
1、对北京18个区县中等职业教育发展水平进行聚类。X1:每万人中职在校生数;X2:每万人中职招生数;X3:每万人中职毕业生数;X4:每万人中职专任教师数;X5:本科以上学校教师占专任教师的比例;X6:高级教师占专任教师的比例;X7:学校平均在校生人数;X8:国家财政预算中职经费占国内生产总值的比例;X9:生均教育经费。
具体步骤如下:
1、导入数据,建立数据文件(data.sav)
2、选择聚类分析(分析—分类—系统聚类分析),选择变量,分群选择个案方式
3、聚类分析描述统计(统计量—合并进程表;聚类成员—单一方案—聚类数3)
4、聚类分析绘制(树状图;冰柱—所有聚类,方向—垂直)
5、聚类分析方法(聚类方法—组间联接,度量标准—区间—平方Euclidean 距离)
6、聚类分析保存(聚类成员—单一方案—聚类数3)
7、保存实验结果,并分析结果
结果与分析:
(1)输出结果文件中的第一部分如下图1所示。
图1中可以看出18个样本都进入了聚类分析,但有效样本为14个,缺失14个。
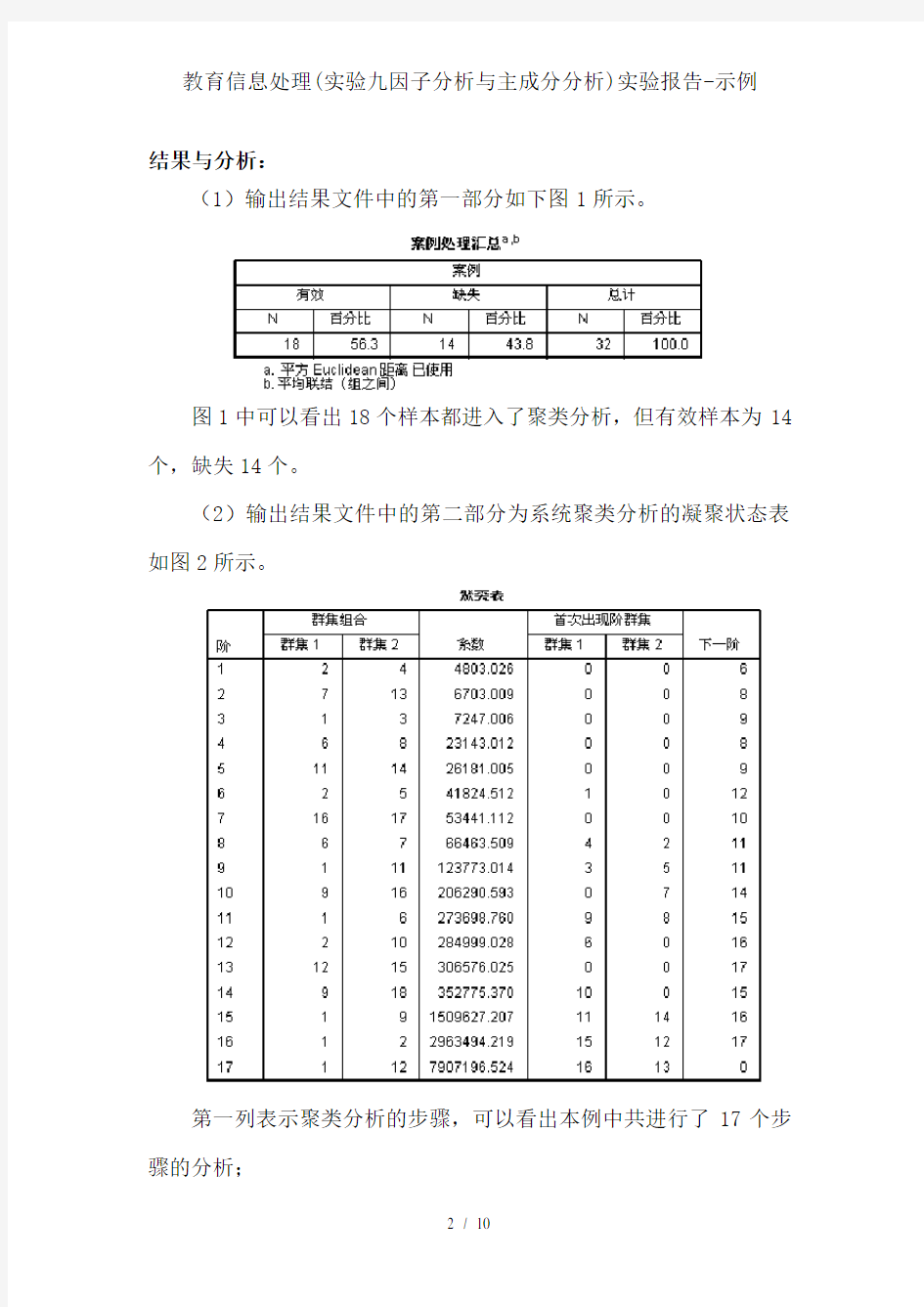
(2)输出结果文件中的第二部分为系统聚类分析的凝聚状态表如图2所示。
第一列表示聚类分析的步骤,可以看出本例中共进行了17个步骤的分析;
第二列和第三列表示某步聚类分析中,哪两个样本或类聚成了一类;
第四列表示两个样本或类间的距离,从表格中可以看出,距离小的样本之间先聚类;
第五列和第六列表示某步聚类分析中,参与聚类的是样本还是类。0表示样本,数字n(非零)表示第n步聚类产生的类参与了本步聚类;
第七列表示本步聚类结果在下面聚类的第几步中用到。
图2给中第一行表示,第二个样本和第四个样本最先进行了聚类,样本间的距离为4803.026,这个聚类的结果将在后面的第六步聚类中用到;第二行表示聚类的第二步中第七个样本和第十三个样本进行了聚类,样本间的距离为6703.009,这个聚类的结果将在后面的第八步骤中用到。其他行的含义和上面的类似。可见,在本例中,经过了17个步骤,18个样本聚成了一个大类。
(3)输出结果文件中第三部分如图3所示。
图3是样本系统聚类分析 3个类时,样本的类归属情况表。从结果可以看出,样本1、3、6、7、8、9、11、13、14、16、17、18属于第一类;样本2、4、5、10属于第二类;样本12、15属于第三类。这3个类恰好反映了北京市18区县的3个不同层次。
(4)输出结果文件中第四部分如图4所示。
图4是系统聚类分析的冰柱图。该图的第一类表示类数。冰柱图一般从其最后一行开始观察。最后一行中,类的数目为17,即样本聚积成17类,其中样本2和样本4用X连接在一起,表示两个样本聚成一类,其余每个样本构成一类。倒数第二行中,类的数目为16,即样本聚积成16类,其中样本7和样本13又聚成一类,其余每个样本构成一类。因此,从冰柱图中可以非常清楚地看到,聚成n类时,各个样本的类归属情况。如聚成3个类时,样本12、15属于第一类;样本2、4、5、10属于第二类;其余属于第三类。
