
南京农业大学实验报告纸
2011—2012 学年1 学期课程类型:必修
课程生物统计与田间试验实验班级学号姓名 888成绩
一.描述统计
题目:100个试验条件相同的小区种植某大豆(kg),各小区的产量的观察值为:139 160 68 60 82 22 43 73 56 76 97 179 25 84 98 69 80 100 136 115 90 78 44 50 58 60 76 78 92 101 62 152 97 81 54 98 75 118 130 90 100 98 141 44 30 66 72 131 79 107 40 135 123 77 84 61 156 62 94 94 154 100 77 34 68 26 48 87 85 95 123 105 107 55 45 73 109 58 101 134 132 99 70 84 118 40 79 58 64 109 93 95 185 90 57 68 24 94 72 70
用SAS程序写出其次数分布表和次数分布图。
[数据来源:《概率统计与SAS应用》,余家林、肖枝洪著,P63]
SAS程序:
data rice_yield;
input y@@;
cards;
139 160 68 60 82 22 43 73 56 76 97 179 25 84 98 69 80 100 136 115
90 78 44 50 58 60 76 78 92 101 62 152 97 81 54 98 75 118 130 90
100 98 141 44 30 66 72 131 79 107 40 135 123 77 84 61 156 62 94 94
154 100 77 34 68 26 48 87 85 95 123 105 107 55 45 73 109 58 101 134
132 99 70 84 118 40 79 58 64 109 93 95 185 90 57 68 24 94 72 70
proc format;
value g_yield 12.5-< 37.5='12.5~ 37.5' 37.5-< 62.5=' 37.5~ 62.5'
62.5-<87.5=' 62.5~87.5' 87.5-<112.5='87.5~112.5'
112.5-<137.5='112.5~137.5' 137.5-<162.5='137.5~162.5'
162.5-<187.5='162.5~187.5'
run;
proc freq;
table y;
format y g_yield.;
run;
proc gchart ;
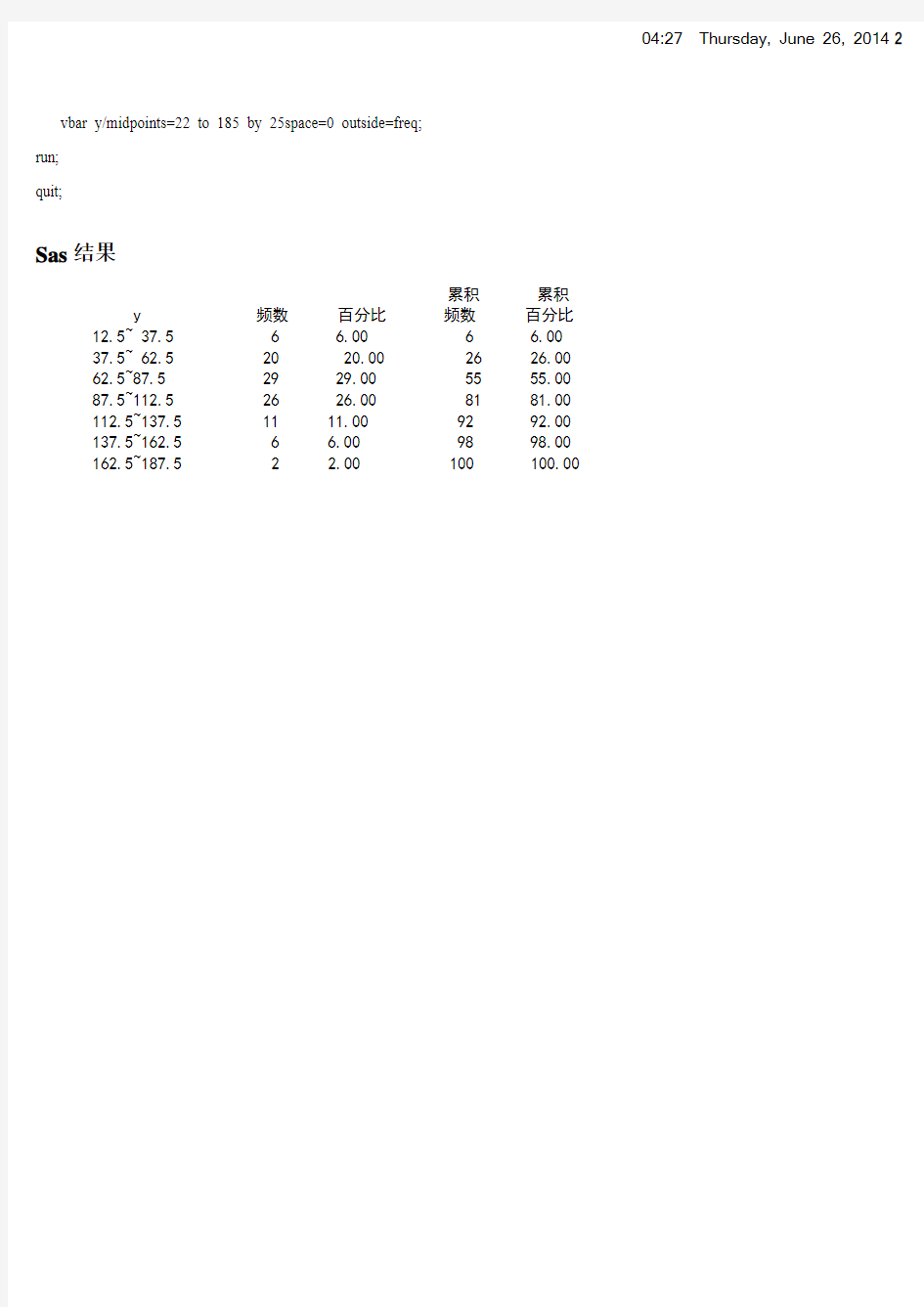
vbar y/midpoints=22 to 185 by 25space=0 outside=freq;
run;
quit;
Sas结果
累积累积 y 频数百分比频数百分比 12.5~ 37.5 6 6.00 6 6.00 37.5~ 62.5 20 20.00 26 26.00 62.5~87.5 29 29.00 55 55.00 87.5~112.5 26 26.00 81 81.00 112.5~137.5 11 11.00 92 92.00 137.5~162.5 6 6.00 98 98.00 162.5~187.5 2 2.00 100 100.00
04:27 Thursday, June 26, 2014 3
结果解释:100个大豆的重量属于连续型数据资料,其中最大值为185,最小值为22,分成7组,每组组距为25,第一组的组中点值为25,第二组组中点值为50,依次类推。根据次数分布图可知,第一组次数为6,第二组次数为15,第三组次数为32,依次最后一组次数为3。
一.假设测验
题目:
某农场为玉米施加矮壮素,为此进行了一次调查。调查玉米株高(cm)结果如下表
y1 Y2
160 270
152 190
170 230
200 250
200 170
试做假设测验.检验两个组是否有显著差异。
[数据来源:《概率统计与SAS应用》]
SAS程序:
data uio;
04:27 Thursday, June 26, 2014 4 input l1 l2 @@;
dif=l2-l1;
cards;
160 270
152 190
170 230
200 250
200 170
;
proc univariate normal;
var dif;
run;
Sas结果:
矩
N 5 权重总和 5
均值45.6 观测总和228
标准差50.3666556 方差2536.8
偏度-0.5294633 峰度 1.69500711
未校平方和20544 校正平方和10147.2
变异系数110.453192 标准误差均值22.5246532
基本统计测度
位置变异性
均值45.60000 标准差50.36666
中位数50.00000 方差2537
众数. 极差140.00000
四分位极差22.00000
位置检验:Mu0=0
检验统计量P 值
学生 t t 2.024448 Pr > |t| 0.1129
符号M 1.5 Pr >= |M| 0.3750
符号秩S 6.5 Pr >= |S| 0.1250
04:27 Thursday, June 26, 2014 5
正态性检验
检验统计量P 值
Shapiro-Wilk W 0.953423 Pr < W 0.7616 Kolmogorov-Smirnov D 0.24003 Pr > D >0.1500 Cramer-von Mises W-Sq 0.046249 Pr > W-Sq >0.2500 Anderson-Darling A-Sq 0.266569 Pr > A-Sq >0.2500
分位数(定义5)
分位数估计值
100% 最大值110
99% 110
95% 110
90% 110
75% Q3 60
50% 中位数50
25% Q1 38
10% -30
5% -30
1% -30
0% 最小值-30
极值观测
最小值最大值
值观
测值观测
-30 5 -30 5 38 2 38 2 50 4 50 4 60 3 60 3 110 1 110 1
W值为0.953423,其对应概率Pr < W为0.7616,远大于0.05,说明
差值数据服从正态分布,此时利用参数t的检验即可。由结果知t值为2.024448,对应概率Pr > |t|为0.1129,说明差值的均值与0没有显著差异,从而得到施加矮壮素对玉米株高没有显著性影响。三.方差分析
题目:
欲了解3个水稻品种和4种化肥之间的互作关系,设计试验,调查结果如下:(单位:kg)
化肥
A B C D
品种
a 400 420 430 410
b 450 460 480 455
c 460 480 500 450
分析水稻品种和化肥种类对产量是否有显著影响。显著水平为0.05。
[数据来源:《试验统计学》,区靖祥编著,2010,广州:广东高等教育出版社]
SAS程序:
data chan;
do pack='a','b','c';
do v='A','B','C','D';
input com @@;
output;
end;
end;
cards;
400 420 430 410
450 460 480 455
460 480 500 450
;
proc anova;
class pack v;
model com=pack v;
means pack v/t bon;
run;
Class Level Information
Class Levels Values
