
Rhcs集群部署文档(websphere+db2)
一、安装环境介绍
这个实例要介绍的是websphere+db2集群的构建,整个RHCS集群共有四台服务器组成,分
别由两台主机搭建web集群,两台主机搭建db2集群,在这种集群构架下,任何一台web服
务器故障,都有另一台web服务器进行服务接管,同时,任何一台db2服务器故障,也有另
一台db2服务器去接管服务,保证了整个应用系统服务的不间断运行。如下图所示:
二、安装前准备工作
W ebsphere和db2采取默认安装,这里就不再描述。Db2安装完毕后运行db2 create db exoa on /opt/ibm/db2/exoa using codeset gbk territory cn创建数据库
操作系统:统一采用rhel5.6版本。为了方便安装RHCS套件,在安装操作系统时,建议选择如下这些安装包:
桌面环境:xwindows system、GNOME desktop environment。
开发工具:development tools、x software development、gnome software development、kde software d
evelopment。
地址规划如下:
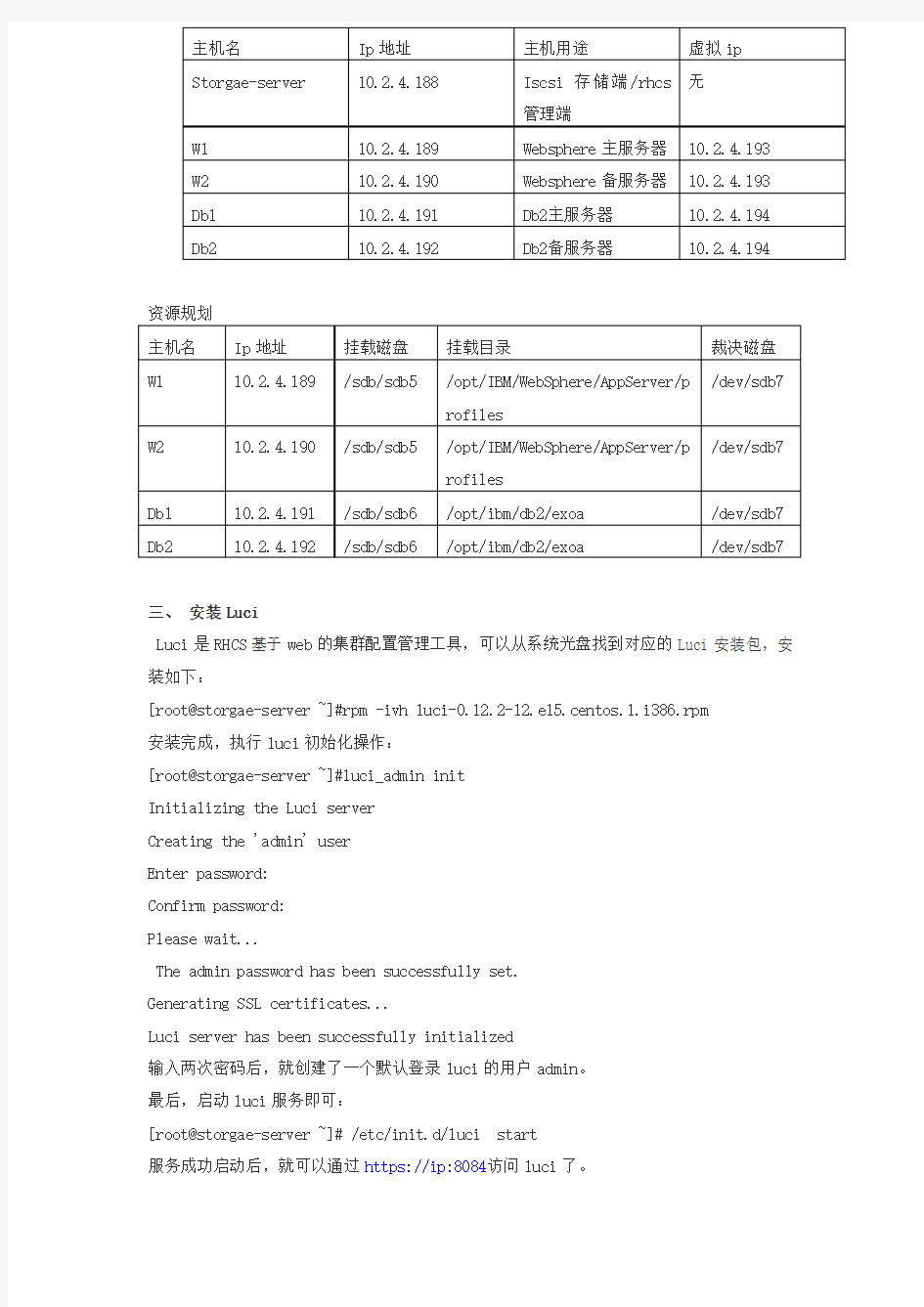
资源规划 主机名 Ip 地址 挂载磁盘 挂载目录
裁决磁盘 W1
10.2.4.189
/sdb/sdb5
/opt/IBM/WebSphere/AppServer/p rofiles
/dev/sdb7
W2
10.2.4.190
/sdb/sdb5
/opt/IBM/WebSphere/AppServer/p rofiles
/dev/sdb7 Db1 10.2.4.191 /sdb/sdb6 /opt/ibm/db2/exoa /dev/sdb7 Db2 10.2.4.192
/sdb/sdb6
/opt/ibm/db2/exoa
/dev/sdb7
三、 安装Luci
Luci 是RHCS 基于web 的集群配置管理工具,可以从系统光盘找到对应的Luci 安装包,安装如下:
[root@storgae-server ~]#rpm -ivh luci-0.12.2-12.el5.centos.1.i386.rpm 安装完成,执行luci 初始化操作:
[root@storgae-server ~]#luci_admin init Initializing the Luci server Creating the 'admin' user Enter password: Confirm password: Please wait...
The admin password has been successfully set. Generating SSL certificates...
