
实验一词法分析程序设计
(6学时)
一、实验目的
设计并实现一个包含预处理功能的词法分析程序,加深对编译中词法分析过程的理解。
二、实验要求
1、实现词法分析功能
输入:所给文法的源程序字符串。
输出:二元组(syn,token)构成的序列。其中,
syn为单词种别码。
Token为存放的单词自身字符串。
具体实现时,可以将单词的二元组用结构进行处理。
2、待分析的C语言子集的词法
1)关键字
main if then while do static int double struct break else long switch case typedef char return const float short
continue for void default sizeof do
所有的关键字都是小写。
2)运算符和界符
+ - * / < <= > >= = ; ( )
3)其他标记ID和NUM
通过以下正规式定义其他标记:
标识符 ID→letter(letter|digit)*
无符号整数 NUM→digit digit*
字母 letter→a|…|z|A|…|Z
数字 digit→0|…|9…
4)空格由空白、制表符和换行符组成
空格一般用来分隔ID、NUM、专用符号和关键字,词法分析阶段通常被忽略。
4、各种单词符号对应的种别码
表1 各种单词符号的种别码
单词符号种别码单词符号种别码
main 1 ; 41
if 2 ( 42
else 3 ) 43
while 4 int 7
do 5 double 8
static 6 struct 9
ID (标识符)25 break 10
NUM (整数) 26 else 11
+ 27 long 12
- 28 switch 13
* 29 case 14
/ 30 typedef 15
: 31 char 16
:= 32 return 17
< 33 const 18
<> 34 float 19
<= 35 short 20
> 36 continue 21
>= 37 for 22
= 38 void 23
default 39 sizeof 24
do 40
5、词法分析程序的主要算法思想
算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到的单词符号的第一个字符的种类,拼出相应的单词符号。
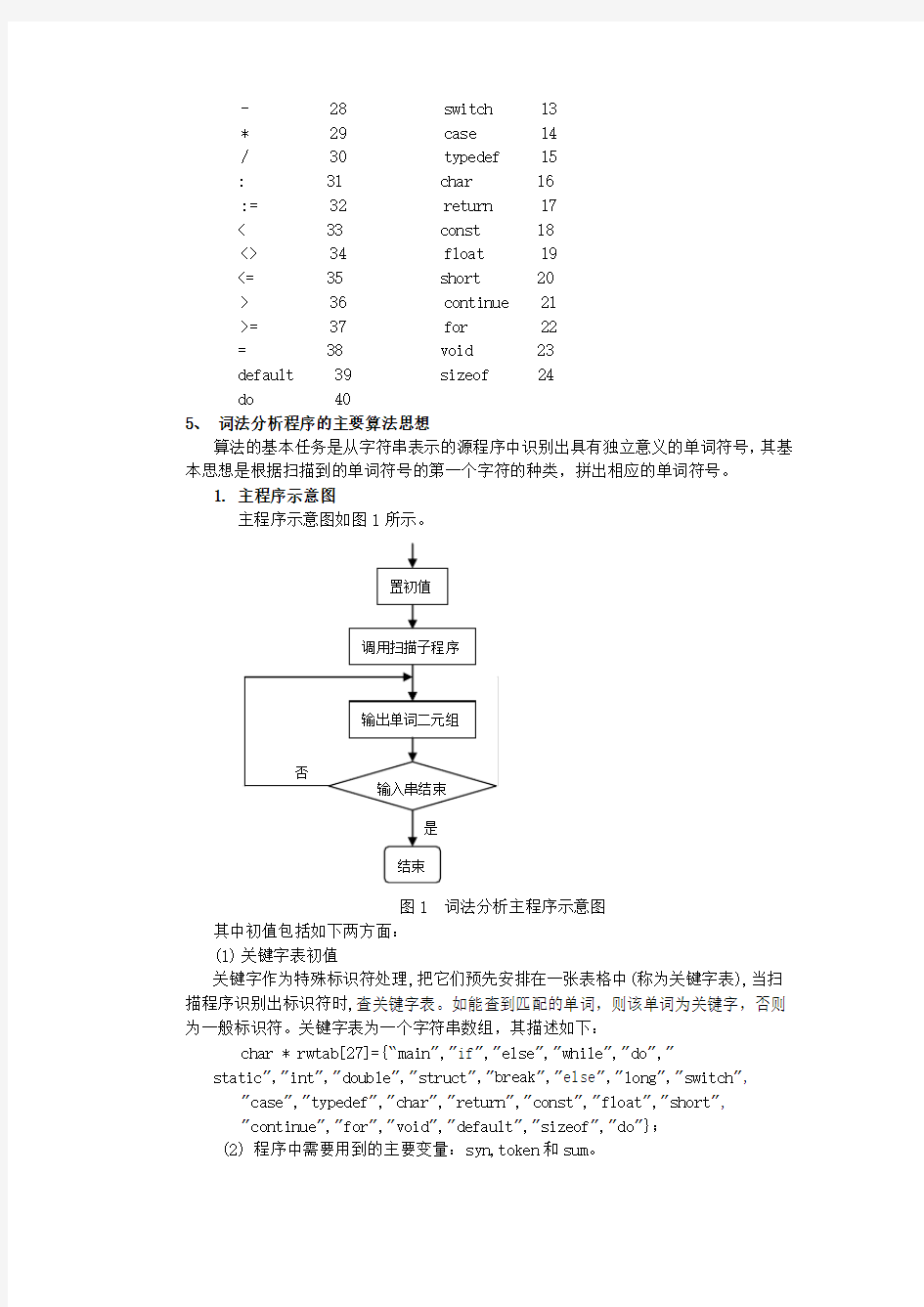
1. 主程序示意图
主程序示意图如图1所示。
图1 词法分析主程序示意图
其中初值包括如下两方面:
(1)关键字表初值
关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下:
char * rwtab[27]={“main”,”if”,”else”,”while”,”do”,”
static”,”int”,”double”,”struct”,”break”,”else”,”long”,”switch”, ”case”,”typedef”,”char”,”return”,”const”,”float”,”short”,
”continue”,”for”,”void”,”default”,”sizeof”,”do”};
(2) 程序中需要用到的主要变量:syn,token和sum。
2. 扫描子程序的算法思想
设置三个变量:
int syn: 用来存放单词符号的种别编码。
char token[255]=""; 单词缓冲区,用来存放构成单词符号的字符串,
int i=0; /*
char input[1024];/*输入缓冲区*/
3. 状态转换图
三、实验报告要求
1.写出编程思路、源代码(或流程图);
2.写出上机调试时发现的问题,以及解决的过程;
3.写出你所使用的测试数据及结果;
4.谈谈你的体会。
5.上机6小时,完成实验报告2小时。
编译原理实验报告实验名称:实验一编写词法分析程序 实验类型:验证型实验 指导教师:何中胜 专业班级:13软件四 姓名:丁越 学号: 电子邮箱: 实验地点:秋白楼B720 实验成绩: 日期:2016年3 月18 日
