
1 流密码算法概述
1.1 Salsa20算法 1.1.1 算法设计背景
2004年ECRYPT 启动了eSTREAM 流密码计划的研究项目,Salsa20是最终胜出的7个算法之一。Salsa20是由Daniel J.Bernstein 提出的基于hash 函数设计的流密码算法,其核心部分是一个基于32比特加、比特异或以及旋转操作的512比特输入512比特输出的hash 函数。
现有的对Salsa20攻击方法包括线性分析、差分分析、非随机性分析、相关密钥分析和滑动分析等,其中以滑动攻击尤其是偶数轮的滑动攻击方式最为有效。在软件仿真方面,算法可以在目前的x86处理器上实现4至14cycles/byte 的加密效率;且具备尚可的硬件性能。
Salsa20没有申请专利,属于公开的应用算法,为了在多个公共领域的共同架构,Bernstein 对算法的实现优化做了进一步研究和改动。 1.1.2 算法介绍
(1)运算符定义
word :word 是一个32比特的二进制数,即集合{}320,1,,21-中的元素之
一。
(2)异或和移位计算
两个word u ,v 的异或用公式表示为:
()22i i i i i i u v u v u v ⊕=+-∑
设非零整数c ,{}0,1,2,3c ∈,
对一个word u 的c 比特左移位表示为u c <<<,用公式表示为:
mod322i c i i u c u +<<<=∑
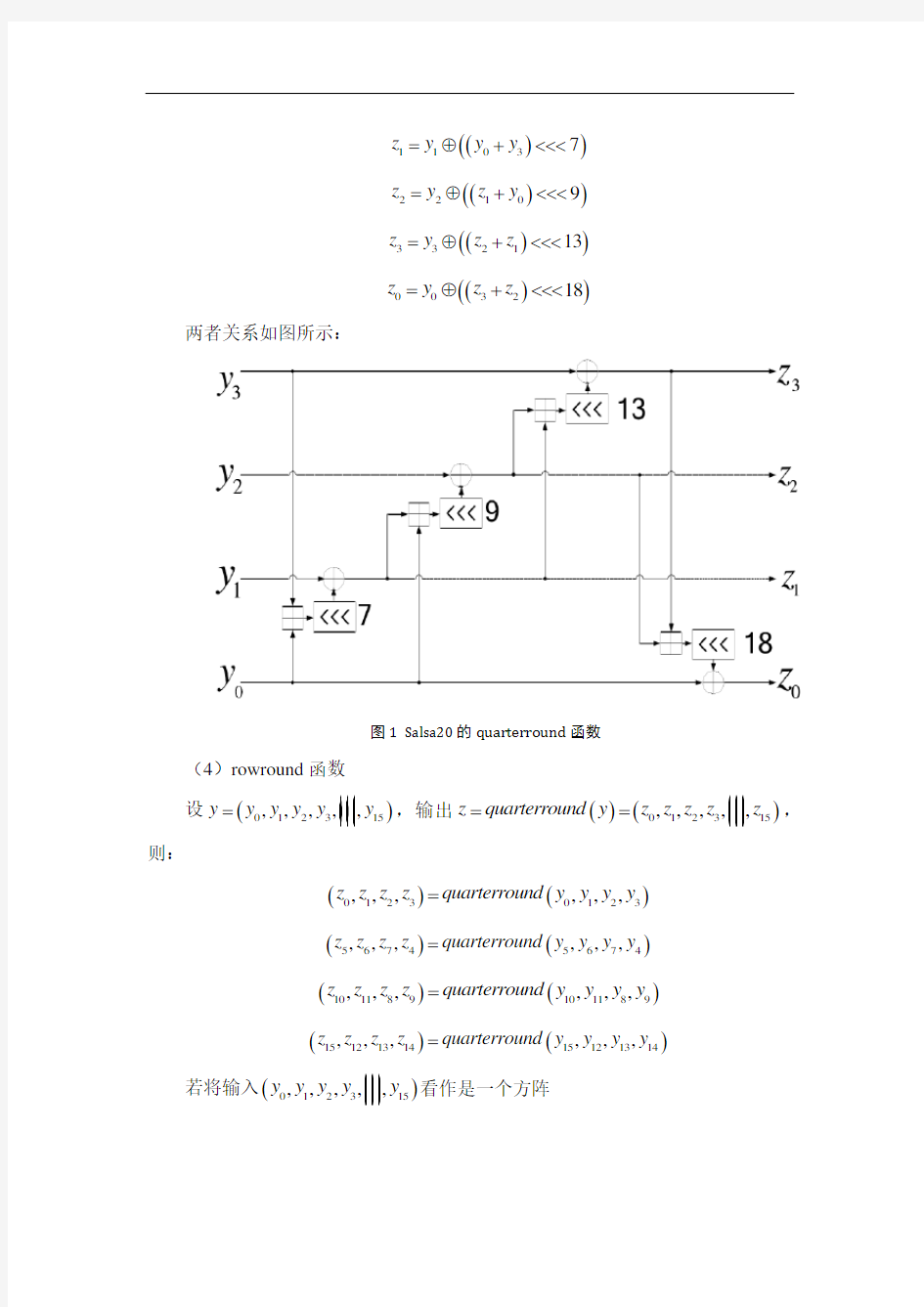
(3)quarterround 函数
设()0123,,,y y y y y =,输出()()0123,,,z quarterround y z z z z ==,则
()()11037z y y y =⊕+<<< ()()22109z y z y =⊕+<<<
()()332113z y z z =⊕+<<< ()()003218z y z z =⊕+<<<
两者关系如图所示:
图1 Salsa20的quarterround 函数
(4)rowround 函数 设()012315,,,,,y y y y y y =,输出()()012315,,,,,z quarterround y z z z z z ==,
则:
()()01230123,,,,,,z z z z quarterround y y y y = ()()56745674,,,,,,z z z z quarterround y y y y = ()()101189101189,,,,,,z z z z quarterround y y y y = ()()1512131415121314,,,,,,z z z z quarterround y y y y =
若将输入()012315,,,,
,y y y y y 看作是一个方阵
0123456789101112
13
14
15y y y y y y y y y y y y y y y y ?? ? ?
? ???
则rowround 函数将方阵的每一行重新排列后作为quarterround 函数的输入,从而并行地修改了所有行。
(5)columnround 函数 设()012315,,,,,x x x x x x =,输出()()012315,,,,,y quarterround x y y y y y ==,
则:
()()0481204812,,,,,,y y y y quarterround x x x x = ()()5913159131,,,,,,y y y y quarterround x x x x = ()()101426101426,,,,,,y y y y quarterround x x x x = ()()153711153711,,,,,,y y y y quarterround x x x x =
若将输入()012315,,,,
,x x x x x 看作是一个方阵
123456789101112
13
14
15x x x x x x x x x x x x x x x x ?? ? ?
? ???
则columnround 函数将方阵的每一列置换后作为quarterround 函数的输入,从而并行地修改了所有列。
(6)doubleround 函数
doubleround 变换由一个列变换(columnround )与一个行变换(rowround )组成。
()()()doubleround X rowround columnround X =
(7)littleendian 函数 设()0123,,,b b b b b =,则
()816240123222littleendian b b b b b =+++
littleendian 函数是将8比特序列转变为32比特的可逆函数。
(8)Salsa20的加密函数
Salsa20算法的核心是一个hash 函数,输入和输出均为512比特,算法的初始状态是由16个word 组成的44?矩阵,其中包括8个密钥017,,
,k k k ,4个常
数0σ、1σ、2σ、3σ,2个初始IV (nonce )0n 、1n ,2个时间标号(block counter )
0c 、1c ,假设用X 表示初始状态,则X 为:
0012310101245
673k k k k n n X c c k k k k σσσσ??
