
词法分析设计
1.
实验目的
通过本实验的编程实践,了解词法分析的任务,掌握词法分析程序设计的原理和构造方 法,对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。 2.
实验内容
用C++语言实现对C++语言子集的源程序进行词法分析。通过输入源程序从左到右对字 符串进行扫描和分解,
依次输出各个单词的内部编码及单词符号自身值;
若遇到错误则显示
“ Error ”,然后跳过错误部分继续显示 ;同时进行标识符登记符号表的管理。
3.
实验原理
本次实验采用 NFA->DFA->DFA0的过程:
对待分析的简单的词法(关键词 /id/num/运算符/空白符等)先分别建立自己的 FA,然
后将他们用三产生式连接起来并设置一个唯一的开始符,终结符不合并。 待分析的简单的词法 (1 )关键字:
"asm","auto","bool","break","case","catch","char","class","co nst","co nst_cast"
(2)界符(查表)
";",",","(",")","[","]","{","}"
(3)运算符
"A=" "|=" relop :
(4)其他单词是标识符(ID )和整型常数(SUM ,通过正规式定义。
id/keywords:
digit:
"*" "/" "%" " + "
I!
I! I!
""A" "|" " + + " " " " + 一" " 一" "*一" "/一" "% 一" "&一"
rckp LTk
(3 J? inrLuni>
J “Lidl
L
金、
辑*?I lelup EQ )
l?lier ur ditfii
(5)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM运算符、界符和关
键字,词法分析阶段通常被忽略。
空白、制表符和换行符
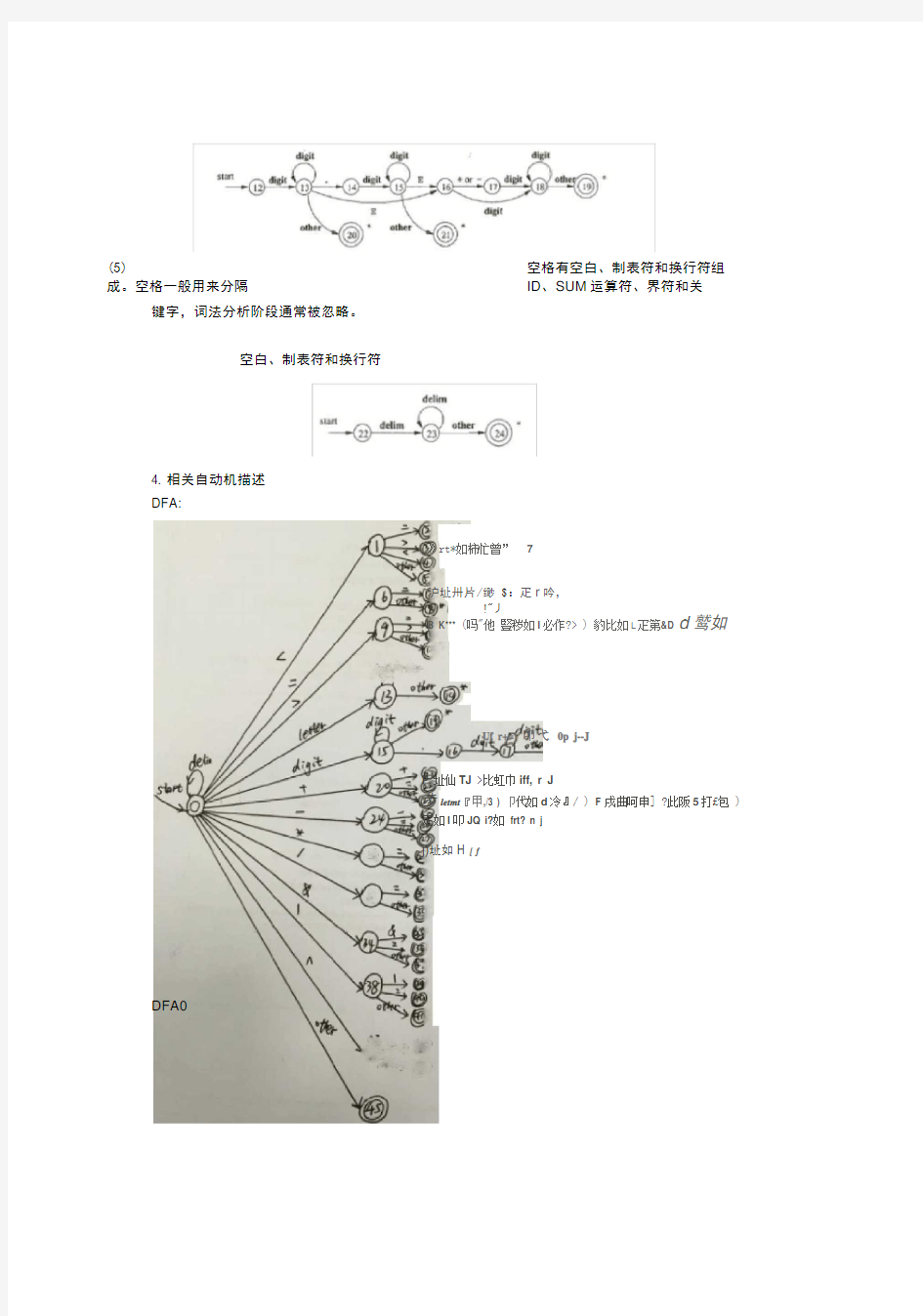
4. 相关自动机描述
DFA:
》rt*如柿忙曾”7
沪址卅片/缈$:疋r吟,
!"丿
B K*** (吗"他豎秽如I必作?> ) 豹比如L疋第&D d鹫如
Uf r+=) 叩弋0p j--J
P 址仙TJ >比虹巾iff, r J
步letmt『甲,/3 ) 卩代如d冷』/ ) F 戌曲呵申] ?此阪5打£包 )
疋如I叩JQ i?如frt? n j
j)址如H [ f
DFA0
L
■'
t 5
流程图
du
5. 核心数据结构描述
(1)生成的token序列由name type、attr 保存。struct token{
stri ng n ame;
stri ng type;
int attr;
};
(2)本文的大多数数据结构都用map来保存,优点是查找方便,大大提高时间复杂度。
map
map
map
map
map
map
vectorvtoken>Token; // 保存token序列,大小未知,所以采用vector保存
6. 核心算法描述
(1) void addToken(string s, int type)s 为找到的字符串,type 为可能类型。
将分析出来的token()序列添加到Token序列表中。如果是类型为1,查看关键词表,
若找到,其类型为关键词并将其以类型为关键词存储到Token表中;若未找到,则查找id 表,若找到,说明该id已经出现过,否则添加新的id到id表中,将该i字符串以类型为id添加到Token表中。如果类型为2,在界符表中查找,如果找到以类型为界符存储到Token 表中,同理其他几种类型。可能类型为1--5,如果出现其他类型表示是词法分析器中发现
额错误,将错误信息记录下来。
void addToken(string s, int type)
{
switch (type){
case 1:
l_i t=Keywords.fi nd(s);
if (l_it!=Keywords.end()){
token t={s, "keywords" ,l」t->second};
Toke n.push_back(t);
}else {
l」t=id.fi nd(s);
if (l_it==id.end())
{
id[s]=idNum;
token t={s, "id" ,idNum++};
Toke n.push_back(t);
} else {
token t={s, "id" ,l」t->second};
Toke n.push_back(t);
}
break;
case 2:
l_it=Sep.fi nd(s);
if (l_it!=Sep.end()){
token t={s, "separatrix" ,l_it->second};
Toke n.push_back(t);
}
break;
case 3:
l」t=Op.fi nd(s);
if (l_it!=Op.end()){
token t={s, "op" ,l_it->second};
Toke n.push_back(t);
}
break;
case 4:
l_it=Relop.fi nd(s);
if (l_it匸Relop.end()){
token t={s, "relop" ,l」t->second};
Toke n.push_back(t);
}
break;
case 5:
l」t=n um.fi nd(s);
if (l_it==num.end())
{
n um[s]=nNum;
toke n t={s, "n um", nN um++};
Toke n.push_back(t);
}else {
token t={s, "num",l_it->second};
Toke n.push_back(t);
}
break;
default : //error
token t={s, "id" ,-1};
Toke n.push_back(t);
break;
}
}
