
https://www.doczj.com/doc/f615783248.html, 模糊集合分析法在汛期划分中的应用
谈亚琦1 王振亚2 刘兴华3
1河海大学水利水电工程学院,江苏南京,210098
2河海大学水利水电工程学院,江苏南京,210098
E_mail:tyq@https://www.doczj.com/doc/f615783248.html,
【摘要】汛期分期划分主要依据水库所在流域的气候、降水规律和江河涨水等具体条件。本文打破“要么是汛期,要么不是汛期”传统硬性划分的观念,应用模糊集合分析法进行汛期划分,从而对汛期描述做进一步研究。
【关键词】模糊集合分析法、汛期划分、主汛期
·1.引言
我国大部地区属季风气候区,多数河流的洪水由暴雨所致,暴雨特性和量级大小在整个汛期内的不同时候有所不同。为提高水库综合利用效益,我国学者曾对如何利用暴雨洪水的季节性变化特征确定汛期分期、利用水库分期汛限水位调控洪水资源来缓解水库防洪与兴利的矛盾进行了有益的探索。
水电部北京勘测设计院、水电部天津勘测设计院和国家气象局北京气象中心[1]在上世纪 80 年代对我国东部地区汛期分期设计洪水研究工作进行了初步总结,从两个方面归纳了以往的汛期分期洪水研究工作。一是汛期分期洪水的气象分析,通过对汛期降水和暴雨特征的统计分析以及对大气环流的季节演变与暴雨的关系的成因分析,为汛期内分期的划分提供成因和定量依据;二是分期洪水的分析与计算,通过汛期洪水特性和汛期内洪水峰量散布图的分析,考虑工程运用的要求。冯尚友等[2]人针对丹江口水库调度的需要对汛期划分进行了研究,主要包括两个方面的分析:一是水文统计分析,具体分析了单站多年旬平均雨量、多年旬平均流量、七日最大降水量的时间分布、历年最大洪峰流量出现过程;二是气候成因分析,具体分析了各种天气系统的变化过程。基于以上两个方面的综合分析,提出了丹江口水库汛期的分期划分方案。 郭荣文[3]针对龙溪河水库的分期设计洪水计算进行了研究,在分期洪水时界的划分上,主要是依据对暴雨天气成因分析、地面气候特征分析、水文历史演变趋势分析做出的;在分期设计洪水的计算上采用了跨期选样方法进行分期洪水样本的选择。 水电部昆明勘测设计院[4]针对澜沧江漫湾电站后期设计洪水进行了分析研究,在分期时段的划分上,主要考虑汛期各月大气环流形势的变化、汛期各月雨量的变化、汛期各旬洪水流量的变化。
·2.系统介绍
在汛期分期的定量描述方法上, 按照美国 L.A.Zadeh 教授提出的模糊集合论,1988 年陈守煜教授[5]首次提出了描述汛期的模糊集合论,认为汛期属于模糊概念,主张利用模糊集合分析方法来解决汛期分期问题,本文着重应用模糊集合分析法进行汛期划分研究,该方法的优点是理论依据强,概念清晰,计算简便。缺点是对于样本散点分布波动较大时,计算
1作者简介:谈亚琦(1981-),男(汉族),江苏宜兴人,硕士研究生,主要从事水能规划研究。
2作者简介:王振亚(1981-),男(汉族),河南正阳人,硕士研究生,主要从事水灾害形成机理研究。
3作者简介:刘兴华(1982-),男(汉族),山西朔州人,硕士研究生,主要从事水资源规划及水利经济研究。
结果容易偏离实际;该方法目前主要应用于主汛期的划分。 ·2主汛期分析
以一场洪水作为指标划分汛期
以形成洪水为入(出)汛为标准划分汛期,即取第i年的第一场洪水的发生时间t 1i 为入汛标准和以最后一场洪水的结束时间t 2i 为出汛标准。
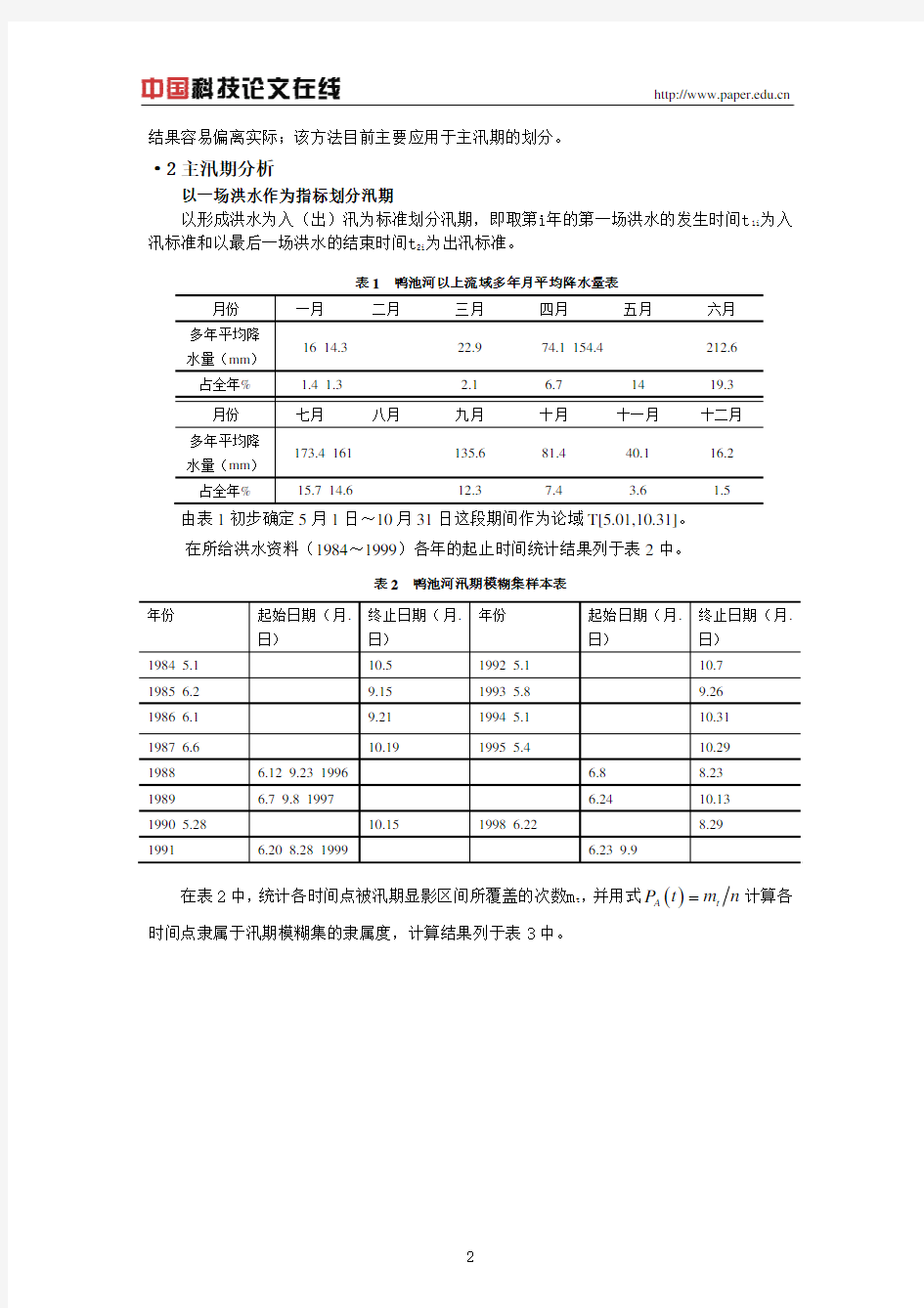
表1 鸭池河以上流域多年月平均降水量表 月份
一月 二月 三月 四月 五月 六月 多年平均降
水量(mm )
16 14.3 22.9 74.1 154.4 212.6 占全年%
1.4 1.3
2.1 6.7 14 19.3 月份
七月 八月 九月 十月 十一月 十二月 多年平均降
水量(mm )
173.4 161 135.6 81.4 40.1 16.2 占全年% 15.7 14.6 12.3 7.4 3.6 1.5
由表1初步确定5月1日~10月31日这段期间作为论域T[5.01,10.31]。
在所给洪水资料(1984~1999)各年的起止时间统计结果列于表2中。
表2 鸭池河汛期模糊集样本表 年份 起始日期(月.