? ?= ? ??? 密钥有两种类型,分别为128比特与256比特。若长度为128比特,则后四个密钥依次重发前四个密钥的值。从安全性角度考虑,使用256比特密钥更加安全。下面针对256比特的密钥长度版本对算法进行说明。
Salsa20首先对8-word 的密钥进行扩展,即将上述初始状态X 经过10轮doubleround 变换后的输出与X 进行模232加。可以用公式简单的表示为:
()()1020Salsa X X doubleround X =+
()20Salsa X 是Salsa20算法的密钥流,它异或一个16-word 的明文分组就得出对该明文分组加密后的密文。设P 是一个明文,C 是相应的密文,加密函数为
C P S =⊕,解密函数为C P S =⊕。具体加密过程如下图所示。
图2 Salsa20的加密原理图
1
1.1.3 安全性分析
随着Salsa20成为eSTREAM 工程的最终胜选算法之一,关于它的各项密码学性质以及如何对Salsa20进行攻击逐渐成为广大学者研究的热点。目前对Salsa20的分析已经取得了一些结果,Paul Crowley 给出了对简化至5轮的Salsa20的一种截断差分攻击。Simon Fischer 等分析了Salsa20的密钥和初始IV 的在载入时存在的问题。他们论证了对6轮Salsa20的攻击可以进行密钥恢复,同时他们观察7轮后仍然存在非随机性。随后Yukiyasu Tsunoo 公开表示在4轮Salsa20后的输出差分概率有一个重要的偏差。利用这个偏差,他们进一步展示攻击密钥长度为256比特的版本Salsa20简化至8轮的可能性,该攻击的计算复杂度较穷举攻击略低。
此外,作为针对Salsa20最有效的攻击方法之一,滑动攻击能大幅降低算法破译的时间复杂度。David Wagner 和 Alex Biryukov 于1999年提出了滑动攻击,滑动攻击使密码体制的轮数变得无关紧要,通过分析密钥编排(key schedule ,指从种子密钥得到轮密钥的过程)并挖掘其弱点来攻破密码。它适用于具有如下性质的密码算法:
迭代过程具有一定的自相似性,且在很多情况下与迭代轮函数的具体性质和执行轮数无关。简单地说,就是任何可以被分解为若干次轮函数(假设该轮函数为F )的算法都可以尝试此攻击(这个F 可能包含多于原算法的一个轮函数)。由于密钥是直接包含在内部状态中的,通过滑动攻击攻击者将能够恢复算法运行的所有内部状态,也同时能对Salsa20施行相关密钥恢复攻击。
首先引入一些符号。假设算法输入为n 比特,密钥为1,
,m k k 。
滑动攻击首先将加密程序划分为完全相同的轮函数F ,F 可能由原算法中一轮以上的函数组成。例如,如果一个加密算法使用轮换的密钥体制,每一轮切换使用1K 和2K 这两个密钥,则F 应该由两轮组成,每一个i K 在F 中至少出现一次。
下一步是收集/22n 个明密文对。根据不同加密算法各自的特点,可能不需要这么多个,但是根据生日悖论,我们期望总数不超过/22n 。用(),P C 表示这些明密文对,并利用它们来寻找滑动对()'',P C 。一个滑动对(slid pair)是指满足如下
性质的两个明密文对:()'i i F P P =,()'
i i F C C =且对应的密钥也相同。一旦我们
找到了这样的滑动对,就可以利用已知明文攻击来攻破密码体制
滑动攻击的基本思想是将一个加密过程相对于另一个加密过程“滑动”一轮。如下图所示:
Figure 1 滑动攻击原理图
寻找滑动对的具体过程依加密体制而定,每一个不尽相同,但基本方法是一致的。所依据的事实是:从F 的一次迭代(iteration)中分离出密钥是相对容易的。
随意挑选明密文对(),P C 和()'',P C ,如果()'i i F P P =,()'i i F C C =且对应的密钥也
相同,我们就找到了一个滑动对,否则检测下一个明密文对。在/22n 个明密文对中总可以找到一个滑动对,根据加密体制的结构,还有一小部分的误判断(false-positives)。这些误判可以通过将密钥用在不同的明密文对并检测加密结果是否正确来排除。对一个好的密码体制来说,错误的密钥能正确加密两个及其以上明文消息的概率是非常低的。有时加密体制的结构能大大降低所需的明密文对数目,因此也降低了很多工作量。最明显的一个例子是使用一个密钥的 Feistel 结构。原因如下,给定()00,P L R =,必须寻找()()'000,,P R L F R K =⊕。这将可能的成对消息从2n 降到/22n ,所以我们只需收集至多/42n 个明密文对来找到滑动对。
在Salsa20中,doubleround 结构可以重写为一个columnround 紧接着一个矩阵转置,以及另一个columnround 和第二个矩阵转置。我们将F 定义为由一个 columnround 紧接着一个矩阵转置组成的函数。这样10轮的doubleround 就转化成为运行了20轮的F 。如果我们有两个三元组()1,1,1key nonce counter 和
()2,2,2key nonce counter ,那么
()()
1,1,1=2,2,2F key nonce counter key nonce counter ????初始状态1初始状态2
这个性质在轮运算的每个对应点都成立。但是Salsa20最后的前馈操作破坏了这个性质。我们将初始状态1和初始状态2称为一个滑动对,它们的关系如下图所示:
Figure 2 Salsa20滑动对
在初始状态中,4 个word ()03σσ是常量,剩下的12 个word 可以任意选
取,因此总共有3842种可能的初始状态。如果期望某个初始状态输入F 后输出初始状态2,可以得到四个word 操作等式。这意味着我们可以为初始状态1任选8个word ,剩下的4个word 由等式及初始状态2的word 决定。这将得到2562个可能的滑动对。
对于密钥长度为128比特的Salsa20,不存在这样的滑动对。原因是初始状态1中少了随意选取4个word 的自由权,而初始状态2多了4个word 级方程式。通过F 可以得到两个方程:()'S F S =和()'X F X =。我们将这些矩阵内的word 表示为:
0012310101245673k k k k n n S c c k k k k σσσσ??
?
?= ?
???
'''00
12'''3
1
1'''012
4'
''567
3k k k k n n S c c k k k k σσσ
σ?? ? ?= ? ? ???‘
0123456789101112131415x x x x x x x x X x x x x x x x x ??
?
?= ?
???
''''
0123'''''4
5
67''''89
10
11'
''
'121314
15x x x x x x x x X x x x x x x x x ?? ? ?= ? ? ???
01234
56789101112
13
14
15z z z z z z z z Z z z z z z z z z ?? ?
?= ?
???
''''0
123'''''4
5
67''''89
10
11'
''
'121314
15z z z z z
z z z Z z z z z z z z z ?? ? ?= ? ? ???
