,所以一般不能用数值来表示。 10、总体和总体单位可能随着研究目的的变化而相互转化。 11、女性是品质标志。
●3.2.某行业管理局所属40个企业2002年的产品销售收入数据如下(单位:万元): 1521241291161001039295127104 10511911411587103118142135125 117108105110107137120136117108 9788123115119138112146113126 (1)根据上面的数据进行适当的分组,编制频数分布表,并计算出累积频数和累积频率; (2)如果按规定:销售收入在125万元以上为先进企业,115万~125万元为良好企业,105万~115万元为一般企业,105万元以下为落后企业,按先进企业、良好企业、一般企业、落后企业进行分组。 解:(1)要求对销售收入的数据进行分组, 全部数据中,最大的为152,最小的为87,知数据全距为152-87=65; 为便于计算和分析,确定将数据分为6组,各组组距为10,组限以整10划分; 为使数据的分布满足穷尽和互斥的要求,注意到,按上面的分组方式,最小值87可能落在最小组之下,最大值152可能落在最大组之上,将最小组和最大组设计成开口形式; 按照“上限不在组内”的原则,用划记法统计各组内数据的个数——企业数,也可以用Excel 进行排序统计(见Excel练习题2.2),将结果填入表内,得到频数分布表如下表中的左两列;将各组企业数除以企业总数40,得到各组频率,填入表中第三列; 在向上的数轴中标出频数的分布,由下至上逐组计算企业数的向上累积及频率的向上累积,由上至下逐组计算企业数的向下累积及频率的向下累积。 整理得到频数分布表如下: 40个企业按产品销售收入分组表 (2)按题目要求分组并进行统计,得到分组表如下: 某管理局下属40个企分组表 按销售收入分组(万元)企业数(个)频率(%) 先进企业良好企业一般企业落后企业11 11 9 9 27.5 27.5 22.5 22.5 合计40100.0
《管理运筹学》第四版课后习题解析(下) 第9章 目 标 规 划 1、解: 设工厂生产A 产品1x 件,生产B 产品2x 件。按照生产要求,建立如下目标规划模型。 112212121211122212min ()() s.t 43452530 555086100 ,,,0,1,2 -- +-+-+-++++-+=+-+==i i P d P d x x x x x x d d x x d d x x d d i ≤≤≥ 由管理运筹学软件求解得 12121211.25,0,0,10, 6.25,0x x d d d d --++ ====== 由图解法或进一步计算可知,本题在求解结果未要求整数解的情况下,满意解有无穷多个,为线段(135/14,15/7)(1)(45/4,0),[0,1]ααα+-∈上的任一点。 2、解: 设该公司生产A 型混凝土x 1吨,生产B 型混凝土x 2吨,按照要求建立如下的目标规划模型。 ) 5,,2,1(0,,0,0145 50.060.015550.040.030000100150100 120275200.)()(min 2121215521442331222111215443 32 211 1 =≥≥≥≤+≤+=-++=-+=-+=-++=-++++++++-+-+-+-+-+-- - - + +- i d d x x x x x x d d x x d d x d d x d d x x d d x x t s d p d d p d p d d p i i 由 管 理 运 筹 学 软 件 求 解 得 . 0,0,20,0,0,0, 0,35,40,0,120,120554433221121============+-+-+-+-+-d d d d d d d d d d x x
2016慕课毛概最全答案 第一章 1.1.马克思主义中国化的科学内涵 1 毛泽东在明确提出“使马克思主义中国化”的命题和任务是在 A、遵义会议 B、中共六届六中全会 C、中共七大 D、中共七届二中全会 正确答案:B 我的答案:B 得分:16.7分 2 在党的七大上,对“马克思主义中国化”、“中国化的马克思主义”两大科学命题加以阐释的党的领导人是 A、毛泽东 B、周恩来 C、邓小平 D、刘少奇 正确答案:D 我的答案:D 得分:16.7分 3 中国共产党确定毛泽东思想为指导思想的会议是 A、遵义会议 B、党的第七次全国代表大会 C、党的第八次全国代表大会 D、中共十一届六中全会 正确答案:B 我的答案:B 得分:16.7分 4 马克思主义中国化的理论成果的精髓是 A、实事求是 B、毛泽东思想 C、邓小平理论 D、“三个代表”重要思想 正确答案:A 我的答案:A 得分:16.7分 5 中国共产党在把马克思列宁主义基本原理与中国革命实际相结合的过程中,在学风问题上曾经反对过的主要错误倾向是
