附录
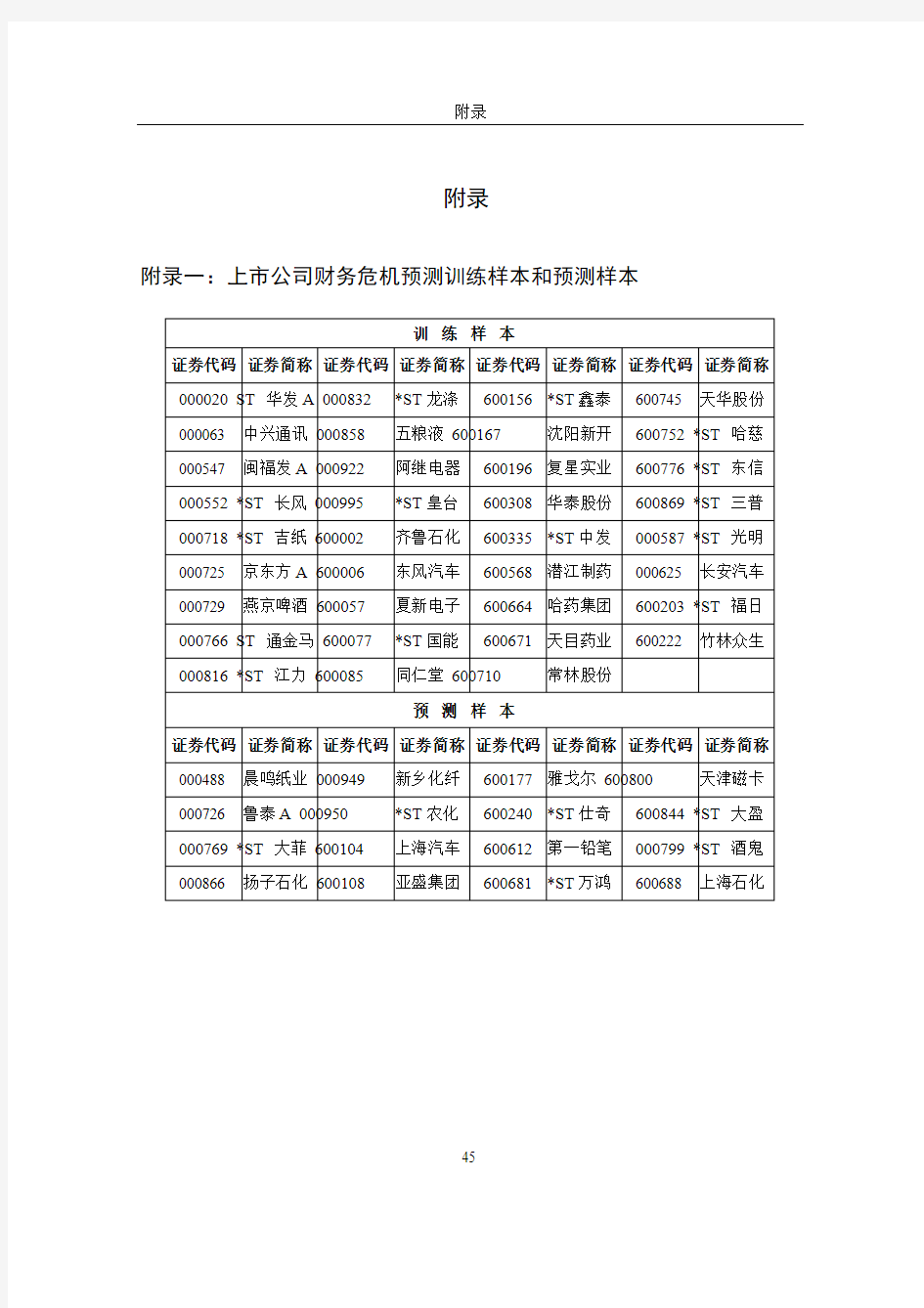
附录一:上市公司财务危机预测训练样本和预测样本
训练样本
证券代码证券简称证券代码证券简称证券代码证券简称证券代码证券简称000020 ST华发A 000832 *ST龙涤600156*ST鑫泰600745 天华股份000063 中兴通讯 000858 五粮液 600167沈阳新开600752 *ST哈慈000547 闽福发A 000922 阿继电器600196复星实业600776 *ST东信000552 *ST长风 000995 *ST皇台600308华泰股份600869 *ST三普000718 *ST吉纸 600002 齐鲁石化600335*ST中发000587 *ST光明000725 京东方A 600006 东风汽车600568潜江制药000625 长安汽车000729 燕京啤酒 600057 夏新电子600664哈药集团600203 *ST福日000766 ST通金马 600077 *ST国能600671天目药业600222 竹林众生000816 *ST江力 600085 同仁堂 600710常林股份
预测样本
证券代码证券简称证券代码证券简称证券代码证券简称证券代码证券简称
天津磁卡000488 晨鸣纸业 000949 新乡化纤600177雅戈尔 600800
*ST农化600240*ST仕奇600844 *ST大盈000726 鲁泰A 000950
000769 *ST大菲 600104 上海汽车600612第一铅笔000799 *ST酒鬼000866 扬子石化 600108 亚盛集团600681*ST万鸿600688 上海石化
45
46
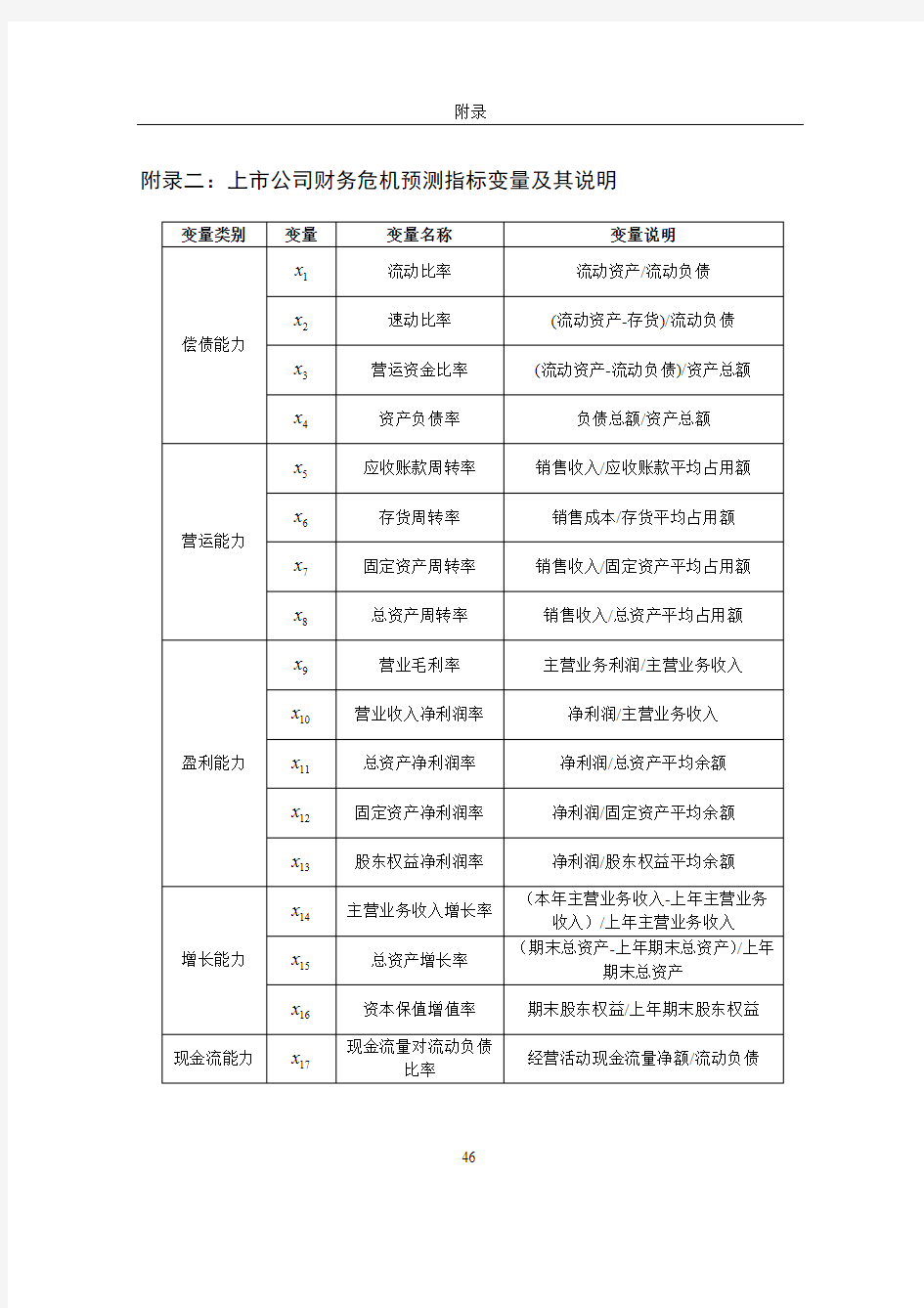
附录二:上市公司财务危机预测指标变量及其说明
变量类别
变量
变量名称 变量说明 1x 流动比率 流动资产/流动负债 2x
速动比率 (流动资产-存货)/流动负债 3x 营运资金比率 (流动资产-流动负债)/资产总额
偿债能力
4x 资产负债率 负债总额/资产总额 5x 应收账款周转率 销售收入/应收账款平均占用额 6x
存货周转率 销售成本/存货平均占用额 7x 固定资产周转率 销售收入/固定资产平均占用额 营运能力
8x 总资产周转率 销售收入/总资产平均占用额 9x 营业毛利率 主营业务利润/主营业务收入
10x
营业收入净利润率 净利润/主营业务收入 11x 总资产净利润率 净利润/总资产平均余额 12x 固定资产净利润率 净利润/固定资产平均余额 盈利能力
13x 股东权益净利润率 净利润/股东权益平均余额 14x
主营业务收入增长率
(本年主营业务收入-上年主营业务
收入)/上年主营业务收入 15x 总资产增长率 (期末总资产-上年期末总资产)/上年
期末总资产 增长能力
16x
资本保值增值率 期末股东权益/上年期末股东权益 现金流能力 17x
现金流量对流动负债
比率
经营活动现金流量净额/流动负债
附录三:GMDH上市公司财务危机预测模型
y = + 5.176e-1z82 - 6.202e-2z81z82 - 4.896e-2 z82 z82 + 4.286e-1
z81= + 1.000e+0z71
z71= + 1.000e+0z61
z61= + 1.000e+0z51
z51= + 1.000e+0z41
z41= + 1.000e+0z31
z31= + 1.000e+0z21
z21= + 1.000e+0z11
z11= + 2.003e+0x12 - 1.301e-1
z82= - 5.597e-1z71 + 1.427e+0z72
z71= + 1.000e+0z61
z61= + 1.000e+0z51
z51= + 1.000e+0z41
z41= + 1.000e+0z31
z31= + 1.000e+0z21
z21= + 1.000e+0z11
z11= - 1.415e+1x13 + 1.879e+1x4x13 + 1.187e-1 z72= - 2.086e-1z61 + 1.087e+0z62
z61= + 1.000e+0z51
z51= + 1.000e+0z41
z41= + 1.000e+0z31
z31= + 1.000e+0z21
z21= + 1.000e+0z11
z11= + 6.947e+0x4 - 3.132e+0
z62= + 1.089e+0z52 + 3.027e-1z51z52 + 1.496e-1z51z51
z51= + 1.000e+0z41
z41= + 1.000e+0z31
z31= + 1.000e+0z21
z21= + 1.000e+0z11
47
z11= + 5.433e+0x9 - 1.354e+0
z52= + 1.024e+0z42 + 2.607e-2z41z41
z41= + 1.000e+0z31
z31= + 1.000e+0z21
z21= + 1.000e+0z11
z11= + 2.535e-1x7 - 7.726e-1
z42= + 1.035e+0z32 - 9.078e-2z31z31
z31= + 1.000e+0z21
z21= + 1.000e+0z11
z11= - 1.375e+1x11 + 2.331e+0x16 - 2.266e+0
z32= - 2.078e-1z21 + 9.378e-1z22 - 5.539e-1z21z22
z21= + 1.000e+0z11
z11= + 7.308e-1x2 - 9.190e-1