注意到()',S S 对角线上的word 相同,因此:
''''''''
123110760000k k k n c c k k +=+=+=+=,,,
由于F 的弱扩散性,攻击者对初始状态S 的每一列都能写出独立的方程组。 将关系式()'S F S =中的quarterround 运算、()'X F X =中的quarterround 运算及Salsa20最后的反馈操作联立,我们可以得到一个由16个方程组成的方程组。这个方程组可以简化为4个方程。要想解出第一个方程,必须猜测两个变量。剩下的三个方程中,总有两个变量是知道的:要么是由猜测得来的s ,要么是计算得来的's 。因此不需要再猜测任何变量就可以解出来。
从而针对某一列的方程组,尽管所有的变量都是未知的,可以通过仅猜测其中两个变量解出来。通过4次复杂度为()642O 的猜测,攻击者就可以完全恢复 512比特的秘密初始状态S 。这表明我们可以很容易地将 Salsa20(不包括对角线常量)和一个随机函数区分开来,因为同样的任务,后者需要()5112O 才能解决。由于我们能够恢复所有的内部状态,这种攻击也能对 Salsa20 施行相关密钥恢复攻击,因为密钥是直接包含在内部状态中的。
下图为滑动攻击与随机预言机的时间复杂度比较情况:
表 1 滑动攻击与随机预言机的时间复杂度比较
1.1.4 仿真情况
Weighted average (Simple Imix):
Encryption speed (cycles/byte): 9.34 Encryption speed (Mbps): 2392.86 Overhead: 22.6% 1.2 ZUC 算法 1.2.1 算法设计背景
ZUC 算法,即祖冲之算法,是3GPP 机密性算法EEA3和完整性算法EIA3的核心,为中国自主设计的流密码算法。2009年5月ZUC 算法获得3GPP 安全算法组SA 立项,正式申请参加3GPPLTE 第三套机密性和完整性算法标准的竞选工作。历时两年多的时间,ZUC 算法经过评估,于2011年9月正式被3GPPSA 全会通过,成为3GPPLTE 第三套加密标准核心算法。ZUC 算法是中国第一个成为国际密码标准的密码算法。 1.2.2 算法原理
ZUC 是一个面向字的流密码。它采用128位的初始密钥作为输入和一个128位的初始向量(IV ),并输出关于字的密钥流(从而每32位被称为一个密钥字)。密钥流可用于对信息进行加密/解密。
ZUC 的执行分为两个阶段:初始化阶段和工作阶段。在第一阶段,密钥和初始向量进行初始化,即不产生输出。第二个阶段是工作阶段,在这个阶段,每一个时钟脉冲产生一个32比特的密钥输出。
(1)运算符说明
mod 整数模
⊕ 整数比特异或
a b 字符串a 和b 的连接 H a a 二进制表示的最左16位值 L a a 二进制表示的最右16位值 n a k <<< a 向左k 比特的循环移位
1a >> a 向右1比特的移位
()()1212,,,,,,n n a a a b b b → i a 值分配到对应i b 的值
(2)算法结构
ZUC 有三个逻辑层,见下图。顶层为一个线性反馈移位寄存器(LFSR )的
16个赛段,中间层是比特重组(BR ),最下层为一个非线性函数F 。
图1 ZUC 的整体结构图
(3) 线性移位反馈寄存器(LFSR )
LFSR 具有16个31比特的单元()0115,,
,s s s ,
每个单元()015i s i ≤≤取值均在下面的集合中:
{}311,2,3,21-
L F S R 有两种模式的操作,即初始化模式和工作模式。在初始化模式中,
LFSR 接收一个31比特的输入u ,u 是删除非线性函数F 的32位输出W 最右边
的位得到的。也就是说,可将初始化模式工作原理表示为: LFSRWithInitialisationMode (u ) {
1、()()1517212083115131040222212mod 21v s s s s s =+++++-;
2、()()3116mod 21s v u =+-;
3、如果160s =,则设311621s =-;
4、()()12160115,,,,,,s s s s s s →
}
在工作模式中,LFSR 不接收任何输入,它的工作原理表示为: LFSRWithWorkMode()
{
1、()()151721208311615131040222212mod 21s s s s s s =+++++-;
2、如果160s =,则设311621s =-;
3、()()12160115,,,,,,s s s s s s →;
}
(4) 比特重组
ZUC 算法的中间层是比特重组,从LFSR 的单元中提取128比特的输出并形成4个32比特的字,前三个字将用于最底层的非线性F 函数中,而最后一个字会在密钥流的产生中用到。
令025********,,,,,,,s s s s s s s s 是LFSR 中的8个单元,则形成4个32比特字
0123,,,X X X X 的比特重组过程如下:
Bitreorganization() {
1、01514H L X s s =;
2、1119L H X s s =;
3、275L H X s s =;
4、320L H X s s = }
(5)非线性函数F
非线性函数F 有2个32位的存储单元,即1R 和2R 。令到F 的输入为0X ,1
X 和2X ,即为比特重组的前三个输出,然后函数F 输出一个32位字W 。F 的详细过程如下:
()012,,F X X X {
1、()32012mod2W X R R =⊕+;
2、32111mod2W R X =+;
3、222W R X =⊕;
4、()()1112L H R S L W W =;
5、()()2221L H R S L W W = }
(6)S 盒
F 函数中包含的S 盒S 是由4个并列的8×8的S 盒组成的
(()0123,,,S S S S S =),其中02S S =、13S S =。0S 、1S 的定义由下面两张表分别给出:
令x 为0S (或1S )的8比特输入。将x 表示成十六进制x h l =,则在查表时h 和l 分别表示S 盒的第h 行和第l 列。
(7)线性变换函数
线性变换1L 和2L 均为32比特字输入到32比特字的输出,具体可定义为:
()()()()()1323232322101824L X X X X X X =⊕<<<⊕<<<⊕<<<⊕<<< ()()()()()2323232328142230L X X X X X X =⊕<<<⊕<<<⊕<<<⊕<<< (8)密钥加载
密钥的加载过程将把初始密钥和初始向量扩展为16个31比特的LFSR 初始状态。设k 为128比特的初始密钥,iv 为128比特的初始向量,则有:
01215k k k k k = 012
15iv iv iv iv iv =
其中,015i ≤≤
同时,设D 为由16个15比特长的子数组组成的240位常值数组:
0115D d d d =
其中,
02d = 100010011010111; 12d = 010011010111100; 22d = 110001*********; 32d = 001001101011110; 42d = 101011110001001; 52d = 011010111100010; 62d = 111000*********; 72d = 000100110101111; 82d = 100110101111000; 92d = 010111100010011; 102d = 110101111000100; 112d = 001101011110001; 122d = 101111000100110; 132d = 011110001001101; 142d = 111100010011010; 152d = 100011110101100;
设015,
,s s 为LFSR 的16个单元,则015i ≤≤,有i i i i s k d iv =。
(9)算法执行
ZUC 的执行过程也分为两个阶段:初始化阶段和工作阶段。
在初始化阶段,算法执行密钥加载过程将128位的初始密钥和128位的初始向量载入LFSR ,同时设置32位的记忆单元为0值。随后算法运行下面的操作32次:
1、Bitreorganization();
2、()012,,X w X F X =;
3、LFSRWithInitialisationMode(1w >>)
初始化操作完成后,算法进入工作阶段。在工作阶段中,算法执行下面的操作1次,并弃掉F 的输出W 。
1、Bitreorganization();
2、()012,,X X X F ;
3、LFSRWithWorkMode().