Luci server has been successfully initialized
输入两次密码后,就创建了一个默认登录luci 的用户admin 。 最后,启动luci 服务即可:
[root@storgae-server ~]# /etc/init.d/luci start 服务成功启动后,就可以通过https://ip:8084访问luci 了。
主机名
Ip 地址 主机用途
虚拟ip Storgae-server
10.2.4.188
Iscsi 存储端/rhcs 管理端
无
W1 10.2.4.189 Websphere 主服务器 10.2.4.193 W2 10.2.4.190 Websphere 备服务器 10.2.4.193 Db1 10.2.4.191 Db2主服务器 10.2.4.194 Db2
10.2.4.192
Db2备服务器
10.2.4.194
为了能让luci访问集群其它节点,还需要在/etc/hosts增加如下内容:
10.2.4.189 w1
10.2.4.190 w2
10.2.4.191 db1
10.2.4.192 db2
到这里为止,在storgae-server主机上的设置完成。
四、在集群节点安装RHCS软件包
为了保证集群每个节点间可以互相通信,需要将每个节点的主机名信息加入/etc/hosts文件中,修改完成的/etc/hosts文件内容如下:
127.0.0.1 localhost
10.2.4.189 w1
10.2.4.190 w2
10.2.4.191 db1
10.2.4.192 db2
将此文件依次复制到集群每个节点的/etc/hosts文件中。
RHCS软件包的安装有两种方式,可以通过luci管理界面,在创建Cluster时,通过在线下载方式自动安装,也可以直接从操作系统光盘找到所需软件包进行手动安装,由于在线安装方式受网络和速度的影响,不建议采用,这里通过手动方式来安装RHCS软件包。
安装RHCS,主要安装的组件包有cman、gfs2和rgmanager,当然在安装这些软件包时可能需要其它依赖的系统包,只需按照提示进行安装即可,下面是一个安装清单,在集群的四个节点分别执行:
#install cman
rpm -ivh perl-XML-NamespaceSupport-1.09-1.2.1.noarch.rpm
rpm -ivh perl-XML-SAX-0.14-8.noarch.rpm
rpm -ivh perl-XML-LibXML-Common-0.13-8.2.2.i386.rpm
rpm -ivh perl-XML-LibXML-1.58-6.i386.rpm
rpm -ivh perl-Net-Telnet-3.03-5.noarch.rpm
rpm -ivh pexpect-2.3-3.el5.noarch.rpm
rpm -ivh openais-0.80.6-16.el5_5.2.i386.rpm
rpm -ivh cman-2.0.115-34.el5.i386.rpm
#install ricci
rpm -ivh modcluster-0.12.1-2.el5.centos.i386.rpm
rpm -ivh ricci-0.12.2-12.el5.centos.1.i386.rpm
#install gfs2
rpm -ivh gfs2-utils-0.1.62-20.el5.i386.rpm
#install rgmanager
rpm -ivh rgmanager-2.0.52-6.el5.centos.i386.rpm
五、在集群节点安装配置iSCSI客户端
安装iSCSI客户端是为了和iSCSI-target服务端进行通信,进而将共享磁盘导入到各个集群节点,这里以集群节点web1为例,介绍如何安装和配置iSCSI,剩余其它节点的安装和配置方式与web1节点完全相同。
iSCSI客户端的安装和配置非常简单,只需如下几个步骤即可完成:
[root@web1 rhcs]# rpm -ivh iscsi-initiator-utils-6.2.0.871-0.16.el5.i386.rpm [root@web1 rhcs]# /etc/init.d/iscsi restart
[root@web1 rhcs]# iscsiadm -m discovery -t sendtargets -p 192.168.12.246
[root@web1 rhcs]# /etc/init.d/iscsi restart
[root@web1 rhcs]# fdisk -l
Disk /dev/sdb: 10.7 GB, 10737418240 bytes
64 heads, 32 sectors/track, 10240 cylinders
Units = cylinders of 2048 * 512 = 1048576 bytes
Disk /dev/sdb doesn't contain a valid partition table
通过fdisk的输出可知,/dev/sdb就是从iSCSI-target共享过来的磁盘分区。
至此,安装工作全部结束。
六、配置RHCS高可用集群
配置RHCS,其核心就是配置/etc/cluster/cluster.conf文件,下面通过web管理界面介绍如何构造一个cluster.conf文件。
在storgae-server主机上启动luci服务,然后通过浏览器访问https://10.2.4.188:8084/,就可以打开luci登录界面,如图1所示:
图1
成功登录后,luci有三个配置选项,分别是homebase、cluster和storage,其中,cluster 主要用于创建和配置集群系统,storage用于创建和管理共享存储,而homebase主要用于添加、更新、删除cluster系统和storage设置,同时也可以创建和删除luci登录用户。如图2所示:
图2
1、创建一个cluster
登录luci后,切换到cluster选项,然后点击左边的clusters选框中的“Create a new cluster”,增加一个cluster,如图3所示:
图3
在图3中,创建的cluster名称为mycluster,“Node Hostname”表示每个节点的主机名称,“Root Password”表示每个节点的root用户密码。每个节点的root密码可以相同,也可以不同。
在下面的五个选项中,“Download packages”表示在线下载并自动安装RHCS软件包,而“Use locally installed packages”表示用本地安装包进行安装,由于RHCS组件包在上面的介绍中已经手动安装完成,所以这里选择本地安装即可。剩下的三个复选框分别是启用共享存储支持(Enable Shared Storage Support)、节点加入集群时重启系统(Reboot nodes before joining cluster)和检查节点密码的一致性(Check if node passwords are identical),这些创建cluster的设置,可选可不选,这里不做任何选择。
“View SSL cert fingerprints”用于验证集群各个节点与luci通信是否正常,并检测每个节点的配置是否可以创建集群,如果检测失败,会给出相应的错误提示信息。如果验证成功,会输出成功信息。
所有选项填写完成,点击“Submit”进行提交,接下来luci开始创建cluster,如图4所示:
图4
