
PnP:Parallel And External Memory Iceberg Cube Computation
Ying Chen Dalhousie University Halifax,Canada ychen@cs.dal.ca
Frank Dehne
Grif?th University
Brisbane,Australia
https://www.doczj.com/doc/b214714465.html,
Todd Eavis
Concordia University
Montreal,Canada
eavis@cs.concordia.ca
Andrew Rau-Chaplin
Dalhousie University
Halifax,Canada
www.cs.dal.ca/~arc
Motivated by the work of Ng et.al.[2]and the recent success of another hybrid sequential method,Star-Cubing [4],we further investigate the use of hybrid approaches for the parallel computation of very large iceberg-cube queries. We present“Pipe’n Prune”(PnP),a new hybrid method for iceberg-cube query computation.The novelty of our method is that it achieves a tight integration of top-down piping for data aggregation with bottom-up Apriori data pruning.A particular strength of PnP is that it is very ef-?cient for all of the following scenarios:(1)Sequential iceberg-cube queries.(2)External memory iceberg-cube queries.(3)Parallel iceberg-cube queries on shared-nothing PC clusters with multiple disks.
PnP is a hybrid,sort-based,algorithm for the computa-tion of very large iceberg-cube queries.The idea behind PnP is to fully integrate data aggregation via top-down pip-ing[3]with bottom-up(BUC[1])Apriori pruning.We introduce a new operator,called the PnP operator.For a group-by v,the PnP operator performs two steps:(1)It builds all group-bys v that are a pre?x of v through one sin-gle sort/scan operation(piping[3])with iceberg-cube prun-ing.(2)It uses these pre?x group-bys to perform bottom-up(BUC[1])Apriori pruning for new group-bys that are starting points of other piping operations.An example of a5-dimensional PnP operator is shown in Figure1a.The PnP operator is applied recursively until all group-bys of the iceberg-cube have been generated.An example of a 5-dimensional PnP Tree depicting the entire process for a 5-dimensional iceberg-cube query is shown in Figure1b.
We performed an extensive performance analysis of PnP for all of the above mentioned scenarios with the following main results:In the?rst scenario,PnP performs very well for both,dense and sparse data sets,providing an interesting alternative to BUC and Star-Cubing.In the second scenario, PnP shows a surprisingly ef?cient handling of disk I/O,with an external memory running time that is less than twice the running time for full in-memory computation of the same iceberg-cube query.In the third scenario,PnP scales very well.In[2],Ng et.al.observe for their parallel iceberg-cube method that“the speedup from8processors to16pro-
Figure1.(a)A PnP Operator.(b)A PnP Tree.(Plain
arrow:Top-Down Piping.Dashed Arrow:Bottom-up Prun-
ing.Bold Arrow:Sorting.)
cessors is below expectation”and attribute this scalability problem to scheduling and load balancing issues.Our anal-ysis shows that PnP solves these problems and scales well for at least up to16processors.In more detail,our analysis of PnP showed the following.
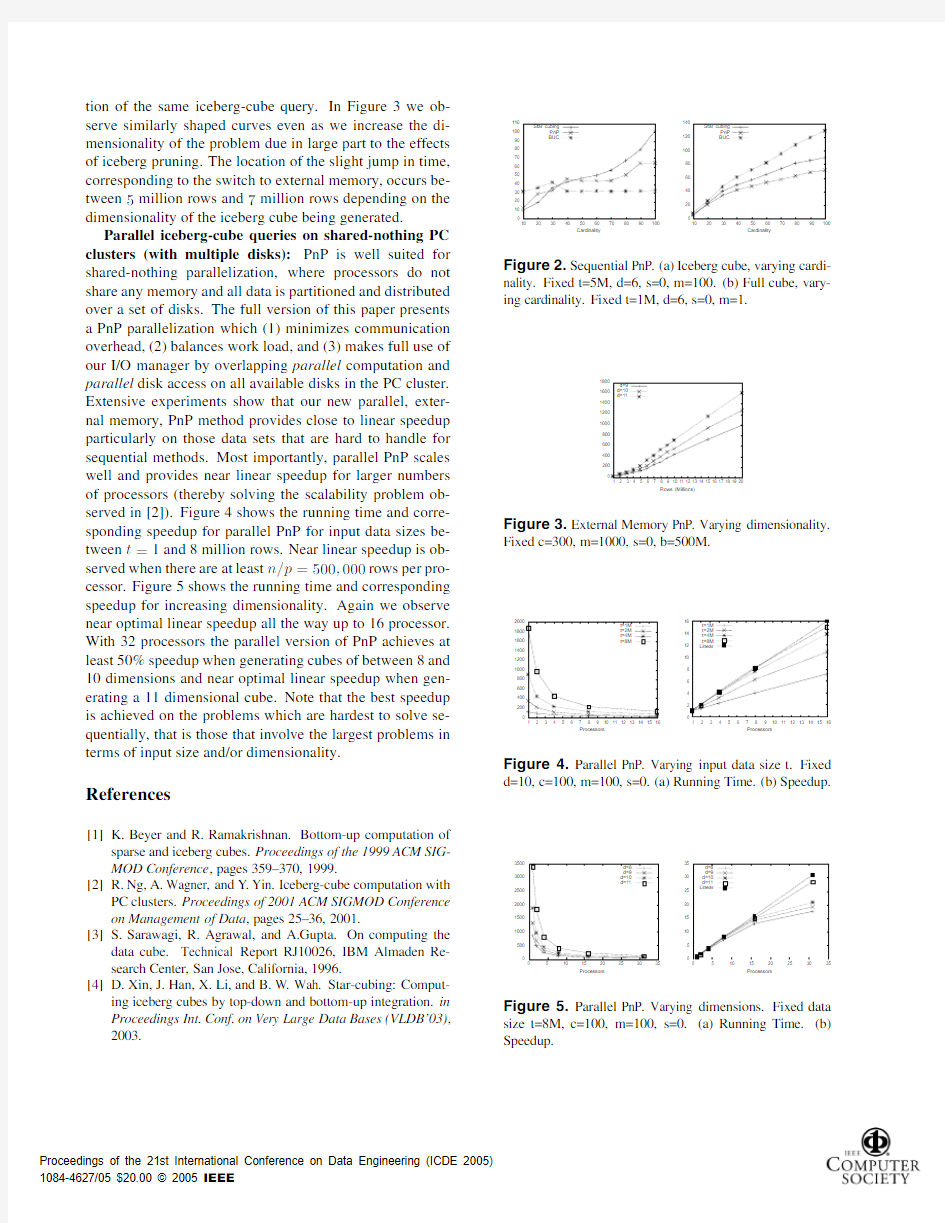
Sequential iceberg-cube queries:We performed an ex-tensive performance analysis of PnP in comparison with BUC[1]and StarCube[4].We observe that the sequen-tial performance of PnP is very stable even for large vari-ations of data density and data skew.Sequential PnP typ-ically shows a performance between BUC and StarCube, while BUC and StarCube have ranges of data density and skew where BUC outperforms StarCube or vice versa(Fig-ure2a).For the special case of full cube computation,PnP outperforms both BUC and StarCube(Figure2b).
