
一元方差分析(one way ANOVA)
Part 1 原理
概念:
一元:输入X(分散性数据)只有一个,但有不同的水平;输出Y(连续型数据)只有一个, 不同的X对于一个Y
目的:检验在不同输入水平下,对应的Y值的均值是否都相等。
前提:
1)当输入变量x只有一个且为离散型数据,y也只有一个,且为连续
型数据;
2)X有m个水平,每个水平下做了n个样本;
3)每个Xi水平下的,所做的n个结果(Yi1, yi2, yij, …,Yin) 服从正态分布;
4) m组数据的方差都相等,即:
σ12=σ22=σi2=…=σm2
目的:检验H0: u1=u2=…=ui=…=um 是否成立,即m组数据的均值是否相等,
H1: u1, u2, …, ui, …, um 至少有一个不等
容易知道,总共有m*n个数据,那么这些数据总的离散程度SST为:
ΣΣ(yij-y)2= ΣΣ[ ( yij-yi )+(yi-y )]2
= ΣΣ(( yij-yi )2+ ΣΣ (yi-y ))2+ 2 ΣΣ(yij-y) (yi-y )
﹛ (a+b)2=a2+b2+2ab , 容易理解吧﹜
容易证明2 ΣΣ(yij-y) (yi-y )=0
所以,上式= ΣΣ(( yij-yi )2+ ΣΣ (yi-y ))2
不难看出,ΣΣ(( yij-yi )2正好是组内离散度的总和,即SSE(error);
而ΣΣ (yi-y ))2正好是组间离散度的总和,即SSF(factor)
所以,SST=SSE+SSF
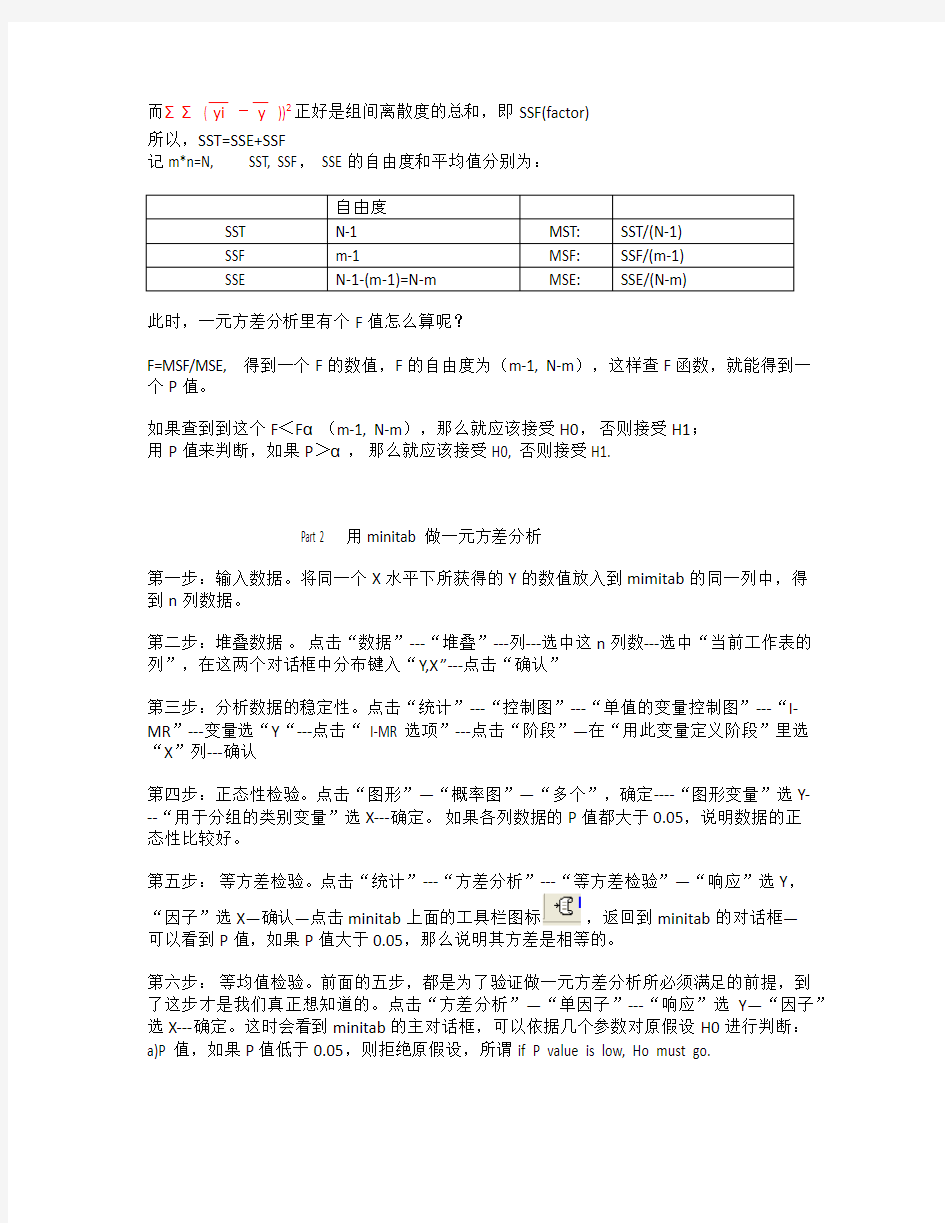
记m*n=N, SST, SSF, SSE的自由度和平均值分别为:
此时,一元方差分析里有个F值怎么算呢?
F=MSF/MSE, 得到一个F的数值,F的自由度为(m-1, N-m),这样查F函数,就能得到一
个P值。
如果查到到这个F<Fα(m-1, N-m),那么就应该接受H0,否则接受H1;
用P值来判断,如果P>α,那么就应该接受H0, 否则接受H1.
