
1.数据检查,即空间数据探索分析(ESDA)
在地统计分析中,克里格方法是建立在平稳假设的基础上,这种假设在一定程度上要求所有数据值具有相同的变异性。另外,一些克里格插值(如普通克里格法、简单克里格法和泛克里格法等)都假设数据服从正态分布。如果数据不服从正态分布,需要进行一定的数据变换使其服从正态分布。因此,在用地统计分析创建表面之前,了解数据的分布状况十分重要。在ArcGIS GA模块中,主要提供了两种方法检验数据的分布:直方图法和正态QQPlot 图法。
(1)直方图显示数据的概率分布特征以及概括性的统计指标
图1
上图中所展示的数据,中值接近均值、峰值指数接近3。从图中观察可认为近似于正态分布。
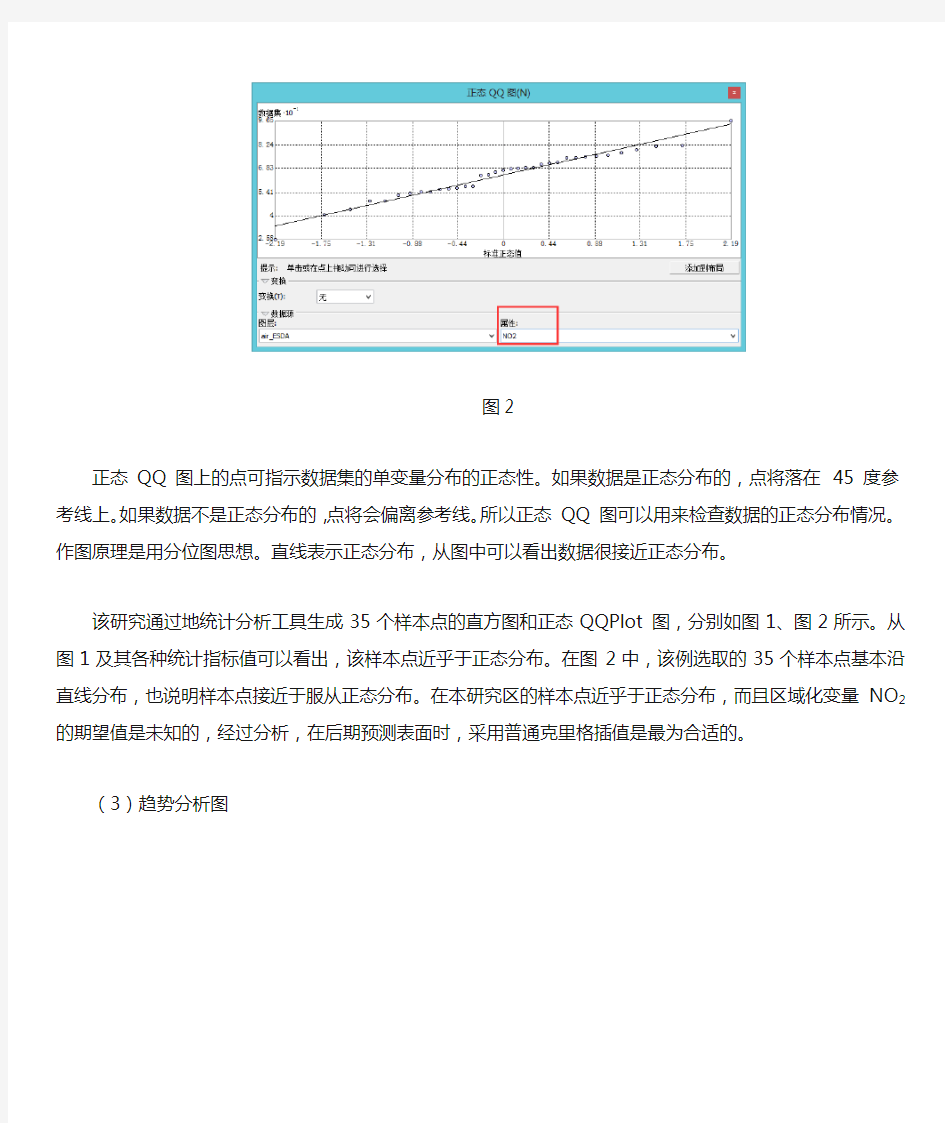
(2)正态QQ Plot 图
图2
正态QQ 图上的点可指示数据集的单变量分布的正态性。如果数据是正态分布的,点将落在45 度参考线上。如果数据不是正态分布的,点将会偏离参考线。所以正态QQ 图可以用来检查数据的正态分布情况。作图原理是用分位图思想。直线表示正态分布,从图中可以看出数据很接近正态分布。
该研究通过地统计分析工具生成35个样本点的直方图和正态QQPlot 图,分别如图1、图2所示。从图1及其各种统计指标值可以看出,该样本点近乎于正态分布。在图2中,该例选取的35个样本点基本沿直线分布,也说明样本点接近于服从正态分布。在本研究区的样本点近乎于正态分布,而且区域化变量NO2的期望值是未知的,经过分析,在后期预测表面时,采用普通克里格插值是最为合适的。
(3)趋势分析图
上图为NO2的空间分布趋势图,x 轴正向指向东,y 轴正向指向北,z 轴正向指向属性(此处为NO2浓度)值增大的方向,采样点(即空气质量监测站)位于xy 平面上,黑色的垂直杆的高度代表NO2浓度的大小,分别将散点投影到xz 平面和yz 平面上,然后分别用二次曲线拟合,xz 平面上的绿色曲线代表东西方向的趋势,yz 平面上的蓝色曲线代表南北方向的趋势。从图中可以看到,NO2的浓度南北方向呈现出倒U 型的趋势,东西方向也呈现出倒U 型的趋势,说明在该地区的中部地区NO2浓度最高。
趋势分析工具提供用户研究区平面上的采样点转化为以感兴趣的属性值为高度的三维视图,然后用户从不同视角分析采样数据集的全局趋势。趋势分析图中的每一根竖棒代表了一个数据点的值(该实验中是NO2的浓度)和位置。这些点被投影到一个东西向的和一个南北向的正交平面上。通过投影点可以做出一条最佳拟合线,并用它来模拟特定方向上存在的趋势。此实验中的趋势分析图中南北方向和东西方向上有明显的趋势出现,因此需要用二次曲面拟合,即在后续剔除趋势的操作中选择二次(second)。可见,使用趋势分析来分析样本点数据的走向,可以使后续的表面拟合更加客观,拟合的结果具有更大的可信程度。
(4)Voronoi 图
Voronoi 图可以用来发现离群值。Voronoi 图的生成方法:每个多边形内有一个样点,多变形内任一点到该点的距离都小于其他多边形到该点的距离,生成多边形后。某个样点的相邻样点便会与该样点的多边形有相邻边。
利用相邻点的这个定义,可计算多种局部统计量。“Voronoi 图”工具提供下列方法来指定或计算面的值。
简单:指定给面的值是在该面内的采样点处记录的值。
平均值:指定给面的值是根据面及其相邻面计算出的平均值。
众数:利用五个组距对所有多边形进行分类。指定给面的值是面及其相邻面的众数(最常出现的组)。
聚类:利用五个组距对所有多边形进行分类。如果面的组距与其每个相邻面的组距都不同,则该面将灰显并放进第六组以区分该面与其相邻面。
熵:所有的面都利用基于数据值(小分位数)的自然分组的五个组进行分类。
(5)半变异函数/协方差函数
该图可以反应数据的空间相关程度,只有数据空间相关,才有必要进行空间插值法。图表的横坐标表示任两点的空间距离,纵标表示该两点的半变异函数值。根据距离越近越相似的原理,因而x 值越小,y 值应该越小。如果任意两点的值都要计算,当采样点很多时,数据量便很大,因而根据距离和方向对样点距离进行了分组。半变异函数表面的范围由步长大小和步长数控制。下列参数便是为此要求而设置:步长大小(步长值),步长组数。步长大小(步长值)和步长组数之乘积应小于采样点区域的坐标范围的一半。
2. 制作表面预测图:
(1)选择输入数据和方法面板(2)地统计方法选择面板(Geostatistical Method Selection)
(3)趋势剔除面板(Detrending)(4)半变异函数/协方差模型面板(Semivariogram/covariance Modeling)
(5)搜索区域面板(Searching Neighbourhood)(6)交叉验证面板(Cross Validation)
(7)数据图层信息面板(Output Layer Information)图略
从上图可以看出,北京市中部的NO2浓度最高,与趋势分析图的分析结果相一致。(8)模型比较
经验贝叶斯克里金法
经验贝叶斯克里金法(EBK) 是一种地统计插值方法,可自动执行构建有效克里金模型过程中的那些最困难的步骤。Geostatistical Analyst 中的其他克里金方法需要您手动调整参数来接收准确的结果,而EBK 可通过构造子集和模拟的过程来自动计算这些参数。