z22= + 1.004e+0z12+ 5.754e-2z11z11
z11= + 2.460e-1x6- 9.018e-1
z12= - 7.657e+0x11 - 1.345e+0x17 + 1.054e+1x11x17
+ 8.950e-2
注:模型含有10个输入变量:x2、x4、x6、x7、x9、x11、x12、x13、x16、x17,各变量具体说明参看附录二。
48
攻读硕士学位期间取得的研究成果
攻读硕士学位期间取得的研究成果
[1] 黄敏, 田益祥. VAR模型的GMDH估计方法及实证研究.中国企业运筹学, 已
录用
[2] Yixiang Tian, Min Huang. The Study of Security Combinational Investment
Prospective Proceeds Model of Two-Level Algorithm of GMDHAR. Lecture
Notes in Decision Sciences, Financial Systems Engineering Ⅱ. Hong Kong:
Global-Link Publisher, 2005, 5: 118-133
[3] Li Zhou, Yixiang Tian, Min Huang. Models of Searching Structural Changes via
GMDH and its application in event studies. Lecture Notes in Decision Sciences, Financial Systems Engineering Ⅲ, Hong Kong: Global-Link Publisher, 2006, 7: 282-290
49
—178 — 基于数据挖掘的符号序列聚类相似度量模型 郑宏珍,初佃辉,战德臣,徐晓飞 (哈尔滨工业大学智能计算中心,264209) 摘 要:为了从消费者偏好序列中发现市场细分结构,采用数据挖掘领域中的符号序列聚类方法,提出一种符号序列聚类的研究方法和框架,给出RSM 相似性度量模型。调整RSM 模型参数,使得RSM 可以变为与编辑距离、海明距离等价的相似性度量。通过RSM 与其他序列相似性度量的比较,表明RSM 具有更强的表达相似性概念的能力。由于RSM 能够表达不同的相似性概念,从而使之能适用于不同的应用环境,并在其基础上提出自组织特征映射退火符号聚类模型,使得从消费者偏好进行市场细分结构研究的研究途径在实际应用中得以实现。 关键词:符号序列聚类;数据挖掘;相似性模型 Symbolic Sequence Clustering Regular Similarity Model Based on Data Mining ZHENG Hong-zhen, CHU Dian-hui, ZHAN De-chen, XU Xiao-fei (Intelligent Computing Center, Harbin Institute of Technology, Harbin 264209) 【Abstract 】From a consumer point of the sequence of preference, data mining is used in the field of symbolic sequence clustering methods to detect market segmentation structure. This paper proposes a symbolic sequence clustering methodology and framework, gives the similarity metric RSM model. By adjusting RSM model, parameters can be changed into RSM and edit distance, Hamming distance equivalent to the similarity metric. RSM is compared with other sequence similarity metric, and is more similar to the expression of the concept of capacity. As to express different similarity, the concept of RSM can be applied to different applications environment. Based on the SOM annealing symbol clustering model, the consumer preference for market segmentation can be studied in the structure, which means it is realized in practical application. 【Key words 】symbolic sequence clustering; data mining; similarity model 计 算 机 工 程Computer Engineering 第35卷 第1期 V ol.35 No.1 2009年1月 January 2009 ·人工智能及识别技术·文章编号:1000—3428(2009)01—0178—02文献标识码:A 中图分类号:TP391 1 概述 在经济全球化的环境下,面对瞬息万变的市场和技术发展,企业要想在国内外市场竞争中立于不败之地,必须对客户和市场需求做出快速响应。