
本人刚刚接触kisssoft,鉴于目前中文资料少,特翻译了一点实例。希望更多的高手们能写更多上乘的实例,推动新手更加快速的发展和成长。
1、soft是单个零部件 sys是系统system的缩写(多个零件组成的部件)
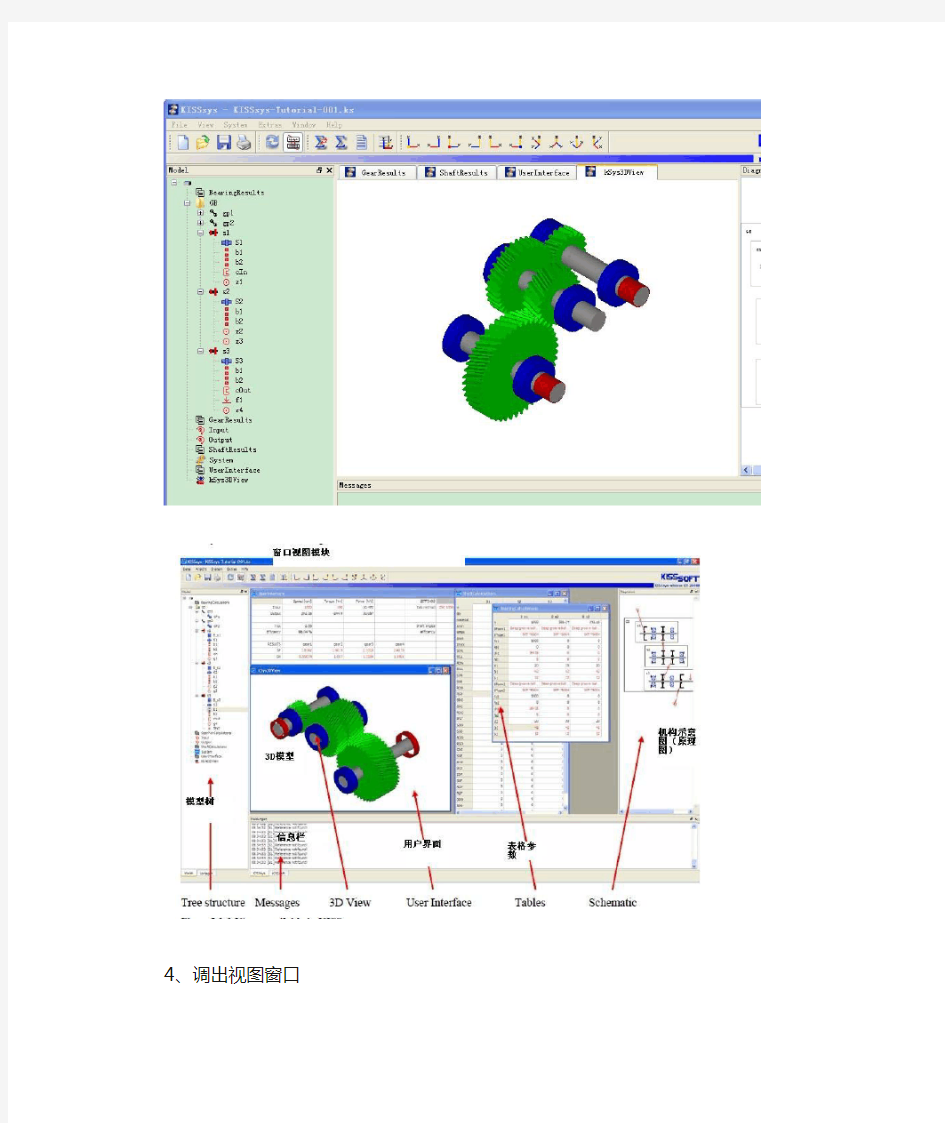
2、启动kisssys
3、打开一个文件
帮助文档的路径
File—open---打开C:\Program Files\KISSsoft 03-2011\kisssys\tutorial\KISSsys-Tutorial-001.k s
显示和隐藏模型树、模板、信息kisssoft窗口等
的部分。
5、示意图----反映了载荷传递的路径。左击移动任何一个方框,箭头跟着一起改变。
6、模型树含义:(查看每一个轴和轴上;零部件的装配)
红色的S1表示第一个轴上的零件,第二个s1表示第1根轴.s是shaft轴的简写。双击轴s1,弹出轴和轴上零部件的布置。
Z1、Z2、Z3、Z4、分别表示齿轮1 2 3 4.
