
第二十六课 协方差分析
当定量的影响因素对观察结果有难以控制的影响,甚至还有交互作用时,采用协方差分析,这些影响变量称为协变量,扣除(或消除)协变量的影响,可以得到修正后的均值估计。
一、 协方差分析概述
1. 协方差分析概念
协方差分析(analysis of covariance )又称带有协变量的方差分析(analysis of variance with covariates ),是将回归分析与方差分析结合起来使用的一种分析方法。在各种试验设计中,对主要变量y 研究时,常常希望其他可能影响和干扰y 的变量保持一致以到达均衡或可比,使试验误差的估计降到最低限度,从而可以准确地获得处理因素的试验效应。但是有时,这些变量难以控制,或者根本不能控制。为此需要在试验中同时记录这些变量的值,把这些变量看作自变量,或称协变量(covariate ),建立因变量y 随协变量变化的回归方程,这样就可以利用回归分析把因变量y 中受协变量影响的因素扣除掉,从而,能够较合理地比较定性的影响因素处在不同水平下,经过回归分析手段修正以后的因变量的总体均值之间是否有显著性的差别。简单地说,协方差分析是扣除协变量的影响,或者将这些协变量处理成相等,再对修正的y 的均值作方差分析。 2. 协方差分析的假定
协方差分析需要满足的假定为:
①各样本来自具有相同方差2
σ的正态分布总体,即要求各组方差齐性。 ②协变量与主要变量y 间的总体回归系数不等于0。 ③各组的回归线平等,即回归系数 ==21ββ。
如果上述的假定满足,就作协方差分析。前述的各种试验设计,如完全随机化设计、随机区组设计、析因设计、拉丁方设计等,都可以带一个或多个协变量,按设计方案扣除协变量的影响后,对主要变量y 的修正均值作比较,得出统计结论。 3. 协方差分析的模型
最简单的单因素一元协方差分析的模型,是由单因素效应模型ij i ij a y εμ++=加上协变量的影响因素)(x x ij -β而得出:
ij ij i ij x x a y εβμ+-++=)(
(26.1)
其中x 为协变量,ij x 为协变量在分类水平i 和j 上的记录值,x 为所有协变量的平均值,β为相关的回归系数。设x βμβ-=0,为平均截距。上式可以化简成
ij ij i ij x a y εββ+++=0
(26.2)
设i i a +=00ββ,上式可以化简成
ij ij i ij x y εββ++=0
(26.3)
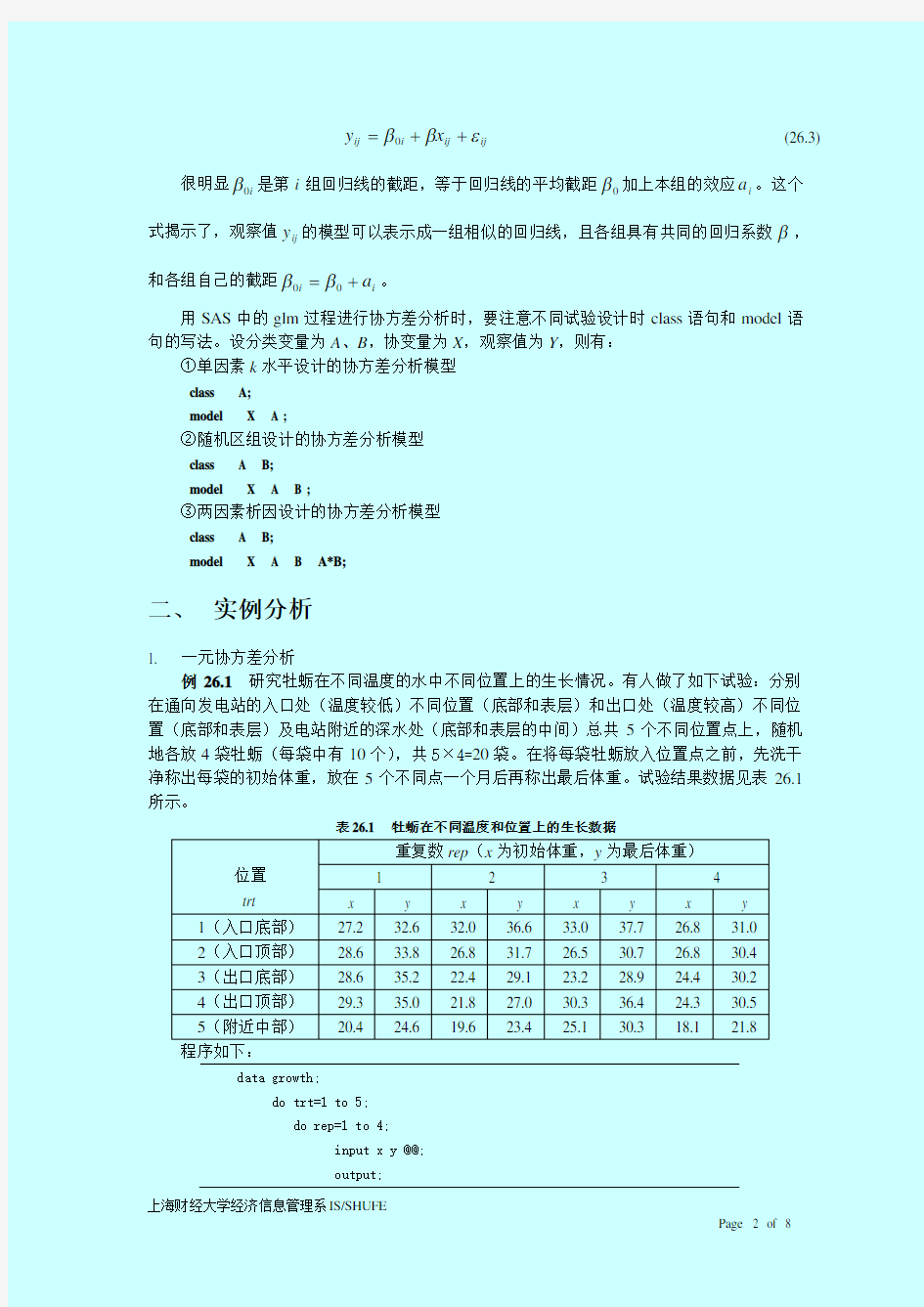
很明显i 0β是第i 组回归线的截距,等于回归线的平均截距0β加上本组的效应i a 。这个式揭示了,观察值ij y 的模型可以表示成一组相似的回归线,且各组具有共同的回归系数β,和各组自己的截距i i a +=00ββ。
用SAS 中的glm 过程进行协方差分析时,要注意不同试验设计时class 语句和model 语句的写法。设分类变量为A 、B ,协变量为X ,观察值为Y ,则有:
①单因素k 水平设计的协方差分析模型
class A; model X A ;
②随机区组设计的协方差分析模型
class A B; model X A B ;
③两因素析因设计的协方差分析模型
class A B;
model X A B A*B;
二、 实例分析
1. 一元协方差分析
例26.1 研究牡蛎在不同温度的水中不同位置上的生长情况。有人做了如下试验:分别在通向发电站的入口处(温度较低)不同位置(底部和表层)和出口处(温度较高)不同位置(底部和表层)及电站附近的深水处(底部和表层的中间)总共5个不同位置点上,随机地各放4袋牡蛎(每袋中有10个),共5×4=20袋。在将每袋牡蛎放入位置点之前,先洗干净称出每袋的初始体重,放在5个不同点一个月后再称出最后体重。试验结果数据见表26.1所示。
表26.1 牡蛎在不同温度和位置上的生长数据
位置 trt 重复数rep (x 为初始体重,y 为最后体重) 1 2
3
4
x y x y x y x y 1(入口底部) 27.2 32.6 32.0 36.6 33.0 37.7 26.8 31.0 2(入口顶部) 28.6 33.8 26.8 31.7 26.5 30.7 26.8 30.4 3(出口底部) 28.6 35.2 22.4 29.1 23.2 28.9 24.4 30.2 4(出口顶部) 29.3 35.0 21.8 27.0 30.3 36.4 24.3 30.5 5(附近中部) 20.4
24.6
19.6
23.4
25.1
30.3
18.1
21.8
程序如下:
data growth;
do trt=1 to 5; do rep=1 to 4;
input x y @@; output;
end;
end;
cards;
27.2 32.6 32.0 36.6 33.0 37.7 26.8 31.0
28.6 33.8 26.8 31.7 26.5 30.7 26.8 30.4
28.6 35.2 22.4 29.1 23.2 28.9 24.4 30.2
29.3 35.0 21.8 27.0 30.3 36.4 24.3 30.5
20.4 24.6 19.6 23.4 25.1 30.3 18.1 21.8
;
proc anova data=growth;
class trt;
model y=trt;
proc glm data=growth;
class trt;
model y=trt x /solution;
means trt;
lsmeans trt /stderr tdiff;
contrast 'trt12 vs trt34' trt -1 -1 1 1 0;
estimate 'trt1 adj mean' intercept 1 trt 1 0 0 0 0 x 25.76;
estimate 'trt2 adj mean' intercept 1 trt 0 1 0 0 0 x 25.76;
estimate 'adj trt diff' trt 1 -1 0 0 0;
estimate 'trt1 unadj mean' intercept 1 trt 1 0 0 0 0 x 29.75;
estimate 'trt2 unadj mean' intercept 1 trt 0 1 0 0 0 x 27.175;
estimate 'unadj trt diff' trt 1 -1 0 0 0 x 2.575;
run;
程序说明:定性变量trt的5个不同位置点对y可能有较大的影响,因此class语句中分组变量为trt,先选用anova过程进行方差分析。然而,牡蛎的初始体重x对牡蛎的最后体重y可能也有一定的影响,故适合选用glm过程进行协方差分析,在model语句中不仅包括分组变量trt,而且应包括协变量x。选择项solution要求输出回归系数的估计值及其标准误差和假设检验等结果。means和lsmeans语句要求输出分组变量trt各水平下y的未修正均值和修正后的均值,选择项stderr要求输出y的修正均值的标准误差、各修正均值与0比较的假设检验结果;选择项tdiff要求输出y的各修正均值之间两两比较所对应的t值和p值。
Contrast语句是用来比较入口处底部和顶部均值之和与出口处底部和顶部均值之和是否相等。前三条estimate语句是用来估计入口处底部和顶部调整后的均值及它们之差,并假设检验是否为0,后三条estimate语句是用来估计入口处底部和顶部未调整的均值及它们之差,并假设检验是否为0。程序输出的主要结果见表26.2(a)(b)(c)所示。
表26.2(a)单因素trt一元x的协方差分析
表26.2(a)中结果分析:对分组变量trt的方差分析表明,即使当初始体重x不考虑,各分
The SAS System
Analysis of Variance Procedure
Dependent Variable: Y
Source DF Sum of Squares Mean Square F Value Pr > F Model 4 198.40700000 49.60175000 4.64 0.0122 Error 15 160.26250000 10.68416667