External memory iceberg-cube queries:Since PnP is composed mainly of linear scans and does not require com-plex in-memory data structures,it is conceptually easy to implement as an external memory method for very large iceberg-cube queries.In order to make good use of PnP’s properties,we have implemented our own I/O manager to have full control over latency hiding through overlapping of computation and disk I/O.Our experiments show mini-mum loss of ef?ciency when PnP switches from in-memory to external memory computation.The measured external memory running time(where PnP is forced to use exter-nal memory by limiting the available main memory)is less than twice the running time for full in-memory computa-
tion of the same iceberg-cube query.In Figure3we ob-serve similarly shaped curves even as we increase the di-mensionality of the problem due in large part to the effects of iceberg pruning.The location of the slight jump in time, corresponding to the switch to external memory,occurs be-tween5million rows and7million rows depending on the
dimensionality of the iceberg cube being generated.
Parallel iceberg-cube queries on shared-nothing PC clusters(with multiple disks):PnP is well suited for shared-nothing parallelization,where processors do not share any memory and all data is partitioned and distributed over a set of disks.The full version of this paper presents a PnP parallelization which(1)minimizes communication overhead,(2)balances work load,and(3)makes full use of our I/O manager by overlapping parallel computation and parallel disk access on all available disks in the PC cluster. Extensive experiments show that our new parallel,exter-nal memory,PnP method provides close to linear speedup particularly on those data sets that are hard to handle for sequential methods.Most importantly,parallel PnP scales well and provides near linear speedup for larger numbers of processors(thereby solving the scalability problem ob-served in[2]).Figure4shows the running time and corre-sponding speedup for parallel PnP for input data sizes be-tween t=1and8million rows.Near linear speedup is ob-served when there are at least n/p=500,000rows per pro-cessor.Figure5shows the running time and corresponding speedup for increasing dimensionality.Again we observe near optimal linear speedup all the way up to16processor. With32processors the parallel version of PnP achieves at least50%speedup when generating cubes of between8and 10dimensions and near optimal linear speedup when gen-erating a11dimensional cube.Note that the best speedup is achieved on the problems which are hardest to solve se-quentially,that is those that involve the largest problems in terms of input size and/or dimensionality. References
[1]K.Beyer and R.Ramakrishnan.Bottom-up computation of
sparse and iceberg cubes.Proceedings of the1999ACM SIG-MOD Conference,pages359–370,1999.
[2]R.Ng,A.Wagner,and Y.Yin.Iceberg-cube computation with
PC clusters.Proceedings of2001ACM SIGMOD Conference on Management of Data,pages25–36,2001.
[3]S.Sarawagi,R.Agrawal,and A.Gupta.On computing the
data cube.Technical Report RJ10026,IBM Almaden Re-search Center,San Jose,California,1996.
[4] D.Xin,J.Han,X.Li,and B.W.Wah.Star-cubing:Comput-
