
一、基本查询语句 1、基本的语法格式:
【select (SQL 关键字)[distinct (滤除重复记录)] * /列名称…… 别名 from table ;】
2、书写SQL 语句遵循的基本原则:①不区分大小写,除非特别指定;②可以写成一行或多行;③关键字不能简写或分割于多行;④子句通常单独行书写,便于编辑和提高可读性;⑤使用Tab 和缩进提高程序可读性;⑥关键字最好使用大写,其他使用小写;⑦在SQL*Plus 中,SQL 语句是在SQL prompt 状态下输入,并且每行都有编号。是SQL 的缓冲区,任何时候在缓冲区中只会存放当前一条语句。
3、| | 表示列与列、列与算术表达式、列与常量之间的合成。 第2章、限定查询和排序语句 1、限定数据行的查询语法格式:
【select [distinct] */ 列名称…… 别名 from table where (限定条件)列名/表达式/常量/比较运算符;】 (其中比较运算符包括:=:等于、>:大于、>=:大于等于、<:小于、<=:小于等于、<>.!=.^=:不等于。 (要查询的列)between (下限)and (上限):两个值之间包括边界范围比较。 (要查询的列)in (集合,用逗号隔开):和多个值中任意一个匹配,相当于多个or 并列在一起。 (要查询的列)like+‘通配符和查询的内容’:模糊查询、is null :是否是空值)
1.1、where 子句中,字符串和日期数值必须用单引号引起来,数值型常量则不需要,字符型数据区分大小写,默认的日期形式是:DD-MON-YY 。 1.2、like (模糊查询):把握不准查询确切的值,通过字形匹配来查询。可以使用通配符:%:表示0或更多任意的字符;_:代表一个字符。可以同时使用。当查询的内容包括%或_时,可以使用escape ,即“/”转义符。
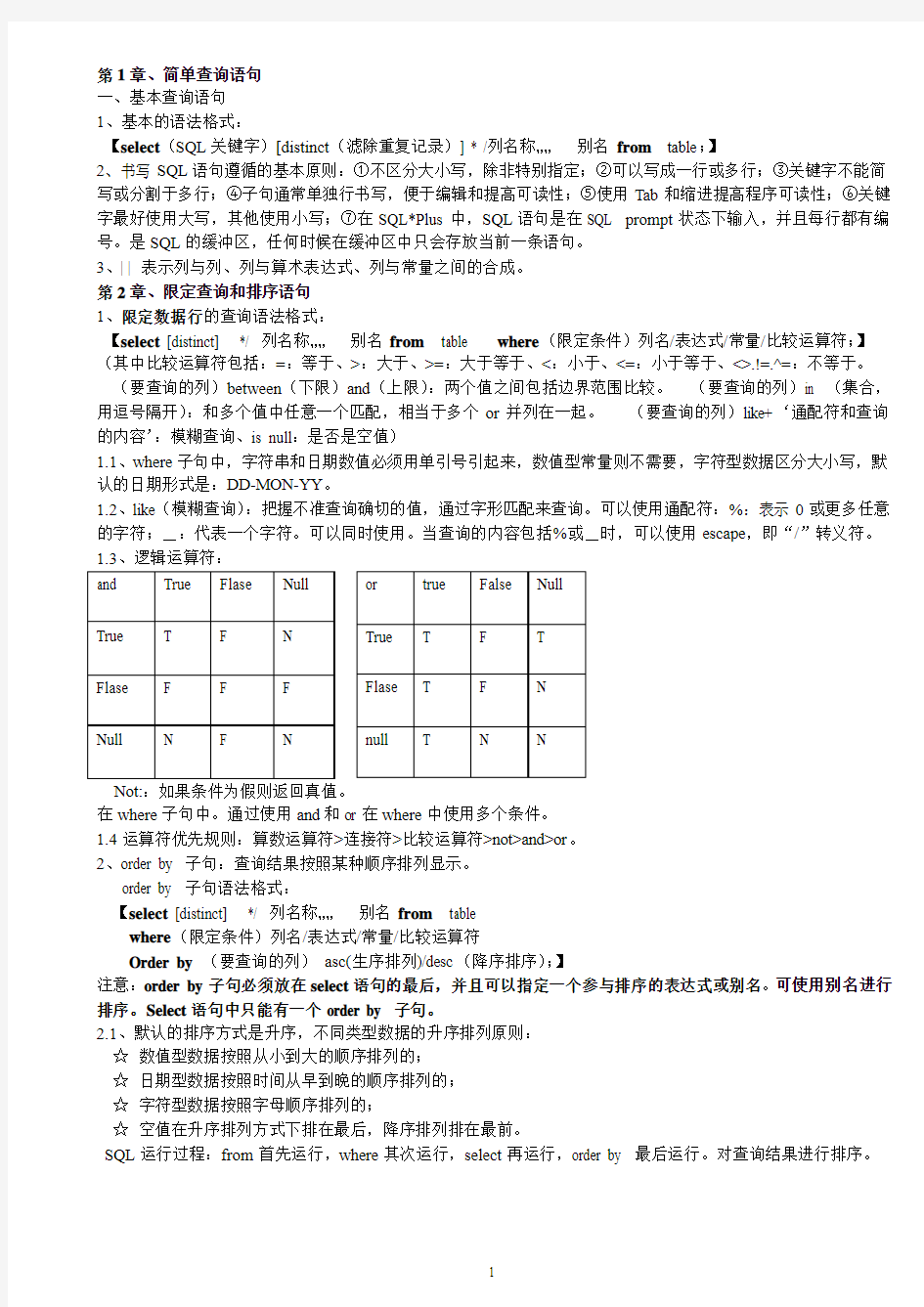
Not::如果条件为假则返回真值。
在where 子句中。通过使用and 和or 在where 中使用多个条件。 1.4运算符优先规则:算数运算符>连接符>比较运算符>not>and>or 。 2、order by 子句:查询结果按照某种顺序排列显示。 order by 子句语法格式:
【select [distinct] */ 列名称…… 别名 from table where (限定条件)列名/表达式/常量/比较运算符
Order by (要查询的列) asc(生序排列)/desc (降序排序);】
注意:order by 子句必须放在select 语句的最后,并且可以指定一个参与排序的表达式或别名。可使用别名进行排序。Select 语句中只能有一个order by 子句。
2.1、默认的排序方式是升序,不同类型数据的升序排列原则: ☆ 数值型数据按照从小到大的顺序排列的; ☆ 日期型数据按照时间从早到晚的顺序排列的; ☆ 字符型数据按照字母顺序排列的;
☆ 空值在升序排列方式下排在最后,降序排列排在最前。
SQL 运行过程:from 首先运行,where 其次运行,select
再运行,order by 最后运行。对查询结果进行排序。
1、单行函数的特点:
☆对查询返回的每一行都起作用。☆可以返回一个数据值或相对于原类型不同类型的数据值。
☆可以有一个或多个参数,参数可以是一列或一个表达式。☆每行返回一个结果。
☆可以用于select、where、order by子句,并且可以相互嵌套。☆只对一行进行操作。
2、单行查询语法格式:
【function_name(函数名称) column(列名)/ expression(字符串或计算表达式) [arg1(参数),arg2……]】
3、字符函数:接受字符输入并且返回字符或数值。
①大小写转换函数:lower(需转换的内容):将字符串转换成小写。Upper(需转换的内容):将字符串转换成大写。initcap(需转换的内容):将每个单词的第一个字母转换成大写,其余字母转换成小写。
②字符处理函数:concat:将字符串连接在一起。substr:提取字符串的某一特定部分;参数:(字符串,截取起始点[负数:从右往前数,然后从前往后截取],截取个数[省略表示截取到最后])。length:获得字符串的个数。instr:在字符串中查找某个字串的位置;参数(字符串,要查找的字符,从那个位置开始查找[默认值为1,负数:一直从右往左数],第几次出现的位置)。lpad:以右对齐的方式填充字符型数据;参数:(字符串,填充长度,填充内容)。rpad:以左对齐的方式填充字符型数据(参数同上)。trim:去掉字符串头部或尾部,如果被去除的字符串和被处理的字符串是原义字符串则必须使用单引号引起来;参数:(去掉的字符串from 被去掉的字符串)。replase:替换;参数(字符串,被替换字符,替换的字符)。
4、数值函数:接受数值输入并返回数值。包括:round:四舍五入;参数:(数字,四舍五入后的小数点后位数[默认值为0,负数为从小数点往左边数])。trunc:截取;参数:(数字,截取后小数点后面的位数[同上,但无四舍五入功能])。mod:求余,多用于判断奇数偶数;参数:(被除数,除数)。
5、日期函数:对日期型进行操作,所有的日期函数都返回一个日期型数据,除了months_between函数,返回一个数值。
Oracel9i默认的显示和输入形式是DD-MON-RR。Oracel有效的日期范围是公元前4712年1月1日到公元9999年12月31日。日期的运算如下表:
YY与RR的比较:Array
◇day:对星期的计算。
6.1数据类型的显示转换:
6.2数据类型转换函数包括如下:
6.4使用日期模式时注意的问题:
☆必须用单引号引起来,对大小写敏感。☆可以包含任意的有效的日期元素。
☆可以用fm消除前导空格或前导0。☆使用‘,’与日期型数据分隔开。
7、通用函数:
8、单行函数的嵌套:嵌套的函数是从里层向最外层的顺序依次计算的。
第四章、多表查询
1、连接:从多个表中获取数据时,需要使用连接条件。通过使用相对应列的公共值进行连接,需在where子句中写出连接条件。
1.1连接语法格式如下:
【select table1.column, table2.column…
from table1,table2…
where table1.column1=table2.column2 】
注:table1.column:指明查询的数据来源的表名和列名;table1.column1:连接条件。连接条件的情况包括:等值连接(内部连接或简单连接),非等值连接,外部连接,和集合运算符。
1.2在编写访问多表的SQL语句时,需注意的问题:
☆用到表连接时,需要在列名之前标示出表名,以提高数据库的访问效率。
☆多个表中存在相同的列名时,列名之前必须用表名标示。
☆n个表相连时,至少需要n-1个链接条件。
1.3连接中使用表的别名需注意的事项:表的别名>=30个字符,但原越短越好;若在from语句中定义了表的别名,在整个select语句中必须使用别名;表的别名要具有一定的意义;表的别名只在当前select语句中有效。
2、笛卡尔积:当连接条件无效或完全被省略以及第一个表中的所有行和第二个表中的所有行都发生连接时,所有行的组合都出现,这种结果称为笛卡尔积。是一种交叉连接,当需要产生大量的数据行模拟海量的数据时才会用到。
3、等值连接(内部链接):在where子句中用“and”加入其它条件进行连接。例:
select emp.empno,emp.ename,emp.deptno,dept.deptno,dept.loc from emp,dept where emp.deptno=dept.deptno and emp.deptno=10; 查询在10号部门工作的雇员的编号、姓名、部门编号和部门位置。
4、非等值连接:不用“=”的连接为非等值连接。例如:
5、外部连接:在SQL: 1999中,内连接只返回满足连接条件的数据。两个表在连接过程中除了返回满足连接条件的行以外还返回左(或右)表中不满足条件的行,这种连接称为左(或右)外连接。两个表在连接过程中除了返回满足连接条件的行以外还返回两个表中不满足条件的行,这种连接称为全外联接。外部连接的运算符是(+),语法格式如下:
右外select table1.column,table2.column 左外select table1.column,table2.column from table1,table2 或from table1,table2
连接where table1.column (+)=table2.column; 连接where table1.column =table2.column(+);
☆(+)在哪边,哪边就用空白填充,即值为null。在连接时,允许出现不匹配的记录。
使用外部连接注意的事项:(+)必须放在连接条件表达式的一侧,即缺少相关连接信息的表一侧,返回该表中那些在另一个表中没有得到匹配的记录;外部连接条件中不能使用in运算符,也不能用or运算符与其他条件相连。
6、自身连接:一般在人事系统当中使用自连接,因为再高级的领导,在财务人员来看,他们也是员工。
7、SQL:1999语法连接:使用连接从多个表中查询数据。
1999语法连接的语法格式如下:
【select table1.column, table2.column table1.column:从哪个表哪个列中查询数据
from table1 table1:表名
[cross join table2] 或cross join(交叉连接):返回两个表的笛卡尔积(连个表的交叉连接) 可单独使用
[natural join table2] 或 natural join (自然连接):用相同名称的列连接两个表,可单独使用 [join table2 using (column_name)] 或
[join table2 on 子句中指定实 [left 或rinht 或full outer join table2
on left 或right 或full outer 外部链接的方式 8、自然连接:natural join 实现具有列名和数据类型相匹配的两个表之间的自动连接。可以写成等值连接方式;若要使用其他连接方式可以通过where 子句实现。注意事项:
? 自然连接子句基于两个表存在相同名称的列;? 返回两个表相匹配列中具有相同值的记录; ? 如果相同名称的列的数据类型不同,则会产生错误。