Corrected Total 19 358.66950000
R-Square C.V. Root MSE Y Mean
0.553175 10.59706 3.26866436 30.84500000
Source DF Anova SS Mean Square F Value Pr > F TRT 4 198.40700000 49.60175000 4.64 0.0122
General Linear Models Procedure
Dependent Variable: Y
Source DF Sum of Squares Mean Square F Value Pr > F Model 5 354.44717675 70.88943535 235.05 0.0001 Error 14 4.22232325 0.30159452
Corrected Total 19 358.66950000
R-Square C.V. Root MSE Y Mean
0.988228 1.780438 0.54917622 30.84500000
Source DF Type I SS Mean Square F Value Pr > F TRT 4 198.40700000 49.60175000 164.47 0.0001 X 1 156.04017675 156.04017675 517.38 0.0001 Source DF Type III SS Mean Square F Value Pr > F TRT 4 12.08935928 3.02233982 10.02 0.0005 X 1 156.04017675 156.04017675 517.38 0.0001
T for H0: Pr > |T| Std Error of Parameter Estimate Parameter=0 Estimate
INTERCEPT 2.494859769 B 2.43 0.0293 1.02786287
组最后体重均值的区别也统计显著(0.0122<0.05),其中分组变量trt的平方和为198.40700000。而在协方差分析中,分组变量trt的类型1的平方和等于方差分析中的平方和198.40700000,分组变量trt的类型3的平方和为12.08935928,大大小于类型1的平方和,是因为类型3的平方和反映了经过共同的协变量x调整后的平方和,减去了协变量的影响,所以平方和大幅减小。类型1是一种未经过调整的平方和,因为它的优先级高于协变量的调整。更进一步分析,我们注意到方差分析中均方误差为10.68416667,而协方差分析中却缩小到0.30159452,相应地分组变量trt的F统计量从4.64增加到10.02,说明包含了协变量后分组的区别更加显著,原因是简单方差分析中,大多数的误差是由于初始体重x的变异造成的。
表中的最后一部分是选择项solution的输出结果,对模型中的截距、各分组变量和协变量的回归系数进行估计和检验,在这个单因素trt的情况下,估计是以最后一个水平trt5(trt=5)为对照组,并且设置它的系数为0,因此截距intercept的估计值是分组trt5的估计值。其他四个分组trt的系数估计是每一个与trt5进行比较而得到的。注意,出口处的trt3和trt4分组是不同与trt5分组。协变量x的系数是合并各组内y和x所得到的回归系数,即是由5个独立
的trt 分组,分别回归y 和x 后得到回归系数然后加权平均。协变量x 的系数估计值表明,初始体重变动1个单位最后体重y 相关地要变动1.083179819单位。
表26.2(b ) 未调整均值和调整均值及均值之间的比较
表26.2(b )中结果分析:means 语句要求计算按trt 每个水平分组的未调整的y 和x 均值。如?1y =34.475=(32.6+36.6+37.7+31)/4,?1x =29.75=(27.2+32+33+26.8)/4。Lsmeans 语句要求计算调整后的y 的均值,或称最小二乘均值估计,我们可以由(26.1)公式求分组平均得到:
)
()(x x y y x x y a i i i ij
ij ij i --=+--=+???βεβμ
(26.4)
再由(25.2)公式求分组平均代入上式:
x
a x x y x x y y i i i i i i βββββ
++=+-=--=?????0)
( (26.5)
例如,初始体重的整体平均值为x =(29.750+27.175+24.650+26.425+20.800)/5=25.76,以trt 1分组为例,调整后?1y =30.1531125=34.475-1.083179819×(29.75-25.76)。tdiff 选择项要求对已调整均值的两两比较采用lsd 检验,可以使用adjust = duncan/waller 等选项替代lsd 检验,获得其他多重比较的检验结果。从最后的5×5修正均值比较结果表中,可得到(???521,,y y y )中的任何一个与(??43,y y )中的任何一个之间有显著或非常显著性差别。
表26.2(c ) 有计划的均值对比和参数估计
The SAS System
General Linear Models Procedure
Level of --------------Y-------------- --------------X-------------- TRT N Mean SD Mean SD 1 4 34.4750000 3.18891309 29.7500000 3.20572405 2 4 31.6500000 1.53731367 27.1750000 0.96046864 3 4 30.8500000 2.95578529 24.6500000 2.75862284 4 4 32.2250000 4.29757684 26.4250000 4.04917687 5 4 25.0250000 3.69898635 20.8000000 3.02103735
Least Squares Means
TRT Y Std Err Pr > |T| LSMEAN LSMEAN LSMEAN H0:LSMEAN=0 Number 1 30.1531125 0.3339174 0.0001 1 2 30.1173006 0.2827350 0.0001 2 3 32.0523296 0.2796295 0.0001 3 4 31.5046854 0.2764082 0.0001 4
表26.2(c )中结果分析:contrast 语句通过其后的参数项设置,用来假设检验我们自己计划的原假设????+=+43210:y y y y H ,结果显示非常显著(0.0001<0.05),即入口处底部和顶部均值之和与出口处底部和顶部均值之和是有显著差异的,说明水中的温度不同对牡蛎生长是不同的。本程序中的estimate 语句,有计划地设计了对入口处的底部和顶部调整后均值进行估计,及它们之差是否为0的假设检验,结果为不显著。但如果对未调整均值之差是
否为0进行假设检验,结果却为非常显著。因此,我们可以看到使用调整后均值进行估计是必要的。
2. 多元协方差分析
例26.2 研究男女儿童的体表面积是否相同。考虑到儿童的身高和体重对表面积可能有影响,在某地测量了男女各15名初生至3周岁儿童的身高、体重和体表面积,得到测量数据见表26.3所示。
表26.3 3周岁男女儿童的身高、体重和体表面积
男(male )
女(female )
身高(x 1)
体重(x 2)
表面积(y ) 身高(x 1)
体重(x 2)