ing iceberg cubes by top-down and bottom-up integration.in Proceedings Int.Conf.on Very Large Data Bases(VLDB’03), 2003.
10
20
30
40
50
60
70
80
90
100
110
10 20 30 40 50 60 70 80 90 100
S
e
c
o
n
d
s
Cardinality
Star cubing
PnP
BUC
20
40
60
80
100
120
140
10 20 30 40 50 60 70 80 90 100
S
e
c
o
n
d
s
Cardinality
Star cubing
PnP
BUC
Figure2.Sequential PnP.(a)Iceberg cube,varying cardi-nality.Fixed t=5M,d=6,s=0,m=100.(b)Full cube,vary-ing cardinality.Fixed t=1M,d=6,s=0,m=1.
200
400
600
800
1000
1200
1400
1600
1800
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
S
e
c
o
n
d
s
Rows (Millions)
d=9
d=10
d=11
Figure3.External Memory PnP.Varying dimensionality. Fixed c=300,m=1000,s=0,b=500M.
200
400
600
800
1000
1200
1400
1600
1800
2000
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
S
e
c
o
n
d
s
Processors
t=1M
t=2M
t=4M
t=8M
R
e
l
a
t
i
v
e
S
p
e
e
d
u
p
Processors
Figure4.Parallel PnP.Varying input data size t.Fixed d=10,c=100,m=100,s=0.(a)Running Time.(b)Speedup.
500
1000
1500
2000
2500
3000
3500
0 5 10 15 20 25 30 35
S
e
c
o
n
d
s
Processors
d=8
d=9
d=10
d=11
R
e
l
a
t
i
v
e
S
p
e
e
d
u
p
Processors
Figure5.Parallel PnP.Varying dimensions.Fixed data size t=8M,c=100,m=100,s=0.(a)Running Time.(b) Speedup.
IC设计完整流程及工具 IC的设计过程可分为两个部分,分别为:前端设计(也称逻辑设计)和后端设计(也称物理设计),这两个部分并没有统一严格的界限,凡涉及到与工艺有关的设计可称为后端设计。 前端设计的主要流程: 1、规格制定 芯片规格,也就像功能列表一样,是客户向芯片设计公司(称为Fabless,无晶圆设计公司)提出的设计要求,包括芯片需要达到的具体功能和性能方面的要求。 2、详细设计 Fabless根据客户提出的规格要求,拿出设计解决方案和具体实现架构,划分模块功能。 3、HDL编码 使用硬件描述语言(VHDL,Verilog HDL,业界公司一般都是使用后者)将模块功能以代码来描述实现,也就是将实际的硬件电路功能通过HDL语言描述出来,形成RTL(寄存器传输级)代码。 4、仿真验证 仿真验证就是检验编码设计的正确性,检验的标准就是第一步制定的规格。看设计是否精确地满足了规格中的所有要求。规格是设计正确与否的黄金标准,一切违反,不符合规格要求的,就需要重新修改设计和编码。设计和仿真验证是反复迭代的过程,直到验证结果显示完全符合规格标准。仿真验证工具Mentor公司的Modelsim,Synopsys的VCS,还有Cadence的NC-Verilog均可以对RTL级的代码进行设计验证,该部分个人一般使用第一个-Modelsim。该部分称为前仿真,接下来逻辑部分综合之后再一次进行的仿真可称为后仿真。 5、逻辑综合――Design Compiler 仿真验证通过,进行逻辑综合。逻辑综合的结果就是把设计实现的HDL代码翻译成门级网表netlist。综合需要设定约束条件,就是你希望综合出来的电路在面积,时序等目标参数上达到的标准。逻辑综合需要基于特定的综合库,不同的库中,门电路基
型号功能 ACP2371NI 多制式数字音频信号处理电路ACVP2205 梳状滤波、视频信号处理电路 AN5071 波段转换控制电路 AN5195K 子图像信号处理电路 AN5265 伴音功率放大电路 AN5274 伴音功率放大电路 AN5285K 伴音前置放大电路 AN5342K 图像水平轮廓校正、扫描速度调制电路AN5348K AI信号处理电路 AN5521 场扫描输出电路 AN5551 枕形失真校正电路 AN5560 50/60Hz场频自动识别电路 AN5612 色差、基色信号变换电路 AN5836 双声道前置放大及控制电路 AN5858K TV/AV切换电路 AN5862K(AN5862S) 视频模拟开关 AN5891K 音频信号处理电路 AT24C02 2线电可擦、可编程只读存储器 AT24C04 2线电可擦、可编程只读存储器 AT24C08 2线电可擦、可编程只读存储器 ATQ203 扬声器切换继电器电路 BA3880S 高分辨率音频信号处理电路 BA3884S 高分辨率音频信号处理电路 BA4558N 双运算放大器 BA7604N 梳状切换开关电路 BU9252S 8bitA/D转换电路 CAT24C16 2线电可擦、可编程只读存储器 CCU-FDTV 微处理器 CCU-FDTV-06 微处理器 CD54573A/CD54573CS 波段转换控制电路 CH0403-5H61 微处理器 CH04801-5F43 微处理器 CH05001(PCA84C841) 微处理器 CH05002 微处理器 CH7001C 数字NTSC/PAL编码电路 CHT0406 微处理器 CHT0803(TMP87CP38N*) 8bit微处理器 CHT0807(TMP87CP38N) 8bit微处理器 CHT0808(TMP87CP38N) 8bit微处理器 CHT0818 微处理器 CKP1003C 微处理器 CKP1004S(TMP87CK38N) 微处理器 CKP1006S(TMP87CH38N) 微处理器
