
长江水质的评价和预测
摘要
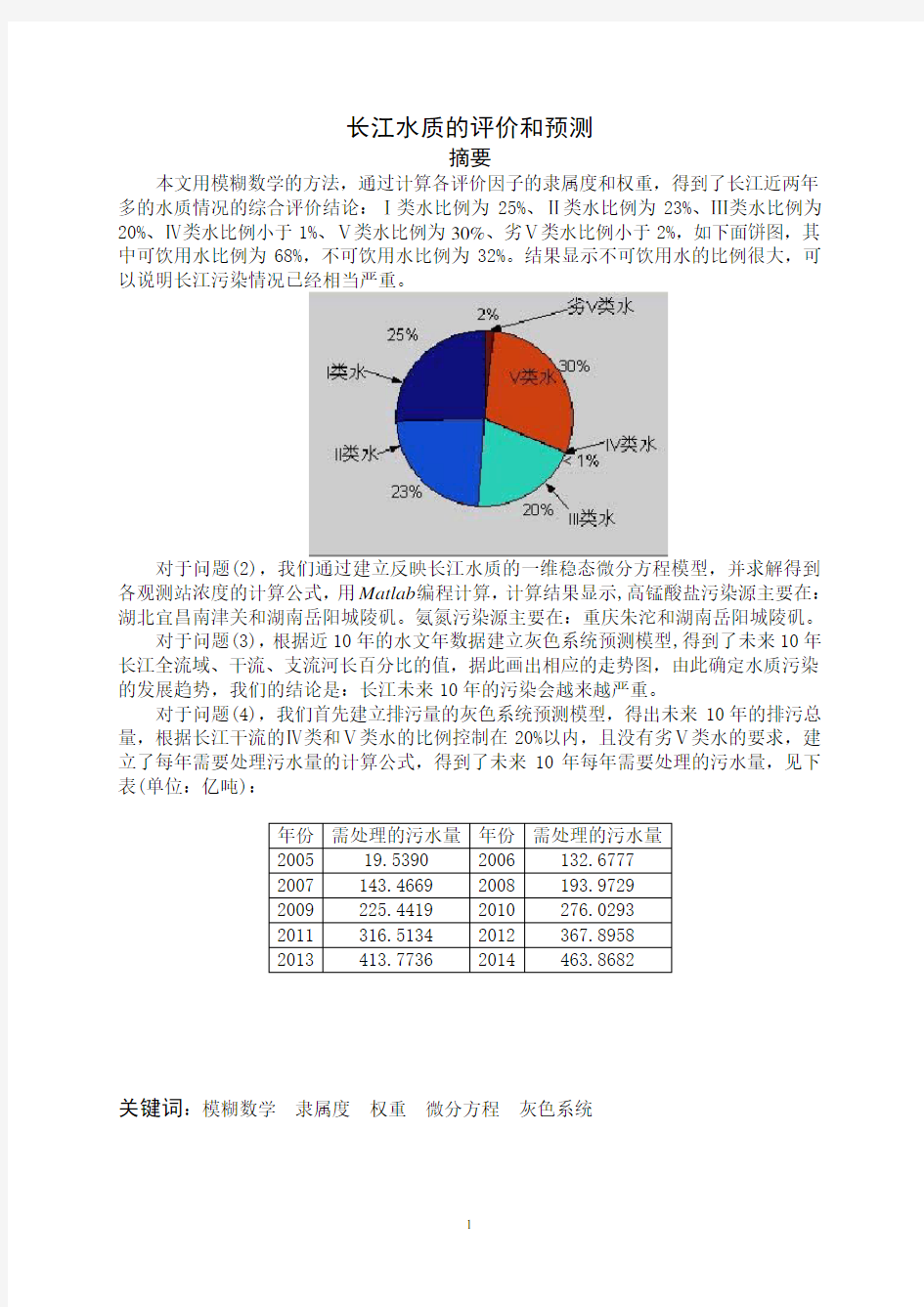
本文用模糊数学的方法,通过计算各评价因子的隶属度和权重,得到了长江近两年多的水质情况的综合评价结论:Ⅰ类水比例为25%、Ⅱ类水比例为23%、Ⅲ类水比例为20%、Ⅳ类水比例小于1%、Ⅴ类水比例为30%、劣Ⅴ类水比例小于2%,如下面饼图,其中可饮用水比例为68%,不可饮用水比例为32%。结果显示不可饮用水的比例很大,可以说明长江污染情况已经相当严重。
对于问题(2),我们通过建立反映长江水质的一维稳态微分方程模型,并求解得到各观测站浓度的计算公式,用Matlab编程计算,计算结果显示,高锰酸盐污染源主要在:湖北宜昌南津关和湖南岳阳城陵矶。氨氮污染源主要在:重庆朱沱和湖南岳阳城陵矶。
对于问题(3),根据近10年的水文年数据建立灰色系统预测模型,得到了未来10年长江全流域、干流、支流河长百分比的值,据此画出相应的走势图,由此确定水质污染的发展趋势,我们的结论是:长江未来10年的污染会越来越严重。
对于问题(4),我们首先建立排污量的灰色系统预测模型,得出未来10年的排污总量,根据长江干流的Ⅳ类和Ⅴ类水的比例控制在20%以内,且没有劣Ⅴ类水的要求,建立了每年需要处理污水量的计算公式,得到了未来10年每年需要处理的污水量,见下表(单位:亿吨):
关键词:模糊数学隶属度权重微分方程灰色系统
一、问题重述
自2004年10月“保护长江万里行”行动发起后,考察团对沿线21个重点城市做了实地考察,认识到了母亲河长江受到了严重的污染,为此,专家提出了拯救长江的呼唤,给出了下面这些有待解决的问题。
(1)对长江近两年多的水质情况做出定量的综合评价,并分析各地区水质的污染状况。
(2)研究、分析长江干流近一年多主要污染物高锰酸盐指数和氨氮的污染源主要在哪些地区?
(3)假如不采取更有效的治理措施,依照过去10年的主要统计数据,对长江未来水质污染的发展趋势做出预测分析,比如研究未来10年的情况。
(4)根据你的预测分析,如果未来10年内每年都要求长江干流的Ⅳ类和Ⅴ类水的比例控制在20%以内,且没有劣Ⅴ类水,那么每年需要处理多少污水?
(5)你对解决长江水质污染问题有什么切实可行的建议和意见。
题目附件中给出了解决上述问题的各类数据。附件3给出了长江沿线17个观测站(地区)近两年多主要水质指标的检测数据,以及干流上7个观测站近一年多的基本数据(站点距离、水流量和水流速);附件4是“1995~2004年长江流域水质报告”给出的主要统计数据;附表是《地表水环境质量标准》中4个主要项目标准限值,其中Ⅰ、Ⅱ、Ⅲ类为可饮用水。污染物高锰酸盐指数和氨氮的降解系数,考虑取0.2 (单位:1/天)。
已知条件:通常认为一个观测站(地区)的水质污染主要来自于本地区的排污和上游的污水;污染物都有一定的自然净化能力(指标称为降解系数);自然净化能力可以认为是近似均匀的。
二、模型假设
1.污染物排放入长江后迅速混合在水中。
2. 把长江认为是一维的,不考虑河宽,水深,横断面。
3. 主要污染物高锰酸盐指数和氨氮的降解系数取为常数0.2。
4. 一个地区的污染只来自于上游的污水和本地区的排污。
5.预测不考虑突变因素,如洪水、干旱等。
三、符号约定
ij S : 第i 监测项目第j 类水的标准限值 (4,3,2,1=i ,6,5,4,3,2,1=j )
ik X : 第k 观测站第i 监测项目在28个月中的平均值 (173,2,1 =k )
ijk Y : 第k 观测站第i 监测项目对第j 类水的隶属度
ik W : 第k 观测站第i 个监测项目的权重。
k B : 第k 观测站模糊数学方法综合评价的结果
k A : 第k 观测站各评价因子的权重向量
k R : 第k 观测站隶属度的模糊关系矩阵
ik c : 第k 观测站第i 个监测项目在近18个月中的平均浓度 (L mg /)
0c : 各污染物的初始浓度
ik C : 第k 观测站第i 个监测项目浓度的计算值
k : 长江干流的降解系数
x : 长江干流相邻观测站间的距离(m )
k u : 第k 观测站在近12个月中水流平均流速(s m /)
n Y : 未来第n 年需要处理的污水量(103,2,1 =n )
n p :未来第n 年的废水排放总量
k t : 分别表示未来10年每年第Ⅳ、Ⅴ和劣Ⅴ类水的百分比(321、、
=k )
四、模型建立与求解
(一)、问题(1)
此问用模糊数学法对长江水质情况作定量的综合评价。
1.模糊数学法基本原理:
把普通集合理论中的非“0”则“1”的绝对隶属函数用[0,1]来刻画。
本文选用监测项目集合=U { PH 值(无量纲)、溶解氧(DO) 、高锰酸盐指数(CODMn)、 氨氮(NH3-N )}4项作为评价因子。由于PH 值标准限值是一个区间范围,无法用模糊数学法对其做定量分析,而且附件3的数据显示,各观测点的PH 值都位于区间[6,9]内,所以此小题只对后3项评价因子做综合评价。
2.模型建立
模糊数学的综合评价是通过模糊关系矩阵k R 和评价因子的权重矩阵k A 的复合运算进行评价,实际上是对各项评价因子进行加权合成,所以可以得到模型:
k k k R A B ?= (1-1)
3.模型求解
3.1 计算各评价因子对各类水的隶属度
用线形隶属函数确定各评价因子对各类水的隶属度的计算公式如下:
1=j 类水: ???????≥<<--≤=2211
22
110
1i ik i ik i i i ik i i ik k i S X S X S S S X S S X Y (1-2) 5,4,3,2=j 类水: ???????????<≤<<--<≤--=+---+++)1()1()1(1
2)1()1()1()1(,0
j i ik j i ik ij ik j i i i j i ik j i ik ij ij
j i ik j i ijk S X S X S X S S S S X S X S S S X S Y (1-3)
6=j 类水:
???????≤<<--≥=5
655
656601i ik i ik i i i i ik
i ik k i S X S X S S S S X S X Y (1-4)
由上述公式(1-2),(1-3),(1-4)可计算求出各观测站中各监测项目对于各类水的隶属度,它们都是1行6列的向量,将各观测站的向量按行放到一个矩阵中,得到各观测站的模糊关系矩阵k R ,以第1个观测站为例:
????