目前,通过市场调研公司或企业自身的信息系统,收集来自市场和消费者的数据相对容易,而如何理解数据反映的市场细分结构和需求规律却是相当困难的。 为解决这一问题,许多研究者选择消费者的职业、收入、年龄、性别等特征数据作为细分变量,利用统计学传统聚类方法得到市场细分结构[1-2]。在实际应用中,不同的细分变量会导致不同的市场细分结果[3]。 为此,本文从用户偏好序列数据对市场进行细分。通过对符号序列数据相似性的研究,给出一个可形式化的RSM 相似性度量模型和算法概要。该度量模型考虑了2对象之间相似与相异2个方面的因素,通过参数的调整,可以根据问题的具体性质表达不同的相似性概念。并在此基础上,将在数值型数据领域表现良好的SOM 神经网络引入到符号序列数据的聚类问题上,给特征符号序列的机器自动识别提供了可能性。 2 符号序列聚类问题 序列聚类问题作为发现知识的一种重要的探索性技术,受到数据挖掘与知识发现研究领域的极大重视。企业决策者在进行市场和产品相关战略时,迫切需要某些技术手段来理解序列数据,这也正是本文研究的序列聚类问题的工程背景。 下面给出符号序列的相关定义。 定义1 设12{,,,}n A a a a ="为有限符号表,A 中的l 个符号12,,,l a a a "构成的有序集称为符号序列,记为s = 12{,,,}l a a a ",并称l 是s 的长度,记为s 。A 上所有有限长 度符号序列集合记为A *。例如:符号表{a , b , c , d , e , f , g },则
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2.时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
资源Github,kaggle Python工具库:Numpy,Pandas,Matplotlib,Scikit-Learn,tensorflow Numpy支持大量维度数组与矩阵运算,也针对数组提供大量的数学函数库 Numpy : 1.aaa = Numpy.genfromtxt(“文件路径”,delimiter = “,”,dtype = str)delimiter以指定字符分割,dtype 指定类型该函数能读取文件所以内容 aaa.dtype 返回aaa的类型 2.aaa = numpy.array([5,6,7,8]) 创建一个一维数组里面的东西都是同一个类型的 bbb = numpy.array([[1,2,3,4,5],[6,7,8,9,0],[11,22,33,44,55]]) 创建一个二维数组aaa.shape 返回数组的维度print(bbb[:,2]) 输出第二列 3.bbb = aaa.astype(int) 类型转换 4.aaa.min() 返回最小值 5.常见函数 aaa = numpy.arange(20) bbb = aaa.reshape(4,5)
numpy.arange(20) 生成0到19 aaa.reshape(4,5) 把数组转换成矩阵aaa.reshape(4,-1)自动计算列用-1 aaa.ravel()把矩阵转化成数组 bbb.ndim 返回bbb的维度 bbb.size 返回里面有多少元素 aaa = numpy.zeros((5,5)) 初始化一个全为0 的矩阵需要传进一个元组的格式默认是float aaa = numpy.ones((3,3,3),dtype = numpy.int) 需要指定dtype 为numpy.int aaa = np 随机函数aaa = numpy.random.random((3,3)) 生成三行三列 linspace 等差数列创建函数linspace(起始值,终止值,数量) 矩阵乘法: aaa = numpy.array([[1,2],[3,4]]) bbb = numpy.array([[5,6],[7,8]]) print(aaa*bbb) *是对应位置相乘 print(aaa.dot(bbb)) .dot是矩阵乘法行乘以列 print(numpy.dot(aaa,bbb)) 同上 6.矩阵常见操作
《海量数据挖掘技术及工程实践》题目 一、单选题(共80题) 1)( D )的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到 和原始数据相同的分析结果。 A.数据清洗 B.数据集成 C.数据变换 D.数据归约 2)某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3)以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4)将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 5)当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数 据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6)建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7)下面哪种不属于数据预处理的方法? (D) A.变量代换 B.离散化