经验贝叶斯克里金法与其他克里金方法也有所不同,它通过估计基础半变异函数来说明所引入的误差。其他克里金方法通过已知的数据位置计算半变异函数,并使用此单一半变异函数在未知位置进行预测;此过程隐式假定估计的半变异函数是插值区域的真实半变异函数。由于不考虑半变异函数估计的不确定性,其他克里金方法都低估了预测的标准误差。经验贝叶斯克里金法在地统计向导中以地理处理工具的形式提供。
经验贝叶斯克里金法与Geostatistical Analyst 中的其他克里金方法不同,它使用固有的0 阶随机函数(IRF-0) 作为克里金模型。其他克里金模型假定过程遵循一个总体平均值(或指定趋势),并且各种变化均围绕该平均值。较大的偏差将向平均值拉回,因此值不会偏差过大。但是,EBK 不会呈现出趋于总体平均值的趋势,因此较大偏差变大变小的可能性相同。
地统计在科学和工程的许多领域中广泛应用,例如:
采矿行业在项目的若干方面应用地统计:最初需量化矿物资源和评估项目的经济可行性,然后需每天使用可用的更新数据确定哪种材料应输送到工厂以及哪种材料是废弃物。
在环境科学中,地统计用于评估污染级别以判断是否对环境和人身健康构成威胁,以及能否保证修复。
最近在土壤科学领域中的新应用着重绘制土壤营养水平(氮、磷、钾等)和其他指标(例如导电率),以便研究它们与作物产量的关系和规定田间每个位置的精确化肥用量。
气象应用包括温度、雨量和相关的变量(例如酸雨)的预测。
最近,地统计在公共健康领域也有一些应用,例如,预测环境污染程度及其与癌症发病率的关系。
在所有这些示例中,普遍情形是某些地区中存在的一些感兴趣的现象(某一污染物对土壤、水或者空气的污染
第7 章空间数据分析模型 7.1 空间数据 按照空间数据的维数划分,空间数据有四种基本类型:点数据、线数据、面数据和体数据。 点是零维的。从理论上讲,点数据可以是以单独地物目标的抽象表达,也可以是地理单元的抽象表达。这类点数据种类很多,如水深点、高程点、道路交叉点、一座城市、一个区域。 线数据是一维的。某些地物可能具有一定宽度,例如道路或河流,但其路线和相对长度是主要特征,也可以把它抽象为线。其他的线数据,有不可见的行政区划界,水陆分界的岸线,或物质运输或思想传播的路线等。 面数据是二维的,指的是某种类型的地理实体或现象的区域范围。国家、气候类型和植被特征等,均属于面数据之列。 真实的地物通常是三维的,体数据更能表现出地理实体的特征。一般而言,体数据被想象为从某一基准展开的向上下延伸的数,如相对于海水面的陆地或水域。在理论上,体数据可以是相当抽象的,如地理上的密度系指单位面积上某种现象的许多单元分布。 在实际工作中常常根据研究的需要,将同一数据置于不同类别中。例如,北京市可以看作一个点(区别于天津),或者看作一个面(特殊行政区,区别于相邻地区),或者看作包括了人口的“体”。 7.2 空间数据分析 空间数据分析涉及到空间数据的各个方面,与此有关的内容至少包括四个领域。 1)空间数据处理。空间数据处理的概念常出现在地理信息系统中,通常指的是空间分析。就涉及的内容而言,空间数据处理更多的偏重于空间位置及其关系的分析和管理。 2)空间数据分析。空间数据分析是描述性和探索性的,通过对大量的复杂数据的处理来实现。在各种空间分析中,空间数据分析是重要的组成部分。空间数据分析更多的偏重于具有空间信息的属性数据的分析。 3)空间统计分析。使用统计方法解释空间数据,分析数据在统计上是否是“典型”的,或“期望”的。与统计学类似,空间统计分析与空间数据分析的内容往往是交叉的。 4)空间模型。空间模型涉及到模型构建和空间预测。在人文地理中,模型用来预测不同地方的人流和物流,以便进行区位的优化。在自然地理学中,模型可能是模拟自然过程的空间分异与随时间的变化过程。空间数据分析和空间统计分析是建立空间模型的基础。 7.3 空间数据分析的一些基本问题 空间数据不仅有其空间的定位特性,而且具有空间关系的连接属性。这些属性主要表现为空间自相关特点和与之相伴随的可变区域单位问题、尺度和边界效应。传统的统计学方法在对数据进行处理时有一些基本的假设,大多都要求“样本是随机的”,但空间数据可能不一定能满足有关假设,因此,空间数据的分析就有其特殊性(David,2003)。
探索性数据分析 探索性数据分析是利用ArcGIS提供的一系列图形工具和适用于数据的插值方法,确定插值统计数据属性、探测数据分布、全局和局部异常值(过大值或过小值)、寻求全局的变化趋势、研究空间自相关和理解多种数据集之间相关性。探索性空间数据分析对于深入了解数据,认识研究对象,从而对与其数据相关的问题做出更好的决策。 一数据分析工具 1.刷光(Brushing)与链接(Linking) 刷光指在ArcMap数据视图或某个ESDA工具中选取对象,被选择的对象高亮度显示。链接指在ArcMap数据视图或某个ESDA工具中的选取对象操作。在所有视图中被选取对象均会执行刷光操作。如在下面章节将要叙述的探索性数据分析过程中,当某些ESDA工具(如直方图、V oronoi图、QQplot图以及趋势分析)中执行刷光时,ArcMap数据视图中相应的样点均会被高亮度显示。当在半变异/协方差函数云中刷光时,ArcMap数据视图中相应的样点对及每对之间的连线均被高亮度显示。反之,当样点对在ArcMap数据视图中被选中,在半变异/协方差函数云中相应的点也将高亮度显示。 2.直方图 直方图指对采样数据按一定的分级方案(等间隔分级、标准差分级)进行分级,统计采样点落入各个级别中的个数或占总采样数的百分比,并通过条带图或柱状图表现出来。