浙江财经学院 学年第一学期
《 SPSS 统计分析软件》课程期末考试试卷(A 卷)参考答案及评分标准
答案:
1. 建立相应的数据文件(5分)
操作过程:
打开新建数据文件,定义变量名、变量类型、变量名标签、变量值标签等。录入数据。 结果:
2.对绩效评分进行降序排列(5分) 操作过程:
执行Data ——sort cases 命令,打开排序主对话框,将绩效评分变量移入sort by 变量框,sort order 选项选择descending 命令。
3.对绩效评分变量求秩,将秩值1赋给评分最高者,节的处理方式为High (5
分) 操作过程:
执行Transform ——Rank Cases 命令,选择“绩效评价”变量移入Variables 变量框,选择Assign rank 1 to largest Value 选项,Ties 功能按钮下选择high 选项。
2、3题操作结果:(请列出前7个观测量)
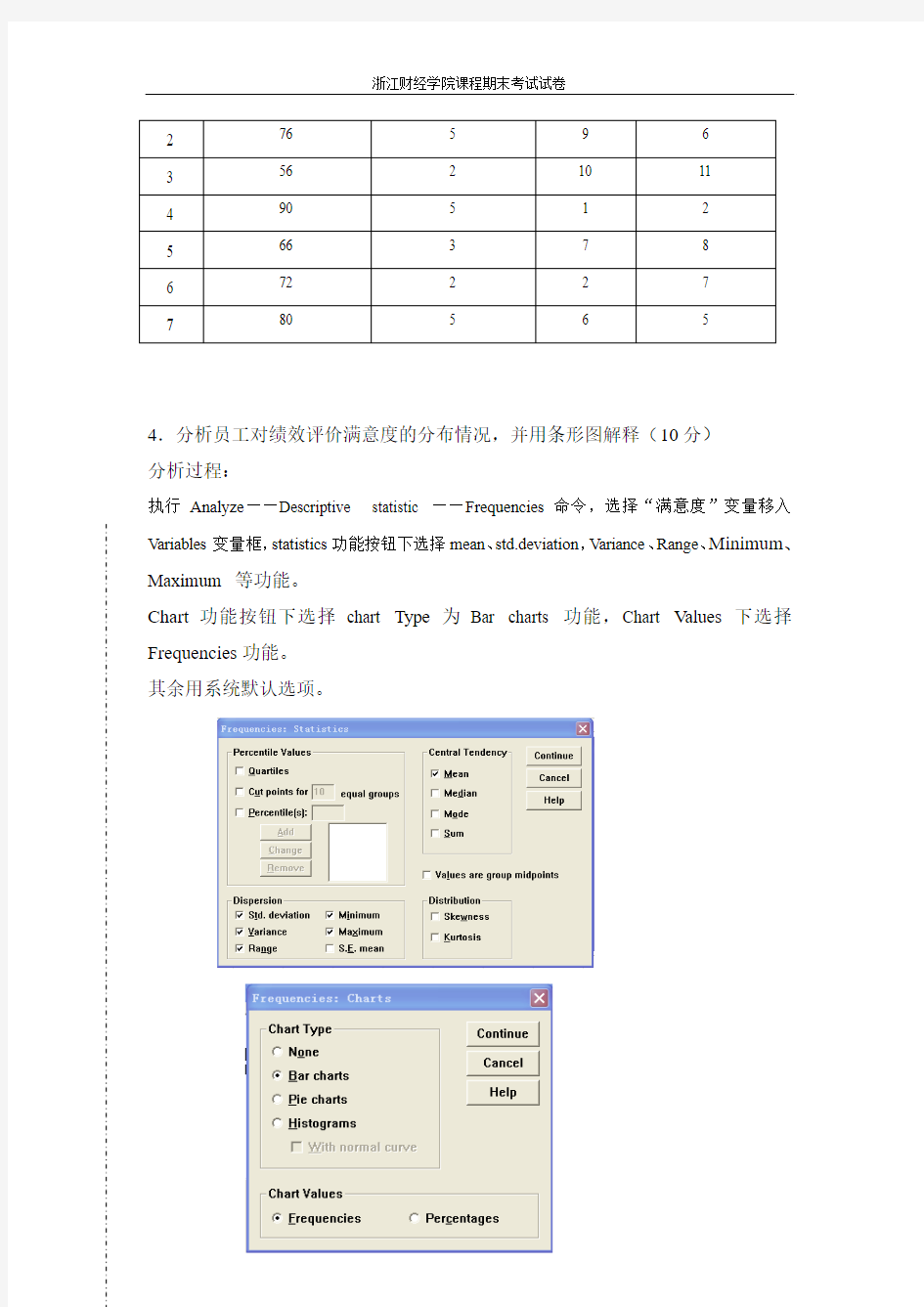
4.分析员工对绩效评价满意度的分布情况,并用条形图解释(10分)
分析过程:
执行Analyze——Descriptive statistic ——Frequencies命令,选择“满意度”变量移入
Variables变量框,statistics功能按钮下选择mean、std.deviation,Variance、Range、Minimum、Maximum 等功能。
Chart功能按钮下选择chart Type为Bar charts 功能,Chart Values下选择Frequencies功能。
其余用系统默认选项。
分析结果及分析:
F r e q u e n c y
5.按员工绩效评分指标对员工进行等级分组,分组标准为:60分以下,61-75分,76-85分,86分以上。(5分) 操作过程:
执行Transform ——recode ——into different Variables 命令,选择“绩效评分”变量移入input Variable ——output Variable 变量框,定义output Variable 的变量名为“评分分组”,点击Change 按钮。定义Old and New Values ,过程及结果如下:
结果分析:
6.统计不同性别员工的奖金情况,奖金金额发放标准为:以绩效评价评分为计算依据,绩效评分的每分奖励98元奖金。描述不同性别员工的平均奖金,最高与最低奖金,总奖金,奖金的标准差等情况(10分)
操作过程:
(1)计算奖金:
执行Transform——compute命令,定义Target Variable 为“奖金”,定义Numeric Expression 计算公式为“绩效评分”×98。
(2)描述不同性别员工的平均奖金,最高与最低奖金,总奖金,奖金的标准差等情况
执行Analyze——Reports——OLAP Cubes命令打开分层报告主对话框,选择性别做为分组变量,奖金变量为描述变量,statistics命令下选择sum、mean、std.deviation,Minimum、Maximum 等功能。
结果分析:
OLAP Cubes
OLAP Cubes
性别:女性
二、比较不同性别人群的绩效评分均值是否存在显著差异(10分)
操作过程:
打开数据文件,执行
Analyze →Compare means →Independent-Sample T Test 命令,打开对话框从源文件量清单中选择绩效评分变量移至Test Variable 框选择性别变量做为分组变量移入Grouping Variable框内,单击按钮Define Grouping功能按钮打开Define groups对话框,group1输入0,group2输入1,单击Options按钮,打开选项对话框,设置置信概率及缺损值的处理方式。单击OK,提交系统运行。结果及分析:
方差分析sig=0.879>0.05 ,接受原假设(方差相等),方差齐性,
t检验值为-0.109,显著性概率为0.916,表明不同性别员工的绩效评分不存在显著差异。
三、试分析对绩效结果的不同满意度员工的绩效评分均值是否存在显著差异(假
设绩效评分服从正态分布,显著性水平为0.05),如果存在显著差异,请用LSD方法检验哪些满意度水平之间存在显著差异?(15分)
操作过程:
执行Analyze →Compare means →One Way ANOV A命令,打开对话框。
选择满意度变量为分组变量,绩效评分为描述变量。
Post Hoc检验选项对话框选择LSD方法进行多重比较检验。其余用系统默认选项。
结果及分析:
Sig=0.113>0.05,方差齐性。由于ANOVA表中Sig.=0.008<0.05,不同满意度员工
的绩效评分均值是否存在显著差异,运用LSD进行多重检验,员工满意度2和3,
4和5对绩效评分均值无显著性差异,其余满意度之间绩效评分均值有显著性差
异。
四、答案
(1)计算相关系数:执行Analyze →Correlate →Bivariate 命令,打开Bivariate Correlate对话框将正点率与投诉次数两个变量选入Variables变量框。选择peason 相关系数法。
结果及分析
相关系数R=-0.888, sig=0.000<0.05 ,拒绝原假设(线性无关),
因此,正点率与投诉次数负相关。
2.用正点率为自变量,投诉次数为因变量,求出估计回归方程,并解释回归系
数的意义(5分)
执行过程:
执行Analyze →Regression →Linear命令,打开对话框
从源文件量清单中选择投诉次数变量移入Dependent框中,选择正点率变量作为自变量移入Independent 框中。
结果及分析
投诉次数=424.145-4.621*正点率
回归系数的意义为正点率每提高一个单位,旅客的投诉次数会相应减少4.6个单位。
常数a和b的显著性概率0.000<0.05,拒绝原假设(B=0),回归效果较好。
