
数据分析
一、数据分析简介......................................................................错误!未定义书签。
二、数据分析案例 (3)
三、互动 (24)
一、【数据分析简介】
数据无处不在,熟谙一些数据分析方法,将有助于在实际工作中把握各类问题的要害,快速准确的进行决策和推进工作内容,也是本次培训的意义所在。
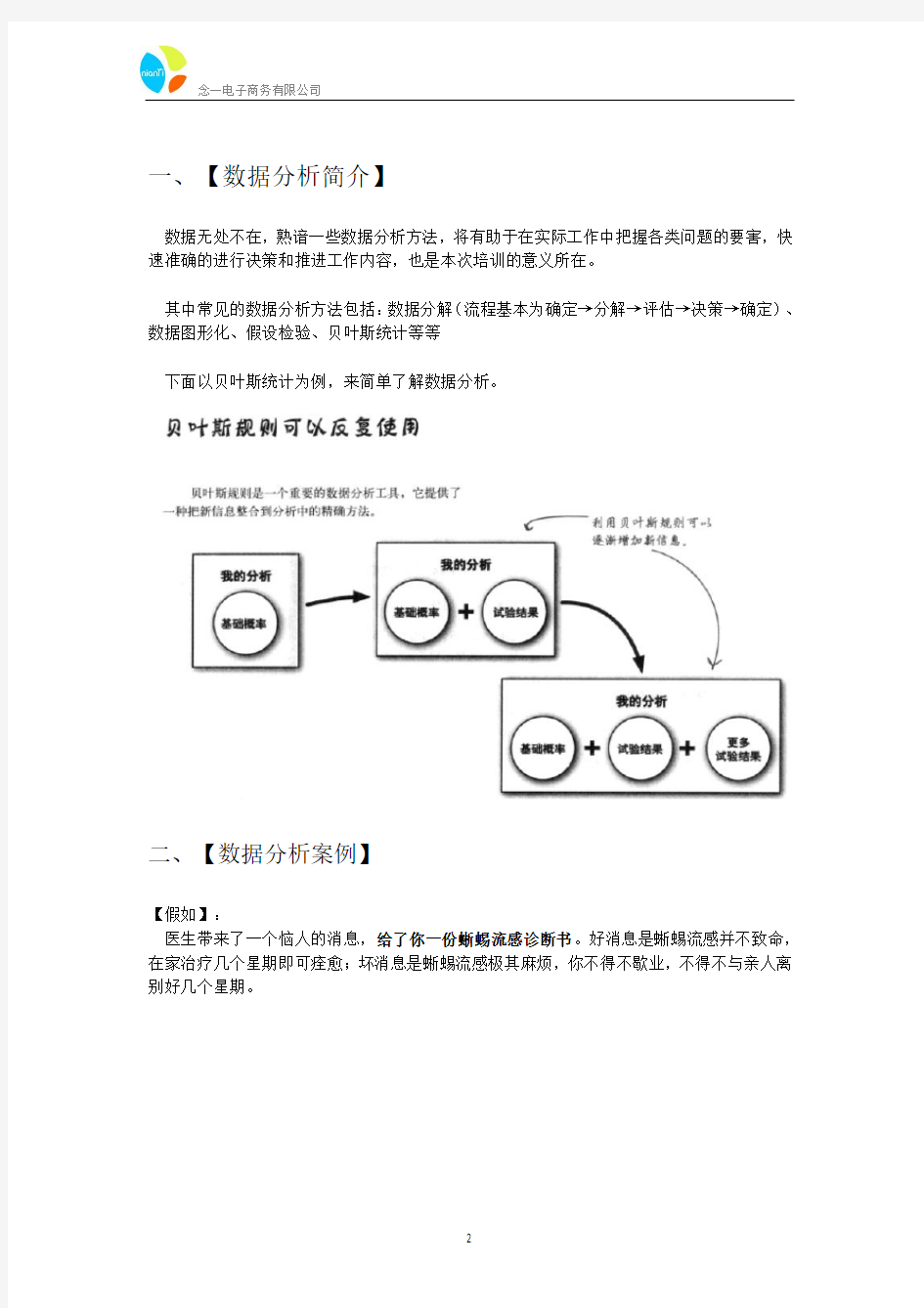
其中常见的数据分析方法包括:数据分解(流程基本为确定→分解→评估→决策→确定)、数据图形化、假设检验、贝叶斯统计等等
下面以贝叶斯统计为例,来简单了解数据分析。
二、【数据分析案例】
【假如】:
医生带来了一个恼人的消息,给了你一份蜥蜴流感诊断书。好消息是蜥蜴流感并不致命,在家治疗几个星期即可痊愈;坏消息是蜥蜴流感极其麻烦,你不得不歇业,不得不与亲人离别好几个星期。
医生确信你已染病在身。不过,由于你对数据分析已经得心应手,所以想通过数据分析来了解试验结果的准确性,并火速上网搜索蜥蜴流感诊断试验,收获如下:试验正确性分析报告。
那么根据这个信息,你觉得自己患蜥蜴流感的概率有多大?(事实上,你更关心未患蜥蜴流感误测阳性的情况)
.