??????= 0 0 0 0 0.0939 0.9061 0 0 0 0 0 00 0 0 0 0 01R 用同样的方法我们可以求得另外16个观测站的模糊关系矩阵k R 。
3.2 各评价因子权重的计算
本文给出的4项评价因子中,溶解氧(DO)在水中含量越高表明水质越好,而高锰酸盐指数(CODMn)和氨氮(NH3-N )在水中含量越低表明水质越好,所以我们取以下的权重公式:
溶解氧(DO)权重公式为:
k
j j k mX S
W 26122∑== (1-5) 高锰酸盐指数(CODMn)、 氨氮(NH3-N )权重公式为:
∑==61
j ij
ik ik S m X W (1-6) 其中m 为水质的类数,即6=m ,且4,3=i 。
用上面公式(1-5), (1-6)计算,得到各观测站各评价因子的权重和可能出现大于1的情况,但模糊数学运算只允许在[0,1]区间取值,故各项权重必须进行归一化处理,公式为:
∑==42i ik
ik
ik W W W ,14
2=∑=i ik W 。 (1-7) 其中172,1 =k 。从而用公式(1-7)处理后得到各观测站中各个评价因子的权重向量k A ,如:0323.02725.06952.01=A 。
同理,可以求出其它16项k A 。
3.3 综合评价
用公式(1-1)计算得各观测站综合评价的结果)172,1( =k B k ,其元素表示各观测站污染程度对各类水的隶属度。
4.模型结果
根据向量k B 依次确定各观测站综合评价后的水质类别,见表1_1:
以观测站1对应的向量()0 0 0 0 0.0030 0.02931=B 为例:观测站1的污染程度对Ⅰ类上的隶属度为0.0293,对Ⅱ类水的隶属度为0.0030,对Ⅲ,Ⅳ,Ⅴ,劣Ⅴ类水的隶属度都为0。由于对Ⅰ类水的隶属度最大,所以观测站1的水质处于Ⅰ类。
注:总计行为每一列的数据相加计算得到,表示长江全河段污染程度对各类水的隶属度。
5. 结果分析
分析数据,对总计行隶属度作百分比换算求得:Ⅰ类水占长江全流域的比例为25%、Ⅱ类水比例为23%、Ⅲ类水比例为20%、Ⅳ类水比例小于1%、Ⅴ类水比例为30%、劣Ⅴ类水比例小于2%,由此可知:长江全流域可饮用水比例为68%,不可饮用水比例为32%,这表明不可饮用水所占比例比较大,长江水质污染情况已经相当严重,所以保护长江,刻不容缓。
(二)、问题(2)
1.模型建立
据查阅水环境专业资料[2],我们考虑用河流的一维稳态水质模式来解决第二个问题。
设污染物在河流横向方向上达到完全混合,为了描述污染物的变化情况,建立以下微分方程模型:
()()()K B L L AS S S A x c A D x x Qc T Ac +++??
? ??????=??+?? (2-1)
A -------------河流横断面面积
Q -------------河流流量
c --------------水质组分浓度
L D ------------综合的纵向离散系数
L S -------------直接的点源或非点源强度
B S -------------上游区域进入的源强
K S -------------动力学转化率(正为源、负为汇)
2.模型求解与模型结果 我们假设:稳态(0=??t
),忽略纵向离散作用,一阶动力学反应速度K ,河流无侧旁入流,河流横断面积为常数,上流来流量u Q ,上游来流水水质浓度u c ,污染排放量e Q ,污染物排放浓度e c ,所以上述微分方程模型的解为:
()u kx c c 86400/exp 0-= (2-2)
式中:()()e u e e u u Q Q Q c Q c c +?+?=0
u ------------河流流速 (s m /)
x ------------沿河流方向距离 (m )
c ------------下游距污染源为x 处的水质浓度 (L mg /)
根据公式(2-2),结合符号假设,我们可以衍生出本小题计算长江干流各观测站浓度的公式:
()k ik u kx c C 86400/exp 0-= (2-3)
2.1 求长江干流各观测站CODMn 和NH3-N 监测浓度的平均值
取附件3表1 中2004-01到2005-09中18个月的数据作为问题(2)的研究数据。根据这些数据计算长江干流中高锰酸盐指数(CODMn)和氨氮(NH3-N )的监测浓度的平均值,计算得到ik c (.72,1;4,3 ==k i )见表2_1:
表2_1:长江干流各观测站CODMn 和NH3-N 监测浓度的平均值 单位:
2.2 求长江干流各观测站水流速的平均值
取附件3表2中数据作为研究数据,根据这些数据计算2004.04到2005.04之间各观测站的平均水流速度,得k u (.72,1 =k )见表2_2:
2.3 求各观测站各监测项目的浓度的计算值
取降解系数2.0=k ,6,3,2,1 =p 。
取观测站p 的高锰酸盐指数(CODMn) 的平均浓度和氨氮(NH3-N)的平均浓度作为计算观测站1+p 的污染物浓度的初始浓度。
依次确定各观测点污染物的初始浓度0c 。
根据公式(2-3),用matlab 软件编程计算得到2,3……7各观测站的浓度的计算值ik C (.73,2;4,3 ==k i )见表2_3:
表2_3:各观测站各项目的浓度的计算值 单位:L mg /
3. 结果分析
比较表2_1 和表2_3,我们用各观测站的污染物浓度计算值减去各相应观测站污染物浓度的平均值,得到浓度差见表2_4:
表2_4:计算浓度与观测浓度平均值之差 单位:L mg /
从表中浓度差数据发现,观测站3和4高锰酸盐指数(CODMn)的浓度差较大,观测站2和4氨氮(NH3-N)的浓度差较大。由此可以说明,长江干流近一年多污染物情况如下:
高锰酸盐指数(CODMn)污染源主要在:
观测站3(湖北宜昌南津关)、4(湖南岳阳城陵矶)地区。
氨氮(NH3-N)污染源主要在:
观测站2(重庆朱沱)、4(湖南岳阳城陵矶)地区。
(三).问题(3)
此问题用灰色系统预测模型来预测长江未来10年水质污染的发展趋势。
1.建模原理
记()0x 为原始数据列()()()()()()(){}
n x x x x 0000,,2,1 =,对()0x 作一次累加生成(AGO -1),得到数据列()()()()()()(){
}n x x x x 1111,,2,1 =,其中AGO -1算式规则为: ()()()()∑==k j j x k x 1
01 n k ,2,1= (3-1)
建立白化形式微分方程()1,1GM :()
()u ax dt
dx =+11。 其中待辨别参数列[]T u a a ,=∧
根据最小二乘法法解白化微分方程()1,1GM 得:()N T T Y B B B a 1-∧
=, 其中()()()(){}()()()(){}()()()(){}
?????????
???????????+--+-+-=11211322112121111111m x m x x x x x B ,()()()()()(){}[]T N m x x x Y 000,,3,2 = (3-2) 所以白化微分方程()1,1GM 的解为: ()()()()a u e a u x k x ak +?????
?-=+-∧1101 (3-3) 由式(3-3)计算出的值为预测值的一阶累加生成数,还需进行累加生成的逆运算(累减运算)还原预测数据列,公式为:
()()()()()()1110--=∧∧∧k x k x k x (3-4)
2.模型建立
根据上述的建模原理,用公式(3-4)对(3-3)进行累减运算,得到本问题的预测模型为:
()()()()()()()??
??