直方图可以直观地反映采样数据分布特征、总体规律,可以用来检验数据分布和寻找数据离群值。 在ArcGIS中,可以方便的提取采样点数据的直方图,基本步骤为: 1)在ArcMap中加载地统计数据点图层。 2)单击Geostatistical Analyst模块的下拉箭头选择Explore Data并单击Histogram。 3)设置相关参数,生成直方图。 A.Bars:直方图条带个数,也就是分级数。 B.Translation:数据变换方式。None:对原始采样数据的值不作变换,直接生成直方图。 Log:首先对原始数据取对数,再生成直方图。Box-Cox:首先对原始数据进行博克斯-考克斯变换(也称幂变换),再生成直方图。 https://www.doczj.com/doc/5513606053.html,yer:当前正在分析的数据图层。 D.Attribute:生成直方图的属性字段。 从图3.1a和图3.1b的对比分析可看出,该地区GDP原始数据并不服从正态分布,经过对数变换处理,分布具有明显的对数分布特征,并在最右侧有一个明显的离群值。 在直方图右上方的窗口中,显示了一些基本统计信息,包括个数(count)、最小值(min)、最大值(max)、平均值(mean)、标准差(std. dev.)、峰度(kurtosis)、偏态(skewness)、
研究生课程探索性空间数据分析 杜世宏 北京大学遥感与GIS研究所
提纲 一、地统计基础 二、探索性数据分析
?地统计(Geostatistics)又称地质统计,是在法国著名统计学家Matheron大量理论研究的基础上逐渐形成的一门新的统计学分支。 它是以区域化变量为基础,借助变异函数,研究既具有随机性又具有结构性,或空间相关性和依赖性的自然现象的一门科学。凡是与空间数据的结构性和随机性,或空间相关性和依赖性,或空间格局与变异有关的研究,并对这些数据进行最优无偏内插估计,或模拟这些数据的离散性、波动性时,皆可应用地统计学的理论与方法。 ?地统计学与经典统计学的共同之处在于:它们都是在大量采样的基础上,通过对样本属性值的频率分布或均值、方差关系及其相应规则的分析,确定其空间分布格局与相关关系。但地统计学区别于经典统计学的最大特点是:地统计学既考虑到样本值的大小,又重视样本空间位置及样本间的距离,弥补了经典统计学忽略空间方位的缺陷。?地统计分析理论基础包括前提假设、区域化变量、变异分析和空间估值。
? 1. 前提假设 –⑴随机过程。与经典统计学相同的是,地统计学也是在大量样本的基础上,通过分析样本间的规律,探索其分布规 律,并进行预测。地统计学认为研究区域中的所有样本值 都是随机过程的结果,即所有样本值都不是相互独立的, 它们是遵循一定的内在规律的。因此地统计学就是要揭示 这种内在规律,并进行预测。 –⑵正态分布。在统计学分析中,假设大量样本是服从正态分布的,地统计学也不例外。在获得数据后首先应对数据 进行分析,若不符合正态分布的假设,应对数据进行变换,转为符合正态分布的形式,并尽量选取可逆的变换形式。
空间数据分析报告 —使用Moran's I统计法实现空间自相关的测度1、实验目的 (1)理解空间自相关的概念和测度方法。 (2)熟悉ArcGIS的基本操作,用Moran's I统计法实现空间自相关的测度。2、实验原理 2.1空间自相关 空间自相关的概念来自于时间序列的自相关,所描述的是在空间域中位置S 上的变量与其邻近位置Sj上同一变量的相关性。对于任何空间变量(属性)Z,空间自相关测度的是Z的近邻值对于Z相似或不相似的程度。如果紧邻位置上相互间的数值接近,我们说空间模式表现出的是正空间自相关;如果相互间的数值不接近,我们说空间模式表现出的是负空间自相关。 2.2空间随机性 如果任意位置上观测的属性值不依赖于近邻位置上的属性值,我们说空间过程是随机的。 Hanning则从完全独立性的角度提出更为严格的定义,对于连续空间变量Y,若下式成立,则是空间独立的: 式中,n为研究区域中面积单元的数量。若变量时类型数据,则空间独立性的定义改写成 式中,a,b是变量的两个可能的类型,i≠j。 2.3Moran's I统计 Moran's I统计量是基于邻近面积单元上变量值的比较。如果研究区域中邻近面积单元具有相似的值,统计指示正的空间自相关;若邻近面积单元具有不相似的值,则表示可能存在强的负空间相关。
设研究区域中存在n 个面积单元,第i 个单位上的观测值记为y i ,观测变量在n 个单位中的均值记为y ,则Moran's I 定义为 ∑∑∑∑∑======n i n j ij n i n j ij n i W W n I 11 11j i 1 2i ) y -)(y y -(y )y -(y 式中,等号右边第二项∑∑==n 1i n 1j j i ij )y -)(y y -(y W 类似于方差,是最重要的项,事 实上这是一个协方差,邻接矩阵W 和) y -)(y y -(y j i 的乘积相当于规定)y -)(y y -(y j i 对邻接的单元进行计算,于是I 值的大小决定于i 和j 单元中的变量值对于均值的偏离符号,若在相邻的位置上,y i 和y j 是同号的,则I 为正;y i 和y j 是异号的, 则I 为负。在形式上Moran's I 与协变异图 {}{}u ?-)Z(s u ?