表面积(y ) 54.0 3.00 2446.2 54.0 3.00 2117.3 50.5 2.25 1928.4 53.0 2.25 2200.2 51.0 2.50 2094.5 51.5 2.50 1906.2 56.5 3.50 2506.7 51.0 3.00 1850.3 52.0 3.00 2121.0 51.0 3.00 1632.5 76.0 9.50 3845.9 77.0 7.50 3934.0 80.0 9.00 4380.8 77.0 10.0 4180.4 74.0 9.50 4314.2 77.0 9.50 4246.1 80.0 9.00 4078.4 74.0 9.00 3358.8 76.0 8.00 4134.5 73.0 7.50 3809.7 96.0 13.5 5830.2 91.0 12.0 5358.4 97.0 14.0 6013.6 91.0 13.0 5601.7 99.0 16.0 6410.6 94.0 15.0 6074.9 92.0 11.0 5283.3 92.0 12.0 5299.4 94.0 15.0
6101.6
91.0
12.5
5291.5
程序如下:
proc format;
The SAS System
Dependent Variable: Y
Contrast DF Contrast SS Mean Square F Value Pr > F trt12 vs trt34 1 8.59108077 8.59108077 28.49 0.0001
T for H0: Pr > |T| Std Error of Parameter Estimate Parameter=0 Estimate trt1 adj mean 30.1531125 90.30 0.0001 0.33391743 trt2 adj mean 30.1173006 106.52 0.0001 0.28273504 adj trt diff 0.0358120 0.09 0.9312 0.40722674
value sexname 1=’male’ 2=’female’;
data child;
do i=1 to 15;
do sex=1 to 2;
input x1 x2 y @@;
format sex sexname.;
output;
end;
end;
cards;
54.0 3.00 2446.2 54.0 3.00 2117.3
50.5 2.25 1928.4 53.0 2.25 2200.2
51.0 2.50 2094.5 51.5 2.50 1906.2
56.5 3.50 2506.7 51.0 3.00 1850.3
52.0 3.00 2121.0 51.0 3.00 1632.5
76.0 9.50 3845.9 77.0 7.50 3934.0
80.0 9.00 4380.8 77.0 10.0 4180.4
74.0 9.50 4314.2 77.0 9.50 4246.1
80.0 9.00 4078.4 74.0 9.00 3358.8
76.0 8.00 4134.5 73.0 7.50 3809.7
96.0 13.5 5830.2 91.0 12.0 5358.4
97.0 14.0 6013.6 91.0 13.0 5601.7
99.0 16.0 6410.6 94.0 15.0 6074.9
92.0 11.0 5283.3 92.0 12.0 5299.4
94.0 15.0 6101.6 91.0 12.5 5291.5
;
proc glm data=child;
class sex;
model y=sex x1 x2 /solution;
lsmeans sex /stderr tdiff;
run;
程序说明:本例为带有两个协变量x1和x2,一个分组变量sex的完全随机化设计的多元协方差分析。data步中为了便于读人数据,sex分组变量取值为1和2,但又为了显示清楚,用format过程自定义了sexname.格式,用于sex变量的显示格式。在class语句中只能有sex 分组变量,而在model语句中应把观察指标放在等号的左边,分组变量和协变量放在等号的右边,solution选项求回归方程的系数估计。lsmeans语句求修正后均值,stderr选项求均值的标准误差,tdiff选项求均值对比的t值和p值。程序输出的主要结果见表26.4所示。
表26.4 单因素的多元协方差分析
表26.4中结果分析:由类型3的平方和计算结果表明,身高、体重对体表面积都有非常显著性的影响(0.0001<0.05,0.0059<0.05),而男、女两性之间无显著性差别(0.0762>0.05)。由回归分析的结果可知道,与x 1、x 2相对应的公共偏回归系数系数为=1β54.477217、
=2β130.645108,它们与0之间差别的检验结果为p =0.0001和p =0.0059。男、女两性体表面
积的修正均值分别为52.32694和52.32694,两者之间无显著性差别(p =0.0762)。
The SAS System
General Linear Models Procedure
Dependent Variable: Y
Source DF Sum of Squares Mean Square F Value Pr > F Model 3 68523072.11494280 22841024.03831420 557.41 0.0001 Error 26 1065399.75872373 40976.91379707 Corrected Total 29 69588471.87366650
R-Square C.V. Root MSE Y Mean 0.984690 5.131187 202.42755197 3945.04333333 Source DF Type I SS Mean Square F Value Pr > F SEX 1 714100.40833333 714100.40833333 17.43 0.0003 X1 1 67440016.91708050 67440016.91708050 1645.81 0.0001 X2 1 368954.78952901 368954.78952901 9.00 0.0059 Source DF Type III SS Mean Square F Value Pr > F SEX 1 139769.33971381 139769.33971381 3.41 0.0762 X1 1 938153.70360865 938153.70360865 22.89 0.0001 X2 1 368954.78952901 368954.78952901 9.00 0.0059 T for H0: Pr > |T| Std Error of Parameter Estimate Parameter=0 Estimate INTERCEPT -1118.730592 B -2.25 0.0331 497.2296650 SEX female -136.828607 B -1.85 0.0762 74.0867551 male 0.000000 B . . . X1 54.477217 4.78 0.0001 11.3853803 X2 130.645108 3.00 0.0059 43.5387744 NOTE: The X'X matrix has been found to be singular and a generalized inverse was used to solve
方差分析和协方差分析,协变量和控制变量 方差分析 方差分析(Analysis of Variance,简称ANOVA),又称“变异数分析”或“F检验”,是R.A.Fisher发明的,用于两个及两个以上样本均数差别的显著性检验。由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。 方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。 假定条件和假设检验? 1. 方差分析的假定条件为:(1)各处理条件下的样本是随机的。(2)各处理条件下的样本是相互独立的,否则可能出现无法解析的输出结果。(3)各处理条件下的样本分别来自正态分布总体,否则使用非参数分析。(4)各处理条件下的样本方差相同,即具有齐效性。 2. 方差分析的假设检验假设有K个样本,如果原假设H0样本均数都相同,K个样本有共同的方差σ,则K个样本来自具有共同方差σ和相同均值的总体。如果经过计算,组间均方远远大于组内均方,则推翻原假设,说明样本来自不同的正态总体,说明处理造成均值的差异有统计意义。否则承认原假设,样本来自相同总体,处理间无差异。 作用 一个复杂的事物,其中往往有许多因素互相制约又互相依存。方差分析的目的是通过数据分析找出对该事物有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。方差分析是在可比较的数组中,把数据间的总的“变差”按各指定的变差来源进行分解的一种技术。对变差的度量,采用离差平方和。方差分析方法就是从总离差平方和分解出可追溯到指定来源的部分离差平方和,这是一个很重要的思想。经过方差分析若拒绝了检验假设,只能说