(2) void lexical 。 词法分析器,按字符读入文法并对其进行处理。
从状态0开始处理,如果是空白符则一直在状态 0,如果第一个字符为字母,继续往后寻找,直至不
是字母或是数字结束;若第一个字符为数字,将其拼凑成一个数字,数字可以有小数点等,详细见状 态转换图,注意以数字开头容易岀现一种例如
3a 类型的错误,所以以数字开头的一定要往下多找
个,看最后一个数字后面是否为空白符或界符或者其他允许岀现的符号, 如上同理分析运算符等。注意每次处理完遇到一个字符串都要将其送到 中并回到状态0,继续往下处理。
void lexical() {
fstream ln( "E:\l n.txt" ); char ch,tempch; int state=0; string s= "" ,key=""; while (!ln.eof()) {
switch (state){ case 0: ch=ln .get();
s=ch;
if (ch==13||ch==10||ch==32||ch==9) {state=0; s= "" ;}
else if (ch== '<' ) state=1; else if (ch== '=' ) state=6; else if (ch== '>' ) state=9; else if (isLetter(ch)) state=13; else if (isDigit(ch)) state=15;
else if (ch== '+' ||ch== '-' ||ch== '*' ||ch== '/'
||ch== '&' ||ch== '|')
{ state=20; tempch=ch;}
else if (ch== s' ) state=44;
else if (isSep(ch)!=-1) state=47;
else if (isOp(s)!=-1) state=48;
else if (isRelop(s)!=-1) state=49;
else state=50;
//error
break; case 1: ch=ln .get();
if (ch== '=' ||ch== '>' ) state=2; else if (ch=='<‘ ) state=4; else state=5; break; case 2:
s+=ch;
addToke n( s,4); state=0; break;
case 4: s+=ch;
addToke n(s,3);
如果后面紧跟着字母则报错。 addToken()添加到 Token 表
state=0;
break;
case 5: //*
addToke n( s,4);
In. seekg(-1,ios::cur); state=0;
break;
case 6: ch=ln .get();
if (ch== '=' ) state=7;
else state=8;
break;
case 7:
s+=ch;
addToke n( s,4);
state=0;
break;
case 8: //*
addToke n(s,3);
ln. seekg(-1,ios::cur); state=0;
break;
case 9: ch=ln .get();
if (ch== '=' ) state=10;
else if (ch=='>' ) state=11;
else state=12;
break;
case 10:
s+=ch;
addToke n( s,4);
state=0;
break;
case 11:
s+=ch;
addToke n(s,3);
state=0;
break;
case 12: //*
state=0; addToke n( s,4);
ln. seekg(-1,ios::cur); break; case 13: ch=ln. get();
if (isDigit(ch)||isLetter(ch)) s+=ch;
else state=14;
break;
case 14: //*
state=0;
addToke n( s,1);
东南大学一九九三年攻读硕士学位研究生入学考试试题 试题编号:553 试题名称:编译原理 一:(15分)判断下列命题的真假,并简述理由: 1.文法G的一个句子对应于多个推导,则G是二义的. 2.LL(1)分析必须对原有文法提取左因子和消除左递归. 3.算符优先分析法采用"移近-归约"技术,其归约过程是规范的. 4.文法S→aA;A→Ab;A→b是LR(0)文法(S为文法的开始符号). 5.一个BASIC解释程序和编译程序的不同在于,解释程序由语法制导翻译成目标代码并立即执行之,而编译程序需产生中间代码及优化. 二:(15分)设计一个最小状态有穷自动机,识别由下列子串组成的任意字符串. GO,GOTO,TOO,ON 例如:GOTOONGOTOOGOON是合法字符串. 三:(15分)构造一个LL(1)文法G,识别语言L: L={ω|ω为{0,1}上不包括两个相邻的1的非空串} 并证明你的结论. 四:(20分)设有一台单累加器计算机,并汇编语言含有通常的汇编指令LOAD,STORE,ADD和MUL. 1.写一个递归下降分析程序,将如下文法所定义的赋值语句翻译成汇编语言: A→i:=E E→E+E|E*E|(E)|i 2.利用加,乘法满足交换率这一性质,改进你的分析程序,以期产生比较高效的目标代码. 五:(15分)C为大家熟知的程序语言. 1.C的参数传递采用传值的方式,而且允许函数定义和调用时的参数个数不一致(如printf).请指出其函数调用语句: f(arg1,arg2,...,argn) 翻译成的中间代码序列,并简述其含义. 2.C语言中的变量具有不同的作用范围,试述C应采用的存储分配策略. 六:(20分)设有一个子程序的四元式序列为: (1) I:=1 (2) if I>20 GOTO (16) (3) T1:=2*J (4) T2:=20*I (5) T3:=T1+T2 (6) T4:=addr(A)-22 (7) T5:=2*I (8) T6:=T5*20 (9) T7:=2*J (10) T8:=T6+T7 (11) T9:=addr(A)-22 (12) T10:=T9[T8] (13) T4[T3]:=T10+J