在经过Install----Reboot----Configure----Join四个过程后,如果没有报错,“mycluster”就创建完成了,其实创建cluster的过程,就是luci将设定的集群信息写入到每个集群节点配置文件的过程。Cluster创建成功后,默认显示“mycluster”的集群全局属性列表,点击cluster-->Cluster list来查看创建的mycluster的状态,如图5所示:
图5
从图5可知,mycluster集群下有四个节点,正常状态下,节点Nodes名称和Cluster Name 均显示为绿色,如果出现异常,将显示为红色。
点击Nodes下面的任意一个节点名称,可以查看此节点的运行状态,如图6所示:
图6
从图6可以看出,cman和rgmanager服务运行在每个节点上,并且这两个服务需要开机自动启动,它们是RHCS的核心守护进程,如果这两个服务在某个节点没有启动,可以通过命令行方式手工启动,命令如下:
/etc/init.d/cman start
/etc/init.d/rgmanager start
服务启动成功后,在图6中点击“Update node daemon properties”按钮,更新节点的状态。通过上面的操作,一个简单的cluster就创建完成了,但是这个cluster目前还是不能工作的,还需要为这个cluster创建Failover Domain、Resources、Service、Shared Fence Device 等,下面依次进行介绍。
2、创建Failover Domain
Failover Domain是配置集群的失败转移域,通过失败转移域可以将服务和资源的切换限制在指定的节点间,下面的操作将创建两个失败转移域,分别是webserver-failover和mysql-failover。
点击cluster,然后在Cluster list中点击“mycluster”,接着,在左下端的mycluster 栏中点击Failover Domains-->Add a Failover Domain,增加一个Failover Domain,如图7所示:
图7
在图7中,各个参数的含义如下:
Failover domain name:创建的失败转移域名称,起一个易记的名字即可。
Prioritized:是否在Failover domain 中启用域成员优先级设置,这里选择启用。
Restrict Failover to this domain’s member:表示是否在失败转移域成员中启用服务故障切换限制。这里选择启用。
Do not fail back services in this domain:表示在这个域中使用故障切回功能,也就是说,主节点故障时,备用节点会自动接管主节点服务和资源,当主节点恢复正常时,集群的服务和资源会从备用节点自动切换到主节点。
然后,在Failover domain membership的Member复选框中,选择加入此域的节点,这里选择的是web1和web2节点,然后,在“priority”处将web1的优先级设置为1,web2的优先级设置为10。需要说明的是“priority”设置为1的节点,优先级是最高的,随着数值的降低,节点优先级也依次降低。
所有设置完成,点击Submit按钮,开始创建Failover domain。
按照上面的介绍,继续添加第二个失败转移域db-failover,在Failover domain membership 的Member复选框中,选择加入此域的节点,这里选择db1和db2节点,然后,在“priority”处将db1的优先级设置为2,db2的优先级设置为8。
3、创建Resources
Resources是集群的核心,主要包含服务脚本、IP地址、文件系统等,RHCS提供的资源如图8所示:
图8
依次添加IP资源、http服务资源、db管理脚本资源、ext3文件系统,如图9所示:
图9
4、创建Service
点击cluster,然后在Cluster list中点击“mycluster”,接着,在左下端的mycluster 栏中点击Services-->Add a Service,在集群中添加一个服务,如图10所示:
图10
所有服务添加完成后,如果应用程序设置正确,服务将自动启动,点击cluster,然后在Cluster list中可以看到两个服务的启动状态,正常情况下,均显示为绿色。如图11所示:
图11
七、配置表决磁盘
(1)使用表决磁盘的必要性
在一个多节点的RHCS集群系统中,一个节点失败后,集群的服务和资源可以自动转移到其它节点上,但是这种转移是有条件的,例如,在一个四节点的集群中,一旦有两个节点发生故障,整个集群系统将会挂起,集群服务也随即停止,而如果配置了存储集群GFS文件系统,那么只要有一个节点发生故障,所有节点挂载的GFS文件系统将hung住。此时共享存储将无法使用,这种情况的出现,对于高可用的集群系统来说是绝对不允许的,解决这种问题就要通过表决磁盘来实现了。
(2)表决磁盘运行机制
表决磁盘,即Quorum Disk,在RHCS里简称qdisk,是基于磁盘的Cluster仲裁服务程序,为了解决小规模集群中投票问题,RHCS引入了Quorum机制机制,Quorum表示集群法定的节点数,和Quorum对应的是Quorate,Quorate是一种状态,表示达到法定节点数。在正常状态下,Quorum的值是每个节点投票值再加上 QDisk分区的投票值之和。
QDisk是一个小于10MB的共享磁盘分区,Qdiskd进程运行在集群的所有节点上,通过Qdiskd 进程,集群节点定期评估自身的健康情况,并且把自身的状态信息写到指定的共享磁盘分区中,同时Qdiskd还可以查看其它节点的状态信息,并传递信息给其它节点。
(3)RHCS中表决磁盘的概念
和qdisk相关的几个工具有mkdisk、Heuristics。
mkdisk是一个集群仲裁磁盘工具集,可以用来创建一个qdisk共享磁盘也可以查看共享磁盘的状态信息。mkqdisk操作只能创建16个节点的投票空间,因此目前qdisk最多可以支持16个节点的RHCS高可用集群。
有时候仅靠检测Qdisk分区来判断节点状态还是不够的,还可以通过应用程序来扩展对节
点状态检测的精度,Heuristics就是这么一个扩充选项,它允许通过第三方应用程序来辅助定位节点状态,常用的有ping网关或路由,或者通过脚本程序等,如果试探失败,qdiskd 会认为此节点失败,进而试图重启此节点,以使节点进入正常状态。
(4)创建一个表决磁盘
在上面章节中,已经划分了多个共享磁盘分区,这里将共享磁盘分区/dev/sdb7作为qdisk 分区,下面是创建一个qdisk分区:
[root@web1 ~]# mkqdisk -c /dev/sdb7 -l myqdisk
[root@web1 ~]# mkqdisk –L #查看表决磁盘信息
(5)配置Qdisk
这里通过Conga的web界面来配置Qdisk,首先登录luci,然后点击cluster,在Cluster list中点击“mycluster”,然后选择“Quorum Partition”一项,如图12所示:
图12
对图12中每个选项的含义解释如下:
Interval:表示间隔多长时间执行一次检查评估,单位是秒。
Votes:指定qdisk分区投票值是多少。
TKO:表示允许检查失败的次数。一个节点在TKO*Interval时间内如果还连接不上qdisk 分区,那么就认为此节点失败,会从集群中隔离。
Minimum Score:指定最小投票值是多少。