A、投降主义 B、经验主义 C、教条主义 D、冒险主义 正确答案:BC 我的答案:AC 得分:0.0分 6 毛泽东思想和中国特色社会主义理论体系都是中国化的马克思主义,它们都 A、体现了马克思列宁主义的基本原理 B、包含了中国共产党人的实践经验 C、揭示了中国革命的特殊规律 D、包含了中华民族的优秀思想 正确答案:ABD 我的答案:AB 得分:8.4分 1.2.毛泽东主义的科学内涵和形成条件 1 在毛泽东思想活的灵魂的几个基本方面中,最具特色、最根本的原则是 A、实事求是 B、群众路线 C、理论联系实际 D、独立自主 正确答案:A 我的答案:A 得分:20.0分 2 下面关于毛泽东思想的论述不正确的是pA、毛泽东思想是毛泽东同志个人正确思想的结晶 B、毛泽东思想是马克思主义中国化第一次历史性飞跃的理论成果 C、毛泽东思想是中国革命和建设的科学指南 D、毛泽东思想是中国共产党和中国人民宝贵的精神财富 正确答案:A 我的答案:A 得分:20.0分 3 毛泽东思想的核心和精髓是 A、武装斗争 B、统一战线 C、党的建设 D、实事求是 正确答案:D 我的答案:D 得分:20.0分 4 毛泽东思想形成的标志是 A、实事求是 B、遵义会议
2. 数据筛选的主要目的是( A 、发现数据的错误 C 、找出所需要的某类数据 3. 为了调查某校学生的购书费用支出, B 、对数据进行排序 D 纠正数据中的错误 将全校学生的名单按拼音顺序排列后,每 ) A H 0:二=0.15;二-0.15 B H o :二二 0.15;二=0.15 C H 0: 一 - 0.15;二:: 0.15 D H 0:二乞 0.15;二 0.15 9. 若甲单位的平均数比乙单位的平均数小, 大,则( )。 A 、甲单位的平均数代表性比较大 C 甲单位的平均数代表性比较小 10. 某组的向上累计次数表明( A 、 大于该组上限的次数是多少 B 、 小于该组下限的次数是多少 但甲单位的标准差比乙单位的标准差 B 、两单位的平均数一样大 D 、无法判断 1.当正态总体方差未知时,在大样本条件下,估计总体均值使用的分布是 ( A )。 z 分布 B 、t 分布 F 分布 D 、 2 分布 A 、比平均数高出2个标准差 C 等于2倍的平均数 D 5.峰态通常是与标准正态分布相比较而言的。 则峰态系数的值( )。 B 比平均数低2个标准差 等于2倍的标准差 如果一组数据服从标准正态分布, A =3 C 、v 3 6. 若相关系数r=0,则表明两个变量之间( A 、相关程度很低 C 不存在任何关系 7. 如果所有变量值的频数都减少为原来的 1/3, 均数( )。 A 、不变 B C 减少为原来的1/3 D > 3, =0 )。 不存在线性相关关系 存在非线性相关关系 而变量值仍然不变,那么算术平 扩大到原来的3倍 不能预测其变化 8. 某贫困地区所估计营养不良的人高达 15%然而有人认为这个比例实际上还要 高,要检验该说法是否正确,则假设形式为( )。 隔50名学生抽取一名进行调查,这种调查方式是( A 、简单随机抽样 B 、分层抽样 C 、系统抽样 D 、整群抽样 4. 如果一组数据标准分数是(-2 ),表明该数据( )。
第1章统计和统计数据 指出下面的变量类型。(1)年龄。(2)性别。(3)汽车产量。 (4)员工对企业某项改革措施的态度(赞成、中立、反对)。(5)购买商品时的支付方式(现金、信用卡、支票)。详细答案:(1)数值变量。(2)分类变量。(3)数值变量。(4)顺序变量。(5)分类变量。 一家研究机构从IT从业者中随机抽取1000人作为样本进行调查,其中60%回答他们的月收入在5000元以上,50%的人回答他们的消费支付方式是用信用卡。 (1)这一研究的总体是什么样本是什么样本量是多少(2)“月收入”是分类变量、顺序变量还是数值变量(3)“消费支付方式”是分类变量、顺序变量还是数值变量详细答案:(1)总体是“所有IT从业者”,样本是“所抽取的1000名IT从业者”,样本量是1000。(2)数值变量。 (3)分类变量。 一项调查表明,消费者每月在网上购物的平均花费是200元,他们选择在网上购物的主要原因是“价格便宜”。 (1)这一研究的总体是什么 (2)“消费者在网上购物的原因”是分类变量、顺序变量还是数值变量详细答案: (1)总体是“所有的网上购物者”。(2)分类变量。 某大学的商学院为了解毕业生的就业倾向,分别在会计专业抽取50人、市场营销专业抽取30、企业管理20人进行调查。 (1)这种抽样方式是分层抽样、系统抽样还是整群抽样(2)样本量是多少详细答案:(1)分层抽样。(2)100。 第3章用统计量描述数据
排队方式各随机抽取9名顾客,得到第一种排队方式的平均等待时间为分钟,标准差为分钟,第二种排队方式的等待时间(单位:分钟)如下: (1)计算第二种排队时间的平均数和标准差。 (2)比两种排队方式等待时间的离散程度。 (3)如果让你选择一种排队方式,你会选择哪一种试说明理由。 详细答案: (1)(岁);(岁)。 (2);。第一中排队方式的离散程度大。 (3)选方法二,因为平均等待时间短,且离散程度小。 在某地区随机抽取120家企业,按利润额进行分组后结果如下:按利润额分组(万元)企业数(个) 300以下19 300~40030 400~50042 500~60018 600以上11 合计120 计算120家企业利润额的平均数和标准差(注:第一组和最后一组的组距按相邻组计算)。 详细答案: =(万元);(万元)。