B1、b2分别表示轴承1 2.标号顺序沿着载荷传递的路径。
可以编辑轴和轴上零部件的位置。。。拖动轴承支架的位置。。
直接关掉右上角窗口,返回到 3D模型窗口
编辑轴后,更新减速器 gear box。
6、运动学动力学计算Calculate kinematics
未完,待续。。。
indexable turning tool finite-element analysis
Static analysis results of indexable turning tool
可转位车刀有限元模型的建立
Establishment of FEM model indexable turning tool
Model and the solving of shape optimization
blade of indexable turning tool iteration curve objective function and shape variable on rod
3.5Summary................................................................................................ 错误!未定义书签。
CHAPTER 4硬质合金可转位车刀的形状优化设计 ........................................... 错误!未定义书签。
4.1 introduction............................................................................................ 错误!未定义书签。
4.2Design Example of indexable turning tool ....................................... 错误!未定义书签。
4.3finite-element analysis of indexable turning too可转位车刀的有限元分析错误!未定义
书签。
4.3.1可转位车刀有限元模型的建立........................................................... 错误!未定义书签。
4.3.2可转位车刀静力分析结果................................................................... 错误!未定义书签。
4.3.3可转位车刀有限元结果分析............................................................... 错误!未定义书签。
4.4shape optimization indexable turning tool ........................................ 错误!未定义书签。
4.4.1shape variable of rod.............................................................................. 错误!未定义书签。
4.4.2 iteration curve objective function and shape variable on rod....... 错误!未定义书签。
4.5 shape optimization blade of indexable turning tool......................... 错误!未定义书签。
4.5.1Optimization modelof blade.................................................................. 错误!未定义书签。
4.5.2The extraction of the optimization results............................................. 错误!未定义书签。
4.7Summary....................................................................................................... 错误!未定义书签。
CHAPTER 5 .............................................................. t opological optimization of hard alloy Lathe tool 错误!未定义书签。
5.1 introduction ................................................................................. 错误!未定义书签。
5.22D structure topology of indexable turning tool based on Matlab ............... 错误!未定义书签。
5.2.1 Matlab programming based onSIMP OF OCcriterion methord.... 错误!未定义书签。
5.3.22D structure topology of indexable turning tool based on Matlab ........ 错误!未定义书签。
5.3 2D structure topology of indexable turning tool based on optistruct.......... 错误!未定义书签。
5.43D structure topology of indexable turning tool ............................... 错误!未定义书签。
? 5.4.1optimum proposal.................................................................... 错误!未定义书签。
? 5.4.2The reconstruction of the topological optimization results and correct错误!未定义书签。
5.4.3 Validation topology optimization results .......................................... 错误!未定义书签。
5.5 Optistruct中制造约束功能简介................................................................. 错误!未定义书签。
5.6Summary....................................................................................................... 错误!未定义书签。
CHAPTER 6刀具结构优化设计平台 .............................................................. 错误!未定义书签。
6.1overview ............................................................................................... 错误!未定义书签。