一、实验目的 通过设计、调试词法分析程序,实现从源程序中分出各种单词的方法;熟悉词法分析 程序所用的工具自动机,进一步理解自动机理论。掌握文法转换成自动机的技术及有穷自动机实现的方法。确定词法分析器的输出形式及标识符与关键字的区分方法。加深对课堂教学的理解;提高词法分析方法的实践能力。通过本实验,应达到以下目标: 1、掌握从源程序文件中读取有效字符的方法和产生源程序的内部表示文件的方法。 2、掌握词法分析的实现方法。 3、上机调试编出的词法分析程序。 二、实验过程 以编写PASCAL子集的词法分析程序为例 1.理论部分 (1)主程序设计考虑 主程序的说明部分为各种表格和变量安排空间。 数组 k为关键字表,每个数组元素存放一个关键字。采用定长的方式,较短的关键字 后面补空格。 P数组存放分界符。为了简单起见,分界符、算术运算符和关系运算符都放在 p表中 (编程时,还应建立算术运算符表和关系运算符表,并且各有类号),合并成一类。 id和ci数组分别存放标识符和常数。 instring数组为输入源程序的单词缓存。 outtoken记录为输出内部表示缓存。 还有一些为造表填表设置的变量。 主程序开始后,先以人工方式输入关键字,造 k表;再输入分界符等造p表。 主程序的工作部分设计成便于调试的循环结构。每个循环处理一个单词;接收键盘上 送来的一个单词;调用词法分析过程;输出每个单词的内部码。 ⑵词法分析过程考虑 将词法分析程序设计成独立一遍扫描源程序的结构。其流程图见图1-1。 图1-1 该过程取名为 lexical,它根据输入单词的第一个字符(有时还需读第二个字符),判断单词类,产生类号:以字符 k表示关键字;i表示标识符;c表示常数;p表示分界符;s表示运算符(编程时类号分别为 1,2,3,4,5)。 对于标识符和常数,需分别与标识符表和常数表中已登记的元素相比较,如表中已有 该元素,则记录其在表中的位置,如未出现过,将标识符按顺序填入数组id中,将常数 变为二进制形式存入数组中 ci中,并记录其在表中的位置。 lexical过程中嵌有两个小过程:一个名为getchar,其功能为从instring中按顺序取出一个字符,并将其指针pint加1;另一个名为error,当出现错误时,调用这个过程, 输出错误编号。 2.实践部分
编译原理实验--词法分析器 实验一词法分析器设计 【实验目的】 1(熟悉词法分析的基本原理,词法分析的过程以及词法分析中要注意的问题。 2(复习高级语言,进一步加强用高级语言来解决实际问题的能力。 3(通过完成词法分析程序,了解词法分析的过程。 【实验内容】 用C语言编写一个PL/0词法分析器,为语法语义分析提供单词,使之能把输入的字符 串形式的源程序分割成一个个单词符号传递给语法语义分析,并把分析结果(基本字, 运算符,标识符,常数以及界符)输出。 【实验流程图】
【实验步骤】 1(提取pl/0文件中基本字的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) {
if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {printf("%s\t",wsym[m]);m=14;n=k+1;} } 2(提取pl/0文件中标识符的源代码 while((ch=fgetc(stream))!='.') { int k=-1; char a[SIZE]=" "; int s=0; while(ch>='a' && ch<='z'||ch>='A' && ch<='Z') { if(ch>='A' && ch<='Z') ch+=32; a[++k]=(char)ch; ch=fgetc(stream); } for(int m=0;m<=12&&k!=-1;m++) for(int n=0;n<=k;n++) { if(a[n]==wsym[m][n]) ++s; else s=0; if(s==(strlen(wsym[m]))) {m=14;n=k+1;} } if(m==13) for(m=0;a[m]!=NULL;m++) printf("%c ",a[m]);
编译原理实验指导 实验安排: 上机实践按小组完成实验任务。每小组三人,分别完成TEST语言的词法分析、语法分析、语义分析和中间代码生成三个题目,语法分析部分可任意选择一种语法分析方法。先各自调试运行,然后每小组将程序连接在一起调试,构成一个相对完整的编译器。 实验报告: 上机结束后提交实验报告,报告内容: 1.小组成员; 2.个人完成的任务; 3.分析及设计的过程; 4.程序的连接; 5.设计中遇到的问题及解决方案; 6.总结。
