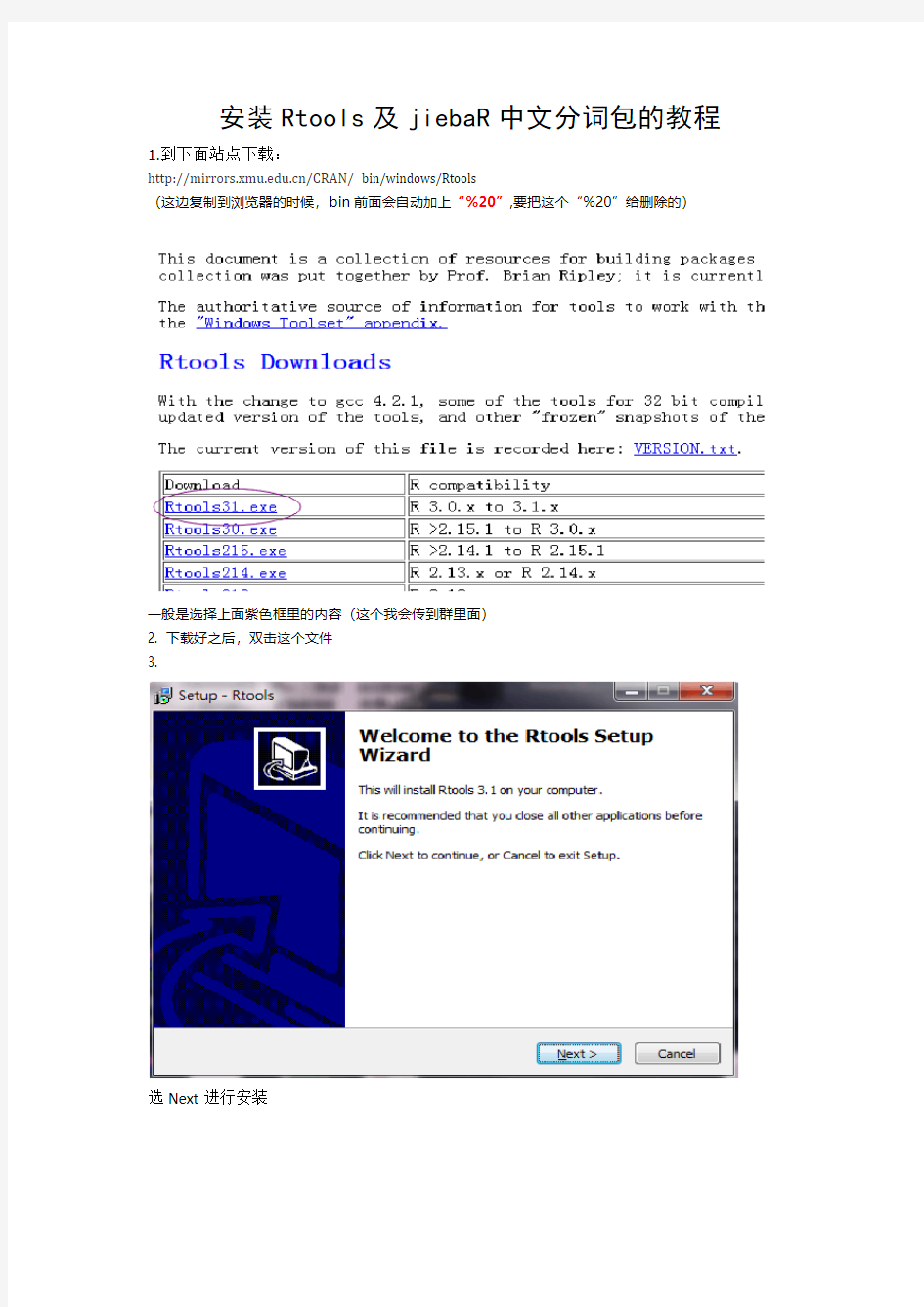
安装Rtools及jiebaR中文分词包的教程
1.到下面站点下载:
https://www.doczj.com/doc/df2428738.html,/CRAN/ bin/windows/Rtools
(这边复制到浏览器的时候,bin前面会自动加上“%20”,要把这个“%20”给删除的)
一般是选择上面紫色框里的内容(这个我会传到群里面)
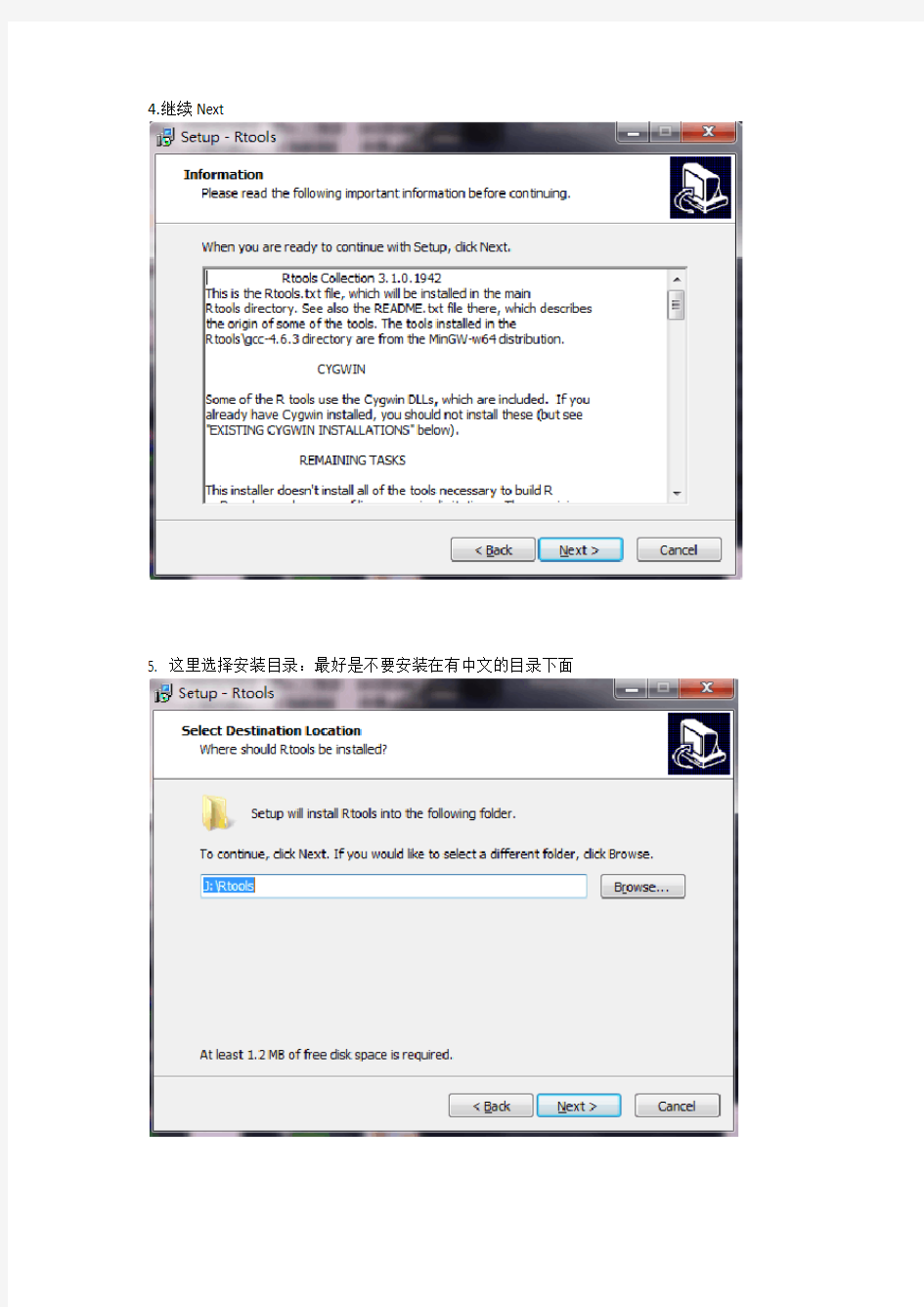
2. 下载好之后,双击这个文件
3.
选Next进行安装
4.继续Next
5. 这里选择安装目录:最好是不要安装在有中文的目录下面
6. 前面3个必选,后面两个,看个人系统,不选也没关系的。如果没有安装Latex的话。
7. 这里画圈的一定要选,不然不会自动添加path。
8.接下来就不截图了,选Next—> Install,再稍微等一下就可以完成了。
9.完成后:
在R里面输入:
没有安装devtools包的,先输入:
install.packages(“devtools”)
然后再输入:
library(devtools)
install_github(“qinwf/jiebaR”)
最后出来的结果应该是这个样子的:
如果安装还不成功。那么极有可能是你的R安装在中文目录下了。导致gcc无法编译,因为一般就卡在那边。把R卸载了,重新安装一下吧。
选择一个或自己创建一个英文目录。
另外推荐英文安装。
前面我们讲个搜索引擎如何搜集网页,今天说下第二个过程网页预处理,其中中文分词就显得尤其重要,下面就详细讲解一下搜索引擎是怎么进行网页预处理的: 网页预处理的第一步就是为原始网页建立索引,有了索引就可以为搜索引擎提供网页快照功能;接下来针对索引网页库进行网页切分,将每一篇网页转化为一组词的集合;最后将网页到索引词的映射转化为索引词到网页的映射,形成倒排文件(包括倒排表和索引词表),同时将网页中包含的不重复的索引词汇聚成索引词表。如下图所示: 一个原始网页库由若干个记录组成,每个记录包括记录头部信息(HEAD)和数据(DATA),每个数据由网页头信息(header),网页内容信息(content)组成。索引网页库的任务就是完成给定一个URL,在原始网页库中定位到该URL所指向的记录。 如下图所示:
对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。中文自动分词是网页分析的前提。文档由被称作特征项的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词(或中文切词)。切词软件中使用的基本词典包括词条及其对应词频。 自动分词的基本方法有两种:基于字符串匹配的分词方法和基于统计的分词方法。 1) 基于字符串匹配的分词方法 这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。 按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长匹配,和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下:
索源网https://www.doczj.com/doc/df2428738.html,/ 中文分词基础件(基础版) 使用说明书 北京索源无限科技有限公司 2009年1月
目录 1 产品简介 (3) 2 使用方法 (3) 2.1 词库文件 (3) 2.2 使用流程 (3) 2.3 试用和注册 (3) 3 接口简介 (4) 4 API接口详解 (4) 4.1初始化和释放接口 (4) 4.1.1 初始化分词模块 (4) 4.1.2 释放分词模块 (4) 4.2 切分接口 (5) 4.2.1 机械分词算法 (5) 4.3 注册接口 (8) 5 限制条件 (9) 6 附录 (9) 6.1 切分方法定义 (9) 6.2 返回值定义 (9) 6.3 切分单元类型定义 (9)
1 产品简介 索源中文智能分词产品是索源网(北京索源无限科技有限公司)在中文信息处理领域以及搜索领域多年研究和技术积累的基础上推出的智能分词基础件。该产品不仅包含了本公司结合多种分词研发理念研制的、拥有极高切分精度的智能分词算法,而且为了适应不同需求,还包含多种极高效的基本分词算法供用户比较和选用。同时,本产品还提供了在线自定义扩展词库以及一系列便于处理海量数据的接口。该产品适合在中文信息处理领域从事产品开发、技术研究的公司、机构和研究单位使用,用户可在该产品基础上进行方便的二次开发。 为满足用户不同的需求,本产品包括了基础版、增强版、专业版和行业应用版等不同版本。其中基础版仅包含基本分词算法,适用于对切分速度要求较高而对切分精度要求略低的环境(正、逆向最大匹配)或需要所有切分结果的环境(全切分)。增强版在基础版的基础上包含了我公司自主开发的复合分词算法,可以有效消除切分歧义。