.
.
.
让我们想象有两个不同的空间:一个空间里有大量的人患蜥蜴流感,另一个空间里几乎没有人患蜥蜴流感;然后再来观察未患蜥蜴流感的人的“阳性”概率。
.
.
.
.
图形展示如下:
在试验结果为阳性的条件下患病的概率=(患病且试验结果为阳性的人数)/{(患病且试验结果为阴性的人数)+(未患病而试验结果为阳性的人数)}=9/(9+89)=0.09
三、【互动】
数据分析可以让判断更有效,结果更真实。
更多的数据分析方法,可查阅wps云中“深入浅出数据分析”烧脑。
使用Excel可以完成很多专业软件才能完成的数据统计、分析工作,比如:直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断,均值推断、线性、非线性回归、多元回归分析、时间序列等。本专题将教您完成几种最常用的专业数据分析工作。 注意:所有操作将通过Excel“分析数据库”工具完成,如果您没有安装这项功能,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 直方图 某班进行期中考试后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel可以直接完成此任务。 [具体方法] 描述统计 某班进行期中考试后,需要统计成绩的平均值、区间,并给出班级内部学生成绩差异的量化标准,借此来作为解决班与班之间学生成绩的参差不齐的依据。要求得到标准差等统计数值。 样本数据分布区间、标准差等都是描述样本数据范围及波动大小的统计量,统计标准差需要得到样本均值,计算较为繁琐。这些都是描述样本数据的常用变量,使用Excel 数据分析中的“描述统计”即可一次完成。[具体方法] 排位与百分比排位 某班级期中考试进行后,按照要求仅公布成绩,但学生及家长要求知道排名。故欲公布成绩排名,学生可以通过成绩查询到自己的排名,并同时得到该成绩位于班级百分比排名(即该同学是排名位于前“X%”的学生)。 排序操作是Excel的基本操作, Excel“数据分析”中的“排位与百分比排位”可以使这个工作简化,直接输出报表。[具体方法]
s p s s的数据分析案例 精选文档 TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-
关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin (起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为%和%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
16 59 17 11 18 9 19 27 20 2 .4 .4 21 1 .2 .2 Tot al 474 上 表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的%,其次为15年,共有116人,占中人数的%。且接受过高于20年的教育的人数只有1人,比例很低。 2、 描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的
网站分析中专业的工具除了Google Analytics, Adobe Sitecatalyst, Webtrends, 腾讯分析和百度统计等外,我想最常用的数据处理工具就是Excel了,Excel里头最基础的就是运算和图表的制作,稍微高级一点就是函数和数据透视表的使用了,当然你可能还会想到VBA和宏,但估计很少高手会使用这些高级的功能。 那对于高级的数据分析而言,也就是涉及统计学的专业分析方法和原理的时候,是不是就一定得求助于SPSS,SAS这类专业的分析工具呢?数据分析从低级到高级层次的跳跃过程中有没有可以起承接作用的工具呢?其实是有的,这就是Excel的数据分析功能。貌似最近比较火的两本Excel书籍《谁说菜鸟不会数据分析》和《让Excel飞》都没有涉及这部分的内容。高级的数据分析会涉及回归分析、方差分析和T检验等方法,不要看这些内容貌似跟日常工作毫无关系,其实往高处走,MBA的课程也是包含这些内容的,所以早学晚学都得学,干脆就提前了解吧,请查看以下内容。 在使用之前,首先得安装Excel的数据分析功能,默认情况下,Excel是没有安装这个扩展功能的,安装如下所示: 1)鼠标悬浮在Office按钮上,然后点击【Excel选项】: 2)找到【加载项】,在管理板块选择【Excel加载项】,然后点击【转到】:
3)选择【分析工具库】,点击【确定】: 4)安装完后,就可以【数据】板块看到【数据分析】功能,如下所示:
安装完后,首先来了解一下回归分析的内容。 一、回归分析 在详细进行回归分析之前,首先要理解什么叫回归?实际上,回归这种现象最早由英国生物统计学家高尔顿在研究父母亲和子女的遗传特性时所发现的一种有趣的现象:身高这种遗传特性表现出”高个子父母,其后代身高也高于平均身高;但不见得比其父母更高,到一定程度后会往平均身高方向发生’回归’”。这种效应被称为”趋中回归”。现在的回归分析则多半指源于高尔顿工作的那样一整套建立变量间的数量关系模型的方法和程序。这里的自变量是父母的身高,因变量是子女的身高。 百度百科对于回归分析的定义是: 回归分析(regression analysis)是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法。运用十分广泛: 1)回归分析按照涉及的自变量的多少,可分为一元回归分析和多元回归分析; 2)按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。 这里举个电商的例子:电子商务的转换率是一定的,网站访问数一般正比对应于销售收入,现在要建立不同访问数情况下对应销售的标准曲线,用来预测搞活动时的销售收入,如下所示:
关于某公司474名职工综合状况的统计分析报告 一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分析能够 了解变量的取值状况,对把握数据的分布特征非常有用。此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下:
上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years)
14 6 1.3 1.3 52.5 15 116 24.5 24.5 77.0 16 59 12.4 12.4 89.5 17 11 2.3 2.3 91.8 18 9 1.9 1.9 93.7 19 27 5.7 5.7 99.4 20 2 .4 .4 99.8 21 1 .2 .2 100.0 Tot 474 100.0 100.0 al 上表及其 直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别和受教
SPSS软件进行主成分分析的应用例子 2002年16家上市公司4项指标的数据[5]见表2,定量综合赢利能力分析如下: 第一,将EXCEL中的原始数据导入到SPSS软件中; 【1】“分析”|“描述统计”|“描述”。 【2】弹出“描述统计”对话框,首先将准备标准化的变量移入变量组中,此时,最重要的一步就是勾选“将标准化得分另存为变量”,最后点击确定。 【3】返回SPSS的“数据视图”,此时就可以看到新增了标准化后数据的字段。
数据标准化主要功能就是消除变量间的量纲关系,从而使数据具有可比性,可以举个简单的例子,一个百分制的变量与一个5分值的变量在一起怎么比较?只有通过数据标准化,都把它们标准到同一个标准时才具有可比性,一般标准化采用的是Z标准化,即均值为0,方差为1,当然也有其他标准化,比如0--1标准化等等,可根据自己的研究目的进行选择,这里介绍怎么进行数据的Z标准化。 所的结论: 标准化后的所有指标数据。 注意: SPSS 在调用Factor Analyze 过程进行分析时, SPSS 会自动对原始数据进行标准化处理, 所以在得到计算结果后的变量都是指经过标准化处理后的变量, 但SPSS 并不直接给出标准化后的数据, 如需要得到标准化数据, 则需调用Descriptives 过程进行计算。 factor过程对数据进行因子分析(指标之间的相关性判定略)。 【1】“分析”|“降维”|“因子分析”选项卡,将要进行分析的变量选入“变量”列表;
【2】设置“描述”,勾选“原始分析结果”和“KMO与Bartlett球形度检验”复选框; 【3】设置“抽取”,勾选“碎石图”复选框; 【4】设置“旋转”,勾选“最大方差法”复选框; 【5】设置“得分”,勾选“保存为变量”和“因子得分系数”复选框; 【6】查看分析结果。 所做工作: a.查看KMO和Bartlett 的检验 KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析; Bartlett 球度度检验的Sig值越小于显著水平0.05,越说明变量之间存在相关关系。 所的结论: 符合因子分析的条件,可以进行因子分析,并进一步完成主成分分析。 注意: 1.KMO(Kaiser-Meyer-Olkin) KMO统计量是取值在0和1之间。当所有变量间的简单相关系数平方和远远大于偏相关系数平方和时,KMO值接近1.KMO值越接近于1,意味着变量间的相关性越强,原有变量越适合作因子分析;当所有变量间的简单相关系数平方和接近0时,KMO值接近0.KMO值越接近于0,意味着变量间的相关性越弱,原有变量越不适合作因子分析。 Kaiser给出了常用的kmo度量标准: 0.9以上表示非常适合;0.8表示适合;0.7表示一般; 0.6表示不太适合;0.5以下表示极不适合。 2.Bartlett 球度检验: 巴特利特球度检验的统计量是根据相关系数矩阵的行列式得到的,如果该值较大,且其对应的相伴概率值小于用户心中的显著性水平,那么应该拒绝零假设,认为相关系数矩阵不可能是单位阵,即原始变量之间存在相关性,适合于做主成份分析;相反,如果该统计量比较小,且其相对应的相伴概率大于显著性水平,则不能拒绝零假设,认为相关系数矩阵可能是单位阵,不宜于做因子分析。 Bartlett 球度检验的原假设为相关系数矩阵为单位矩阵,Sig值为0.001小于显著水平0.05,因此拒绝原假设,说明变量之间存在相关关系,适合做因子分析。 所做工作: b. 全部解释方差或者解释的总方差(Total Variance Explained)