Part 2 用minitab 做一元方差分析
第一步:输入数据。将同一个X水平下所获得的Y的数值放入到mimitab的同一列中,得
到n列数据。
第二步:堆叠数据。点击“数据”---“堆叠”---列---选中这n列数---选中“当前工作表的列”,在这两个对话框中分布键入“Y,X”---点击“确认”
第三步:分析数据的稳定性。点击“统计”---“控制图”---“单值的变量控制图”---“I-MR”---变量选“Y“---点击“ I-MR 选项”---点击“阶段”—在“用此变量定义阶段”里选“X”列---确认
第四步:正态性检验。点击“图形”—“概率图”—“多个”,确定----“图形变量”选Y---“用于分组的类别变量”选X---确定。如果各列数据的P值都大于0.05,说明数据的正
态性比较好。
第五步:等方差检验。点击“统计”---“方差分析”---“等方差检验”—“响应”选Y,
“因子”选X—确认—点击minitab上面的工具栏图标,返回到minitab的对话框—
可以看到P值,如果P值大于0.05,那么说明其方差是相等的。
第六步:等均值检验。前面的五步,都是为了验证做一元方差分析所必须满足的前提,到了这步才是我们真正想知道的。点击“方差分析”—“单因子”---“响应”选Y—“因子”选X---确定。这时会看到minitab的主对话框,可以依据几个参数对原假设H0进行判断:a)P 值,如果P值低于0.05,则拒绝原假设,所谓if P value is low, Ho must go.
b) 各个u的置信区间,如果没有相互重叠的区域,则拒绝H0,否则接受H0.
如果想知道是哪几个u不等,可以在minitab中执行以下操作:
同时按下ctrl 键和E键,这时会跳出刚才操作的界面,点击“图形”----点击“比较”---选
择“Fisher”---确认。这时,minitab会逐一地比较各个u 值的差异,就可以知道哪些是不相等的了。
还可以看看其残差如何。点击“图形“—选择“四合一”—确定。这时会跳出一个残差图,分别由“正态概率图”、“与拟合值”、“直方图”、“与顺序”四个图组成。
更进一步,看ε2检验。ε2=SSF/SST. SSF是组间(因子)的变异,SSE是组内(噪音)的变异,SST=SSE+SSF。如果ε2大于0.8,那么说明变异主要是人员造成的。
单因素方差分析实例 [例6-8]在1990 年秋对“亚运会期间收看电视的时间”调查结果如下表所示。 问:收看电视的时间比平日减少了(第一组)、与平日无增减(第二组)、比平日增加了(第三组)的三组居民在“对亚运会的总态度得分”上有没有显著的差异?即要检验从“态度”上看,这三组居民的样本是取自同一总体还是取自不同的总体 在SPSS 中进行方差分析的步骤如下: (1)定义“居民对亚运会的总态度得分”变量为X(数值型),定义组类变量为G(数 值型),G=1、2、3 表示第一组、第二组、第三组。然后录入相应数据,如图6-66所示 图6-66 方差分析数据格式 (2)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图6-67所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G,单击按钮使之进入[Factor]框。单击[OK]按钮完成。
图6-67 方差分析对话框 (3)分析结果如下: 因此,收看电视时间不同的三个组其对亚运会的态度是属于三个不同的总体。 多因素方差分析 [例6-11]从由五名操作者操作的三台机器每小时产量中分别各抽取1 个不同时段的产 量,观测到的产量如表6-31所示。试进行产量是否依赖于机器类型和操作者的方差分析。
SPSS 的操作步骤为: (1)定义“操作者的产量”变量为X(数值型),定义机器因素变量为G1(数值型)、操作 者因素变量为G2(数值型),G1=1、2、3 分别表示第一、二、三台机器,G2=1、2、3、4、5 分别表示第1、2、3、4、5 位操作者。录入相应数据,如图6-68所示。 图6-68 双因素方差分析数据格式 (2)选择[Analyze]=>[General Linear Model]=>[Univariate...],打开[Univariate]主对话框(如图6-69所示)。从主对话框左侧的变量列表中选定X,单击按钮使之进入[Dependent List]框,再选定变量G1 和G2,单击按钮使之进入[Fixed Factor(s)]框。单击[OK]按钮
SPSS 第二次作业——方差分析 1、案例背景: 在一些大型考试中,为了保证结果的准确和一致性,通常针对一些主观题,都采取由多个老师共同评审的办法。在评分过程中,老师对学生的信息不可见,同时也无法看到其他评分,保证了结果的公正性。然而也有特殊情况的发生,导致了成绩的不稳定,这就使得对不同教师的评分标准考察变得十分必要。 2、案例所需资料及数据的获取方式和表述,变量的含义以及类型: 所需资料:抽样某地某次考试中不同教师对不同的题目的学生成绩的评分; 获取方式:让一组学生前后参加四次考试,由三位教师进行批改后收集数据; 变量含义、类型:一份试卷的每道主观题由三名教师进行评定,3个教师的评定结果可看成事从同一总体中抽出的3个区组,它们在四次评定的成绩是相关样本。 表1如下: 3、分析方法: 用方差分析的方法对四个总体的平均数差异进行综合性的F 检验。 4、数据的检验和预处理: a) 奇异点的剔除:经检验得无奇异点的剔除; b) 缺失值的补齐:无; c) 变量的转换(虚拟变量、变量变换):无; d) 对于所用方法的假设条件的检验:进行正态性和方差齐性的检验。 正态性,用QQ 图进行分析得下图: 教师 题目 1 2 3 a 27.3 28.5 29.1 b 29.0 29.2 28.3 c 26.5 28.2 29.3 d 29.7 25.7 27.2
得到近似满足正态性。 ?对方差齐性的检验: 用SPSS对方差齐性的分析得下表: Test of Homogeneity of Variances 分数 Levene Statistic df1 df2 Sig. .732 2 9 .508 易知P〉0.05,接受方差齐性的假设。 5、分析过程: a) 所用方法:单因素方差分析;方差分析中的多重比较。 b) 方法细节: ●单因素方差分析 第一步,提出假设: H0:μ1=μ2=μ3;(教师的评定基本合理,即均值相同) H1:μi(i=1,2,3)不全相等;(教师的评定不够合理,均值有差异)第二步,为检验H0是否成立,首先计算以下统计量:
第九章 方差分析(讲义) 第一节 方差分析的基本原理和步骤 思考: 1.如果想要分析A 总体和B 总体平均数的差异,可以用什么方法来检验? 2.如果想要分析A 、B 、C 三个总体平均数的差异,又该用什么方法来证明? 如果是两个总体,用Z 和t 检验。 那是不是三个总体A 、B 、C 的比较就是拿A 和B 做比较,然后那A 与C 做比较 然后再拿B 和C 做比较? 一、方差分析的基本原理:综合的F 检验 方差分析主要处理两个以上的平均数之间的差异检查问题,需要检验的虚无 假设就是“任何一对平均数”之间是否有显著性差异,因此虚无假设为,样本 所属的所有总体的平均数都相等。 一般把这个假设称为“综合虚无假设“,表达式为: 3210:μμμ==H 方差分析最关键的步骤就是变异的分解。 看一个例子9-1:不同噪音强度下解数学题犯错频次 图9-1 数据变异示意图 (一)数据变异文字层面上的分解 从数据可知:不仅组与组之间数据存在不同,而且同一组被试内部也存在着不同。 1.前者称组间变异,因听了不同的噪音而不同。 2.后者称组内变异,因个案本身的不同而造成的不同。 3.而每个数据之间的差异叫做总变异。 2 5 13 3 6 10 2 5 12 2 5 1 4 n=4 1 4 16 无(C ) 中(50)(B ) 强(100(A) K=3 噪音
可以知道:总变异=组间变异+组内变异 一般而言: 1.组间变异是我们想要的结果,即实验条件产生了作用才会令各组之间的数值存在差异。它越大越好! 2.组内变异不是我们研究的目的,但是需要分解它,借助它分析实验是否成功。组内变异其实是实验的误差。它越小越好! 3.问题来了:组间差异多大,组内差异多小才好? (二)数据变异的数学层面的分解 1.数学上如何表示变异? 总变异的数学意义是每一原始分数( )与总平均数( )的离差,记为: 组间变异的数学意义是每一组的平均数( )与总平均数的离差,记为: 组内变异的数学意义是每一组内部的原始分数与其组平均数( )的离差,记为: 2. 先看某一个数据的情况 分析可知,任一个数据( )与总平均数的差异等于他与本组平均数( )之差加上小组平均数与总平均数( )的差。即: 例如: 3.再看总变异的分解及计算 根据变异的可加性,任何一个原始分数都有: 2 67 .6=
第五章方差分析 序号:5-004 题型:名词解释题 章节:方差分析 题目:方差分析的任务 答案:①求参数μ、μj 、α 1、α 2 ……αm的估计值(参数估计) ②分析观测值的偏差 ③检验各水平效应α 1、α 2 ……αm(等价μ 1 、μ 2 ……μm)有无显著差异 难度:高 评分标准:每题2分,少一条扣去1分。 序号:5-002 题型: 判断题 章节:方差分析 题目:方差分析是一种比较总体方差差异的统计方法。() 答案:错误 难度:中 评分标准:1分 序号:5-003 题型:综合题 章节:方差分析 题目:设有三个车间以不同的工艺生产同一种产品,为考察不同工艺对产品产量的影响,现对每个车间各纪录5天的日产量,如表所示,问三个车间的日产量是否有显著差异? (取α=0.05)。 将最终的计算结果填入下表:
F >)12,2(05.0F 存在显著差异。 解:(1)计算各水平均值和总平均值,465 46 484745441=++++= X , 同理46,5232==X X ,483 46 5246=++=X (2’分) (2)计算总离差平方和S T ,组内平方和S E ,组间平方和S A 。 S T =(44-48)2+(46-48)2+……(45-48)2=172 (1’分) S A =Σ120)4846(5)4852(5)4846(5)(2222j =-+-?+-=-X X (1’分) S E =S T -S A =172-120=52(1’分) (3)计算方差 MS A = 601 3120 =- MS E = 33.43 1552 =-(1’分) (4)作F 检验 85.1333 .460 === E A MS MS F (1’分) 89.3)21,2(),1(05.02==--F m n m F (1’分) 难度:中 评分标准: 每题8分 序号:5-004 题型:综合题 章节:方差分析 题目: 有重复双因素方差分析,A 因素有3个水平,B 因素有3个水平,在A i 、B j 所有可能组合条件下,重复观测2次。试用观测值X ijk 、均值??i X 、??j X ……, i =1、2……n , j =1、2……m , k =1、2…… l 制表。并指定Excel 单元格对应。 有重复双因素方差分析数据表
第10章方差分析与试验设计 三、选择题 1.方差分析的主要目的是判断()。 A. 各总体是否存在方差 B. 各样本数据之间是否有显著差异 C. 分类型自变量对数值型因变量的影响是否显著 D. 分类型因变量对数值型自变量的影响是否显著 2.在方差分析中,检验统计量F是()。 A. 组间平方和除以组内平方和B. 组间均方除以组内均方C. 组间平方除以总平方和D. 组间均方除以总均方 3.在方差分析中,某一水平下样本数据之间的误差称为()。A. 随机误差B. 非随机误差C. 系统误差D. 非系统误差 4.在方差分析中,衡量不同水平下样本数据之间的误差称为()。A. 组内误差B. 组间误差C. 组内平方D. 组间平方 5.组间误差是衡量不同水平下各样本数据之间的误差,它()。A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 6.组内误差是衡量某一水平下样本数据之间的误差,它()。A. 只包括随机误差 B. 只包括系统误差 C. 既包括随机误差,也包括系统误差 D. 有时包括随机误差,有时包括系统误差 7.在下面的假定中,哪一个不属于方差分析中的假定()。 A. 每个总体都服从正态分布B. 各总体的方差相等