-)Z(s N(h)1(h)C ?j i ∑=相联系。 Moran's I 指数的变化范围为(-1,1)。如果空间过程是不相关的,则I 的期望接近于0,当I 取负值时,一般表示负自相关,I 取正值,则表示正的自相关。用I 指数推断空间模式还必须与随机模式中的I 指数作比较。 通过使用Moran's I 工具,会返回Moran's I Index 值以及Z Score 值。如果Z score 值小于-1.96获大于1.96,那么返回的统计结果就是可采信值。如果Z score 为正且大于1.96,则分布为聚集的;如果Z score 为负且小于-1.96,则分布为离散的;其他情况可以看作随机分布。 3、实验准备 3.1实验环境 本实验在Windows 7的操作系统环境中进行,使用ArcGis 9.3软件。 3.2实验数据 此次实习提供的数据为以湖北省为目标区域的bount.dbf 文件。.dbf 数据中包括第一产业增加值,第二产业增加值万元,小学在校学生数,医院、卫生院床位数,乡村人口万人,油料产量,城乡居民储蓄存款余额,棉花产量,地方财政一般预算收入,年末总人口(万人),粮食产量,普通中学在校生数,肉类总产量,规模以上工业总产值现价(万元)等属性,作为分析的对象。
空间统计分析实验报告 一、空间点格局的识别 1、平均最邻近分析 平均最邻近距离指点间最邻近距离均值。该分析方法通过比较计算最邻近点对的平均距离与随机分布模式中最邻近点对的平均距离,来判断其空间格局,分析结果如图1所示。 图1 平均最邻近分析结果图最邻近比率小于1,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0
计算结果共有5个参数,平均观测距离,预期平均距离,最邻近比率,Z 得分,P值。 P值就是概率值,它表示观测到的空间模式是由某随机过程创建而成的概率,P 值越小,也就是观测到的空间模式是随机空间模式的可能性越小,也就是我们越可以拒绝开始的零假设。最邻近比率值表示要素是否有聚集分布的趋势,对于趋势如何,要根据Z值和P值来判断。 本实验中的最邻近比率小于1 ,聚集分布,Z值为-7.007176,P值为0,即这种情况是随机分布的概率为0,该结果说明省详细居民点的分布是聚集分布的,不存在随机分布。 2、多距离空间聚类分析 基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离围的空间相关性(要素聚类或要素扩散)。 本实验中第一次将距离段数设为10,距离增量设为1,第二次将距离段数设为5,距离增量同样为1,得到如图2和图3所示的结果。 从图中可以看出,小于3千米的距离,观测值大于预测值,居民点聚集,大于3千米,观测值小于预测值,居民点离散。且聚集具有统计意义上的聚集,离散并未具有统计意义上的显著性。 图2 K函数聚类分析结果1
1.数据检查,即空间数据探索分析(ESDA) 在地统计分析中,克里格方法是建立在平稳假设的基础上,这种假设在一定程度上要求所有数据值具有相同的变异性。另外,一些克里格插值(如普通克里格法、简单克里格法和泛克里格法等)都假设数据服从正态分布。如果数据不服从正态分布,需要进行一定的数据变换使其服从正态分布。因此,在用地统计分析创建表面之前,了解数据的分布状况十分重要。在ArcGIS GA模块中,主要提供了两种方法检验数据的分布:直方图法和正态QQPlot 图法。 (1)直方图显示数据的概率分布特征以及概括性的统计指标 图1 上图中所展示的数据,中值接近均值、峰值指数接近3。从图中观察可认为近似于正态分布。 (2)正态QQ Plot 图 图2 正态QQ 图上的点可指示数据集的单变量分布的正态性。如果数据是正态分布的,点将落在45 度参考线上。如果数据不是正态分布的,点将会偏离参考线。所以正态QQ 图可以用来检查数据的正态分布情况。作图原理是用分位图思想。直线表示正态分布,从图中可以看出数据很接近正态分布。 该研究通过地统计分析工具生成35个样本点的直方图和正态QQPlot 图,分别如图1、图2所示。从图1及其各种统计指标值可以看出,该样本点近乎于正态分布。在图2中,该例选取的35个样本点基本沿直线分布,也说明样本点接近于服从正态分布。在本研究区的样本点近乎于正态分布,而且区域化变量NO2的期望值是未知的,经过分析,在后期预测表面时,采用普通克里格插值是最为合适的。
(3)趋势分析图 上图为NO2的空间分布趋势图,x 轴正向指向东,y 轴正向指向北,z 轴正向指向属性(此处为NO2浓度)值增大的方向,采样点(即空气质量监测站)位于xy 平面上,黑色的垂直杆的高度代表NO2浓度的大小,分别将散点投影到xz 平面和yz 平面上,然后分别用二次曲线拟合,xz 平面上的绿色曲线代表东西方向的趋势,yz 平面上的蓝色曲线代表南北方向的趋势。从图中可以看到,NO2的浓度南北方向呈现出倒U 型的趋势,东西方向也呈现出倒U 型的趋势,说明在该地区的中部地区NO2浓度最高。 趋势分析工具提供用户研究区平面上的采样点转化为以感兴趣的属性值为高度的三维视图,然后用户从不同视角分析采样数据集的全局趋势。趋势分析图中的每一根竖棒代表了一个数据点的值(该实验中是NO2的浓度)和位置。这些点被投影到一个东西向的和一个南北向的正交平面上。通过投影点可以做出一条最佳拟合线,并用它来模拟特定方向上存在的趋势。