pack 3 a b c
v 4 A B C D
Number of Observations Read 12 Number of Observations Used 12
Source DF
Sum of
Squares Mean Square F Value Pr>F
Model 5 9602.083333 1920.416667 35.91 0.0002 Error 6 320.833333 53.472222
Corrected Total 11 9922.916667
R-Square Coeff
Var Root MSE com Mean
0.967667 1.626499 7.312470 449.5833
Source DF Anova SS Mean Square F Value Pr>F pack 2 7429.166667 3714.583333 69.47 <.0001 v 3 2172.916667 724.305556 13.55 0.0044
Alpha 0.05
Error Degrees of Freedom 6
Error Mean Square 53.47222
Critical Value of t 2.44691
Least Significant Difference 12.652
04:27 Thursday, June 26, 2014 8
Means with the same letter are not
significantly different.
t Grouping Mean N pack
A 472.500 4 c
A 461.250 4 b
B 415.000 4 a
Alpha 0.05
Error Degrees of Freedom 6
Error Mean Square 53.47222
Critical Value of t 3.28746
Minimum Significant Difference 16.998
Means with the same letter are not
significantly different.
Bon Grouping Mean N pack
A 472.500 4 c
A
A 461.250 4 b
B 415.000 4 a
Alpha 0.05
Error Degrees of Freedom 6
Error Mean Square 53.47222
Critical Value of t 2.44691
Least Significant Difference 14.61
04:27 Thursday, June 26, 2014 9 Means with the same letter are
not significantly different.
t Grouping Mean N v
A 470.000 3 C
B 453.333 3 B
C 438.333 3 D
C
C 436.667 3 A
Alpha 0.05
Error Degrees of Freedom 6
Error Mean Square 53.47222
Critical Value of t 3.86299
Minimum Significant Difference 23.064
Means with the same letter are not
significantly different.
Bon Grouping Mean N v
A 470.000 3 C
A
B A 453.333 3 B
B
B 438.333 3 D
B
B 436.667 3 A
结果解释:
检测结果告诉我们,因素作物品种的F检验值为69.47,其对应概率小于0.0001;因素化肥品种的F检验值为13.55,其对应概率为0.0044.
04:27 Thursday, June 26, 2014 10
因此在0.05的显著水平上,作物品种和
化肥品种对作物的产量都有显著影响。
为进一步了解不同作物品种和不同化肥对作物产量的影响差异,又对
此进行了多重比较检验,检验结果见输出。对于给定的显著水平0.05,
关于不同作物品种由T检验法给出的临界值为2.44691,而最小显著
性差为12.652。结果为:三个作物品种平均产量均不同a,b,c平均
产量分别为:415.000,461.250,472.500.由BON法检验给出的临界值
为3.2874,而最小显著性差为16.998.两种方法检验结果一致,即三
个作物品种的产量均显著不同。
关于不同化肥,由T检验法给出的临界值为3.86299,而最小显著性
差为23.064。结果为:四个化肥品种导致平均产量均不同a,b,c平
均产量分别为:415.000,461.250,472.500.由BON法检验给出的临界
值为3.2874,而最小显著性差为16.998.两种方法检验结果一致,即
三个作物品种的产量均显著不同。检测结果是A,D化肥产量相差不
大,B高于A,D,C则显著高于其他三种。结果为C化肥与A,B,D均
有显著差异;B与A,D均有显著差异;A与D无显著差异。
BON法给出的化肥品对均产量检验结果为:B,C无显著差异;B,D,A
无显著差异;C和D,A均有显著差异。
四卡方测验:
题目:
数据如下表,试分析大豆与否和等位基因是否有关。
等位基因1 等位基因2 等位基因3 总数
04:27 Thursday, June 26, 2014 11 野生大豆29(23.66) 68(123.87)96(45.47)193
栽培大豆22(27.34) 199(143.13)2(52.53)223 总数51 267 98 416
[数据来源:《试验统计学》,区靖祥编著,2010,广州:广东高等教育出版社]
SAS程序:
data tn68;
do r=1to3;
do c=1to2;
input y @@;
output;
end;
end;
cards;
29 68 96
22 199 2
;
Ods rtf file = "c:\long.doc";
proc freq;
weight y;
tables r*c/chisq expected;
run;
Ods rtf close;
Sas结果:
表—r X c
r C
频数
期望
百分比
行百分比
列百分比 1 2 合计
1 29
75.548
6.97
29.90
8.95
68
21.452
16.35
70.10
73.91
97
23.32
04:27 Thursday, June 26, 2014 12
结果
解释:
ν=(2-1)=1,查表得X 2
0.05
,1=3.84,现实得
X 2c =182.5631> X 2 0.05,P<0.0001 所以不同品种与不同等位基因频率有
2 96 91.904 23.08
81.36 29.63 22
26.096 5.29 18.64 23.91
118
28.37
3 199 156.55 47.84
99.00 61.42
2
44.452 0.48 1.00 2.17 201
48.32
合计 324
77.88 92
22.12 416
100.00
“r * c ”表的统计量
统计量 自由度
值
概率
卡方 2 182.5631 <.0001 似然比卡方
2 185.3200 <.0001 Mantel-Haenszel 卡方 1 168.6630 <.0001 Phi 系数 0.6625 列联系数 0.552
3 Cramer V 统计量
0.6625
样本大小 = 416
04:27 Thursday, June 26, 2014 13 显著相关!