实验一词法分析 一、实验目的 通过设计编制调试TEST语言的词法分析程序,加深对词法分析原理的理解。并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。 编制一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本字、标识符、常数、运算符、分隔符五大类。并依次输出各个单词的内部编码及单词符号自身值。 二、实验预习提示 1.词法分析器的功能和输出格式 词法分析器的功能是输入源程序,输出单词符号。词法分析器的单词符号常常表示 成以下的二元式(单词种别码,单词符号的属性值)。 2.TEST语言的词法规则
实验1-3 《编译原理》S语言词法分析程序设计方案 一、实验目的 了解词法分析程序的两种设计方法之一:根据状态转换图直接编程的方式; 二、实验内容 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 三、实验要求 1.能对任何S语言源程序进行分析 在运行词法分析程序时,应该用问答形式输入要被分析的S源语言程序的文件名,然后对该程序完成词法分析任务。 2.能检查并处理某些词法分析错误 词法分析程序能给出的错误信息包括:总的出错个数,每个错误所在的行号,错误的编号及错误信息。 本实验要求处理以下两种错误(编号分别为1,2): 1:非法字符:单词表中不存在的字符处理为非法字符,处理方式是删除该字符,给出错误信息,“某某字符非法”。 2:源程序文件结束而注释未结束。注释格式为:/* …… */ 四、保留字和特殊符号表
编译技术实验报告 实验题目:词法分析 学院:信息学院 专业:计算机科学与技术学号: 姓名:
一、实验目的 (1)理解词法分析的功能; (2)理解词法分析的实现方法; 二、实验内容 PL0的文法如下 …< >?为非终结符。 …::=? 该符号的左部由右部定义,可读作“定义为”。 …|? 表示…或?,为左部可由多个右部定义。 …{ }? 表示花括号内的语法成分可以重复。在不加上下界时可重复0到任意次 数,有上下界时可重复次数的限制。 …[ ]? 表示方括号内的成分为任选项。 …( )? 表示圆括号内的成分优先。 上述符号为“元符号”,文法用上述符号作为文法符号时需要用引号…?括起。 〈程序〉∷=〈分程序〉. 〈分程序〉∷= [〈变量说明部分〉][〈过程说明部分〉]〈语句〉 〈变量说明部分〉∷=V AR〈标识符〉{,〈标识符〉}:INTEGER; 〈无符号整数〉∷=〈数字〉{〈数字〉} 〈标识符〉∷=〈字母〉{〈字母〉|〈数字〉} 〈过程说明部分〉∷=〈过程首部〉〈分程序〉{;〈过程说明部分〉}; 〈过程首部〉∷=PROCEDURE〈标识符〉; 〈语句〉∷=〈赋值语句〉|〈条件语句〉|〈过程调用语句〉|〈读语句〉|〈写语句〉|〈复合语句〉|〈空〉 〈赋值语句〉∷=〈标识符〉∶=〈表达式〉 〈复合语句〉∷=BEGIN〈语句〉{;〈语句〉}END 〈条件〉∷=〈表达式〉〈关系运算符〉〈表达式〉 〈表达式〉∷=〈项〉{〈加法运算符〉〈项〉} 〈项〉∷=〈因子〉{〈乘法运算符〉〈因子〉} 〈因子〉∷=〈标识符〉|〈无符号整数〉|'('〈表达式〉')' 〈加法运算符〉∷=+|- 〈乘法运算符〉∷=* 〈关系运算符〉∷=<>|=|<|<=|>|>= 〈条件语句〉∷=IF〈条件〉THEN〈语句〉 〈字母〉∷=a|b|…|X|Y|Z 〈数字〉∷=0|1|2|…|8|9 实现PL0的词法分析
词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
3.1 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 3.2 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。
[实验任务] 完成以下正则文法所描述的Pascal语言子集单词符号的词法分析程序。 <标识符>→字母︱<标识符>字母︱<标识符>数字 <无符号整数>→数字︱<无符号整数>数字 <单字符分界符> →+ ︱-︱* ︱; ︱(︱) <双字符分界符>→<大于>=︱<小于>=︱<小于>>︱<冒号>=︱<斜竖>* <小于>→< <等于>→= <大于>→> <冒号> →: <斜竖> →/ 该语言的保留字:begin end if then else for do while and or not 说明:1 该语言大小写不敏感。 2 字母为a-z A-Z,数字为0-9。 3可以对上述文法进行扩充和改造。 4 ‘/*……*/’为程序的注释部分。 [设计要求] 1、给出各单词符号的类别编码。 2、词法分析程序应能发现输入串中的错误。 3、词法分析作为单独一遍编写,词法分析结果为二元式序列组成的中间文件。 4、设计两个测试用例(尽可能完备),并给出测试结果。 demo.cpp #include