浅谈数字IC设计技术(一) 摘要:随着数字电路设计的规模以及复杂程度的提高,对其进行设计所花费的时间和费用也随之而提高。根据近年来的统计,对数字系统进行设计所花的时间占到了整个研发过程的60%以上。所以减少设计所花费的实践成本是当前数字电路设计研发的关键,这就必须在设计的方法上有所突破。 关键词:数字系统;IC;设计 一、数字IC设计方法学 在目前CI设计中,基于时序驱动的数字CI设计方法、基于正复用的数字CI设计方法、基于集成平台进行系统级数字CI设计方法是当今数字CI设计比较流行的3种主要设计方法,其中基于正复用的数字CI设计方法是有效提高CI设计的关键技术。它能解决当今芯片设计业所面临的一系列挑战:缩短设计周期,提供性能更好、速度更快、成本更加低廉的数字IC芯片。 基于时序驱动的设计方法,无论是HDL描述还是原理图设计,特征都在于以时序优化为目标的着眼于门级电路结构设计,用全新的电路来实现系统功能;这种方法主要适用于完成小规模ASIC的设计。对于规模较大的系统级电路,即使团队合作,要想始终从门级结构去实现优化设计,也很难保证设计周期短、上市时间快的要求。 基于PI复用的数字CI设计方法,可以满足芯片规模要求越来越大,设计周期要求越来越短的要求,其特征是CI设计中的正功能模块的复用和组合。采用这种方法设计数字CI,数字CI包含了各种正模块的复用,数字CI的开发可分为模块开发和系统集成配合完成。对正复用技术关注的焦点是,如何进行系统功能的结构划分,如何定义片上总线进行模块互连,应该选择那些功能模块,在定义各个功能模块时如何考虑尽可能多地利用现有正资源而不是重新开发,在功能模块设计时考虑怎样定义才能有利于以后的正复用,如何进行系统验证等。基于PI复用的数字CI的设计方法,其主要特征是模块的功能组装,其技术关键在于如下三个方面:一是开发可复用的正软核、硬核;二是怎样做好IP复用,进行功能组装,以满足目标CI的需要;三是怎样验证完成功能组装的数字CI是否满足规格定义的功能和时序。 二、典型的数字IC开发流程 典型的数字CI开发流程主要步骤包含如下24方面的内容: (1)确定IC规格并做好总体方案设计。 (2)RTL代码编写及准备etshtnehc代码。 (3)对于包含存储单元的设计,在RTL代码编写中插入BIST(内建自我测试)电路。 (4)功能仿真以验证设计的功能正确。 (5)完成设计综合,生成门级网表。 (6)完成DFT(可测试设计)设计。 (7)在综合工具下完成模块级的静态时序分析及处理。 (8)形式验证。对比综合网表实现的功能与TRL级描述是否一致。 (9)对整个设计进行Pre一layout静态时序分析。 (10)把综合时的时间约束传递给版图工具。 (11)采样时序驱动的策略进行初始化nooprlna。内容包括单元分布,生成时钟树 (12)把时钟树送给综合工具并插入到初始综合网表。 (13)形式验证。对比插入时钟树综合网表实现的功能与初始综合网表是否一致。 (14)在步骤(11)准布线后提取估计的延迟信息。 (15)把步骤(14)提取出来的延迟信息反标给综合工具和静态时序分析工具。 (16)静态时序分析。利用准布线后提取出来的估计延时信息。 (17)在综合工具中实现现场时序优化(可选项)。
设计流程 IC的设计过程可分为两个部分,分别为:前端设计(也称逻辑设计)和后端设计(也称物理设计),这两个部分并没有统一严格的界限,凡涉及到与工艺有关的设计可称为后端设计。 前端设计的主要流程: 1、规格制定 芯片规格,也就像功能列表一样,是客户向芯片设计公司(称为Fabless,无晶圆设计公司)提出的设计要求,包括芯片需要达到的具体功能和性能方面的要求。 2、详细设计 Fabless根据客户提出的规格要求,拿出设计解决方案和具体实现架构,划分模块功能。 3、HDL编码 使用硬件描述语言(VHDL,Verilog HDL,业界公司一般都是使用后者)将模块功能以代码来描述实现,也就是将实际的硬件电路功能通过HDL语言描述出来,形成RTL(寄存器传输级)代码。 4、仿真验证 仿真验证就是检验编码设计的正确性,检验的标准就是第一步制定的规格。看设计是否精确地满足了规格中的所有要求。规格是设计正确与否的黄金标准,一切违反,不符合规格要求的,就需要重新修改设计和编码。设计和仿真验证是反复迭代的过程,直到验证结果显示完全符合规格标准。仿真验证工具Mentor公司的Modelsim,Synopsys的VCS,还有Cadence的NC-Verilog均可以对RTL级的代码进行设计验证,该部分个人一般使用第一个-Modelsim。该部分称为前仿真,接下来逻辑部分综合之后再一次进行的仿真可称为后仿真。 5、逻辑综合――Design Compiler
仿真验证通过,进行逻辑综合。逻辑综合的结果就是把设计实现的HDL代码翻译成门 级网表netlist。综合需要设定约束条件,就是你希望综合出来的电路在面积,时序等目标参数上达到的标准。逻辑综合需要基于特定的综合库,不同的库中,门电路基本标准单元(standard cell)的面积,时序参数是不一样的。所以,选用的综合库不一样,综合出来的电路在时序,面积上是有差异的。一般来说,综合完成后需要再次做仿真验证(这个也称为后仿真,之前的称为前仿真)逻辑综合工具Synopsys的Design Compiler,仿真工具选 择上面的三种仿真工具均可。 6、STA Static Timing Analysis(STA),静态时序分析,这也属于验证范畴,它主要是在时序上对电路进行验证,检查电路是否存在建立时间(setup time)和保持时间(hold time)的违例(violation)。这个是数字电路基础知识,一个寄存器出现这两个时序违例时,是没有办法正确采样数据和输出数据的,所以以寄存器为基础的数字芯片功能肯定会出现问题。STA工具有Synopsys的Prime Time。 7、形式验证 这也是验证范畴,它是从功能上(STA是时序上)对综合后的网表进行验证。常用的就是等价性检查方法,以功能验证后的HDL设计为参考,对比综合后的网表功能,他们是否在功能上存在等价性。这样做是为了保证在逻辑综合过程中没有改变原先HDL描述的电路功能。形式验证工具有Synopsys的Formality。前端设计的流程暂时写到这里。从设计程度上来讲,前端设计的结果就是得到了芯片的门级网表电路。 Backend design flow后端设计流程: 1、DFT Design ForTest,可测性设计。芯片内部往往都自带测试电路,DFT的目的就是在设计的时候就考虑将来的测试。DFT的常见方法就是,在设计中插入扫描链,将非扫描单元(如寄存器)变为扫描单元。关于DFT,有些书上有详细介绍,对照图片就好理解一点。DFT工具Synopsys的DFT Compiler
1:什么是同步逻辑和异步逻辑?(汉王) 同步逻辑是时钟之间有固定的因果关系。异步逻辑是各时钟之间没有固定的因果关系。 同步时序逻辑电路的特点:各触发器的时钟端全部连接在一起,并接在系统时钟端,只有当时钟脉冲到来时,电路的状态才能改变。改变后的状态将一直保持到下一个时钟脉冲的到来,此时无论外部输入x 有无变化,状态表中的每个状态都是稳定的。 异步时序逻辑电路的特点:电路中除可以使用带时钟的触发器外,还可以使用不带时钟的触发器和延迟元件作为存储元件,电路中没有统一的时钟,电路状态的改变由外部输入的变化直接引起。 2:同步电路和异步电路的区别: 同步电路:存储电路中所有触发器的时钟输入端都接同一个时钟脉冲源,因而所有触发器的状态的变化都与所加的时钟脉冲信号同步。 异步电路:电路没有统一的时钟,有些触发器的时钟输入端与时钟脉冲源相连,只有这些触发器的状态变化与时钟脉冲同步,而其他的触发器的状态变化不与时钟脉冲同步。 3:时序设计的实质: 时序设计的实质就是满足每一个触发器的建立/保持时间的要求。 4:建立时间与保持时间的概念? 建立时间:触发器在时钟上升沿到来之前,其数据输入端的数据必须保持不变的最小时间。保持时间:触发器在时钟上升沿到来之后,其数据输入端的数据必须保持不变的最小时间。 5:为什么触发器要满足建立时间和保持时间? 因为触发器内部数据的形成是需要一定的时间的,如果不满足建立和保持时间,触发器将进入亚稳态,进入亚稳态后触发器的输出将不稳定,在0和1之间变化,这时需要经过一个恢复时间,其输出才能稳定,但稳定后的值并不一定是你的输入值。这就是为什么要用两级触发器来同步异步输入信号。