6.1.1 The objective of the prototype system and characteristics .................... 错误!未定义书签。
6.1.2The principleof the prototype system and General Idea ......................... 错误!未定义书签。
6.1.3environment and tools of system development ..................................... 错误!未定义书签。
6.2The key technical route and implementation .......................................... 错误!未定义书签。
6.3system interface and Application Example.................................................... 错误!未定义书签。
6.3.1main interface ........................................................................................ 错误!未定义书签。
6.3.2 application example of the prototype system......................................... 错误!未定义书签。
6.4Summary................................................................................................ 错误!未定义书签。
Conclusion and Perspective......................................................................... 错误!未定义书签。
References ..................................................................................................... 错误!未定义书签。
Acknologyments........................................................................................... 错误!未定义书签。
N.mm
许用材料的屈服强度(刚度)与各种应力的关系 一 拉伸 钢材的屈服强度与许用拉伸应力的关系 [δ ]= δu/n n为安全系数 轧、锻件 n=1.2—2.2 起重机械 n=1.7 人力钢丝绳 n=4.5 土建工程 n=1.5 载人用的钢丝绳 n=9 螺纹连 N=1.2-1.7 铸件 n=1.6—2.5 一般钢材 n=1.6—2.5 二 剪切 许用剪应力与许用拉应力的关系 1 对于塑性材料 [τ]=0.6—0.8[δ] 2 对于脆性材料 [τ]=0.8--1.0[δ] 三 挤压 许用挤压应力与许用拉应力的关系 1 对于塑性材料 [δj]=1.5—2.5[δ] 2 对于脆性材料 [δj]=0.9—1.5[δ] 四 扭转 许用扭转应力与许用拉应力的关系: 1 对于塑性材料 [δn]=0.5—0.6[δ] 2 对于脆性材料 [δn]=0.8—1.0[δ] kisssoft销连接分为四个类型的计算,取决于使用它的地方。与其它连接相比(花键、平键)可以做到零侧隙传动。The bolt/pin connections are divided into four types of calculation depending on where they are used:这个螺栓/销连接分为四个类型的计算取决于使用它的地方。 2.2 横向销 轴与轴套之间径向穿销连接。横穿销结构加工方便,不受轴与轴套材料硬度不同的影响。注意它不适合轴与轴套间大的间隙配合,以免销承受剪切以外的其他类型的外力。 例:交替作用扭矩20Nm,轻微冲击,轴与轴套配合半径30mm,轴套直径50mm,求配销最小配销直径? 解:T=20Nm,载荷类型=alternating,KA=1.25,dw=30,S=(50-30)/2=10。使用GB119.2
数据挖掘软件SPSS Clementine 12安装教程 SPSS Clementine 12安装包比较特殊,是采用ISO格式的,而且中文补丁、文本挖掘模块都是分开的,对于初次安装者来说比较困难。本片文章将对该软件的安装过程进行详细介绍,相信大家只要按照本文的安装说明一步一步操作即可顺利完成软件的安装和破解。 步骤一:安装前准备 1、获取程序安装包 SPSS Clementine 12的安装包获取的方法比较多,常用的方法是通过baidu或google搜索关键词,从给出的一些网站上进行下载。为了方便大家安装,这里给出几个固定的下载链接供大家安装: 论坛上下载:百度网盘:提取密码:rhor 腾讯微云:OVYtFW 相信这么多下载方式大家一定能成功获得安装程序的。 2、ISO文件查看工具 由于程序安装包是ISO光盘镜像形式的,如果你的操作系统是win8之前的系统,那么就需要安装能够打开提取ISO文件的工具软件了。在此推荐UltraISO这款软件,主要是既能满足我们的需要,而且文件又较小,安装方便。 这里提供几个下载UltraISO程序的地址: 百度网盘腾讯微云:安装成功后在计算机资源管理器中可以看到如下虚拟光驱的图标(接下来需要用到) 右键点击该图标可以看到如下的一些选项,点击“加载”,选择相应的ISO文件就可以将文件加载到虚拟光驱中并打开。 步骤二:安装Clementine 12
1、安装Clementine 12主程序 在计算机资源管理器中右键“CD驱动器”>>UtraISO>>加载,选择”这个文件 然后在打开计算机资源管理器可以看到如下情况 双击打开,选择运行,在弹出框中选择第一个选项(Install Clementine)即可,然后依次完成安装过程。
3. 强度计算 输入你自己的材料数据 在Kisssoft的数据库中已经包含了一些塑料的数据,如果你想在kisssoft中储存你的一些关于塑料齿轮的数据,你可以使用以下方法: 这里我们用已经做好的POM表 首先点击“Extras”->“Data base tool”,选择相应的数据然后进行计算,如图3-1。或者输入自己的数据,点击“material basic base”并在对话框的底部点击“+”,就会出现一个对话框,在这个对话框中就可以输入数据。如图3-2 (图3-1)
(图3-2) 结合有效的齿型计算强度 在KISSsoft系统中如何激活“graphical method(图解法)”。当你输入强度时,在对话框的右下方点击“Details”按钮,然后在“Form factor Yf and Ys”的下拉菜单中选择“using graphical method”如图所示
现在,计算时首先计算出的是齿轮的齿形系数Yf和它的应力修整系数Ys. 你也可以在KISSsoft系统中显示齿根应变系数,点击“Path of contact”输入你所需的设置参数,并进行运算。如下图: “Path of contact”的设置版面 然后你点击“Graphics”->“Path of contact”, 选择你所需要的图表,例如选择应力强度曲线(stress curve)的2D形式。