C. 观测值是独立的 D. 各总体的方差等于0 8.在方差分析中,所提出的原假设是210:μμ=H = ···=k μ,备择假设是( ) A. ≠≠H 211:μμ···k μ≠ B. >>H 211:μμ···k μ> C. < Single(7) 单因素单向分组方差分析 例1、北京农业大学从南斯拉夫引进15个T型恢复材料,为了研究其应用价值,以农大139为对照,进行了个农艺性状表现的观察。其中6个恢复材料和农大139各5个单株抽穗期观察结果如表1: 表1 引进恢复系抽穗期观察资料 恢复系 单株抽穗期 1 2 3 4 5 PI277 11 Lot-1 13 13 12 14 14 Texas 12 12 13 12 12 zgR 2 13 13 zgR 8 18 19 vk-64-28 19 18 20 19 19 农大10 例2、5个玉米品种的盆栽试验,调查了穗长(cm)性状,得资料如下表2,试检验品种穗长间有无差异。(各处理的重复数不等) 表2 5个玉米品种的穗长 品种穗长(cm)重复数 B 1 21.5 19.5 20 22 18 20 6 B 2 16 18.5 17 15.5 20 16 6 B 3 19 17.5 20 18 17 5 B 4 21 18.5 19 20 4 B 5 15.5 18 17 16 4 例3、表3为同一公猪配种的3头母猪所产的各头仔猪的断奶时体重(斤),试分析母猪对仔猪体重效应的差异显著性。(每组样本容量不等) 表3 三头母猪的仔猪断奶时体重 母猪别n i观察值 No.1 8 24 22.5 24 20 22 23 22 22.5 No.2 7 19 19.5 20 23.5 19 21 16.5 No.3 9 16 16 15.5 20.5 14 17.5 14.5 15.5 19 单因素双向分组方差分析 小区内没有重复观察值 例4、5个水稻品种的产量比较试验,随机区组设计,4次重复,获得每个小区产量(Kg)资料如表4所示:试分析这5个水稻品种间产量水平有无显著差异。 表4 水稻5个品种的每区产量(Kg) 品种 区组(重复) ⅠⅡⅢⅣ 农林 西海67 53 52 50 51 十石52 58 55 57 农林87 58 56 53 53 农林18 53 51 54 55 例5、将一种生长激素配成M1、M2、M3、M4、M5五种浓度,并用H1、H2、H3、三种时间浸渍某大豆品种的种子,45天后得各处理每一植株的平均干物重(g)于下表5,试作方差分析。 表5 生长激素对大豆干重的影响 M i (生长激素) H i (时间) H 1 H 2 H 3 M113 14 14 M212 12 13 M3 3 3 3 M410 9 10 M5 2 5 4 1.(20分)一研究者为了研究市场环境对企业战略行为的影响对MBA学员做了一个模拟实验。60名学员每人管理一个企业,以利润最大化为目标模拟经营。模拟一段时间后,市场环境发生变化。学员随机分为3组,其中第一组为对照组,第二组市场环境转变为恶性竞争,第三组市场环境为合作竞争。在新环境下继续模拟。研究者收集了每个学员在市场环境变化前后的市场份额和利润率数据,形成两个分析指标: Y1: 环境变化后市场份额/环境变化前市场份额*100(Y1=100意味着环境变化前后市场份额无变化) Y2: 环境变化后利润率/环境变化前利润率*100(Y2=100意味着环境变化前后该企业利润无变化) 然后,对这两个指标做多响应变量方差分析,并做LSD多重均值比较。研究者还担心MBA学员工作经历不同可能影响分析结果,特别设计了一个反映工作经历的指标EXP,作为协变量。SPSS输出结果如下。请回答下列问题: (1)解释以下各输出图表的含义 (2)从输出结果中你能得出什么结论? 2.(20分)为了帮助人们找到更好的工作,某市政府制定了一个培训计划。为了检验该计划是否达到预期目的,研究者收集了参加培训和未参加培训人员(对照组)样本数据,做了一个单因素分析。响应变量为incomes after the program,因素为培训状态变量prog,prog=0-未参加培训,prog=1-参加培训。考虑到培训前工资可能对结果产生影响,引入协变量:incbef (培训前工资)。软件分析输出结果如下: Tests of Between-Subjects Effects(协变量调 整前) Dependent Variable: Income after the program Source Type III Sum of Squares df Corrected Model 5136.897(a) 1 Intercept 277571.145 1 prog 5136.897 1 Error 16656.454 998 Total 297121.000 1000 Corrected Total 21793.351 999 a R Squared = .236 (Adjusted R Squared = .235) Tests of Between-Subjects Effects(协变量调 整后) Dependent Variable: Income after the program Source Type III Sum of Squares df Corrected Model 12290.741(a) 2 Intercept 131.400 1 incbef 7153.844 1 prog 4735.662 1 Error 9502.610 997 Total 297121.000 1000 Corrected Total 21793.351 999 a R Squared = .564 (Adjusted R Squared = .563) (1)分别对协变量调整前和协变量调整后的方差分析结果做假设检验, (2)你认为在此分析中是否应该引入协变量?为什么? (3)下表是协变量调整后方差分析的参数估计表,从该表中你能得出什么结论? Parameter Estimates Dependent Variable: Income after the program Parameter B Std. Error t Sig. 95% Confidence Interval Partial Eta 一元线性回归分析及方差分析与显著性检验 某位移传感器的位移x 与输出电压y 的一组观测值如下:(单位略) 设x 无误差,求y 对x 的线性关系式,并进行方差分析与显著性检验。 (附:F 0。10(1,4)=4.54,F 0。05(1,4)=7.71,F 0。