1、20世纪70年代,人们就已发现,高达50%的疾病或死亡因素与什么有关? 行为及不健康的生活方式 2哪一年在上海成立的精武体育会是当时影响最大,传播最广,维持时间最长的武术组织?1910 3.网球比赛的第一原则是什么? 增加进攻(这个不确定,是根据网球老师说的选的) 4. 网球比赛中要赢得一局比赛,必须比对手多赢几分才可以? 2分 5. 联合国报告认为什么将会是21世纪最严重的健康问题? 体质下降 6. 国际羽联在哪一年正式恢复了我国的合法席位后,开始了我国羽毛球运动的鼎盛时期。1981 7. 哪一个季节人体脂肪合成速度最快? 冬天 8. 哪一年被世界公认为现代足球的诞生日? 1863 9. 下列哪位运动员是新中国历史上第一个获得世界锦标赛冠军的运动员? 容国团 10.在哪届奥运会上,乒乓球成为正式比赛项目? 汉城奥运会 11.篮球规则规定,篮圈离地垂直高度为多少? 3.05米 12. 1895年,由美国人()发明了排球运动。 威廉·G·摩根
13,。有助于提高肌肉力量的训练方法有哪些? 卧推 14.下列不易于发展柔韧素质的练习时段或状态有哪些?(这个也不清楚,是看它字体颜色不一样)身体极其疲惫 15.20世纪50年代末期,巴西人创造了哪种阵型被誉为足球史上的第二次变革。 “四二四”阵形 16.曾经在NBA总决赛中受伤,坚持参加比赛最后获得冠军并取得最有价值称号的凯尔特人球星是()? 保罗皮尔斯 17.体育锻炼与传统心理治疗手段同样具有抗抑郁效能,是治疗抑郁症的()手段;体育锻炼治疗抗抑郁症的效果与药物相比比较()。 辅助;持久 18.在运动中不慎扭伤,下列做法不正确的是() 马上揉搓患处 19.20XX年伦敦奥运会羽毛球囊括多少枚金牌? 5 20.“让参与者成为享受运动,实现人生潜能的一代”是哪一个健康促进的愿景? 为动而生 21.减小肚皮应采用哪一类运动? 长时间低强度 22.棍多以抡、劈、扫、云等法为主,大多是横方向用力,动作幅度较大,其特点:一招一式虎虎生威,动如疾风骤雨,产生"棍打一大片"的效果。棍被称为() 百兵之首 23.作为当下盛行的舞蹈元素,以人体中段(腰、腹、臀部)的各种动作为主,具有阿拉伯风情的舞蹈形式是()。肚皮舞
统计学题库及题库详细答案
————————————————————————————————作者:————————————————————————————————日期:
统计学题库及题库答案 题库1 一、单项选择题(每题2分,共20分) 1、调查时间是指( ) A 、调查资料所属的时间 B 、进行调查的时间 C 、调查工作的期限 D 、调查资料报送的时间 2、对某城市工业企业未安装设备进行普查,总体单位是( )。 A 、工业企业全部未安装设备 B 、企业每一台未安装设备 C 、每个工业企业的未安装设备 D 、每一个工业企业 3、对比分析不同性质的变量数列之间的变异程度时,应使用( )。 A 、全距 B 、平均差 C 、标准差 D 、变异系数 4、在简单随机重复抽样条件下,若要求允许误差为原来的2/3,则样本容量( ) A 、扩大为原来的3倍 B 、扩大为原来的2/3倍 C 、扩大为原来的4/9倍 D 、扩大为原来的2.25倍 5、某地区组织职工家庭生活抽样调查,已知职工家庭平均每月每人生活费收入的标准差为12元,要求抽样调查的可靠程度为0.9545,极限误差为1元,在简单重复抽样条件下,应抽选( )。 A 、576户 B 、144户 C 、100户 D 、288户 6、当一组数据属于左偏分布时,则( ) A 、平均数、中位数与众数是合而为一的 B 、众数在左边、平均数在右边 C 、众数的数值较小,平均数的数值较大 D 、众数在右边、平均数在左边 7、某连续变量数列,其末组组限为500以上,又知其邻组组中值为480,则末组的组中值为( )。 A 、520 B 、 510 C 、 500 D 、490 8、用组中值代表组内变量值的一般水平有一定的假定性,即( ) A 、各组的次数必须相等 B 、变量值在本组内的分布是均匀的 C 、组中值能取整数 D 、各组必须是封闭组 9、 n X X X ,,,21 是来自总体 ),(2 N 的样本,样本均值X 服从( )分布 A 、),(2 N B.、)1,0(N C.、 ),(2 n n N D 、) , (2 n N 10、测定变量之间相关密切程度的指标是( ) A 、估计标准误 B 、两个变量的协方差 C 、相关系数 D 、两个变量的标准差 二、多项选择题(每题2分,共10分)
