
试验报告
13.在研究某种新措施对猪白痢的防治效果问题时,获得了如下数据:
试问新措施对防治该种痴病是否有显著疗效( =)
解:组数:1→对照,2→新措施。
存活与死亡数:1→存活数,2→死亡数。
在SPSS中输入数据后选择选择数据→加权个案,然后再选择分析→描述统计→交叉表。得到如下表:
表2:卡方检验
值df 渐进 Sig. (双
侧)
精确Sig.(双
侧)
精确Sig.(单
侧)
Pearson 卡方1.007连续校正b1.011似然比1.006
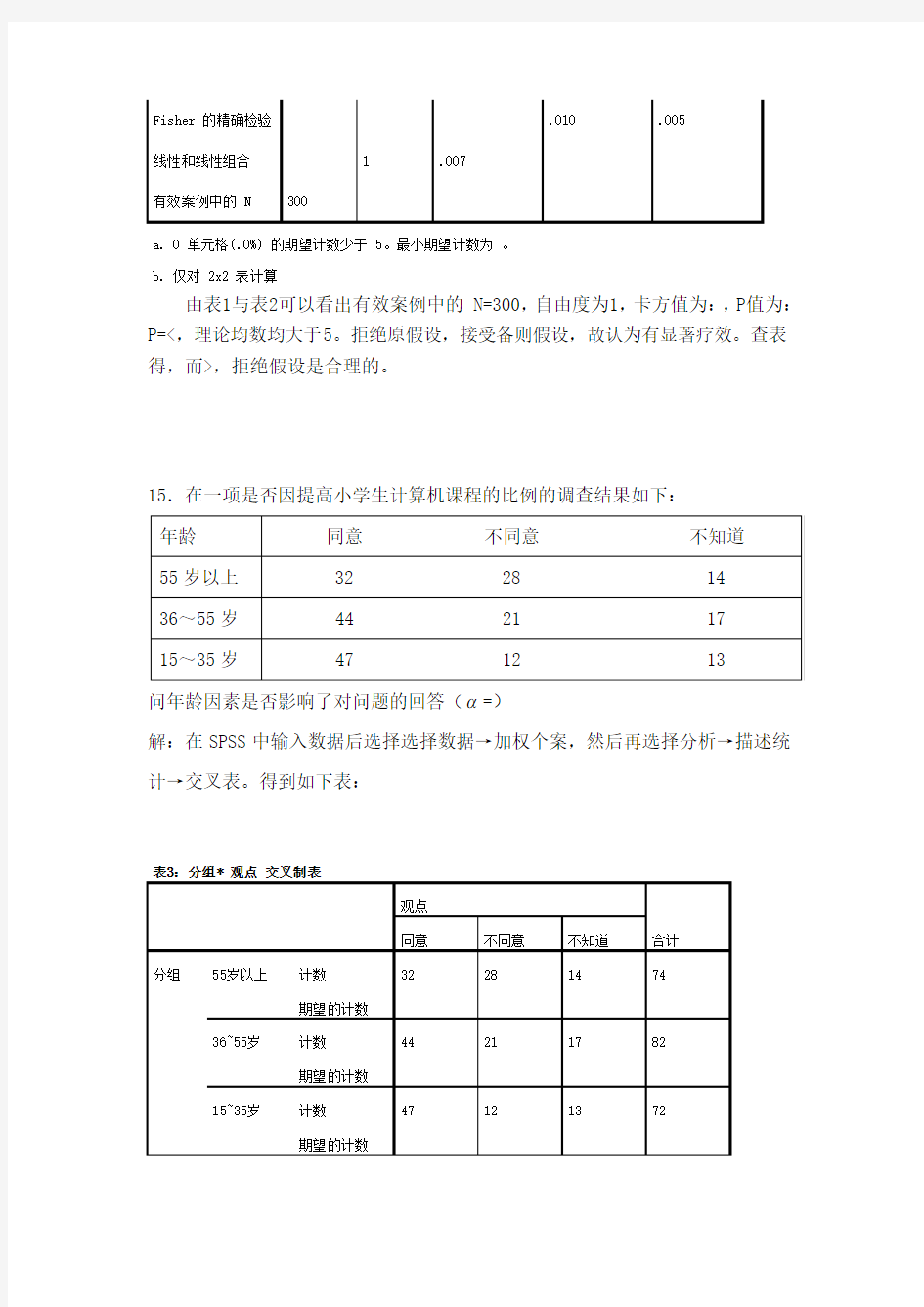
由表1与表2可以看出有效案例中的 N=300,自由度为1,卡方值为:,P值为:P=<,理论均数均大于5。拒绝原假设,接受备则假设,故认为有显著疗效。查表得,而>,拒绝假设是合理的。
15.在一项是否因提高小学生计算机课程的比例的调查结果如下:
问年龄因素是否影响了对问题的回答( =)
解:在SPSS中输入数据后选择选择数据→加权个案,然后再选择分析→描述统计→交叉表。得到如下表:
合计计数1236144228
期望的计数
表4:卡方检验
值df渐进 Sig. (双侧) Pearson 卡方4.047
似然比4.047
线性和线性组合1.078
有效案例中的 N228
a. 0 单元格(.0%) 的期望计数少于 5。最小期望计数为。
SPSS相关分析实验报告 篇一:spss对数据进行相关性分析实验报告 实验一 一.实验目的 掌握用spss软件对数据进行相关性分析,熟悉其操作过程,并能分析其结果。 二.实验原理 相关性分析是考察两个变量之间线性关系的一种统计分析方法。更精确地说,当一个变量发生变化时,另一个变量如何变化,此时就需要通过计算相关系数来做深入的定量考察。P值是针对原假设H0:假设两变量无线性相关而言的。一般假设检验的显著性水平为0.05,你只需要拿p值和0.05进行比较:如果p值小于0.05,就拒绝原假设H0,说明两变量有线性相关的关系,他们无线性相关的可能性小于0.05;如果大于0.05,则一般认为无线性相关关系,至于相关的程度则要看相关系数R值,r越大,说明越相关。越小,则相关程度越低。而偏相关分析是指当两个变量同时与第三个变量相关时,将第三个变量的影响剔除,只分析另外两个变量之间相关程度的过程,其检验过程与相关分析相似。三、实验内容 掌握使用spss软件对数据进行相关性分析,从变量之间的相关关系,寻求与人均食品支出密切相关的因素。 (1)检验人均食品支出与粮价和人均收入之间的相关关系。 a.打开spss软件,输入“回归人均食品支出”数据。
b.在spssd的菜单栏中选择点击,弹出一个对话窗口。 C.在对话窗口中点击ok,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入之间的相关系数为0.921,t检验的显著性概率为0.0000.01,拒绝零假设,表明两个变量之间显著相关。人均食品支出与粮食平均单价之间的相关系数为0.730,t检验的显著性概率为 0.0000.01,拒绝零假设,表明两个变量之间也显著相关。 (2)研究人均食品支出与人均收入之间的偏相关关系。 读入数据后: A.点击系统弹出一个对话窗口。 B.点击OK,系统输出结果,如下表。 从表中可以看出,人均食品支出与人均收入的偏相关系数为0.8665,显著性概率p=0.0000.01,说明在剔除了粮食单价的影响后,人均食品支出与人均收入依然有显著性关系,并且0.86650.921,说明它们之间的显著性关系稍有减弱。通过相关关系与偏相关关系的比较可以得知:在粮价的影响下,人均收入对人均食品支出的影响更大。 三、实验总结 1、熟悉了用spss软件对数据进行相关性分析,熟悉其操作过程。 2、通过spss软件输出的数据结果并能够分析其相互之间的关系,并且解决实际问题。 3、充分理解了相关性分析的应用原理。
数据分析实验报告 文稿归稿存档编号:[KKUY-KKIO69-OTM243-OLUI129-G00I-FDQS58-
第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出: 统计量 全国居民 农村居民 城镇居民 N 有效 22 22 22 缺失 均值 1116.82 747.86 2336.41 中值 727.50 530.50 1499.50 方差 1031026.918 399673.838 4536136.444 百分位数 25 304.25 239.75 596.25 50 727.50 530.50 1499.50 75 1893.50 1197.00 4136.75 3画直方图,茎叶图,QQ 图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民 Stem-and-Leaf Plot Frequency Stem & Leaf 5.00 0 . 56788 数据分析实验报告 【最新资料,WORD 文档,可编辑修改】
2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689 1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验