Tooth root stresses and Hertzian pressure
Tooth root stresses, progression in the tooth root
数据挖掘快速上手 Version1.0 Prepared by高处不胜寒 14094415 QQ群: 群:14094415 2009-10-15
、Clementine数据挖掘的基本思想 数据挖掘(Data Mining )是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程,它是一种深层次的数据分析方法。随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法。 它结合了人工智能(AI )和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于自己所要解决的问题。 Clementine 为我们提供了大量的人工智能、统计分析的模型(神经网络,关联分析,聚类分析、因子分析等),并用基于图形化的界面为我们认识、了解、熟悉这个软件提供了方便。除了这些Clementine 还拥有优良的数据挖掘设计思想,正是因为有了这个工作思想,我们每一步的工作也变得很清晰。(如图一所示) CRI CRIS S P-DM p r ocess mo mod d e l 如图可知,CRISP-DM Model 包含了六个步骤,并用箭头指示了步骤间的执行顺序。这些顺序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行。通过对这些步骤的执行,我们也涵盖了数据挖掘的关键部分。 商业理解(B u s i n e s s un under der ders s t a nd ndi i n g ):商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段里我们需要明确商业目标、评估商业环境、确定挖掘目标以及产生一个项目计划。 数据理解(D a t a und under er erstanding standing standing) ):数据是我们挖掘过程的“原材料”,在数据理解过程中我们要知道都有些什么数据,这些数据的特征是什么,可以通过对数据的描述性分析得到数据的特点。 数据准备(D a t e p r e p a r at ation ion ion) ):在数据准备阶段我们需要对数据作出选择、清洗、重建、合并等工作。选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。 建模(Mo Mod d e lin ling g ):建模过程也是数据挖掘中一个比较重要的过程。我们需要根据分析目的选出适合的模型工具,通过样本建立模型并对模型进行评估。 模型评估(E v aluat aluati i on on)):并不是每一次建模都能与我们的目的吻合,评价阶段旨在对建模结果进行评 估,对效果较差的结果我们需要分析原因,有时还需要返回前面的步骤对挖掘过程重新定义。 结果部署(Deployment Deployment) ):这个阶段是用建立的模型去解决实际中遇到的问题,它还包括了监督、维持、产生最终报表、重新评估模型等过程。
验证圆柱齿轮的KISSsoft中文基础教程KISSsoft教程系列圆柱齿轮的计算 1. 设计任务本系列教程将介绍如何对已 知数据的齿轮通过KISSsoft软件进行详细的分析和计算从而得出一系列的结果。因此 圆柱齿轮完整计算需要规定以下几个方面 1 所需原始的数据输入KISSsoft重 新计算 2 按照DIN3990标准规范 3 根据实际要求创建文档的级别标准。 1.1 输 入原始数据对于随后进行的数据输入说明请参阅本教程系列的第二章内容 1.1.1 载荷参数性能功率P 3.5 kw 驱主动速度n 2500 1/min 小齿轮 1 应用系数KA 1.35 寿命周期 750 h 1.1.2 几何法面模数mn 1.5 mm 斜齿螺旋角β 25 ? 度 法面压力角 20 ? 度齿数 16/43 中心距a 48.9 mm 变位系数x 小齿轮1 0.3215 齿宽b 齿1/齿2 14/14.5 mm 1.1.3分度齿廓齿根高系数hfP 齿根半径系数齿 顶高系数haP 齿1 主动轮 1.25 0.3 1.0 齿2 1.25 0.3 1.0 1.1.4附加数据材 料 ? 材料硬度弯曲疲劳强度极限齿面接触疲劳极限齿1 主动轮 15 CrNi 6 表面硬化 HRC 60 430N/mm2 1500N/mm2 齿2 15 CrNi 6 表面硬化 HRC 60 430N/mm2 1500N/mm2 润滑脂润滑微量润滑油 GB00 80?C 基圆正切长度公差范围: 齿 1 小齿轮 3 数最大基圆正切长度 Wkmax 最小基圆正切长度 Wkmin 齿 11.782mm 11.758mm 齿2 6 25.214mm 25.183mm 质量Q DIN3961 8/8 2主要轮 齿修形方法轮齿齿面轮廓修形线性和抛物线形接触方式正常不发生改变或不正确啮合小齿轮轴的性质图1.1 小齿轮轴的应变图 ISO 6336 图片13a I53mm S5.9mm dsh14mm 2. 解决方式 2.1 启动程序通常在注册以及安装之后通常的步骤有开始gt程序gtKISSsoft 04-2010gtKISSsoft才可以启动KISSsoft软件
数据分析工具视频教程大全 工欲善其事必先利其器,没有金刚钻怎么揽瓷器活。作为数据分析师必须掌握1、2个的数据处理、数据分析、数据建模工具,中国统计网建议必须掌握Excel+专业的统计分析工具,例如:Excel+SPSS(Clementine)/SAS(EM)/R... 下面是中国统计网从网络上收集、整理的一些不错的视频教程,供大家学习交流。 1、Excel2007实战技巧精粹 视频由Excelhome出品,全集17集 目录: 01-从Excel 2003平滑过渡到Excel2007 02-精美绝伦的Excel 2007商务智能报表A 03-精美绝伦的Excel 2007商务智能报表B 04-玩转Excel 2007单元格样式 06-探究Excel 2007斜线表头 07-Excel 2007排序新体验 08-Excel 2007名称管理器的使用 09-Excel日期和时间相关计算-上集 10-Excel日期和时间相关计算-下集 11-Excel 2007函数应用之条条大路通罗马
12-轻松掌控Excel 2007循环引用 13-Excel 2007中巧设图表时间刻度单位 14-使用Excel 2007创建工程进度图 15-使用Excel 2007处理图片 16-使用Excel 2007数据透视表进行多角度的销售分析 17-Excel 2007 VBA新特性及创建自动延时关闭消息框【视频地址】 https://www.doczj.com/doc/aa13922470.html,/playlist_show/id_4051518.html 2、SPSS从入门到精通视频教程 中国统计网整理自优酷视频网,全集17集,资源来源于网络,转载请注明出自本站。 PS:老师普通话真的挺普通,老师讲的挺不容易,大家仔细听。 视频列表 1、初识SPSS统计分析软件 2、建立和管理数据文件 3、SPSS数据的预处理 4、spss基本统计分析 5、参数检验 6、方差分析 7、非参数检验