这样做可以防止由于异步输入信号对于本级时钟可能不满足建立保持时间而使本级触发器产生的亚稳态传播到后面逻辑中,导致亚稳态的传播。 (比较容易理解的方式)换个方式理解:需要建立时间是因为触发器的D端像一个锁存器在接受数据,为了稳定的设置前级门的状态需要一段稳定时间;需要保持时间是因为在时钟沿到来之后,触发器要通过反馈来锁存状态,从后级门传到前级门需要时间。 6:什么是亚稳态?为什么两级触发器可以防止亚稳态传播? 这也是一个异步电路同步化的问题。亚稳态是指触发器无法在某个规定的时间段内到达一个可以确认的状态。使用两级触发器来使异步电路同步化的电路其实叫做“一位同步器”,他只能用来对一位异步信号进行同步。两级触发器可防止亚稳态传播的原理:假设第一级触发器的输入不满足其建立保持时间,它在第一个脉冲沿到来后输出的数据就为亚稳态,那么在下一个脉冲沿到来之前,其输出的亚稳态数据在一段恢复时间后必须稳定下来,而且稳定的数据必须满足第二级触发器的建立时间,如果都满足了,在下一个脉冲沿到来时,第二级触发器将不会出现亚稳态,因为其输入端的数据满足其建立保持时间。同步器有效的条件:第一级触发器进入亚稳态后的恢复时间+ 第二级触发器的建立时间< = 时钟周期。
IC设计流程之实现篇——全定制设计 要谈IC设计的流程,首先得搞清楚IC和IC设计的分类。 集成电路芯片从用途上可以分为两大类:通用IC(如CPU、DRAM/SRAM、接口芯片等)和专用IC(ASIC)(Application Specific Integrated Circuit),ASIC是特定用途的IC。从结构上可以分为数字IC、模拟IC和数模混合IC三种,而SOC(System On Chip,从属于数模混合IC)则会成为IC设计的主流。从实现方法上IC设计又可以分为三种,全定制(full custom)、半定制(Semi-custom)和基于可编程器件的IC设计。全定制设计方法是指基于晶体管级,所有器件和互连版图都用手工生成的设计方法,这种方法比较适合大批量生产、要求集成度高、速度快、面积小、功耗低的通用IC或ASIC。基于门阵列(gate-array)和标准单元(standard-cell)的半定制设计由于其成本低、周期短、芯片利用率低而适合于小批量、速度快的芯片。最后一种IC设计方向,则是基于PLD或FPGA器件的IC设计模式,是一种“快速原型设计”,因其易用性和可编程性受到对IC制造工艺不甚熟悉的系统集成用户的欢迎,最大的特点就是只需懂得硬件描述语言就可以使用EDA工具写入芯片功能。从采用的工艺可以分成双极型(bipolar),MOS和其他的特殊工艺。硅(Si)基半导体工艺中的双极型器件由于功耗大、集成度相对低,在近年随亚微米深亚微米工艺的的迅速发展,在速度上对MOS管已不具优势,因而很快被集成度高,功耗低、抗干扰能力强的MOS管所替代。MOSFET工艺又可分为NMOS、PMOS和CMOS三种;其中CMOS工艺发展已经十分成熟,占据IC市场的绝大部分份额。GaAs器件因为其在高频领域(可以在0.35um下很轻松作到10GHz)如微波IC中的广泛应用,其特殊的工艺也得到了深入研究。而应用于视频采集领域的CCD传感器虽然也使用IC一样的平面工艺,但其实现和标准半导体工艺有很大不同。在IC开发中,常常会根据项目的要求(Specifications)、经费和EDA工具以及人力资源、并考虑代工厂的工艺实际,采用不同的实现方法。 其实IC设计这个领域博大精深,所涉及的知识工具领域很广,本系列博文围绕EDA工具展开,以实现方法的不同为主线,来介绍这三种不同的设计方法:全定制、半定制和基于FPGA
2017年数字IC设计工程师招聘面试笔试100 题附答案 1:什么是同步逻辑和异步逻辑?(汉王) 同步逻辑是时钟之间有固定的因果关系。异步逻辑是各时钟之间没有固定的因果关系。 同步时序逻辑电路的特点:各触发器的时钟端全部连接在一起,并接在系统时钟端,只有当时钟脉冲到来时,电路的状态才能改变。改变后的状态将一直保持到下一个时钟脉冲的到来,此时无论外部输入x 有无变化,状态表中的每个状态都是稳定的。 异步时序逻辑电路的特点:电路中除可以使用带时钟的触发器外,还可以使用不带时钟的触发器和延迟元件作为存储元件,电路中没有统一的时钟,电路状态的改变由外部输入的变化直接引起。 2:同步电路和异步电路的区别: 同步电路:存储电路中所有触发器的时钟输入端都接同一个时钟脉冲源,因而所有触发器的状态的变化都与所加的时钟脉冲信号同步。 异步电路:电路没有统一的时钟,有些触发器的时钟输入端与时钟脉冲源相连,只有这些触发器的状态变化与时钟脉冲同步,而其他的触发器的状态变化不与时钟脉冲同步。 3:时序设计的实质: 时序设计的实质就是满足每一个触发器的建立/保持时间的要求。
4:建立时间与保持时间的概念? 建立时间:触发器在时钟上升沿到来之前,其数据输入端的数据必须保持不变的最小时间。 保持时间:触发器在时钟上升沿到来之后,其数据输入端的数据必须保持不变的最小时间。 5:为什么触发器要满足建立时间和保持时间? 因为触发器内部数据的形成是需要一定的时间的,如果不满足建立和保持时间,触发器将进入亚稳态,进入亚稳态后触发器的输出将不稳定,在0和1之间变化,这时需要经过一个恢复时间,其输出才能稳定,但稳定后的值并不一定是你的输入值。这就是为什么要用两级触发器来同步异步输入信号。这样做可以防止由于异步输入信号对于本级时钟可能不满足建立保持时间而使本级触发器产生的亚稳态传播到后面逻辑中,导致亚稳态的传播。 (比较容易理解的方式)换个方式理解:需要建立时间是因为触发器的D端像一个锁存器在接受数据,为了稳定的设置前级门的状态需要一段稳定时间;需要保持时间是因为在时钟沿到来之后,触发器要通过反馈来锁存状态,从后级门传到前级门需要时间。 6:什么是亚稳态?为什么两级触发器可以防止亚稳态传播?
鹏运发科技有限公司收音机用集成电路 序号产品型号功能与用途封装形式境外同类产品 1 YD1000 DTS用AM/FM单片立体声收音机电路 TSSOP24 DTS是数字化影院系统 2 YD1191 AM/FM单片收音机电路 SOP28 CXA1191 3 YD1600 AM单片收音机电路 SIP9 LA1600 4 YD1619 AM/FM单片收音机电路 SOP28/SDIP30 CXA1619 5 YD1800 AM/FM单片收音机电路 SDIP22 LA1800 6 YD2003 AM/FM单片收音机电路 DIP16 TA2003 7 YD2111 AM/FM单片立体收音机电路 SDIP24/SSOP24 TA2111 8 YD2149 DTS用AM/FM单片立体声收音机电路 SDIP24/SSOP24 TA2149 9 YD7088 FM自动搜索单片收音机电路 SOP16 TDA7088T 10 YD72130 AM/FM频率锁相环 SDIP24 LC72130 11 YD72131 AM/FM频率锁相环 SDIP22 LC72131 12 YD7343 FM立体声解调电路 SIP9 TA7343 13 YD7640 AM/FM单片收音机电路 DIP16 TA7640 音频功率放大集成电路 序号产品型号功能与用途封装形式境外同类产品 1 YD1001 720mW单声道音频功放电路 DIP8 2 YD1006 18W单声道音频功放电路 TO-220B 3 YD1008 22W单声道音频功放电路 TO-220B 4 YD1026 具有待机、静音功能的25W双声道音频功放电路 FZIP12 5 YD131 6 2W双声道音频功放电路 FDIP14 μPC1316C 6 YD1519 具有待机、静音功能的6W双声道音频功放电路 FSIP9 TDA1519 7 TDA2003 10W单声道音频功放电路 TO-220B TDA2003 8 YD2025 2.3W单声道音频功放电路 DIP16 TEA2025B 9 YD2025A 2.4W单声道音频功放电路 DIP16 TEA2025B 10 YD2025H 2.4W单声道音频功放电路 HDIP12 11 YD2030 18W单声道音频功放电路 TO-220B TDA2030 12 YD2030A 20W单声道音频功放电路 TO-220B TDA2030A
