
优化与统计建模试验
专业
学号:
姓名:
2015年5月24日
摘要
在优化与系统建模试验这门课程当中,我们学习了Lingo,Cplex这两种优化软件以及SPSS,R语言这两种统计软件,并且简单了解了如何进行优化求解,学会了如何对数据进行简单分析。本文运用了Lingo软件,对物流配送中心选址问题进行求解;采用优化软件Cplex对运输问题进行了求解,最后是使用了SPSS软件,对我国城镇居民消费进行统计分析。
关键词:Lingo;Cplex; SPSS
一、Lingo求解物流配送中心选址问题
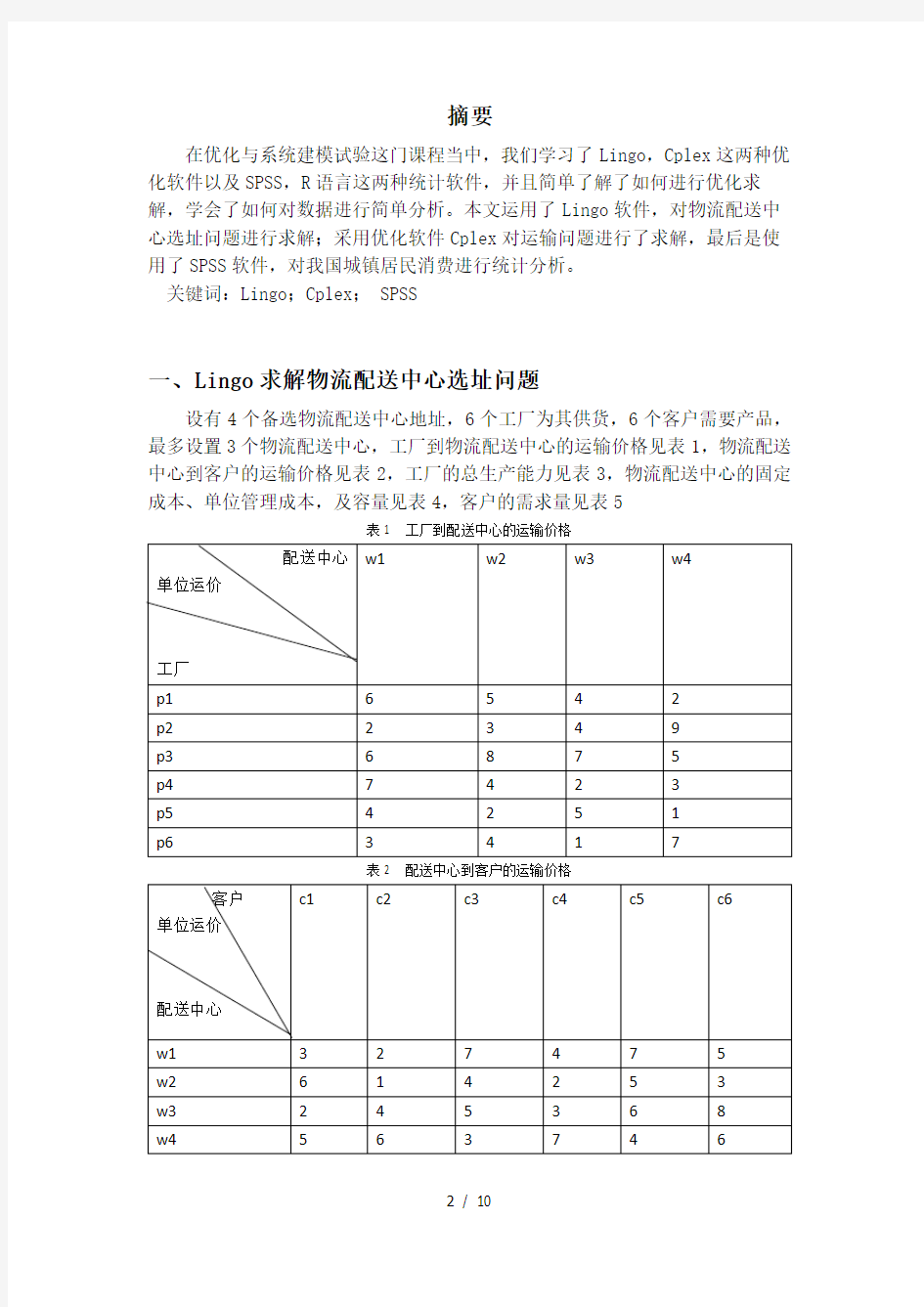
设有4个备选物流配送中心地址,6个工厂为其供货,6个客户需要产品,最多设置3个物流配送中心,工厂到物流配送中心的运输价格见表1,物流配送中心到客户的运输价格见表2,工厂的总生产能力见表3,物流配送中心的固定成本、单位管理成本,及容量见表4,客户的需求量见表5
表1 工厂到配送中心的运输价格
表2 配送中心到客户的运输价格
表3 工厂的总生产能力
表4 备选物流配送中心的固定成本,单位管理成本,容量
表5 客户的需求量
利用Lingo软件求解以上混合整数规划,编程如下:model:
sets:
factory/p1..p6/:p;
warhouse/w1..w4/:a,f,g;
customer/c1..c6/:d;
tr/tr1..tr4/:z;
link1(factory,warhouse):c,w;
link2(warhouse,customer):h,x;
endsets
data:
p=40000,50000,60000,70000,60000,40000;
a=70000,60000,70000,50000;
f=500000,300000,400000,400000;
g=3,2,5,4;
d=10000,20000,10000,20000,30000,10000;
c=6 5 4 2
2 3 4 9
6 8
7 5
7 4 2 3
4 2
5 1
3 4 1 7;
h=3 2 7 4 7 5
6 1 4 2 5 3
2 4 5
3 6 8
5 6 3 7 4 6;
enddata
min=@sum(link1(k,i):c(k,i)*w(k,i))+@sum(link2(i,j):h(i,j)*x(i,j))
+@sum(link1(k,i):g(i)*w(k,i))+@sum(warhouse(i):f(i)*z(i));
@for(factory(k):@sum(link1(k,i):w(k,i))<=p(k));
@for(warhouse(i):@sum(link2(i,j):x(i,j))=@sum(link1(k,i):w(k,i)));
@for(customer(j):@sum(link2(i,j):x(i,j))>=d(j));
@for(warhouse(i):@sum(link1(k,i):w(k,i))<=(a(i)*z(i)));
@sum(tr(i):z(i))<=3;
@for(tr(i):@bin(z));
end
直接按Lingo求解按钮,就可以得到以上问题的解,部分结果如下:
Global optimal solution found.