01(1,4)=21.2) 回归分析是研究变量之间相关关系的一种统计推断法。 一. 一元线性回归的数学模型 在一元线性回归中,有两个变量,其中 x 是可观测、可控制的普通变量,常称它为自变量或控制变量,y 为随机变量,常称其为因变量或响应变量。通过散点图或计算相关系数判定y 与x 之间存在着显著的线性相关关系,即y 与x 之间存在如下关系: y =a +b ?x +ε (1) 通常认为ε~N (0,δ2)且假设δ2与x 无关。将观测数据(x i ,y i ) (i=1,……,n)代入(1)再注意样本为简单随机样本得: {y i =a +b ?x i +εi ε1?εn 独立同分布N (0,σ2) (2) 称(1)或(2)(又称为数据结构式)所确定的模型为一元(正态)线性回归模型。 对其进行统计分析称为一元线性回归分析。 模型(2)中 EY= a +b ?x ,若记 y=E(Y),则 y=a+bx,就是所谓的一元线性回归方程,其图象就是回归直线,b 为回归系数,a 称为回归常数,有时也通称 a 、b 为回归系数。 设得到的回归方程 bx b y +=0? 残差方程为N t bx b y y y v t t t i ,,2,1,?0Λ=--=-= 根据最小二乘原理可求得回归系数b 0和b 。 对照第五章最小二乘法的矩阵形式,令 ?????? ? ??=??? ? ??=??? ???? ??=??????? ??=N N N v v v V b b b x x x X y y y Y M M M M 2102121?111 则误差方程的矩阵形式为 V b X Y =-? 对照X A L V ?-=,设测得值 t y 的精度相等,则有 方差分析方法 方差分析是统计分析方法中,最重要、最常用的方法之一。本文应用多个实例来阐明方差分析的应用。在实际操作中,可采用相应的统计分析软件来进行计算。 1. 方差分析的意义、用途及适用条件 1.1 方差分析的意义 方差分析又称为变异数分析或F检验,其基本思想是把全部观察值之间的变异(总变异),按设计和需要分为二个或多个组成部分,再作分析。即把全部资料的总的离均差平方和(SS)分为二个或多个组成部分,其自由度也分为相应的部分,每部分表示一定的意义,其中至少有一个部分表示各组均数之间的变异情况,称为组间变异(MS组间);另一部分表示同一组内个体之间的变异,称为组内变异(MS组内),也叫误差。SS除以相应的自由度(υ),得均方(MS)。如MS组间>MS组内若干倍(此倍数即F值)以上,则表示各组的均数之间有显著性差异。 方差分析在环境科学研究中,常用于分析试验数据和监测数据。在环境科学研究中,各种因素的改变都可能对试验和监测结果产生不同程度的影响,因此,可以通过方差分析来弄清与研究对象有关的各个因素对该对象是否存在影响及影响的程度和性质。 1.2 方差分析的用途 1.2.1 两个或多个样本均数的比较。 1.2.2 分离各有关因素,分别估计其对变异的影响。 1.2.3 分析两因素或多因素的交叉作用。 1.2.4 方差齐性检验。 1.3 方差分析的适用条件 1.3.1 各组数据均应服从正态分布,即均为来自正态总体的随机样本(小样本)。 1.3.2 各抽样总体的方差齐。 1.3.3 影响数据的各个因素的效应是可以相加的。 1.3.4 对不符合上述条件的资料,可用秩和检验法、近似F值检验法,也可以经过变量变换,使之基本符合后再按其变换值进行方差分析。一般属Poisson分布的计数资料常用平方根变换法;属于二项分布的百分数可用反正弦函数变换法;当标准差与均数之间呈正比关系,用平方根变换法又不易校正时,也可用对数变换法。 2. 单因素方差分析(单因素多个样本均数的比较) 根据某一试验因素,将试验对象按完全随机设计分为若干个处理组(各组的样本含量可相等或不等),分别求出各组试验结果的均数,即为单因素多个样本均数。 用方差分析比较多个样本均数的目的是推断各种处理的效果有无显著性差异,如各组方差齐,则用F检验;如方差不齐,用近似F值检验,或经变量变换后达到方差齐,再用变换值作F检验。如经F检验或近似F值检验,结论为各总体均数不等,则只能认为各总体均数之间总的来说有差异,但不能认为任何两总体均数之间都有差异,或某两总体均数之间有差异。必要时应作均数之间的两两比较,以判断究竟是哪几对总体均数之间存在差异。 在环境科学研究中,常常要分析比较不同季节对江、河、湖水中某种污染物的含量 2.1.1 单因素一元方差分析 2.1.1.1 Anova1函数 MATLAB统计工具箱中提供了anova1函数,用来作单因素一元方差分析,其调用格式为: (1)p = anova1(X) 根据样本观测值矩阵X进行均衡试验的单因素一元方差分析,检验矩阵X的各列所对应的总体是否具有相同的均值,原假设是X的各列所对应的总体具有相同的均值。矩阵X的列数表示因素的水平数,X的每一列对应因素的一个水平,矩阵X的行数表示因素的每个水平下重复试验的次数(即样本容量),所谓均衡试验是指因素的每个水平下重复试验次数相同的试验。anova1函数的输出参数p是检验的p值,对于给定的显著性水平α,若p≤α,则拒绝原假设,认为X的各列所对应的总体具有不完全相同的均值,否则接受原假设,认为X的各列所对应的总体具有相同的均值。 anova1函数还生成两个图形。第1个图为方差分析表,它将X中数据的误差分成两部分:由于列值的差异导致的误差(组间差); 由于每一列数据与该列均值的差异导致的误差(组内差)。 方差分析表中有6列: 第1列显示误差的来源; 第2列显示每一个误差来源的平方和(SS); 第3列显示与每一个误差来源相关的自由度(df); 第4列显示均值平方和(MS),它是误差来源平方和与自由度的比值,即SS/df; 第5列显示F统计量,它是均值平方和的比值; 第6列显示p值,p值是F函数(fcdf);当F增加时p值减小。 第2个图显示X的每一列的箱形图。箱形图中心线上较大的差异对应于较大的F值和较小的p值。 (2)p = anova1(X,group) 当X是一个矩阵时,这种调用只适合于均衡试验,anova1函数把X的每一列作为一个独立的组,检验各组多对应总体是否具有相同的均值。输入参数group可以是字符数组或者字符串元胞数组,用来指定每组的组名,X的每一列对应一个组名字符串,在箱线图中,组名字符串被作为箱线图的标签。