编译原理上机实验试题 一、实验目的 通过本实验使学生进一步熟悉和掌握程序设计语言的词法分析程序的设计原理及相关的设计技术, 如何针对确定的有限状态自动机进行编程序;熟悉和 掌握程序设计语言的语法分析程序的设计原理、熟悉 和掌握算符优先分析方法。 二、实验要求 本实验要求:①要求能熟练使用程序设计语言编程;②在上机之前要有详细的设计报告(预习报告); ③要编写出完成相应任务的程序并在计算机上准确 地运行;④实验结束后要写出上机实验报告。 三、实验题目 针对下面文法G(S): S→v = E E→E+E│E-E│E*E│E/E│(E)│v │i 其中,v为标识符,i为整型或实型数。要求完成 ①使用自动机技术实现一个词法分析程序; ②使用算符优先分析方法实现其语法分析程序,在 语法分析过程中同时完成常量表达式的计算。
1、题目(见“编译原理---实验题目.doc,“实验题目”中的第一项) 2、目的与要求(见“编译原理---实验题目.doc”) 3、设计原理: (1)单词分类:标识符,保留字,常数,运算符,分隔符等等 (2)单词类型编码 (3)自动机 4、程序流程框图 5、函数原型(参数,返回值) 6、关键代码(可打印,只打印关键代码) 7、调试: (1)调试过程中遇到的错误,如何改进的; (2)需要准备测试用例(至少3个,包含输入和输出)——(可打印) 8、思考: (1)你编写的程序有哪些要求是没有完成的,你觉得该采用什么方法去完成; (2)或者是你觉得程序有哪些地方可以进一步完善,简述你的完善方案。
1、题目(见“编译原理---实验题目.doc,“实验题目”中的第二项) 2、目的与要求(见“编译原理---实验题目.doc”) 3、设计原理:构造出算法优先关系表 4、程序流程框图 5、函数原型(参数,返回值) 6、关键代码(可打印,只打印关键代码) 7、调试: (1)调试过程中遇到的错误,如何改进的; (2)需要准备测试用例(至少3个,包含输入和输出)——(可打印) 8、思考: (1)你编写的程序有哪些要求是没有完成的,你觉得该采用什么方法去完成; (2)或者是你觉得程序有哪些地方可以进一步完善,简述你的完善方案。
词法分析器实验报告 一、实验目的 选择一种编程语言实现简单的词法分析程序,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 : = + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 各种单词符号对应的种别码: 表各种单词符号对应的种别码 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根
据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 主程序示意图: 主程序示意图如图3-1所示。其中初始包括以下两个方面: ⑴关键字表的初值。 关键字作为特殊标识符处理,把它们预先安排在一张表格中(称为关键字表),当扫描程序识别出标识符时,查关键字表。如能查到匹配的单词,则该单词为关键字,否则为一般标识符。关键字表为一个字符串数组,其描述如下: Char *rwtab[6] = {“begin”, “if”, “then”, “while”, “do”, “end”,}; 图3-1 (2)程序中需要用到的主要变量为syn,token和sum 扫描子程序的算法思想: 首先设置3个变量:①token用来存放构成单词符号的字符串;②sum用来整型单词;③syn 用来存放单词符号的种别码。扫描子程序主要部分流程如图3-2所示。
编译原理实验报告
实验一 一、实验名称:词法分析器的设计 二、实验目的:1,词法分析器能够识别简单语言的单词符号 2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。 三、实验要求:给出一个简单语言单词符号的种别编码词法分析器 四、实验原理: 1、词法分析程序的算法思想 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 2、程序流程图 (1 (2)扫描子程序