Objective value: 1480000.
Objective bound: 1480000. Infeasibilities: 0.000000
Extended solver steps: 7
Total solver iterations: 44
Model Class: MILP
Total variables: 52
Nonlinear variables: 0
Integer variables: 4
Total constraints: 22
Nonlinear constraints: 0
Total nonzeros: 180
Nonlinear nonzeros: 0
从以上结果中可以得到,选择2号和4号备选地址作为物流配送中心地址,最小物流成本为1480。
二、Cplex求解运输问题
某公司经销甲产品。它下设三个加工厂。每日的产量分别是:A1为7吨,A2为4吨,A3为9吨。该公司把这些产品分别运往四个销售点。各销售点每日销量为:B1为3吨,B2为6吨,B3为5吨,B4为6吨。已知从各工厂到各销售点的单位产品运价如下表 6 ,问该公司应如何调运产品,在满足各销点的需要量的前提下,使总运费最少。
表6 产销平衡表
目标函数:
Min Z =∑∑c ij x ij n
j=1
m i=1
约束条件:
x 11+x 12+x 13+x 14=7 x 21+x 22+x 23+x 24=4 x 31+x 32+x 33+x 34=9 x 11+x 21+x 31=3 x 12+x 22+x 23=6, x 13+x 23+x 33=5, x 14+x 24+x 34=56 x ij ≥0(i =1,2,3;j =1,2,3,4)
利用CPLEX 软件对上述问题进行求解,编程如下:
{string}SCities=...; {string}DCities=...;
float Supply[SCities]=...; float Demand[DCities]=...; assert
sum(o in SCities)Supply[o]==sum(d in DCities)Demand[d]; float Cost[SCities][DCities]=...; dvar float+ Trans[SCities][DCities]; minimize
sum(o in SCities, d in DCities) Cost[o][d]*Trans[o][d]; subject to{
forall(o in SCities) ctSupply:
sum(d in DCities)
Trans[o][d]==Supply[o];
forall(d in DCities)
ctDemand:
sum(o in SCities)
Trans[o][d]==Demand[d];
}
Cplex问题数据文件编码:
SCities={A1 A2 A3};
DCities={B1 B2 B3 B4};
Supply=#[A1:7 A2:4 A3:9]#;
Demand=#[B1:3 B2:6B3:5 B4:6]#;
Cost=#[A1: #[B1:3 B2:11 B3:3 B4:10]#
A2: #[B1:1 B2:9 B3:2 B4:8]#
A3:#[B1:7 B2:4 B3:10 B4:5]# ]#;
运行Cplex得到如下结果:
// solution (optimal) with objective 85
// Quality There are no bound infeasibilities.
// There are no reduced-cost infeasibilities.
// Maximum Ax-b residual = 0
// Maximum c-B'pi residual = 0
// Maximum |x| = 9
// Maximum |pi| = 11
// Maximum |red-cost| = 1
// Condition number of unscaled basis = 9.0e+000
//
Trans = [[0 0 5 2]
[3 0 0 1]
[0 6 0 3]];
根据以上解答结果,得到最佳的运输方案如表7所示:
表7 运输方案
故表中的解为最优解,这时得到的总费用最小为85元。
三、SPSS对我国城镇居民消费进行统计分析
下图是出自《中国统计年鉴—2009》这一资料性年刊,它系统收录了全国和各省、自治区、直辖市2008年经济、社会各方面的统计数据,以及近三十年和其他重要历史年份的全国主要统计数据。此年鉴正文内容分为24个篇章,本文选取其中的第九篇章-人民生活,用以探究我国城镇居民消费结构及其趋势。
表8 城镇居民家庭基本情况
图1给出了基本的描述性统计图,图中显示各个变量的全部观测量的Mean (均值)、Std.Deviation(标准差)和观测值总数N。图2给出了相关系数矩阵表,其中显示3个自变量两两间的Pearson相关系数,以及关于相关关系等于零的假设的单尾显著性检验概率。
图1 描述性统计表
图2 相关系数矩阵
从表中看到因变量家庭设备用品及服务与自变量食品、衣着之间相关关系数依次为0.869、0.684,反映家庭设备用品及服务与食品、衣着之间存在显著的相关关系。说明食品与衣着对于家庭设备用品及服务条件的好转有显著的作用。自变量居住于因变量家庭设备用品及服务之间的相关系数为-0.894,它于其他几个自变量之间的相关系数也都为负,说明它们之间的线性关系不显著。此外,食品与衣着之间的相关系数为0.950,这也说明它们之间存在较为显著的相关关系。按照常识,它们之间的线性相关关系也是符合事实的。
图3给出了回归系数表和变量显著性检验的T值,我们发现,变量居住的T值太小,没有达到显著性水平,因此我们要将这个变量剔除,从这里我们也可以看出,模型虽然通过了设定检验,但很有可能不能通过变量的显著性检验。
图3 回归系数表
图4给出了模型整体拟合效果的概述,模型的拟合优度系数为0.982,反映了因变量于自变量之间具有高度显著的线性关系。表里还显示了R平方以及经调整的R值估计标准误差,另外表中还给出了杜宾-瓦特森检验值DW=2.634,杜宾-瓦特森检验统计量DW是一个用于检验一阶变量自回归形式的序列相关问题的统计量,DW在数值2到4之间的附近说明模型变量无序列相关。
图4 模型概述表
图5给出了方差分析表,我们可以看到模型的设定检验F统计量的值为9.214,显著性水平的P值为0.237。
图5 方差分析表
图6给出了残差分析表,表中显示了预测值、残差、标准化预测值、标准化残差的最小值、最大值、均值、标准差及样本容量等,根据概率的3西格玛原则,标准化残差的绝对值最大为1.618,小于3,说明样本数据中没有奇异值。
图6 残差统计表
