基础知识
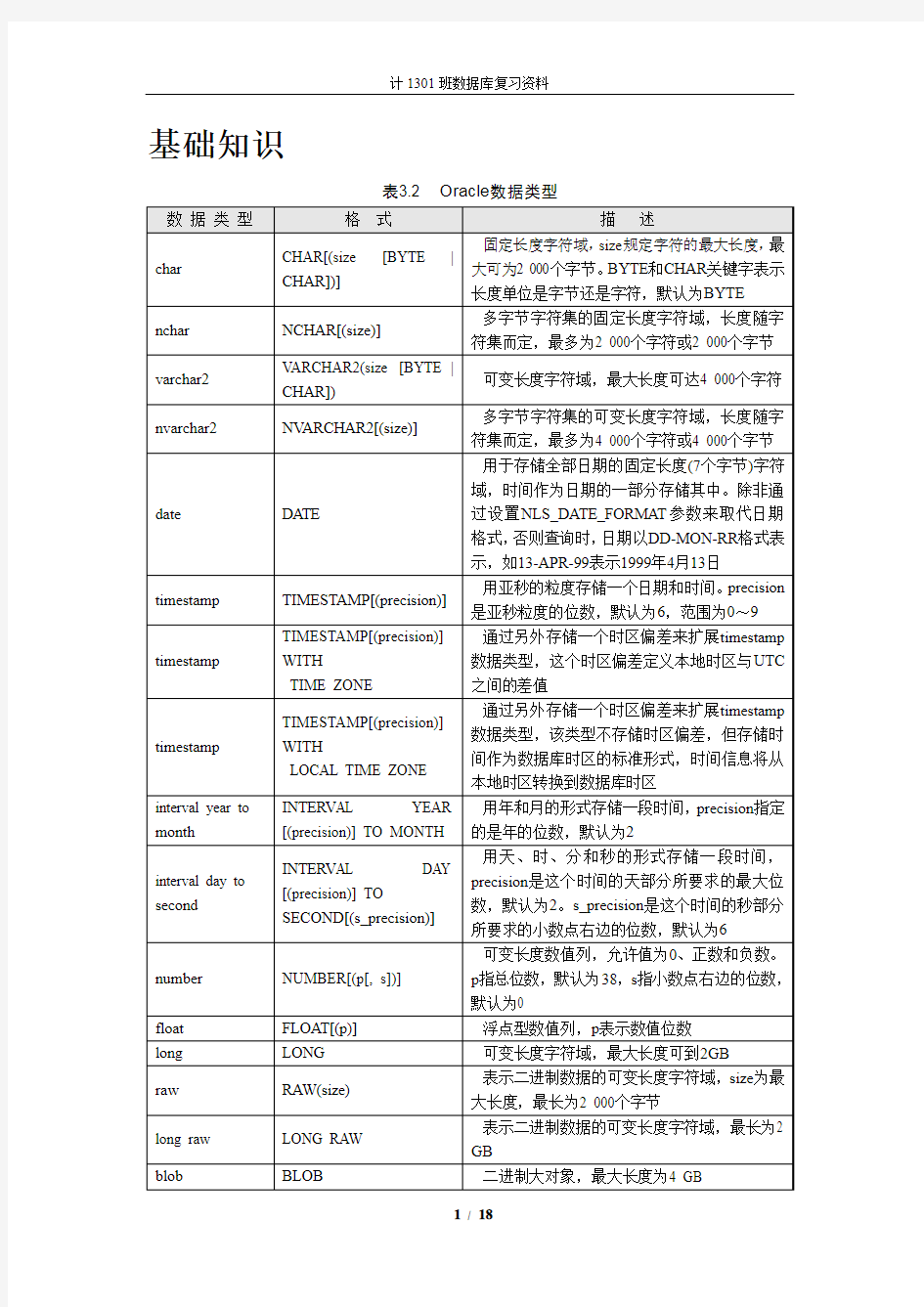
表3.2 Oracle数据类型
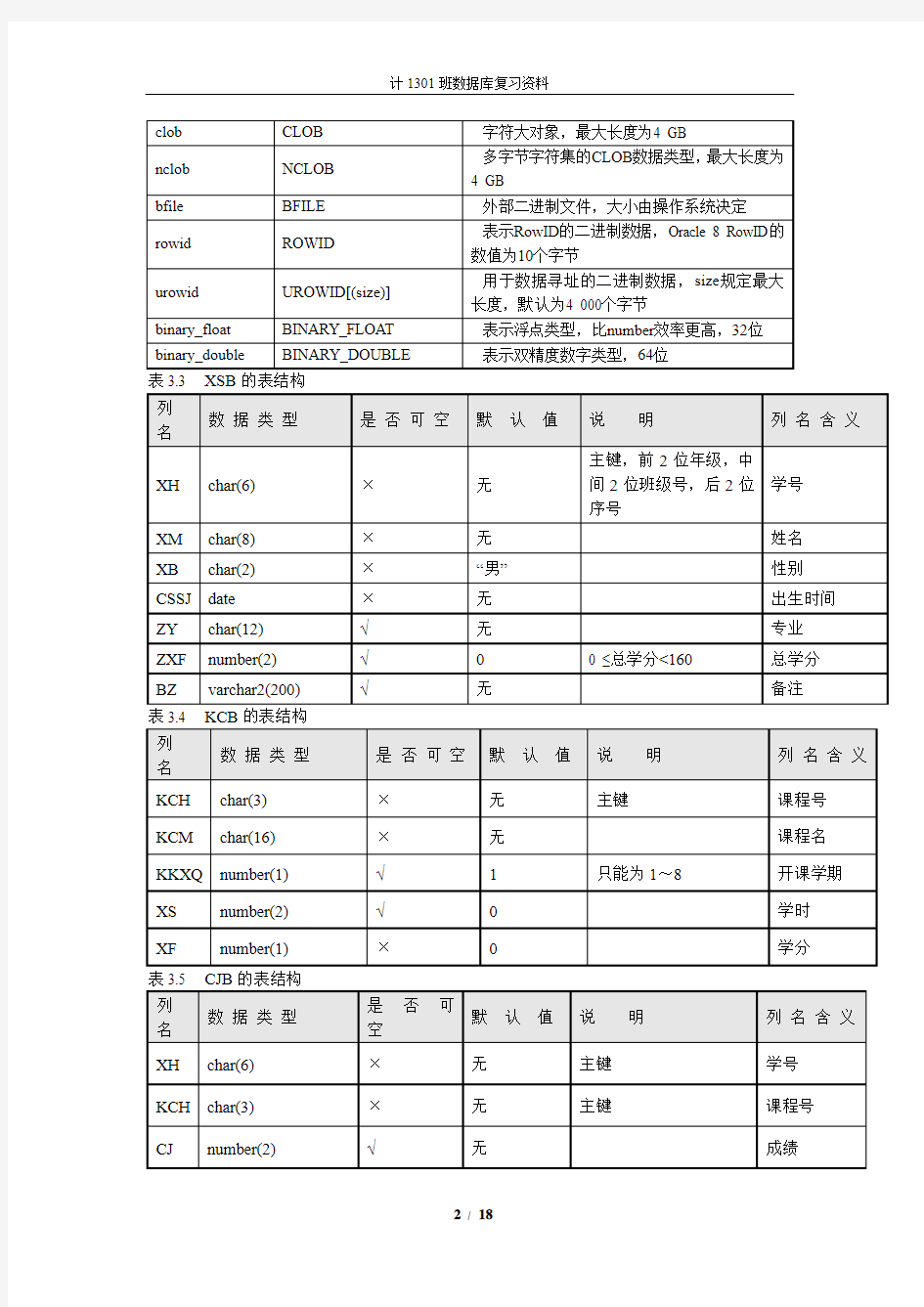
表3.3 XSB的表结构
操作表
创建表
CREATE TABLE [schema.] table_name
(
column_namedatatype [DEFAULT expression] [column_constraint][,…n]
)
[PCTFREE integer]
[PCTUSED integer]
[INITRANS integer]
[MAXTRANS integer]
[TABLESPACE tablespace_name]
[STORGE storage_clause]
[CLUSTER cluster_name(cluster_column,…n)]
[ENABLE | DISABLE ]
[AS subquery]
【例】使用CRETE TABLE命令为XSCJ数据库建立表XSB,表结构参照表3.3。
打开SQL*Plus工具,以system方案连接数据库,输入以下语句:
CREATE TABLE XSB
(
XH char(6) NOT NULL PRIMARY KEY,
XM char(8) NOT NULL,
XB char(2) DEFAULT '1' NOT NULL,
CSSJ date NOT NULL,
ZY char(12) NULL,
ZXF number(2) NULL,
BZ varchar2(200) NULL
);
修改表
ALTER TABLE [schema.] table_name
[ ADD(column_namedatatype [DEFAULT expression][column_constraint],…n) ]
/*增加新列*/ [ MODIFY([ datatype ] [ DEFAULT expression ]
[column_constraint],…n) ] /*修改已有列的属性*/ [ STORAGE storage_clause ] *修改存储特征*/
[ DROP drop_clause ] /*删除列或约束条件*/ 【例】使用ALTER TABLE语句修改XSCJ数据库中的表。
(1)在表XSB中增加两列:JXJ(奖学金等级)、DJSM(奖学金等级说明)。
ALTER TABLE XSB
ADD ( JXJ number(1),
DJSM varchar2(40) DEFAULT '奖金1000元');
(2)在表XSB中修改名为DJSM的列的默认值。
ALTER TABLE XSB
MODIFY ( DJSM DEFAULT '奖金800元' );
(3)在表XSB中删除名为JXJ和DJSM的列。
ALTER TABLE XSB
DROP COLUMN JXJ;
ALTER TABLE XSB
DROP COLUMN DJSM;
(4)修改KCB表的存储特征。
ALTER TABLE KCB
PCTFREE 20 MAXTRANS 200;
(5)为表XS_JSJ添加主键。
ALTER TABLE XS_JSJ
ADD (CONSTRAINT "PK_JSJ" PRIMARY KEY(XH) );
删除表
DROP TABLE [schema.] table_name
操作表数据
插入记录
INSERT INTO table_name[(column_list)]
V ALUES(constant1,constant2,…)
【例】向XSCJ数据库的表XSB中插入如下的一行:
101101 王林计算机男19900210 50
可以使用如下的PL/SQL语句:
INSERT INTO XSB(XH, XM, XB, CSSJ, ZY, ZXF)
V ALUES('101101', '王林', '男',TO_DA TE('19900210','YYYYMMDD'), '计算机', 50);
删除记录
DELETE FROM table_name∣view_name
[WHERE condition]
【例】将XSCJ数据库的XSB表中总学分小于50的行删除,使用如下的PL/SQL语句。
DELETE FROM XSB
WHERE ZXF<50;
修改记录
UPDATE table_name∣view_name
SET column_name=expression,[…n]
[WHERE condition]
【例】将姓名为“罗林琳”的同学的专业改为“通信工程”,备注改为“转专业学习”,学号改为“101241”。
UPDATE XS
SET ZY='通信工程',
BZ='转专业学习',
XH='101241'
WHERE XM= '罗林琳';
查询
基本语法
SELECT select_list /*指定要选择的列及其限定*/
FROM table_source /*FROM子句,指定表或视图*/
[ WHERE search_condition ] /*WHERE子句,指定查询条件*/
[ GROUP BY group_by_expression ] /*GROUP BY子句,指定分组表达式*/
[ HA VING search_condition ] /*HA VING子句,指定分组统计条件*/
[ ORDER BY order_expression [ ASC | DESC ]] /*ORDER子句,指定排序表达式顺序*/ 选择指定列
SELECT column_name[ ,column_name [,…n] ]
FROM table_name
[WHERE search_condition]
【例】查询XSB表中ZXF大于50同学的XH、XM和ZXF。
SELECT XH, XM, ZXF
FROM XSB
WHERE ZXF>50;
修改查询结果中的列标题
【例】查询XSB表中计算机系同学的XH、XM和ZXF,结果中各列的标题分别指定为学
号、姓名和总学分。
SELECT XH AS 学号,XM AS 姓名,ZXF AS 总学分
FROM XSB
WHERE ZY= '计算机';
模式匹配
string_expression[ NOT ] LIKE string_expression [ ESCAPE escape_character ]
【例】查询CP表中产品名含有“冰箱”的产品情况。
SELECT *
FROM CP
WHERE CPMC
LIKE '%冰箱%';
【例】查询XSB表中姓“王”且单名的学生情况。
SELECT *
FROM XSB
WHERE XM LIKE '王_';
范围比较
expression [ NOT ] BETWEEN expression1 AND expression2
【例】①查询CP表中价格在2000元与4000元之间的产品情况。
SELECT *
FROM CP
WHERE JG BETWEEN 2000 AND 4000;
执行结果如右图所示。
②查询XSB表中不在1989年出生的学生情况。
SELECT *
FROM XSB
WHERE CSSJ NOT BETWEEN TO_DA TE('19890101', 'YYYYMMDD')
AND TO_DA TE('19891231', 'YYYYMMDD');
使用IN关键字可以指定一个值表,值表中列出所有可能的值,当表达式与值表中的任意一个匹配时,即返回TRUE,否则返回FALSE。使用IN关键字指定值表的格式为:expression IN ( expression [,…n])
【例】查询CP表中库存量为“200”“300”和“500”的情况。
SELECT *
FROM CP
WHERE KCL IN (200,300,500);
空值比较
【例】查询XSCJ数据库中总学分尚不定的学生情况。
SELECT *
FROM XSB
WHERE ZXF IS NULL;
子查询
IN子查询。IN子查询用于进行一个给定值是否在子查询结果集中的判断,格式为:expression [ NOT ] IN ( subquery )
【例】查找未选修离散数学的学生的情况。
SELECT XH, XM, ZY, ZXF
FROM XSB
WHERE XH NOT IN
( SELECT XH
FROM CJB
WHERE KCH IN
( SELECT KCH
FROM KCB
WHERE KCM = '离散数学'
)
);
比较子查询。
expression { < | <= | = | > | >= | != | <> } { ALL | SOME | ANY } ( subquery )