日) 终止日期(月.日) 年份 起始日期(月.日) 终止日期(月.日)
1984 5.1 10.5 1992 5.1 10.7 1985 6.2 9.15 1993 5.8 9.26 1986 6.1 9.21 1994 5.1 10.31 1987 6.6 10.19 1995 5.4 10.29 1988 6.12 9.23 1996 6.8 8.23 1989 6.7 9.8 1997 6.24 10.13 1990 5.28 10.15 1998 6.22 8.29 1991 6.20 8.28 1999 6.23 9.9 在表2中,统计各时间点被汛期显影区间所覆盖的次数m t ,并用式()A t P t m n =计算各时间点隶属于汛期模糊集的隶属度,计算结果列于表3中。
表3 鸭池河汛期隶属频率统计表
月份
日期
5 6 7 8 9 10
隶属频率隶属频率隶属频率隶属频率隶属频率隶属频率
0.4375 1 1 0.8125 0.4375
1 0.01875
2 0.01875 0.5 1 1 0.8125 0.4375
3 0.01875 0.5 1 1 0.8125 0.4375
4 0.062
5 0.5 1 1 0.8125 0.4375
5 0.0625 0.5 1 1 0.8125 0.4375
6 0.0625
0.5625 1 1 0.8125 0.375 7 0.0625 0.625 1 1 0.8125 0.375
0.6875 1 1 0.8125 0.3125 8 0.3125
0.6875 1 1 0.75 0.3125
9 0.3125
10 0.3125 0.6875 1 1 0.6875 0.3125
11 0.3125 0.6875 1 1 0.6875 0.3125
12 0.3125 0.75 1 1 0.6875 0.3125
13 0.3125 0.75 1 1 0.6875 0.3125
14 0.3125 0.75 1 1 0.6875 0.25
15 0.3125 0.75 1 1 0.6875 0.25
16 0.3125 0.75 1 1 0.625 0.1875
17 0.3125 0.75 1 1 0.625 0.1875
18 0.3125 0.75 1 1 0.625 0.1875
19 0.3125 0.75 1 1 0.625 0.1875
20 0.3125 0.8125 1 1 0.625 0.125
21 0.3125 0.8125 1 1 0.625 0.125
22 0.3125 0.875 1 1 0.5625 0.125
23 0.3125 0.9375 1 1 0.5625 0.0625
24 0.3125 1 1 0.9375 0.5 0.0625
25 0.3125 1 1 0.9375 0.5 0.0625
26 0.3125 1 1 0.9375 0.5 0.0625
27 0.3125 1 1 0.9375 0.4375 0.0625
0.4375 0.0625
28 0.375 1 1 0.9375
29 0.375 1 1 0.875 0.4375 0.0625
0.4375 0.0625
30 0.375 1 1 0.8125
31 0.375 1 0.8125 0.0625 根据上表作出汛期隶属函数曲线,如图2
按隶属度为1划分,由表3和图2可确定主汛期为6月23日到8月23日。
0.0
0.2
0.4
0.6
0.81.0日 期隶属度 图2 鸭池河以上流域以一场洪水为指标的隶属函数曲线 以一场洪水为指标将鸭池河以上流域的汛期划分为: 前汛期5月1日至6月22日; 主汛期6月23日至8月23日; 后汛期8月24日至10月31日。 同样的,洪家渡以上流域的汛期可划分为,: 前汛期5月1日至6月20日; 主汛期6月21日至8月10日; 后汛期8月11日至10月31日。 表4 洪家渡、鸭池河水库汛期分期结果总结表 分期(月.日) 前汛期 主汛期 后汛期 鸭池河 5.1—6.22 6.23—8.23 8.24—10.31 洪家渡 5.1—6.20 6.21—8.10 8.11—10.31 鸭池河和洪家渡都属于乌江流域,此分析结果显然与乌江流域内降水基本气候特征分析和暴雨特征分析结果所提到的降水主要集中期在6月中旬~8月上旬基本吻合。 但考虑到乌江上游暴雨时空分布不稳定而导致暴雨洪水规律的不清晰,以及基于乌江梯级调度安全及上下库标准统一两方面考虑,进行微调,最终确定乌江流域主汛期为:介于6月中旬至8月上旬期间。 乌江流域汛期划分为:前汛期5月1日至6月19日; 主汛期6月20日至8月10日; 后汛期8月11日至10月31日。 https://www.doczj.com/doc/f615783248.html,