??????=>??? ??--=+-∧010111000k x k e a u x e k x ak
a (3-5)
3.模型求解
附件4中,水文年是一年内所有监测数据的平均值,反应了长江一年内的总体状况,所以我们在用灰色系统预测模型来求解时,取水文年的数据作为研究对象,分别对全流域、干流和支流各类水的河长百分比作预测。
3.1.计算步骤
(1).数据的累加生成(AGO 生成),按公式(1)计算。
(2).确定数据矩阵N Y B ,,按公式(2)计算。
(3).计算()1-B B T 。
(4).求参数列[]()N T T T Y B B B u a a 1,-∧
==。
(5).计算系数c b ,:()()a
u c a u x b =-=,10。 (6).确定白化微分方程解模型:c be k x
ak +=+-)1(?)1( 。 (7).累减运算,按公式(4)计算。
(8).根据()0x 预测模型(6)进行预测计算。
3.2. 计算结果
根据3.1计算步骤,利用matlab 软件编程计算得到全流域,干流和支流各类水的河长百分比在未来10年的预测值,由于每年百分比预测值之和有可能不等于100,所以对预测值作归一化处理,得到处理后的预测值,列于附表中(见附录表3_1、表3_2、表3_3)。
4.结果分析
研究表3_1发现Ⅰ,Ⅱ,Ⅲ类水河长百分比的和(总计1)在未来10年内逐渐降低,而Ⅳ,Ⅴ和劣Ⅴ类水河长百分比的和(总计2 )逐渐增加,所以定性分析知道长江未来10年水质污染一定会越来越严重。
同理研究表3_2,表3_3中总计3、总计4和总计5、总计6,亦可看出长江未来10年干流和支流水质污染呈显著上升趋势。
下面我们分别做出长江全流域、干流和支流Ⅰ,Ⅱ,Ⅲ类水河长百分比之和与Ⅳ,Ⅴ和劣Ⅴ类水河长百分比之和的走势图如下:
全流域
干流
支流
从走势图来看,长江全流域、干流和支流前3类水河长百分比之和,在未来10年减少,且速度很快;而后3类水河长百分比之和增加,这亦说明长江未来10年水质污染会越来越严重,若不及时处理,长江生态10年内将濒临崩溃。
(四)、问题(4)
1.模型建立
本问我们要解决在满足长江干流Ⅳ类和Ⅴ类水的比例在20%以内,且没有劣Ⅴ类水的条件下,计算长江干流每年需要处理多少污水的问题。如果某年预测得到Ⅳ类和Ⅴ类水的比例大于20%,那么需要处理大于20%的部分,否则不用处理。只要有劣Ⅴ类水,就必须对其处理。经此分析可以建立每年排污量的计算模型,如下:
()???>++-+?<+?=2.02.02.021321213t t t t t p t t t p Y n
n n ,其中102,1 =n (4-1)
2.模型求解
2.1 预测未来10年每年的废水排放总量
要预测未来10年每年的废水排放总量,我们仍采用灰色系统预测模型,具体模型和计算步骤相同于问题3对百分比的预测求解。
所以我们仍采用模型(3—6)和相应的计算步骤,用matlab 软件编程求得未来10年每年的废水排放总量,见表4_1:
表4_1
2.2.引用干流第Ⅳ、Ⅴ 、劣Ⅴ类水的百分比
我们在问题3的求解过程中,已经预测得到长江干流在水文年第Ⅳ、Ⅴ 、劣Ⅴ类水的百分比的预测值,具体数据见表表4_2:
2.3.计算结果
由公式(4-1),和上述表4_1和表4_2数据,计算得到未来10年,即2005年至2014年每年需要处理的污水量
Y,计算结果见表表4_3:
n
(五)、问题(5)
长江水质污染问题的一些建议
2005年建模竞赛不仅仅是我们大学生在知识上的竞技、解决问题能力的比拼,它更是教育我们这一代人增强环保意识的有利措施。建模过程中,我们深刻地意识到长江流域,甚至是中国环境所处的紧迫现状,一种保护长江的使命感油然而生。
经过几天的思考,我们在此谈谈对长江水质污染问题的一些见解:
1.首先是要意识到并重视母亲河的污染问题。有人曾说“意识决定一切”,不怕做不到就怕想不到,让所有人都去思考、都去在意我们的母亲河所面临的危难,再与实际行动配合,就会达到事半功倍的效果。我们提倡在提高人口素质的基础上增强人们的环保意识,要治本而不是治表。
2.加强科学技术的发展是重中之重。对于生产污染比较严重的产品,可以研究先进、清洁的生产技术,投入到生产中去,推进循环经济;另外研究先进的污水处理技术,降低处理成本。这样既可以避免企业再额外开销污水处理的费用,又提高了企业生产的积极,同时降低了执法人员的工作难度。
3.完善法律体系。如对保护长江立法、加强行政管理和严格追究刑事责任、严格实施排水许可制度,杜绝任意乱排污水、废水等等。
4.执法到位。杜绝官商勾结,猫鼠游戏、严格惩处违法分子、将环保作为考核干部指标之一、揭露污水厂的表面游戏,让其发挥到真正的作用。
5.协调人口-资源-环境-经济的关系,走可持续发展战略目标。保护天然林,建设长江上游的防护林体系,让母亲河有一个舒适的生态环境。
6.培养环保后备人才,组织一支专业性强的队伍对长江进行不定期的考察和检验验,保持对现状的准确掌握,以便于采取相应措施及时治理。
我们还有很多没有考虑到的地方,出于对长江水质污染现状的忧虑,在此,我们希望有关部门能够加大力度维护母亲河长江清澈的面容,让我们中华民族的历史继续源远流长。
五、模型检验
灰色系统预测模型的可行性检验
1.检验原理(准则):若计算出的时间序列的预测值与每个站点的实际测量值的绝对误差较小,我们就认为这种模型可以用来做预测。
2.我们用1999~2004全流域数据预测2005年时的数据做为范例。1999~2004年各种
3.检验步骤:
(1)、令i=2005,
(2)、构造表a,初始为1999~2004年各类型水的百分比测量当i=2006时,表a
的数据变为2000~2005年的数据。表a的数据构造法依此类推。
(3)、把表a的数据代入灰色系统预测模型可得到表b
(4)、根据表a和b算出预测值与测量值的绝对误差,如表c
(5)、若绝对误差较小,预测出i年各种类型水的百分比,如表d,并转入步骤(6);
否则结束检验,此模型不能用来预测第i年各种类型水的百分比。
(6)、i=i+1;转到步骤(2),直到所需要预测的数据都已经预测出来。
凡是用到此预测模型的地方,我们都根据上面的检验步骤,用matlab编程,对计算出的绝对误差做了分析,都比较小,所以此模型可以较好地预测未来数据。
六、模型评价与应用
水质综合评价中的污染程度、水质类别、分类界限等等都是一系列模糊的概念,用模糊数学的方法解决水质评价问题,更符合客观情况,更能反映水质的实际状况。本文(1)问通过污染程度对各类水的隶属度确定综合评价结果,比较准确的反映了长江水质所处状况。
问题(2)用微分方程来解决污染源所在地区问题,可以充分考虑到河流本生的降解能力。一维稳态水质模式贴近我们所做的假设,通过计算浓度差值,对确定污染源所在地区一目了然。
第(3),(4)小题用灰色预测系统模型求解,较好的解决了由于数据不足,用数理统计方法误差较大的局限性,所以灰色预测系统模型比较适合此类需要预测较多数据的问题,且绝对误差较小。
文章中的模糊数学综合评价方法和灰色预测模型可以用于很多领域,如农业产量预报、气象预报、宏观经济预测、人才需求预测、投资分析等。
由于原始数据受外界因素影响(如干旱,洪水,污染物意外泄漏等),局部波动性较大,对计算结果带来一些不可避免的误差。
七、参考文献
[1] 杨海燕、夏正楷,模糊数学在地下水资源污染中的应用,水土保持研究,12卷第
4期:107-110,2005。
[2] 国家环境保护总局工程评估中心,环境影响评价方法,北京:中国环境科学出版
社,2005。
[3] 李祚泳、丁晶、彭荔红,环境质量评价原理与方法,北京:化学工业出版社,2004。
[4] 李兴东、杨殿,灰色系统预测模型及建模计算机程序,湖南有色金属,12卷第4
期:8-11,1996。
附录:
一.表格
说明:表3_1、表3_2、表3_3中总计1、3、5列为各流域各年中Ⅰ,Ⅱ,Ⅲ类水河长百分比的和,总计2、4、6分别为各流域Ⅳ,Ⅴ和劣Ⅴ类水河长百分比的和。
二.程序:见电子文档
附件1 是问题1的计算程序;附件2 是问题2的计算程序;附件3 是问题3的计算程序;附件4 是问题4的计算程序;附件5 是模型检验的程序。
承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B中选择一项填写): B 我们的参赛报名号为(如果赛区设置报名号的话): 所属学校(请填写完整的全名):成都纺织高等专科学校 参赛队员(打印并签名) :1. XXX(机电XXX) 2. XXX国贸XXX) 3. XXX(电商XXX) 指导教师或指导教师组负责人(打印并签名): 日期: 2014 年 06 月 06 日赛区评阅编号(由赛区组委会评阅前进行编号):