【例】查找比所有计算机系学生年龄都大的学生。
SELECT *
FROM XSB
WHERE CSSJ ( SELECT CSSJ FROM XSB WHERE ZY= '计算机' ); EXISTS子查询。EXISTS谓词用于测试子查询的结果是否为空表,若子查询的结果集不为空,则EXISTS返回TRUE,否则返回FALSE。EXISTS还可与NOT结合使用,即NOT EXISTS,其返回值与EXIST刚好相反。格式为: [ NOT ] EXISTS ( subquery ) 【例】查找选修了全部课程的同学姓名。 SELECT XM FROM XSB WHERE NOT EXISTS ( SELECT * FROM KCB WHERE NOT EXISTS ( SELECT * FROM CJB WHERE XH=XSB.XH AND KCH=KCB.KCH ) ); 查询对象 【例】查找与101102号同学所选修课程一致的同学的学号。 本例即要查找这样的学号y,对所有的课程号x,若101102号同学选修了该课,那么y也选修了该课。 SELECT DISTINCT XH FROM CJB CJ1 WHERE NOT EXISTS ( SELECT * FROM CJB CJ2 WHERE CJ2.XH ='101102' AND NOT EXISTS ( SELECT * FROM CJB CJ3 WHERE CJ3.XH= CJ1.XH AND CJ3.KCH = CJ2. KCH ) ); 【例】在XSB表中查找1990年1月1日以前出生的学生的姓名和专业。 SELECT XM, ZY FROM (SELECT * FROM XSB WHERE CSSJ 自然连接 【例】查找选修了“计算机基础”课程且成绩在80分以上的学生学号、姓名、课程名及成绩。 SELECT XSB.XH, XM, KCM, CJ FROM XSB, KCB, CJB WHERE XSB.XH = CJB.XH AND KCB.CH = CJB. KCH AND KCM = '计算机基础' AND CJ >= 80; JOIN关键字指定的连接 内连接。内连接按照ON所指定的连接条件合并两个表,返回满足条件的行。 【例】用FROM的JOIN关键字表达下列查询:查找选修了“计算机基础”课程且成绩在80分以上的学生学号、姓名、课程名及成绩。 SELECT XSB.XH , XM , KCM , CJ FROM XSB JOIN CJB JOIN KCB ON CJB.KCH = KCB.KCH ON XSB.XH = CJB.XH WHERE KCM = '计算机基础' AND CJ>=80; 外连接。外连接的结果表不但包含满足连接条件的行,还包括相应表中的所有行。外连接包括以下三种。 ●左外连接(LEFT OUTER JOIN):结果表中除了包括满足连接条件的行外,还包括左表的所有行; ●右外连接(RIGHT OUTER JOIN):结果表中除了包括满足连接条件的行外,还包括右表的所有行; ●完全外连接(FULL OUTER JOIN):结果表中除了包括满足连接条件的行外,还包括两个表的所有行。 【例】查找被选修了的课程的选修情况和所有开设的课程名。 SELECT CJB.* , KCM FROM CJB RIGHT JOIN KCB ON CJB.KCH= KCB.KCH; 交叉连接 交叉连接实际上是将两个表进行笛卡尔积运算,结果表是由第1个表的每一行与第2个表的每一行拼接后形成的表,因此结果表的行数等于两个表行数之积。 【例】列出学生所有可能的选课情况。 SELECT XH, XM, KCH, KCM FROM XSB CROSS JOIN KCB; 统计函数 SUM和A VG函数、MAX和MIN函数、COUNT函数 【例】求选修了课程的学生总人数。 SELECT COUNT(DISTINCT XH) AS 选修了课程的总人数 FROM CJB; GROUP BY分组统计 GROUP BY子句用于对表或视图中的数据按字段分组,语法格式为: GROUP BY [ ALL ] group_by_expression [,…n] 【例】求XSCJ数据库中各专业的学生数。 SELECT ZY AS 专业,COUNT(*) AS 学生数 FROM XSB GROUP BY ZY; HAVING子句 HA VING子句的语法格式为: [ HA VING 【例】其中,search_condition为查询条件,与WHERE子句的查询条件类似,不过不同的是HA VING子句可以使用统计函数,而WHERE子句不可以。 查找通信工程专业平均成绩在85分以上的学生的学号和平均成绩。 SELECT XH AS 学号,A VG(CJ) AS 平均成绩 FROM CJB WHERE XH IN ( SELECT XH FROM XSB WHERE ZY= '通信工程' ) GROUP BY XH HA VING A VG(CJ) > =85; ORDER BY子句 ORDER BY子句的语法格式为: [ ORDER BY { order_by_expression [ ASC | DESC ] } [ ,…n ] 【例】将计算机专业学生的“计算机基础”课程成绩按降序排列。 SELECT XM AS 姓名, KCM AS 课程名, CJ AS 成绩 FROM XSB, KCB, CJB WHERE XSB.XH=CJB.XH AND CJB.KCH= KCB.KCH AND KCM= '计算机基础' AND ZY= '计算机' ORDER BY CJ DESC; UNION子句 使用UNION子句可以将两个或多个SELECT查询的结果合并成一个结果集,其语法格式为: { UNION [ A LL ] [ UNION [ A LL ] 【例】查找学号为101101和学号为101210两位同学的信息。 SELECT * FROM XSB WHERE XH= '101101' UNION ALL SELECT * FROM XSB WHERE XH= '101210'; 视图 创建视图 CREATE [ OR REPLACE ] [FORCE | NOFORCE] VIEW [schema.]view_name [ (column_name [ ,…n ] ) ] AS select_statement [WITH CHECK OPTION[CONSTRAINT constraint_name]] [WITH READ ONL Y] 【例】查找平均成绩在80分以上的学生的学号和平均成绩。 本例首先创建学生平均成绩视图XS_KC_A VG,包括学号(在视图中列名为num)和平均成绩(在视图中列名为score_avg)。 CREATE OR REPLACE VIEW XS_KC_A VG ( num,score_avg ) AS SELECT XH, A VG(CJ) FROM CJB GROUP BY XH; 再对XS_KC_A VG视图进行查询。 SELECT * FROM XS_KC_A VG WHERE score_avg>=80; 更新视图 【例】在XSCJ数据库中使用以下语句创建可更新视图CS_XS1。 CREATE OR REPLACE VIEW CS_XS1 AS SELECT * FROM XSB WHERE ZY= '通信工程'; 插入数据、修改数据、删除数据与表相似 删除视图 DROP VIEW [schema.]view_name 修改视图 跟创建视图一样 【例】修改视图CS_KC的定义,包括学号、姓名、选修的课程号、课程名和成绩。CREATE OR REPLACE FORCE VIEW CS_KC AS SELECT XS.XH, XS.XM, XS_KC.KCH, KC.KCM, CJ FROM XS, XS_KC, KC WHERE XS.XH=XS_KC.XH AND XS_KC.KCH=KC.KCH AND ZYM='通信工程' WITH CHECK OPTION; 索引 创建索引 CREATE [UNIQUE∣BITMAP] INDEX /*索引类型*/ [schema.]index_name /*索引名称*/ ON [schema.]table_name(column_name | column_expression [ASC∣DESC] [,…n]) [LOGGING | NOLOGGING] /*指定是否创建相应的日志记录*/ [COMPUTE STATISTICS] /*生成统计信息*/ [COMPAESS | NOCOMPRESS] /*对复合索引进行压缩*/ [TABLESPACE tablespace_name] /*索引所属表空间*/ [SORT | NOSORT] /*指定是否对表进行排序*/ [REVERSE] 【例】根据XSB表的姓名列和出生时间列创建复合索引。 