图7给出了模型的直方图,由于我们在模型中始终假设残差服从正态分布,因此我们可以从这张图中直观地看出回归后的实际残差是否符合我们的假设,从回归残差的直方图于附于图上的正态分布曲线相比较,可以认为残差的分布不是明显地服从正态分布。尽管这样也不能盲目的否定残差服从正态分布的假设,因为我们用了进行分析的样本太小,样本容量仅为5。
图7 残差分布直方图
LINGO 软件简介 LINGO 软件是一个处理优化问题的专门软件,它尤其擅长求解线性规划、非线性规划、整 数规划等问题。 一个简单示例 有如下一个混合非线性规划问题: ?????≥≤≤+++---+为整数 213 212 13213 2 2212121,;0,,210022..15023.027798max x x x x x x x x x x t s x x x x x x x 。 LINGO 程序(模型): max =98*x1+277*x2-x1^*x1*x2-2*x2^2+150*x3; x1+2*x2+2*x3<=100; x1<=2*x2; @gin (x1);@gin (x2);! Lingo 默认变量非负 (注意:@bin(x)表示x 是0-1变量;@gin(x)表示x 是整数变量;@bnd(L,x,U)表示 限制LxU ;@free(x)表示取消对x 的符号限制,即可正、可负。) 结果: Global optimal solution found. Objective value: Extended solver steps: 0 Total solver iterations: 45 Variable Value Reduced Cost X1 X2 X3 Row Slack or Surplus Dual Price 1 2 3 ———————— 非常简单! 在LINGO 中使用集合 为了方便地表示大规模的规划问题,减少模型、数据表示的复杂程度,LINGO 引进了“集合”的用法,实现了变量、系数的数组化(下标)表示。 例如:对?? ? ??? ? ==-++-==≤++∑=.,,;10)0(;4,3,2,1),()())()1()(;4,3,2,1,20)(..)} (20)(450)(400{min 4 ,3,2,1均非负INV OP RP INV I I DEM I OP I RP I INV I INV I I RP t s I INV I OP I RP I 求解程序: model : sets : mark/1,2,3,4/:dem,rp,op,inv;!也可以vmark/1..4/:dem,rp,op,inv;
物流配送中心选址分析 在物流系统中,配送中心居于重要的枢纽地位。物流配送中心的选址,是指在一个具有若干供应点及若干需求点的经济区域内,选一个或多个地址设置配送中心的规划过程。较佳的物流配送中心选址方案可以有效地节约费用,促进生产和消费的协调与配合,保证物流系统的平衡发展。因此,物流配送中心的合理选址就显得十分重要。 一、物流配送中心选址的影响因素 (一)货物分布和数量。这是配送中心配送的对象,如货物来源和去向的分布情况、历史和现在以及将来的预测和发展等。配送中心应该尽可能地与生产地和配送区域形成短距离优化。货物数量是随配送规模的增长而不断增长的。货物增长率越高,越是要求配送中心选址的合理性,从而减少输送过程中不必要的浪费。 (二)运输条件。物流配送中心的选址应接近交通运输枢纽,使配送中心形成物流过程中的一个恰当的结点。在有条件的情况下,配送中心应尽可能靠近铁路货运站、港口及公路。 (三)用地条件。物流配送中心的占地问题在土地日益昂贵的今天显得越来越重要。是利用现有的土地,还是重新征地?地价如何?是否符合政府规划要求等等,在建设配送中心时都要进行综合考虑。 (四)商品流动。企业生产的消费品随着人口的转移而变化,应据此更好地为企业的配送系统定位。同时,工业产品市场也会转移变化,为了确定原材料和半成品等商品的流动变化情况,在进行物流配送中心的选址时,应考虑有关商品流动的具体情况。 (五)其他因素。如劳动力、运输与服务的方便程度、投资额的限制等。 二、物流配送中心选址方法 (一)定性分析法。定性分析法主要是根据选址影响因素和选址原则,依靠专家或管理人员丰富的经验、知识及其综合分析能力,确定配送中心的具体选址。主要有专家打分法、德尔菲法。定性方法的优点是注重历史经验,简单易行。其缺点是容易犯经验主义和主观主义的错误,并且当可选地点较多时,不易做出理想的决策,导致决策的可靠性不高。 (二)定量分析法。定量的方法主要包括重心法、鲍莫尔-沃尔夫法、运输规划法、Cluster法、CFLP法、混合0-1整数规划法、双层规划法、遗传算法等。定量方法选址的优点是能求出比较准确可信的解。其中,重心法是研究单个物流配送中心选址的常用方法,这种方法将物流系统中的需求点和资源点看成是分布在某一平面范围内的物流系统,各点的需求量和资源量分别看成是物体的重量,物体系统的重心作为物流网点的最佳设置点。
第10卷第4期 2010卑8月 潍坊学院学报 Journal of Weifang University V01.10No.4 Aug.2010 多物流配送中心选址规划的算法分析。 王 (潍坊学院,山东 鑫 潍坊261061 摘要:通过对多物流配送中心选址规划的不同算法进行分析,研究了鲍摩一瓦尔夫模型、单阶段 CFLP模型和多阶段CFLP模型、多产品模型、动态模型等的优缺点,指出了各自适用的不同条件和环境, 在进行多物流配送中心选址规划时,可根据实际情况和具体条件进行选用。 关键词:物流配送中心;选址;算法 中图分类号:U491文献标识码:A 文章编号:1671—4288(201004--0046—03 物流配送中心的地址几乎决定了整个物流系统的模式、结构和形状,物流配送中心选址决策包括设施的数量、位置和规模等。如果要配送的货物范围比较小,一般来讲配送货物的目的地都非常明确,可以考虑建设一个物流配送中心,在这种情况下,选址的因素主要考虑运费率和该点的货物吞吐量。如果要配送的货物范围分布广,用一个物流配送中心无法满足需求,就需要考虑设立两个或多个物流配送中心。实际上几乎所有的大公司的物流系统都有一个以上的物流配送中心,由于这些物流配送中心不能看成是经济上相互独立的,且可能的选址布局方案很多。文章结合选
址的普遍性问题如物流网络中物流配送中心数量、规模、地点等问题对一些常用的多物流配送中心选址方法进行了比较分析。 1鲍摩一瓦尔夫模型(Baumol--Wolfe model 对于从几个工厂经过几个物流配送中心向用户输送货物的问题,物流配送中心的选址分析一般只考虑运费为最小时的情况。这里需要考虑的问题是:各个工厂向哪些物流配送中心运输多少商品?各个物流配送中心向哪些用户发送多少商品? 总费用算法: f(X驰一∑(%+h。x。。+∑口i(硼i8+∑Fir(w: (1 i。J,j 2 f0(W.=0 式中,o划<1, “㈣2{l (W:>0 其中,cb为从工厂k到物流配送中心i每单位运量的运输费;h,j为从物流配送中心i向用户j发送单位运量的发送费㈣C k为从工厂k通过物流配送中心i向用户j 发送单位运量的运费,即Cijk=Cki+hi,;X。k为从工厂k通过物流配送中心i向用户j 运送的运量;w.为通过物流配送中心i的运量,即W;一≥:xot;v.为 j,女 物流配送中心i的单位运量的可变费用;Fi为物流配送中心i的固定费用(与其规模无关的固定费用。总费用函数f(X¨k的第一项是运输费和发送费,第二项是配送中心的可变费用,第三项是物流配送中心的固定费用(这项费用函数是非线性的。 该模型的计算方法是首先给出费用的初始值,求初始解;然后进行迭代计算,使其逐步接近费用最小的运输规划。 这个模型具有一些优点,但也有些缺点,使用时应加以注意。
