
概率部分MATLAB实验一
(随机变量及其分布)
一、实验学时
2学时
二、实验目的
1、掌握随机数的产生与操作命令
2、掌握计算概率的命令
3、掌握离散型与连续型随机变量有关的操作命令
4、理解随机变量的分布
三、实验准备
1、复习随机变量及分布函数的概念
2、复习离散型随机变量及其分布律和分布函数
3、复习连续型随机变量及其概率密度函数和分布函数
四、实验内容
1、常见离散型随机变量分布的计算及图形演示
(1)0-1分布、二项分布、泊松分布概率的计算;
(2)0-1分布、二项分布、泊松分布的分布函数的计算;2、常见连续型随机变量分布的计算及图形演示
(1)均匀分布、指数分布、正态分布概率密度函数的计算;(2)均匀分布、指数分布、正态分布的分布函数的计算;
3、求单个随机变量落在某个区间内的概率
4、求一个随机变量的函数的分布的计算
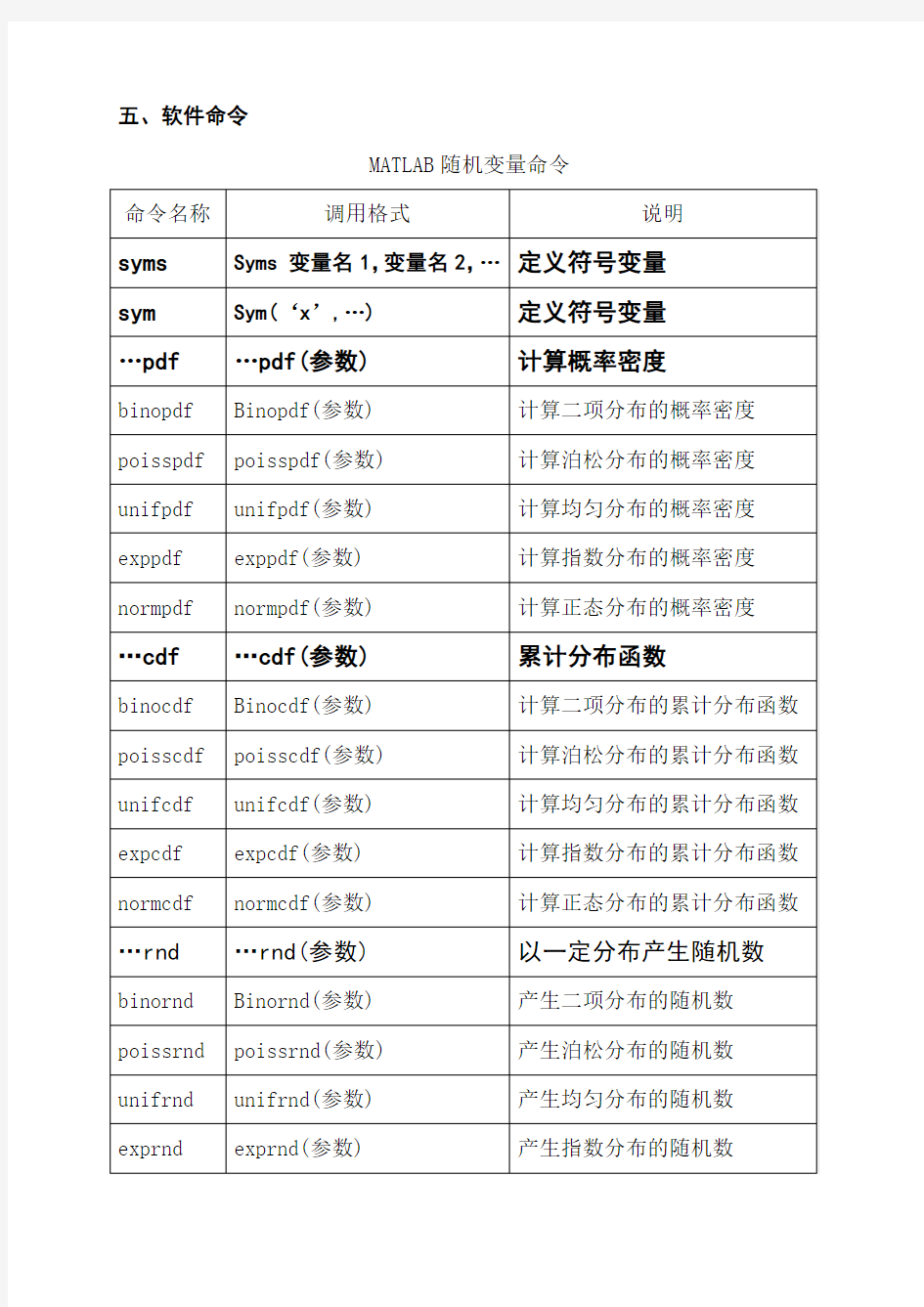
五、软件命令
MATLAB随机变量命令
六、实验示例
(一)关于概率密度函数(或分布律)的计算
1、一个质量检验员每天检验500个零件。如果1%的零件有缺陷,一天内检验员没有发现有缺陷零件的概率是多少?检验员发现有缺陷零件的数量最有可能是多少?
【理论推导】设X 表示检验员每天发现有缺陷零件的数量,X 服从二项分布B(500,0.01)。
(1)50050000
500
99.0)01.01(01.0)0(=-==C X P (2)500*1%=5 【计算机实现的命令及功能说明】
利用二项分布的概率密度函数binopdf()计算 格式:Y=binopdf(X,N,P)
说明:(1)根据相应的参数N,P 计算X 中每个值的二项分布概率密度。
(2)输入的向量或矩阵时,X,N,P 必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数N 必须是正整数,P 中的值必须在区间【0,1】上。 【计算机实现的具体应用过程】
(1)P=binopdf(0,500,0.01) %结果为0.0066 (2)y=binopdf([0:500],500,0.01) [x,i]=max(y)
%结果为x=0.1764,i=6(i 是从0开始计算,所以此时取5)
2、一个硬盘生产商观察到在硬盘生产过程中瑕疵的出现是随机的,且平均几率是每一个4GB 的硬盘中有两个瑕疵,这种几率是可以接受的。问生产出一个没有瑕疵的硬盘的概率是多少?
【理论推导】设X 表示每一个4GB 的硬盘中有瑕疵的数量,X 服从泊松分布P(λ),其中λ=2。设A 表示“生产出一个没有瑕疵的硬盘”这个事件。则
2
0!
02)(-=e A P
【计算机实现的命令及功能说明】
利用泊松分布的概率密度函数poisspdf()计算 格式:Y=poisspdf(X, λ)
说明:(1)根据相应的参数λ,计算X 中每个值的泊松分布概率密度。 (2)输入的向量或矩阵时,X, λ必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数λ必须是正数,X 中的值必须是非负整数。 【计算机实现的具体应用过程】
P=poisspdf(0,2) %结果为0.1353
3、对于X 服从【0,1】、【-1,1】上的均匀分布,请计算
(1)X=0.5对应的概率密度函数值;(2)X=5对应的概率密度函数值; (3)X=(0.1,0.2,0.3,0.4,0.5,0.6)对应的概率密度函数值; 【理论推导】
?????≤≤-=?