专业版提供智能复合分词算法,较之增强版增加了未登录词识别功能,进一步提高了切分精度。行业应用版提供我公司多年积累的包含大量各行业关键词的扩展词库,非常适合面向行业应用的用户选用。 2 使用方法 2.1 词库文件 本产品提供了配套词库文件,使用时必须把词库文件放在指定路径中的“DictFolder”文件夹下。产品发布时默认配置在产品路径下。 2.2 使用流程 产品使用流程如下: 1)初始化 首先调用初始化函数,通过初始化函数的参数配置词库路径、切分方法、是否使用扩展词库以及使用扩展词库时扩展词的保存方式等。经初始化后获得模块句柄。 2)使用分词函数 初始化后可反复调用各分词函数。在调用任何函数时必要把模块句柄传入到待调用函数中。 3)退出系统 在退出系统前需调用释放函数释放模块句柄。 2.3 试用和注册 本产品初始提供的系统是试用版。在试用版中,调用分词函数的次数受到限制。用户必须向索源购买本产品,获取注册码进行注册后,方可正常使用本产品。 注册流程为: 1)调用序列号获取接口函数获取产品序列号; 2)购买产品,并将产品序列号发给索源。索源确认购买后,生成注册码发给用户; 3)用户使用注册码,调用注册接口对产品进行注册; 4)注册成功后,正常使用本产品。
中文分词实验 一、实验目的: 目的:了解并掌握基于匹配的分词方法,以及分词效果的评价方法。 实验要求: 1、从互联网上查找并构建不低于10万词的词典,构建词典的存储结构; 2、选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等)。 3、在不低于1000个文本文件,每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、分词速度。 预期效果: 1、平均准确率达到85%以上 二、实验方案: 1.实验平台 系统:win10 软件平台:spyder 语言:python 2.算法选择 选择正向减字最大匹配法,参照《搜索引擎-原理、技术与系统》教材第62页的描述,使用python语言在spyder软件环境下完成代码的编辑。 算法流程图:
Figure Error! No sequence specified.. 正向减字最大匹配算法流程
Figure Error! No sequence specified.. 切词算法流程算法伪代码描述:
3.实验步骤 1)在网上查找语料和词典文本文件; 2)思考并编写代码构建词典存储结构; 3)编写代码将语料分割为1500个文本文件,每个文件的字数大于1000字; 4)编写分词代码; 5)思考并编写代码将语料标注为可计算准确率的文本; 6)对测试集和分词结果集进行合并; 7)对分词结果进行统计,计算准确率,召回率及F值(正确率和召回率的 调和平均值); 8)思考总结,分析结论。 4.实验实施 我进行了两轮实验,第一轮实验效果比较差,于是仔细思考了原因,进行了第二轮实验,修改参数,代码,重新分词以及计算准确率,效果一下子提升了很多。 实验过程:
百度中文分词技巧 什么是中文分词?我们都知道,英文句子都是由一个一个单词按空格分开组成,所以在分词方面就方便多了,但我们中文是一个一个汉字连接而成,所以相对来说是比较复杂的。中文分词指的是将一个汉语句子切分成一个一个单独的词,按照一定的规则重新组合成词序列的过程。这个也称做“中文切词”。 分词对于搜索引擎有着很大的作用,是文本挖掘的基础,可以帮助程序自动识别语句的含义,以达到搜索结果的高度匹配,分词的质量直接影响了搜索结果的精确度。目前搜索引擎分词的方法主要通过字典匹配和统计学两种方法。 一、基于字典匹配的分词方法 这种方法首先得有一个超大的字典,也就是分词索引库,然后按照一定的规则将待分词的字符串与分词库中的词进行匹配,若找到某个词语,则匹配成功,这种匹配有分以下四种方式: 1、正向最大匹配法(由左到右的方向); 2、逆向最大匹配法(由右到左的方向); 3、最少切分(使每一句中切出的词数最小); 4、双向最大匹配法(进行由左到右、由右到左两次扫描) 通常,搜索引擎会采用多种方式组合使用。但这种方式也同样给搜索引擎带来了难道,比如对于歧义的处理(关键是我们汉语的博大精深啊),为了提高匹配的准确率,搜索引擎还会模拟人对句子的理解,达到识别词语的效果。基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息,当然我们的搜索引擎也在不断进步。 二、基于统计的分词方法 虽然分词字典解决了很多问题,但还是远远不够的,搜索引擎还要具备不断的发现新的词语的能力,通过计算词语相邻出现的概率来确定是否是一个单独的词语。所以,掌握的上下文越多,对句子的理解就越准确,分词也越精确。举个例子说,“搜索引擎优化”,在字典中匹配出来可能是:搜索/引擎/优化、搜/索引/擎/优化,但经过后期的概率计算,发现“搜索引擎优化”在上下文相邻出现的次数非常多,那么基于统计就会将这个词语也加入进分词索引库。关于这点我在《关于电商与圈的分词测试》就是同样的一个例子。 中文分词的应用分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。 参考文档及网站: https://www.doczj.com/doc/df2428738.html, https://www.doczj.com/doc/df2428738.html, https://www.doczj.com/doc/df2428738.html, https://www.doczj.com/doc/df2428738.html,
