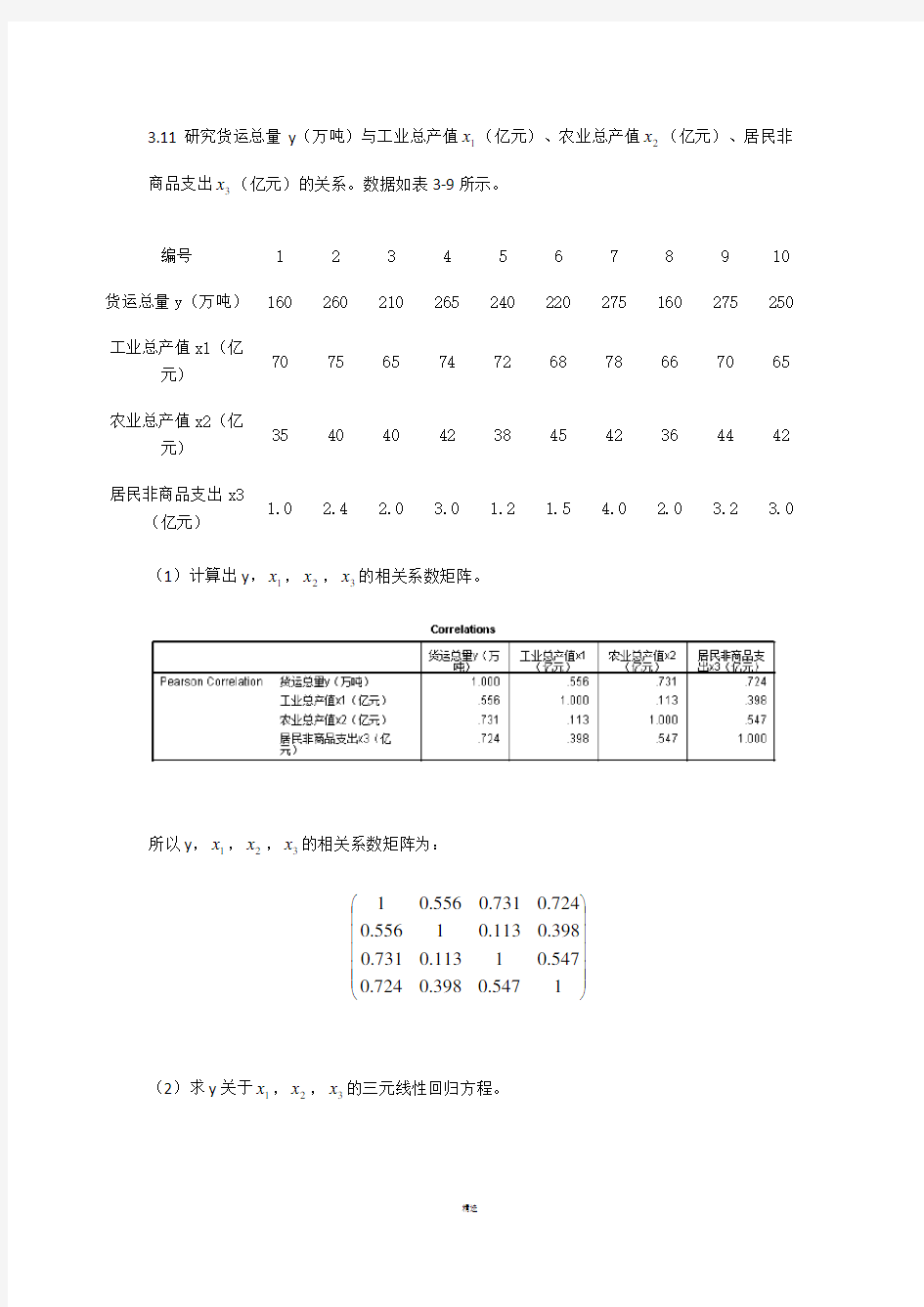

3.11研究货运总量y (万吨)与工业总产值1x (亿元)、农业总产值2x (亿元)、居民非商品支出3x (亿元)的关系。数据如表3-9所示。
(1)计算出y ,1x ,2x ,3x 的相关系数矩阵。
所以y ,1x ,2x ,3x 的相关系数矩阵为:
???
??
?