288 Chapter 8: Confidence Interval Estimation CHAPTER 8 8.1 X ±Z ?σ n = 85±1.96? 864 83.04 ≤μ≤ 86.96 8.2 X ±Z ? σ n = 125±2.58?24 36 114.68 ≤μ≤ 135.32 8.3 If all possible samples of the same size n are taken, 95% of them include the true population average monthly sales of the product within the interval developed. Thus you are 95 percent confident that this sample is one that does correctly estimate the true average amount. 8.4 Since the results of only one sample are used to indicate whether something has gone wrong in the production process, the manufacturer can never know with 100% certainty that the specific interval obtained from the sample includes the true population mean. In order to have 100% confidence, the entire population (sample size N ) would have to be selected. 8.5 To the extent that the sampling distribution of sample means is approximately normal, it is true that approximately 95% of all possible sample means taken from samples of that same size will fall within 1.96 times the standard error away from the true population mean. But the population mean is not known with certainty. Since the manufacturer estimated the mean would fall between 10.99408 and 11.00192 inches based on a single sample, it is not necessarily true that 95% of all sample means will fall within those same bounds. 8.6 Approximately 5% of the intervals will not include the true population. Since the true population mean is not known, we do not know for certain whether it is contained in the interval (between 10.99408 and 11.00192 inches) that we have developed. 8.7 (a) X ±Z ?σ n =0.995±2.58? 0.02 50 0.9877≤μ≤1.0023 (b) Since the value of 1.0 is included in the interval, there is no reason to believe that the mean is different from 1.0 gallon. (c) No. Since σ is known and n = 50, from the Central Limit Theorem, we may assume that the sampling distribution of X is approximately normal. (d) The reduced confidence level narrows the width of the confidence interval. X ±Z ? σ n =0.995±1.96? 0.02 50 0.9895≤μ≤1.0005 (b) Since the value of 1.0 is still included in the interval, there is no reason to believe that the mean is different from 1.0 gallon.