编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):
目录 一、问题的重述 (1) 1.1 背景资料与条件 (1) 1.2 需要解决的问题 (1) 二、问题的分析 (2) 2.1 问题的重要性分析 (2) 2.2问题的思路分析 (3) 三、模型的假设 (4) 四、符号及变量说明 (4) 五、模型的建立与求解 (4) 5.1建立层次结构模型 (4) 5.2构造成对比较矩阵 (5) 5.3成对比较矩阵的最大特征根和特征向量的实用算法 (6) 5.4一致性检验 (7) 5.5层次分析模型的求解与分析 (8) 5.5.1 构造成对比较矩阵 (8) 5.5.2计算25优秀大学生的综合得 (9) 六、模型的应用与推广 (11) 七、模型的评价与改进 (12) 7.1模型的优点分析 (12) 7.2模型的缺点分析 (12) 7.3模型的进一步改进 (12) 八、参考文献 (13) 附件一 (14) 附件二 (16)
交巡警服务平台的设置与调度 摘要 由于警务资源有限,需要根据城市的实际情况与需求建立数学模型来合理地确定交巡警服务平台数目与位置、分配各平台的管辖范围、调度警务资源。设置平台的基本原则是尽量使平台出警次数均衡,缩短出警时间。用出警次数标准差衡量其均衡性,平台与节点的最短路衡量出警时间。 对问题一,首先以出警时间最短和出警次数尽量均衡为约束条件,利用无向图上任意两点最短路径模型得到平台管辖范围,并运用上下界网络流模型优化解,得到A区平台管辖范围分配方案。发现有6个路口不能在3分钟内被任意平台到达,最长出警时间为5.7分钟。 其次,利用二分图的完美匹配模型得出20个平台封锁13个路口的最佳调度方案,要完全封锁13个路口最快需要8.0分钟。 最后,以平台出警次数均衡和出警时间长短为指标对方案优劣进行评价。建立基于不同权重的平台调整评价模型,以对出警次数均衡的权重u和对最远出警距离的权重v 为参数,得到最优的增加平台方案。此模型可根据实际需求任意设定权重参数和平台增数,由此得到增加的平台位置,权重参数可反映不同的实际情况和需求。如确定增加4个平台,令u=0.6,v=0.4,则增加的平台位置位于21、27、46、64号节点处。 对问题二,首先利用各区平台出警次数的标准差和各区节点的超距比例分析评价六区现有方案的合理性,利用模糊加权分析模型以城区的面积、人口、总发案次数为因素来确定平台增加或改变数目。得出B、C区各需改变2个平台的位置,新方案与现状比较,表明新方案比现状更合理。D、E、F区分别需新增4、2、2个平台。利用问题一的基于不同权重的平台调整评价模型确定改变或新增平台的位置。 其次,先利用二分图的完美匹配模型给出80个平台对17个出入口的最优围堵方案,最长出警时间12.7分钟。在保证能够成功围堵的前提下,若考虑节省警力资源,分析全市六区交通网络与平台设置的特点,我们给出了分阶段围堵方案,方案由三阶段构成。最多需调动三组警力,前后总共需要29.2分钟可将全市路口完全封锁。此方案在保证成功围堵嫌疑人的前提下,若在前面阶段堵到罪犯,则可以减少警力资源调度,节省资源。 【关键字】:不同权重的平台调整评价模糊加权分析最短路二分图匹配
车道被占用对城市道路通行能力的影响 摘要 随着城市化进程加快,城市车辆数的增加,致使道路的占用现象日益严重,同时也导致了更多交通事故的发生。而交通事故发生过程中,路边停车、占道施工、交通流密增大等因素直接导致车道被占用,进而影响了城市道路的通行能力。本文在视频提供的背景下通过数据采集,利用数据插值拟合、差异对比、车流波动理论等对这一影响进行了分析,具体如下: 针对问题一,首先根据视频1中交通事故前后道路通行情况的变化过程运用物理观察测量类比法、数学控制变量法提取描述变量(如事故横断面处的车流量、车流速度以及车流密度)的数据,从而通过研究各变量的变化,来分析其对通行能力的影响。而视频1中有一些时间断层,我们可根据现有的数据先用统计回归对各变量数据插值后再进行拟合,拟合过程中利用残差计算值的大小来选择较好的模型来反应各变量与事故持续时间的关系,进而更好地说明事故发生至撤离期间,事故所处横断面实际通行能力的变化过程。 针对问题二:沿用问题一中的方法,对视频2中影响通行能力的各个变量进行数据采集,同样使用matlab对时间断层处进行插值拟合处理,再将所得到的的变化图像与题一中各变量的变化趋势进行对比分析,其中考虑到两视频的时间段与两视频的事故时长不同,从而采用多种对比方式(如以事故发生前、中、后三时段比较差值、以事故相同持续时间进行对比、以整个事故时间段按比例分配时间进行对比)来更好地说明这一差异。由于小区口的位置不同、时间段是否处于车流高峰期以及1、2、3道车流比例不同等因素的影响,采用不同的数据采集方式使采集的变量数据的实用性更强,从而最后得到视频1中的道路被占用影响程度高于视频2中的影响程度,再者从差异图像的变化波动中得到验证,使其合理性更强。 针对问题三:运用问题1、2中三个变量与持续时间的关系作为纽带,再根据附件5中的信号相位确定出车流量的测量周期为一分钟,测量出上游车流量随时间的变化情况,而事故横断面实际通行能力与持续时间的关系已在1、2问中由拟合得到,所以再根据波动理论预测道路异常下车辆长度模型的结论,结合采集数据得到的函数关系建立数学模型,最后得出事故发生后,车辆排队长度与事故横断面实际通行能力、事故持续时间以及路段上游车流量这三者之间的关系式。 针对问题四:在问题3建立的模型下,利用问题4中提供的变量数据推导出其它相关变量值,然后代入模型,估算出时间长度,以此检验模型的操作性及可靠性。 关键词:通行能力车流波动理论车流量车流速度车流密度
2017年高教社杯全国大学生数学建模竞赛题目 (请先阅读“全国大学生数学建模竞赛论文格式规范”) B题“拍照赚钱”的任务定价 “拍照赚钱”是移动互联网下的一种自助式服务模式。用户下载APP,注册成为APP的会员,然后从APP上领取需要拍照的任务(比如上超市去检查某种商品的上架情况),赚取APP对任务所标定的酬金。这种基于移动互联网的自助式劳务众包平台,为企业提供各种商业检查和信息搜集,相比传统的市场调查方式可以大大节省调查成本,而且有效地保证了调查数据真实性,缩短了调查的周期。因此APP成为该平台运行的核心,而APP中的任务定价又是其核心要素。如果定价不合理,有的任务就会无人问津,而导致商品检查的失败。 附件一是一个已结束项目的任务数据,包含了每个任务的位置、定价和完成情况(“1”表示完成,“0”表示未完成);附件二是会员信息数据,包含了会员的位置、信誉值、参考其信誉给出的任务开始预订时间和预订限额,原则上会员信誉越高,越优先开始挑选任务,其配额也就越大(任务分配时实际上是根据预订限额所占比例进行配发);附件三是一个新的检查项目任务数据,只有任务的位置信息。请完成下面的问题: 1.研究附件一中项目的任务定价规律,分析任务未完成的原因。 2.为附件一中的项目设计新的任务定价方案,并和原方案进行比较。 3.实际情况下,多个任务可能因为位置比较集中,导致用户会争相选择,一种 考虑是将这些任务联合在一起打包发布。在这种考虑下,如何修改前面的定价模型,对最终的任务完成情况又有什么影响? 4.对附件三中的新项目给出你的任务定价方案,并评价该方案的实施效果。 附件一:已结束项目任务数据 附件二:会员信息数据 附件三:新项目任务数据
全国大学生数学建模竞赛的准备方法 全国大学生数学建模竞赛于每年9月上旬(今年是9月7日)举行。但是在此之前,需要做好哪些准备,让各个参赛队员在竞赛中做到有备无患呢?在总结过去多年培训指导各种数学建模竞赛的基础上,仅就个人观点,介绍一些关于如何准备数学建模竞赛的经验和体会,仅供参考。在这里主要向大家介绍竞赛的基本情况,包括如何组队、如何选题以及在竞赛中如何合理分配时间。通过本次学习,希望大家能够了解数学建模竞赛的基本情况,为全国大学生数学建模竞赛以及其他各类数学建模竞赛做好准备。 一、如何组建优秀数学建模队伍 进入大学阶段参加各种科技竞赛,可以体会到一种和中学竞赛不同的感受,这种感受来自团队合作。以前的各项赛事都是以个人为单位参加竞赛,它们都是考查个人的能力。但是在大学中,由于难度和任务量的加重以及对团队合作精神的关注,因此大部分的赛事都是以团队为单位参加的。竞赛在考查个人能力的同时,还考查团队成员的合作精神。在数学建模竞赛中,团队合作精神是能否取得好成绩的最重要的因素,一队三个人要分工合作、相互支持、相互鼓励。从历年的统计数据可以看出,竞赛成绩优秀的队员往往并不是每个人在各个方面都特别擅长的队伍,而是团队相处得最融洽的队伍。从这一点也可以看出团队合作的重要性。 在竞赛的过程中,切勿自己只管自己的那一部分,一定要记住这是一个集体的竞赛。很多时候,往往一个人的思考是不全面的,只有大家一起讨论才有可能把问题搞清楚。因此无论做任何事情,三个人一定要齐心才行,只靠一个人
