
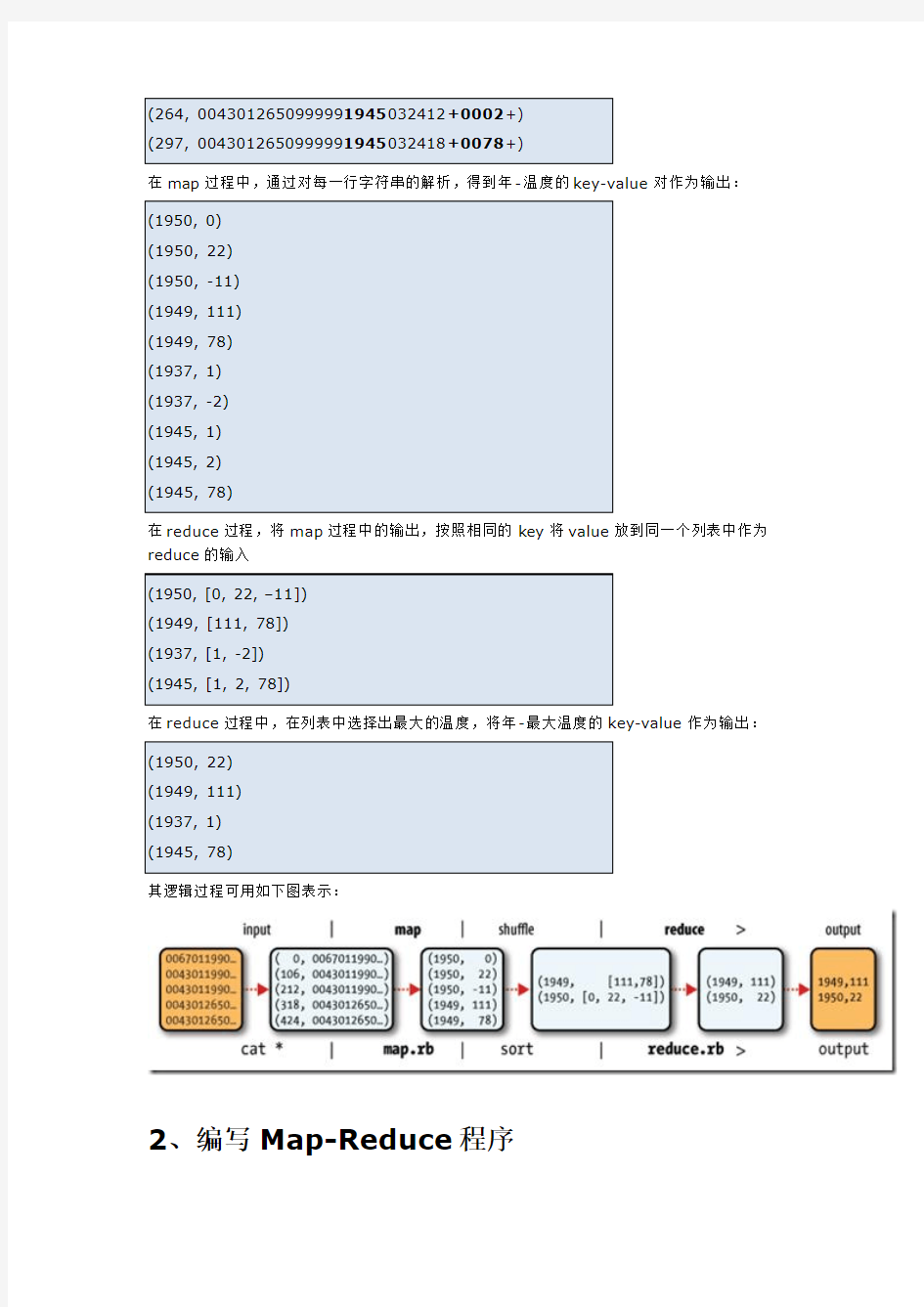
1、Map-Reduce的逻辑过程
假设我们需要处理一批有关天气的数据,其格式如下:
?按照ASCII码存储,每行一条记录
?每一行字符从0开始计数,第15个到第18个字符为年
?第25个到第29个字符为温度,其中第25位是符号+/-
现在需要统计出每年的最高温度。
Map-Reduce主要包括两个步骤:Map和Reduce
每一步都有key-value对作为输入和输出:
?map阶段的key-value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本
?map阶段的输出的key-value对的格式必须同reduce阶段的输入key-value对的格式相对应
对于上面的例子,在map过程,输入的key-value对如下:
在map过程中,通过对每一行字符串的解析,得到年-温度的key-value对作为输出:
在reduce过程,将map过程中的输出,按照相同的key将value放到同一个列表中作为reduce的输入
在reduce过程中,在列表中选择出最大的温度,将年-最大温度的key-value作为输出:
其逻辑过程可用如下图表示:
2、编写Map-Reduce程序
编写Map-Reduce程序,一般需要实现两个函数:mapper中的map函数和reducer中的reduce函数。
一般遵循以下格式:
?map: (K1, V1) ->list(K2, V2)
?reduce: (K2, list(V)) ->list(K3, V3)
对于上面的例子,则实现的mapper如下:
实现的reducer如下:
欲运行上面实现的Mapper和Reduce,则需要生成一个Map-Reduce得任务(Job),其基本包括以下三部分:
?输入的数据,也即需要处理的数据
?Map-Reduce程序,也即上面实现的Mapper和Reducer
?此任务的配置项JobConf
欲配置JobConf,需要大致了解Hadoop运行job的基本原理:
?Hadoop将Job分成task进行处理,共两种task:map task和reduce task ?Hadoop有两类的节点控制job的运行:JobTracker和TaskTracker
o JobTracker协调整个job的运行,将task分配到不同的TaskTracker上
o TaskTracker负责运行task,并将结果返回给JobTracker ?Hadoop将输入数据分成固定大小的块,我们称之input split
?Hadoop为每一个input split创建一个task,在此task中依次处理此split中的一个个记录(record)
?Hadoop会尽量让输入数据块所在的DataNode和task所执行的DataNode(每个DataNode上都有一个TaskTracker)为同一个,可以提高运行效率,所以input split 的大小也一般是HDFS的block的大小。
?Reduce task的输入一般为Map Task的输出,Reduce Task的输出为整个job的输出,保存在HDFS上。
?在reduce中,相同key的所有的记录一定会到同一个TaskTracker上面运行,然而不同的key可以在不同的TaskTracker上面运行,我们称之为partition
o partition的规则为:(K2, V2) –> Integer,也即根据K2,生成一个partition 的id,具有相同id的K2则进入同一个partition,被同一个TaskTracker上
被同一个Reducer进行处理。
下图大概描述了Map-Reduce的Job运行的基本原理:
下面我们讨论JobConf,其有很多的项可以进行配置:
?setInputFormat:设置map的输入格式,默认为TextInputFormat,key为LongWritable, value为Text
?setNumMapTasks:设置map任务的个数,此设置通常不起作用,map任务的个数取决于输入的数据所能分成的input split的个数
?setMapperClass:设置Mapper,默认为IdentityMapper
?setMapRunnerClass:设置MapRunner, map task是由MapRunner运行的,默认为MapRunnable,其功能为读取input split的一个个record,依次调用Mapper 的map函数
?setMapOutputKeyClass和setMapOutputValueClass:设置Mapper的输出的key-value对的格式
?setOutputKeyClass和setOutputValueClass:设置Reducer的输出的key-value 对的格式
?setPartitionerClass和setNumReduceTasks:设置Partitioner,默认为HashPartitioner,其根据key的hash值来决定进入哪个partition,每个partition 被一个reduce task处理,所以partition的个数等于reduce task的个数?setReducerClass:设置Reducer,默认为IdentityReducer
?setOutputForm at:设置任务的输出格式,默认为TextOutputFormat
?FileInputForm at.addInputPath:设置输入文件的路径,可以使一个文件,一个路径,一个通配符。可以被调用多次添加多个路径
?FileOutputFormat.setOutputPath:设置输出文件的路径,在job运行前此路径不应该存在
当然不用所有的都设置,由上面的例子,可以编写Map-Reduce程序如下:
3、Map-Reduce数据流(data flow)
Map-Reduce的处理过程主要涉及以下四个部分:
?客户端Client:用于提交Map-reduce任务job