9、using 子句连接:使用时注意的问题:在natural join 子句创建等值连接时,如果有多个名字相同,数据类型不同的列,那么可以使用 using 子句指定等值连接中需要用到的列。 使用 using 可以在有多个列满足条件时进行选择相匹配的一列进行查询。 不要给选中的列使用表名和别名作为前缀。 自然连接不能和on 和using 子句同时使用,因为自然连接特别定义了连接表所用的搜索条件——两表中具有相同字段名的所有字段必须匹配。
10、用on 创建连接:自然连接中是以具有相同名字的列为连接条件的。可以使用 on 子句指定任意的或特殊的
列作为连接条件进行查询。 这个连接条件是与其它条件分开的。 on 子句使语句具有更高的易读性。 第5章、组函数和分组统计
1、组函数:组函数作用于一行数据的集合,并对一行数据集合返回一个值。要写在select 子句后面。 1.1、组函数的语法格式如下:
【 select [column,] 组函数参数(column 列名), ... from table
[where condition] where 条件 [group by
column] 分组子句
[drder by column]; 】 按照某种顺序排列 放在最后 1.3、组函数使用原则:使用distinct 排除重复值,all 包括所有值,默认情况下,为all ,所以不用专门指出all 。 参数的数据类型类型可以是:char 、varchar2(字符串)、number 、date 。 除了count (*),所有组函数均忽略空值,可以使用nvl 函数将空值转换成一个实际值。 当使用order by 子句时,结果集合按升序排列,要改变排列方式则在order by 子句中使用desc 关键字。
2、group by 子句:可以使用group by 子句将表中的数据分成若干组;在select 列表中所有未包含在组函数中的列都应该包含在 group by 子句中;包含在 group by 子句中的列不必包含在select 列表中。必须放在where 子句后面。
group by 子句使用原则:在select 子句中使用组函数,就不能同时查询出个体信息,除非在group by 子句中包含了所指定的列;如果未能包含列组成的列表,将得到一个错误提示; 使用where 子句时可以在分组前将某些记录排除;group by 子句必须包含指定的列;group by 子句中不能使用列的别名。 3、使用函数组的非法查询:所用包含于select 列表中,而未包含于组函数中的列或表达式都必须包含于 group by 子句中;不能在 where 子句中使用组函数;可以在having 子句中使用组函数。错误:1)、此处不允许使用分组
行数。解决办法:使用having子句纠正。2)、非单组分组函数。解决办法:增加group by子句纠正。
4、having 子句:使用having 过滤分组:①行已经被分组。②使用了组函数。③满足having 子句中条件的分组将被显示。在组函数结果基础上对记录加以限制,则必须在使用group by 的同时使用having子句。当使用having 子句时,Oracle服务器执行过程:①对记录分组;②在分组基础上应用组函数;③与having子句匹配的组结果输出。having子句可放在group by 子句前或后,但逻辑上放在后比较合适。
第6章、子查询
1、子查询:是嵌套在select语句中的另一个select语句,当需要从一个表中查询信息,而查询的条件又是来自该表本身的内部数据时用到。可以嵌于where、having和from子句中。子查询(内查询) 在主查询之前执行,并且只执行一次。子查询的结果被主查询(外查询)使用。可以在select语句的form子句中使用子查询,就像使用视图一样。
1.1、其语法格式如下:
【select select_list from table where expr operator ( select select_list from table )】
其中:select_list:列名;expr operator:运算符,包括(>,=,>=,<,<>,<= 单行运算符;in,any,all多行运算符)1.2、使用子查询的原则:子查询要包含在括号内。将子查询放在比较运算符的右侧。
除非进行Top-N 分析,否则不要在子查询中使用ORDER BY子句。
单行操作符对应单行子查询,多行操作符对应多行子查询。
1.3、子查询的分类:
①单行子查询:内部select语句只返回一行结果的查询(单列)。只能使用单行运算符:>,=,>=,<,<>,<=。
☆单行子查询中可以使用组函数;
☆having子句中可以使用单行子查询,首先执行子查询,向主查询中的HA VING 子句返回结果。
☆使用单行子查询的复合查询容易出现的问题:子查询的结果多于一行;结果没有返回的行。
②多行子查询:内部select语句返回多行结果的查询(单列)。使用多行运算符:in,any,all。
☆any运算符(同义运算符some)将和子查询的结果逐个比较:
☆all运算符和子查询返回的每一个结果进行比较:>all表示大于最大数; ☆not运算符可与in、any、all运算符联合使用。 ③多列子查询:内部select语句返回多个列结果的查询。单行和多行子查询只有一个列在select语句的where或having子句中进行比较,若同时进行多列比较,则必须使用逻辑运算符编写一个复合where子句,多列子查询可以将where子句中的多个条件合并成一个。多列子查询分为:成对比较多列子查询:主查询的每一行中的列都要与子查询返回列表中相对应的列进行比较,只有各个列完全匹配时才显示主查询中的该数据行。非成对比较多列子查询。 1.4、子查询中的空值:无论什么时候只要空值有可能成为子查询结果集合中的一部分,就不能使用not in运算符,not in运算符等效于<>all。 1.5、在什么时候遇到什么问题应该使用子查询。 ☆Sql语句在逻辑上被分为多步。 ☆主查询的查询条件依赖于子查询的执行结果。 ☆在查询是基于未知的值时应使用子查询。 ☆除非特别需要,一般我们建议大家使用连接的方式,尽量避免使用子查询。 第7章、使用替代变量 在SQL语句中使用&来识别每一个变量而不需要定义变量的值。课本94页。 第8章、数据操作 1、DML 可以在下列条件下执行: 向表中插入数据;修改现存数据;删除现存数据。 2、事务是由完成若干项工作的DML语句组成的逻辑单位。 3、基本的插入语句语法格式如下: 【insert into table [(column [, column...])] table:被插表名;column:列名; values(value [, value...]); 】values:要插入的数据,顺序、数据类型要和column得相同。 注:使用这种语法一次只能向表中插入一条数据。 3.1为每一列添加一个新值。按列的默认顺序列出各个列的值。在INSERT 子句中随意列出列名和他们的 值。字符和日期型数据应包含在单引号中。 3.2若插入的记录包含每一列的值,则可以不列出列名,但是值必须按照表中的默认顺序进行排列。 4、向表中插入空值:首先使用SQL*Plus的describe命令查看“是否为空?”选项可以知道该项是否允许为空。隐式方式: 在列名表中省略该列的值。显示方式: 在V ALUES 子句中指定空值。 5、向表中插入特殊值。(课本111页) 6、创建脚本:在SQL 语句中使用& 变量指定列值。& 变量放在valuse子句中。例如: INSERT INTO departments (department_id, department_name, location_id) VALUES (&department_id, '&department_name',&location); 7、从其他表中复制数据:使用insert语句向表中插入来自另一个表中的数据,方法是在原来values子句的位置使用子查询,语法格式如下: 【insert into】注:insert子句中列的数量和类型必须和子查询中列的数量 和类型相匹配。不必书写values 子句。 表名列名从另一个表中取得数据的子查询 8、基本的更新语句语法格式如下: 【update table set column = value [,column = value] 同时修改多个列可更改多条记录[where condition]; 】value:与列对应的值或子查询;condition:限定被更新的记录,由列名、表达式、常量、子查询及比较运算符组成。 8.1、使用WHERE 子句指定需要更新的数据。如果省略WHERE子句,则表中的所有数据都将被更新。 8.2、基于另一个表更新记录语法格式如下: 【update table set(column,column…)= (select column,column…from table where condition)】 8.3、更新数据完整性约束错误:不存在的表或者列等。 9、基本的删除语句语法格式如下: 【delete[from] table [ where condition] 】condition:指定删除的记录,由列名、表达式、常量、子查询及比较运算符组成,若省略了where子句则删除整个表的数据。 9.1、delete只能删除一条记录,最小单位为删除一行记录。使用WHERE 子句删除指定的记录。在delete 中使用子查询,使删除基于另一个表中的数据。 9.2、删除记录时的完整性约束错误:不能删除正在被其他表使用的记录。 10、基本的合并语句语法格式如下: 【merge into table_name table_alias —要修改的表名,表的别名 using (table|view|sub_query) alias —(用的表名/用的视图/用哪个子查询)别名 on (join condition) —连接条件,若为真,则进行更新;若为假,则进行插入。 when update set col2 = col2_val = 更新的值 insert values插入的值 10.1、根据指定的条件执行插入或更新操作。 如果满足条件的行存在,执行更新操作;否则执行插入操作: 避免独立的数据更新;提高效率而且使用方便;在数据仓库应用中经常使用。 