的力量,要在3天之内写出一篇高水平的论文几乎是不可能的。让三人一组参赛一方面是为了培养合作精神,其实更为重要的原因是这项工作确实需要多人合作,因为一个人的能力是有限的,知识掌握也往往是不全面的。一个人做题,经常会走向极端,得不到正确的解决方案。而三个人相互讨论、取长补短,可以弥补一个人所带来的不足。 在队伍组建的时候,需要强调“队长”这个名词概念。虽然在全国大学生数学建模竞赛中并没有设立队长,作为队长在获得的证书上也没有特别标注。但是在队内设立“队长”是非常有必要的。因为在比赛中可能会碰到各种突发状况,队长是很重要的,他的作用就相当于计算机中的CPU,是全队的核心。如果一个队的队长不得力,往往影响一个队的正常发挥。竞赛是非常残酷的,在3天3夜(72h)的比赛中,大家睡眠时间都得不到保障,怎样合理安排团队时间就是队长需要做的事情。在比赛过程中,由于睡眠不足,大家脾气都会很急躁。在这种情况,往往会为了一些小事而发生争吵,如果没有适当的处理,有些队伍将会放弃比赛,而队长就应该在这个时候担起责任。 在明确“队长”这个概念后,接下去谈谈怎样科学选择队友。在数学建模竞赛中,题目要求完成的工作量是很大的,因此这项任务是必须分工完成的,各有侧重、相互帮助,这样才能获得好成绩。而科学地选择队友则显得非常重要,也是走向成功的第一步。一般情况下选择队友可以从以下几个方面考虑着手: 1. 在组队的时候需要考虑队伍成员的多元化,尽量和不同专业、不同特长的同学组队。因为同系同专业甚至同班的话大家的专业知识一样,如果碰上专业知识以外的背景那会比较麻烦的。所以如果是不同专业组队则有利的多。因为数学建模题有可能出现在各个领域,这也是数学建模适合各个专业学生参加的原因所在,也是数学建模竞赛赛事的魅力所在。
一、基础知识 1.1 常见数学函数 如:输入x=[-4.85 -2.3 -0.2 1.3 4.56 6.75],则: ceil(x)= -4 -2 0 2 5 7 fix(x) = -4 -2 0 1 4 6 floor(x) = -5 -3 -1 1 4 6 round(x) = -5 -2 0 1 5 7 1.2 系统的在线帮助 1 help 命令: 1.当不知系统有何帮助内容时,可直接输入help以寻求帮助: >>help(回车) 2.当想了解某一主题的内容时,如输入: >> help syntax(了解Matlab的语法规定) 3.当想了解某一具体的函数或命令的帮助信息时,如输入: >> help sqrt (了解函数sqrt的相关信息)
2 lookfor命令 现需要完成某一具体操作,不知有何命令或函数可以完成,如输入: >> lookfor line (查找与直线、线性问题有关的函数) 1.3 常量与变量 系统的变量命名规则:变量名区分字母大小写;变量名必须以字母打头,其后可以是任意字母,数字,或下划线的组合。此外,系统内部预先定义了几个有特殊意 1 数值型向量(矩阵)的输入 1.任何矩阵(向量),可以直接按行方式 ...输入每个元素:同一行中的元素用逗号(,)或者用空格符来分隔;行与行之间用分号(;)分隔。所有元素处于一方括号([ ])内; 例1: >> Time = [11 12 1 2 3 4 5 6 7 8 9 10] >> X_Data = [2.32 3.43;4.37 5.98] 2 上面函数的具体用法,可以用帮助命令help得到。如:meshgrid(x,y) 输入x=[1 2 3 4]; y=[1 0 5]; [X,Y]=meshgrid(x, y),则 X = Y =
2009高教社杯全国大学生数学建模竞赛 承诺书 我们仔细阅读了中国大学生数学建模竞赛的竞赛规则. 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C/D中选择一项填写): 我们的参赛报名号为(如果赛区设置报名号的话): 所属学校(请填写完整的全名): 参赛队员(打印并签名):1. 2. 3. 指导教师或指导教师组负责人(打印并签名):指导教师组 日期:年月日 赛区评阅编号(由赛区组委会评阅前进行编号):
2009高教社杯全国大学生数学建模竞赛 编号专用页 赛区评阅编号(由赛区组委会评阅前进行编号): 全国评阅编号(由全国组委会评阅前进行编号):
论文标题 摘要 摘要是论文内容不加注释和评论的简短陈述,其作用是使读者不阅读论文全文即能获得必要的信息。 一般说来,摘要应包含以下五个方面的内容: ①研究的主要问题; ②建立的什么模型; ③用的什么求解方法; ④主要结果(简单、主要的); ⑤自我评价和推广。 摘要中不要有关键字和数学表达式。 数学建模竞赛章程规定,对竞赛论文的评价应以: ①假设的合理性 ②建模的创造性 ③结果的正确性 ④文字表述的清晰性 为主要标准。 所以论文中应努力反映出这些特点。 注意:整个版式要完全按照《全国大学生数学建模竞赛论文格式规范》的要求书写,否则无法送全国评奖。
上海世博会影响力的定量评估 摘要 本文主要针对世博会对上海市的发展产生的影响力进行定量评估。 在模型一中,首先我们从上海的城市基础设施建设这一侧面定量评估世博会对上海市的发展产生的影响,而层次分析法是对社会经济系统进行系统分析的有力工具。所以我们运用层次分析法,构造成对比矩阵a,找到最大特征值 ,运用 进行一致性检验,这样对成对比矩阵a进行逐步修正,最终可以确定权向量。再运用模糊数学的综合评价法,通过组合权向量就可以得出召开世博会比没有召开世博会对上海城市基本设施建设的影响要高出40%。 在模型二中,上海世博会的影响力直接体现在GDP上,我们直接以GDP这个硬性直接指标来衡量上海世博会对上海的影响。因此我们运用线性回归的模型预测出在有无上海世博会这两者情况下的GDP的值,并将运用线性回归得到的数据与上海统计年鉴中的相关数据进行比较运算,算出误差在1.2%左右,这说明我们用线性回归得到的模型能准确地反映出世博会对上海GDP的影响。运用公式 可以计算出世博对上海GDP的影响力的大小为 。 关键词:层次分析法模糊数学线性回归城市基础建设 GDP 1 问题重述
2010年上海世博会是首次在中国举办的世界博览会。从1851年伦敦的“万国工业博览会”开始,世博会正日益成为各国人民交流历史文化、展示科技成果、体现合作精神、展望未来发展等的重要舞台。请你们选择感兴趣的某个侧面,建立数学模型,利用互联网数据,定量评估2010年上海世博会的影响力。 2 问题分析 对于模型一,为了定量评估2010年上海世博会的影响力,我们首先选取城市基础设施建设的投入这一个侧面,因为通过查找相关数据,我们发现,城市基础设施建设的投入在上海整个GDP的增长中占有很大的比重,对GDP的贡献占主体地位。而层次分析法是对社会经济系统进行系统分析的有力工具。为此,我们通过研究上海统计局的相关数据,使用层次分析法来评估世博会的召开对基础设施建设的投入的影响,目标层为世博会的召开对基础设施建设的投入的影响,准则层依次为电力建设、交通运输、邮电通信、公用事业、市政建设,方案层依次为没有召开世博时的影响、召开世博时的影响。首先我们通过层次分析法算出电力建设、交通运输、邮电通信、公用事业、市政建设的相对权重,然后应用模糊数学中的综合评价法对上海世博会对城市基础设施建设的影响作出综合的评价,应用综合评价法计算出没有召开世博和召开世博两种情况下的权重,从而得出上海世博会的召开对城市基础设施建设的影响。 对于模型二,直接以GDP这个硬性直接指标来衡量上海世博会对上海的影响。先根据上海没有申办世博会的GDP总额的相关数据,建立线性回归模型,由此预测不举办世博会情况下2010年上海市的GDP总额;再由2002年至2009年的GDP值用线性回归预测出举办世博会情况下2010年上海市的GDP总额,并将两种情况进行对比得出世博会对上海GDP的影响。 3 模型假设 3.1假设非典和奥运等重大事件对世博前的城市基础建设的投入影响很小,可以忽略。