此实验中的趋势分析图中南北方向和东西方向上有明显的趋势出现,因此需要用二次曲面拟合,即在后续剔除趋势的操作中选择二次(second)。可见,使用趋势分析来分析样本点数据的走向,可以使后续的表面拟合更加客观,拟合的结果具有更大的可信程度。 (4)Voronoi 图 Voronoi 图可以用来发现离群值。Voronoi 图的生成方法:每个多边形内有一个样点,多变形内任一点到该点的距离都小于其他多边形到该点的距离,生成多边形后。某个样点的相邻样点便会与该样点的多边形有相邻边。 利用相邻点的这个定义,可计算多种局部统计量。“Voronoi 图”工具提供下列方法来指定或计算面的值。 简单:指定给面的值是在该面内的采样点处记录的值。 平均值:指定给面的值是根据面及其相邻面计算出的平均值。 众数:利用五个组距对所有多边形进行分类。指定给面的值是面及其相邻面的众数(最常出现的组)。 聚类:利用五个组距对所有多边形进行分类。如果面的组距与其每个相邻面的组距都不同,则该面将灰显并放进第六组以区分该面与其相邻面。 熵:所有的面都利用基于数据值(小分位数)的自然分组的五个组进行分类。
空间统计简介 1.空间统计经典案例 最早应用空间统计分析思想可以追溯150多年前一次重大的公共卫生事件,1854年英国伦敦霍乱大流行。在这次事件中,John Snow博士利用基于地图的空间分析原理,将死亡病例标注在伦敦地图上,同时还将水井的信息也标注在地图上,通过相关分析,最后将污染源锁定在城中心的一个水井的抽水机上。在他的建议下市政府将该抽水机停用,此后霍乱大幅度下降,并得到有效的控制。John Snow利用空间分析思想控制疫情这件事具有重要的里程碑意义,它被看成了空间统计分析和流行病学两个学科的共同起源;但是此后相当长的一段时间内由于缺乏刻画数据的空间相关性和异质性的方法,人们在分析空间属性的数据时,往往把所涉及的数据自身空间效应作为噪声或者误差来处理,这种缺乏对空间自相关和异质性的刻画,限制了以地图为基础的空间属性数据在公共卫生领域中应用的深入研究。直到1950年Moran首次提出空间自相关测度来研究二维或更高维空间随机分布的现象,1951年南非学者Krige提出了空间统计学萌芽思想,后经法国数学家Matheron完善,于1963年和1967年提出了地统计学和克里金技术。1973年, Cliff和Ord发表了空间自相关(Spatial Autocorrelation)的分析方法,1981年出版了Spatial Process:Model and Application专著,形成了空间统计理论体系,以及Getis’G和Lisa提出的空间异质性的局部统计使空间统计理论日趋成熟[1][2]。近年来随着空间分析技术以及空间分析软件(如GIS、Geoda、SaTScan、Winbugs等)的迅速发展,与疾病分布有关的空间统计分析也得以较快发展。 2.什么是空间统计 空间统计具有明显的多学科交叉特征,其显著特点是思想多源、方法多样、技术复杂,并随着相关学科如计算机软硬件技术的发展而发展。空间统计分析是以地理实体为研究对象,以空间统计模型为工具,以地理实体空间相关性和空间变异性为出发点,来分析地理对象空间格局、空间关系、时空变化规律,进而揭示其成因的一门新科学。经典统计学与空间统计学的区别与联系归纳如表错误!文档中没有指定样式的文字。-1。 表错误!文档中没有指定样式的文字。-1经典统计学与空间统计学的区别与联 系
统计分析方法 思考题与练习题 9.假设Z (x )是一维区域化随机变量,满足二阶平稳假设,已知()121,z x =()215,z x =()318,z x =()423,z x =()524,z x =()621,z x =()713, z x =()814,z x =()916,z x =()1019z x =,观测点之间的距离 h=10m ,如下图所 示是计算h=10m ,20m ,…80m 时该区域化变量Z (x )的变异函数()h γ。 由公式()()()()() 21 1 2N h i i i h z x z x h N h γ==-+????∑可得h=10m ,20m ,…80m 时 该区域化变量Z (x )的变异函数()h γ如下: ()()()()()()()()()()222222222 112115151818232324242121131314141616192*91 *1588.7818 γ??= -+-+-+-+-+-+-+-+-? ?= = ()()()()()()()()()22222222 12211815231824232124132114131614192*81 *31719.8116 γ??=-+-+-+-+-+-+-+-? ?= = ()()()()()()()()2222222 1321231524182123132414211613192*71 *35525.3614 γ??= -+-+-+-+-+-+-? ?= = ()()()()()()()222222 142124152118132314241621192*61 *21918.2512 γ??= -+-+-+-+-+-? ?= = ()()()()()()22222 11521211513181423162419*949.42*510γ??= -+-+-+-+-==?? ()()()()()2222 1162113151418162319*8510.6252*48γ??=-+-+-+-==? ?