电路实验 实验报告 第二次实验 实验名称:弱电实验 院系:信息科学与工程学院专业:信息工程姓名:学号:
实验时间:年月日 实验一:PocketLab的使用、电子元器件特性测试和基尔霍夫定理 一、仿真实验 1.电容伏安特性 实验电路: 图1-1 电容伏安特性实验电路 波形图:
图1-2 电容电压电流波形图 思考题: 请根据测试波形,读取电容上电压,电流摆幅,验证电容的伏安特性表达式。 解:()()mV wt wt U C cos 164cos 164-=+=π, ()mV wt wt U R sin 10002cos 1000=??? ? ? -=π,us T 500=; ()mA wt R U I I R R C sin 213.0== =∴,ππ40002==T w ; 而()mA wt dt du C C sin 206.0= dt du C I C C ≈?且误差较小,即可验证电容的伏安特性表达式。 2.电感伏安特性 实验电路: 图1-3 电感伏安特性实验电路 波形图:
图1-4 电感电压电流波形图 思考题: 1.比较图1-2和1-4,理解电感、电容上电压电流之间的相位关系。对于电感而言,电压相位 超前 (超前or 滞后)电流相位;对于电容而言,电压相位 滞后 (超前or 滞后)电流相位。 2.请根据测试波形,读取电感上电压、电流摆幅,验证电感的伏安特性表达式。 解:()mV wt U L cos 8.2=, ()mV wt wt U R sin 10002cos 1000=??? ? ? -=π,us T 500=; ()mA wt R U I I R R L sin 213.0===∴,ππ 40002==T w ; 而()mV wt dt di L L cos 7.2= dt di L U L L ≈?且误差较小,即可验证电感的伏安特性表达式。 二、硬件实验 1.恒压源特性验证 表1-1 不同电阻负载时电压源输出电压 电阻()Ωk 0.1 1 10 100 1000 电源电压(V ) 4.92 4.98 4.99 4.99 4.99 2.电容的伏安特性测量
编译技术 班级网络0802 学号3080610052姓名叶晨舟 指导老师朱玉全2011年 7 月 4 日
一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为
词法分析设计 1. 实验目的 通过本实验的编程实践,了解词法分析的任务,掌握词法分析程序设计的原理和构造方法,对编译的基本概念、原理和方法有完整的和清楚的理解,并能正确地、熟练地运用。 2. 实验内容 用C++语言实现对C++语言子集的源程序进行词法分析。通过输入源程序从左到右对字符串进行扫描和分解,依次输出各个单词的内部编码及单词符号自身值;若遇到错误则显示“Error”,然后跳过错误部分继续显示;同时进行标识符登记符号表的管理。 3. 实验原理 本次实验采用NFA->DFA->DFA0的过程: 对待分析的简单的词法(关键词/id/num/运算符/空白符等)先分别建立自己的FA,然后将他们用产生式连接起来并设置一个唯一的开始符,终结符不合并。 待分析的简单的词法 (1)关键字: "asm","auto","bool","break","case","catch","char","class","
const","const_cast"等 (2)界符(查表) ";",",","(",")","[","]","{","}" (3)运算符 "*","/","%","+","-","<<","=",">>","&","^","|","++","--"," +=","-=","*=","/=","%=","&=","^=","|=" relop: (4)其他单词是标识符(ID)和整型常数(SUM),通过正规式定义。 id/keywords: digit: (5)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。
编译原理实验报告 班级 姓名: 学号: 自我评定:
实验一词法分析程序实现 一、实验目的与要求 通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符形式的源程序流转化为一个由各类单词符号组成的流的词法分析方法。 二、实验内容 根据教学要求并结合学生自己的兴趣和具体情况,从具有代表性的高级程序设计语言的各类典型单词中,选取一个适当大小的子集。例如,可以完成无符号常数这一类典型单词的识别后,再完成一个尽可能兼顾到各种常数、关键字、标识符和各种运算符的扫描器的设计和实现。 输入:由符合或不符合所规定的单词类别结构的各类单词组成的源程序。 输出:把单词的字符形式的表示翻译成编译器的内部表示,即确定单词串的输出形式。例如,所输出的每一单词均按形如(CLASS,VALUE)的二元式编码。对于变量和常数,CLASS字段为相应的类别码;VALUE字段则是该标识符、常数的具体值或在其符号表中登记项的序号(要求在变量名表登记项中存放该标识符的字符串;常数表登记项中则存放该常数的二进制形式)。对于关键字和运算符,采用一词一类的编码形式;由于采用一词一类的编码方式,所以仅需在二元式的CLASS字段上放置相应的单词的类别码,VALUE字段则为“空”。另外,为便于查看由词法分析程序所输出的单词串,要求在CLASS字段上放置单词类别的助记符。 三、实现方法与环境 词法分析是编译程序的第一个处理阶段,可以通过两种途径来构造词法分析程序。其一是根据对语言中各类单词的某种描述或定义(如BNF),用手工的方式(例如可用C语言)构造词法分析程序。