最后算法进入密钥流产生阶段,每次迭代执行以下操作1次,Z 是一个32位字的输出:
1、Bitreorganization();
2、()0123,,X Z F X X X =⊕;
3、LFSRWithWorkMode() . 1.2.3 安全性分析
加密算法所生成密钥流序列的随机性是其安全性的重要指标,NIST 的随机性测试标准中讨论了16种随机数测试项,分别为频数测试、块内频数测试、游程测试、块内最长连续1测试、矩阵秩的测试、离散傅里叶变换测试、非重叠模板匹配测试、重叠模板匹配测试、通用统计测试、压缩测试、线性复杂度测试、连续性测试、近似熵测试、部分和测试、随机游走测试和随机游走变量测试等。随机性测试的数学依据是假设检验,给定显著性水平α,计算当前样本统计量的
值P value -。当P v
a l u e α-≥时,就认为待测试序列是随机的,通过测试;否则,
就是非随机的,其中P value -值越大其随机性越好。本文将依据该标准,使用随机性测试工具,选择12个测试项,对这两种算法在不同密钥和初始向量所输出的密钥流进行测试,其结果如下表 (其中α=0.01)。
表2 随机性测试结果
-由上表数据可以明显看出,Snow 3G算法和ZUC算法的测试项的P value
值均大于α,即通过了随机性测试。在这12项测试中,ZUC算法的8项测试的
-值大于Snow3G算法相应的值,这8项分别是块内频数测试、块内最长P value
连续1测试、非重叠模板匹配测试、重叠模板匹配测试、线性复杂度测试、连续
-值相同,性测试、近似墒测试、部分和测试;另外,表中有2个测试项的P value
分别是矩阵秩和离散傅里叶变换;Snow 3G算法的测试项中只有频率测试和游程
-值比ZUC算法的大。根据以上信息,可以判断ZUC算法所输出测试的P value
的密钥流序列其随机性更好,相对而言,ZUC算法的安全性比Snow 3G的安全
性更高一些。当然,还需要对ZUC算法和Snow 3G算法进行更深入的分析和进
一步的评估。
1.2.4 仿真情况
(1)软件仿真
根据ZUC算法说明1.5版本,DCS中心在以下各个平台上用软件实现了ZUC
算法,其参考数据如下表所示:
(2)硬件仿真
根据ZUC算法说明1.5版本,DCS中心使用Verilog语言在FPGA上实现了以下ZUC IP核,实现平台为Virtex-5 xc5vlx110t-3ff1136,综合软件为ISE 11.5。所实现ZUC IP核的参考数据如下表所示:
排序算法 一、插入排序(Insertion Sort) 1. 基本思想: 每次将一个待排序的数据元素,插入到前面已经排好序的数列中的适当位置,使数列依然有序;直到待排序数据元素全部插入完为止。 2. 排序过程: 【示例】: [初始关键字] [49] 38 65 97 76 13 27 49 J=2(38) [38 49] 65 97 76 13 27 49 J=3(65) [38 49 65] 97 76 13 27 49 J=4(97) [38 49 65 97] 76 13 27 49 J=5(76) [38 49 65 76 97] 13 27 49 J=6(13) [13 38 49 65 76 97] 27 49 J=7(27) [13 27 38 49 65 76 97] 49 J=8(49) [13 27 38 49 49 65 76 97] Procedure InsertSort(Var R : FileType); //对R[1..N]按递增序进行插入排序, R[0]是监视哨// Begin for I := 2 To N Do //依次插入R[2],...,R[n]// begin R[0] := R[I]; J := I - 1; While R[0] < R[J] Do //查找R[I]的插入位置// begin R[J+1] := R[J]; //将大于R[I]的元素后移// J := J - 1 end R[J + 1] := R[0] ; //插入R[I] // end End; //InsertSort // 二、选择排序 1. 基本思想: 每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。 2. 排序过程: 【示例】: 初始关键字[49 38 65 97 76 13 27 49] 第一趟排序后13 [38 65 97 76 49 27 49] 第二趟排序后13 27 [65 97 76 49 38 49] 第三趟排序后13 27 38 [97 76 49 65 49] 第四趟排序后13 27 38 49 [49 97 65 76] 第五趟排序后13 27 38 49 49 [97 97 76]
项目多目标融合评价 一、项目评价的涵义 项目评价,是指论证和评价从正反两方面提出意见,为决策者选择项目及实施方案提供多方面的告诫,并力求客观、准确地将与项目执行有关的资源、技术、市场、财务、经济、社会等方面的数据资料和实况真实、完整地汇集、呈现于决策者面前,使其能够处于比较有利的地位,实事求是地作出正确、合适的决策,同时也为投资项目的执行和全面检查奠定基础。项目评价是项目管理的重要组成部分,它贯穿于项目周期的全过程。 广义的项目评价,即项目在其生命周期全过程中,为了更好地进行项目管理,针对项目生命周期每阶段特点应用科学的评价理论和方法,采用适当的评价尺度所进行的“根据确定的目地来测定对象系统属性,并将这种属性变为客观定量的计值或者主观效用的行为”。 二、传统项目评价 (一)评价的周期 传统的项目评价体系是建立在项目进行的不同周期之上的,项目周期是指一个建设项目从项目设想、项目策划、项目建设、项目运行,直至项目终止的全过程,项目的性质不同,则项目周期的时间跨度也不尽相同。一般来说,可以将项目周期分为三个时期:投资前期、投资期和投资后期。以时间序列为轴,项目投资决策及之前的阶段为投资前期,项目建成并投入使用以后的阶段为投资后期,中间的部分即为投资期。 (二)评价体系 评价体系是项目评价在项目周期的不同阶段的不同表现形式的有机组合,在项目周期的不同阶段,项目评价的目的、性质、对象、主要内容、使用的数据来源以及评价结果的用途都有所不同,主要分为项目前期评价、项目中期评价和项目后评价。 (三)评价方法 对于建设项目而言,经济评价是项目评价的重点,往往起着决定性的作用,而一个项目的最终决定还是要对其进行综合评价。其评价内容涉及:政治评价、国防评价、社会评价、技术评价、经济评价、生态环境评价、自然资源评价,其评价方法有:综合评价定量法、加权评估法、层次分析法、模糊综合评价法、主成份分析法等。 三、传统项目评价的优劣势 (一)优势 传统项目评价是根据项目实施周期来确定的,也就是说在项目实施的前、中、后都各自有一个系统及方法,评价结果具有针对性,且能对后来项目的实施过程起到一定的指导性作用,能有效收集项目在实施过程中所遇到的各种问题,并能总结经验及教训成为后上项目的前车之鉴。 (二)劣势
HUNAN UNIVERSITY 课程实习报告 题目:排序算法的时间性能学生姓名 学生学号 专业班级 指导老师李晓鸿 完成日期
设计一组实验来比较下列排序算法的时间性能 快速排序、堆排序、希尔排序、冒泡排序、归并排序(其他排序也可以作为比较的对象) 要求 (1)时间性能包括平均时间性能、最好情况下的时间性能、最差情况下的时间性能等。 (2)实验数据应具有说服力,包括:数据要有一定的规模(如元素个数从100到10000);数据的初始特性类型要多,因而需要具有随机性;实验数据的组数要多,即同一规模的数组要多选几种不同类型的数据来实验。实验结果要能以清晰的形式给出,如图、表等。 (3)算法所用时间必须是机器时间,也可以包括比较和交换元素的次数。 (4)实验分析及其结果要能以清晰的方式来描述,如数学公式或图表等。 (5)要给出实验的方案及其分析。 说明 本题重点在以下几个方面: 理解和掌握以实验方式比较算法性能的方法;掌握测试实验方案的设计;理解并实现测试数据的产生方法;掌握实验数据的分析和结论提炼;实验结果汇报等。 一、需求分析 (1) 输入的形式和输入值的范围:本程序要求实现各种算法的时间性能的比 较,由于需要比较的数目较大,不能手动输入,于是采用系统生成随机数。 用户输入随机数的个数n,然后调用随机事件函数产生n个随机数,对这些随机数进行排序。于是数据为整数 (2) 输出的形式:输出在各种数目的随机数下,各种排序算法所用的时间和 比较次数。 (3) 程序所能达到的功能:该程序可以根据用户的输入而产生相应的随机 数,然后对随机数进行各种排序,根据排序进行时间和次数的比较。 (4)测试数据:略 二、概要设计