10.2、在DML语句中使用WITH CHECK OPTION 关键字;使用子查询表示DML 语句中使用的表;WITH CHECK OPTION 关键字避免修改子查询范围外的数据。 10.3、使用DEFAULT 关键字表示默认值;符合SQL:1999标准;可以使用显示默认值控制默认值的使用; 显示默认值可以在INSERT 和UPDA TE 语句中使用。 11、数据库事务 11.1、以第一个DML 语句的执行作为开始,以下面的其中之一作为结束: –显示的COMMIT 或ROLLBACK 语句 –DDL 或DCL 语句被执行(自动提交) –用户退出SQL*Plus,会话正常结束 –系统异常终止 11.2、COMMIT和ROLLBACK语句的优点:确保数据的完整性。在数据的改变被提交之前重新检查我们所改变的数据是否正确。将逻辑上相关的操作分组。 11.3、回滚到保留点:使用SA VEPOINT 语句在当前事务中创建保存点。使用ROLLBACK TO SA VEPOINT 语句回滚到创建的保存点。 11.4、隐式事务进程:自动提交在以下情况中执行: –DDL 语句。(DDL:数据定义语言) –DCL 语句。(DCL:数据操作语言) –不使用COMMIT 或ROLLBACK 语句提交或回滚,正常结束会话。 会话异常结束或系统异常会导致自动回滚。 11.5、提交或回滚前的数据状态: ?改变前的数据状态是可以恢复的 ?执行DML 操作的用户可以通过SELECT 语句查询之前的修正 ?其他用户不能看到当前用户所做的改变,直到当前用户结束事务。 ?DML语句所涉及到的行被锁定,其他用户不能操作。 11.6、提交后的数据状态: ?数据的改变已经被保存到数据库中。 ?改变前的数据已经丢失。 ?所有用户可以看到结果。 ?锁被释放,其他用户可以操作涉及到的数据。 ?所有保存点被释放。 11.7、数据回滚后的状态: 使用ROLLBACK 语句可使数据变化失效: ?数据改变被取消。 ?修改前的数据状态可以被恢复。 ?锁被释放。 11.8、语句级回滚: ?单独DML 语句执行失败时,只有该语句被回滚。 ?Oracle 服务器自动创建一个隐式的保留点。 ?其他数据改变仍被保留。 ?用户应执行COMMIT 或ROLLBACK 语句结束事务。 11.9、读一致性: ?读一致性保证在任何时间任何用户所看到的数据都是一致的。 ?一个用户的对数据的改变不会影响其他用户的改变。 ?对于相同的数据读一致性保证: –查询不等待修改(读者不等待写者)。 –修改不等待查询(写者不等待读者)。 11.10、锁: Oracle 数据库中,锁是 : ? 并行事务中避免资源竞争。 ? 避免用户动作。 ? 自动使用最低级别的限制。 ? 在事务结束结束前存在。 ? 两种类型: 显示和隐式。 ? 隐式锁:两种模式: ? 独占锁: 屏蔽其他用户。 ? 共享锁: 允许其他用户操作。 ? 高级别的数据并发性: ? DML: 表共享,行独占 ? Queries: 不需要加锁 ? DDL: 保护对象定义 ? 提交或回滚后锁被释放。 第9章、创建和管理表 1、Oracel 数据库的数据结构(对象)包括: 表:基本的数据存储单位,由行和列组成。 视图:从表中抽出的逻辑上相关的数据集合。 序列:提供有规律的数值。 索引:提高查询的效率。 同义词:给对象起别名。 2、表的命名规则:必须以字母开头;必须在 1–30 个字符之间;必须只能包含 A –Z, a –z, 0–9, _, $, 和 # 必须不能和用户定义的其他对象重名;必须不能是Oracle 的关键字。 3、创建表的基本语句语法格式如下: 【create table [给哪个用户创建.] table (新表名) (列名、当前列的数据类型和长度) [default 默认值] 】 4、使用子查询创建表 其语法格式如下: 指定列和子查询列要一一对应。 【 create table table [column (,column …)] subquery 被创建表名 列名、默认值 子查询语句 4.1、使用指导:用 AS subquery 选项,将创建表和插入数据结合起来;指定的列和子查询中的列要一一对应;通过列名和默认值定义列;未指定创建表的列时,创建出的新表的列的名称和子查询中各个列的名称相同。 5alter table 语句。 5.1、(追加列)语法格式如下:可追加多个列,新增的列总是在最后边显示。 【 alter table table add (column datatype [default expr] [,column datatype]…); 】 表名 新列数据类型、长度 新列名 5.2、(修改列)在alter table 语句中,使用modify 子句可以修改中已经存在的列,列的修改可以包括数据类型、长度及默认值。如果修改列的默认值,只会影响后来插入的新纪录。语法格式如下: 【 alter table table modify (column datatype [default expr] [,column datatype]…); 】 5.3、(删除列)drop table 语句用于删除表的定义,语法格式如下: 【alter table table drop(要删除的列名)】 6、(修改表的名称)使用rename语句可以对表、视图、序列或同义词进行改名。语法格式如下: 【rename old_name to new_name;】 7、(清空表)使用truncate table 语句删除表中的所有记录并释放该表的存储空间。数据和结构都被删除;所有正在运行的相关事务被提交;所有相关索引被删除;DROP TABLE 语句不能回滚。表存在数据没有了。 语法格式如下: 【truncate table table;】 7.1、三个删除的比较:delete:是一条DML语句,只删除表里的数据,最少只能删除一行记录,可以回滚,不是放表的存储空间;drop table:是一条DDL语句,删除表的结构和表里的数据,数据库中该表的所有数据将丢失并且该表的相关索引也被删除,相关的视图和同义词仍存在,但不能使用,悬而未决的事务被提交,不能在回滚;truncate table:删除表里所有数据,表仍存在,并释放表的存储空间,不能回滚。 8、给表添加注释:给表添加不超过2000字节的注释,可以从字典表comments列中查询。相关查询: all_col_comments:查询所有列注释;user_col_comments:用户当前查询; all_tab_comments:所有表的查询;user_tab_comments:用户表的查询; 8.1、语法格式如下: 【comment on table table / colume table.column is ‘注释文字’】 第10章、约束 1、什么是约束:约束是表级的强制规定,约束放置在表中删除有关联关系的数据,有以下五种约束:NOT NULL(只能定义在列级);UNIQUE ;PRIMARY KEY;FOREIGN KEY;CHECK;注意事项:如果不指定约束名Oracle server 自动按照SYS_C n 的格式指定约束名;在什么时候创建约束:建表的同时;建表之后;可以在表级或列级定义约束;可以通过数据字典视图查看约束。 2、定义约束的语法格式如下: 【 列)],……, 当前用户数据类型、长度 3、五种约束类型介绍: ①not null(非空约束):确保该列不能存放空值,如果列没有使用not null约束,则该列可以为空;它只能定义在列一级上,不能定义在表一级上。利用插入的方法检测not null是否起作用。 ②unique(唯一性约束):要求列或列集合中的每一个值都是唯一的,就是说表中没有两条记录在该列或列集合上的值是相同的,unique允许输入空值,除非定义not null约束。Unique可以定义在表或列一级上,由unique 约束的多个列组成复合唯一关键字是在表一及上定义的。 ③primary key(主键约束):可以创建主关键字,每个表只能有一个主关键字,primary key可以是单独一个列也可以是多个列组合,作为表中唯一性标志,确保主关键字中的列不能含有空值;primary key可以定义在列一级或表一级上,复合主关键字只能定义在表一级上。 ④foreign key(外键约束):也成为引用完整性约束,用于指定列或列的组合作为一个外键,并且和同一个表或其他的主关键字或唯一关键字建立关系,外键值必须和父表中的值相匹配或者为空,外键与主键连用,并关联主键;外键定义在子表上,并且包含对父表的引用,使用以下关键词定义外键: Foreign key:在表或列一级上定义外键;references:标识父表及相应的列;on delete cascade:如果删除父表中的记录,则允许级联删除子表中的相关联的记录。如果没有on delete cascade选项,若子表中存在对父表中某些记录的引用,则不能删除父表中这些被引用的记录。 对于已经建立引用完整性的子表和父表,应注意以下问题:在进行插入操作时,只有子表才会产生违反引用完整性的问题,而在父表这一端是不会产生的;在进行修改操作时,子表和父表都有可能产生违反引用完整性的问题;在进行删除操作时,只有父表才会产生违反引用完整性的问题,子表不会产生。 ⑤check(条件约束):定义每条记录都必须满足的条件,这个条件可以和查询的条件的结构相同,但是以下情况除外:引用currval、nextval、level及rownum伪列;调用sysdate、uid、user及userenv函数;其他记录的其他值的查询。 一个列可以定义多个check约束,同一个列上check约束的数量没有限制,check约束可以定义在列一级或 表一级。 4、添加约束:使用alter table 语句可以为已存在的表添加约束;添加或删除约束, 但是不能修改约束。语法格式如下: 【alter table table add[constraint constraint] type ( column ); 】 表名约束名约束类型被约束的列名 4.1、有效化或无效化约束;向已存在的表中添加not null 约束要使用modify 语句; 5、删除约束语法格式如下: 【alter table table drop type (column)constraint constraint [cascade] ; 】 表名约束类型被约束的列名约束名外键约束被删除 5.1、删除主键的同时级联的删除外键约束时,使用cascade选项删除约束;可以从user_constraints(查询数据字典)和user_cons_columns(查询定义的约束列)数据字典查询相关的约束名;当删除一个完整性约束时,该约束不再有效并且数据字典中也不存在被删除约束的相关信息。 