结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。 (2 )W 检验 结果:在Shapiro-Wilk 检验结果972.00 w ,p=0.174大于0.05 接受原假设,即数据来自正太总体。 习题1.5 5 多维正态数据的统计量 数据:
2014——2015学年第 1 学期 合肥学院数理系 实验报告 课程名称:统计软件选讲 实验项目:区间估计与假设检验 实验类别:综合性□设计性□验证性□√ 专业班级: 12级信息与计算科学 姓名:马坤鹏学号: 1207011017 实验地点:数理系数学模型实验室 实验时间: 2014.9.24 指导教师:段宝彬成绩:
一、实验目的 掌握使用SAS对总体参数进行区间估计与假设检验方法。 二、实验内容 1、用INSIGHT对总体参数进行区间估计与假设检验 2、用“分析家”对总体参数进行区间估计与假设检验 3、编程对总体参数进行区间估计与假设检验 三、实验步骤或源程序 1、生成来自标准正态总体的10000个随机数: (1) 求总体的平均值和方差的置信水平为90%的置信区间; (2) 改变随机数的个数,观察并总结样本均值、样本方差的变化以及总体均值和方差的置信区间的变化规律。 2、从某大学总数为500名学生的“数学”课程的考试成绩中,随机地抽取60名学生的考试成绩如表5-6(lx5-2.xls)所示: 表5-6 学生成绩 (1) 分别求500名学生平均成绩的置信水平为98%、90%和85%的置信区间,并观察置信水平与置信区间的关系。 (2) 分别求500名学生成绩的标准差的置信水平为98%和85%的置信区间。 3、装配一个部件时可以采用不同的方法,所关心的问题是哪一个方法的效率更高。劳动效率可以用平均装配时间反映。现从不同的装配方法中各抽取12件产品,记录下各自的装配时间如表5-7(lx5-3.xls)所示: 表5-7 装配时间(单位:分钟) 设两总体为正态总体,且方差相同。问两种方法的装配时间有无显著不同(α = 0.05)?data my.five1; input m n$@@; cards; 31 m 34 m 29 m 32 m 35 m 38 m 34 m 30 m 29 m 32 m 31 m 26 m 26 n 24 n 28 n 29 n 30 n 29 n 32 n 26 n 31 n 29 n 32 n 28 n ; proc ttest h0 = 0alpha = 0.05data= my.five1; var m; class n; run;
本科教学实验报告 (实验)课程名称:数据分析技术系列实验
实验报告 学生姓名: 一、实验室名称: 二、实验项目名称:相关分析 三、实验原理 相关关系是不完全确定的随机关系。在相关关系的情况下,当一个或几个相互联系的变量取一定值得时候,与之相应的另一变量的值虽然不确定,但它仍然按照某种规律在一定的范围内变化。 按照数据度量的尺度不同,相关分析的方法也不同,连续变量之间的相关性常用Pearson简单相关系数测定;定序变量的相关系数常用Spearman秩相关系数和Kendall 秩相关系数测定;定类变量的相关分析要使用列连表分析法。 四、实验目的 理解相关分析的基本原理,掌握在SPSS软件中相关分析的主要参数设置及其含义,掌握SPSS软件分析结果的含义及其分析。 五、实验内容及步骤 实验内容:以雇员表为例,共有474条数据,运用相关分析方法对变量间的相关关系进行分析。
1)分析性别与工资之间是否存在相关关系。 2)分析教育程度与工资之间是否存在相关关系。 实验要求:掌握相关分析方法的计算思路及其在SPSS环境下的操作方法,掌握输出结果的解释。 1. 分析性别与工资之间是否存在相关关系。 分析:性别属于定类变量,是离散值,因使用卡方检验。 Step1.操作为Analyze \ Descriptive Statistics \ Crosstabs Step2.将性别(Gender)和收入(Current Salary)分别移入Rows列表框和Columns 列表框。
Step3.单击Statistics按钮,在弹出的子对话框中选中默认的Chi-square,进行卡方检验。退回到主对话框,单击ok。
质量管理实验 实验一质量数据测定 一、实验任务 以减速器中的轴(输入轴和输出轴)为对象进行抽样检测,对测得的数据分别进行质量检验。 二、实验目的及训练要点 1)了解抽样的基本原理和方法。 2)了解测试仪器的选择、调整技巧。 3)了解测量数据的质量判定与检验。 三、实验内容 数据测试工作是工业企业生产的重要环节,是质量管理的一项基础工作,是确保产品质量的重要手段和方法,并且它可为各类质量问题的统计分析提供科学的依据,本次实验的主要内容包括: 1)外径千分尺的调整和校正。 2)游标卡尺的调整和校正。 3)减速器中各个轴(输入轴和输出轴)的外径宽度的抽样测量。 4)对所测数据进行处理和质量判定。 5)完成实验报告的攥写。 四、实验设备、仪器、工具及资料 外径千分尺1把,游标卡尺1把,减速器50个,标准件一组。