C.聚集 D.估计遗漏值 8)假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A.第一个 B.第二个 C.第三个 D.第四个 9)下面哪个不属于数据的属性类型:(D) A.标称 B.序数 C.区间 D.相异 10)只有非零值才重要的二元属性被称作:( C ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 11)以下哪种方法不属于特征选择的标准方法: (D) A.嵌入 B.过滤 C.包装 D.抽样 12)下面不属于创建新属性的相关方法的是: (B) A.特征提取 B.特征修改 C.映射数据到新的空间 D.特征构造 13)下面哪个属于映射数据到新的空间的方法? (A) A.傅立叶变换 B.特征加权 C.渐进抽样 D.维归约 14)假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方 法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A.0.821 B.1.224 C.1.458 D.0.716 15)一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年 级110人。则年级属性的众数是: (A) A.一年级 B.二年级 C.三年级 D.四年级
一、解答题(满分30分,每小题5分) 1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之 首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。 知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。 2. 时间序列数据挖掘的方法有哪些,请详细阐述之 时间序列数据挖掘的方法有: 1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。 2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。 3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
《数据挖掘论文》 数据挖掘分类方法及其应用 课程名称:数据挖掘概念与技术姓名 学号: 指导教师:
数据挖掘分类方法及其应用 作者:来煜 摘要:社会的发展进入了网络信息时代,各种形式的数据海量产生,在这些数据的背后隐藏这许多重要的信息,如何从这些数据中找出某种规律,发现有用信息,越来越受到关注。为了适应信息处理新需求和社会发展各方面的迫切需要而发展起来一种新的信息分析技术,这种局势称为数据挖掘。分类技术是数据挖掘中应用领域极其广泛的重要技术之一。各种分类算法有其自身的优劣,适合于不同的领域。目前随着新技术和新领域的不断出现,对分类方法提出了新的要求。 。 关键字:数据挖掘;分类方法;数据分析 引言 数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥
有知识的有局限性,所以对于获得知识的可信度就应该打个折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。 数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行科学研究、商业决策或者企业管理,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是为了解决传统分析方法的不足,并针对大规模数据的分析处理而出现的。数据挖掘通过在大量数据的基础上对各种学习算法的训练,得到数据对象间的关系模式,这些模式反映了数据的内在特性,是对数据包含信息的更高层次的抽象。目前,在需要处理大数据量的科研领域中,数据挖掘受到越来越多的关注,同时,在实际问题中,大量成功运用数据挖掘的实例说明了数据挖掘对科学研究具有很大的促进作用。数据挖掘可以帮助人们对大规模数据进行高效的分析处理,以节约时间,将更多的精力投入到更高层的研究中,从而提高科研工作的效率。 分类技术是数据挖掘中应用领域极其广泛的重要技术之一。至今已提出了多种分类算法,主要有决策树、关联规则、神经网络、支持向量机和贝叶斯、k-临近法、遗传算法、粗糙集以及模糊逻辑技术等。大部分技术都是使用学习算法确定分类模型,拟合输入数据中样本类别和属性集之间的联系,预测未知样本的类别。训练算法的主要目标是建立具有好的泛化能力的模型,该模型能够准确地预测未知样本的类别。 1.数据挖掘概述 数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。 数据挖掘是通过分析每个数据,从大量数据中寻找其规律的技术,主要有数据
单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 2. 以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision, Recall B. Recall, Precision A. Precision, ROC D. Recall, ROC 3. 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 4. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 5. 什么是KDD? (A) A. 数据挖掘与知识发现 B. 领域知识发现 C. 文档知识发现 D. 动态知识发现 6. 使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?