??≤≤=其它其它,
011,21
)(,010,1)(x x f x x f
【计算机实现的命令及功能说明】
利用均匀分布的概率密度函数unifpdf()计算 格式:Y=unifpdf(X, A,B)
说明:(1)根据相应的参数A,B,计算X 中每个值的均匀分布概率密度。 (2)输入的向量或矩阵X, A,B 必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)B 中参数必须大于A 中的参数。 【计算机实现的具体应用过程】
(1)P=unifpdf(0.5,0,1)或P=unifpdf(0.5) %结果为1
P=unifpdf(0.5,-1,1) %结果为0.5
(2)P=unifpdf(5,0,1) 或P=unifpdf(5) %结果为0
P=unifpdf(5,-1,1) %结果为0 (3)x= 0.1:0.1:0.6;
P=unifpdf(x,0,1) %结果为1 1 1 1 1 1 或 P=unifpdf(x) %结果为1 1 1 1 1 1
x= 0.1:0.1:0.6;P=unifpdf(x,-1,1) %结果为0.5 0.5 0.5 0.5 0.5 0.5 4、对于X 服从参数 θ分别为1,2,3的指数分布,请计算 (1)X=2对应的概率密度函数值;
(2)(X, θ)分别取(1,1),(2,2),(3,3)对应的概率密度函数值; (3)X=(1,2,3)对应的概率密度函数值; 【理论推导】
.0,,
00,1)(>?????≥=-θθθ
其它x e x f x
【计算机实现的命令及功能说明】
利用指数分布的概率密度函数exppdf()计算 格式:Y=exppdf(X, θ)
说明:(1)根据相应的参数θ,计算X 中每个值的指数分布概率密度。 (2)输入的向量或矩阵X, θ,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数θ必须大于0。 【计算机实现的具体应用过程】
(1)y=exppdf(2, 1:3) %结果为0.1353 0.1839 0.1711或y=exppdf(2,1); y=exppdf(2,2); y=exppdf(2,3) (2)x=1:1:3; theta=1:1:3;
y=exppdf(x, theta) %结果为0.3679 0.1839 0.1226 或 y=exppdf(1:3,1:3) %结果为0.3679 0.1839 0.1226
(3)x=1:1:3; y=exppdf(x,1) %结果为0.3679 0.1353 0.0498
x=1:1:3; y=exppdf(x,2) %结果为0.3033 0.1839 0.1116 x=1:1:3; y=exppdf(x,3) %结果为0.2388 0.1711 0.1226 或
theta=1:1:3;y=exppdf(1,theta) %结果为0.3679 0.3033 0.2388 theta=1:1:3;y=exppdf(2,theta) %结果为 0.1353 0.1839 0.1711 theta=1:1:3;y=exppdf(3,theta) %结果为0.0498 0.1116 0.1226
请注意(2)(3)在计算程序上的不同结果。
5、对于X 服从正态分布N(mu,sigma)
(1)mu=0,0.1,0.2,0.3,0.4,0.5,sigma=2,计算X=5对应的概率密度函数值; (2)请说明对于(1)中的mu 取何值时,X=5对应的概率密度函数值最大? 【理论推导】 .
0,21
)(2
22)(>=
--
σσ
πσμx e x f
【计算机实现的命令及功能说明】
利用正态分布N(mu,sigma)的概率密度函数normpdf()计算 格式:Y=normpdf(X, mu,sigma)
说明:(1)根据相应的参数mu,sigma,计算X 中每个值的正态分布N(mu,sigma)概率密度。
(2)输入的向量或矩阵X, mu,sigma,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数sigma 必须大于0。 【计算机实现的具体应用过程】
(1)y=normpdf(5, 0:0.1:0.5,2)
%结果为0.0088 0.0099 0.0112 0.0126 0.0142 0.0159
或mu=0:0.1:0.5;y=normpdf(5, mu,2)
%结果为0.0088 0.0099 0.0112 0.0126 0.0142 0.0159
(2)mu=[0:0.1:0.5];[y i]=max(normpdf(5, mu,2));mumax=mu(i) %结果为0.5(其实从上面的计算结果也可以看出 mu=0.5时对应的概率密度值最大)
6、(1)X服从二项分布B(500,0.01)、泊松分布P(2),请分别计算P(X=5) (2)X服从【-1,1】上的均匀分布、参数 为2的指数分布、正态分布N(-1,3),请分别计算x=5对应的概率密度函数值。
【理论推导】略
【计算机实现的命令及功能说明】
利用概率密度函数pdf()计算
格式:Y=pdf(‘name’,X, A1,A2,A3)
说明:(1)根据相应的参数A1,A2,A3,计算X中每个值的对应的特定分布’name’的概率密度。
(2)输入的向量或矩阵X, A1,A2,A3,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。A1,A2,A3中的一些参数不是必须的,根据具体分布‘name’来定它们的取值情况。
【计算机实现的具体应用过程】
(1)y=pdf(‘bino’,5,500, 0.01) %结果为0.1764
y=pdf(‘poiss ’5, 2) %结果为0.0361 (2)y=pdf(‘unif ’,5,-1 , 1) %结果为 0
y=pdf(‘exp ’5, 2) %结果为 0.0410 y=pdf(‘norm ’,5,-1, 3) %结果为0.0180 (二)关于概率分布函数的计算
1、如果一个足球队在一个赛季中有78场比赛,任一场比赛获胜的机会都为50%,请问:(1)这支球队在一个赛季中获胜超过50场的概率是多少?(2)这支球队在一个赛季中获胜不超过45场的概率是多少?(3)这支球队在一个赛季中获胜在450至50场之间的概率是多少?
【理论推导】设X 表示该球队在一个赛季中获胜的场数,X 服从二项分布B(78,0.5)。 ∑=--=≤k
k k n k k n p p C k X P 0)1()(
(1)∑∑=-=---=-=>50
787878
517878
)5.01(5.01)
5.01(5.0)50(k k k k
k k
k
k
C C X P
(2)∑=--=≤45
7878
)5.01(5.0)45(k k k k
C X P (3)
70787050
7845
787850
787849
46
7878
)5.01(5.0)5.01(5.0)5.01(5.0)5.01(5.0)5045(-=-=-=------=-=
<<∑∑∑C C C C
X P k k k k k k k k k k
k k
【计算机实现的命令及功能说明】
利用二项分布的概率分布函数binocdf()计算 格式:Y=binocdf(X,N,P)
说明:(1)根据相应的参数N,P 计算X 中每个值的二项分布概率分布函数值。
(2)输入的向量或矩阵时,X,N,P 必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数N 必须是正整数,P 中的值必须在区间【0,1】上。 【计算机实现的具体应用过程】
(1)P=1-binocdf(50,78,0.5) %结果为0.0044 (2)p=binocdf(45,78,0.5) %结果为0.9297 (3)p=binocdf(50,78,0.5)- binocdf(45,78,0.5)
- binopdf(50,78,0.5) %结果为0.0618
2、一个质量监督机构对硬盘进行随机抽样检验。他们的原则是如果一个监督员在一个硬盘上发现的坏扇区超过6个,就将停止生产过程。如果坏扇区的平均数(λ)为2,问停止生产过程的概率为多大?
【理论推导】设X 表示每一个硬盘上发现的坏扇区的数量,X 服从泊松分布P(λ),其中λ=2。设A 表示“停止生产过程”这个事件。则
)6(1)6()(≤-=>=X P X P A P 。【 ∑
=-=≤k
k k
e k k X P 0
!
)(λλ】
【计算机实现的命令及功能说明】 利用泊松分布的分布函数poisscdf()计算 格式:Y=poisspdf(X, λ)
说明:(1)根据相应的参数λ,计算X 中每个值的泊松分布的分布函数值。 (2)输入的向量或矩阵时,X, λ必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数λ必须是正数,X 中的值必须是非负整数。 【计算机实现的具体应用过程】
P=1-poisscdf(6,2) %结果为0.0045
3、X 服从【-5,35】上的均匀分布,求)70(≤X P ;)13(≤X P 【理论推导】
X 服从【-5,35】上的均匀分布,则??-∞-===≤35
5
701401
)()70(dx dx x f X P 及 ??
-∞
-===
=
≤13
5
13
45.04018401
)()13(dx dx x f X P 的值为所求。 【计算机实现的命令及功能说明】
利用均匀分布的概率分布函数unifcdf()计算 格式:Y=unifcdf(X, A,B)
说明:(1)根据相应的参数A,B,计算X 中每个值的均匀分布概率密度。 (2)输入的向量或矩阵X, A,B 必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)B 中参数必须大于A 中的参数。 【计算机实现的具体应用过程】 P=unifcdf(70,-5,35) %结果为1 P=unifcdf(13,-5,35) %结果为0.45
4、对于X 服从参数 θ分别为3的指数分布,请计算 (1)X 小于等于2对应的概率分布函数值; (2)X 小于2对应的概率分布函数值; 【理论推导】
.