五、相关回归
题目:
为研究小麦主穗小穗数与主穗粒数关系,在小麦试验地随机抽选8个小麦品种作为样本,下面是这8个品种的有关数据:
平均主穗小穗数 12.2,12.3,13.9,18.9,14.8,15.5,14.8,14.8
平均主穗粒数 18.8,23.7,20.3,34.3,32.2,34.4,28.5,28.1
[数据来源:《统计分析及其SAS实现》,张晓冉编著,2011,清华大学出版社] SAS程序:
data t4;
input x y @@;
cards;
12.2 18.8 12.3 23.7 18.9 34.3 14.8 32.2 15.5 34.4 14.8 28.5 14.8 28.1 ;
ods rtf file="c:\book.doc";
proc reg corr;
model y=x/clm cli;
plot y*x/conf pred;
run;
ods rtf close;
Sas结果:
Number of Observations Read 7
Number of Observations Used 7
Correlation
Variable x y
x 1.000
0 0.838
2
y 0.838
2 1.000
Number of Observations Read 7 Number of Observations Used 7
Analysis of Variance
Source DF
Sum of
Squares
Mean
Square F Value Pr > F
Model 1 140.1026
1 140.1026
1
11.81 0.0185
Error 5 59.29168 11.85834
Corrected Total 6 199.3942
9
Root MSE 3.44359 R-Square 0.702
6
Dependent Mean 28.5714
3 Adj R-Sq 0.643
2
Coeff Var 12.0525
8
Parameter Estimates
Variable DF Parameter
Estimate
Standard
Error t Value Pr > |t|
Intercept 1 -3.16255 9.32367 -0.34 0.7482 x 1 2.15041 0.62562 3.44 0.0185
Output Statistics
Obs Dependent
Variable
Predicted
Value
Std Error
Mean Predict 95% CL Mean 95% CL Predict Residual
1 18.8000 23.0725 2.0624 17.771
0 28.374
12.754
3
33.390
7
-4.2725
2 23.7000 23.2876 2.0142 18.109
8 28.465
3
13.032
4
33.542
7
0.4124
3 34.3000 37.4803 2.9003 30.024
8 44.935
8
25.906
9
49.053
6
-3.1803
4 32.2000 28.6636 1.3018 25.317
1 32.010
1
19.200
1
38.127
1
3.5364
5 34.4000 30.1689 1.3820 26.616
2 33.721
5
20.630
5
39.707
2
4.2311
6 28.5000 28.6636 1.3018 25.317
1 32.010
1
19.200
1
38.127
1
-0.1636
7 28.1000 28.6636 1.3018 25.317
1 32.010
1
19.200
1
38.127
1
-0.5636
Sum of Residuals 0
Sum of Squared Residuals 59.29168
Predicted Residual SS (PRESS) 207.4383
8
由结果可知否定无效假设,即回归方程是显著的。
结论分析:
1、相关系数r=0.8382〉0.75,两变量相关性较好。
2、回归方程y=-3.1626+2.1504x
3、假设测验:
无效假设β=0,备择假设β≠0,
显著性水平α=0.05,
统计量t=3.44,P=0.0185〉0.01
所以否定无效假设H0,接受HA,即回归方程是显著的,总体存在回归关系。
≠β农学《田间试验与统计分析》题库1 一、判断题:判断结果填入括弧,以√表示正确,以×表示错误。(每小题2分,共14分) 1 多数的系统误差是特定原因引起的,所以较难控制。( × ) 2 否定正确无效假设的错误为统计假设测验的第一类错误。( √ ) 3 A 群体标准差为5,B 群体的标准差为12, B 群体的变异一定大于A 群体。( × ) 4 “唯一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( √ ) 5 某班30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已知 84.32 1,05.0=χ) 。 ( √ ) 6 在简单线性回归中,若回归系数,则所拟合的回归方程可以用于由自变数X 可靠地预测依变数Y 。( × ) 7 由固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于 推断处理的总体。( √ ) 二、填空题:根据题意,在下列各题的横线处,填上正确的文字、符号或数值。(每个空1分,共16分 ) 1 对不满足方差分析基本假定的资料可以作适当尺度的转换后再分析,常用方法有 平方根转换 、 对数转换 、 反正旋转换 、 平均数转换 等。 2 拉丁方设计在 两个方向 设置区组,所以精确度高,但要求 重复数 等于 处理数 ,所以应用受到限制。 3 完全随机设计由于没有采用局部控制,所以为保证较低的试验误差,应尽可能使 试验的 环境因素相当均匀 。 4 在对单个方差的假设测验中:对于C H =20σ:,其否定区间为2,2 12 να χχ-<或 2 ,22ν αχχ>;对于C H ≥2 0σ:,其否定区间为2,12 ναχχ -<;而对于C H ≤2 0σ:,其 否定区间为2 ,2ναχχ>。 5 方差分析的基本假定是 处理效应与环境效应的可加性 、 误差的正态性 、 误差的同质性 。 6 一批玉米种子的发芽率为80%,若每穴播两粒种子,则每穴至少出一棵苗的概率为 0.96 。 7 当多个处理与共用对照进行显著性比较时,常用 最小显著差数法(LSD) 方法进行多重比较。 三、选择题:将正确选择项的代码填入题目中的括弧中。(每小题2分,共10分 ) 1 田间试验的顺序排列设计包括 ( C )。 A 、间比法 B 、对比法 C 、间比法、对比法 D 、阶梯排列 2 测定某总体的平均数是否显著大于某一定值时,用( C )。 A 、两尾测验 B 、左尾测验 C 、右尾测验 D 、无法确定 3分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( D )。