·3前汛期、后汛期理论隶属函数分析
陈守煜教授[6]
提出:非汛期向主汛期过渡段前汛期的隶属函数采用升半正态分布,主汛期隶属函数为矩形分布,主汛期向非汛期过渡段后汛期为降半正态分布,表达式为: (1)
2
1
1222()1112()22 , t0() 1 ,a t a , t>a ,b >0,a t b A t a b e U t e
???????=≤≤???? 式中,a 1、a 2为主汛期开始、结束时间,可从经验隶属函数曲线上得到;参数b 1、b 2可通过采用最小二乘法进行曲线拟合得到:
1b = (2)
(3)
2b =
将参数a 1、a 2、b 1、b 2代入(1)式中,即可得到任一时刻 t 的隶属度。
在以直接模糊统计分析方法得出汛期模糊集合的隶属函数的基础上,利用origin 软件进行试算。通过试算,可以得出前汛期理论隶属函数曲线(见图3)。从而在理论隶属函数曲线上就可得出水库前汛期的隶属度(见表5)。
0.0
0.1
0.2
0.30.40.50.60.70.80.9日期隶属度 图3 升半正态分布隶属函数拟合曲线图
表5 洪家渡水库流域前汛期的理论隶属度(5月1日至6月19日)
月份
日期
5月份6月份
试验隶属度理论隶属度试验隶属度理论隶属度
1 0.1875 0.22
2 0.5625 0.962
2 0.1875 0.227 0.625 0.966
0.970
0.625
3 0.25 0.233
0.973
4 0.2
5 0.239
0.6875
5 0.3125 0.245 0.75 0.976
6 0.3125 0.251 0.75 0.979
7 0.375 0.257 0.75 0.982
0.985
8 0.375 0.263
0.8125
9 0.375 0.270 0.875 0.987
10 0.375 0.276 0.875 0.989
11 0.375 0.283 0.875 0.991
12 0.375 0.289 0.875 0.993
13 0.375 0.296 0.875 0.995
14 0.375 0.303 0.9375 0.996
15 0.375 0.309 0.9375 0.997
16 0.375 0.316 0.9375 0.998
17 0.375 0.323 0.9375 0.999
18 0.375 0.331 0.9375 1.000
19 0.375 0.338 0.9375 1.000
20 0.375 0.345
21 0.375 0.353
22 0.375 0.360
23 0.375 0.368
24 0.375 0.375
25 0.375 0.383
26 0.375 0.391
27 0.375 0.398
28 0.4375 0.406
29 0.4375 0.414
30 0.5 0.422
31 0.5 0.431
同样的,可求得洪家渡水库流域后汛期的理论隶属度。
·4 结论
本文利用模糊集合分析法求得的前汛期和后汛期的理论隶属度,可直接应用洪家渡水库的库容曲线及主汛期防洪限制水位和校核洪水位,推求前汛期、后汛期的防洪动态限制水位过程线,达到指导水库前汛期、后汛期合理进行防汛调度的目的。
参考文献
[1] 水电部天津勘测设计院,国家气象局北京气象中心,岳城水库汛期后期暴雨特性及设计洪水分析.水文计算,1982 年 4 期,217-228
[2] 冯尚友,余敷秋.丹江口水库汛期划分的研究和实践效果[J].水利水电技术,1982 年 2 期,56-61
[3] 郭荣文.龙溪河梯级水电站等级标准设计洪水及防洪发电的复核研究.全国水文计算进展和展望学术讨论会论文集. 河海大学出版社.1998.