?JobTracker:协调整个job的运行,其为一个Java进程,其main class为JobTracker ?TaskTracker:运行此job的task,处理input split,其为一个Java进程,其main class为TaskTracker
?HDFS:hadoop分布式文件系统,用于在各个进程间共享Job相关的文件
3.1、任务提交
JobClient.runJob()创建一个新的JobClient实例,调用其submitJob()函数。
?向JobTracker请求一个新的job ID
?检测此job的output配置
?计算此job的input splits
?将Job运行所需的资源拷贝到JobTracker的文件系统中的文件夹中,包括job jar文件,job.xml配置文件,input splits
?通知JobTracker此Job已经可以运行了
提交任务后,runJob每隔一秒钟轮询一次job的进度,将进度返回到命令行,直到任务运行完毕。
3.2、任务初始化
当JobTracker收到submitJob调用的时候,将此任务放到一个队列中,job调度器将从队列中获取任务并初始化任务。
初始化首先创建一个对象来封装job运行的tasks, status以及progress。
在创建task之前,job调度器首先从共享文件系统中获得JobClient计算出的input splits。其为每个input split创建一个map task。
每个task被分配一个ID。
3.3、任务分配
TaskTracker周期性的向JobTracker发送heartbeat。
在heartbeat中,TaskTracker告知JobTracker其已经准备运行一个新的task,JobTracker 将分配给其一个task。
在JobTracker为TaskTracker选择一个task之前,JobTracker必须首先按照优先级选择一个Job,在最高优先级的Job中选择一个task。
TaskTracker有固定数量的位置来运行map task或者reduce task。
默认的调度器对待map task优先于reduce task
当选择reduce task的时候,JobTracker并不在多个task之间进行选择,而是直接取下一个,因为reduce task没有数据本地化的概念。
3.4、任务执行
TaskTracker被分配了一个task,下面便要运行此task。
首先,TaskTracker将此job的jar从共享文件系统中拷贝到TaskTracker的文件系统中。TaskTracker从distributed cache中将job运行所需要的文件拷贝到本地磁盘。
其次,其为每个task创建一个本地的工作目录,将jar解压缩到文件目录中。
其三,其创建一个TaskRunner来运行task。
TaskRunner创建一个新的JVM来运行task。
被创建的child JVM和TaskTracker通信来报告运行进度。
3.4.1、Map的过程
MapRunnable从input split中读取一个个的record,然后依次调用Mapper的map函数,将结果输出。
map的输出并不是直接写入硬盘,而是将其写入缓存memory buffer。
当buffer中数据的到达一定的大小,一个背景线程将数据开始写入硬盘。
在写入硬盘之前,内存中的数据通过partitioner分成多个partition。
在同一个partition中,背景线程会将数据按照key在内存中排序。
每次从内存向硬盘flush数据,都生成一个新的spill文件。
当此task结束之前,所有的spill文件被合并为一个整的被partition的而且排好序的文件。reducer可以通过http协议请求map的输出文件,tracker.http.threads可以设置http服务线程数。
3.4.2、Reduce的过程
当map task结束后,其通知TaskTracker,TaskTracker通知JobTracker。
对于一个job,JobTracker知道TaskTracer和map输出的对应关系。
reducer中一个线程周期性的向JobTracker请求map输出的位置,直到其取得了所有的map 输出。
reduce task需要其对应的partition的所有的map输出。
reduce task中的copy过程即当每个m ap task结束的时候就开始拷贝输出,因为不同的map task完成时间不同。
reduce task中有多个copy线程,可以并行拷贝map输出。
当很多map输出拷贝到reduce task后,一个背景线程将其合并为一个大的排好序的文件。当所有的map输出都拷贝到reduce task后,进入sort过程,将所有的map输出合并为大的排好序的文件。
最后进入reduce过程,调用reducer的reduce函数,处理排好序的输出的每个key,最后的结果写入HDFS。
3.5、任务结束
当JobTracker获得最后一个task的运行成功的报告后,将job得状态改为成功。
当JobClient从JobTracker轮询的时候,发现此job已经成功结束,则向用户打印消息,从runJob函数中返回。
云凡教育Hadoop网络培训第二期 开课时间:2014年1月20日 授课方式:YY在线教育+课程视频+资料、笔记+辅导+推荐就业 YY教育平台:20483828 课程咨询:1441562932 大胃 云凡教育Hadoop交流群:306770165 费用: 第二期优惠特价:999元; 授课对象: 对大数据领域有求知欲,想成为其中一员的人员 想深入学习hadoop,而不只是只闻其名的人员 基础技能要求: 具有linux操作一般知识(因为hadoop在linux下跑) 有Java基础(因为hadoop是java写的并且编程也要用java语言) 课程特色 1,以企业实际应用为向导,进行知识点的深入浅出讲解; 2,从零起步,循序渐进,剖析每一个知识; 3,萃取出实际开发中最常用、最实用的内容并以深入浅出的方式把难点化于无形之中 学习安排: Hadoop的起源与生态系统介绍(了解什么是大数据;Google的三篇论文;围绕Hadoop形成的一系列的生态系统;各个子项目简要介绍)