如果不需要指定组名,可以输入空数组([])或者忽略group 这个输入。 当X是一个向量,这种调用不仅适用于均衡试验,还适用于非均衡试验。anova1函数对X 中的样本进行单因素方差分析,通过输入变量group来标识X中的每个元素的水平,所以,group与X的长度必须相等。group中包含的标签同样用于箱形图的标注。anova1函数的矢量输入形式不需要每个样本中的观测值个数相同,所以它适用于不平衡数据。 (3)p = anova1(X,group,displayopt) 当‘displayopt’参数设置为‘on’(默认设置)时,激活ANOV A表和箱形图的显示;‘displayopt’参数设置为‘off’时,不予显示。 (4)[p,table] = anova1(...) 返回单元数组表中的ANOV A表(包含列标签和行标签)。(使用“Edit”菜单中的“Copy Text”选项可以将ANOV A表以文本形式复制到记事本中。) (5)[p,table,table] = anova1(...) 返回stats结构,用于进行多重比较检验。anova1检验评价所有样本均值相等的零假设和均值不等的备择假设。有时进行检验,决定哪对均值差异显著,哪对均值差异不显著是很有效的。提供stats结构作为输入,使用multcompare函数可以进行此项检验。 让4名学生前后做3份测验卷,得到如下表的分数,运用方差分析法可以推断分析的问题是:3份测验卷测试的效果是否有显著性差异? 1、确定类型 由于4名学生前后做3份试卷,是同一组被试前后参加三次考试,4位学生的考试成绩可看成是从同一总体中抽出的4个区组,它们在三个测验上的得分是相关样本。 2、用方差分析方法对三个总体平均数差异进行综合性地F检验 检验步骤如下: 第一步,提出假设: 第二步,计算F检验统计量的值: 因为是同一组被试前后参加三次考试,4位学生的考试成绩可看成是从同一总体中抽出的4个区组,它们在三个测验上的得分是相关样本,所以可将区组间的个别差异从组内差异中分离出来,剩下的是实验误差,这样就可以选择公式(6.6)组间方差与误差方差的F比值来检验三个测验卷的总体平均数差异的显著性。 ①根据表6.4的数据计算各种平方和为: 总平方和: 组间平方和: 区组平方和: 误差平方和: ②计算自由度 总自由度: 组间自由度: 区组自由度: 误差自由度: ③计算方差 组间方差: 区组方差: 误差方差: ④计算F值 第三步,统计决断 根据,α=0.01,查F值表,得到,而实际计算的F检验统计量的值为,即P(F >10.9)<0.01, 样本统计量的值落在了拒绝域内,所以拒绝零假设,接受备择假设,即三个测验中至少有两个总体平均数不相等。 3、用q检验法对逐对总体平均数差异进行检验 检验步骤如下: 第一步,提出假设: 第二步,因为是多个相关样本,所以选择公式(6.8)计算q检验统计量的值: 在为真的条件下,将一次样本的有关数据及代入上式中,得到A和B两组的平均数之差的q值,即: 以此类推,就可得到每对样本平均数之间差异比较的q值,如下表所示: 第三步,统计决断 为了进行统计决断,在本例中,将A,B,C共3组学生英语单词测验成绩的等级排列为: A与C之间和B与C之间包含有1,2两个组,a=2;A与B之间包含有1,2,3三个组,a=3。 根据,得到当a=2时,q检验的临界值为 ; 当a=3时,q检验的临界值为;将表(6.5)中的q检验统计量的值与q临界值进行比较,得到表(6.6)中的3次测验成绩各对平均数之间的比较结果:表6.6 3次测试各对样本平均数之差q值的比较结果 第九章方差分析 【思考与练习】 一、思考题 1. 方差分析的基本思想及其应用条件是什么? 2. 在完全随机设计方差分析中SS SS SS 、、各表示什么含义? 总组间组内 3. 什么是交互效应?请举例说明。 4. 重复测量资料具有何种特点? 5. 为什么总的方差分析的结果为拒绝原假设时,若想进一步了解两两之间的差别需要进行多重比较? 二、最佳选择题 1. 方差分析的基本思想为 A. 组间均方大于组内均方 B. 误差均方必然小于组间均方 C. 总变异及其自由度按设计可以分解成几种不同来源 D. 组内方差显著大于组间方差时,该因素对所考察指标的影响显著 E. 组间方差显著大于组内方差时,该因素对所考察指标的影响显著 3. 完全随机设计的方差分析中,下列式子正确的是 4. 总的方差分析结果有P<0.05,则结论应为 A. 各样本均数全相等 B. 各总体均数全相等 C. 各样本均数不全相等 D. 各总体均数全不相等 E. 至少有两个总体均数不等 5. 对有k 个处理组,b 个随机区组的资料进行双因素方差分析,其误差的自由度为 A. kb k b -- B. 1kb k b --- C. 2kb k b --- D. 1kb k b --+ E. 2kb k b --+ 6. 2×2析因设计资料的方差分析中,总变异可分解为 A. MS MS MS =+B A 总 B. MS MS MS =+B 总误差 C. SS SS SS =+B 总误差 D. SS SS SS SS =++B A 总误差 E. SS SS SS SS SS =+++B A AB 总误差 7. 观察6只狗服药后不同时间点(2小时、4小时、8小时和24小时)血药浓度的变化,本试验应选用的统计分析方法是 A. 析因设计的方差分析 一元线性回归分析及方差分析与显著性检验 某位移传感器的位移x 与输出电压y 的一组观测值如下:(单位略) 设x 无误差,求y 对x 的线性关系式,并进行方差分析与显著性检验。 (附:F 0。10(1,4)=,F 0。05(1,4)=,F 0。01(1,4)=) 回归分析是研究变量之间相关关系的一种统计推断法。 一. 一元线性回归的数学模型 在一元线性回归中,有两个变量,其中 x 是可观测、可控制的普通变量,常称它为自变量或控制变量,y 为随机变量,常称其为因变量或响应变量。通过散点图或计算相关系数判定y 与x 之间存在着显著的线性相关关系,即y 与x 之间存在如下关系: (1) / 通常认为 且假设与x 无关。将观测数据 (i=1,……,n)代入(1) 再注意样本为简单随机样本得: (2) 称(1)或(2)(又称为数据结构式)所确定的模型为一元(正态)线性回归模型。 对其进行统计分析称为一元线性回归分析。 