第一节三端稳压IC 电子产品中常见到的三端稳压集成电路有正电压输出的78××系列和负电压输出的79××系列。故名思义,三端IC是指这种稳压用的集成电路只有三条引脚输出,分别是输入端、接地端和输出端。它的样子象是普通的三极管,TO-220的标准封装,也有9013样子的TO-92封装。 用78/79系列三端稳压IC来组成稳压电源所需的外围元件极少,电路内部还有过流、过热及调整管的保护电路,使用起来可靠、方便,而且价格便宜。该系列集成稳压IC型号中的78或79后面的数字代表该三端集成稳压电路的输出电压,如7806表示输出电压为正6V,7909表示输出电压为负9V。 78/79系列三端稳压IC有很多电子厂家生产,80年代就有了,通常前缀为生产厂家的代号,如TA7805是东芝的产品,AN7909是松下的产品。(点击这里,查看有关看前缀识别集成电路的知识) 有时在数字78或79后面还有一个M或L,如78M12或79L24,用来区别输出电流和封装形式等,其中78L调系列的最大输出电流为100mA,78M系列最大输出电流为1A,78系列最大输出电流为1.5A。它的封装也有多种,详见图。塑料封装的稳压电路具有安装容易、价格低廉等优点,因此用得比较多。79系列除了输出电压为负。引出脚排列不同以外,命名方法、外形等均与78系列的相同。 因为三端固定集成稳压电路的使用方便,电子制作中经常采用,可以用来改装分立元件的稳压电源,也经常用作电子设备的工作电源。电路图如图所示。 注意三端集成稳压电路的输入、输出和接地端绝不能接错,不然容易烧坏。一般三端集成稳压电路的最小输入、输出电压差约为2V,否则不能输出稳定的电压,一般应使电压差保持在4-5V,即经变压器变压,二极管整流,电容器滤波后的电压应比稳压值高一些。 在实际应用中,应在三端集成稳压电路上安装足够大的散热器(当然小功率的条件下不用)。当稳压管温度过高时,稳压性能将变差,甚至损坏。 当制作中需要一个能输出1.5A以上电流的稳压电源,通常采用几块三端稳压电路并联起来,使其最大输出电流为N个1.5A,但应用时需注意:并联使用的集成稳压电路应采用同一厂家、同一批号的产品,以保证参数的一致。另外在输出电流上留有一定的余量,以避免个别集成稳压电路失效时导致其他电路的连锁烧毁。 第二节语音集成电路 电子制作中经常用到音乐集成电路和语言集成电路,一般称为语言片和音乐片。它们一般都是软包封,即芯片直接用黑胶封装在一小块电路板上。语音IC一般还需要少量外围元件才能工作,它们可直接焊到这块电路板上。
基本后端流程(漂流&雪拧) ----- 2010/7/3---2010/7/8 本教程将通过一个8*8的乘法器来进行一个从verilog代码到版图的整个流程(当然只是基本流程,因为真正一个大型的设计不是那么简单就完成的),此教程的目的就是为了让大家尽快了解数字IC设计的大概流程,为以后学习建立一个基础。此教程只是本人探索实验的结果,并不代表容都是正确的,只是为了说明大概的流程,里面一定还有很多未完善并且有错误的地方,我在今后的学习当中会对其逐一完善和修正。 此后端流程大致包括以下容: 1.逻辑综合(逻辑综合是干吗的就不用解释了把?) 2.设计的形式验证(工具formality) 形式验证就是功能验证,主要验证流程中的各个阶段的代码功能是否一致,包括综合前RTL 代码和综合后网表的验证,因为如今IC设计的规模越来越大,如果对门级网表进行动态仿真的话,会花费较长的时间(规模大的话甚至要数星期),这对于一个对时间要求严格(设计周期短)的asic设计来说是不可容忍的,而形式验证只用几小时即可完成一个大型的验证。另外,因为版图后做了时钟树综合,时钟树的插入意味着进入布图工具的原来的网表已经被修改了,所以有必要验证与原来的网表是逻辑等价的。 3.静态时序分析(STA),某种程度上来说,STA是ASIC设计中最重要的步骤,使用primetime 对整个设计布图前的静态时序分析,没有时序违规,则进入下一步,否则重新进行综合。 (PR后也需作signoff的时序分析) 4.使用cadence公司的SOCencounter对综合后的网表进行自动布局布线(APR) 5.自动布局以后得到具体的延时信息(sdf文件,由寄生RC和互联RC所组成)反标注到 网表,再做静态时序分析,与综合类似,静态时序分析是一个迭代的过程,它与芯片布局布线的联系非常紧密,这个操作通常是需要执行许多次才能满足时序需求,如果没违规,则进入下一步。 6.APR后的门级功能仿真(如果需要) 7.进行DRC和LVS,如果通过,则进入下一步。 8.用abstract对此8*8乘法器进行抽取,产生一个lef文件,相当于一个hard macro。 9.将此macro作为一个模块在另外一个top设计中进行调用。 10.设计一个新的ASIC,第二次设计,我们需要添加PAD,因为没有PAD,就不是一个完整的 芯片,具体操作下面会说。 11.重复第4到7步
COMPOSER - CADENCE 逻辑图输入 这个工具主要针对中小规模的ASIC以及MCU电路的逻辑设计,大的东西可能需要综合了。虽然现在电路越设计越大,有人言必称SYNOPSYS,但只要仔细到市场上端详一下,其实相当大部分真正火暴卖钱的东西还是用CADENCE的COMPOSER加VIRTUOSO加VERILOG—XL加DRACULA流程做的。原因很简单,客户可不买你什么流程的帐,什么便宜性能又好就买什么。备用PC上的工具:WORKVIEW OFFICE DC - SYNOPSYS 逻辑综合 这个不用说了,最经典的。但老实说在我们现在的设计流程里用得还不多,最关键问题还是一个市场切入问题。备用工作站上的工具:AMBIT,这个工具其实很不错,它和SE都是CADENCE出的,联合起来用的优势就很明显了。PC上用的备用工具可以选NT版的SYNOPSYS,SYNPILIFY也不错,但主要是用做FPGA综合的。其实最终你拿到的库有时最能说明问题,它不支持某工具,转换?急吧。 VIRTUOSO - CADENCE 版图设计 这个大家比较熟了,但个人还是喜欢用PC上的TANNER。原因是层与层之间的覆盖关系用调色的模式显示出来比直接覆盖显示就是舒服。可惜人家老大,国产的《熊猫》也学了这个模式。倒是以前有个COMPASS,比较好用,可惜现在不知哪去了。 SE - CADENCE 自动布局布线 有了它,很多手工版图的活儿就可以不用做的,实在是一大进步。可惜残酷市场上如果规模不大的东西人家手画的东西比你自动布的小40%,麻烦就大了。APOLLO用的人还不是很多吧。PC上的TANNER 据说也能做,针对线宽比较粗,规模不太大的设计。 VERILOG—XL - CADENCE 逻辑仿真 VERILOG就是CADENCE的发明,我们的版本比较老,现在该工具是不是停止开发了?CADENCE 新推都叫NC-VERILOG。SYNOPSYS的VCS是不是比NC强,反正两公司喊的挺凶,哪位对这个两个东西都比较了解,不妨对比一下。PC上的Model Sim也很不错。我一直觉得仿真是数字逻辑设计的核心,DEGUG 靠脑子和手推是不够用的。可惜往往有时候还不能过分依赖仿真结果,因为一些因素还是不能完全包罗进去。如果哪天真的仿真完芯片就必定OK了,做芯片的乐趣也没了。 DRACULA - CADENCE LVS、DRC、ERC、LPE 虽然比较老,已经成了CADENCE搭售的产品,但是经典了。 STAR—SIM - SYNOPSYS(原A VANT!)后仿真 如果你对小规模的电路不放心(尤其是自建库的设计),用这个做一次FULL-CHIP的后仿真,问题就不大了。还有一个是查电路的故障,一个芯片所有逻辑设计都对的,东西就出不来,可以针对性的仿真内部的关键信号。不看过就不知道,其实内部信号的传输远不如你在数字仿真时漂亮。 以上都是传统工具,还有好多新出的工具,因为只是停留在概念基础上,不敢评论了。 以下是几个硬件工具: 示波器、信号发生器、逻辑分析仪: 尤其是逻辑分析仪,查找硬件故障,甚至分析简单的通讯协议,好东西。