一般地,可以根据文法或状态转换图构造相应的状态矩阵,该状态矩阵同控制程序便组成了编译器的词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。构造词法分析程序的另外一种途径是所谓的词法分析程序的自动生成,即首先用正规式对语言中的各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程序所应进行的语义处理工作,然后由一个所谓词法分析程序的构造程序对上述信息进行加工。如美国BELL实验室研制的LEX就是一个被广泛使用的词法分析程序的自动生成工具。 总的来说,开发一种新语言时,由于它的单词符号在不停地修改,采用LEX等工具生成的词法分析程序比较易于修改和维护。一旦一种语言确定了,则采用手工编写词法分析程序效率更高。 四、实验设计 1)题目1:试用手工编码方式构造识别以下给定单词的某一语言的词法分析程序。 语言中具有的单词包括五个有代表性的关键字begin、end、if、then、else;标识符;整型常数;六种关系运算符;一个赋值符和四个算术运算符。参考实现方法简述如下。 单词的分类:构造上述语言中的各类单词符号及其分类码表。 表I 语言中的各类单词符号及其分类码表 单词符号类别编码类别码的助记符单词值
词法分析器实验报告 词法分析器实验报告实验目的: 设计、编制、调试一个词法分析子程序,识别单词,加深对词法分析原理的理 解。 实验要求: 该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立 意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。并依次输出 各个单词的内部编码及单词符号自身值。 (一)实验内容 (1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二 元式(单词种别码,单词符号的属性值)显示。而本程序则是通过对给定路径的文件 的分析后以单词符号和文字提示显示。 (2)程序结构描述: 函数调用格式: 函数调用格式函数名(实在参数表 ) Switch(m)、 isKey(String string)、isLetter(char c)、实参 isDigit(char c)、isOperator(char c) isKey(String string)、isLetter(char c)、调作为表达式 isDigit(char c)、isOperator(char c) 用 方 作为语句 getChar()、judgement()、 法 函数的递归调用 isOperator(char c) 、isLetter(char c)、isDigit(char c)
参数含义: 1 String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型, 函数之间的调用关系图: main Complier..judgement isOperate() M=0 getChar( ) isDigit() M=4 For(ch ) isLet ter() M=2 Switch(m) isKey() M=3 函数功能: Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空; isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空; isOperator(char c)判断是否为运算符的,返回值为Boolean类型; isKey(String string)判断是否为关键字的,返回值为Boolean类型; isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。测试结果:
东南大学计算方法与实习实验报告 学院:电子科学与工程学院 学号:06A12528 姓名:陈毓锋 指导老师:李元庆
实习题1 4、设S N=Σ (1)编制按从大到小的顺序计算S N的程序; (2)编制按从小到大的顺序计算S N的程序; (3)按两种顺序分别计算S1000,S10000,S30000,并指出有效位数。 解析:从大到小时,将S N分解成S N-1=S N-,在计算时根据想要得到的值取合适的最大的值作为首项;同理从小到大时,将S N=S N-1+ ,则取S2=1/3。则所得式子即为该算法的通项公式。 (1)从大到小算法的C++程序如下: /*从大到小的算法*/ #include
学年第学期《编译原理》实验报告 学院(系):计算机科学与工程学院 班级:11303070A 学号:11303070*** 姓名:无名氏 指导教师:保密式 时间:2016 年7 月
目录 1.实验目的 (1) 2.实验内容及要求 (1) 3.实验方案设计 (1) 3.1 编译系统原理介绍 (1) 3.1.1 编译程序介绍 (2) 3.1.2 对所写编译程序的源语言的描述 (2) 3.2 词法分析程序的设计 (3) 3.3 语法分析程序设计 (4) 3.4 语义分析和中间代码生成程序的设计 (4) 4. 结果及测试分析 (4) 4.1软件运行环境及限制 (4) 4.2测试数据说明 (5) 4.3运行结果及功能说明 (5) 5.总结及心得体会 (7)