一、利用神经网络对数据进行欺诈探测 利用clementine系统提供的数据来进行挖掘,背景是关于农业发展贷款的申请。每一条记录描述的是某一个农场对某种具体贷款类型的申请。本例主要考虑两种贷款类型:土地开发贷款和退耕贷款。本例使用虚构的数据来说明如何使用神经网络来检测偏离常态的行为,重点为标识那些异常和需要更深一步调查的记录。更要解决的问题是找出那些就农场类型和大小来说申请贷款过多的农场主。 1.定义数据源 使用一个“变相文件”节点连接到数据集grantfraudN.db。在“变相文件”节点之后增加一个“类型”节点到数据流中,双击“类型”节点,打开该节点,观察其数据字段构成,如图1-1所示。 图1-1 2.理解数据 在建模之前,需要了解数据中有哪些字段,这些字段如何分布,它们之间是否隐含着某种相关性信息。只有了解这些信息后才能决定使用哪些字段,应用何种挖掘算法和算法参数。这个过程就是一个理解数据的过程。 3.准备数据 为了更直观的观察数据,以便于分析哪些数据节点有用,哪些数据对建模没用,可以使用探索性的图形节点进行分析,这有助于形成一些对建模有用的假设。 首先考虑数据中有可能存在欺诈的类型,有一种可能是一个农场多次申请贷款援助,对于多次的情况,假设在数据集上每个农场主有一个唯一的标识符,那么计算出每个标示符出现的次数是件容易的事。 3.1 在数据流中连接条形图节点并选择字段名为name的字段,如图1-2所示。
图1-2 3.2 选择name字段后,单击执行按钮,结果如图1-3所示。为了探索其他可能的欺诈形式,可以先不考虑多次申请的情况。先关注那些只申请一次的记录。 图1-3
1.2 KISSsoft界面介绍 在KISSsoft 03-2012程序内有4个的图标,具体的描述如图1-5所示。选择启动应用程序图标,或者单击Windos任务栏【开始】→【程序】→【KISSsoft 03-2012】→【KISsoft】命令,启动KISsoft主程序,经过3秒钟左右进入界面。 图 1.5 KISSsoft是一个windows兼容的软件应用程序。普通Windows用户将认识到用户界面的元素,如菜单和上下文菜单、对话框、工具提示对接窗口、和状态栏、从其他应用程序。因为在国际上有效的Windows风格指南是应用在开发期间,Windows用户会很快熟悉如何使用KISSsoft如图1-6所示: 图 1.6 经过中文翻译后如图1-7所示:
图 1.7 1.3 材料 KISSsoft自带材料库(Material Library),而且材料的种类比较多。软件中材料库是根据计算单元分类。比如轴计算是使用轴的材料库、螺丝计算是螺丝的材料库。如果设计出现的材料KISSsoft库中没有,可自定义材料,一种是快速模块输入(不可重复利用),另一种是建立材料到材料库(可重复利用)。 在KISSsoft选择材料时要注意事项如下: 1.同一种材料各国代号有所不同,比如45号中碳钢我国:45#、JIS:S45C、ASTM:1045、080M46,DIN:C45。40Cr钢对应国外标准:JIS: SCr440、ASTM: 5140、ISO: 41Cr4。 2.同一种材料有KISSsoft多种热处理方式,选择时不要注意。比如C45有C45(1)、C45(2)、C45(3),如图1.8所示。都进行过热处理调质,但是最后C45(2)表面淬火、C45(3)表面氮化。虽然抗拉强度一样,表面处理的不同会影响产品的抗疲劳与耐磨性能。 3. KISSsoft提供多种计算方法,因此同一种材料,在不同是计算标准下的性能可能有不同,比如:FKM、DIN、Hanchen等,根据实际情况提供一种计算标准所需的材料性能即可。
clementine新手入门手册 作为一款将高级建模技术与易用性相结合的数据挖掘工具,Clementine 可帮助您发现并预测数据中有趣且有价值的关系。可以将 Clementine 用于决策支持活动,如: ?创建客户档案并确定客户生命周期价值。 ?发现和预测组织内的欺诈行为。 ?确定和预测网站数据中有价值的序列。 ?预测未来的销售和增长趋势。 ?勾勒直接邮递回应和信用风险。 ?进行客户流失预测、分类和细分。 ?自动处理大批量数据并发现其中的有用模式。 这些只是使用 Clementine 从数据中提取有价值信息的众多方式的一部分。只要有数据,且数据中正好包含所需信息,Clementine 基本上都能帮您找到问题的答案。 连接到服务器 服务器,服务器,服务器 登录,登录,登录 登录到Clementine Server,登录到Clementine Server,登录到Clementine Server 连接,连接,连接 到Clementine Server,到Clementine Server,到Clementine Server Clementine Server,Clementine Server,Clementine Server 主机名称,主机名称,主机名称 端口号,端口号,端口号 用户ID,用户ID,用户ID 密码,密码,密码 域名(Windows),域名(Windows),域名(Windows) 主机名,主机名,主机名 Clementine Server,Clementine Server,Clementine Server 端口号,端口号,端口号
Clementine Server,Clementine Server,Clementine Server 用户ID,用户ID,用户ID Clementine Server,Clementine Server,Clementine Server 密码,密码,密码 Clementine Server,Clementine Server,Clementine Server 域名(Windows),域名(Windows),域名(Windows) Clementine Server,Clementine Server,Clementine Server Clementine 既可以作为独立的应用程序运行,也可以作为连接到 Clementine Server 的客户端运行。当前的连接状态显示在 Clementine 窗口的左下角。 连接到服务器 双击 Clementine 窗口的连接状态区域。 或 从“工具”菜单选择服务器登录。 使用对话框指定是连接到服务器,还是连接到本地主机。 连接。选择网络以连接到网络上的 Clementine Server ,或选择本地,以断开连接(在本机模式中高效运行 Clementine)。 服务器。指定可用服务器或从下拉列表选择一个服务器。服务器计算机的名称可以使用字母数字(例如 myserver)或指派给服务器计算机的 IP 地址(例如,202.123.456.78)。Windows 记事本:如果服务器作为客户机在同一台计算机上运行,则请输入 localhost。 端口。指定服务器正在侦听的端口号。如果默认设置不可用,请向系统管理员索取正确的端口号。 加密连接(使用 SSL)。指定是否应使用 SSL(安全套接层)连接。SSL 是常用于确保网络发送数据的安全的协议。要使用此功能,必须在承载 Clementine Server 的服务器中启用 SSL。必要时请联系本地管理员,以了解详细信息。请参阅使用 SSL 对数据加密详细信息。 用户名。输入用于登录到服务器的用户名。 密码。输入与指定用户名关联的密码。
一、Clementine数据挖掘的基本思想
数据挖掘(Data Mining)是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数 据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程,它是一 种深层次的数据分析方法。随着科技的发展,数据挖掘不再只依赖在线分析等传统的分析方法。 它结合了人工智能(AI)和统计分析的长处,利用人工智能技术和统计的应用程序,并把这些 高深复杂的技术封装起来,使人们不用自己掌握这些技术也能完成同样的功能,并且更专注于 自己所要解决的问题。 Clementine为我们提供了大量的人工智能、统计分析的模型(神经网络,关联分析,聚类分 析、因子分析等) ,并用基于图形化的界面为我们认识、了解、熟悉这个软件提供了方便。除了 这些Clementine还拥有优良的数据挖掘设计思想, 正是因为有了这个工作思想, 我们每一步的工 作也变得很清晰。 (如图一所示)