1 附录四、常用集成电路及主要参数 4.1 常用集成电路的引线端子识别及使用注意事项 4.1.1 集成电路引出端的识别 使用集成电路前,必须认真查对和识别集成电路的引线端,确认电源、地、输入、输出及控制端的引线号,以免因错接损坏元器件。 贴片封装(A、B)型,如附图4.1-1所示,识别时,将文字符 号正放,定位销向左,然后,从左下角起,按逆时针方向依次 为1、2、3……。 扁形和双列直插型集成电路:如附图 4.1-2(b)所示,识别 时,将文字符号标记正放,由顶部俯视,其面上有一个缺口或 小圆点,附图4.1-1贴片型,有时两者都有,这是“1”号引线 端的标记,如将该标记置于左边,然后,从左下角起,按逆时 针方向依次为1、2、3……。 一般圆型和集成电路:如附图4.1-2(a)所示,识别时,面向引出端,从定位销顺时针依次为1、2、3……。圆形多用于模拟集成电路。 (a) 园形外型(b)扁平双列直插型 附图4.1-2 集成电路外引线的识别 4.1.2 数字集成电路的使用 数字集成电路按内部组成的元器件的不同又分为:TTL电路和CMOS电路。不论哪一种集成电路,使用时,首先应查阅手册,识别集成电路的外引线端排列图,然后按照功能表使用芯片,尤其是牛规模的集成电路,应注意使能端的使用,时序电路还应注意“同步”和“异步”功能等。 使用集成路时应注意以下方面的问题。 1、TTL电路 (1)电源 ①只允许工作在5V±10%的范围内。若电源电压超过5.5V或低于4.5V,将使器件损坏或导致器件工作的逻辑功能不正常。 ②为防止动态尖峰电流造成的干扰,常在电源和地之间接人滤波电容。消除高频干扰的滤波电容取0.01~0.1PF,消除低频干扰取10—50/uF ③不要将“电源”和“地”颠倒,例如将741S00插反,缺口或小圆点置于右面,则电源的引线端与“地”引线端恰好颠倒,若不注意,这种情况极易发生,将造成元器件的损坏。 ④TTL电路的工作电流较大,例如中规模集成TTL电路需要几十毫安的工作电流,因此使用干电池长期工作,既不经济,也不可靠。 (2)输出端 ①不允许直接接地或接电源,否则将使器件损坏。 ②图腾柱输出的TTL门电路的输出端不能“线与”使用,OC门的输出端可以
[FPGA/CPLD]典型的FPGA设计流程 skycanny 发表于 2005-12-8 22:17:00 转自EDA专业论坛作者:lixf 1.设计输入 1)设计的行为或结构描述。 2)典型文本输入工具有UltraEdit-32和Editplus.exe.。
3)典型图形化输入工具-Mentor的Renoir。 4)我认为UltraEdit-32最佳。 2.代码调试 1)对设计输入的文件做代码调试,语法检查。 2)典型工具为Debussy。 3.前仿真 1)功能仿真 2)验证逻辑模型(没有使用时间延迟)。 3)典型工具有Mentor公司的ModelSim、Synopsys公司的VCS和VSS、Aldec公司的Active、Ca dense公司的NC。 4)我认为做功能仿真Synopsys公司的VCS和VSS速度最快,并且调试器最好用,Mentor公司的ModelSim对于读写文件速度最快,波形窗口比较好用。 4.综合 1)把设计翻译成原始的目标工艺 2)最优化 3)合适的面积要求和性能要求 4)典型工具有Mentor公司的LeonardoSpectrum、Synopsys公司的DC、Synplicity公司的Synp lify。 5)推荐初学者使用Mentor公司的LeonardoSpectrum,由于它在只作简单约束综合后的速度和面积最优,如果你对综合工具比较了解,可以使用Synplicity公司的Synplify。 5.布局和布线 1)映射设计到目标工艺里指定位置 2)指定的布线资源应被使用 3)由于PLD市场目前只剩下Altera,Xilinx,Lattice,Actel,QuickLogic,Atmel六家公司,其中前5家为专业PLD公司,并且前3家几乎占有了90%的市场份额,而我们一般使用Altera,Xilinx公司的PLD居多,所以典型布局和布线的工具为Altera公司的Quartus II和Maxplus II、Xilinx公司的ISE和Foudation。 4)Maxplus II和Foudation分别为Altera公司和Xilinx公司的第一代产品,所以布局布线一般使用Quartus II和ISE。 6.后仿真 1)时序仿真 2)验证设计一旦编程或配置将能在目标工艺里工作(使用时间延迟)。 3)所用工具同前仿真所用软件。 7.时序分析 4)一般借助布局布线工具自带的时序分析工具,也可以使用Synopsys公司的 PrimeTime软件和Mentor Graphics公司的Tau timing analysis软件。 8.验证合乎性能规范 1)验证合乎性能规范,如果不满足,回到第一步。 9.版图设计 1)验证版版图设计。
施耐德ezd系列选型 ▲断路器是指能够关合、承载和开断正常回路条件下的电流并能关合、在规定的时间内承载和开断异常回路条件下的电流的开关装置。断路器按其使用范围分为高压断路器与低压断路器,高低压界线划分比较模糊,一般将3kV以上的称为高压电器。 ▲断路器可用来分配电能,不频繁地启动异步电动机,对电源线路及电动机等实行保护,当它们发生严重的过载或者短路及欠压等故障时能自动切断电路,其功能相当于熔断器式开关与过欠热继电器等的组合。而且在分断故障电流后一般不需要变更零部件。目前,已获得了广泛的应用。 ▲电的产生、输送、使用中,配电是一个极其重要的环节。配电系统包括变压器和各种高低压电器设备,低压断路器则是一种使用量大面广的电器 ▲断路器应垂直安装,且在安装前应先检查断路器铭牌上所列的技术参数是否符合使用要求。 ▲通电前应人工操作几次断路器,其机构动作应灵活可靠、无阻滞现象。 ▲按下闭合按钮(黑色),电路处于接通状态;按下断开按钮(红色),电路处于断开状态。 ▲使用过程中,应对断路器进行定期检查(一般为一个月),即在断路器合闸通电状态下,拨动试验按钮(试验按钮用符号“Test”表示),断路器应可靠断开。 ▲当断路器因线路发生过载、短路故障而断开时,应先排除故障后再使断路器重新合闸。 ▲本断路器为非维护型,所以当断路器发生故障不能正常工作时,用户不得私自打开断路器进行维修。 ▲使用电流调节旋钮,须按线路实际电流调节至相应位置,请勿超负荷使用 ▲如需近一步了解施耐德接触器,ABB断路器,西门子接触器,西门子断路器,常熟开关,价格,厂家,批发,参数等。请关注科旭机电https://www.doczj.com/doc/b214714465.html,