(A) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7. 为数据的总体分布建模;把多维空间划分成组等问题属于数据挖掘的哪一类任务?(B) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 8. 建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 9. 用户有一种感兴趣的模式并且希望在数据集中找到相似的模式,属于数据挖掘哪一类任务?(A) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 11.下面哪种不属于数据预处理的方法? (D) A变量代换 B离散化 C 聚集 D 估计遗漏值 12. 假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A 第一个 B 第二个 C 第三个 D 第四个 13.上题中,等宽划分时(宽度为50),15又在哪个箱子里? (A) A 第一个 B 第二个 C 第三个 D 第四个 14.下面哪个不属于数据的属性类型:(D) A 标称 B 序数 C 区间 D相异 15. 在上题中,属于定量的属性类型是:(C) A 标称 B 序数 C区间 D 相异 16. 只有非零值才重要的二元属性被称作:( C )
龙源期刊网 https://www.doczj.com/doc/533102520.html, 浅谈大数据时代的数据分析与挖掘 作者:单海波 来源:《科技创新与应用》2016年第24期 摘要:随着改革开放的进一步深化,以及经济全球化的快速发展,我国各行各业都有了 质的飞跃,发展方向更加全面。特别是近年来科学技术的发展和普及,更是促进了各领域的不断发展,各学科均出现了科技交融。在这种社会背景下,数据形式和规模不断向着更加快速、精准的方向发展,促使经济社会发生了翻天覆地的变化,同时也意味着大数据时代即将来临。就目前而言,数据已经改变传统的结构模式,在时代的发展推动下积极向着结构化、半结构化,以及非结构化的数据模式方向转换,改变了以往的只是单一地作为简单的工具的现象,逐渐发展成为具有基础性质的资源。文章主要针对大数据时代下的数据分析与挖掘进行了分析和讨论,并论述了建设数据分析与挖掘体系的原则,希望可以为从事数据挖掘技术的分析人员提供一定的帮助和理论启示,仅供参考。 关键词:大数据;数据分析;数据挖掘;体系建设 引言 进入21世纪以来,随着高新科技的迅猛发展和经济全球化发展的趋势,我国国民经济迅速增长,各行业、领域的发展也颇为迅猛,人们生活水平与日俱增,在物质生活得到极大满足的前提下,更加追求精神层面以及视觉上的享受,这就涉及到数据信息方面的内容。在经济全球化、科技一体化、文化多元化的时代,数据信息的作用和地位是不可小觑的,处理和归类数据信息是达到信息传递的基础条件,是发展各学科科技交融的前提。 然而,世界上的一切事物都包含着两个方面,这两个方面既相互对立,又相互统一。矛盾即对立统一。矛盾具有斗争性和同一性两种基本属性,我们必须用一分为二的观点、全面的观点看问题。同时要积极创造条件,促进矛盾双方的相互转变。数据信息在带给人们生产生活极大便利的同时,还会被诸多社会数据信息所困扰。为了使广大人民群众的日常生活更加便捷,需要其客观、正确地使用、处理数据信息,完善和健全数据分析技术和数据挖掘手段,通过各种切实可行的数据分析方法科学合理地分析大数据时代下的数据,做好数据挖掘技术工作。 1 实施数据分析的方法 在经济社会快速发展的背景下,我国在科学信息技术领域取得长足进步。科技信息的发展在极大程度上促进了各行各业的繁荣发展和长久进步,使其发展更加全面化、科学化、专业化,切实提升了我国经济的迅猛发展,从而形成了一个最佳的良性循环,我国也由此进入了大数据时代。对于大数据时代而言,数据分析环节是必不可少的组成部分,只有科学准确地对信息量极大的数据进行处理、筛选,才能使其更好地服务于社会,服务于广大人民群众。正确处理数据进行分析过程是大数据时代下数据分析的至关重要的环节。众所周知,大数据具有明显
数据分析的特征选择实例分析 1.数据挖掘与聚类分析概述 数据挖掘一般由以下几个步骤: (l)分析问题:源数据数据库必须经过评估确认其是否符合数据挖掘标准。以决定预期结果,也就选择了这项工作的最优算法。 (2)提取、清洗和校验数据:提取的数据放在一个结构上与数据模型兼容的数据库中。以统一的格式清洗那些不一致、不兼容的数据。一旦提取和清理数据后,浏览所创建的模型,以确保所有的数据都已经存在并且完整。 (3)创建和调试模型:将算法应用于模型后产生一个结构。浏览所产生的结构中数据,确认它对于源数据中“事实”的准确代表性,这是很重要的一点。虽然可能无法对每一个细节做到这一点,但是通过查看生成的模型,就可能发现重要的特征。 (4)查询数据挖掘模型的数据:一旦建立模型,该数据就可用于决策支持了。 (5)维护数据挖掘模型:数据模型建立好后,初始数据的特征,如有效性,可能发生改变。一些信息的改变会对精度产生很大的影响,因为它的变化影响作为基础的原始模型的性质。因而,维护数据挖掘模型是非常重要的环节。 聚类分析是数据挖掘采用的核心技术,成为该研究领域中一个非常活跃的研究课题。聚类分析基于”物以类聚”的朴素思想,根据事物的特征,对其进行聚类或分类。作为数据挖掘的一个重要研究方向,聚类分析越来越得到人们的关注。聚类的输入是一组没有类别标注的数据,事先可以知道这些数据聚成几簇爪也可以不知道聚成几簇。通过分析这些数据,根据一定的聚类准则,合理划分记录集合,从而使相似的记录被划分到同一个簇中,不相似的数据划分到不同的簇中。 