1_Linux系统环境搭建和基本命令使用 针对很多同学对linux命令不熟悉,在课程的学习中,由于命令不熟悉导致很多错误产生,所以特意增加一节linux基础课程,讲解一些常用的命令,对接下来的学习中做好入门准备; 02_Hadoop本地(单机)模式和伪分布式模式安装 本节是最基本的课程,属于入门级别,主要对Hadoop 介绍,集中安装模式,如何在linux上面单机(本地)和伪分布模式安装Hadoop,对HDFS 和MapReduce进行测试和初步认识。 03_HDFS的体系结构、Shell操作、Java API使用和应用案例 本节是对hadoop核心之一——HDFS的讲解。HDFS是所有hadoop操作的基础,属于基本的内容。对本节内容的理解直接影响以后所有课程的学习。在本节学习中,我们会讲述hdfs的体系结构,以及使用shell、java不同方式对hdfs 的操作。在工作中,这两种方式都非常常用。学会了本节内容,就可以自己开发网盘应用了。在本节学习中,我们不仅对理论和操作进行讲解,也会讲解hdfs 的源代码,方便部分学员以后对hadoop源码进行修改。 04_MapReduce入门、框架原理、深入学习和相关MR面试题 本节开始对hadoop核心之一——mapreduce的讲解。mapreduce是hadoop 的核心,是以后各种框架运行的基础,这是必须掌握的。在本次讲解中,掌握mapreduce执行的详细过程,以单词计数为例,讲解mapreduce的详细执行过程。还讲解hadoop的序列化机制和数据类型,并使用自定义类型实现电信日志信息的统计。最后,还要讲解hadoop的RPC机制,这是hadoop运行的基础,通过该节学习,我们就可以明白hadoop是怎么明白的了,就不必糊涂了,本节内容特别重要。 05_Hadoop集群安装管理、NameNode安全模式和Hadoop 1.x串讲复习 hadoop就业主要是两个方向:hadoop工程师和hadoop集群管理员。我们课程主要培养工程师。本节内容是面向集群管理员的,主要讲述集群管理的知
基于hadoop的大规模文本处理技术实验专业班级:软件1102 学生姓名:张国宇 学号: Setup Hadoop on Ubuntu 11.04 64-bit 提示:前面的putty软件安装省略;直接进入JDK的安装。 1. Install Sun JDK<安装JDK> 由于Sun JDK在ubuntu的软件中心中无法找到,我们必须使用外部的PPA。打开终端并且运行以下命令: sudo add-apt-repository ppa:ferramroberto/java sudo apt-get update sudo apt-get install sun-java6-bin sudo apt-get install sun-java6-jdk Add JAVA_HOME variable<配置环境变量>: 先输入粘贴下面文字: sudo vi /etc/environment 再将下面的文字输入进去:按i键添加,esc键退出,X保存退出;如下图: export JAVA_HOME="/usr/lib/jvm/java-6-sun-1.6.0.26" Test the success of installation in Terminal<在终端测试安装是否成功>: sudo . /etc/environment
java –version 2. Check SSH Setting<检查ssh的设置> ssh localhost 如果出现“connection refused”,你最好重新安装 ssh(如下命令可以安装): sudo apt-get install openssh-server openssh-client 如果你没有通行证ssh到主机,执行下面的命令: ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys 3. Setup Hadoop<安装hadoop> 安装 apache2 sudo apt-get install apache2 下载hadoop: 1.0.4 解压hadoop所下载的文件包: tar xvfz hadoop-1.0.4.tar.gz 下载最近的一个稳定版本,解压。编辑/ hadoop-env.sh定义java_home “use/library/java-6-sun-1.6.0.26”作为hadoop的根目录: Sudo vi conf/hadoop-env.sh 将以下内容加到文件最后: # The java implementation to use. Required. export JAVA_HOME=/usr/lib/jvm/java-6-sun-1.6.0.26
?项目 ?维基 ?Hadoop 0.18文档 Last Published: 07/01/2009 00:38:20 文档 概述 快速入门 集群搭建 HDFS构架设计 HDFS使用指南 HDFS权限指南 HDFS配额管理指南 命令手册 FS Shell使用指南 DistCp使用指南 Map-Reduce教程 Hadoop本地库 Streaming Hadoop Archives Hadoop On Demand API参考 API Changes 维基 常见问题 邮件列表 发行说明 变更日志 PDF Hadoop快速入门 ?目的 ?先决条件 o支持平台 o所需软件 o安装软件 ?下载 ?运行Hadoop集群的准备工作 ?单机模式的操作方法 ?伪分布式模式的操作方法