毕业设计(论文)题目:关于物流配送中心的选址模型研究 学生姓名: 学号: 班级: 专业:工商管理(物流管理方向)本科 所在系: 管理系 指导教师:
关于物流配送中心的选址模型研究 摘要 在物流网络中,配送中心连接着供货点和需求点,是两者之间的桥梁,在物流系统中有着举足轻重的作用,因此搞好配送中心的选址将对物流系统作用的发挥乃至物流经济效益的提高产生重要的影响。 本论文在综述配送中心选址问题研究现状的基础上,对配送中心选址的模型和算法进行了研究。本课题的第一部分对物流配送中心选址的研究背景进行介绍,阐述物流配送中心选址的重要性;第二部分对国内的物流配送中心选址问题的研究进行平述。第三部分物流配送中心选址的模型的理论模型。深入分析改进的重心法模型与整数规划模型的理论模型和算法。第四部分是实证研究,以验证本文所构建的重心法模型的合理性及可行性。本文结论是:采用改进的重心法建立选址模型,然后利用多元线性回归对重心法模型中的总成本函数方程中的系数进行优化。这样使重心法模型克服对于系数的数据处理的主观性,减小了主观因素带来的偏差,也使模型在配送中心的选址中具有实用性。通过指派问题模型可以实现配送中心资源的重新优化配置,并且其为配送中心选址提供一条新的途径。 关键词:物流配送中心选址重心法分派问题模型
ABOUT THE LOCATION OF LOGISTICS DISTRIBUTION CENTER MODEL RESEARCH ABSTRACT In the logistics network, the distribution center point and needs to connect the supply point is a bridge between the two, in the logistics system has a pivotal role, it will improve the logistics distribution center location and even played the role of the logistics system economic efficiency have an important effect. In the review of this paper the problem of distribution center location based on the current situation, on the distribution center location model and algorithm research. The first part of this issue of logistics distribution center location of the background briefing, explained the importance of logistics distribution center location; the second part of the domestic logistics distribution center location problem to level out. The third part of the logistics distribution center location model of the theoretical model. In-depth analysis of the improved center of gravity model and the theoretical model of integer programming models and algorithms. The fourth part is the empirical study to validate the constructed model of gravity method is reasonable and feasible. This conclusion is: the establishment of an improved center of gravity location model, and then using multiple linear regression model on the center of gravity of the total cost function to optimize the coefficients of the equation. This model of gravity method to overcome the subjective factor of data processing and reduce the bias caused by subjective factors, but also the model for Distribution Center's location is practical. Model can be achieved through the assignment of distribution centers to re-optimize the allocation of resources, and its location for the distribution center to provide a new way.
Lingo12软件培训教案 Lingo 主要用于求解线性规划,整数规划,非线性规划,V10以上版本可编程。 例1 一个简单的线性规划问题 0 , 600 2 100 350 st. 3 2max >=<=+=<<=++=y x y x x y x y x z ! 源程序 max = 2*x+3*y; [st_1] x+y<350; [st_2] x<100; 2*x+y<600; !决策变量黙认为非负; <相当于<=; 大小写不区分 当规划问题的规模很大时,需要定义数组(或称为矩阵),以及下标集(set) 下面定义下标集和对应数组的三种方法,效果相同::r1 = r2 = r3, a = b = c. sets : r1/1..3/:a; r2 : b; r3 : c; link2(r1,r2): x; link3(r1,r2,r3): y; endsets data : ALPHA = ; a=11 12 13 ; r2 = 1..3; b = 11 12 13; c = 11 12 13; enddata
