
第38卷 第6期 海 洋 与 湖 沼
Vol.38, No.6
2007年11月
OCEANOLOGIA ET LIMNOLOGIA SINICA Nov ., 2007
*国家高技术研究发展计划项目(遥感应用模块检测与验证技术研究), 2005AA604150号。纪永刚, 博士, E-mail: jiyonggang@https://www.doczj.com/doc/215062970.html,
收稿日期: 2006-01-04, 收修改稿日期: 2007-12-06
神舟四号高度计波形数据预处理和信息提取*
纪永刚1 张 杰1 张有广2 孟俊敏1
(1. 国家海洋局第一海洋研究所 青岛 266061; 2. 国家卫星海洋应用中心 北京 100081)
提要 神舟四号(SZ-4)高度计在国内首次提供了星载雷达高度计回波波形数据。本文中作者分析了SZ-4高度计回波波形的特点, 完成波形数据的预处理, 并在此基础上完成初步的信息提取。在数据预处理方面, 通过SZ-4高度计水陆边界处波形的特点, 提出了波形最大幅度控制的方法, 筛选回波波形。在波形归一化处理过程中, 发现SZ-4高度计波形中存在双峰现象, 并指出第二个峰为异常波形区。在波形信息提取方面, 利用波形重新跟踪得到的半功率点计算出SZ-4高度计高度跟踪补偿误差, 并根据高度计天线指向角和回波波形下降沿斜率之间的关系, 从波形后沿提取天线指向角信息。分析结果表明, SZ-4高度计天线指向比较平稳, 而跟踪补偿由于变化较大, 在计算海面高度时, 应作为一项误差源被考虑到。 关键词 神舟四号高度计, 回波波形, 波形重跟踪, 高度跟踪补偿, 指向角 中图分类号 TP753
国外雷达高度计卫星从最早的Skylab 开始, 已经发射了GEOS-3、Seasat 、Geosat 、ERS-1/2、TOPEX/Poseidon, 一直到最新的GFO 、Jason-1、Envisat 、ICESat 等多颗高度计卫星; Cryosat 、Jason-2等已在计划发射阶段。2002年12月30日凌晨发射的“神舟四号”(SZ-4)飞船是中国发射的第四艘无人飞船, 其主要载荷是多模态微波遥感器, 其中高度模态(高度计)是多模态微波遥感器中的一个主要模态。在近5个月的时间内, SZ-4高度计在留轨期间的五次对地观测内获取了大量的航天雷达高度计回波数据。利用获取的大量波形数据, 加上GPS 定轨信息, 可提取海面高度、有效波高和海面风速等基本物理量, 并通过对提取物理量的分析和处理, 开展大地测量学、地球物理学和海洋动力学的研究(王广运等, 1995; Fu et al , 2001)。
与国外已业务化运行的卫星高度计不同, SZ-4高度计为一试验系统, 需要根据其波形数据来提取有效波高、海面高度、海面风速等信息, 并通过与实测数据的比对来验证其功能体制。而SZ-4高度计波形数据的预处理是波形数据信息
提取前的数据处理阶段, 此过程必不可少, 其数据处理质量的好坏, 直接影响到后续信息提取的效果。国外业务化运行的卫星高度计的波形数据预处理甚至一些波形信息的提取, 如有效波高的信息提取, 都是在卫星上完成的。而SZ-4高度计波形数据的预处理需要在数据下传到地面后进行, 其主要过程包括数据的质量控制、多波形平均、波形归一化等处理过程。同时, 一些基本的波形信息是在波形预处理过程中完成的, 如高度跟踪补偿和高度计天线指向角, 都是在波形分析的基础上提取得到的。
1 SZ-4数据预处理
1.1 数据质量控制
当高度计足印靠近陆地或位于浅水海区时, 陆地散射表面的不规则性及散射特性的多变性, 会造成地表倾角变化的不连续, 对处于陆地跟踪模式的高度计, 将造成高度偏差信号的很大误差, 从而导致跟踪环失锁。由于雷达回波信号的幅度过强, 波动起伏过大, 使得高度计总是处于锁 定—失锁—再锁定的不稳定状态。此时具有较大脉冲幅度的回波波形已明显不同于足印位于深水
488 海洋与湖沼38卷
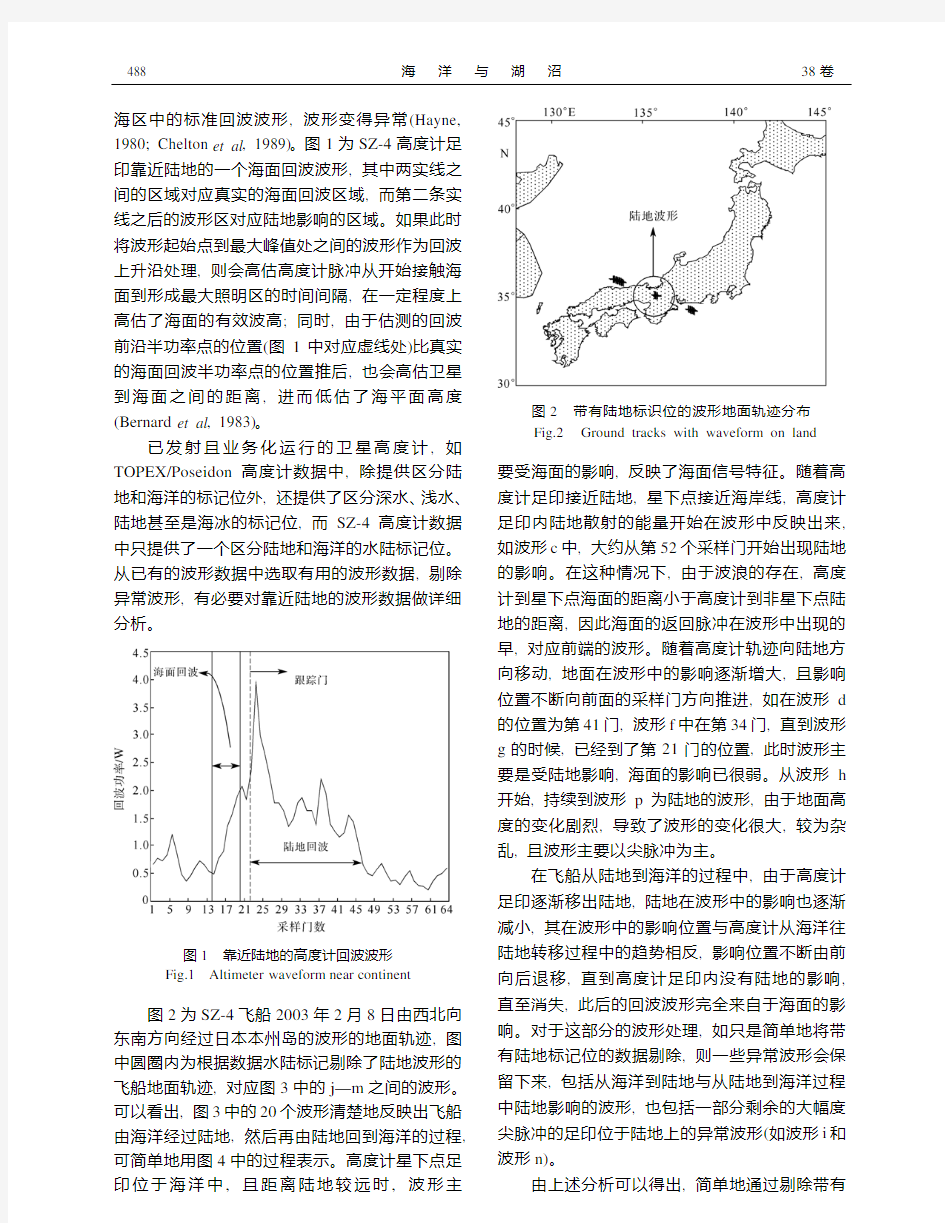
海区中的标准回波波形, 波形变得异常(Hayne, 1980; Chelton et al, 1989)。图1为SZ-4高度计足印靠近陆地的一个海面回波波形, 其中两实线之间的区域对应真实的海面回波区域, 而第二条实线之后的波形区对应陆地影响的区域。如果此时将波形起始点到最大峰值处之间的波形作为回波上升沿处理, 则会高估高度计脉冲从开始接触海面到形成最大照明区的时间间隔, 在一定程度上高估了海面的有效波高; 同时, 由于估测的回波前沿半功率点的位置(图1中对应虚线处)比真实的海面回波半功率点的位置推后, 也会高估卫星到海面之间的距离, 进而低估了海平面高度(Bernard et al, 1983)。
已发射且业务化运行的卫星高度计, 如TOPEX/Poseidon高度计数据中, 除提供区分陆地和海洋的标记位外, 还提供了区分深水、浅水、陆地甚至是海冰的标记位, 而SZ-4高度计数据中只提供了一个区分陆地和海洋的水陆标记位。从已有的波形数据中选取有用的波形数据, 剔除异常波形, 有必要对靠近陆地的波形数据做详细分析。
图1 靠近陆地的高度计回波波形
Fig.1 Altimeter waveform near continent