2.特征选择与聚类分析算法 Relief为一系列算法,它包括最早提出的Relief以及后来拓展的Relief和ReliefF,其中ReliefF算法是针对目标属性为连续值的回归问题提出的,下面仅介绍一下针对分类问题的Relief和ReliefF算法。 2.1 Relief算法 Relief算法最早由Kira提出,最初局限于两类数据的分类问题。Relief算法是一种特征权重算法(Feature weighting algorithms),根据各个特征和类别的相关性赋予特征不同的权重,权重小于某个阈值的特征将被移除。Relief算法中特征和类别的相关性是基于特征对近距离样本的区分能力。算法从训练集D中随机选择一个样本R,然后从和R同类的样本中寻找最近邻样本H,称为Near Hit,从和R不同类的样本中寻找最近邻样本M,称为NearMiss,然后根据以下规则更新每个特征的权重:如果R和Near Hit在某个特征上的距离小于R和Near Miss 上的距离,则说明该特征对区分同类和不同类的最近邻是有益的,则增加该特征的权重;反之,如果R和Near Hit 在某个特征的距离大于R和Near Miss上的距离,说明该特征对区分同类和不同类的最近邻起负面作用,则降低该特征的权重。以上过程重复m次,最后得到各特征的平均权重。特征的权重越大,表示该特征的分类能力越强,反之,表示该特征分类能力越弱。Relief算法的运行时间随着样本的抽样次数m和原始特征个数N的增加线性增加,因而运行效率非常高。具体算法如下所示:
数据挖掘及其应用 Revised by Jack on December 14,2020
《数据挖掘论文》 数据挖掘分类方法及其应用 课程名称:数据挖掘概念与技术 姓名 学号: 指导教师: 数据挖掘分类方法及其应用 作者:来煜 摘要:社会的发展进入了网络信息时代,各种形式的数据海量产生,在这些数据的背后隐藏这许多重要的信息,如何从这些数据中找出某种规律,发现有用信息,越来越受到关注。为了适应信息处理新需求和社会发展各方面的迫切需要而发展起来一种新的信息分析技术,这种局势称为数据挖掘。分类技术是数据挖掘中应用领域极其广泛的重要技术之一。各种分类算法有其自身的优劣,适合于不同的领域。目前随着新技术和新领域的不断出现,对分类方法提出了新的要求。 。 关键字:数据挖掘;分类方法;数据分析 引言 数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我
们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥有知识的有局限性,所以对于获得知识的可信度就应该打个折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。 数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行科学研究、商业决策或者企业管理,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是为了解决传统分析方法的不足,并针对大规模数据的分析处理而出现的。数据挖掘通过在大量数据的基础上对各种学习算法的训练,得到数据对象间的关系模式,这些模式反映了数据的内在特性,是对数据包含信息的更高层次的抽象。目前,在需要处理大数据量的科研领域中,数据挖掘受到越来越多的关注,同时,在实际问题中,大量成功运用数据挖掘的实例说明了数据挖掘对科学研究具有很大的促进作用。数据挖掘可以帮助人们对大规模数据进行高效的分析处理,以节约时间,将更多的精力投入到更高层的研究中,从而提高科研工作的效率。 分类技术是数据挖掘中应用领域极其广泛的重要技术之一。至今已提出了多种分类算法,主要有决策树、关联规则、神经网络、支持向量机和贝叶斯、k-临近法、遗传算法、粗糙集以及模糊逻辑技术等。大部分技术都是使用学习算法确定分类模型,拟合输入数据中样本类别和属性集之间的联系,预测未知样本的类别。训练算法的主要目标是建立具有好的泛化能力的模型,该模型能够准确地预测未知样本的类别。 1.数据挖掘概述 数据挖掘又称库中的知识发现,是目前人工智能和领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平
(一)概述 为什么要数据挖掘(Data Mining)? 存在可以广泛使用的大量数据,并且迫切需要将数据转转换成有用的信息和知识 什么是数据挖掘? 数据挖掘(Data Mining)是指从大量数据中提取或“挖掘”知识。 对何种数据进行数据挖掘? 关系数据库、数据仓库、事务数据库 空间数据 超文本和多媒体数据 时间序列数据 流数据 (二)数据预处理 为什么要预处理数据? 为数据挖掘过程提供干净、准确、简洁的数据,提高数据挖掘的效率和准确性,是数据挖掘中非常重要的环节; 数据库和数据仓库中的原始数据可能存在以下问题: 定性数据需要数字化表示 不完整 含噪声 度量单位不同 维度高 数据的描述 度量数据的中心趋势:均值、加权均值、中位数、众数 度量数据的离散程度:全距、四分位数、方差、标准差 基本描述数据汇总的图形显示:直方图、散点图 度量数据的中心趋势 集中趋势:一组数据向其中心值靠拢的倾向和程度。 集中趋势测度:寻找数据水平的代表值或中心值。 常用的集中趋势的测度指标: 均值: 缺点:易受极端值的影响 中位数:对于不对称的数据,数据中心的一个较好度量是中位数 特点:对一组数据是唯一的。不受极端值的影响。 众数:一组数据中出现次数最多的变量值。 特点:不受极端值的影响。有的数据无众数或有多个众数。