五、实验步骤 1.准备工作 1)熟悉“实验数据记录表”及检测仪器的使用方法。 2)准备所需资料,确定待选取的抽样方法及与之适宜的测量工具。 2.外径千分尺的调整和校正 外径千分尺主要用于工件的外尺寸测量。使用前应将测量面仔细擦净,检查或调整零位到正确位置。调整步骤如下: 1)校正或调整零位方法: 转动测力装置,使两测量面轻轻地接触(>25mm的外径千分尺应用校对量杆校正),当听到棘轮摩擦声时,即为零位。若此时不是零位则将固定套管上的螺钉松开用扳手转动固定套管使零位对准,然后紧固固定套管上的螺钉; 2)压线或离线的调整: 当微分筒压线或离线超过标准规定时,则松开取下测力装置,并取下盖板,取下微分桶及锥套,将锥套向前移或向后退来调整压线或离线,锥套向前移调压线,锥套向后移调离线,调好后将微分筒,及锥套装上,零位对准,盖上盖板。将测力装置装上拧紧则调整完毕。 3)测量时必须使用测力装置,以恒定测量压力进行测量,禁止测量运动的被测物。 3.游标卡尺的调整和校正 游标卡尺用于工件的内、外尺寸,外尺寸、深度、台阶等尺寸的测量。
云南大学滇池学院 方差分析与假设检验实验报告二 学生姓名:方炜学号:20092123080 专业:软件工程 一、实验目的和要求: 1、初步了解SPSS的基本命令; 2、掌握方差分析和假设检验。 二、实验内容: 1、为比较5中品牌的合成木板的耐久性,对每个品牌取4个样本作摩擦试验测量磨损量,得以下数据: (1)它们的耐久性有无明显差异? (2)有选择的作两品牌的比较,能得出什么结果?
2、将土质基本相同的一块耕地分成5块,每块又分成均等的4小块。在每块地内把4个品 种的小麦分钟在4小块内,每小块的播种量相同,测得收获量如下: 考察地块和品种对小麦的收获量有无显著影响?并在必要时作进一步比较。 3、为了研究合成纤维收缩率和拉伸倍数对纤维弹性的影响进行了一些试验。收缩率取0,4, 8,12四个水平;拉伸倍数取460,520,580,640四个水平,对二者的每个组合重复作两次试验,所得数据如下:
(1)收缩率,拉伸倍数及其交互作用对弹性有无显著影响? (2)使弹性达到最大的生产条件是什么? 三、实验结果与分析: 1、运行结果截图: 1、结果分析: (1)、Sig<0.05,耐久性有明显差异 (2)、由样本分析,品牌3分为一类;品牌1,2,5分为一类;品牌4分为一类。而品牌3和品牌4差距最大,品牌3的耐久性最差,品牌4的耐久性最好。 2、运行结果截图:
2、结果分析: (1)、地块(A组)Sig>0.05对小麦的收获量无显著影响,品种(B组)Sig<0.05对小麦的收获量有显著影响。 (2)、由图得,地块4最适合种小麦,地块1最不适合种小麦;而品种2的小麦收获量最大,品种4的小麦收获量最小。 3、运行结果截图:
实验报告 假设检验 学院: 参赛队员: 参赛队员: 参赛队员: 指导老师:
一、实验目的 1.了解假设检验的基本内容; 2.了解单样本t检验; 3.了解独立样本t检验;、 4.了解配对样本t检验; 5.学会运用spss软件求解问题; 6.加深理论与实践相结合的能力。 二、实验环境 Spss、office 三、实验方法 1.单样本t检验; 2.独立样本t检验; 3.配对样本t检验。 四、实验过程 实验过程 依题意,设H0:μ= 82,H1:μ>82 (1)定义变量为成绩,将数据输入SPSS;
(2)选择:分析比较均值单样本T检验; (3)将变量成绩放置Test栏中,并在Test框中输入数据82; (4)观察结果 实验结果
结果分析 该题是右尾检验,所以右尾P=2=因为P值明显小于, 表明在水平上变量与检验值有显著性差异,故接受原假设,所以该县的英语教学改革成功。 问题二: 实验过程 依题意,设H0:μ= 500,H1:μ≠500 (1)定义变量为成绩,将数据输入SPSS; 某工艺研究所研究出一种自动装罐机,它可以用来自动装罐头食品,并且可以达到每罐的标准重量为500克。现在需要检验它的性能。假定装罐重量服从正态分布。现随机抽取10罐来检查机器工作情况,这10罐的重量如下:
(2)选择:分析比较均值单样本T检验; (3) 将变量成绩放置Test栏中,并在Test框中输入数据500; 实验结果 结果分析 该题是双检验,所以双尾P=因为P值明显大于, 表明在水平上变量与检验值无显著性差异,故不能拒绝原假设 ,接受备择假设,所以自动装罐机性能良好 问题三: 某对外汉语中心进行了一项汉字教学实验,同一年级的两个平行班参与了该实验。一个班采用集中识字的方式,然后学习课文;另一班采用分散识字的方式,边学习课文边学习生字。为了考察两种教学方式对生字读音的记忆效果是否有影响,教学效果是否有差异,分别从一班和二班随机抽取20人,进行汉字注音考试,请计算二个班的平均成绩、标准差分别是多少两种教学方式对汉字读音的记忆效果是否有差异哪一种教学方式更有效
数据分析实验报告 【最新资料,WORD文档,可编辑修改】 第一次试验报告 习题1.3 1建立数据集,定义变量并输入数据并保存。 2数据的描述,包括求均值、方差、中位数等统计量。 分析—描述统计—频率,选择如下: 输出:
方差1031026.918399673.8384536136.444百分位数25304.25239.75596.25 50727.50530.501499.50 751893.501197.004136.75 3画直方图,茎叶图,QQ图。(全国居民) 分析—描述统计—探索,选择如下: 输出: 全国居民Stem-and-Leaf Plot Frequency Stem & Leaf 9.00 0 . 122223344 5.00 0 . 56788 2.00 1 . 03 1.00 1 . 7 1.00 2 . 3 3.00 2 . 689