3
五、实验内容: 1、实验分析 编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。 2 实验词法分析器源程序: #include
本代码只供学习参考: 词法分析源代码: #include
5. 目标代码生成 本章实验为实验四,是最后一次实验,其任务是在词法分析、语法分析、语义分析和中间代码生成程序的基础上,将C 源代码翻译为MIPS32指令序列(可以包含伪指令),并在SPIM Simulator上运行。当你完成实验四之后,你就拥有了一个自己独立编写、可以实际运行的编译器。 选择MIPS作为目标体系结构是因为它属于RISC范畴,与x86等体系结构相比形式简单便于我们处理。如果你对于MIPS体系结构或汇编语言不熟悉并不要紧,我们会提供详细的参考资料。 需要注意的是,由于本次实验的代码会与之前实验中你已经写好的代码进行对接,因此保持一个良好的代码风格、系统地设计代码结构和各模块之间的接口对于整个实验来讲相当重要。 5.1 实验内容 5.1.1 实验要求 为了完成实验四,我们建议你首先下载并安装SPIM Simulator用于对生成的目标代码进行检查和调试,SPIM Simulator的官方下载地址为:https://www.doczj.com/doc/d917785696.html,/~larus/spim.html。这是由原Wisconsin-Madison的Jame Larus教授(现在在微软)领导编写的一个功能强大的MIPS32汇编语言的汇编器和模拟器,其最新的图形界面版本QtSPIM由于使用了Qt组件因而可以在各大操作系统平台如Windows、Linux、Mac等上运行,推荐安装。我们会在后面介绍有关SPIM Simulator的使用方法。 你需要做的就是将实验三中得到的中间代码经过与具体体系结构相关的指令选择、寄存器选择以及栈管理之后,转换为MIPS32汇编代码。我们要求你的程序能输出正确的汇编代码。“正确”是指该汇编代码在SPIM Simulator(命令行或Qt版本均可)上运行结果正确。因此,以下几个方面不属于检查范围: 1)寄存器的使用与指派可以不必遵循MIPS32的约定。只要不影响在SPIM Simulator中的 正常运行,你可以随意分配MIPS体系结构中的32个通用寄存器,而不必在意哪些寄存器应该存放参数、哪些存放返回值、哪些由调用者负责保存、哪些由被调用者负责保存,等等。 2)栈的管理(包括栈帧中的内容及存放顺序)也不必遵循MIPS32的约定。你甚至可以使 用栈以外的方式对过程调用间各种数据的传递进行管理,前提是你输出的目标代码(即MIPS32汇编代码)能运行正确。
信息工程学院实验报告(2010 ~2011 学年度第一学期) 姓名:柳冠天 学号:2081908318 班级:083
词法分析 一、实验目的 设计、编制并调试一个词法分析程序,加深对词法分析原理的理解。 二、实验要求 2.1 待分析的简单的词法 (1)关键字: begin if then while do end 所有的关键字都是小写。 (2)运算符和界符 := + - * / < <= <> > >= = ; ( ) # (3)其他单词是标识符(ID)和整型常数(SUM),通过以下正规式定义: ID = letter (letter | digit)* NUM = digit digit* (4)空格有空白、制表符和换行符组成。空格一般用来分隔ID、SUM、运算符、界符和关键字,词法分析阶段通常被忽略。 2.2 各种单词符号对应的种别码: 表2.1 各种单词符号对应的种别码 2.3 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或sum)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; sum为整型常数。 例如:对源程序begin x:=9: if x>9 then x:=2*x+1/3; end #的源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…… 三、词法分析程序的算法思想: 算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。 3.1 主程序示意图:
实验2 词法分析程序的设计 一、实验目的 掌握计算机语言的词法分析程序的开发方法。 二、实验内容 编制一个能够分析三种整数、标识符、主要运算符和主要关键字的词法分析程序。 三、实验要求 1、根据以下的正规式,编制正规文法,画出状态图; 标识符<字母>(<字母>|<数字字符>)* 十进制整数0 | ((1|2|3|4|5|6|7|8|9)(0|1|2|3|4|5|6|7|8|9)*) 八进制整数0(1|2|3|4|5|6|7)(0|1|2|3|4|5|6|7)* 十六进制整数0x(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)(0|1|2|3|4|5|6|7|8|9|a|b|c|d|e|f)* 运算符和界符+ - * / > < = ( ) ; 关键字if then else while do 2、根据状态图,设计词法分析函数int scan( ),完成以下功能: 1)从文本文件中读入测试源代码,根据状态转换图,分析出一个单词, 2)以二元式形式输出单词<单词种类,单词属性> 其中单词种类用整数表示: 0:标识符 1:十进制整数 2:八进制整数 3:十六进制整数 运算符和界符,关键字采用一字一符,不编码 其中单词属性表示如下: 标识符,整数由于采用一类一符,属性用单词表示 运算符和界符,关键字采用一字一符,属性为空 3、编写测试程序,反复调用函数scan( ),输出单词种别和属性。 四、实验环境 PC微机 DOS操作系统或Windows 操作系统 Turbo C 程序集成环境或Visual C++ 程序集成环境 五、实验步骤 1、根据正规式,画出状态转换图;
实验四中间代码生成 一.实验目的: 掌握中间代码的四种形式(逆波兰式、语法树、三元式、四元式)。 二.实验内容: 1、逆波兰式定义:将运算对象写在前面,而把运算符号写在后面。用这种表示法表示的表 达式也称做后缀式。 2、抽象(语法)树:运算对象作为叶子结点,运算符作为内部结点。 3、三元式:形式序号:(op,arg1,arg2) 4、四元式:形式(op,arg1,arg2,result) 三、以逆波兰式为例的实验设计思想及算法 (1)首先构造一个运算符栈,此运算符在栈内遵循越往栈顶优先级越高的原则。 (2)读入一个用中缀表示的简单算术表达式,为方便起见,设该简单算术表达式的右端多加上了优先级最低的特殊符号“#”。 (3)从左至右扫描该算术表达式,从第一个字符开始判断,如果该字符是数字,则分析到该数字串的结束并将该数字串直接输出。 (4)如果不是数字,该字符则是运算符,此时需比较优先关系。 做法如下:将该字符与运算符栈顶的运算符的优先关系相比较。如果,该字符优先关系高于此运算符栈顶的运算符,则将该运算符入栈。倘若不是的话,则将此运算符栈顶的运算符从栈中弹出,将该字符入栈。 (5)重复上述操作(1)-(2)直至扫描完整个简单算术表达式,确定所有字符都得到正确处理,我们便可以将中缀式表示的简单算术表达式转化为逆波兰表示的简单算术表达式。 四、程序代码: //这是一个由中缀式生成后缀式的程序 #include<> #include<> #include<> #include<> #define maxbuffer 64 void main() { char display_out(char out_ch[maxbuffer], char ch[32]); //int caculate_array(char out_ch[32]); static int i=0; static int j=0; char ch[maxbuffer],s[maxbuffer],out[maxbuffer]; cout<<"请输入中缀表达式: ";
编译原理实验报告 实验一 实验题目:词法分析 指导老师:任姚鹏 专业班级:计算机科学与技术系网络工程方向1002班姓名:xxxx
2013年 4月13日 实验类型__验证性__ 实验室_软件实验室三__ 一、实验项目的目的和任务: 了解和掌握词法分析的方法,编程实现给定源语言程序的词法分析器,并利用该分析器扫描源语言程序的字符串,按照给定的词法规则,识别出单词符号作为输出,发现其中的词法错误。 二、实验内容: 1.设计一个简单的程序设计语言(语言中有若干运算符和分界符;有若干关健字;若干标识符及若干常数) 2.确定编译中使用的表格、词法分析器的输出形式、标识符与关键字的区分方法。 3.把词法分析器设计成一个独立的过程。 三、实验要求: 1.从键盘上输入源程序; 2.处理各单词,计算个单词的值和类型; 3.输出个单词名、单词的值和类型。 四、实验代码 #include