空间分析与建模复习 名词解释: 空间分析:采用逻辑运算、数理统计和代数运算等数学方法,对空间目标的位置、形态、分布及空间关系进行描述、分析和建模,以提取和挖掘地理空间目标的隐含信息为 目标,并进一步辅助地理问题求解的空间决策支持技术。 空间数据结构:是对空间数据的合理组织,是适合于计算机系统存储、管理和处理地图图形的逻辑结构,是地理实体的空间排列方式和相互关系的抽象描述与表达。 空间量测:对GIS数据库中各种空间目标的基本参数进行量算与分析, 元数据:描述数据及其环境的数据。 空间元数据:关于地理空间数据和相关信息的描述性信息。 空间尺度:数据表达的空间范围的相对大小以及地理系统中各部分规模的大小 尺度转换:信息在不同层次水平尺度范围之间的变化,将某一尺度上所获得的信息和知识扩展或收缩到其他尺度上,从而实现不同尺度之间辨别、推断、预测或演绎的跨越。 地图投影:将地球椭球面上的点映射到平面上的方法,称为地图投影。 地图代数:作用于不同数据层面上的基于数学运算的叠加运算 重分类:将属性数据的类别合并或转换成新类,即对原来数据中的多种属性类型按照一定的原则进行重新分类 滤波运算:通过一移动的窗口,对整个栅格数据进行过滤处理,将窗口最中央的像元的新值定义为窗口中像元值的加权平均值 邻近度:是定性描述空间目标距离关系的重要物理量之一,表示地理空间中两个目标地物距离相近的程度。缓冲区分析、泰森多边形分析。 缓冲区:是指为了识别某一地理实体或空间物体对其周围地物的影响度而在其周围建立的具有一定宽度的带状区域。 缓冲区分析:对一组或一类地物按缓冲的距离条件,建立缓冲区多边形,然后将这一图层与需要进行缓冲区分析的图层进行叠加分析,得到所需结果的一种空间分析方法 泰森多边形:所有点连成三角形,作三角形各边的垂直平分线,每个点周围的若干垂直平分线便围成的一个多边形 网络分析:是通过研究网络的状态以及模拟和分析资源在网络上的流动和分配情况,对网络结构及其资源等的优化问题进行研究的一种空间分析方法。(理论基础:计算机图论和运筹学) 自相关:空间统计分析所研究的区域中的所有的值都是非独立的,相互之间存在相关性。在空间和时间范畴内,这种相关性被称为自相关。
空间数据分析方法 一、绪论 1、空间分析的概念 空间分析( Spatial Analysis):包括空间数据操作、空间数据分析、空间统计分析、空间建模。 1)空间分析是对数据的空间信息、属性信息或二者共同信息的统计描述或说明。 2)空间分析是对于地理空间现象的定量研究,其常规能力是操纵空间数据成为不同的形式,并且提取潜在信息。 3)空间分析是结果随着分析对象位置变化而改变的一系列方法。4)空间分析是基于地理对象的位置和形态特征的空间数据分析技术,其目的在于提取和传输空间信息。 2、空间数据的类型 空间点数据、空间线数据、空间面数据、地统计数据 3、属性数据的类型 属性:与空间数据库中一个独立对象(记录)关联的数据项。属性已成为描述一个位置任何可记录特征或性质的术语。又分为一下几种:1)名义属性:最简单的属性类型,即对地理实体的测度,本质上是对地球实体的分类。包括数字、文字、颜色,即名义属性是数值。其作用只是区分特定的实体类。可以用众数和频率分布进行概括和比较。 2)序数属性:其定义的类型之间存在等级关系,属性值具有逻辑顺
序,本质上是一种分类等级数据,即类型必须分为不同的等级。可以进行优先级的比较运算,对名义和序数数据能够进行分类计数,所以常被称为离散变量,或定性变量。其可以用中位数和箱线图进行概括和比较。 3)间距属性:是一种对地理实体或现象的数量测度方法。其测度的是一个值对另一个值差异的幅度,但不是该值和真实零点之间的差值。由于间距属性的数值测度不是基于自然的或绝对的零点,因此数量关系的运算收到限制。间距属性之间的加减算术运算时有效的,但是乘除运算时无效的。其还可以使用均值、标准差等进行描述。4)比率属性:是数值和其真实零点之间的差异幅度的测度。对于比率属性的数据可以实施各种数学运算。 4、空间分析框架 基于Anselin和Getis(1992)提出的一般框架,GIS环境下空间分析模块的关系见右图。参照GIS输入、存储、分析和输出等功能,GIS环境下空间分析可进一步细分为选择、操作、探索和确认4种。
Statistics for spatial data; Noel A.C. Cressie, Wiley& Sons,1991 空间统计学 0 引言 0.1定义 空间统计学由于许多学科的需求发展迅速。 空间统计学涉及的领域:生物学、空间经济学、遥感科学、图像处理、环境与地球科学( 大地测量、地球物理、空间物理、大气科学等等)、生态学、地理学、流行病学、农业经济学、林学及其它学科 空间过程或随机场定义: {}(),Z s s =∈Z S (1) 式中S 是空间位置s 的集合,可以是预先确定的,也可以随机的,2d d ?=S R 是二维欧 氏空间;()Z s 取值于状态空E 。 空时过程:如考虑时间,则 {} (,),,(,)d Z s t s s t + =∈∈?Z S R R 式中S 是空间位置s 的集合,可以是预先确定的,也可以随机的;t + ∈R ;()Z s 取值于状态空E 。 注意:上述为标量值过程,但也可扩展为向量过程。 0.2 空间数据类型 0.2.1 连续型地学统计数据(Geostatistical data ) 此时, 2d d ?=S R 是连续欧氏子空间,即连续点的集合,随机场{} (),Z s s ∈S 在实值空间E 上的n 个固定位置n s s s ,,,21 取值。如图为连续型空间数据