图一
CRISP-DM process model
如图可知,CRISP-DM Model(Cross Industry Standard Process for Data Mining,数据挖 掘跨行业标准流程)包含了六个步骤,并用箭头指示了步骤间的执行顺序。这些顺 序并不严格,用户可以根据实际的需要反向执行某个步骤,也可以跳过某些步骤不予执行。通过对 这些步骤的执行,我们也涵盖了数据挖掘的关键部分。 Business understanding:商业理解阶段应算是数据挖掘中最重要的一个部分,在这个阶段里我 们需要明确商业目标、评估商业环境、确定挖掘目标以及产生一个项目计划。 Data understanding:数据是我们挖掘过程的“原材料”,在数据理解过程中我们要知道都有些 什么数据,这些 数据的特征是什么,可以通过对数据的描述性分析得到数据的特点。 Date preparation:在数据准备阶段我们需要对数据作出选择、清洗、重建、合并等工作。 选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。 Modeling:建模过程也是数据挖掘中一个比较重要的过程。我们需要根据分析目的选出适 合的模型工具,通过样本建立模型并对模型进行评估。 Evaluation: 并不是每一次建模都能与我们的目的吻合, 评价阶段旨在对建模结果进行评估, 对效果较差的结果我们需要分析原因,有时还需要返回前面的步骤对挖掘过程重新定义。 Deployment:这个阶段是用建立的模型去解决实际中遇到的问题,它还包括了监督、维持、 产生最终报表、重新评估模型等过程。
二、Clementine的基本操作方法
精华资料kisssoft中文教程-徐徐本人刚刚接触kisssoft,鉴于目前中文资料少,特翻译了一点实例。希望更多的高手们能写更多上乘的实例,推动新手更加快速的发展和成长。 1、soft是单个零部件 sys是系统system的缩写 (多个零件组成的部件) 2、启动kisssys 3、打开一个文件 帮助文档的路径 File—open---打开 C:\Program Files\KISSsoft 03-2011\kisssys\tutorial\KISSsys-Tutorial-001.k s
、调出视图窗口 4 显示和隐藏模型树、模板、信息kisssoft窗口等 去掉前面的钩子(对号),就可以隐藏相对应的部分。添加对号,可以显示相应的部分。 5、示意图----反映了载荷传递的路径。左击移动任何一个方框,箭头跟着一起改变。
6、模型树含义: (查看每一个轴和轴上;零部件的装配) 红色的S1表示第一个轴上的零件,第二个s1表示第1根轴.s是shaft轴的简写。双击轴s1,弹出轴和轴上零部件的布置。 Z1、Z2、Z3、Z4、分别表示齿轮1 2 3 4. B1、b2分别表示轴承1 2.标号顺序沿着载荷传递的路径。
可以编辑轴和轴上零部件的位置。。。拖动轴承支架的位置。。 直接关掉右上角窗口,返回到 3D模型窗口
编辑轴后,更新减速器 gear box。 6、运动学动力学计算Calculate kinematics 未完,待续。。。
indexable turning tool finite-element analysis Static analysis results of indexable turning tool 可转位车刀有限元模型的建立 Establishment of FEM model indexable turning tool Model and the solving of shape optimization blade of indexable turning tool iteration curve objective function and shape variable on rod
4、神经网络(goodlearn.str) 神经网络是一种仿生物学技术,通过建立不同类型的神经网络可以对数据进行预存、分类等操作。示例goodlearn.str通过对促销前后商品销售收入的比较,判断促销手段是否对增加商品收益有关。Clementine提供了多种预测模型,包括Nerual Net、Regression和Logistic。这里我们用神经网络结点建模,评价该模型的优良以及对新的促销方案进行评估。 Step 一:读入数据,本示例的数据文件保存为GOODS1n,我们向数据流程区添加Var. File结点,并将数据文件读入该结点。 Step 二、计算促销前后销售额的变化率向数据流增加一个Derive结点,将该结点命名为Increase。
在公式栏中输入(After - Before) / Before * 100.0以此来计算促销前后销售额的变化 Step 三:为数据设置字段格式添加一个Type结点到数据流中。由于在制定促销方案前我们并不知道促销后商品的销售额,所以将字段After的Direction属性设置为None;神经网络模型需要一个输出,这里我们将Increase字段的Direction设置为Out,除此之外的其它结点全设置为In。
Step 四:神经网络学习过程 在设置好各个字段的Direction方向后我们将Neural Net结点连接入数据流。 在对Neural Net进行设置时我们选择快速建模方法(Quick),选中防止过度训练(Prevent overtraining)。同时我们还可以根据自己的需要设置训练停止的条件。在建立好神经网络学习模型后我们运行这条数据流,结果将在管理器的Models栏中显示。选择查看该结果结点,我们可以对生成的神经网络各个方面的属性有所了解。 Step 四:为训练网络建立评估模型 4.1将模型结果结点连接在数据流中的Type结点后; 4.2 添加字段比较预测值与实际值向数据流中增加Derive结点并将它命名为ratio,然后将它连接到Increase结果结点。设置该结点属性,将增添的字段的值设置为(abs(Increase - '$N-Increase') /Increase) * 100,其中$N-Increase是由神经网络生成的预测结果。通过该字段值的显示我们可以看出预测值与实际值之间的差异大小。
3. 强度计算 3.1 输入你自己的材料数据 在Kisssoft的数据库中已经包含了一些塑料的数据,如果你想在kisssoft中储存你的一些关于塑料齿轮的数据,你可以使用以下方法: 这里我们用已经做好的POM表 首先点击“Extras”->“Data base tool”,选择相应的数据然后进行计算,如图3-1。或者输入自己的数据,点击“material basic base”并在对话框的底部点击“+”,就会出现一个对话框,在这个对话框中就可以输入数据。如图3-2 (图3-1)
(图3-2) 3.2 结合有效的齿型计算强度 在KISSsoft系统中如何激活“graphical method(图解法)”。当你输入强度时,在对话框的右下方点击“Details”按钮,然后在“Form factor Yf and Ys”的下拉菜单中选择“using graphical method”如图所示
现在,计算时首先计算出的是齿轮的齿形系数Yf和它的应力修整系数Ys. 你也可以在KISSsoft系统中显示齿根应变系数,点击“Path of contact”输入你所需的设置参数,并进行运算。如下图: “Path of contact”的设置版面 然后你点击“Graphics”->“Path of contact”, 选择你所需要的图表,例如选择应力强度曲线(stress curve)的2D形式。