o配置 o免密码ssh设置 o执行 ?完全分布式模式的操作方法 目的 这篇文档的目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop 分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等。 先决条件 支持平台 ?GNU/Linux是产品开发和运行的平台。 Hadoop已在有2000个节点的GNU/Linux主机组成的集群系统上得到验证。 ?Win32平台是作为开发平台支持的。由于分布式操作尚未在Win32平台上充分测试,所以还不作为一个生产平台被支持。 所需软件 Linux和Windows所需软件包括: 1.Java TM1.5.x,必须安装,建议选择Sun公司发行的Java版本。 2.ssh必须安装并且保证sshd一直运行,以便用Hadoop 脚本管理远端 Hadoop守护进程。 Windows下的附加软件需求 1.Cygwin - 提供上述软件之外的shell支持。 安装软件 如果你的集群尚未安装所需软件,你得首先安装它们。 以Ubuntu Linux为例: $ sudo apt-get install ssh $ sudo apt-get install rsync
Hadoop云计算实验报告
Hadoop云计算实验报告 1实验目的 在虚拟机Ubuntu上安装Hadoop单机模式和集群; 编写一个用Hadoop处理数据的程序,在单机和集群上运行程序。 2实验环境 虚拟机:VMware 9 操作系统:ubuntu-12.04-server-x64(服务器版),ubuntu-14.10-desktop-amd64(桌面版)Hadoop版本:hadoop 1.2.1 Jdk版本:jdk-7u80-linux-x64 Eclipse版本:eclipse-jee-luna-SR2-linux-gtk-x86_64 Hadoop集群:一台namenode主机master,一台datanode主机salve, master主机IP为10.5.110.223,slave主机IP为10.5.110.207。 3实验设计说明 3.1主要设计思路 在ubuntu操作系统下,安装必要软件和环境搭建,使用eclipse编写程序代码。实现大数据的统计。本次实验是统计软件代理系统操作人员处理的信息量,即每个操作人员出现的次数。程序设计完成后,在集成环境下运行该程序并查看结果。 3.2算法设计 该算法首先将输入文件都包含进来,然后交由map程序处理,map程序将输入读入后切出其中的用户名,并标记它的数目为1,形成
Hadoop是一个分布式系统基础架构,由Apache基金会开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力高速运算和存储。简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。 Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。 搜索了一些WatchStor存储论坛关于hadoop入门的一些资料分享给大家希望对大家有帮助 jackrabbit封装hadoop的设计与实现 https://www.doczj.com/doc/4b4883922.html,/thread-60444-1-1.html 用Hadoop进行分布式数据处理 https://www.doczj.com/doc/4b4883922.html,/thread-60447-1-1.html
Hadoop源代码eclipse编译教程 https://www.doczj.com/doc/4b4883922.html,/thread-60448-1-2.html Hadoop技术讲解 https://www.doczj.com/doc/4b4883922.html,/thread-60449-1-2.html Hadoop权威指南(原版) https://www.doczj.com/doc/4b4883922.html,/thread-60450-1-2.html Hadoop源代码分析完整版 https://www.doczj.com/doc/4b4883922.html,/thread-60451-1-2.html 基于Hadoop的Map_Reduce框架研究报告 https://www.doczj.com/doc/4b4883922.html,/thread-60452-1-2.html Hadoop任务调度 https://www.doczj.com/doc/4b4883922.html,/thread-60453-1-2.html Hadoop使用常见问题以及解决方法 https://www.doczj.com/doc/4b4883922.html,/thread-60454-1-2.html HBase:权威指南
1、VMware安装 我们使用Vmware 14的版本,傻瓜式安装即可。(只要) 双击 如过 2.安装xshell 双击 3.安装镜像: 解压centos6.5-empty解压 双击打开CentOS6.5.vmx 如果打不开,在cmd窗口中输入:netsh winsock reset 然后重启电脑。 进入登录界面,点击other 用户名:root 密码:root 然后右键open in terminal 输入ifconfig 回车 查看ip地址
打开xshell
点击链接 如果有提示,则接受 输入用户名:root 输入密码:root 4.xshell连接虚拟机 打开虚拟机,通过ifconfig查看ip
5.安装jkd 1.解压Linux版本的JDK压缩包 mkdir:创建目录的命令 rm -rf 目录/文件删除目录命令 cd 目录进入指定目录 rz 可以上传本地文件到当前的linux目录中(也可以直接将安装包拖到xshell窗口) ls 可以查看当前目录中的所有文件 tar 解压压缩包(Tab键可以自动补齐文件名)