1.00 3 . 1 Stem width: 1000 Each leaf: 1 case(s) 分析—描述统计—QQ图,选择如下: 输出: 习题1.1 4数据正态性的检验:K—S检验,W检验数据: 取显着性水平为0.05 分析—描述统计—探索,选择如下:(1)K—S检验 单样本Kolmogorov-Smirnov 检验 身高N60正态参数a,,b均值139.00
标准差7.064 最极端差别绝对值.089 正.045 负-.089 Kolmogorov-Smirnov Z.686 渐近显着性(双侧).735 a. 检验分布为正态分布。 b. 根据数据计算得到。 结果:p=0.735 大于0.05 接受原假设,即数据来自正太总体。(2)W检验
实验五相关分析实验报关费 一、实验目的: 学习利用spss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表1如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析和肯德尔等级相关 分析。 2.在控制物理成绩不变的条件下,做数学成绩与英语成绩的相关分析(这 种情况下的相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中的相关分析。 三、实验步骤: 1.选择分析→相关→双变量,弹出窗口,在对话框的变量列表中选变量 “数学成绩”、“物理成绩”,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)和肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差和均值。单击确定,得出输出结果,对结果 进行分析解释。 2.选择分析→相关→偏相关,弹出窗口,在对话框的变量列表选变量“数 学成绩”、“英语成绩”,在控制列表选择要控制的变量“物理成绩” 以在控制物理成绩的影响下对变量数学成绩与英语成绩进行偏相关分 析;在“显著性检验”框中选双侧检验,单击确定,得出输出结果, 对结果进行分析解释。 3.选择分析→描述统计→交叉表,弹出窗口,对交叉表的行和列进行选 择,行选择为数学成绩,列选择为物理成绩。然后对统计量进行设置, 选择相关性,点击继续→确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
表1
五、实验结果及其分析:
分析一:由实验结果可观察出,数学成绩与物理成绩的积差相关系数r=,肯德尔等级相关系数r=可知该班物理成绩和数学成绩之间存在显著相关。
熟练使用SPSS 17.0进行假设检验[例] 某克山病区测得11例克山病患者与13名健康人的血磷值mmol/L如下,问该地急性克山病患者与健康人的血磷值是否不同。 表1 克山病区调查数据结果 1.录入数据。将组别设为g,可将患者组设为1,健康人设为2,血磷值设为x,如患者组中第一个测量到的血磷值为0.84,则g为1,x为0.84,其他数据均仿此录入,如下图所示。 图1 数据输入界面 2.统计分析。依次选择“Analyze”、“ Compare means”、“ Independent Samples T Test”。
图2 选择分析工具 3.弹出对话框如下图所示,将x选入Test Variables、g选入Grouping Variable,并单击下方的Define Groups按钮,弹出定义组对话框,默认选项为Use Specified Value,在Group1和Group2框中分别填入1和2,即要对组别变量值为1和2的两个组做t检验,另外Options 对话框中可选择置信度和处理缺失值的方法。 图3 选择变量进入右侧的分析列表 SPSS输出的结果和结果说明:
图4 输出结果 表2 统计量描述列表 表3 假设检验结果表 第一个表格是统计描述,给出了两个组的样本数N、均值Mean、标准偏差Std.Deviation、标准误差Std. Error Mean。 第二个表格分两部分 (1)方差齐次检验(Levene 检验)。F=0.032、P(Sig)=0.860 。
(2)t 检验。因方差齐次与不齐方法不同,(Equal variances assumed 方差齐次和Equal variances not assumed 方差不齐),结果分两行给出。由使用者根据方差齐次检验结果来判断。本例尚不能认为方差不齐,故取方差齐次的结果t= 2.524,df 自由度22, 双侧t 检验概率=0.019 即可认为两组间血磷值有差别。结果中还给出了两组间差值的均值标准误差和95%置信区间。
血液检查实验报告 篇一:血型测定实验报告 血型测定实验报告 一、实验目的: 学习ABO型血的鉴定原理和方法。观察红细胞凝集现象,了解抗原抗体反应。 二、实验原理: 血型就是红细胞膜上特异抗原的类型。在ABO血型系统中,红细胞膜上抗原分A和B两种抗原,而血清抗体分抗A 和抗B两种抗体。A抗原加抗A抗体或B抗原加抗B抗体,则产生凝集现象。血型鉴定是将受试者的红细胞加入标准A 型血清(含有抗B抗体)与标准B型血清(含有抗A抗体)中,观察有无凝集现象,从而测知受试者红细胞膜上有无A 或/和B抗原。在ABO血型系统,根据红细胞膜上是否含A、B抗原而分为A、B、AB、O四型。(见表4-3-1-1)三消毒采血针;载玻片;消毒棉签;抗A、抗B血型定型试剂;75%乙醇;受检者血液四、实验步骤 (1)取双凹玻片一块,用干净纱布轻拭使之洁净,在玻片两端用腊笔标明A及B,并分别各滴入A及B标准血清一滴。 (2)细胞悬液制备从指尖或耳垂取血一滴,加入含1ml 生理盐水的小试管内,混匀,即得约5%红细胞悬液。采血