图2为SZ-4飞船2003年2月8日由西北向东南方向经过日本本州岛的波形的地面轨迹, 图中圆圈内为根据数据水陆标记剔除了陆地波形的飞船地面轨迹, 对应图3中的j—m之间的波形。可以看出, 图3中的20个波形清楚地反映出飞船由海洋经过陆地, 然后再由陆地回到海洋的过程, 可简单地用图4中的过程表示。高度计星下点足印位于海洋中,且距离陆地较远时,波形主
图2 带有陆地标识位的波形地面轨迹分布
Fig.2 Ground tracks with waveform on land
要受海面的影响, 反映了海面信号特征。随着高度计足印接近陆地, 星下点接近海岸线, 高度计足印内陆地散射的能量开始在波形中反映出来, 如波形c中, 大约从第52个采样门开始出现陆地的影响。在这种情况下, 由于波浪的存在, 高度计到星下点海面的距离小于高度计到非星下点陆地的距离, 因此海面的返回脉冲在波形中出现的早, 对应前端的波形。随着高度计轨迹向陆地方向移动, 地面在波形中的影响逐渐增大, 且影响位置不断向前面的采样门方向推进, 如在波形d 的位置为第41门, 波形f中在第34门, 直到波形g的时候, 已经到了第21门的位置, 此时波形主要是受陆地影响, 海面的影响已很弱。从波形h 开始, 持续到波形p为陆地的波形, 由于地面高度的变化剧烈, 导致了波形的变化很大, 较为杂乱, 且波形主要以尖脉冲为主。
在飞船从陆地到海洋的过程中, 由于高度计足印逐渐移出陆地, 陆地在波形中的影响也逐渐减小, 其在波形中的影响位置与高度计从海洋往陆地转移过程中的趋势相反, 影响位置不断由前向后退移, 直到高度计足印内没有陆地的影响, 直至消失, 此后的回波波形完全来自于海面的影响。对于这部分的波形处理, 如只是简单地将带有陆地标记位的数据剔除, 则一些异常波形会保留下来, 包括从海洋到陆地与从陆地到海洋过程中陆地影响的波形, 也包括一部分剩余的大幅度尖脉冲的足印位于陆地上的异常波形(如波形i和波形n)。
由上述分析可以得出, 简单地通过剔除带有
6期 纪永刚等: 神舟四号高度计波形数据预处理和信息提取
489
图3 所有地面轨迹的高度计回波波形
Fig.3 Altimeter waveforms of all ground tracks
图4 经过陆地的波形过程图
Fig.4 The waveforms during land passing
陆地标识位的波形数据, 必然还会保留浅水海域或者陆地影响的部分异常波形, 因此仅仅根据波形数据中提供的水陆标记位剔除异常波形是不够的。很明显的是, 保留下来的异常波形, 特别是受陆地影响较大的波形都是幅度较大的尖脉冲(如图3的波形i)。在图5中, 作者做出了较大幅度尖脉冲异常波形的位置统计分布, 其中异常波形处用实心圆表示。从图5可以看出, 出现的异常波形很大一部分集中在靠近陆地或岛屿附近, 其主要波形形状为图6中波形a 。但出现在103.89°E—14.5°S 处的一条数量较大的异常波形带, 波形主要为双尖峰波形, 见图6波形b 。这部分异常波形带出现的位置并不是在陆地或岛屿附近浅水区, 且数量很大, 其原因可能与当时的飞船运行状态、高度计仪器跟踪状态或仪器的增益不稳定有关。因此根据异常波形具有较大幅度的
特点, 作者除利用陆地标志位剔除部分异常波形外, 还可以简单地利用限制波形脉冲幅度的方法对波形做进一步筛选。通过这种限制波形最大脉冲幅度的方法, 剔除2.3%数量的异常波形(以2月8日的SZ-4高度计数据为例)。利用限制脉冲幅度的方法进行筛选是较为简单的方法, 进一步的波形筛选可以结合具体的波形分析和处理方式对波形数据加以控制。
1.2 波形处理
1.2.1 波形一秒平均 为减小波形中的随机噪声及其他系统误差的影响, 需要对多个波形进行平均, 常用的是一秒平均(Hayne, 1980), 即20个波形(50ms 平均)对应采样门值的平均。一秒平均的过程本身就是对波形数据进行筛选的过程,因此需要按照前面提出的水陆交界处波形的质量控制条件, 对每一个参与一秒平均的波形进行筛
490 海 洋 与 湖 沼 38卷
图5 异常波形分布
Fig.5 Distribution of abnormal waveforms
图6 异常波形 Fig.6 Abnormal waveforms
选, 即每次选取20个原始波形数据, 首先剔除其中带有陆地标记位的数据, 然后利用限制波形脉冲幅度的方法剔除异常波形, 最后计算剩余的波形对应采样门值的平均值。
1.2.2 波形热噪声消除 图7a 为参与一秒平均的一个原始波形, 图7b 是20个波形平均之后的波形。从图7b 可以看出, 平均后的回波波形主要有四部分组成:跟踪器精距离调整区(第1和12个采样门之间)、较为平坦的热噪声区(13和19个采样门之间)、波形前沿上升区(21个采样门和第37个采样门之间)和波形后沿衰减区。其中, 热噪声对整个波形产生影响, 需求出平均热噪声分量, 然后将其从波形对应采样门值中减去, 以消除其影响。对SZ-4高度计波形, 热噪声分量可通过求波形上升沿以前连续且稳定的5个采样门值的平均来估计:
P thermal =4
1()5k i k
FFT i +=∑, 064i ≤≤ (1)
其中, ()FFT i 为第i 个波形采样门值,
k 是波形
中第一个出现稳定采样门的位置。由于波形前沿存在跟踪器精距离调整区, 文中选取第13采样门到波形前言起始点之间的相对平坦的区域作为热噪声区, 热噪声消除处理见公式(2), 处理后结果见图7c 。
()()()thermal ,1364
0,113FFT i FFT i P i FFT i i ?=???
=??