一、实验目的 了解词法分析程序的两种设计方法:1.根据状态转换图直接编程的方式;2.利用DFA 编写通用的词法分析程序。 二、实验内容及要求 1.根据状态转换图直接编程 编写一个词法分析程序,它从左到右逐个字符的对源程序进行扫描,产生一个个的单词的二元式,形成二元式(记号)流文件输出。在此,词法分析程序作为单独的一遍,如下图所示。 具体任务有: (1)组织源程序的输入 (2)拼出单词并查找其类别编号,形成二元式输出,得到单词流文件 (3)删除注释、空格和无用符号 (4)发现并定位词法错误,需要输出错误的位置在源程序中的第几行。将错误信息输出到屏幕上。 (5)对于普通标识符和常量,分别建立标识符表和常量表(使用线性表存储),当遇到一个标识符或常量时,查找标识符表或常量表,若存在,则返回位置,否则返回0并且填写符号表或常量表。 标识符表结构:变量名,类型(整型、实型、字符型),分配的数据区地址 注:词法分析阶段只填写变量名,其它部分在语法分析、语义分析、代码生成等阶段逐步填入。 常量表结构:常量名,常量值 2.编写DFA模拟程序 算法如下: DFA(S=S0,MOVE[][],F[],ALPHABET[]) /*S为状态,初值为DFA的初态,MOVE[][]为状态转换矩阵,F[] 为终态集,ALPHABET[] 为字母表,其中的字母顺序与MOVE[][] 中列标题的字母顺序一致。*/ { Char Wordbuffer[10]=“”//单词缓冲区置空 Nextchar=getchar();//读 i=0; while(nextchar!=NULL)//NULL代表此类单词 { if (nextcha r!∈ALPHABET[]){ERROR(“非法字符”),return(“非法字符”);} S=MOVE[S][nextchar] //下一状态 if(S=NULL)return(“不接受”);//下一状态为空,不能识别,单词错误 wordbuffer[i]=nextchar ;//保存单词符号 i++; nextchar=getchar(); } Wordbuffer[i]=‘\0’;
编译原理实验报告 ******************************************************************************* ******************************************************************************* PL0语言功能简单、结构清晰、可读性强,而又具备了一般高级程序设计语言的必须部分,因而PL0语言的编译程序能充分体现一个高级语言编译程序实现的基本方法和技术。PL/0语言文法的EBNF表示如下: <程序>::=<分程序>. <分程序> ::=[<常量说明>][<变量说明>][<过程说明>]<语句> <常量说明> ::=CONST<常量定义>{,<常量定义>}; <常量定义> ::=<标识符>=<无符号整数> <无符号整数> ::= <数字>{<数字>} <变量说明> ::=VAR <标识符>{, <标识符>}; <标识符> ::=<字母>{<字母>|<数字>} <过程说明> ::=<过程首部><分程序>{; <过程说明> }; <过程首部> ::=PROCEDURE <标识符>; <语句> ::=<赋值语句>|<条件语句>|<当循环语句>|<过程调用语句> |<复合语句>|<读语句><写语句>|<空> <赋值语句> ::=<标识符>:=<表达式> <复合语句> ::=BEGIN <语句> {;<语句> }END <条件语句> ::= <表达式> <关系运算符> <表达式> |ODD<表达式> <表达式> ::= [+|-]<项>{<加法运算符> <项>} <项> ::= <因子>{<乘法运算符> <因子>} <因子> ::= <标识符>|<无符号整数>| ‘(’<表达式>‘)’ <加法运算符> ::= +|- <乘法运算符> ::= *|/ <关系运算符> ::= =|#|<|<=|>|>= <条件语句> ::= IF <条件> THEN <语句> <过程调用语句> ::= CALL 标识符 <当循环语句> ::= WHILE <条件> DO <语句> <读语句> ::= READ‘(’<标识符>{,<标识符>}‘)’ <写语句> ::= WRITE‘(’<表达式>{,<表达式>}‘)’ <字母> ::= a|b|…|X|Y|Z <数字> ::= 0|1|…|8|9 【预处理】 对于一个pl0文法首先应该进行一定的预处理,提取左公因式,消除左递归(直接或间接),接着就可以根据所得的文法进行编写代码。 【实验一】词法分析 【实验目的】给出PL/0文法规,要求编写PL/0语言的词法分析程序。 【实验容】已给PL/0语言文法,输出单词(关键字、专用符号以及其它标记)。