1.实验目的 根据Sample语言或者自定义的某种语言,设计该语言的编译前端。包括词法分析,语法分析、语义分析及中间代码生成部分。 2.实验内容及要求 (1)词法分析器 输入源程序,输出对应的token表,符号表和词法错误信息。按规则拼单词,并转换成二元形式;滤掉空白符,跳过注释、换行符及一些无用的符号;进行行列计数,用于指出出错的行列号,并复制出错部分;列表打印源程序;发现并定位词法错误; (2)语法分析器 输入token串,通过语法分析,寻找其中的语法错误。要求能实现Sample 语言或自定义语言中几种最常见的、基本的语法单位的分析:算术表达式、布尔表达式、赋值语句、if语句、for语句、while语句、do while语句等。 (3)语义分析和中间代码生成 输入token串,进行语义分析,修改符号表,寻找其中的语义错误,并生 成中间代码。要求能实现Sample语言或自定义语言中几种最常见的、基本的语法单位的分析:算术表达式、布尔表达式、赋值语句、if语句、for语句、while 语句、do while语句等。 实验要求:功能相对完善,有输入、输出描述,有测试数据,并介绍不足。3.实验方案设计 3.1 编译系统原理介绍 编译器逐行扫描高级语言程序源程序,编译的过程如下: (1).词法分析 识别关键字、字面量、标识符(变量名、数据名)、运算符、注释行(给人看的,一般不处理)、特殊符号(续行、语句结束、数组)等六类符号,分别归类等待处理。 (2).语法分析 一个语句看作一串记号(Token)流,由语法分析器进行处理。按照语言的文法检查判定是否是合乎语法的句子。如果是合法句子就以内部格式保存,否则报错。直至检查完整个程序。 (3).语义分析 语义分析器对各句子的语法做检查:运算符两边类型是否相兼容;该做哪些类型转换(例如,实数向整数赋值要"取整");控制转移是否到不该去的地方;是
词法分析器实验报告 词法分析器设计 一、实验目的: 对C语言的一个子集设计并实现一个简单的词法分析器,掌握利用状 态转换图设计词法分析器的基本方法。利用该词法分析器完成对源程 序字符串的词法分析。输出形式是源程序的单词符号二元式的代码, 并保存到文件中。 二、实验内容: 1. 设计原理 词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号。 理论基础:有限自动机、正规文法、正规式 词法分析器(Lexical Analyzer) 又称扫描器(Scanner):执行词法分析的程序 2. 词法分析器的功能和输出形式 功能:输入源程序、输出单词符号 程序语言的单词符号一般分为以下五种:关键字、标识符、常数、运算符,界符 3. 输出的单词符号的表示形式: 单词种别用整数编码,关键字一字一种,标识符统归为一种,常数一种,各种符号各一种。 4. 词法分析器的结构 单词符号 5. 状态转换图实现
三、程序设计 1.总体模块设计 /*用来存储目标文件名*/ string file_name; /*提取文本文件中的信息。*/ string GetText(); /*获得一个单词符号,从位置i开始查找。并且有一个引用参数j,用来返回这个单词最后一个字符在str的位置。*/ string GetWord(string str,int i,int& j); /*这个函数用来除去字符串中连续的空格和换行 int DeleteNull(string str,int i); /*判断i当前所指的字符是否为一个分界符,是的话返回真,反之假*/ bool IsBoundary(string str,int i); /*判断i当前所指的字符是否为一个运算符,是的话返回真,反之假*/ bool IsOperation(string str,int i);
编译原理实验报告 课程:编译原理 系别:计算机系 班级:11网络 姓名:王佳明 学号:110912049 教师:刘老师 实验小组:第二组 1
实验一熟悉C程序开发环境、进行简单程序的调试 实验目的: 1、初步了解vc++6.0环境; 2、熟悉掌握调试c程序的步骤: 实验内容: 1、输入下列程序,练习Turbo C 程序的编辑、编译、运行。 #include
实验二词法分析器 一、实验目的: 设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。 二、实验要求: 1.对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。 2.本程序自行规定: (1)关键字"begin","end","if","then","else","while","write","read", "do", "call","const","char","until","procedure","repeat" (2)运算符:"+","-","*","/","=" (3)界符:"{","}","[","]",";",",",".","(",")",":" (4)其他标记如字符串,表示以字母开头的标识符。 (5)空格、回车、换行符跳过。 在屏幕上显示如下: ( 1 , 无符号整数) ( begin , 关键字) ( if , 关键字) ( +, 运算符) ( ;, 界符) ( a , 普通标识符) 三、使用环境: Windows下的visual c++6.0; 四、调试程序: 1.举例说明文件位置:f:、、11.txt目标程序如下: begin x:=9 if x>0 then x:=x+1; while a:=0 do 3
(此文档为word格式,下载后您可任意编辑修改!) 编译技术 班级网络0802 学号 姓名叶晨舟 指导老师朱玉全 2011年 7 月 4 日
一、目的 编译技术是理论与实践并重的课程,而其实验课要综合运用一、二年级所学的多门课程的内容,用来完成一个小型编译程序。从而巩固和加强对词法分析、语法分析、语义分析、代码生成和报错处理等理论的认识和理解;培养学生对完整系统的独立分析和设计的能力,进一步培养学生的独立编程能力。 二、任务及要求 基本要求: 1.词法分析器产生下述小语言的单词序列 这个小语言的所有的单词符号,以及它们的种别编码和内部值如下表: 单词符号种别编码助记符内码值 DIM IF DO STOP END 标识符 常数(整)= + * ** , ( )1 2 3 4 5 6 7 8 9 10 11 12 13 14 $DIM $IF $DO $STOP $END $ID $INT $ASSIGN $PLUS $STAR $POWER $COMMA $LPAR $RPAR - - - - - - 内部字符串 标准二进形式 - - - - - - 对于这个小语言,有几点重要的限制: 首先,所有的关键字(如IF﹑WHILE等)都是“保留字”。所谓的保留字的意思是,用户不得使用它们作为自己定义的标示符。例如,下面的写法是绝对禁止的: IF(5)=x 其次,由于把关键字作为保留字,故可以把关键字作为一类特殊标示符来处理。也就是说,对于关键字不专设对应的转换图。但把它们(及其种别编码)预先安排在一张表格中(此表叫作保留字表)。当转换图识别出一个标识符时,就去查对这张表,确定它是否为一个关键字。 再次,如果关键字、标识符和常数之间没有确定的运算符或界符作间隔,则必须至少用一个空白符作间隔(此时,空白符不再是完全没有意义的了)。例如,一个条件语句应写为 IF i>0 i= 1;
