
一、就本期学习而言,请尽可能多地列举自己认为所学到的新知识点,并就其中感受深刻的
两点,给出自己的学习体会或感悟。(一般不会考)
二、在本学期的学习中,有如下的古典假定:
(1)强外生性(|)0i E ε=X ;(2)球型扰动2
(|)Var Cov εσ-=X I ;
(3)弱外生性(,|)0ji i Cov x ε=X ;(4)满秩()Rank k =X ;(5)正态性2~(0,)i N εσ。 简述自己对这些古典假定的认识,以及这些假设对参数估计统计性质的作用。
解答:(1)零均值,即()
(|)0,|0i ij i E Cov x εε=?=X X ;
(2)同方差与无自相关假定,即随机扰动项的方差2
(|)T Var εσ=X I ;
(3)随机扰动项与解释变量不相关,即(,|)0ji i Cov x ε=X ; (4)无多重共线性,即各解释变量之间线性无关,()Rank k =X ;
(5)正态性假定,即2~(0,)i N εσ。
以上假设条件可总结为:①解释变量的强外生性;②球形扰动;③解释变量的外生性;④满秩;⑤正态性。而它们的作用在于:
第一,条件均值为零(或强外生性)能保证最小二乘估计量的无偏性。
第二,球形扰动,是指随机扰动项的方差-协方差矩阵为同方差和无自相关同时成立时的情况。违反此假设条件,被称为非球形扰动,将会影响到参数估计的有效性问题。
第三,外生性条件,表示随机扰动项中不包含有解释变量的任何信息。注意,外生性条件的不同表述方式和内涵。外生性条件的违反将影响到参数估计的一致性问题。
第四,满秩性条件,它是为了保证条件期望的唯一性,参数可求解。
第五,正态性条件,它主要与我们的统计检验和推断有关,用于推断估计式的分布。
三、对于线性模型 y X βε=+,写出下述假定条件的表达式,并说明其含义和作用。 (1)强外生性;(2)弱外生性;(3)球型扰动;(4)正态性。 解答同上。
四、什么是估计量的无偏性,有效性和一致性?计量经济学中哪些古典假定能保证这些性质
成立?
解答:无偏性:如果参数的估计量?β的期望等于参数的真实值β,即()
?E β
β=,则称?β是参数β的无偏估计。强外生性或者条件均值为零可以保证最小二乘估计量的无偏性。
有效性:一个估计量若不仅具有无偏性而且具有最小方差时,称这个估计量为有效估计量。球型扰动2
(|)Var Cov εσ-=X I 能保证估计量的有效性。
一致性:当样本容量趋于无穷大时,如果估计量?β
的抽样分布依概率收敛于总体参数的真实值β,即?lim x P β
β→∞
=或()
?lim 1x P ββε→∞
??-<=?
?
,则称估计量?β为一致估计量。弱外生性(,|)0ji i Cov x ε=X 能够保证估计量的一致性。
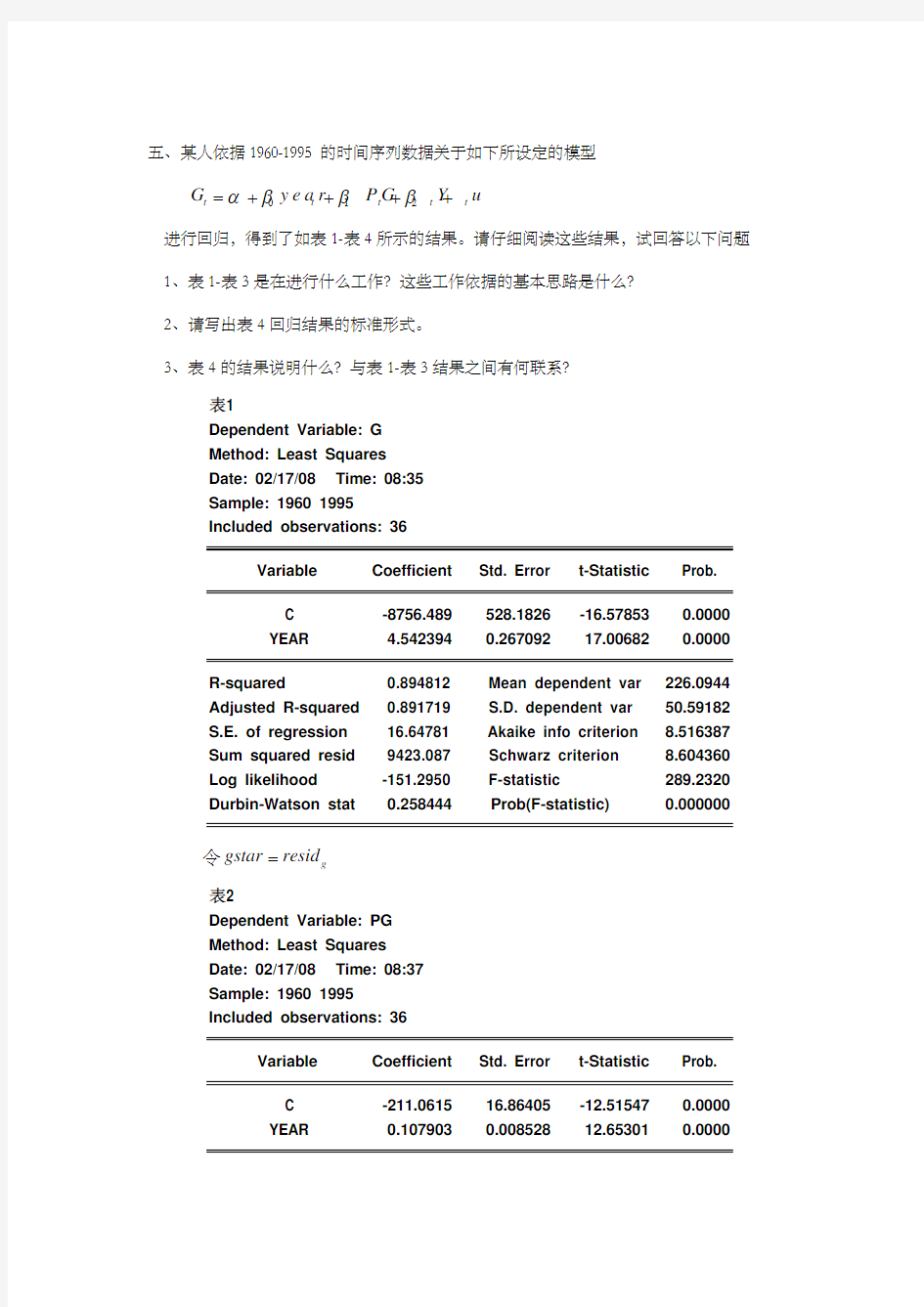
五、某人依据1960-1995的时间序列数据关于如下所设定的模型 01
2
t t t t
t G y e a r P G Y u
αβββ=++++ 进行回归,得到了如表1-表4所示的结果。请仔细阅读这些结果,试回答以下问题 1、表1-表3是在进行什么工作?这些工作依据的基本思路是什么? 2、请写出表4回归结果的标准形式。
3、表4的结果说明什么?与表1-表3结果之间有何联系?
表1
Dependent Variable: G Method: Least Squares Date: 02/17/08 Time: 08:35 Sample: 1960 1995 Included observations: 36
Variable
Coefficient Std. Error t-Statistic Prob.