≤≤≤≤ (2) 1.2.3 波形归一化 波形归一化处理, 即
()(),
164max FFT i FFT i i FFT
=
≤≤ (3)
其中, Max FFT 为去噪波形前沿的最大采样门值, 满足max FFT= max [FFT ( i )]。
归一化过程中, 需要通过对回波形状、回波幅度的分析, 找出波形最大值。通过对大量回波
6期 纪永刚等: 神舟四号高度计波形数据预处理和信息提取
491
图7 1秒平均前的原始波形(a)、1秒平均的波形(b)、去噪后的波形 (c)
Fig.7 Original waveform before one-second average process (a); one-second averaged waveform (b); Waveform clear
of thermal noise (c)
波形的统计分析发现, 原始50ms 波形(图7a) 和一秒平均后的波形(图7b), 都存在明显的两个波峰, 且两峰值低谷的位置基本在固定的位置, 大约在第41个采样门处。
图8给出具有典型双峰波形。从这几个波形中可以看出, 从波形前沿起始处到第一个高峰之间的波形真实地反映了波形平缓上升的趋势, 对应高度计星下点照明区面积连续增大的过程。而第二个峰值在波形后沿衰减区出现的较大幅值, 属于波形异常区, 就其形成原因可能是由于在量化器中存在直流偏压以及其他未知信号的影响造成的(Deng et al , 2001), 此异常信号在波形的影响范围主要集中在第二峰值周围的5个采样门。经过上述分析, 文中选取第一个峰值为最大峰值进行归一化操作。找到波形最大峰值之后, 代入公式(3), 完成波形的归一化处理。归一化后的波形见图9。
图8 神舟四号高度计双峰波形
Fig.8
The altimeter waveform with two peaks
图9 归一化波形
Fig.9 Normalized waveform
2 高度计波形信息提取
2.1 高度跟踪补偿
从高度计得到的海面高度, 并不对应真实的
海平面, 而是有一定的偏差。为了补偿由于波形半功率点与跟踪门之间的偏差而引起的海面高度偏差, 即跟踪补偿误差, 需要重新跟踪波形。半功率点位置通过在波形中临近阈值交叉门的线性插值确定(Michael et al , 1999):
0(1)
(1)()(1)
TL FFT n t n FFT n FFT n ??=?+
?? (4)
其中, TL 为阈限值, n 是在归一化波形中第一个超过阈值的采样门的位置。根据得到的半功率 点0t , 求出跟踪补偿量dr (单位m)( Michael et al ,
1999):
dr =()02
r c
ts t t ×? (5)
492 海 洋 与 湖 沼
38卷
其中, ts 为脉冲宽度(SZ-4 高度计的脉冲宽度为3ns), c 为光速, r t 为高度计跟踪门位置。代入c
和ts 后, 公式(7)可进一步得:
dr =()00.4497r t t ×? (6)
根据上述公式, 计算得到了2月8日SZ-4高度计数据的跟踪补偿的时间序列分布, 见图10。 2.2 SZ-4高度计天线指向角估计
由于高度计天线指向角ξ的平方和回波波形下降沿斜率B 之间存在如下的关系式(Batoulas et al , 1999):
2/142B αξγ
+=+
其中, 41c
H H R αγ=
??+
????
, 20.725sin γθ=, c 为光
速, H 为卫星高度, θ为天线孔径, R 为地球半径。
可以看出, 指向角的平方2
ξ除了主要取决于波形下降沿的斜率外, 还与卫星高度、天线孔径有关。波形后沿的衰减反映天线指向, 对测量卫星到海面之间的距离产生很大的影响, 可以通过波形拟合的方法得到回波波形下降沿沿的斜率B , 然后求出飞船指向角, 详细过程见参考文献(张有广等, 2007)。
对于波形下降沿的拟合通常采用分段拟合, 而不是对整个下降沿的波形进行拟合, 分段的方法对于每个高度计都不尽相同。对于SZ-4高度计来说, 考虑到双峰现象中第二个波峰(41采样门位置)的影响, 这里是选取44—60采样门之间的一段波形进行拟合。图11中列出了2003年2月8日波形数据得到的天线指向角的分布图。结果
表明, 利用回波波形后沿拟合得到的SZ-4高度计天线指向角在计算时间内比较平稳, 大部分在
图10 高度跟踪补偿量的分布
Fig.10 Distribution of range retracking correction
图11 高度计天线指向角分布
Fig.11 Distribution of altimeter antenna pointing angle
6期纪永刚等: 神舟四号高度计波形数据预处理和信息提取 493
0.01o以内变化, 变化不大, 说明SZ-4高度计运行指向较为稳定。
3结论与讨论
通过对SZ-4高度计波形的分析和处理, 做SZ-4高度计波形的预处理与初步的信息提取, 得出如下主要结论:
(1) SZ-4高度计异常波形以较大幅度脉冲出现, 可通过限制其最大脉冲幅度的方法加以剔除。
(2) SZ-4高度计波形中存在双峰现象, 其中第二个波峰为中心的波形区域为波形异常区。
(3) SZ-4高度计的跟踪补偿误差较大, 是计算海面高度中的一个较大误差源。
(4) SZ-4高度计天线指向比较平稳。
此外, 作者利用限制脉冲最大幅度的方法来筛选回波波形, 进一步的异常波形剔除可结合具体的波形分析和处理加以控制, 如进行有效波高反演时, 通过控制前沿上升沿斜率等方式来做波形数据的进一步筛选。同时, 在利用波形进行信息提取的过程中, 应注意回波波形中出现的双峰现象, 尽量减少其影响。
参考文献
王广运,王海瑛,许国昌等, 1995. 卫星测高原理. 北京: 科学出版社, 25—31
张有广, 林明森, 2007. “SZ-4”飞船高度计天线指向角反
演方法. 海洋学报, 29(3): 47—50
Bernard J, Barlier F, Bethoux J P et al, 1983. First Seasat Altimeter Data Analysis on the Western Mediterranean
Sea. Journal of Geophysical Research, 88(C3): 1581—1588
Batoulas S, Ouan-Zan Zanife,1999. ERS-2 radar altimeter off pointing impact study: Task1-Impact of the Mispointing on the Altimeters Measurements by Simulation. 195: 4—9
Chelton D B, Walsh E J, MacArthur J L, 1989. Pulse Compression and Sea Level Tracking in Satellite
Altimetry. Journal of Atmospheric and Oceanic Technology, 6(3): 407—438
Deng X, Featherstone W, Berry P et al, 2001. Retracking ERS-2 Radar altimetry waveform data in Australia’s
coastal zone. IAG 2001 Scientific Assembly, Budapest,
Hungary, 2—7
Ernesto R, Jan M, 1994. Martin. Assessment of the Topex altimeter performance using waveform retracking.
Journal of Geophysical Research, 99(C12): 24957—24969
Fu L L, Anny Cazenave, 2001. Satellite Altimetry and Earth Sciences. San Diego: Academic Press, 2—15
Hayne G S, 1980. Radar altimeter mean return waveform from near-normal-incidence Ocean surface scattering.