SPSS数据案例分析 目录 _Toc438655006 一.手机APP 广告点击意愿的模型构建 (2) 1.1构建研究模型 (2) 1.2研究变量及定义 (2) 1.3研究假设 (2) 1.4变量操作化定义 (2) 1.5问卷设计 (2) 二.实证研究 (2) 2.1基础数据分析 (2) 2.2频数分布及相关统计量 (2) 2.3相关分析 (2) 2.4回归分析 (2) 2.5假设检验 (2)
一.手机APP 广告点击意愿的模型构建 1.1构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显著影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显著影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。
1.3研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机APP 广告点击意愿没有显著影响
谈用Excel做数据分析(doc 19页)
用Excel做数据分析——回归分析 2006-12-04 14:02作者:大鸟原创出处:天极软件责任编辑:still 在数据分析中,对于成对成组数据的拟合是经常遇到的,涉及到的任务有线性描述,趋势预测和残差分析等等。很多专业读者遇见此类问题时往往寻求专业软件,比如在化工中经常用到的Origin和数学中常见的MATLAB等等。它们虽很专业,但其实使用Excel就完全够用了。我们已经知道在Excel自带的数据库中已有线性拟合工具,但是它还稍显单薄,今天我们来尝试使用较为专业的拟合工具来对此类数据进行处理。 点这里看专题:用Excel完成专业化数据统计、分析工作 注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘支持下加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项实例某溶液浓度正比对应于色谱仪器中的峰面积,现欲建立不同浓度下对应峰面积的标准曲线以供测试未知样品的实际浓度。已知8组对应数据,建立标准曲线,并且对此曲线进行评价,给出残差等分析数据。 这是一个很典型的线性拟合问题,手工计算就是采用最小二乘法求出拟合直线的待定参数,同时可以得出R的值,也就是相关系数的大小。在Excel中,可以采用先绘图再添加趋势线的方法完成前两步的要求。 选择成对的数据列,将它们使用“X、Y散点图”制成散点图。 在数据点上单击右键,选择“添加趋势线”-“线性”,并在选项标签中要求给出公式和相关系数等,可以得到拟合的直线。
在选项卡中显然详细多了,注意选择X、Y对应的数据列。“常数为零”就是指明该模型是严格的正比例模型,本例确实是这样,因为在浓度为零时相应峰面积肯定为零。先前得出的回归方程虽然拟合程度相当高,但是在x=0时,仍然有对应的数值,这显然是一个可笑的结论。所以我们选择“常数为零”。 “回归”工具为我们提供了三张图,分别是残差图、线性拟合图和正态概率图。重点来看残差图和线性拟合图。 在线性拟合图中可以看到,不但有根据要求生成的数据点,而且还有经过拟和处理的预测数据点,拟合直线的参数会在数据表格中详细显示。本实例旨在提供更多信息以起到抛砖引玉的作用,由于涉及到过多的专业术语,请各位读者根据实际,在具体使用中另行参考各项参数,此不再对更多细节作进一步解释。
第一章SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下:
1.将数据输入SPSS,并存盘以防断电。 2.进行必要的预分析(分布图、均数标准差的描述等),以确定应采 用的检验方法。 3.按题目要求进行统计分析。 4.保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下: 请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、
[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
图 ???对话框(图框。 图 钮返回 图11.3?描述性指标选择对话框 ???点击Extraction...钮,弹出FactorAnalysis:Extraction对话框(图11.4),系统提供如下因子提取方法: 图11.4?因子提取方法选择对话框 ???Principalcomponents:主成分分析法;