CREATE INDEX XSB_ind ON XSB(XM, CSSJ) 维护索引 ALTER INDEX [schema.]index_name [LOGGING | NOLOGGING] [TABLESPACE tablespace_name] [SORT | NOSORT] [REVERSE] [RENAME TO new_index_name] 【例】重命名索引kc_name_idx。 ALTER INDEX kcb_name_idx RENAME TO kcb_idx; 删除索引 DROP INDEX [schema.]index_name 数据完整性(详见表格创建) 域完整性(CHECK) 实体完整性(PRIMARY KEY/UNIQUE) 参照完整性(REFERNCES) 用户自定义函数 创建函数 语法格式: CREATE [OR REPLACE] FUNCTION function_name /*函数名称*/ ( parameter_name1, mode1 datatype1, /*参数定义部分*/ parameter_name2, mode2 datatype2, pa rameter_name3, mode3 datatype3,…) RETURN return_datatype /*定义返回值类型*/ {IS | AS} [声明变量] BEGIN function_body; /*函数体部分*/ [RETURN scalar_expression;] /*返回语句*/ END [function_name]; 下面给出一个函数,说明其3种参数的合法性。 CREATE OR REPLACE FUNCTION explain_parameter ( in_pmt IN char, out_pmt OUT char, in_out_pmt IN OUT char ) RETURN char AS return_char char; BEGIN <函数语句序列> RETURN(return_char); END [explain_parameter]; 函数语句序列及其可能出现的情况如下。 in_pmt:= 'hello'; 该语句是错误的,因为IN类型的参数只能作为形参来传递值,不能在函数体中赋值。return_char:=in_pmt; 该语句语法正确。因为IN类型参数本身就是用来传递值,而return_char是作为返回值变量。通过IN类型参数in_pmt赋值给return_char。 out_pmt:= 'hello'; 该语句正确。因为out_pmt作为OUT类型参数,在函数体内被赋值是允许的。 return_char:= out_pmt; 该语句不正确。因为OUT类型参数不能传递值。 in_out_pmt:= 'world'; 该语句正确。因为IN OUT参数可以在函数体中被赋值。 return_char:=in_out_pmt; 该语句正确,因为IN OUT 类型参数既能传递值,也可以复制。 【例】计算某门课程全体学生的平均成绩。 CREATE OR REPLACE FUNCTION average (cnum IN char) RETURN number AS avger number; /*定义返回值变量*/ BEGIN SELECT A VG(CJ) INTO avger FROM CJB WHERE KCH=cnum GROUP BY KCH; RETURN(avger); END; 调用函数 variable_name:=function_name[(实参1,实参2,…)] 【例】用函数count_num统计表XSB中有多少男同学。 SET SERVEROUTPUT ON; DECLARE man_num number; BEGIN man_num:=count_num('男'); DBMS_OUTPUT.PUT_LINE(TO_CHAR(man_num)); END; 输出结果为:14。 删除函数 语法格式: DROP FUNCTION [schema.]function_name 存储过程 创建存储过程 CREATE [OR REPLACE] PROCEDURE [schema.]procedure_name /*定义过程名*/ [ (parameter parameter_modedate_type [ DEFAULT expr ] [, …n])] /*定义参数类型及属性*/ { IS | AS } [declare_section] /*变量声明部分*/ BEGIN sql_statement /*PL/SQL过程体*/ END [procedure_name][;] 【例】计算某专业总学分大于40的人数,存储过程使用了一个输入参数和一个输出参数。CREATE OR REPLACE PROCEDURE count_grade ( zy IN char, person_num OUT number ) AS BEGIN SELECT COUNT(XH) INTO person_num FROM XSB WHERE ZY=zy AND ZXF>40; END; 调用存储过程 [ { EXEC | EXECUTE } ] procedure_name [ ( [parameter =>] value | @variable [,…n]) ] [;] 【例】调用例7.1中的存储过程proc。 SET SERVEROUT ON; EXEC proc; 输出结果: hello world 以下命令运行的结果与之相同: BEGIN proc; END; 删除存储过程 DROP PROCEDURE [schema.] procedure_name; 触发器 DML触发器 CREATE [OR REPLACE] TRIGGER [schema.] trigger_name /*指定触发器名称*/ { BEFORE∣AFTER∣INSTEAD OF } { DELETE | INSERT | UPDATE [ OF column,…n ]}/*定义触发器种类*/ [OR { DELETE | INSERT | UPDA TE [ OF column,…n ]}] ON [schema.] {table_name∣view_name} /*指定操作对象*/ [ FOR EACH ROW [ WHEN(condition) ] ] sql_statement[…n]/*PL/SQL块*/ 【例】创建一个表table1,其中只有一列a。在表上创建一个触发器,每次插入操作时,将变量str的值设为“TRIGGER IS WORKING”并显示。 创建表table1: CREATE TABLE table1(a number); 创建INSERT触发器table1_insert CREATE OR REPLACE TRIGGER table1_insert AFTER INSERT ON table1 DECLARE str char(100) :='TRIGGER IS WORKING'; BEGIN DBMS_OUTPUT.PUT_LINE(str); END; 向table1中插入一行数据: INSERT INTO table1 V ALUES(10); 输出结果: TRIGGER IS WORKING 替代触发器 【例】在XSCJ数据库中创建视图stu_view,包含学生学号、专业、课程号、成绩。该视图依赖于表XSB和CJB,是不可更新视图。可以在视图上创建INSTEAD OF触发器,当向视图中插入数据时分别向表XSB和CJB插入数据,从而实现向视图插入数据的功能。 首先创建视图: CREATE VIEW stu_view AS SELECT XSB.XH, ZY, KCH, CJ FROM XSB, CJB WHERE XSB.XH=CJB.XH 创建INSTEAD OF触发器: CREATE TRIGGER InsteadTrig INSTEAD OF INSERT ON stu_view FOR EACH ROW DECLARE xm char(8); xb char(2); cssj date; BEGIN xm:='佚名'; xb:= '男'; cssj:= '01-1月-90'; INSERT INTO XSB(XH, XM, XB, CSSJ, ZY) V ALUES(:NEW.XH,xm, xb, cssj, :NEW.ZY); INSERT INTO CJB V ALUES(:NEW.XH, :NEW.KCH, :NEW.CJ); END; 向视图插入一行数据: INSERT INTO stu_view V ALUES('091102', '计算机', '101', 85 ); 查看数据是否插入: SELECT * FROM stu_view WHERE XH= '091102'; 执行结果如图所示。 