将18个区县聚成3类,各个样本的类归属情况保存为一个变量,因此在SPSS数据编辑窗口中就新增了一个变量的值,如图5所示。
2、同上例对北京地区18区县各中职教育发展指标进行聚类,分析哪些指标是属于一类的。
具体步骤如下:
1、导入数据,建立数据文件(data.sav)
2、选择聚类分析(分析—分类—系统聚类分析),选择变量,分群选择变量方式
3、聚类分析描述统计(统计量—合并进程表—相似性矩阵;聚类成员—单一方案—聚类数3)
4、聚类分析绘制(树状图;冰柱—所有聚类,方向—垂直)
5、聚类分析方法(聚类方法—组间联接,度量标准—区间—Pearson相关性)
6、保存实验结果,并分析结果
结果与分析:
(1)输出结果文件中的第一部分如下图6所示。
图6中可以看出18个样本都进入了聚类分析,但有效样本为14
个,缺失14个。
(2)输出结果文件中的第二部分如下图7所示。
图7所示的是系统聚类分析各变量的距离矩阵。从中可以看出各个变量之间的距离(有正负,因为在设置样本间距离计算公式时选择了Pearson相关分析,相关分析有正负之分)。
(3)输出结果文件中的第三部分如下图8所示。
图8是系统聚类分析的凝聚状态表。第一行表示第一个变量和第二个变量首先进行了聚类,变量间的相关系数为0.959,这个聚类的结果将在后面的第二步聚类中用到。第二行表示第二步聚类中,第一个变量和第三个变量进行了聚类,变量间的相关系数为0.910,这个
聚类的结果将在后面的第四步聚类中用到,等等。
(4)输出结果文件中的第四部分如下图9所示。
图9是变量系统聚类分析聚成3个类时,变量的类归属情况表。从该图中可以看出,x1(每万人中职生在校生数)、x2(每万人中职招生数)、x3(每万人中职毕业生数)、x4(每万人中职专任教师数)、x8(国家财政预算中职经费占国内生产总值的比例)属于第一类;x5(本科以上学校教师占专任教师的比例)、x6(高级教师占专任教师的比例)、x9(生均教育经费)属于第二类;x7(学校平均在校生人数)属于第三类。
(5)输出结果文件中的第五部分如下图10所示。
图10是系统聚类分析的冰柱图。图的第一类表示类数。冰柱图一般从其最后一行开始观察。最后一行中,类的数目为8,即变量聚积成8类,其中变量x1和变量x2用X连接在一起,表示两个变量首先聚成一类,其余每个变量构成一类。倒数第二行中,类的数目为2,即变量聚积成两类,其中x1、x2、x3聚成一类。从冰柱图中可以非常清楚地看到,各个变量的类归属情况。倒数第三行中,类的树目为3,x5、x9聚成一类,等等,一直到聚成一类。
(6)输出结果文件中的第六部分如下图11所示。
图11是聚类分析的树形图。从图中可以看出,各个类中间的距离在25的坐标内。从树形图可以很直观地看出整个聚类的过程和结果。