实验数据的处理与分析 1. 0.80 g CuSO 4·5H 2O 样品受热脱水过程的热重曲线(样品质 量随温度变化的曲线)如下图所示。 请回答下列问题: (1)试确定200 ℃时固体物质的化学式________________________________________ ________________________________________________________________________; (要求写出推断过程)。 (2)取270 ℃所得样品,于570 ℃灼烧得到的主要产物是黑色粉末和一种氧化性气体,该反应的化学方程式为________________________;把该黑色粉末溶解于稀硫酸中,经浓缩、冷却,有晶体析出,该晶体的化学式为________,其存在的最高温度是________。 答案 (1)CuSO 4·H 2O CuSO 4·5H 2O=====200 ℃ CuSO 4·(5-n )H 2O +n H 2O 250 18n 0.80 g 0.80 g -0.57 g =0.23 g 可列式:2500.80 g =18n 0.23 g ,求得n ≈4,200 ℃时产物为CuSO 4·H 2O 晶体。 (2)CuSO 4=====570 ℃ CuO +SO 3↑ CuSO 4·5H 2O 102 ℃ 解析 (1)分析CuSO 4·5H 2O 受热脱水过程的热重曲线可知,200 ℃时和113 ℃时的产物相同,可根据113 ℃时样品质量确定脱水产物,设113 ℃时产物为CuSO 4·(5-n )H 2O ,则有 CuSO 4·5H 2O=====200 ℃CuSO 4·(5-n )H 2O +n H 2O 250 18n 0.80 g 0.80 g -0.57 g =0.23 g 可列式:2500.80 g =18n 0.23 g ,求得n ≈4,200 ℃时产物为CuSO 4·H 2O 晶体。 (2)根据灼烧产物是黑色粉末可知分解生成CuO ,则具有氧化性的另一产物为SO 3,所以灼烧时反应方程式为CuSO 4=====570 ℃ CuO +SO 3↑,CuO 溶于稀硫酸得CuSO 4溶液,结晶时又生成CuSO 4·5H 2O ,由脱水过程的热重曲线可知其存在的最高温度为102 ℃。 2.现有一份CuO 和Cu 2O 的混合物,用H 2还原法测定其中的CuO 质量x g ,实验中可以测定以 下数据:①W :混合物的质量(g)、②W (H 2O):生成水的质量(g)、③W (Cu):生成Cu 的质量(g)、④V (H 2):标准状况下消耗H 2的体积(L)。 (已知摩尔质量:Cu :64 g·mol -1、CuO :80 g·mol -1、Cu 2O :144 g·mol -1、 H 2O :18 g·mol -1) (1)为了计算x 至少需要测定上述4个数据中的________个,这几个数据的组合共有________种。请将
0≠β农学《田间试验与统计分析》题库1 一、判断题:判断结果填入括弧,以√表示正确,以×表示错误。(每小题2分,共14分) 1 多数的系统误差是特定原因引起的,所以较难控制。( × ) 2 否定正确无效假设的错误为统计假设测验的第一类错误。( √ ) 3 A 群体标准差为5,B 群体的标准差为12, B 群体的变异一定大于A 群体。( × ) 4 “唯一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( √ ) 5 某班30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已知 84.32 1,05.0=χ) 。 ( √ ) 6 在简单线性回归中,若回归系 数,则所拟合的回归方程可以用于由自变数X 可靠地预测依变数Y 。( × ) 7 由固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于 推断处理的总体。( √ ) 二、填空题:根据题意,在下列各题的横线处,填上正确的文字、符号或数值。(每个空1分,共16分 ) 1 对不满足方差分析基本假定的资料可以作适当尺度的转换后再分析,常用方法有 平方根转换 、 对数转换 、 反正旋转换 、 平均数转换 等。 2 拉丁方设计在 两个方向 设置区组,所以精确度高,但要求 重复数 等于 处理数 ,所以应用受到限制。 3 完全随机设计由于没有采用局部控制,所以为保证较低的试验误差,应尽可能使 试验的 环境因素相当均匀 。 4 在对单个方差的假设测验中:对于C H =20σ:,其否定区间为2 ,2 12 ν α χχ-<或 2 ,22ν αχχ>;对于C H ≥2 0σ:,其否定区间为2,12 ναχχ -<;而对于C H ≤2 0σ:,其 否定区间为2 ,2ναχχ>。 5 方差分析的基本假定是 处理效应与环境效应的可加性 、 误差的正态性 、 误差的同质性 。
1 【多选题】 田间试验任务的主要来源有()。 A、 农业生产实践中发现或提出了新的问题,需要通过田间试验进行解决。 B、 农业科学工作者经常需要通过田间试验开展有关作物生长发育和遗传规律以及作物与环境之间相互关系等研究。 C、 不同地区和不同单位之间经常有相同或类似的项目需要进行研究,受其它地区或单位的委托进行研究也是田间试验任务的一个重要来源。 D、 根据农业生产发展的需要,各级农业行政部门或科研主管部门经常会下达一些田间试验项目。 我的答案:ABCD 2 【判断题】 田间试验的任务就是在大田条件下评价农业生产新技术、新产品和新品种的实际效果,解决农业生产中需要解决的问题。 我的答案:√ 1 【单选题】 试验目的要明确就是()。 A、 要求田间试验的各项试验条件要接近试验结果欲推广地区的自然条件和生产条件 B、 对试验要解决的问题有充分的了解,对预期结果做到心中有数 C、 必须坚持唯一差异原则 D、 在相同或类似的条件下进行同样的试验或生产实践,能获得类似的结果 我的答案:B 2 【单选题】 试验条件要有代表性就是要求田间试验的各项试验条件要接近试验结果欲推广地区的(),只有这样才能使试验结果在欲推广地区的生产上发挥增产增效作用。 A、 自然条件、生产条件 B、 天气条件 C、 土壤条件 D、
市场条件 我的答案:A 3 【单选题】 为了保证试验结果的准确可靠,进行田间试验时,必须坚持(),随时随地注意试验的准确性,力求避免造成不应有的试验误差。 A、 重复原则 B 随机排列 C、 唯一差异原则 D、 一致原则 我的答案:C 4 【多选题】 田间试验的基本要求包括()。 A、 试验目的要明确 B、 试验条件要有代表性 C、 试验结果要准确可靠 D、 试验结果要有重演性 我的答案:ABCD 5 【多选题】 为了满足重演性的要求,有哪些要注意的环节 ( ) A 完全掌握试验所处的自然条件和生产条件 B、 有及时、准确、完整的田间观察记载,以便分析产生各种试验结果的原因,找出规律性的东西 C、 每一项试验最好在本地重复进行2~3年,以便弄清作物对不同年份气候条件的反应 D、 如果将试验结果推广到其他地区,还应进行多点试验。 我的答案:ABCD 6 【判断题】 为了保证试验结果的重演性,必须严格注意试验中的一系列环节,尤其应严格要求试验的正确执行和试验条件的代表性这两个前提。
《田间试验与统计分析》是农学专业的主干课程,也是生物科学、生物技术、植物保护、动植物检疫、草业科学等相关专业的基础课。本课程群的教学理念是以应用为导向,以试验设计、统计分析原理和思路为重点,以灵活应用数据处理软件为支撑。通过本课程的学习,可以掌握试验设计的基本原理、基本设计方法及其数据分析方法,提高科学研究、逻辑推理、试验设计及数据处理的能力,特别是科学创新能力。使用优良的设计方法及分析技术可以更好地解决农业科学(或生物科学)研究中的实际问题。 本课程自2004年被列为河北省精品课程以来,从教学体系、教学内容、教学手段、教师队伍建设、实践教学、网络资源等方面进行了建设,已完成预期建设目标。分述如下: 1.课程建设目标 (1)在现代化教学理念指导下,制定适合与我校人才培养模式和植物生产类人才培养目标的教学大纲,构建适应于不同专业、不同学历层次的课程体系,体现教育教学的现代性、科学性和先进性。 (2)摸索能够培养学生的分析问题和解决问题能力、挖掘学生的创造能力和创新能力的课堂教学和实践教学的方法与手段。 (3)探索以科研带动教学,以教学推进科研,教学科研同步提高的途径。改善教师的知识结构,提升学术水平和素质。 (4)选用国内优秀的教材,并组织或参与《田间试验与统计分析》系列教材的编写,建设一套具有鲜明特色的教材体系。 (5)完善网络资源的建设,为学生课下学习提供丰富、多样化的资料和案例。