IEEE Transaction on Antennas and Propagation, 28(5):
687—692
Michael A, Shum C K, Renstch M et al,1999. Coastal altimetry and applications. Ohio Columbus: Department
of Civil and Environmental Engineering and Geodetic
Science of the Ohio State University, Report No. 464:
4—14
Thomas V, MARTIN H J, ZWALLY A et al, 1983. Analysis and retracking of continental ice sheet radar altimeter
waveforms. Journal of Geophysical Research, 88(C3):
1608—1616
494 海洋与湖沼38卷THE PRETREATMENT AND INFORMATION RETRIEVAL OF WAVEFORM
DATA OF CHINESE SPACECRAFT SHENZHOU-4 BORNE ALTIMETER
JI Yong-Gang1, ZHANG Jie1, ZHANG You-Guang2, MENG Jun-Min1
(1. First Institute of Oceanography, State Oceanic Administration, Qingdao, 266061;2. National Satellite
Ocean Application Service, Beijing, 100081)
Abstract The space borne altimeter flown on Chinese spacecraft Shenzhou-4 has provided waveform data for the first time in China. The data pre?process is necessary before the waveform data are used to retrieve parameters, such as wind speed and significant wave height. First, the waveforms near land-ocean borders were analyzed to eliminate abnormal waveforms. Second, the waveforms were averaged to remove thermal noise. Finally, normalized waveforms were obtained for further application. After re-tracking the waveforms, the range retracking correction and the altimeter antenna pointing angle were calculated. The results show that the most abnormal waveforms could be cleared by limiting the maximum amplitude. In normal waveforms, double peaks were found, of which the second one is abnormal. Meanwhile, the antenna pointing angle is relatively stable while the range retracking correction varies considerably so that it should be considered as an error source when extracting the sea surface height.
Key words Shenzhou-4 spaceborne altimeter, Echo waveform, Waveform retracking, Range retracking correction, Antenna pointing angle
信息管理数据库作业答案 下载office 文档附件 1. 2.视图消解 因为视图没有真实数据,所以对视图的查询要转换为对相应表的查询,这个过程叫视图消解,视图消解过程由DBMS自动完成 正确答案: 视图是从一个或几个基本表(或视图)导出的表,是一个虚表。将对视图的查询 转换为对基本表的查询的过程称为视图的消解。 3.函数依赖 函数依赖是从数学角度来定义的,在关系中用来刻画关系各属性之间相互制约而又相互依赖的情况。其类型包括部分函数依赖、完全函数依赖、传递函数依赖。 正确答案: 设R(U)是属性集U上的关系模式。X,丫是U的子集。若对于R(U)的任意一个 可能的关系r ,r 中不可能存在两个元组在X上的属性值相等,而在丫上的属性值 不等,则称X函数确定丫或丫函数依赖于X,记作X?Y。 4.事务 事务(Transaction) 是用户定义的一个对数据库读写操作序列,是一个不可分 割的工作单位,也是数据库恢复和并发控制的基本单位。数据库系统中通常有多个 事务并行运行。在关系数据库中,事务可以是一条、一组SQL语句,或整个程序。 正确答案: 事务是用户定义的一个数据库操作序列,这些操作要么全做要么全不做,是个不可分割的工作单位。
5.数据字典 数据字典(Data dictionary) 是一种用户可以访问的记录数据库和应用程序元数据的目录。主动数据字典是指在对数据库或应用程序结构进行修改时,其内容可以由DBMS自动更新的数据字典。被动数据字典是指修改时必须手工更新其内容的数据字典。正确答案: 数据字典是系统中各类数据描述的集合,是进行详细的数据收集和数据分析所获得的主要成果。 6. 数据库角色 对某个Analysis Services 数据库具有相同访问权限的用户和组的集合。可以将数据库角色指派给数据库中的多个多维数据集,从而将该角色的用户访问权限授予这些多维数据集。正确答案: 对某个数据库具有相同访问权限的用户和组的集合。 7. 简述数据库恢复的基本技术 当系统运行过程中发生故障时,数据库恢复技术将数据库从错误状态恢复到某个一致状态,它是数据库可靠性的保证。数据库恢复的基本原理是利用存储在系统别处的冗余数据来重建其恢复技术的两个关键:(1) 如何建立冗余数据(2) 如何利用冗余数据恢复数据库正确答案: 数据转储:所谓转储即DBA定期地将整个数据库复制到磁盘或另一个磁盘上保存起来的过程。这些备用的数据文本成为后备副本或后援副本。 静态转储:在系统中无运行事物时进行的转储操作。动态转储:在转储期间允许对数据库进行存取或修改。即转储和用户事务可以并发执行。海量转储:每次转储全部数据库增量转储:每次只转储上一次转储后更新过的数据。登记日志文件:日志文件是用来记录事务对数据库的更新操作的文件。为保证数据库是可恢复的,登记日志文件时必须
https://www.doczj.com/doc/215062970.html,/u2/80678/showart_1931389.html 一、课题背景概述 文本挖掘是一门交叉性学科,涉及数据挖掘、机器学习、模式识别、人工智能、统计学、计算机语言学、计算机网络技术、信息学等多个领域。文本挖掘就是从大量的文档中发现隐含知识和模式的一种方法和工具,它从数据挖掘发展而来,但与传统的数据挖掘又有许多不同。文本挖掘的对象是海量、异构、分布的文档(web);文档内容是人类所使用的自然语言,缺乏计算机可理解的语义。传统数据挖掘所处理的数据是结构化的,而文档(web)都是半结构或无结构的。所以,文本挖掘面临的首要问题是如何在计算机中合理地表示文本,使之既要包含足够的信息以反映文本的特征,又不至于过于复杂使学习算法无法处理。在浩如烟海的网络信息中,80%的信息是以文本的形式存放的,WEB文本挖掘是WEB内容挖掘的一种重要形式。 文本的表示及其特征项的选取是文本挖掘、信息检索的一个基本问题,它把从文本中抽取出的特征词进行量化来表示文本信息。将它们从一个无结构的原始文本转化为结构化的计算机可以识别处理的信息,即对文本进行科学的抽象,建立它的数学模型,用以描述和代替文本。使计算机能够通过对这种模型的计算和操作来实现对文本的识别。由于文本是非结构化的数据,要想从大量的文本中挖掘有用的信息就必须首先将文本转化为可处理的结构化形式。目前人们通常采用向量空间模型来描述文本向量,但是如果直接用分词算法和词频统计方法得到的特征项来表示文本向量中的各个维,那么这个向量的维度将是非常的大。这种未经处理的文本矢量不仅给后续工作带来巨大的计算开销,使整个处理过程的效率非常低下,而且会损害分类、聚类算法的精确性,从而使所得到的结果很难令人满意。因此,必须对文本向量做进一步净化处理,在保证原文含义的基础上,找出对文本特征类别最具代表性的文本特征。为了解决这个问题,最有效的办法就是通过特征选择来降维。 目前有关文本表示的研究主要集中于文本表示模型的选择和特征词选择算法的选取上。用于表示文本的基本单位通常称为文本的特征或特征项。特征项必须具备一定的特性:1)特征项要能够确实标识文本内容;2)特征项具有将目标文本与其他文本相区分的能力;3)特征项的个数不能太多;4)特征项分离要比较容易实现。在中文文本中可以采用字、词或短语作为表示文本的特征项。相比较而言,词比字具有更强的表达能力,而词和短语相比,词的切分难度比短语的切分难度小得多。因此,目前大多数中文文本分类系统都采用词作为特征项,称作特征词。这些特征词作为文档的中间表示形式,用来实现文档与文档、文档与用户目标之间的相似度计算。如果把所有的词都作为特征项,那么特征向量的维数将过于巨大,从而导致计算量太大,在这样的情况下,要完成文本分类几乎是不可能的。特征抽取的主要功能是在不损伤文本核心信息的情况下尽量减少要处理的单词数,以此来降低向量空间维数,从而简化计算,提高文本处理的速度和效率。文本特征选择对文本内容的过滤和分类、聚类处理、自动摘要以及用户兴趣模式发现、知识发现等有关方面的研究都有非常重要的影响。通常根据某个特征评估函数计算各个特征的评分值,然后按评分值对这些特征进行排序,选取若干个评分值最高的作为特征词,这就是特征抽取(Feature Selection)。