中文自动分词技术是以“词”为基础,但汉语书面语不是像西方文字那样有天然的分隔符(空格),而是在语句中以汉字为单位,词与词之间没有明显的界限。因此,对于一段汉字,人可以通过自己的知识来明白哪些是词,哪些不是词,但如何让计算机也能理解?其处理过程词,就要应用到中文自动分词技术。下面依次介绍三种中文自动分词算法:基于词典的机械匹配的分词方法、基于统计的分词方法和基于人工智能的分词方法。 1、基于词典的机械匹配的分词方法: 该算法的思想是,事先建立词库,让它它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到该字符串,则识别出一个词。按照扫描方向的不同,串匹配分词的方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,又可以分为最大匹配和最小匹配。按这种分类方法,可以产生正向最大匹配、逆向最大匹配,甚至是将他们结合起来形成双向匹配。由于汉字是单字成词的,所以很少使用最小匹配法。一般来说,逆向匹配的切分精度略高于正向匹配,这可能和汉语习惯将词的重心放在后面的缘故。可见,这里的“机械”是因为该算法仅仅依靠分词词表进行匹配分词 a)、正向减字最大匹配法(MM) 这种方法的基本思想是:对于每一个汉字串s,先从正向取出maxLength 个字,拿这几个字到字典中查找,如果字典中有此字,则说明该字串是一个词,放入该T的分词表中,并从s中切除这几个字,然后继续此操作;如果在字典中找不到,说明这个字串不是一个词,将字串最右边的那个字删除,继续与字典比较,直到该字串为一个词或者是单独一个字时结束。 b)、逆向减字最大匹配法(RMM ) 与正向减字最大匹配法相比,这种方法就是从逆向开始遍历。过程与正向减字最大匹配法基本相同,可以对文本和字典先做些处理,把他们都倒过来排列,然后使用正向减字最大匹法。 机械匹配算法简洁、易于实现.其中,最大匹配法体现了长词优先的原则,在实际工程中应用最为广泛。机械匹配算法实现比较简单,但其局限也是很明显的:效率和准确性受到词库
IKAnalyzer IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始,IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为面向Java的公用分词组件,独立于Lucene 项目,同时提供了对Lucene的默认优化实现。 语言和平台:基于java 语言开发,最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer 3.0 则发展为面向 Java 的公用分词组件,独立于 Lucene 项目,同时提供了对Lucene 的默认优化实现。 算法:采用了特有的“正向迭代最细粒度切分算法”。采用了多子处理器分析模式,支持:英文字母( IP 地址、 Email 、 URL )、数字(日期,常用中文数量词,罗马数字,科学计数法),中文词汇(姓名、地名处理)等分词处理。优化的词典存储,更小的内存占用。支持用户词典扩展定义。针对 Lucene 全文检索优化的查询分析器 IKQueryParser ;采用歧义分析算法优化查询关键字的搜索排列组合,能极大的提高 Lucene 检索的命中率。 性能:60 万字 / 秒 IKAnalyzer基于lucene2.0版本API开发,实现了以词典分词为基础的正反向全切分算法,是LuceneAnalyzer接口的实现。该算法适合与互联网用户的搜索习惯和企业知识库检索,用户可以用句子中涵盖的中文词汇搜索,如用"人民"搜索含"人民币"的文章,这是大部分用户的搜索思维;不适合用于知识挖掘和网络爬虫技术,全切分法容易造成知识歧义,因为在语义学上"人民"和"人民币"是完全搭不上关系的。 je-anlysis的分词(基于java实现) 1. 分词效率:每秒30万字(测试环境迅驰1.6,第一次分词需要1-2秒加载词典) 2. 运行环境: Lucene 2.0 3. 免费安装使用传播,无限制商业应用,但暂不开源,也不提供任何保证 4. 优点:全面支持Lucene 2.0;增强了词典维护的API;增加了商品编码的匹配;增加了Mail地址的匹配;实现了词尾消歧算法第二层的过滤;整理优化了词库; 支持词典的动态扩展;支持中文数字的匹配(如:二零零六);数量词采用“n”;作为数字通配符优化词典结构以便修改调整;支持英文、数字、中文(简体)混合分词;常用的数量和人名的匹配;超过22万词的词库整理;实现正向最大匹配算法;支持分词粒度控制 ictclas4j ictclas4j中文分词系统是sinboy在中科院张华平和刘群老师的研制的FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复