? ??1547.0398.0724.0547.01113.0731.0398.0113.01556
.0724.0731.0556.01
(2)求y 关于1x ,2x ,3x 的三元线性回归方程。
编号 1 2 3 4 5 6 7 8 9 10 货运总量y (万吨) 160 260
210
265
240
220
275
160
275
250
工业总产值x1(亿
元)
70 75 65 74 72 68 78 66 70 65
农业总产值x2(亿
元)
35 40 40 42 38 45 42 36 44 42
居民非商品支出x3
(亿元)
1.0
2.4 2.0
3.0 1.2 1.5
4.0 2.0 3.2 3.0
由系数表可以知道,y 关于1x ,2x ,3x 的三元线性回归方程为:
280.348447.12101.7574.3321-++=x x x y
(3)对所求得的方程作拟合优度检验。
由模型汇总可知,样本的决定系数为0.806,所以可以认为回归方程为样本观测值的拟合程度较好,即回归方程的显著性较高。 (4)对回归方程作显著性检验。
对方差分析表可以知道p 值为0.015<0.05 说明自变量1x ,2x ,3x 对因变量y 产生的线性影响较显著。而F=8.283>74.405.0=F 时,就拒绝原假设,认为在显著性水平0.05下,y 与1x ,
2x ,3x 有显著的线性关系,即回归方程是显著的。
(5)对每一个回归系数作显著性检验。
由系数表可以知道,1x ,2x 的P 值分别为0.1和0.049说明回归系数较显著,3x 的P 值为0.284>0.05说明3x 的回归系数不显著,应该予以剔除。
(6)如果有的回归系数没通过显著性检验,将其剔除,重新建立回归方程,作回归方程的显著性检验和回归系数的显著性检验。
由系数表可以知道,重新建立的回归方程:624.459971.8676.4211-+=x x y
由方差分析表可知,P 值为0.07说明自变量1x ,2x 对因变量y 产生的线性影响较显著。 由系数表可知,此时各个回归系数的P 值均很小,说明回归系数的显著性较高。
(7)求出每一个回归系数的置信水平为95%的置信区间。
由上表可知,1x 的系数的95%的置信区间为(0.381,8.970)
2x 的系数的95%的置信区间为(3.134,14.808) (8)求标准化回归方程。
由系数表可知,标准化后的回归方程为6
2110*441.6676.0479.0--+=x x y
(9)求当01x =75,02x =42,03x =3.1时的0?y
,给定置信水平为95%,用SPSS 软件计算精确置信区间,手工计算近似预测区间。
由上表可知,0?y
=267.8 0y 的置信水平为95%的置信区间为(260.05895,334.12038) ()0y E 的置信水平为95%的近似区间估计为(241.63377,298.54556)
(10)结合回归方程对问题作一些基本分析。
对于前面的分析,虽然R 方的值蛮大的,但这并不能说明回归方程显著,此时还需要通过对回归方程以及回归方程系数进行检验。
当一个回归方程通过显著性检验之后,并不能说明这个方程中所以自变量都对因变量y 有显著影响,因此还需对回归系数进行检验。
第8章 非线性回归 思考与练习参考答案 8.1 在非线性回归线性化时,对因变量作变换应注意什么问题? 答:在对非线性回归模型线性化时,对因变量作变换时不仅要注意回归函数的形式, 还要注意误差项的形式。如: (1) 乘性误差项,模型形式为 e y AK L αβε =, (2) 加性误差项,模型形式为y AK L αβ ε = + 对乘法误差项模型(1)可通过两边取对数转化成线性模型,(2)不能线性化。 一般总是假定非线性模型误差项的形式就是能够使回归模型线性化的形式,为了方便通常省去误差项,仅考虑回归函数的形式。 8.2为了研究生产率与废料率之间的关系,记录了如表8.15所示的数据,请画出散点图,根据散点图的趋势拟合适当的回归模型。 表8.15 生产率x (单位/周) 1000 2000 3000 3500 4000 4500 5000 废品率y (%) 5.2 6.5 6.8 8.1 10.2 10.3 13.0 解:先画出散点图如下图: 5000.00 4000.003000.002000.001000.00x 12.00 10.00 8.006.00 y
从散点图大致可以判断出x 和y 之间呈抛物线或指数曲线,由此采用二次方程式和指数函数进行曲线回归。 (1)二次曲线 SPSS 输出结果如下: Model Summ ary .981 .962 .942 .651 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x. ANOVA 42.571221.28650.160.001 1.6974.424 44.269 6 Regression Residual Total Sum of Squares df Mean Square F Sig.The independent variable is x. Coe fficients -.001.001-.449-.891.4234.47E -007.000 1.417 2.812.0485.843 1.324 4.414.012 x x ** 2 (Constant) B Std. E rror Unstandardized Coefficients Beta Standardized Coefficients t Sig. 从上表可以得到回归方程为:72? 5.8430.087 4.4710y x x -=-+? 由x 的系数检验P 值大于0.05,得到x 的系数未通过显著性检验。 由x 2的系数检验P 值小于0.05,得到x 2的系数通过了显著性检验。 (2)指数曲线 Model Summ ary .970 .941 .929 .085 R R Square Adjusted R Square Std. E rror of the Estimate The independent variable is x.
第十一章一元线性回归 11.1从某一行业中随机抽取12家企业,所得产量与生产费用的数据如下: 要求: (1)绘制产量与生产费用的散点图,判断二者之间的关系形态。 (2)计算产量与生产费用之间的线性相关系数。 (3)对相关系数的显著性进行检验(α = 0.05),并说明二者之间的关系强度。 解:(1)利用Excel的散点图绘制功能,绘制的散点图如下: 从散点图的形态可知,产量与生产费用之间存在正的线性相关。 (2)利用Excel的数据分析中的相关系数功能,得到产量与生产费用的线性相关系数r = 0.920232。 (3)计算t统计量,得到t = 7.435453,在α = 0.05的显著性水平下,临界值为2.6337,统计量远大于临界值,拒绝原假设,产量与生产费用之间存在显著