模型(2)中 EY= ,若记 y=E(Y),则 y=a+bx,就是所谓的一元线性回归方程, 其图象就是回归直线,b 为回归系数,a 称为回归常数,有时也通称 a 、b 为回归系数。 设得到的回归方程 bx b y +=0? 残差方程为N t bx b y y y v t t t i ,,2,1,?0 =--=-= 根据最小二乘原理可求得回归系数b 0和b 。 对照第五章最小二乘法的矩阵形式,令 ¥ ?????? ? ??=??? ? ??=??? ???? ??=??????? ??=N N N v v v V b b b x x x X y y y Y 2102121?111 则误差方程的矩阵形式为 “地域”与“抑郁” 朱平辉改编自西南财大网(案例分析者刘玲同学) 一、案例简介 美国人作了一项调查,研究地理位置与患抑郁症之间的关系。他们选择了60个65岁以上的健康人组成一个样本,其中20个人居住在佛罗里达,20个人居住在纽约、20个人居住在北卡罗来纳。对中选的每个人给出了测量抑郁症的一个标准化检验,搜集到表1中的资料,较高的得分表示较高的抑郁症水平。 研究的第二部分考虑地理位置与患有慢性病的65岁以上的人患抑郁症之间的关系,这些慢性病诸如关节炎、高血压、心脏失调等。这种身体状况的人也选出60个组成样本,同样20个人居住在佛罗里达,20个人居住在纽约、20个人居住在北卡罗来纳。这个研究记录 央视主持人崔永元对外公开其患有抑郁症后,使人们对这种精神疾病有了更多的关注。通过对以上两个数据集统计分析,你能从中看出什么结论?你对该疾病有什么认识? 二、抑郁症的相关知识 抑郁症有两种含义,广义的抑郁症包括情感性精神病、抑郁性神经症、反应性抑郁症、更年期抑郁症等;狭义的则仅指情感性精神病抑郁症。抑郁症在国外是一种十分常见的精神 疾病,据报告,其患病率最高竟占人群的10%左右,而且社会经济情况较好的阶层,患病率越高。世界卫生组织预测,抑郁症将成为21世纪人类的主要杀手。全世界患有抑郁症的人数在不断增长,而抑郁症患者中有10—15%面临自杀的危险……引起抑郁症的原因有很多,为了了解地理位置对抑郁症是否有影响,我们做如下的案例分析: 三、地理位置与患抑郁症之间是否有关系 作为对65岁以上的人长期研究的一部分,在纽约洲北部地区的Wentworth医疗中心的社会学专家和内科医生进行了一项研究,以调查地理位置与患抑郁症之间的关系。选择了60个相当健康的人组成一个样本,其中20人居住在佛罗里达,20人居住在纽约,20人居住在北卡罗米纳。对中选的人给出了测量抑郁症的一个标准化实验,搜集到表1中的资料,较高的分表示较高的抑郁症水平。 研究的第二部分考虑地理位置与患有慢性病的65岁以上的人患抑郁症之间的关系,这些慢性病诸如关节炎、高血压、心脏失调等。这种状况的人也选出60个组成样本,同样20人居住在佛罗里达,20人居住在纽约,20人居住在北卡罗米纳。 要求根据所给的样本数据,做出以下管理报告: 描述统计学方法概括说明两部分研究的资料,关于抑郁症的得分,你的初步观测结果是什么? 对两个数据集使用方差分析方法,陈述每种情况下被检验的假设,你的结论是什么? 用推断法说明单个处理均值的合理性 讨论这个研究的推广和你认为有用的其他分析 四、有关统计方法 本案例是通过单因素的方差分析,对各个地区的抑郁症得分均值进行假设检验。分别检验地理位置对健康人群和慢性病患者是否有影响,以及影响程度,进而得出结论。 五、案例分析 首先:数据资料中的数据,并不能直接看出地区与患抑郁症之间有联系与否。我们可以根据所给的样本资料,得到以下信息: (一)健康的被调查者中:佛罗里达地区平均得分=5.55 纽约地区平均得分=8 北卡罗米纳地区平均得分=7.05 (二)患抑郁症的被调查者中:佛罗里达地区平均得分=13.6 纽约地区平均得分=15.25 北卡罗米纳地区平均得分=13.95 (三)我们给出不同地区所有被调查者的平均得分情况 佛罗里达地区平均得分=9.575 纽约地区平均得分=11.625 北卡罗米纳地区平均得分=10.5 第九章 方差分析与回归分析习题参考答案 1. 为研究不同品种对某种果树产量的影响,进行试验,得试验结果(产量)如下表,试分析果树品种对产量是否有显著影响. (0.05(2,9) 4.26F =,0.01(2,9) 8.02F =) 解 : r=3, 12 444n n 321=++=++=n n , T=120 ,120012 1202 2===n T C 计 算 统 计 值 722 8.53, 389 A A A e e SS f F SS f = =≈…… 方差分析表 方差来源 平方和 自由度 均方 F 值 临界值 显著性 品种A 72 2 36 8.53 误差 38 9 4.22 总 计 110 11 结论:由于0.018.53(2,9)8.02, A F F ≈>=故果树品种对产量有特别显著影响. 2. 解 : 22..4,3,12,180122700 l m n lm C x n ======= 计算 统 计 值 90310.52 51.43,3.56 3.56 A A B B A B e e e e S f S f F F S f S f = =≈==≈ 方差来源 平方和 自由度 F 值 临界值 显著性 品种 试验结果 行和??=i x T i 行均值.i x A 1 10 7 13 10 40 10 A 2 12 13 15 12 52 13 A 3 8 4 7 9 28 7 试验 结果 燃料B B 1 B 2 B 3 推进器 A A 1 14 13 12 39 13 A 2 18 16 14 48 16 A 3 13 12 11 36 12 A 4 20 18 19 57 19 65 59 56 180 16.25 14.75 14 15 单因素方差分析的应用实例 PROC ANOVA [DATA= <数据集名> MANOVA 按多元分析的要求略去有任一缺失值的记录OUTSTAT= <数据集名>] ; 指定统计结果输出的数据集名 CLASS <处理因素名列>; 必需,指定要分析的处理因素 MODEL <应变量名=处理因素名列> / [选项]; 必需,给出分析用的方差分析模型 MEANS <变量名列> / [选项] ; 指定要两两比较的因素及比较方法 BY <变量名列>; FREQ <变量名>; MANOVA H= 效应E= 效应M= 公式...; 指定多元方差分析的选项 例1:研究6种氮肥施用法对小麦的效应,每种施肥法种5盆小麦,完全随机设计。