C -8756.489 528.1826 -16.57853 0.0000 YEAR
4.542394
0.267092
17.00682
0.0000
R-squared
0.894812 Mean dependent var 226.0944 Adjusted R-squared 0.891719 S.D. dependent var 50.59182 S.E. of regression 16.64781 Akaike info criterion 8.516387 Sum squared resid 9423.087 Schwarz criterion 8.604360 Log likelihood -151.2950 F-statistic 289.2320 Durbin-Watson stat
0.258444 Prob(F-statistic)
0.000000
令g gstar resid = 表2
Dependent Variable: PG Method: Least Squares Date: 02/17/08 Time: 08:37 Sample: 1960 1995 Included observations: 36
Variable
Coefficient Std. Error t-Statistic Prob.
C -211.0615 16.86405 -12.51547 0.0000 YEAR 0.107903
0.008528 12.65301 0.0000
R-squared
0.824831 Mean dependent var 2.316611 Adjusted R-squared 0.819679 S.D. dependent var 1.251735 S.E. of regression 0.531539 Akaike info criterion 1.627872 Sum squared resid 9.606140 Schwarz criterion 1.715845 Log likelihood -27.30169 F-statistic 160.0987 Durbin-Watson stat
0.292859 Prob(F-statistic)
0.000000
令pg pgstar resid = 表3
Dependent Variable: Y Method: Least Squares
Date: 02/17/08 Time: 08:38 Sample: 1960 1995 Included observations: 36
Variable
Coefficient Std. Error t-Statistic Prob.
C -322893.7 7888.457 -40.93243 0.0000 YEAR
167.9528
3.989051
42.10344
0.0000
R-squared
0.981181 Mean dependent var 9232.861 Adjusted R-squared 0.980628 S.D. dependent var 1786.381 S.E. of regression 248.6366 Akaike info criterion 13.92381 Sum squared resid 2101886. Schwarz criterion 14.01179 Log likelihood -248.6287 F-statistic 1772.700 Durbin-Watson stat
0.364489 Prob(F-statistic)
0.000000
令y ystar resid = 表4
Dependent Variable: GSTAR Method: Least Squares Date: 02/17/08 Time: 08:57 Sample: 1960 1995 Included observations: 36
Variable Coefficient Std. Error t-Statistic Prob.
PGSTAR -11.98265 2.117186 -5.659707 0.0000 YSTAR
0.047818
0.004526
10.56485
0.0000
R-squared
0.867908 Mean dependent var 0.000000 Adjusted R-squared 0.864023 S.D. dependent var 16.40826 S.E. of regression 6.050558 Akaike info criterion 6.492131 Sum squared resid
1244.715 Schwarz criterion
6.580104
Log likelihood -114.8584 Durbin-Watson stat 0.792275
解答:1、表1为一元回归,G 对year 回归,得到回归的残差,令g gstar resid =;表
2为一元回归,PG 对year 回归,得到回归的残差,令pg pgstar resid =;表3为一元回归,
Y 对year 回归,得到回归的残差,令y ystar resid =。
依据的基本思想:若求PG 、Y 变量对G 的影响,即β1、β2,可以先将PG 、Y 与G 中扣除掉包含year 的信息,然后运用扣除G 中包含year 的信息得到残差gstar ,扣除PG 中包含year 的信息得到残差pgstar ,扣除Y 中包含year 的信息得到残差ystar ,再将gstar 对pgstar 和ystar 进行回归,则得到在扣除year 影响后,PG 与Y 对G 的作用情况。同时说明了系数β1、β2表示的是变量PG 、Y 与G 的偏相关。
2、表4回归结果标准形式:
????*11.9826*0.0478*g
pg y =-+ t=(-5.6597) (10.56485)
20.8679R = DW=0.79227 df=34
3、表4是利用双残差回归思想得出的结果,说明在扣除year 变量的影响后,PG 与Y
对G 有显著影响,分别为-11.9826、0.0478。表1-表3是表4做残差回归的基础工作,表4的估计参数与原模型直接回归所得结果的β1、β2相等。
六、分析解释双残差回归的基本思想和步骤。
解答:双残差回归思想的理解:假设在一个典型的线性回归方程1122y X X ββε=++中,变量集2X 是我们的关注变量集,相应的1X 就是我们的控制变量集。估计系数2β表示的就是在控制了变量集1X 后,2X 对y 的影响。也就是通常说的,在其他变量保持不变的情况下,2X 的变化引起的y 的变化。很显然,在不同的情况下,我们可以改变我们的控制变量集,来看我们的关注变量系数是否发生显著的变化,这在实证中是很重要步骤和思想。控制变量的t 值大小可以不必过于在意。
具体步骤:假设典型回归方程1122Y =X β+X β+ε
-1221221b =(X 'M X )(X 'M Y)**-1**
222=(X 'X )X Y
其中:-111111M =I -X (X 'X )X ',*212X =M X ,*1Y =M Y
假设现在要求的是系数2β
(1)2X 对1X 进行回归,得到回归的残差记为2e 。 (2)Y 对1X 进行回归,得到回归的残差记为1e
(3)1e 对2e 回归,得到的参数估计'-1'
22221b =(e e )e e 就是2β的估计值。残差1e 中扣
除了Y 中包含的1X 的信息;残差2e 扣除了2X 中包含的1X 的信息。因此双残差(1e 、2e )回归仅反应了,在扣除了1X 的影响,2X 对Y 的作用情况,同样说明了系数2b 表示的是变
量2X 与Y 的偏相关。
七、设随机变量x 服从Weibull 分布,()()
1, ,,0f x x exp x x ββαβααβ-=->,若在随机
抽样过程中得到n 个样本,试求
1.关于n 个样本的对数似然函数 2.参数α的极大似然估计表达式 解:1.
()(
)(
)1
1
1
n
i i
i
i
i
i f x x exp x L x
exp x ββ
ββ
αβααβα--==-?=-∏
()()
()
1
1
1
1ln n
n
i
i
i
i i i lnL x exp x ln x
exp x ββ
ββαβααβα--===-=-∑∏
()(
)1
1n
i i
i ln ln lnx x β
αββα==++--∑
()1
1
1n
n
i i i i nln nln lnx x β
αββα===++--∑∑
2.()111
10n n
n i i i i i i lnL n nln nln lnx x x ββαββαααα===????=++--=-= ?????∑∑∑
1
ML n
i
i n
x
βα=?=
∑
八、设随机变量x 服从指数分布,()1
, 0, 0x f x exp x θθθ-??
=
>> ???
,若在随机抽样过程中得到n 个样本,试求
1.关于n 个样本的对数似然函数 2.参数θ的极大似然估计表达式
解答:1、()11
1n i
i
i i x
x f x exp L exp θθ
θθ=--????
=?=∏ ? ?????
1111
11ln ln exp ln exp ln n n n
i i i i i i x x x L θθθθθθ===-?-???????
=∏==- ? ? ? ???????
??∑∑ 1
1
ln n
i i n x θθ
==--
∑
2、211ln 11ln 0n n
i i i i L n n x x θθθθθθ==????=--=-+= ????