例2 运输问题 解: 设决策变量ij x = 第i 个发点到第j 个售点的运货量,i =1,2,…m; j =1,2,…n; 记为ij c =第i 个发点到第j 个售点的运输单价,i =1,2,…m; j =1,2,…n 记i s =第i 个发点的产量, i =1,2,…m; 记j d =第j 个售点的需求量, j =1,2,…n. 其中,m = 6; n = 8. 设目标函数为总成本,约束条件为(1)产量约束;(2)需求约束。 于是形成如下规划问题: n j m i x n j d x m i s x x c ij j n i ij i m j ij m i n j ij ij ,...,2,1,,...,2,1,0 ,...,2,1, ,...,2,1, st. z min 11 11==>=<==<==∑∑∑∑==== 把上述程序翻译成LINGO 语言,编制程序如下: ! 源程序
物流配送中心选址模型 姓名:学号:班级: 摘要:在现代络中,配送中心不仅执行一般的职能,而且越来越多地执行指挥调度、信息处理、作业优化等神经中枢的职能,是整个络的灵魂所在。因此,发展现代化配送中心是现代业的发展方向。文章首先使用重心法计算出较为合适的备选地,再考虑到各项配送中心选址的固定成本和可变成本,从而使配送中心选址更加优化和符合实际。 关键词:物流选址;选址;重心法;优化模型; 1.背景介绍 1.1 研究主题 如下表中,有四个零售点的坐标和物资需求量,计算并确定物流节点的位置。 前人研究进展 1.2.1国内外的研究现状:
国外对物流配送选址问题的研究已有60余年的历史,对各种类型物流配送中心的选址问题在理论和实践方面都取得了令人注目的成就,形成了多种可行的模型和方法。归纳起来,这些配送中心选址方法可分为三类:(1)应用连续型模型选择地点; (2)应用离散型模型选择地点; (3)应用德尔菲(Delphi)专家咨询法选择地点。 第一类是以重心法为代表,认为物流中心的地点可以在平面取任意点,物流配送中心设置在重心点时,货物运送到个需求点的距离将最短。这种方法通常只是考虑运输成本对配送中心选址的影响,而运输成本一般是运输需求量、距离以及时间的函数,所以解析方法根据距离、需求量、时间或三者的结合,通过坐标上显示,以配送中心位置为因变量,用代数方法来求解配送中心的坐标。解析方法考虑影响因素较少,模型简单,主要适用于单个配送中心选址问题。解析方法的优点在于计算简单,数据容易搜集,易于理解。由于通常不需要对进行整体评估,所以在单一设施定位时应用解析方法简便易行。 第二类方法认为物流中心的各个选址地点是有限的几个场所,最适合的地址只能按照预定的目标从有限个可行点中选取。 第二类方法的中心思想则是将专家凭经验、专业知识做出的判断用数值形式表示,从而经过分析后对选址进行决策。 国内在物流中心选址方面的研究起步较晚,只有10余年历史,但也有许多学者对其进行了较深入的研究,在理论和实践上都取得了较大的成果。北方交通大学鲁晓春等对配送中心的重心法地址做出了深入的研究,认为原有的重心法存在着问题,并把原有的计算公式用流通费用偏微分方程来取代。中国矿业
海南大学 《数学模型课程设计》论文 题目:基于Lingo的旅游计划制定方法班级:信息与计算科学 姓名:体贴的瑾色 学号: 指导教师: 日期:2017.06
目录 基于Lingo的旅游计划制定方法 (3) 摘要 (3) 一、问题描述 (3) 二、模型假设 (3) 三、问题分析 (3) 四、符号说明 (4) 五、模型建立 (4) 六、问题解决 (7) 七、回答问题 (9) 八、模型推广 (10) 九、心得体会 (11) 参考文献 (11) 程序附录 (11)
基于Lingo 的旅游计划制定方法 摘要 本文针对海南十八个城市制定旅游规划,在收集了大量的数据情况下,建立评价指标,找到最优的旅游路线。 对于问题一因为不要求求出具体的路程最小值,所以我们使用matlab 处理海南省的地图,找到每个城市在地图的相对坐标,从而得到城市之间的相对距离。以距离为权,以旅程的长度为评价标准建立模型,规划最优路线得到最小相对距离1488。11,注意这里的最小距离并不是实际上的最小距离。 对于问题二将最小费用矩阵代替距离矩阵,以旅程的总车费为评价标准建立模型,规划最优路线,得到最小费用为276元。 对于问题三,在一二问的基础上,综合考虑省时省钱,得到评价标准表达式 1488.11276 min 0.50.51488.11276 D M --=+,建立模型,规划最优路线。 一、问题描述 本题要求在不同的约束条件下规划出海南的最佳旅游路线,路线的基本要求是 必须从海口出发并回到海口,并且经过且经过海南的每个城市(包括县城)一次,并且每个市县玩两天。不同的问题约束条件是: (1)要求总路程最短。 (2)允许选择动车和大巴作为出行工具,规划的路线使得出行总交通费用最少。 (3)综合考虑一二问的条件,得到最优路线,设定出相应的评价准则和指标,修正模型。 二、模型假设 (1) 城市之间路程用城市的直线距离代替。 (2) 近期城市之间的动车价格和大巴价格视为定值。 (3) 城市之间路费取自动车价格和大巴价格的最小值。 (4) 假设不同城市之间的交通工具的速度均相差不大,即旅行时间由旅行 路程唯一决定。 三、问题分析 通过查询知道海南的市县数量总共是有18个(三沙市除外),那么显然这个问题是一个18个城市的TSP 问题。用图论的内容来等价话描述为:设(,,) G V E W =
(三)物流配送中心选址的主要方法与类型 1.选址方法类型 近年来,随着选址理论迅速发展,各种各样的选址越来越多,层出不穷。特别是计算机技术的发展与应用,促进了物流系统选址的理论发展,对不同方案的可行性分析提供了强有力的工具。但是现阶段选址的理论方法大体上有以下几类: (1)运筹法 运筹法是通过数学模型进行物流网点布局的方法。采用这种方法首先根据问题的特征、己知条件以及内在的联系建立数学模型或者是图论模型。然后对模型求解获得最佳布局方案。采用这种方法的优点是能够获得较为精确的最优解缺乏是对一些复杂问题建立适当的模型比较困难,因而在实际应用中受到很大的限制。解析法中最常用的有重心法和线性规划法。 (2)专家意见法 专家意见法是以专家为索取信息的对象,运用专家的知识和经验考虑选址对象的社会环境和客观背景,直观地对选址对象进行综合分析研究寻求其特点和发展规律并进行选择的一类选址方法是专家选择法,其中最常用的有因素评分法和德尔菲法。 (3)仿真法 仿真法是将实际问题用数学方法和逻辑关系表示出来然后通过模拟计算及逻辑推理确定最佳布局方案。这种方法的优化是比较简单,缺点是选用这种方法进行选址,分析者必须提供预定的各种网点组合力案以供分析评价,从中找出最佳组合。因此,决策的效果依赖于分析者预定的组合方案是否接近最佳方案该法是针对模型的求解而言的,是种逐次逼近的方法。对这种方法进行反复判断实践修正直到满意为止。该方法的优点是模型简单,需要进行方案组合的个数少,因而,容易寻求最佳的答案。缺点是这种方法得出的答案很难保证是最优化的一般情况下只能得到满意的近似解用启发式进行选址,一般包括以下步骤: ①定义一个计算总费用的方法;
