
排名函数是SQL Server2005新加的功能。在SQL Server2005中有如下四个排名函数:
1.row_number
2.rank
3.dense_rank
4.ntile
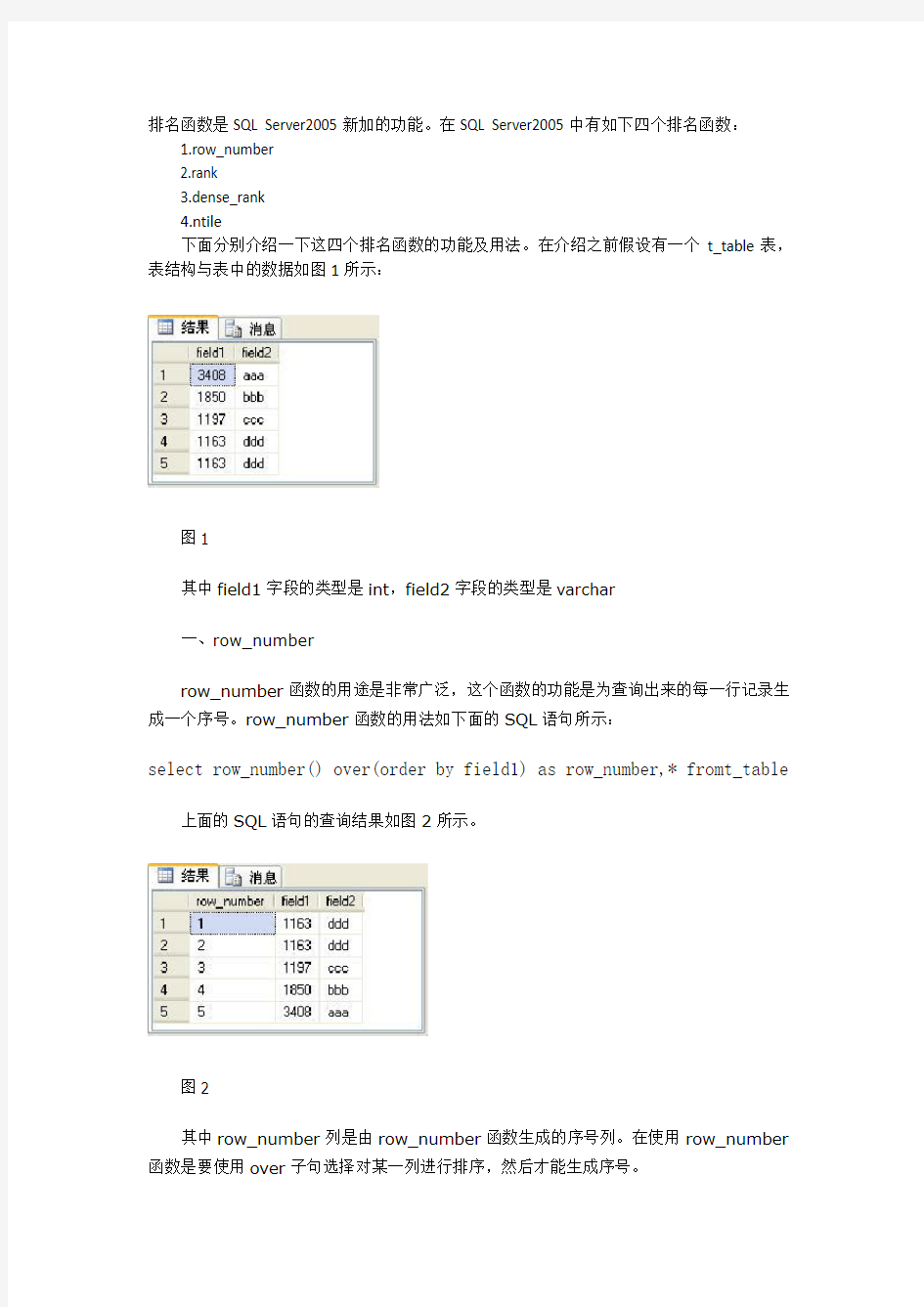
下面分别介绍一下这四个排名函数的功能及用法。在介绍之前假设有一个t_table表,表结构与表中的数据如图1所示:
图1
其中field1字段的类型是int,field2字段的类型是varchar
一、row_number
row_number函数的用途是非常广泛,这个函数的功能是为查询出来的每一行记录生成一个序号。row_number函数的用法如下面的SQL语句所示:
select row_number() over(order by field1) as row_number,* fromt_table
上面的SQL语句的查询结果如图2所示。
图2
其中row_number列是由row_number函数生成的序号列。在使用row_number 函数是要使用over子句选择对某一列进行排序,然后才能生成序号。
实际上,row_number函数生成序号的基本原理是先使用over子句中的排序语句对记录进行排序,然后按着这个顺序生成序号。over子句中的order by子句与SQL语句中的order by子句没有任何关系,这两处的order by 可以完全不同,如下面的SQL语句所示
select row_number() over(order by field2 desc) as row_number,*from
t_table order by field1 desc
上面的SQL语句的查询结果如图3所示。
图3
我们可以使用row_number函数来实现查询表中指定范围的记录,一般将其应用到Web应用程序的分页功能上。下面的SQL语句可以查询t_table表中第2条和第3条记录:
with t_rowtable
as
(
select row_number() over(order by field1) as row_number,*from
t_table
)
select * from t_rowtable where row_number>1 and row_number<4 order by field1
上面的SQL语句的查询结果如图4所示。
图4
上面的SQL语句使用了CTE,关于CTE的介绍将读者参阅《SQL Server2005杂谈(1):使用公用表表达式(CTE)简化嵌套SQL》。
另外要注意的是,如果将row_number函数用于分页处理,over子句中的order by 与排序记录的order by 应相同,否则生成的序号可能不是有续的。
当然,不使用row_number函数也可以实现查询指定范围的记录,就是比较麻烦。一般的方法是使用颠倒Top来实现,例如,查询t_table表中第2条和第3条记录,可以先查出前3条记录,然后将查询出来的这三条记录按倒序排序,再取前2条记录,最后再将查出来的这2条记录再按倒序排序,就是最终结果。SQL语句如下:
select * from(select top2 * from(select top3 * from t_table order by field1)a
order by field1 desc) b order by field1
上面的SQL语句查询出来的结果如图5所示。
图5
这个查询结果除了没有序号列row_number,其他的与图4所示的查询结果完全一样。
二、rank
rank函数考虑到了over子句中排序字段值相同的情况,为了更容易说明问题,在
t_table表中再加一条记录,如图6所示。
图6
在图6所示的记录中后三条记录的field1字段值是相同的。如果使用rank函数来生成序号,这3条记录的序号是相同的,而第4条记录会根据当前的记录数生成序号,后面的记录依此类推,也就是说,在这个例子中,第4条记录的序号是4,而不是2。rank函数的使用方法与row_number函数完全相同,SQL语句如下:
select rank() over(order by field1),* from t_table order by field1上面的SQL语句的查询结果如图7所示。
图7
三、dense_rank
dense_rank函数的功能与rank函数类似,只是在生成序号时是连续的,而rank 函数生成的序号有可能不连续。如上面的例子中如果使用dense_rank函数,第4条记录的序号应该是2,而不是4。如下面的SQL语句所示:
select dense_rank() over(order by field1),* from t_table order by field1上面的SQL语句的查询结果如图8所示。
图8
读者可以比较图7和图8所示的查询结果有什么不同
四、ntile
ntile函数可以对序号进行分组处理。这就相当于将查询出来的记录集放到指定长度的数组中,每一个数组元素存放一定数量的记录。ntile函数为每条记录生成的序号就是这条记录所有的数组元素的索引(从1开始)。也可以将每一个分配记录的数组元素称为“桶”。ntile函数有一个参数,用来指定桶数。下面的SQL语句使用ntile函数对t_table表进行了装桶处理:
select ntile(4) over(order by field1)as bucket,* from t_table 上面的SQL语句的查询结果如图9所示。
图9
由于t_table表的记录总数是6,而上面的SQL语句中的ntile函数指定了桶数为4。
也许有的读者会问这么一个问题,SQL Server2005怎么来决定某一桶应该放多少记录呢?可能t_table表中的记录数有些少,那么我们假设t_table表中有59条记录,而桶数是5,那么每一桶应放多少记录呢?