个人信息管理系统数据库设计 河海大学计算机及信息工程学院,常州, 学年学期 2012第二学期 项目名称个人信息管理 项目组员曹清云、陈天昊 指导教师景雪琴 组号:8 .. 目录 一、课题背景及意 义 ..................................................................... .......................................... 3 二、需求分 析 ..................................................................... ...................................................... 3 三、概要设 计 ..................................................................... ...................................................... 7 四、数据库实施阶 段 ..................................................................... .......................................... 7 五、详细设 计 ..................................................................... ...................................................... 8 六、总 结 ..................................................................... ............................................................ 20 七、参考文
国内主要信息抓取软件盘点 近年来,随着国内大数据战略越来越清晰,数据抓取和信息采集系列产品迎来了巨大的发展 机遇,采集产品数量也出现迅猛增长。然而与产品种类快速增长相反的是,信息采集技术相 对薄弱、市场竞争激烈、质量良莠不齐。在此,本文列出当前信息采集和数据抓取市场最具 影响力的六大品牌,供各大数据和情报中心建设单位采购时参考: TOP.1 乐思网络信息采集系统 乐思网络信息采系统的主要目标就是解决网络信息采集和网络数据抓取问题。是根据用户自定义的任务配置,批量而精确地抽取因特网目标网页中的半结构化与非结构化数据,转化为结构化的记录,保存在本地数据库中,用于内部使用或外网发布,快速实现外部信息的获取。 主要用于:大数据基础建设,舆情监测,品牌监测,价格监测,门户网站新闻采集,行业资讯采集,竞争情报获取,商业数据整合,市场研究,数据库营销等领域。 TOP.2 火车采集器 火车采集器是一款专业的网络数据采集/信息挖掘处理软件,通过灵活的配置,可以很轻松迅速地从网页上抓取结构化的文本、图片、文件等资源信息,可编辑筛选处理后选择发布到网站后台,各类文件或其他数据库系统中。被广泛应用于数据采集挖掘、垂直搜索、信息汇聚和门户、企业网信息汇聚、商业情报、论坛或博客迁移、智能信息代理、个人信息检索等领域,适用于各类对数据有采集挖掘需求的群体。 TOP.3 熊猫采集软件 熊猫采集软件利用熊猫精准搜索引擎的解析内核,实现对网页内容的仿浏览器解析,在此基础上利用原创的技术实现对网页框架内容与核心内容的分离、抽取,并实现相似页面的有效比对、匹配。因此,用户只需要指定一个参考页面,熊猫采集软件系统就可以据此来匹配类似的页面,来实现用户需要采集资料的批量采集。 TOP.4 狂人采集器 狂人采集器是一套专业的网站内容采集软件,支持各类论坛的帖子和回复采集,网站和博客文章内容抓取,通过相关配置,能轻松的采集80%的网站内容为己所用。根据各建站程序
012. 数据预处理(1)——剔除异常值及平滑处理测量数据在其采集与传输过程中,由于环境干扰或人为因素有可能造成个别数据不切合实际或丢失,这种数据称为异常值。为了恢复数据的客观真实性以便将来得到更好的分析结果,有必要先对原始数据(1)剔除异常值; 另外,无论是人工观测的数据还是由数据采集系统获取的数据,都不可避免叠加上“噪声”干扰(反映在曲线图形上就是一些“毛刺和尖峰”)。为了提高数据的质量,必须对数据进行(2)平滑处理(去噪声干扰); (一)剔除异常值。 注:若是有空缺值,或导入Matlab数据显示为“NaN”(非数),需要①忽略整条空缺值数据,或者②填上空缺值。 填空缺值的方法,通常有两种:A. 使用样本平均值填充;B. 使用判定树或贝叶斯分类等方法推导最可能的值填充(略)。 一、基本思想: 规定一个置信水平,确定一个置信限度,凡是超过该限度的误差,就认为它是异常值,从而予以剔除。
二、常用方法:拉依达方法、肖维勒方法、一阶差分法。 注意:这些方法都是假设数据依正态分布为前提的。 1. 拉依达方法(非等置信概率) 如果某测量值与平均值之差大于标准偏差的三倍,则予以剔除。 3x i x x S -> 其中,11 n i i x x n ==∑为样本均值,1 2 211()1n x i i S x x n =?? ??? =--∑为样本的标准偏差。 注:适合大样本数据,建议测量次数≥50次。 代码实例(略)。 2. 肖维勒方法(等置信概率) 在 n 次测量结果中,如果某误差可能出现的次数小于半次时,就予以剔除。 这实质上是规定了置信概率为1-1/2n ,根据这一置信概率,可计算出肖维勒系数,也可从表中查出,当要求不很严格时,还可按下列近似公式计算:
遥感讲座——遥感影像预处理 据预处理是遥感应用的第一步,也是非常重要的一步。目前的技术也非常成熟,大多数的商业化软件都具备这方面的功能。预处理的大致流程在各个行业中有点差异,而且注重点也各有不同。下面是预处理中比较常见的流程。 1、数据预处理一般流程 数据预处理的过程包括几何精校正、配准、图像镶嵌与裁剪、去云及阴影处理和光谱归一化几个环节,具体流程图如图所示。 各个行业应用会有所不同,比如在精细农业方面,在大气校正方面要求会高点,因为它需要反演;在测绘方面,对几何校正的精度要求会很高。 2、数据预处理的各个流程介绍 (一)几何精校正与影像配准 引起影像几何变形一般分为两大类:系统性和非系统性。系统性一般有传感器本身引起的,有规律可循和可预测性,可以用传感器模型来校正;非系统性几何变形是不规律的,它可以是传感器平台本身的高度、姿态等不稳定,也可以是地球曲率及空气折射的变化以及地形的变化等。 在做几何校正前,先要知道几个概念: 地理编码:把图像矫正到一种统一标准的坐标系。 地理参照:借助一组控制点,对一幅图像进行地理坐标的校正。 图像配准:同一区域里一幅图像(基准图像)对另一幅图像校准
影像几何精校正,一般步骤如下, (1)GCP(地面控制点)的选取 这是几何校正中最重要的一步。可以从地形图(DRG)为参考进行控制选点,也可以野外GPS测量获得,或者从校正好的影像中获取。选取得控制点有以下特征: 1、GCP在图像上有明显的、清晰的点位标志,如道路交叉点、河流交叉点等; 2、地面控制点上的地物不随时间而变化。 GCP均匀分布在整幅影像内,且要有一定的数量保证,不同纠正模型对控制点个数的需求不相同。卫星提供的辅助数据可建立严密的物理模型,该模型只需9个控制点即可;对于有理多项式模型,一般每景要求不少于30个控制点,困难地区适当增加点位;几何多项式模型将根据地形情况确定,它要求控制点个数多于上述几种模型,通常每景要求在30-50个左右,尤其对于山区应适当增加控制点。 (2)建立几何校正模型 地面点确定之后,要在图像与图像或地图上分别读出各个控制点在图像上的像元坐标(x,y)及其参考图像或地图上的坐标(X,Y),这叫需要选择一个合理的坐标变换函数式(即数据校正模型),然后用公式计算每个地面控制点的均方根误差(RMS)根据公式计算出每个控制点几何校正的精度,计算出累积的总体均方差误差,也叫残余误差,一般控制在一个像元之内,即RMS<1。 (3)图像重采样 重新定位后的像元在原图像中分布是不均匀的,即输出图像像元点在输入图像中的行列号不是或不全是正数关系。因此需要根据输出图像上的各像元在输入图像中的位置,对原始图像按一定规则重新采样,进行亮度值的插值计算,建立新的图像矩阵。常用的内插方法包括: 1、最邻近法是将最邻近的像元值赋予新像元。该方法的优点是输出图像仍然保持原来的像元值,简单,处理速度快。但这种方法最大可产生半个像元的位置偏移,可能造成输出图像中某些地物的不连贯。 2、双线性内插法是使用邻近4个点的像元值,按照其距内插点的距离赋予不同的权重,进行线性内插。该方法具有平均化的滤波效果,边缘受到平滑作用,而产生一个比较连贯的输出图像,其缺点是破坏了原来的像元值。 3、三次卷积内插法较为复杂,它使用内插点周围的16个像元值,用三次卷积函数进行内插。这种方法对边缘有所增强,并具有均衡化和清晰化的效果,当它仍然破坏了原来的像元值,且计算量大。 一般认为最邻近法有利于保持原始图像中的灰级,但对图像中的几何结构损坏较大。后两种方法虽然对像元值有所近似,但也在很大程度上保留图像原有的几何结构,如道路网、水系、地物边界等。