?∑∑
1
?n
i
i ML
x
x n
θ
=?=
=∑
九、简述工具变量(IV )估计和两阶段最小二乘(2SLS )估计的基本含义
解答:工具变量:假设有如下模型,011k k y x x u βββ=++
++
k x 与扰动项u 可能相关,而其他解释变量都是外生的。
采用工具变量估计,需要找到一个可观测的工具变量z ,且工具变量满足两个条件: 1、z 与误差项u 不相关,()cov ,0z u =;
2、z 与k x 高度相关。或者说z 与k x 存在偏相关(即扣除其他外生变量的影响),也就是k x 对所有外生变量的映射中,01111k k k x x x z αααδε--=++
+++ 只要系数0δ≠,
该工具变量就是有效的。也就是说,必须保证z 与k x 是在扣除了其他外生变量的影响下,
仍然是相关的。这样,根据回归得到了k x 的估计值01111?????k k k x
x x z α
αα
δ--=++++ 用估计出的?k x
代替原来的k x ,进行OLS 估计,就可以得到产生的无偏估计。这实际上是将内生变量分成了内生部分和外生部分,通过投影得到了外生的部分,然后进入回归方程。
当使用多个工具变量来解决内生解释变量时,基本做法与上述类似。
两阶段最小二乘:解决内生解释变量的基本做法是采用工具变量估计模型,基本思想是利用工具变量替代内生解释变量,然后用OLS 估计模型。这一过程通常使用了两次OLS ,因此称之为两阶段最小二乘(2SLS)。
十、简要阐述矩估计和OLS 估计、IV 估计之间的关系。
解答:矩方法是工具变量估计方法(IV )和广义矩估计方法(GMM)的基础。在矩方法中关键是利用了()
'0E X μ=。
当样本矩条件和参数个数为R = K : 存在唯一解()0T
g θ=时,参数正好识别,此时
可采用OLS 估计和IV 估计,即如果某个解释变量与随机项相关,只要能找到1个工具变量,仍然可以构成一组矩条件,这就是IV 估计,OLS 估计和IV 估计是GMM 估计的特例。
当R > K 时,这时方程组中方程的个数多于参数的个数,此为过度识别,如果存在>k+1个变量与随机项不相关,可以构成一组包含>k+1方程的矩条件。这就是GMM 。
十一、什么是工具变量?简述工具变量在实证分析中的具体步骤及注意事项。
解答:工具变量:假设有如下模型,011k k y x x u βββ=++
++
k x 与扰动项u 可能相关,而其他解释变量都是外生的。
采用工具变量估计,需要找到一个可观测的工具变量z ,且工具变量满足两个条件: 1、z 与误差项u 不相关,()cov ,0z u =;
2、z 与k x 高度相关。或者说z 与k x 存在偏相关(即扣除其他外生变量的影响),也就是k x 对所有外生变量的映射中,01111k k k x x x z αααδε--=++
+++ 只要系数0δ≠,
该工具变量就是有效的。也就是说,必须保证z 与k x 是在扣除了其他外生变量的影响下,
仍然是相关的。这样,根据回归得到了k x 的估计值01111?????k k k x
x x z α
αα
δ--=++++ 用估计出的?k x
代替原来的k x ,进行OLS 估计,就可以得到产生的无偏估计。这实际上是将内生变量分成了内生部分和外生部分,通过投影得到了外生的部分,然后进入回归方程。
当使用多个工具变量来解决内生解释变量时,基本做法与上述类似。 工具变量在实证分析中的具体步骤与注意事项: 依据工具变量的选择原则,首先选取替代内生解释变量的适当工具变量,然后进行如下的两阶段最小二乘估计:使用。
第一,将这个内生解释变量关于模型中所有的外生变量和选定的工具变量进行回归,得到回归方程。若工具变量系数的t 值显著,并且方程的整体拟合程度较好(F 统计量值大于30),则该工具变量是一个有效的工具变量,并由本步骤中建立的回归方程进行预测,得到内生解释变量的估计值。
第二,将内生解释变量的估计值带入原方程进行回归,即在原方程中,内生解释变量由内生解释变量的预测替代,再次进行回归,就可以得到方程参数的无偏估计。
十二.何为内生性问题?什么是工具变量?
在分析女性工资收入的模型
2012log()wage exper exper educ u δδδλ=++++
中,发现受教育年限educ 具有内生性,exper 和2
exper 是外生的。若仍使用OLS 估
计会有什么后果?如果用父亲受教育年限fatheduc 、母亲受教育年限motheduc 和丈夫受教育年限huseduc 作为educ 的工具变量,应该如何解决内生性问题?
解答:内生性问题:如果外生性假定被违背,即()
0j i E x u ≠,解释变量与扰动项相关,那么模型存在内生性问题。与扰动项相关的解释变量称为内生解释变量。此时最小二乘估计量将是不一致的。
工具变量:假设有如下模型,011k k y x x u βββ=++
++
k x 与扰动项u 可能相关,而其他解释变量都是外生的。
采用工具变量估计,需要找到一个可观测的工具变量z ,且工具变量满足两个条件: 1、z 与误差项u 不相关,()cov ,0z u =;
2、z 与k x 高度相关。或者说z 与k x 存在偏相关(即扣除其他外生变量的影响),也就是k x 对所有外生变量的映射中,01111k k k x x x z αααδε--=++
+++ 只要系数0δ≠,
该工具变量就是有效的。也就是说,必须保证z 与k x 是在扣除了其他外生变量的影响下,
仍然是相关的。这样,根据回归得到了k x 的估计值01111?????k k k x
x x z α
αα
δ--=++++ 用估计出的?k x
代替原来的k x ,进行OLS 估计,就可以得到产生的无偏估计。这实际上是将内生变量分成了内生部分和外生部分,通过投影得到了外生的部分,然后进入回归方程。
当使用多个工具变量来解决内生解释变量时,基本做法与上述类似。
解决内生性问题:解决内生解释变量的基本做法是采用工具变量估计模型,基本思想是利用工具变量替代内生解释变量,然后用OLS 估计模型。
首先假设,父亲受教育年限fatheduc 、母亲受教育年限motheduc 和丈夫受教育年限
huseduc 这三个工具变量满足第一个条件,即与原模型的扰动项不相关;
接下来,看第二个条件,为此需要估计以下模型。
2012123educ exper exper motheduc fatheduc huseduc αααδδδε=++++++
模型估计结果为
Dependent Variable: EDU Method: Least Squares Date: 06/11/10 Time: 11:25 Sample: 1 753
Included observations: 753
Variable Coefficient Std. Error t-Statistic Prob. EXPER 0.053241 0.021844 2.437276 0.0150 EXPERSQ -0.000740 0.000708 -1.045546 0.2961 FATHEDUC 0.101361 0.021442 4.727168 0.0000 HUSEDUC 0.371564 0.022047 16.85364 0.0000 MOTHEDUC
0.130004 0.022379 5.809222 0.0000 C
5.115778
0.298017
17.16606
0.0000
R-squared 0.465594 Mean dependent var 12.28685 Adjusted R-squared 0.462017 S.D. dependent var 2.280246 S.E. of regression 1.672500 Akaike info criterion 3.874452 Sum squared resid 2089.549 Schwarz criterion 3.911297 Log likelihood -1452.731 F-statistic 130.1626 Durbin-Watson stat
2.003097 Prob(F-statistic)
0.000000
根据外生性第二个条件,要求
1δ、2δ、3δ至少一个不为零,即要检验原假设为
0123:0
H δδδ===,采用线性约束F 检验,
计算结果()()(3846.19-2089.54)/3118.252089.54R U U RSS RSS q F RSS n k -===- 拒绝原假设,表明第二个条件成立。
于是我们使用两阶段最小二乘2SLS 估计原模型: 1、生成educ 的替代变量,即educ 对所有外生变量回归,用educ 的估计量作为工具变量z ;
2、用z 替代educ 估计工资方程,2
0123log()wage exper exper z u δδδδ=++++
十三、关于参数θ有两个相互独立的无偏估计量1?θ,2
?θ,它们的方差分别为1v ,2v 。问:当1c ,2c 为何值时,线性组合1122???c c θθθ=+是关于参数θ的最小方差无偏估计?