1、统计学与统计工作的研究对象就是完全一致的。F 2、运用大量观察法,必须对研究对象的所有单位进行观察调查。T 3、统计学就是对统计实践活动的经验总结与理论概括。T 4、一般而言,指标总就是依附在总体上,而总体单位则就是标志的直接承担者。T 5、数量指标就是由数量标志汇总来的,质量指标就是由品质标志汇总来的。F 6、某同学计算机考试成绩80分,这就是统计指标值。F 7、统计资料就就是统计调查中获得的各种数据。F 8、指标都就是用数值表示的,而标志则不能用数值表示。F 9、质量指标就是反映工作质量等内容的,所以一般不能用数值来表示F。 10、总体与总体单位可能随着研究目的的变化而相互转化。T11、女性就是品质标志。T 12、以绝对数形式表示的指标都就是数量指标以相对数或平均数表示的指标都就是质量指标 T 13、构成统计总体的条件就是各单位的差异性。F 14、变异就是指各种标志或各种指标之间的名称的差异。F 9、调查某校学生,学生“一天中用于学习的时间”就是(A)A、标志 13、研究某企业职工文化程度时,职工总人数就是(B) B数量指标 14、某银行的某年末的储蓄存款余额(C)C、可能就是统计指标,也可能就是数量标志 15、年龄就是(B)B、离散型变量 四、多项选择题 1、全国第四次人口普查中(BCE)A、全国人口数就是统计总体B、总体单位就是每一个人 C、全部男性人口数就是统计指标 D、男女性别比就是总体的品质标志 E、人的年龄就是变量 2、统计总体的特征表现为(ACD)A、大量性B、数量性C、同质D、差异性E、客观性 3、下列指标中属于质量指标的有(ABCDE)A、劳动生产率B、产品合格率C、人口密度 D、产品单位成本 E、经济增长速度 4、下列指标中属于数量指标的有(ABC) A、国民生产总值B、国内生产总值C、固定资产净值D、劳动生产率E、平均工资 5、下列标志中属于数量标志的有(BD)A、性别B、出勤人数C、产品等级D、产品产量E 文化程度 6、下列标志中属于品质标志的有(ABE)A、人口性别B、工资级别C、考试分数D、商品使用寿命E、企业所有制性质 7、下列变量中属于离散型变量的有(BE)A、粮食产量B、人口年龄C、职工工资 D、人体身高 E、设备台数 8、研究某企业职工的工资水平,“工资”对于各个职工而言就是(ABE)A、标志B、数量标
3.3 某百货公司连续40天的商品销售额如下: 单位:万元 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 要求:根据上面的数据进行适当的分组,编制频数分布表,并绘制直方图。 1、确定组数: ()l g 40l g () 1.60206 111 6.32l g (2)l g 20.30103 n K =+ =+=+=,取k=6 2、确定组距: 组距=( 最大值 - 最小值)÷ 组数=(49-25)÷6=4,取5 3、分组频数表 销售收入(万元) 频数 频率% 累计频数 累计频率% <= 25 1 2.5 1 2.5 26 - 30 5 12.5 6 15.0 31 - 35 6 15.0 12 30.0 36 - 40 14 35.0 26 65.0 41 - 45 10 25.0 36 90.0 46+ 4 10.0 40 100.0 总和 40 100.0 频数 246810121416<= 25 26 - 30 31 - 35 36 - 40 41 - 45 46+ 销售收入 频数 频数 3.9.下面是某考试管理中心对2002年参加成人自学考试的12000名学生的年龄分组数据: 年龄 18~19 21~21 22~24 25~29 30~34 35~39 40~44 45~59 % 1.9 34.7 34.1 17.2 6.4 2.7 1.8 1.2 (1) 对这个年龄分布作直方图; (2) 从直方图分析成人自学考试人员年龄分布的特点。 解:(1)制作直方图:将上表复制到Excel 表中,点击:图表向导→柱形图→选择子图表类型→完成。即得到如下的直方图:(见Excel 练习题2.6)