[4] 水利电力部昆明勘测设计院水文组.澜沧江漫湾电站后期设计洪水分析.水文计算汇编第四集,1982,(4):196-203
[5] 陈守煜.从研究汛期描述论水文系统模糊集分析的方法论[J].水科学进展,1995(2):133-138
[6] 陈守煜.工程水文水资源模糊集分析理论与实践[M].大连:大连理工大学出版社,1998
the application of fuzzy set analytical means in seasonal
flood periods classification
Tan Yaqi1, Wang zhenya2
1 Hydro-electric Engineering College of Hohai University,Nanjing,Jiangsu,210098
2 Hydro-electric Engineering College of Hohai University,Nanjing,Jiangsu,210098
Abstract
·Seasonal flood periods classification is mainly based on climate,precipitation patterns and river rises.Applied with fuzzy set analytical means,this paper breaks with the traditional concept of mandatory of either flood period or not the flood period for further research on flood period desciption. ·Key Words: fuzzy set analytical means, seasonal flood periods classification, the main flood season
定量研究和定性研究的比较分析 在做定量研究和定性研究的比较之前,我们必须弄清楚两者的概念,毕竟对症下药是一种负责任的行为。可是,要我完整的解释什么是定量研究和定性研究,我是做不到的。本人认为定量研究重在于对“量”的一种深层次解释,而定性研究重在于对现象的一种实质性的高度表述。当然,我们还是得看看名家们的解释,毕竟那才是权威嘛,相对于大多数人来说,那是具有相当强的说服力。由文献资料可得,定性研究是指通过发掘问题、理解事件现象、分析人类的行为与观点以及回答提问来获取敏锐的洞察力。定量研究是指确定事物某方面量的规定性的科学研究,就是将问题与现象用数量来表示,进而去分析、考验、解释,从而获得意义的研究方法和过程。这就是两者的含义,应该是比较可以的。 我们都知道任何事物的解释大多是人们根据其事物本身的特性而得来的,也就是说,研究两者事物的不同,我们是可以依据其含义来进行挖掘,从而探索出两者事物的联系和区别。定量研究和定性研究既然是作为两种不同的研究方式,可以从某种程度上说研究两者的联系是不太有必要的。所以,我们还主要探讨两者的区别吧。
我们就先来说一下定性研究吧。定性研究也称质化研究,从而我认为其研究方式是具有实质性的,它更多的是描述性的解释所研究的某种社会现象。我看了一下符平的《次生庇护的交易模式、商业观与市场发展——惠镇石灰市场的个案研究》,发现这是比较典型的定性研究(个人认为)。整篇文章基本就是由访谈或调查的资料来解释这种现象,当然,如何挖掘出有实质性的结论,还是得益于研究者的洞察力。定性研究的有效性在于研究者在实地研究时是否能很好的把握所获取的资料能真实的反应所研究的现象,可以这么说,研究者要尽可能的减少被调查者的保守回答。因此,定性研究对于数据上的要求不是很高,也就是不注重对数据的具体分析。上篇文章中大多是对访谈的内容进行总结性的描述,具体分析石灰老板在经营的历程中是如何应对市场的,在分析这种市场经营中,解释由此产生的次生庇护的交易模式、商业观是如何影响这方面市场的发展。也就是,定性研究是通过分析无序信息探寻某个主题的“为什么”,而不是“怎么办”。因此,定性研究就是研究者运用历史回顾、文献分析、访问、观察、参与经验等方法获得教育研究的资料,并用非量化的手段对其进行分析、获得研究结论的方法。其研究方法主要有小组座谈会、一对一深度访谈、观察法、德尔菲法、头脑风暴法与反向头脑风暴法。
基于层次分析法的模糊综 合评价模型 Prepared on 22 November 2020
2016江西财经大学数学建模竞赛A题 城市交通模型分析 参赛队员:黄汉秦、乐晨阳、金霞 参赛队编号:2016018 2016年5月20日~5月25日
承诺书 我们仔细阅读了江西财经大学数学建模竞赛的竞赛章程。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的,如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C中选择一项填写):A 我们的参赛队编号为2016018 参赛队员(打印并签名): 队员1.姓名专业班级计算机141 队员2.姓名专业班级计算机141 队员3.姓名专业班级计算机141 日期:2016年5月25日