最后测定它们的含氮量(mg),试作方差分析 施氮法 SAS程序 data exam1; input g x @@; cards; 1 12.9 2 14.0 3 12.6 4 10. 5 5 14. 6 6 14.0 1 12.3 2 13.8 3 13.2 4 10.8 5 14. 6 6 13.3 1 12. 2 2 13.8 3 13. 4 4 10.7 5 14.4 6 13.7 1 12.5 2 13.6 3 13. 4 4 10.8 5 14.4 6 13.5 1 12.7 2 13.6 3 13.0 4 10. 5 5 14.4 6 13.7 ; procanova data=exam1; class g; model x=g ; run; data exam2; input x1 g j @@; cards; 60 1 1 62 2 1 61 3 1 60 4 1 65 1 2 65 2 2 68 3 2 65 4 2 63 1 3 61 2 3 61 3 3 60 4 3 64 1 4 67 2 4 63 3 4 61 4 4 62 1 5 65 2 5 62 3 5 64 4 5 61 1 6 62 2 6 62 3 6 65 4 6 ; procanova data=exam2; class g j; model x1=g j; run; 例2:对某地区农村的6名2周岁男婴的身高、胸围、上半臂围进行测量,得样本数据如下表。根据以往资料,该地区城市2周岁男婴的这三个指标的均值 现欲在多元正态性假定下检验该地区农村2周岁男婴是否与城市2周岁男婴有相同的均值。取 data exam4_2_1; input id x1 x2 x3; cards; 1 78 60.6 16.5 1.某湖水在不同季节氯化物含量测定值如表5-3所示。问不同季节氯化物含量有无差别?若有差别,进行32个水平的两两比较。 表5-3 某湖水不同季节氯化物含量(mg/L ) 春 夏 秋 冬 22.6 19.1 18.9 19.0 22.8 22.8 13.6 16.9 21.0 24.5 17.2 17.6 16.9 18.0 15.1 14.8 20.0 15.2 16.6 13.1 21.9 18.4 14.2 16.9 21.5 20.1 16.7 16.2 21.2 21.2 19.6 14.8 ∑ij X 167.9 159.3 131.9 129.3 588.40 i n 8 8 8 8 32 i X 20.99 19.91 16.49 16.16 18.39 ∑ij X 2 3548.51 3231.95 2206.27 2114.11 11100.84 i s 2 3.53 8.56 4.51 3.47 1.完全随机设计单因素芳差分析 解:H 0:4个季节湖水中氯化物含量相等,即μ1=μ2=μ3=μ4 H 1:4个季节湖水中氯化物含量不等或不全相等。 α=0.05 205.1081932/4.588/)(22===∑∑n X C ij 635.281205.1081984.111002=-=-=∑∑C X SS ij 总 170 .141205.108198/)3.1299.1313.1599.167(]/)[(22222=-+++=-=∑∑C n X SS i ij 组间 465.140141170635.281=-=-=组间总组内SS SS SS 表5-8 方差分析表 变异来源 SS νMS F 总变异 组间变异 组内变异 281.635 141.170 140.465 31 3 28 47.057 5.017 9.380 查F 界值表,95.228 ,3,05.0=F 。因>28,3,05.0F 所以<0.05。按α=0.05水准,拒绝H 0,接 SPSS-单因素方差分析(ANOVA) 案例解析 2011-08-30 11:10 这几天一直在忙电信网上营业厅用户体验优化改版事情,今天将我最近学习SPSS单因素方差分析(ANOVA)分析,今天希望跟大家交流和分享一下: 继续以上一期的样本为例,雌性老鼠和雄性老鼠,在注射毒素后,经过一段时间,观察老鼠死亡和存活情况。 研究的问题是:老鼠在注射毒液后,死亡和存活情况,会不会跟性别有关? 样本数据如下所示:(a代表雄性老鼠 b代表雌性老鼠 0代表死亡 1 代表活着 tim 代表注射毒液后,经过多长时间,观察结果) 点击“分析”——比较均值———单因素AVOVA, 如下所示: 从上图可以看出,只有“两个变量”可选, 对于“组别(性别)”变量不可选,这里可能需要进行“转换”对数据重新进行编码, 点击“转换”—“重新编码为不同变量” 将a,b"分别用8,9进行替换,得到如下结果” 此时的8 代表a(雄性老鼠) 9代表b雌性老鼠,我们将“生存结局”变量移入“因变量列表”框内,将“性别”移入“因子”框内,点击“两两比较”按钮,如下所示: “ 勾选“将定方差齐性”下面的 LSD 选项,和“未假定方差齐性”下面的Tamhane's T2选项点击继续 点击“选项”按钮,如下所示: 勾选“描述性”和“方差同质检验” 以及均值图等选项,得到如下结果: 结果分析:方差齐性检验结果,“显著性”为0,由于显著性0<0.05 所以,方差齐性不相等,在一般情况下,不能够进行方差分析 但是对于SPSS来说,即使方差齐性不相等,还是可以进行方差分析的, 由于此样本组少于三组,不能够进行多重样本对比 从结果来看“单因素ANOVA” 分析结果,显著性0.098,由于 0.098>0.05 所以可以得出结论: 生存结局受性别的影响不显著 很多人,对这个结果可能存在疑虑,下面我们来进一步进行论证,由于“方差齐性不相等”下面我们来进行“非参数检验”检验结果如下所示:(此处采用的是“Kruskal-Wallis "检验方法)ANOVA分析例题
方差分析练习题
一元线性回归,方差分析,显著性分析
方差分析几个案例
方差分析
最新方差分析实例
第9章方差分析思考与练习-带答案
一元线性回归,方差分析,显著性分析
方差分析案例
方差分析与回归分析习题答案
单因素方差分析的应用实例
方差分析例题
SPSS-单因素方差分析(ANOVA) 案例解析
相关主题
文本预览