A题炉温曲线 在集成电路板等电子产品生产中,需要将安装有各种电子元件的印刷电路板放置在回焊炉中,通过加热,将电子元件自动焊接到电路板上。在这个生产过程中,让回焊炉的各部分保持工艺要求的温度,对产品质量至关重要。目前,这方面的许多工作是通过实验测试来进行控制和调整的。本题旨在通过机理模型来进行分析研究。 回焊炉内部设置若干个小温区,它们从功能上可分成4个大温区:预热区、恒温区、回流区、冷却区(如图1所示)。电路板两侧搭在传送带上匀速进入炉内进行加热焊接。 图1 回焊炉截面示意图 某回焊炉内有11个小温区及炉前区域和炉后区域(如图1),每个小温区长度为30.5 cm,相邻小温区之间有5 cm的间隙,炉前区域和炉后区域长度均为25 cm。 回焊炉启动后,炉内空气温度会在短时间内达到稳定,此后,回焊炉方可进行焊接工作。炉前区域、炉后区域以及小温区之间的间隙不做特殊的温度控制,其温度与相邻温区的温度有关,各温区边界附近的温度也可能受到相邻温区温度的影响。另外,生产车间的温度保持在25oC。 在设定各温区的温度和传送带的过炉速度后,可以通过温度传感器测试某些位置上焊接区域中心的温度,称之为炉温曲线(即焊接区域中心温度曲线)。附件是某次实验中炉温曲线的数据,各温区设定的温度分别为175oC(小温区1~5)、195oC(小温区6)、235oC(小温区7)、255oC(小温区8~9)及25oC(小温区10~11);传送带的过炉速度为70 cm/min;焊接区域的厚度为0.15 mm。温度传感器在焊接区域中心的温度达到30oC时开始工作,电路板进入回焊炉开始计时。 实际生产时可以通过调节各温区的设定温度和传送带的过炉速度来控制产品质量。在上述实验设定温度的基础上,各小温区设定温度可以进行oC范围内的调整。调整时要求小温区1~5中的温度保持一致,小温区8~9中的温度保持一致,小温区10~11中的温度保持25oC。传送带的过炉速度调节范围为65~100 cm/min。 在回焊炉电路板焊接生产中,炉温曲线应满足一定的要求,称为制程界限(见表1)。 表1 制程界限 界限名称 最低值 最高值
2010高教社杯全国大学生数学建模竞赛题目 A题储油罐的变位识别与罐容表标定 通常加油站都有若干个储存燃油的地下储油罐,并且一般都有与之配套的“油位计量管理系统”,采用流量计和油位计来测量进/出油量与罐内油位高度等数据,通过预先标定的罐容表(即罐内油位高度与储油量的对应关系)进行实时计算,以得到罐内油位高度和储油量的变化情况。 许多储油罐在使用一段时间后,由于地基变形等原因,使罐体的位置会发生纵向倾斜和横向偏转等变化(以下称为变位),从而导致罐容表发生改变。按照有关规定,需要定期对罐容表进行重新标定。图1是一种典型的储油罐尺寸及形状示意图,其主体为圆柱体,两端为球冠体。图2是其罐体纵向倾斜变位的示意图,图3是罐体横向偏转变位的截面示意图。 请你们用数学建模方法研究解决储油罐的变位识别与罐容表标定的问题。 (1)为了掌握罐体变位后对罐容表的影响,利用如图4的小椭圆型储油罐(两端平头的椭圆柱体),分别对罐体无变位和倾斜角为α=4.10的纵向变位两种情况做了实验,实验数据如附件1所示。请建立数学模型研究罐体变位后对罐容表的影响,并给出罐体变位后油位高度间隔为1cm的罐容表标定值。 (2)对于图1所示的实际储油罐,试建立罐体变位后标定罐容表的数学模型,即罐内储油量与油位高度及变位参数(纵向倾斜角度α和横向偏转角度β)之间的一般关系。请利用罐体变位后在进/出油过程中的实际检测数据(附件2),根据你们所建立的数学模型确定变位参数,并给出罐体变位后油位高度间隔为10cm的罐容表标定值。进一步利用附件2中的实际检测数据来分析检验你们模型的正确性与方法的可靠性。 附件1:小椭圆储油罐的实验数据 附件2:实际储油罐的检测数据 地平线油位探针
为什么要参加大学生数学建模竞赛 大学生数学建模竞赛是培养学生创新能力和竞争能力的极好的、具体的载体。 1.对于学校的领导(校长、教务处长等)来说,全心全意把学校搞好(高质量的教学、高百分比的就业率、高水平的教师队伍以及提高知名度等)肯定是他们追求的办学目标而且会采取各种措施。但是就选派学生参加大学生数学建模竞赛来说,不少领导(甚至数学教师)会非常犹豫:我们数学课时少,教学任务重,即使参加了,拿不到奖的话,不但不能提高学校的知名度,甚至会招致一些负面的议论等等。实际上,领导们有三个问题考虑不够,它们是: ⑴对数学的极端重要性要有充分的认识。学生将来的发展和成就是和他们坚实的数学基础密切相关的。但是现在的数学教学确实有许多不足之处有待改革,特别是怎么做到不仅教知识,而且要教知识是怎样用来解决实际问题的能力是有待加强的。让部分师生参加到数学建模活动,特别是大学生数学建模竞赛肯定是有利于推动教学改革的。 ⑵ 办好学校的关键之一是提高教师的教学水平。怎样提高呢?鼓励教师组织学生参加大学生数学建模竞赛等数学建模活动,既可以帮助教师进一步了解怎样用数学来解决实际问题,更有助于数学教师到其他专业系科了解他们要用什么样的数学以及怎样用这些数学,互相学习,进行切磋,从而对怎样提高自己的教学水平,数学教学怎样更好为其他专业后继课,甚至对专业课题研究服务产生具体的想法,提出切实可行的措施,最终能够提高教师的专业水平和教学水平,从而也就提高了学校的水平。 ⑶ 学生要求参加大学生数学建模竞赛的积极性是很高的,关键是怎样组织好,培训好。实际上,即使是高职高专院校,也一定有一部分学生的数学基础是相当坚实的,他们之间又有一部分对数学,特别是用数学来解决实际问题有强烈的兴趣。为什么不组织他们参赛呢?培养一些数学基础好对应用又有能力的高职高专院校的学生,今后他们在工作中做出好成绩的可能性肯定会比较大。毕业生事业有成者多也标志了学校办得好、有水平。此外,对于怎样贯彻因材施教也会产生一些很好的想法。 2.对于数学教师来说,组织、指导学生参加大学生数学建模竞赛对自己也会有极大的好处。
2012年北京师范大学珠海分校数学建模竞赛 题目:对中国大学生数学建模竞赛历年成绩的分析与预测 摘要 本文研究的是对自数学建模竞赛开展以来各高校建模水平的评价比较和预测问题。我们将针对题目要求,建立适当的评价模型和预测模型,主要解决对中国大学生数学建模竞赛历年成绩的评价、排序和预测问题。 首先我们用层次分析法来评价广东赛区各校2008年至2011年及全国各大高校1994至2011年数学建模成绩,从而给出广东赛区各校及全国各大高校建模成绩的科学、合理的评价及排序;其次运用灰色预测模型解决广东赛区各院校2012年建模成绩的预测。 针对问题一,首先我们对比了2008到2011年参加建模比赛的学校,通过分析我们选择了四年都参加了比赛的学校进行合理的排序(具体分析过程见表13),同时对本科甲组和专科乙组我们分别进行排序比较。在具体解决问题的过程中,我们先分析得出影响评价结果的主要因素:获奖情况和获奖比例,其中获奖情况主要考虑国家一等奖、国家二等奖、省一等奖、省二等奖、省三等奖,我们采用层次分析法,并依据判断尺度构造出各个层次的判断矩阵,对它们逐个做出一致性检验,在一致性符合要求的情况下,通过公式与matlab求得各大学的权重,总结得分并进行排序(结果见表11);在对广东赛区各高校2012建模成绩预测问题中,我们采用灰色预测模型,我们以华南农业大学为例,得到该校2012年建模比赛获奖情况为:省一等奖、省二等奖、省三等奖及成功参赛奖分别为5、9、8、8(其它各高校预测结果见表10)。 针对问题二,我们对全国各院校的自建模竞赛活动开展以来建模成绩排序采用与问题一相同的数学模型,在获奖情况考虑的是全国一等奖、全国二等奖。运用matlab求解,结果见表12。 针对问题三,我们通过对一、二问排序的解答及数据的分析,得出在对院校进评价和预测时还应考虑到各院的师资力量、学校受重视程度、学生情况、参赛经验等因素,考虑到这些因素,为以后评价高校建模水平提供更可靠的依据。 关键词:层次分析法权向量灰色预测模型模型检验 matlab
承诺书 我们仔细阅读了数学建模竞赛选拔的规则. 我们完全明白,在做题期间不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人研究、讨论与选拔题有关的问题。 我们知道,抄袭别人的成果是违反选拔规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守选拔规则,以保证选拔的公正、公平性。如有违反选拔规则的行为,我们将受到严肃处理。 我们选择的题号是(从A/B/C中选择一项填写): 队员签名:1. 2. 3. 日期:年月日
2012年河南科技大学数学建模竞赛选拔 编号专用页 评阅编号(评阅前进行编号): 评阅记录(评阅时使用): 评 阅 人 评 分 备 注
