
多元统计分析中的应用研究
,
摘要:许多实际问题往往需要对数据进行统计分析,建立合适的统计模型,过去一般采用SAS 、SPSS软件分析,本文给出 Matlab软件在多元统计分析上的应用, 主要介绍Matlab 在聚类分析、判别分析、主成份分析上的应用,文中均给以实例, 结果令人满意。
关键词:Matlab软件;聚类分析;主成份分析
Research for application of Multivariate Statistical
Analysis
Abstract:Many practice question sometimes need Statistical Analysis to data.,and establish appropriate Statistical model SAS and SPSS software were commonly used in foretime ,this paper give the application of Matlab software in Multivariate Statistical Analysis,mostly introduce the application of Matlab software in priciple component analysis and cluster analysis and differentiate analysis.The example are given in writing and the result are satisfaction.
Key words: Matlab software; cluster analysis; priciple component analysis
0 引言
许多实际问题往往需要对数据进行多元统计分析, 建立合适的模型, 在多元统计分析方面, 常用的软件有SAS 、SPSS 、S-PLUS等。我们在这里给出Matlab在多元统计分析上的应用, 在较早的版本中, 统计功能不那么强大, 而在Matlab6.x版本中, 仅在统计工具中的功能函数就达200多个, 功能已足以赶超任何其他专用的统计软件,在应用上Matlab具有其他软件不可比拟的操作简单,接口方便, 扩充能力强等优势, 再加上Matlab的应用范围广泛, 因此可以预见其在统计应用上越来越占有极其重要的地位,下面用实例给出Matlab 在聚类分析、主成份分析上的应用。
1 聚类分析
聚类分析法是一门多元统计分类法,其目的是把分类对象按一定规则分成若干类,所分成的类是根据数据本身的特征确定的。聚类分析法根据变量(或样品或指标)的属性或特征的相似性,用数学方法把他们逐步地划类,最后得到一个能反映样品之间或指标之间亲疏关系的客观分类系统图,称为谱系聚类图。
聚类分析的步骤有:数据变换,计算n个样品的两两间的距离,先分为一类,在剩下的n-1个样品计算距离,按照不同距离最小的原则,增加分类的个数,减少所需要分类的样品的个数,循环进行下去,直到类的总个数为1时止。根
据类之间的距离,画出谱系聚类图。
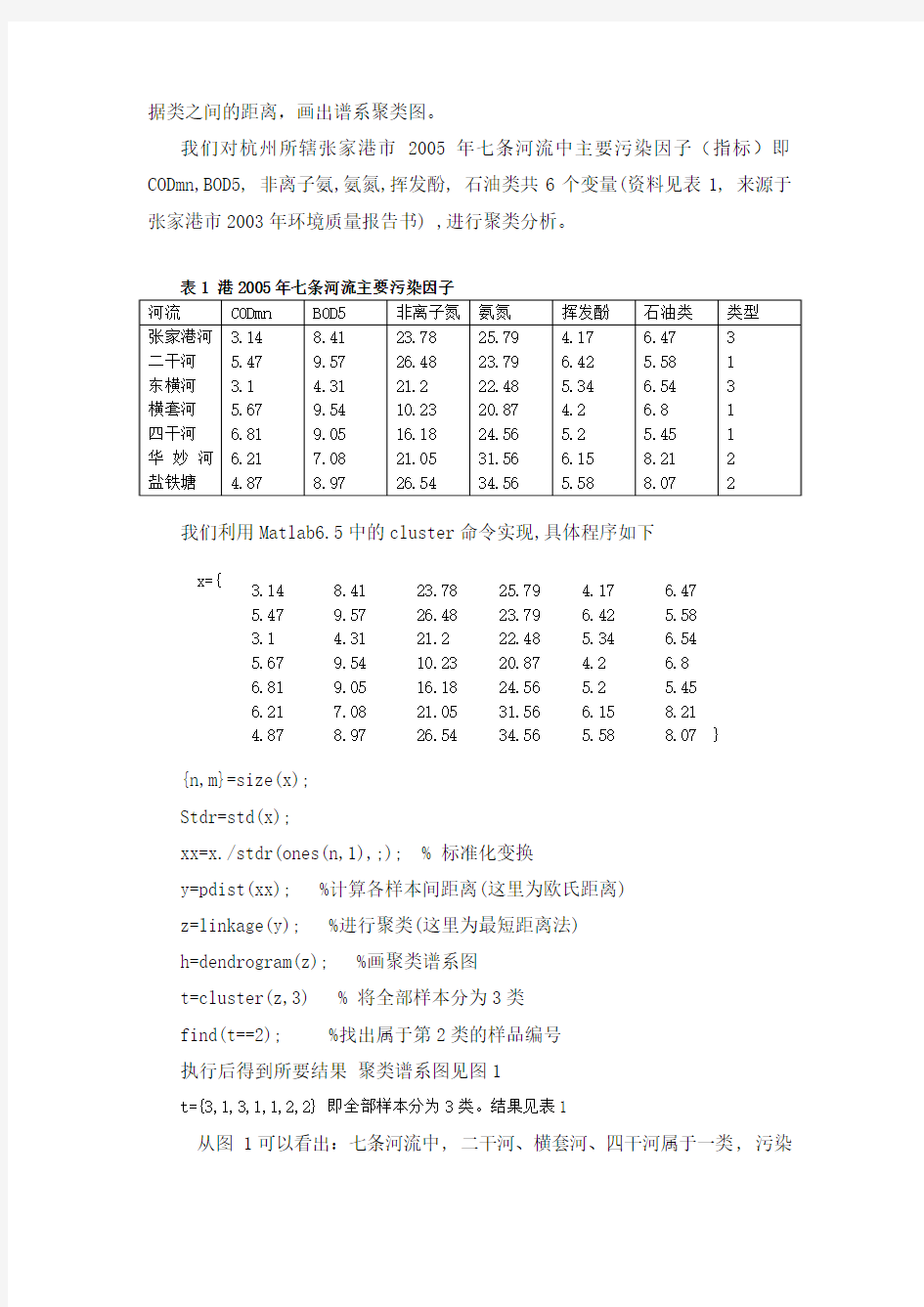
我们对杭州所辖张家港市2005年七条河流中主要污染因子(指标)即CODmn,BOD5, 非离子氨,氨氮,挥发酚, 石油类共6个变量(资料见表1, 来源于张家港市2003年环境质量报告书) ,进行聚类分析。
我们利用Matlab6.5中的cluster 命令实现,具体程序如下
x={
{n,m}=size(x); Stdr=std(x);
xx=x./stdr(ones(n,1),;); % 标准化变换
y=pdist(xx); %计算各样本间距离(这里为欧氏距离) z=linkage(y); %进行聚类(这里为最短距离法) h=dendrogram(z); %画聚类谱系图 t=cluster(z,3) % 将全部样本分为3类 find(t==2); %找出属于第2类的样品编号 执行后得到所要结果 聚类谱系图见图1
t={3,1,3,1,1,2,2} 即全部样本分为3类。结果见表1
从图 1可以看出:七条河流中, 二干河、横套河、四干河属于一类, 污染
3.14 5.47 3.1 5.67 6.81 6.21
4.87
8.41 9.57 4.31 9.54 9.05 7.08 8.97
23.78 26.48 21.2 10.23 16.18 21.05 26.54
25.79 23.79 22.48 20.87 24.56 31.56 34.56
4.17 6.42
5.34 4.2 5.2
6.15 5.58
6.47 5.58 6.54 6.8 5.45 8.21 8.07 }
较重, 主要是CODmn、BOD5超标多; 华妙河、盐铁塘属于一类, 污染一般, 主要是氨氮、石油类超标; 张家港河、东横河属于一类,污染较轻, 总的来说,各河流都存在不同程度的污染,因此全市应对各河流严格监督管理, 着力实施水污染防治工作, 太湖流域水污染源应限期治理达标排放, 巩固水污染防治工作成果,加大投入,新建或改、扩建废水治理工程, 确保达标排放。