Label:Qdisk分区对应的卷标名,也就是在创建qdisk时指定的“myqdisk”,这里建议用卷标名,因为设备名有可能会在系统重启后发生变化,但卷标名称是不会发生改变的。 Device:指定共享存储在节点中的设备名是什么。
Path to program:配置第三方应用程序来扩展对节点状态检测的精度,这里配置的是ping命令
Score:设定ping命令的投票值。
interval:设定多长时间执行ping命令一次。
(6)启动Qdisk服务
在集群每个节点执行如下命令,启动qdiskd服务:
[root@web1 ~]# /etc/init.d/qdiskd start
qdiskd启动后,如果配置正确,qdisk磁盘将自动进入online状态:
[root@web1 ~]# clustat -l
Cluster Status for mycluster @ Sat Aug 21 01:25:40 2010
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
w2 1 Online, rgmanager
db1 2 Online, rgmanager
db2 3 Online, rgmanager
w1 4 Online, Local, rgmanager
/dev/sdb7 0 Online, Quorum Disk
至此,Qdisk已经运行起来了。
八、配置Fence设备
配置Fence设备是RHCS集群系统中必不可少的一个环节,通过Fence设备可以防止集群资源(例如文件系统)同时被多个节点占有,保护了共享数据的安全性和一致性节,同时也可以防止节点间脑裂的发生。
GFS是基于集群底层架构来传递锁信息的,或者说是基于RHCS的一种集群文件系统,因此使用GFS文件系统也必须要有fence设备。
RHCS提供的fence device有两种,一种是内部fence设备。常见的有:
IBM服务器提供的RSAII卡
HP服务器提供的iLO卡
DELL服务器提供的DRAC卡
智能平台管理接口IPMI
常见的外部fence设备有:UPS、SAN SWITCH、NETWORK SWITCH,另外如果共享存储是通过GNBD Server实现的,那么还可以使用GNBD的fence功能。
点击cluster,然后点击“cluster list”中的“mycluster”,在左下角的mycluster栏目中选择Shared Fence Devices-->Add a Sharable Fence Device,在这里选择的Fence Device为“virtual machine fencing”,Fence的名称为“v-Fence”,如图13所示:
图13
点击“add a fence device to this level”为各个节点添加fence设备
由于wasphere启动需要设别主机名称,在配置集群时必须把主机名及单元修改成虚拟ip操作如下:
为使切换后能顺利启动was服务,必须修改安装was时所建立cell概要(包括一个部署管理器和受管server)的hostname,将其值设为虚拟IP 10.1.0.13。
在此,可专门建立一账户用于启动或停止WAS服务。环境中建立了was账户,并将挂载点的所有权授予该账户。
#chown –R was /opt/IBM/was
切换到was用户
#su - was
* 指定WAS_HOME 环境变量
export W AS_HOME=/opt/IBM/was/WebSphere/AppServer
* 启动wsadmin,但是不要连接到WebSphere 进程
$WAS_HOME/bin/wsadmin.sh -conntype NONE -lang jython
* 执行修改主机名的交互脚本
wsadmin> AdminTask.changeHostName ('[-interactive]')
changeHostName
* (nodeName): : oaappCellManager01
* (hostName):10.1.0.13
* (systemName):oaapp
* 输入F表示脚本编辑完毕,显示编辑组成的脚本
changeHostName
F (Finish)
C (Cancel)
Select [F, C]: [F] F
WASX7278I: Generated command line: AdminTask.changeHostName('[-nodeName oaappCellManager01 -hostName 10.1.0.13 -systemName oaapp ]')
''
* 保存修改操作
wsadmin>AdminConfig.save()
* 退出was脚本命令行
wsadmin>exit
创建完成数据库后创建编目
db2 catalog database exoa on /opt/ibm/db2/exoa
修改各个节点的db2nodes.cfg文件与hostname一致
vim /home/db2inst1/sqllib/db2nodes.cfg
关闭集群
为什么选择容错 Stratus容错服务器与双机热备方案比较
一、容错技术和集群的比较: 1、可靠性比较:
容错服务器的可靠性可达到99.999%以上,其设计原理是“容错原则---容忍错误发生,当出现任意单点故障时,不会对系统造成任何影响,系统仍然连续工作”。而集群方案的可靠性只能在99.9%~99.99%之间,其设计原理是“避错原则----当系统出现故障时,如何补救错误、避免错误进一步扩大”。 2、拓扑结构比较: 计算机业界对可靠性的定义 容错服务器独立服务器 阵的独立服务器 系统 消除单点心 系统结构复杂 环节过多,外部连接 故障发生点多 系统结构简单 如同单机,内部连接 故障发生点少 无单点故障的集群方案 无单点故障的容错方案
3、软硬件架构: 在系统架构中,容错服务器结构简单,且是单软件映像。 1、 工作原理比较: 硬软件结构复杂 依赖集群软件 对所有软件和硬件要求苛刻 切换机制只能覆盖部分实际应用情况 硬软件结构简单 纯硬件容错结构 对所有软件无特殊要求 时钟同步,无需切换
容错方案在出现任何单点故障的情况之下系统工作状态均不会中断,且是零切换时间,进而完整的保护了静态数据及动态数据。 2、维护管理及实施比较: 由于容错服务器的冗余全部是依靠硬件完成的,避免了对软件及人为因素的依赖,因此,其实施及维护非常简单、方便。 3、集群和容错软硬件可靠性实测比较: System Application Fault-Tolerant Cluster Conventional 容错方案的软硬件可靠性是最高的;集群方案虽然略微提高了硬件的可靠性,但却牺牲了软件本身的可靠性。
存储集群双机热备方案
目录 一、前言 (3) 1、公司简介 (3) 2、企业构想 (3) 3、背景资料 (4) 二、需求分析 (4) 三、方案设计 (5) 1.双机容错基本架构 (5) 2、软件容错原理 (6) 3、设计原则 (7) 4、拓扑结构图 (7) 四、方案介绍 (10) 方案一1对1数据库服务器应用 (10) 方案二CLUSTER数据库服务器应用 (11) 五、设备选型 (12) 方案1:双机热备+冷机备份 (12) 方案2:群集+负载均衡+冷机备份 (13) 六、售后服务 (15) 1、技术支持与服务 (15) 2、用户培训 (15)