6、禁用约束:不采用删除约束,通过disable语句的使用来禁用约束,语法格式如下: 【alter table table disable constraint constraint [cascade] ; 使子约束也无效化】 6.1、关于禁用约束:disable子句可以应用于create table及alter table 语句中;cascade可以使子约束同时失效。 7、启用约束:通过enable子句的使用来启用被禁用的约束,语法格式如下: 【alter table table enable constraint constraint ; 】 7.1、关于启用约束:若启用一个约束,该约束会应用于表中所有记录,所有记录必须符合约束条件;当定义或激活unique 或primary key 约束时系统会自动创建unique 或primary key索引;enable子句可以应用于create table及alter table 语句中。 8、级联约束:cascade constraints 子句在drop column 子句中使用 在删除表的列时cascade constraints 子句指定将相关的约束一起删除 在删除表的列时cascade constraints 子句同时也删除多列约束 第11章、视图 1、视图:是基于一个或多个表或视图的逻辑表,本身并不包含数据,只是一个定义,可以查询或修改表中的数据,视图所基于的表成为基表。 2、为什么使用视图(优点)?限制对数据访库的访问;简化查询;提供数据的独立性;给相同的数据提供不同的数据表象;删除时不删除数据;子查询是临时视图的一种;Top-N 分析。 4、创建视图语使用create view嵌套子查询创建视图,法格式如下: 【create[or replace] [ force/ noforce ] view view 视图名称 重建存在的视图强制创建视图基表存在才建视图(默认) [ ( alias [, alias]…)] as subquery 子查询语句,可定义别名,可以是复杂的select语句视图列创建别名,数量和长生的列相同 [with check option [constraint constraint ] ] 按子查询的结果插入或修改数据行约束名 [ with read only ] 】 只读,在视图上不能进行DML操作 4.1、创建视图的原则: ☆可用复杂的select语句,可包括连接、分组、子查询; ☆定义视图查询不能使用order by子句,order by子句可以在从视图中查询数据时使用; ☆创建视图时没有为约束命名,系统会自动为其命名; ☆使用or replace选项不用删除已存在的视图就可以重建它或重新授予对象权限; 创建视图时在子查询中给列定义别名;在选择视图中的列时应使用别名。 5、查询视图:和表的查询是一样的。数据字典user_views查询视图名称和视图定义,视图定义的select语句保存在long型的text字段中。 6、修改视图:使用create or replace view 子句修改视图,create view 子句中各列的别名应和子查询中各列相对应。 7、复杂视图举例:使用组函数,查询两个表。例如: CREA TE VIEW dept_sum_vu (name, minsal, maxsal, avgsal) AS SELECT d.department_name, MIN(e.salary), MAX(e.salary),A VG(e.salary) FROM employees e, departments d WHERE e.department_id = d.department_id GROUP BY d.department_name; 8、视图上的DML操作 8.1、视图上执行DML操作遵循的规则: ①可以在简单视图中执行DML 操作; ②当视图定义中包含以下元素之一时不能删除行数据:组函数、group by 子句、distinct 关键字、rownum 伪列; ③当视图定义中包含以下元素之一时不能修改(基表中)行数据:组函数、group by 子句、distinct 关键字、rownum 伪列、列为计算表达式 ④当视图定义中包含以下元素之一时不能插入(基表中)行数据:组函数、group by 子句、distinct 关键字、rownum 伪列、列为计算表达式、表中非空的列在视图定义中未包括; 8.2、with check option子句使用:使用with check option 子句确保DML只能在子查询的范围内执行;通过视图执行的inserts和updates操作不能创建该视图检索不到的数据行。任何违反with check option 约束的请求都会失败。 8.3、屏蔽DML 操作:可以使用with read only 选项屏蔽对视图的DML 操作;任何DML 操作都会返回一个Oracle server 错误。 9、删除视图:删除视图只是删除视图的定义,并不会删除基表的数据。语法:【drop view view;】 10、临时视图:临时视图可以是嵌套在SQL语句中的子查询;在FROM 子句中的的子查询是临时视图;临时视图不是数据库对象。 第12章、其他数据库对象 一、序列 1、序列(squence):Oracle中的序列产生器。序列的特性: ☆自动提供唯一的数值;☆共享对象;☆主要用于提供主键值;☆代替应用代码;☆将序列值装入内存提高访问效率。 2、序列创建语法格式如下: 【create sequence sequence →序列名 [increment by n] →n表示以多少递增,若省略表示以1为递增量,为负数表示递减 [start whit n] →n表示起始序列值,省略表示起始值为1 [maxvalue n / nomaxvalue] →n表示指定最大序列值,n<=10的27次方,降序最大值为-1 [minvalue n / nominvalue] →n指定最小序列值,升序最小值为1,降序最小值为-10的26次方 [cycle/ nocycle] →表示序列值达到顶值后继续循环产生。 [cache n / nocache]; 】→序列值预先分配并存贮在内存中,n为正整数。默认为20个。 其中:各个n不相同,都是整数。_____表示为默认值。 3、查询数列:查询数据字典视图user_sequences获取序列定义信息;如果指定nocache 选项,则list_number 显示序列中下一个有效的值; 4、nextval和currval伪列: 4.1、nextval:返回下一个有效的序列值;任何用户都可以引用。currval:显示当前用户产生的序列值。注意:nextval 应在currval 之前指定,二者应同时有效。 4.2、使用nextval和currval伪列的情况包括:☆select语句的select列表中,但不包括子查询中的select语句;☆insert语句中的子查询select列表中;☆insert语句中的values子句中;☆update语句中set子句中; 不能使用nextval和currval伪列的情况包括:☆在视图的select列表中;☆包含distinct关键字的select语句中;☆包含group by,having,order by,子句中的select语句中;☆select,delete,update语句的子查询中;☆含有default表达式的creat table,alter table语句中。 5、序列的使用:将序列值装入内存可提高访问效率。 ?序列在下列情况下出现裂缝: –回滚 –系统异常 –多个表同时使用同一序列 ?如果不将序列的值装入内存(nocache), 可使用表user_sequences 查看序列中下一个有效值。 6、修改序列:可修改的项目有增量, 最大值, 最小值, 循环选项, 或是缓冲选项;语法格式如下: 【alter sequence sequence [increment by n] [start whit n] →n不可改变 [maxvalue n / nomaxvalue] n的值可以改变 [minvalue n / nominvalue] [cycle/ nocycle] [cache n / nocache]; 】 ●修改序列的注意事项:必须是序列的拥有者或对序列有alter 权限;只有后续的序列值会被改变;改变序 列的初始值只能通过删除序列之后重建序列的方法实现;执行一些校验。 7、删除序列:使用drop sequence 语句删除序列。【drop sequence 被删除的序列名;】 二、索引:相当于书籍的目录;一种数据库对象;通过指针加速Oracle 服务器的查询速度;通过快速定位数据的方法,减少磁盘I/O;索引与表相互独立;Oracle 服务器自动使用和维护索引。 1、创建索引: ?自动创建: 在定义primary key 或unique 约束后系统自动在相应的列上创建唯一性索引 ?手动创建: 用户可以在其它列上创建非唯一的索引,以加速查询 2、手动创建语法格式如下: 【create index index on table (column[, column]...); 】 索引的名称表的名称创建索引的列 3、什么时候创建索引? ?列中数据值分布范围很广 ?列中包含大量空值 ?列经常在WHERE 子句或连接条件中出现 ?表经常被访问而且数据量很大,访问的数据大概占数据总量的2%到4% 4、何时不创建索引? ?表很小 ?列不经常作为连接条件出现在WHERE子句中 ?查询的数据大于2%到4% ?表经常更新 ?加索引的列包含在表达式中 5、查询索引:可以使用数据字典视图USER_INDEXES 和USER_IND_COLUMNS 查看索引的信息。 6、基于函数的索引: ?基于函数的索引是一个基于表达式的索引 ?