图1 :聚类谱系图
,
2 主成分分析
主成分分析是将多个指标化为少数几个综合指标的一种多元统计分析方法。对于实际工作中遇到的多指标系统评估问题,主成分分析可以将多个指标综合为单个指数的形式。
主成分的计算步骤如下:
第一步,原始数据零均值标准化。
设每个指标的样本数据为x
i,1,x
i,2
,Lx
i,N
x
i,1
,x
i,2
,Lx
i,N
.作如下变换,令
x'ij=(x ij- x i)/S i
(i=1,2,L,P; j=1,2,L,N) 第二步,计算相关矩阵R=(rij),其中
第三步,求矩阵R 的特征值λi 与相应的标准正交化的特征向量Ai。第四步,计算第j 个主成分yi 的贡献率
当前q 个主成分(即新的综合指标)的累积贡献率超过85%时,就提取前q 个主成分作为评价指标,它们保持原始数据总信息量的85%以上。
这里给出江苏省生态城市主成份分析实例
城市环境生态化是城市发展的必然趁势, 表现为社会、经济、环境与生态全方位的现代化水平, 一个符合生态规律的生态城市应该是结构合理、功能高效和关系协调的城市生态系统所谓结构合理是指适度的人口密度, 合理的土地利用, 良好的环境质量, 充足的绿地系统, 完善的基础设施, 有效的自然保护功能高效是指资源的优化配置、物力的经济投入、人力的充分发挥、物流的畅通有序、信息流的快捷关系协调是指人和自然协调、社会关系协调、城乡
协调、资源利用和更新协调一个城市要实现生态城市的发展目标, 关键是在市场经济的体制下逐步改善城市的生态环境质量, 防止生态环境质量恶化, 因此, 对城市的生态环境水平调查评价很有必要。
我们对江苏省十个城市的生态环境状况进行了调查, 得到生态环境指标的指数值, 见表2。现对生态环境水平分析和评价
表2 指标指数值
我们利用Matlab6.5中的princomp命令实现,具体程序如下
x=x’
stdr=std(x); %求各变量标准差
{n,m}=size(x);
Sddsta=x./stdr(ones(n,1),:); % 标准化变换
{p,princ,egenvalue}=princomp(sddata) %调用主成分分析程序
P3=(:,1:3) %输出前三个主成分系数
sc=princ(:,1:3) %输出前三个主成分得分
egenvalue %输出特征根
per=100* egenvalue/sum(egenvalue) %输出各个主成分贡献率
执行后得到所要结果, 这里是前三个主成分、主成分得分、特征根即
Egenvalue=[3.8811,2.6407,1.0597]’, per=[43.12,29.34,11.97]’这样, 前三个主成分为
Z1=-0.3677x1+0.3702x2+0.1364x3+0.4048x4+0.3355x5-0.1318x6+0.4236x7+0. 4815x8-0.0643x9
Z2=0.1442x1+0.2313x2-0.5299x3+0.1812x4-0.1601x5+0.5273x6+0.3116x7-0.0 267x8+0.4589x9
Z3=-0.3282x1-0.3535x2+0.0498x3+0.0582x4+0.5664x5-0.0270x6-0.0958x7-0. 2804x8+0.5933x9
第一主成分贡献率为43.12%,第二主成分贡献率为29.34%, 第三主成分贡献率为11.97%,前三个主成分累计贡献率达84.24%如果按80%以上的信息量选取新因子, 则可以选取前三个新因子第一新因子Z1包含的信息量最大为43.12%, 它的主要代表变量为X8(城市文明)、X7(生产效率)、X4(城市绿化), 其权重系数分别为0.4815、0.4236、0.4048, 反映了这三个变量与生态环境水平密切相关,第二新因子Z2包含的信息量次之为29.34%, 它的主要代表变量为X3(地理结构)、X6(资源配置)、X9(可持续性), 其权重系数分别为0.5299、0.5273、0.4589, 第三新因子Z3包含的信息量为11.97%, 代表总量为X9(可持续性)、X5(物质还原), 权重系数分别为0.5933、0.5664这些代表变量反映了各自对该新因子作用的大小, 它们是生态环境系统中最重要的影响因素。
根据前三个主成分得分, 用其贡献率加权, 即得十个城市各自的总得分
F=43.12%princ(:,1)+29.34% princ(:,2)+11.97% princ(:,3)
=[0.0970,-0.6069,-1.5170,1.1801,0.0640,-0.8178,-0.9562,1.1383,0.1107 ,1.3077]’
根据总得分排序, 结果见表2
参考文献
[1 ] 高惠璇. 应用多元统计分析[M] . 北京:北京大学出社,2005.