解答:根据已知条件有:1
?()E θ
θ=,2
?()E θθ=,1
1
?()Var v θ=,2
2
?()Var v θ= 1122???c c θθθ=+是无偏的,则有:112212???()()()E E c c c c θθθθθ=+=+=
所以:121c c +=
因为1?θ、2
?θ相互独立,所以 22112211221122?????()()()()Var Var c c Var c Var c c v c v θθθθθ=+=+=+
代入121c c +=,
可得:22222
11221112121212(1)()2c v c v c v c v v v c v c v +=+-=+-+
求偏导
()
()()()22
1122212121212121
1
2220c v c v v v c v c v v v c v c c ?+?
=
+-+=+-=?? ?θ具有最小方差性,得到:2112v c v v =
+,1
212
v c v v =+。
十四、假设y 和(1,2,
)j x j k =存在有限的二阶矩,且有如下的回归方程:
0110k k y x x βββεβε=++++=++x β
()0E ε=,2var(|)x εεσ= ()0j E x ε=(1,2,
)j k =
(1)在(1,2,
)j x j k =是随机变量的条件下求y 的方差2
y σ
(2)定义总体拟合优度为2
2
2
1y
ε
ρσσ=-。证明21R RSS TSS =-是2ρ的一致估计。 解答:(1)()()2
var()var |var |y y E y x E y x σ==+????????
其中,()()[]20var |var |var(|)E y x E x E x εβεεσ=++==????????
x β ()[]var |var E y x =????x β
所以,[]22var()var y y εσσ==+x β
(2)2
11/RSS N
R RSS TSS N
=-=-
所以,()22
2
2lim lim 1lim 11/lim /y p RSS N RSS N p R p TSS N p TSS N εσρσ????=-=-=-=????????
十五、在对多元回归模型 12233i i i k ki i Y X X X u ββββ=+++
++
的方程显著性检验中,通常对假设023:0k H βββ==
==进行F 检验,检验统计量为
()()
1ESS k F RSS
n k -=
-,其中k 为模型中待估参数的个数。证明:此F 统计量是一般的F 统计量
的特例,即: ()()
()
()1R U U R
U
U RSS RSS ESS
k k k F RSS
RSS n k n k ---=
=
--。
(注:下标U 代表无约束,R 代表有约束)。 证明:()()()
R u U R u U RSS RSS k k F RSS n k --=
- (1)
由()2
2
11R R R R RSS R RSS R TSS TSS
=-
?=-
同理可得()
2
1u u RSS R TSS =-
带入(1)式得
()()()()()()()()()()2222
22
11()
1()
)
1(R u U R u R U R R u U R u
u U u
U U
R TSS R TSS k k R R k k RSS RSS k k F RSS n k R TSS
n k n R k
-?--?-----===
---?-- (2) 有约束模型 1i i Y u β=+ 有()1i E Y β= 又1Y β=
∴有()2
221
1
n n
i i i
i i R i i u Y Y u Y Y e RSS ===-?=-==∑∑∑
由()2
21
0n
i R R i TSS Y Y RSS TSS R ==
-?=?=∑
带入(2)式得
()()()()()()()()2222211()
()()u
R
U
R
u
U
R
U U R U
U U
u
u
U
R R k k R k k ESS TSS k k F RSS
TSS n k n k n k R R ------===
--- ()()
1()()u R U ESS k ESS k k RSS n k RSS n k --=
=
--
十六、结合下图,简述Wald 、LM 以及LR 三个检验的基本思想。
解答:如上图所示
Wald 检验是在约束条件()0c θ=的条件下,考察无约束的参数估计量?θ
是否满足?()0c θ=的约束条件,实际上也就是考察?()c θ与0的距离。构造一个马氏距离为:1
???()(())()c Var c c θθθ-??'??
。如果满足约束条件,该构造的马氏距离与0的距离在统计上就会很接近,此时就可以认为约束条件是满足的。在实际的应用中,Wald 检验中?θ
的方差?()Var θ可以采用White 的稳健估计,因此在异方差的情况下,Wald 统计量仍然是有效的。但是在
约束条件是非线性的情况,不同的约束条件表达式得到的Wald 统计量是不同的,
22
202
2
0?()??()()1ii
nR
W I c R
βββββσ-=-=
=- (度量?β与0
β之间的水平距离),这就影响了非线性约束下Wald 统计量的有限样本性质。
LM 检验主要考察约束条件下求得的有约束的参数估计值θ,是否满足无约束条件下的最优化一阶条件
ln ()
0d L d θθ
=。如果约束条件是成立的,那么无约束估计量?θ与约束估计量θ之间的差别就会很小,约束估计量θ也就会近似的满足无约束的一阶优化条件
ln ()
0d L d θθ
=。在实际的应用中,LM 统计量的缺陷在于计算量大,表达式比较复杂,21200()()LM s I nR ββ-==(考察对数似然函数在0β处的斜率)。但是在同方差假定下,
其计算表达式可以大大简化。进一步的,即使在异方差条件下,也可以通过回归的方法来避免复杂的计算,同样能够得到LM 统计量。
LR 检验的思想是考察无约束条件下最优化和约束条件下最优化求得的值函数的大小。无约束条件下的最优化值函数总是大于或等于约束条件下的值函数。如果二者的差别很小,就可以认为约束条件是成立的。在实际的应用中,LR 统计量的思想比较直观,但是必须在同方差假定下,构造出的LR 统计量才是有效的;另一方面,由于LR 统计量的构造要求同
时计算无约束和有约束的参数估计式,20
?2ln ()2ln ()ln(1)LR L L n R ββ=-=--(考察?β与0β之间的“垂直”距离),在实际应用中就增加了计算量,使得其应用受到一定的制约。
十七
1、考虑如下模型, 无约束模型(U):
t LnC ∧
= 0.3181 + 0.8756 LnI t + 0.6466 LnC t -1 - 0.6078 LnI t -1 + 0.0218 LnP t -1. t = (2.75) (10.97) (4.72) (-4.86) (2.09) R 2 = 0.9989, RSS = 0.0015, DW = 1.95, LnL = 105.87, n= 30 和约束模型(R):
t LnC ∧
= 0.1932 + 0.9600 LnC t -1 - 0.0168 LnP t -1. t = (0.88) (19.95) (-0.78)
R 2
= 0.9935, RSS = 0.0088, DW = 2.27, LnL = 79.47, n= 30
试用似然比(LR)检验判断,对模型(U)施加约束LnI t 和LnI t -1的系数β0 = β1 = 0是否成立。 (注:显著性水平0.05时,χ 2(2) = 5.99 )
2、对某生产函数模型,
t Lny ∧
= -8.4 + 0.67 Lnx t 1 + 1.18 Lnx t 2 (4.4) (3.9) R 2 = 0.89, F = 48.45, DW=1.3
检验β2/β3 = 0.5是否成立。下表运用了什么方法?说明了什么结果?
解答:1、似然比检验:()()2ln 2ln ln 279.47105.8752.8R U LR L L λ=-=--=-?-=
()2
0.0552.82 5.99LR x =>=
所以拒绝原假设001:0H ββ==,对模型(U)施加约束LnI t 和LnI t -1的系数β0 = β1 = 0不成立,选择无约束模型。
如果运用F 检验:()()
0.00880.00152
60.830.0015305R U U RSS RSS q F RSS n k --=
==--
()2
0.0560.832 5.99F x =>=
所以拒绝原假设001:0H ββ==,对模型(U)施加约束LnI t 和LnI t -1的系数β0 = β1 = 0不成立,选择无约束模型。
2、表中运用了wald 检验方法,检验结果0.7975730.05P =>,接受原假设,约束条件
2
30.5
ββ=成立。
十八、在计量经济分析中,经常讨论随机扰动项的分布设定问题。
例如,对于Γ分布()
11()(,,,)()
i i y x i i i x f y x y e ρβρββρρ--+-+=Γ,若设1ρ=,则其成为
指数分布()1
(,,)i
i y x i i i
f y x e x βββ-+=
+。这里,约束条件为1ρ=。为此,某人进行了如下检验:
01H ρ=:; 11H ρ≠:
利用极大似然估计ML ,得到如下结果(括号内数据为标准差):
Unrestricted Restricted ρ
3.1517 (0.794292) 1.00
β -4.7198 (2.341235) 15.6052 (6.790987) InL
-82.91444 -88.43771 ln L β?