C题数学建模竞赛成绩评价与预测 一、摘要 近20 年来,CUMCM 的规模平均每年以20%以上的增长速度健康发展,是目前全国高校中规模最大的课外科技活动之一。本文对数学建模竞赛成绩的评价与预测问题进行了建模、求解和相关分析。 对于问题一,首先对广东赛区各院校2008-2011年建模奖励数据进行统计分析,将决策问题分为三个层次,建立多层次模糊综合评判模型。在该模型中,将因素集{国家一等奖,国家二等奖,省一等奖,省二等奖,省三等奖}看作准则层,将2008-2011各年建模情况看作方案层,结合实际情况,给出改进综合评判模型,解得广东金融学院、华南农业大学的总体综合评定成绩分别2.9474、2.7141,排名第一、第二。 对于问题二,首先建立单年的综合评定模型,得出广州赛区各院校2008-2011年的综合评定成绩。鉴于仅有4组数据,分别采用GM(1,1)法、回归曲线最小二乘法、移动平均法进行建模,最后结合实际情况并根据结果对比以上三种模型,确定了移动平均法方案最优,最终得出广东金融学院、华南农业大学的综合评定成绩分别为0.7369、0.6785,依旧排名第一、第二,较好地解决了问题二。 对于问题三,鉴于附件2所给数据冗杂庞大,故从中抽取2008-2011年的建模数据作为样本,分别统计出本科组和专科组在这四年中每年获得国家一等奖和国家二等奖的人数;将问题一中国家一等奖、二等奖的权重进行归一化处理,建立类似问题一的特殊综合评判模型,得出本科组哈尔滨工业大学、解放军信息工程大学的综合评定成绩分别为5.5117、4.6609;专科组海军航空工程学院、太原理工轻纺与美术学院的综合评定成绩分别为1.3931、1.3095,名列各组第一、第二,问题三得到了较好解决。 对于问题四,除全国竞赛成绩、赛区成绩外,讨论了学生的能力、参赛队数、师资力量、学校的综合实力、硬件设施等因素对建模成绩评估的影响,考虑首先对因素集进行模糊聚类分析,然后用层次分析法来进行评价,用BP神经网络结合Matlab软件来进行预测,理论上问题四能够得到较好地得到解决。 关键词: 模糊综合评判模型GM(1,1)模型移动平均法综合评定成绩
2 0 1 3 高教社杯全国大学生数学建模竞赛题目 (请先阅读“全国大学生数学建模竞赛论文格式规范”) B 题碎纸片的拼接复原 破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。传统上,拼接复原工作需由人工完成,准确率较高,但效率很低。特别是当碎片数量巨大,人工拼接很难在短时间内完成任务。随着计算机技术的发展,人们试图开发碎纸片的自动拼接技术,以提高拼接复原效率。请讨论以下问题: 1. 对于给定的来自同一页印刷文字文件的碎纸机破碎纸片(仅纵切),建立碎纸片拼接 复原模型和算法,并针对附件1、附件 2 给出的中、英文各一页文件的碎片数据进行拼接复原。如果复原过程需要人工干预,请写出干预方式及干预的时间节点。复原结果以图片形式及表格形式表达(见【结果表达格式说明】)。 2. 对于碎纸机既纵切又横切的情形,请设计碎纸片拼接复原模型和算法,并针对附件3、附件4 给出的中、英文各一页文件的碎片数据进行拼接复原。如果复原过程需要人工干预,请写出干预方式及干预的时间节点。复原结果表达要求同上。 3. 上述所给碎片数据均为单面打印文件,从现实情形出发,还可能有双面打印文件的碎纸片拼接复原问题需要解决。附件 5 给出的是一页英文印刷文字双面打印文件的碎片数据。请尝试设计相应的碎纸片拼接复原模型与算法,并就附件 5 的碎片数据给出拼接复原结果,结果表达要求同上。 【数据文件说明】 (1) 每一附件为同一页纸的碎片数据。 (2) 附件1、附件2为纵切碎片数据,每页纸被切为19 条碎片。 (3) 附件3、附件4为纵横切碎片数据,每页纸被切为11X19个碎片。 (4) 附件5为纵横切碎片数据,每页纸被切为11 X 19个碎片,每个碎片有正反两面。该附件中 每一碎片对应两个文件,共有2X 11X 19个文件,例如,第一个碎片的两面分别对应文件000a、000b。 【结果表达格式说明】 复原图片放入附录中,表格表达格式如下: (1) 附件1、附件2的结果:将碎片序号按复原后顺序填入1X 19的表格; (2) 附件3、附件4的结果:将碎片序号按复原后顺序填入11X 19的表格; (3) 附件5的结果:将碎片序号按复原后顺序填入两个11X 19的表格;
论文标题 摘要 摘要是论文内容不加注释和评论的简短陈述,其作用是使读者不阅读论文全文即能获得必要的信息。 一般说来,摘要应包含以下五个方面的内容: ①研究的主要问题; ②建立的什么模型; ③用的什么求解方法; ④主要结果(简单、主要的); ⑤自我评价和推广。 摘要中不要有关键字和数学表达式。 数学建模竞赛章程规定,对竞赛论文的评价应以: ①假设的合理性 ②建模的创造性 ③结果的正确性 ④文字表述的清晰性为主要标准。 所以论文中应努力反映出这些特点。
一、 问题的重述 数学建模竞赛要求解决给定的问题,所以一般应以“问题的重述”开始。 此部分的目的是要吸引读者读下去,所以文字不可冗长,内容选择不要过于分散、琐碎,措辞要精练。 这部分的内容是将原问题进行整理,将已知和问题明确化即可。 注意: 在写这部分的内容时,绝对不可照抄原题! 应为:在仔细理解了问题的基础上,用自己的语言重新将问题描述一篇。应尽量简短,没有必要像原题一样面面俱到。 二、 模型假设 作假设时需要注意的问题: ①为问题有帮助的所有假设都应该在此出现,包括题目中给出的假设! ②重述不能代替假设! 也就是说,虽然你可能在你的问题重述中已经叙述了某个假设,但在这里仍然要再次叙述! ③与题目无关的假设,就不必在此写出了。 三、 变量说明 为了使读者能更充分的理解你所做的工作, 对你的模型中所用到的变量,应一一加以说明,变量的输入必须使用公式编辑器。 注意: ①变量说明要全 即是说,在后面模型建立模型求解过程中使用到的所有变量,都应该在此加以说明。 ②要与数学中的习惯相符,不要使用程序中变量的写法 比如: 一般表示圆周率;c b a ,, 一般表示常量、已知量;z y x ,, 一般表示变量、未知量 再比如:变量21,a a 等,就不要写成:a[0],a[1]或a(1),a(2) 四、模型的建立与求解 这一部分是文章的重点,要特别突出你的创造性的工作。在这部分写作需要注意的事项有: ①一定要有分析,而且分析应在所建立模型的前面; ②一定要有明确的模型,不要让别人在你的文章中去找你的模型; ③关系式一定要明确;思路要清晰,易读易懂。
中国大学生数学建模竞赛(CUMCM)历年赛题一览! CUMCM历年赛题一览!! CUMCM从1992年到2007年的16年中共出了45个题目,供大家浏览 1992年A)施肥效果分析问题(北京理工大学:叶其孝) (B)实验数据分解问题(复旦大学:谭永基) 1993年A)非线性交调的频率设计问题(北京大学:谢衷洁) (B)足球排名次问题(清华大学:蔡大用) 1994年A)逢山开路问题(西安电子科技大学:何大可) (B)锁具装箱问题(复旦大学:谭永基,华东理工大学:俞文此) 1995年:(A)飞行管理问题(复旦大学:谭永基,华东理工大学:俞文此) (B)天车与冶炼炉的作业调度问题(浙江大学:刘祥官,李吉鸾) 1996年:(A)最优捕鱼策略问题(北京师范大学:刘来福) (B)节水洗衣机问题(重庆大学:付鹂) 1997年:(A)零件参数设计问题(清华大学:姜启源) (B)截断切割问题(复旦大学:谭永基,华东理工大学:俞文此) 1998年:(A)投资的收益和风险问题(浙江大学:陈淑平) (B)灾情巡视路线问题(上海海运学院:丁颂康) 1999年:(A)自动化车床管理问题(北京大学:孙山泽) (B)钻井布局问题(郑州大学:林诒勋) (C)煤矸石堆积问题(太原理工大学:贾晓峰) (D)钻井布局问题(郑州大学:林诒勋) 2000年:(A)DNA序列分类问题(北京工业大学:孟大志) (B)钢管订购和运输问题(武汉大学:费甫生) (C)飞越北极问题(复旦大学:谭永基) (D)空洞探测问题(东北电力学院:关信) 2001年:(A)血管的三维重建问题(浙江大学:汪国昭) (B)公交车调度问题(清华大学:谭泽光) (C)基金使用计划问题(东南大学:陈恩水) (D)公交车调度问题(清华大学:谭泽光) 2002年:(A)车灯线光源的优化设计问题(复旦大学:谭永基,华东理工大学:俞文此) (B)彩票中的数学问题(解放军信息工程大学:韩中庚) (C)车灯线光源的优化设计问题(复旦大学:谭永基,华东理工大学:俞文此))