[2 ] 袁志发. 多元统计分析 [M ]. 北京 :科学出版社 , 2002.
[3] 梁邦助. 多元统计分析在教学质量评价中的应用[J]. 天津工业大学学报,2002(3). [4]于秀林,任雪松.多元统计分析[M].中国统计出版社,1999.
[5] 王学民. 应用多元分析 [ M ] . 上海 :上海财经大学出版社 ,1999.
[6] 陈桂明等.MATLAB数理统计(6.x)[M]北京科学出版社,2002
[7 刘则毅.科学计算技术与MATLAB[M]北京科学出版社,2001
多元统计分析实例 院系:商学院 学号: 姓名:
多元统计分析实例 本文收集了2012年31个省市自治区的农林牧渔和相关农业数据,通过对对收集的数据进行比较分析对31个省市自治区进行分类.选取了6个指标农业产值,林业产值.牧业总产值,渔业总产值,农村居民家庭拥有生产性固定资产原值,农村居民家庭经营耕地面积. 数据如下表: 一.聚类法
设定4个群聚,采用了系统聚类法.下表为spss分析之后的结果.
Rescaled Distance Cluster Combine C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+ 内蒙 5 -+ 吉林 7 -+ 云南 25 -+-+ 江西 14 -+ +-+ 陕西 27 -+-+ | 新疆 31 -+ +-+ 安徽 12 -+-+ | | 广西 20 -+ +-+ +-------+ 辽宁 6 ---+ | | 浙江 11 -+-----+ | 福建 13 -+ | 重庆 22 -+ +---------------------------------+ 贵州 24 -+ | | 山西 4 -+---+ | | 甘肃 28 -+ | | | 北京 1 -+ | | | 青海 29 -+ +---------+ | 天津 2 -+ | | 上海 9 -+ | | 宁夏 30 -+---+ | 西藏 26 -+ | 海南 21 -+ | 河北 3 ---+-----+ | 四川 23 ---+ | | 黑龙江 8 -+-+ +-------------+ | 湖南 18 -+ +---+ | | | 湖北 17 -+-+ +-+ +-------------------------+ 广东 19 -+ | | 江苏 10 -------+ | 山东 15 -----------+-----------+ 河南 16 -----------+
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
Matlab 与多元统计分析 胡云峰 安庆师范学院 第三章习题 3.1对某地区的6名2周岁男婴的身高、胸围、上半臂进行测量。得样本数据如表3.1所示。 假设男婴的测量数据X (a )(a=1,…,6)来自正态总体N 3(μ,∑) 的随机样本。根据以往的资料,该地区城市2周岁男婴的这三项的均值向量μ0=(90,58,16)’,试检验该地区农村男婴与城市男婴是否有相同的均值向量。 表3.1 某地区农村2周岁男婴的体格测量数据 1.预备知识 ∑未知时均值向量的检验: H 0:μ=μ0 H 1:μ≠μ0 H 0成立时 122)(0,)(1)(1,) ()'((1)))()'()(,1)(1)1(,) (1)P P X N n S W n n X n S X n X S X T p n n p T F P n p n p μμμμμ---∑--∑??∴----=-----+∴-- 当 2 (,)(1) n p T F p n p p n α-≥--或者22T T α≥拒绝0H 当 2 (,)(1) n p T F p n p p n α-<--或者22T T α<接受0H 这里2 (1) (, )p n T F p n p n p αα-= -- 2.根据预备知识用matlab 实现本例题 算样本协方差和均值 程序x=[78 60.6 16.5;76 58.1 12.5;92 63.2 14.5;81 59.0 14.0;81 60.8 15.5;84 59.5 14.0]; [n,p]=size(x); i=1:1:n; xjunzhi=(1/n)*sum(x(i,:));
多元统计分析方法 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