查看与视图关联的XSB表的情况: SELECT * FROM XSB WHERE XH= '091102'; 系统触发器 从Oracle 8i开始,Oracle提供的系统触发器可以在DDL或数据库系统上被触发。DDL指的是数据定义语句,如CREATE、ALTER和DROP等。而数据库系统事件包括数据库服务器的启动(STARTUP)或关闭(SHUTDOWN),数据库服务器出错(SERVERERROR)等。语法格式: CREATE OR REPLACE TRIGGER [scache.] trigger_name { BEFORE︱AFTER } { ddl_event_list︱databse_event_list } ON { DATABASE︱[schema.] SCHEMA } [when_clause] tigger_body 【例】创建一个用户事件触发器,记录用户SYSTEM所删除的所有对象。 首先以用户SYSTEM身份连接数据库,创建一个存储用户信息的表: CREATE TABLE dropped_objects ( object_namevarchar2(30), object_typevarchar(20), dropped_date date ); 创建BEFORE DROP触发器,在用户删除对象之前记录到信息表dropped_objects中。CREATE OR REPLACE TRIGGER dropped_obj_trigger BEFORE DROP ON SYSTEM.SCHEMA BEGIN INSERT INTO dropped_objects V ALUES(ora_dict_obj_name, ora_dict_obj_type, SYSDATE); END; 现在删除SYSTEM模式下的一些对象,并查询表dropped_objects: DROP TABLE table1; DROP TABLE table2; SELECT * FROM dropped_objects; 触发器删除 删除触发器使用DROP TRIGGER语句,语法格式: DROP TRIGGER [schema.] trigger_name 启用和禁用触发器 ALTER TRIGGER [schema.]trigger_name DISABLE | ENABLE; 其中,DISABLE表示禁用触发器,ENABLE表示启用触发器。例如要禁用触发器del_xs,使用如下语句: ALTER TRIGGER del_xs DISABLE; 如果要启用或禁用一个表中的所有触发器,还可以使用如下的语法: ALTER TABLE table_name { DISABLE | ENABLE } ALL TRIGGERS; SQL Server 数据库基本知识点一、数据类型 二、常用语句 (用到的数据库Northwind) 查询语句 简单的Transact-SQL查询只包括选择列表、FROM子句和WHERE子句。它们分别说明所查询列、查询的 表或视图、以及搜索条件等。例如,下面的语句查询Customers 表中公司名称为“Alfreds Futterkiste”的ContactName字段和Address字段。 SELECT ContactName, Address FROM Customers WHERE CompanyName='Alfreds Futterkiste' (一) 选择列表 选择列表(select_list)指出所查询列,它可以是一组列名列表、星号、表达式、变量(包括局部变量和全局变量)等构成。 1、选择所有列 例如,下面语句显示Customers表中所有列的数据: SELECT * FROM Customers 2、选择部分列并指定它们的显示次序查询结果集合中数据的排列顺序与选择列表中所指定的列名排列顺序相同。 例如: SELECT ContactName, Address FROM Customers 3、更改列标题 在选择列表中,可重新指定列标题。定义格式为: 列标题 as 列名 列名列标题如果指定的列标题不是标准的标识符格式时,应使用引号定界符,例如,下列语句使用汉字显示列标题: SELECT ContactName as 联系人名称, Address as地址 FROM Customers 4、删除重复行 SELECT语句中使用ALL或DISTINCT选项来显示表中符合条件的所有行或删除其中重复的数据行,默认 为ALL。使用DISTINCT选项时,对于所有重复的数据行在SELECT返回的结果集合中只保留一行。 SELECT DISTINCT(Country) FROM Customers 5、限制返回的行数 使用TOP n [PERCENT]选项限制返回的数据行数,TOP n说明返回n行,而TOP n PERCENT 时,说明n是 表示一百分数,指定返回的行数等于总行数的百分之几。 例如: SELECT TOP 2 * FROM Customers SELECT TOP 20 PERCENT * FROM Customers (二)FROM子句 FROM子句指定SELECT语句查询及与查询相关的表或视图。在FROM子句中最多可指定256个表或视图,它们之间用逗号分隔。在FROM子句同时指定多个表或视图时,如果选择列表中存在同名列,这时应使用对象名限定这些列 所属的表或视图。例如在Orders和Customers表中同时存在CustomerID列,在查询两个表中的CustomerID时应 使用下面语句格式加以限定: select * from Orders,Customers where Orders.CustomerID =Customers.CustomerID 在FROM子句中可用以下两种格式为表或视图指定别名: 表名 as 别名 表名别名 select * from Orders as a,Customers as b where a.CustomerID =b.CustomerID SELECT不仅能从表或视图中检索数据,它还能够从其它查询语句所返回的结果集合中查询数据。 例如: select * from Customers where CustomerID in (select CustomerID from Orders where EmployeeID=4) 此例中,将SELECT返回的结果集合给予一别名CustomerID,然后再从中检索数据。 (三) 使用WHERE子句设置查询条件 WHERE子句设置查询条件,过滤掉不需要的数据行。例如下面语句查询年龄大于20的数据:select CustomerID from Orders where EmployeeID=4 试题十 一、单项选择题 (本大题共15小题,每小题2分,共30分) 在每小题列出的四个备选项中只有一个是符合题目要 求的,错选、多选或未选均无分。 1. 数据库系统的特点是( )、数据独立、减少数据冗余、避免数据不一致和加强了数据保护。 A .数据共享 B .数据存储 C .数据应用 D .数据保密 2. 数据库系统中,物理数据独立性是指( )。 A .数据库与数据库管理系统的相互独立 B .应用程序与DBMS 的相互独立 C .应用程序与存储在磁盘上数据库的物理模式是相互独立的 D .应用程序与数据库中数据的逻辑结构相互独立 3. 在数据库的三级模式结构中,描述数据库中全体数据的全局逻辑结构和特征的是( )。 A .外模式 B .内模式 C .存储模式 D .模式 4. E-R 模型用于数据库设计的哪个阶段( )? A .需求分析 B .概念结构设计 C .逻辑结构设计 D .物理结构设计 5. 现有关系表:学生(宿舍编号,宿舍地址,学号,姓名,性别,专业,出生日期)的主码是( )。 A .宿舍编号 B .学号 C .宿舍地址,姓名 D .宿舍编号,学号 6. 自然连接是构成新关系的有效方法。一般情况下,当对关系R 和S 使用自然连接时,要求R 和S 含有一个或多个共有的( )。 A .元组 B .行 C .记录 D .属性 7. 下列关系运算中,( )运算不属于专门的关系运算。 A .选择 B .连接 C .广义笛卡尔积 D .投影 8. SQL 语言具有( )的功能。 ( 考 生 答 题 不 得 超 过 此 线 ) A.关系规范化、数据操纵、数据控制 B.数据定义、数据操纵、数据控制 C.数据定义、关系规范化、数据控制 D.数据定义、关系规范化、数据操纵 9.如果在一个关系中,存在某个属性(或属性组),虽然不是该关系的主码或只是主码的一部分,但却是另一个关系的主码时,称该属性(或属性组)为这个关系的() A.候选码 B.主码 C. 外码 D. 连接码 10.下列关于关系数据模型的术语中,()术语所表达的概念与二维表中的 “行”的概念最接近? A.属性 B.关系 C. 域 D. 元组 11.假定学生关系是S(S#,SNAME,SEX,AGE),课程关系是C(C#,CNAME, TEACHER),学生选课关系是SC(S#,C#,GRADE)。 要查找某个学生的基本信息及其选课的平均成绩,将使用关系()A.S和SC B.SC和C C.S和C D.S、SC和C 12.在SQL语言的SELECT语句中,用于对结果元组进行排序的是()子句。 A. GROUP BY B.HAVING C.ORDER BY D.WHERE 13.设有关系SC(SNO,CNO,GRADE),主码是(SNO,CNO)。遵照实体完整性规则,下面()选项是正确的。 A.只有SNO不能取空值B.只有CNO不能取空值 C.只有GRADE不能取空值D.SNO与CNO都不能取空值 14.下面关于函数依赖的叙述中,()是不正确的。 A.若X→Y,WY→Z,则XW→Z B.若Y X,则X→Y C.若XY→Z,则X→Z,Y→Z D.若X→YZ,则X→Y,X→Z 15.设有关系R(A,B,C)和S(C,D)。与SQL语句select A,B,D from R,S where R.C=S.C等价的关系代数表达式是() A.σR.C=S.C(πA,B,D(R×S)) B.πA,B,D(σR,C= S.C(R×S)) C.σR.C=S.C((πA,B(R))×(πD(S))) D.σR,C=S.C(πD((πA,B(R))×S)) A1、以下()内存区不属于SGA。 A.PGA B.日志缓冲区C.数据缓冲区D.共享池 D2、()模式存储数据库中数据字典的表和视图。 A.DBA B.SCOTT C.SYSTEM D.SYS C3、在Oracle中创建用户时,若未提及DEFAULT TABLESPACE 关键字,则Oracle就将()表空间分配给用户作为默认表空间。 A.HR B.SCOTT C.SYSTEM D.SYS A4、()服务监听并按受来自客户端应用程序的连接请求。 A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer B5、()函数通常用来计算累计排名、移动平均数和报表聚合等。 A.汇总B.分析C.分组D.单行 B6、()SQL语句将为计算列SAL*12生成别名Annual Salary A.SELECT ename,sal*12 …Annual Salary? FROM emp; B.SELECT ename,sal*12 “Annual Salary” FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM emp; B7、锁用于提供( )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 C8、( )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 B9、带有( )子句的SELECT语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH C10、使用( )命令可以在已分区表的第一个分区之前添加新分区。 A.添加分区B.截断分区 C.拆分分区D.不能在第一个分区前添加分区 C11、( )分区允许用户明确地控制无序行到分区的映射。 A.散列B.范围C.列表D.复合 C12、可以使用()伪列来访问序列。 A.CURRVAL和NEXTVAL B.NEXTVAL和PREVAL C.CACHE和NOCACHE D.MAXVALUE和MINVALUE A13、带有错误的视图可使用()选项来创建。 A.FORCE B.WITH CHECK OPTION C.CREATE VIEW WITH ERROR 《数据库原理》知识点总结标准化文件发布号:(9312-EUATWW-MWUB-WUNN-INNUL-DQQTY- 目录未找到目录项。 一数据库基础知识(第1、2章) 一、有关概念 1.数据 2.数据库(DB) 3.数据库管理系统(DBMS) Access 桌面DBMS VFP SQL Server Oracle 客户机/服务器型DBMS MySQL DB2 4.数据库系统(DBS) 数据库(DB) 数据库管理系统(DBMS) 开发工具 应用系统 二、数据管理技术的发展 1.数据管理的三个阶段 概念模型 一、模型的三个世界 1.现实世界 2.信息世界:即根据需求分析画概念模型(即E-R图),E-R图与DBMS 无关。 3.机器世界:将E-R图转换为某一种数据模型,数据模型与DBMS相关。 注意:信息世界又称概念模型,机器世界又称数据模型 二、实体及属性 1.实体:客观存在并可相互区别的事物。 2.属性: 3.关键词(码、key):能唯一标识每个实体又不含多余属性的属性组合。 一个表的码可以有多个,但主码只能有一个。 例:借书表(学号,姓名,书号,书名,作者,定价,借期,还期) 规定:学生一次可以借多本书,同一种书只能借一本,但可以多次续借。 4.实体型:即二维表的结构 例 student(no,name,sex,age,dept) 5.实体集:即整个二维表 三、实体间的联系: 1.两实体集间实体之间的联系 1:1联系 1:n联系 m:n联系 2.同一实体集内实体之间的联系 1:1联系 1:n联系 m:n联系 四、概念模型(常用E-R图表示) 属性: 联系: 说明:① E-R图作为用户与开发人员的中间语言。 ② E-R图可以等价转换为层次、网状、关系模型。 举例: 学校有若干个系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授 和副教授每人各带若干研究生。每个班有若干学生,每个学生选修若干课程,每门课程有若干学生选修。用E-R图画出概念模型。 目录未找到目录项。 一数据库基础知识(第1、2章) 一、有关概念 1.数据 2.数据库(DB) 3.数据库管理系统(DBMS) Access 桌面DBMS VFP SQL Server Oracle 客户机/服务器型DBMS MySQL DB2 4.数据库系统(DBS) 数据库(DB) 数据库管理系统(DBMS) 开发工具 应用系统 二、数据管理技术的发展 1.数据管理的三个阶段 概念模型 一、模型的三个世界 1.现实世界 2.信息世界:即根据需求分析画概念模型(即E-R图),E-R图与DBMS无关。 3.机器世界:将E-R图转换为某一种数据模型,数据模型与DBMS相关。 注意:信息世界又称概念模型,机器世界又称数据模型 二、实体及属性 1.实体:客观存在并可相互区别的事物。 2.属性: 3.关键词(码、key):能唯一标识每个实体又不含多余属性的属性组合。 一个表的码可以有多个,但主码只能有一个。 例:借书表(学号,姓名,书号,书名,作者,定价,借期,还期) 规定:学生一次可以借多本书,同一种书只能借一本,但可以多次续借。 4.实体型:即二维表的结构 例student(no,name,sex,age,dept) 5.实体集:即整个二维表 三、实体间的联系: 1.两实体集间实体之间的联系 1:1联系 1:n联系 m:n联系 2.同一实体集内实体之间的联系 1:1联系 1:n联系 m:n联系 四、概念模型(常用E-R图表示) 属性: 联系: 说明:①E-R图作为用户与开发人员的中间语言。 ②E-R图可以等价转换为层次、网状、关系模型。 举例: 学校有若干个系,每个系有若干班级和教研室,每个教研室有若干教员,其中有的教授和副教授每人各带若干研究生。每个班有若干学生,每个学生选修若干课程,每门课程有若干学生选修。用E-R图画出概念模型。 一、数据管理的发展阶段 1、人工管理阶段 2、文件系统阶段 3、数据库管理阶段 注意了解各阶段的背景和特点 二、数据库系统的特点 1、面向全组织的复杂的数据结构 2、数据的冗余度小,易扩充 3、具有较高的数据和程序的独立性:数据独立性 数据的物理独立性 数据的逻辑独立性 三、数据结构模型三要素 1、数据结构 2、数据操作 3、数据的约束性条件 四、数据模型反映实体间的关系 1、一对一的联系(1:1) 2、一对多的联系(1:N) 3、多对多的联系(M:N) 五、数据模型: 是数据库系统中用于提供信息表示和操作手段的形式构架。 