常用集成电路功能简 介:2
IAP722 调频高放、混频集成电路 IFC380HC 图像中频放大集成电路 IN065 二本振压控振荡集成电路 IN706 数字混响延时集成电路 IR2112 半桥式变换驱动集成电路 IR2E01 发光二极管五位显示驱动集成电路IR2E02 发光二极管七位显示驱动集成电路IR3N06 调频中频放大集成电路 IR3R15 音频前置放大集成电路 IR3R18 双声道前置放大集成电路 IR3R20A 自动选曲集成电路 IR3R49 伺服控制集成电路 IR3Y29AM 色度解码集成电路 IRT1260 红外遥控信号发射集成电路 IS61C256AH-15N 存储集成电路 IS93C46 存储集成电路 IX0035CE 场扫描输出集成电路 IX0040AG 音频功率放大集成电路 IX0040TA 音频功率放大集成电路
IX0042CE 伴音制式切换6MHZ集成电路 IX0052CE 伴音中频放大、鉴频及前置放大集成电路IX0062CE 图像中频放大、视频放大集成电路 IX0064CE 图像中频放大、检波、视频放大集成电路IX0096CE 伴音信号处理集成电路 IX0101SE 微处理集成电路 IX0113 图像中频放大、检波、预视放集成电路 IX0113CEZZ 图像中频放大、检波及预视放集成电路IX0118CE 视频放大集成电路 IX0129CE 色度解码集成电路 IX0132CE 液晶显示解码集成电路 IX0147CE 电子选台集成电路 IX0162GE 伺服控制集成电路 IX0195CE 色度信号处理集成电路 IX0203GE 频段转换集成电路 IX0205CE 开关电源稳压集成电路 IX0211CE 图像中频放大、视频信号处理集成电路IX0212G 高频、中频放大集成电路 IX0214CE 音频控制集成电路
摘要:随着数字电路设计的规模以及复杂程度的提高,对其进行设计所花费的时间和费用也随之而提高。根据近年来的统计,对数字系统进行设计所花的时间占到了整个研发过程的60%以上。所以减少设计所花费的实践成本是当前数字电路设计研发的关键,这就必须在设计的方法上有所突破。 关键词:数字系统;IC;设计 一、数字IC设计方法学 在目前CI设计中,基于时序驱动的数字CI设计方法、基于正复用的数字CI设计方法、基于集成平台进行系统级数字CI设计方法是当今数字CI设计比较流行的3种主要设计方法,其中基于正复用的数字CI设计方法是有效提高CI设计的关键技术。它能解决当今芯片设计业所面临的一系列挑战:缩短设计周期,提供性能更好、速度更快、成本更加低廉的数字IC芯片。 基于时序驱动的设计方法,无论是HDL描述还是原理图设计,特征都在于以时序优化为目标的着眼于门级电路结构设计,用全新的电路来实现系统功能;这种方法主要适用于完成小规模ASIC的设计。对于规模较大的系统级电路,即使团队合作,要想始终从门级结构去实现优化设计,也很难保证设计周期短、上市时间快的要求。 基于PI复用的数字CI设计方法,可以满足芯片规模要求越来越大,设计周期要求越来越短的要求,其特征是CI设计中的正功能模块的复用和组合。采用这种方法设计数字CI,数字CI包含了各种正模块的复用,数字CI的开发可分为模块开发和系统集成配合完成。对正复用技术关注的焦点是,如何进行系统功能的结构划分,如何定义片上总线进行模块互连,应该选择那些功能模块,在定义各个功能模块时如何考虑尽可能多地利用现有正资源而不是重新开发,在功能模块设计时考虑怎样定义才能有利于以后的正复用,如何进行系统验证等。 基于PI复用的数字CI的设计方法,其主要特征是模块的功能组装,其技术关键在于如下三个方面:一是开发可复用的正软核、硬核;二是怎样做好IP复用,进行功能组装,以满足目标CI的需要;三是怎样验证完成功能组装的数字CI是否满足规格定义的功能和时序。 二、典型的数字IC开发流程 典型的数字CI开发流程主要步骤包含如下24方面的内容: (1)确定IC规格并做好总体方案设计。 (2)RTL代码编写及准备etshtnehc代码。 (3)对于包含存储单元的设计,在RTL代码编写中插入BIST(内建自我测试)电路。 (4)功能仿真以验证设计的功能正确。 (5)完成设计综合,生成门级网表。 (6)完成DFT(可测试设计)设计。 (7)在综合工具下完成模块级的静态时序分析及处理。 (8)形式验证。对比综合网表实现的功能与TRL级描述是否一致。 (9)对整个设计进行Pre一layout静态时序分析。 (10)把综合时的时间约束传递给版图工具。 (11)采样时序驱动的策略进行初始化nooprlna。内容包括单元分布,生成时钟树 (12)把时钟树送给综合工具并插入到初始综合网表。 (13)形式验证。对比插入时钟树综合网表实现的功能与初始综合网表是否一致。 (14)在步骤(11)准布线后提取估计的延迟信息。 (15)把步骤(14)提取出来的延迟信息反标给综合工具和静态时序分析工具。 (16)静态时序分析。利用准布线后提取出来的估计延时信息。
20106 前置放大器 258N 分离式双电源双运放 4N25 光电耦合晶体管输出 4N25MC 光电耦合晶体管输出4N26 光电耦合晶体管输出 4N27 光电耦合晶体管输出 4N28 光电耦合晶体管输出 4N29 光电耦合达林顿输出 4N30 光电耦合达林顿输出 4N31 光电耦合达林顿输出 4N32 光电耦合达林顿输出 4N33 光电耦合达林顿输出 4N33MC 光电耦合达林顿输出4N35 光电耦合达林顿输出 4N36 光电耦合晶体管输出 4N37 光电耦合晶体管输出 4N38 光电耦合晶体管输出 4N39 光耦可控硅输出 6N135 高速光耦晶体管输出6N136 高速光耦晶体管输出6N137 高速光耦晶体管输出6N138 光电耦合达林顿输出
6N139 光电耦合达林顿输出 74F00 高速四2输入与非门 74F02 高速四2输入或非门 74F04 高速六反相器 74F08 高速四2输入与门 74F10 高速三3输入与门 74F139 高速双2-4线译码/驱动器74F14 高速六反相斯密特触发 74F151 高速双2-4线译码/驱动器74F153 高速双4选1数据选择器74F157 高速双4选1数据选择器74F161 高速6D型触发器 74F174 高速6D型触发器 74F175 高速4D型触发器 74F244 高速八总线3态缓冲器 74F245 高速八总线收发器 74F32 高速四2输入或门 74F373 高速8D锁存器 74F38 高速四2输入或门 74F74 高速双D型触发器 74F86 高速四2输入异或门 CA3140 单BIMOS运行
CA3240 单BIMOS运行 CD4001 4二输入或非门 CD4002 双4输入或非门 CD4006 18位静态移位寄存器 CD4007 双互补对加反相器 CD4009 六缓冲器/转换-倒相CD4010 六缓冲器/转换-正相CD40103 同步可预置减法器 CD40106 六斯密特触发器 CD40107 双2输入与非缓冲/驱动CD4011 四2输入与非门 CD40110 计数/译码/锁存/驱动CD4012 双4输入与非门 CD4013 置/复位双D型触发器CD4014 8位静态同步移位寄存CD4015 双4位静态移位寄存器CD4016 四双向模拟数字开关 CD4017 10译码输出十进制计数器CD40174 6D触发器 CD40175 4D触发器 CD4018 可预置1/N计数器 CD4019 四与或选择门