多元统计分析概述 目录 一、引言 (3) 二、多元统计分析方法的研究对象和主要内容 (3) 1.多元统计分析方法的研究对象 (3) 2.多元统计分析方法的主要内容 (3) 三、各种多元统计分析方法 (3) 1.回归分析 (3) 2.判别分析 (6) 3.聚类分析 (8) 4.主成分分析 (10) 5.因子分析 (10) 6. 对应分析方法 (11) 7. 典型相关分析 (11) 四、多元统计分析方法的一般步骤 (12) 五、多元统计分析方法在各个自然领域中的应用 (12) 六、总结 (13) 参考文献 (14) 谢辞 (15)
一、引言 统计分布是用来刻画随机变量特征及规律的重要手段,是进行统计分布的基础和提高。多元统计分析方法则是建立在多元统计分布基础上的一类处理多元统计数据方法的总称,是统计学中的具有丰富理论成果和众多应用方法的重要分支。在本文中,我们将对多元统计分析方法做一个大体的描述,并通过一部分实例来进一步了解多元统计分析方法的具体实现过程。 二、多元统计分析方法的研究对象和主要内容 (一)多元统计分析方法的研究对象 由于大量实际问题都涉及到多个变量,这些变量又是随机变量,所以要讨论多个随机变量的统计规律性。多元统计分析就是讨论多个随机变量理论和统计方法的总称。其内容包括一元统计学中某些方法的直接推广,也包括多个随即便量特有的一些问题,多元统计分析是一类范围很广的理论和方法。 现实生活中,受多个随机变量共同作用和影响的现象大量存在。统计分析中,有两种方法可同时对多个随机变量的观测数据进行有效的分析和研究。一种方法是把多个随机变量分开分析,一次处理一个随机变量,分别进行研究。但是,这样处理忽略了变量之间可能存在的相关性,因此,一般丢失的信息太多,分析的结果不能客观全面的反映整个问题,而且往往也不容易取得好的研究结论。另一种方法是同时对多个随机变量进行研究分析,此即多元统计方法。通过对多个随即便量观测数据的分析,来研究随机变量总的特征、规律以及随机变量之间的相互
多元统计分析思考题
《多元统计分析思考题》 第一章回归分析 1、回归分析是怎样的一种统计方法,用来解决什么问题? 概念:回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。 解决的问题:自变量对因变量的影响程度、方向、形式 2、线性回归模型中线性关系指的是什么变量之间的关系?自变量与因变量之 间一定是线性关系形式才能做线性回归吗?为什么? 3、实际应用中,如何设定回归方程的形式? 4、多元线性回归理论模型中,每个系数(偏回归系数)的含义是什么? 5、经验回归模型中,参数是如何确定的?有哪些评判参数估计的统计标准? 最小二乘估计两有哪些统计性质?要想获得理想的参数估计值,需要注意一些什么问题? 6、理论回归模型中的随机误差项的实际意义是什么?为什么要在回归模型中 加入随机误差项?建立回归模型时,对随机误差项作了哪些假定?这些假定的实际意义是什么? 7、建立自变量与因变量的回归模型,是否意味着他们之间存在因果关系?为什么? 8、回归分析中,为什么要作假设检验?检验依据的统计原理是什么?检验的 过程是怎样的?
9、回归诊断可以大致确定哪些问题?回归分析有哪些基本假定?如果实际应 用中不满足这些假定,将可能引起怎样的后果?如何检验实际应用问题是否满足这些假定?对于各种不满足假定的情形,分别采用哪些改进方法? 10、回归分析中的R2有何意义?它能用来衡量模型优劣吗? 11、如何确定回归分析中变量之间的交互作用?存在交互作用时,偏回归系 数的意义与不存在交互作用的情形下是否相同?为什么? 12、有哪些确定最优回归模型的准则?如何选择回归变量? 13、在怎样的情况下需要建立标准化的回归模型?标准化回归模型与非标准 化模型有何关系?形式有否不同? 14、利用回归方法解决实际问题的大致步骤是怎样的? 15、你能够利用哪些软件实现进行回归分析?能否解释全部的软件输出结 果? 第二章判别分析 1、判别分析的目的是什么? 根据分类对象个体的某些特征或指标来判断其属于已知的某个类中的哪一类。 2、有哪些常用的判别分析方法?这些方法的基本原理或步骤是怎样的?它 们各有什么特点或优劣之处? 3、判别分析与回归分析有何异同之处? 4、判别分析对变量与样本规模有何要求? 5、如何度量判别效果?有哪些影响判别效果的因素?