0,,
00,1)(>?????≥=-θθθ
其它x e x f x
??--∞--===≤2
32
3
2
131)()2(e dx e dx x f X P x
【计算机实现的命令及功能说明】
利用指数分布的概率分布函数expcdf()计算 格式:Y=expcdf(X, θ)
说明:(1)根据相应的参数θ,计算X 中每个值的指数分布概率密度。 (2)输入的向量或矩阵X, θ,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数θ必须大于0。 【计算机实现的具体应用过程】
(1)y=expcdf(2, 3) %结果为0.4866 (2)y=expcdf(2, 3) %结果为0.4866
5、对于X 服从正态分布N(-1,2),计算X 小于5对应的概率分布函数值; 【理论推导】 .
0,21
)(2
22)(>=
--
σσ
πσμx e x f
【计算机实现的命令及功能说明】
利用正态分布N(mu,sigma)的概率分布函数normcdf()计算 格式:Y=normcdf(X, mu,sigma)
说明:(1)根据相应的参数mu,sigma,计算X 中每个值的正态分布N(mu,sigma)概率密度。
(2)输入的向量或矩阵X, mu,sigma,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。
(3)参数sigma必须大于0。
【计算机实现的具体应用过程】
y=normcdf(5, -1,2) %结果为0.9987
6、(1)X服从二项分布B(500,0.01)、泊松分布P(2),请分别计算P(X<=5) (2)X服从【-1,1】上的均匀分布、参数 为2的指数分布、正态分布N(-1,3),请分别计算x<5对应的概率分布函数值。
【理论推导】略
【计算机实现的命令及功能说明】
利用概率分布函数cdf()计算
格式:Y=cdf(‘name’,X, A1,A2,A3)
说明:(1)根据相应的参数A1,A2,A3,计算X中每个值的对应的特定分布’name’的概率分布函数值。
(2)输入的向量或矩阵X, A1,A2,A3,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。A1,A2,A3中的一些参数不是必须的,根据具体分布‘name’来定它们的取值情况。
【计算机实现的具体应用过程】
(1)y=cdf(‘bino’,5,500, 0.01) %结果为 0.6160
y=cdf(‘poiss’5, 2) %结果为 0.9834
(2)y=cdf(‘unif’,5,-1 , 1) %结果为 1
y=cdf(‘exp’5, 2) %结果为 0.9179
y=cdf(‘norm’,5,-1, 3) %结果为 0.9772
1、如果一个足球队在一个赛季中有78场比赛,任一场比赛获胜的机会都为50%,请问:这支球队在一个赛季中至少要获胜多少场次,才能保证它们获胜的概率达到95%?
【理论推导】设X表示该球队在一个赛季中获胜的场数,X服从二项分布
B(78,0.5)。∑
=
--
=≤
k
k
k
n
k
k
n
p
p
C
k
X
P
) 1(
) (
∑∑
=-
=
--
-
=
-
=
≥
n
k
k
k
k
n k
k
k
k C C
n
X
P
78 78
78
78 78
)5.0
1(
5.0
1
)5.0
1(
5.0
)
(
【计算机实现的命令及功能说明】
利用二项分布的逆概率分布函数binoinv()计算
格式:X=binoinv(Y,N,P)
说明:(1)返回二项分布函数值大于或等于Y的最小的整数值X。根据相应的参数N,P计算X中每个值的二项分布概率分布函数值。
(2)输入的向量或矩阵时,Y,N,P必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。
(3)参数N必须是正整数,Y,P中的值必须在区间【0,1】上。
【计算机实现的具体应用过程】
X=binoinv(0.95,78,0.5) %结果为46
2、由某商店过去的销售记录知道,某种商品每月的销售数可以用参数λ=50的泊松分布来描述,为了有95%以上的把握不使商品脱销,问商店在每月月
底应进该种商品多少件?
【理论推导】设X 表示某种商品每月的销售的数量,X 服从泊松分布P(λ),其中λ=50。则 ∑
=-=≤k
k k
e k k X P 0!
)(λλ
【计算机实现的命令及功能说明】
利用泊松分布的逆概率分布函数poissinv()计算 格式:X=poissinv(P, λ)
说明:(1)根据相应的参数λ,返回泊松分布函数值大于或等于P 的最小的正整数X.
(2)输入的向量或矩阵时,P, λ必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数λ必须是正数。 【计算机实现的具体应用过程】 X=poissinv(0.95,50) %结果为62
3、X 服从【-1,1】上的均匀分布, 01.0)(=>x X P ,求 x
【理论推导】显然,x 是【-1,1】上的均匀分布的99%上侧分位数,即上
0.01分位数。则99.021
21)()(1
=+==
=
≤??
-∞
-x
x
x dx dx x f x X P ,故得到 98.01299.0=-?=x 。
【计算机实现的命令及功能说明】
利用均匀分布的逆概率分布函数unifinv()计算 格式:X=unifinv(P, A,B)
说明:(1)根据相应的参数A,B,计算P 中概率值的连续均匀分布逆概率分
布函数值。
(2)输入的向量或矩阵P, A,B 必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)B 中参数必须大于A 中的参数。标准连续均匀分布中A=0,B=1. 【计算机实现的具体应用过程】 X=unifinv(0.99,-1,1) %结果为0.98
4、对于X 服从参数 θ分别为30的指数分布,68.0)(=≤x X P ,求 x 【理论推导】
.
0,,
00,1)(>???
??≥=-θθθ其它x e x f x
68.01301)()(0
3030
=-===≤??--∞-x
x
x
x
e dx e dx x
f x X P
【计算机实现的命令及功能说明】
利用指数分布的逆概率分布函数expinv()计算 格式:X=expinv(P, θ)
说明:(1)根据相应的参数θ,计算P 中概率值的指数分布逆概率分布函数值。
(2)输入的向量或矩阵P, θ,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数θ必须大于0, P 的值必须在【0,1】上。 【计算机实现的具体应用过程】
X=expinv(0.68, 30) %结果为34.1830
5、对于X 服从标准正态分布N(0,1), 95.0)(21=≤≤x X x P ,求 21,x x 【理论推导】 .
0,21)(22)(>=
--σσ
πσ
μx e x f 95.0)()(2
1
21==
≤≤?dx x f x X x P x x
【计算机实现的命令及功能说明】
利用正态分布N(mu,sigma)的逆概率分布函数norminv()计算 格式:X=norminv(P, mu,sigma)
说明:(1)根据相应的参数mu,sigma,计算P 中概率值的正态分布N(mu,sigma)逆概率分布函数值。
(2)输入的向量或矩阵P, mu,sigma,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。 (3)参数sigma 必须大于0, P 的值必须在【0,1】上。 【计算机实现的具体应用过程】
X=norminv([0.025,0.975], 0,1) %结果为 -1.9600 1.9600 或X=norminv([0.01,0.96], 0,1) %结果为-2.3263 1.7507 注意:说明本题结果不唯一;但是,第一个区间比第二个要小。
6、X 服从【-1,1】上的均匀分布、参数 θ为2的指数分布、正态分布N(-1,3),且68.0)(=≤x X P ,分别求 x 【理论推导】略
【计算机实现的命令及功能说明】 利用逆概率分布函数icdf()计算 格式:X=icdf(‘name ’,P, A1,A2,A3)
说明:(1)根据相应的参数A1,A2,A3,计算P 中概率值的对应的特定分布’name ’的逆概率分布函数值。
(2)输入的向量或矩阵P, A1,A2,A3,必须形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。A1,A2,A3中的一些参数不是必须的,根据具体分布‘name ’来定它们的取值情况。
【计算机实现的具体应用过程】
X=icdf(‘unif ’,0.68,-1 , 1) %结果为 0.3600 X=icdf (‘exp ’,0.68, 2) %结果为 2.2789 X=icdf (‘norm ’,0.68,-1, 3) %结果为 0.4031 (四)关于随机数发生函数的计算
1、产生参数为20,概率为0.25的二项分布的随机数。 (1)产生1个随机数; (2)产生5个随机数;
(3)产生15个(3行5列)的随机数 【理论推导】设X 服从二项分布B(20,0.25)。
k n k k
k n k k n C p p C k X P ---=-==)25.01(25.0)1()(20
【计算机实现的命令及功能说明】 利用二项分布的随机数函数binornd()计算 格式:R=binornd(N,P)
R=binornd(N,P,mm) R=binornd(N,P,mm,nn)
说明:(1)R=binornd(N,P),生成一个服从参数N,P的二项分布的随机数;输入的向量或矩阵时,N,P必须形式相同,输出R也和它们形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。
(2)R=binornd(N,P,mm),生成mm个(1行mm列)服从参数N,P的二项分布的随机数,其中mm是1行2列的行向量;输入的向量或矩阵时,N,P必须形式相同,输出R也和它们形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。
(3)R=binornd(N,P,mm,nn),生成mm nn个服从参数N,P的二项分布的随机数矩阵;输入的向量或矩阵时,N,P必须形式相同,输出R也和它们形式相同;如果其中有一个按标量输入,则自动扩展成和其它输入具有相同维数的常数矩阵或数组。
【计算机实现的具体应用过程】
R=binornd(20,0.25) %结果为3(每次结果可能不同,为什么?) R=binornd(20,0.25,1,5) %结果为 6 5 8 4 5
R=binornd(20,0.25,3,5) %结果为
8 6 3 5 0
5 4 3 7 5
2 5
3 5 4
2、产生参数为2的泊松分布的随机数。
(1)产生1个随机数;
(2)产生5个随机数;
(3)产生15个(3行5列)的随机数 【理论推导】X 服从泊松分布P(λ),其中λ=2。 则 ,....2,1,0,0,!