一、前言 1.1、公司简介 《公司名称》成立于2000年,专业从事网络安全设备营销。随着业务的迅速发展,经历了从计算机营销到综合系统集成的飞跃发展。从成立至今已完成数百个网络工程,为政府、银行、公安、交通、电信、电力等行业提供了IT相关系统集成项目项目和硬件安全产品,并取得销售思科、华为、安达通、IBM、HP、Microsoft等产品上海地区市场名列前茅的骄人业绩。 《公司名称》致力于实现网络商务模式的转型。作为国内领先的联网和安全性解决方案供应商,《公司名称》对依赖网络获得战略性收益的客户一直给予密切关注。公司的客户来自全国各行各业,包括主要的网络运营商、企业、政府机构以及研究和教育机构等。 《公司名称》推出的一系列互联网解决方案,提供所需的安全性和性能来支持国内大型、复杂、要求严格的关键网络,其中包括国内的20余家企事业和政府机关. 《公司名称》成立的唯一宗旨是--企业以诚信为本安全以创新为魂。今天,《公司名称》通过以下努力,帮助国内客户转变他们的网络经济模式,从而建立强大的竞争优势:(1)提出合理的解决方案,以抵御日益频繁复杂的攻击 (2)利用网络应用和服务来取得市场竞争优势。 (3)为客户和业务合作伙伴提供安全的定制方式来接入远程资源 1.2、企业构想 《公司名称》的构想是建立一个新型公共安全网络,将互联网广泛的连接性和专用网络有保障的性能和安全性完美地结合起来。《公司名称》正与业界顶尖的合作伙伴协作,通过先进的技术和高科产品来实施这个构想。使我们和国内各大企业可通过一个新型公共网络来获得有保障的安全性能来支持高级应用。 《公司名称》正在帮助客户改进关键网络的经济模式、安全性以及性能。凭借国际上要求最严格的网络所开发安全产品,《公司名称》正致力于使联网超越低价商品化连接性的境界。《公司名称》正推动国内各行业的网络转型,将今天的"尽力而为"网络改造成可靠、安全的高速网络,以满足今天和未来应用的需要。 1.3、背景资料 随着计算机系统的日益庞大,应用的增多,客户要求计算机网络系统具有高可靠,高
双机容错系统方案 1.前言 对现代企业来说,利用计算机系统来提供及时可靠的信息和服务是必不可少的,另一方面,计算机硬件和软件都不可避免地会发生故障,这些故障有可能给企业带来极大的损失,甚至整个服务的终止,网络的瘫痪。可见,对一些行业,如:金融(银行、信用合作社、证券公司)等,系统的容错性和不间断性尤其显得重要。因此,必须采取适当的措施来确保计算机系统的容错性和不间断性,以维护系统的高可用性和高安全性,提高企业形象,争取更多的客户,保证对客户的承诺,减少人工操作错误、达到系统可用性和可靠性为99.999%。 2.双机容错系统简介 根据用户提出的系统高可用性和高安全性的需求,推出基于Cluster集群技术的双机容错解决方案,包括用于对双服务器实时监控的Lifekeeper容错软件和作为数据存储设备的系列磁盘阵列柜。通过软硬件两部分的紧密配合,提供给客户一套具有单点故障容错能力,且性价比优越的用户应用系统运行平台。 3.Cluster集群技术 Cluster集群技术可如下定义:一组相互独立的服务器在网络中表现为单一的系统,并以单一系统的模式加以管理。此单一系统为客户工作站提供高可靠性的服务。 Cluster大多数模式下,集群中所有的计算机拥有一个共同的名称,集群内任一系统上运行的服务可被所有的网络客户所使用。Cluster必须可以协调管理各分离的组件的错误和失败,并可透明的向Cluster中加入组件。 一个Cluster包含多台(至少二台)拥有共享数据储存空间的服务器。任何一台服务器运行一个应用时,应用数据被存储在共享的数据空间内。每台服务器的操作系统和应用程序文件存储在其各自的本地储存空间上。 Cluster内各节点服务器通过一内部局域网相互通讯。当一台节点服务器发生故障时,这台服务器上所运行的应用程序将在另一节点服务器上被自动接管。当一个应用服务发生故障时,应用服务将被重新启动或被另一台服务器接管。当以上任一故障发生时,客户将能很快连接到新的应用服务上。 4.工作拓扑图
被误读的NEC容错服务器 误读一:容错很好很昂贵 由于容错服务器采用的是硬件全冗余的技术,而且在两套硬件之间还通过独立芯片和软件保证故障时零时间切换,因而其价格要比同规格的PC服务器高出许多。 更为典型的一个用户反馈是:NEC容错服务器产品很好,可用性很高,但是不是像IBM的z系列和HP的NonStop系列动辄都是百万美元? 从上述两种态度可以看出中国用户对容错的应用定位尚属模糊。根据IDC 数据,广义概念上的容错市场约占整个服务器市场的4%,包括IBM的System z、HP的NonStop和NEC的Santa Clara、Express 5800/ft以及Stratus的ftServer 6200,前三者为传统大型主机,后二者为容错服务器。显而易见,这一市场面对的是属于中高端的窄众用户。 而了解上述用户特征后自然明白,容错所谓的昂贵其实纯属误读:如果只需要进行基础IT建设的成长型企业,完全可以采用普通的塔式和机架式服务器,而不必使用容错产品;如果是需要高可用性的中高端用户,那么容错服务器相对大型主机而言,其实相当便宜。以NEC的容错服务器Express 5800/ft为例,目前最低配置的成本甚至已经与同规格的双机热备方案相当。 误读二:虚拟化取代容错 随着用户对计算资源利用率、灵活调度的高度渴求,导致近几年来虚拟技术在PC服务器上快速增长,VMware、Citrix等技术供应商也迅速走红,由此也产生了这样一种观念:虚拟万能,即通过虚拟就能实现计算资源的灵活配置、调度并保证故障时的自动迁移。 虚拟化真是万灵丹吗?显然不是。从硬件架构的层次上看,虚拟层位于底层硬件之上,只能解决虚拟机及其应用的故障迁移。如果是底层硬件故障,诸如主板故障、电源故障、CPU损坏等,虚拟技术是无能为力的。 随着虚拟化技术的普及,容错服务器会变得越来越重要。因为当物理机宕掉的时候,它会影响运行在其上的虚拟机,所以越是依赖虚拟技术的用户越需要保证底层硬件的高可用。 误读三:容错使用很复杂 对于使用过大型主机和双机热备等高可用方案的用户来说,配置及管理系统绝对是一个技术上的考验。这也使得一些用户产生了“高可用等于高复杂”的观点。
1、Linux集群主要分成三大类( 高可用集群,负载均衡集群,科学计算集群)(下面只介绍负载均衡集群) 负载均衡集群(Load Balance Cluster) 负载均衡系统:集群中所有的节点都处于活动状态,它们分摊系统的工作负载。一般Web服务器集群、数据库集群和应用服务器集群都属于这种类型。 负载均衡集群一般用于相应网络请求的网页服务器,数据库服务器。这种集群可以在接到请求时,检查接受请求较少,不繁忙的服务器,并把请求转到这些服务器上。从检查其他服务器状态这一点上看,负载均衡和容错集群很接近,不同之处是数量上更多。 2、负载均衡系统:负载均衡又有DNS负载均衡(比较常用)、IP负载均衡、反向代理负载均衡等,也就是在集群中有服务器A、B、C,它们都是互不影响,互不相干的,任何一台的机器宕了,都不会影响其他机器的运行,当用户来一个请求,有负载均衡器的算法决定由哪台机器来处理,假如你的算法是采用round算法,有用户a、b、c,那么分别由服务器A、B、C来处理; 3、分布式是指将不同的业务分布在不同的地方。 而集群指的是将几台服务器集中在一起,实现同一业务。 分布式中的每一个节点,都可以做集群。 而集群并不一定就是分布式的。 举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成。 而分布式,从窄意上理解,也跟集群差不多,但是它的组织比较松散,不像集群,有一个组织性,一台服务器垮了,其它的服务器可以顶上来。 分布式的每一个节点,都完成不同的业务,一个节点垮了,哪这个业务就不可访问了。