应用多元统计分析课后答案 第五章 聚类分析 判别分析和聚类分析有何区别 答:即根据一定的判别准则,判定一个样本归属于哪一类。具体而言,设有n 个样本,对每个样本测得p 项指标(变量)的数据,已知每个样本属于k 个类别(或总体)中的某一类,通过找出一个最优的划分,使得不同类别的样本尽可能地区别开,并判别该样本属于哪个总体。聚类分析是分析如何对样品(或变量)进行量化分类的问题。在聚类之前,我们并不知道总体,而是通过一次次的聚类,使相近的样品(或变量)聚合形成总体。通俗来讲,判别分析是在已知有多少类及是什么类的情况下进行分类,而聚类分析是在不知道类的情况下进行分类。 试述系统聚类的基本思想。 答:系统聚类的基本思想是:距离相近的样品(或变量)先聚成类,距离相远的后聚成类,过程一直进行下去,每个样品(或变量)总能聚到合适的类中。 对样品和变量进行聚类分析时, 所构造的统计量分别是什么简要说明为什么这样构造 答:对样品进行聚类分析时,用距离来测定样品之间的相似程度。因为我们把n 个样本看作p 维空间的n 个点。点之间的距离即可代表样品间的相似度。常用的距离为 (一)闵可夫斯基距离:1/1 ()() p q q ij ik jk k d q X X ==-∑ q 取不同值,分为 (1)绝对距离(1q =) 1 (1)p ij ik jk k d X X ==-∑ (2)欧氏距离(2q =) 2 1/21 (2)()p ij ik jk k d X X ==-∑ (3)切比雪夫距离(q =∞) 1()max ij ik jk k p d X X ≤≤∞=- (二)马氏距离 (三)兰氏距离 2 1()()()ij i j i j d M -'=--X X ΣX X 11()p ik jk ij k ik jk X X d L p X X =-=+∑
经济管理类“十二五”规划教材统计学 -基于典型案例、问题和思想 主讲林海明
第一章绪论 【引言】我们从如下9个重要事例,说明统计学有什么用。 事例1:二次世界大战中,最激烈的空战是英国抗击德国的空战,英军为了提高战斗力,急需找到英军战机空战中的危险区域加固钢板,统计学家瓦尔德用统计学
方法找到了危险区域,英军用钢板加固了这些危险区域,使英军取得了空战的胜利。 事例2:上世纪20-30年代,为了找到中国革命的主力军和道路,政治家毛泽东悟出了统计学的频数方法,用此找到了中国革命的主力军是农民,中国革命的道路是农村包围城市。由此不屈不饶的奋斗,由弱变强,建立了独立自主的中华人民共和国,他还发现了“没有调查,就没有发
言权”的科学论断。 事例3:1998年,美国博耶研究型大学本科生教育委员会发表了题为《重建本科生教育:美国研究型大学发展蓝图》的报告,该报告指出:为了培养科学、技术、学术、政治和富于创造性的领袖,研究型大学必须“植根于一种深刻的、永久性的核心:探索、调查和发现”。这说明了统计学中调查的重要性。
事例4:在居民收入贫富差距的测度方面,美国统计学家洛仑兹(1907)、意大利经济学家基尼(1922)找到了统计学的洛仑兹曲线、基尼系数,由此给出了居民收入贫富差距的划分结果,为政府改进居民收入贫富不均的问题提供了政策依据。 事例5:二战后产品质量差的日本,以田口玄一为代表的质量管理学者用统计学方法找到了3σ质量管理原则,用其大幅提
高了企业的产品质量,其产品畅销海内外,日本因此成为当时的第二经济强国。该学科现已发展到了6σ质量管理原则。 事例6:在第二次世界大战的苏联卫国战争中,专家们用英国统计学家费歇尔(1 925)的最大似然法、无偏性,帮助苏军破解了德军坦克产量的军事秘密,由此苏军组织了充足的军事力量并联合盟军,打败了德军的疯狂进攻并占领了柏林。
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章:
二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: 2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . )' ,...,,(),,,(2121P p EX EX EX EX μμμ='= )' )((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ) ,(~∑μP N X μ ∑ p X X X ,,,21
特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 μ ) ,(~∑μP N X ) ,('A A d A N s ∑+μ) () 1(,,n X X X )' ,,,(21p X X X )' )(() () (1 X X X X i i n i --∑=n 1 X μ∑μ X ) 1 , (~∑n N X P μ) ,1(∑-n W p X X
多元统计分析中的应用研究 , 摘要:许多实际问题往往需要对数据进行统计分析,建立合适的统计模型,过去一般采用SAS 、SPSS软件分析,本文给出 Matlab软件在多元统计分析上的应用, 主要介绍Matlab 在聚类分析、判别分析、主成份分析上的应用,文中均给以实例, 结果令人满意。 关键词:Matlab软件;聚类分析;主成份分析 Research for application of Multivariate Statistical Analysis Abstract:Many practice question sometimes need Statistical Analysis to data.,and establish appropriate Statistical model SAS and SPSS software were commonly used in foretime ,this paper give the application of Matlab software in Multivariate Statistical Analysis,mostly introduce the application of Matlab software in priciple component analysis and cluster analysis and differentiate analysis.The example are given in writing and the result are satisfaction. Key words: Matlab software; cluster analysis; priciple component analysis 0 引言 许多实际问题往往需要对数据进行多元统计分析, 建立合适的模型, 在多元统计分析方面, 常用的软件有SAS 、SPSS 、S-PLUS等。