数据库结构的基础就是数据模型。数据模型是描述数据(数据结构)、数据之间的联系、数据语义即数据操作,以及一致性(完整性)约束的概念工具的集合。 概念数据模型:按用户的观点来对数据和信息建模。ER模型 结构数据模型:从计算机实现的观点来对数据建模。层次、网状模型、关系 六、数据模型的类型和特点 1、层次模型: 优点:结构简单,易于实现 缺点:支持的联系种类太少,只支持二元一对多联系 数据操纵不方便,子结点的存取只能通过父结点来进行 2、网状模型: 优点:能够更为直接的描述世界,结点之间可以有很多联系 具有良好的性能,存取效率高 缺点:结构比较复杂 网状模型的DDL、DML复杂,并且嵌入某一种高级语言,不易掌握,不易使用 3、关系模型: 特点:关系模型的概念单一;(定义、运算) 关系必须是规范化关系; 在关系模型中,用户对数据的检索操作不过是从原来的表中得到一张新的表。 优点:简单,表的概念直观,用户易理解。 非过程化的数据请求,数据请求可以不指明路径。 数据独立性,用户只需提出“做什么”,无须说明“怎么做”。 坚实的理论基础。 缺点:由于存储路径对用户透明,存储效率往往不如非关系数据模型 4、面向对象模型 5、对象关系模型 七、三个模式和二级映像 1、外模式(Sub-Schema):用户的数据视图。是数据的局部逻辑结构,模式的子集。 2、模式(Schema):所有用户的公共数据视图。是数据库中全体数据的全局逻辑结构和特性的描述。 3、内模式(Storage Schema):又称存储模式。数据的物理结构及存储方式。 4、外模式/模式映象:定义某一个外模式和模式之间的对应关系,映象定义通常包含在各外模式中。当模式改变时,修改此映象,使外模式保持不变,从而应用程序可以保持不变,称为逻辑独立性。 5、模式/内模式映象:定义数据逻辑结构与存储结构之间的对应关系。存储结构改变时,修改此映象,使模式保持不变,从而应用程序可以保持不变,称为物理独立性。 八、数据视图 数据库管理系统的一个主要作用就是隐藏关于数据存储和维护的某些细节,而为用户提供数据在不同层次上的抽象视图,即不同的使用者从不同的角度去观察数据库中的数据所得到的结果—数据抽象。 九、规范化 1、几个概念 候选码(候选关键字):如果一个属性(组)能惟一标识元组,且又不含有其余的属性,那么这个属性(组)称为关系的一个候选码(候选关键字)。 码(主码、主键、主关键字):从候选码中选择一个唯一地标识一个元组候选码作为码 主属性:任何一个候选码中的属性(字段) 非主属性:除了候选码中的属性 外码:关系模式R中属性或属性组X并非R的码,但X是另一个关系模式的码,则称X是R的外部码,简称外码。 2、函数依赖 (1)设R(U)是一个属性集U上的关系模式,X和Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称“X函数确定Y”或“Y函数依赖于X”,记作X→Y。X称为这个函数依赖的决定属性集(Determinant)。Y=f(x) 期末考试卷(卷) 课程名称:数据库考试方式:开卷()闭卷(√) 、本试卷共4 页,请查看试卷中是否有缺页。 2、考试结束后,考生不得将试卷、答题纸带出考场。 1、以下(a )内存区不属于SGA。 A.PGA B.日志缓冲区 C.数据缓冲区 D.共享池 2、d )模式存储数据库中数据字典的表和视图。 (A.DBA B.SCOTT C.SYSTEM D.SYS 3、Oracle 中创建用户时,在若未提及DEFAULT TABLESPACE 关键字,Oracle 就将 c )则(表空间分配给用户作为默认表空间。A.HR B.SCOTT C.SYSTEM D.SYS 4、a )服务监听并按受来自客户端应用程序的连接请求。(A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer 5、b )函数通常用来计算累计排名、移动平均数和报表聚合等。(A.汇总B.分析C.分组D.单行 6、b)SQL 语句将为计算列SAL*12 生成别名Annual Salary (A.SELECT ename,sal*12 …Annual Salary? FROM emp; B.SELECT ename,sal*12 “Annual Salary” FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM emp; 7、锁用于提供(b )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 8、( c )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 9、带有( b )子句的SELECT 语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH UNIT 1 四个基本概念 1.数据(Data):数据库中存储的基本对象 2.数据库的定义 :数据库(Database,简称DB)是长期储存在计算机内、有组织的、可共享的大量数据集合 3.数据库管理系统(简称DBMS):位于用户与操作系统之间的一层数据管理软件(系统软件)。 用途:科学地组织和存储数据;高效地获取和维护数据 主要功能: 数据定义功能; 数据操纵功能; 数据库的运行管理; 数据库的建立和维护功能(实用程序) 4.数据库系统(Database System,简称DBS):指在计算机系统中引入数据库后的系统 数据库系统的构成 数据库 数据库管理系统(及其开发工具) 应用系统 数据库管理员(DBA)和用户 数据管理技术的发展过程 人工管理阶段 文件系统阶段 数据库系统阶段 数据库系统管理数据的特点如下 (1) 数据共享性高、冗余少;(2) 数据结构化;(3) 数据独立性高;(4) 由DBMS进行统一的数据控制功能 数据模型 用来抽象、表示和处理现实世界中的数据和信息的工具。通俗地讲数据模型就是现实世界数据的模拟。 数据模型三要素。 数据结构:是所研究的对象类型的集合,它是刻画一个数据模型性质最重要的方面;数据结构是对系统静态特性的描述 数据操作:对数据库中数据允许执行的操作及有关的操作规则;对数据库中数据的操作主要有查询和更改(包括插入、修改、删除);数据操作是对系统动态特性的描述 数据的约束条件:数据及其联系应该满足的条件限制 E-R图 实体:矩形框表示 属性:椭圆形(或圆角矩形)表示 联系:菱形表示 组织层数据模型 层次模型 网状模型 关系模型(用“二维表”来表示数据之间的联系) 基本概念: 关系(Relation) :一个关系对应通常说的一张表 元组(记录): 表中的一行 属性(字段):表中的一列,给每一个属性名称即属性名 分量:元组中的一个属性值,分量为最小单位,不可分 主码(Key):表中的某个属性组,它可以唯一确定一个元组。 域(Domain):属性的取值范围。 目录 1.1.1 四个基本概念 (1) 数据(Data) (1) 数据库(Database,简称DB) (1) 长期储存在计算机内、有组织的、可共享的大量数据的集合、 (1) 基本特征 (1) 数据库管理系统(DBMS) (1) 数据定义功能 (1) 数据组织、存储和管理 (1) 数据操纵功能 (2) 数据库的事务管理和运行管理 (2) 数据库的建立和维护功能(实用程序) (2) 其它功能 (2) 数据库系统(DBS) (2) 1.1.2 数据管理技术的产生和发展 (3) 数据管理 (3) 数据管理技术的发展过程 (3) 人工管理特点 (3) 文件系统特点 (4) 1.1.3 数据库系统的特点 (4) 数据结构化 (4) 整体结构化 (4) 数据库中实现的是数据的真正结构化 (4) 数据的共享性高,冗余度低,易扩充、数据独立性高 (5) 数据独立性高 (5) 物理独立性 (5) 逻辑独立性 (5) 数据独立性是由DBMS的二级映像功能来保证的 (5) 数据由DBMS统一管理和控制 (5) 1.2.1 两大类数据模型:概念模型、逻辑模型和物理模型 (6) 1.2.2 数据模型的组成要素:数据结构、数据操作、数据的完整性约束条件. 