美国stratus公司:容错服务器的简单理 【IT168 资讯】美国stratus容错公司出品的容错服务器是一种可以实现零时间停机的服务器,在一些关键性领域里应用非常广泛,例如:电信、机场、银行、冶金行业、安全、医院的HIS系统、电视台、公安、电力行业、大的零售业,等一切要求高可用性的行业, 这类用户以前在没有办法的情况下选用的是高可用性集群,英文原文为High Availability Cluster, 简称双机HA Cluster,是指以减少服务中断(宕机)时间为目的的服务器集群技术,简称双机,这种方式实现起来非常复杂,后期维护成本也很高,对技术人员的依赖也非常严重,而且因为cluster不能实现0时间停机(消除单点故障的集群可用性是99.99%),所以他的设计目标是减少停机时间而不是避免停机时间,而容错服务器设计上就是避免停机,高可用性的时间是99.9998%,如果2个方案价格相当,您选择减少停机还是选择避免停机的服务器呢? 容错的优势 容错服务器的几点优势简单说说!(主要是和双机的区别说一下) 1:国际著名检测组织IDC公布:容错服务器的高可用性是99.9998%,而消除单点故障的集群是99.99%,IBM的大型机为99.995% 2:设计上容错的目标是避免停机,而集群是减少停机(当我们有避免停机的方案,我们为什么还要选择减少停机的方案呢?) 3:容错能有效的保护动态数据不丢失,而双机只能保证写入硬盘的数据; 4:容错能支持热插拔任意的硬件,包括主板,CPU等关键性硬件, 5:布置非常简单,只需要装单套系统,数据库也只需要一套,免去双机软件和研发代码的麻烦,从而大大的减少工程师的工作量,也大大的减少了软件成本. 6:速度比同配置的双机要快20%以上. 7:后期维护成本几乎为零,而双机的话需要工程师的支持,或许由于系统补丁的升级需要额外的研发双机代码来保证系统的切换成功; 8:容错是没有切换时间的,而双机由于硬件宕机后会发生停顿的情况,还有就是双机切换工作是有可能不成功的. 9.容错的windows系统因为有容错揪错芯片,所以容错的windows系统比传统的windows系统稳定,也许您用很多年都不需要重起windows,因为它永远和刚开机一样快,容错因此承诺容错的windows比IBM的AIX还稳定.因为您用上了容错就不知道什么叫停机. 上面说了很多与双机对比的优势,下面我们通过案例来实际了解容错到底有多好:
容错服务器技术vs双机冗余 2009-05-21 来自:网界网作者:宋家雨收藏 单机容错技术以Stratus公司的ftServer、惠普公司的NonStop服务器和NEC公司的Express5800/ft为代表。这种技术具有比双机冗余方案更高的容错能力。 1980年,当Bill Fost先生苦思冥想在为新公司取个什么名字的时候,无意间看到了飞机外层层叠叠的云层,由此“Stratus”诞生了。但是Bill Fost没有想到,1990当他们注册北京办事处的时候,竟然可以使用“美国容错计算机公司”,这种用技术术语命名公司的现象,此后再也没有出现过。不知道国内有多少用户知道“美国容错计算机公司”,进而了解容错技术,但是相信,这几年数量有限与很多技术领先型公司相类似,“酒香不怕巷子深”是其风格,市场上的低调在一定程度上制约了发展。 容错的含义比较宽泛,这种不确定性容易引发歧义,增加理解上的难度。从概念上来说,容错是指服务器对于错误的容纳能力,是应用过程中对于服务器稳定性追求的一个目标。为了这样一个目标,有几种技术上的实现方法,目前国内谈论最多的是三种:服务器群集技术、双机冗余服务器方案和单机容错技术。 实际上,服务器群集和双机冗余的技术比较类似,双机冗余是最简单的集群,是其一个特例,也可以把服务器集群技术视为双机冗余的延伸,可以理解为一种多机容错的方案。在一般的讨论之中,集群技术是为了解决计算性能不足的问题,通过多台服务器的集群计算,为高性能计算领域应用提供所需要的高性能。采用集群技术,通过多台服务器之间的负载均衡,可以解决服务器单点故障所引发的系统不稳定,提高系统的可靠性,因此集群具有更好的容错能力,但是在实际的应用中,集群技术多用于高性能计算。 单机容错技术以Stratus公司的ftServer、惠普公司的NonStop服务器和NEC公司的Express5800/ft为代表。这种技术具有比双机冗余方案更高的容错能力。据记者查阅有关技术资料,双机冗余系统的可靠性可以达到99.9%,也就是3个9的能力,而Stratus公司的方案,其可靠性可以达到5个9。在记者的采访中,惠普公司企业服务器产品经理陈武胜表示,其NonStop服务器作为目前惠普公司最高档的服务器,其可靠性可以达到7个9的水平。在记者看来,双机冗余与单机容错有很多的差异,绝不是3个9和5个9的区别。为了了解这些区别,记者分别采访了有关软硬件厂商,并结合实际的应用案例,帮助读者了解有关容错服务器的技术。 产品技术篇之一“没有错误”的容错服务器技术 单机容错技术是我们为了区别双机冗余技术对Stratus等容错服务器的称谓,但是在我的采访中,有关服务器厂商都不愿意采用这个称谓,他们更愿意采用容错服务器,因为单机只是一个表现形式,并不能准确表达其技术的特征。IDC资询师将这种技术称之为“没有错误”的容错服务器技术。 容错与同步技术
简单说,分布式是以缩短单个任务的执行时间来提升效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。 例如:如果一个任务由10个子任务组成,每个子任务单独执行需1小时,则在一台服务器上执行改任务需10小时。 采用分布式方案,提供10台服务器,每台服务器只负责处理一个子任务,不考虑子任务间的依赖关系,执行完这个任务只需一个小时。 而采用集群方案,同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,10小后,10个任务同时完成,这样,整身来看,还是1小时内完成一个任务! 集群概念 1. 两大关键特性 集群是一组协同工作的服务实体,用以提供比单一服务实体更具扩展性与可用性的服务平台。在客户端看来,一个集群就象是一个服务实体,但事实上集群由一组服务实体组成。与单一服务实体相比较,集群提供了以下两个关键特性: · 可扩展性--集群的性能不限于单一的服务实体,新的服务实体可以动态地加入到集群,从而增强集群的性能。 · 高可用性--集群通过服务实体冗余使客户端免于轻易遇到out of service的警告。在集群中,同样的服务可以由多个服务实体提供。如果一个服务实体失败了,另一个服务实体会接管失败的服务实体。集群提供的从一个出 错的服务实体恢复到另一个服务实体的功能增强了应用的可用性。 2. 两大能力 为了具有可扩展性和高可用性特点,集群的必须具备以下两大能力: · 负载均衡--负载均衡能把任务比较均衡地分布到集群环境下的计算和网络资源。 · 错误恢复--由于某种原因,执行某个任务的资源出现故障,另一服务实体中执行同一任务的资源接着完成任务。这种由于一个实体中的资源不能工作,另一个实体中的资源透明的继续完成任务的过程叫错误恢复。 负载均衡和错误恢复都要求各服务实体中有执行同一任务的资源存在,而且对于同一任务的各个资源来说,执行任务所需的信息视图(信息上下文)必须是一样的。 3. 两大技术 实现集群务必要有以下两大技术: · 集群地址--集群由多个服务实体组成,集群客户端通过访问集群的集群地址获取集群内部各服务实体的功能。具有单一集群地址(也叫单一影像)是集群的一个基 本特征。维护集群地址的设置被称为负载均