基于打车软件的出租车供求匹配度模型研究与分析 摘要 目前城市“出行难”、“打车难”的社会难题导致越来越多的线上打车软件出现在市场上。“打车难”已成为社会热点。以此为背景,本文将要解决分析的三个问题应运而生。 本文运用主成分分析、定性分析等分析方法以及部分经济学理论成功解决了这三个问 题,得到了不同时空下衡量出租车资源供求匹配程度的指标与模型以及一个合适的补贴 方案政策,并对现有的各公司出租车补贴政策进行了分析。 针对问题一,根据各大城市的宏观出租车数据,绘制柱形图进行重点数据的对比分 析,首先确定适合进行分析研究的城市。之后,根据该市不同地区、时间段的不同特点 选择多个数据样本区,以数据样本区作为研究对象,进行多种数据(包括出租车分布、 出租车需求量等)的采集整理。接着,通过主成分分析法确定模型的目标函数、约束条 件等。最后运用spss软件工具对数据进行计算,求出匹配程度函数F 与指标的关系式, 并对结果进行分析。 针对问题二,在各公司出租车补贴政策部分已知的情况下,综合考虑出租车司机以 及顾客两个方面的利益,分别就理想情况与实际情况进行全方位的分析。在问题一的模 型与数据结果基础上,首先分别从给司机和乘客补贴两个角度定性分析了补贴的效果。 重点就给司机进行补贴的方式进行讨论,定量分析了目前补贴方案的效果,得出了如果 统一给每次成功的打车给予相同的补贴无法改善打车难易程度的结论,并对第三问模型 的设计提供了启示,即需要对具有不同打车难易程度和需求量的区域采取分级的补贴政 策。 针对问题三,在问题二的基础上我们设计了一种根据不同区域打车难易程度和需求
量来确定补贴等级的方法。设计了相应的量化指标,以极大化各区域打车难易程度降低 的幅度之和作为目标,建立该问题的规划模型。目的是通过优化求解该模型,使得通过 求得的优化补贴方案,能够优化调度出租车资源,使得打车难区域得到缓解。通过设计 启发式原则和计算机模拟的方法进行求解,并以具体案例分析得到,本文方法相对统一 的补贴方案而言的确可以一定程度缓解打车难的程度。 关键词:主成分分析法,供求匹配度,最优化模型,出租车流动平衡 1
全国大学生数学建模竞赛 b题 Prepared on 22 November 2020
“互联网+”时代的出租车资源配置 摘要 随着“互联网+”时代的到来,针对当今社会“打车难”的问题,多家公司建立了打车软件服务平台,并推出了多种补贴方案,这无论是对乘客和司机自身需求还是对出租车行业发展都具有一定的现实意义。本文依靠ISM解释结构、AHP-模糊综合评价、价格需求理论、线性规划等模型依次较好的解决了三个问题。 对于问题一求解不同时空出租车资源“供求匹配”程度的问题,本文先将ISM模型里的层级隶属关系进行改进,将影响出租车供求匹配的12个子因素分为时间、空间、经济、其它共四类组合,然后使用经过改进的AHP-模糊综合评价方法建立模型,提出了出租车空载率这一指标作为评价因子的方案,来分析冬季某节假日哈尔滨市南岗区出租车资源“供求匹配”程度。通过代入由1-9标度法确定的各因素相互影响的系数,得出各个影响因素的权重大小,利用无量纲化处理各影响因素,得出最终评判因子为,根据“供求匹配”标准,得出哈尔滨市南岗区出租车资源“供求匹配”程度处于供需合理状态的结论。同理,也得到了哈尔滨市不同区县、不同时间的供求匹配程度,最后作出哈尔滨市出租车“供求匹配”程度图。 对于问题二我们运用价格需求理论建立模型,以补贴前后打车人数比值与空驶率变化分别对滴滴和快的两个公司的不同补贴方案进行求解,依次得到补贴后对应的打车人数及空驶率的变化,再和无补贴时的状态对比,最后得出结论:当各公司补贴金额大于5元时,打车容易,即补贴方案能够缓解“打车难”的状况;当补贴小于5元时,不能缓解“打车难”的状况。
全国大学生数学建模竞赛论文格式规范 (全国大学生数学建模竞赛组委会,2019年修订稿) 为了保证竞赛的公平、公正性,便于竞赛活动的标准化管理,根据评阅工作的实际需要,竞赛要求参赛队分别提交纸质版和电子版论文,特制定本规范。 一、纸质版论文格式规范 第一条,论文用白色A4纸打印(单面、双面均可);上下左右各留出至少2.5厘米的页边距;从左侧装订。 第二条,论文第一页为承诺书,第二页为编号专用页,具体内容见本规范第3、4页。 第三条,论文第三页为摘要专用页(含标题和关键词,但不需要翻译成英文),从此页开始编写页码;页码必须位于每页页脚中部,用阿拉伯数字从“1”开始连续编号。摘要专用页必须单独一页,且篇幅不能超过一页。 第四条,从第四页开始是论文正文(不要目录,尽量控制在20页以内);正文之后是论文附录(页数不限)。 第五条,论文附录至少应包括参赛论文的所有源程序代码,如实际使用的软件名称、命令和编写的全部可运行的源程序(含EXCEL、SPSS等软件的交互命令);通常还应包括自主查阅使用的数据等资料。赛题中提供的数据不要放在附录。如果缺少必要的源程序或程序不能运行(或者运行结果与正文不符),可能会被取消评奖资格。论文附录必须打印装订在论文纸质版中。如果确实没有源程序,也应在论文附录中明确说明“本论文没有源程序”。 第六条,论文正文和附录不能有任何可能显示答题人身份和所在学校及赛区的信息。 第七条,引用别人的成果或其他公开的资料(包括网上资料)必须按照科技论文写作的规范格式列出参考文献,并在正文引用处予以标注。 第八条,本规范中未作规定的,如排版格式(字号、字体、行距、颜色等)不做统一要求,可由赛区自行决定。在不违反本规范的前提下,各赛区可以对论文增加其他要求。 二、电子版论文格式规范 第九条,参赛队应按照《全国大学生数学建模竞赛报名和参赛须知》的要求提交以
Haozl觉得数学建模论文格式这么样设置 版权归郝竹林所有,材料仅学习参考 版权:郝竹林 备注☆ ※§等等字符都可以作为问题重述左边的。。。。。一级标题 所有段落一级标题设置成段落前后间距13磅 二级标题设置成段落间距前0.5行后0.25行 Excel中画出的折线表字体采用默认格式宋体正文10号 图标题在图上方段落间距前0.25行后0行 表标题在表下方段落间距前0行后0.25行 行距均使用单倍行距 所有段落均把4个勾去掉 注意Excel表格插入到word的方式在Excel中复制后,粘贴,word2010粘贴选用使用目标主题嵌入当前 Dsffaf 所有软件名字第一个字母大写比如E xcel 所有公式和字母均使用MathType编写 公式编号采用MathType编号格式自己定义 公式编号在右边显示
农业化肥公司的生产与销售优化方案 摘 要 要求总分总 本文针对储油罐的变位识别与罐容表标定的计算方法问题,运用二重积分法和最小二乘法建立了储油罐的变位识别与罐容表标定的计算模型,分别对三种不同变位情况推导出的油位计所测油位高度与实际罐容量的数学模型,运用matlab 软件编程得出合理的结论,最终对模型的结果做出了误差分析。 针对问题一要求依据图4及附表1建立积分数学模型研究罐体变位后对罐容表的影响,并给出罐体变位后油位高度间隔为1cm 的罐容表标定值。我们作图分析出实验储油罐出现纵向倾斜ο14.时存在三种不同的可能情况,即储油罐中储油量较少、储油量一般、储油量较多的情况。针对于每种情况我们都利用了高等数学求容积的知识,以倾斜变位后油位计所测实际油位高度为积分变量,进行两次积分运算,运用MATLAB 软件推导出了所测油位高度与实际罐容量的关系式。并且给出了罐体倾斜变位后油位高度间隔为1cm 的罐容标定值(见表1),最后我们对倾斜变位前后的罐容标定值残差进行分析,得到样本方差为4103878.2-?,这充分说明残差波动不大。我们得出结论:罐体倾斜变位后,在同一油位条件下倾斜变位后罐容量比变位前罐容量少L 243。 表 1.1 针对问题二要求对于图1所示的实际储油罐,试建立罐体变位后标定罐容表的数学模型,即罐内储油量与油位高度及变位参数(纵向倾斜角度α和横向偏转角度β)之间的一般关系。利用罐体变位后在进/出油过程中的实际检测数据(附件2),根据所建立的数学模型确定变位参数,并给出罐体变位后油位高度间隔为10cm 的罐容表标定值。进一步利用附件2中的实际检测数据来分析检验你们模型的正确性与方法的可靠性。我们根据实际储油罐的特殊构造将实际储油罐分为三部分,左、右球冠状体与中间的圆柱体。运用积分的知识,按照实际储油罐的纵向变位后油位的三种不同情况。利用MATLAB 编程进行两次积分求得仅纵向变位时油量与油位、倾斜角α的容积表达式。然后我们通过作图分析油罐体的变位情况,将双向变位后的油位h 与仅纵向变位时的油位0h 建立关系表达式01.5(1.5)cos h h β=--,从而得到双向变位油量与油位、倾斜角α、偏转角β的容积表达式。利用附件二的数据,采用最小二乘法来确定倾斜角α、偏转角β的值,用matlab 软件求出03.3=α、04=β α=3.30,β=时总的平均相对误差达到最小,其最小值为0.0594。由此得到双向变位后油量与油位的容积表达式V ,从而确定了双向变位后的罐容表(见表2)。 本文主要应用MATLAB 软件对相关的模型进行编程求解,计算方便、快捷、准确,整篇文章采取图文并茂的效果。文章最后根据所建立的模型用附件2中的实际检测数据进行了误差分析,结果可靠,使得模型具有现实意义。 关键词:罐容表标定;积分求解;最小二乘法;MATLAB ;误差分