7 数据的完整性约束条件: (7) 关系数据模型的优缺点 (8) 1.3.1 数据库系统模式的概念 (8) 型(Type):对某一类数据的结构和属性的说明 (8) 值(Value):是型的一个具体赋值 (8) 模式(Schema) (8) 实例(Instance) (8) 1.3.2 数据库系统的三级模式结构 (9) 外模式[External Schema](也称子模式或用户模式), (9) 模式[Schema](也称逻辑模式) (9) 内模式[Internal Schema](也称存储模式) (9) 1.3.3 数据库的二级映像功能与数据独立性 (9) 外模式/模式映像:保证数据的逻辑独立性 (10) 模式/内模式映象:保证数据的物理独立性 (10) 1.4 数据库系统的组成 (10) 数据库管理员(DBA)职责: (10) 所有内容主要针对期末考试卷内容,也具有一定数据库这门课程的重点指向性。 所有写的内容为老师期末考试之前统一带着复习时所说的重点 没有写的或者空着的就是老师当时没说的 蓝色字体表示比较重要的专业名词 红色字体表示重要的程度 第一章: 1.数据模型的三个要素 数据结构,数据操作,完整性约束 2.数据库领域常用的逻辑模型 层次网状关系,最常用的是关系数据模型 3.E-R图是一定要掌握的,一定要会画 实体-矩形框联系-菱形框 画E-R图时要注意几个点: a.每一个实体一定要画上属性 b.联系和联系之间是一对一还是多对多一定要画上 4.三级模式结构 外模式模式内模式 哪两个映像保证了哪两个独立性这个一定要清楚 怎么保证的 外模式就是我们说的子模式,也就是数据库里的视图 一个数据库里的模式有1个,内模式有?个,外模式有多个 第二章: 1. 什么叫关系的域 简单来说,就是一个属性的取值范围,它的取值是整型还是字符串型 2. 什么叫笛卡儿积 要会求笛卡儿积,其他的像选择,投影,自然连接等都要会求,看清楚题目是求等值连接还是自然连接,这两个是不一样的 3. 什么叫关系 关系的元组是什么,属性是什么 4.提到关系有一组码的概念一定要清楚 候选码主码外部码这三个码的概念非常重要 候选码:它能够唯一的标识出整个元组来,候选码不是只有一个属性,有可能是一 个或多个属性,候选码的属性不能是空值 主码:多个候选码中选定一个作为主码 外部码:一个属性它在当前这个关系中不是码,但是它和另外一个关系当中的主码 相对应,我们就说这个属性是当前这个关系的一个外部码。 外部码与参照完整性密切相关 在外部码中要知道哪一个是参照关系,哪一个是被参照关系 外部码的取值约束:外部码的取值不是任意的,或者为空,或者为所参照关系的主码的某一个值 全码:所有的属性全部加在一起才能当作码,其中任一部分都不能构成码的叫全码在多值依赖里全码的例子比较多 5.关系数据模型的第二个要素关系数据操作我们分为三大类 关系代数关系演算SQL 关系代数是考察的重点 关系代数的两种考察方法:1.考计算题 2.考表达式 8种运算符:4种集合运算符(并,交,差,笛卡儿积)这四个求结果一定要会求 求结果时先把属性列写出来。 4种专门的关系运算符(选择,投影,连接,除)符号不要写错 选择:选出来满足条件的元组(从行的角度来进行运算) oracle数据库期末考试试题及答案 A1、以下()内存区不属于SGA。 A.PGA B.日志缓冲区C.数据缓冲区D.共享池 D2、()模式存储数据库中数据字典的表和视图。 A.DBA B.SCOTT C.SYSTEM D.SYS C3、在Oracle中创建用户时,若未提及DEFAULT TABLESPACE 关键字,则Oracle就将()表空间分配给用户作为默认表空间。A.HR B.SCOTT C.SYSTEM D.SYS A4、()服务监听并按受来自客户端应用程序的连接请求。A.OracleHOME_NAMETNSListener B.OracleServiceSID C.OracleHOME_NAMEAgent D.OracleHOME_NAMEHTTPServer B5、()函数通常用来计算累计排名、移动平均数和报表聚合等。A.汇总B.分析C.分组D.单行 B6、()SQL语句将为计算列SAL*12生成别名Annual Salary A.SELECT ename,sal*12 ‘Annual Salary' FROM emp; B.SELECT ename,sal*12 “Annual Salary”FROM emp; C.SELECT ename,sal*12 AS Annual Salary FROM emp; D.SELECT ename,sal*12 AS INITCAP(“Annual Salary”) FROM 12 / 1 emp; B7、锁用于提供( )。 A.改进的性能 B.数据的完整性和一致性 C.可用性和易于维护 D.用户安全 C8、( )锁用于锁定表,允许其他用户查询表中的行和锁定表,但不允许插入、更新和删除行。 A.行共享B.行排他C.共享D.排他 B9、带有( )子句的SELECT语句可以在表的一行或多行上放置排他锁。 A.FOR INSERT B.FOR UPDATE C.FOR DELETE D.FOR REFRESH C10、使用( )命令可以在已分区表的第一个分区之前添加新分区。A.添加分区B.截断分区 C.拆分分区D.不能在第一个分区前添加分区 C11、( )分区允许用户明确地控制无序行到分区的映射。 A.散列B.范围C.列表D.复合 C12、可以使用()伪列来访问序列。 A.CURRVAL和NEXTVAL B.NEXTVAL和PREVAL C.CACHE和NOCACHE D.MAXVALUE和MINVALUE 第一章:绪论 数据库(DB):长期存储在计算机内、有组织、可共享的大量数据的集合。数据库中的数据按照一定的数据模型组织、描述和存储,具有娇小的冗余度、交稿的数据独立性和易扩展性,并可为各种用户共享。 数据库管理系统(DBMS):位于用户和操作系统间的数据管理系统的一层数据管理软件。用途:科学地组织和存储数据,高效地获取和维护数据。包括数据定义功能,数据组织、存储和管理,数据操纵功能,数据库的事物管理和运行管理,数据库的建立和维护功能,其他功能。 数据库系统(DBS):在计算机系统中引入数据库后的系统,一般由数据库。数据库管理系统(及其开发工具)、应用系统、数据库管理员构成。目的:存储信息并支持用户检索和更新所需的信息。 数据库系统的特点:数据结构化;数据的共享性高,冗余度低,易扩充;数据独立性高;数据由DBMS统一管理和控制。 概念模型实体,客观存在并可相互区别的事物称为实体。 属性,实体所具有的某一特性称为属性。 码,唯一标识实体的属性集称为码。 域,是一组具有相同数据类型的值的集合。 实体型,具有相同属性的实体必然具有的共同的特征和性质。 实体集,同一类型实体的集合称为实体集。 联系 两个实体型之间的联系一对一联系;一对多联系;多对多联系 关系模型关系,元组,属性,码,域,分量,关系模型 关系数据模型的操纵与完整性约束关系数据模型的操作主要包括查询,插入,删除和更新数据。这些操作必须满足关系完整性约束条件。关系的完整性约束条件包括三大类:实体完整性,参照完整性和用户定义的完整性。 数据库系统三级模式结构外模式,模式,内模式 模式:(逻辑模式)数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。一个数据库只有一个模式。 基础知识 表3.2 Oracle数据类型 表3.3 XSB的表结构 操作表 创建表 CREATE TABLE [schema.] table_name ( column_namedatatype [DEFAULT expression] [column_constraint][,…n] 期末复习顺便总结下,书本为高等教育出版社的《数据库系统概论》。 第一章知识点 数据库是长期储存之计算机内的、有组织的、可共享的大量数据的集合。?1,数据库数据特点P4 永久存储,有组织,可共享。?2,数据独立性及其如何保证P10,P34 逻辑独立性:用户的应用程序与数据库的逻辑结构互相独立。(内模式保证) 物理独立性:用户的应用程序与存储在磁盘上的数据库中的数据相互(外模式保证) 3,数据模型的组成要素P13 数据结构、数据操作、完整性约束。 4,用ER图来表示概念模型P17 实体、联系和属性。联系本身也是一种实体型,也可以有属性。 第二章 1,关系的相关概念(如关系、候选码、主属性、非主属性) P42-P44单一的数据结构----关系。现实世界的实体以及实体间的各种联系均用关系来表示。 域是一组具有相同数据类型的值的集合。 若关系中的某一属性组的值能唯一地标识一个元组,则称该属性组为候选码 关系模式的所有属性组是这个关系模式的候选码,称为全码 若一个关系有多个候选码,则选定其中一个为主码 候选码的诸属性称为主属性 不包含在任何侯选码中的属性称为非主属性 2关系代数运算符P52 自然连接是在广义笛卡尔积R×S中选出同名属性上符合相等条件元组,再进行投影,去掉重复的同名属性,组成新的关系。 