索引表达式由列, 常量, SQL 函数和用户自定义的函数组成 例如:CREA TE INDEX upper_dept_name_idx ON departments(UPPER(department_name)); Index created SELECT * FROM departments WHERE UPPER(department_name) = 'SALES'; ?7、删除索引:使用drop index 命令删除索引;删除索引upper_last_name_idx;只有索引的拥有者或拥有drop any index权限的用户才可以删除索引。 三、同义词 1、使用同义词访问相同的对象: ?方便访问其它用户的对象 ?缩短对象名字的长度 2、创建同义词的语法格式如下: 【create[ public ] synonym synonym for object;】 可被所有用户引用同义词名称同义词所指的对象 3、删除同义词与非格式如下: 【drop synonym synonym ;】注:只有数据库管理员才能删除带public的同义词。 第13章、控制用户权限 1、当用户同时拥有用户名、密码和权限才能够访问数据库。 2、数据库的权限: ?数据库安全性: –系统安全性 –数据安全性 ?系统权限: 对于数据库的权限 ?对象权限: 操作数据库对象的权限 ?方案: 一组数据库对象集合, 例如表, 视图,和序列 3、系统权限: ?超过一百多种有效的权限 ?数据库管理员具有高级权限以完成管理任务,例如: –创建新用户 –删除用户 –删除表 –备份表 4、DBA(数据库管理员)创建用户及授予系统权限: 4.1、创建用户语法格式如下: 【create user user identified by password ;】 用户名称用户密码 4.2、创建成功后授予系统权限的语法格式如下: 【grant privilege [,privilege…] to user [, user…];】 权限名称被授权的用户名 权限名称包括: 5、角色的使用:角色:一组命名的系统权限。其使用分为以下三个步骤: 5.1、步骤一:创建角色语法格式: 【create role role;(角色名称)】 步骤二:为角色赋予权限语法格式: 【grant privilege(权限名称)to role(角色名称);】 步骤三:将角色赋予用户语法格式: 【grant role(角色名称) to user[,user…](用户名称);】 6、修改密码:DBA可以创建用户和初期化密码;用户本人可以使用alter user 语句修改密码。语法如下:【alter user user(用户名) identified by password (新密码); 】 7.1、对象权限: ?不同的对象具有不同的对象权限 ?对象的拥有者拥有该用户下所有权限 ?对象的拥有者可以向外分配权限 7.2、用户将其拥有的对象权限赋予其他用户或角色的语法格式: 【grant object_priv [(columns)] object_priv:对象权限;columns:指定被授权的,来自表或视图的列on object object:被授权对象 to {user|role|public} to →标志授权给哪个用户或角色 [with grant option]; 】允许被授权用户再次给其他用户授权 8.1、回收权限语法格式如下: 【revoke {privilege [, privilege...] | ALL} on object from {user[, user...]|role| public} [cascade constraints];】移去外键时使用 第13章、set集合运算符 1、union操作符: union 操作符返回两个查询union all 操作符返回两个查询 的结果集的不重复部分的并集的结果集的并集以及两个结果集的重复部分(不去重) 2、intersect操作符: 3、minus操作符: intersect 操作符返回两个结果集的交集 minus 操作符返回两个结果集的补集4、使用SET 集合操作符注意事项 ?在SELECT 列表中的列和表达式在数量和数据类型上要相对应 ?括号可以改变执行的顺序 ?ORDER BY子句: –只能在语句的最后出现 –可以使用第一个查询中的列名, 别名或相对位置 5、SET 集合操作符 ?除UNION ALL之外,系统会自动将重复的记录删除 ?系统将第一个查询的列名显示在输出中 ?除UNION ALL之外,系统自动按照第一个查询中的第一个列的升序排列 数据库增删改查基本语句 adoquery1.Fielddefs[1].Name; 字段名 dbgrid1.columns[0].width:=10; dbgrid的字段宽度 adoquery1.Fields[i].DataType=ftString 字段类型 update jb_spzl set kp_item_name=upper(kp_item_name) 修改数据库表中某一列为大写select * from master.dbo.sysobjects ,jm_https://www.doczj.com/doc/2710806624.html,ers 多库查询 adotable1.sort:='字段名称ASC' adotable排序 SQL常用语句一览 sp_password null,'新密码','sa' 修改数据库密码 (1)数据记录筛选: sql="select * from 数据表where 字段名=字段值orderby 字段名[desc] " sql="select * from 数据表where 字段名like '%字段值%' orderby 字段名[desc]" sql="select top10 * from 数据表where 字段名orderby 字段名[desc]" sql="select * from 数据表where 字段名in('值1','值2','值3')" sql="select * from 数据表where 字段名between 值1 and 值2" (2)更新数据记录: sql="update 数据表set 字段名=字段值where 条件表达式" sql="update 数据表set 字段1=值1,字段2=值2……字段n=值n where 条件表达式" (3)删除数据记录: sql="delete from 数据表where 条件表达式" sql="delete from 数据表"(将数据表所有记录删除) (4)添加数据记录: sql="insert into 数据表(字段1,字段2,字段3…) values(值1,值2,值3…)" sql="insert into 目标数据表select * from 源数据表"(把源数据表的记录添加到目标数据表) SAS中的SQL语句完全教程之一:SQL简介与基本查询功能 本系列全部内容主要以《SQL Processing with the SAS System (Course Notes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。 1 SQL过程步介绍 1.1 SQL过程步可以实现下列功能: 查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS 数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL语句、可以和SAS的数据步进行替换使用。注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。 1.2 SQL过程步的特征 SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL过程步 1.3 SQL过程步语句 SELECT:查询数据表中的数据 ALTER:增加、删除或修改数据表的列 CREATE:创建一个数据表 DELETE:删除数据表中的列 DESCRIBE:列出数据表的属性 DROP:删除数据表、视图或索引 INSERT:对数据表插入数据 RESET:没用过,不知道什么意思 SELECT:选择列进行打印 UPDATE:对已存在的数据集的列的值进行修改 2 SQL基本查询功能 2.1 SELECT语句基本语法介绍 SELECT 无论您是一位SQL 的新手,或是一位只是需要对SQL 复习一下的资料仓储业界老将,您就来对地方了。这个SQL 教材网站列出常用的SQL 指令,包含以下几个部分: ? SQL 指令: SQL 如何被用来储存、读取、以及处理数据库之中的资料。 ?表格处理: SQL 如何被用来处理数据库中的表格。 ?进阶SQL: 介绍SQL 进阶概念,以及如何用SQL 来执行一些较复杂的运算。 ? SQL 语法: 这一页列出所有在这个教材中被提到的SQL 语法。 对于每一个指令,我们将会先列出及解释这个指令的语法,然后用一个例子来让读者了解这个指令是如何被运用的。当您读完了这个网站的所有教材后,您将对SQL 的语法会有一个大致上的了解。另外,您将能够正确地运用SQL 来由数据库中获取信息。笔者本身的经验是,虽然要对SQL 有很透彻的了解并不是一朝一夕可以完成的,可是要对SQL 有个基本的了解并不难。希望在看完这个网站后,您也会有同样的想法。 SQL指令 SELECT 是用来做什么的呢?一个最常用的方式是将资料从数据库中的表格内选出。从这一句回答中,我们马上可以看到两个关键字:从(FROM) 数据库中的表格内选出(SELECT)。(表格是一个数据库内的结构,它的目的是储存资料。在表格处理这一部分中,我们会提到如何使用SQL 来设定表格。) 我们由这里可以看到最基本的SQL 架构: SELECT "栏位名" FROM "表格名" 我们用以下的例子来看看实际上是怎么用的。假设我们有以下这个表格: store_name Sales Date Los Angeles $1500 Jan-05-1999 San Diego $250 Jan-07-1999 Los Angeles $300 Jan-08-1999 Boston $700 Jan-08-1999 S A S中的S Q L语句完全教程之一:S Q L简介与基本查询功能本系列全部内容主要以《SQLProcessingwiththeSASSystem(CourseNotes)》为主进行讲解,本书是在网上下载下来的,但忘了是在哪个网上下的,故不能提供下载链接了,需要的话可以发邮件向我索取,我定期邮给大家,最后声明一下所有资料仅用于学习,不得用于商业目的,否则后果自负。 