pwd 可以查看当前路径 文档编辑命令: vim 文件编辑命令 i:进入编辑状态 Esc(左上角):退出编辑状态 :wq 保存并退出 :q! 不保存退出 mkdir /home/software #按习惯用户自己安装的软件存放到/home/software目录下 cd /home/software #进入刚刚创建的目录 rz 上传jdk tar包 #利用xshell的rz命令上传文件(如果rz命令不能用,先执行yum install lrzsz -y ,需要联网) tar -xvf jdk-7u51-linux-x64.tar.gz #解压压缩包 2.配置环境变量 1)vim /etc/profile 2)在尾行添加 #set java environment JAVA_HOME=/home/software/jdk1.8.0_65 JAVA_BIN=/home/software/jdk1.8.0_65/bin PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH Esc 退出编辑状态 :wq #保存退出 注意JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安
Hadoop云计算平台实验报告V1.1
目录 1实验目标 (3) 2实验原理 (4) 2.1H ADOOP工作原理 (4) 2.2实验设计 (6) 2.2.1可扩展性 (6) 2.2.2稳定性 (7) 2.2.3可靠性 (7) 3实验过程 (9) 3.1实验环境 (9) 3.1.1安装Linux操作系统 (10) 3.1.2安装Java开发环境 (14) 3.1.3安装SSH (15) 3.1.4配置网络 (15) 3.1.5创建SSH密钥安全联机 (19) 3.1.6配置Hadoop云计算系统 (19) 3.1.7配置Slaves节点 (23) 3.1.8格式化Hadoop系统 (23) 3.1.9启动Hadoop集群 (23) 3.22.实验过程 (25) 3.2.1可扩展性 (25) 3.2.1.1动态扩展 (25) 3.2.1.2动态缩减 (27) 3.2.2稳定性 (28) 3.2.3可靠性 (31) 3.2.4MapReduce词频统计测试 (32) 4实验总结 (35)
1. 掌握Hadoop安装过程 2. 理解Hadoop工作原理 3. 测试Hadoop系统的可扩展性 4. 测试Hadoop系统的稳定性 5. 测试Hadoop系统的可靠性
2.1Hadoop工作原理 Hadoop是Apache开源组织的一个分布式计算框架,可以在大量廉价的硬件设备组成集群上运行应用程序,为应用程序提供一组稳定可靠的接口,旨在构建一个具有高可靠性和良好扩展性的分布式系统。Hadoop框架中最核心的设计就是:MapReduce和HDFS。MapReduce 的思想是由Google的一篇论文所提及而被广为流传的,简单的一句话解释MapReduce就是“任务的分解与结果的汇总”。HDFS是Hadoop分布式文件系统(Hadoop Distributed File System)的缩写,为分布式计算、存储提供了底层支持。 HDFS采用C/S架构,对外部客户机而言,HDFS就像一个传统的分级文件系统。可以对文件执行创建、删除、重命名或者移动等操作。HDFS中有三种角色:客户端、NameNode和DataNode。HDFS的结构示意图见图1。 NameNode是一个中心服务器,存放着文件的元数据信息,它负责管理文件系统的名字空间以及客户端对文件的访问。DataNode节点负责管理它所在节点上的存储。NameNode对外暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,文件被分成一个或多个数据块,这些块存储在一组DataNode上,HDFS通过块的划分降低了文件存储的粒度,通过多副本技术和数据校验技术提高了数据的高可靠性。NameNode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体DataNode节点的映射。DataNode负责存放数据块和处理文件系统客户端的读写请求。在NameNode的统一调度下进行数据块的创建、删除和复制。
学院 课程教学进度计划表(20 ~20 学年第二学期) 课程名称Hadoop大数据开发基础授课学时48 主讲(责任)教师 参与教学教师 授课班级/人数 专业(教研室) 填表时间 专业(教研室)主任 教务处编印 年月
一、课程教学目的 通过本课程的学习,使学生了解Hadoop集群的基本框架,Hadoop的基本理论,以及Hadoop的核心组件HDFS和MapReduce的原理和使用。为学生今后使用大数据技术挖掘、学习其他大数据技术奠定基础。同时,本课程将紧密结合实际,不仅通过大量的实践操作和练习提高学生的动手实践能力;而且会提供实际的案例,讲解实际项目的开发流程,通过案例讲解启发学生思维,并通过学生的实际操作来增强学生对于实际案例的思考以及实现,为学生毕业后能更快地适应工作环境创造条件。 二、教学方法及手段 本课程将采用理论与实践相结合的教学方法。在理论上,通过任务引入概念、原理和方法。在实践上,对于安装配置的内容,先有教师讲解与演练,再将安装教程发给学生,由学生自主完成;教学过程中的任务、实践操作、练习,可由教师提供简单思路,学生自主完成。 要求学生自己动手搭建Hadoop集群、分析实例,学习基本理论和方法,结合已有的知识,适当布置练习、实践题,组织一些讨论,充分调动学生的主观能动性,提高学生的动手实践能力,以达到本课程的教学目的。 三、课程考核方法 突出学生解决实际问题的能力,加强过程性考核。课程考核的成绩构成= 平时作业(20%)+ 课堂参与(10%)+ 期末考核(70%),期末考试建议采用开卷形式,试题应包括基本概念、基本理论、程序设计、综合应用等部分,题型可采用判断题、选择、简答、应用题等方式。
期末实践报告 题目:Linux集群、MapReduce和 CloudSim实践 成绩: 学号:161440119 姓名:罗滔 登录邮箱:750785185@https://www.doczj.com/doc/4b4883922.html, 任课老师:许娟 2016年11月12日 目录 实验一:AWS身份与访问管理(P2~P11)实验二:Amazon Relational Database Service(P11~P20) 实验三:Hadoop实验报告(P21~)