(6)建立适合于本课程特点的考试方式和评定标准,扩充试题库。 2.课程建设内容及进展情况 (1)理论课程体系建设的情况 按照我校植物生产类专业的人才培养模式和教学目标的要求,对原《田间试验与统计分析》课程体系进行整改,按照专业类别、学历层次组织教学,构建一个既能够体现植物生产类特色、又能传授试验设计与数据处理分析方法的课程群。田间试验与统计分析课程群中包括有《田间试验与统计分析》(专科)、《生物统计学》(本科)、《试验设计与分析》(本科)和《应用统计学》(本科)四门课程。 (2)教学手段、教学方法和教材建设的情况 ①将科学研究经验、教训、成果引入课堂教学,丰富教学内容、凸显课程特色。在课堂讲授的恰当时候向学生们阐释科研处理数据资料的经典实例,使学生们意识到只有灵活使用统计方法,才能发挥其最大的效益;把所承担的国家、省部级科研项目的内容从试验设计学和统计分析的侧面讲述给学生,激发学生的学习兴趣,潜移默化地培养学生的科学研究和创新的能力。 ②改变传统的灌输式教学法,对于教学中的重点、难点采取案例式教学、形象化教学、实践参与式教学等方式来组织教学。并利用本精品课程网上在线答疑、Bb (Blackboard Academic Suite?)网络教学平台讨论区、教师的BLOG网页等多种形式实现课下辅导。
≠β 一、判断题:判断结果填入括弧,以√表示正确,以×表示错误。(每小题2分,共14分) 1 多数的系统误差是特定原因引起的,所以较难控制。( × ) 2 否定正确无效假设的错误为统计假设测验的第一类错误。( √ ) 3 A 群体标准差为5,B 群体的标准差为12, B 群体的变异一定大于A 群体。( × ) 4 “唯一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( √ ) 5 某班30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已知 84.32 1,05.0=χ) 。 ( √ ) 6 在简单线性回归中,若回归系数,则所拟合的回归方程可以用于由自变数X 可靠地预测依变 数Y 。( × ) 7 由固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于 推断处理的总体。( √ ) 二、填空题:根据题意,在下列各题的横线处,填上正确的文字、符号或数值。(每个空1分,共16分 ) 1 对不满足方差分析基本假定的资料可以作适当尺度的转换后再分析,常用方法有 平方根转换 、 对数转换 、 反正旋转换 、 平均数转换 等。 2 拉丁方设计在 两个方向 设置区组,所以精确度高,但要求 重复数 等于 处 理数 ,所以应用受到限制。 3 完全随机设计由于没有采用局部控制,所以为保证较低的试验误差,应尽可能使 试验的环境 因素相当均匀 。 4 在对单个方差的假设测验中:对于C H =20σ:,其否定区间为2 ,2 12 να χχ -<或2 ,2 2ν α χχ>; 对于C H ≥20σ:,其否定区间为2 ,12ναχχ-<;而对于C H ≤20σ:,其否定区间为2 ,2ναχχ>。 5 方差分析的基本假定是 处理效应与环境效应的可加性 、 误差的正态性 、 误差的同质性 。 6 一批玉米种子的发芽率为80%,若每穴播两粒种子,则每穴至少出一棵苗的概率为 0.96 。 7 当多个处理与共用对照进行显著性比较时,常用 最小显著差数法(LSD) 方法进行多重比较。 三、选择题:将正确选择项的代码填入题目中的括弧中。(每小题2分,共10分 ) 1 田间试验的顺序排列设计包括 ( C )。 A 、间比法 B 、对比法 C 、间比法、对比法 D 、阶梯排列 2 测定某总体的平均数是否显著大于某一定值时,用( C )。 A 、两尾测验 B 、左尾测验 C 、右尾测验 D 、无法确定 3分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( D )。 A 、[-9.32,11.32] B 、[-4.16,6.16] C 、[-1.58,3.58] D 、都不是
植物科学与技术专业090122 田间试验与统计分析课程代码2677 试题C 一、单项选择题(每小题1分、共20分。在每小题列出的四个备选项中只有一个是符合题 目要求的,请将其代码涂在答题卡上。) 1. 因素的水平是指 A.因素量的级别 B.因素质的不同状态 C.研究的范围与内容 D.因素量的级别和质的不同状态 2. 误差根据形成的原因不同,可分为 A.随机误差、系统误差 B.随机误差、人为误差 C.系统误差 D.偶然误差 3.如果田间试验无法在一天内完成,以下那种做法是正确的 A.同一小区必须在一天完成 B.几个区组可以同时操作 C.同一区组必须在一天完成 D.灵活安排 4.局部控制的主要作用是 A.降低误差 B.无偏估计误差 C.控制误差 D.分析误差 5.随机区组设计在田间布置时可采用以下策略 A.同一区组内小区可以拆开 B.不同区组可以放在不同田块 C.所有区组必须放在同一田块 D.区组内的小区可以顺序排列 6.随机区组设计 A.只能用于单因素试验 B.既能用于单因素又可用于多因素试验 C.只能用于多因素试验 D.只能用于田间试验 7.进行叶面施肥的试验中,对照小区应设置为 A.喷等量清水B.不喷C.减量喷D.以上均不正确 8.标准差的数值越大,则表明一组数据的分布()。 A.越分散,平均数的代表性越低 B.越集中,平均数的代表性越高 C.越分散,平均数的代表性越高 D.越集中,平均数的代表性越低 9.在使用变异系数表示样本变异程度时,宜同时列出()。 A.方差、全距 B.平均数、方差 C.平均数、标准差 D. 平均数、标准误 10.二项概率的正态近似应用连续性矫正时,其正态标准离差的表达中,错误的是 A、 c ||0.5 Y u μ σ -- =B、 c 0.5 Y u μ σ - =± C、 ()0.5 c Y u μ σ - = D、 c u= 11.盒中有24个球,从中随机抽取3个球,其中有1个球是红球,则可以判断该盒中的红球数为()。 A.肯定是8个 B.8个以上 C.8个以下 D.8个上下 12.与样本均值的抽样分布的标准差成反比的是 A.样本容量 B.样本容量的平方 C.样本容量的平方根 D.样本容量的二分之一13.正态曲线的理论取值范围是 A.6个标准差 B.± 3 C.±∞ D.没有限制 14.算术平均数的重要特性之一是离均差之和
实验数据的处理分析 [考纲要求] 能分析和处理实验数据,得出合理的结论。 热点实验数据筛选与处理 实验所得的数据,可分为有用、有效数据,正确、合理数据,错误、无效数据,及无用、多余数据等。能从大量的实验数据中找出有用、有效、正确、合理的数据是实验数据分析处理题的一个重要能力考查点,也是近年来命题变化的一个重要方向。 解题策略 对实验数据筛选的一般方法和思路为“五看”:一看数据是否符合测量仪器的精度特点,如用托盘天平测得的质量的精度为,若精度值超过了这个范围,说明所得数据是无效的;二看数据是否在误差允许范围内,若所得的数据明显超出误差允许范围,要舍去;三看反应是否完全,是否是过量反应物作用下所得的数据,只有完全反应时所得的数据,才能进行有效处理和应用;四看所得数据的测试环境是否一致,特别是气体体积数据,只有在温度、压强一致的情况下才能进行比较、运算;五看数据测量过程是否规范、合理,错误和违反测量规则的数据需要舍去。 典例导悟(·江苏,).对硝基甲苯是医药、染料等工业的一种重要有机中间体,它常以浓硝酸为硝化剂,浓硫酸为催化剂,通过甲苯的硝化反应制备。 一种新的制备对硝基甲苯的实验方法是:以发烟硝酸为硝化剂,固体为催化剂(可循环使用),在溶液中加入乙酸酐(有脱水作用), ℃反应。反应结束后,过滤,滤液分别用溶液、水洗至中性,再经分离提纯得到对硝基甲苯。 ()上述实验中过滤的目的是。 ()滤液在分液漏斗中洗涤静置后,有机层处于层(填“上”或“下”);放液时,若发现液体流不下来,其可能原因除分液漏斗活塞堵塞外,还有。 ②由甲苯硝化得到的各种产物的含量可知,甲苯硝化反应的特点是。 ③与浓硫酸催化甲苯硝化相比,催化甲苯硝化的优点有、。 热点实验数据综合分析 如何用好、选好数据,是解决这类试卷的关键所在。解决这类试卷的一般方法为:比较数据,转变物质,分析利弊,确定方案。 解题策略