0.000 0.000 ln L ρ?? 0.000 7.9162 22ln L β?? -0.85628 -0.021654 22ln L ρ? -7.4569 -32.8987 2ln L βρ
??
-2.2423
-0.66885
试依据上述结果,回答下列问题(给定()2
0.051 3.842χ=):
1、计算似然比检验(Likelihood Ratio Test )统计量的值,并进行判断;
2、计算沃尔德检验(Wald Test )统计量的值,并进行判断。
解答:1、似然比检验
()()2ln ln 288.4377182.9144411.04654R U LR L L =--=-?-+=
()2
0.0511.046541 3.842LR x =>=,所以拒绝原假设01H ρ=:,选择无约束模型。
2、Wald 检验,0:10H ρ-= 1:10H ρ-≠
()()()1
1'
??????()(())()1var 11W c Var c c θθθρρρ--??'==---??????
其中?θ
表示无约束条件下的参数估计量 所以()()()()()()22
1
'
2
?1 3.15171???1var 117.3348?var 10.794292W ρρρρρ---=---===????-
()2
0.057.33481 3.842W x =>=,所以拒绝原假设0:10H ρ-=,选择无约束模型。
十九、简要阐述两步广义矩估计的基本步骤
解答:1、先取加权矩阵W=单位矩阵I ,或者对于线性模型Y X u β=+,取
1(')W X X -=得到初始GMM 估计量θ(或β)。
2、取加权矩阵1
11
?()[
(,)(,)']i i i i W m z m z n
θθθ--=Ω
=∑,可以证明它是1-Ω的一致估计量。于是'1?argmin ()()()g g θθθθ-=Ω
即是通过两步完成的GMM 估计量。
二十、考虑如下有K 个解释变量的线性回归
1122T T T
t t t t t t y x x x ββεβε=++=+
其中1t x 为外生变量,即()10t t E x ε=,2t x 是内生变量,()20t t E x ε≠。假设存在工具变量
()12,T T
t t t
z x z =,其中Z 的维数为R ,且R K >,()()()
10T t t t t t R E z E z y x εβ?=-=。试推导?GMM β。
解答:回归方程:1122T T T
t t t t t t y x x x ββεβε=++=+
由:()0t t E z ε=
则有()()()
0T
T t t t t t t t t t E z E z y x E z y z x εββ??=-=-=??
得:()()
T t t t t E z y E z x β=
()()()()1
1
T T T t t t t t t t t E z x E z y E z x E z x β--=
()()1
T t t t t E z x E z y β-=
所以,()()1
1111?n n T GMM
t t t t t z x z y n n β---??=????
∑∑
计量经济学模拟试题答案 一、单项选择题:本大题共10个小题,每小题2分,共20分。 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指(D )。 A 、使 () ∑=-n t t t Y Y 1 ?达到最小值 B 、使∑=-n t t t Y Y 1 ?达到最小值 C 、使t t Y Y ?max -达到最小值 D 、使() 2 1 ?∑=-n t t t Y Y 达到最小值 2、为了研究制造业设备利用率和通货膨胀之间的关系,做以下回归:Y=b 0+b 1X ,Y :通胀率,X :制造业设备利用率,输入数据,回归结果如下:(C ) Y=-70.85 +0.888X ,各系数t 值分别为5.89,5.90。那么以下说法错误的是: A 、先验的,预期X 的符号为正。 B 、回归得到的斜率的显著不为零 C 、回归得到的斜率显著不为1 D.、依据理论,X 和Y 应当正相关 3、.容易产生异方差的数据为(C ) A.时序数据 B.修匀数据 C.横截面数据 D.年度数据 4、在多元线性回归分析中,调整的判定系数2R 与一般判定系数2R 之间( A )。 A 、2R ≤2R B 、2R ≥2R B 、2R 只能大于零 D 、2R 恒为负 5、Goldfeld —Quandt 检验法可用于检验( B )。 A 复杂异方差性 B.递增异方差性 C.序列相关 D.设定误差 6、已知三元线性回归模型估计的残差平方和为8002=∑t e ,估计用样本容量为24=n , 则随机误差项t u 的方差估计量2 S 为(B )。 A 、33.33 B 、 40 C 、 38.09 D 、36.36 7、在给定的显著性水平之下,若DW 统计量的下和上临界值分别为L d 和u d ,则当 L d 计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用 计量经济学模拟考试题第5套 一、单项选择题 1、下列说法正确的有( C ) A.时序数据和横截面数据没有差异 B.对总体回归模型的显著性检验没有必要 C.总体回归方程与样本回归方程是有区别的 D.判定系数2R 不可以用于衡量拟合优度 2、所谓异方差是指( A ) 3、在给定的显著性水平之下,若DW 统计量的下和上临界值分别为dL 和du,则当dL 《计量经济学》期末考试试卷(A )(课程代码:070403014) 1.计量经济模型的计量经济检验通常包括随机误差项的序列相关检验、异方差性检验、解释变量的多重共线性检验。 2. 普通最小二乘法得到的参数估计量具有线性,无偏性,有效性统计性质。 3.对计量经济学模型作统计检验包括_拟合优度检验、方程的显著性检验、变量的显著性检验。 4.在计量经济建模时,对非线性模型的处理方法之一是线性化,模型β α+= X X Y 线性 化的变量变换形式为Y *=1/Y X *=1/X ,变换后的模型形式为Y *=α+βX *。 5.联立方程计量模型在完成估计后,还需要进行检验,包括单方程检验和方程系统检验。 1.计量经济模型分为单方程模型和(C )。 A.随机方程模型 B.行为方程模型 C.联立方程模型 D.非随机方程模型 2.经济计量分析的工作程序(B ) A.设定模型,检验模型,估计模型,改进模型 B.设定模型,估计参数,检验模型,应用模型 C.估计模型,应用模型,检验模型,改进模型 D.搜集资料,设定模型,估计参数,应用模型 3.对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的(B )。 A.i C (消费)i I 8.0500+=(收入) B.di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格) C.si Q (商品供给)i P 75.020+=(价格) D.i Y (产出量)6.065.0i K =(资本)4 .0i L (劳动) 4.回归分析中定义的(B ) A.解释变量和被解释变量都是随机变量 B.解释变量为非随机变量,被解释变量为随机变量 C.解释变量和被解释变量都为非随机变量 D.解释变量为随机变量,被解释变量为非随机变量 5.最常用的统计检验准则包括拟合优度检验、变量的显著性检验和(A )。 A.方程的显著性检验 B.多重共线性检验 C.异方差性检验 D.预测检验 6.总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是(B )。 A.RSS=TSS+ESS B.TSS=RSS+ESS C.ESS=RSS-TSS D.ESS=TSS+RSS 7.下面哪一个必定是错误的(C )。 A. i i X Y 2.030?+= 8.0=XY r B. i i X Y 5.175? +-= 91.0=XY r 计量经济学题库、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是(A )。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.( B )是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是( A )。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指( D )。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性 计量经济学题库 、单项选择题(每小题1分) 1?计量经济学是下列哪门学科的分支学科(C)O A.统计学 B.数学 C.经济学 D.数理统计学 2?计量经济学成为一门独立学科的标志是(B)。 A. 1930年世界计量经济学会成立 B. 1933年《计量经济学》会刊出版 C. 1969年诺贝尔经济学奖设立 D. 1926年计量经济学(EConOIniCS) —词构造出来 3.外生变量和滞后变量统称为(D)O A.控制变量B?解释变量 C.被解释变量 D.前定变量 4.横截面数据是指(A)O A.