[收稿日期]2010-06-26 [基金项目]河南省教育厅高等学校青年骨干教师项目(2009G GJS -108)。 [作者简介]于江德(1971-),男,博士,副教授,主要从事自然语言处理、信息抽取、文本数据挖掘等。①可以从以下地址下载:http ://cr fpp .so ur cefo rg e .net [汉语词法·甲骨文] 汉语词法分析是中文信息处理的首要任务,主要包括分词、词性标注、命名实体识别三项子任务,它是句法分析与语义分析的基础,其性能将直接影响到中文信息处理的后续应用。安阳师范学院计算机与信息工程学院依托河南省高等学校“甲骨文信息处理”重点实验室培育基地,“中文信息处理”校级重点实验室“计算语言学”校级研究所等平台。对汉语词法分析中的这三项子任务、甲骨文进行了较深入的研究,取得了部分研究成果,现借学报这个平台展示给各位同仁,敬请各位专家学者指正。 词位标注汉语分词技术详解 于江德,王希杰 (安阳师范学院计算机与信息工程学院,河南安阳455002) [摘 要]近年来基于字的词位标注的方法极大地提高了汉语分词的性能,该方法将汉语分词转化为字的词位标注问题,借助于优秀的序列标注模型,基于字的词位标注汉语分词方法逐渐成为分词的主要技术路线。本文简要介绍了词位标注汉语分词的基本思想,探析了基于条件随机场实现词位标注汉语分词的机理,并对采用四词位标注集,使用CRF ++0.53工具包实现字串序列词位标注进行了详解。最后在Bakeo ff2006的评测语料上进行了封闭测试。 [关键词]汉语分词;条件随机场;词位标注;特征模板 [中图分类号]T P391 [文献标识码]A [文章编号]1671-5330(2010)05-0001-05 在中文信息处理领域,词是最小的能够独立运用的有意义的语言单位。但汉语书写时却以字为基本的书写单位,词语之间不存在明显的分隔标记,因此,中文信息处理领域的一项基础性研究课题是如何将汉语的字串切分为合理的词语序列,即汉语分词。它不仅是句法分析、语义分析、篇章理解等深层中文信息处理的基础,也是机器翻译、自动问答系统、信息检索和信息抽取等应用的关键环节[1,2]。 近年来,尤其是2003年7月首届国际中文分词评测活动Bakeo ff 开展以来,汉语分词技术取得了可喜的进步,该领域的研究取得了令人振奋 的成果[3,4]。其中,基于字的词位标注汉语分词技术(也称为基于字标注的汉语分词或由字构词)得到了广泛关注,在可比的评测中性能领先的系统几乎无一例外都应用了类似的标注思想[3,5]。基于字的词位标注汉语分词将分词看作序列数据的标注问题,使用序列数据标注模型实现,例如,可采用条件随机场(Co nditional Random Fields ,简称CRFs )实现。CRFs 是Lafferty 等[6]于2001年提出的一种用于序列数据标注的条件概率模型。本文简要介绍了词位标注汉语分词的基本思想,探析了基于条件随机场实现词位标注汉语分词的机理,并对采用B 、M 、E 、S 四词位标注集,使 1 2010年 安阳师范学院学报
自然语言处理调研报告(课程论文、课程设计) 题目:最大正向匹配中文分词系统 作者:陈炳宏吕荣昌靳蒲 王聪祯孙长智 所在学院:信息科学与工程学院 专业年级:信息安全14-1 指导教师:努尔布力 职称:副教授 2016年10月29日
目录 一、研究背景、目的及意义 (3) 二、研究内容和目标 (4) 三、算法实现 (5) 四、源代码 (7) 1.seg.java 主函数 (7) 2. dict.txt 程序调用的字典 (10) 3.实验案例 (11) 五、小结 (12)
一、研究背景、目的及意义 中文分词一直都是中文自然语言处理领域的基础研究。目前,网络上流行的很多中文分词软件都可以在付出较少的代价的同时,具备较高的正确率。而且不少中文分词软件支持Lucene扩展。但不过如何实现,目前而言的分词系统绝大多数都是基于中文词典的匹配算法。 在这里我想介绍一下中文分词的一个最基础算法:最大匹配算法(Maximum Matching,以下简称MM算法) 。MM算法有两种:一种正向最大匹配,一种逆向最大匹配。
二、研究内容和目标 1、了解、熟悉中科院中文分词系统。 2、设计程序实现正向最大匹配算法。 3、利用正向最大匹配算法输入例句进行分词,输出分词后的结果。
三、算法实现 图一:算法实现 正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的。 算法示例: 待分词文本: content[]={"中","华","民","族","从","此","站","起","来","了","。"} 词表: dict[]={"中华", "中华民族" , "从此","站起来"} (1) 从content[1]开始,当扫描到content[2]的时候,发现"中华"已经在