的正线性相关关系。r大于0.8,高度相关。 11.2 学生在期末考试之前用于复习的时间(单位:h)和考试分数(单位:分)之间是否有关系?为研究这一问题,以为研究者抽取了由8名学生构成的一个随机样本,得到的数据如下: 要求: (1)绘制复习时间和考试分数的散点图,判断二者之间的关系形态。 (2)计算相关系数,说明两个变量之间的关系强度。 解:(1)利用Excel的散点图绘制功能,绘制的散点图如下: 从散点图的形态来看,考试分数与复习时间之间似乎存在正的线性相关关系。 (2)r = 0.862109,大于0.8,高度相关。 11.3根据一组数据建立的线性回归方程为?100.5 =-。 y x
要求: ?β的意义。 (1)解释截距 ?β意义。 (2)解释斜率 1 (3)计算当x = 6时的E(y)。 解:(1)在回归模型中,一般不能对截距项赋予意义。 ?β的意义为:当x增加1时,y减小0.5。 (2)斜率 1 (3)当x = 6时,E(y) = 10 – 0.5 * 6 = 7。 11.4 设SSR = 36,SSE = 4,n = 18。 要求: (1)计算判定系数R2并解释其意义。 (2)计算估计标准误差s e并解释其意义。 解:SST = SSR+SSE = 36+4 = 40, R2 = SSR / SST = 36 /40 = 0.9,意义为自变量可解释因变量变异的90%,自因变量与自变量之间存在很高的线性相关关系。 s== 0.5,这是随机项的标准误差的估计值。 (2) e 11.5一家物流公司的管理人员想研究货物的运送距离和运送时间的关系,因此,他抽出了公司最近10辆卡车运货记录的随机样本,得到运送距离(单位:km)和运送时间(单位:天)的数据如下:
回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: 2010年中国各地区城市居民人均年消费支出和可支配收入
2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1:
表2 模型汇总b 表3 相关性 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX
表4 系数a 3、结果分析 表2模型汇总:相关系数为0.965,判定系数为0.932,调整判定系数为0.930,估计值的标准误877.29128 表3是相关分析结果。消费性支出Y与可支配收入X相关系数为0.965,相关性很高。 表4是回归分析中的系数:常数项b=704.824,可支配收入X的回归系数a=0.668。a的标准误差为0.034,回归系数t的检验值为19.921,P值为0,满足95%的置信区间,可认为回归系数有显著意义。得线性回归方程Y=0.668X+704.824. 【实验结论】 (1)结果显示,变量之间具有如下关系式:Y=0.668X+704.824.也就是说消费与收入之间存在稳定的函数关系。随着收入的增加,消费将增加,但消费的增长低于收入的增长。这与凯尔斯的绝对收入消费理论刚好吻合。但为了研究方便,这里假设边际消费倾向为常数。由公式知X每增长1个单位,Y增加0.668个单位。
2.1 一元线性回归模型有哪些基本假定? 答:1. 解释变量 1x , ,2x ,p x 是非随机变量,观测值,1i x ,,2 i x ip x 是常数。 2. 等方差及不相关的假定条件为 ? ? ? ? ? ? ??????≠=====j i n j i j i n i E j i i ,0),,2,1,(,),cov(,,2,1, 0)(2 σεεε 这个条件称为高斯-马尔柯夫(Gauss-Markov)条件,简称G-M 条件。在此条件下,便可以得到关于回归系数的最小二乘估计及误差项方差2σ估计的一些重要性质,如回归系数的最小二乘估计是回归系数的最小方差线性无偏估计等。 3. 正态分布的假定条件为 ???=相互独立 n i n i N εεεσε,,,,,2,1),,0(~212 在此条件下便可得到关于回归系数的最小二乘估计及2σ估计的进一步结果,如它们分别是回归系数的最及2σ的最小方差无偏估计等,并且可以作回归的显著性检验及区间估计。 4. 通常为了便于数学上的处理,还要求,p n >及样本容量的个数要多于解释变量的个数。 在整个回归分析中,线性回归的统计模型最为重要。一方面是因为线性回归的应用最广泛;另一方面是只有在回归模型为线性的假设下,才能的到比较深入和一般的结果;再就是有许多非线性的回归模型可以通过适当的转化变为线性回归问题进行处理。因此,线性回归模型的理论和应用是本书研究的重点。 1. 如何根据样本),,2,1)(;,,,(21n i y x x x i ip i i =求出p ββββ,,,,210 及方差2σ的估计; 2. 对回归方程及回归系数的种种假设进行检验; 3. 如何根据回归方程进行预测和控制,以及如何进行实际问题的结构分析。 2.2 考虑过原点的线性回归模型 n i x y i i i ,,2,1,1 =+=εβ误差n εεε,,,21 仍满足基本假定。求1β的最小二 乘估计。 答:∑∑==-=-=n i n i i i i x y y E y Q 1 1 2112 1)())(()(ββ
第11章 多重线性回归分析 思考与练习参考答案 一、 最佳选择题 1. 逐步回归分析中,若增加自变量的个数,则( D )。 A. 回归平方和与残差平方和均增大 B. 回归平方和与残差平方和均减小 C. 总平方和与回归平方和均增大 D. 回归平方和增大,残差平方和减小 E. 总平方和与回归平方和均减小 2. 下面关于自变量筛选的统计学标准中错误的是( E )。 A. 残差平方和(残差SS )缩小 B. 确定系数(2 R )增大 C. 残差的均方(残差MS )缩小 D. 调整确定系数(2 ad R )增大 E. p C 统计量增大 3. 多重线性回归分析中,能直接反映自变量解释因变量变异百分比的指标为 ( C )。 A. 复相关系数 B. 简单相关系数 C.确定系数 D. 偏回归系数 E. 偏相关系数 4. 多重线性回归分析中的共线性是指( E )。 A.Y 关于各个自变量的回归系数相同 B.Y 关于各个自变量的回归系数与截距都相同 C.Y 变量与各个自变量的相关系数相同 D.Y 与自变量间有较高的复相关 E. 自变量间有较高的相关性 5. 多重线性回归分析中,若对某一自变量的值加上一个不为零的常数K ,则有( D )。 A. 截距和该偏回归系数值均不变 B. 该偏回归系数值为原有偏回归系数值的K 倍 C. 该偏回归系数值会改变,但无规律 D. 截距改变,但所有偏回归系数值均不改变 E. 所有偏回归系数值均不会改变 二、思考题 1. 多重线性回归分析的用途有哪些? 答:多重线性回归在生物医学研究中有广泛的应用,归纳起来,可以包括以下几个方面:定量地建立一个反应变量与多个解释变量之间的线性关系,筛选危险因素,通过较易测量的变量估计不易测量的变量,通过解释变量预测反应变量,通过反应变量控制解释变量。