同一时点上不同统计单位相同统计指标组成的数据 B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据 D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)O A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据 6.在计量经济模型中,由模型系统部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是(B )o A.生变量 B.外生变量 C.滞后变量 D.前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是(A )o A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量 经济模型 &经济计量模型的被解释变量一定是(C )o A.控制变量 B.政策变量 C.生变量 D.外生变量 9.下面属于横截面数据的是(D )o A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )0 A.设定理论模型一收集样本资料一估计模型参数一检验模型 B.设定模型一估计参数一检验模型一应用模型 C:个体设计f总体估计f估计模型f应用模型D.确定模型导向一确定变量及方程式一估计模型一应用模型 11.将生变量的前期值作解释变量,这样的变量称为( A.虚拟变量 B.控制变量 12.( B )是具有一定概率分布的随机变量, A.外生变量 B.生变量 13.同一统计指标按时间顺序记录的数据列称为( A.横截面数据 B.时间序列数据据 14?计量经济模型的基本应用领域有( A.结构分析、经济预测、政策评价 C.消费需求分析、生产技术分析、 15.变量之间的关系可以分为两大类, A.函数关系与相关关系 C.正相关关系和负相关关系 D )0 C.政策变量 它的数值由模型本身决定。 C.前定变量 B )0 C.修匀数据 A )0 B.弹性分析、D.季度分析、它们是(A 乘数分析、政策模拟年度分析、中长期分析 )o B.线性相关关系和非线性相关关系D.简单相关关系和复杂相关关系 D ?滞后变量D.滞后变量D.原始数 模拟试题一 一、单项选择题 1.一元线性样本回归直线可以表示为() A.B. C.D. 2.如果回归模型中的随机误差存在异方差性,则参数的普通最小二乘估计量是() A.无偏的,但方差不是最小的 B.有偏的,且方差不少最小C.无偏的,且方差最小D.有偏的,但方差仍最小 3.如果一个回归模型中包含截距项,对一个具有k个特征的质的因素需要引入()个虚拟变量 A.(k-2) B.(k-1)C.kD.K+1 4.如果联立方程模型中某结构方程包含了模型系统中所有的变量,则这个方程是() A.恰好识别的 B.不可识别的C.过渡识别的D.不确定 5.平稳时间序列的均值和方差是固定不变的,自协方差只与()有关 A.所考察的两期间隔xxB.与时间序列的上升趋势C.与时间序列的下降趋势D.与时间的变化 6.对于某样本回归模型,已求得DW统计量的值为1,则模型残差的自相关系数近似等于() A.0B..-0.5D.1 7.对于自适应预期模型,估计参数应采取的方法为()A.普通最小二乘法 B.甲醛最小二乘法 C.工具变量法D.xx差分法 8.如果同阶单整变量的线性组合是平稳时间序列,则这些变量之间的关系就是() A.协整关系B.完全线性关系 C.伪回归关系 D.短期均衡关系 9.在经济数学模型中,依据经济法规认为确定的参数,如税率、利息率等,称为() A.定义参数B.制度参数C.内生参数D.短期均衡关系 10.当某商品的价格下降时,如果其某需求量的增加幅度稍大雨价格的下降幅度,则该商品的需求() A.缺乏弹性B.富有弹性C.完全无弹性D.完全有弹性 二、多项选择题 1.在经济计量学中,根据建立模型的目的不同,将宏观经济计量模型分为() A.经济预测模型B.经够分析模型 C.政策分析模型D.专门模型 E.发达市场经济国家模型 2.设k为回归模型中参数的个数,F统计量表示为() A.B.C.D.E. 2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入 第一套 一、单项选择题 1、双对数模型 μββ++=X Y ln ln ln 10中,参数1β的含义是 ( ) A. Y 关于X 的增长率 B .Y 关于X 的发展速度 C. Y 关于X 的边际变化 D. Y 关于X 的弹性 2、设k 为回归模型中的参数个数,n 为样本容量。则对多元线性回归方 程进行显著性检验时,所用的F 统计量可表示为( ) A. )1() (--k RSS k n ESS B .) ()1()1(2 2k n R k R --- C .) 1()1()(2 2---k R k n R D .)()1/(k n TSS k ESS -- 3、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则 是指( ) A. 使() ∑=-n t t t Y Y 1 ?达到最小值 B. 使() 2 1 ?∑=-n t t t Y Y 达到最小值 C. 使t t Y Y ?max -达到最小值 D. 使?min i i Y Y -达到最小值 4、 对于一个含有截距项的计量经济模型,若某定性因素有m 个互斥的类型, 为将其引入模型中,则需要引入虚拟变量个数为( ) A. m B. m+1 C. m-1 D. m-k 5、 回归模型中具有异方差性时,仍用OLS 估计模型,则以下说法正确的是( ) A. 参数估计值是无偏非有效的 B. 参数估计量仍具有最小方差性 C. 常用F 检验失效 D. 参数估计量是有偏的 6、 在一元线性回归模型中,样本回归方程可表示为( ) A. t t t u X Y ++=10ββ B. i t t X Y E Y μ+=)/( C. t t X Y 10???ββ+= D. ()t t t X X Y E 10/ββ+= 7、 在经济发展发生转折时期,可以通过引入虚拟变量方法来表示这种变化。 例如,研究中国城镇居民消费函数时。1991年前后,城镇居民商品性实际支出Y 对实际可支配收入X 的回归关系明显不同。现以1991年为转折时期,设虚拟变 量?? ?=年以前 , 年以后 , 1991019911t D ,数据散点图显示消费函数发生了结构性变化:基本 消费部分下降了,边际消费倾向变大了。则城镇居民线性消费函数的理论方程可 《计量经济学》复习资料 第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间的_________关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即选择变量、确定变量之间的数学关系、拟定模型中待估计参数的取值范围。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有_外生经济_变量、_外生条件_变量、_外生政策_变量和_滞后被解释_变量。 9.选择模型数学形式的主要依据是_经济行为理论_。 10.研究经济问题时,一般要处理三种类型的数据:_时间序列_数据、_截 面_数据和_虚变量_数据。 11.样本数据的质量包括四个方面_完整性_、_可比性_、_准确性_、_一致性_。 12.模型参数的估计包括_对模型进行识别_、_估计方法的选择_和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是_经济意义_检验、_统计_检验、_计量经济学_检验和_预测_检验。 14.计量经济模型的计量经济检验通常包括随机误差项的_异方差_检验、_序列相关_检验、解释变量的_多重共线性_检验。 15.计量经济学模型的应用可以概括为四个方面,即_结构分析_、_经济预测_、_政策评价_、_检验和发展经济理论_。 16.结构分析所采用的主要方法是_弹性分析_、_乘数分析_和_比较静力分析_。 二、单选题: 1.计量经济学是一门(B)学科。 A.数学 B.经济 C.统计 D.测量 2.狭义计量经济模型是指(C)。 A.投入产出模型 B.数学规划模型 C.包含随机方程的经济数学模型 D.模糊数学模型 3.计量经济模型分为单方程模型和(C)。 练习题一 一、单选题(15小题,每题2分,共30分) 1.有关经济计量模型的描述正确的为( ) A.经济计量模型揭示经济活动中各个因素之间的定性关系 B.经济计量模型揭示经济活动中各个因素之间的定量关系,用确定性的数学方程加以描述 C.经济计量模型揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述 D.经济计量模型揭示经济活动中各个因素之间的定性关系,用随机性的数学方程加以描述 2.在X 与Y 的相关分析中( ) A.X 是随机变量,Y 是非随机变量 B.Y 是随机变量,X 是非随机变量 C.X 和Y 都是随机变量 D.X 和Y 均为非随机变量 3.对于利用普通最小二乘法得到的样本回归直线,下面说法中错误的是( ) A. 0i e =∑ B.0i i e X =∑ C. 0i i eY ≠∑ D.?i i Y Y =∑∑ 4.