1SQL过程步介绍 过程步可以实现下列功能: 查询SAS数据集、从SAS数据集中生成报表、以不同方式实现数据集合并、创建或删除SAS数据集、视图、索引等、更新已存在的数据集、使得SAS系统可以使用SQL 语句、可以和SAS的数据步进行替换使用。注意,SQL过程步并不是用来代替SAS数据步,也不是一个客户化的报表工具,而是数据处理用到的查询工具。 过程步的特征 SQL过程步并不需要对每一个查询进行重复、每条语句都是单独处理、不需要print 过程步就能打印出查询结果、也不用sort过程步进行排序、不需要run、要quit来结束SQL过程步 过程步语句 SELECT:查询数据表中的数据 ALTER:增加、删除或修改数据表的列 CREATE:创建一个数据表 DELETE:删除数据表中的列 DESCRIBE:列出数据表的属性 DROP:删除数据表、视图或索引 RESET:没用过,不知道什么意思 SELECT:选择列进行打印 UPDATE:对已存在的数据集的列的值进行修改 2SQL基本查询功能 语句基本语法介绍 SELECT 1 SQL 基础教程 SQL 就是用于访问与处理数据库得标准得计算机语言。 在本教程中,您将学到如何使用 SQL 访问与处理数据系统中得数据,这类数据库包括:Oracle, Sybase, SQL Server, DB2, Access 等等。rMbjYrd。 RZAN5q3。Koh0QFg。 2 SQL 简介 SQL 就是用于访问与处理数据库得标准得计算机语言。 什么就是 SQL? ?SQL 指结构化查询语言 ?SQL 使我们有能力访问数据库 ?SQL 就是一种 ANSI 得标准计算机语言 编者注:ANSI,美国国家标准化组织 SQL 能做什么? ?SQL 面向数据库执行查询 ?SQL 可从数据库取回数据 ?SQL 可在数据库中插入新得记录 ?SQL 可更新数据库中得数据 ?SQL 可从数据库删除记录 ?SQL 可创建新数据库 ?SQL 可在数据库中创建新表 ?SQL 可在数据库中创建存储过程 ?SQL 可在数据库中创建视图 ?SQL 可以设置表、存储过程与视图得权限 SQL 就是一种标准 - 但就是、、、 SQL 就是一门 ANSI 得标准计算机语言,用来访问与操作数据库系统。SQL 语句用于取回与更新数据库中得数据。SQL 可与数据库程序协同工作,比如 MS Access、DB2、Informix、MS SQL Server、Oracle、Sybase 以及其她数据库系统。Bde7Dth。x1uZBAw。eomc8l0。 不幸地就是,存在着很多不同版本得 SQL 语言,但就是为了与 ANSI 标准相兼容,它们必须以相似得方式共同地来支持一些主要得关键词(比如 SELECT、UPDATE、DELETE、INSERT、WHERE 等等)。uxTiDPz。39Y8LCi。yh1Gca0。 注释:除了 SQL 标准之外,大部分 SQL 数据库程序都拥有它们自己得私有扩展! 数据库基本SQL 语句大全 学会数据库是很实用D ??记录一些常用的sql 语句…有入门有提高 有见都没见过的…好全…收藏下… 其实一般用的就是查询,插入,删除等语句而已....但学学存储过程是好 事…以后数据方面的东西就不用在程序里搞喽?.而且程序与数据库只要 一个来回通讯就可以搞定所有数据的操作 一、基础 1、说明:创建数据库 Create DATABASE database-name 2、说明:删除数据库 drop database dbn ame 3、说明:备份sql server ---创建 备份数据的device USE master EXEC sp_addumpdevice ‘ disk ‘ c: MyNwind_1.dat ---开始备份 BACKU P DATABASE pubs TO testBack 4、说明:创建新表 create table tab name(col1 type1 [not n ull] [p rimary key],col2 type2 [not null],..) 根据已有的表创建新表: A : create table tab_new like tab_old 使用旧表创建新表) B : create table tab_new as select col1,col2 5、说明:删除新表 drop table tab name ‘ testBack ??- from tab_old defi niti on only 6、说明:增加一个列 Alter table tab name add colu mn col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一 能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tab name add p rimary key(col) 说明:删除主键:Alter table tab name drop p rimary key(col) 8、说明:仓J建索弓丨:c reate [uniq ue] in dex idx name on tab name(col ….) 删除索引:drop in dex idx name 注:索引是不可更改的,想更改必须删除重新 建。 9、说明:创建视图:create view view name as select stateme nt 删除视图:drop view view name 10、说明:几个简单的基本的sql语句 选择: select * from tablel where 范围 插入: in sert into table1(field1,field2) values(value1,value2) 删除: delete from table1 where 范围 更新: up date table1 set field1=value1 where 范围 查找: select * from tablel where fieldi like '%vkee的语法很精 妙,查资料! 排序: select * from tablei order by field1,field2 [desc] 总数: select count as totalco unt from tablei 求和: select sum(fieldi) as sumvalue from tablei 平均: select avg(fieldi) as avgvalue from tablei 最大: select max(fieldi) as maxvalue from tablei 常用SQL语句大全 一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 DROP database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2…from tab_old definition only 5、说明:删除新表 DROP table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键:Alter table tabname DROP primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:DROP index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:DROP view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 求和:select sum(field1) as sumvalue from table1 平均:select avg(field1) as avgvalue from table1 最大:select max(field1) as maxvalue from table1 最小:select min(field1) as minvalue from table1 11、说明:几个高级查询运算词 一、基本查询语句 1、基本的语法格式: 【select (SQL 关键字)[distinct (滤除重复记录)] * /列名称…… 别名 from table ;】 2、书写SQL 语句遵循的基本原则:①不区分大小写,除非特别指定;②可以写成一行或多行;③关键字不能简写或分割于多行;④子句通常单独行书写,便于编辑和提高可读性;⑤使用Tab 和缩进提高程序可读性;⑥关键字最好使用大写,其他使用小写;⑦在SQL*Plus 中,SQL 语句是在SQL prompt 状态下输入,并且每行都有编号。是SQL 的缓冲区,任何时候在缓冲区中只会存放当前一条语句。 3、| | 表示列与列、列与算术表达式、列与常量之间的合成。 第2章、限定查询和排序语句 1、限定数据行的查询语法格式: 【select [distinct] */ 列名称…… 别名 from table where (限定条件)列名/表达式/常量/比较运算符;】 (其中比较运算符包括:=:等于、>:大于、>=:大于等于、<:小于、<=:小于等于、<>.!=.^=:不等于。 (要查询的列)between (下限)and (上限):两个值之间包括边界范围比较。 (要查询的列)in (集合,用逗号隔开):和多个值中任意一个匹配,相当于多个or 并列在一起。 (要查询的列)like+‘通配符和查询的内容’:模糊查询、is null :是否是空值) 1.1、where 子句中,字符串和日期数值必须用单引号引起来,数值型常量则不需要,字符型数据区分大小写,默认的日期形式是:DD-MON-YY 。 1.2、like (模糊查询):把握不准查询确切的值,通过字形匹配来查询。可以使用通配符:%:表示0或更多任意的字符;_:代表一个字符。可以同时使用。当查询的内容包括%或_时,可以使用escape ,即“/”转义符。 Not::如果条件为假则返回真值。 在where 子句中。通过使用and 和or 在where 中使用多个条件。 1.4运算符优先规则:算数运算符>连接符>比较运算符>not>and>or 。 2、order by 子句:查询结果按照某种顺序排列显示。 