运筹学部分课后习题解答P47 1.1 用图解法求解线性规划问题 a) 12 12 12 12 min z=23 466 ..424 ,0 x x x x s t x x x x + +≥ ? ? +≥ ? ?≥ ? 解:由图1可知,该问题的可行域为凸集MABCN,且可知线段BA上的点都为 最优解,即该问题有无穷多最优解,这时的最优值为 min 3 z=2303 2 ?+?= P47 1.3 用图解法和单纯形法求解线性规划问题 a) 12 12 12 12 max z=10x5x 349 ..528 ,0 x x s t x x x x + +≤ ? ? +≤ ? ?≥ ? 解:由图1可知,该问题的可行域为凸集OABCO,且可知B点为最优值点, 即 1 12 122 1 349 3 528 2 x x x x x x = ? += ?? ? ?? +== ?? ? ,即最优解为* 3 1, 2 T x ?? = ? ?? 这时的最优值为 max 335 z=1015 22 ?+?=
单纯形法: 原问题化成标准型为 121231241234 max z=10x 5x 349 ..528,,,0x x x s t x x x x x x x +++=?? ++=??≥? j c → 10 5 B C B X b 1x 2x 3x 4x 0 3x 9 3 4 1 0 0 4x 8 [5] 2 0 1 j j C Z - 10 5 0 0 0 3x 21/5 0 [14/5] 1 -3/5 10 1x 8/5 1 2/5 0 1/5 j j C Z - 1 0 - 2 5 2x 3/2 0 1 5/14 -3/14 10 1x 1 1 0 -1/7 2/7 j j C Z - -5/14 -25/14
1计算之树中,通用计算环境的演化思维是怎样概括的?________。 A.程序执行环境—由CPU-内存环境,到CPU-存储体系环境,到多CPU-多存储器环境,再到云计算虚拟计算环境 B.网络运行环境---由个人计算机、到局域网广域网、再到Internet C.元器件---由电子管、晶体管、到集成电路、大规模集成电路和超大规模集成电路 D.上述全不对 正确答案:A
2计算之树中,网络化思维是怎样概括的________。 A.局域网、广域网和互联网 B.机器网络、信息网络和人-机-物互联的网络化社会 C.机器网络、信息网络和物联网 D.局域网络、互联网络和数据网络 正确答案: B
3人类应具备的三大思维能力是指_____。 A.抽象思维、逻辑思维和形象思维 B.实验思维、理论思维和计算思维 C逆向思维、演绎思维和发散思维 D.计算思维、理论思维和辩证思维 正确答案:B
4如何学习计算思维?_____。 A.为思维而学习知识而不是为知识而学习知识 B.不断训练,只有这样才能将思维转换为能力 C.先从贯通知识的角度学习思维,再学习更为细节性的知识,即用思维引导知识的学习 D.以上所有 正确答案:D
5自动计算需要解决的基本问题是什么?_______。 A.数据的表示,数据和计算规则的表示 B.数据和计算规则的表示与自动存储 C数据和计算规则的表示、自动存储和计算规则的自动执行D.上述说法都不正确 正确答案:C
6计算机器的基本目标是什么? _______。 A.能够辅助人进行计算,能够执行简单的四则运算规则 B.能够执行特定的计算规则,例如能够执行差分计算规则等 C.能够执行一般的任意复杂的计算规则 D.上述说法都不正确 正确答案:C