(一)原理 一、基本思想 在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。这种影响的变量称为协变量(一般是连续变量)。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。 协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。 协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。 当有一个协变量时,称为一元协方差分析,当有两个或两个以上的协变量时,称为多元协方差分析。
二、协方差分析需要满足的条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量;对连续变量或定距变量的协变量的测量不能有误差; (2)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;协变量的回归系数(即各回归线的斜率)是相同的,且不等于0,即各组的回归线是非水平的平行线。否则,就有可能犯第一类错误,即错误地接受虚无假设; (3) 自变量与协变量相互独立,若协方差受自变量的影响,那么协方差分析在检验自变量的效应之前对因变量所作的控制调整将是偏倚的,自变量对因变量的间接效应就会被排除; (4)各样本来自具有相同方差σ2的正态分布总体,即要求各组方差齐性。 三、基本理论 1. 观测值=均值+分组变量影响+协变量影响+随机误差. 即 ()ij i ij ij y u t x x βε=++-+ (1) 其中,X 为所有协变量的平均值。 注:在方差分析中,协变量影响是包含在随机误差中的,在协方差分析中需要分离出来。 用协变量进行修正,得到修正后的y ij (adj)为 (adj)()ij ij ij i ij y y x x u t βε=--=++ 就可以对y ij (adj)做方差分析了。关键问题是求出回归系数β. 2. 总离差=分组变量离差+协变量离差+随机误差,
协方差分析理论与案例 假设我们有N 个个体的K 个属性在T 个不同时期的样本观测值,用it y ,it x ,…,N,t=1,…,T,k=1,…,K 表示。一般假定y 的观测值是某随机实验的结果,该实验结果在属性向量x 和参数向量θ下的条件概率分布为(,)f y x θ。使用面板数据的最终目标之一就是利用获取的信息对参数θ进行统计推断,譬如常假设假定的y 是关于x 的线性函数的简单模型。协方差分析检验是识别样本波动源时广泛采用的方法。 方差分析:常指一类特殊的线性假设,这类假设假定随机变量y 的期望值仅与所考察个体所属的类(该类由一个或多个因素决定)有关,但不包括与回归有关的检验。而协方差分析模型具有混合特征,既像回归模型一样包含真正的外生变量,同时又像通常的方差一样允许每个个体的真实关系依赖个体所属的类。 常用来分析定量因素和定性因素影响的线性模型为: *,1,,,1,,it it it it it y x u i N t T αβ'=++=???=??? 从两个方面对回归系数估计量进行检验:首先,回归斜率系数的同质性;其 次,回归截距系数的同质性。检验过程主要有三步: (1) 检验各个个体在不同时期的斜率和截距是否都相等; (2) 检验(各个体或各时期的)回归斜率(向量)是否都相等; (3) 检验各回归截距是否都相等。 显然,如果接受完全同同质性假设(1),则检验步骤中止。但如果拒绝了完全同质性性假设,则(2)将确定回归斜率是否相同。如果没有拒绝斜率系数的同质性假设,则(3)确定回归截距是否相等。(1)是从(2)、(3)分离出来的。 基本思想:在作两组或多组均数1y ,2y ,…,k y 的假设检验前,用线性回归分析方法找出协变量X 与各组Y 之间的数量关系,求得在假定X 相等时修定均数1y ',2y ',…,k y '然后用方差分析比较修正均数间的差别,这就是协方差分析的基本思想。 协方差分析的应用条件:⑴要求各组资料都来自正态总体,且各组的方差相等;(t 检验或方差分析的条件)⑵各组的总体回归系数i β相等,且都不等于0(回归方程检验)。因此,应用协方差分析前,要对资料进行方差齐性检验和回归系数的假设检验(斜率同质性检验),只有满足上述两个条件之后才能应用,否则不宜使用。 ⑴各比较组协变量X 与分析指标Y 存在线性关系(按直线回归分析方法进行判断)。 ⑵各比较组的总体回归系数i β相等,即各直线平行(绘出回归直线,看是否
方差分析(ANOVA)与协方差分析(ANCOVA) 第5章方差分析(ANOVA)与协方差分析(ANCOVA) ——野外竞争试验 Deborah E.Goldberg Samuel M.Scheiner 5.1 引言 自从达尔文时期,竞争就占据了生态理论的中心,关于竞争的实验在许多来自许多不同环境的多生物种之间开展过(Jackson,1981综述; Connell,1984; Schoener,1984; Hairston,1989; Gurevitch,1992)。有各种各样的竞争实验,而本章的重点则放在怎样为具体的竞争问题选择适当的实验设计和统计分析。这类选择取决于所研究问题及系统的许多方面。对于大多数我们所给出的设计、基本的统计方法、方差分析(ANOVA)和协方差分析(ANCOVA)在实验设计与分析的教科书中也有详尽描述,我们在这里就不像本书其他章节那样提供详细的统计细节。对于ANOVA的基本介绍见第四章。虽然我们着重于竞争,但许多观点对其他类型的种间关系实验同样有效,如捕食者—猎物关系或者互惠共生关系。 5.2 关于竞争的生态问题 我们可以提出关于竞争的最简单问题莫过于竞争是否在野外存在,要回答这个问题,就必须利用实验处理,使潜在竞争者们的绝对多度可被控制,同时检验处理中存在低多度潜在竞争者时物种是否可能生长的更好。这类多度处理之间生长的差异即是竞争的量纲(或促进facilitation的量纲如果在较高多度下生长较佳)。在任何野外竞争调查中,发现是否存在竞争是重要的第一步,但是,就其本身而言,并没有什么意义。多数关于竞争的重要问题包括竞争强度的比较以及随之而来的实