《统计分析软件》试(题)卷 班级 xxx班姓名 xxx 学号 xxx 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: 描述统计量 性别N极小值极大值均值标准差 男数学477.0085.0082.2500 3.77492有效的 N (列表状态)4 女数学1667.0090.0078.50007.09930有效的 N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
课程名称:《SPSS分析方法与应用》 课程号: 2007422 一、单项选择题(共112小题) 1、试题编号:1000110,答案:RetEncryption(D)。 SPSS的安装类型有() A. 典型安装 B.压缩安装 C.用户自定义安装 D.以上都是 2、试题编号:1000310,答案:RetEncryption(D)。 数据编辑窗口的主要功能有() A.定义SPSS数据的结构 B.录入编辑和管理待分析的数据 C.结果输出 和B 3、试题编号:1000410,答案:RetEncryption(A)。 ()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。 4、试题编号:1000510,答案:RetEncryption(D)。 ()是SPSS为用户提供的基本运行方式。 A.完全窗口菜单方式 B.程序运行方式 C.混合运行方式 D.以上都是 5、试题编号:1000810,答案:RetEncryption(D)。 ()是SPSS中有可用的基本数据类型 A.数值型 B.字符型 C.日期型 D.以上都是 6、试题编号:1000910,答案:RetEncryption(D)。 spss数据文件的扩展名是( ) A..htm B..xls C..dat D..sav 7、试题编号:1001010,答案:RetEncryption(B)。 数据编辑窗口中的一行称为一个() A.变量 B.个案 C.属性 D.元组 8、试题编号:1001110,答案:RetEncryption(C)。
变量的起名规则一般:变量名的字符个数不多于() A. 6 B. 7 C. 8 D. 9 9、试题编号:1001210,答案:RetEncryption(A)。 统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 B.定距型数据 C.定序型数据 D.定类型数据 10、试题编号:1001310,答案:RetEncryption(A)。 在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 B.降序排序 C.不排序 D.可升可降 11、试题编号:1001810,答案:RetEncryption(A)。 SPSS算术表达式中,字符型()应该用引号引起来。 A 常量 B变量 C算术运算符 D函数 12、试题编号:1001910,答案:RetEncryption(A)。 复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 B AND C OR D都不是 13、试题编号:1002010,答案:RetEncryption(A)。 数据选取的方法中,()是按符合条件的数据进行选取。 A 按指定条件选取 B 随即选取 C选取某一区域内样本 D过滤变量选取 14、试题编号:1002110,答案:RetEncryption(B)。 通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的。 A 数据转置 B 加权处理 C 数据才分 D以上都是 15、试题编号:1002210,答案:RetEncryption(A)。 SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 B 加权处理 C 数据才分 D以上不都是 16、试题编号:1002310,答案:RetEncryption(B)。 SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。 A、哈佛大学 B、斯坦福大学 C、波士顿大学 D、剑桥大学 17、试题编号:1002710,答案:RetEncryption(D)。 SPSS中进行参数检验应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 18、试题编号:1002810,答案:RetEncryption(A)。 SPSS中进行输出结果的保存应选择()主窗口菜单。 A、视图 B、编辑 C、文件 D、分析 19、试题编号:1002910,答案:RetEncryption(C)。 SPSS中进行数据的排序应选择()主窗口菜单。 A、视图 B、编辑 C、数据 D、分析
《统计分析软件》试(题)卷 班级XXX 班姓名XXX 学号XXX ____________ 1. 2. 考试时间为100分钟; 3. 每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav ;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav ”与“学生成绩二.sav ”合并,并保存为“成绩.sav. ” (2)对所建立的数据文件“成绩.sav ”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X > 85),良(75 < X < 84),中(X < 74),并对优良中的人数进行统计
分析: (2) 描述统计量