实验八:抽样定理实验(PAM ) 一. 实验目的: 1. 掌握抽样定理的概念 2. 掌握模拟信号抽样与还原的原理和实现方法。 3. 了解模拟信号抽样过程的频谱 二. 实验内容: 1. 采用不同频率的方波对同一模拟信号抽样并还原,观测并比较抽样信号及还原信号的波形和频谱。 2. 采用同一频率但不同占空比的方波对同一模拟信号抽样并还原,观测并比较抽样信号及还原信号的波形和频谱 三. 实验步骤: 1. 将信号源模块、模拟信号数字化模块小心地固定在主机箱中,确保电源接触良好。 2. 插上电源线,打开主机箱右侧的交流开关,在分别按下两个模块中的电源开关,对应的发光二极管灯亮,两个模块均开始工作。 3. 信号源模块调节“2K 调幅”旋转电位器,是“2K 正弦基波”输出幅度为3V 左右。 4. 实验连线 5. 不同频率方波抽样 6. 同频率但不同占空比方波抽样 7. 模拟语音信号抽样与还原 四. 实验现象及结果分析: 1. 固定占空比为50%的、不同频率的方波抽样的输出时域波形和频谱: (1) 抽样方波频率为4KHz 的“PAM 输出点”时域波形: 抽样方波频率为4KHz 时的频谱: 50K …… …… PAM 输出波形 输入波形
分析: 理想抽样时,此处的抽样方波为抽样脉冲,则理想抽样下的抽样信号的频谱应该是无穷多个原信号频谱的叠加,周期为抽样频率;但是由于实际中难以实现理想抽样,即抽样方波存在占空比(其频谱是一个Sa()函数),对抽样频谱存在影响,所以实际中的抽样信号频谱随着频率的增大幅度上整体呈现减小的趋势,如上面实验频谱所示。仔细观察上图可发现,某些高频分量大于低频分量,这是由于采样频率为4KHz ,正好等于奈奎斯特采样频率,频谱会在某些地方产生混叠。 (2) 抽样方波频率为8KHz 时的“PAM 输出点”时域波形: 2KHz 6K 10K 14K 输入波形 PAM 输出波形
实验一词法分析程序实现 一、实验目得与要求 通过编写与调试一个词法分析程序,掌握在对程序设计语言得源程序进行扫描得过程中,将字符流形式得源程序转化为一个由各类单词符号组成得流得词法分析方法 二、实验内容 基本实验题目:若某一程序设计语言中得单词包括五个关键字begin、end、if、then、else;标识符;无符号常数;六种关系运算符;一个赋值符与四个算术运算符,试构造能识别这些单词得词法分析程序(各类单词得分类码参见表I)。 表I语言中得各类单词符号及其分类码表 输入:由符合与不符合所规定得单词类别结构得各类单词组成得源程序文件。 输出:把所识别出得每一单词均按形如(CLASS,VALUE)得二元式形式输出,并将结果放到某个文件中。对于标识符与无符号常数,CLASS字段为相应得类别码得助记符;V AL UE字段则就是该标识符、常数得具体值;对于关键字与运算符,采用一词一类得编码形式,仅需在二元式得CLASS字段上放置相应单词得类别码得助记符,V ALUE字段则为“空". 三、实现方法与环境 词法分析就是编译程序得第一个处理阶段,可以通过两种途径来构造词法分析程序.其一就是根据对语言中各类单词得某种描述或定义(如BNF),用手工得方式(例如可用C语言)构造词法分析程序。一般地,可以根据文法或状态转换图构造相应得状态矩阵,该状态矩阵连同控制程序一起便组成了编译器得词法分析程序;也可以根据文法或状态转换图直接编写词法分析程序。构造词法分析程序得另外一种途径就是所谓得词法分析程序得自动生成,即首先用正规式对语言中得各类单词符号进行词型描述,并分别指出在识别单词时,词法分析程
S o ut he a s t Uni v e r si ty E xa mi na ti o n P a per (i n-t e r m) Course Name Principles of Compiling Examination Term Score Related Major Computer & Software Examination Form Close test Test Duration120 Mins There are 5 problems in this paper. Y ou can write the answers in English or Chinese on the attached paper sheets. 1.Please construct context-free grammars with ε-free productions for the following languages (20%). (1){i|i∈N(Natural number), and i is a palindrome, and (i mod 5)=0} (2){ω| ω∈(a,b,c,d)* and the numbers of a’s ,b’s and c’s occurred in ω are even, and ωstarts with a or c , ends with d } 2.Please construct a DFA with minimum states for the following regular expression. (20%) (((a|b)*a)*(a|b))*(a|b) 3.Please eliminate the left recursions (if there are)and extract maximum common left factors (if there are) from the following context free grammar, and then decide the resulted grammar is whether a LL(1) grammar by constructing the related LL(1) parsing table.(20%) Please obey the rules of examination. If you violate the rules, your answer sheets will be invalid 共 2 页第 1 页