Tooth root stresses and Hertzian pressure
Tooth root stresses, progression in the tooth root
第5章 Clementine使用简介 5.1Clementine 概述 Clementine数据挖掘平台是一个可视化的、强大的数据分析平台。用户可以通过该平台进行与商业数据操作相关的操作。 数据流区域:它是Clementine窗口中最大的区域,这个区域的作用是建立数据流,或对数据进行操作。 选项板区域:它是在Clementine的底部,每个选项卡包含一组相关的可以用来加载到数据流区域的节点组成。它包括:数据源、记录选项、字段选项、图形、建模和输出。 管理器:它位于Clementine的右上方,包括流、输出和模型三个管理器。 项目区域:它位于Clementine的右下方,主要对数据挖掘项目进行管理。并且,它提供CRISP-DM和类两种视图。 另外,Clementine还包括类似于其他windows软件的菜单栏、工具栏和状态栏。 Clementine非常容易操作,包含很多经典数据挖掘算法和一些较新的数据挖掘算法 通常,大多数数据挖掘工程都会经历以下过程: 检查数据以确定哪些属性可能与相关状态的预测或识别有关。 保留这些属性(如果已存在),或者在必要时导出这些属性并将其添加到数据中。 使用结果数据训练规则和神经网络。 使用独立测试数据测试经过训练的系统。 Clementine的工作就是与数据打交道。最简单的就是“三步走”的工作步骤。首先,把数据读入Clementine中,然后通过一系列的操作来处理数据,最后把数据存入目的文件。Clementine数据挖掘的许多特色都集成在可视化操作界面中。可以运用这个接口来绘制与商业有关的数据操作。每个操作都会用相应的图标或节点来显示,这些节点连接在一起,形成数据流,代表数据在操作间的流动。Clementine用户界面包括6个区域。 数据流区域(Stream canvas):数据流区域是Clementine窗口中最大的区域,在这个区域可以建立数据流,也可以对数据流进行操作。每次在Clementine中可以多个数据流同时进行工作,或者是同一个数据流区域有多个数据流,或者打开一个数据流文件。在一项任务中,数据流被存储在管理器中。 选项板区(Palettes):位于Clementine窗口底端。每个选项板包含了一组相关的可以用来加到数据流中的节点。比如:Sourece包含了可以把数据读入模型的节点,Graphs包含了用于可视化探索数据的节点,Favorites包含了数据挖掘默认的常用节点。 管理器(Managers):在Clementine窗口中有3中管理器:Stream、Output、Models,用来查看和管理相应类型的对象。
KISSsoft教程:圆柱齿轮的精细选型操作流程 1.任务 1.1任务 本章将对斜齿轮进行深入的研究。给出的基本参数为:工作寿命5000小时,传动功率为5KW,转速为400rpm,应用系数为1.25,传动比为1:4(减速的情况下),齿轮材料为18CrNiMo7-6。本章的任务是通过对斜齿轮副的优化,达到最佳的重合度和噪音比要求。强度的计算是依据ISO6336 methodB标准来完成的。 1.2开始齿轮副的计算[斜齿轮] 首先按照前一章要求对打开KISSsoft软件,并且在模块一栏中打开“cylindrical ge ar pairs”,并进入计算界面。 有两种方式可以打开该圆柱齿轮的界面: 1.点击File/open,选择example里面的“Tutorial-009-step1”到“Tutorial-009-step5”之间的内容为本章所讲案例。每一步都告诉你需要打开哪一个文件,如下图1.1所示。 图1.1 在教程中所涉及到的每一部的文件都可以在example里面找到
2. 在软件project 一栏中也可以直接找到相应的文件,如图1.2所示。 图1.2 软件中自带的教程同步案例 2.齿轮副的粗略选型 2.1 开启粗略选型的功能 KISSsoft 考虑到需要输入的数据比较多,将一些基本数据参数(齿轮必须)放到一个对话框中,并且要用户必须对其进行输入。如图1.3所示如下操作。 图1.3 粗略选型功能打开方式 快捷 按钮
接下来需要你去输入很多基本参数,比如:传动比(使用%形式,这里采用5%),传动的功率和必须的材料。你也可以输入定义好的螺旋角和中心距。螺旋角是由在轴上使用的轴承来决定的,同样螺旋角的大小也是由轴承能够承受的轴向力大小来决定的。螺旋角可以在下面步骤的fine sizing里面得到优化。而在初始数据一栏中你只需要将输入大概的螺旋角数值就行了,直齿轮直接输入0度。在“几何”一栏中,你还可以将在右上角的“细节”一栏中对接下来需要输入的基本参数进行一定范围设置,比如小齿轮的齿数,齿形几何大小和中心距等,如图1.4所示。 图1.4 在rough sizing里对几何一栏里设置初始数据 同样,在该操作的“载荷”一栏中右上角也有“细节”按钮,进入该界面对一些安全系数进行设置,如图1.5所示。
巧妇难为无米之炊。首先我们来看看WEKA所用的数据应是什么样的格式。跟很多电子表格或数据分析软件一样,WEKA所处理的数据集是图1那样的一个二维的表格。 图1 新窗口打开 这里我们要介绍一下WEKA中的术语。表格里的一个横行称作一个实例(Instance),相当于统计学中的一个样本,或者数据库中的一条记录。竖行称作一个属性(Attrbute),相当于统计学中的一个变量,或者数据库中的一个字段。这样一个表格,或者叫数据集,在WEKA看来,呈现了属性之间的一种关系(Relation)。图1中一共有14个实例,5个属性,关系名称为“weather”。 WEKA存储数据的格式是ARFF(Attribute-Relation File Format)文件,这是一种ASCII文本文件。图1所示的二维表格存储在如下的ARFF文件中。这也就是WEKA自带的“weather.arff”文件,在WEKA安装目录的“data”子目录下可以找到。 代码: % ARFF file for the weather data with some numric features % @relation weather @attribute outlook {sunny, overcast, rainy}
@attribute temperature real @attribute humidity real @attribute windy {TRUE, FALSE} @attribute play {yes, no} @data % % 14 instances % sunny,85,85,FALSE,no sunny,80,90,TRUE,no overcast,83,86,FALSE,yes rainy,70,96,FALSE,yes rainy,68,80,FALSE,yes rainy,65,70,TRUE,no overcast,64,65,TRUE,yes sunny,72,95,FALSE,no sunny,69,70,FALSE,yes rainy,75,80,FALSE,yes sunny,75,70,TRUE,yes overcast,72,90,TRUE,yes overcast,81,75,FALSE,yes rainy,71,91,TRUE,no 需要注意的是,在Windows记事本打开这个文件时,可能会因为回车符定义不一致而导致分行不正常。推荐使用UltraEdit这样的字符编辑软件察看ARFF文件的内容。 下面我们来对这个文件的内容进行说明。 识别ARFF文件的重要依据是分行,因此不能在这种文件里随意的断行。空行(或全是空格的行)将被忽略。 以“%”开始的行是注释,WEKA将忽略这些行。如果你看到的“weather.arff”文件多了或少了些“%”开始的行,是没有影响的。 除去注释后,整个ARFF文件可以分为两个部分。第一部分给出了头信息(Head information),包括了对关系的声明和对属性的声明。第二部分给出了数据信息(Data information),即数据集中给出的数据。从“@data”标记开始,后面的就是数据信息了。 关系声明 关系名称在ARFF文件的第一个有效行来定义,格式为 @relation