性别:rj sxcj 11391.0090.0061.00242.0D 1.00 r 214女91.0090.0061 Q0242,00 1.D0 31女95.0079.0065.00239.03200匸4Q女95.0079.0065 00239.00 2.D0 53立92.00B4.0062.00230.00200 S 4 女92.0084.0062 00238.00 2.00 79女眨00S2.0062.00236.00200 310女92.0002.0062 0023G.OO 2 DO 95男39.00S5.0D69 00233.03 1.00 10E男39.0085.0059 00233.00 1.00 1111立9U.OO SO.OO60.00230.0J200「1212女90.0080.0060 00230.00 2.00 1319立眨0075.0062.00229.03200 20女92.0076.00G2 00229.00 2 DO 1 1516男SB.00B2.0053.00220.03200 15男38.0077.0068 00223.00200 1 1717女91.0071.00 61 00223.00 3.00 女91.0071.0061 00223.03 3.00 1016 1 19 1女89.0067.0059 00215.00 3.00 202女39.0067.0069 00215.0J 3. DO 注:成绩优良表示栏位sxcj 优为1良为2中为3 由表统计得,成绩为优的同学有4人,占总人数的20%良的同学有12人,占总人数的60%中的同学有4人,占总人数的40% 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进 行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调 查.exe ”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查.Sav ”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
t检验:一般是用于检验两组观测值的均值之间差异是否显著的统计分析方法。 单样本t检验:用于检验样本均值与总体均值或某个已知值之间的差异的显著性。如果总体均值已知,那么样本均值与总体均值之间的差异显著性检验就属于单样本的t检验。 独立样本t检验:独立样本指的是样本之间彼此独立,没有任何关联。两个独立样本的t检验用于检验两个不相关样本在相同变量上的观测值均值之间差异的显著性。要求①正态性,各个样本均来自于正态分布的总体;②方差齐性,各个样本所在的总体的方差相等;③独立性,两组数据之间是相互独立的,不能够相互影响。 配对样本t检验:配对样本(或相关样本)指两个样本的数据之间彼此有关联。配对样本t 检验用于检验两个相关样本的均值或一个样本,两次测量结果的均值之间差异的显著性。 方差分析:是一种通过分析样本数据的各项变异来源,以检验三个或三个以上样本平均 数是否具有显著性差异的一种统计方法。 单因素方差分析:用于检验一个因素变量的不同水平是否给一个(或几个相互独立的)因变量造成了显著的差异或变化。 多重比较:进行了全方差分析之后,当自变量有3个或3个以上水平时,还有要对每两个组之间均值的差异进行比较,这称作事后组间均值的“多重比较”。 多因素方差分析:是检验两个或两个以上因素变量(自变量)的不同水平是否给一个(或几个相互独立的)因变量造成了显著的差异或变化的分析方法。 主效应和“交互作用”效应:主效应考察的是在忽略其他因素的情况下一个自变量对观察变量的影响,即这一个因素变量的不同水平分组下的观测值的均值之间的差异是否显著。当一个自变量的单独效应随另一个自变量的水平的不同而不同时,则这两个自变量对因变量的影响存在交互作用。 协变量方差分析:是在进行方差分析时将那些除了要考察的自变量之外的、很难控制的、且对因变量产生显著影响的无关变量作为“协变量”,在分析自变量对因变量的影响时,消除协变量对因变量的影响,从而使分析的结果更准确。。 多元方差分析:有两个或两个以上的因变量的方差分析(可以是单因素的,也可以是多因素的)称为多元方差分析。 重复测量的方差分析:用于某个测量指标对每个被试在不同的时间内进行多次(3次或3次以上)重复测量的情况。 组间因素:是被试分组的因素,组间因素有几个水平就把被试划分成几个组。 组内因素:又称重复测量因素,就是测试的不同水平或不同次数,是在每个被试内的因素。组内因素的不同水平决定了重复测量的次数。 方差成分分析:是对混合效应模型的分析,如对单变量重复测量和随机区组设计的分析,用于分析混合效应模型中各随机效应对因变量变异贡献的大小。通过对方差的成分进行分析,可以确定如何减小方差。 相关分析:是分析两个变量观测值变化的一致性程度或密切程度的统计方法。 简单相关分析:用于只对两个变量的数据做相关分析,其中包括两个连续变量之间的相关和两个等级变量之间的秩相关。 偏相关分析:是控制第三变量(或其他多个变量)的影响后,两变量间相关程度的统计方法。皮尔逊相关:是对两列变量为连续等间隔(等距、等比)数据,而且数据呈正态分布的相关
SPSS在教育研究中的应用某大学学生对本校的满意度调查 学院:教育学院 专业:课程与教学论 学号:201411000156 姓名:李平 2014年12月13日
目录 一、研究问题的提出 (3) 二、研究内容与方法 (3) (一) 研究内容 (3) (二) 研究方法 (3) 三、调查对象及人数 (4) 四、问卷分析 (5) (一)回收情况 (5) (二)信度分析 (5) 五、数据统计与分析 (6) (一)数据输入 (6) (二)数据分析 (7) 1.描述统计 (7) (1)多选题描述统计 (7) (2)单选题描述统计 (9) 2.推断统计 (12) (1)独立样本T检验 (12) (2)单一样本T检验 (15) (3)单因素方差分析 (17) (4) X2检验 (21) 3.相关分析 (22) (1)变量间相关分析 (22) (2)维度间相关分析 (23) 六、结论 (27) 七、附录 (28)