)(=>=
=-k e k k X P k
λλλ
【计算机实现的命令及功能说明】
利用泊松分布的随机数函数poissrnd()计算 格式:R=poissrnd (λ)
R= poissrnd (λ,m) R= poissrnd (λ,m,n)
说明:(1)R=poissrnd (λ),生成一个服从参数λ的泊松分布的随机数; R, λ必须形式相同。
(2)R= poissrnd (λ,m),生成m 个服从参数λ的泊松分布的随机数; R, λ必须形式相同.其中m 是1行2列的行向量。
(3)R= poissrnd (N,P ,m,n),生成m ?n 个服从参数λ的泊松分布的随机数; R, λ必须形式相同.其中m ?n 是m 行n 列的随机数矩阵。 【计算机实现的具体应用过程】
R= poissrnd (2) %结果为1(每次结果可能不同,为什么?) R= poissrnd (2,1,5) %结果为 0 0 4 1 5 R= poissrnd (2,3,5) %结果为
1 3 0 0 1 4 4 3
2 1 1 2
3 0 3 3、产生参数为-1,1的均匀分布的随机数。
Matlab 概率论与数理统计一、matlab基本操作 1.画图 【例01.01】简单画图 hold off; x=0:0.1:2*pi; y=sin(x); plot(x,y,'-r'); x1=0:0.1:pi/2; y1=sin(x1); hold on; fill([x1, pi/2],[y1,1/2],'b'); 【例01.02】填充,二维均匀随机数 hold off; x=[0,60];y0=[0,0];y60=[60,60]; x1=[0,30];y1=x1+30; x2=[30,60];y2=x2-30; xv=[0 0 30 60 60 30 0];yv=[0 30 60 60 30 0 0]; fill(xv,yv,'b'); hold on; plot(x,y0,'r',y0,x,'r',x,y60,'r',y60,x,'r'); plot(x1,y1,'r',x2,y2,'r'); yr=unifrnd (0,60,2,100); plot(yr(1,:),yr(2,:),'m.') axis('on'); axis('square'); axis([-20 80 -20 80 ]);
2. 排列组合 C=nchoosek(n,k):k n C C =,例nchoosek(5,2)=10, nchoosek(6,3)=20. prod(n1:n2):从n1到n2的连乘 【例01.03】至少有两个人生日相同的概率 公式计算n n n n N N n N N N N n N N N C n p )1()1(1)! (! 1!1+--?-=--=- = 365364 (3651)365364 3651 11365365365365 rs rs rs ?-+-+=- =-? rs=[20,25,30,35,40,45,50]; %每班的人数 p1=ones(1,length(rs)); p2=ones(1,length(rs)); % 用连乘公式计算 for i=1:length(rs) p1(i)=prod(365-rs(i)+1:365)/365^rs(i); end % 用公式计算(改进) for i=1:length(rs) for k=365-rs(i)+1:365 p2(i)=p2(i)*(k/365); end ; end % 用公式计算(取对数) for i=1:length(rs)
Matlab 概率论与数理统计一、m atlab基本操作 1.画图 hold off; x=0:0.1:2*pi; y=sin(x); plot(x,y,'-r'); x1=0:0.1:pi/2; y1=sin(x1); hold on; fill([x1, pi/2],[y1,1/2],'b'); hold off; x=[0,60];y0=[0,0];y60=[60,60]; x1=[0,30];y1=x1+30; x2=[30,60];y2=x2-30; xv=[0 0 30 60 60 30 0];yv=[0 30 60 60 30 0 0]; fill(xv,yv,'b'); hold on; plot(x,y0,'r',y0,x,'r',x,y60,'r',y60,x,'r'); plot(x1,y1,'r',x2,y2,'r'); yr=unifrnd (0,60,2,100); plot(yr(1,:),yr(2,:),'m.') axis('on'); axis('square'); axis([-20 80 -20 80 ]);
2. 排列组合 C=nchoosek(n,k):k n C C =,例nchoosek(5,2)=10, nchoosek(6,3)=20. prod(n1:n2):从n1到n2的连乘 【例01.03】至少有两个人生日相同的概率 公式计算n n n n N N n N N N N n N N N C n p )1()1(1)! (! 1!1+--?-=--=- = 365364 (3651)365364 3651 11365365365365 rs rs rs ?-+-+=- =-? rs=[20,25,30,35,40,45,50]; %每班的人数 p1=ones(1,length(rs)); p2=ones(1,length(rs)); % 用连乘公式计算 for i=1:length(rs) p1(i)=prod(365-rs(i)+1:365)/365^rs(i); end % 用公式计算(改进) for i=1:length(rs) for k=365-rs(i)+1:365 p2(i)=p2(i)*(k/365); end ; end % 用公式计算(取对数)
概率特性仿真实验与程序-Matlab 仿真-随机数生成-负指数分布-k 阶 爱尔兰分布-超指数分布 使用Java 中的SecureRandom .nextDouble()生成一个0~1之间的随机浮点数,然后使用反函数法生成一个符合指数分布的随机变量(反函数求得为λ) 1ln(R x --=)。指数分布的 参数λ为getExpRandomValue 函数中的参数lambda 。生成一个指数分布的随机变量的代码如下,后面都将基于该函数生成一组负指数分布、K 阶爱尔兰分布、2阶超指数分布随机变量,然后将生成的随机数通过matlab 程序进行仿真,对随机数的分布特性进行验证。 生成一组参数为lambda (λ)的负指数分布的随机变量 通过下面的函数生成一组λ参数为lambda 的随机变量,其中size 表示随机变量的个数。通过该函数生成之后,可以将这些随机值保存在文件中,以备分析和验证,比如保存在exp.txt 文件中,供下面介绍的matlab 程序分析。 通过genExp (1000000, 0.2)生成1000000个参数为0.2的随机变量,然后保存到exp.txt 中,然后使用下面的matlab 程序对这些随机数的性质进行验证,如果这些随机数符合λ=0.2的负指数分布,则其均值应为1/λ,即1/0.2=5,其方差应为1/λ2=1/(0.2*0.2)=25。然后对这些随机数的概率分布进行统计分析,以长度为1的区间为统计单位,统计各区间内随机数出现的频数,求出在各区间的概率,绘制图形,与参数为λ的真实负指数分布曲线进行对比。下图为matlab 代码
如下图所示,均值为4.996423,约等于5,方差为24.96761,约等于25,与实际情况相符。此外,通过matlab统计的概率密度函数曲线与真实曲线基本重合(其中在0-1之间没有重合的原因是,实际情况是在0-1之间有无数个点,而matlab统计时以1为一个区间进行统计,只生成了一个统计项,而这无数个点的概率全部加到1点处,因此两条线没有重合,而且1点处的值远大于实际值,如果统计单位划分越细,0-1之间的拟合度更高),表明生成的随机数符合负指数分布。
统计数据的描述性分析 一、实验目的 熟悉在matlab中实现数据的统计描述方法,掌握基本统计命令:样本均值、样本中位数、样本标准差、样本方差、概率密度函数pdf、概率分布函数df、随机数生成rnd。 二、实验内容 1 、频数表和直方图 数据输入,将你班的任意科目考试成绩输入 >> data=[91 78 90 88 76 81 77 74]; >> [N,X]=hist(data,5) N = 3 1 1 0 3 X = 75.7000 79.1000 82.5000 85.9000 89.3000 >> hist(data,5)