双机热备份技术在方案中的应用实例 双机热备份技术是企业在进行自己的存储服务上经常使用的技术,当我们在使用的时候会出现很多不解的问题,下面我们就实际情况来了解下双机热备份技术的具体工作流程。 目前主流应用的服务器容错技术有三类,它们分别是:服务器群集技术、双机热备份技术和单机容错技术。它们各自所对应的容错级别是从低到高的,也就是说服务器群集技术容错级别最低,而单机容错技术级别最高。由此可知它们各自应用的行业容错级别需求也是从低到高的。本文主要介绍后两种容错技术,先来看一下双机热备份技术。 一、双机热备份技术 双机热备份技术是一种软硬件结合的较高容错应用方案。该方案是由两台服务器系统和一个外接共享磁盘阵列柜(也可没有,而是在各自的服务器中采取RAID卡)及相应的双机热备份技术软件组成。 在这个容错方案中,操作系统和应用程序安装在两台服务器的本地系统盘上,整个网络系统的数据是通过磁盘阵列集中管理和数据备份的。数据集中管理是通过双机热备份技术系统,将所有站点的数据直接从中央存储设备读取和存储,并由专业人员进行管理,极大地保护了数据的安全性和保密性。用户的数据存放在外接共享磁盘阵列中,在一台服务器出现故障时,备机主动替代主机工作,保证网络服务不间断。 双机热备份技术系统采用“心跳”方法保证主系统与备用系统的联系。所谓“心跳”,指的是主从系统之间相互按照一定的时间间隔发送通讯信号,表明各自系统当前的运行状态。一旦“心跳”信号表明主机系统发生故障,或者备用系统无法收到主机系统的“心跳” 信号,则系统的高可用性管理软件认为主机系统发生故障,主机停止工作,并将系统资源转移到备用系统上,备用系统将替代主机发挥作用,以保证网络服务运行不间断。 双机热备份技术方案中,根据两台服务器的工作方式可以有三种不同的工作模式,即:双机热备模式、双机互备模式和双机双工模式。下面分别予以简单介绍。 双机热备模式即目前通常所说的active/standby 方式,active服务器处于工作状态;而standby 服务器处于监控准备状态,服务器数据包括数据库数据同时往两台或多台服务器写入(通常各服务器采用RAID磁盘阵列卡),保证数据的即时同步。当active服务器出现故障的时候,通过软件诊测或手工方式将standby机器激活,保证应用在短时间内完全恢复正常使用。典型应用在证券资金服务器或行情服务器。这是目前采用较多的一种模式,但由于另外一台服务器长期处于后备的状态,从计算资源方面考量,就存在一定的浪费。
容错之"错" 容错服务器技术vs双机冗余 1980年,当Bill Fost先生苦思冥想在为新公司取个什么名字的时候,无意间看到了飞机外层层叠叠的云层,由此“Stratus”诞生了。但是Bill Fost没有想到,1990当他们注册北京办事处的时候,竟然可以使用“美国容错计算机公司”,这种用技术术语命名公司的现象,此后再也没有出现过。不知道国内有多少用户知道“美国容错计算机公司”,进而了解容错技术,但是相信,这几年数量有限与很多技术领先型公司相类似,“酒香不怕巷子深”是其风格,市场上的低调在一定程度上制约了发展。 容错的含义比较宽泛,这种不确定性容易引发歧义,增加理解上的难度。从概念上来说,容错是指服务器对于错误的容纳能力,是应用过程中对于服务器稳定性追求的一个目标。为了这样一个目标,有几种技术上的实现方法,目前国内谈论最多的是三种:服务器群集技术、双机冗余服务器方案和单机容错技术。 实际上,服务器群集和双机冗余的技术比较类似,双机冗余是最简单的集群,是其一个特例,也可以把服务器集群技术视为双机冗余的延伸,可以理解为一种多机容错的方案。在一般的讨论之中,集群技术是为了解决计算性能不足的问题,通过多台服务器的集群计算,为高性能计算领域应用提供所需要的高性能。采用集群技术,通过多台服务器之间的负载均衡,可以解决服务器单点故障所引发的系统不稳定,提高系统的可靠性,因此集群具有更好的容错能力,但是在实际的应用中,集群技术多用于高性能计算。 单机容错技术以Stratus公司的ftServer、惠普公司的NonStop服务器和NEC公司的Express5800/ft为代表。这种技术具有比双机冗余方案更高的容错能力。据记者查阅有关技术资料,双机冗余系统的可靠性可以达到99.9%,也就是3个9的能力,而Stratus公司的方案,其可靠性可以达到5个9。在记者的采访中,惠普公司企业服务器产品经理陈武胜表示,其NonStop服务器作为目前惠普公司最高档的服务器,其可靠性可以达到7个9 的水平。在记者看来,双机冗余与单机容错有很多的差异,绝不是3个9和5个9的区别。为了了解这些区别,记者分别采访了有关软硬件厂商,并结合实际的应用案例,帮助读者了解有关容错服务器的技术。 产品技术篇之一“没有错误”的容错服务器技术 单机容错技术是我们为了区别双机冗余技术对Stratus等容错服务器的称谓,但是在我的采访中,有关服务器厂商都不愿意采用这个称谓,他们更愿意采用容错服务器,因为单机只是一个表现形式,并不能准确表达其技术的特征。IDC资询师将这种技术称之为“没有错误”的容错服务器技术。 容错与同步技术 美国容错公司技术顾问高峰在接受记者采访时表示,容错服务器的技术并不难理解,计算机自诞生之日起,其系统结构并没有发生任何改变,仍然是冯诺依曼教授所提出的由运算器(CA)、控制器(CC)、存储器M和输入/输出装置所组成,而容错服务器的思路就是把所
容错服务器同集群技术的比较 上海海得控制系统股份有限公司系统事业部 ?技术原理: Stratus的容错服务器所采用专利的硬件Lockstep(锁步)技术,系统保持多CPU/内存单元在精确的同步状态——同一时钟周期执行相同的指令。Lockstep能够确保包括瞬时错误在内的任何错误都不会影响到系统运行,系统可以在任何CPU/内存单元,或IO单元发生错误的情况下不丢失动态数据或状态,也不需产生中断进行错误处理。因此容错服务器避免了一主一备的双机集群所产生的故障切换和恢复时间,以及该过程中和动态数据的丢失。集群的这种切换由于是建立在软件的基础上,随着数据库越来越大,应用的复杂性,切换时间可以从几分钟甚至几十分钟,切换时间内的实时数据将随之无法重新采集,对外服务停止。 ?系统结构: 容错服务器采用的是部件级别的冗余,即主机内部有冗余的CPU部件和I/O部件,同时CPU部件和I/O部件交叉通讯(如图),用部件冗余的方式消除了系统内部包括CPU,内存、I/O控制设备以及硬盘(RAID1)甚至底板的单点故障。而集群方案仅仅是系统级别(即服务器级别)的冗余,而且严格意义上必须配置两个镜像的外置磁盘阵列柜,才能真正意义从物理结构上消除系统和存储的单点故障,但整个系统依然在连接两台服务器的心跳线上存在切换的单点故障。另外,这种物理上的系统级别冗余还必须依靠脚本程序的设计和集群的实施水平,容错服务器也避免了这种无法确定的人为因素。 ?系统可靠性: 容错的可靠性级别完全符合业界对容错服务器99.999%可靠性指标的要求,这种服务器可靠性指标要求系统包括操作系统之内的年平均计划外停机时间必须小于5分钟,而Stratus多年来的实测证明, Windows平台下的容错服务器甚至达到99.9997%的可靠性,平均每年非计划外的停机时间小于3分钟。这种实测数据包括了操作系统和其他软件的因素,从某种程度上说明,Windows平台的容错服务器的可靠性甚至超过了任何UNIX操作系统平台下的服务器。而且从业界对集群技术的可靠性指标分析来讲,集群的可靠性指标通常只能达到99.9%--99.99%,即集群只能保证系统的每年平均计划外停机时间在8小时到53分钟,而且无法对单个集群系统进行可靠性预测。 ?数据可靠性(内存动态数据): 同集群技术相比,容错服务器简化了整个系统的结构,在数据容量要求不高的情况下(400*3GB 以内),避免了使用集群技术所必须的外置式共享存储柜,减少了系统的故障点。而且容错服务器在数据存储的设计上完全采用安全性最高的RAID 1镜像保护,在设计上只在数据写入硬盘之后,系统才认为完成一次真正的写操作,保证数据的完整性和安全性。而采用具有高容量缓存的硬RAID的技术,一旦RAID卡出现故障,没有写入硬盘、驻留在缓存中的数据存在丢失的可能。容错服务器独特的冗余硬