一、研究问题的提出 学生的学校生活和成长密切相关。我们通过对他们的大学生活满意度的调查结果向有关部门提出建议,并希望能引起学校对这一系列问题的关注,最终希望大学生对其大学的满意度有所提升,大学生是一个庞大的群体,特别是近几年,随着高校的扩招,我国越来越多人能够上大学。上大学是很多人的梦想,他们都憧憬着大学校园的生活,然而当他们进了大学后才发现大学生活并非所想的美好,取而代之的却是对校园生活的不满,大学生是十分宝贵的人才资源,他们对校园生活的体验和感受,与他们的更好的学习。 二、研究内容与方法 (一)研究内容 了解学生对于学校的师资水平、环境、日常管理等各方面的满意度。 (二)研究方法 1.问卷编制 本研究采用自编问卷,问卷共由两部分组成:基本情况部分包括被调查者的性别、年级等,问卷主体部分包括师资水平、学校环境、日常管理三大维度,细分为12个三级指标(见表2-1),问卷采用五点制计分法,即“非常满意”、“满意”、“一般”、“不满意”、“非常不满意”,分别赋值5分、4分、3分、2分、1分。 表2-1 某大学学生对本校的满意度测评指标体系 一 级指标 二级指标(潜在变量)三级指标(观测变量) 对自己师资水平对教师教学方法、对教师工作态 度、对教师人品修养、对师资配备 学校的意学校环境对学习环境、对就餐环境、对居住 环境、对校园绿化环境 满度指数日常管理对专业课时安排、对收费标准、对 奖、助学金制度、对学校治安
●一。变量的赋值 1.乘方(**),例如二的三次方:2**3 2.不同规则的赋值:转换→计算变量(如果),每一个规则的赋值都要重新进行此步骤(但注意每一遍的变量名都不变,并且他都会问你要不要替换成新的变量,你选是就行了) 3.不同规则的赋值:(1)转换→重新编码为不同变量:输入变量,输出变量,要点击“变化量”才可保存输出变量→新值和旧值:值(直接选取取值)、范围(最大到最小的范围,包含端点值),点击“添加”成功保存新值和旧值→所有不同取值规则都完成后点击继续、确定,则在变量视图多出一个新变量(2)若不想包含端点值,可以采取小数的方式变换,eg. 899.9(小数位比该变量属性的小数位多一位就行了) (3)这种要先把BMI按照男女分开,然后再分组的,可以在对话框中点击“如果”选项进行设置,并且要分别对男女进行上述操作(一共做两遍)。 二。离散化 1可视离散化:转换→可视分箱,分割点:所以想生成几组,就定义几个分割点;填写第一个分割点的时候就必须填写最小值;一定要选中上端点排除。 三。排序 1.转换→自动重新编码:不分组,从头到尾排序 2.转换→个案排秩(1)多层次数据:基于A变量对B变量进行排序。(例如,基于职称对收入进行排序,就是不同职称各自组内排工资的高低)(2)设置秩1;绑定值 四。时间序列:转换→变动值 五。查找与计数:转换→对个案内的值计数(查找“基本工资800-900女职工”,生成新变量,满足这个条件的标为1,不符合这个标准的标为0,男职工标为缺失。范围:包含上限下限) ●六。数据→个案排序:把变量顺序完全按照你想要的标准排序,所有的变量顺序都会改变 七。拆分文件:要分男女进行数据统计:数据→拆分文件→比较组/按组输出,分组依据。不分男女进行数据统计:数据→拆分文件→分析所有个案 八。选择个案(例如只选择三年级的变量进行分析):数据→选择个案→如果条件满足:如果;随机个案样本;基于时间或个案范围;使用过滤变量(例如要把身高为缺失值和值为0的剔除)→输出:过滤(不符合条件的数据会画上“/”,原始数据并未删除);将选定个案复制到新数据集(形成一个新的SPSS数据文件,原始数据并未删除);删除未选定的个案(删除原始数据,不建议使用)→之后在分析的时候就只会分析三年级的变量。不想只分析三年及,记得重新做这一步。 九。加权个案:数据→加权个案(例。100分的有5人)。不想加权了,记得重新做这一步。 十。分类汇总(1)例如算不同年级的人的身高的均值、方差…(只能计算函数)(2)数据→汇总,分界变量(分类标准变量),变量摘要(计算变量),函数:选择计算变量函数,变量名称与标签:定义新生成变量的名称与标签 ●十一。长宽数据的转换 1.长数据变宽数据:索引变量消失变成score的尾缀 (1)数据→重组(重构)→个案重组为变量,标识变量,索引变量,电脑会自动帮你选出是xx xx要重构(不同疗程值不同的变量)。选完上述这些之后就一直点下一步&完成&立即重构&确定即可 (2)注意:当有多个变量需要重构时要自己决定“新变量组的顺序”。(A1A2B1B2;A1B1A2B2) 2.宽数据变长数据:score的尾缀消失变成索引变量 (1)数据→重组(重构)→变量重组为个案,个案组标识:使用选定变量,固定变量(手动选择,电脑不会自动帮你选出了),要转置的变量即值不固定的要重构的变量(手动选择,电脑不会自动帮你选出了)。选完上述这些之后就一直点击下一步&完成&立即重构数据&确定就行了 (2)当有多个变量需要重构时,这块的操作要特别注意:○1首先在“变量组数目”中选择“多个”○2然后在“选择变量”里要对于不同的“目标变量”分别定义“要转置的变量”(在本题中,即对于kidid目标变量定义一遍要转置的变量;对于age目标变量在定义一遍要转置的变量。其中,这两个要转置的变量必须是完全不同的)。但只需要定义一次“个案组标识”&“固定变量”(固定变量是相对于kidid & age都固定的那些变量;而不是说在对kidid进行转置的时候,age就是固定变量了;因此,固定变量只用定义一次且固定变量可以为空)。并且,你要特别注意,“个案组标识”里选择的变量& n个“要转置的变量”里选择的变量&“固定变量”里选择的变量都必须是完全不相同的。