一、为什么要进行中文分词? 词是最小的能够独立活动的有意义的语言成分,英文单词之间是以空格作为自然分界符的,而汉语是以字为基本的书写单位,词语之间没有明显的区分标记,因此,中文词语分析是中文信息处理的基础与关键。 Lucene中对中文的处理是基于自动切分的单字切分,或者二元切分。除此之外,还有最大切分(包括向前、向后、以及前后相结合)、最少切分、全切分等等。 二、中文分词技术的分类 我们讨论的分词算法可分为三大类:基于字典、词库匹配的分词方法;基于词频度统计的分词方法和基于知识理解的分词方法。 第一类方法应用词典匹配、汉语词法或其它汉语语言知识进行分词,如:最大匹配法、最小分词方法等。这类方法简单、分词效率较高,但汉语语言现象复杂丰富,词典的完备性、规则的一致性等问题使其难以适应开放的大规模文本的分词处理。第二类基于统计的分词方法则基于字和词的统计信息,如把相邻字间的信息、词频及相应的共现信息等应用于分词,由于这些信息是通过调查真实语料而取得的,因而基于统计的分词方法具有较好的实用性。 下面简要介绍几种常用方法: 1).逐词遍历法。 逐词遍历法将词典中的所有词按由长到短的顺序在文章中逐字搜索,直至文章结束。也就是说,不管文章有多短,词典有多大,都要将词典遍历一遍。这种方法效率比较低,大一点的系统一般都不使用。 2).基于字典、词库匹配的分词方法(机械分词法) 这种方法按照一定策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功。识别出一个词,根据扫描方向的不同分为正向匹配和逆向匹配。根据不同长度优先匹配的情况,分为最大(最长)匹配和最小(最短)匹配。根据与词性标注过程是否相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。常用的方法如下: (一)最大正向匹配法 (MaximumMatchingMethod)通常简称为MM法。其基本思想为:假定分词词典中的最长词有i个汉字字符,则用被处理文档的当前字串中的前i个字作为匹配字段,查找字典。若字典中存在这样的一个i字词,则匹配成功,匹配字段被作为一个词切分出来。如果词典中找不到这样的一个i字词,则匹配失败,将匹配字段中的最后一个字去掉,对剩下的字串重新进行匹配处理……如此进行下去,直到匹配成功,即切分出一个词或剩余字串的长度为零为止。这样就完成了一轮匹配,然后取下一个i字字串进行匹配处理,直到文档被扫描完为止。
Baidu查询分词算法 查询处理以及分词技术 如何设计一个高效的搜索引擎?我们可以以百度所采取的技术手段来探讨如何设计一个实用的搜索引擎.搜索引擎涉及到许多技术点,比如查询处理,排序算法,页面抓取算法,CACHE机制,ANTI-SPAM等等.这些技术细节,作为商业公司的搜索引擎服务提供商比如百度,GOOGLE等是不会公之于众的.我们可以将现有的搜索引擎看作一个黑盒,通过向黑盒提交输入,判断黑盒返回的输出大致判断黑盒里面不为人知的技术细节. 查询处理与分词是一个中文搜索引擎必不可少的工作,而百度作为一个典型的中文搜索引擎一直强调其”中文处理”方面具有其它搜索引擎所不具有的关键技术和优势.那么我们就来看看百度到底采用了哪些所谓的核心技术. 我们分两个部分来讲述:查询处理/中文分词. 一. 查询处理 用户向搜索引擎提交查询,搜索引擎一般在接受到用户查询后要做一些处理,然后在索引数据库里面提取相关的信息.那么百度在接受到用户查询后做了些什么工作呢? 1. 假设用户提交了不只一个查询串,比如”信息检索理论工具”.那么搜 索引擎首先做的是根据分隔符比如空格,标点符号,将查询串分割成若干子查询串,比如上面的查询就会被解析为:<信息检索,理论,工具>三个子字符串;这个道理 简单,我们接着往下看. 2. 假设提交的查询有重复的内容,搜索引擎怎么处理呢?比如查询”理论 工具理论”,百度是将重复的字符串当作只出现过一次,也就是处理成等价的”理论工具”,而GOOGLE显然是没有进行归并,而是将重复查询子串的权重增大进行处理.那么是如何得出这个结论的呢?我们可以将”理论工具”提交给百度,返回341,000篇文档,大致看看第一页的返回内容.OK.继续,我们提交查询”理论工具理论”,在看看返回结果,仍然是那么多返回文档,当然这个不能说明太多问题,那 看看第一页返回结果的排序,看出来了吗?顺序完全没有变化,而GOOGLE则排序有些变动,这说明百度是将重复的查询归并成一个处理的,而且字符串之间的先后出现顺序基本不予考虑(GOOGLE是考虑了这个顺序关系的). 3. 假设提交的中文查询包含英文单词,搜索引擎是怎么处理的?比如查询”电影BT下载”,百度的方法是将中文字符串中的英文当作一个整体保留,并以此为断点将中文切分开,这样上述的查询就切为<电影,BT,下载>,不论中间的英文是否一个字典里能查到的单词也好,还是随机的字符也好,都会当作一个整体来对待.