实验 SQL语言 一、实验目的 1、理解数据库以及数据表的设计; 2、熟悉SQL Server2005中的数据类型; 3、熟悉使用SQL语句创建和删除模式和索引; 4、掌握使用SQL语句创建、修改和删除数据表; 5、掌握使用SQL语句查询表中的数据; 6、掌握使用SQL语句插入、修改和删除数据表中的数据; 7、掌握使用SQL语句创建、删除、查询和更新视图。 二、实验容 (一)创建数据库和模式 1、通过SQL语句创建图书信息管理数据库,命名为“db_Library”,数据文件和日志文件放在D盘下以自己学号和命名的文件夹中,数据文件的逻辑名为db_Library_data,数据文件的操作系统名为db_Library_data.mdf,文件初始大小为10MB,最大可增加至300MB,增幅为10%;日志文件的逻辑名为db_Library_log,日志文件的操作系统名为db_Library_data.ldf,文件初始大小为5MB,最大可增加至200MB,增幅为2MB。 2、通过SQL语句在该数据库中创建模式L-C。 (二)创建和管理数据表 要求为各数据表的字段选择合适的数据类型及名称;为各数据表设置相应的完整性约束条件。 1、通过SQL语句将以下数据表创建在L-C模式下: 课程信息表(tb_course)——课程编号Course number 、课程名Course name 、先修课The first course 、学分credit 2、通过SQL语句将以下数据表创建在该数据库的默认模式dbo下: 图书类别信息表(tb_booktype)——类别编号Type number 、类别名称Category name 图书信息表(tb_book)——图书编号ISBN 、类别编号Type number、书名title 、作者author、BookPublic、定价BookPrice、库存数Inventory number 读者信息表(tb_reader)——读者编号Reader ID 、、性别、学号Student ID 、班级、系部pastern 借阅信息表(tb_borrow)——图书编号、读者编号、借阅日期Borrowing date 、归还日期Return date 3、通过SQL语句对读者信息表进行修改:删除系部字段、添加所在系字段。 4、通过SQL语句对图书信息表进行修改:将定价的数据类型改为REAL。 5、通过SQL语句删除课程信息表。 (三)创建和删除索引 1、使用SQL语句在图书信息表上创建一个非聚簇索引IX_S_QUANTITY,要求按照该表中库存数字段的降序创建。 2、使用SQL语句在读者信息表上创建一个唯一的非聚簇索引IX_S_NAME,要求按照该表中的字段的升序创建。 3、使用SQL语句删除之前创建的两个索引。 (四)数据库及数据表设计
Introduction to database information management system The database is stored together a collection of the relevant data, the data is structured, non-harmful or unnecessary redundancy, and for a variety of application services, data storage independent of the use of its procedures; insert new data on the database , revised, and the original data can be retrieved by a common and can be controlled manner. When a system in the structure of a number of entirely separate from the database, the system includes a "database collection." Database management system (database management system) is a manipulation and large-scale database management software is being used to set up, use and maintenance of the database, or dbms. Its unified database management and control so as to ensure database security and integrity. Dbms users access data in the database, the database administrator through dbms database maintenance work. It provides a variety of functions, allows multiple applications and users use different methods at the same time or different time to build, modify, and asked whether the database. It allows users to easily manipulate data definition and maintenance of data security and integrity, as well as the multi-user concurrency control and the restoration of the database. Using the database can bring many benefits: such as reducing data redundancy, thus saving the data storage space; to achieve full sharing of data resources, and so on. In addition, the database technology also provides users with a very simple means to enable users to easily use the preparation of the database applications. Especially in recent years introduced micro-computer relational database management system dBASELL, intuitive operation, the use of flexible, convenient programming environment to extensive (generally 16 machine, such as IBM / PC / XT, China Great Wall 0520, and other species can run software), data-processing capacity strong. Database in our country are being more and more widely used, will be a powerful tool of economic management. The database is through the database management system (DBMS-DATA BASE MANAGEMENT SYSTEM) software for data storage, management and use of dBASELL is a database management system software. Information management system is the use of data acquisition and transmission technology, computer network technology, database construction, multimedia