《统计分析软件》试(题)卷 班级xxx班姓名xxx 学号xxx 题号一二三四五六总成绩成绩 说明:1.本试卷分析结果写在每个题目下面(即所留空白处); 2.考试时间为100分钟; 3.每个试题20分。 一、(20分)已经给出某个班的学生基本情况及其学习成绩的两个SPSS数据文件,学生成绩一.sav;学生成绩二.sav。要求: (1)将所给的两个SPSS数据文件“学生成绩一.sav”与“学生成绩二.sav”合并,并保存为“成绩.sav.” (2)对所建立的数据文件“成绩.sav”进行以下处理: 1)按照性别求出男、女数学成绩的各种统计量(包括平均成绩、标准差等)。 2)计算每个学生的总成绩、并按照总成绩的大小进行排序 3)把数学成绩分成优、良、中三个等级,规则为优(X≥85),良(75≤X ≤84),中(X≤74),并对优良中的人数进行统计。
分析: (2) 描述统计量 性别N 极小值极大值均值标准差 男数学 4 77.00 85.00 82.2500 3.77492 有效的N (列表状态) 4 女数学16 67.00 90.00 78.5000 7.09930 有效的N (列表状态)16
注:成绩优良表示栏位sxcj 优为1 良为2 中为3 由表统计得,成绩为优的同学有4人,占总人数的20%;良的同学有12人,占总人数的60%;中的同学有4人,占总人数的40%。 二、(20分)为了解笔记本电脑的市场情况,针对笔记本电脑的3种品牌,进行了满意度调查,随机访问了30位消费者,让他们选出自己满意的品牌,调查结果见下表,其中变量“职业”的取值中,1表示文秘人员,2表示管理人员,3表示工程师,4表示其他人;3个品牌变量的取值中,1表示选择,0表示未选数据见Excel数据文件“调查.exe”。根据所给数据完成以下问题 (1)将所给数据的Excel文件导入到SPSS中,要求SPSS数据文件写出数据结构(包括变量名,变量类型,变量值标签等)命,并保存为:“调查. Sav”。 (2)试利用多选项分析,利用频数分析来分析消费者对不同品牌电脑的满意度状况;分析不同职业消费者对笔记本品牌满意度状况。 分析:
江苏理工学院2017—2018学年第1学期 《spss软件应用》上机操作题库 1.随机抽取100人,按男女不同性别分类,将学生成绩分为中等以上及中等以下两类,结果 如下表。问男女生在学业成绩上有无显著差异? 中等以上中等以下 男 女 性别* 学业成绩交叉制表 计数 学业成绩 中等以上中等以下 合计 性别男23 17 40 女38 22 60 合计61 39 100 根据皮尔逊卡方检验,p=0.558〉0.05 所以男生女生在学业成绩上无显著性差异。 2.为了研究两种教学方法的效果。选择了6对智商、年龄、阅读能力、家庭条件都相同的儿童进行了实验。结果(测试分数)如下。问:能否认为新教学方法优于原教学方法(采用非参数检验)? 序号新教学方法原教学方法 1 83 78
2 3 4 5 6 69 87 93 78 59 65 88 91 72 59 答:由威尔逊非参数检验分析可知p=0.08〉0.05,所以不能认为新教学方法显著优于原教学方法。 3.下面的表格记录了某公司采用新、旧两种培训前后的工作能力评分增加情况,分析目的是比较这两种培训方法的效果有无差异。考虑到加盟公司时间可能也是影响因素,将加盟时间按月进行了记录。 方法加盟时间分数方法加盟时间分数 旧方法 1.5 9 新方法 2 12 旧方法 2.5 10.5 新方法 4.5 14 旧方法 5.5 13 新方法7 16 旧方法 1 8 新方法0.5 9 旧方法 4 11 新方法 4.5 12 旧方法 5 9.5 新方法 4.5 10 旧方法 3.5 10 新方法 2 10 旧方法 4 12 新方法 5 14 旧方法 4.5 12.5 新方法 6 16 (1)分不同的培训方法计算加盟时间、评分增加量的平均数。 (2)分析两种培训方式的效果是否有差异? 答:(1) 描述统计量 N 极小值极大值均值标准差 培训方法 = 1 (FILTER) 9 1 1 1.00 .000 加盟时间9 .50 7.00 4.0000 2.09165 分数增加量9 9.00 16.00 12.5556 2.60342 有效的 N (列表状态)9 所以新方法的加盟时间平均数为4 分数增加量的平均数为12.5556
spss期末考试上机复习题(含答案)
————————————————————————————————作者:————————————————————————————————日期:
江苏理工学院2017—2018学年第1学期 《spss软件应用》上机操作题库 1.随机抽取100人,按男女不同性别分类,将学生成绩分为中等以上及中等以下两类,结果 如下表。问男女生在学业成绩上有无显著差异? 中等以上中等以下 男23 17 女38 22 性别* 学业成绩交叉制表 计数 学业成绩 合计 中等以上中等以下 性别男23 17 40 女38 22 60 合计61 39 100 卡方检验 值df 渐进 Sig. (双侧) 精确 Sig.(双侧) 精确 Sig.(单侧) Pearson 卡方.343a 1 .558 连续校正b.142 1 .706 似然比.342 1 .558 Fisher 的精确检验.676 .352 线性和线性组合.340 1 .560 有效案例中的 N 100 a. 0 单元格(.0%) 的期望计数少于 5。最小期望计数为 15.60。 b. 仅对 2x2 表计算 根据皮尔逊卡方检验,p=0.558〉0.05 所以男生女生在学业成绩上无显著性差异。 2.为了研究两种教学方法的效果。选择了6对智商、年龄、阅读能力、家庭条件都相同的儿童进行了实验。结果(测试分数)如下。问:能否认为新教学方法优于原教学方法(采用非参数检验)? 序号新教学方法原教学方法 1 2 3 83 69 87 78 65 88