中文分词器解析hanlp分词器接口设计:
提供外部接口: 分词器封装为静态工具类,并提供了简单的接口
标准分词是最常用的分词器,基于HMM-Viterbi实现,开启了中国人名识别和音译人名识别,调用方法如下: HanLP.segment其实是对StandardTokenizer.segment的包装。 /** * 分词 * * @param text 文本 * @return切分后的单词 */ publicstatic List
* 这是一个工厂方法
* 与直接new一个分词器相比,使用本方法的好处是,以后HanLP升级了,总能用上最合适的分词器 * @return一个分词器 */ publicstatic Segment newSegment() }
publicclass StandardTokenizer { /** * 预置分词器 */ publicstaticfinalSegment SEGMENT = HanLP.newSegment(); /** * 分词 * @param text 文本 * @return分词结果 */ publicstatic List
分词算法设计中的几个基本原则: 1、颗粒度越大越好:用于进行语义分析的文本分词,要求分词结果的颗粒度越大,即单词的字数越多,所能表示的含义越确切,如:“公安局长”可以分为“公安局长”、“公安局长”、“公安局长”都算对,但是要用于语义分析,则“公安局长”的分词结果最好(当然前提是所使用的词典中有这个词) 2、切分结果中非词典词越少越好,单字字典词数越少越好,这里的“非词典词”就是不包含在词典中的单字,而“单字字典词”指的是可以独立运用的单字,如“的”、“了”、“和”、“你”、“我”、“他”。例如:“技术和服务”,可以分为“技术和服务”以及“技术和服务”,但“务”字无法独立成词(即词典中没有),但“和”字可以单独成词(词典中要包含),因此“技术和服务”有1个非词典词,而“技术和服务”有0个非词典词,因此选用后者。 3、总体词数越少越好,在相同字数的情况下,总词数越少,说明语义单元越少,那么相对的单个语义单元的权重会越大,因此准确性会越高。 下面详细说说正向最大匹配法、逆向最大匹配法和双向最大匹配法具体是如何进行的: 先说说什么是最大匹配法:最大匹配是指以词典为依据,取词典中最长单词为第一个次取字数量的扫描串,在词典中进行扫描(为提升扫描效率,还可以跟据字数多少设计多个字典,然后根据字数分别从不同字典中进行扫描)。例如:词典中最长词为“中华人民共和国”共7个汉字,则最大匹配起始字数为7个汉字。然后逐字递减,在对应的词典中进行查找。 下面以“我们在野生动物园玩”详细说明一下这几种匹配方法: 1、正向最大匹配法: 正向即从前往后取词,从7->1,每次减一个字,直到词典命中或剩下1个单字。 第1次:“我们在野生动物”,扫描7字词典,无
关于百度中文分词系统研究
所谓分词就是把字与字连在一起的汉语句子分成若干个相互独立、完整、正确的单词。词是最小的、能独立活动的、有意义的语言成分。计算机的所有语言知识都来自机器词典(给出词的各项信息) 、句法规则(以词类的各种组合方式来描述词的聚合现象) 以及有关词和句子的语义、语境、语用知识库。中文信息处理系统只要涉及句法、语义(如检索、翻译、文摘、校对等应用) ,就需要以词为基本单位。当汉字由句转化为词之后,才能使得句法分析、语句理解、自动文摘、自动分类和机器翻译等文本处理具有可行性。可以说,分词是机器语言学的基础。 分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页, 如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。 分词算法的三种主要类型 现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。 》基于字符串匹配的分词方法。 这种方法又叫做机械分词方法,它是按照一定的策略将待分析的汉字串与一个“充分大的”机器词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功 (识别出一个词) 。按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大(最长) 匹配 和最小(最短) 匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方 法和分词与标注相结合的一体化方法。常用的几种机械分词方法如下: 1) 正向最大匹配法(由左到右的方向) 。 通常简称为MM(Maximum Matching Method) 法。其基本思想为:设D 为词典,MAX 表示D 中的最大词长,STR 为待切分的字串。MM 法是每次从STR 中取长度为MAX 的子串与D 中的词进行匹配。若成功,则该子串为词,指针后移MAX 个汉字后继续匹配,否则子串逐次减一进行匹配。 2) 逆向最大匹配法(由右到左的方向) 。 通常简称为RMM ( Reverse Maximum MatchingMethod) 法。RMM 法的基本原理与MM 法相同,不同的是分词的扫描方向,它是从右至左取子串进行匹配。 3) 最少切分法(使每一句中切出的词数最小) 。 还可以将上述各种方法相互组合,例如,可以将正向最大匹配方法和逆向 最大匹配方法结合起来构成双向匹配法。由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。统计结果表明,单纯使用正向最大匹配的错误率为1/169 ,单纯使用逆向最大匹配的错误率为1/ 245 。但这种精度还远远不能满足实际的需要。实际使用的分词系统,都是把机械分词作为一种初分手段,还需通过利用各种其它的语言信息来进一步提高切分的准确率。一种方法是改进