《编译原理》实验报告软件131 陈万全132852
一、需求分析 通过对一个常用高级程序设计语言的简单语言子集编译系统中词法分析、语法分析、语义处理模块的设计、开发,掌握实际编译系统的核心结构、工作流程及其实现技术,获得分析、设计、实现编译程序等方面的实际操作能力,增强设计、编写和调试程序的能力。 通过开源编译器分析、编译过程可视化等扩展实验,促进学生增强复杂系统分析、设计和实现能力,鼓励学生创新意识和能力。 1、词法分析程序设计与实现 假定一种高级程序设计语言中的单词主要包括五个关键字begin、end、if、then、else;标识符;无符号常数;六种关系运算符;一个赋值符和四个算术运算符,试构造能识别这些单词的词法分析程序。 输入:由符合和不符合所规定的单词类别结构的各类单词组成的源程序文件。 输出:把所识别出的每一单词均按形如(CLASS,VALUE)的二元式形式输出,并将结果放到某个文件中。对于标识符和无符号常数,CLASS字段为相应的类别码的助记符;VALUE字段则是该标识符、常数的具体值;对于关键字和运算符,采用一词一类的编码形式,仅需在二元式的CLASS字段上放置相应单词的类别码的助记符,VALUE字段则为“空”。 2、语法分析程序设计与实现 选择对各种常见高级程序设计语言都较为通用的语法结构——算术表达式的
一个简化子集——作为分析对象,根据如下描述其语法结构的BNF定义G2[<算术表达式>],任选一种学过的语法分析方法,针对运算对象为无符号常数和变量的四则运算,设计并实现一个语法分析程序。 G2[<算术表达式>]: <算术表达式>→<项> | <算术表达式>+<项> | <算术表达式>-<项> <项>→<因式>|<项>*<因式>|<项>/<因式> <因式>→<运算对象> | (<算术表达式>) 若将语法范畴<算术表达式>、<项>、<因式>和<运算对象>分别用E、T、F和i 代表,则G2可写成: G2[E]:E → T | E+T | E-T T → F | T*F | T/F F → i | (E) 输入:由实验一输出的单词串,例如:UCON,PL,UCON,MU,ID······输出:若输入源程序中的符号串是给定文法的句子,则输出“RIGHT”,并且给出每一步分析过程;若不是句子,即输入串有错误,则输出“ERROR”,并且显示分析至此所得的中间结果,如分析栈、符号栈中的信息等,以及必要的出错说明信息。 3、语义分析程序设计与实现 对文法G2[<算术表达式>]中的产生式添加语义处理子程序,完成运算对象是简单变量(标识符)和无符号数的四则运算的计值处理,将输入的四则运算转换为四元式形式的中间代码。 输入:包含测试用例(由标识符、无符号数和+、?、*、/、(、)构成的算术表达式)的源程序文件。 输出:将源程序转换为中间代码形式表示,并将中间代码序列输出到文件中。 若源程序中有错误,应指出错误信息 二、设计思路 1、词法分析程序设计与实现 1)单词分类 为了编程的实现。我们假定要编译的语言中,全部关键字都是保留字,程序员不得将它们作为源程序中的标识符;作了这些限制以后,就可以把关键字和标识符的识别统一进行处理。即每当开始识别一个单词时,若扫视到的第一个字符为字母,则把后续输入的字母或数字字符依次进行拼接,直至扫视到非字母、数字字符为止,以期获得一个尽可能长的字母数字字符串,然后以此字符串查所谓保留字表(此保留字表要事先造好),若查到此字符串,则取出相应的类别码;反之,则表明该字符串应为一标识符。
编译系统课程实验报告实验1:词法分析
常数: digits -> digit digit* optionalFraction -> .digits|ε optionalExponent -> E(+|-|ε)digits|ε number -> digits optionalFraction optionalExponent 运算符: (除/,/=外的)op -> + | - | * | += | -= | *= | % | ++ | -- | != | == | > | < | >= | <= | >> | << | ^ | | | & | && | || | ! | != (以/开头的)op->/|/= 界符:Boundary -> { | } | [ | ] | ( | ) | , | ; | : | ? |~ 行//注释:Comment->//(除\n外的字符)*\n 块/**/注释:Comment->/*(除*/外的字符)*/ 8进制:OCT -> 0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 16进制:HEX -> 0x(1|…|9|a|…|f) (0|…|9|a|…|f)* 字符常数:char -> ' (a|b|c|...|z|A|B|C|...|Z|_) ' 字符串常数:string-> "((((除\和”外的字符)*|\(所有字符)+)(除\和”外的字符|\”))*)"(2)各类单词的转换图 标识符: 8进制,16进制,10进制常数: 运算符:
界符: 行//注释: 块/**/注释:字符常数:字符串常数:
东南大学 《传感器技术·检测技术》 实验报告 实验一金属箔式应变片——单臂电桥性能实验 实验二金属箔式应变片——半桥性能实验 实验三金属箔式应变片——全桥性能实验 实验五差动变压器的性能实验 院(系):自动化专业:自动化 姓名:学号: 实验室:常州楼5楼实验时间:2016 年11月17日评定成绩:审阅教师:
目录 实验一金属箔式应变片——单臂电桥性能实验 一、实验目的 (4) 二、基本原理 (4) 三、实验器材 (4) 四、实验步骤 (5) 五、实验数据处理 (6) 六、思考题 (7) 实验二金属箔式应变片——半桥性能实验 一、实验目的 (8) 二、基本原理 (8) 三、实验器材 (8) 四、实验步骤 (8) 五、实验数据处理 (9) 六、思考题 (10) 实验三金属箔式应变片——全桥性能实验 一、实验目的 (11) 二、基本原理 (11) 三、实验器材 (11) 四、实验步骤 (11) 五、实验数据处理 (12) 六、思考题 (12) 实验五差动变压器的性能实验 一、实验目的 (16) 二、基本原理 (16) 三、实验器材 (16) 四、实验步骤 (16) 五、实验数据处理 (19) 六、思考题 (21)
设计思考 1、设计原理 (21) 2、设计框图 (21) 3、电路设计 (21)
实验一金属箔式应变片——单臂电桥性能实验 一、实验目的 了解金属箔式应变片的应变效应及单臂电桥工作原理和性能。 二、基本原理 1、电阻丝在外力作用下发生机械变形时,其电阻值发生变化,这就是电阻应变效应。 2、描述电阻应变效应的关系式为:ΔR/R=Kε式中:ΔR/R 为电阻丝电阻相对变化, K 为应变灵敏系数,ε=ΔL/L 为电阻丝长度相对变化。 3、金属箔式应变片就是通过光刻、腐蚀等工艺制成的应变敏感元件,通过它反映被测部 位受力状态的变化。电桥的作用是完成电阻到电压的比例变化,电桥的输出电压反映了相应的受力状态。单臂电桥输出电压 Uo 1 = EKε/4。 三、实验器材 主机箱(±4V、±15V、电压表)、应变传感器实验模板、托盘、砝码、万用表、导线等。 图2.1 应变传感器安装示意图 1、如图 2-1,将托盘安装到应变传感器的托盘支点上,应变式传感器(电子秤传感器) 已安装在应变传感器实验模板上。传感器左下角应变片为 R1,右下角为 R2,右上角为 R3,左上角为 R4。当传感器托盘支点受压时,R1、R3 阻值增加,R2、R4 阻值减小。 2、如图 2-2,应变传感器实验模板中的 R1、R2、R 3、R4 为应变片。没有文字标记的 5 个电阻是空的,其中 4 个组成电桥模型是为实验者组成电桥方便而设的。
《编译原理》实验报告 班级:计C104 姓名:李云霄 学号:108490
实验一词法分析程序实现 一、实验目的与要求 通过编写和调试一个词法分析程序,掌握在对程序设计语言的源程序进行扫描的过程中,将字符形式的源程序流转化为一个由各类单词符号组成的流的词法分析方法。 二、实验内容 选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。 输入:由无符号数和+,-,*,/, ( , ) 构成的算术表达式,如1.5E+2-100。 输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。 三、实现方法与环境 1、首先设计识别各类单词的状态转换图。 描述无符号常数的确定、最小化状态转换图如图1所示。其中编号0,1,2,…,6代表非终结符号<无符号数>、<余留无符号数>、<十进小数>、<小数部分>、<指数部分>、<整指数>及<余留整指数>, 1,2和6为终态,分别代表整数、小数和科学计数的识别结束状态。 图1 文法G[<无符号数>]的状态转换图 其中编号0,1,2,…,6代表非终结符号<无符号数>、<余留无符号数>、<十进小数>、<小数部分>、<指数部分>、<整指数>及<余留整指数>, 1,2和6为终态,分别代表整数、小数和科学计数的识别结束状态。 在一个程序设计语言中,一般都含有若干类单词符号,为此可首先为每类单词建立一张状态转换图,然后将这些状态转换图合并成一张统一的状态图,即得到了一个有限自动机,再进行必要的确定化和状态数最小化处理,最后据此构造词法分析程序。 四则运算算术符号的识别很简单,直接在状态图的0状态分别引出相应标记的矢
竭诚为您提供优质文档/双击可除编译原理词法分析器实验报告 篇一:编译原理词法分析器实验报告 曲阜师范大学实验报告 计算机系20XX年级软件工程一班组日期20XX年10月17日星期日 姓名 陈金金同组者姓名 课程编译原理成绩 实验名称:教师签章词法分析器 一、实验目的: 1·掌握词法分析的原理。 2·熟悉保留字表等相关的数据结构与单词的分类方法。 3·掌握词法分析器的设计与调试。 二、实验内容: 根据编译中的分词原理,编写一个词法分析程序: 1.输入:任意一个c语言程序的源代码。 2.处理:对输入进行分析,分离出保留字、标识符、常
量、算符和界符。 3.输出:对应的二元式(种别编码自定,可暂编为一类对应一个编码)。 三、实验要求: 1.任选c/c++/Java中的一种高级程序语言编程完成词法分析器。 2.词法分析器应以教材所述分词原理为依据,使用恰当的数据结构和方法,结构清晰、高效。 四、实验环境: windowsxp操作系统,J2se,eclipse集成开发环境 五、实验分析: 将源代码作为长字符串进行读入,之后通过switch语句,及状态转换图进行词素识别,并对识别的词素进行分类整理以二元式的形式输出。 六、实验过程: 1、建立词法分析器界面,很简单:输入框,输出框,执行分析按钮,清空按钮,退出程序按钮。主要的地方是,考虑mvc开发模式,为model及controller提供接口。实现界面如下所示: 2、核心代码的编写,考虑到需要进行词素的匹配,创建符号表类symTable。提供两个变量,分别存放如下内容:并提供方法insert(),lookup(),分别负责标志符的插