度量数据的离散程度 反映各变量值远离其中心值的程度(离散程度),从另一个侧面说明了集中趋势测度值的代表程度。 常用指标: 全距(极差):全距也称极差,是一组数据的最大值与最小值之差。 R=最大值-最小值 组距分组数据可根据最高组上限-最低组下限计算。 受极端值的影响。 四分位距 (Inter-Quartilenge, IQR):等于上四分位数与下四分位数之差(q3-q1) 反映了中间50%数据的离散程度,数值越小说明中间的数据越集中。 不受极端值的影响。 可以用于衡量中位数的代表性。 四分位数: 把顺序排列的一组数据分割为四(若干相等)部分的分割点的数值。 分位数可以反映数据分布的相对位置(而不单单是中心位置)。 在实际应用中四分位数的计算方法并不统一(数据量大时这些方法差别不大)。对原始数据: SPSS中四分位数的位置为(n+1)/4, 2(n+1)/4, 3 (n+1)/4。 Excel中四分位数的位置分别为(n+3)/4, 2(n+1)/4,(3 n+1)/4。 如果四分位数的位置不是整数,则四分位数等于前后两个数的加权平均。 方差和标准差:方差是一组数据中各数值与其均值离差平方的平均数,标准差是方差正的平方根。 是反映定量数据离散程度的最常用的指标。 基本描述数据汇总的图形显示 直方图(Histogram):使人们能够看出这个数据的大体分布或“形状” 散点图 如何进行预处理 定性数据的数字化表示: 二值描述数据的数字化表示 例如:性别的取值为“男”和“女”,男→1,女→0 多值描述数据的数字化表示 例如:信誉度为“优”、“良”、“中”、“差” 第一种表示方法:优→1,良→2,中→3,差→4 第二种表示方法:
数据挖掘毕业论文 ---------数据挖掘技术及其应用 摘要:随着网络、数据库技术的迅速发展以及数据库管理系统的广泛应用,人们积累的数据越来越多。数据挖掘(Data Mining)就是从大量的实际应用数据中提取隐含信息和知识,它利用了数据库、人工智能和数理统计等多方面的技术,是一类深层次的数据分析方法。本文介绍了数据库技术的现状、效据挖掘的方法以及它在Bayesian网建网技术中的应用:通过散据挖掘解决Bayesian网络建模过程中所遇到的具体问题,即如何从太规模效据库中寻找各变量之间的关系以及如何确定条件概率问题。 关键字:数据挖掘、知识获取、数据库、函数依赖、条件概率 一、引言: 数据是知识的源泉。但是,拥有大量的数据与拥有许多有用的知识完全是两回事。过去几年中,从数据库中发现知识这一领域发展的很快。广阔的市场和研究利益促使这一领域的飞速发展。计算机技术和数据收集技术的进步使人们可以从更加广泛的范围和几年前不可想象的速度收集和存储信息。收集数据是为了得到信息,然而大量的数据本身并不意味信息。尽管现代的数据库技术使我们很容易存储大量的数据流,但现在还没有一种成熟的技术帮助我们分析、理解并使数据以可理解的信息表示出来。在过去,我们常用的知识获取方法是由知识工程师把专家经验知识经过分析、筛选、比较、综合、再提取出知识和规则。然而,由于知识工程师所拥有知识的有局限性,所以对于获得知识的可信度就应该打个 折扣。目前,传统的知识获取技术面对巨型数据仓库无能为力,数据挖掘技术就应运而生。 数据的迅速增加与数据分析方法的滞后之间的矛盾越来越突出,人们希望在对已有的大量数据分析的基础上进行科学研究、商业决策或者企业管理,但是目前所拥有的数据分析工具很难对数据进行深层次的处理,使得人们只能望“数”兴叹。数据挖掘正是为了解决传统分析方法的不足,并针对大规模数据的分析处理而出现的。数据挖掘通过在大量数据的基础上对各种学习算法的训练,得到数据对象间的关系模式,这些模式反映了数据的内在特性,是对数据包含信息的更高层次的抽象[1]。目前,在需要处理大数据量的科研领域中,数据挖掘受到越来越多
For personal use only in study and research; not for commercial use 单选题 1. 某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3. 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 4. 当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6. 使用交互式的和可视化的技术,对数据进行探索属于数据挖掘的哪一类任务?(A) A. 探索性数据分析 B. 建模描述 C. 预测建模 D. 寻找模式和规则 11.下面哪种不属于数据预处理的方法?(D) A变量代换B离散化 C 聚集 D 估计遗漏值 12. 假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内?(B) A 第一个 B 第二个 C 第三个 D 第四个 13.上题中,等宽划分时(宽度为50),15又在哪个箱子里?(A) A 第一个 B 第二个 C 第三个 D 第四个 16. 只有非零值才重要的二元属性被称作:( C ) A 计数属性 B 离散属性C非对称的二元属性 D 对称属性 17. 以下哪种方法不属于特征选择的标准方法:(D) A嵌入 B 过滤 C 包装 D 抽样 18.下面不属于创建新属性的相关方法的是:(B) A特征提取B特征修改C映射数据到新的空间D特征构造 22. 假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A 0.821 B 1.224 C 1.458 D 0.716 23.