应用回归分析课后答案 第二章一元线性回归 解答:EXCEL结果: SUMMARY OUTPUT 回归统计 Multiple R R Square Adjusted R Square 标准误差 观测值5 方差分析 df SS MS F Significance F 回归分析125 残差3 总计410 Coefficients标准误差t Stat P-value Lower 95%Upper 95%下限%上限% Intercept X Variable 15 RESIDUAL OUTPUT 观测值预测Y残差 1 2 3 4 5 SPSS结果:(1)散点图为:
(2)x 与y 之间大致呈线性关系。 (3)设回归方程为01y x ββ∧ ∧ ∧ =+ 1β∧ = 12 2 1 7()n i i i n i i x y n x y x n x -- =- =-=-∑∑ 0120731y x ββ-∧- =-=-?=- 17y x ∧ ∴=-+可得回归方程为 (4)22 n i=1 1()n-2i i y y σ∧∧=-∑ 2 n 01i=1 1(())n-2i y x ββ∧∧=-+∑ =222 22 13???+?+???+?+??? (10-(-1+71))(10-(-1+72))(20-(-1+73))(20-(-1+74))(40-(-1+75)) []1 169049363 110/3= ++++= 1 330 6.13 σ∧=≈ (5)由于2 11(, )xx N L σββ∧ :
t σ ∧ == 服从自由度为n-2的t分布。因而 /2 |(2)1 P t n α α σ ?? ?? <-=- ?? ?? 也即: 1/211/2 (p t t αα βββ ∧∧ ∧∧ -<<+=1α - 可得 1 95% β∧的置信度为的置信区间为(7-2.3537+2.353即为:(,) 2 2 00 1() (,()) xx x N n L ββσ - ∧ + : t ∧∧ == 服从自由度为n-2的t分布。因而 /2 (2)1 P t n α α ∧ ?? ?? ?? <-=- ?? ?? ?? ?? ?? 即 0/200/2 ()1 pβσββσα ∧∧∧∧ -<<+=- 可得 1 95%7.77,5.77 β∧- 的置信度为的置信区间为() (6)x与y的决定系数 2 21 2 1 () 490/6000.817 () n i i n i i y y r y y ∧- = - = - ==≈ - ∑ ∑ (7)
第11章多重线性回归分析 案例辨析及参考答案 案例11-1预测人体吸入氧气的效率。为了解和预测人体吸入氧气的效率,某人收集了31名中年男 性的健康调查资料。一共调查了 7个指标,分别是吸氧效率(Y , %)、年龄(X1,岁)、体重(X2, kg )、 跑1.5 km所需时间(X3, min )、休息时的心跳频率(X4,次/min )、跑步时的心跳频率(X5,次/min) 和最高心跳频率(X6,次/min )(教材表11-9)。试用多重线性回归方法建立预测人体吸氧效率的模型。 教材表11 -9 吸氧效率调查数据 Y X1 X2X3 X4 X5 X6 Y X1 X2X3 X4 X5 X6 44.609 44 89.47 11.37 62 178 182 40.836 51 69.63 10.95 57 168 172 45.313 40 75.07 10.07 62 185 185 46.672 51 77.91 10.00 48 162 168 54.297 44 85.84 8.65 45 156 168 46.774 48 91.63 10.25 48 162 164 59.571 42 68.15 8.17 40 166 172 50.388 49 73.37 10.08 67 168 168 49.874 38 89.02 9.22 55 178 180 39.407 57 73.37 12.63 58 174 176 44.811 47 77.45 11.63 58 176 176 46.080 54 79.38 11.17 62 156 165 45.681 40 75.98 11.95 70 176 180 45.441 56 76.32 9.63 48 164 166 49.091 43 81.19 10.85 64 162 170 54.625 50 70.87 8.92 48 146 155 39.442 44 81.42 13.08 63 174 176 45.118 51 67.25 11.08 48 172 172 60.055 38 81.87 8.63 48 170 186 39.203 54 91.63 12.88 44 168 172 50.541 44 73.03 10.13 45 168 168 45.790 51 73.71 10.47 59 186 188 37.388 45 87.66 14.03 56 186 192 50.545 57 59.08 9.93 49 148 155 44.754 45 66.45 11.12 51 176 176 48.673 49 76.32 9.40 56 186 188 47.273 47 79.15 10.60 47 162 164 47.920 48 61.24 11.50 52 170 176 51.855 54 83.12 10.33 50 166 170 47.467 52 82.78 10.50 53 170 172 49.156 49 81.42 8.95 44 180 185 资料来自:张家放主编?医用多元统计方法?武汉:华中科技大学出版社,2002。 该研究员采用后退法对自变量进行筛选,最后得到结果如教材表11-10所示。 教材表11-10 多重线性回归模型的参数估计 Table 11-10 Parameter estimati on of regressi on model Variable Un sta ndardized Coefficie nts Stan dardized Coefficie nts t P B Std. Error In tercept 100.079 11.577 8.644 0.000 X1 -0.213 0.091 -0.214 -2.337 0.027 X3 -2.768 0.331 -0.721 -8.354 0.000 X5 -0.339 0.116 -0.653 -2.939 0.007 X6 0.255 0.132 0.439 1.936 0.064