(a )降雨量分布图;(b) 土壤孔穴分布图。(符号大小正比于属性变量值) Geostatistical (spatial) data is usually processed by the geostatistical method that has been set out in considerable detail since Krige published his important paper. In summary, this method consists of an exploratory spatial data analysis, positing a model of (non-stationary) mean plus ( intrinsically stationary) error, non-parametrically estimating variogram or covariogram, fitting a valid model to the estimate, and kriging ( predicting )unobserved parts from the available data. This last step yields not only a predictor, but a mean squared prediction error. 0.2.2 离散型格网数据(Lattice data ) 此时, 2d d ?=S R 是固定的离散空间点,非随机点集合,随机场{}(),Z s s ∈S 在 2d d ?=S R 的空间点采样。空间点可以是给定邻接图关系、表示成网状的地理区域, 如图2-a 。()Z s 是在s 观测的某种感兴趣的值状态空间可以是、也可以不是实值的,比如GDP 、工业产值、农业产值、房产价格;在遥感图像分析领域,空间点就是规则的像元(pixel)集合图2-b 。 Goals for these types of data includes constructing and analyzing explicative models, quantifying spatial correlations, classification, segmentation, prediction and image restoration
§12. 使用ArcGIS进行空间统计分析 一、软硬件环境 软件:ArcGIS 8.0版本以上,需要具有Geostatistics模块的许可; 硬件:目前主流配置即可。 二、软件及数据的准备 本例以ArcGIS 9.0为软件平台,对甘肃省30年平均降水进行空间插值的。 (1)打开ArcGIS 9.0,并把Geostatistics模块加载上。首先在工具>扩展中将相应模块选中,如图1。 图1 其次,在工具条上点击右键,把Geostatistical Analyst选中,如
图2。 图2 (2)数据准备 本例需要的是各个气象站点和观测数据,所以首先需要各个气象观测站的点图层,各个站点30年观测的平均降水量、蒸发量以及该站点的海拔高程作为属性数据,附在上述点图层上。因为是对甘肃省省域内气候进行插值,因此还必须有甘肃省的省界。并过数据加载按钮将上述数据加载上,如图3所示。
图3 (3)分析数据框架设定 在Layers上右击,点击属性,选择数据框架(Data Frame)面板,然后将甘肃省边界图层作为分析时显示的数据框架(即只显示省内区 域)。如图4:
图4 三、探索性空间数据分析(ESDA) 空间插值的模型和方法有很多,通过探索性空间数据分析,目的是寻找数据内在的规律性,再根据这些规律寻找适合的空间插值模型;或者通过数据变换(例如常见的COX-BOX变换、对数变换),使原来不适合于插值的数据可以进行插值。对于ESDA可以说是一门 学问,这里简单介绍,Geostatistical Analyst所带的几种方法,如图5。
图5 1、直方图 点击Histogram,然后在右下选择需要分析的属性,则就显示直方图分布情况,并在右上角给出各种相关的统计指标,图6。 图6 在左下方的下拉框可以选择直方的数量,变换方法,软件提供了
空间统计学原理及应用 GIS 本作业主要分为四大部分,分别是: 一、问答题 二、计算题 三、操作题 四、收获与感想 一、问答题(50分) 1.简述区域化变量与随机变量的区别?(12) (1)地理学中大多变量都具有空间分布特点,如海拔、气温、降雨量、土壤含氮量、臭氧浓度、品位等,它们通常随所在空间位置的不同表现出不同的数量特征,这些变量称为区域化变量。区域化变量描述的现象具有空间分布的特点,常常反映某种空间现象的特征,其所描述的现象称为区域化现象。 (2)设随机实验E的样本空间为S={e}。若对于任一e∈S,都有一实数z 与之对应,而且对任何实数z,事件{Z≤z}都有确定的概率,则称Z是一个随机变量。从定义可以看出,随机变量Z是一个实值变量,具有一个可能的取值范围,随着随机实验结果的不同而取不同的值,当取值于任何区间内时都有一定的概率。 (3)区别:普通随机变量的取值按某种概率分布而变化,而区域化变量则根据其在一个域内的位置取不同的值,即区域化变量时普通随机变量在域内确定位置上的特定取值,它是随机变量与位置有关的随机函数。区域化变量有的是三维的,有的是二维的,现在二维的区域化变量研究较多。在实际研究中,许多变量都可看成区域化变量,如气温、降雨量、海拔、土壤重金属含量、大气污染浓度、矿石品位、矿体厚度等。 2.试论述影响空间统计插值计算结果精度的因素?(18分) 空间统计插值计算结果精度的影响因素主要以理论基础、模型算法、时空尺度效应和站点数据属性为主。 (1)模型的理论基础不同,插值结果的精度不同。由于考虑了地理要素之间在空间分布上的关联性,同时兼顾到要素分布自身的自相关特性,回归要素选择得当,空间异相关模型可以很好地反映空间变异性与相关性,一般能够得到精度较高的插值结果。 (2)模型算法的差异导致插值结果精度的差异:反距离加权方法、克里格方法通常优于趋势面方法与函数方法。这些精度差异,可以通过其对插值要素空间