大数据平台建设方案 (项目需求与技术方案) 一、项目背景 “十三五”期间,随着我国现代信息技术的蓬勃发展,信息化建设模式发生根本性转变,一场以云计算、大数据、物联网、移动应用等技术为核心的“新 IT”浪潮风起云涌,信息化应用进入一个“新常态”。***(某政府部门)为积极应对“互联网+”和大数据时代的机遇和挑战,适应全省经济社会发展与改革要求,大数据平台应运而生。 大数据平台整合省社会经济发展资源,打造集数据采集、数据处理、监测管理、预测预警、应急指挥、可视化平台于一体的大数据平台,以信息化提升数据化管理与服务能力,及时准确掌握社会经济发展情况,做到“用数据说话、用数据管理、用数据决策、用数据创新”,牢牢把握社会经济发展主动权和话语权。 二、建设目标 大数据平台是顺应目前信息化技术水平发展、服务政府职能改革的架构平台。它的主要目标是强化经济运行监测分析,实现企业信用社会化监督,建立规范化共建共享投资项目管理体系,推进政务数据共享和业务协同,为决策提供及时、准确、可靠的信息依据,提高政务工作的前瞻性和针对性,加大宏观调控力度,促进经济持续健康发展。 1、制定统一信息资源管理规范,拓宽数据获取渠道,整合业务信
息系统数据、企业单位数据和互联网抓取数据,构建汇聚式一体化数据库,为平台打下坚实稳固的数据基础。 2、梳理各相关系统数据资源的关联性,编制数据资源目录,建立信息资源交换管理标准体系,在业务可行性的基础上,实现数据信息共享,推进信息公开,建立跨部门跨领域经济形势分析制度。 3、在大数据分析监测基础上,为政府把握经济发展趋势、预见经济发展潜在问题、辅助经济决策提供基础支撑。 三、建设原则 大数据平台以信息资源整合为重点,以大数据应用为核心,坚持“统筹规划、分步实施,整合资源、协同共享,突出重点、注重实效,深化应用、创新驱动”的原则,全面提升信息化建设水平,促进全省经济持续健康发展。
图像特征提取方法 摘要 特征提取是计算机视觉和图像处理中的一个概念。它指的是使用计算机提取图像信息,决定每个图像的点是否属于一个图像特征。特征提取的结果是把图像上的点分为不同的子集,这些子集往往属于孤立的点、连续的曲线或者连续的区域。 至今为止特征没有万能和精确的图像特征定义。特征的精确定义往往由问题或者应用类型决定。特征是一个数字图像中“有趣”的部分,它是许多计算机图像分析算法的起点。因此一个算法是否成功往往由它使用和定义的特征决定。因此特征提取最重要的一个特性是“可重复性”:同一场景的不同图像所提取的特征应该是相同的。 特征提取是图象处理中的一个初级运算,也就是说它是对一个图像进行的第一个运算处理。它检查每个像素来确定该像素是否代表一个特征。假如它是一个更大的算法的一部分,那么这个算法一般只检查图像的特征区域。作为特征提取的一个前提运算,输入图像一般通过高斯模糊核在尺度空间中被平滑。此后通过局部导数运算来计算图像的一个或多个特征。 常用的图像特征有颜色特征、纹理特征、形状特征、空间关系特征。当光差图像时,常 常看到的是连续的纹理与灰度级相似的区域,他们相结合形成物体。但如果物体的尺寸很小 或者对比度不高,通常要采用较高的分辨率观察:如果物体的尺寸很大或对比度很强,只需 要降低分辨率。如果物体尺寸有大有小,或对比有强有弱的情况下同事存在,这时提取图像 的特征对进行图像研究有优势。 常用的特征提取方法有:Fourier变换法、窗口Fourier变换(Gabor)、小波变换法、最 小二乘法、边界方向直方图法、基于Tamura纹理特征的纹理特征提取等。
设计内容 课程设计的内容与要求(包括原始数据、技术参数、条件、设计要求等):一、课程设计的内容 本设计采用边界方向直方图法、基于PCA的图像数据特征提取、基于Tamura纹理特征的纹理特征提取、颜色直方图提取颜色特征等等四种方法设计。 (1)边界方向直方图法 由于单一特征不足以准确地描述图像特征,提出了一种结合颜色特征和边界方向特征的图像检索方法.针对传统颜色直方图中图像对所有像素具有相同重要性的问题进行了改进,提出了像素加权的改进颜色直方图方法;然后采用非分割图像的边界方向直方图方法提取图像的形状特征,该方法相对分割方法具有简单、有效等特点,并对图像的缩放、旋转以及视角具有不变性.为进一步提高图像检索的质量引入相关反馈机制,动态调整两幅图像相似度中颜色特征和方向特征的权值系数,并给出了相应的权值调整算法.实验结果表明,上述方法明显地优于其它方法.小波理论和几个其他课题相关。所有小波变换可以视为时域频域的形式,所以和调和分析相关。所有实际有用的离散小波变换使用包含有限脉冲响应滤波器的滤波器段(filterbank)。构成CWT的小波受海森堡的测不准原理制约,或者说,离散小波基可以在测不准原理的其他形式的上下文中考虑。 通过边缘检测,把图像分为边缘区域和非边缘区域,然后在边缘区域内进行边缘定位.根据局部区域内边缘的直线特性,求得小邻域内直线段的高精度位置;再根据边缘区域内边缘的全局直线特性,用线段的中点来拟合整个直线边缘,得到亚像素精度的图像边缘.在拟合的过程中,根据直线段转角的变化剔除了噪声点,提高了定位精度.并且,根据角度和距离区分出不同直线和它们的交点,给出了图像精确的矢量化结果 图像的边界是指其周围像素灰度有阶跃变化或屋顶变化的那些像素的集合,边界广泛的存在于物体和背 景之间、物体和物体之间,它是图像分割所依赖的重要特征.边界方向直方图具有尺度不变性,能够比较好的 描述图像的大体形状.边界直方图一般是通过边界算子提取边界,得到边界信息后,需要表征这些图像的边 界,对于每一个边界点,根据图像中该点的梯度方向计算出该边界点处法向量的方向角,将空间量化为M级, 计算每个边界点处法向量的方向角落在M级中的频率,这样便得到了边界方向直方图. 图像中像素的梯度向量可以表示为[ ( ,),),( ,),)] ,其中Gx( ,),),G ( ,),)可以用下面的
数据库技术 实 验 报 告 学校 专业 年级 学号 姓名 年月日
学生信息管理系统数据库设计 一、数据库的建立 1. 建库说明 数据库的建立用企业管理器,基本表的建立用SQL语言。 数据库名称为:学生信息管理系统。 2. 建立数据库命令如下: Create database 学生信息管理系统 二、数据表的建立 1. 建表 命令: CREATE TABLE [dbo].[学生档案信息] ( [Sno] [varchar] (50) NOT NULL , [Sname] [char] (10) NOT NULL , [Ssex] [char] (10) NOT NULL , [Sclass] [char] (10) NOT NULL , [Birth] [int] (4) NOT NULL , [Saddress] [char] (10) NOT NULL , [Sdept] [varchar] (50) NOT NULL , [Stime] [int] (4) NOT NULL ,
) ON [PRIMARY] GO (2)班级设置信息表: 命令: CREATE TABLE [dbo].[班级设置信息] ( [Sgrade] [char] (10) NOT NULL , [Szclass] [int] (4) NOT NULL , [Syear] [char] (5) NOT NULL , [Scroom] [char] (5) NOT NULL , [Steacher] [char] (10) NOT NULL , [Stotal] [int] (4) NOT NULL , [Ssub] [varchar] (8000) NOT NULL , ) ON [PRIMARY] GO (3)院系信息表: 命令: CREATE TABLE [dbo].[院系信息] ( [Syname] [varchar] (50) NOT NULL , [Spro] [varchar] (1000) NOT NULL ,
https://www.doczj.com/doc/215062970.html, 大数据抓取工具推荐 大数据已经成了互联网时代最热门的词之一,采集器也成了数据行业人人都需要的工具。作为一个不会打代码的小白,如何进行数据采集呢?市面上有一些大数据抓取工具。八爪鱼和造数就是其中两款采集器,对于不会写爬虫代码的朋友来说,找到一款合适的采集器,可以达到事半功倍的效果。本文就两款采集器的优缺点做一个对比,仅供大家参考。 造数是一个基于云端爬取的智能云爬虫服务站点,通过一套网页分析的算法,分析出网页中结构化的数据,然后再爬取页面中的数据,无需编程基础,只需输入网址,选取所需的数据,就可轻松获取互联网的公开数据,并以 Excel 表格等形式下载,或使用 API 与企业内部系统深度整合。 造数有什么优缺点呢? 优点: 云端采集网页,不需要占用电脑资源下载软件 采集到数据以后可以设置数据自动推送 缺点: 1、不支持全自动网站登录采集,也不支持本地采集,采集比较容易受到限制 2、不能采集滚动页面,最多支持两个层级的采集,采集不是很灵活 然后我们看一下八爪鱼 八爪鱼是非常适合技术小白的一款采集器,技术比较成熟,功能强大,操作简单。八爪鱼采集器的各方面的功能都比较完善,云采集是它的一大特色,相比其他采集软件,云采集能够做到更加精准、高效和大规模。还有识别验证码、提供优质代理IP 、UA 自动切换等智能防封的组合功能,在采集过程都不用担心网站的限制。如果不想创建采集任务,可以到客户端直接使用简易采集模式,选择模板,设置参数马上就可以拿到数据。