我们在这里给出Matlab在多元统计分析上的应用, 在较早的版本中, 统计功能不那么强大, 而在Matlab6.x版本中, 仅在统计工具中的功能函数就达200多个, 功能已足以赶超任何其他专用的统计软件,在应用上Matlab具有其他软件不可比拟的操作简单,接口方便, 扩充能力强等优势, 再加上Matlab的应用范围广泛, 因此可以预见其在统计应用上越来越占有极其重要的地位,下面用实例给出Matlab 在聚类分析、主成份分析上的应用。 1 聚类分析 聚类分析法是一门多元统计分类法,其目的是把分类对象按一定规则分成若干类,所分成的类是根据数据本身的特征确定的。聚类分析法根据变量(或样品或指标)的属性或特征的相似性,用数学方法把他们逐步地划类,最后得到一个能反映样品之间或指标之间亲疏关系的客观分类系统图,称为谱系聚类图。 聚类分析的步骤有:数据变换,计算n个样品的两两间的距离,先分为一类,在剩下的n-1个样品计算距离,按照不同距离最小的原则,增加分类的个数,减少所需要分类的样品的个数,循环进行下去,直到类的总个数为1时止。根
精品资料 一、对我国30个省市自治区农村居民生活水平作聚类分析 1、指标选择及数据:为了全面分析我国农村居民的生活状况,主要考虑从收入、消费、就业等几个方面对农村居民的生活状况进行考察。因此选取以下指标:农村产品价格指数、农村住宅投资、农村居民消费水平、农村居民消费支出、农村居民家庭人均纯收入、耕地面积及农村就业人数。现从2010年的调查资料中
2、将数据进行标准化变换:
3、用K-均值聚类法对样本进行分类如下:
分四类的情况下,最终分类结果如下: 第一类:北京、上海、浙江。 第二类:天津、、辽宁、、福建、甘肃、江苏、广东。 第三类:浙江、河北、内蒙古、吉林、黑龙江、安徽、山东、河南、湖北、四川、云南。 第四类:山西、青海、宁夏、新疆、重庆、贵州、陕西、湖南、广西、江西、。从分类结果上看,根据2010年的调查数据,第一类地区的农民生活水平较高,第二类属于中等水平,第三类、第四类属于较低水平。 二、判别分析 针对以上分类结果进行判别分析。其中将新疆作作为待判样本。判别结果如下:
**. 错误分类的案例 从上可知,只有一个地区判别组和原组不同,回代率为96%。 下面对新疆进行判别: 已知判别函数系数和组质心处函数如下: 判别函数分别为:Y1=0.18x1 +0.493x2 + 0.087x3 + 1.004x4 + 0.381x5 -0.041x6 -0.631x7 Y2=0.398x1+0.687x2 + 0.362x3 + 0.094x4 -0.282x5 + 1.019x6 -0.742x7 Y3=0.394x1-0.197x2 + 0.243x3-0.817x4 + 0.565x5-0.235x6 + 0.802x7 将西藏的指标数据代入函数得:Y1=-1.08671 Y2=-0.62213 Y3=-0.84188 计算Y值与不同类别均值之间的距离分别为:D1=138.5182756 D2=12.11433124 D3=7.027544292 D4=2.869979346 经过判别,D4最小,所以新疆应归于第四类,这与实际情况也比较相符。 三,因子分析: 分析数据在上表的基础上去掉两个耕地面积和农村固定资产投资两个指标。经spss软件分析结果如下:
Matlab多元统计分析程序 1. 主成分分析M程序 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % 主成分分析 % % 设对变量x1,x2,...,xp进行n次观测,得到n×p数据矩阵x=x(i,j), % 本程序对初始数据进行主成分分析,要求先请将观测矩阵输入到变 % 量x,再运行本程序。 % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % % 确定观测矩阵x 的尺寸,以便数据标准化. % [n,p]=size(x); % % 数据处理方式设置,即是否先将数据标准化. % fprintf('\n 1---使用原始数据直接计算距离') fprintf('\n 2---使用标准化后的数据计算距离') k=input('请输入你的选择(1~2)'); % % 数据标准化 % switch k case 1 xs=x; case 2 mx=mean(x);
xs=(x-repmat(mx,n,1))./repmat(stdr,n,1); end % % 主成分分析,返回各主成分pc,所谓的z-得分score,x的协方差 % 矩阵的特征值latent和每个数据点的Hotelling统计量tsquare. % [pc score latent tsquare]=princomp(xs) 2. 典型相关分析M程序 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % % 在运行本程序之前,请先把数据输入/导入到MATLAB 的 % 内存空间,并存放在变量x 中,每行存放一个样本。 % %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% % % 确定观测矩阵x 的尺寸 % [n,h]=size(x); % % 输入基本参数 % p=input('\n第一组变量的个数p = ? '); fprintf('\n1--使用样本协方差矩阵计算典型相关变量') fprintf('\n2--使用样本相关矩阵计算典型相关变量') ctl=input('\n请输入你的选择'); % % 默认的显著性水平为alpha=0.05,可以改变下面语句中的alpha值。 % alpha=0.05; % % 按要求计算样本协方差矩阵或样本相关矩阵 % switch ctl case 1 st=cov(x); case 2