数据结构课程设计报告 实验一:计算器 设计要求 1、问题描述:设计一个计算器,可以实现计算器的简单运算,输出并检验结果的正确性,以及检验运算表达式的正确性。 2、输入:不含变量的数学表达式的中缀形式,可以接受的操作符包括+、-、*、/、%、(、)。 具体事例如下: 3、输出:如果表达式正确,则输出表达式的正确结果;如果表达式非法,则输出错误信息。 具体事例如下: 知识点:堆栈、队列 实际输入输出情况: 正确的表达式
对负数的处理 表达式括号不匹配 表达式出现非法字符 表达式中操作符位置错误 求余操作符左右出现非整数 其他输入错误 数据结构与算法描述 解决问题的整体思路: 将用户输入的中缀表达式转换成后缀表达式,再利用转换后的后缀表达式进行计算得出结果。 解决本问题所需要的数据结构与算法: 用到的数据结构是堆栈。主要算法描述如下: A.将中缀表达式转换为后缀表达式: 1. 将中缀表达式从头逐个字符扫描,在此过程中,遇到的字符有以下几种情况: 1)数字 2)小数点 3)合法操作符+ - * / %
4)左括号 5)右括号 6)非法字符 2. 首先为操作符初始化一个map 数据结构课程设计 课程名称:内部排序算法比较 年级/院系:11级计算机科学与技术学院 姓名/学号: 指导老师: 第一章问题描述 排序是数据结构中重要的一个部分,也是在实际开发中易遇到的问题,所以研究各种排算法的时间消耗对于在实际应用当中很有必要通过分析实际结合算法的特性进行选择和使用哪种算法可以使实际问题得到更好更充分的解决!该系统通过对各种内部排序算法如直接插入排序,冒泡排序,简单选择排序,快速排序,希尔排序,堆排序、二路归并排序等,以关键码的比较次数和移动次数分析其特点,并进行比较,估算每种算法的时间消耗,从而比较各种算法的优劣和使用情况!排序表的数据是多种不同的情况,如随机产生数据、极端的数据如已是正序或逆序数据。比较的结果用一个直方图表示。 第二章系统分析 界面的设计如图所示: |******************************| |-------欢迎使用---------| |-----(1)随机取数-------| |-----(2)自行输入-------| |-----(0)退出使用-------| |******************************| 请选择操作方式: 如上图所示该系统的功能有: (1):选择1 时系统由客户输入要进行测试的元素个数由电脑随机选取数字进行各种排序结果得到准确的比较和移动次数并 打印出结果。 (2)选择2 时系统由客户自己输入要进行测试的元素进行各种排序结果得到准确的比较和移动次数并打印出结果。 (3)选择0 打印“谢谢使用!!”退出系统的使用!! 第三章系统设计 (I)友好的人机界面设计:(如图3.1所示) |******************************| |-------欢迎使用---------| |-----(1)随机取数-------| |-----(2)自行输入-------| |-----(0)退出使用-------| 各种排序算法的总结和比较 1 快速排序(QuickSort) 快速排序是一个就地排序,分而治之,大规模递归的算法。从本质上来说,它是归并排序的就地版本。快速排序可以由下面四步组成。 (1)如果不多于1个数据,直接返回。 (2)一般选择序列最左边的值作为支点数据。(3)将序列分成2部分,一部分都大于支点数据,另外一部分都小于支点数据。 (4)对两边利用递归排序数列。 快速排序比大部分排序算法都要快。尽管我们可以在某些特殊的情况下写出比快速排序快的算法,但是就通常情况而言,没有比它更快的了。快速排序是递归的,对于内存非常有限的机器来说,它不是一个好的选择。 2 归并排序(MergeSort) 归并排序先分解要排序的序列,从1分成2,2分成4,依次分解,当分解到只有1个一组的时候,就可以排序这些分组,然后依次合并回原来的序列中,这样就可以排序所有数据。合并排序比堆排序稍微快一点,但是需要比堆排序多一倍的内存空间,因为它需要一个额外的数组。 3 堆排序(HeapSort) 堆排序适合于数据量非常大的场合(百万数据)。 堆排序不需要大量的递归或者多维的暂存数组。这对于数据量非常巨大的序列是合适的。比如超过数百万条记录,因为快速排序,归并排序都使用递归来设计算法,在数据量非常大的时候,可能会发生堆栈溢出错误。 堆排序会将所有的数据建成一个堆,最大的数据在堆顶,然后将堆顶数据和序列的最后一个数据交换。接下来再次重建堆,交换数据,依次下去,就可以排序所有的数据。 Shell排序通过将数据分成不同的组,先对每一组进行排序,然后再对所有的元素进行一次插入排序,以减少数据交换和移动的次数。平均效率是O(nlogn)。其中分组的合理性会对算法产生重要的影响。现在多用D.E.Knuth的分组方法。 Shell排序比冒泡排序快5倍,比插入排序大致快2倍。Shell排序比起QuickSort,MergeSort,HeapSort慢很多。但是它相对比较简单,它适合于数据量在5000以下并且速度并不是特别重要的场合。它对于数据量较小的数列重复排序是非常好的。 5 插入排序(InsertSort) 插入排序通过把序列中的值插入一个已经排序好的序列中,直到该序列的结束。插入排序是对冒泡排序的改进。它比冒泡排序快2倍。一般不用在数据大于1000的场合下使用插入排序,或者重复排序超过200数据项的序列。 单片机十进制加法计算器设计 摘要 本设计是基于51系列的单片机进行的十进制计算器系统设计,可以完成计 算器的键盘输入,进行加、减、乘、除3位无符号数字的简单四则运算,并在LED上相应的显示结果。 设计过程在硬件与软件方面进行同步设计。硬件方面从功能考虑,首先选择内部存储资源丰富的AT89C51单片机,输入采用4×4矩阵键盘。显示采用3位7段共阴极LED动态显示。软件方面从分析计算器功能、流程图设计,再到程序的编写进行系统设计。编程语言方面从程序总体设计以及高效性和功能性对C 语言和汇编语言进行比较分析,针对计算器四则运算算法特别是乘法和除法运算的实现,最终选用全球编译效率最高的KEIL公司的μVision3软件,采用汇编语言进行编程,并用proteus仿真。 引言 十进制加法计算器的原理与设计是单片机课程设计课题中的一个。在完成理论学习和必要的实验后,我们掌握了单片机的基本原理以及编程和各种基本功能的应用,但对单片机的硬件实际应用设计和单片机完整的用户程序设计还不清楚,实际动手能力不够,因此对该课程进行一次课程设计是有必要的。 单片机课程设计既要让学生巩固课本学到的理论,还要让学生学习单片机硬件电路设计和用户程序设计,使所学的知识更深一层的理解,十进制加法计算器原理与硬软件的课程设计主要是通过学生独立设计方案并自己动手用计算机电路设计软件,编写和调试,最后仿真用户程序,来加深对单片机的认识,充分发挥学生的个人创新能力,并提高学生对单片机的兴趣,同时学习查阅资料、参考资料的方法。 关键词:单片机、计算器、AT89C51芯片、汇编语言、数码管、加减乘除 目录 摘要 (01) 引言 (01) 一、设计任务和要求............................. 1、1 设计要求 1、2 性能指标 1、3 设计方案的确定 二、单片机简要原理............................. 2、1 AT89C51的介绍 2、2 单片机最小系统 2、3 七段共阳极数码管 三、硬件设计................................... 3、1 键盘电路的设计 3、2 显示电路的设计 四、软件设计................................... 4、1 系统设计 4、2 显示电路的设计 五、调试与仿真................................. 5、1 Keil C51单片机软件开发系统 5、2 proteus的操作 六、心得体会.................................... 参考文献......................................... 附录1 系统硬件电路图............................ 附录2 程序清单.................................. 常见内部排序算法比较 排序算法是数据结构学科经典的内容,其中内部排序现有的算法有很多种,究竟各有什么特点呢?本文力图设计实现常用内部排序算法并进行比较。