协方差分析的基本原理 1.协方差分析的提出 无论是单因素方差分析还是多因素方差分析,它们都有一些人为可以控制的控制变量。在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。又比如,考查受教育程度对个人工资是否有显著影响,这时必须考虑工作年限因素。一般情况下,工作年限越长,工资就越高。在研究此问题时必须排除工作年限因素的影响,才能得出正确的结论。再如,如果要了解接受不同处理的小白鼠经过一段时间饲养后体重增加量有无差别,已知体重的增加和小白鼠的进食量有关,接受不同处理的小白鼠其进食量可能不同,这时为了控制进食量对体重增加的影响,可在统计阶段利用协方差分析(Analysis of Covariance),通过统计模型的校正使得各组在“进食量”这个变量的影响上相等,即将进食量作为协变量,然后分析不同处理对小白鼠体重增加量的影响。 为了更加准确地控制变量不同水平对结果的影响,应该尽量排除其它在实验设计阶段难以控制或者是无法严格控制的因素对分析结果的影响。利用协方差分析就可以完成这样的功能。协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。当有一个协变量时,称为一元协方差分析,当有两个或两个以上的协变量时,称为多元协方差分析。以下将以一元协方差分析为例,讲述协方差分析的基本思想和步骤。 2.协方差分析的计算公式 以单因素协方差分析为例,总的变异平方和表示为: Q Q Q Q ++ 总控制变量协变量随机变量 = 协方差分析仍然采用F检验,其零假设 H为多个控制变量的不同水平下,各总体平均值没有显著差异。 F统计量计算公式为: 2 2 S F S 控制变量 控制变量 随机变量 =, 2 2 S F S 协变量 协变量 随机变量 = 以上F统计量服从F分布。SPSS将自动计算F值,并根据F分布表给出相应的相伴概率值。 如果F 控制变量 的相伴概率小于或等于显著性水平,则控制变量的不同水平对观察变量产生了显著的影响;如 果F 协变量 的相伴概率小于或等于显著性水平,则协变量的不同水平对观察变量产生了显著的影响。 3.协方差分析需要满足的假设条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量; (2)对连续变量或定居变量的协变量的测量不能有误差; (3)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;(4)协变量的回归系数是相同的。在分类变量形成的各组中,协变量的回归系数(即各回归线的斜率)必须是相等的,即各组的回归线是平行线。如果违背了这一假设,就有可能犯第一类错误,即错误地接受虚无假设。
协方差分析 某城市教育局在一次对全市初中一年级至高中三年级学生的调查研究中想要考察身心发展对学习成绩的影响,研究者手机了各学校初一年级至高三年级学生的学业成绩以及相关身心发展量表得分,在分析时以学生所在年级来代表年龄差异,但是由于男同学与女同学的身心发展存在差异,因此需要在结果中排除性别因素,然而无法在收集数据时只收集男同学的数据或收集女同学的数据,那么该如何排除性别因素对结果的影响呢? 在实验设计中,考虑到实际的实验情形,无法一一排除某些会影响实验结果的无关变量(干扰变量),为了排除这些不能在实验处理中所操作的变量,而其结果又会影响因变量,可以通过“统计控制”的方法来弥补实验控制的不足,为了提高实验研究的内在效率,必须将可能干扰实验结果的无关变量加以控制,不致产生严重的系统性误差。控制系统误差的方法有很多,例如以随机的方式将被试分配至不同群体;将系统误差加入实验设计,使其变成一个自变量;尽可能控制可控制的系统误差如光纤亮度、噪音等。 实验研究的优点众所周知,即其严密的逻辑性以及可以良好的控制误差,但是让一个标准的实验设计走出实验室,在社会科学领域实施通常比较困难。因此在社会科学领域中经常实施的是准实验设计,在准实验设计中无法使用实验控制法来完全控制无关的干扰变量,故经常增加实验内在效度的方法——统计控制法,最常用的便是协方差分析(analysis of covariance,ANCOV A)。 顾名思义,协方差分析是方差分析的一种,它也包括自变量与因变量,同方差分析,因变量为连续变量且需要满足方差分析关于因变量的假设条件,自变量为分类变量。不同的是,并不是实验所关注的自变量却为研究者进行控制的一类变量被加入分析,它们被称为“协变量”(covariate),要注意,协变量是连续变量。 1.协方差分析的假设 协方差分析的基本假设与方差分析相同,包括变量的正态性、观测值独立、方差齐性等,此外还有三个重要的假设: 1)因变量与协方差之间直线关系; 2)所测量的协变量不应有误差,如果选用的是多项的量表,应有高的内部一致性信度或重 测信度,α系数最好大于0.80。这一假设若被违反会造成犯一类错误的概率上升,降低统计检验力。 3)“组内回归系数同质性”(homogeneity of with in rgression),各实验处理组中一举 协变量(X)预测因变量(Y)的回归线的回归系数要相等,即斜率相等,各条回归线平行。如果斜率不等则不宜直接进行协方差分析。 2.协方差分析的方差分解 方差分析的原理是将因变量的总方差分解成自变量效果(组间)与误差效果(组内)两个部分,再进行F检验。协方差使用的也是这样的方差分析思路,将因变量的总方差先行分割为协变量可解释部分与不可解释部分,不可解释的部分再由方差分析原理进行拆解。协方差分析的方差拆解如下: 3.协方差分析的步骤 协方差分析结合了回归分析与方差分析的方法,计算方法比较复杂,由于涉及回归分析的基本思路,因此一下内容也许需要在阅读了本章第六部分“一元线性回归分析”后理解得更加透彻。 以单因素协方差分析为例说明协方差分析的步骤: 1)协方差分析的准备 (B:组间;W:组内;T:总和;n:组内样本容量;k:组间容量;x:协变量;y:因变量)
第四章方差分析 方差分析(Analysis of Variance,ANOVA)是将待分析资料的总变异剖分为不同的变异来源,以获得不同变异来源的总体方差的估计值。通过F检验,完成多个样本平均数之间的差异显著性检验(即多重比较),若处理效应为随机模型时,则进行方差组分的估计。 4.1 方差分析的SAS过程 用于方差分析的主要过程有方差分析(ANOVA)和广义线性模型(GLM)。对于无缺省(缺值、缺组等)资料,或称平衡资料,一般采用(ANOVA)过程,对缺省资料(非平衡资料)应采用(GLM)过程。事实上根据效应模型的不同,还有VARCOME(方差组分)过程,MIXED(混合模型)过程等。 4.1.1 ANOVA过程 1. 名词解释 自变量与依变量在方差分析中,自变量可称为独立变量、定性变量(Qualitative Variale)、分类变量(Classiflcation Variable)或类别变量(Categorcal Variable),相当于因素处理、水平变量。依变量又称反应变量(Response Variable),相当于观察值变量。 实验效应方差分析的目的是找出对依变量产生的实验效应,这种效应可分为3种:主效应,常以自变量的英文字母表示,如A、B等。互作效应,常以星号联接自变量表示,如A*B。嵌套效应,以小括号表示,如A(B)表示A效应嵌套在B效应之内。 2 语句说明: CLASS指令必须出现在MODEL指令之前,如选用TEST、MANOVA指令,则它们必须出现在MODEL指令之后。MEANS、TEST及MANOVA等指令可重复使用,其他指令则只能出现一次。
PROC ANOV A选项串中:⑴DA TA=输入数据集名称,指明对它执行ANOV A分析。⑵MANOV A 要求将含一个或一个以上依变量遗漏数据的观察值剔除。⑶OUTPUT=(含分析结果的)输出文件名称,包括平方和(SS),F检验值,以及各效应的显著程度。 CLASS变量名称串指明自变量,自变量可以是数值的或文字的。 MODEL指令定义分析所用的线性数学模型(见表6—1),删除号(/)后的选项:⑴NOUNI:不印出单变量方差分析的结果,适用于多变量的方差分析。⑵INT:要求SAS把线性模型内的截距(即资料的总平均数)当成一个参数,同时对这个截距作是否为零的假设检验。 MEANS指令前半部要求算出某些自变量(或互作)中各组的平均数,后半部(删除号后)共有24个选项,前17个选项分别对MEANS指令中所列的主效应平均数进行多种方法的多重比较。这些选项有:⑴BON:修正最小显著差异t检验。⑵DUNCAN:邓肯多重范围检验,即邓肯氏新复极差法。⑶DUNNETT(控制组组名):邓尼特控制差异检验。它是依据t分布由各组平均数与控制组(指定组如对照组)进行比较,采用双尾检验。⑷DUNNETTL(控制组组名):邓尼特小于控制均数检验。与控制组平均数的比较,采用单尾检验,临界值订在t分布的下端。⑸DUNNETTU(控制组组名):邓尼特大于控制均数检验。与控制组平均数的比较,采用单尾检验,临界值订在t分布的上端。⑹GABRIEL:贵博氏多重比较。⑺REGWF:R—E—G—W多重F检验。⑻REGWQ:R—E—G—W多种t检验。⑼SCHEFFE:执行沙菲氏(Scheffe)的多重比较检验。⑽SIDAK:Sidak调整T检验。⑾SUM(或⑿GTI):Sidak独立样本t检验。当两组样本含量不等时为哈氏(Hochberg)的GTI 检验。