中文分词入门之最大匹配法 发表于2009年01月12号由52nlp 中文分词在中文信息处理中是最最基础的,无论机器翻译亦或信息检索还是其他相关应用,如果涉及中文,都离不开中文分词,因此中文分词具有极高的地位。中文分词入门最简单应该是最大匹配法了,当年师兄布置给我的第一个学习任务就是实现最大匹配法的分词算法(正向、逆向)。记得当时对自己参考学习最有帮助的是北大詹卫东老师“中文信息处理基础”的课件和源程序,不过他实现的是mfc程序,词表存储在数据库里。自己实现时用纯c++实现,利用hash_map 存储词表。这里我介绍一下相关的知识和一个简单的程序示例,部分参考自詹老师的讲义。 正向最大匹配法算法如下所示: (注:以上最大匹配算法图来自于詹老师讲义) 逆向匹配法思想与正向一样,只是从右向左切分,这里举一个例子: 输入例句:S1=”计算语言学课程有意思” ; 定义:最大词长MaxLen = 5;S2= ” “;分隔符= “/”;
假设存在词表:…,计算语言学,课程,意思,…; 最大逆向匹配分词算法过程如下: (1)S2=”";S1不为空,从S1右边取出候选子串W=”课程有意思”; (2)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有意思”; (3)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有意思”; (4)查词表,W不在词表中,将W最左边一个字去掉,得到W=”意思” (5)查词表,“意思”在词表中,将W加入到S2中,S2=” 意思/”,并将W从S1中去掉,此时S1=”计算语言学课程有”; (6)S1不为空,于是从S1左边取出候选子串W=”言学课程有”; (7)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程有”; (8)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程有”; (9)查词表,W不在词表中,将W最左边一个字去掉,得到W=”程有”; (10)查词表,W不在词表中,将W最左边一个字去掉,得到W=”有”,这W是单字,将W 加入到S2中,S2=“ /有/意思”,并将W从S1中去掉,此时S1=”计算语言学课程”; (11)S1不为空,于是从S1左边取出候选子串W=”语言学课程”; (12)查词表,W不在词表中,将W最左边一个字去掉,得到W=”言学课程”; (13)查词表,W不在词表中,将W最左边一个字去掉,得到W=”学课程”; (14)查词表,W不在词表中,将W最左边一个字去掉,得到W=”课程”; (15)查词表,“意思”在词表中,将W加入到S2中,S2=“课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”计算语言学”; (16)S1不为空,于是从S1左边取出候选子串W=”计算语言学”; (17)查词表,“计算语言学”在词表中,将W加入到S2中,S2=“计算语言学/ 课程/ 有/ 意思/”,并将W从S1中去掉,此时S1=”"; (18)S1为空,输出S2作为分词结果,分词过程结束。 相应程序示例: 准备文件:建立一个词表文件wordlexicon,格式如下 计算语言学 课程 意思 输入文件:test,格式如下 计算语言学课程有意思 编译后执行如下:SegWord.exe test 输出分词结果文件:SegmentResult.txt 源代码如下: // Dictionary.h #include
搜索引擎中文分词原理与实现 因为中文文本中,词和词之间不像英文一样存在边界,所以中文分词是一个专业处理中文信息的搜索引擎首先面对的问题,需要靠程序来切分出词。 一、Lucene中的中文分词 Lucene在中处理中文的常用方法有三种,以“咬死猎人的狗”为例说明之:单字:【咬】【死】【猎】【人】【的】【狗】 二元覆盖:【咬死】【死猎】【猎人】【人的】【的狗】 分词:【咬】【死】【猎人】【的】【狗】 Lucene中的StandardTokenizer采用单子分词方式,CJKTokenizer采用二元覆盖方式。1、Lucene切分原理 Lucene中负责语言处理的部分在org.apache.lucene.analysis包,其中,TokenStream类用来进行基本的分词工作,Analyzer类是TokenStream的包装类,负责整个解析工作,Analyzer 类接收整段文本,解析出有意义的词语。 通常不需要直接调用分词的处理类analysis,而是由Lucene内存内部来调用,其中:(1)在索引阶段,调用addDocument(doc)时,Lucene内部使用Analyzer来处理每个需要索引的列,具体如下图: 图1 Lucene对索引文本的处理 IndexWriter index = new IndexWriter(indexDirectory, new CnAnalyzer(), //用于支持分词的分析器 !incremental, IndexWriter.MaxFieldLength.UNLIMITED); (2)在搜索阶段,调用QueryParser.parse(queryText)来解析查询串时,QueryParser 会调用Analyzer来拆分查询字符串,但是对于通配符等查询不会调用Analyzer。 Analyzer analyzer = new CnAnalyzer(); //支持中文的分词 QueryParser parser = new QueryParser(Version.LUCENE_CURRENT, "title", analyzer); 因为在索引和搜索阶段都调用了分词过程,索引和搜索的切分处理要尽量一致,所以分词效果改变后需要重建索引。 为了测试Lucene的切分效果,下面是直接调用Analysis的例子: Analyzer analyzer = new CnAnalyzer(); //创建一个中文分析器 TokenStream ts = analyzer.tokenStream("myfield", new StringReader("待切分文本")); //取得Token流 while (ts.incrementToken()) { //取得下一个词