分别为起泡排序,直接插入排序,简单选择排序,快速排序,堆排序,针对关键字的比较次数和移动次数进行测试比较。 问题分析和总体设计 ADT OrderableList { 数据对象:D={ai| ai∈IntegerSet,i=1,2,…,n,n≥0} 数据关系:R1={〈ai-1,ai〉|ai-1, ai∈D, i=1,2,…,n} 基本操作: InitList(n) 操作结果:构造一个长度为n,元素值依次为1,2,…,n的有序表。Randomizel(d,isInverseOrser) 操作结果:随机打乱 BubbleSort( ) 操作结果:进行起泡排序 InserSort( ) 操作结果:进行插入排序 SelectSort( ) 操作结果:进行选择排序 QuickSort( ) 操作结果:进行快速排序 HeapSort( ) 操作结果:进行堆排序 ListTraverse(visit( )) 操作结果:依次对L种的每个元素调用函数visit( ) }ADT OrderableList 待排序表的元素的关键字为整数.用正序,逆序和不同乱序程度的不同数据做测试比较,对关键字的比较次数和移动次数(关键字交换计为3次移动)进行测试比较.要求显示提示信息,用户由键盘输入待排序表的表长(100-1000)和不同测试数据的组数(8-18).每次测试完毕,要求列表现是比较结果. 要求对结果进行分析. 详细设计 1、起泡排序 算法:核心思想是扫描数据清单,寻找出现乱序的两个相邻的项目。当找到这两个项目后,交换项目的位置然后继续扫描。重复上面的操作直到所有的项目都按顺序排好。 bubblesort(struct rec r[],int n) { int i,j; struct rec w; unsigned long int compare=0,move=0; for(i=1;i<=n-1;i++) for(j=n;j>=i+1;j--) { if(r[j].key 多目标优化方法 基本概述 几个概念 优化方法 一、多目标优化基本概述 现今,多目标优化问题应用越来越广,涉及诸多领域。在日常生活和工程中,经常要求不只一项指标达到最优,往往要求多项指标同时达到最优,大量的问题都可以归结为一类在某种约束条件下使多个目标同时达到最优的多目标优化问题。例如:在机械加工时,在进给切削中,为选择合适的切削速度和进给量,提出目标:1)机械加工成本最低2)生产率低3)刀具寿命最长;同时还要满足进给量小于加工余量、刀具强度等约束条件。 多目标优化的数学模型可以表示为: X=[x1,x2,…,x n ]T----------n维向量 min F(X)=[f1(X),f2(X),…,f n(X)]T----------向量形式的目标函数s.t. g i(X)≤0,(i=1,2,…,m) h j(X)=0,(j=1,2,…,k)--------设计变量应满足的约束条件多目标优化问题是一个比较复杂的问题,相比于单目标优化问题,在多目标优化问题中,约束要求是各自独立的,所以无法直接比较任意两个解的优劣。 二、多目标优化中几个概念:最优解,劣解,非劣解。 最优解X*:就是在X*所在的区间D中其函数值比其他任何点的函数值要小即f(X*)≤f(X),则X*为优化问题的最优解。 劣解X*:在D中存在X使其函数值小于解的函数值,即f(x)≤f(X*), 即存在比解更优的点。 非劣解X*:在区间D中不存在X使f(X)全部小于解的函数值f(X*). 如图:在[0,1]中X*=1为最优解 在[0,2]中X*=a为劣解 在[1,2]中X*=b为非劣解 多目标优化问题中绝对最优解存在可能性一般很小,而劣解没有意义,所以通常去求其非劣解来解决问题。 微机课程设计报告 题目简易计算器仿真 学院(部)信息学院 专业通信工程 班级2011240401 学生姓名张静 学号33 12 月14 日至12 月27 日共2 周 指导教师(签字)吴向东宋蓓蓓 单片机十进制加法计算器设计 摘要 本设计是基于51系列的单片机进行的十进制计算器系统设计,可以完成计 算器的键盘输入,进行加、减、乘、除3位无符号数字的简单四则运算,并在LED上相应的显示结果。 软件方面从分析计算器功能、流程图设计,再到程序的编写进行系统设计。编程语言方面从程序总体设计以及高效性和功能性对C语言和汇编语言进行比较分析,针对计算器四则运算算法特别是乘法和除法运算的实现,最终选用全球编译效率最高的KEIL公司的μVision3软件,采用汇编语言进行编程,并用proteus仿真。 引言 十进制加法计算器的原理与设计是单片机课程设计课题中的一个。在完成理论学习和必要的实验后,我们掌握了单片机的基本原理以及编程和各种基本功能的应用,但对单片机的硬件实际应用设计和单片机完整的用户程序设计还不清楚,实际动手能力不够,因此对该课程进行一次课程设计是有必要的。 单片机课程设计既要让学生巩固课本学到的理论,还要让学生学习单片机硬件电路设计和用户程序设计,使所学的知识更深一层的理解,十进制加法计算器原理与硬软件的课程设计主要是通过学生独立设计方案并自己动手用计算机电路设计软件,编写和调试,最后仿真用户程序,来加深对单片机的认识,充分发挥学生的个人创新能力,并提高学生对单片机的兴趣,同时学习查阅资料、参考资料的方法。 关键词:单片机、计算器、AT89C52芯片、汇编语言、数码管、加减乘除 信息学部算法分析 上机报告 学号0901******** 姓名陈龙 指导老师秦明 时间2011.11.1~11.23 一.上机实验题目 实验1 比较归并排序和快速排序的区别。 实验2 利用贪心算法对背包问题进行求解。 二.算法设计思路 归并排序: 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列,设定两个指针,最初位置分别为两个已经排序序列的起始位置,比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置,重复步骤直到某一指针达到序列尾,将另一序列剩下的所 有元素直接复制到合并序列尾。 快速排序: 设置两个变量I、J,排序开始的时候:I=0,J=N-1;以第一个数组元素作为关键数据,赋值给key,即key=A[0];从J开始向前搜索,即由后开始向前搜索(J=J-1),找到第一个小于key的值A[J],并与key交换;从I开始向后搜索,即由前开始向后搜索(I=I+1),找到第一个大于key的A[I],与key交换;重复第3、4、5步,直到I=J;(3,4步是在程序中没找到时候j=j-1,i=i+1,直至找到为止。找到并交换的时候i,j指针位置不变。另外当i=j这过程一定正好是i+或j-完成的最后另循环结束。) 背包问题: 用子问题定义状态:即f[i][v]表示前i件物品恰放入一个容量为v的背包可以获得的最大价值。则其状态转移方程便是:f[i][v]=max{f[i-1][v],f[i-1][v-c[i]]+w[i]} 。可以压缩空间,f[v]=max{f[v],f[v-c[i]]+w[i]} 三. 源程序 归并排序 #include 安卓应用程序设计 ——简易计算器的实现院(系)名称 专业名称 学生姓名 学生学号 课程名称 2016年6月日 1.系统需求分析 Android是以Linux为核心的手机操作平台,作为一款开放式的操作系统,随着Android 的快速发展,如今已允许开发者使用多种编程语言来开发Android应用程序,而不再是以前只能使用Java开发Android应用程序的单一局面,因而受到众多开发者的欢迎,成为真正意义上的开放式操作系统。计算器通过算法实行简单的数学计算从而提高了数学计算的效率,实现计算器的界面优化,使界面更加友好,操作更加方便。基于android的计算器的设计,系统具有良好的界面;必要的交互信息;简约美观的效果。使用人员能快捷简单地进行操作,即可单机按钮进行操作,即时准确地获得需要的计算的结果,充分降低了数字计算的难度和节约了时间。 2.系统概要设计 2.1计算器功能概要设计 根据需求,符合用户的实际要求,系统应实现以下功能:计算器界面友好,方便使用,,具有基本的加、减、乘、除功能,能够判断用户输入运算数是否正确,支持小数运算,具有清除功能。 图2.1系统功能图 整个程序基于Android技术开发,除总体模块外主要分为输入模块、显示模块以及计算模块这三大部分。在整个系统中总体模块控制系统的生命周期,输入模块部分负责读取用户输入的数据,显示模块部分负责显示用户之前输入的数据以及显示最终的计算结果,计算模块部分负责进行数据的运算以及一些其他的功能。具体的说,总体模块的作用主要是生成应用程序的主类,控制应用程序的生命周期。 