编号和阅卷专用页 2016年5月15日制定
城市交通模型分析 摘要 随着国民经济的高速发展和城市化进程的加快,我国机动车保有量及道路交通流量急剧增加,交通出行结构发生了根本变化,城市道路交通拥挤堵塞问题已成为制约经济发展、降低人民生活质量、削弱经济活力的瓶颈之一。本篇论文针对道路拥挤的问题采用层次分析法进行数学建模分析,讨论拥堵的深层次问题及解决方案。 首先建立绩效评价指标的层次结构模型,确定了目标层,准则层(一级指标),子准则层(二级指标)。 其次,建立评价集V=(优,良,中,差)。对于目标层下每个一级评价指标下相对于第m 个评价等级的隶属程度由专家的百分数u 评判给出,即U =[0,100]应用模糊统计建立它们的隶属函数A(u),B(u),C(u),D(u),最后得出目标层的评价矩阵Ri ,(i=1,2,3,4,5)。利用A,B 两城相互比较法,根据实际数据建立二级指标对于相应一级指标的模糊判断矩阵P i (i=1,2,3,4,5) 然后,我们经过N 次试验调查,明确了各层元素相对于上层指标的重要性排序,构造模糊判断矩阵P ,利用公式 []R W R W R W R W R W W R W O 5 5 4 4 3 3 2 2 1 1 ,,,,==计算出权重值,经过一致性检验公式 RI CI CR = 检验后,均有0.1CR <,由此得出各层次的权向量()12,,T n W W W W =。然后 后,给出建立绩效评价模型(其中O 是评价结果向量),应用模糊数学中最大隶属度原则,对被评价城市交通的绩效进行分级评价。 接着在改进方案中,我们具体以交叉口为中心建立模型,其中包括道路长度、宽度、车辆平均长度、车速等等考虑因素。通过车辆排队长度可以间接判断交通拥堵情况,不需要测量车速、时间等因素而浪费的人力物力和财力,有效的提高了工作成本和效率。为管理城市交通要道提供了良好的模型和依据。 【关键字】交通拥堵层次分析法模糊综合评判绩效评价隶属度 一、问题重述 随着我国经济社会持续快速发展,群众购车刚性需求旺盛,汽车保有量继续呈快速增长趋势,2015年新注册登记的汽车达2385万辆,保有量净增1781万辆,均为历史最高水平。汽车占机动车的比率迅速提高,近五年汽车占机动车比率从%提高到%,群众机动化出行方式经历了从摩托车到汽车的转变,交通出行结构发生了根本性变化。 2015年,小型载客汽车达亿辆,其中,以个人名义登记的小型载客汽车(私家车)达到亿辆,占小型载客汽车的%。与2014年相比,私家车增加1877万辆,增长%。全国有40个城市的汽车保有量超过百万辆,北京、成都、深圳、上海、重庆、天津、苏州、郑州、杭州、广州、西安11个城市汽车保有量超过200万辆。全国平均每百户家庭拥有31辆私家车,北京、成都、深圳等大城市每百户家庭拥有私家车超过60辆。
2016江西财经大学数学建模竞赛 A题 城市交通模型分析 参赛队员: 黄汉秦、乐晨阳、金霞 参赛队编号:2016018 2016年5月20日~5月25日
承诺书 我们仔细阅读了江西财经大学数学建模竞赛的竞赛章程。 我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人研究、讨论与赛题有关的问题。 我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出。 我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性。如有违反竞赛规则的行为,我们将受到严肃处理。 我们参赛选择的题号是(从A/B/C中选择一项填写): A 我们的参赛队编号为2016018 参赛队员(打印并签名) : 队员1. 姓名专业班级计算机141 队员2. 姓名专业班级计算机141 队员3. 姓名专业班级计算机141 日期: 2016 年 5 月 25 日
编号和阅卷专用页 江西财经大学数学建模竞赛组委会 2016年5月15日制定
城市交通模型分析 摘要 随着国民经济的高速发展和城市化进程的加快,我国机动车保有量及道路交通流量急剧增加,交通出行结构发生了根本变化,城市道路交通拥挤堵塞问题已成为制约经济发展、降低人民生活质量、削弱经济活力的瓶颈之一。本篇论文针对道路拥挤的问题采用层次分析法进行数学建模分析,讨论拥堵的深层次问题及解决方案。 首先建立绩效评价指标的层次结构模型,确定了目标层,准则层(一级指标),子准则层(二级指标)。 其次,建立评价集V=(优,良,中,差)。对于目标层下每个一级评价指标下相对于第m 个评价等级的隶属程度由专家的百分数u 评判给出,即U =[0,100]应用模糊统计建立它们的隶属函数A(u), B(u), C(u) ,D(u),最后得出目标层的评价矩阵Ri ,(i=1,2,3,4,5)。