时应注意先用75%酒精消毒指尖或耳垂。 (3)用滴管吸取红细胞悬液,分别各滴一滴于玻片两端的血清上,注意勿使滴管与血清相接触。 (4)竹签两头分别混合,搅匀。 (5) 10~30min后观察结果。如有凝集反应可见到呈红色点状或小片状凝集块浮起。先用肉眼看有无凝集现象,肉眼不易分辨时,则在低倍显微镜下观察,如有凝集反应,可见红细胞聚集成团。 (6)判断血型根据被试者红细胞是否被A,B型标准血清所凝集,判断其血型。五、实验结果: 我们组本次实验中,载玻片1左边为抗B型定型试剂,呈淡红色,未发生凝聚;右边为抗A型定型试剂,血液在试剂中凝结,试剂较清亮。该受试者1血型为A。 载玻片2左右边的试剂内的血液皆不出现凝结现象,受试者2为O型血。 六、实验讨论: 1.实验中要分清牙签,不要用一牙签一端同时在抗A血清和抗B血清中搅拌,以免造成抗体试剂不纯。 2.实验中我们组发现15分钟后没有出现血凝现象,可用牙签轻轻搅拌一会儿,有些载玻片上就不现了血块,但有些经搅拌后仍不出现血凝现象,表示确实不含相应的抗原。篇二:血糖的测定实验报告
实验报告——第5章统计假设检验 姓名杨秀娟班级人力10001学号 【实验1】 某外企对员工英语水平进行调查,开发部门总结该部门员工英语水平很高,如果按照英语六级考试标准考核,一般平均分为75分。现从开发部门雇员中随机选出11人参加考试,得分如下:80,81,72,60,78,65,56,79,77,87,76 ^ 请问该开发部门的英语水平是否真的很高(即高于75分,且差异显著) 【解】 (1)数据和变量说明 本题所用数据是:外企英语六级考试成绩样本 该文件为11个样本,1个变量,如变量视图 (2)操作方法 (3)结果报告
, 上图为单样本t检验表,第一行注明了用于比较的已知的总体均数为75,下面从左到右依次为t值(t)、自由度(df)、P值(Sig)、两均数的差值、差值的95%可信区间。 由上表可知,t= , P=, P>,接受Ho,与平均成绩75相等,无显著差异,因此,该开发部门的英语水平不是真的很高。 【实验2】 以下是对某产品促销团队进行培训前后的销售业绩数据,试分析该培训是否产生了显著效果。 表5-20 培训前后销售业绩数据 56789 序号123' 4 7488827185 培训前677074~ 97 7687867895 培训后786778{ 98 【解】 (1)数据和变量说明 本文件有2个变量,9个数据 (2)操作方法 *
(3)结果报告 由上表可知,P=, P<,不接受无效假设,有显著差异,所以该培训产生了显著效果。 【实验3】 饲养队制定了两种喂养方案喂猪,希望通过试验了解一下不同喂养方案的喂养效果。
方案一:用一只猪喂不同的饲料所测得的体内钙留存量数据如下: 表 5-21 方案一喂养数据 序号! 1 23456789 饲料1" 饲料2/ 方案二:甲队有11只猪喂饲料1,乙队有9只猪喂饲料2,所得的钙留存量数据如下: ; 表5-22方案二喂养数据 序号12345678· 9 1011甲队饲料1; 乙队饲料2\ 请选用恰当方法对上述两种方案所获得的数据进行分析,研究不同饲料是否使小猪体内钙留存量有显著不同。 【解】 方案一 (1)《 (2)数据和变量说明 答:9个数据,2个变量 (3)操作方法
概率论与数理统计实验报告 一、实验目的 1.学会用matlab求密度函数与分布函数 2.熟悉matlab中用于描述性统计的基本操作与命令 3.学会matlab进行参数估计与假设检验的基本命令与操作 二、实验步骤与结果 概率论部分: 实验名称:各种分布的密度函数与分布函数 实验内容: 1.选择三种常见随机变量的分布,计算它们的方差与期望<参数自己设 定)。 2.向空中抛硬币100次,落下为正面的概率为0.5,。记正面向上的次数 为x, (1)计算x=45和x<45的概率, (2)给出随机数x的概率累积分布图像和概率密度图像。 3.比较t(10>分布和标准正态分布的图像<要求写出程序并作图)。 程序: 1.计算三种随机变量分布的方差与期望 [m0,v0]=binostat(10,0.3> %二项分布,取n=10,p=0.3 [m1,v1]=poisstat(5> %泊松分布,取lambda=5 [m2,v2]=normstat(1,0.12> %正态分布,取u=1,sigma=0.12 计算结果: m0 =3 v0 =2.1000 m1 =5 v1 =5 m2 =1 v2 =0.0144 2.计算x=45和x<45的概率,并绘图 Px=binopdf(45,100,0.5> %x=45的概率 Fx=binocdf(45,100,0.5> %x<45的概率 x=1:100。 p1=binopdf(x,100,0.5>。 p2=binocdf(x,100,0.5>。 subplot(2,1,1>