空间统计分析实习报告 Spatial statistics tools 分析模式工具集中的工具采用推论式统计,以零假设为起点,假设要素与要素相关的值均表现随机分布。然后计算P 值说明,这种分布属于随机分布的概率。在应用中,返回Z 得分和P值判断是否可以接受或拒绝零假设,同时在不同的工具中,还表示分布是聚集,或分散 是标准差的倍 数,在0.5-P的概 率下接受随机分 布的接受域 Average Nearest Neighbor 最邻近分析 根据每个要素预期最近要素的平均距离来计算最邻近指数,当指数大于1,要素有聚集分布的趋势,对于趋势如何,还要依据z—value和P—value 来判断,小于1时,趋向分散分布 最近邻指数的表示方法为:平均观测距离与预期平均距离的比率,预期平均距离是假设随机分布中领域间的平均距离 这种方法对面积指值非常敏感(期望平均距离计算中需要面积参与运算),如果未指定
面积参数,则使用输入要素周围最小外接矩形的面积(不一定合坐标轴垂直)Spatial Autocorrelation (Morans I) 空间自相关分析 更具要素位置的属性使用Global Moran’s I 统计量量测空间自相关性 Moran’s I是计算所评估属性的均值和方差,然后将每个要素减去均值,得到与均值的偏差,将所有相邻要素的偏差相称,得到叉积。统计量的分子便是这些叉积之和。 如果相邻要素的值均大于均值,这叉积为正,如果以要素小于均值而一要素大于均值,则为负 如果数据集中的值倾向于在空间上集聚(高值聚集在高值附近,低值聚集在低值附近)则指数为正,如果高值排斥高值,倾向于低值,则指数为负 之后,将计算期望指数值,将之与其比较,在给定的数据集中的要素个数和全部熟知的方差下,将计算Z得分和P值,用来指示次差异是否具有统计学上的显著性 Multi-Distance Spatial Cluster Analysis K函数分析 确定要素(后与之有关连的值)是否显示某一距离范围内统计意义显著的聚类或离散 基于Ripley's K 函数的多距离空间聚类分析工具是另外一种分析事件点数据的空间模式的方法。该方法不同于此工具集中其他方法(空间自相关和热点分析)的特征是可汇总一定距离范围内的空间相关性(要素聚类或要素扩散) Ripley's K 函数可表明要素质心的空间聚类或空间扩散在邻域大小发生变化时是如何变化的。 如果特定距离的k观测值大于k预期值,则与该距离下的随机分布相比,该分布的聚集程度更高,反之亦可。如果,k观测值大于HIConfEnv,则该距离的空间聚类具有统计学上的显著性,如果k观测值小于LwConFEnv,则该距离的空间离散具有统计学上的显著性对于置信区间,点的每个随机分布称为“排列”将一组点随机分布多次,将对每个距离选择相对预期k值向下和向上最大的k值,作为置信区间 Anselin Local Moran’s I局部Moran’s I 分析 给定一组加权要素,使用局部Moran’s I统计量来识别具有统计显著性的热点,冷点和空间异常值。 Z得分和p值是统计显著性的指标,用于逐个要素判断是否拒绝零假设。他们可指示表面相似性和向异性 如果要素Z值是一个较高的正数,则表示周围的要素拥有相似值,输出要素Cotype字段会将具有统计显著性的高值聚类表示为HH,低值聚类表示为LL ?如果要素的z 得分是一个较低的负值,则表示有一个具有统计显著性的空间异常值。输出要素类中的COType 字段将指明要素是否是高值要素而四周围绕的是低值要素(HL),或者要素是否是低值要素而四周围绕的是高值要素(LH)。
空间统计与空间数据挖掘之地统计分析 空间统计与空间数据挖掘之地统计分析地统计是统计 的一类,用于分析和预测与空间或时空现象相关的值。它将数据的空间坐标纳入分析中,以变异函数为主要工具,研究那些分布于空间上既有随机性又有结构性的自然或社会现 象的科学,接下来将介绍地统计研究的工作流程和主要步骤,并结合ArcGIS Geostatistical Analyst工具进行实践演示。 地统计是用于分析和预测与空间或时空现象相关联的值得 统计数据类。利用GIS工具可以构建使用空间坐标的模型。这些模型可以应用于各种情况并通常用于生成未采样位置 的预测,也可以用于生成这些预测的不确定性的度量值。 一般情况下,地统计研究的流程为:第一步仔细检查数据。第二步构建地统计模型,根据研究目的和数据集要素的不同,建模过程的步骤会有些差异。在这一阶段,对数据集进行严密地探索并收集信息,扩增对所研究对象的先验知识,这将决定模型的复杂程度和内插值的准确性,以及不确定性的度量值的准确性。第三步将所建模型与数据集结合来生成感兴趣区域内所有未采样位置的内插值。最后模型的输出应该经过检查,确保内插值和相关的不确定性的度量值是合理的并与预期相匹配。我们继续以上文中提到的某市区垃圾站数据为例,结合GIS工具具体介绍如何利用地统计建模插值。1
探索性空间数据分析19世纪60年代的Tukey面向数据分析的主题,提出了探索性数据分析(EDA,exploratory data analysis)的新思路,解决了传统统计分析中数据不能满足正态假设,基于均值、方差的模型在实际数据分析中缺乏稳定性的问题,并且满足了对海量数据进行分析的要求。EDA 的特点是对数据来源的总体不作假设,并且假设检验也经常被排除在外。这一技术使用统计图表、图形和统计概况的方法对数据的特征进行分析和描述,技术核心是“让数据说话”,在探索的基础上对数据进行更为复杂的建模分析(王远飞,何洪林,2007)。在EDA的基础上衍生而出的是探索性空间数据分析(ESDA,exploratory spatial data analysis),是EDA在空间数据分析领域的推广。 在使用插值方法之前,应该使用ESDA工具浏览数据。此工具能使我们更深入地了解数据并为插值模型选择最合适的 方法和参数。例如,如果使用普通克里金法生成分位数图,应该事先检查数据的分布,因为是在数据是呈正态分布的前提下才能采用这一方法,如果数据不是正态分布的,应该在插值模型中包含数据变换的操作。检测数据的空间趋势也是ESDA的一大功能。ESDA环境允许用户用图形的方法研究数据集,从而能更好的理解所要研究的数据集。每个ESDA 工具都对该数据给出一个不同的视图并在单独的窗口中显 示出来。这些不同的视图包括直方图(histogram)、voronoi