AWS 管理控制台 使用 qwikLABS 登录 AWS 管理控制台 6. 在 AWS 管理控制台中,单击【服务/Services】,然后单击【IAM 或身份与访问管理/ IAM or Identity & Access Management】。 7. 在 IAM 控制台的左侧面板中,单击【用户/Users】。
8. 找到“userone”,然后单击其名称以显示有关该用户的详细信息。在用户详细信息中,找到有关该用户的以下三方面的信息: a. 已向该用户分配了一个密码 b. 该用户不属于任何组 c. 目前没有任何策略与该用户关联(“附加到”该用户)
9. 现在,单击左侧导航窗格中的【组/Groups】。 本实验的 CloudFormation 模板还创建了三个组。在 IAM 控制台中的【用户/Users】仪表板中可以看到, 自动化 CloudFormation 脚本在创建这些组时为其提供了唯一的名称。这些唯一名称包含以下字符串: “EC2support” “EC2admin” “S3admin” 完整组名的格式如下所示: arn:aws:iam::596123517671:group/spl66/qlstack2--labinstance--47090--666286a4--f8c--EC2support--GA9LGREA 7X4S 从现在开始,我们在本实验中将使用上面这些简写名称来指代这些组。您可以在【组/Groups】仪表板中搜 索子字符串,以便为后续实验操作确定正确的组。 10. 单击“EC2support”对应的组名。其格式应与上面的类似。 11. 向下滚动至组详细信息页面中的【权限/Permissions】部分后,在【内联策略/Inline Policies】部分, 可以看到一个名称为“EC2supportpolicy”的策略与该组关联。 在策略中,您可以规定将允许或拒绝对特定 AWS 资源执行哪些操作。您可以使用自定义策略,或通过 选择 AWS 托管策略来使用一组预定义的权限。 12. 虽然我们不会更改此策略,但请单击【编辑策略/Edit Policy】,使其显示在一个窗口中,以便您进行查 看和滚动。 请留意 IAM 策略中语句的基本结构。“Action”部分指定了该服务内的 AWS 服务和功能。“Resource”部 分定义了该策略规则所涵盖的实体范围,而“Effect”部分则定义了所需结果。更多有关定义 IAM 策略的 信息,请访问“AWS Identity and Access Management:权限和策略”文档页面。
Hadoop平台搭建说明 1.Hadoop节点规划 本次安装规划使用三个节点,每个节点都使用centos系统。 三个节点的hostname分别规划为:centoshadoop1、centoshadoop2、centoshadoop3(此处为本教程参数,可根据实际环境情况修改) 三个节点的ip地址分别规划为:192.168.65.57、192.168.65.58、192.168.65.59(此处为本教程参数,根据实际环境情况修改) 2.平台搭建使用的软件 下载如下软件 操作系统安装包:Centos6.3_x64 Jdk安装包:jdk-6u37-linux-x64.bin Hadoop安装包:hadoop-1.1.2.tar.gz 3.安装centos操作系统 安装三个节点的操作系统,安装过程省略。 4.配置centoshadoop1节点 4.1.修改节点hostname [root@localhost ~]# vi /etc/sysconfig/network HOSTNAME=centoshadoop1 [root@localhost ~]# vi /etc/hosts …… 192.168.65.57 centoshadoop1 192.168.65.58 centoshadoop2 192.168.65.59 centoshadoop3 [root@localhost ~]#reboot
4.2.关闭iptables防火墙 [root@centoshadoop1~]#service iptables stop 注意每次操作系统重启后都要操作 4.3.建立无ssh密码登陆 生成签名文件 [root@centoshadoop1~]#cd /root [root@centoshadoop1~]#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa [root@centoshadoop1~]#cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys [root@centoshadoop1~]# 测试本地SSH无密码登录 [root@centoshadoop1~]#sshcentoshadoop1 4.4.安装jdk 上传jdk-6u37-linux-x64.bin到/root目录下 [root@centoshadoop1~]#chmod 777 jdk-6u37-linux-x64.bin [root@centoshadoop1~]#./jdk-6u37-linux-x64.bin [root@centoshadoop1~]#ll 查看生成jdk-6u37-linux-x64目录 4.5.安装hadoop软件 上传hadoop-1.1.2.tar.gz到/root目录下 [root@centoshadoop1~]#tar -zvxfhadoop-1.1.2.tar.gz [root@centoshadoop1~]#ll 查看生成hadoop-1.1.2目录 [root@centoshadoop1~]#vi/conf/core-site.xml
实验报告 课程名称虚拟化与云计算学院计算机学院 专业班级11级网络工程3班学号3211006414 姓名李彩燕 指导教师孙为军 2014 年12 月03日