[说明]物流配送中心选址分析和意义物流配送中心选址分析和意义 物流中心的选址和布局 3.1物流中心的选址重要性和考虑因素 3.1.1物流中心的选址重要性 因为建设物流中心投资规模大,占用大量城市土地以及建成后不易调整,对社会物流和企业经营具有长期的影响,所以对物流中心的选址决策必须进行详细的论证。地址的失误对于社会物流系统而言,可能会导致社会生产和商品交换的无秩序和低效率;对于企业经营而言,可能因为效率低下不能满足客户需要而直接影响企业的经营利润。新华书店的物流是经常性和长期性的,能很好的选址就能节省大量的运输等费用,加强货物的周转率和及时送达率,满足客户的费用和实效的要求。 3.1.2物流中心选址考虑的因素 影响物流中心选址的因素很多,下面四个方面是评价物流配送中心选址合理与否时必须要重点考虑的因素。社会环境因素 (1)要充分考虑运输费用。新建物流配送中心要使总的物流运输成本最小化,大多数物流配送中心选择接近物流服务需求地,以便缩短运输距离,降低费用。 (2)要能实现准时配送。应保证客户在任何时候提出物流需求都能获得快速满意的服务。 (3)新建物流配送中心要能很好地适应货物的特性,经营不同类型货物的物流配送中心最好能分别布局在不同地域。 (二)自然环境因素 1.地质条件 2.气象条件 3.地形条件 4.水文条件 (三)经营环境因素 (1)经营环境。物流配送中心所在地区优惠的物流产业政策对物流企业的经济效益将产生重要影响;数量充足和素质较高的劳动力条件也是物流配送中心选址考
虑的因素之一。 (2)物流费用是物流配送中心选址的重点考虑因素之一。大多数物流配送中心选择进阶物流服务需求地,例如接近大型工业区,商业区,以便缩短运输距离,降低运费等物流费用。 (3)货物特性。经营不同类型货物的物流配送中心最好能布局在不同地域。 (4)服务水平是物流配送中心选址的考虑因素之一,由于在现代物流过程中能否实现准时配送是服务水平高低的重要指标,因此,在物流配送中心选址时,应保证用户在任何时候向物流配送中心提出需求时,都能获得快孙满意的物流服务。 (四)基础设施状况。 (1)交通条件。物流配送中心必须具备方便的交通运输条件,最好靠近交通枢纽布局,如紧邻港口,交通主干道枢纽,铁路编组站或机场,有两种以上运输方式相衔接。公路运输是物流配送中心的主要货运方式,靠近交通便捷的主干道进出口是物流配送中心选址的主要考虑因素之一。由于我国地域辽阔,铁路的运力强,费用低,同时水域也有运输成本低的优势,因此,大规模的物流配送中心最好能靠近铁路港口。 (2)公共设施状况。物流配送中心的所在地要求道路,通信等公共设施齐备,有充足的供电,水,热,燃气的能力。基础设施状况因素的权重系数一般是 0.2,0.4,该因素仅次于经营因素,应在物流配送中心选址评价时占较大的权重。 (五)其他因素 (1)土地资源利用。物流配送中心的规划应贯彻节约用地,充分利用国土资源的原则,物流配送中心一般占地面积较大,周围还需留有足够发展的空间,因此低价的高低对布局规划有重要影响。此外,物流配送中心的布局还要兼顾区域与城市规划用地的其他要素。 (2)环境保护要求。物流配送中心的选址需要考虑保护自然环境与人文环境等因素,尽可能降低对城市生活的干扰。对大型转运枢纽,应适当设置在远离市中心
一.实验目的 1、学会使用LINGO 软件求解运输问题的步骤与方法。 2、掌握使用LINGO 对运输问题的求解功能,并对结果进行分析。 二.实验内容 1.已知某企业有甲、乙、丙三个分厂生产一种产品,其产量分别为7、9、7个单位,需运往A 、B 、C 、D 四个门市部,各门市部需要量分别为3、5、7、8个单位。已知单位运价如下表。试确定运输计划使总运费最少。 2.现在要在五个工人中确定四个人来分别完成四项工作中的一项工作。由于每个工人的技术特长不同,他们完成各项工作所需的工时也不同。每个工人完成各项工作所需工时如下表所示,试找出一个工作分配方案,使总工时最小。 三. 模型建立 1.由题设知,总产量为:7+9+7=23个单位,总销量为:3+5+7+8=23个单位,所以这是一个产销平衡的运输问题。 设)4,3,2,1;3,2,1(==j i x ij 代表从第i 个产地运往第j 个销地的数量,z 为总运费。i a 表示第i 个产地的产量,j b 表示第j 个销地的销量ij c 表示从第i 个产地运往第j 个销地的单位产
品运输费用。则该问题的数学模型为: 3 4 1 1 4 13 1 max 0,1,2,3;1,2,3,4ij ij i j ij i j ij j i ij Z c x x a x b x i j =====?=???=???≥==??∑ ∑ ∑∑ 2. 设0-1变量,1,0ij i x i ?=??当第个人完成某j 项工作 ,当第个人不完成某j 项工作 则该问题的数学模型为: 5 4 115 141 min 1,1,01ij ij i j ij i ij j ij Z c x x j x i x i j =====?= =1,2,3,4??? = = 1,2,3,4,5???= =1,2,3,4,5;=1,2,3,4?? ∑∑∑∑或, 四. 模型求解(含经调试后正确的源程序) 1、编写程序1-1.m 如下: model : sets : warehouses/wh1..wh3/: capacity; vendors/v1..v4/: demand; links(warehouses,vendors): cost, volume; endsets data : capacity=7 9 7; demand=3 5 7 8; cost= 12 13 10 11 10 12 14 10 14 11 15 12; enddata min =@sum (links(I,J): cost(I,J)*volume(I,J));