2、基本统计量 1) 样本均值 语法: m=mean(x) 若x 为向量,返回结果m是x 中元素的均值; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的均值。 2) 样本中位数 语法: m=median(x) 若x 为向量,返回结果m是x 中元素的中位数; 若x 为矩阵,返回结果m是行向量,它包含x 每列数据的中位数3) 样本标准差 语法:y=std(x) 若x 为向量,返回结果y 是x 中元素的标准差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的标准差
std(x)运用n-1 进行标准化处理,n是样本的个数。 4) 样本方差 语法:y=var(x); y=var(x,1) 若x 为向量,返回结果y 是x 中元素的方差; 若x 为矩阵,返回结果y 是行向量,它包含x 每列数据的方差 var(x)运用n-1 进行标准化处理(满足无偏估计的要求),n 是样本的个数。var(x,1)运用n 进行标准化处理,生成关于样本均值的二阶矩。 5) 样本的极差(最大之和最小值之差) 语法:z= range(x) 返回结果z是数组x 的极差。 6) 样本的偏度 语法:s=skewness(x) 说明:偏度反映分布的对称性,s>0 称为右偏态,此时数据位于均值右边的比左边的多;s<0,情况相反;s 接近0 则可认为分布是对称的。 7) 样本的峰度 语法:k= kurtosis(x) 说明:正态分布峰度是3,若k 比3 大得多,表示分布有沉重的尾巴,即样本中含有较多远离均值的数据,峰度可以作衡量偏离正态分布的尺度之一。 >> mean(data) ,
班级:土木01 姓名:赵翔宇 学号:2010072023 概 论 实 验 报 告
实验名称:考试录取问题 实验目的:1. 掌握正态分布的有关计算 2. 掌握正态分布在实际问题处理中的应用 3. 掌握MATLAB软件在概率计算中的应用 实验要求:掌握综合使用MATLAB的命令解决实际问题的方法 一.试验问题 1. 某公司准备通过招聘考试招收320名职工,其中正式工280名,临时工40名;报考的人数是1821人,考试满分是400分。考试后得知,考试平均成绩μ=166分,360分以上的高分考生有31人。王瑞在这次考试中得了256分,问他能否否录取?能否被聘为正式工? 二,问题分析 运算任务:只要求出王瑞的成绩排名即可,假设成绩分布为正态分布,已知均值,须先求出方差,获得两个正态分布参数后,可以估计出王瑞的考试情况。 三,程序设计 1.求方差命令:
这里利用了一般的正态分布向标准正态分布转换的公式: σ u x x -=' 求出了本次考试成绩的方差是91.5310,下面求王瑞的名次: 其中normcdf(256,166,91)=0.8387是小于256分的概率,1821*(1-ans)=293是分数大于256分的人数,即王瑞的排名。所以王瑞不能成为正式工,可以成为临时工。 题目二:某单位招聘2500人,按考试成绩从高分到低分依次录取,共有10000人报名.假设报名者的考试成绩X近似服从正态分布N(μ,σ2)。已知90分以上有359人,60分以下有1151人。问被录用者中最低分为多少? 问题分析:本题的思路和上题一样,我们可以得到两个上位分位数,利用非标准正态分布向标准生态分布的方法列出两个方程解出本次考试的平均分,方差。
一、实验名称 已知随机向量(X ,Y )独立同服从标准正态分布,D={(x,y)|a
p=erchong(a,b,c,d) end if e==2 p=wangge(a,b,c,d); end if e==3 p=fenbu(a,b,c,d); end if e==4 p=mente(a,b,c,d); end if e==5 [X,Y]=meshgrid(-3:0.2:3); Z=1/(2*pi)*exp(-1/2*(X.^2+Y.^2)); meshz(X,Y,Z); end e=input('请选择: \n'); end % ===============================用二重积分计算function p=erchong(a,b,c,d) syms x y; f0=1/(2*pi)*exp(-1/2*(x^2+y^2)); f1=int(f0,x,a,b); %对x积分 f1=int(f1,y,c,d); %对y积分 p=vpa(f1,9); % ================================等距网格法function p=wangge(a,b,c,d) syms x y ; n=100; r1=(b-a)/n; %求步长 r2=(d-c)/n; za(1)=a;for i=1:n,za(i+1)=za(i)+r1;end %分块 zc(1)=c;for j=1:n,zc(j+1)=zc(j)+r2;end for i=1:n x(i)=unifrnd(za(i),za(i+1));end %随机取点 for i=1:n y(i)=unifrnd(zc(i),zc(i+1));end s=0; for i=1:n for j=1:n s=1/(2*pi)*exp(-1/2*(x(i)^2+y(j)^2))+s;%求和end end p=s*r1*r2;
概率论与数理统计 实验报告 概率论部分实验二 《正态分布综合实验》
实验名称:正态分布综合实验 实验目的:通过本次实验,了解Matlab在概率与数理统计领域的应用,学会用matlab做概率密度曲线,概率分布曲线,直方图,累计百分比曲线等简单应用;同时加深对正态分布的认识,以更好得应用之。 实验内容: 实验分析: 本次实验主要需要运用一些matlab函数,如正态分布随机数发生器normrnd函数、绘制直方图函数hist函数、正态分布密度函数图形绘制函数normpdf函数、正态分布分步函数图形绘制函数normcdf等;同时,考虑到本次实验重复性明显,如,分别生成100,1000,10000个服从正态分布的随机数,进行相同的实验操作,故通过数组和循环可以简化整个实验的操作流程,因此,本次实验程序中要设置数组和循环变量。 实验过程: 1.直方图与累计百分比曲线 1)实验程序 m=[100,1000,10000]; 产生随机数的个数 n=[2,1,0.5]; 组距 for j=1:3 for k=1:3 x=normrnd(6,1,m(j),1); 生成期望为6,方差为1的m(j)个 正态分布随机数
a=min(x); a为生成随机数的最小值 b=max(x); b为生成随机数的最大值 c=(b-a)/n(k); c为按n(k)组距应该分成的组数 subplot(1,2,1); 图形窗口分两份 hist(x,c);xlabel('频数分布图'); 在第一份里绘制频数直方图 yy=hist(x,c)/1000; yy为各个分组的频率 s=[]; s(1)=yy(1); for i=2:length(yy) s(i)=s(i-1)+yy(i); end s[]数组存储累计百分比 x=linspace(a,b,c); subplot(1,2,2); 在第二个图形位置绘制累计百分 比曲线 plot(x,s,x,s);xlabel('累积百分比曲线'); grid on; 加网格 figure; 另行开辟图形窗口,为下一个循 环做准备 end end 2)实验结论及过程截图 实验结果以图像形式展示,以下分别为产生100,1000,10000个正态分布随机数,组距分别为2,1,0.5的频数分布直方图和累积百分比曲线,从实验结果看来,随着产生随机数的数目增多,组距减小,累计直方图逐渐逼近正态分布密度函数图像,累计百分比逐渐逼近正态分布分布函数图像。
Matlab 概率论与数理统计 、matlab 基本操作 1. 画图 【例01.01】简单画图 hold off; x=0:0.1:2*pi; y=sin (x); plot(x,y, '-r'); x1=0:0.1:pi/2; y1=s in( x1); hold on; fill([x1, pi/2],[y1,1/2], 'b'); 【例01.02】填充,二维均匀随机数 hold off ; x=[0,60];y0=[0,0];y60=[60,60]; x1=[0,30];y1=x1+30; x2=[30,60];y2=x2-30; plot(x,y0, 'r' ,y0,x, plot(x1,y1, 'r' ,x2,y2, yr=u nifrnd (0,60,2,100); plot(yr(1,:),yr(2,:), axis( 'on'); axis( 'square' ); axis([-20 80 -20 80 ]); xv=[0 0 30 60 60 30 0];yv=[0 30 60 60 30 0 0]; fill(xv,yv, 'b'); hold on ; 'r' ,x,y60, 'r' ,y60,x, 'r') 'r'); 'm.')