EXSI 5.1.0安装 安装准备 安装VSPHERE HYPERVISOR SEVER(EXSI 5.1.0)需要准备: 无操作系统的机器(如有系统,安装过程中会格式化掉),需切换到光盘启动模式。BOIS中开启虚拟化设置(virtualization设置成enable) VMware vSphere Hypervisor 自启动盘 安装过程 1.安装VMware vSphere Hypervisor确保机器中无操作系统,并且设置BIOS到光盘启 动模式 2.插入光盘,引导进入安装界面。 3.选择需要安装在硬盘 4.选择keyboard 类型,默认US DEFAULT
5.设置ROOT的密码 6.安装完毕后,请注意弹出光盘。然后重启。 7.F2进入系统配置界面。
8.选择到Configure management network去配置网络。
9.配置完毕后,注意重启网络以使设置生效,点击restart management network,测 试网络设置是否正确,点test management network。至此,sever端安装完毕。配置 1.添加机器名:在DNS服务器上添加相关正反解析设置。 2.License设置:Vsphere client登陆后,清单→配置→已获许可的功能→编辑 输入license
3.时间与NTP服务设置:Vsphere client登陆后,清单→配置→时间配置→属性 钩选上NTP客户端 选项中,NTP设置设添加NTP服务器,然后在常规中开启NTP服务
1.Hadoop集群可以运行的3个模式分别是什么, 都有哪些注意点? ?单机(本地)模式:这种模式在一台单机上运行,没有分布式文件系统,而是直接读写本地操作系统的文件系统。在单机模式(standalone)中不会存在守护进程,所有东西都运行在一个JVM上。这里同样没有DFS,使用的是本地文件系统。单机模式适用于开发过程中运行MapReduce程序,这也是最少使用的一个模式。 ?伪分布式模式:也是在一台单机上运行,但用不同的Java进程模仿分布式运行中的各类结点 (NameNode,DataNode,JobTracker,TaskTracker,SecondaryNameNode),伪分布式(Pseudo)适用于开发和测试环境,在这个模式中,所有守护进程都在同一台机器上运行。 ?全分布式模式:全分布模式通常被用于生产环境,使用N台主机组成一个Hadoop集群,Hadoop守护进程运行在每台主机之上。这里会存在Namenode 运行的主机,Datanode运行的主机,以及task tracker运行的主机。 在分布式环境下,主节点和从节点会分开。 2. VM是否可以称为Pseudo? 不是,两个事物,同时Pseudo只针对Hadoop。 3. 当Job Tracker宕掉时,Namenode会发生什么? 当Job Tracker失败时,集群仍然可以正常工作,只要Namenode没问题。 4. 是客户端还是Namenode决定输入的分片? 这并不是客户端决定的,在配置文件中以及决定分片细则。 5. 是否可以在Windows上运行Hadoop? 可以,但是最好不要这么做,Red Hat Linux或者是Ubuntu才是Hadoop的最佳操作系统。 6. Hadoop是否遵循UNIX模式? 是的,在UNIX用例下,Hadoop还拥有“conf”目录。 7. Hadoop安装在什么目录下? Cloudera和Apache使用相同的目录结构,Hadoop被安装在 cd/usr/lib/hadoop-0.20/。 8. Namenode、Job tracker和task tracker的端口号是? Namenode,70;Job tracker,30;Task tracker,60。
云计算实验报告Hadoop 云计算实验报告Hadoop 实验目的1在虚拟机上安装单机模式和集群;Ubuntu Hadoop编写一个用处理数据的程序,在单机和集群上运行程序。Hadoop 实验环境2虚拟机:9VMware(桌面(服务器版),操作系统: -desktop--server-x64amd64ubuntu-14.10ubuntu-12.04 版)版本: 1.2.1hadoop Hadoop版本: x647u80-linuxJdk -jdk-版本:x86_64-gtk-jee-luna-SR2-linuxEclipse eclipse-,主机集群:一台主机,一台mastersalve datanodeHadoop namenode 。,主机为主机为master IP IP 10.5.110.22310.5.110.207slave 实验设计说明3 主要设计思路 3.1 eclipse编写程序代码。实现在ubuntu操作系统下,安装必要软件和环境搭建,使用大数据的统计。本次实验是统计软件代理系统操作人员处理的信息量,即每个操作人员出现的次数。程序设计完成后,在集成环境下运行该程序并查看结果。算法设计 3.2 程序将输入读入后该算法首先将输入文件都包含进来,然后交由map程序处理,map处理,切出其中的用户名,并标记它的数目为1,形成
ubuntu 下安装配置hadoop 1.0.4 第一次搞hadoop,折腾我2天,功夫不负有心人,终于搞好了,现在来分享下, 我的环境 操作系统:wmv虚拟机中的ubuntu12.04 hadoop版本:hadoop-1.0.4(听说是稳定版就下了) eclipse版本:eclipse-jee-indigo-SR2-win32 1.先安装好jdk,然后配置好jdk的环境变量,在这里我就不累赘了!网上多的是 2.安装ssh这个也不用说了 2.把hadoop-1.0.4.tar.gz拖到虚拟机中,解压,比如: /home/wys/Documents/hadoop-1.0.4/ (有的还单独建了个用户,为了舍去不必要的麻烦我都是用root用户来操作的) 3.修改hadoop-1.0.4/conf 下面的core-site.xml文件,如下:
192.168.116.128这个是虚拟机中ubuntu的ip,听说用localhost,127.0.0.1都不行,我没试过,直接写上ip地址了 tmp是预先创建的一个目录 4.修改hadoop-env.sh 把export JAVA_HOME=xxxxxx 这行的#号去掉,写上jdk的目录路径 5.修改hdfs-site.xml如下:
大数据技术概论实验报告 作 业 三 姓名:郭利强 专业:工程管理专业 学号: 2015E8009064028
目录 1.实验要求 (3) 2.环境说明 (4) 2.1系统硬件 (4) 2.2系统软件 (4) 2.3集群配置 (4) 3.实验设计 (4) 3.1第一部分设计 (4) 3.2第二部分设计 (6) 4.程序代码 (11) 4.1第一部分代码 (11) 4.2第二部分代码 (17) 5.实验输入和结果 (21) 实验输入输出结果见压缩包中对应目录 (21)
1.实验要求 第一部分:采用辅助排序的设计方法,对于输入的N个IP网络流量文件,计算得到文件中的各个源IP地址连接的不同目的IP地址个数,即对各个源IP地址连接的目的IP地址去重并计数 举例如下: 第二部分:输入N个文件,生成带详细信息的倒排索引 举例如下,有4个输入文件: – d1.txt: cat dog cat fox – d2.txt: cat bear cat cat fox – d3.txt: fox wolf dog – d4.txt: wolf hen rabbit cat sheep 要求建立如下格式的倒排索引: – cat —>3: 4: {(d1.txt,2,4),(d2.txt,3,5),(d4.txt,1,5)}–单词—>出现该单词的文件个数:总文件个数: {(出现该单词的文件名,单词在该文件中的出现次数,该文件的总单词数),……}
2.环境说明 2.1系统硬件 处理器:Intel Core i3-2350M CPU@2.3GHz×4 内存:2GB 磁盘:60GB 2.2系统软件 操作系统:Ubuntu 14.04 LTS 操作系统类型:32位 Java版本:1.7.0_85 Eclipse版本:3.8 Hadoop插件:hadoop-eclipse-plugin-2.6.0.jar Hadoop:2.6.1 2.3集群配置 集群配置为伪分布模式,节点数量一个 3.实验设计 3.1第一部分设计
https://www.doczj.com/doc/4b4883922.html, Hadoop入门-WordCount示例_光环大数据培训 光环大数据培训,WordCount的过程如图,这里记录下入门的过程,虽然有很多地方理解的只是皮毛。 hadoop的安装 安装比较简单,安装完成后进行单机环境的配置。 hadoop-env.sh:指定JAVA_HOME。 # The only required environment variable is JAVA_HOME. All others are# optional. When running a distributed configuration it is best to# set JAVA_HOME in this file, so that it is correctly defined on# remote nodes.# The java implementation to use.export JAVA_HOME="$(/usr/libexec/java_home)" core-site.xml:设置Hadoop使用的临时目录,NameNode的地址。
1、VMware 安装 我们使用Vmware 14的版本,傻瓜式安装即可。(只要) 双击如过 2.安装xshell 双击 3.安装镜像: 解压centos6.5-empty 解压双击打开 CentOS6.5.vmx 如果打不开,在cmd 窗口中输入:netsh winsock reset 然后重启电脑。
进入登录界面,点击other 用户名:root 密码:root 然后右键open in terminal 输入ifconfig回车 查看ip地址 xshell 打开
点击链接 如果有提示,则接受
输入用户名:root 输入密码:root 4.xshell 连接虚拟机 打开虚拟机,通过ifconfig 查看 ip 5.安装jkd
1. 解压Linux版本的JDK压缩包 mkdir:创建目录的命令 rm -rf 目录/文件删除目录命令 cd 目录进入指定目录 rz可以上传本地文件到当前的linux目录中(也可以直接将安装包拖到xshell窗口) ls可以查看当前目录中的所有文件 tar解压压缩包(Tab键可以自动补齐文件名) pwd可以查看当前路径 文档编辑命令: vim文件编辑命令 i:进入编辑状态 Esc(左上角):退出编辑状态 :wq保存并退出 :q!不保存退出 mkdir /home/software#按习惯用户自己安装的软件存放到 /home/software目录下 cd /home/software #进入刚刚创建的目录
rz 上传jdk tar包#利用xshell的rz命令上传文件(如果rz 命令不能用,先执行yum install lrzsz -y ,需要联网) tar -xvf jdk-7u51-linux-x64.tar.gz#解压压缩包 2. 配置环境变量 1)vim /etc/profile 2)在尾行添加 #set java environment JAVA_HOME=/home/software/jdk1.8.0_65 JAVA_BIN=/home/software/jdk1.8.0_65/bin PATH=$JAVA_HOME/bin:$PATH CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export JAVA_HOME JAVA_BIN PATH CLASSPATH Esc退出编辑状态 :wq#保存退出 注意JAVA_HOME要和自己系统中的jdk目录保持一致,如果是使用的rpm包安 装的jdk,安装完之后jdk的根目录为:/usr/java/jdk1.8.0_111,也可 以通过命令:rpm -qal|grep jdk 来查看目录 3)source /etc/profile使更改的配置立即生效 4)java -version查看JDK版本信息。如显示版本号则证明成功。