???Unweightedleastsquares:未加权最小平方法; ???Generalizedleastsquares:综合最小平方法; ???Maximumlikelihood:极大似然估计法; ???Principalaxisfactoring:主轴因子法; ???Alphafactoring:α因子法; ???对话框。 ???5种因图 ???旋转的目的是为了获得简单结构,以帮助我们解释因子。本例选正交旋转法,之后点击Continue钮返回FactorAnalysis对话框。 ???点击Scores...钮,弹出弹出FactorAnalysis:Scores对话框(图11.6),系统提供3种估计因子得分系数的方法,本例选Regression(回归因子得分),之后点击Continue钮返回FactorAnalysis对话框,再点击OK钮即完成分析。
图11.6?估计因子分方法对话框? ?11.2.3?结果解释 ??在输出结果窗口中将看到如下统计数据: ??系统首先输出各变量的均数(Mean)与标准差(StdDev),并显示共有25例观察单位进入分析;接着输出相关系数矩阵(CorrelationMatrix),经Bartlett检验表明:Bartlett值=326.28484,P<0.0001,即相关矩阵不是一个单位矩阵,故考虑进行因子分析。 好。今KMO值 NumberofCases?=?????25 CorrelationMatrix: X1???????X2???????X3???????X4???????X5???????X6???????X7 X1????????1.00000 X2?????????.58026??1.00000
利用Excel实现的数据分析方法 利用Excel实现的数据分析方法 随着客服中心的规范化、精细化管理成为行业发展方向,数据分析在运营管理及决策支撑中扮演了越来越重要的角色,很多客服中心认识到数据分析的重要性并积极开始追求各种复杂数据分析技术的应用,但效果往往不佳。其实,笔者认为就国内客服中心运营管理的发展状态而言,能够熟练运用基础的数据分析方法就能够解决运营管理中的大部分问题。分析方法的优劣不在于数学复杂度或者理论高度,而应该注意的是能否科学有效地达到分析目的。 说到分析工具的选择,笔者认为有两点原则需要分析人员注意。第一条原则是选择能够达到分析效果的最简单工具,第二条原则是选择最能够清晰展现分析结果的工具。在目前服务运营分析中出现最多的工具就是Excel,Excel的好处是操作简单,不像SAS、MATLAB需要输入代码命令,对于没有统计分析基础的人来说使用Excel是再好不过的选择。但这是有前提的,就是数据分析人员必须对业务有深刻的了解,因为数据是属于业务的,一个不了解业务的分析人员分析出来的结果往往会偏离现实,不会对管理层的决策与执行层的实施起到任何帮助。下面就介绍一些利用Excel就可以实现的简单有效的数据分析方法。 1、对比分析法 对比分析是客服中心运营分析中运用最多的基础方法,对比分析适用于指标间的横纵向比较、时间序列的比较分析、不同业务或不同人员的比较。
举个例子,拿中国移动某省客服中心接通率数据来看,从时间的维度上分析,我们可以看到品牌A、品牌B与品牌C三个品牌之间接通率随时间的变化趋势,了解在此期间哪个品牌的接通率相对较高,趋势比较稳定。再例如我们分析各品牌话务量情况,首先可以从单一品牌做分析(如图1),各年份话务量基本保持在一致的水平上,但2009年11月份与12月份相对于其他年份话务量明显过高,这可能是由于某些突发事件导致。其次还可以从某一时间点上做分析(如图2),整体上来看,2011年的话务量相对于前两个年份显著降低了很多,这就需要进一步挖掘原因了,一方面可能是已经有一部分客户流失,需要我们找出客户流失的原因并马上制定出客户挽留计划,防止客户继续流失;另一方面就是我们在日常运营时通过有效的方法对话务做分流处理,缓解了一线的话务压力。 图1
相关分析 一、两个变量的相关分析:Bivariate 1.相关系数的含义 相关分析是研究变量间密切程度的一种常用统计方法。相关系数是描述相关关系强弱程度和方向的统计量,通常用r 表示。 ①相关系数的取值范围在-1和+1之间,即:–1≤r ≤ 1。 ②计算结果,若r 为正,则表明两变量为正相关;若r 为负,则表明两变量为负相关。 ③相关系数r 的数值越接近于1(–1或+1),表示相关系数越强;越接近于0,表示相关系数越弱。如果r=1或–1,则表示两个现象完全直线性相关。如果=0,则表示两个现象完全不相关(不是直线相关)。 ④3.0 如何运用E X C E L进行 数据分析答案 Document number【980KGB-6898YT-769T8CB-246UT-18GG08】 如何运用EXCEL进行数据分析 课后测试 如果您对课程内容还没有完全掌握,可以点击这里再次观看。 观看课程 测试成绩:90.0分。恭喜您顺利通过考试! 单选题 1. 人力资源专员希望统计表能够自动将合同快要到期的员工姓名突出显示出来,以免耽误续签,这时需要用到EXCEL工具中的:√ A 条件格式 B 排序法 C 数据透视图 D 数据透视表 正确答案:A 2. 在OFFICE2003版本中,EXCEL条件格式中的条件按钮最多有:√ A 1个 B 3个 C 10个 D 无限个 正确答案:B 3. 