一.单项选择题(10分) 1、株高、粒重、穗长这一类数据属于 。 (1)离散性数据 (2)计数数据(3)连续性数据(4)属性数据 2、概率概念的正确表达是 。 (1)事物发生的可能性(2)事件在试验结果中出现可能性大小的定量计量 (3)某一事件占全部事件的百分比(4)样本中某一类型数据个数与样本含量比值的百分数 3、标准正态分布曲线的展开度是由 决定的。 (1)σ (2)μ (3)df (4) u 4、样本标准误差是 。 (1)用来度量样本平均数偏离总体平均数的程度 (2)度量样本内每个个体偏离样本平均数的程度 (3)度量样本内每个个体偏离总体平均数的程度 (4)度量样本标准差偏离总体标准差的程度 5、在一个成组数据t 测验中,把两个样本方差合并为一个公共方差,其理由是 。 (1)合并后才能检验(2)它们总体平均数相等(3)两总体方差相等(4)计算工作需要 6、在σ未知情况下,单个样本平均数显著性检验应使用以下 检验统计量。 (1) σ μ -x (2) n s x μ-- (3) s x μ-- (4) n s x μ- 7、对应于备择假设21μμ>,无效假设的否定区域应是 。 (1)t>t α (2) t<-t α (3) ︱t ︱>t α/2 (4)说不清 8、在一孟德尔实验中,F 2代两种表现型后代数目为398和129,为判断这一分离比例是否符合3:1分利弊,需使用以下 方法作检验。 (1)u 检验 (2)t 检验 (3)2χ适合性检验 (4)F 检验 9、SSe 是由计算 得到的。 (1)重复间平方和(2)各水平平均数的平方和 (3)各观察值平方和(4)累积各处理内重复间平方和 10、一尾检验和两尾检验比较 。 (1)两尾检验更容易检验出差异 (2)在同样的检验要求下一尾检验需更大样本 (3)一尾检验比两尾检验更易计算(4)在样本含量相同时一尾检验效率更高 二、名词解释题(5分) 1、参 数 2、自由度 3、显著性水平 4、参数估计 5、水 平 三、问答题(12分) 1、为什么要计算数据标准差?标准差含义是什么? 2、田间试验设计基本原则及相互关系
注:装订线内禁止答题,装订线外禁止有姓名和其他标记。 0≠β东北农业大学成人教育学院考试题签 田间试验与统计方法(A ) 一、判断题:判断结果填入括弧,以√表示正确,以×表示错误。(每小题2分,共14分) 1 多数的系统误差是特定原因引起的,所以较难控制。( ) 2 否定正确无效假设的错误为统计假设测验的第一类错误。( ) 3 A 群体标准差为5,B 群体的标准差为12, B 群体的变异一定大于A 群体。( ) 4 “唯一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( ) 5 某班30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1(已知84.32 1,05.0=χ) 。 ( ) 6 在简单线性回归中,若回归系数,则所拟合的回归方程可以用于由自变数X 可靠地 预测依变数Y 。( ) 7 由固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于 推断处理的总体。( ) 二、填空题(每空2分,共30分 ) 1 对不满足方差分析基本假定的资料可以作适当尺度的转换后再分析,常用方法有 、 、 、 等。 2 拉丁方设计在 设置区组,所以精确度高,但要求 等 于 ,所以应用受到限制。 3 完全随机设计由于没有采用局部控制,所以为保证较低的试验误差,应尽可能使 。 4 在对单个方差的假设测验中:对于C H =20σ:,其否定区间为 或 ; 对于C H ≥20σ:,其否定区间为 ;而对于C H ≤20σ:,其否定区间为 。 5 方差分析的基本假定是 、 、 。 三、选择题(每小题2分,共10分 ) 1 田间试验的顺序排列设计包括 ( )。 A 、间比法 B 、对比法 C 、间比法、对比法 D 、阶梯排列 2 测定某总体的平均数是否显著大于某一定值时,用( )。 A 、两尾测验 B 、左尾测验 C 、右尾测验 D 、无法确定 3分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( )。 A 、[-9.32,11.32] B 、[-4.16,6.16] C 、[-1.58,3.58] D 、都不是 4 正态分布不具有下列哪种特征( )。 A 、左右对称 B 、单峰分布 C 、中间高、两头低 D 、概率处处相等 5 对一个单因素6个水平、3次重复的完全随机设计进行方差分析,若按最小显著差数法进行多重 比较,比较所用的标准误及计算最小显著差数时查表的自由度分别为( )。 A 、 2MSe/6 , 3 B 、 MSe/6 , 3 C 、 2MSe/3 , 12 D 、 MSe/3 , 12
讲座 实验误差及数据处理 教学要求 1、了解实验误差及其表示方法; 2、掌握了解有效数字的概念,熟悉其运算规则; 3、初步掌握实验数据处理的方法。 重点及难点 重点:实验误差及其表示方法;有效数字;实验数据处理。 难点:有效数字运算规则;实验数据的作图法处理。 教学方法与手段 讲授,ppt演示。 教学时数 4学时 教学内容 引言 化学实验中经常使用仪器对一些物理量进行测量,从而对系统中的某些化学性质和物理性质作出定量描述,以发现事物的客观规律。但实践证明,任何测量的结果都只能是相对准确,或者说是存在某种程度上的不可靠性,这种不可靠性被称为实验误差。产生这种误差的原因,是因为测量仪器、方法、实验条件以及实验者本人不可避免地存在一定局限性。 对于不可避免的实验误差,实验者必须了解其产生的原因、性质及有关规律,从而在实验中设法控制和减小误差,并对测量的结果进行适当处理,以达到可以接受的程度。 一、误差及其表示方法 1.准确度和误差 ⑴准确度和误差的定义 准确度是指某一测定值与“真实值”接近的程度。一般以误差E表示, E=测定值-真实值 当测定值大于真实值,E为正值,说明测定结果偏高;反之,E为负值,说明测定结果偏低。误差愈大,准确度就愈差。 实际上绝对准确的实验结果是无法得到的。化学研究中所谓真实值是指由有经验的研究人员同可靠的测定方法进行多次平行测定得到的平均值。以此作为真实值,或者以公认的手册上的数据作为真实值。 ⑵绝对误差和相对误差 误差可以用绝对误差和相对误差来表示。 绝对误差表示实验测定值与真实值之差。它具有与测定值相同的量纲。如克、毫升、百分数等。例如,对于质量为0.1000g的某一物体。在分析天平上称得其质量为0.1001g,则称量的绝对误差为+0.0001g。 只用绝对误差不能说明测量结果与真实值接近的程度。分析误差时,除要去
《生物统计与田间试验》考试题 20151231
《生物统计与田间试验》2006-2007学年第1学期 A 卷参考答案 一、判断题:判断结果填入括弧,以√表示正确,以×表示错误。(每小题2分,共14分) 1 多数的系统误差是特定原因引起的,所以较难控制。( × ) 2 否定正确无效假设的错误为统计假设测验的第一类错误。( √ ) 3 A 群体标准差为5,B 群体的标准差为12, B 群体的变异一定大于A 群体。( × ) 4 “唯一差异”是指仅允许处理不同,其它非处理因素都应保持不变。( √ ) 5 某班30位学生中有男生16位、女生14位,可推断该班男女生比例符合1∶1 (已知84.32 1,05.0=χ)。 ( √ ) 6 在简单线性回归中,若回归系数0≠β,则所拟合的回归方程可以用于由自变 数X 可靠地预测依变数Y 。( × ) 7 由固定模型中所得的结论仅在于推断关于特定的处理,而随机模型中试验结论则将用于 推断处理的总体。( √ ) 二、填空题:根据题意,在下列各题的横线处,填上正确的文字、符号或数值。(每个空1分,共16分 ) 1 对不满足方差分析基本假定的资料可以作适当尺度的转换后再分析,常用方法有 平方根转换 、 对数转换 、 反正旋转换 、 平均数转换 等。 2 拉丁方设计在 两个方向 设置区组,所以精确度高,但要求 重复数 等于 处理数 ,所以应用受到限制。 3 完全随机设计由于没有采用局部控制,所以为保证较低的试验误差,应尽可能 使 试验的环境因素相当均匀 。