实际上通过两个约定就可以产生一个算法来决定哪一个桶应放多少记录,这两个约定如下:
1.编号小的桶放的记录不能小于编号大的桶。也就是说,第1捅中的记录数只能大于等于第2桶及以后的各桶中的记录。
2.所有桶中的记录要么都相同,要么从某一个记录较少的桶开始后面所有捅的记录数都与该桶的记录数相同。也就是说,如果有个桶,前三桶的记录数都是10,而第4捅的记录数是6,那么第5桶和第6桶的记录数也必须是6。
根据上面的两个约定,可以得出如下的算法:
//mod表示取余,div表示取整
if(记录总数mod桶数==0)
{
recordCount=记录总数div桶数;
将每桶的记录数都设为recordCount
}
else
{
recordCount1=记录总数div桶数+1;
intn=1; // n表示桶中记录数为recordCount1的最大桶数
m=recordCount1*n;
while(((记录总数-m) mod (桶数- n)) !=0)
{
n++;
m=recordCount1*n;
}
recordCount2=(记录总数-m)div (桶数-n);
将前n个桶的记录数设为recordCount1
将n+1个至后面所有桶的记录数设为recordCount2
}
根据上面的算法,如果记录总数为59,桶数为5,则前4个桶的记录数都是12,最后一个桶的记录数是11。
如果记录总数为53,桶数为5,则前3个桶的记录数为11,后2个桶的记录数为10。
就拿本例来说,记录总数为6,桶数为4,则会算出recordCount1的值为2,在结束while循环后,会算出recordCount2的值是1,因此,前2个桶的记录是2,后2个桶的记录是1。
ROW_NUMBER、RANK、DENSE_RANK 和NTILE,这些新函数使您可以有效地分析数据以及向查询的结果行提供排序值。您可能发现这些新函数有用的典型方案包括:将连续整数分配给结果行,以便进行表示、分页、计分和绘制直方图。
Speaker Statistics 方案
下面的Speaker Statistics 方案将用来讨论和演示不同的函数和它们的子句。大型计算会议包括三个议题:数据库、开发和系统管理。十一位演讲者在会议中发表演讲,并且为他们的讲话获得范围为1 到9 的分数。结果被总结并存储在下面的SpeakerStats 表中:
CREATE TABLE SpeakerStats(
speaker VARCHAR(10) NOT NULL PRIMARY KEY
, track VARCHAR(10) NOT NULL
, score INT NOT NULL
, pctfilledevals INT NOT NULL
, numsessions INT NOT NULL)
SET NOCOUNT ON
INSERT INTO SpeakerStats VALUES('Dan', 'Sys', 3, 22, 4)
INSERT INTO SpeakerStats VALUES('Ron', 'Dev', 9, 30, 3)
INSERT INTO SpeakerStats VALUES('Kathy', 'Sys', 8, 27, 2)
INSERT INTO SpeakerStats VALUES('Suzanne', 'DB', 9, 30, 3)
INSERT INTO SpeakerStats VALUES('Joe', 'Dev', 6, 20, 2)
INSERT INTO SpeakerStats VALUES('Robert', 'Dev', 6, 28, 2)
INSERT INTO SpeakerStats VALUES('Mike', 'DB', 8, 20, 3)
INSERT INTO SpeakerStats VALUES('Michele', 'Sys', 8, 31, 4)
INSERT INTO SpeakerStats VALUES('Jessica', 'Dev', 9, 19, 1)
INSERT INTO SpeakerStats VALUES('Brian', 'Sys', 7, 22, 3)
INSERT INTO SpeakerStats VALUES('Kevin', 'DB', 7, 25, 4)
每个演讲者都在该表中具有一个行,其中含有该演讲者的名字、议题、平均得分、填写评价的与会者相对于参加会议的与会者数量的百分比以及该演讲者发表演讲的次数。本节演示如何使用新的排序函数分析演讲者统计数据以生成有用的信息。
ROW_NUMBER
ROW_NUMBER 函数使您可以向查询的结果行提供连续的整数值。例如,假设您要返回所有演讲者的speaker、track 和score,同时按照score 降序向结果行分配从1 开始的连续值。以下查询通过使用ROW_NUMBER 函数并指定OVER (ORDER BY score DESC) 生成所需的结果:
SELECT ROW_NUMBER() OVER(ORDER BY score DESC) AS rownum, speaker, track, scoreFROM SpeakerStatsORDER BY score DESC以下为结果集:
rownum speaker track score
------ ---------- ---------- -----------
1 Jessica Dev 9
2 Ron Dev 9
3 Suzanne DB 9
4 Kathy Sys 8
5 Michele Sys 8
6 Mike DB 8
7 Kevin DB 7
8 Brian Sys 7
9 Joe Dev 6
10 Robert Dev 6
11 Dan Sys 3
得分最高的演讲者获得行号1,得分最低的演讲者获得行号11。ROW_NUMBER 总是按照请求的排序为不同的行生成不同的行号。请注意,如果在OVER() 选项中指定的ORDER BY 列表不唯一,则结果是不确定的。这意味着该查询具有一个以上正确的结果;在该查询的不同调用中,可能获得不同的结果。例如,在我们的示例中,有三个不同的演讲者获得相同的最高得分(9):Jessica、Ron 和Suzanne。由于SQL Server 必须为不同的演讲者分配不同的行号,因此您应当假设分别分配给Jessica、Ron 和Suzanne 的值1、2 和3 是按任意顺序分配给这些演讲者的。如果值1、2 和 3 被分别分配给Ron、Suzanne 和Jessica,则结果应该同样正确。
如果您指定一个唯一的ORDER BY 列表,则结果总是确定的。例如,假设在演讲者之间出现得分相同的情况时,您希望使用最高的pctfilledevals 值来分出先后。如果值仍然相同,则使用最高的numsessions 值来分出先后。最后,如果值仍然相同,则使用最低词典顺序speaker 名字来分出先后。由于ORDER BY 列表— score、pctfilledevals、numsessions 和speaker —是唯一的,因此结果是确定的:
SELECT ROW_NUMBER() OVER(ORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker) AS rownum, speaker, track, score, pctfilledevals, numsessionsFROM SpeakerStatsORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker以下为结果集:
rownum speaker track score pctfilledevals numsessions
------ ---------- ---------- ----------- -------------- -----------
1 Ron Dev 9 30 3