实验六用SPSS进行非线性回归分析 例:通过对比12个同类企业的月产量(万台)与单位成本(元)的资料(如图1),试配合适当的回归模型分析月产量与单位成本之间的关系
图1原始数据和散点图分析 一、散点图分析和初始模型选择 在SPSS数据窗口中输入数据,然后插入散点图(选择Graphs→Scatter命令),由散点图可以看出,该数据配合线性模型、指数模型、对数模型和幂函数模型都比较合适。进一步进行曲线估计:从Statistic下选Regression菜单中的Curve Estimation命令;选因变量单位成本到Dependent框中,自变量月产量到Independent框中,在Models框中选择Linear、Logarithmic、Power和Exponential四个复选框,确定后输出分析结果,见表1。 分析各模型的R平方,选择指数模型较好,其初始模型为 但考虑到在线性变换过程可能会使原模型失去残差平方和最小的意义,因此进一步对原模型进行优化。 模型汇总和参数估计值 因变量: 单位成本 方程模型汇总参数估计值 R 方 F df1 df2 Sig. 常数b1 线性.912 1 10 .000 对数.943 1 10 .000 幂.931 1 10 .000 指数.955 1 10 .000 自变量为月产量。 表1曲线估计输出结果
二、非线性模型的优化 SPSS提供了非线性回归分析工具,可以对非线性模型进行优化,使其残差平方和达到最小。从Statistic下选Regression菜单中的Nonlinear命令;按Paramaters按钮,输入参数A:和B:;选单位成本到Dependent框中,在模型表达式框中输入“A*EXP(B*月产量)”,确定。SPSS输出结果见表2。 由输出结果可以看出,经过6次模型迭代过程,残差平方和已有了较大改善,缩小为,误差率小于, 优化后的模型为: 迭代历史记录b 迭代数a残差平方和参数 A B +133 .087 导数是通过数字计算的。 a. 主迭代数在小数左侧显示,次迭代数在小数右侧显 示。 b. 由于连续残差平方和之间的相对减少量最多为 SSCON = ,因此在 22 模型评估和 10 导数评估之后, 系统停止运行。
第7章岭回归 思考与练习参考答案 7.1 岭回归估计是在什么情况下提出的? 答:当自变量间存在复共线性时,|X’X|≈0,回归系数估计的方差就很大,估计值就很不稳定,为解决多重共线性,并使回归得到合理的结果,70年代提出了岭回归(Ridge Regression,简记为RR)。 7.2岭回归的定义及统计思想是什么? 答:岭回归法就是以引入偏误为代价减小参数估计量的方差的一种回归方法,其统计思想是对于(X’X)-1为奇异时,给X’X加上一个正常数矩阵 D, 那么X’X+D接近奇异的程度就会比X′X接近奇异的程度小得多,从而完成回归。但是这样的回归必定丢失了信息,不满足blue。但这样的代价有时是值得的,因为这样可以获得与专业知识相一致的结果。 7.3 选择岭参数k有哪几种方法? 答:最优 是依赖于未知参数 和 的,几种常见的选择方法是: 岭迹法:选择 的点能使各岭估计基本稳定,岭估计符号合理,回归系数没有不合乎经济意义的绝对值,且残差平方和增大不太多;
方差扩大因子法: ,其对角线元 是岭估计的方差扩大因子。要让 ; 残差平方和:满足 成立的最大的 值。 7.4 用岭回归方法选择自变量应遵循哪些基本原则? 答:岭回归选择变量通常的原则是: 1. 在岭回归的计算中,我们通常假定涉及矩阵已经中心化和标准化了,这样可以直接比较标准化岭回归系数的大小。我们可以剔除掉标准化岭回归系数比较稳定且绝对值很小的自变量; 2. 当k值较小时,标准化岭回归系数的绝对值并不很小,但是不稳定,随着k的增加迅速趋近于零。像这样岭回归系数不稳定、震动趋于零的自变量,我们也可以予以剔除; 3. 去掉标准化岭回归系数很不稳定的自变量。如果有若干个岭回归系数不稳定,究竟去掉几个,去掉那几个,要根据去掉某个变量后重新进行岭回归分析的效果来确定。
SPSS 统计分析 多元线性回归分析方法操作与及分析 实验目的: 引入1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。 实验变量: 以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。 实验方法:多元线性回归分析法 软件:spss19.0 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open;
2. Opening excel data source——OK. 第二步: 1.在最上面菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房平均售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率、房屋空置率;Method选择Stepwise. 进入如下界面:
2.点击右侧Statistics,勾选Regression Coefficients(回归系数)选项组中的Estimates;勾选Residuals(残差)选项组中的 Durbin-Watson、Casewise diagnostics默认;接着选择Model fit、Collinearity diagnotics;点击Continue.
3.点击右侧Plots,选择*ZPRED(标准化预测值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的Histogram、Normal probability plot;点击Continue. 4.点击右侧Save,勾选Predicted Vaniues(预测值)和Residuals (残差)选项组中的Unstandardized;点击Continue.