输入模块主要描述了计算器键盘以及键盘的监听即主要负责读取用户的键盘输入以及 响应触屏的按键,需要监听手机动作以及用指针事件处理方法处理触屏的单击动作。同时提供了较为直观的键盘图形用户界面。 显示模块描述了计算器的显示区,即该区域用于显示用户输入的数据以及最终的计算结 数据结构各种排序算法的时间性能. HUNAN UNIVERSITY 课程实习报告 题目:排序算法的时间性能 学生姓名 学生学号 专业班级 指导老师李晓鸿完成日期 设计一组实验来比较下列排序算法的时间性能 快速排序、堆排序、希尔排序、冒泡排序、归并排序(其他排序也可以作为比较的对象) 要求 (1)时间性能包括平均时间性能、最好情况下的时间性能、最差情况下的时间性能等。 (2)实验数据应具有说服力,包括:数据要有一定的规模(如元素个数从100到10000);数据的初始特性类型要多,因而需要具有随机性;实验数据的组数要多,即同一规模的数组要多选几种不同类型的数据来实验。实验结果要能以清晰的形式给出,如图、表等。 (3)算法所用时间必须是机器时间,也可以包括比较和交换元素的次数。 (4)实验分析及其结果要能以清晰的方式来描述,如数学公式或图表等。 (5)要给出实验的方案及其分析。 说明 本题重点在以下几个方面: 理解和掌握以实验方式比较算法性能的方法;掌握测试实验方案的设计;理解并实现测试数据的产生方法;掌握实验数据的分析和结论提炼;实验结果汇报等。 一、需求分析 (1) 输入的形式和输入值的范围:本程序要求实现各种算法的时间性能的比 较,由于需要比较的数目较大,不能手动输入,于是采用系统生成随机数。 用户输入随机数的个数n,然后调用随机事件函数产生n个随机数,对这些随机数进行排序。于是数据为整数 (2) 输出的形式:输出在各种数目的随机数下,各种排序算法所用的时间和 比较次数。 (3) 程序所能达到的功能:该程序可以根据用户的输入而产生相应的随机 数,然后对随机数进行各种排序,根据排序进行时间和次数的比较。 (4)测试数据:略 VB应用程序的设计方法 ——“简易计算器”教学设计 揭阳第一中学卢嘉圳 教学内容:利用所学知识制作Visual Basic程序“简易计算器” 教学目标:能熟练运用CommandButton控件及TextBox控件进行Visual Basic(以下简称VB)程序的设计,能熟练运用条件语句编写代码 教学重点:运用开发VB程序一般过程的思路来开发“简易计算器” 教学难点:分析得出实现“简易计算器”各运算功能的算法。 教材分析: 当我刚开始进行程序设计的教学时,便感觉比较难教。这是因为程序设计本身枯燥、严谨,较难理解,而且学生大多数都是初学者,没有相应的知识基础。对于《程序设计实例》,我们选用的教材是广东教育出版社出版的《信息技术》第四册,该书采用的程序设计语言是VB,而学生是仅学过了一点点简单的QB编程之后就进入《程序设计实例》的学习的。 教材为我们总结了设计VB程序的一般步骤:创建用户界面;设置控件属性;编写事件程序代码;运行应用程序。我总结了一下,其实VB程序设计可分为设计用户界面及编写程序代码两个环节。 教学过程: 一、引入新课 任务:让学生按照书上提示完成一个非常简单的VB程序——“计算器”(仅包含开方、平方、求绝对值功能)的制作。 目的:加强对CommandButton控件及TextBox控件的掌握,复习对开方、求绝对值函数的使用。 引入本节课的学习任务:设计一个简易计算器,包含加、减、乘、除、开方、平方等运算。程序界面可参考下图。 具体功能为:在Text1中输入一个数值,然后单击代表运算符的按钮则运算结果会在text2中显示出来;比如在text1中输入一个2,然后按“+”按钮,再输入一个3按“-”按钮,再输入一个-4按“*”按钮,则实际为(2-3)*(-4);最后在text2中显示结果为4。 五种排序算法的分析与比较 广东医学院医学信息专业郭慧玲 摘要:排序算法是计算机程序设计广泛使用的解决问题的方法,研究排序算法具有重要的理论意义和广泛的应用价值。文章通过描述冒泡、选择、插入、归并和快速5种排序算法,总结了它们的时间复杂度、空间复杂度和稳定性。通过实验验证了5种排序算法在随机、正序和逆序3种情况下的性能,指出排序算法的适用原则,以供在不同条件下选择适合的排序算法借鉴。 关键词:冒泡排序;选择排序;插入排序;归并排序;快速排序。 排序是计算机科学中基本的研究课题之一,其目的是方便记录的查找、插入和删除。随着计算机的发展与应用领域的越来越广,基于计算机硬件的速度和存储空间的有限性,如何提高计算机速度并节省存储空间一直成为软件设计人员的努力方向。其中,排序算法已成为程序设计人员考虑的因素之一[1],排序算法选择得当与否直接影响程序的执行效率和内外存储空间的占用量,甚至影响整个软件的综合性能。排序操作[2,3],就是将一组数据记录的任意序列,重新排列成一个按关键字有序的序列。而所谓排序的稳定性[4]是指如果在排序的序列中,存在前后相同的两个元素,排序前和排序后他们的相对位臵不发生变化。 1 算法与特性 1.1冒泡排序 1.1.1冒泡排序的基本思想 冒泡排序的基本思想是[5,6]:首先将第1个记录的关键字和第2个记录的关键字进行比较,若为逆序,则将2个记录交换,然后比较第2个和第3个记录的关键字,依次类推,直至n-1个记录和第n个记录的关键字进行过比较为止。然后再按照上述过程进行下一次排序,直至整个序列有序为止。 1.1.2冒泡排序的特性 容易判断冒泡排序是稳定的。可以分析出它的效率,在最好情况下,只需通过n-1次比较,不需要移动关键字,即时间复杂度为O(n)(即正序);在最坏情况下是初始序列为逆序,则需要进行n-1次排序,需进行n(n-1)/2次比较,因此在最坏情况下时间复杂度为O(n2),附加存储空间为O(1)。 1.2选择排序 1.2.1选择排序的基本思想 选择排序的基本思想是[5,6]:每一次从待排序的记录中选出关键字最小的记录,顺序放在已排好序的文件的最后,直到全部记录排序完毕.常用的选择排序方法有直接选择排序和堆排序,考虑到简单和易理解,这里讨论直接选择排序。直接选择排序的基本思想是n个记录的文件的直接排序可经过n-1次直接选择排序得到有序结果。 1.2.2选择排序的特性 容易得出选择排序是不稳定的。在直接选择排序过程中所需进行记录移动的操作次数最少为0,最大值为3(n-1)。然而,无论记录的初始排序如何,所需进行的关键字间的比较次数相同,均为n(n-1)/2,时间 常用排序算法比较与分析 一、常用排序算法简述 下面主要从排序算法的基本概念、原理出发,分别从算法的时间复杂度、空间复杂度、算法的稳定性和速度等方面进行分析比较。依据待排序的问题大小(记录数量 n)的不同,排序过程中需要的存储器空间也不同,由此将排序算法分为两大类:【排序】、【外排序】。 排序:指排序时数据元素全部存放在计算机的随机存储器RAM中。 外排序:待排序记录的数量很大,以致存一次不能容纳全部记录,在排序过程中还需要对外存进行访问的排序过程。 先了解一下常见排序算法的分类关系(见图1-1) 图1-1 常见排序算法 二、排序相关算法 2.1 插入排序 核心思想:将一个待排序的数据元素插入到前面已经排好序的数列中的适当位置,使数据元素依然有序,直到待排序数据元素全部插入完为止。 2.1.1 直接插入排序 核心思想:将欲插入的第i个数据元素的关键码与前面已经排序好的i-1、i-2 、i-3、… 数据元素的值进行顺序比较,通过这种线性搜索的方法找到第i个数据元素的插入位置,并且原来位置的数据元素顺序后移,直到全部排好顺序。 直接插入排序中,关键词相同的数据元素将保持原有位置不变,所以该算法是稳定的,时间复杂度的最坏值为平方阶O(n2),空间复杂度为常数阶O(l)。 Python源代码: 1.#-------------------------直接插入排序-------------------------------- 2.def insert_sort(data_list): 3.#遍历数组中的所有元素,其中0号索引元素默认已排序,因此从1开始 4.for x in range(1, len(data_list)): 5.#将该元素与已排序好的前序数组依次比较,如果该元素小,则交换 6.#range(x-1,-1,-1):从x-1倒序循环到0 7.for i in range(x-1, -1, -1): 8.