2 Suzanne DB 9 30 3
3 Jessica Dev 9 19 1
4 Michele Sys 8 31 4
5 Kathy Sys 8 27 2
6 Mike DB 8 20 3
7 Kevin DB 7 25 4
8 Brian Sys 7 22 3
9 Robert Dev 6 28 2
10 Joe Dev 6 20 2
11 Dan Sys 3 22 4
新的排序函数的重要好处之一是它们的效率。SQL Server 的优化程序只需要扫描数据一次,以便计算值。它完成该工作的方法是:使用在排序列上放置的索引的有序扫描,或者,如果未创建适当的索引,则扫描数据一次并对其进行排序。
另一个好处是语法的简单性。为了让您感受一下通过使用在SQL Server 的较低版本中采用的基于集的方法来计算排序值是多么困难和低效,请考虑下面的SQL Server 2000 查询,它返回与上一个查询相同的结果:
SELECT (SELECT COUNT(*) FROM SpeakerStats AS S2
WHERE S2.score > S1.score
OR (S2.score = S1.score AND S2.pctfilledevals >
S1.pctfilledevals)
OR (S2.score = S1.score AND S2.pctfilledevals =
S1.pctfilledevals AND S2.numsessions > S1.numsessions)
OR (S2.score = S1.score AND S2.pctfilledevals =
S1.pctfilledevals AND S2.numsessions = S1.numsessions AND
S2.speaker < S1.speaker)
) + 1 AS rownum
, speaker, track, score, pctfilledevals, numsessions
FROM SpeakerStats AS S1
ORDER BY score DESC, pctfilledevals DESC, numsessions DESC, speaker
该查询显然比SQL Server 2005 查询复杂得多。此外,对于SpeakerStats 表中的每个基础行,SQL Server 都必须扫描该表的另一个实例中的所有匹配行。对于基础表中的每个行,平均大约需要扫描该表的一半(最少)行。SQL Server 2005 查询的性能恶化是线性的,而SQL Server 2000 查询的性能恶化是指数性的。即使是在相当小的表中,性能差异也是显著的。
行号的一个典型应用是通过查询结果分页。给定页大小(以行数为单位)和页号,需要返回属于给定页的行。例如,假设您希望按照“score DESC, speaker”顺序从SpeakerStats 表中返回第二页的行,并且假定页大小为三行。下面的查询首先按照指定的排序计算派生表D 中的行数,然后只筛选行号为4 到6 的行(它们属于第二页):
SELECT *
FROM (SELECT ROW_NUMBER() OVER(ORDER BY score DESC, speaker) AS
rownum,
speaker, track, score
FROM SpeakerStats) AS D
WHERE rownum BETWEEN 4 AND 6
ORDER BY score DESC, speaker
以下为结果集:
rownum speaker track score
------ ---------- ---------- -----------
4 Kathy Sys 8
5 Michele Sys 8
6 Mike DB 8
用更一般的术语表达就是,给定@pagenum 变量中的页号和@pagesize 变量中的页大小,以下查询返回属于预期页的行:
DECLARE @pagenum AS INT, @pagesize AS INT
SET @pagenum = 2
SET @pagesize = 3
SELECT * FROM (SELECT ROW_NUMBER() OVER(ORDER BY score DESC, speaker) AS rownum
,speaker
, track
, score
FROM SpeakerStats)
AS DWHERE rownum BETWEEN (@pagenum-1)*@pagesize+1 AND @pagenum*@pagesize
ORDER BY score DESC, speaker
上述方法对于您只对行的一个特定页感兴趣的特定请求而言已经足够了。但是,当用户发出多个请求时,该方法就不能满足需要了,因为该查询的每个调用都需要您对表进行完整扫描,以便计算行号。当用户可能反复请求不同的页时,为了更有效地进行分页,请首先用所有基础表行(包括计算得到的行号)填充一个临时表,并且对包含这些行号的列进行索引:
SELECT ROW_NUMBER() OVER(ORDER BY score DESC, speaker) AS rownum, * INTO #SpeakerStatsRN
FROM SpeakerStats
CREATE UNIQUE CLUSTERED INDEX idx_uc_rownum ON
#SpeakerStatsRN(rownum)
然后,对于所请求的每个页,发出以下查询:
SELECT rownum, speaker, track, score
FROM #SpeakerStatsRN
WHERE rownum BETWEEN (@pagenum-1)*@pagesize+1 AND
@pagenum*@pagesize
ORDER BY score DESC, speaker
只有属于预期页的行才会被扫描。
分段
可以在行组内部独立地计算排序值,而不是为作为一个组的所有表行计算排序值。为此,请使用PARTITION BY 子句,并且指定一个表达式列表,以标识应该为其独立计算排序值的行组。例如,以下查询按照“score DESC, speaker”顺序单独分配每个track 内部的行号:
SELECT track,
ROW_NUMBER() OVER(
PARTITION BY track
ORDER BY score DESC, speaker) AS pos,
speaker, score
FROM SpeakerStats
ORDER BY track, score DESC, speaker
以下为结果集:
track pos speaker score
---------- --- ---------- -----------
DB 1 Suzanne 9
DB 2 Mike 8
DB 3 Kevin 7
Dev 1 Jessica 9
Dev 2 Ron 9
Dev 3 Joe 6
Dev 4 Robert 6
Sys 1 Kathy 8
Sys 2 Michele 8
Sys 3 Brian 7
Sys 4 Dan 3
在PARTITION BY 子句中指定track 列会使得为具有相同track 的每个行组单独计算行号。
RANK, DENSE_RANK
RANK 和DENSE_RANK 函数非常类似于ROW_NUMBER 函数,因为它们也按照指定的排序提供排序值,而且可以根据需要在行组(分段)内部提供。但是,与ROW_NUMBER 不同的是,RANK 和DENSE_RANK 向在排序列中具有相同值的行分配相同的排序。当ORDER BY 列表不唯一,并且您不希望为在ORDER BY 列表中具有相同值的行分配不同的排序时,RANK 和DENSE_RANK 很有用。RANK 和DENSE_RANK 的用途以及两者之间的差异可以用示例进行最好的解释。以下查询按照score DESC 顺序计算不同演讲者的行号、排序和紧密排序值:
SELECT speaker, track, score,
ROW_NUMBER() OVER(ORDER BY score DESC) AS rownum,
RANK() OVER(ORDER BY score DESC) AS rnk,
DENSE_RANK() OVER(ORDER BY score DESC) AS drnk
FROM SpeakerStats
ORDER BY score DESC
以下为结果集:
speaker track score rownum rnk drnk
---------- ---------- ----------- ------ --- ----
Jessica Dev 9 1 1 1
Ron Dev 9 2 1 1
Suzanne DB 9 3 1 1
Kathy Sys 8 4 4 2
Michele Sys 8 5 4 2
Mike DB 8 6 4 2
Kevin DB 7 7 7 3
Brian Sys 7 8 7 3
Joe Dev 6 9 9 4
Robert Dev 6 10 9 4
Dan Sys 3 11 11 5
正如前面讨论的那样,score 列不唯一,因此不同的演讲者可能具有相同的得分。行号确实代表下降的score 顺序,但是具有相同得分的演讲者仍然获得不同的行号。但是请注意,在结果中,所有具有相同得分的演讲者都获得相同的排序和紧密排序值。换句话说,当ORDER BY 列表不唯一时,ROW_NUMBER 是不确定的,而RANK 和DENSE_RANK
sql查询月记录,一周记录,当天记录时间:2011-08-09 03:48来源:未知作者:admin 点击: 157 次SELECT * FROM 表WHERE CONVERT(Nvarchar, dateandtime, 111) = CONVERT(Nvarchar, GETDATE(), 111) ORDER BY dateandtime DESC 本月记录SELECT * FROM 表WHERE datediff(month,[dateadd],getdate())=0 本周记录SELECT * FROM 表WHERE datediff(week,[d SELECT * FROM 表WHERE CONVERT(Nvarchar, dateandtime, 111) = CONVERT(Nvarchar, GETDATE(), 111) ORDER BY dateandtime DESC 本月记录 SELECT * FROM 表WHERE datediff(month,[dateadd],getdate())=0 本周记录 SELECT * FROM 表WHERE datediff(week,[dateadd],getdate())=0 当天记录 SELECT * FROM 表WHERE datediff(day,[dateadd],getdate())=0 sql server中的时间函数 1. 当前系统日期、时间 select getdate() 2. dateadd 在向指定日期加上一段时间的基础上,返回新的datetime 值 例如:向日期加上2天 select dateadd(day,2,'2004-10-15') --返回:2004-10-17 00:00:00.000 3. datediff 返回跨两个指定日期的日期和时间边界数。 select datediff(day,'2004-09-01','2004-09-18') --返回:17 4. datepart 返回代表指定日期的指定日期部分的整数。 SELECT DATEPART(month, '2004-10-15') --返回10 5. datename 返回代表指定日期的指定日期部分的字符串 SELECT datename(weekday, '2004-10-15') --返回:星期五 6. day(), month(),year() --可以与datepart对照一下 select 当前日期=convert(varchar(10),getdate(),120) ,当前时间=convert(varchar(8),getdate(),114)
sql 函数大全比较常用的一些函数整理 select语句中只能使用sql函数对字段进行操作(链接sql server), select 字段1 from 表1 where 字段1.IndexOf("云")=1; 这条语句不对的原因是indexof()函数不是sql函数,改成sql对应的函数就可以了。left()是sql函数。 select 字段1 from 表1 where charindex('云',字段1)=1; 字符串函数对二进制数据、字符串和表达式执行不同的运算。此类函数作用于CHAR、VARCHAR、 BINARY、和VARBINARY 数据类型以及可以隐式转换为CHAR 或VARCHAR的数据类型。可以在SELECT 语句的SELECT 和WHERE 子句以及表达式中使用字符串函数。 常用的字符串函数有: 一、字符转换函数 1、ASCII() 返回字符表达式最左端字符的ASCII 码值。在ASCII()函数中,纯数字的字符串可不用‘'括起来,但含其它字符的字符串必须用‘'括起来使用,否则会出错。 2、CHAR() 将ASCII 码转换为字符。如果没有输入0 ~ 255 之间的ASCII 码值,CHAR()返回NULL 。 3、LOWER()和UPPER() LOWER()将字符串全部转为小写;UPPER()将字符串全部转为大写。 4、STR() 把数值型数据转换为字符型数据。 STR (
SQL Server2008函数大全(完整版) SQL2008表达式:是常量、变量、列或函数等与运算符的任意组合。 一、字符串函数 函数名称参数示例说明 ascii(字符串表达式) select ascii('abc')返回97 说明:返回字符串中最左侧的字符的ASCII码。 char(整数表达式) select char(100)返回d 说明:把ASCII码转换为字符。 介于0和255之间的整数。如果该整数表达式不在此范围内,将返回 NULL值。 charindex(字符串表达式1,字符串表达式2[,整数表达式])instr select charindex('ab','BCabTabD')返回3 select charindex('ab','BCabTabD',4)返回6 说明:在字符串2中查找字符串1,如果存在返回第一个匹配的位置,如果不存在返回0。如果字符串1和字符串2中有一个是null则返回null。可以指定在字符串2中查找的起始位置。 patindex(字符串表达式1,字符串表达式2) select patindex('%ab%','123ab456')返回4 select patindex('ab%','123ab456')返回0 select patindex('___ab%','123ab456')返回1 select patindex('___ab_','123ab456')返回0 说明:在字符串表达式1中可以使用通配符,此字符串的第一个字符和最后一个字符通常是%。%表示任意多个字符,_表示任意字符返回字符串表达式2中字符串表达式1所指定模式第一次出现的起始位置。没有找到返回0。 difference(字符串表达式1,字符串表达式2) select difference('Green','Greene')返回4 返回一个0到4的整数值,指示两个字符表达式的之间的相似程度。 0表示几乎不同或完全不同, 4表示几乎相同或完全相同。 说明:注意相似并不代表相等 left(字符串表达式,整数表达式) select left('abcdefg',2)返回ab 说明:返回字符串中从左边开始指定个数的字符。