利用A,B 两城相互比较法,根据实际数据建立二级指标对于相应一级指标的模糊判断矩阵P i (i=1,2,3,4,5) 然后,我们经过N 次试验调查,明确了各层元素相对于上层指标的重要性排序,构造模糊判断矩阵P ,利用公式 1 ,ij ij n kj k u u u == ∑ 1 ,n i ij j w u ==∑ 1 ,i i n j j w w w == ∑ []R W R W R W R W R W W R W O 5 5 4 4 3 3 2 2 1 1 ,,,,==计算出权重值,经过一致性检验公式 RI CI CR = 检验后,均有0.1CR <,由此得出各层次的权向量()12,,T n W W W W =K 。然后后, 给出建立绩效评价模型(其中O 是评价结果向量),应用模糊数学中最大隶属度原则,对被评价城市交通的绩效进行分级评价。 接着在改进方案中,我们具体以交叉口为中心建立模型,其中包括道路长度、宽度、车辆平均长度、车速等等考虑因素。通过车辆排队长度可以间接判断交通拥堵情况,不需要测量车速、时间等因素而浪费的人力物力和财力,有效的提高了工作成本和效率。为管理城市交通要道提供了良好的模型和依据。 【关键字】交通拥堵 层次分析法 模糊综合评判 绩效评价 隶属度
1. 模糊聚类分析模型 环境区域的污染情况由污染物在4个要素中的含量超标程度来衡量。设这5个环境区域的污染数据为1x =(80, 10, 6, 2), 2x =(50, 1, 6, 4), 3x =(90, 6, 4, 6), 4x =(40, 5, 7, 3), 5x =(10, 1, 2, 4). 试用模糊传递闭包法对X 进行分类。 解 : 由题设知特性指标矩阵为: * 80106250164906464057310124X ????????=???????? 数据规格化:最大规格化' ij ij j x x M = 其中: 12max(,,...,)j j j nj M x x x = 00.8910.860.330.560.1 0.860.671 0.60.5710.440.510.50.11 0.1 0.290.67X ????????=?? ?????? 构造模糊相似矩阵: 采用最大最小法来构造模糊相似矩阵55()ij R r ?=, 1 0.540.620.630.240.5410.550.700.530.62 0.5510.560.370.630.700.5610.380.240.530.370.381R ?? ??? ???=?? ?????? 利用平方自合成方法求传递闭包t (R ) 依次计算248,,R R R , 由于84R R =,所以4()t R R =
2 10.630.620.630.530.6310.560.700.530.62 0.5610.620.530.630.700.6210.530.530.530.530.531R ?? ??????=?? ??????, 4 10.630.620.630.530.6310.620.700.530.62 0.6210.620.530.630.700.6210.530.53 0.530.530.531R ????????=?? ?????? =8R 选取适当的置信水平值[0,1]λ∈, 按λ截矩阵进行动态聚类。把()t R 中的元素从大到小的顺序编排如下: 1>0.70>0.63>062>053. 依次取λ=1, 0.70, 0.63, 062, 053,得 11 000001000()0 010******* 0001t R ????? ? ??=?? ??????,此时X 被分为5类:{1x },{2x },{3x },{4x },{5x } 0.7 1000001010()001000101000001t R ?????? ??=?? ??????,此时X 被分为4类:{1x },{2x ,4x },{3x },{5x } 0.63 1101011010()001001101000001t R ?????? ??=?? ??????,此时X 被分为3类:{1x ,2x ,4x },{3x },{5x } 0.62 1111011110()11110111100 0001t R ?????? ??=?? ?????? ,此时X 被分为2类:{1x ,2x ,4x ,3x },{5x }
比较分析的方法要点 比较分析方法是自然科学、社会以及日常生活中常用的分析方法之一。比较分析试图通过事物异同点的比较,区别事物,达到对各个事物深入的了解认识,从而把握各个事物。在调查资料的理论分析中,当需要通过比较两个或者两个以上事物或者对象的异同来达到某个事物的认识时,一般采用比较分析方法。 进行比较分析,应把握如下几点: 1.横向比较与纵向比较相结合 横向比较是将同一时期的相关的事物进行比较。这种比较既可在同类事物内部的不同部分之间进行。通过横向比较可以发现两类事物或同类事物不同部分之间在某一方面的差异,进而分析出造成这种差异的原因。 纵向比较是对同一对象在不同时期的具体特点进行比较。纵向比较可以揭示认识对象在不同时期不同阶段上的特点及其变化发展的趋势。 横向比较和纵向比较各有其长短。横向比较的优点是现实性强,容易理解,便于掌握,它侧重从质与量上对认识对象加以区分;缺点是一种静态比较法,难以揭示事物的本质规律及发展趋势。纵向比较的长处在于能够揭示事物之间的有机联系,认识事物之间的发展趋势;但它往往对事物之间横向联系注意不够。因此,需要将横向比较与纵向比较相结合,以达到对事物的深入了解和认识。 