对比办公软件的不同版本,2007及以上版本相对于2003版本在条件格式中的优势不包括:× A 可以做条形图或色阶 B 自动提供大于、小于等条件的选择 C 可以添加个性化出错警告 D 自动根据文本界定更改颜色 正确答案:C 4. 在EXCEL中,数据透视表的作用可以归纳为:√ A 排序筛选 B 数据统计 C 逻辑运算 D 分类汇总 正确答案:D 5. 数据透视表的所有操作可以概括为:√ A 拖拽、左键 B 拖拽、右键 C 复制、粘贴 D 双击、右键 正确答案:B 6. 使用数据透视表表示公司各部门中员工的平均年龄、平均工资时,分类是(),汇总是()。√ A 部门年龄、工资 B 部门、年龄工资 C 年龄、工资部门 D 年龄工资、部门 正确答案:A 判断题 7. 数据分析的实质是将结论转化为结果,将简单的问题复杂化。此种说法:√ 正确 错误 正确答案:错误 8. 在EXCEL中,做排序和筛选之前必须先选中想要操作的列。此种说法:√ 正确 错误 正确答案:错误 9. EXCEL不仅能够针对数值排序,还能对文本排序。此种说法:√ 正确 错误 正确答案:正确 10. 在数据透视表制作过程中,选区内原始数据标题没有重名、没有合并、没有阿拉伯数字的叫做字段表。此种说法:√ 正确 用Excel做数据分析——直方图 使用Excel自带的数据分析功能可以完成很多专业软件才有的数据统计、分析,这其中包括:直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断,均值推断、线性、非线性回归、多元回归分析、时间序列等内容。下面将对以上功能逐一作使用介绍,方便各位普通读者和相关专业人员参考使用。 注:本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 某班级期中考试进行后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel中的“数据分析”功能可以直接完成此任务。 操作步骤 1.打开原始数据表格,制作本实例的原始数据要求单列,确认数据的范围。本实例为化学成绩,故数据范围确定为0-100。 2.在右侧输入数据接受序列。所谓“数据接受序列”,就是分段统计的数据间隔,该区域包含一组可选的用来定义接收区域的边界值。这些值应当按升序排列。在本实例中,就是以多少分数段作为统计的单元。可采用拖动的方法生成,也可以按照需要自行设置。本实例采用10分一个分数统计单元。 3.选择“工具”-“数据分析”-“直方图”后,出现属性设置框,依次选择: 输入区域:原始数据区域; 接受区域:数据接受序列; 如果选择“输出区域”,则新对象直接插入当前表格中; 若选择“累计百分率”,则会在直方图上叠加累计频率曲线; 4.输入完毕后,则可立即生成相应的直方图,这张图还需要比较大的调整。 关于某公司474名职工综合状况的统计分析报告一、数据介绍: 本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。 二、数据分析 1、频数分析。基本的统计分析往往从频数分析开始。通过频数分 析能够了解变量的取值状况,对把握数据的分布特征非常有用。 此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。 Statistics 首先,对该公司的男女性别分布进行频数分析,结果如下: 上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。 其次对原有数据中的受教育程度进行频数分析,结果如下表: Educational Level (years) 上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。且接受过高于20年的教育的人数只有1人,比例很低。 2、描述统计分析。再通过简单的频数统计分析了解了职工在性别 和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。 Descriptive Ststistics 用Excel进行数据分析:数据分析工具在哪里? 郑来轶发表于 2013-04-14 22:05 来源:本站原创 说到数据分析,大家可能想的比较多的是SPSS、SAS、R、Matlab等,其实Excel里面自带的数据分析功能也可以完成这些专业统计软件有的数据分析工作,这其中包括:描述性统计、相关系数、概率分布、均值推断、线性、非线性回归、多元回归分析、时间序列等内容。 接下来的用Excel进行数据分析系列教程,都是基于Excel 2007,今天我们讲讲Excel2007的数据分析工具在哪里? 分析工具库是在安装 Microsoft Office 或 Excel 后可用的 Microsoft Office Excel 加载项(加载项:为 Microsoft Office 提供自定义命令或自定义功能的补充程序。)程序。但是,要在 Excel 中使用它,您需要先进行加载。 