create table test (id int, value varchar(10)) insertinto test values('1','aa') insertinto test values('1','bb') insertinto test values('2','aaa') insertinto test values('2','bbb') insertinto test values('2','ccc') insertinto test values('3','aa') insertinto test values('4','bb') select*from test select id, [values] =stuff((select','+ [values] from test t where id = test.id forxmlpath('')), 1 , 1 ,'') from test groupby id stuff(param1,startIndex,length, param2) 说明:将param1中自startIndex(SQL中都是从1开始,而非0)起,删除length个字符,然后用param2替换删掉的字符。*/
COUNT()函数用于返回一个列内所有非空值的个数,这是一个整型值。 由于COUNT(*)函数会忽略NULL值,所以这个查询的结果是2。 三、SUM()函数 SUM()函数是最常用的聚合函数之一,它的功能很容易理解:和AVG()函数一样,它用于数值数据类型,返回一个列范围内所有非空值的总和。 四、CAST()函数 CAST()函数的参数是一个表达式,它包括用AS关键字分隔的源值和目标数据类型。 以下例子用于将文本字符串'123'转换为整型: SELECT CAST('123' AS int) 返回值是整型值123。 如果试图将一个代表小数的字符串转换为整型值,又会出现什么情况呢? SELECT CAST('123.4' AS int) CAST()函数和CONVERT()函数都不能执行四舍五入或截断操作。由于123.4不能用int数据类型来表示,所以对这个函数调用将产生一个错误。 Server: Msg 245, Level 16, State 1, Line 1 Syntax error converting the varchar value '123.4' to a column of data type int. 在将varchar值'123.4' 转换成数据类型int时失败。 要返回一个合法的数值,就必须使用能处理这个值的数据类型。对于这个例子,存在多个可用的数据类型。如果通过CAST()函数将这个值转换为decimal类型,需要首先定义decimal 值的精度与小数位数。在本例中,精度与小数位数分别为9与2。精度是总的数字位数,包括小数点左边和右边位数的总和。而小数位数是小数点右边的位数。这表示本例能够支持的最大的整数值是9999999,而最小的小数是0.01。 SELECT CAST('123.4' AS decimal(9,2)) decimal数据类型在结果网格中将显示有效小数位:123.40 精度和小数位数的默认值分别是18与0。如果在decimal类型中不提供这两个值,SQL Server 将截断数字的小数部分,而不会产生错误。 SELECT CAST('123.4' AS decimal) 结果是一个整数值:123 五、CONVERT()函数 对于简单类型转换,CONVERT()函数和CAST()函数的功能相同,只是语法不同。 CAST()函数一般更容易使用,其功能也更简单。 CONVERT()函数的优点是可以格式化日期和数值,它需要两个参数:第1个是目标数据类型,第2个是源数据。 CONVERT()函数还具有一些改进的功能,它可以返回经过格式化的字符串值,且可以把日期值格式化成很多形式。有28种预定义的符合各种国际和特殊要求的日期与时间输出格式。 六、STR()函数 这是一个将数字转换为字符串的快捷函数。这个函数有3个参数:数值、总长度和小数位数。如果数字的整数位数和小数位数(要加上小数点占用的一个字符)的总和小于总长度,对结果中左边的字符将用空格填充。在下面第1个例子中,包括小数点在内一共是5个字符。结果
SQL Server 日期和时间函数 1、常用日期方法(下面的GetDate() = '2006-11-08 13:37:56.233') (1)DATENAME ( datepart ,date ) 返回表示指定日期的指定日期部分的字符串。Datepart详见下面的列表. SELECT DateName(day,Getdate()) –返回8 (2)DATEPART ( datepart , date ) 返回表示指定日期的指定日期部分的整数。 SELECT DATEPART(year,Getdate()) –返回2006 (3)DATEADD (datepart , number, date ) 返回给指定日期加上一个时间间隔后的新datetime 值。 SELECT DATEADD(week,1,GetDate()) --当前日期加一周后的日期 (4)DATEDIFF ( datepart , startdate , enddate ) 返回跨两个指定日期的日期边界数和时间边界数。 SELECT DATEDIFF(month,'2006-10-11','2006-11-01') --返回1 (5)DAY ( date ) 返回一个整数,表示指定日期的天datepart 部分。 SELECT day(GetDate()) –返回8 (6)GETDATE() 以datetime 值的SQL Server 2005 标准内部格式返回当前系统日期和时间。SELECT GetDate() --返回2006-11-08 13:37:56.233 (7)MONTH ( date ) 返回表示指定日期的―月‖部分的整数。 SELECT MONTH(GETDATE()) --返回11 (8)YEAR ( date ) 返回表示指定日期的―年‖部分的整数。 SELECT YEAR(GETDATE()) --返回2006 2、取特定日期 (1)获得当前日期是星期几 SELECT DateName(weekday,Getdate()) --Wednesday
一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份sql server --- 创建备份数据的 device USE master EXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1. dat' --- 开始备份 BACKUP DATABASE pubs TO testBack 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键:Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围 查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料! 排序:select * from table1 order by field1,field2 [desc] 总数:select count as totalcount from table1