实验:中文分词实验 小组成员:黄婷苏亮肖方定山 一、实验目的: 1.实验目的 (1)了解并掌握基于匹配的分词方法、改进方法、分词效果的评价方法等 2.实验要求 (1)从互联网上查找并构建不低于10万词的词典,构建词典的存储结构;(2)选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等),同时实现至少一种改进算法。 (3)在不低于1000个文本文件(可以使用附件提供的语料),每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、召回率、F-值、分词速度。 二、实验方案: 1. 实验环境 系统:win10 软件平台:spyder 语言:python 2. 算法选择 (1)选择正向减字最大匹配法
(2)算法伪代码描述: 3. 实验步骤 ● 在网上查找语料和词典文本文件; ● 思考并编写代码构建词典存储结构;
●编写代码将语料分割为1500 个文本文件,每个文件的字数大于1000 字; ●编写分词代码; ●思考并编写代码将语料标注为可计算准确率的文本; ●对测试集和分词结果集进行合并; ●对分词结果进行统计,计算准确率,召回率及 F 值(正确率和召回率的调 和平均值); ●思考总结,分析结论。 4. 实验实施 实验过程: (1)语料来源:语料来自SIGHAN 的官方主页(https://www.doczj.com/doc/df2428738.html,/ ),SIGHAN 是国际计算语言学会(ACL )中文语言处理小组的简称,其英文全称为“Special Interest Group for Chinese Language Processing of the Association for Computational Linguistics”,又可以理解为“SIG 汉“或“SIG 漢“。SIGHAN 为我们提供了一个非商业使用(non-commercial )的免费分词语料库获取途径。我下载的是Bakeoff 2005 的中文语料。有86925 行,2368390 个词语。语料形式:“没有孩子的世界是寂寞的,没有老人的世界是寒冷的。” (2)词典:词典用的是来自网络的有373 万多个词语的词典,采用的数据结构为python 的一种数据结构——集合。
分词技术研究报告 研究内容 目前,国内的每个行业、领域都在飞速发展,这中间产生了大量的中文信息资源,为了能够及时准确的获取最新的信息,中文搜索引擎是必然的产物。中文搜索引擎与西文搜索引擎在实现的机制和原理上大致雷同,但由于汉语本身的特点,必须引入对于中文语言的处理技术,而汉语自动分词技术就是其中很关键的部分。汉语自动分词到底对搜索引擎有多大影响?对于搜索引擎来说,最重要的并不是找到所有结果,最重要的是把最相关的结果排在最前面,这也称为相关度排序。中文分词的准确与否,常常直接影响到对搜索结果的相关度排序。分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。 研究汉语自动分词算法,对中文搜索引擎的发展具有至关重要的意义。快速准确的汉语自动分词是高效中文搜索引擎的必要前提。本课题研究中文搜索引擎中汉语自动分词系统的设计与实现,从目前中文搜索引擎的发展现状出发,引出中文搜索引擎的关键技术------汉语自动分词系统的设计。首先研究和比较了几种典型的汉语自动分词词典机制,指出各词典机制的优缺点,然后分析和比较了几种主要的
汉语自动分词方法,阐述了各种分词方法的技术特点。针对课题的具体应用领域,提出改进词典的数据结构,根据汉语中二字词较多的特点,通过快速判断二字词来优化速度;分析中文搜索引擎下歧义处理和未登陆词处理的技术,提出了适合本课题的自动分词算法,并给出该系统的具体实现。最后对系统从分词速度和分词准确性方面进行了性能评价。本课题的研究将促进中文搜索引擎和汉语自动分词新的发展。 二、汉语自动分词系统的研究现状 1、几个早期的自动分词系统 自80年代初中文信息处理领域提出了自动分词以来,一些实用性的分词系统逐步得以开发,其中几个比较有代表性的自动分词系统在当时产生了较大的影响。 CDWS分词系统是我国第一个实用的自动分词系统,由北京航空航天大学计算机系于1983年设计实现,它采用的自动分词方法为最大匹配法,辅助以词尾字构词纠错技术。其分词速度为5-10字/秒,切分精度约为1/625。 ABWS是山西大学计算机系研制的自动分词系统,系统使用“两次扫描联想-回溯”方法,运用了较多的词法、句法等知识。其切分正确率为98.6%(不包括非常用、未登录的专用名词),运行速度为48词/分钟。 CASS是北京航空航天大学于1988年实现的分词系统。它使用正向增字最大匹配,运用知识库来处理歧义字段。其机械分词速度为
中文分词工具介绍 分词工具支持语言原理分词速度文档 完整 性 词典及扩展性 NLPIR(ICTCLAS)中文、英文隐马尔科夫模型(HHMM)50万字/秒 (996Kb/s)详细支持单条导入用户 词典,也可以批量导 入用户词典 IKAnalyzer英文字母、数 字、中文词汇 等分词处理, 兼容韩文、日 文字符正向迭代最细粒度切分算法83 万字/秒 (1600Kb/s) 详细收录27万中文词汇, 支持用户词典扩展 定义、支持自定义停 止词 Paoding-Analysis中文100万字/秒 (1900Kb/s)极少支持不限制个数的 用户自定义词库 MMSeg4j 中文,包括一 些字符的处 理英文、俄 文、希腊、数 字用Chih-Hao Tsai 的 MMSeg 算法。MMSeg 算法 有两种分词方法:Simple和 Complex,都是基于正向最 大匹配。在complex基础上 实现了最多分词 (max-word) Complex 60万字/秒 (1200Kb/s) Simple 97万字/秒 1900Kb/s 极少使用sougou词库, 也可自定义覆盖 Imdict-Chinese-Analyzer中文、英文、 数字隐马尔科夫模型(HHMM)25万字/秒 (480Kb/s) 极少算法和语料库词典 来自于ictclas1.0项 目 JE-Analysis中文、英文、 数字 极少
中文分词工具分词测试 Paoding 运行时间:7s 分词数:160841 IK 运行时间:6s 分词数:149244 imdict运行时间: 12.426 s 分词数:235548 je运行时间: 7.834 s 分词数:220199 Mmseg4j运行时间: 9.612 s 分词数为:200504