双机容错技术简介 随着网络应用的不断增多,对网络服务的可靠性要求也越来越强。 服务器系统作为整个网络系统提供服务的核心,如果一旦有故障就会影响整个业务系统的正常运行,给企事业单位带来无可估量的经济损失。根据有关机构的调查表明,在系统服务器硬件中,最容易发生故障的仍然是传统的的机械部分即硬盘(故障发生率为50%左右),其次是内存和电源。目前,对上述三者所实行的基本可靠性措施已经相当完备。然而在软件故障中,有系统本身或应用引起的故障越来越多。群集备份技术是解决由软硬件引起可靠性降低的有效措施。群集技术是用网络将两个以上的服务器连接起来,当一台服务器停机时,群集中的其他服务器在保证自身业务的基础上,将停机服务器的业务接管。 在群集系统中,最简单、最为典型的是双机热备系统。双机热备份是提供计算机网络系统可靠性的有力措施。在一台服务器出现故障时,备机主动替代主机工作,保证网络服务不间断。 双机热备份系统是一种软硬件结合的高可靠性应用模式。该系统由两台服务器系统和一个外接共享磁盘阵列柜及相应的双机热备份软件组成。用户的数据存放在外接共享磁盘阵列中。操作系统和应用程序安装在两台服务器的本地系统盘上。双机热备份系统采用“心跳”方法保证主系统与备用系统的联系(所谓“心跳”,指的是主从系统之间,相互按照一定的间隔发送通讯信号,表明系统目前的运行状态)。一旦“心跳”信号表明主机系统发生故障,或者备用系统无法收到主机系统的“心跳”信号,则系统的高可用性管理软件认为主机系统发生故障,主机停止工作,并将系统资源转移到备用系统上,备用系统将替代主机发挥作用,以保证网络服务运行不间断。 双机热备份系统图
Stratus ftServer 1、关于容错服务器: 容错的含义比较宽泛,这种不确定性容易引发歧义,增加理解上的难度。从概念上来说,容错是指服务器对于错误的容纳能力,是应用过程中对于服务器稳定性追求的一个目标。为了这样一个目标,有几种技术上的实现方法,目前国内谈论最多的是三种:服务器群集技术、双机冗余服务器方案和单机容错技术。 实际上,服务器群集和双机冗余的技术比较类似,双机冗余是最简单的集群,是其一个特例,也可以把服务器集群技术视为双机冗余的延伸,可以理解为一种多机容错的方案。在一般的讨论之中,集群技术是为了解决计算性能不足的问题,通过多台服务器的集群计算,为高性能计算领域应用提供所需要的高性能。采用集群技术,通过多台服务器之间的负载均衡,可以解决服务器单点故障所引发的系统不稳定,提高系统的可靠性,因此集群具有更好的容错能力,但是在实际的应用中,集群技术多用于高性能计算。 单机容错技术以Stratus公司的ftServer、惠普公司的NonStop服务器和NEC公司的Express5800/ft为代表。这种技术具有比双机冗余方案更高的容错能力。据记者查阅有关技术资料,双机冗余系统的可靠性可以达到99.9%,也就是3个9的能力,而Stratus公司的方案,其可靠性可以达到5个9。 2、容错服务器的必要性: 进入21世纪以来,制造、中小企业、能源、交通等领域对服务器,特别是中低端IA 服务器的需求激增,过去仅仅可以应用在RISC平台、HP-UX环境下的容错产品也面临着新的挑战。另一方面,企业越来越依赖信息系统来完成关键业务的应用,同时他们不可能配备更多的专业人员来进行专职维护。双机热备、集群服务器遇到难题。尤其对24小时不间断,长期工作负责核心的服务系统,需要具备容错服务。 容错技术相对于双机冗余群集的技术的优势: 1:国际著名检测组织IDC公布:容错服务器的高可用性是99.9998%,而消除单点故障的集群是99.99%,IBM的大型机为99.995% 2:设计上容错的目标是避免停机,而集群是减少停机(当我们有避免停机的方案,我们为什么还要选择减少停机的方案呢?) 3:容错能有效的保护动态数据不丢失,而双机只能保证写入硬盘的数据; 4:容错能支持热插拔任意的硬件,包括主板,CPU等关键性硬件, 5:布置非常简单,只需要装单套系统,数据库也只需要一套,免去双机软件和研发代码的麻烦,从而大大的减少工程师的工作量,也大大的减少了软件成本. 6:速度比同配置的双机要快20%以上. 7:后期维护成本几乎为零,而双机的话需要工程师的支持,或许由于系统补丁的升级需要额外的研发双机代码来保证系统的切换成功; 8:容错是没有切换时间的,而双机由于硬件宕机后会发生停顿的情况,还有就是双机切换工作是有可能不成功的. 9.容错的windows系统因为有容错揪错芯片,所以容错的windows系统比传统的windows 系统稳定,也许您用很多年都不需要重起windows,因为它永远和刚开机一样快,容错因此承诺容错的windows比IBM的AIX还稳定。 以下用典型案例进行比较说明:
1.1.1主流容错架构 在磁盘容错系统用定义了RAID标准,那么在设备级的容错又是怎么做的呢? 双机容错提供两种基本架构: 模式一双机互备援(Dual Active)(支持多台主机的集群系统) 模式二双机热备份(Hot Standby)(支持多台主机的集群系统) 1、双机互备援(Dual Active)基本简介 所谓双机互备援就是两台服务器均为工作机,在正常情况下,两台工作机均为信息系统提供支持,并互相监视对方的运行情况。当一台主机出现异常时,不能支持信息系统正常运营,另一主机则主动接管(Take Over)异常机的工作,继续支持信息的运营,从而保证信息系统能够不间断地运行,而达到不停机的功能(Non-Stop),但正常运行主机的负载(Loading)会有所增加。此时必须尽快将异常机修复以缩短正常机负载持续时间,当异常机经过维修恢复正常后,它会自动抓回先前的工作,恢复以前正常时的工作状态。 双机互备援(Dual Active)切换时机(Take Over) -—系统软件或应用软件造成服务器当机 -—服务器没当机,但系统软件或应用软件工作不正常 -—连接卡(SAS HBA、IP、FC HBA)损坏,造成服务器与磁盘阵列无法存取资料
-—服务器内硬件损坏,造成服务器当机 -—服务器不正常关机 -—网络故障,网卡故障或网络不通等 2、双机热备份(Hot Standby)基本简介 所谓双机热备份就是一台主机为工作机(Primary Server),另一台主机为备份机(Standby Server),在系统正常情况下,工作机为信息系统提供支持,备份机监视工作机的运行情况(工作机也同时监视备份机是否正常,有时备份机因某种原因出现异常,工作机可尽早通知系统管理工作人员解决,确保下一次切换的可靠性)。当工作机出现异常,不能支持信息系统运营时,备份机主动接管(Take Over)工作机的工作,继续支持信息的运营,从而保证信息系统能够不间断地运行(Non-Stop)。当工作机经过维修恢复正常后,它会将其先前的工作自动抓回,恢复以前正常时的工作状态。 双机热备份(Hot Standby)切换时机(Take Over) -—系统软件或应用软件造成服务器当机 -—服务器没当机,但系统软件或应用软件工作不正常 -—服务器内连接卡损坏,造成服务器与磁盘阵列无法存取资料 -—服务器内硬件损坏,造成服务器当机 -—服务器不正常关机 -—网络故障,网卡故障或网络不通等