在一元回归模型中,回归系数2β通过了显著性t 检验,表示( ) A.20β= B.2?0β≠ C.20β=,2?0β≠ D.22 ?0,0ββ≠= 5.如果X 为随机解释变量,X i 与随机误差项u i 相关,即有Cov(X i ,u i )≠0,则普通最小二乘估计β?是( ) A .有偏的、一致的 B .有偏的、非一致的 C .无偏的、一致的 D .无偏的、非一致的 6.有关调整后的判定系数2 R 与判定系数2 R 之间的关系叙述正确的是( ) A.2R 与2 R 均非负 B.模型中包含的解释个数越多,2R 与2 R 就相差越小 C.只要模型中包括截距项在内的参数的个数大于1,则2 2 R R < D.2 R 有可能大于2 R 7.如果回归模型中解释变量之间存在完全的多重共线性,则最小二乘估计量( ) A .不确定,方差无限大 B.确定,方差无限大 C .不确定,方差最小 D.确定,方差最小 8.逐步回归法既检验又修正了( ) A .异方差性 B.自相关性 C .随机解释变量 D.多重共线性 9.如果线性回归模型的随机误差项存在异方差,则参数的普通最小二乘估计量是( ) A .无偏的,但方差不是最小的 B .有偏的,且方差不是最小的 C .无偏的,且方差最小 D .有偏的,但方差仍为最小 10.如果dL 一、填空题(本大题共10小题,每空格1分,共20分) 1、数理经济模型揭示经济活动中各个因素之间的_理论_关系,用__确定___性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间的___定量____关系,用__随机___性的数学方程加以描述。 2、选择模型数学形式的主要依据是____经济行为理论______。 3、被解释变量的观测值i Y 与其回归理论值)(Y E 之间的偏差,称为___随机误差 项_______;被解释变量的观测值i Y 与其回归估计值i Y ? 之间的偏差,称为___残差_______。 4、对计量经济学模型作统计检验包括__拟合优度检验、方程的显著性检验、变量的显著性检验 5、总体平方和TSS 反映__被解释变量观测值与其均值__之离差的平方和;回归平方和ESS 反映了_被解释变量其估计值与其均值之离差的平方和;残差平方和RSS 反映了_被解释变量观测值与其估计值之差的平方和。 6、在多元线性回归模型中,解释变量间呈现线性关系的现象称为_多重共线____问题。 7、工具变量法并没有改变原模型,只是在原模型的参数估计过程中用工具变量“替代” 随机解释变量 8、以截面数据为样本建立起来的计量经济模型中的随机误差项往往存在_异方差_________。 9、在联立方程模型中,___内生变量_______既可作为被解释变量,又可以在不同的方程中作为解释变量。 10多元线性回归中,如果自变量的量纲不同,需要对样本原始数据进行 __标准化__处理,然后用最小二乘法去估计未知参数,这样做的目的是可以考察各个自变量的__相对重要性_。 二、选择题(本大题共15小题,每小题2分,共30分) 1、下图中“{”所指的距离是( B ) A. 随机误差项 B. 残差 C. i Y 的离差 D. i Y ?的离差 2、总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是(B )。 X 1?β+ i Y 计量经济学试题一答案 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。(F) 2.多元回归模型统计显著是指模型中每个变量都是统计显著的。(F) 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。(F) 4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。(Y) (F)5.线性回归是指解释变量和被解释变量之间呈现线性关系。 2R(F)6.判定系数的大小不受回归模型中所包含的解释变量个数的影响。 7.多重共线性是一种随机误差现象。(F) (F)8.当存在自相关时,OLS估计量是有偏的并且也是无效的。 2R变大。(估计量误差放大的原因是从属回归的F)9.在异方差的情况下,OLS 2R都是可以比较的。(F10.任何两个计量经济模型的) 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 答: 1)经济理论或假说的陈述 2)收集数据 3)建立数理经济学模型 4)建立经济计量模型 5)模型系数估计和假设检验 6)模型的选择 7)理论假说的选择 8)经济学应用 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 表示可支配收入,定义X为个人消费支出;Y答案:设季季季其其其如果设定模型此时模型仅影响截距项,差异表现为截距项的和,因此也称为加法模型 如果设定模型 此时模型不仅影响截距项,而且还影响斜率项。差异表现为截距和斜率的双重变化,因 也称为乘法模型 三.下面是我1990-200GDM间归结果分 lnGD1.30.7ln1s(0.150.039.12 自由度10.051.78 求出空白处的数值,填在括号内分分系数是否显著,给出理由都大9.125的临界值,因此系数都是统计显著的答:根统计量 分试述异方差的后果及其补救措施1四 答案分布后果OL估计量是线性无偏的,不是有效的,估计量方差的估计有偏。建立 分布之上的置信区间和假设检验是不可靠的 补救措施:加权最小二乘法WL 已知,则对模型进行如下变换.假 .如未i 第二套 一、单项选择题 1、把反映某一总体特征的同一指标的数据,按一定的时间顺序和时间间隔排列起来,这样的数据称为( ) A. 横截面数据 B. 时间序列数据 C. 修匀数据 D. 原始数据 2、多元线性回归分析中,调整后的可决系数2R 与可决系数2R 之间的关系( ) A. k n n R R ----=1) 1(122 B. 2R ≥2R C. 02>R D. 1) 1(122----=n k n R R 3、半对数模型i i LnX Y μββ++=10中,参数1β的含义是( ) A. Y 关于X 的弹性 B. X 的绝对量变动,引起Y 的绝对量变动 C. Y 关于X 的边际变动 D. X 的相对变动,引起Y 的期望值绝对量变动 4、已知五元线性回归模型估计的残差平方和为8002 =∑t e ,样本容量为46,则随机 误差项t u 的方差估计量2 ?σ 为( ) A. B. 40 C. D. 20 5、线设OLS 法得到的样本回归直线为i i i e X Y ++=21??ββ ,以下说法A 不正确的是( ) A .0=∑i e B .0),(≠i i e X COV C .Y Y =? D .),(Y X 在回归直线上 6、Goldfeld-Quandt 检验法可用于检验( ) A.异方差性 B.多重共线性 C.序列相关 D.设定误差 7、用于检验序列相关的DW 统计量的取值范围是( ) A. 0≤DW ≤1 B.-1≤DW ≤1 C. -2≤DW ≤2 ≤DW ≤4 8、对联立方程组模型估计的方法主要有两类,即( ) A. 单一方程估计法和系统估计法 B. 间接最小二乘法和系统估计法 C. 单一方程估计法和二阶段最小二乘法 D. 工具变量法和间接最小二乘法 9、在模型t t t t u X X Y +++=33221βββ的回归分析结果报告中,有 23.263489=F ,000000 .0=值的p F ,则表明( ) A 、解释变量 t X 2 对t Y 的影响是显著的 B 、解释变量 t X 3对t Y 的影响是显著的 C 、解释变量 t X 2和t X 3对t Y 的联合影响是显著的. D 、解释变量t X 2和t X 3对t Y 的影响是均不显著 10、如果回归模型中解释变量之间存在完全的多重共线性,则最小二乘估计量( ) A.不确定,方差无限大 B.确定,方差无限大 C.不确定,方差最小 D.确定,方差最小 11、应用DW 检验方法时应满足该方法的假定条件,下列不是其假 定条件的为( ) A.解释变量为非随机的 B.被解释变量为非随机的 C.线性回归模型中不能含有滞后内生变量 D.随机误差项服从一阶自回归 12、在具体运用加权最小二乘法时, 如果变换的结果是 x u x x x 1x y 21+β+β= 则Var(u)是下列形式中的哪一种( ) x D x C x B x A log ....22222σσσσ 计量经济学题库(超完整版)及答案 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C )。 A .统计学 B .数学 C .经济学 D .数理统计学 2.计量经济学成为一门独立学科的标志是(B )。 A .1930年世界计量经济学会成立 B .1933年《计量经济学》会刊出版 C .1969年诺贝尔经济学奖设立 D .1926年计量经济学(Economics )一词构造出来3.外生变量和滞后变量统称为(D )。 A .控制变量 B .解释变量 C .被解释变量 D .前定变量 4.横截面数据是指(A )。 A .同一时点上不同统计单位相同统计指标组成的数据 B .同一时点上相同统计单位相同统计指标组成的数据 C .同一时点上相同统计单位不同统计指标组成的数据 D .