y1 1 x11 x12 x1p 0 1 3.1 y2 1 x21 x22 x2p 1 + 2 即y=x + yn 1 xn1 xn2 xnp p n 基本假定 (1) 解释变量x1,x2…,xp 是确定性变量,不是随机变量,且要求 rank(X)=p+1 n 注 tr(H) h 1 3.4不能断定这个方程一定很理想,因为样本决定系数与回归方程中 自变量的数目以及样本量n 有关,当样本量个数n 太小,而自变量又较 多,使样本量与自变量的个数接近时, R 2易接近1,其中隐藏一些虚 假成分。 3.5当接受H o 时,认定在给定的显著性水平 下,自变量x1,x2, xp 对因变量y 无显著影响,于是通过x1,x2, xp 去推断y 也就无多大意 义,在这种情况下,一方面可能这个问题本来应该用非线性模型去描 述,而误用了线性模型,使得自变量对因变量无显著影响;另一方面 可能是在考虑自变量时,把影响因变量y 的自变量漏掉了,可以重新 考虑建模问题。 当拒绝H o 时,我们也不能过于相信这个检验,认为这个回归模型 已经完美了,当拒绝H o 时,我们只能认为这个模型在一定程度上说明 了自变量x1,x2, xp 与自变量y 的线性关系,这时仍不能排除排除我 们漏掉了一些重要的自变量。 3.6中心化经验回归方程的常数项为0,回归方程只包含p 个参数估计 值1, 2, p 比一般的经验回归方程减少了一个未知参数,在变量较 SSE (y y)2 e12 e22 1 2 1 E( ) E( - SSE* - n p 1 n p n 2 [D(e) (E(e ))2 ] 1 n (1 1 n 2 en n E( e 1 1 n p 1 1 n p 1 1 "1 1 n p 1 J (n D(e) 1 (p 1)) 1_ p 1 1 1 n p 1 2 2 n E(e 2 ) (1 h ) 2 1 第十五章 SPSS回归分析与市场预测 市场营销活动中常常要用到市场预测。市场预测就是运用科学的方法,对影响市场供求变化的诸因素进行调查研究,分析和预见其发展趋势,掌握市场供求变化的规律,为经营决策提供可靠的依据。预测的目的是为了提高管理的科学水平,减少盲目的决策,通过预测来把握经济发展或者未来市场变化的有关动态,减少未来的不确定性,降低决策可能遇到的风险,进而使决策目标得以顺利实现。 回归分析是研究两个变量或多个变量之间因果关系的统计方法。其基本思想是,在相关分析的基础上,对具有相关关系的两个或多个变量之间数量变化的一般关系进行测定,确立一个合适的数学模型,以便从一个已知量来推断另一个未知量。 15.1 回归分析概述 相关回归分析预测法,是在分析市场现象自变量和因变量之间相关关系的基础上,建立变量之间的回归方程,并将回归方程作为预测模型,根据自变量在预测期的数量变化来预测因变量在预测期变化结果的预测方法。根据市场现象所存在的相关关系,对它进行定量分析,从而达到对市场现象进行预测的目的,就是相关回归分析市场预测法。 相关回归分析市场预测法的种类:根据相关关系中自变量不同分类,有以下几种主要类型:1、一元相关回归分析市场预测法,也称简单相关回归分析市场预测法。它是用相关回归分析法对一个自变量与一个因变量之间的相关关系进行分析,建立一元回归方程作为预测模型,对市场现象进行预测的方法。2、多元相关回归市场预测法,也称复相关回归分析市场预测法。它是用相关分析法对多个自变量与一个因变量之间的相关关系进行分析,建立多元回归方程作为预测模型,对市场现象进行预测的方法。 回归模型的建立步骤: 1)做出散点图,观察变量间的趋势。如果是多个变量,则还应当做出散点图矩阵、重叠散点图和三维散点图。 2)考察数据的分布,进行必要的预处理。即分析变量的正态性、方差齐等问题。并确定是否可以直接进行线性回归分析。如果进行了变量变换,则应当重新绘制散点图,以确保线性趋势在变换后任然存在。 应用回归分析课后习题 参考答案 Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】 第二章一元线性回归分析 思考与练习参考答案 一元线性回归有哪些基本假定 答:假设1、解释变量X是确定性变量,Y是随机变量; 假设2、随机误差项ε具有零均值、同方差和不序列相关性:E(ε i )=0 i=1,2, …,n Var (ε i )=2i=1,2, …,n Cov(ε i, ε j )=0 i≠j i,j= 1,2, …,n 假设3、随机误差项ε与解释变量X之间不相关: Cov(X i , ε i )=0 i=1,2, …,n 假设4、ε服从零均值、同方差、零协方差的正态分布 ε i ~N(0, 2) i=1,2, …,n 考虑过原点的线性回归模型 Y i =β 1 X i +ε i i=1,2, …,n 误差εi(i=1,2, …,n)仍满足基本假定。求β1的最小二乘估计解: 得: 证明(式),e i =0 ,e i X i=0 。 证明: ∑ ∑+ - = - = n i i i n i X Y Y Y Q 1 2 1 2 1 )) ? ?( ( )? (β β 其中: 即:e i =0 ,e i X i=0 2 1 1 1 2) ? ( )? ( i n i i n i i i e X Y Y Y Qβ ∑ ∑ = = - = - = ) ? ( 2 ?1 1 1 = - - = ? ?∑ = i i n i i e X X Y Q β β ) ( ) ( ? 1 2 1 1 ∑ ∑ = = = n i i n i i i X Y X β 01 ?? ?? i i i i i Y X e Y Y ββ =+=- 01 00 ?? Q Q ββ ?? == ?? 1、 变量间统计关系和函数关系的区别是什么 答:函数关系是一种确定性的关系,一个变量的变化能完全决定另一个变量的变化;统计关系是非确定的,尽管变量间的关系密切,但是变量不能由另一个或另一些变量唯一确定。 2、 回归分析与相关分析的区别和联系是什么 答:联系:刻画变量间的密切联系; 区别:一、回归分析中,变量y 称为因变量,处在被解释的地位,而在相关分析中,变量y 与x 处于平等地位;二、相关分析中y 与x 都是随机变量,而回归分析中y 是随机的,x 是非随机变量。三、回归分析不仅可以刻画线性关系的密切程度,还可以由回归方程进行预测和控制。 