编译原理词法分析程序实现实验报告实验一词法分析程序实现 一、实验内容 选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来。输入:由无符号数和+,,,*,/, ( , ) 构成的算术表达式,如 1.5E+2,100。输出:对识别出的每一单词均单行输出其类别码(无符号数的值暂不要求计算)。二、设计部分 因为需要选取无符号数的算术四则运算中的各类单词为识别对象,要求将其中的各个单词识别出来,而其中的关键则为无符号数的识别,它不仅包括了一般情况下的整数和小数,还有以E为底数的指数运算,其中关于词法分析的无符号数的识别过程流程图如下: 输入字符p指向第一个字符 符号识别*p=+||-||*||/ YYNN*p=0~9*p=E*p=0~9||"." N无效符号Y *p=“.”GOTO 2 GOTO 1 GOTO 1: NY无符号数GOTO 1*p=0~9*p='/0' YN P++NNP++*p=E*p='+'||'-' YY P++P++continue
YY *p=0~9*p=0~9 NN 无符号数无符号数 P++P++ continuecontinue GOTO 2: GOTO 2 *p=Econtinue Y 无符号数 P++ continue 三、源程序代码部分 #include
编译原理实验 词 法 分 析 程 序
实验一:词法分析程序 1、实验目的 从左至右逐个字符的对源程序进行扫描,产生一个个单词符号,把字符串形式的源程序改造成单词符号形式的中间程序。 2、实验内容 表C语言子集的单词符号及内码值 单词符号种别编码助记符内码值 while 1 while -- if 2 if -- else 3 else -- switch 4 switch -- case 5 case -- 标识符 6 id id在符号表中的位置 常数7 num num在常数表中的位置 + 8 + -- - 9 - -- * 10 * -- <= 11 relop LE < 11 relop LT == 11 relop LQ = 12 = -- ; 13 ; -- 输入源程序如下 if a==1 a=a+1; else a=a+2; 输出对应的单词符号形式的中间程序 3、实验过程 实验上机程序如下: #include "stdio.h" #include "string.h" int i,j,k; char s ,a[20],token[20]; int letter() { if((s>=97)&&(s<=122))return 1; else return 0; } int Digit() {if((s>=48)&&(s<=57))return 1;
else return 0; } void get() { s=a[i]; i=i+1; } void retract() {i=i-1;} int lookup() { if(strcmp(token, "while")==0) return 1; else if(strcmp(token, "if")==0) return 2; else if(strcmp(token,"else")==0) return 3; else if(strcmp(token,"switch")==0) return 4; else if(strcmp(token,"case")==0) return 5; else return 0; } void main() { printf("please input you source program,end('#'):\n"); i=0; do { i=i+1; scanf("%c",&a[i]); }while(a[i]!='#'); i=1; memset(token,0,sizeof(char)*10); j=0; get(); while(s!='#') { if(s==' '||s==10||s==13) get(); else { switch(s)