#判断:如果符合条件则交换 9.if data_list[i] > data_list[i+1]: 10.temp= data_list[i+1] 11.data_list[i+1] = data_list[i] 12.data_list[i] = temp 2.1.2 希尔排序 核心思想:是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序;随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止。 希尔排序时间复杂度会比O(n2)好一些,然而,多次插入排序中,第一次插入排序是稳定的,但在不同的插入排序过程中,相同的元素可能在各自的插入排序中移动,所以希尔排序是不稳定的。 Python源代码: 1.#-------------------------希尔排序------------------------------- 2.def insert_shell(data_list): 3.#初始化step值,此处利用序列长度的一半为其赋值 4.group= int(len(data_list)/2) 5.#第一层循环:依次改变group值对列表进行分组 6.while group> 0: 7.#下面:利用直接插入排序的思想对分组数据进行排序 8.#range(group,len(data_list)):从group开始 9.for i in range(group, len(data_list)): 10.#range(x-group,-1,-group):从x-group开始与选定元素开始倒序比较,每个比较元素之间间隔group 11.for j in range(i-group, -1, -group): 12.#如果该组当中两个元素满足交换条件,则进行交换 13.if data_list[j] > data_list[j+group]: 14.temp= data_list[j+group] 15.data_list[j+group] = data_list[j] 16.data_list[j] = temp 17.#while循环条件折半 18.group= int(group/ 2) 2.2 选择排序 模拟计算器 学生姓名:**** 指导老师:**** 摘要本课程设计的课题是设计一个模拟计算器的程序,能够进行表达式的计算,并且表达式中可以包含Abs()和Sqrt()运算。在课程设计中,系统开发平台为Windows ,程序设计设计语言采用C++,程序运行平台为Windows 或*nix。本程序的关键就是表达式的分离和处理,在程序设计中,采用了将输入的中缀表达式转化为后缀表达式的方法,具有可靠的运行效率。本程序做到了对输入的表达式(表达式可以包含浮点数并且Abs()和Sqrt()中可以嵌套子表达式)进行判定表达式是否合法并且求出表达式的值的功能。经过一系列的调试运行,程序实现了设计目标,可以正确的处理用户输入的表达式,对海量级数据都能够通过计算机运算快速解决。 关键词C++程序设计;数据结构;表达式运算;栈;中缀表达式;后缀表达式;字符串处理;表达式合法判定; 目录 1 引言 (3) 1.1课程设计目的 (3) 1.2课程设计内容 (3) 2 设计思路与方案 (4) 3 详细实现 (5) 3.1 表达式的合法判定 (5) 3.2 中缀表达式转化为后缀表达式 (5) 3.3 处理后缀表达式 (7) 3.4 表达式嵌套处理 (8) 4 运行环境与结果 (9) 4.1 运行环境 (9) 4.2 运行结果 (9) 5 结束语 (12) 参考文献 (13) 附录1:模拟计算器源程序清单 (14) 1 引言 本课程设计主要解决的是传统计算器中,不能对表达式进行运算的问题,通过制作该计算器模拟程序,可以做到快速的求解表达式的值,并且能够判定用户输入的表达式是否合法。该模拟计算器的核心部分就在用户输入的中缀表达式的转化,程序中用到了“栈”的后进先出的基本性质。利用两个“栈”,一个“数据栈”,一个“运算符栈”来把中缀表达式转换成后缀表达式。最后利用后缀表达式来求解表达式的值。该算法的复杂度为O(n),能够高效、快速地求解表达式的值,提高用户的效率。 1.1课程设计目的 数据结构主要是研究计算机存储,组织数据,非数值计算程序设计问题中所出现的计算机操作对象以及它们之间的关系和操作的学科。数据结构是介于数学、计算机软件和计算机硬件之间的一门计算机专业的核心课程,它是计算机程序设计、数据库、操作系统、编译原理及人工智能等的重要基础,广泛的应用于信息学、系统工程等各种领域。学习数据结构是为了将实际问题中涉及的对象在计算机中表示出来并对它们进行处理。通过课程设计可以提高学生的思维能力,促进学生的综合应用能力和专业素质的提高。 模拟计算器程序主要利用了“栈”这种数据结构来把中缀表达式转化为后缀表达式,并且运用了递归的思想来解决Abs()和Sqrt()中嵌套表达式的问题,其中还有一些统计的思想来判定表达式是否合法的算法。 1.2课程设计内容 本次课程设计为计算器模拟程序,主要解决表达式计算的问题,实现分别按表达式处理的过程分解为几个子过程,详细的求解过程如下:1 用户输入表达式。 2 判定表达式是否合法。 3 把中缀表达式转化为后缀表达式。 4 求出后缀表达式的结果。 5 输出表达式的结果。通过设计该程序,从而做到方便的求出一个表达式的值,而不需要一步一步进行运算。 一、冒泡排序 已知一组无序数据a[1]、a[2]、……a[n],需将其按升序排列。首先比较a[1]与 a[2]的值,若a[1]大于a[2]则交换两者的值,否则不变。再比较a[2]与a[3]的值,若a[2]大于a[3]则交换两者的值,否则不变。再比较a[3]与a[4],以此类推,最后比较a[n-1]与a[n]的值。这样处理一轮后,a[n]的值一定是这组数据中最大的。再对a[1]~a[n- 1]以相同方法处理一轮,则a[n-1]的值一定是a[1]~a[n-1]中最大的。再对a[1]~a[n-2]以相同方法处理一轮,以此类推。共处理 n-1轮后a[1]、a[2]、……a[n]就以升序排列了。 优点:稳定; 缺点:慢,每次只能移动相邻两个数据。 二、选择排序 每一趟从待排序的数据元素中选出最小(或最大)的一个元素,顺序放在已排好序的数列的最后,直到全部待排序的数据元素排完。 选择排序是不稳定的排序方法。 n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果: ①初始状态:无序区为R[1..n],有序区为空。 ②第1趟排序 在无序区R[1..n]中选出关键字最小的记录R[k],将它与无序区的第1个记录R[1]交换,使R[1..1]和R[2..n]分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。 …… ③第i趟排序 第i趟排序开始时,当前有序区和无序区分别为R[1..i-1]和R(1≤i≤n-1)。该趟排序从当前无序区中选出关键字最小的记录 R[k],将它与无序区的第1个记录R交换,使R[1..i]和R分别变为记录个数增加1个的新有序区和记录个数减少1个的新无序区。 这样,n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果。 优点:移动数据的次数已知(n-1次); 缺点:比较次数多。 三、插入排序 已知一组升序排列数据a[1]、a[2]、……a[n],一组无序数据b[1]、 b[2]、……b[m],需将二者合并成一个升序数列。首先比较b[1]与a[1]的值,若b[1]大于a[1],则跳过,比较b[1]与a[2]的值,若b[1]仍然大于a[2],则继续跳过,直到b[1]小于a数组中某一数据a[x],则将a[x]~a[n]分别向后移动一位,将b[1]插入到原来 a[x]的位置这就完成了b[1] 的插入。b[2]~b[m]用相同方法插入。(若无数组a,可将b[1]当作n=1的数组a) 优点:稳定,快; 缺点:比较次数不一定,比较次数越少,插入点后的数据移动越多,特别是当数据总量庞大的时候,但用链表可以解决这个问题。 四、缩小增量排序 由希尔在1959年提出,又称希尔排序(shell排序)。 已知一组无序数据a[1]、a[2]、……a[n],需将其按升序排列。发现当n不大时,插入排序的效果很好。首先取一增量d(d数据结构课程设计(内部排序算法比较_C语言)
各种排序算法的总结和比较
简易计算器
几种常见内部排序算法比较
多目标优化问题
微机课设简易计算器
排序算法比较实验报告
基于安卓的计算器的设计与实现
数据结构各种排序算法的时
计算器制作
五种排序算法的分析与比较
常用排序算法比较与分析报告
模拟计算器程序-课程设计
各种排序算法的优缺点
相关主题
文本预览