具体操作步骤如下: 1、单击“Microsoft Office 按钮” ,然后单击“Excel 选项”。 2、单击“加载项”,然后在“管理”框中,选择“Excel 加载宏”,单击“转到”。 3、在“可用加载宏”框中,选中“分析工具库”复选框,然后单击“确定”。 提示:如果“可用加载宏”框中未列出“分析工具库”,请单击“浏览”以找到它。 如果系统提示计算机当前未安装分析工具库,请单击“是”以安装它。 4、OK 加载分析工具库之后,“数据分析”命令将出现在“数据”选项卡上的“分析”组中。 注释若要包括用于分析工具库的 Visual Basic for Application (VBA) 函数,可以按加载分析工具库的相同方式加载“分析工具库 - VBA”加载宏。在“可用加载宏”框中,选中“分析工具库 - VBA”复选框,然后单击“确定”。 SPSS数据案例分析 目录 一.手机APP 广告点击意愿的模型构建 构建研究模型 我们知道效用期望、努力期望、社会影响对行为意愿会产生一定的影响,在模型中的性别、年龄、经验与自愿性等四个控制变量,通常都是作为控制变量来观察他们对采用因素与使用意向之间的关系的影响。因此,目前手机APP 广告的使用人群年龄相对比较年轻,而且年龄特征分布高度集中,年龄在30 岁以下的人群占到70%以上,因此本研究考虑性别了这一变量,同时根据手机APP 广告用户的特性,加入了手机流量作为控制变量,去观察它们对外部变量与点击意愿之间的关系是否有显着影响。 在本研究中,主要把调节变量和控制变量作为两个不同的研究变量,对于调节变量感知风险来说,它是直接影响了感知风险与手机APP 广告点击意愿二者的关系;而控制变量性别、手机流量这些变量是对广告效用期望、APP 效用期望和社会影响与点击意愿直接的关系是否有显着影响。最后,本文根据手机APP 广告的特点对UTAUT 模型进行扩展,构建了手机APP 广告点击意愿的影响因素研究模型。 研究变量及定义 研究假设 (1) 广告效用期望、APP 效用期望、社会影响与手机APP 点击意向的关系 H1:用户的广告效用期望与点击手机APP 广告意愿正相关。 H2:用户的APP 效用期望与点击手机APP 广告意愿正相关 H3:社会影响与手机APP 广告点击意愿正相关 (2)感知风险与点击手机APP 广告意愿的关系 H4:感知风险与手机APP 广告点击意愿负相关 H5:性别,手机流量对手机APP 广告点击意愿没有显着影响 变量操作化定义 ?广告效用期望:广告对我了解某品牌来说很有用 ?APP 效用期望:使用APP 能够让我了解到多方面的信息 ?社会影响:身边的人都在使用手机APP 广告,所以我也要使用 ?感知风险:在点击手机APP 广告时,我担心我的个人隐私安全得不到保护?感知隐私安全重要性:确保点击手机APP 广告是安全的,对我来说是很重要的 ?使用意向:我愿意把手机APP 广告推荐给我周围的人 问卷设计 1.使用APP 能够让我了解到多方面的信息[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 2.广告对我了解某品牌来说很有用[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 3.身边的人都在使用手机APP 广告,所以我也要使用[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 4.在点击手机APP 广告时,我担心我的个人隐私安全得不到保护[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 5.确保点击手机APP 广告是安全的,对我来说是很重要的[单选题] [必答题] ???很不同意?????○?1???○?2???○?3???○?4???○?5??很同意 6.我愿意把手机APP 广告推荐给我周围的人[单选题] [必答题] 直方图 某班进行期中考试后,需要统计各分数段人数,并给出频数分布和累计频数表的直方 图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此 表格为基础建立数据统计直方图。使用Excel可以直接完成此任务。[具体方法] 本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 实例1 某班级期中考试进行后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel中的“数据分析”功能可以直接完成此任务。 操作步骤 1.打开原始数据表格,制作本实例的原始数据要求单列,确认数据的范围。本实例为化学成绩,故数据范围确定为0-100。 2.在右侧输入数据接受序列。所谓“数据接受序列”,就是分段统计的数据间隔,该区域包含一组可选的用来定义接收区域的边界值。这些值应当按升序排列。在本实例中,就是以多少分数段作为统计的单元。可采用拖动的方法生成,也可以按照需要自行设置。本实例采用10分一个分数统计单元。 3.