2. 排列组合 k C=nchoosek(n,k) : C C n ,例 nchoosek(5,2)=10, nchoosek(6,3)=20. prod(n1:n2):从 n1 至U n2 的连乘 【例01.03】至少有两个人生日相同的概率 365 364|||(365 rs 1) rs 365 365 364 365 rs 1 365 365 365 rs=[20,25,30,35,40,45,50]; %每班的人数 p1= on es(1,le ngth(rs)); p2=on es(1,le ngth(rs)); %用连乘公式计算 for i=1:le ngth(rs) p1(i)=prod(365-rs(i)+1:365)/365A rs(i); end %用公式计算(改进) for i=1:le ngth(rs) for k=365-rs(i)+1:365 p2(i)=p2(i)*(k/365); end ; end %用公式计算(取对数) for i=1:le ngth(rs) p1(i)=exp(sum(log(365-rs(i)+1:365))-rs(i)*log(365)); end 公式计算P 1 n!C N N n N! 1 (N n)! 1 N n N (N 1) (N n 1)
概率统计实验报告 班级16030 学号16030 姓名 2018 年1 月3 日
1、 问题概述和分析 (1) 实验内容说明: 题目12、(综合性实验)分析验证中心极限定理的基本结论: “大量独立同分布随机变量的和的分布近似服从正态分布”。 (2) 本门课程与实验的相关内容 大数定理及中心极限定理; 二项分布。 (3) 实验目的 分析验证中心极限定理的基本结论。 2、实验设计总体思路 2.1、引论 在很多实际问题中,我们会常遇到这样的随机变量,它是由大量的相互独立的随机 因素的综合影响而形成的,而其中每一个个别因素在总的影响中所起的作用是微小的,这种随机变量往往近似的服从正态分布。 2.2、 实验主题部分 2.2.1、实验设计思路 1、 理论分析 设随机变量X1,X2,......Xn ,......独立同分布,并且具有有限的数学期望和方差:E(Xi)=μ,D(Xi)=σ2(k=1,2....),则对任意x ,分布函数 满足 该定理说明,当n 很大时,随机变量 近似地服从标准正 态分布N(0,1)。因此,当n 很大时, 近似地服从正 态分布N(n μ,n σ2). 2、实现方法(写清具体实施步骤及其依据) (1) 产生服从二项分布),10(p b 的n 个随机数, 取2.0=p , 50=n , 计算n 个随 机数之和y 以及 ) 1(1010p np np y --; 依据:n 足够大,且该二项分布具有有限的数学期望和方差。 (2) 将(1)重复1000=m 组, 并用这m 组 ) 1(1010p np np y --的数据作频率直方图进 行观察. 依据:通过大量数据验证随机变量的分布,且符合极限中心定理。
概率论与数理统计实验报告 一、实验目的 1.学会用matlab求密度函数与分布函数 2.熟悉matlab中用于描述性统计的基本操作与命令 3.学会matlab进行参数估计与假设检验的基本命令与操作 二、实验步骤与结果 概率论部分: 实验名称:各种分布的密度函数与分布函数 实验内容: 1.选择三种常见随机变量的分布,计算它们的方差与期望<参数自己设 定)。 2.向空中抛硬币100次,落下为正面的概率为0.5,。记正面向上的次数 为x, (1)计算x=45和x<45的概率, (2)给出随机数x的概率累积分布图像和概率密度图像。 3.比较t(10>分布和标准正态分布的图像<要求写出程序并作图)。 程序: 1.计算三种随机变量分布的方差与期望 [m0,v0]=binostat(10,0.3> %二项分布,取n=10,p=0.3 [m1,v1]=poisstat(5> %泊松分布,取lambda=5 [m2,v2]=normstat(1,0.12> %正态分布,取u=1,sigma=0.12 计算结果: m0 =3 v0 =2.1000 m1 =5 v1 =5 m2 =1 v2 =0.0144 2.计算x=45和x<45的概率,并绘图 Px=binopdf(45,100,0.5> %x=45的概率 Fx=binocdf(45,100,0.5> %x<45的概率 x=1:100。 p1=binopdf(x,100,0.5>。 p2=binocdf(x,100,0.5>。 subplot(2,1,1>
plot(x,p1> title('概率密度图像'> subplot(2,1,2> plot(x,p2> title('概率累积分布图像'> 结果: Px =0.0485 Fx =0.1841 3.t(10>分布与标准正态分布的图像 subplot(2,1,1> ezplot('1/sqrt(2*pi>*exp(-1/2*x^2>',[-6,6]> title('标准正态分布概率密度曲线图'> subplot(2,1,2> ezplot('gamma((10+1>/2>/(sqrt(10*pi>*gamma(10/2>>*(1+x^2/10>^(-(10+1>/2>',[-6,6]>。b5E2RGbCAP title('t(10>分布概率密度曲线图'> 结果:
概率论与数理统计数学实验 目录 实验一几个重要的概率分布的MATLAB实现 p2-3 实验二数据的统计描述和分析 p4-8 实验三参数估计 p9-11 实验四假设检验 p12-14 实验五方差分析 p15-17 实验六回归分析 p18-27
实验一 几个重要的概率分布的MATLAB 实现 实验目的 (1) 学习MATLAB 软件与概率有关的各种计算方法 (2) 会用MATLAB 软件生成几种常见分布的随机数 (3) 通过实验加深对概率密度,分布函数和分位数的理解 Matlab 统计工具箱中提供了约20种概率分布,对每一种分布提供了5种运算功能,下表给出了常见8种分布对应的Matlab 命令字符,表2给出了每一种运算功能所对应的Matlab 命令字符。当需要某一分布的某类运算功能时,将分布字符与功能字符连接起来,就得到所要的命令。 例1 求正态分布()2,1-N ,在x=1.2处的概率密度。 解:在MATLAB 命令窗口中输入: normpdf(1.2,-1,2) 结果为: 0.1089 例2 求泊松分布()3P ,在k=5,6,7处的概率。 解:在MATLAB 命令窗口中输入: poisspdf([5 6 7],3) 结果为: 0.1008 0.0504 0.0216 例3 设X 服从均匀分布()3,1U ,计算{}225P X .-<<。 解:在MATLAB 命令窗口中输入: unifcdf(2.5,1,3)-unifcdf(-2,1,3) 结果为: 0.75000
例4 求概率995.0=α的正态分布()2,1N 的分位数αX 。 解:在MATLAB 命令窗口中输入: norminv(0.995,1,2) 结果为: 6.1517 例5 求t 分布()10t 的期望和方差。 解:在MATLAB 命令窗口中输入: [m,v]=tstat(10) m = 0 v = 1.2500 例6 生成一个2*3阶正态分布的随机矩阵。其中,第一行3个数分别服从均值为1,2,3;第二行3个数分别服从均值为4,5,6,且标准差均为0.1的正态分布。 解:在MATLAB 命令窗口中输入: A=normrnd([1 2 3;4 5 6],0.1,2,3) A = 1.1189 2.0327 2.9813 3.9962 5.0175 6.0726 例7 生成一个2*3阶服从均匀分布()3,1U 的随机矩阵。 解:在MATLAB 命令窗口中输入: B=unifrnd(1,3,2,3) B = 1.8205 1.1158 2.6263 2.7873 1.7057 1.0197 注:对于标准正态分布,可用命令randn(m,n);对于均匀分布()1,0U ,可用命令rand(m,n)。
Matlab 概率 论与数理统 计 、matlab 基本操作 1.画图 【例01.01】简单画图 hold off; x=0:0.1:2*pi; y=sin (x); plot(x,y, '-r'); x1=0:0.1:pi/2; y1=s in( x1); hold on; fill([x1, pi/2],[y1,1/2], 'b'); 【例01.02】填充,二维均匀随机数 hold off ; x=[0,60];y0=[0,0];y60=[60,60]; x1=[0,30];y1=x1+30; x2=[30,60];y2=x2-30; plot(x,y0, 'r' ,y0,x, plot(x1,y1, 'r' ,x2,y2, yr=u nifrnd (0,60,2,100); plot(yr(1,:),yr(2,:), axis( 'on'); axis( 'square' ); xv=[0 0 30 60 60 30 0];yv=[0 30 60 60 30 0 0]; fill(xv,yv, 'b'); hold on ; 'r' ,x,y60, 'r' ,y60,x, 'r') 'r'); 'm.')