order by 子句语法格式: 【select [distinct] */ 列名称…… 别名 from table where (限定条件)列名/表达式/常量/比较运算符 Order by (要查询的列) asc(生序排列)/desc (降序排序);】 注意:order by 子句必须放在select 语句的最后,并且可以指定一个参与排序的表达式或别名。可使用别名进行排序。Select 语句中只能有一个order by 子句。 2.1、默认的排序方式是升序,不同类型数据的升序排列原则: ☆ 数值型数据按照从小到大的顺序排列的; ☆ 日期型数据按照时间从早到晚的顺序排列的; ☆ 字符型数据按照字母顺序排列的; ☆ 空值在升序排列方式下排在最后,降序排列排在最前。 SQL 运行过程:from 首先运行,where 其次运行,select 再运行,order by 最后运行。对查询结果进行排序。 第一章数据库基础知识 本章以概念为主,主要是了解数据库的基本概念,数据库技术的发展,数据模型,重点是关系型数据。 第一节:信息,数据与数据处理 一、信息与数据: 1、信息:是现实世界事物的存在方式或运动状态的反映。或认为,信息是一种已经被加工为特定形式的数据。 信息的主要特征是:信息的传递需要物质载体,信息的获取和传递要消费能量;信息可以感知;信息可以存储、压缩、加工、传递、共享、扩散、再生和增值 2、数据:数据是信息的载体和具体表现形式,信息不随着数据形式的变化而变化。数据有文字、数字、图形、声音等表现形式。 3、数据与信息的关系:一般情况下将数据与信息作为一个概念而不加区分。 二、数据处理与数据管理技术: 1、数据处理:数据处理是对各种形式的数据进行收集、存储、加工和传输等活动的总称。 2、数据管理:数据收集、分类、组织、编码、存储、检索、传输和维护等环节是数据处理的基本操作,称为数据管理。数据管理是数据处理的核心问题。 3、数据库技术所研究的问题不是如何科学的进行数据管理。 4、数据管理技术的三个阶段:人工管理,文件管理和数据库系统。 第二节:数据库技术的发展 一、数据库的发展:数据库的发展经历了三个阶段: 1、层次型和网状型: 代表产品是1969年IBM公司研制的层次模型数据库管理系统IMS。 2、关系型数据型库: 目前大部分数据库采用的是关系型数据库。1970年IBM公司的研究员E.F.Codd提出了关系模型。其代表产品为sysem R和Inges。 3、第三代数据库将为更加丰富的数据模型和更强大的数据管理功能为特征,以提供传统数据库系统难以支持的新应用。它必须支持面向对象,具有开放性,能够在多个平台上使用。 二、数据库技术的发展趋势: 1、面向对象的方法和技术对数据库发展的影响: 数据库研究人员借鉴和吸收了面向对旬的方法和技术,提出了面向对象数据模型。 2、数据库技术与多学科技术的有机组合: 3、面向专门应用领域的数据库技术 三、数据库系统的组成: 数据库经典SQL语句大全 篇一:经典SQL语句大全 下列语句部分是Mssql语句,不可以在access中使用。 SQL分类: DDL—数据定义语言(CREATE,ALTER,DROP,DECLARE) DML—数据操纵语言(SELECT,DELETE,UPDATE,INSERT) DCL—数据控制语言(GRANT,REVOKE,COMMIT,ROLLBACK) 首先,简要介绍基础语句: 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk','testBack', 'c:mssql7backupMyNwind_1.dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2? from tab_old definition only 5、说明: 删除新表: tabname 6、说明: 增加一个列:Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明: 添加主键:Alter table tabname add primary key(col) 说明: 删除主键:Alter table tabname drop primary key(col) 8、说明: 创建索引:create [unique] index idxname on tabname(col?.) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 数据库基本SQL语句大全 数据库基本----SQL语句大全 一、基础 1、说明:创建数据库 Create DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1、d at' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 typ e2 [not null],、、) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2…from tab_old definit ion only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的就是增加varchar类型的长度。 7、说明:添加主键: Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col…、) 删除索引:drop index idxname 注:索引就是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 整理了一下,希望对大家有用 SQL语句大全 --语句功能 --数据操作 SELECT --从数据库表中检索数据行和列INSERT --向数据库表添加新数据行 DELETE --从数据库表中删除数据行 UPDATE --更新数据库表中的数据 --数据定义 CREATE TABLE --创建一个数据库表 DROP TABLE --从数据库中删除表 ALTER TABLE --修改数据库表结构 CREATE VIEW --创建一个视图 DROP VIEW --从数据库中删除视图 CREATE INDEX --为数据库表创建一个索引DROP INDEX --从数据库中删除索引 CREATE PROCEDURE --创建一个存储过程 DROP PROCEDURE --从数据库中删除存储过程CREATE TRIGGER --创建一个触发器 DROP TRIGGER --从数据库中删除触发器CREATE SCHEMA --向数据库添加一个新模式DROP SCHEMA --从数据库中删除一个模式CREATE DOMAIN --创建一个数据值域 ALTER DOMAIN --改变域定义 DROP DOMAIN --从数据库中删除一个域 --数据控制 GRANT --授予用户访问权限 DENY --拒绝用户访问 REVOKE --解除用户访问权限 --事务控制 COMMIT --结束当前事务 ROLLBACK --中止当前事务 SET TRANSACTION --定义当前事务数据访问特征--程序化SQL DECLARE --为查询设定游标 EXPLAN --为查询描述数据访问计划 OPEN --检索查询结果打开一个游标 FETCH --检索一行查询结果 CLOSE --关闭游标 PREPARE --为动态执行准备SQL 语句EXECUTE --动态地执行SQL 语句 DESCRIBE --描述准备好的查询 SQL 教程 1)SQL 简介 SQL(Structured Query Language,结构查询语言)是一个功能强大的数据库语言。SQL通常使用于数据库的通讯。ANSI(美国国家标准学会)声称,SQL是关系数据库管理系统的标准语言。SQL语句通常用于完成一些数据库的操作任务,比如在数据库中更新数据,或者从数据库中检索数据。使用SQL的常见关系数据库管理系统有:Oracle、 Sybase、 Mi crosoft SQL Server、 Access、 Ingres等等。虽然绝大多数的数据库系统使用SQL,但是它们同样有它们自立另外的专有扩展功能用于它们的系统。但是,标准的SQL命令,比如"Select"、 "Insert"、 "Update"、 "Delete"、 "Create"和 "Drop"常常被用于完成绝大多数数据库的操作。 但是,不像其它的语言,如C、Pascal等,SQL没有循环结构(比如if-then-else、d o-while)以及函数定义等等的功能。而且SQL只有一个数据类型的固定设置,换句话说,你不能在使用其它编程语言的时候创建你自己的数据类型。 SQL功能强大,但是概括起来,它可以分成以下几组: DML(Data Manipulation Language,数据操作语言):用于检索或者修改数据; DDL(Data Definition Language,数据定义语言):用于定义数据的结构,比如创建、修改或者删除数据库对象; DCL(Data Control Language,数据控制语言):用于定义数据库用户的权限。 2)SQL 常用语句 2.1 ??SELECT 语句 作用:SELECT 语句用于从表中选取数据。结果被存储在一个结果表中(称为结果集)。 语法: SQL语句得概述 SQL语言得分类 数据定义语言(Data Definition Language)主要用于修改、创建与删除数据库对象,其中包括CREATE ALTER DROP语句。 数据查询语言(Data Query Language)主要用于查询数据库中得数据,其主要就是SELECT 语句,SELECT语句包括五个子句,分别就是FROM WHERE HAVING GROUP BY 与WITH语句。 数据操作语言(Data Manipulation Language)主要用于更新数据库里数据表中得数据,包括INSERT UODATE DELETE语句。 数据控制语言(Data Control Language)主要用于授予与回收访问数据库得某种权限。包括GRANT REVOKE等语句。 事物控制语言,主要用于数据库对事物得控制,保证数据库中数据得一致性,包括MIT ROLLBACK语句。 