3、 回归模型中随机误差项ε的意义是什么主要包括哪些因素 答:随机误差项ε的引入,才能将变量间的关系描述为一个随机方程。主要包括:时间、费用、数据质量等的制约;数据采集过程中变量观测值的观测误差;理论模型设定的误差;其他随机误差。 4、 线性回归模型的基本假设是什么 答:1、解释变量非随机;2、样本量个数要多于解释变量(自变量)个数;3、高斯-马尔科夫条件;4、随机误差项相互独立,同分布于2(0,)N σ。 5、 回归变量设置的理论根据在设置回归变量时应注意哪些问题 答:因变量与自变量之间的因果关系。需注意问题:一、对所研究的问题背景要有足够了解;二、解释变量之间要求不相关;三、若某个重要的变量在实际中没有相应的统计数据,应考虑用相近的变量代替,或者由其他几个指标复合成一个新的指标;四、解释变量并非越多越好。 6、 收集、整理数据包括哪些内容 答:一、收集数据的类型(时间序列、截面数据);二、数据应注意可比性和数据统计口径问题(统计范围);三、整理数据时要注意出现“序列相关”和“异 第4章违背基本假设的情况 思考与练习参考答案 4.1 试举例说明产生异方差的原因。 答:例4.1:截面资料下研究居民家庭的储蓄行为 Y i=β0+β1X i+εi 其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。 由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以εi的方差呈现单调递增型变化。 例4.2:以某一行业的企业为样本建立企业生产函数模型 Y i=A iβ1K iβ2L iβ3eεi 被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。 4.2 异方差带来的后果有哪些? 答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果: 1、参数估计量非有效 2、变量的显著性检验失去意义 3、回归方程的应用效果极不理想 总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。 4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。 答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。然而在异方差 的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。这样对残差所提供信息的重要程度作一番校正,以提高参数估计的精度。 加权最小二乘法的方法: 4.4简述用加权最小二乘法消除多元线性回归中异方差性的思想与方法。 答:运用加权最小二乘法消除多元线性回归中异方差性的思想与一元线性回归的类似。多元线性回归加权最小二乘法是在平方和中加入一个适当的权数i w ,以调整各项在平方和中的作用,加权最小二乘的离差平方和为: ∑=----=n i ip p i i i p w x x y w Q 1211010)( ),,,(ββββββ (2) 加权最小二乘估计就是寻找参数p βββ,,,10 的估计值pw w w βββ?,,?,?10 使式(2)的离差平方和w Q 达极小。所得加权最小二乘经验回归方程记做 22011 1 ???()()N N w i i i i i i i i Q w y y w y x ββ===-=--∑∑22 __ 1 _ 2 _ _ 02 222 ()() ?()?1 11 1 ,i i N w i i i w i w i w w w w w kx i i i i m i i i m i w x x y y x x y x w kx x kx w x σβββσσ==---=-= = ===∑∑1N i =1 1表示=或 第十一章分类资料的回归分析 ――Regression菜单详解(下) (医学统计之星:张文彤) 在很久很久以前,地球上还是一个阴森恐怖的黑暗时代,大地上恐龙横行,我们的老祖先--类人猿惊恐的睁大了双眼,围坐在仅剩的火堆旁,担心着无边的黑暗中不知何时会出现的妖魔鬼怪,没有电视可看,没有网可上... 我是疯了,还是在说梦话?都不是,类人猿自然不会有机会和恐龙同时代,只不过是我开机准备写这一部分的时候,心里忽然想到,在10年前,国内的统计学应用上还是卡方检验横行,分层的M-H卡方简直就是超级武器,在流行病学中称王称霸,更有那些1:M的配对卡方,N:M的配对卡方,含失访数据的N:M 配对卡方之类的,简直象恐龙一般,搞得我头都大了。其实恐龙我还能讲出十多种来,可上面这些东西我现在还没彻底弄明白,好在社会进步迅速,没等这些恐龙完全统制地球,Logistic模型就已经飞速进化到了现代人的阶段,各种各样的Logistic模型不断地在蚕食着恐龙爷爷们的领地,也许还象贪吃的人类一样贪婪的享用着恐龙的身体。好,这是好事,这里不能讲动物保护,现在我们就远离那些恐龙,来看看现代白领的生活方式。 特别声明:我上面的话并非有贬低流行病学的意思,实际上我一直都在做流行病学,我这样写只是想说明近些年来统计方法的普及速度之快而已。 据我一位学数学的师兄讲,Logistic模型和卡方在原理上是不一样的,在公 式推演上也不可能划等号,只是一般来说两者的检验结果会非常接近而已,多数情况下可忽略其不同。 §10.3 Binary Logistic过程 所谓Logistic模型,或者说Logistic回归模型,就是人们想为两分类的应变量作一个回归方程出来,可概率的取值在0~1之间,回归方程的应变量取值可是在实数集中,直接做会出现0~1范围之外的不可能结果,因此就有人耍小聪明,将率做了一个Logit变换,这样取值区间就变成了整个实数集,作出来的结果就不会有问题了,从而该方法就被叫做了Logistic回归。 随着模型的发展,Logistic家族也变得人丁兴旺起来,除了最早的两分类Logistic外,还有配对Logistic模型,多分类Logistic模型、随机效应的Logistic模型等。由于SPSS的能力所限,对话框只能完成其中的两分类和多分类模型,下面我们就介绍一下最重要和最基本的两分类模型。 SPSS多元线性回归分析试验 在科学研究中,我们会发现某些指标通常受到多个因素的影响,如血压值除了受年龄影响之外,还受到性别、体重、饮食习惯、吸烟情况等因素的影响,用方程定量描述一个因变量y与多个自变量x1、x2、x3.......