给定关系r(R)和s(S), S? R,则r ÷s是最大的关系t(R-S) 满足tx s?r 3,关系代数表达式 第三章 1,SQL的特点P79-P80 1. 综合统一 2. 高度非过程化 3. 面向集合的操作方式 4.以同一种语法结构提供多种使用方式 5. 语言简洁,易学易用 2,基本表的定义、删除和修改P84-P87 PRIMARY KEY PRIMARYKEY (Sno,Cno) UNIQUE FOREIGN KEY(Cpno) REFERENCES Course(Cno) ALTER TABLE <表名> [ ADD <新列名><数据类型>[完整性约束] ] [ DROP<完整性约束名>] [ALTER COLUMN<列名> <数据类型> ]; DROP TABLE<表名>[RESTRICT|CASCADE]; 3,索引的建立与删除P89-P90 CREATE [UNIQUE] [CLUSTER] INDEX <索引名> ON <表名>(<列名>[<次序>][,<列名>[<次序>] ]…); 唯一索引UNIQUE、非唯一索引或聚簇索引CLUSTER 一、选择 1 )CBO与RULE的区别,RBO根据规则选择最佳执行路径来运 行查询,CBO根据表统计找到最低成本的访问数据的方法确定执行 计划。使用CBO需要注意: a ) 需要使用提示(Hint) b ) 优化SQL的写法 c ) 选择最有效率的表名顺序 d ) 需要经常对表进行ANALYZE命令进行分析统计 d ) 需要稳定执行计划 2 ) 在Oracle中,一个用户拥有的所有数据库对象统称为()。 a ) 数据库 b ) 模式 c ) 表空间 d ) 实例 3 )在Oracle中,可用于提取日期时间类型特定部分(如年、 月、日、时、分、秒)的函数有()。 a ) DATEPART b ) EXTRACT c ) TO_CHAR d ) TRUNC 4 )在Oracle中,有一个教师表teacher的结构如下:IDNUMBER(5) NAMEVARCHAR2(25) EMAILVARCHAR2(50) 下面哪个语句显示没有Email地址的教师姓名()。a ) SELECTnameFROMteacherWHEREemail=NULL; b ) SELECTnameFROMteacherWHEREemail<>NULL; c SELECTnameFROMteacherWHEREemailISNULL; ) d ) SELECTnameFROMteacherWHEREemailISNOTNULL; 5 )在Oracle数据库的逻辑结构中有以下组件:A表空间B数据块C区D段 这些组件从大到小依次是()。 a ) A→B→C→D b ) A→D→C→B c ) A→C→B→D d ) D→A→C→B 6 )在Windows操作系统中,Oracle的()服务监听并接受来 自客户端应用程序的连接请求。 a ) OracleHOME_NAMETNSListener b ) OracleServiceSID c ) OracleHOME_NAMEAgent SELECT查询包括条件项、内连接、分组汇总(含HAVING)、排序、简单子查询(不考EXIS TS)及一些输出选项。 数据库管理系统(DBMS)特点(1)数据结构化(2)数据共享性好、冗余度低、(3)数据独立性强(4)DBMS统一管理。 数据库(DB),就是相关联的数据的集合。 数据库系统(DBS),是指在计算机中引入数据库后的系统构成,由计算机软硬件、数据库、D BMS、应用程序以及数据库管理员(DBA)和数据库用户构成。 关系模型是一种数据模型关系模型中最重要的概念就是关系。关系(Relation),直观的看,就是由行和列组成的二维表,一个关系就是一张二维表。 关系中的一列称为关系的一个属性(Attribute),一行称为关系的一个元组(Tuple)。 组称为候选键(Candidate Key),从候选键中挑选一个作为该关系的主键(Primary Key)。一个关系中存放的另一个关系的主键称为外键(Foreign Key)。并不是任何的二维表都可以称为关系。关系具有以下特点: ?关系中的每一列属性都是原子属性,即属性不可再分; ?关系中的每一列属性都是同质的,即每一个元组的该属性取值都表示同类信息; ?关系中的属性间没有先后顺序; ?关系中元组没有先后顺序; ?关系中不能有相同的元组。 关系模型,就是对一个数据处理系统中所有数据对象的数据结构的形式化描述。将一个系统中所有不同的关系模式描述出来,就建立了该系统的关系模型。 关系数据库,是依据关系模型建立的数据库,是目前各类数据处理系统中最普遍采用的数据库类型。依照关系理论设计的DBMS,称为关系DBMS。数据库设计指:对于给定的应用环境,设计构造最优的数据库结构,建立数据库及其应用系统,使之能有效地存储数据,对数据进行操作和管理,以满足用户各种需求的过程。 联系有三种类型,转化为关系模式后,与其他关系模式可进行合并优化。 1:1的联系,一般不必要单独成为一个关系模式,可以将它与联系中的任何一方实体转化成的关系模式合并(一般与元组较少的关系合并)。 1:n的联系也没有必要单独作为一个关系模式,可将其与联系中的n方实体转化成的关系模式合并。 m:n的联系必须单独成为一个关系模式,不能与任何一方实体合并。 、模型的三个世界 1 ?现实世界 3 ?机器世界:将 E-R 图转换为某一种数据模型,数据模型与 注意:信息世界又称概念模型,机器世界又称数据模型 二、实体及属性 1.实体:客观存在并可相互区别的事物。 2 .属性: 3 .关键词:能唯一标识每个实体又不含多余属性的属性组合。 一个表的码可以有多个,但主码只能有一个。 4 .实体型:即二维表的结构 数据库系统概述 一、有关概念 1.数据 2 .数据库(DB ) 3 ?数据库管理系统 DBMS ) ccess 桌面DBMS SQL Server 客户机/服务器型 DBMS Oracle MySQL DB2 4 .数据库系统( DBS ) 厂数据库(DB ) J 数据库管理系统 幵发工具 DBMS ) 应用系统 二、数据管理技术的发展 1 ?数据管理的三个阶段 (1)人工管理阶段 (2)文件系统阶段 (3 )数据库系统阶段 概念模型 2 ?信息世界:即根据需求分析画概念模型(即 E-R 图),E-R 图与 DBMS 无关。 DBMS 相关。 5?实体集:即整个二维表三、实体间的联系: 1.两实体集间实体之间的联系 1:1 联系、 1:n 联系、 m :n 联系 2.同一实体集内实体之间的联系 1:1 联系、 1:n 联系、 m :n 联系 1.重要术语: 关系:一个关系就是一个二维表; 元组:二维表的一行,即实体; 关系模式:在实体型的基础上,注明主码。 关系模型:指一个数据库中全部二维表结构的集合。 数据库系统结构 数据库系统的 模式结构 三级模式 1.模式:是数据库中全体数据的逻辑结构和特征的描述。 ①模式只涉及数据库的结构;模式既不涉及应用程序,又不涉及数据库结构的存储; ② 外模式:是模式的一个子集,是与某一个应用程序有关的逻辑表示。 特点:一个应用程序只能使用一个外模式,但同一个外模式可为多个应用程序使用。 内模式:描述数据库结构的存储,但不涉及物理记录。 外模式 /模式映象:保证数据库的逻辑独立性; 模式 /内模式映象:保证数据库的物理独立性; 使数据库与应用系统完全分开,数据库改变时,应用系统不必改变。 数据的存取完全由 DBMS 管理,用户不必考虑存取路径。 数据库管理系统 DBMS 的功能:负责对数据库进行统一的管理与控制。 数据定义:即定义数据库中各对象的结构 数据操纵:包括对数据库进行查询、插入、删除、修改等操作。 数据控制:包括安全性控制、完整性控制、并发控制、数据库恢复。 一、层次模型: 用树型结构表示实体之间的联系。 二、网状模型: 用图结构表示实体之间的联系。 三、关系模型: 用二维表表示实体之间的联系。 数据模型 2. DBMS 的组成: DDL 4五 厶" 语言 DML 语言 2. 两级映象 3. 两级映象的意义 1.(整理)SQLServer数据库基本知识点.
数据库系统概论期末试题及答案(重点知识)
中南大学oracle数据库期末考试试题及答案
《数据库原理》知识点总结
《数据库原理》知识点总结 (3)
空间数据库期末复习重点总结
ORACLE数据库期末考试题目及答案
数据库知识点整理(全)
数据库原理王珊知识点整理
数据库重点整理
oracle数据库期末考试试题及复习资料
数据库系统概论知识点
Oracle数据库期末复习知识点整理
数据库知识点总结
oracle数据库期末考试试题及答案(一)
access数据库知识点总结
《数据库原理》知识点总结
相关主题
文本预览