⒀SNK:纽曼—库尔多重范围检验,即q检验。⒁T(或⒂LSD):配对t检验或费歇尔最小显著差异检验。⒃TUKEY:图基固定极差检验。⒄W ALLER:娃尔—邓肯K—比率t检验。以上17种检验法最常用的为⑵、⑶、⑸、⒀、⒁。其它主要选项还有⒅ALPHA=P:界定检验的显著水准。内设值为P=0.05。当上面选项与选项⑵并用时,P值必须是0.10、0.05、0.01三者之一。与上面其他检验选项时,P可以是0.0001与0.9999间任何的值。⒆LINES:将显著性检验的平均数,由大到小排列。若某一对平均数之间无显著差异,则将它们印在同一行上,并以虚线将它们与其他有显著差异的平均数分开。当选用⑵、⑺、⑻、⒀或⒄等检验时,此选项会自动被包括在内,否则,必须附加此选项。⒇CLM:效应的各组平均数以置信区间方式表示。此项必须与⑴、⑹、⑼、⑽、⑾、⒁、⒂等联用。(21)CLDIFF:与(20)相仿,选用⑵、⑺、⑻、⒀、⒄时,附加此选项,将以置信区间方式显示各组平均数。(22)E=效应名称:它界定各显著检验的分母,缺省时以误差项的均方自动成为分母。 FREQ指令指明该变量值为各观察值重复出现的次数。 TEST指令用来指定F检验的分子与分母,H=分子,E=分母;一般而言,系统自动采用误差项的均方作为F检验的分母。但对于随机模型等,可选此项。 MANOV A指令主要用于执行多变量(多元)方差分析。 BY指令用于把数据文件分成几个小文件,然后逐一进行ANOV A分析,但文件内的数据必须先按照BY变量串的值做由小到大的重新排列。此步骤可籍PROC SORT达成。 以上指令中MODEL指令至关重要,同一资料,分析结果依模型不同而异。常用的模型定义语句有:MODEL Y=A;单因素方差分析,MODEL Y=A B两因素主效应模型,MODEL Y=A B A*B两因素带互作模型,MODEL Y=A B(A)嵌套(NESTED)模型用
23. 协方差分析 一、基本原理 1. 基本思想 在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。这种影响的变量称为协变量(一般是连续变量)。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。 协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。 协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。 当有一个协变量时,称为一元协方差分析,当有两个或两个以上
的协变量时,称为多元协方差分析。 2. 协方差分析需要满足的条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量;对连续变量或定距变量的协变量的测量不能有误差; (2)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;协变量的回归系数(即各回归线的斜率)是相同的,且不等于0,即各组的回归线是非水平的平行线。否则,就有可能犯第一类错误,即错误地接受虚无假设; (3) 自变量与协变量相互独立,若协方差受自变量的影响,那么协方差分析在检验自变量的效应之前对因变量所作的控制调整将是偏倚的,自变量对因变量的间接效应就会被排除; (4)各样本来自具有相同方差σ2的正态分布总体,即要求各组方差齐性。 二、协方差理论 1. 观测值=均值+分组变量影响+协变量影响+随机误差. 即 ()ij i ij ij y u t x x βε=++-+ (1) 其中,X 为所有协变量的平均值。 注:在方差分析中,协变量影响是包含在随机误差中的,在协方差分析中需要分离出来。 用协变量进行修正,得到修正后的y ij (adj)为 (adj)()ij ij ij i ij y y x x u t βε=--=++
协方差分析在教学评价中的应用
协方差分析在教学评价中的应用 摘要:通过回归分析和方差分析方法的结合,协方差分析方法能够有效地消除混杂因素对分析指标的影响.运用SPSS软件,对某 高校六个班一门基础课和一门专业课上下学期的期末成绩进 行了协方差分析.结论显示,协方差分析方法能够对教学效率 做出更合理的评价. 关键词: 协方差分析教学效率方差分析 一前言 方差分析是从质量因子探讨不同因素水平对实验指标影响的差异.一般来说,质量因子是可以人为控制的.回归分析是从数量因子的角度出发,通过建立回归方程来研究实验指标与一个(或几个)因子之间的数量关系.大多数情况下,数量因子是不可以人为加以控制的. 协方差分析是建立在方差分析和回归分析基础之上的一种统计分析方法.在许多有关效果评价的实验中,经常会出现可控制的质量因子和不可控制的数量因子同时影响实验结果的情况,这时就需要采用协方差分析的统计处理方法,将质量因子与数量因子(即协变量)综合起来加以考虑. 比如,在实际的教学管理中,要评价教学效率和质量,比较不同班级同一课程的学习效率,除了要考虑使用教程、教师素质、教学方法、
班级学风、学生学习努力程度这些当前影响因素以外,学生的前期学习基础差异也影响着当前的教学效率.为了能够准确地考查评价教学效率,必须消除前期学习基础差异这些因素的影响,才能得到正确的评价. 方差分析法忽视了学生的基础成绩对当前成绩的影响,没有考虑学生的基础成绩这一混杂因素的影响,仅仅对当前的学生学习成绩进行评价,得出的结论就不能全面客观地反映实际教学效率. 本研究采用协方差分析法,利用一个教学班两个学期的物流管理课程期末成绩和配送中心管理课程期末成绩的数据,对教学效率的评价问题进行了研究. 二协方差分析及公式 为了提高实验效果的精确性,需要尽力排除影响实验结果的其他因素,即非处理因素(混杂因素)的干扰和影响,使各处理间尽量一致,再对各处理因素做方差分析,这就是协方差分析. 协方差分析的基本思想是在作两组或多组均数yi(i =1,2,…, n)之间的比较前,用直线回归方法找出各组因变量与协变量之间的数量关系,求得在假定协变量相等时的修正均数yi(i =1,2,…, n),然后用方差分析比较修正均数的差别.协方差分析涉及一些较深的统计理论, (1)计算各组的均值、平方和及协方和:
一、方差分析和回归分析的区别与联系?(以双变量为例) 联系: 1、概念上的相似性 回归分析是为了分析变量间的因果关系,研究自变量X取不同值时,因变量平均值Y的变化。运用回归分析方法,可以从变量的总偏差平方和中分解出已被自变量解释掉的误差(解释掉误差)和未被解释掉的误差(剩余误差); 方差分析是为了分析或检验总体间的均值是否有所不同。通过对样本中自变量X取不同值时所对应的因变量Y均值的比较,推论到总体变量间是否存在关系。运用方差分析,也可以从变量的总离差平方和中分解出已被自变量解释掉的误差和未被自变量解释掉的误差。因此两种分析在概念上所具有的相似性是显而易见的。 2、统计分析步骤的相似性 回归分析在确定自变量X是否为因变量Y的影响因素时,从分析步骤上先对X和Y进行相关分析,然后建立变量间的回归模型。最后再进行参数的统计显着性检验或对回归模型的统计显着性进行检验。 方差分析在确定X是否是Y的影响因素时,是先从样本所的数据的分析入手,然后考察数据模型,最后对样本均值是否相等进行显着性检验。二者在分析步骤上也具有相似性。 3、假设条件具有一定的相似性 回归分析有五个基本假定,分别是:自变量可以是随机变量也可以是非随机变量;X与Y之间存在的非确定性的相关关系,要求Y的所有子总体,其方差都相等;子总体均值在一条直线上;随机变量Y i是统计独立的,即Y1的数值不影响Y2的数值,各Y值之间都没有关系;Y 值的每一个子总体都满足正态分布。 方差分析的基本假定有:等方差性(总体中自变量的每一取值所对应因变量Y i的分布都具有相同方差);Y i的分布为正态分布。 二者在假设条件上存在着相同。 4、在总离差平方和中的分解形式和逻辑上的相似性 回归分析中,TSS=RSS+RSSR,而在方差分析中,TSS=RSS+BSS。二者均是以已解释掉的误差与未被解释掉的误差之和为总离差平方和。 5、确定影响因素上的相似性 为简化分析起见,我们假设只有一个自变量X影响因变量Y。在回归分析中,要确定X是否是Y 的影响因素,就要看当X已知时,对Y的总偏差有无影响。如果X不是影响Y的因素,等同于只知变数Y的数据列一样,此时用Y去估计每个丫的值,所犯的错误(即偏差)为最小。如果因素X 是影响Y的因素,那么当已知X值后 6、在统计显着性检验上具有相似性 回归分析的总显着性检验,是一种用R2测量回归的全部解释功效的检验。检验RSSR*(N-2)/RSS,方差分析的显着性检验是一种根据样本数据提取信息所进行的显着性检验。它也是通过F检验进行的。 区别: 1、研究变量的分析点不同 回归分析法既研究变量Y又研究变量X并在此基础上集中研究变量Y与X的函数关系,得到的是在不独立的情况下自变量与因变量之间的更加精确的回归函数式,也即判断相关关系的类型,因此需建立模型并估计参数。方差分析法集中研究变量Y的值及其变差而变量X值仅用来把Y值划分为子群或组,得到的是自变量(因素)对总量Y是否具有显着影响的整体判断,因此不需要建立模型和估计参数。