axis([-20 80 -20 80 ]);
2. 排列组合 k C=nchoosek(n,k) : C C n ,例 nchoosek(5,2)=10, nchoosek(6,3)=20. prod(n1:n2):从 n1 至U n2 的连乘 【例01.03】至少有两个人生日相同的概率 365 364|||(365 rs 1) rs 365 365 364 365 rs 1 365 365 365 rs=[20,25,30,35,40,45,50]; %每班的人数 p1= on es(1,le ngth(rs)); p2=on es(1,le ngth(rs)); %用连乘公式计算 for i=1:le ngth(rs) p1(i)=prod(365-rs(i)+1:365)/365A rs(i); end %用公式计算(改进) for i=1:le ngth(rs) for k=365-rs(i)+1:365 p2(i)=p2(i)*(k/365); end ; end %用公式计算(取对数) for i=1:le ngth(rs) p1(i)=exp(sum(log(365-rs(i)+1:365))-rs(i)*log(365)); 公式计算P 1 n!C N N n N! 1 (N n)! 1 N n N (N 1) (N n 1)
概率统计实验报告 (1)实验内容说明:(验证性实验)使用Matlab软件绘制正态分布、指数分布、均匀分布密度函数图象。 (2)本门课程与实验的相关内容:本实验与教材中第二章“随机变量及其分布”相关,通过matlab中的函数来绘制第二章中学过的几种重要的连续型随机变量概率密度函数图像。(3)实验目的:通过本实验学习一些经常使用的统计数据的作图命令,提高进行实验数据处理和作图分析的能力。 2、实验设计总体思路 2.1、引论 利用教材中的相关知识,通过Matlab来绘制正态分布、指数分布、均匀分布密度函数图象,从而加深对概率统计知识的理解,并提高进行实验数据处理和作图分析的能力。 2.2、实验主题部分 2.2.1、实验设计思路 1、理论分析 1.参数为μ和σ2的正态分布的概率密度函数是: 可以用函数normpdf计算正态分布的概率密度函数值,调用格式: y=normpdf(x, mu, sigma) %输入参数可以是标量、向量、矩阵。 2.参数为μ的指数分布的概率密度函数是: 可以用函数exppdf计算指数分布的概率密度函数值,调用格式: y=exppdf(x, mu) % 输入参数可以是标量、向量或矩阵。 3.参数为a, b的均匀分布的概率密度函数是: 可以用函数exppdf计算均匀分布的概率密度函数值,调用格式: y=unifpdf(x, a, b) %输入参数可以是标量、向量、矩阵。 最后调用plot函数绘制图像。 1、实现方法
1.x=a:0.1:b % 将区间[a,b]以 0.1 为步长等分, 赋给变量 x 2.通过调用函数normpdf、exppdf、unifpdf分别计算出对应的概率密度函数。 3.调用函数plot绘制图像。 2.2.2、实验结果及分析 绘制分别服从均值是0, 标准差分别是0.5,1, 1.5的正态分布概率密度函数图像:
概率论与数理统计实验报告 应物12班郭帅 2110903026 一、实验内容:用蒙特卡洛方法估计积分值 ,,,2222xy,xxxdxsinedx1用蒙特卡洛方法估计积分,和edxdy的值,并将估计值与真,,,,2200xy1,, 值进行比较。 121xdxdy2用蒙特卡洛方法估计积分edx和的值,并对误差进行估 计。 ,,,4422,,xy10xy,,1 二、要求:(1)针对要估计的积分选择适当的概率分布设计蒙特卡洛方法; (2)利用计算机产生所选分布的随机数以估计积分值; (3)进行重复试验,通过计算样本均值以评价估计的无偏性;通过计算均方误差(针对第1类题)或样本方差(针对第2类题)以评价估计结果的精度。 1)能通过 MATLAB 或其他数学软件了解随机变量的概率密度、分布三、目的:( 函数及其期望、方差、协方差等; (2) 熟练使用 MATLAB 对样本进行基本统计,从而获取数据的基本信息; (3) 能用 MATLAB 熟练进行样本的一元回归分析。 蒙特卡洛方法:当所求解问题是某种随机事件出现的概率,或者是某个随机变量的期望值时,通过某种“实验”的方法,以这种事件出现的频率估计这一随机事件的概率,或者得到这个随机变量的某些数字特征,并将其作为问题的解。 四、实验步骤: ,2 xxdxsin(1) ,0 方法:x在0至pi/2区间上随机取10000个数为均匀分布的简单随机样本,然后计算y的值一共计算二十次,即可用样本均值作为积分的估计值.