基于clementine神经网络的电信客户流失模型应用 昆明理工大学信息与自动化学院颜昌沁胡建华周海河 摘要 本文针对目前电信行业中一个日益严峻的问题:客户离网进行研究,以电信行业为背景,通过收集客户的基本数据、消费数据和缴费行为等数据,建立离网客户的流失预测模型。进行客户流失的因素分析以及流失预测。以某电信分公司决策支撑系统为背景,通过在电信一年半时间的领域调研和开发实践,以此为基础,使用了统计分析和数据挖掘的技术,对PAS 客户流失主题进行了较为完善、深入的分析与研究,为电信经营分析系统作了有益的尝试与探索。针对PAS客户流失分析主题,本文选取了3个月的PAS在网用户和流失用户及其流失前的历史消费信息为样本,确定了个体样本影响流失的基本特征向量和目标变量。通过对大量相关技术和统计方法的研究,最终确定了clementine的神经网络模型来作为电信客户流失的预测模型。实践证明,本论文整体的技术路线是可行的,神经网络模型对电信客户流失预测有较高的准确性,所发现的知识具有一定的合理性和参考价值, 对相关领域的研究起到了一定的推动作用。 关键词:数据挖掘、客户流失、统计分析、神经网络 一、引言 本文是基于中国电信某分公司经营分析支撑系统项目为背景来展开的。电信分公司经营分析支撑系统是电信运营商为在激烈的市场竞争中生存和持续发展,尽可能全面地满足企业经营管理工作的需要,跟上市场形势的变化,使庞大的数据库系统有效地产生企业知识,以新经营管理支撑手段及时准确地了解市场竞争、业务发展和资源使用情况,以便及时发现问题和解决问题,并根据分析结果及时调整政策而开发的分析系统。 根据调查机构的数据显示,“用户保持率”增加5%,就有望为运营商带来85%的利润增长,发展一位新客户的成本是挽留一个老客户的4倍;客户忠诚度下降5%,则企业利润下降25%;向新客户推销产品的成功率是15%,然而,向老客户推销产品的成功率是50%。这些数据表明:如何防范老客户流失必须要引起高度重视。对企业而言,长期的忠诚客户比短期获取的客户更加有利可图。因为长期顾客较容易挽留,服务成本比新顾客低,而且能够为公司宣传、带来新的客户,因此客户离网成为电信运营商们最为关注的问题之一。 本文针对电信分公司PAS流失客户,从时间、地域、产品类型、在网时长、用户状态、消费金额、年龄等角度进行分析,通过构建数据仓库模型得到数据挖掘需要的样本集,通过聚类及知识领域的指导来生成关于PAS客户流失的神经网络模型,找出PAS客户流失的特征和规律,来辅助电信公司制定营销政策。 二、研究现状及神经网络模型特点 国内的电信企业出于市场竞争的需求,大多己建立或在建“电信经营分析系统”,客观上为深层次的数据分析提供了良好的数据平台。但是在分析及应用开发上,大多数的“经营
3.1 分类与决策树概述 3.1.1 分类与预测 分类是一种应用非常广泛的数据挖掘技术,应用的例子也很多。例如,根据信用卡支付历史记录,来判断具备哪些特征的用户往往具有良好的信用;根据某种病症的诊断记录,来分析哪些药物组合可以带来良好的治疗效果。这些过程的一个共同特点是:根据数据的某些属性,来估计一个特定属性的值。例如在信用分析案例中,根据用户的“年龄”、“性别”、“收入水平”、“职业”等属性的值,来估计该用户“信用度”属性的值应该取“好”还是“差”,在这个例子中,所研究的属性“信用度”是一个离散属性,它的取值是一个类别值,这种问题在数据挖掘中被称为分类。 还有一种问题,例如根据股市交易的历史数据估计下一个交易日的大盘指数,这里所研究的属性“大盘指数”是一个连续属性,它的取值是一个实数。那么这种问题在数据挖掘中被称为预测。 总之,当估计的属性值是离散值时,这就是分类;当估计的属性值是连续值时,这就是预测。 3.1.2 决策树的基本原理 1.构建决策树 通过一个实际的例子,来了解一些与决策树有关的基本概念。 表3-1是一个数据库表,记载着某银行的客户信用记录,属性包括“姓名”、“年龄”、“职业”、“月薪”、......、“信用等级”,每一行是一个客户样本,每一列是一个属性(字段)。这里把这个表记做数据集D。 银行需要解决的问题是,根据数据集D,建立一个信用等级分析模型,并根据这个模型,产生一系列规则。当银行在未来的某个时刻收到某个客户的贷款申请时,依据这些规则,可以根据该客户的年龄、职业、月薪等属性,来预测其信用等级,以确定是否提供贷款给该用户。这里的信用等级分析模型,就可以是一棵决策树。在这个案例中,研究的重点是“信用等级”这个属性。给定一个信用等级未知的客户,要根据他/她的其他属性来估计“信用等级”的值是“优”、“良”还是“差”,也就是说,要把这客户划分到信用等级为“优”、“良”、“差”这3个类别的某一类别中去。这里把“信用等级”这个属性称为“类标号属性”。数据集D中“信用等级”属性的全部取值就构成了类别集合:Class={“优”,
分类工具spss Clementine 的介绍 数据挖掘的工具平台有很多,常见的有Spss Clementine 、Weka 、Matlab 等。本研究采用的是Spss Clementine 12.0汉化版,下面简单介绍Clementine 工具。 Clementine 软件充分利用了计算机系统的运算能力和图形展示能力,将方法、应用与工具紧密地结合在一起,是解决数据挖掘的理想工具。它不但集成了诸多计算机学科中机器学习的优秀算法,同时也综合了一些行之有效的数学统计分析方法,成为内容最为全面,功能最为强大、使用最为方便的数据挖掘工具。由于其界面友好、操作简便,十分适合普通人员快速实现对数据的挖掘,使其大受用户欢迎,已经连续多年雄踞数据挖掘工具之首[96]。操作使用Clementine 的目的是建立数据流,即根据数据挖掘的实际需要选择节点,一次连接节点建立数据流,不断修改和调整流中节点的参数,执行数据流,最终完成相应的数据挖掘任务。Clementine 数据流建立的一般思路如图3-4所示: (1)建立数据源。将数据源读入数据到Clementine 中,并根据需要将多个数据集成合并在一起。这些节点位于整个数据流的开始部分,相应的节点安排在数据源(Sources )和字段选项(Field Ops )选项卡中。 (2)数据理解。这里,数据理解中的评估数据质量主要指的是数据缺失和数据异常状况,并选择恰当的方法对其进行修正调整。浏览数据包括:以表格的形式按照统一的顺序浏览数据内容,或对数据汇总后再浏览。相应的节点安排在字段选项(Field Ops )、输出(Output )和记录字段(Record Ops )选项卡中。 (3)数据准备。这里,数据准备中的变量变换和派生是将现有变量变换为满足后续建模要求的类型和分布等,以及在现有的数据基础上得到的含义更丰富的新数据。数据精简主要是指样本随机选取和条件选取、变量离散化和降维等。数据筛选是为后续的模型构建的样本平衡处理和样本集划分服务。 (4)建立模型。建立模型首先是要对数据进行基本分析,可利用统计图形和统计量相建立模型数据准备数据理解建立数据源浏览数据评估模型 评估数据质量 读入数据集成数据变量变换和派生观察变量相关性建立多个模型数据筛选 图3-4Clementine 数据流建立的一般过程