23. 协方差分析 (一)原理 一、基本思想 在实际问题中,有些随机因素是很难人为控制的,但它们又会对结果产生显著影响。如果忽略这些因素的影响,则有可能得到不正确的结论。这种影响的变量称为协变量(一般是连续变量)。 例如,研究3种不同的教学方法的教学效果的好坏。检查教学效果是通过学生的考试成绩来反映的,而学生现在考试成绩是受到他们自身知识基础的影响,在考察的时候必须排除这种影响。 协方差分析将那些难以控制的随机变量作为协变量,在分析中将其排除,然后再分析控制变量对于观察变量的影响,从而实现对控制变量效果的准确评价。 协方差分析要求协变量应是连续数值型,多个协变量间互相独立,且与控制变量之间没有交互影响。前面单因素方差分析和多因素方差分析中的控制变量都是一些定性变量,而协方差分析中既包含了定性变量(控制变量),又包含了定量变量(协变量)。 协方差分析在扣除协变量的影响后再对修正后的主效应进行方差分析,是一种把直线回归或多元线性回归与方差分析结合起来的方法,其中的协变量一般是连续性变量,并假设协变量与因变量间存在线性关系,且这种线性关系在各组一致,即各组协变量与因变量所建立的回归直线基本平行。 当有一个协变量时,称为一元协方差分析,当有两个或两个以上
的协变量时,称为多元协方差分析。 二、协方差分析需要满足的条件 (1)自变量是分类变量,协变量是定距变量,因变量是连续变量;对连续变量或定距变量的协变量的测量不能有误差; (2)协变量与因变量之间的关系是线性关系,可以用协变量和因变量的散点图来检验是否违背这一假设;协变量的回归系数(即各回归线的斜率)是相同的,且不等于0,即各组的回归线是非水平的平行线。否则,就有可能犯第一类错误,即错误地接受虚无假设; (3)自变量与协变量相互独立,若协方差受自变量的影响,那么协方差分析在检验自变量的效应之前对因变量所作的控制调整将是偏倚的,自变量对因变量的间接效应就会被排除; (4)各样本来自具有相同方差σ2的正态分布总体,即要求各组方差齐性。 三、基本理论 1. 观测值=均值+分组变量影响+协变量影响+随机误差. 即 ()ij i ij ij y u t x x βε=++-+(1) 其中,X 为所有协变量的平均值。 注:在方差分析中,协变量影响是包含在随机误差中的,在协方差分析中需要分离出来。 用协变量进行修正,得到修正后的y ij (adj)为 (adj)()ij ij ij i ij y y x x u t βε=--=++ 就可以对y ij (adj)做方差分析了。关键问题是求出回归系数β.
《统计学》实验五 一、实验名称:方差分析 二、实验日期: 2010年12月3日 三、实验地点:经济管理系实验室 四、实验目的和要求 目的:培养学生利用EXCEL进行数据处理的能力,熟练掌握利用EXCEL 进行方差分析,对方差分析结果进行分析 要求:就本专业相关问题收集一定数量的数据,用EXCEL进行方差分析 五、实验仪器、设备和材料:个人电脑(人/台),EXCEL 软件 六、实验过程 (一)问题与数据 消费者与产品生产者、销售者或服务的提供者之间经常发生纠纷。当分生纠纷后,消费者常常会向消费者协会投诉。为了对几个行业的服务质量进行评价,消费者协会在零售业、旅游业、航空公司、家电制造业分别抽取了不同的企业作为样本。其中零售业抽取7家、旅游业抽取6家、航空公司抽取5家、家电制造业抽取5家。具体数据如下: 取显著性水平α=0.05,检验行业不同是否会导致消费者投诉的显著性差异?(二)实验步骤 1、进行假设 2、将数据拷贝到EXCEL表格中 3、选择“工具——数据分析——单因素方差分析”,得到如下结果:
(三)实验结果分析:由以上结果可知:F>F crit=3.4066或P-value=0.0387657<0.05,拒绝原假设,表明行业对消费者投诉有着显著差异。 实验心得体会 在这学习之前我们只学习了简单的方差计算,现在运用计算机进行方差分析,可以做出更多的比较。通过使用计算机可以很快的计算出组间和组内的各种数值,便于我们进行比较分析。
《统计学》实验六 一、实验名称:相关分析与回归分析 二、实验日期: 2010年12月3日 三、实验地点:经济管理系实验室 四、实验目的和要求 目的:培养学生利用EXCEL进行数据处理的能力,熟练掌握EXCEL绘制散点图,计算相关系数,拟合线性回归方程,拟合简单的非线性回归方程,利用回归方程进行预测。 要求:就本专业相关问题收集一定数量的数据,用EXCEL进行相关回归分析(计算相关系数,一元线性回归分析,一元线性回归预测) 五、实验仪器、设备和材料:个人电脑(人/台),EXCEL 软件 六、实验过程 (一)问题与数据 10个学生每天用于学习英语的时间和期末考试的成绩的数据如下表所示。要求, (1)绘制学习英语的时间和期末考试的成绩的散点图,判断2者之间的关系 形态 (2)计算学习英语的时间和期末考试的成绩的线性相关系数 (3)用学习英语的时间作自变量,期末考试成绩作因变量,求出估计的回归方程。 (4)求每天学习英语的时间为150分钟时,销售额95%的置信区间和预测区间。 学生时间(分钟)成绩(分) A 120 85 B 60 65 C 100 76 D 70 71 E 80 74 F 60 65 G 30 54 H 40 60 I 50 62
方差分析和回归分析的区 别与联系 Prepared on 22 November 2020
一、方差分析和回归分析的区别与联系(以双变量为例) 联系: 1、概念上的相似性 回归分析是为了分析变量间的因果关系,研究自变量X取不同值时,因变量平均值Y的变化。运用回归分析方法,可以从变量的总偏差平方和中分解出已被自变量解释掉的误差(解释掉误差)和未被解释掉的误差(剩余误差); 方差分析是为了分析或检验总体间的均值是否有所不同。通过对样本中自变量X取不同值时所对应的因变量Y均值的比较,推论到总体变量间是否存在关系。运用方差分析,也可以从变量的总离差平方和中分解出已被自变量解释掉的误差和未被自变量解释掉的误差。因此两种分析在概念上所具有的相似性是显而易见的。 2、统计分析步骤的相似性 回归分析在确定自变量X是否为因变量Y的影响因素时,从分析步骤上先对X 和Y进行相关分析,然后建立变量间的回归模型。最后再进行参数的统计显着性检验或对回归模型的统计显着性进行检验。 方差分析在确定X是否是Y的影响因素时,是先从样本所的数据的分析入手,然后考察数据模型,最后对样本均值是否相等进行显着性检验。二者在分析步骤上也具有相似性。 3、假设条件具有一定的相似性 回归分析有五个基本假定,分别是:自变量可以是随机变量也可以是非随机变量;X与Y之间存在的非确定性的相关关系,要求Y的所有子总体,其方差都相等;子总体均值在一条直线上;随机变量Y i是统计独立的,即Y1的数值不