多元统计分析重点宿舍版 第一讲:多元统计方法及应用;多元统计方法分类(按变量、模型、因变量等) 多元统计分析应用 选择题:①数据或结构性简化运用的方法有:多元回归分析,聚类分析,主成分分析,因子分析 ②分类和组合运用的方法有:判别分析,聚类分析,主成分分析 ③变量之间的相关关系运用的方法有:多元回归,主成分分析,因子分析, ④预测与决策运用的方法有:多元回归,判别分析,聚类分析 ⑤横贯数据:{因果模型(因变量数):多元回归,判别分析相依模型(变量测度):因子分析,聚类分析 多元统计分析方法 选择题:①多元统计方法的分类:1)按测量数据的来源分为:横贯数据(同一时间不同案例的观测数据),纵观数据(同样案例在不同时间的多次观测数据) 2)按变量的测度等级(数据类型)分为:类别(非测量型)变量,数值型(测量型)变量 3)按分析模型的属性分为:因果模型,相依模型 4)按模型中因变量的数量分为:单因变量模型,多因变量模型,多层因果模型 第二讲:计算均值、协差阵、相关阵;相互独立性 第三讲:主成分定义、应用及基本思想,主成分性质,主成分分析步骤 主成分定义:何谓主成分分析 就是将原来的多个指标(变量)线性组合成几个新的相互无关的综合指标(主成分),并使新的综合指标尽可能多地反映原来的指标信息。 主成分分析的应用 :(1)数据的压缩、结构的简化;(2)样品的综合评价,排序 主成分分析概述——思想:①(1)把给定的一组变量X1,X2,…XP ,通过线性变换,转换为一组不相关的变量Y1,Y2,…YP 。(2)在这种变换中,保持变量的总方差(X1,X2,…Xp 的方差之和)不变,同时,使Y1具有最大方差,称为第一主成分;Y2具有次大方差,称为第二主成分。依次类推,原来有P 个变量,就可以转换出P 个主
作业一
1.2 分析2016年经济发展情况 排名省gdp 占比累计占比 1 广东79512.05 10.30 10.30 2 江苏76086.2 9.86 20.17 3 山东67008.2 8.68 28.85 4 浙江4648 5 6.02 34.87 5 河南40160.01 5.20 40.08 6 四川32680.5 4.24 44.31 7 湖北32297.9 4.19 48.50 8 河北31827.9 4.12 52.62 9 湖南31244.7 4.05 56.67 10 福建28519.2 3.70 60.37 11 上海27466.2 3.56 63.93 12 北京24899.3 3.23 67.16 13 安徽24117.9 3.13 70.28 14 辽宁22037.88 2.86 73.14 15 陕西19165.39 2.48 75.62 16 内蒙古18632.6 2.41 78.04 17 江西18364.4 2.38 80.42 18 广西18245.07 2.36 82.78 19 天津17885.4 2.32 85.10 20 重庆17558.8 2.28 87.37 21 黑龙江15386.09 1.99 89.37 22 吉林14886.23 1.93 91.30 23 云南14869.95 1.93 93.22 24 山西12928.3 1.68 94.90 25 贵州11734.43 1.52 96.42 26 新疆9550 1.24 97.66 27 甘肃7152.04 0.93 98.59 28 海南4044.51 0.52 99.11 29 宁夏3150.06 0.41 99.52 30 青海2572.49 0.33 99.85 31 西藏1150.07 0.15 100.00 将2016各省的GDP进行排名,可以发现,经济发达的的地区主要集中在东部地区。西部gdp的占比较小。作出2016各省的gdp直方图如下:
《多元统计分析》思考题答案 记得老师课堂上说过考试内容不会超出这九道思考题, 如下九道题题目中有错误的或不清楚 的地方,欢迎大家指出、更改、补充。 1、 简述信度分析 答题提示:要答可靠度概念,可靠度度量,克朗巴哈 系数、拆半系数、单项 与总体相 关系数、稀释相关系数等(至少要答四个系数,至少要给出两个指标的公式) 答: 信度( Reliability )即可靠性,它是指采用同样的方法对同一对象重复测量时所得结果 的一致性程度。 信度指标多以相关系数表示, 大致可分为三类: 稳定系数 (跨时间的一致性) 等值系数(跨形式的一致性)和内在一致性系数(跨项目的一致性) 。信度分析的方法主要 有以下四种: 1)、重测信度法 这一方法是用同样的问卷对同一组被调查者间隔一定时间重复施测, 计算两次施测结果 的相关系数。 重测信度属于稳定系数。 重测信度法特别适用于事实式问卷, 如果没有突发事 件导致被调查者的态度、 意见突变, 这种方法也适用于态度、 意见式问卷。 由于重测信度法 需要对同一样本试测两次, 被调查者容易受到各种事件、 活动和他人的影响, 而且间隔时间 长短也有一定限制,因此在实施中有一定困难。 2)、复本信度法 复本信度法是让同一组被调查者一次填答两份问卷复本,计算两个复本的相关系数。复 本信度属于等值系数。复本信度法要求两个复本除表述方式不同外,在内容、格式、难度和 对应题项的提问方向等方面要完全一致,而在实际调查中,很难使调查问卷达到这种要求, 因此采用这种方法者较少。 3)、折半信度法 折半信度法是将调查项目分为两半,计算两半得分的相关系数,进而估计整个量表的信 度。折半信度属于内在一致性系数, 测量的是两半题项得分间的一致性。 这种方法一般不适 用于事实式问卷(如年龄与性别无法相比) ,常用于态度、意见式问卷的信度分析。在问卷 调查中,态度测量最常见的形式是 5 级李克特( Likert )量表。进行折半信度分析时,如果 量表中含有反意题项, 应先将反意题项的得分作逆向处理, 以保证各题项得分方向的一致性, 然后将全部题项按奇偶或前后分为尽可能相等的两半,计算二者的相关系数。 为了校正差异,两半测验的方差相等时,常运用斯皮尔曼 - 布朗公式( Spearman- Brown Formula ):rxx=2rhh/(1+rhh ) ,其中, rhh :两半测验的相关系数; rxx :估计或修正后的信度。 该公式可以估计增长或缩短一个测验对其信度系数的影响。 当两半测验的方差不同时, 应采 用卢伦公式( Rulon Formula )或弗拉纳根公式( Flanagan Formula )进行修正。 4)、α信度系数法 Cronbach α信度系数是目前最常用的信度系数,其公式为: S i 从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。其中, n n1 i1 S X S i 2 为每一项目的方差; S X 2 为测验总分方差。