假定用于分析的数据包含属性age。数据元组中age的值如下(按递增序):13,15,16,16,19,20,20,21,22,22,25,25,25,30,33,33,35,35,36,40,45,46,52,70, 问题:使用按箱平均值平滑方法对上述数据进行平滑,箱的深度为3。第二个箱子值为:(A) A 18.3 B 22.6 C 26.8 D 27.9 28. 数据仓库是随着时间变化的,下面的描述不正确的是(C) A. 数据仓库随时间的变化不断增加新的数据内容; B. 捕捉到的新数据会覆盖原来的快照; C. 数据仓库随事件变化不断删去旧的数据内容; D. 数据仓库中包含大量的综合数据,这些综合数据会随着时间的变化不断地进行重新综合. 29. 关于基本数据的元数据是指: (D) A. 基本元数据与数据源,数据仓库,数据集市和应用程序等结构相关的信息; B. 基本元数据包括与企业相关的管理方面的数据和信息;
大数据、数据分析和数据挖掘的区别 大数据、数据分析、数据挖掘的区别是,大数据是互联网的海量数据挖掘,而数据挖掘更多是针对内部企业行业小众化的数据挖掘,数据分析就是进行做出针对性的分析和诊断,大数据需要分析的是趋势和发展,数据挖掘主要发现的是问题和诊断。具体分析如下: 1、大数据(big data): 指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产; 在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)Veracity(真实性) 。 2、数据分析:
是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。 数据分析的数学基础在20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。数据分析是数学与计算机科学相结合的产物。 3、数据挖掘(英语:Data mining): 又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。 简而言之: 大数据是范围比较广的数据分析和数据挖掘。 按照数据分析的流程来说,数据挖掘工作较数据分析工作靠前些,二者又有重合的地方,数据挖掘侧重数据的清洗和梳理。 数据分析处于数据处理的末端,是最后阶段。 数据分析和数据挖掘的分界、概念比较模糊,模糊的意思是二者很难区分。 大数据概念更为广泛,是把创新的思维、信息技术、统计学等等技术的综合体,每个人限于学术背景、技术背景,概述的都不一样。
1.4 数据仓库和数据库有何不同?有哪些相似之处? 答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。它用表组织数据,采用ER数据模型。 相似:它们都为数据挖掘提供了源数据,都是数据的组合。 1.3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。 答:特征化是一个目标类数据的一般特性或特性的汇总。例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息, 还有所修的课程的最大数量。 区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。 关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。例如,一个数据挖掘系统可能发现的关联规则为:major(X, “computing science”) ? owns(X, “personal computer”) [support=12%, confidence=98%] 其中,X 是一个表示学生的变量。这个规则指出正在学习的学生,12% (支持度)主修计算机科学并且拥有一台个人计算机。这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度)。 分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。它们的相似性是他们都是预测的工具: 分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值。 聚类分析的数据对象不考虑已知的类标号。对象根据最大花蕾内部的相似性、最小化类之间的相似性的原则进行聚类或分组。形成的每一簇可以被看作一个对象类。聚类也便于分类法组织形式,将观测组织成类分 层结构,把类似的事件组织在一起。 数据演变分析描述和模型化随时间变化的对象的规律或趋势,尽管这可能包括时间相关数据的特征化、区分、关联和相关分析、分类、或预测,这种分析的明确特征包括时间序列数据分析、序列或周期模式匹配、和基于相似性的数据分析 2.3 假设给定的数据集的值已经分组为区间。区间和对应的频率如下。――――――――――――――――――――――――――――――――――――― 年龄频率――――――――――――――――――――――――――――――――――――― 1~5 200 5~15 450 15~20 300 20~50 1500 50~80 700 80~110 44 ―――――――――――――――――――――――――――――――――――――计算数据的近似中位数值。 解答:先判定中位数区间:N=200+450+300+1500+700+44=3194;N/2=1597 ∵ 200+450+300=950<1597<2450=950+1500; ∴ 20~50 对应中位数区间。