4 在对单个方差的假设测验中:对于C H =20σ:,其否定区间为2 ,2 12ν α χχ-<或 2 ,22ν αχχ>;对于C H ≥2 0σ:,其否定区间为2 ,12ναχχ-<;而对于 C H ≤20σ:,其否定区间为2 ,2ναχχ>。 5 方差分析的基本假定是 处理效应与环境效应的可加性 、 误差的正态 性 、 误差的同质性 。 6 一批玉米种子的发芽率为80%,若每穴播两粒种子,则每穴至少出一棵苗的概率为 0.96 。 7 当多个处理与共用对照进行显著性比较时,常用 最小显著差数法(LSD) 方法进行多重比较。 三、选择题:将正确选择项的代码填入题目中的括弧中。(每小题2分,共10分 ) 1 田间试验的顺序排列设计包括 ( C )。 A 、间比法 B 、对比法 C 、间比法、对比法 D 、阶梯排列 2 测定某总体的平均数是否显著大于某一定值时,用( C )。 A 、两尾测验 B 、左尾测验 C 、右尾测验 D 、无法确定 3分别从总体方差为4和12的总体中抽取容量为4的样本,样本平均数分别为3和2,在95%置信度下总体平均数差数的置信区间为( D )。 A 、[-9.32,11.32] B 、[-4.16,6.16] C 、[-1.58,3.58] D 、都不是 4 正态分布不具有下列哪种特征( D )。 A 、左右对称 B 、单峰分布 C 、中间高、两头低 D 、概率处处相等 5 对一个单因素6个水平、3次重复的完全随机设计进行方差分析,若按最小显 著差数法进行多重比较,比较所用的标准误及计算最小显著差数时查表的自由度分别为( C )。 A 、2MSe/6, 3 B 、MSe/6 , 3 C 、2MSe/3, 12 D 、MSe/3, 12
田间试验与统计分析-习题集及解答
1. 2. 3. 在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、 间比法 若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁 方设计 如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相 乘性, 则在进行方差分析之前, 须作数据转换。 其数据转换的方法宜采用: 对数转换。 对于百分数资料,如果资料的百分数有小于 30%或大于 70%的,则在进 行方差分析之前,须作数据转换。其数据转换的方法宜采用:反正弦转换 (角度转换)。 样本平均数显著性测验接受或否定假设的根据是: 小概率事件实际不可能性 原理。 对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。 为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分 测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著 表。 选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应 选择:LSD 法。 如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用: 空白试验 = = (两样本 所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t 测验 因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应 若算出简单相差系数 大于 1 时,说明:计算中出现了差错。 田间试验要求各处理小区作随机排列的主要作用是: 获得无偏的误差估计值 正态分布曲线与 轴之间的总面积为:等于 1。 描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计 数,用拉丁字母表示。 确定 分布偏斜度的参数为:自由度
4.
5. 6. 7. 8. 9. 10.
11. 当总体方差为末知,且样本容量小于 30,但可假设 12. 13. 14. 15. 16. 17.
18. 用最小显著差数法作多重比较时,当两处理平均数的差数大于 LSD0.01 时, 推断两处理间差异为:极显著 19. 要比较不同单位, 或者单位相同但平均数大小相差较大的两个样本资料的变 异度宜采用:变异系数 20. 选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用: q 测验。 21. 顺序排列设计的主要缺点是:估计的试验误差有偏性 22. 田间试验贯彻以区组为单位的局部控制原则的主要作用是: 更有效地降低试 验误差。
生物统计与田间试验 第一章绪论—科学试验及其误差控制 1.科学研究的基本方法:选题、文献、假说、假说的检验、试验的规划与设计。 2.唯一差异性原则:除需要比较的因素以外,其余的因素必须保持在同一水平。 3.试验方案:指根据试验目的和要求所拟进行比较的一组试验处理(treatment)的总称。 4.处理因素必须是:①可控的;②在数量上或质量上具有不同等级或水平。 5.水平(level):因素内的不同状态或者数量等级称为水平。 6.处理(treatment) :试验中的具体比较项目叫做处理。在单因素试中,每一个水平就是一个处理;在多因素试验中,每一个水平组合是一个处理。 7.试验因素、水平、处理是三个密切联系的概念:①凡一个因素就有若干个水平,因素与水平是联系在一起的。②水平组合是针对多因素试验而言的;一个水平组合是每个因素各出一个水平构成,为一个处理。③一个多因素试验的所有不同的水平组合数是各因素水平数之积。 8.试验指标:衡量试验处理效果的标准,简称指标。包括试验单元、抽样单元、测量单元。 9.试验效应(experimental effect) :试验因素对试验指标所起的增加或减少的作用。简单效应(simple effect):在同一因素内两种水平间试验指标的相差。主要效应(main effect);简称主效:一个因素内各简单效应的平均数称平均效应;交互作用效应(interaction effect),简称互作:两个因素简单效应间的平均差异。 9.一级互作(first order interaction) :两个因素间的互作,A×B、B×C ……。易于理解,实际意义明确;二级互作(second order interaction) :三个因素间的互作。 10.应有对照水平或处理,简称对照(check,CK)。 11.观察值(observation):将每次所取样品测定的结果称为一个观察值,记为y i。 12.误差(error):观察值与真值之间的差异。 13.偶然性误差(spontaneous error)或随机误差(random error):这是由于许多无法控制的内在和外在的偶然因素所造成。随机误差影响试验的精确性。 14.系统误差(systematic error)也叫片面误差(lopsided error):是由于试验材料、管理指施相差较大,仪器不准、标准试剂未经校正,以及观测、记载、抄录、计算中的差异所引起。系统误差影响试验的准确性。 15.准确性(accuracy)也叫准确度:指在调查或试验中某一试验指标或性状的观测值与其真值接近的程度,系统误差影响了数据的准确性。 16.精确性(precision)也叫精确度:指调查或试验中同一试验指标或性状的重复观测值彼此接近的程度,偶然误差影响了数据的精确性。 17.统计(statistics):指对某一现象的有关的数据的收集、整理、计算和分析等。 第二章田间试验的设计与实施 1.田间试验的基本要求:(1) 试验目的要明确;(2)试验条件要有代表性; (3)试验结果要可靠;(4)试验结果要能够重演;(5)体现唯一差异原则。