4 5 6 93 78 59 91 72 59 检验统计量b 原教学方法 - 新 教学方法 Z -1.753a 渐近显著性(双侧) .080 a. 基于正秩。 b. Wilcoxon 带符号秩检验 答:由威尔逊非参数检验分析可知p=0.08〉0.05,所以不能认为新教学方法显著优于原教学方法。 3.下面的表格记录了某公司采用新、旧两种培训前后的工作能力评分增加情况,分析目的是比较这两种培训方法的效果有无差异。考虑到加盟公司时间可能也是影响因素,将加盟时间按月进行了记录。 方法加盟时间分数方法加盟时间分数 旧方法 1.5 9 新方法 2 12 旧方法 2.5 10.5 新方法 4.5 14 旧方法 5.5 13 新方法7 16 旧方法 1 8 新方法0.5 9 旧方法 4 11 新方法 4.5 12 旧方法 5 9.5 新方法 4.5 10 旧方法 3.5 10 新方法 2 10 旧方法 4 12 新方法 5 14 旧方法 4.5 12.5 新方法 6 16 (1)分不同的培训方法计算加盟时间、评分增加量的平均数。 (2)分析两种培训方式的效果是否有差异? 答:(1) 描述统计量 N 极小值极大值均值标准差 培训方法 = 1 (FILTER) 9 1 1 1.00 .000 加盟时间9 .50 7.00 4.0000 2.09165 分数增加量9 9.00 16.00 12.5556 2.60342 有效的 N (列表状态)9 所以新方法的加盟时间平均数为4 分数增加量的平均数为12.5556 描述统计量
第1题:基本统计分析1 分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。 1、基本思路: (1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。分组后进行频数分析并绘制带正态曲线的直方图。 (2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。 操作步骤: (1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。 存取款金额1 频率百分比有效百分比累积百分比 有效1.00 82 34.6 34.6 34.6 2.00 76 32.1 32.1 66.7 3.00 10 4.2 4.2 70.9 4.00 22 9.3 9.3 80.2 5.00 47 19.8 19.8 100.0 合计237 100.0 100.0 (2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。 统计量 存(取)款金额 20岁以下 N 有效 1 缺失 0 百分位数 25 50.00 50 50.00 75 50.00 20~35岁 N 有效 131 缺失 0 百分位数 25 500.00 50 1000.00 75 5000.00 35~50岁 N 有效 73 缺失 0 百分位数 25 500.00 50 1000.00 75 4500.00 50岁以上 N 有效 32 缺失 0 百分位数 25 525.00 50 1000.00 75 2000.00 结果及结果描述: 频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
SPSS四种输出结果:枢轴表/轻量表、文本格式、统计图表、模型 SPSS四种窗口:语法窗口、输出窗口、数据窗口、脚本窗口 SPSS三种运行方式:命令行方式、批程序方式、菜单对话框 SPSS默认文件类型: 数据文件*.sav:此为SPSS软件默认的数据文件格式,双击可由SPSS直接读取。 命令文件*.sps:可在语法编辑程序(syntax)中先编写或贴上欲执行之分析指令,并将其存贮起来,供日后重复使用或检查之用。 输出文件*.spo: 允许直接加以编辑或转贴到其他编辑软件,SPSS 16.0版之后将输出文件的默认格式改为*.spv。 数据文件清洗——多余重复的数据筛选清楚,将确实的数据补充完整,将错误的数据纠正或删除。数据→标识重复个案标识异常个案 问题的答案被称作变量的取值。将答案转变成可用于统计分析的数据,需要经过一个被称作“编码coding”的过程。 数据阵/数据文件:n个案例、m个变量构成的阵列 SPSS对数据的处理是以变量为基础的。 所以,数据录入前一定先定义变量及其属性,包括指定名称、(存储)类型、宽度、小数、标签、值、缺失、列(宽)、对齐、度量标准和角色。这也被称作建立数据框架。 变量名必须以字母、汉字或字符@开头,数字不可以,其他字符可以是任何字母、数字或_、@、#、$等符号。变量名中不能有空白字符或其他特殊字符(如“!”、“?”、“*”等)。变量名最后一个字符不能是英文句号(.)。 在SPSS中不区分大小写。例如,HXH、hxh或Hxh对SPSS而言,均被视为同一个变量。 SPSS的保留字不能作为变量的名称,如ALL、AND、BY、EQ、GE、GT、LT、NE、NOT、OR、TO、WITH等。 SPSS中变量有3种基本类型:数值型、字符型(区分大小写)和日期型。 但根据不同的显示方式,数值型又被区分成:数值、逗号、圆点、科学计数法、美元、(用户)设定货币等6个子类型。不过,只有数值(N)最为常用。 默认状态下,所有变量的类型均为数值型,且宽度是8位、小数位是2位。 对话框界面可修改宽度和小数位,然后“确定”,但宽度必须大于小数位。