DB2函数大全 函数名函数解释函数举例 AVG() 返回一组数值的平均值. SELECTAVG(SALARY)FROMBSEMPMS; CORR(),CORRELATION() 返回一对数值的关系系数. SELECT CORRELATION(SALARY,BONUS)FROM BSEMPMS; COUNT() 返回一组行或值的个 数.SELECTCOUNT(*)FROMBSEMPMS; COVAR(),COVARIANCE() 返回一对数值的协方差. SELECTCOVAR(SALARY,BONUS)FROMBSEMPMS; MAX() 返回一组数值中的最大值. SELECTMAX(SALARY)FROMBSEMPMS; MIN() 返回一组数值中的最小值. SELECTMIN(SALARY)FROMBSEMPMS; STDDEV() 返回一组数值的标准偏差. SELECTSTDDEV(SALARY)FROMBSEMPMS; SUM() 返回一组数据的和. SELECTSUM(SALARY)FROMBSEMPMS; VAR(),VARIANCE() 返回一组数值的方差. SELECTVARIANCE(SALARY)FROMBSEMPMS; ABS(),ABSVAL() 返回参数的绝对值. SELECTABS(-3.4)FROMBSEMPMS; ACOS() 返回参数的反余弦值. SELECTACOS(0.9)FROMBSEMPMS; ASCII() 返回整数参数最左边的字符的ASCII码. SELECTASCII('R')FROMBSEMPMS; ASIN() 返回用弧度表示的角度的参数的反正弦函数. SELECTASIN(0.9)FROMBSEMPMS; ATAN() 返回参数的反正切值,该参数用弧度表示的角度的参数. SELECTATAN(0.9)FROMBSEMPMS; ATAN2() 返回用弧度表示的角度的X和Y坐标的反正切值. SELECTATAN2(0.5,0.9)FROMBSEMPMS;
sql server 系统函数大全 一、字符转换函数 1、ASCII() 返回字符表达式最左端字符的ASCII 码值。在ASCII()函数中,纯数字的字符串可不用‘’括起来,但含其它字符的字符串必须用‘’括起来使用,否则会出错。 2、CHAR() 将ASCII 码转换为字符。如果没有输入0 ~ 255之间的ASCII 码值,CHAR()返回NULL 。 3、LOWER()和UPPER() LOWER()将字符串全部转为小写;UPPER()将字符串全部转为大写。 4、STR() 把数值型数据转换为字符型数据。 STR (
RIGHT (
在SQL Server在线图书或者在线帮助系统中,函数的可选参数用方括号表示。在下列的CONVERT()函数例子中,数据类型的length和style参数是可选的: CONVERT (data-type [(length)], expression[,style]) 可将它简化为如下形式,因为现在不讨论如何使用数据类型: CONVERT(date_type, expression[,style]) 根据上面的定义,CONVERT()函数可接受2个或3个参数。因此,下列两个例子都是正确的: SELECT CONVERT(Varchar(20),GETDATE()) SELECT CONVERT(Varchar(20),GETDATE(), 101) 这个函数的第一个参数是数据类型Varchar(20),第2个参数是另一个函数GETDATE()。GETDATE()函数用datetime数据类型将返回当前的系统日期和时间。第2条语句中的第3个参数决定了日期的样式。这个例子中的101指以mm/dd/yyyy格式返回日期。本章后面将详细介绍GETDATE()函数。即使函数不带参数或者不需要参数,调用这个函数时也需要写上一对括号,例如GETDATE()函数。注意在书中使用函数名引用函数时,一定要包含括号,因为这是一种标准形式。 确定性函数 由于数据库引擎的内部工作机制,SQL Server必须根据所谓的确定性,将函数分成两个不同的组。这不是一种新时代的信仰,只和能否根据其输入参数或执行对函数输出结果进行预测有关。如果函数的输出只与输入参数的值相关,而与其他外部因素无关,这个函数就是确定性函数。如果函数的输出基于环境条件,或者产生随机或者依赖结果的算法,这个函数就是非确定性的。例如,GETDATE()函数是非确定性函数,因为它不会两次返回相同的值。为什么要把看起来简单的事弄得如此复杂呢?主要原因是非确定性函数与全局变量不能在一些数据库编程对象中使用(如用户自定义函数)。部分原因是SQL Server缓存与预编译可执行对象的方式。例如,即席查询可以使用任何函数,不过如果打算构建先进的、可重用的编程对象,理解这种区别很重要。 以下这些函数是确定性的: ●?AVG()(所有的聚合函数都是确定性的) ●?CAST() ●?CONVERT() ●?DATEADD() ●?DATEDIFF() ●?ASCII() ●?CHAR() ●?SUBSTRING() 以下这些函数与变量是非确定性的: ●?GETDATE()
在Oracle中 可以使用instr函数对某个字符串进行判断,判断其是否含有指定的字符。 其语法为: instr(sourceString,destString,start,appearPosition). instr('源字符串' , '目标字符串' ,'开始位置','第几次出现') 其中sourceString代表源字符串; destString代表想聪源字符串中查找的子串; start代表查找的开始位置,该参数可选的,默认为1; appearPosition代表想从源字符中查找出第几次出现的destString,该参数也是可选的,默认为1; 如果start的值为负数,那么代表从右往左进行查找,但是位置数据仍然从左向右计算。 返回值为:查找到的字符串的位置。 对于instr函数,我们经常这样使用:从一个字符串中查找指定子串的位置。例如:SQL> select instr('yuechaotianyuechao','ao') position from dual; POSITION ---------- 6 从第7个字符开始搜索 SQL> select instr('yuechaotianyuechao','ao', 7) position from dual; POSITION ---------- 17 从第1个字符开始,搜索第2次出现子串的位置 SQL> select instr('yuechaotianyuechao','ao', 1, 2) position from dual; POSITION ---------- 17 注意:1。若‘起始位置’=0 时返回结果为0, 2。这里只有三个参数,意思是查找第一个要查找字符的位置(因为‘第几次出现’默认为1), 当‘起始位置’不大于要查找的第一个字符的位置时,返回的值都将是第一个字符的位置,如果‘起始位置’大于要查找的第一个字符的位置时,返回的值都将是第2个字符的位置,依此类推……(但是也是以第一个字符开始计数)
Sql Server中的日期与时间函数 1.GetDate( ) 返回系统目前的日期与时间'瞫濾#縶? 当前系统日期、时间select getdate() 2.DateAdd (interval,number,date) 以interval指定的方式,加上number之后的日期" 鐺e蠅5流 dateadd 在向指定日期加上一段时间的基础上,返回新的datetime 值,例如:向日期加上2天 select dateadd(day,2,'2004-10-15') --返回:2004-10-17 00:00:00.000?礛娞>?? 3. datediff 返回跨两个指定日期的日期和时间边界数。 select datediff(day,'2004-09-01','2004-09-18') --返回:17? 4.DatePart (interval,date) 返回日期date中,interval指定部分所对应的整数值。 