田间试验与统计分析 概论: 1.生物统计的内容包括哪三个方面? ①统计原理②统计方法③试验设计 2.生物统计的作用是什么? ①提供试验或调查的方法②提供整理或分析资料的方法 3.通常把样本容量小于或等于30的样本称为小样本。样本容量大于30的样本称为大样本。 4.生物统计:应用概率论和数据统计原理方法来确定生物界数量变化的学科。 根据研究目的确定的研究对象的全体称为总体。 总体的一部分称为样本。 由总体计算的特征数称为参数。是真值,不受抽样变动的影响。 由样本计算的特征数称为统计量,是参数的估计值,受抽样变动的影响。 准确性:也叫准确度,指在试验或调查中某一试验指标或性状的观测值与其真值接近的程度。 精确性:也叫精确度,指在试验或调查中同一试验指标或性状的重复观测值彼此接近的程度。 随机误差也叫抽样误差,这是由于许多无法控制的内在和外在的偶然因素所造成。 系统误差也叫片面误差,这是由于试验的初始条件相差较大,其条件未控制相同,测量的仪器不准,操作错误等所引起。(影响准确性) 第一章 1.田间试验:指在田间土壤、自然气候等环境条件下栽培作物,并进行与作物有关的各种科学研究试验。 试验指标:在试验中具体测定的性状或观测项目称为试验指标。 试验因素:指试验中人为控制的、影响试验指标的原因。 因素水平:对试验因素所设定的量的不同级别或质的不同状态称为因素水平。 试验处理:事先设计好的实施在试验单位上的具体项目叫试验处理。 试验小区:安排一个试验处理的小块地段称为试验小区。 试验单位:指施加试验处理的材料单位,也称为试验单元。 2.田间试验的特点?要求? 特点:①田间试验研究的对象和材料是农作物,以农作物生长发育的反应作为试验指标研究其生长发育规律、各项栽培技术或条件的效果。 ②田间试验具有严格的地区性和季节性。 田间试验普遍存在试验误差。 要求:①试验目的要明确 ②试验要有代表性和先进性 ③试验结果要正确可靠 ④试验结果要具有重演性 3.土壤差异的表现形式:梯度变化斑块状变化 4.田间试验对照的设置形式:空白对照互为对照标准对照试验对照自身对
田间试验与统计分析-习题集及解答
在种田间试验设计方法中,属于顺序排列的试验设计方法为:对比法设计、 间比法 2. 若要控制来自两个方面的系统误差,在试验处理少的情况下,可采用:拉丁 方设计 3. 如果处理内数据的标准差或全距与其平均数大体成比例,或者效应为相 乘性, 则在进行方差分析之前, 须作数据转换。 其数据转换的方法宜采用: 对数转换。 4. 对于百分数资料,如果资料的百分数有小于 30%或大于 70%的,则在进 行方差分析之前,须作数据转换。其数据转换的方法宜采用:反正弦转换 (角度转换)。 小概率事件实际不可能性 5. 样本平均数显著性测验接受或否定假设的根据是: 原理。 6. 对于同一资料来说,线性回归的显著性和线性相关的显著性:一定等价。 7. 为了由样本推论总体,样本应该是:从总体中随机地抽取的一部分 8. 测验回归和相关显著性的最简便的方法为:直接按自由度查相关系数显著 表。 9. 选择多重比较的方法时,如果试验是几个处理都只与一个对照相比较,则应 选择:LSD 法。 10. 如要更精细地测定土壤差异程度,并为试验设计提供参考资料,则宜采用: 空白试验 1. 11. 当总体方差为末知,且样本容量小于 30,但可假设 12. 13. 14. 15. 16. 17. 18. 19. 20. 21. 22. = = (两样本 所属的总体方差同质)时,作平均数的假设测验宜用的方法为:t 测验 因素内不同水平使得试验指标如作物性状、特性发生的变化,称为:效应 若算出简单相差系数 大于 1 时,说明:计算中出现了差错。 田间试验要求各处理小区作随机排列的主要作用是: 获得无偏的误差估计值 正态分布曲线与 轴之间的总面积为:等于 1。 描述总体的特征数叫:参数,用希腊字母表示;描述样本的特征数叫:统计 数,用拉丁字母表示。 确定 分布偏斜度的参数为:自由度 用最小显著差数法作多重比较时,当两处理平均数的差数大于 LSD0.01 时, 推断两处理间差异为:极显著 要比较不同单位, 或者单位相同但平均数大小相差较大的两个样本资料的变 异度宜采用:变异系数 选择多重比较方法时,对于试验结论事关重大或有严格要求的试验,宜用: q 测验。 顺序排列设计的主要缺点是:估计的试验误差有偏性 田间试验贯彻以区组为单位的局部控制原则的主要作用是: 更有效地降低试 验误差。
湖北省高等教育自学考试大纲 课程名称:生物统计学课程代码:02078 第一部分课程性质与目标 一、课程性质与特点生物统计学是运用数理统计的原理和方法,来分析和解释生物科学试验中各种现象和试验调查资料的一门科学,它涉及生物科学试验的设计、试验方案的实施、数据的收集、整理和统计分析等;是生物科学专业必修的一门专业基础课。 二、课程目标与基本要求通过本课程的学习,使学生了解生物科学试验的任务、要求,掌握生物科学试验设计的原则和技术,能熟练制定试验方案,进行生物科学试验的设计,并能根据生物统计学原理正确选用统计分析模型,进行数据的处理与分析,作出科学的结论。 三、与本专业其他课程的关系生物统计学以数学的概率论和数理统计为基础,涉及到数列、排列、组合、矩阵、微积分等知识,但本课程并不将这些知识作为重点进行过多的讨论,而主要偏重于统计原理的介绍和具体分析方法的应用,培养学生运用统计学原理分析和解决试验资料所提供信息的能力。 第二部分考核内容与考核目标 第一章概论 一、学习目的与要求通过本章的学习,了解课程的性质、地位和任务;生物统计学的发展史、现状及发展趋势;生物统计学在生物科学研究中的应用;深刻理解统计学术语的含义。 二、考核知识点与考核目标 (一)概论(重点)识记:常用统计学术语理解:生物统计学的基本概念应用:理解几组常用统计学术语及各组概念的含义,并根据概念回答一些基本问题。 (二)概论(次重点)识记:生物统计学的内容理解:生物统计学的作用 (三)概论(一般)识记:生物统计学的发展概况及发展趋势理解:近代描述统计学、现代推断统计学 第二章试验资料的整理与特征数的计算 一、学习目的与要求试验资料的搜集和整理是对数据资料进行统计分析的首要环节。通过本章学习,了解试验资料的类型,掌握试验资料的收集与整理、次数分布表的制作方法,重点掌握资料的分组方法、特征数的计算(平均数、变异数等)方法,深刻理解相关概念的含义。 二、考核知识点与考核目标 (一)试验资料的搜集、平均数、变异数(重点)识记:调查、试验、平均数的种类、极差、方差、标准差理解:算数平均数的计算方法及应用、标准差的计算应用:对给出的试验资料进行具体分析,包括制备图表,计算平均数和变异数等,并要求能根据分析结果得出结论。 (二)试验资料的整理(次重点)识记:原始资料的检查与核对理解:计数资料的整理、计量资料的整理应用:试验资料的整理,次数分布表、次数分布图的制作 (三)试验资料的类型(一般)识记:数量性状、质量性状的资料理解:统计次数法、平分法应用:识别试验资料的类型 第三章概率与概率分布 一、学习目的与要求本章是统计推断的理论基础。通过本章的学习,了解概率的基础知识,掌握概率的计算方法,深刻理解几种常见的理论分布及抽样试验和统计数的分布意义。 二、考核知识点与考核目标
99级 田间试验与统计分析期末试卷A 一. 是非题:判断结果填入括弧,以√表示正确,以×表示错误。(本大题分 10小题,每小题1分,共10分) 1.χ2 应用于独立性测验,当观察的χ2 <χ2 α,ν时,即认为两个变数独立;当观察的χ2≥χ2α,ν时,即认为两个变数相关。(X ) 2.如果无效假设H 0正确,通过测验却被否定,是α错误;若假设H 0错误,测验后却被接受,是β错误(√) 3.统计假设测验H 0:μ≥μ0,H A :μ<μ0时,否定区域在右尾。(√) 4.成对数据资料的比较假设测验,是假设每个样本中的各观察值来源于同一总体。(X ) 5.凡是经过方差分析F 测验,处理效应差异显著的资料,必须进一步作多重比 较,判断各个处理均数彼此间的差异显著性。(√) 6.对于一双变数资料(x,y ),若决定系数r 2=0.8371,则表示了在y 总变异的 平方和由x 不同而引起变异平方占83.71%;或在x 总变异的平方和由x 不同而引起变异平方占83.71%。(X ) 7.研究作物产量(y )与施肥(x )的关系得线性回归方程?=58.375+1.1515x(r=0.2731**),在一定的区间(x 观察值范围内),产量随施肥量的增加而增加的。(X ) 8.综合性试验中各因素的各水平不构成平衡处理组合,而是将若干因素某些水平结合在一起形成少数几个处理组合。(√) 9.误差的同质性假定,是指假定各个处理的εij 都具有N (0,σ2)的。(X ) 10.在标准正态分布曲线下,其概率P(0≤u ≤1)=0.6827。(X ) 二. 选择题:(本大题分5小题,每小题2分,共20分) 1. 若变数x 与y 回归系数估计值为b ,则c 1x 与c 2y 的回归系数估计值为 A. b B. c 1c 2b C. b c c 1