2.比较事物的相同点与相异点 比较可以在异类对象之间进行,也可以在同类对象之间进行,还可以在同一对象的不同部分之间进行。分析社会调查资料,重视同类对象和同一对象的不同方面、不同部分之间的比较。 比较事物或对象的同和异是比较分析的两项内容。首先是共同点的比较。确定事物或对象的共同点包括两个方面:一是找出共同性质,即同类事物的“同类”性,如男女职工的比较分析,“职工”就是共同性质,表明具有共同的劳动性质,这就是比较分析的前提条件。二是找出调查对象表现出来的共同特点。 其次是差异点的比较。这是比较分析主要的和重要的工作。确定差异点,就是找出调查对象表现出来的不同特点。 3.要对可比的事物作比较,不要在不可比的事物之间作比较。 例如,社会指标和经济指标的比较常常应当弄清指标的可比口径问题,弄清指标概念的含义和指标数值的计算方法。具有相同含义和相同计算口径的统计指标,都是可比,反之是不可比的,对于调查对象的比较来说,要选择可比的方面开展比较分析。 4.选择和制定精确的、稳定的比较标准 定量比较的计量单位应选择精确统一的标准,如长度基本单位使用米,重量基本单位使用公斤,容积基本单位使用升,等等。再比如家庭生活水平,主要看人均收入水平,用人民币为基本单位等。定性比较的标准应具有相对稳定性,比如全面普遍开展“五好家庭”的活动,其择定标准也应具有相对稳定性。只有选择和制定精确的稳定的比较标准,比较分析才有章可循,得以坚持。 比较分析示例一:传统社会的家庭和现代社会的家庭基本特征比较。
目录 1引言: (3) 2 理论准备: (3) 2.1 模糊集合理论 (3) 2.2模糊C均值聚类(FCM) (4) 2.3 加权模糊C均值聚类(WFCM) (4) 3 聚类分析实例 (5) 3.1数据准备 (5) 3.1.1数据表示 (5) 3.1.2数据预处理 (5) 3.1.3 确定聚类个数 (6) 3.2 借助clementine软件进行K-means聚类 (7) 3.2.1 样本在各类中集中程度 (8) 3.2.2 原始数据的分类结果 (8) 3.2.3结果分析 (9) 3.3模糊C均值聚类 (10) 3.3.1 数据集的模糊C划分 (10) 3.3.2 模糊C均值聚类的目标函数求解方法 (10) 3.3.3 MATLAB软件辅助求解参数设置 (11) 3.3.4符号表示 (11)
3.3.5代码实现过程 (11) 3.3.6 FCM聚类分析 (11) 3.4 WFCM算法 (14) 3.4.1 WFCM聚类结果展示 (14) 3.4.2样本归类 (16) 3.4.3归类代码实现 (16) 4.结论 (17) 5 参考文献 (18) 6 附录 (18)
模糊聚类与非模糊聚类比较分析 摘要: 聚类分析是根据样本间的相似度实现对样本的划分,属于无监督分类。传统的聚类分析是研究“非此即彼”的分类问题,分类结果样本属于哪一类很明确,而很多实际的分类问题常伴有模糊性,即它不仅仅是属于一个特定的类,而是“既此又彼”。因此为了探究模糊聚类与非模糊聚类之间聚类结果的差别,本文首先采用系统聚类方法对上市公司132支股票数据进行聚类,确定比较合理的聚类数目为11类,然后分别采用K-means聚类与模糊聚类方法对股票数据进行聚类分析,最终得出模糊聚类在本案例中比K-means聚类更符合实际。 关键字:模糊集合,K-means聚类,FCM聚类,WFCM聚类 1引言: 聚类分析是多元统计分析的方法之一,属于无监督分类,是根据样本集的内在结构,按照样本之间相似度进行划分,使得同类样本之间相似性尽可能大,不同类样本之间差异性尽可能大。传统的聚类分析属于硬化分,研究对象的性质是非此即彼的,然而,现实生活中大多数事物具有亦此亦彼的性质。因此传统的聚类分析方法往往不能很好的解决具有模糊性的聚类问题。为此,模糊集合理论开始被应用到分类领域,并取得不错成果。 本文的研究目的是通过对比传统聚类和模糊聚类的聚类结果,找出二者之间的不同之处,并说明两种聚类分析方法在实例中应用的优缺点。 2理论准备: 2.1 模糊集合理论 模糊集合定义:设U为论域,则称由如下实值函数μA:U→ [ 0,1 ],u →μ ( u )所确定的集合A 为U上的模糊集合,而称μA为模糊集合A 的隶A 属函数,μ A ( u)称为元素u 对于A 的隶属度。若μA(u) =1,则认为u完全属于A;若μA(u) =0,则认为u完全不属于A,模糊集合是经典集合的推广。
模糊聚类分析方法 对所研究的事物按一定标准进行分类的数学方法称为聚类分析,它是多元统计“物以类聚”的一种分类方法。载科学技术、经济管理中常常要按一定的标准(相似程度或亲疏关系)进行分类。例如,根据生物的某些性状可对生物分类,根据土壤的性质可对土壤分类等。由于科学技术、经济管理中的分类界限往往不分明,因此采用模糊聚类方法通常比较符合实际。 一、模糊聚类分析的一般步骤 1、第一步:数据标准化[9] (1) 数据矩阵 设论域12{,,,}n U x x x =为被分类对象, 每个对象又有m 个指标表示其性状,即 12{,, ,}i i i im x x x x = (1,2,,) i n =, 于是,得到原始数据矩阵为 1112 1 21222 12 m m n n nm x x x x x x x x x ?? ? ? ? ??? 。 其中nm x 表示第n 个分类对象的第m 个指标的原始数据。 (2) 数据标准化 在实际问题中,不同的数据一般有不同的量纲,为了使不同的量纲也能进行比较,通常需要对数据做适当的变换。但是,即使这样,得到的数据也不一定在区间[0,1]上。因此,这里说的数据标准化,就是要根据模糊矩阵的要求,将数据压缩到区间[0,1]上。通常有以下几种变换: ① 平移·标准差变换