Y=pi/2*x.*sin(x) y*f(x)即为被积函数 2,,,,x[0,],fx(),2,, ,其他0,, clc clear x=rand(20,10000)*pi/2 y=(pi/2)*x.*sin(x) a=sum(y,2)/10000 u=sum(a,1)/20 H=1 E=abs(H-u) b=abs(H-u)^2 D=sum(b,1)/19 结果样本均值为u= 0.9987 E = 0.0013 D =8.971e-008=0.00000008971 真值计算: clc clear symsx f='x*sin(x)' int(f,x,0,pi/2) 结果真值为1 ,,2xedx(2),0 方法:x在负无穷到正无穷之间按标准正态分布取10000个样本,然后计算y值二十次,即可
《管理数学实验》实验报告 班级姓名 实验1:MATLAB的数值运算 【实验目的】 (1)掌握MATLAB变量的使用 (2)掌握MATLAB数组的创建, (3)掌握MA TLAB数组和矩阵的运算。 (4)熟悉MATLAB多项式的运用 【实验原理】 矩阵运算和数组运算在MA TLAB中属于两种不同类型的运算,数组的运算是从数组元素出发,针对每个元素进行运算,矩阵的运算是从矩阵的整体出发,依照线性代数的运算规则进行。 【实验步骤】 (1)使用冒号生成法和定数线性采样法生成一维数组。 (2)使用MA TLAB提供的库函数reshape,将一维数组转换为二维和三维数组。 (3)使用逐个元素输入法生成给定变量,并对变量进行指定的算术运算、关系运算、逻辑运算。 (4)使用MA TLAB绘制指定函数的曲线图,将所有输入的指令保存为M文件。 【实验内容】 (1)在[0,2*pi]上产生50个等距采样数据的一维数组,用两种不同的指令实现。 0:(2*pi-0)/(50-1):2*pi 或linspace(0,2*pi,50) (2)将一维数组A=1:18,转换为2×9数组和2×3×3数组。 reshape(A,2,9) ans = Columns 1 through 7 1 3 5 7 9 11 13 2 4 6 8 10 12 14 Columns 8 through 9 15 17 16 18 reshape(A,2,3,3) ans(:,:,1) = 1 3 5 2 4 6 ans(:,:,2) = 7 9 11 8 10 12 ans(:,:,3) = 13 15 17 14 16 18
xx大学xx学院 数学类 课程实习报告 课程名称:概率论与数理统计实习题目:概率论与数理统计姓名: 系:信息与计算科学系专业:信息与计算科学年级:2010 学号: 指导教师: 职称:讲师 年月日
福建农林大学计算机与信息学院数学类课程实习报告结果评定
目录 1实习的目的和任务 (2) 2实习要求 (2) 3实习地点 (2) 4主要仪器设备(实验用的软硬件环境) (2) 5实习内容 (2) 5.1 MATLAB基础与统计工具箱初步 (2) 5.2 概率分布及应用实例 (4) 5.3 统计描述及应用实例 (5) 5.4 区间估计及应用实例 (8) 5.5 假设检验及应用实例 (11) 5.6 方差分析及应用实例 (13) 5.7 回归分析及应用实例 (15) 5.8 数理统计综合应用实例 (18) 6 结束语 (26) 7 参考文献 (27)
概率论与数理统计 (Probabilily theroy and Mathemathical Statistics) 1.实习的目的和任务 目的:通过课程实习,让学生巩固所学的理论知识并且能够应用MATLAB数学软件来解决实际问题。 任务:通过具体的案例描述,利用MATLAB软件计算问题的结果,作 出图形图象分析问题的结论。 2.实习要求 要求:学生能够从案例的自然语言描述中,抽象出其中的数学模型,能够熟练应用所学的概率论与数理统计知识,能够熟练使用MATLAB软件。3.实习地点:校内数学实验室,宿舍 4.主要仪器设备 计算机 Microsoft Windows XP Matlab 7.0 5.实习内容 5.1 MATLAB基础与统计工具箱初步 一、目的:初步了解和掌握MATLAB的操作和统计工具箱的简单应用. 二、任务:熟悉MATLAB的基本命令的调用和基本函数及其基本操作. 三、要求:掌握安装MATLAB的方法,并运用统计工具箱进行简单MATLAB编程. 四、项目: (一)、实例:产生一组试验,假设随机变量X的分布函数为X~N(10,42)的随机数,并绘出该正态分布的图像。 (二)、实验步骤: (1)、在MATLAB命令窗口中输入以下程序: >> R=normrnd(10,4,5,5) %返回均值为10,标准差为4的正态分布的5行5列个随机数据。
概率部分MATLAB实验一 (随机变量及其分布) 一、实验学时 2学时 二、实验目的 1、掌握随机数的产生与操作命令 2、掌握计算概率的命令 3、掌握离散型与连续型随机变量有关的操作命令 4、理解随机变量的分布 三、实验准备 1、复习随机变量及分布函数的概念 2、复习离散型随机变量及其分布律和分布函数 3、复习连续型随机变量及其概率密度函数和分布函数 四、实验内容 1、常见离散型随机变量分布的计算及图形演示 (1)0-1分布、二项分布、泊松分布概率的计算; (2)0-1分布、二项分布、泊松分布的分布函数的计算;2、常见连续型随机变量分布的计算及图形演示 (1)均匀分布、指数分布、正态分布概率密度函数的计算;(2)均匀分布、指数分布、正态分布的分布函数的计算; 3、求单个随机变量落在某个区间内的概率 4、求一个随机变量的函数的分布的计算
五、软件命令 MATLAB随机变量命令
六、实验示例 (一)关于概率密度函数(或分布律)的计算 1、一个质量检验员每天检验500个零件。如果1%的零件有缺陷,一天内检验员没有发现有缺陷零件的概率是多少?检验员发现有缺陷零件的数量最有可能是多少? 【理论推导】设X 表示检验员每天发现有缺陷零件的数量,X 服从二项分布B(500,0.01)。 (1)50050000 500 99.0)01.01(01.0)0(=-==C X P (2)500*1%=5 【计算机实现的命令及功能说明】 利用二项分布的概率密度函数binopdf()计算 格式:Y=binopdf(X,N,P) 说明:(1)根据相应的参数N,P 计算X 中每个值的二项分布概率密度。
数学实验-概率 学院:理学院 班级:xxxx 姓名:xxxx 学号:xxxx 指导教师:xxxxx
实验名称:概率 试验目的: 1)通过对mathematica软件的练习与运用,进一步熟悉和掌握mathematica软件的用法与功能。 2)通过试验过程与结果将随机实验可视化,直观理解概率论中的一些基本概念,并初步体验随机模拟方法。 实验步骤: 1)打开数学应用软件——Mathematica ,单击new打开Mathematica 编辑窗口; 2)根据各种问题编写程序文件; 3)运行程序文件并调试; 4)观察运行结果(数值或图形); 5)根据观察到的结果写出实验报告,并析谈学习心和体会。 实验内容:1)概率的统计定义 2)古典概型 3)几种重要分布 1)二项分布 2)泊松分布 4)概率问题的应用 (一)概率的统计定义
我们以抛掷骰子为例,按古典概率的定义,我们要假设各面出现的机会是等可能的,这就要假设: (1)骰子的质料绝对均匀; (2)骰子是绝对的正方体: (3)掷骰子时离地面有充分的高度。 但在实际问题中是不可能达到这些要求的,假设我们要计算在一次抛掷中出现一点这样一个事件 的概率为多少,这时,已无法仅通过一种理论的考虑来确定,但我们可以通过试验的方法来得到事件 概率:设反复地将骰子抛掷大量的次数,例如n 次,若在n 次抛 掷中一点共发生了 次,则称 是 这个事件在这n 次试验中的频率,概率的统计定义就是将 作为事件 的概率P( ) 的估计。 这个概念的直观背景是:当一个事件发生的可能性大(小)时,如果在同样条件下反复重复这个实验时,则该事件发生的频繁程度就大(小)。同时,我们在数学上可以证明:对几何任何一组试验,当n 趋向无穷时,频率 趋向同一个数。 <练习一> 模拟掷一颗均匀的骰子,可用产生1-6的随机整数来模拟实验结果 1) 作n=200组实验,统计出现各点的次数,计算相应频率并与概率值1/6比较; 2) 模拟n=1000,2000,3000组掷骰子试验,观察出现3点的频率随试验次数n 变化的情形,从中体会频率和概率的关系。 1/m n 1A 1A 1/m n 1/m n 1A 1A 1A 1m
基于MATLAB的概率统计数值实验 三、数理统计 1. Matlab统计工具箱中常见的统计命令 2. 直方图和箱线图实验 3. 抽样分布实验 4. 参数估计和假设检验实验 1
Matlab统计工具箱中常见的统计命令 1、基本统计量 对于随机变量x,计算其基本统计量的命令如下: ●均值:mean(x) 标准差:std(x) ●中位数:median(x) 方差:var(x) ●偏度:skewness(x) 峰度:kurtosis(x) 2、频数直方图的描绘 ●A、给出数组data的频数表的命令为:[N,X]=hist(data,k) ●此命令将区间[min(data),max(data)]分为k个小区间(缺省为10),返回数组 data落在每一个小区间的频数N和每一个小区间的中点X。 ●B、描绘数组data的频数直方图的命令为:hist(data,k) 2
3、参数估计 ●A、对于正态总体,点估计和区间估计可同时由以下命令获得: ●[muhat,sigmahat,muci,sigmaci]=normfit(x,alpha) ●此命令在显著性水平alpha下估计x的参数(alpha缺省值为5%),返回值 muhat是均值的点估计值,sigmahat是标准差的点估计值,muci是均值的区 间估计,sigmaci是标准差的区间估计。 ●B、对其他分布总体,两种处理办法:一是取容量充分大的样本,按中 心极限定理,它近似服从正态分布,仍可用上面估计公式计算;二是使用特定分布总体的估计命令,常用的命令如: ●[muhat,muci]=expfit(x,alpha) ●[lambdahat, lambdaci]=poissfit(x,alpha) ●[phat, pci]=weibfit(x,alpha)3