同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C )。 A .时期数据 B .混合数据 C .时间序列数据 D .横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A .内生变量 B .外生变量 C .滞后变量 D .前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A .微观计量经济模型 B .宏观计量经济模型 C .理论计量经济模型 D .应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A .控制变量 B .政策变量 C .内生变量 D .外生变量 9.下面属于横截面数据的是()。 A .1991-2003年各年某地区20个乡镇企业的平均工业产值 B .1991-2003年各年某地区20个乡镇企业各镇的工业产值 C .某年某地区20个乡镇工业产值的合计数 D .某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。 A .设定理论模型→收集样本资料→估计模型参数→检验模型 B .设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A .虚拟变量 B .控制变量 C .政策变量 D .滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A .外生变量 B .内生变量 C .前定变量 D .滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A .横截面数据 B .时间序列数据 C .修匀数据 D .原始数据 14.计量经济模型的基本应用领域有()。 A .结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C .消费需求分析、生产技术分析、 D .季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A .函数关系与相关关系 B .线性相关关系和非线性相关关系 计量经济学题库 、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学B.数学C.经济学D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量B.解释变量C.被解释变量D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据B.混合数据C.时间序列数据D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( B )。 A.内生变量B.外生变量C.滞后变量D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是(A )。 A.微观计量经济模型B.宏观计量经济模型C.理论计量经济模型D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量B.政策变量C.内生变量D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用模型 C.个体设计→总体估计→估计模型→应用模型D.确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量B.控制变量C.政策变量D.滞后变量 12.( B )是具有一定概率分布的随机变量,它的数值由模型本身决定。 A.外生变量B.内生变量C.前定变量D.滞后变量 13.同一统计指标按时间顺序记录的数据列称为( B )。 A.横截面数据B.时间序列数据C.修匀数据D.原始数据 14.计量经济模型的基本应用领域有( A )。 A.结构分析、经济预测、政策评价B.弹性分析、乘数分析、政策模拟 C.消费需求分析、生产技术分析、D.季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是( A )。 A.函数关系与相关关系B.线性相关关系和非线性相关关系 C.正相关关系和负相关关系D.简单相关关系和复杂相关关系 16.相关关系是指( D )。 A.变量间的非独立关系B.变量间的因果关系C.变量间的函数关系D.变量间不确定性 财大计量经济学期末考试标准试题 计量经济学试题一 (1) 计量经济学试题一答案 (4) 计量经济学试题二 (9) 计量经济学试题二答案 (11) 计量经济学试题三 (15) 计量经济学试题三答案 (18) 计量经济学试题四 (22) 计量经济学试题四答案 (25) 计量经济学试题一 课程号:课序号:开课系:数量经济系 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。() 2.多元回归模型统计显着是指模型中每个变量都是统计显着的。() 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。() 4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。()5.线性回归是指解释变量和被解释变量之间呈现线性关系。() R的大小不受到回归模型中所包含的解释变量个数的影响。()6.判定系数2 7.多重共线性是一种随机误差现象。() 8.当存在自相关时,OLS估计量是有偏的并且也是无效的。() 9.在异方差的情况下,OLS估计量误差放大的原因是从属回归的2R变大。()10.任何两个计量经济模型的2R都是可以比较的。() 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 三.下面是我国1990-2003年GDP对M1之间回归的结果。(5分) 1.求出空白处的数值,填在括号内。(2分) 2.系数是否显着,给出理由。(3分) 四.试述异方差的后果及其补救措施。(10分) 五.多重共线性的后果及修正措施。(10分) 六.试述D-W检验的适用条件及其检验步骤?(10分) 七.(15分)下面是宏观经济模型 变量分别为货币供给M、投资I、价格指数P和产出Y。 1.指出模型中哪些是内是变量,哪些是外生变量。(5分) 2.对模型进行识别。(4分) 3.指出恰好识别方程和过度识别方程的估计方法。(6分) 八、(20分)应用题 为了研究我国经济增长和国债之间的关系,建立回归模型。得到的结果如下:Dependent Variable: LOG(GDP) Method: Least Squares Date: 06/04/05 Time: 18:58 Sample: 1985 2003 Included observations: 19 Variable Coefficient Std. Error t-Statistic Prob. 计量经济学期末考试试题 1、选择题(每题2分,共60分) 1、下列数据中属于面板数据(panel data )的是:( ) A 、某地区1991-2004年各年20个乡镇的平均农业产值; B 、某地区1991-2004年各年20个乡镇的各镇农业产值; C 、某年某地区20个乡镇农业产值的总和; D 、某年某地区20个乡镇各镇的农业产值。 2、参数 β 的估计量β? 具有有效性是指:( ) A 、0)?var(=β ; B 、)?var(β为最小; C 、0)?(=-ββ ; D 、)?(ββ-为最小。 3、对于i i u x y ++=110??ββ,以σ?表示估计的标准误,i y ?表示回归的估计值,则:( ) A 、σ?=0时,∑-)?(i i y y =0; B 、σ?=0时,2 )?(∑-i i y y =0; C 、σ ?=0时,∑-)?(i i y y 为最小; D 、σ?=0时,2)?(∑-i i y y 为最小。 4、对回归模型i i u x y ++=110ββ进行统计检验时,通常假定i u 服从:( ) A 、),0(2i N σ; B 、t (n-2) ; C 、 ),0(2 σN ; D 、t (n)。 5、用OLS 估计经典线性模型i i u x y ++=110ββ,则样本回归线通过点:( ) A 、),(y x ; B 、)?,(y x ; C 、)?,(y x ; D 、),(y x 。 6、已知回归模型i i u x y ++=110ββ的判定系数为0.64,则解释变量与被解释变量之间的相关系数为: ( ) A 、0.64; B 、0.8; C 、0.4; D 、0.32计量经济学题库及答案
计量经济学模拟考试题第5套(含答案)
计量经济学试卷及答案
计量经济学期末考试题库完整版)及答案
计量经济学期末考试题库(完整版)及答案
计量经济学模拟试题及答案
计量经济学题库及答案
计量经济学 模拟考试题(第1套)
计量经济学试题与答案
计量经济学期末考试试题 是模拟试卷
计量经济学试题
计量经济学试题一答案汇总
计量经济学模拟考试题(第2套)附答案
计量经济学题库及答案71408
计量经济学期末考试题库(完整版)及答案
计量经济学期末考试试卷集含答案
计量经济学期末考试试题()
相关主题
文本预览