选择“工具”-“数据分析”-“直方图”后,出现属性设置框,依次选择:输入区域:原始数据区域; 接受区域:数据接受序列; 如果选择“输出区域”,则新对象直接插入当前表格中; 选中“柏拉图”,此复选框可在输出表中按降序来显示数据; 若选择“累计百分率”,则会在直方图上叠加累计频率曲线; 1 重复测方差分析实例操作 分析过程 1.数据格式 2.软件实验步骤 3.结果解释与描述 原始数据 group t0 t1 t2 t3 group t0 t1 t2 t3 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 1.1 数据格式 1.2 软件实验步骤 些处的描述过程输出无标准差, group=2时可用Analyze\ Explorer过程实现描述, group=3时可用Analyze→General Lineal Model→Multivariate去实现描述。 1.3 结果解释与描述 表1 有无合并症患者LC含量(s x ) 例数 重复测量时间 麻醉前麻醉后20分钟电切手术30分钟手术结束时 无合并症42 ±±±±有合并症18 ±±±± 统计描述可以通过Analyze\ Explorer过程实现,该过程较简单不赘述。 统计分析教程.(高级篇)张文彤P37 也就是说,在分析时,我们首先要判断,重复测量的不同时间点之间的结果是否存在相关性,也就是进行球形检验,即Mauchly's Test of Sphericity 。 如果P<,不符合 Huynh-Feldt 条件,说明重复测量数据之间存在相关性,不可按单因素方差分析方法处理,需要进行多变量方差分析。以多元检验结果为准。 统计分析教程.(高级篇)张文彤P41 如果P> ,符合Huynh-Feldt 条件,说明重复测量数据之间不存在相关性,可按单因素方差分析方法处理。 统计分析教程.(高级篇)张文彤P40 Table 2 Mauchly's Test of Sphericity Within Subjects Effect Mauchly's W Approx. Chi-Square df Sig. Epsilon a Greenhouse-G eisser Huynh-Feldt Lower-b ound Time 5 .000 用Excel实行统计趋势预测分析 在统计工作中使用电脑技术,不但仅需要使用专门的统计软件,还理应使用一些其他软件为我们的统计工作服务,excel以强大的处理表格、图表和数据的功能被广泛地应用于统计领域。预测分析是统计数据分析工作中的重要组成部分之一,Excel 中不但能够用函数,也能够用“趋势线”来实行趋势预测分析。下面介绍一下具体使用方法。 一、函数法 1、简单平均法 简单平均法非常简单,以往若干时期的简单平均数就是对未来的预测数。 例如,某企业今年1-6月份的各月实际销售额资料如图1。在c9中输入公式av erage(b3:b8)即可预测出7月份的销售额。 图1 2、简单移动平均法 简单移动平均法预测所用的历史资料要随预测期的推移而顺延。仍用上例,我们假设预测时用前面3个月的资料,我们能够用两种方法实现用该法预测销售额:一是 在d6输入公式average(b3:b5),拖曳d6到d9,这样就能够预测出4-7月的销售额;二是使用excel的数据分析功能,选择工具菜单中的数据分析项(如没有此项,则选择加载宏来加载此项),然后选择移动平均,在输入区域输入b3:b8,输出区域输入d4:d9,也能够得到相同的结果。 3、加权移动平均法 加权移动平均法在简单移动平均法的基础上对所用的资料分别确定一定的权数,算出加权平均数即为预测数。还是用上例,在e6输入公式sum(b3*1+b4*2+b5*3) /6,把e6拖曳到e9即可预测出4-7月的销售额。 4、指数平滑法 指数平滑法是通过导入平滑系数对本期的实际数和本期的预测数实行加权平均计算后作为下期预测数的一种方法。仍用上例(b2,f3的数据都为1月份的预测销售额),假设平滑系数为0.3,我们也能够用两种方法实现。用该法预测销售额:一是在f4输入公式0.3*b3+0.7*f3,把f4拖曳到f9即可;二是使用数据分析功能,在工具菜单中选择数据分析项后,选择指数平滑,在输入区域输入b2:b9,阻尼系数输入0.7,输出区域输入f2:f11,也可得到2-7月份的预测销售额。 5、直线回归分析法 直线回归分析法就是使用直线回归方程来实行预测。手工情况下实行直线回归分析需要实行大量的计算,而利用excel中的forecast函数能很快地计算出预测数。我们还是用上面的例子,在g9输入公式forecast(a9,b3:b8,a3:a8),就可得到7月份的预测销售额。 6、曲线回归分析法 曲线回归分析法就是使用二次或二次以上的回归方程所实行的预测,如抛物线、指数曲线、双曲线等曲线形式。本文仅以指数曲线为例来说明预测的过程。如何运用EXCEL进行数据分析答案
用Excel做数据分析——直方图
spss的数据分析案例
用Excel进行数据分析:数据分析工具在哪里
SPSS数据案例分析
Excel软件的数据分析工具
SPSS操作实例-重复测量
用Excel进行统计趋势预测分析
相关主题
文本预览