https://www.doczj.com/doc/215062970.html, 八爪鱼有什么优缺点呢? 1、功能强大。八爪鱼采集器是一款通用爬虫,可应对各种网页的复杂结构(瀑布流等)和防采集措施(登录、验证码、封IP),实现百分之九十九的网页数据抓取。 2、入门容易。7.0版本推出的简易网页采集,内置主流网站大量数据源和已经写好的采集规则。用户只需输入关键词,即可采集到大量所需数据 3、流程可视化。真正意义上实现了操作流程可视化,用户可打开流程按钮,直接可见操作流程,并对每一步骤,进行高级选项的设置(修改ajax/ xpath等)。 缺点: 1、不能提供文件托管,不能直接发布采集到的数据 2、不支持视频和app采集 相关链接: 八爪鱼使用功能点视频教程 https://www.doczj.com/doc/215062970.html,/tutorial/videotutorial/videognd 八爪鱼爬虫软件入门准备 https://www.doczj.com/doc/215062970.html,/tutorial/xsksrm/rmzb
学生信息管理系统 ---- 数据库版本 学院: 计算机学院 班级: 03级计算机科学与技术02班 姓名:周子杰 学号:57 班级:03级计科2班 日期:2007年3月22日 广东工业大学
一.系统功能流程图: 二.程序主要功能实现代码: 1. ConnectionFrame类://连接数据库函数 /** * 进行参数检查,进行数据库连接 * @param e ActionEvent */ public void jButton1_actionPerformed(ActionEvent e) { driver=jTextField1.getText(); URL=jTextField2.getText(); table=jTextField3.getText(); name=jTextField4.getText(); password=jTextField5.getText(); try{ Class.forName(driver); //加载驱动程序 con = DriverManager.getConnection(URL, name,password); //创建连接 this.setVisible(false); new MainFrame(); con.close(); } catch (Exception e1) { JOptionPane.showMessageDialog(null, "数据库连接出错!请检查参数!", "系统
提示", JOptionPane. INFORMA TION_MESSAGE); } } 2. MainFrame类://主界面类,处理程序各种功能 //作者信息 public void jMenuItem1_actionPerformed(ActionEvent e) { JOptionPane.showMessageDialog(null,"学生: 周子杰\n"+ "学院: 计算机学院\n"+ "专业:计算机科学与技术03级02班\n"+ "学号:3103003157\n"+ "指导老师:杨劲涛","作者信息",https://www.doczj.com/doc/215062970.html,RMA TION_MESSAGE); } //版本信息 public void jMenuItem5_actionPerformed(ActionEvent e) { JOptionPane.showMessageDialog(null,"学生管理系统数据库版本1.0" ,"版本信息",https://www.doczj.com/doc/215062970.html,RMATION_MESSAGE); } //退出系统 public void jMenuItem2_actionPerformed(ActionEvent e) { Object ob=JOptionPane.showConfirmDialog(null,"真的要退出本系统吗?","系统提示",JOptionPane.YES_NO_OPTION); if(ob.equals(JOptionPane.OK_OPTION)) { this.setVisible(false); System.exit(0); } } //按学号查询 public void jButton1_actionPerformed(ActionEvent e) { Column col=queryDataSet1.getColumn("sno"); sno=jTextField1.getText(); formatter=col.getFormatter(); choice=1; queryDataSet1.refilter();//表刷新 } public void jButton2_actionPerformed(ActionEvent e) { choice=2; queryDataSet1.refilter();//表刷新 } //刷新表
个人信息管理系统 第六组小组分工 组长: 周倩:录入数据,整理文档 组员: 高久玲:界面制作,数据库调试与运行 张帆:约束表的建立,录入数据 柴宇濛:界面制作,数据库调试与运行 1、系统功能描述 个人信息管理系统,用户可以通过注册一个用户来对个人的个人信息进行管理。个人信息包括用户登录名、用户登录密码、用户真实姓名、用户性别、出生日期、用户民族、学历、职称、电话、地址、邮箱;通讯录信息包括通讯人姓名、联系方式、地址、备注;备忘录信息包括记录时间、地点、事件、人物;个人财务管理包括总收入、消费项目、消费金额、消费时间、剩余金额等。系统可以对个人信息进行相关的添加、查看、修改或删除等处理。 个人信息管理系统主要由个人信息管理、通讯录管理、个人财务管理、备忘录管理模块组成。进入系统后用户可以对系统中的信息进行查询、添加、修改、删除等操作。具体实现的功能有: (1)个人信息管理:可以进行查看个人信息、修改个人信息、修改个人密码等操作; (2)通讯录管理:可以进行增加联系人、查看联系人、修改或删除联系人等操作; (3)个人财务管理:可以进行查看个人财务、添加或删除个人财务信息等操作; (4)备忘录管理:可以进行查看备忘录、修改或删除备忘录、增加备忘录信息等操作; 图1 功能模块图 2、数据库关系分析 个人信息管理系统。该系统存在4个实体集: (1)“用户”实体集,主键:用户登录名,属性有用户登录密码、用户真实姓名(name)、用户性别(gender)、出生日期(brith)、用户民族(nation)、学历(edu)、职称(post)、电话
(phone)、地址(address)、邮箱(email)。 图2.1 个人信息实体集 (2)“通讯录”实体集,主键:联系人联系方式(tphone),属性:联系人姓名(tname)、地址(taddress)、备注(remark)。 图2.2 通讯录实体集 (3)“备忘录”实体集,主键:记录时间(mtime),属性:地点(msite)、事件(event)、人物(person)。
HEFEI UNIVERSITY 管理信息系统设计报告 系别电子信息与电气工程系专业电气信息类 班级 学号 姓名 指导老师 完成时间
第1章设计目的与要求 (2) 1.1设计目的 (2) 1.2设计环境 (2) 1.3主要参考资料 (3) 1.4设计内容及要求 (3) 第2章设计内容 (3) 2.1数据库设计 (3) 2.1.1需求分析 (3) 2.1.2概念设计 (7) 2.1.3逻辑设计 (8) 2.1.4物理设计 (9) 2.1.5数据库实现 (10) 2.2程序设计 (14) 2.2.1概要设计 (14) 2.2.2程序实现 (16) 第3章设计总结 (18) 第1章设计目的与要求 1.1设计目的 本实践课的主要目的是:(1)、掌握运用管理系统及数据库原理知识进行系统分析和设计的方法;(2)掌握关系数据库的设计方法;(3)掌握SQL Server 2000技术应用;(4)掌握简单的数据库应用程序编写方法;(5)理解C/S模式结构。 1.2设计环境 硬件:一台Pentium 4 cpu 以上的微机及兼容 VGA 彩显一台
软件: Windows XP Visual Basic 6.0和SQL Sever 2000 1.3主要参考资料 1.《管理信息系统》黄梯云高等教育出版社 2.《数据库系统概论》萨师煊高等教育出版社 3.《SQL Server 2000 数据库应用系统开发技术》朱如龙编,机械工业出版社。 4.《SQL Server 2000 数据库应用系统开发技术实验指导》朱如龙编,机械工业出版社 1.4设计内容及要求 一、内容 1.要求根据管理信息系统及数据库设计原理,按照数据库系统设计的步骤和规范,完成各阶段的设计内容。 2.需求分析具体实际,数据流图、数据字典、关系模型要正确规范 3.在SQL Sever2000 上实现设计的数据库模型。 4.对应用程序进行概要设计。 5.用VB实现简单的应用程序编写。 二、要求 设计过程中,要严格遵守课程设计的时间安排,听从指导教师的指导。正确地完成上述内容,规范完整地撰写出课程设计报告。 第2章设计内容 2.1数据库设计 2.1.1需求分析 “学生管理信息系统”包括十个模块:用户信息管理,班级信息管理,学籍信息管理,课程信息管理,成绩信息管理,奖惩信息管理,个人收费信息管理,消息信息管理。这十个模块既相互联系又相互独立。 (1)在系统管理模块中,当点击“退出”时,系统能够正常的关闭;(2)在学生管理模块:添加学生。当生刚进校时要进行添加信息的添加;删除学生。当学生毕业后,学生信息转移备份数据库中,系统的基本数据库中需要删除学生信息。该功能主要进行删除学生信