SPSS期末考试题型总结 一、单样本t检验(单个正态总体的均值检验与置信区间)(P48) 1、题目类型:某糖厂打包机打包的糖果标准值为,给出一系列抽取值。 问:(1)这天打包机的工作是否正常? (2)这天打包机平均装糖量的置信区间是多少? 2、操作:(1)Analyze Compare mean One-Sample T Test (2)将左边源变量X送入Test Variable(s)中,在Test Value中输入 3、结果分析:若Sig.>0.05,接受假设,即没有显著性差异 若Sig.<0.05,拒绝假设,即有显著性差异 置信区间(100+Lower,100+uppper) 二、两个样本t检验(两个正态总体的均值检验与置信区间)(P50) 1、题目类型:从A批导线抽取4根,从B批导线抽取5根。 问:这两批导线的平均电阻是否有显著差异?并求的置信区间。 2、操作:(1)Analyze Compare mean Indepvendent Sample T Test (2)将检验变量x送入Test Variable(s),将分组变量group送入 Grouping Variable (3)选按钮define Groups Use specified values,分别输入1和2. 3、结果分析:(1)若F显著性概率Sig.>0.05,接受假设,两组方差没有显著 性差异,即可认为两组方差是相等的 (2)若t显著性概率Sig.2-tailed>0.05,可以得出A、B两批电 线的电阻值没有显著差异。 三、单因素方差分析(P54) 1、题目类型:6种不同农药在相同条件下的杀虫率。 问:杀虫率是否因农药的不同而有显著性差异? 2、操作:(1)Analyze Compare mean One-Way ANOV (2)将源变量x送入Dependent List(因变量),将类型变量kind送入Factor. 3、结果分析:(1)若Sig.>0.05,接受假设,即没有显著性差异 (2)若Sig.<0.05,拒绝假设,有显著性差异,此时进一步操作:继续操作:(a)Options Homogeneity of variance test (b)Post Hoc LSD
统计分析与SPSS的应用 摘要:为对统计分析与spss应用分析所学知识进行巩固和检验,特运用所学知识进行简单的统计分析应用,下文以某校学生学期成绩进行模拟分析。 一:原始数据:10级市场营销2班成绩 分析一:综测成绩四分位数 上表表明:综测成绩的最小值为68.61分,最大值为89.15分。其中25%的学生综测成绩为74.4100分,50%的学生综测成绩为80.3740分,75%的学生综测成绩为85.2200分。四分位数差从侧面证实了学生综测成绩呈一定左偏分布。
分析二:综测成绩直方图 上图表明:该班学生的综测成绩均分为80.07分,标准差为5.62。从图中可以看出,综测成绩呈左偏性分布,在85分左右的学生人数最多,70分左右的学生人数最少。 分析三:综测成绩的基本统计量分析 上表表明:综测成绩的极差为20.55分,意味着数据相对较分散。另外,综测成绩的最小值和最大值分别为68.61分和89.15分,平均分为80.0734分,标准差为5.61963。从偏度系数可以看出,系数小于0,偏度标准误差为0.421,因而该班综测成绩呈左偏分布,。从峰度系数可以看出,峰度值小于0,峰度标准误差为0.821,因而数据的分布比标准正态分布更加平缓,称
为平峰分布。 分析四:各科成绩的统计量分析比较 各科成绩统计量结果分析表 由上表可知:宏观经济学的全距最大,而生产与运作管理的全距最小,表明宏观经济学的成绩离散程度最高,而生产与运作管理的成绩离散程度最低;同时,对于标准差而言,也是宏观经济学的标准差最大而生产与运作管理的标准差最小。各科成绩平均分最高的为体育成绩,平均分最低的为英语成绩。各科成绩中只有人力资源管理的成绩是呈右偏分布,其他各科成绩均呈左偏分布。另外,各科成绩中,只有宏观经济学的成绩呈尖峰分布,其他各科呈平峰分布。
《经济数据分析与SPSS软件应用》期末综合作业 学号:姓名:专业:班级: 注意事项: 1、请在规定的位置书写学号、姓名、专业、班级信息。 2、结合SPSS软件,呈现计量软件操作关键结果,写出必要的操作步骤,每题答案写在相应题目后面,规范回答问题。 3、规范格式:宋体五号字;(软件结果为默认即可);单倍行间距;排版整齐,不留空行。 综合作业题目(一、二题每题20分,三、四题每题30分,共100分) 一、某医药研究所考察一种药品对男性和女性的治疗效果是否有显著差异,调查了10名男性服用者及7名女性服用者,对他们服药后的各项指标进行综合评分,服用的效果越好,分值就越高,每人所得的总分见“1(综合效果).sav”,试根据表中的数据检验这种药品对男性和女性的治疗效果是否存在显著差异。 答: 群組統計資料 性别N 平均數標準偏差標準錯誤平均值 综合得分男10 105.40 34.394 10.876 女7 109.57 23.143 8.747 从检验结果看,两样本数据的方差没有显著差异,假设检验的P值大于显著性水平0.05,所以说这种药品对男性和女性的治疗效果并无显著差异。 二、为了考察火柴销售量的影响因素,选择煤气户数、卷烟销量、蚊香销量、打火石销量作为影响因素,得数据“2(多元回归).sav”。试求:(1)火柴销售量与煤气户数的偏相关系数;(2)考察火柴销售量与各影响因素之间的相关关系,建立火柴销售量对于相关因素煤气户数、卷烟销量、蚊香销量、打火石销量的线性回归模型,通过对模型的分析,找出合适的线性回归方程。 答:
从上表结果分析,排除显著性大于0.05的蚊香销量,对剩下的煤气户数、卷烟销量、打火石销量进行逐步分析。
2 SPSS四种输出结果:枢轴表/轻量表、文本格式、统计图表、模型 SPSS四种窗口:语法窗口、输出窗口、数据窗口、脚本窗口 SPSS三种运行方式:命令行方式、批程序方式、菜单对话框 SPSS默认文件类型: 数据文件*.sav:此为SPSS软件默认的数据文件格式,双击可由SPSS直接读取。 命令文件*.sps:可在语法编辑程序(syntax)中先编写或贴上欲执行之分析指令,并将其存贮起来,供日后重复使用或检查之用。 输出文件*.spo: 允许直接加以编辑或转贴到其他编辑软件,SPSS 16.0版之后将输出文件的默认格式改为*.spv。 数据文件清洗——多余重复的数据筛选清楚,将确实的数据补充完整,将错误的数据纠正或删除。数据→标识重复个案标识异常个案 问题的答案被称作变量的取值。将答案转变成可用于统计分析的数据,需要经过一个被称作“编码coding”的过程。 数据阵/数据文件:n个案例、m个变量构成的阵列 SPSS对数据的处理是以变量为基础的。 所以,数据录入前一定先定义变量及其属性,包括指定名称、(存储)类型、宽度、小数、标签、值、缺失、列(宽)、对齐、度量标准和角色。