plot(x,p1> title('概率密度图像'> subplot(2,1,2> plot(x,p2> title('概率累积分布图像'> 结果: Px =0.0485 Fx =0.1841 3.t(10>分布与标准正态分布的图像 subplot(2,1,1> ezplot('1/sqrt(2*pi>*exp(-1/2*x^2>',[-6,6]> title('标准正态分布概率密度曲线图'> subplot(2,1,2> ezplot('gamma((10+1>/2>/(sqrt(10*pi>*gamma(10/2>>*(1+x^2/10>^(-(10+1>/2>',[-6,6]>。b5E2RGbCAP title('t(10>分布概率密度曲线图'> 结果:
假设检验的SPSS实现 、实验目的与要求 1. 掌握单样本 t检验的基本原理和 spss实现方法。 2. 掌握两样本 t检验的基本原理和 spss实现方法。 3. 熟悉配对样本 t检验的基本原理和 spss实现方法。 二、实验内容提要 1. 从一批木头里抽取 5根,测得直径如下(单位: cm),是否能认为这批木头的平均直径是1 2.3cm 12.3 12.8 12.4 12.1 12.7 2. 比较两批电子器材的电阻,随机抽取的样本测量电阻如题表2所示,试比较两批电子器 材的电阻是否相同(需考虑方差齐性的问题) 3. 配对 t检验的实质就是对差值进行单样本t检验,要求按此思路对例课本 13.4进行重新分析,比较其结果和配对 t检验的结果有什么异同。 4.一家汽车厂设计出 3种型号的手刹,现欲比较它们与传统手刹的寿命。分别在传统手刹,型号I、II、和型号 III中随机选取了 5只样品,在相同的试验条件下,测量其使用寿命(单位:月),结果如下: 传统手刹:21.213.417.015.212.0 型号 I :21.412.015.018.924.5 型号 II :15.219.114.216.524.5 型号 III :38.735.839.332.229.6 ( 1)各种型号间寿命有无差别 ? (2)厂家的研究人员在研究设计阶段,便关心型号III 与传统手刹寿命的比较结果。此时应 当考虑什么样的分析方法?如何使用 SPSS实现? 三、实验步骤 为完成实验提要 1. 可进行如下步骤 1. 在变量视图中新建一个数据,在数据视图中录入数据,在分析中选择比较均值,单样本t 检验,将直径添加到检验变量,点击确定。
实验五相关分析实验报关费 一、实验目得: 学习利用s pss对数据进行相关分析(积差相关、肯德尔等级相关)、偏相关分析。利用交叉表进行相关分析。 二、实验内容: 某班学生成绩表 1 如实验图表所示。 1.对该班物理成绩与数学成绩之间进行积差相关分析与肯德尔等级相关分 析. 2.在控制物理成绩不变得条件下,做数学成绩与英语成绩得相关分析(这 种情况下得相关分析称为偏相关分析)。 3.对该班物理成绩与数学成绩制作交叉表及进行其中得相关分析。 三、实验步骤: 1.选择分析—相关—双变量,弹出窗口,在对话框得变量列表中选变量 “数学成绩"、“物理成绩” ,在相关系数列进行选择,本次实验选择 皮尔逊相关(积差相关)与肯德尔等级相关。单击选项,对描述统计 量进行选择,选择标准差与均值.单击确定,得出输出结果,对结果进 行分析解释。 2.选择分析一相关一偏相关,弹出窗口,在对话框得变量列表选变量数学 成绩”、“英语成绩”,在控制列表选择要控制得变量“物理成绩”以 在控制物理成绩得影响下对变量数学成绩与英语成绩进行偏相关分析; 在“显著性检验”框中选双侧检验,单击确定,得出输出结果,对结果 进行分析解释. 3.选择分析一描述统计-交叉表,弹出窗口,对交叉表得行与列进行选 择,行选择为数学成绩,列选择为物理成绩.然后对统计量进行设置, 选择相关性,点击继续-确定,得出输出结果,对结果进行分析解释。 四、实验结果与分析:
囲戏变量相关0 变旻(Y): 歹物理戍悄 相关浆勤 0 Pearson 叼兰endsll 的tau-b(K) J Spearman 叼标记SL苦性徇关(E) I ?―I粘址妃)][賞Jt? ][ ■備~ [ 鹽 ,丘示渎际說曹性水半(D 确定 ]|殆贴(E) H St賣(B)][ 取禱选顶(2)… 农孝号 /其 语威纽 显著性检验 双侧檢勉I) 单侧檢验(D 选他…]
75 假设检验 Ⅰ.学习目的 假设检验包括参数检验与非参数检验,是一种最能体现统计推断思想和特点的方法。通过本章学习,要求:1.掌握统计检验的基本原理,理解该检验的规则及犯两类错误的性质;2.熟练掌握总体均值、总体成数及总体方差指标的各种检验方法,包括:z 检验、t 检验和p 值检验;3.掌握2 检验、符号检验、秩和检验及游程检验四种基本的非参数检验方法。 Ⅱ.课程内容要点 第一节 假设检验的基本原理 一、假设检验的基本原理 “小概率原理”:小概率事件在一次试验中几乎是不会发生的。 事先所做的假设,是假设检验中关键的一项工作。它包括原假设和备选假设两部分。原假设是建立在假定原来总体参数没有发生变化的基础之上的。备选假设是原假设的对立,是在否认原假设之后所要接受的,通常这是我们真正感兴趣的一个判断。 二、假设检验的规则与两类错误 1、假设检验的规则 假设检验的步骤: (1)首先根据实际应用问题确定合适的原假设0H 和备选假设1H ; (2)确定检验统计量,通过数理统计分析确定该统计量的抽样分布;