常用得数据类型 MYSQL: SQL语句中不区分关键字得大小写 SQL语句中不区分列名与对象名得大小写 SQL语句对数据库中数据得大小写敏感 SQL语句中使用--注释,当使用--注释时,--后面至少有--个空格,多行注释用/* */ 数据库得创建与删除 数据库得创建 CREATE DATABASE database_name; 在MYSQL MAND LINE CLIENT中书写SQL语句时,在SQL语句后面都要加上分号 数据库得删除 DROP DATABASE database_name; 数据表得创建与更新 数据库中得表 数据记录:在数据表中得每一行被称为数据记录 字段:数据表中得每一列被称为字段 主键(PRIMARY KEY):作为数据表中唯一得表示,保证了每一天数记录得唯一性。主键在关系数据库中约束实体完整性。所谓得实体完整性,就是指对数据表中行得约束。 外键(FOREIGN KEY):外键用来定义表与表之间得关系。在数据表中,如果属性列F就是关系B中得一个属性(并不就是关系B得主键),并且属性列F就是关系A得主键,则F就就是B 得外键。外键在关系数据库中约束参照完整性。所谓得参照完整性就是指表与表之间得约束。 索引:索引就是指向数据表中得一个指针,指向索引字段在数据表中得物理位置。一般可以在如下几种情况下建立索引 在主键列中创建索引 多表连接时,在经常使用得连接列上创建索引 在经常使用WHERE子句查询得列上创建索引 在经常进行分组GROUP BY及排序ORDER BY得列上创建索引 约束:为了保证数据得完整需要使用约束 1.唯一约束(UNIQUE)使用唯一约束得某一列或者某一组中没有相同得值,即保证了值 得唯一性。但就是唯一约束中可以插入NULL值 2.主键约束(PRIMARY KEY)保证使用主键约束得列中只能有唯一得值,并且不能包含 NULL值,数据表中每一列只能定义一个PRIMARY KEY 3.外键约束(FOREIGN KEY)保证表参照完整性,确保对一个数据表得数据操作不会对与 之关联得表造成不利得影响 4.检查约束(CHECK)限制列得取值范围或者取值条件,可以为一个列定义多个CHECK约 束 5.非空约束(NOT NULL)用于对列得约束 创建数据表 CREATE TABLE table_name( column_name1 datatype [constraint_condition1] [,column name2 datatype [constraint_condition2] …) 使用约束 1、唯一约束(UNIQUE)用来保证某一列或者某一组列中没有相同得值,一般为列创建了一 个唯一约束后,数据库会自动为该列建立一个唯一索引,其索引名与约束名相同 例如:CREATE TABLE T_dept( dept_ID VARCHAR(15) UNIQUE, dept_Name VARCHAR(10) 2、主键约束 CREATE TABLE T_result( stuID VARCHAR(15), cruID VARCHAR(15), result DOUBLE, PRIMARY KEY(stuID,curID) ) 3、外键约束 Microsoft SQL Server 2008 R2 SQL Server 2008基础教程前言 前言 本书针对那些想成为开发人员、数据库管理员或者兼为两者,但对SQL Server 2008还不熟悉的读者。无论你是否拥有数据库知识,是否了解桌面数据库(如Microsoft Access),甚至是否具有服务器(如Oracle)的背景,本书都能为你提供SQL Server 2008入门和运行的知识。 从现在开始,本书将使你的基础知识得以扩展,让你很快从初学者成长为合格的专业开发人员。本书面向广大开发人员,从喜欢使用图形界面的程序员,到希望成为SQL Server 2008编程语言Transact SQL(T-SQL)高手的程序员。本书将尽可能贴近实际地演示、说明和展开叙述每一种使用SQL Server 2008的方法,以便你能够判断哪种方式最适合自己。 本书包含大量的示例,以使你了解SQL Server的各个领域是如何工作的,以及怎样才能把技术应用到自己的工作中。你将学习完成某项任务的最佳方法,你甚至能学会在面临两个或更多的选择时,如何做出正确的决策。只要学习完本书,你就能游刃有余地设计和创建坚实可靠的数据库解决方案。 读者对象 本书适用的对象是刚开始使用SQL Server 2008的开发人员,或立志成为数据库管理人员的读者。本书在结构安排上兼顾了这两类读者。 本书的结构 本书将帮助你决定购买SQL Server 2008的哪种版本,为你展示如何安装和配置SQL Server 2008,并阐释如何使用图形用户界面工具SSMS(SQL Server Management Studio)。你将使用该工具完成一个功能完备的数据库示例,该数据库根据本书中介绍的设计方案,利用图形的和基于代码的练习创建而成。然后,你将学习数据库安全方面的知识,并了解如何实施安全可靠的数据库设置。只要备份了数据库,你就可以学习如何操作数据。先从简单的代码编写技术入手,逐渐过渡到更加复杂的技术。最后的任务是在数据库上创建和生成报表。本书会贯穿始终地说明每一个细节,告知你正在发生什么,并确保随着对本书阅读的深入,你将在从之前章节中获取的知识上,不断提高。你将以一种有条理、有组织的方式发展构筑自己的专业知识。 必要准备 要学习本书,你必须有SQL Server 2008开发版本的完整版或评估版。此外,如果想要为特定的Windows登录更改安全设置,有Windows Vista旗舰版或商业版将十分理想,但并非必须如此。 西门子ABB等PLC专用经典SQL语句大全一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1. dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxna me on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1 SQL语句的概述 SQL语言的分类 数据定义语言(Data Definition Language)主要用于修改、创建和删除数据库对象,其中包括CREATE ALTER DROP语句。 数据查询语言(Data Query Language)主要用于查询数据库中的数据,其主要是SELECT 语句,SELECT语句包括五个子句,分别是FROM WHERE HAVING GROUP BY 和WITH语句。 数据操作语言(Data Manipulation Language)主要用于更新数据库里数据表中的数据,包括INSERT UODATE DELETE语句。 数据控制语言(Data Control Language)主要用于授予和回收访问数据库的某种权限。包括GRANT REVOKE等语句。 事物控制语言,主要用于数据库对事物的控制,保证数据库中数据的一致性,包括COMMIT ROLLBACK语句。 常用的数据类型 MYSQL: SQL语句的书写规范 SQL语句中不区分关键字的大小写 SQL语句中不区分列名和对象名的大小写 SQL语句对数据库中数据的大小写敏感 SQL语句中使用--注释,当使用--注释时,--后面至少有--个空格,多行注释用/* */ 数据库的创建与删除 数据库的创建 CREATE DATABASE database_name; 在MYSQL COMMAND LINE CLIENT中书写SQL语句时,在SQL语句后面都要加上分号数据库的删除 DROP DATABASE database_name; 数据表的创建与更新 数据库中的表 数据记录:在数据表中的每一行被称为数据记录 字段:数据表中的每一列被称为字段 主键(PRIMARY KEY):作为数据表中唯一的表示,保证了每一天数记录的唯一性。主键在关系数据库中约束实体完整性。所谓的实体完整性,是指对数据表中行的约束。 外键(FOREIGN KEY):外键用来定义表与表之间的关系。在数据表中,如果属性列F是关系B中的一个属性(并不是关系B的主键),并且属性列F是关系A的主键,则F就是B 的外键。外键在关系数据库中约束参照完整性。所谓的参照完整性是指表与表之间的约束。 索引:索引是指向数据表中的一个指针,指向索引字段在数据表中的物理位置。一般可以在如下几种情况下建立索引 在主键列中创建索引 多表连接时,在经常使用的连接列上创建索引 在经常使用WHERE子句查询的列上创建索引 在经常进行分组GROUP BY及排序ORDER BY的列上创建索引 约束:为了保证数据的完整需要使用约束 1.唯一约束(UNIQUE)使用唯一约束的某一列或者某一组中没有相同的值,即保证 了值的唯一性。但是唯一约束中可以插入NULL值 2.主键约束(PRIMARY KEY)保证使用主键约束的列中只能有唯一的值,并且不能包 含NULL值,数据表中每一列只能定义一个PRIMARY KEY 3.外键约束(FOREIGN KEY)保证表参照完整性,确保对一个数据表的数据操作不会 对与之关联的表造成不利的影响 4.检查约束(CHECK)限制列的取值范围或者取值条件,可以为一个列定义多个CHECK 约束 5.非空约束(NOT NULL)用于对列的约束 创建数据表 CREATE TABLE table_name( column_name1 datatype [constraint_condition1] [,column name2 datatype [constraint_condition2] …) 使用约束 1.唯一约束(UNIQUE)用来保证某一列或者某一组列中没有相同的值,一般为列创建 了一个唯一约束后,数据库会自动为该列建立一个唯一索引,其索引名与约束名相同 例如:CREATE TABLE T_dept(数据库增删改查基本语句
最新SAS中的SQL语句大全
SQL语句基础教程汇总
SAS中的SQL语句大全
SQL基础教程
数据库基本SQL语句大全
常用SQL语句大全
SQL基础语句
数据库基础知识和sql语句
数据库经典SQL语句大全
数据库基本SQL语句大全
SQL SEVER 常用语句
sql语句基础教程
SQL入门基础语法
Microsoft SQL Server 2008 R2基础教程
西门子ABB等PLC专用经典SQL语句大全一、基础
SQL入门基础语法
相关主题
文本预览