MATLAB的统计工具箱中的多元统计分析中提供了聚类分析的两种方法: 1.层次聚类hierarchical clustering 2.k-means聚类 这里用最简单的实例说明以下层次聚类原理和应用发法。 层次聚类是基于距离的聚类方法,MATLAB中通过pdist、linkage、dendrogram、cluster等函数来完成。层次聚类的过程可以分这么几步: (1) 确定对象(实际上就是数据集中的每个数据点)之间的相似性,实际上就是定义一个表征对象之间差异的距离,例如最简单的平面上点的聚类中,最经常使用的就是欧几里得距离。 这在MATLAB中可以通过Y=pdist(X)实现,例如 >> X=randn(6,2) X = -0.4326 1.1892 -1.6656 -0.0376 0.1253 0.3273 0.2877 0.1746 -1.1465 -0.1867 1.1909 0.7258 >> plot(X(:,1),X(:,2),'bo') %给个图,将来对照聚类结果把 >> Y=pdist(X) Y = Columns 1 through 14 1.7394 1.0267 1.2442 1.5501 1.6883 1.8277 1.9648 0.5401 2.9568 0.2228 1.3717 1.1377 1.4790 1.0581 Column 15
2.5092 例子中X数据集可以看作包含6个平面数据点,pdist之后的Y是一个行向量,15个元素分别代表X 的第1点与2-6点、第2点与3-6点,......这样的距离。那么对于M个点的数据集X,pdist之后的Y 将是具有M*(M-1)/2个元素的行向量。Y这样的显示虽然节省了内存空间,但对用户来说不是很易懂,如果需要对这些距离进行特定操作的话,也不太好索引。MATLAB中可以用squareform把Y转换成方阵形式,方阵中
基于SPSS的多元统计分析三种算法的实例研究 摘要 本文主要应用多元统计中的多元回归分析模型、因子分析模型、判别分析模型解决三个有关经济方面的问题,从而能更深的理解多元统计分析这门课程,并熟悉SPSS软件的一些基本操作。 关键词:多元回归分析,因子分析,判别分析,SPSS
第一章 多元线性回归分析 1.1 研究背景 消费是宏观经济必不可少的环节,完善的消费模型可以为宏观调控提供重要的依据。根据不同的理论可以建立不同的消费函数模型,而国内的许多学者研究的主要是消费支出与收入的单变量之间的函数关系,由于忽略了对消费支出有显著影响的变量,其所建立的方程必与实际有较大的偏离。本文综合考察影响消费的主要因素,如收入水平、价格、恩格尔系数、居住面积等,采用进入逐步、向前、向后、删除、岭回归方法,对消费支出的多元线性回归模型进行研究,找出能较准确描述客观实际结果的最优模型。 1.2 问题提出与描述、数据收集 按照经济学理论,决定居民消费支出变动的因素主要有收入水平、居民消费意愿、消费环境等。为了符合我国经济发展的不平衡性的现状,本文主要研究农村居民的消费支出模型。文中取因变量Y 为农村居民年人均生活消费支出(单位:元),自变量为农村居民人均纯收入X 1(单位:元)、商品零售价格定基指数X 2(1978年的为100)、消费价格定基指数X 3(1978年的为100)、家庭恩格尔系数X 4(%)、人均住宅建筑面积X 5(单位:m 2)。本文取1900年至2009年的数据(数据来源:中华人民共和国国家统计局网公布的1996至2010年中国统计年鉴)列于附录的表一中。 1.3 模型建立 1.3.1 理论背景 多元线性回归模型如下: εββββ+++++=p p X X X Y ...... 22110 Y 表示因变量,X i (i=1,…,p )表示自变量,ε表示随机误差项。 对于n 组观测值,其方程组形式为 εβ+=X Y 即
多元统计分析模拟试题(两套:每套含填空、判断各二十道) A卷 1)判别分析常用的判别方法有距离判别法、贝叶斯判别法、费歇判别法、逐步 判别法。 2)Q型聚类分析是对样品的分类,R型聚类分析是对变量_的分类。 3)主成分分析中可以利用协方差矩阵和相关矩阵求解主成分。 4)因子分析中对于因子载荷的求解最常用的方法是主成分法、主轴因子法、极 大似然法 5)聚类分析包括系统聚类法、模糊聚类分析、K-均值聚类分析 6)分组数据的Logistic回归存在异方差性,需要采用加权最小二乘估计 7)误差项的路径系数可由多元回归的决定系数算出,他们之间的关系为 P e= 1?R2 8)最短距离法适用于条形的类,最长距离法适用于椭圆形的类。 9)主成分分析是利用降维的思想,在损失很少的信息前提下,把多个指标转化 为几个综合指标的多元统计方法。 10)在进行主成分分析时,我们认为所取的m(m m a t l a b与多元统计分 析 Company Document number:WTUT-WT88Y-W8BBGB-BWYTT-19998 Matlab 与多元统计分析 胡云峰 安庆师范学院 第三章习题 对某地区的6名2周岁男婴的身高、胸围、上半臂进行测量。得样本数据如表所示。假设男婴的测量数据X (a )(a=1,…,6)来自正态总体N 3(,∑) 的 随机样本。根据以往的资料,该地区城市2周岁男婴的这三项的均值向量0= (90,58,16)’,试检验该地区农村男婴与城市男婴是否有相同的均值向量。 表 某地区农村2周岁男婴的体格测量数据 解 1.预备知识 ∑未知时均值向量的检验: H 0:=0 H 1:≠0 H 0成立时 122)(0,)(1)(1,) ()'((1)))()'()(,1)(1)1(,) (1)P P X N n S W n n X n S X n X S X T p n n p T F P n p n p μμμμμ---∑--∑??∴----=-----+∴-- 当 2 (,)(1) n p T F p n p p n α-≥--或者22T T α≥拒绝0H 当 2 (,)(1) n p T F p n p p n α-<--或者22T T α<接受0H 这里2(1) (, )p n T F p n p n p αα-= -- 2.根据预备知识用matlab 实现本例题 算样本协方差和均值 程序x=[78 ;76 ;92 ;81 ;81 ;84 ]; [n,p]=size(x); i=1:1:n; xjunzhi=(1/n)*sum(x(i,:)); y=rand(p,n); for j=1:1:n y(:,j)= x(j,:)'-xjunzhi'; y=y; end A=zeros(p,p); for k=1:1:n; A=A+(y(:,k)*y(:,k)'); end xjunzhi=xjunzhi' S=((n-1)^(-1))*A 输出结果xjunzhi = S = 然后u=[90;58;16]; t2=n*(xjunzhi-u)'*(S^(-1))*(xjunzhi-u) f=((n-p)/(p*(n-1)))*t2 输出结果t2 = f = 所以21()'()T n X S X μμ-=--=matlab与多元统计分析
相关主题
文本预览