SELECT DATEPART(month, '2004-10-15') --返回10 5.datename 返回代表指定日期的指定日期部分的字符串 SELECT datename(weekday, '2004-10-15') --返回:星期五S 6.day(), month(),year() --可以与datepart对照一下 select 当前日期=convert(varchar(10),getdate(),120) ,当前时间=convert(varchar(8),getdate(),114) select datename(dw,'2004-10-15') select 本年第多少周=datename(week,'2004-10-15') 今天是周几=datename(weekday,'2004-10-15') 7.DateDiff (interval,date1,date2) 以interval 指定的方式,返回date2 与date1两个日期之间的差值date2-date1 8.DateName (interval,date) 返回日期date中,interval指定部分所对应的字符串名称 参数interval的设定值如下: Year Yy yyyy 年1753 ~ 9999 Quarter Qq q 季 1 ~ 4 Month Mm m 月 1 ~ 12 Day of year Dy y 一年中的第几日1-366 Day Dd d 日1-31 Weekday Dw w 一周中的第几日1-7 Week Wk ww 一年中的第几周0 ~ 51 Hour Hh h 时0 ~ 23 Minute Mi n 分钟0 ~ 59 Second Ss s 秒0 ~ 59 Millisecond Ms - 毫秒0 ~ 999 举例:/0R符?氦? DateDiff('s','2005-07-20','2005-7-25 22:56:32')返回值为514592 秒 DateDiff('d','2005-07-20','2005-7-25 22:56:32')返回值为5 天 DatePart('w','2005-7-25 22:56:32')返回值为2 即星期一(周日为1,周六为7) DatePart('d','2005-7-25 22:56:32')返回值为25即25号 DatePart('y','2005-7-25 22:56:32')返回值为206即这一年中第206天 DatePart('yyyy','2005-7-25 22:56:32')返回值为2005即2005年
PLSQL常用函数 1)处理字符的函数 || CONCAT ---并置运算符。 格式∶CONCAT(STRING1, STRING2) 例:’ABC’|| ’DE’=’ABCDE’ CONCAT(‘ABC’,’DE’) =’ABCDE’ INSTR---搜索子串位置 格式∶INSTR(STRING , SET[ , 开始位置[ , 出现次数]]) 例∶ INSTR (‘this is a test’ , ‘i’ , 1,2)=6 LENGTH----计算串长 格式∶ LENGTH(string) LTRIM,RTRIM,TRIM -----左截断,右截断,左右截断。默认为删除空格。 格式∶ LTRIM(STRING[,‘SET’]) 例∶ LTRIM(‘***tes*t***’,’*’)=’tes*t***’ LOWER----将字符串转换为小写 格式∶LOWER(string) UPPER---将字符串转换为大写 格式∶UPPER(string) SUBSTR----提取子串。START为正数时从左开始、为负数时从右开始 格式∶ SUBSTR(STRING , START [ , COUNT]) 例∶ SUBSTR(‘WORDSTAR’ , 2 , 3)=’ ORD’ REPLACE---搜索指定字符串并替换 格式∶REPLACE(string , substring , replace_string) 例∶ REPLACE(‘this is a test’ , ‘this’ , ‘that an’)=’that an is a test’
2)处理数字的函数 ROUND---返回固定小数位数。 格式∶ROUND (value)value为数字 例∶ROUND (66.123,2)= 66.12 CELL---返回大于等于特定值的最小整数 格式∶CELL(value) 例∶ CELL(-10,9)= -10 3)处理日期 SYSDATE---系统时间。精确至秒 例:TO_CHAR(SYSDATE,'YYYY-MM-DD') 2011-05-11(返回日期) TO_CHAR(SYSDATE,'YYYY-MM-DD HH:MI:SS') 2011-05-11 11:05:15(返回日期+时间) 常用日期数据格式 Y或YY或YYY 年的最后一位,两位或三位Select to_char(sysdate,’YYY’) from dual; SYEAR或YEAR SYEAR使公元前的年份前加一负号Select to_char(sysdate,’SYEAR’) from dua l;-1112表示公元前111 2年 Q 季度,1~3月为第一季度Select to_char(sysdate,’Q’) from dual;2表示第二季度① MM 月份数Select to_char(sysdate,’MM’) from dual;12表示12月 RM 月份的罗马表示Select to_char(sysdate,’RM’) from dual;IV表示4月 Month 用9个字符长度表示的月份名Select to_char(sysdate,’Month’) from dual;May后跟6个空格表示5月 WW 当年第几周Select to_char(sysdate,’WW’) from dual;24表示2002年6月13日为第24周W 本月第几周Select to_char(sysdate,’W’) from dual;2002年10月1日为第1周 DDD 当年第几, 1月1日为001,2月1日为032 Select to_char(sysdate,’DDD’) from dual;36 3 2002年1 2月2 9日为第363天 DD 当月第几天Select to_char(sysdate,’DD’) from dual;04 10月4日为第4天 D 周内第几天Select to_char(sysdate,’D’) from dual;5 2002年3月14日为星期一 DY 周内第几天缩写Select to_char(sysdate,’DY’) from dual;SUN 2002年3月24日为星期天
通常,你需要获得当前日期和计算一些其他的日期,例如,你的程序可能需要判断一个月的第一天或者最后一天。你们大部分人大概都知道怎样把日期进行分割(年、月、日等),然后仅仅用分割出来的年、月、日等放在几个函数中计算出自己所需要的日期!在这篇文章里,我将告诉你如何使用DATEADD和DATEDIFF函数来计算出在你的程序中可能你要用到的一些不同日期。 在使用本文中的例子之前,你必须注意以下的问题。大部分可能不是所有例子在不同的机器上执行的结果可能不一样,这完全由哪一天是一个星期的第一天这个设置决定。第一天(DATEFIRST)设定决定了你的系统使用哪一天作为一周的第一天。所有以下的例子都是以星期天作为一周的第一天来建立,也就是第一天设置为7。假如你的第一天设置不一样,你可能需要调整这些例子,使它和不同的第一天设置相符合。你可以通过@@DATEFIRST函数来检查第一天设置。 为了理解这些例子,我们先复习一下DATEDIFF和DATEADD函数。DATEDIFF函数计算两个日期之间的小时、天、周、月、年等时间间隔总数。DATEADD函数计算一个日期通过给时间间隔加减来获得一个新的日期。要了解更多的DATEDIFF和DATEADD函数以及时间间隔可以阅读微软联机帮助。 使用DATEDIFF和DATEADD函数来计算日期,和本来从当前日期转换到你需要的日期的考虑方法有点不同。你必须从时间间隔这个方面来考虑。比如,从当前日期到你要得到的日期之间有多少时间间隔,或者,从今天到某一天(比如1900-1-1)之间有多少时间间隔,等等。