四、基于重心法的物流配送中心选址应用实例分析 本文选择上海通用(沈阳)北盛汽车制造有限公司外租库的实际案例,结合自身在实习过程中的亲身经历,运用重心法的相关理论知识加以分析,对比理论计算结果与实际决策分析结果的差距,找出造成差距的原因并加以分析总结,提出自己的建议与看法。 (一)背景资料 上海通用汽车有限公司成立于1997年6月12日,由上海汽车工业(集团)总公司、通用汽车公司各出资50%组建而成。从诞生之日起,上海通用汽车就胸怀“国内领先并具国际竞争力”的远景目标,建构起基础坚实、有持续发展能力的世界级企业。上海通用汽车2005、2006、2007年连续三年销量在国内乘用车市场排名第一。上海通用汽车也是唯一一家连续6年当选“中国最受尊敬企业”的汽车企业,堪称中国汽车工业的重要力量。 坚持“以客户为中心、以市场为导向”的经营理念,上海通用汽车不断以丰富、差异化的产品线和高效优质的服务满足日益增长的市场需求,成为“多品牌、全系列”汽车公司。上海通用汽车目前已拥有别克、凯迪拉克、雪佛兰,以及萨博四大品牌,共二十四大系列八十多个品种的产品矩阵,覆盖了顶级豪华车、高档车、中高档车、中级车、大众普及型轿车及MPV、SUV等宽泛的领域,且各系列车型均含有多项先进技术,在安全性、动力性、舒适性和环保方面表现优越,在各自的细分市场中处于领先地位。 依托全球领先技术和产品资源,上海通用汽车架构起世界一流的精益生产体系,建立了一套完整的采购、物流、制造、销售与售后服务体系和质量管理体系,并在整个业务链环节全面实施了汽车行业信息技术集成解决方案。上海通用汽车建立了中国第一条具有国际先进水平的柔性化生产线实现不同平台车型的共线生产。 目前,上海通用汽车拥有金桥、烟台、沈阳3大生产基地,金桥南厂、金桥北厂、烟台东岳汽车、沈阳北盛汽车4个整车生产厂,以及金桥动力总成、烟台东岳动力总成2个动力总成厂。其中金桥基地的生产能力为年产32万辆整车,10万台自动变速箱、20万台发动机;烟台基地年设计产能为12万辆整车,37.5
第四章物流节点选址模型与方法 第一节物流设施选址问题 固定设施选址问题是物流网络中一项十分重要的战略决策。 一、物流设施选址问题类型
?按备选点的离散程度分连续选址模型(Continuous Location Models)和离散选址模型(Discrete Location Models)两类。 ?从选址目标来看,物流设施选址有三种差不多类型 (成本最小化、服务最优化、物流量最大化)和综 合型。 二、物流设施选址问题的特点 在选址问题的研究中,Daskin总结了五个特点: (一)选址决策是研究不同层次的人类组织的选址问题,从个人、家庭到公司、政府机构甚至是国际机构(二)选址决策是一个战略决策,需要考虑长期的资金利用和经济效益 (三)选址决策还涵盖了经济的外延含义,包括污染、
交通拥挤和经济潜力等。 (四)由于大多数选址问题是NP-HARD问题,专门难求得选址模型的最优解,特不是大型问题。 (五)选址问题都有相应的应用背景,模型的结构(目标函数、变量和约束)由相应的应用背景决定。
第二节物流设施选址的程序和步骤 一、物流设施选址约束条件分析 (一)需求条件
(二)运输条件 (三)配送服务的条件 (四)用地条件 (五)法律法规 (六)流通职能条件 (七)其他 二、搜集整理资料 (一)掌握业务量 1. 工厂到物流设施之间的运输量 2. 向顾客配送的物资数量 3.物流设施保管的数量 4. 配送路线上的其他业务量 (二)掌握费用 1. 工厂至物流设施之间的运输费; 2.物流设施到顾客之音质配送费; 3. 与设施、土地有关的费用及人工费、业务费等。
优化与统计建模试验 专业 学号: 姓名: 2015年5月24日
摘要 在优化与系统建模试验这门课程当中,我们学习了Lingo,Cplex这两种优化软件以及SPSS,R语言这两种统计软件,并且简单了解了如何进行优化求解,学会了如何对数据进行简单分析。本文运用了Lingo软件,对物流配送中心选址问题进行求解;采用优化软件Cplex对运输问题进行了求解,最后是使用了SPSS软件,对我国城镇居民消费进行统计分析。 关键词:Lingo;Cplex; SPSS 一、Lingo求解物流配送中心选址问题 设有4个备选物流配送中心地址,6个工厂为其供货,6个客户需要产品,最多设置3个物流配送中心,工厂到物流配送中心的运输价格见表1,物流配送中心到客户的运输价格见表2,工厂的总生产能力见表3,物流配送中心的固定成本、单位管理成本,及容量见表4,客户的需求量见表5 表1 工厂到配送中心的运输价格 表2 配送中心到客户的运输价格
表3 工厂的总生产能力 表4 备选物流配送中心的固定成本,单位管理成本,容量 表5 客户的需求量 利用Lingo软件求解以上混合整数规划,编程如下:model: sets: factory/p1..p6/:p; warhouse/w1..w4/:a,f,g; customer/c1..c6/:d; tr/tr1..tr4/:z; link1(factory,warhouse):c,w; link2(warhouse,customer):h,x; endsets data: p=40000,50000,60000,70000,60000,40000; a=70000,60000,70000,50000; f=500000,300000,400000,400000; g=3,2,5,4; d=10000,20000,10000,20000,30000,10000; c=6 5 4 2 2 3 4 9 6 8 7 5 7 4 2 3 4 2 5 1 3 4 1 7; h=3 2 7 4 7 5 6 1 4 2 5 3 2 4 5 3 6 8 5 6 3 7 4 6; enddata
多个配送中心的选址问题 1.奎汉-哈姆勃兹(Kuehn-Hamburger)模型 奎汉-哈姆勃兹模型是多个配送中心地址选定的典型方法。本方法是一种启发式的算法。所谓的“启发式的算法”确实是逐次求近似解得的方法,即简单地先求出初次解,然后通过反复运算修改那个解,使之逐步达到近似最佳解的方法。奎汉-哈姆勃兹模型是按式(5-9)~式(5-11)确定它的目标函数和约束条件的。 f(x) =(A hij +B hjk)X hijk+∑F j Z j+∑S hj(∑X hijk)+∑D hk(T hk) (5-9) ∑x hijk = Q hk (5-10) ∑x hijk ≤ Y hi (5-11) I j(∑x hijk) ≤ W j (5-12) 式中 h—产品(1,…,p); i—工厂(1,…,p); j—仓库(1,…,p); k—顾客(1,…,p); A hij—从工厂(j)到仓库(j)运输产品(h)的单位运输费; B hjk—从仓库(j)到顾客(k)之间配送产品(h)时的单位运输费;
X hijk—从工厂(i)通过仓库(j)向顾客运输产品(h)的数量; F i—在仓库(j)期间的平均固定治理费; Z j—当∑x hik >0时取1,否则取0; S hj(∑x hijk)—在仓库(i)中,为保管产品(h)而产生的部分可变费用(治理费,保管费,税金以及投资的利息等); D hk(T hk)—向顾客(k)配送产品(h)时,因为延误时刻(T)而支付的缺失费; Q hk—顾客(k)配送产品(h)时,因为延误时刻(T)而支付的缺失费; W j—仓库(j)的能力; I j∑x hijk—各工厂经由仓库(j)向所有顾客配送产品的最大库存定额。 这是用上述各项条件,按图的流程求解算术解的方法。 2.鲍摩-瓦尔夫(Baumol-Wolfe)模型 (1)鲍摩-瓦尔夫模型的建立如图5-4所示的是从几个工厂通过几个配送中心,向用户输送物资。对此咨询题,一样只考虑运费为最小时配送中心的选址咨询题。 那个地点所要考虑的咨询题是:各个工厂向哪些配送中心运输多少商品?各个配送中心向哪些用户发送多少商品? 规划的总费用应包括以下内容。 总费用函数为:
用lingo解决运输问题 (一)实验目的 1. 运输问题求解的编程实现 2.掌握使用matlab、Lingo、Excel的求解功能求解运输问题,并对结果进行分析。(二)实验内容 《运筹学》清华三版P98页 3.3题 Lingo程序代码及运行结果(选取部分): <1>3.3(1): 程序代码: model: sets: xiao/1..4/:s; chan/1..3/:h; link(chan,xiao):x,y; endsets data: y=3 7 6 4 2 4 3 2 4 3 8 5; h=5 2 3; s=3 3 2 2; enddata min=@sum(link:x*y); @for(xiao(j):@sum(chan(i):x(i,j))=s(j)); @for(chan(i):@sum(xiao(j):x(i,j))=h(i)); 运行结果及结果分析: Objective value: 32.00000 产地1分别将数量为3和2的产品运往销地甲和丁;产地2将数量为2的产品运往销地丙;产地3将数量为3的产品运往销地乙;该运输问题的最小费用为32. <2>3.3(2):
model: sets: xiao/1..4/:s; chan/1..3/:h; link(chan,xiao):x,y; endsets data: y=10 6 7 12 16 10 5 9 5 4 10 10; h=4 9 4; s=5 2 4 6; enddata min=@sum(link:x*y); @for(xiao(j):@sum(chan(i):x(i,j))=s(j)); @for(chan(i):@sum(xiao(j):x(i,j))=h(i)); 运行结果及结果分析: Objective value: 118.0000 产地1将数量为1、2、1的产品分别运往销地甲、乙、丙;产地将数量为3、6的产品运往销地丙、丁;产地3将数量为4的产品运往销地甲。最小费用为118. <3>3.3(3): 程序代码: model: sets: xiao/1..5/:s; chan/1..4/:h; link(chan,xiao):x,y; endsets data: y=10 20 5 9 10 2 10 8 30 6 1 20 7 10 4
数学建模物流配送中心 选址模型 文件管理序列号:[K8UY-K9IO69-O6M243-OL889-F88688]
物流配送中心选址模型 姓名:学号:班级: 摘要:在现代络中,配送中心不仅执行一般的职能,而且越来越多地执行指挥调度、信息处理、作业优化等神经中枢的职能,是整个络的灵魂所在。因此,发展现代化配送中心是现代业的发展方向。文章首先使用重心法计算出较为合适的备选地,再考虑到各项配送中心选址的固定成本和可变成本,从而使配送中心选址更加优化和符合实际。 关键词:物流选址;选址;重心法;优化模型; 1.背景介绍 1.1 研究主题 如下表中,有四个零售点的坐标和物资需求量,计算并确定物流节点的位置。 1.2 前人研究进展 1.2.1国内外的研究现状:
国外对物流配送选址问题的研究已有60余年的历史,对各种类型物流配送中心的选址问题在理论和实践方面都取得了令人注目的成就,形成了多种可行的模型和方法。归纳起来,这些配送中心选址方法可分为三类: (1)应用连续型模型选择地点; (2)应用离散型模型选择地点; (3)应用德尔菲(Delphi)专家咨询法选择地点。 第一类是以重心法为代表,认为物流中心的地点可以在平面取任意点,物流配送中心设置在重心点时,货物运送到个需求点的距离将最短。这种方法通常只是考虑运输成本对配送中心选址的影响,而运输成本一般是运输需求量、距离以及时间的函数,所以解析方法根据距离、需求量、时间或三者的结合,通过坐标上显示,以配送中心位置为因变量,用代数方法来求解配送中心的坐标。解析方法考虑影响因素较少,模型简单,主要适用于单个配送中心选址问题。解析方法的优点在于计算简单,数据容易搜集,易于理解。由于通常不需要对进行整体评估,所以在单一设施定位时应用解析方法简便易行。 第二类方法认为物流中心的各个选址地点是有限的几个场所,最适合的地址只能按照预定的目标从有限个可行点中选取。 第二类方法的中心思想则是将专家凭经验、专业知识做出的判断用数值形式表示,从而经过分析后对选址进行决策。 国内在物流中心选址方面的研究起步较晚,只有10余年历史,但也有许多学者对其进行了较深入的研究,在理论和实践上都取得了较大的成果。北方交通大学鲁晓春等对配送中心的重心法地址做出了深入的研究,认为原有的重心法存在着问题,并把原有的计算公式用流通费用偏微分方程来取代。中国矿业大学周梅
用lingo解决运输问题 Lingo程序代码及运行结果(选取部分): 程序代码: model: sets: xiao/1..4/:s; chan/1..3/:h; link(chan,xiao):x,y; endsets data: y=3 7 6 4 2 4 3 2 4 3 8 5; h=5 2 3; s=3 3 2 2; enddata min=@sum(link:x*y); @for(xiao(j):@sum(chan(i):x(i,j))=s(j)); @for(chan(i):@sum(xiao(j):x(i,j))=h(i)); 运行结果及结果分析: Objective value: 32.00000 产地1分别将数量为3和2的产品运往销地甲和丁;产地2将数量为2的产品运往销地丙;产地3将数量为3的产品运往销地乙;该运输问题的最小费用为32. 程序代码: model: sets: xiao/1..4/:s; chan/1..3/:h; link(chan,xiao):x,y; endsets
data: y=10 6 7 12 16 10 5 9 5 4 10 10; h=4 9 4; s=5 2 4 6; enddata min=@sum(link:x*y); @for(xiao(j):@sum(chan(i):x(i,j))=s(j)); @for(chan(i):@sum(xiao(j):x(i,j))=h(i)); 运行结果及结果分析: Objective value: 118.0000 产地1将数量为1、2、1的产品分别运往销地甲、乙、丙;产地将数量为3、6的产品运往销地丙、丁;产地3将数量为4的产品运往销地甲。最小费用为118. 程序代码: model: sets: xiao/1..5/:s; chan/1..4/:h; link(chan,xiao):x,y; endsets data: y=10 20 5 9 10 2 10 8 30 6 1 20 7 10 4 8 6 3 7 5; h=5 6 2 9; s=4 4 6 2 4; enddata min=@sum(link:x*y); @for(xiao(j):@sum(chan(i):x(i,j))=s(j)); @for(chan(i):@sum(xiao(j):x(i,j))<=h(i));