统计学题库及题库答案 ) B 、进行调查的时间 D 、调查资料报送的时间 2、对某城市工业企业未安装设备进行普查,总体单位是( ) A 、工业企业全部未安装设备 B 、企业每一台未安装设备 C 、每个工业企业的未安装设备 D 、每一个工业企业 3、 对比分析不同性质的变量数列之间的变异程度时 ,应使用( )。 A 、全距 B 、平均差 C 、标准差 D 、变异系数 4、 在简单随机重复抽样条件下,若要求允许误差为原来的 2/3,则样本容量( ) A 、扩大为原来的 3倍 B 、扩大为原来的 2/3倍 C 、扩大为原来的 4/9倍 D 、扩大为原来的 2.25倍 5、 某地区组织职工家庭生活抽样调查 ,已知职工家庭平均每月每人生活费收入的标准差为 可靠程度为0.9545,极限误差为1元,在简单重复抽样条件下,应抽选( )。 A 、576 户 B 、144 户 C 、100 户 D 、288 户 6、当一组数据属于左偏分布时,则( ) A 、 平均数、中位数与众数是合而为一的 B 、 众数在左边、平均数在右边 C 、 众数的数值较小,平均数的数值较大 D 、众数在右边、平均数在左边 7、 某连续变量数列,其末组组限为 500以上,又知其邻组组中值为 480,则末组的组中值为( ) A 、 520 B 、 510 C 、 500 D 、 490 8、 用组中值代表组内变量值的一般水平有一定的假定性,即( ) A 、 各组的次数必须相等 B 、 变量值在本组内的分布是均匀的 C 、 组中值能取整数 D 、 各组必须是封闭组 9、 XjX 2’…,X n 是来自总体的样本,样本均值 X 服从( )分布 A 、N(F 2) B.、N(0,1) C 、 N(n 巴nb 2 ) N(=) D 、 n 10、测定变量之间相关密切程度的指标是( ) A 、估计标准误 B 、两个变量的协方差 C 、相关系数 D 、两个变量的标准差 二、多项选择题(每题 2分,共10分) 1、抽样推断中,样本容量的多少取决于( )。 A 、总体标准差的大小 B 、 允许误差的大小 c 、抽样估计的把握程度 D 、总体参 题库1 、单项选择题(每题 2分,共20分) 1、调查时间是指( A 、调查资料所属的时间 C 、调查工作的期限 12元,要求抽样调查的
附录:教材各章习题答案 第1章统计与统计数据 1.1(1)数值型数据;(2)分类数据;(3)数值型数据;(4)顺序数据;(5) 分类数据。 1.2(1)总体是“该城市所有的职工家庭”,样本是“抽取的2000个职工家庭”; (2)城市所有职工家庭的年人均收入,抽取的“2000个家庭计算出的年人均收入。 1.3(1)所有IT从业者;(2)数值型变量;(3)分类变量;(4)观察数据。1.4(1)总体是“所有的网上购物者”;(2)分类变量;(3)所有的网上购物者 的月平均花费;(4)统计量;(5)推断统计方法。 1.5(略)。 1.6(略)。 第2章数据的图表展示 2.1(1)属于顺序数据。 (2)频数分布表如下 (4)帕累托图(略)。 2.2(1)频数分布表如下
2.3 2.5(1)排序略。 (2)频数分布表如下 (4)茎叶图如下
2.6 (3)食品重量的分布基本上是对称的。 2.7 2.8(1)属于数值型数据。
2.9 (1)直方图(略)。 (2)自学考试人员年龄的分布为右偏。 布比A 班分散, 且平均成绩较A 班低。 2.11 (略)。 2.12 (略)。 2.13 (略)。 2.14 (略)。 2.15 箱线图如下:(特征请读者自己分析) 第3章 数据的概括性度量 3.1 (1)100=M ;10=e M ;6.9=x 。