理解怎样着眼于时间间隔有助于你轻松的理解我的不同的日期计算例子。 一个月的第一天 第一个例子,我将告诉你如何从当前日期去这个月的最后一天。请注意:这个例子以及这篇文章中的其他例子都将只使用DATEDIFF和DATEADD函数来计算我们想要的日期。每一个例子都将通过计算但前的时间间隔,然后进行加减来得到想要计算的日期。 这是计算一个月第一天的SQL 脚本: SELECT DATEADD(mm, DATEDIFF(mm,0,getdate()), 0) 我们把这个语句分开来看看它是如何工作的。最核心的函数是getdate(),大部分人都知道这个是返回当前的日期和时间的函数。下一个执行的函数DATEDIFF(mm,0,getdate())是计算当前日期和“1900-01-01 00:00:00.000”这个日期之间的月数。记住:时期和时间变量和毫秒一样是从“1900-01-01 00:00:00.000”开始计算的。这就是为什么你可以在DATEDIFF函数中指定第一个时间表达式为“0”。下一个函数是DATEADD,增加当前日期到“1900-01-01”的月数。通过增加预定义的日期“1900-01-01”和当前日期的月数,我们可以获得这个月的第一天。另外,计算出来的日期的时间部分将会是“00:00:00.000”。 这个计算的技巧是先计算当前日期到“1900-01-01”的时间间隔数,然后把它加到“1900-01-01”上来获得特殊的日期,这个技巧可以用来计算很多不同的日期。下一个例子也是用这个技巧从当前日期来产生不同的日期。 本周的星期一 这里我是用周(wk)的时间间隔来计算哪一天是本周的星期一。 SELECT DATEADD(wk, DATEDIFF(wk,0,getdate()), 0)
sql server日期比较日期查询常用语句 关键字: sql sql server日期比较日期查询常用语句 通常,你需要获得当前日期和计算一些其他的日期,例如,你的程序可能需要判断一个月的第一天或者最后一天。你们大部分人大概都知道怎样把日期进行分割(年、月、日等),然后仅仅用分割出来的年、月、日等放在几个函数中计算出自己所需要的日期!在这篇文章里,我将告诉你如何使用DATEADD和DATEDIFF函数来计算出在你的程序中可能你要用到的一些不同日期。 在使用本文中的例子之前,你必须注意以下的问题。大部分可能不是所有例子在不同的机器上执行的结果可能不一样,这完全由哪一天是一个星期的第一天这个设置决定。第一天(DATEFIRST)设定决定了你的系统使用哪一天作为一周的第一天。所有以下的例子都是以星期天作为一周的第一天来建立,也就是第一天设置为7。假如你的第一天设置不一样,你可能需要调整这些例子,使它和不同的第一天设置相符合。你可以通过@@DATEFIRST函数来检查第一天设置。 为了理解这些例子,我们先复习一下DATEDIFF和DATEADD函数。DATEDIFF函数计算两个日期之间的小时、天、周、月、年等时间间隔总数。DATEADD函数计算一个日期通过给时间间隔加减来获得一个新的日期。要了解更多的DATEDIFF和DATEADD函数以及时间间隔可以阅读微软联机帮助。 使用DATEDIFF和DATEADD函数来计算日期,和本来从当前日期转换到你需要的日期的考虑方法有点不同。你必须从时间间隔这个方面来考虑。比如,从当前日期到你要得到的日期之间有多少时间间隔,或者,从今天到某一天(比如1900-1-1)之间有多少时间间隔,等等。理解怎样着眼于时间间隔有助于你轻松的理解我的不同的日期计算例子。 一个月的第一天 第一个例子,我将告诉你如何从当前日期去这个月的最后一天。请注意:这个例子以及这篇文章中的其他例子都将只使用DATEDIFF和DATEADD函数来计算我们想要的日期。每一个例子都将通过计算但前的时间间隔,然后进行加减来得到想要计算的日期。 这是计算一个月第一天的SQL 脚本: SELECT DATEADD(mm, DATEDIFF(mm,0,getdate()), 0) 我们把这个语句分开来看看它是如何工作的。最核心的函数是getdate(),大部分人都知道这个是返回当前的日期和时间的函数。下一个执行的函数DATEDIFF(mm,0,getdate())是计算当前日期和"1900-01-01 00:00:00.000"这个日期之间的月数。记住:时期和时间变量和毫秒一样是从"1900-01-01 00:00:00.000"开始计算的。这就是为什么你可以在DATEDIFF 函数中指定第一个时间表达式为"0"。下一个函数是DATEADD,增加当前日期到"1900-01-01"的月数。通过增加预定义的日期"1900-01-01"和当前日期的月数,我们可以获得这个月的第一天。另外,计算出来的日期的时间部分将会是"00:00:00.000"。 这个计算的技巧是先计算当前日期到"1900-01-01"的时间间隔数,然后把它加到"1900-01-01"上来获得特殊的日期,这个技巧可以用来计算很多不同的日期。下一个例子也
数据库常用函数
一、基础 1、说明:创建数据库 CREATE DATABASE database-name 2、说明:删除数据库 drop database dbname 3、说明:备份和还原 备份:exp dsscount/sa@dsscount owner=dsscount file=C:\dsscount_data_backup\dsscount.dmp log=C:\dsscount_data_backup\outputa.log 还原:imp dsscount/sa@dsscount file=C:\dsscount_data_backup\dsscount.dmp full=y ignore=y log=C:\dsscount_data_backup\dsscount.log statistics=none 4、说明:创建新表 create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..) CREATE TABLE ceshi(id INT not null identity(1,1) PRIMARY KEY,NAME VARCHAR(50),age INT) id为主键,不为空,自增长 根据已有的表创建新表: A:create table tab_new like tab_old (使用旧表创建新表) B:create table tab_new as select col1,col2… from tab_old definition only 5、说明:删除新表 drop table tabname 6、说明:增加一个列 Alter table tabname add column col type 注:列增加后将不能删除。DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。 7、说明:添加主键: Alter table tabname add primary key(col) 说明:删除主键: Alter table tabname drop primary key(col) 8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname 注:索引是不可更改的,想更改必须删除重新建。 9、说明:创建视图:create view viewname as select statement 删除视图:drop view viewname 10、说明:几个简单的基本的sql语句 选择:select * from table1 where 范围 插入:insert into table1(field1,field2) values(value1,value2) 删除:delete from table1 where 范围 更新:update table1 set field1=value1 where 范围