(3)给定检验的显著性水平α。在原假设成立的条件下,结合备选假设的定义,由检验统计量的抽样分布情况求出相应的临界值,该临界值为原假设的接受域与拒绝域的分界值; (4)从样本资料计算检验的样本统计量,并将其与临界值进行比较,判断是否接受或拒绝原假设。 从检验程序我们可以看出,统计量的取值范围可以分为接受域和拒绝域两个区域。拒绝域正是统计量取值的小概率区域。按照我们将这个拒绝域安排在所检验统计量的抽样分布的某一侧还是两端,可以将检验分为单侧检验或双侧检验。双侧检验中,又可以根据拒绝域,是在左侧还是在右侧而分为左侧检验和右侧检验。对于这些双侧、左、右单侧检验,我们要结合备选假设来考虑。 在检验规则中,我们经常碰到两种重要的检验方法:z检验与t检验。 p值检验的原理:给出原假设后,在假定原假设正确的情况下,参照备选假设,可以计算出检验统计量超过或者小于(还要依照分布的不同、单侧检验、双侧检验的差异而定)由样本所计算的检验统计量的数值的概率,这便是p值;而后将此概率值跟事先给出的显著性水平值α进行比较。如果该值小于α,否定原假设,取对应的备选假设。如果该值大于α,我们不就能否定原假设。 2、两类错误 H实际为真,但我们却依据样本信息,做出拒绝的错误结论当原假设 时,称为“弃真”错误;当原假设实际为假,而我们却错误接受时,称为“纳伪”错误。通常记显著性水平α为犯“弃真”错误的可能性大小,β为犯“纳伪”错误的可能性大小。由于两类错误是一对矛盾,在其他条件不变得情况下,减少犯“弃真”错误的可能性大小(α),势必增大犯“纳伪”错误的可能性大小(β),也就是说,β的大小和显著性水平α的大小成相反方向变化。 三、检验功效 -可以用来表明所做假设检验工作好坏的一个指标,我们称之为检1β 76
《多元统计分析分析》实验报告 2012 年月日学院经贸学院姓名学号 实验 实验成绩名称 一、实验目的 (一)利用SPSS对主成分回归进行计算机实现. (二)要求熟练软件操作步骤,重点掌握对软件处理结果的解释. 二、实验内容 以教材例题为实验对象,应用软件对例题进行操作练习,以掌握多元统计分析方法的应用 三、实验步骤(以文字列出软件操作过程并附上操作截图) 1、数据文件的输入或建立:(文件名以学号或姓名命名) 将表数据输入spss:点击“文件”下“新建”——“数据”见图1: 图1 点击左下角“变量视图”首先定义变量名称及类型:见图2: 图2: 然后点击“数据视图”进行数据输入(图3): 图3
完成数据输入 2、具体操作分析过程: (1)首先做因变量Y与自变量X1-X3的普通线性回归: 在变量视图下点击“分析”菜单,选择“回归”-“线性”(图4): 图4 将因变量Y调入“因变量”栏,将x1-x3调入“自变量”栏(图5): 然后选择相关要输出的结果:①点击右上角“统计量(s)”:“回归系数”下选择“估计”;“残差”下选择“”;在右上角选择输出“模型拟合度”、“部分相关和偏相关”“共线性诊断”(后两项是做多重共线性检验)。选完后点击“继续”(见图6)②如果需要对因变量与残差进行图形分析则需要在“绘制”下选择相关项目(图7),一般不需要则继续③如果需要将相关结果如因变量预测值、残差等保存则点击“保存”(图8),选择要保存的项目④如果是逐步回归法或者设置不带常数项的回归模型则点击“选项”(图9) 其他选项按软件默认。最后点击“确定”,运行线性回归,输出相关结果(见表1-3)
实验编号:1四川师大SPSS实验报告2017 年3月27日 计算机科学学院2015级5班实验名称:参数假设检验 姓名:唐雪梅学号:2015110538 指导老师:__朱桂琼___ 实验成绩:___ 实验三参数假设检验 一.实验目的及要求 1.了解SPSS 特点结构操作 2.利用SPSS进行简单数据统计 二.实验内容 1.对12名来自城市的学生与14名来自农村的学生进行心理素质测验,他们的分数如下: 城市学生得分:4.75 6.40 2.62 3.44 6.50 5.30 5.60 3.80 4.30 5.78 3.76 4.15 农村学生得分:2.38 2.60 2.10 1.80 1.90 3.65 2.30 3.80 4.60 4.85 5.80 4.25 4.22 3.84 试分析农村学生与城市学生心理素质有无显著差别。 2、一汽车厂商声称其发动机排放标准的一个指标平均低于20个单位。在抽查了10台发动机之后,得到下面的排放数据:17.0、21.7、17.9、22.9、20.7、22.4、17. 3、21.8、24.2、25.4。目的是检验该申明是否正确 3. 用SPSS Samples数据文件“Employee data.sav”资料, 问:清洁工(jobcat=1)的受教育年数(Educational Level)与保管员(jobcat=2)和经理(jobcat=3)的受教育年数是否有显著差异?其中,显著性水平ɑ=0.05. ? 4. 用SPSS Samples数据文件“Employee data.sav”资料, 分析:美国企业现在工资(Current Salary)与过去工资(beginning Salary)是否有显著差异? 三、实验主要流程、基本操作或核心代码、算法片段(该部分如不够填写,请另加附页) 1.数据录入
SPSS聚类分析实验报告 一.实验目的: 1、理解聚类分析的相关理论与应用 2、熟悉运用聚类分析对经济、社会问题进行分析、 3、熟练SPSS软件相关操作 4、熟悉实验报告的书写 二.实验要求: 1、生成新变量总消费支出=各变量之和 2、对变量食品支出和居住支出进行配对样本T检验,并说明检验结果 3、对各省的总消费支出做出条形图(用EXCEL做图也行) 4、利用K-Mean法把31省分成3类 5、对聚类分析结果进行解释说明 6、完成实验报告 三.实验方法与步骤 准备工作:把实验所用数据从Word文档复制到Excel,并进一步导入到SPSS数据文件中。 分析:由于本实验中要对31个个案进行分类,数量比较大,用系统聚类法当然也可以得出结果,但是相比之下在数据量较大时,K均值聚类法更快速高效,而且准确性更高。 四、实验结果与数据处理: 1.用系统聚类法对所有个案进行聚类:
生成新变量总消费支出=各变量之和如图所示: 2. 对变量食品支出和居住支出进行配对样本T检验,如图所示:
得出结论: 3. 对各省的总消费支出做出条形图,如图所示: 4.对聚类分析结果进行解释说明: K均值分析将这样的城市分为三类: 第一类北京、上海、广东 第二类除第一类第三类以外的 第三类天津、福建、内蒙古、辽宁、山东 第一类经济发展水平高,各项支出占总支出比重高,人民生活水平高。第二类城市位于中西部地区,经济落后,人民消费水平低。第三类城市位于中东部地区,经济发展较好。
迭代历史记录a 迭代 聚类中心内的更改 1 2 3 1 1250.592 1698.865 1216.114 2 416.864 70.786 173.731 3 138.955 2.949 24.819 4 46.318 .123 3.546 5 849.114 319.179 1362.411 6 805.004 15.199 606.915 7 161.001 .724 75.864 8 32.200 .034 9.483 9 6.440 .002 1.185 10 1.288 7.815E-5 .148 初始聚类中心 聚类 1 2 3 食品支出 7776.98 3052.57 5790.72 衣着支出 1794.06 1205.89 1281.25 居住支出 2166.22 1245.00 1606.27 家庭设备及服务支出 1800.19 612.59 972.24 医疗保健支出 1005.54 774.89 617.36 交通和通信支出 4076.46 1340.90 2196.88 文化与娱乐服务支出 3363.25 1229.68 1786.00 其它商品和服务支出 1217.70 331.14 499.30 总消费支出 23200.40 9792.66 14750.02
相关分析与回归分析 一、试验目标与要求 本试验项目的目的是学习并使用SPSS软件进行相关分析与回归分析,具体包括: (1)皮尔逊pearson简单相关系数的计算与分析 (2)学会在SPSS上实现一元及多元回归模型的计算与检验。 (3)学会回归模型的散点图与样本方程图形。 (4)学会对所计算结果进行统计分析说明。 (5)要求试验前,了解回归分析的如下内容。 参数α、β的估计 回归模型的检验方法:回归系数β的显着性检验(t-检验); 回归方程显着性检验(F-检验)。 二、试验原理 1.相关分析的统计学原理 相关分析使用某个指标来表明现象之间相互依存关系的密切程度。用来测度简单线性相关关系的系数是Pearson简单相关系数。 2.回归分析的统计学原理 相关关系不等于因果关系,要明确因果关系必须借助于回归分析。回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数据模型,以便从一个已知量推断另一个未知量。回归分析的主要任务就是根据样本数据估计参数,建立回归模型,对参数与模型进行检验与判断,并进行预测等。 线性回归数学模型如下: 在模型中,回归系数是未知的,可以在已有样本的基础上,使用最小二乘法对回归系数进行估计,得到如下的样本回归函数: 回归模型中的参数估计出来之后,还必须对其进行检验。如果通过检验发现模型有缺陷,则必须回到模型的设定阶段或参数估计阶段,重新选择被解释变量与解释变量及其函数形式,或者对数据进行加工整理之后再
次估计参数。回归模型的检验包括一级检验与二级检验。一级检验又叫统计学检验,它是利用统计学的抽样理论来检验样本回归方程的可靠性,具体又可以分为拟与优度评价与显着性检验;二级检验又称为经济计量学检验,它是对线性回归模型的假定条件能否得到满足进行检验,具体包括序列相关检验、异方差检验等。 三、试验演示内容与步骤 1.连续变量简单相关系数的计算与分析 在上市公司财务分析中,常常利用资产收益率、净资产收益率、每股净收益与托宾Q值4个指标来衡量公司经营绩效。本试验利用SPSS对这4个指标的相关性进行检验。操作步骤与过程: 打开数据文件“上市公司财务数据(连续变量相关分析).sav”,依次选择“【分析】→【相关】→【双变量】”打开对话框如图,将待分析的4个指标移入右边的变量列表框内。其他均可选择默认项,单击ok提交系统运行。 图5.1 Bivariate Correlations对话框 结果分析: 表给出了Pearson简单相关系数,相关检验t统计量对应的p值。相关系数右上角有两个星号表示相关系数在0.01的显着性水平下显着。从表中可以看出,每股收益、净资产收益率与总资产收益率3个指标之间的相关系数都在0.8以上,对应的p值都接近0,表示3个指标具有较强的正相关关系,而托宾Q值与其他3个变量之间的相关性较弱。 表5.1 Pearson简单相关分析 Correlations 每股收益 率净资产 收益率 资产收益 率 托宾Q 值 每股收益率Pearson Correlation 1 .877(* *) .824(**)-.073 Sig. ..000.000.199