之间的线性依存关系,称为多元线性回归。 有学者认为血清中低密度脂蛋白增高是引起动脉硬化的一个重要原因。现测量30名怀疑患有动脉硬化的就诊患者的载脂蛋白A、载脂蛋白B、载脂蛋白E、载脂蛋白C、低密度脂蛋白中的胆固醇含量。资料如下表所示。求低密度脂蛋白中的胆固醇含量对载脂蛋白A、载脂蛋白B、载脂蛋白E、载脂蛋白C的线性回归方程。 表1 30名就诊患者资料表 221101499.524.7184 2316086 5.310.8118 241121238.016.6127 251471108.518.4137 26204122 6.121.0126 27131102 6.613.4130 281701278.424.7135 291731238.719.0188 3013213113.829.2122 spss数据处理步骤: (1)打开spss输入数据后,点击“分析”-“回归”-“线性”。然后将“低密度脂蛋白”选入因变量框,将“载脂蛋白A”“载脂蛋白B”“载脂蛋白E”“载脂蛋白C”依次选入自变量框。方法选为“逐步”。 (2)单击“统计量”选项,原有选项基础上选择“R方变化”。在残差中选“Durbin-Watson”,单击“继续”。 (3)单击“绘制”,将“DEPENDNT”选入“X2”中,将“*SRESID”选入“Y”中,在标准残差图选项中选择“直方图”和“正态概率图”。单击“继续”。 (4)单击“选项”,在原有选项的基础上单击“继续”,最后单击“确定”,就完 第9章 含定性变量的回归模型 思考与练习参考答案 9.1 一个学生使用含有季节定性自变量的回归模型,对春夏秋冬四个季节引入4个0-1型自变量,用SPSS 软件计算的结果中总是自动删除了其中的一个自变量,他为此感到困惑不解。出现这种情况的原因是什么? 答:假如这个含有季节定性自变量的回归模型为: t t t t kt k t t D D D X X Y μαααβββ++++++=332211110 其中含有k 个定量变量,记为x i 。对春夏秋冬四个季节引入4个0-1型自变量,记为D i ,只取了6个观测值,其中春季与夏季取了两次,秋、冬各取到一次观测值,则样本设计矩阵为: ????? ? ?? ?? ? ?=00011001011000101001 0010100011 )(6 165154143 132121 11k k k k k k X X X X X X X X X X X X D X, 显然,(X,D)中的第1列可表示成后4列的线性组合,从而(X,D)不满秩,参数无法唯一求出。这就是所谓的“虚拟变量陷井”,应避免。 当某自变量x j 对其余p-1个自变量的复判定系数2j R 超过一定界限时,SPSS 软件将拒绝这个自变量x j 进入回归模型。称Tol j =1-2 j R 为自变量x j 的容忍度(Tolerance ),SPSS 软件的默认容忍度为0.0001。也就是说,当2j R >0.9999时,自变量x j 将被自动拒绝在回归方程之外,除非我们修改容忍度的默认值。 ??? ??? ? ??=k βββ 10β??? ??? ? ??=4321ααααα 第11章多重线性回归分析 思考与练习参考答案 一、最佳选择题 1. 逐步回归分析中,若增加自变量的个数,则( D )。 A. 回归平方和与残差平方和均增大 B. 回归平方和与残差平方和均减小 C. 总平方和与回归平方和均增大 D. 回归平方和增大,残差平方和减小 E. 总平方和与回归平方和均减小 2. 下面关于自变量筛选的统计学标准中错误的是( E )。 A. 残差平方和()缩小 B. 确定系数()增大 C. 残差的均方()缩小 D. 调整确定系数()增大 E. 统计量增大 3. 多重线性回归分析中,能直接反映自变量解释因变量变异百分比的指标为( C )。 A. 复相关系数 B. 简单相关系数 C.确定系数 D. 偏回归系数 E. 偏相关系数 4. 多重线性回归分析中的共线性是指( E )。 A.关于各个自变量的回归系数相同 B.关于各个自变量的回归系数与截距都相同 C.变量与各个自变量的相关系数相同 D.与自变量间有较高的复相关 E. 自变量间有较高的相关性 5. 多重线性回归分析中,若对某一自变量的值加上一个不为零的常数,则有( D )。 A. 截距和该偏回归系数值均不变 B. 该偏回归系数值为原有偏回归系数值的倍 C. 该偏回归系数值会改变,但无规律 D. 截距改变,但所有偏回归系数值均不改变 E. 所有偏回归系数值均不会改变 二、思考题 1. 多重线性回归分析的用途有哪些? 答:多重线性回归在生物医学研究中有广泛的应用,归纳起来,可以包括以下几个方面:定量地建立一个反应变量与多个解释变量之间的线性关系,筛选危险因素,通过较易测量的变量估计不易测量的变量,通过解释变量预测反应变量,通过反应变量控制解释变量。 2. 多重线性回归模型中偏回归系数的含义是什么? 答:偏回归系数的含义是:在控制其他自变量的水平不变的情况下,该自变量每改变一个单位,反应变量平均改变的单位数。 3. 请解释用于多重线性回归参数估计的最小二乘法的含义。 答:最小二乘法的含义是:残差的平方和达到最小。 4. 如何判断和处理多重共线性? 答:如果自变量之间存在较强的相关,则存在多重共线性。可以通过分析自变量之间的相关系数、计算方差膨胀因子和容忍度等指标判断是否存在多重共线性。如果自变量间存在多重共线性,最简单的处理办法是删除变量,即在相关性较强的变量中删除测量误差大的、缺失数据多的、从专业上看意义不是很重要的或者在其他方面不太满意的变量。其次,也可采用主成分回归方法。 5. 如何判断、分析自变量间的交互作用? 答:基于专业背景知识,构造可能的交互作用项,并检验交互作用项是否有统计学意义。 6. 多重线性回归模型的基本假定有哪些?如何判断资料是否满足这些假定?如果资料不满足假定条件,常用的处理方法有哪些?第15章 SPSS回归分析与市场预测.
应用回归分析课后习题参考答案
第一章课后习题解答(应用回归分析)
应用回归分析,第4章课后习题参考答案.
第十一章 分类资料的回归分析
spss多元线性回归分析92134
应用回归分析-第9章课后习题答案
第11章多重线性回归分析思考与练习参考答案
相关主题
文本预览