(2)5.5=L Q ;12=U Q 。 (3)2.4=s 。 (4)左偏分布。 3.2 (1)190=M ;23=e M 。 (2)5.5=L Q ;12=U Q 。 (3)24=x ;65.6=s 。 (4)08.1=SK ;77.0=K 。 (5)略。 3.3 (1)略。 (2)7=x ;71.0=s 。 (3)102.01=v ;274.02=v 。 (4)选方法一,因为离散程度小。 3.4 (1)x =274.1(万元);M e=272.5 。 (2)Q L =260.25;Q U =291.25。 (3)17.21=s (万元)。 3.5 甲企业平均成本=19.41(元),乙企业平均成本=18.29(元);原 因:尽管两个企业的单位成本相同,但单位成本较低的产品在乙企业的产量中所占比重较大,因此拉低了总平均成本。 3.6 (1)x =426.67(万元);48.116=s (万元)。 (2)203.0=SK ;688.0-=K 。 3.7 (1)(2)两位调查人员所得到的平均身高和标准差应该差不多相 同,因为均值和标准差的大小基本上不受样本大小的影响。 (3)具有较大样本的调查人员有更大的机会取到最高或最低者,因为样本越大,变化的范围就可能越大。 3.8 (1)女生的体重差异大,因为女生其中的离散系数为0.1大于男生 体重的离散系数0.08。 (2) 男生:x =27.27(磅),27.2=s (磅); 女生:x =22.73(磅),27.2=s (磅); (3)68%; (4)95%。 3.9 通过计算标准化值来判断,1=A z ,5.0=B z ,说明在A项测试中 该应试者比平均分数高 出1个标准差,而在B 项测试中只高出平均分数0.5个标准差,由于A 项测试的标准化值高于B 项测试,所以A 项测试比较理想。 3.10 通过标准化值来判断,各天的标准化值如下表 日期 周一 周二 周三 周四 周五 周六 周日 标准化值Z 3 -0.6 -0.2 0.4 -1.8 -2.2 0 周一和周六两天失去了控制。
统计学题库及题库答案 题库1 一、单项选择题(每题2分,共20分) 1、调查时间就是指( ) A 、调查资料所属的时间 B 、进行调查的时间 C 、调查工作的期限 D 、调查资料报送的时间 2、对某城市工业企业未安装设备进行普查,总体单位就是( )。 A 、工业企业全部未安装设备 B 、企业每一台未安装设备 C 、每个工业企业的未安装设备 D 、每一个工业企业 3、对比分析不同性质的变量数列之间的变异程度时,应使用( )。 A 、全距 B 、平均差 C 、标准差 D 、变异系数 4、在简单随机重复抽样条件下,若要求允许误差为原来的2/3,则样本容量( ) A 、扩大为原来的3倍 B 、扩大为原来的2/3倍 C 、扩大为原来的4/9倍 D 、扩大为原来的2、25倍 5、某地区组织职工家庭生活抽样调查,已知职工家庭平均每月每人生活费收入的标准差为12元,要求抽样调查的可靠程度为0、9545,极限误差为1元,在简单重复抽样条件下,应抽选 ( )。 A 、576户 B 、144户 C 、100户 D 、288户 6、当一组数据属于左偏分布时,则( ) A 、平均数、中位数与众数就是合而为一的 B 、众数在左边、平均数在右边 C 、众数的数值较小,平均数的数值较大 D 、众数在右边、平均数在左边 7、某连续变量数列,其末组组限为500以上,又知其邻组组中值为480,则末组的组中值为 ( )。 A 、520 B 、 510 C 、 500 D 、490 8、用组中值代表组内变量值的一般水平有一定的假定性,即( ) A 、各组的次数必须相等 B 、变量值在本组内的分布就是均匀的 C 、组中值能取整数 D 、各组必须就是封闭组 9、n X X X ,,,21 就是来自总体 ),(2 N 的样本,样本均值X 服从( )分布 A 、),(2 N B 、、)1,0(N C 、、),(2 n n N D 、) ,(2n N 10、测定变量之间相关密切程度的指标就是( ) A 、估计标准误 B 、两个变量的协方差 C 、相关系数 D 、两个变量的标准差 二、多项选择题(每题2分,共10分)