影响Y2的数值,各Y值之间都没有关系;Y值的每一个子总体都满足正态分布。 方差分析的基本假定有:等方差性(总体中自变量的每一取值所对应因变量Y i 的分布都具有相同方差);Y i的分布为正态分布。 二者在假设条件上存在着相同。 4、在总离差平方和中的分解形式和逻辑上的相似性 回归分析中,TSS=RSS+RSSR,而在方差分析中,TSS=RSS+BSS。二者均是以已解释掉的误差与未被解释掉的误差之和为总离差平方和。 5、确定影响因素上的相似性 为简化分析起见,我们假设只有一个自变量X影响因变量Y。在回归分析中,要确定X是否是Y的影响因素,就要看当X已知时,对Y的总偏差有无影响。如果X不是影响Y的因素,等同于只知变数Y的数据列一样,此时用Y去估计每个丫的值,所犯的错误(即偏差)为最小。如果因素X是影响Y的因素,那么当已知X 值后 6、在统计显着性检验上具有相似性 回归分析的总显着性检验,是一种用R2测量回归的全部解释功效的检验。检验RSSR*(N-2)/RSS, 方差分析的显着性检验是一种根据样本数据提取信息所进行的显着性检验。它也是通过F检验进行的。 区别: 1、研究变量的分析点不同
方差分析 方差分析(Analysis of Variance,简称ANOVA),又称“变异数分析”或“F检验”,是R.A.Fisher发明的,用于两个及两个以上样本均数差别的显著性检验。由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。 方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。 方差分析的作用 一个复杂的事物,其中往往有许多因素互相制约又互相依存。方差分析的目的是通过数据分析找出对该事物有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。方差分析是在可比较的数组中,把数据间的总的“变差”按各指定的变差来源进行分解的一种技术。对变差的度量,采用离差平方和。方差分析方法就是从总离差平方和分解出可追溯到指定来源的部分离差平方和,这是一个很重要的思想。 经过方差分析若拒绝了检验假设,只能说明多个样本总体均数不相等或不全相等。若要得到各组均数间更详细的信息,应在方差分析的基础上进行多个样本均数的两两比较。 方差分析的分类及举例
一、单因素方差分析 (一)单因素方差分析概念理解步骤 是用来研究一个控制变量的不同水平是否对观测变量产生 了显著影响。这里,由于仅研究单个因素对观测变量的影响,因此称为单因素方差分析。 例如,分析不同施肥量是否给农作物产量带来显著影响,考察地区差异是否影响妇女的生育率,研究学历对工资收入的影响等。这些问题都可以通过单因素方差分析得到答案。 单因素方差分析的第一步是明确观测变量和控制变量。例如,上述问题中的观测变量分别是农作物产量、妇女生育率、工资收入;控制变量分别为施肥量、地区、学历。 单因素方差分析的第二步是剖析观测变量的方差。方差分析认为:观测变量值的变动会受控制变量和随机变量两方面的影响。据此,单因素方差分析将观测变量总的离差平方和分解为组间离差平方和和组内离差平方和两部分,用数学形式表述为:SST=S SA+SSE。 单因素方差分析的第三步是通过比较观测变量总离差平方和各部分所占的比例,推断控制变量是否给观测变量带来了显著影响。 (二)单因素方差分析原理总结 容易理解:在观测变量总离差平方和中,如果组间离差平方和所占比例较大,则说明观测变量的变动主要是由控制变量引起
方差分析 方差分析(Analysis of Variance,简称ANOVA),又称“变异数分析”或“F检验”,是R.A.Fisher发明的,用于两个及两个以上样本均数差别的显著性检验。由于各种因素的影响,研究所得的数据呈现波动状。造成波动的原因可分成两类,一是不可控的随机因素,另一是研究中施加的对结果形成影响的可控因素。 方差分析是从观测变量的方差入手,研究诸多控制变量中哪些变量是对观测变量有显著影响的变量。 方差分析的作用 一个复杂的事物,其中往往有许多因素互相制约又互相依存。方差分析的目的是通过数据分析找出对该事物有显著影响的因素,各因素之间的交互作用,以及显著影响因素的最佳水平等。方差分析是在可比较的数组中,把数据间的总的“变差”按各指定的变差来源进行分解的一种技术。对变差的度量,采用离差平方和。方差分析方法就是从总离差平方和分解出可追溯到指定来源的部分离差平方和,这是一个很重要的思想。 经过方差分析若拒绝了检验假设,只能说明多个样本总体均数不相等或不全相等。若要得到各组均数间更详细的信息,应在方差分析的基础上进行多个样本均数的两两比较。 方差分析的分类及举例
一、单因素方差分析 (一)单因素方差分析概念理解步骤 是用来研究一个控制变量的不同水平是否对观测变量产生了显著影响。这里,由于仅研究单个因素对观测变量的影响,因此称为单因素方差分析。 例如,分析不同施肥量是否给农作物产量带来显著影响,考察地区差异是否影响妇女的生育率,研究学历对工资收入的影响等。这些问题都可以通过单因素方差分析得到答案。 单因素方差分析的第一步是明确观测变量和控制变量。例如,上述问题中的观测变量分别是农作物产量、妇女生育率、工资收入;控制变量分别为施肥量、地区、学历。 单因素方差分析的第二步是剖析观测变量的方差。方差分析认为:观测变量值的变动会受控制变量和随机变量两方面的影响。据此,单因素方差分析将观测变量总的离差平方和分解为组间离差平方和和组内离差平方和两部分,用数学形式表述为:SST=S SA+SSE。 单因素方差分析的第三步是通过比较观测变量总离差平方和各部分所占的比例,推断控制变量是否给观测变量带来了显著影响。 (二)单因素方差分析原理总结 容易理解:在观测变量总离差平方和中,如果组间离差平方和 所占比例较大,则说明观测变量的变动主要是由控制变量引起的,
残差平方和 概念: 为了明确解释变量和随机误差各产生的效应是多少,统计学上把数据点与它在回归直线上相应位置的差异称残差,把每个残差的平方后加起来称为残差平方和,它表示随机误差的效应。 意义: 每一点的y值的估计值和实际值的差的平方之和称为残差平方和,而y 的实际值和平均值的差的平方之和称为总平方和。 定义: 协方差是关于如何调节协变量对因变量的影响效应,从而更加有效地分析实验处理效应的一种统计技术,也是对实验进行统计控制的一种综合方差分析和回归分析的方法。 意义 当研究者知道有些协变量会影响因变量,却不能够控制和不感兴趣时(当研究学习时间对学习绩效的影响,学生原来的学习基础、智力学习兴趣就是协变量),可以在实验处理前予以观测,然后在统计时运用协方差分析来处理。 将协变量对因变量的影响从自变量中分离出去,可以进一步提高实验精确度和统计检验灵敏度。 方差是用来度量单个变量“自身变异”大小的总体参数,方差越大,该变量的变异越大; 协方差是用来度量两个变量之间“协同变异”大小的总体参数,即二个变量相互影响大小的参数,协方差的绝对值越大,二个变量相互影响越大。
对于仅涉及单个变量的试验资料,由于其总变异仅为“自身变异”(如单因素完全随机设计试验资料,“自身变异”是指由处理和随机误差所引起的变异),因而可以用方差分析法进行分析; 对于涉及两个变量的试验资料,由于每个变量的总变异既包含了“自身变异”又包含了“协同变异”(是指由另一个变量所引起的变异),须采用协方差分析法来进行分析,才能得到正确结论。 方法 (一)回归模型的协方差分析 如果那些不能很好地进行试验控制的因素是可量测的,且又和试验结果之间存在直线回归关系,就可利用这种直线回归关系将各处理的观测值都矫正到初始条件相同时的结果,使得处理间的比较能在相同基础上进行,而得出正确结论。这一做法在统计上称为统计控制。 这时所进行的协方差分析是将回归分析和方差分析结合起来的一种统计分析方法,这种协方差分析称为回归模型的协方差分析。 (二)相关模型的协方差分析 方差分析中根据均方MS与期望均方EMS间的关系,可获得不同变异来源的方差分量估计值;在协方差分析中,根据均积MP与期望均积EMP间的关系,可获得不同变异来源的协方差分量估计值。 这种协方差分析称为相关模型的协方差分析。 残差平方和: 为了明确解释变量和随机误差各产生的效应是多少,统计学上把数据点与它在回归直线上相应位置的差异称残差,把每个残差的平方后加起来称为残差平方和,它表示随机误差的效应。 回归平方和 总偏差平方和=回归平方和+ 残差平方和。 残差平方和与总平方和的比值越小,判定系数 r2 的值就越大。 协变量:在实验的设计中,协变量是一个独立变量(解释变量),不为实验者所操纵,但仍影响实验结果。