这也被称作建立数据框架。 变量名必须以字母、汉字或字符@开头,数字不可以,其他字符可以是任何字母、数字或_、@、#、$等符号。变量名中不能有空白字符或其他特殊字符(如“!”、“?”、“*”等)。变量名最后一个字符不能是英文句号(.)。 在SPSS中不区分大小写。例如,HXH、hxh或Hxh对SPSS而言,均被视为同一个变量。SPSS的保留字不能作为变量的名称,如ALL、AND、BY、EQ、GE、GT、LT、NE、NOT、OR、TO、WITH等。 SPSS中变量有3种基本类型:数值型、字符型(区分大小写)和日期型。 但根据不同的显示方式,数值型又被区分成:数值、逗号、圆点、科学计数法、美元、(用户)设定货币等6个子类型。不过,只有数值(N)最为常用。 默认状态下,所有变量的类型均为数值型,且宽度是8位、小数位是2位。 对话框界面可修改宽度和小数位,然后“确定”,但宽度必须大于小数位。 变量标签是对变量名的进一步描述,可长达120个字符 SPSS有两类缺失值:系统默认缺失值和用户定义缺失值。 对于数值型变量值,系统默认缺失值为圆点“.”,而字符型变量值的系统默认缺失值为空字符串(什么也没有)。 指定“列”实际上是设定变量的显示宽度,默认为8个字符的宽度。 统计学中,按照对事物描述的精确程度,将度量标准从低到高区分为4种类型: 定类尺度:仅能测定类别差,不能比较大小,各类之间没有顺序和等级,只能计算频数频率百分比,可以使用数值型变量,也可以是字符型变量。要符合穷尽和互斥的原则。定序尺度:可比较优劣或排序,但数值不代表绝对数量大小,可以是数值型变量,可以是字符型变量。可以计算频数、频率和累计频率、累计频数。 定距尺度:不仅能区分不同类型并排序,还能指出类别之间的差距是多少,最典型的是温度。严格来说只能加减。其0值没有物理含义,没有绝对的“0”点,故不能做乘、除运算。 定比尺度:测算两个测度值之间比值,与定距变量相比差别是有一个固定的绝对“零点”。0在定距变量中仅是一个测量值,而定比变量真正表示没有。可以加减乘除。E.g.重量、年龄
《SPSS统计软件》课程作业 要求:数据计算题要求注明选用的统计分析模块和输出结果;并解释结果的意义。完成后将作业电子稿发送至 1. 某单位对100名女生测定血清总蛋白含量,数据如下: 74.3 78.8 68.8 78.0 70.4 80.5 80.5 69.7 71.2 73.5 79.5 75.6 75.0 78.8 72.0 72.0 72.0 74.3 71.2 72.0 75.0 73.5 78.8 74.3 75.8 65.0 74.3 71.2 69.7 68.0 73.5 75.0 72.0 64.3 75.8 80.3 69.7 74.3 73.5 73.5 75.8 75.8 68.8 76.5 70.4 71.2 81.2 75.0 70.4 68.0 70.4 72.0 76.5 74.3 76.5 77.6 67.3 72.0 75.0 74.3 73.5 79.5 73.5 74.7 65.0 76.5 81.6 75.4 72.7 72.7 67.2 76.5 72.7 70.4 77.2 68.8 67.3 67.3 67.3 72.7 75.8 73.5 75.0 73.5 73.5 73.5 72.7 81.6 70.3 74.3 73.5 79.5 70.4 76.5 72.7 77.2 84.3 75.0 76.5 70.4 计算样本均值、中位数、方差、标准差、最大值、最小值、极差、偏度和峰度,并给出均值的置信水平为95%的置信区间。 解: 描述 统计量标准误 血清总蛋白含量均值73.6680 .39389 均值的 95% 置信区间下限72.8864 上限74.4496 5% 修整均值73.6533 中值73.5000 方差15.515
一、单项选择题(共112小题) 1、SPSS的安装类型有()D.以上都是 2、数据编辑窗口的主要功能有() D.A和B 3、()文件格式是SPSS独有的,一般无法通过Word,Excel等其他软件打开。A.sav 4、()是SPSS为用户提供的基本运行方式。D.以上都是 5、()是SPSS中有可用的基本数据类型 D.以上都是 6、spss数据文件的扩展名是( ) D..sav 7、数据编辑窗口中的一行称为一个()B.个案 8、变量的起名规则一般:变量名的字符个数不多于()C. 8 9、统计学依据数据的计量尺度将数据划分为三大类,它不包括() A. 定值型数据 10、在横向合并数据文件时,两个数据文件都必须事先按关键变量值() A.升序排序 11、SPSS算术表达式中,字符型()应该用引号引起来。A 常量 12、复合条件表达式又称逻辑表达式,在逻辑运算中,下列()运算最优先。 A.NOT 13、数据选取的方法中,()是按符合条件的数据进行选取。A 按指定条件选取 14、通过()可以达到将数据编辑窗口中的技术数据还原为原始数据的目的. B 加权处理 15、SPSS的()就是将数据编辑窗口中数据的行列互换 A 数据转置 16、SPSS软件是20世纪60年代末,由()大学的三位研究生最早研制开发的。B、斯坦福大学 17、SPSS中进行参数检验应选择()主窗口菜单。D、分析 18、SPSS中进行输出结果的保存应选择()主窗口菜单。A、视图 19、SPSS中进行数据的排序应选择()主窗口菜单。C、数据 20、SPSS中绘制散点图应选择()主窗口菜单。C、图形 21、SPSS中生成新变量应选择()主窗口菜单。A、转换 22、SPSS中聚类分析应选择()主窗口菜单。D、分析 23、()的功能是定义SPSS数据的结构、录入编辑和管理待分析的数据。 A.数据编辑窗口 24、()的功能是显示管理SPSS统计分析结果、报表及图形。 B.结果输出窗口 25、Spss输出结果保存时的文件扩展名是()B..spv 26、()是访问和分析Spss变量的唯一标识。B.变量名