i k k ik k x x x s -'= (1,2,,;1,2,i n k m == 其中 11n k i k i x x n ==∑, k s =。 经过变换后,每个变量的均值为0,标准差为1,且消除了量纲的影响。但 是,再用得到的ik x '还不一定在区间[0,1]上。 ② 平移·极差变换 111m i n { }m a x {}m i n {}i k i k i n ik ik ik i n i n x x x x x ≤≤≤≤≤≤''-''=''- ,(1,2, ,)k m = 显然有01ik x ''≤≤,而且也消除了量纲的影响。 ③ 对数变换 lg ik ik x x '= (1,2,,;1,2,i n k m == 取对数以缩小变量间的数量级。 2、第二步:标定(建立模糊相似矩阵) 设论域12{,, ,}n U x x x =,12{,,,}i i i im x x x x =,依照传统聚类方法确定相似 系数,建立模糊相似矩阵,i x 与j x 的相似程度(,)ij i j r R x x =。确定(,)ij i j r R x x =的方法主要借用传统聚类的相似系数法、距离法以及其他方法。具体用什么方法,可根据问题的性质,选取下列公式之一计算。 (1) 相似系数法 ① 夹角余弦法 2 2m ik jk ij m ik jk x x r x = ∑∑ ② 最大最小法 11() () m ik jk k ij m ik jk k x x r x x ==∧= ∨∑∑。 ③ 算术平均最小法
谈谈我对比较研究方法的认识 摘要:所谓比较研究方法,是根据一定的标准,对某类现象在不同情况下的不同表现,进行比较研究,找出所存在的普遍规律及其特殊本质,力求得出符合客观实际结论的方法。比较是认识事物的基础,是人类认识、区别和确定事物异同关系的最常用的思维方法。比较研究法现已被广泛运用于科学研究的各个领域。本文根据课程所学的内容,结合自身学习的实践,分析了本人对比较研究方法的认识。主要通过比较研究方法的概念、种类、作用、运用条件和一般工作步骤等几个方面出发阐述对社会主体研究方法的认识。 关键词:比较研究方法认识事物 一、比较研究方法的概念 比较研究法是对事物同异关系进行对照、比较,从而揭示事物本质的思维过程和方法。它是人们根据一定的标准或以往的经验、教训把彼此有某种联系的事物加以对照,从而确定其相同与相异之点,对事物进行分类,并对各个事物的内部矛盾的各个方面进行比较后,得出事物的内在联系,从而认清事物的本质。 比较是和观察、分析、综合等活动交织在一起的,是一种复杂的智力劳动。比较研究法是一种思维方法,也是一种具体的研究方法。它与其它研究方法不同之处在于: (一)从比较的角度把握对象特有的规定性; (二)研究对象必须具有可比较性,从而限定了研究的内容和范围; (三)研究方法上以比较分析方法为主。比较研究,方法简单、生动、鲜明。由于研究结论是从比较分析的推论中得出,其客观性程度还有待实践证明并加以检验修正。
二、比较研究法的种类 根据不同的标准,我们可以把比较研究法分成如下几类。 (一)按属性,可分为单项比较和综合比较。 单项比较是按事物的一种属性所作的比较。综合比较是按事物的所有(或多种)属性进行的比较,单项比较是综合比较的基础。但只有综合比较才能达到真正把握事物本质的目的。因为在科学研究中,需要对事物的多种属性加以考察,只有通过这样的比较,尤其是将外部属性与内部属性一起比较才能把握事物的本质和规律。 (二)按时空,可分为横向比较(类型比较法),与纵向比较(历史比较法)横向比较就是对空间上同时并存的事物的既定形态进行比较。纵向比较即时间上的比较,就是比较同一事物在不同时期的形态,从而认识事物的发展变化过程,揭示事物的发展规律。 (三)按目的,可分为求同比较和求异比较。 求同比较是寻求不同事物的共同点以寻求事物发展的共同规律。求异比较是比较两个事物的不同属性,从而说明两个事物的不同,以发现事物发生发展的特殊性。通过对事物的“求同”、“求异”分析比较,可以使我们更好地认识事物发展的多样性与统一性。 (四)按比较方法,可分成定性比较与定量比较。 任何事物都是质与量的统一,所以在科学研究过程中既要把握事物的质,也要把握事物的量。定性比较就是通过事物间的本质属性比较来确定事物的性质。定量比较是对事物属性进行量的分析以准确地制定事物的变化。定性分析与定量分析各有长处,应追求两者的统一,而不能盲目追求量化;但也不能一点数量观念都没有,而应做到心中有“数”,并让数字来讲话。 三、比较研究法的作用 比较研究作为一种思维方法,贯穿在教育研究的全过程。通过比较研究,选定有重要价值的研究课题;通过比较分析,在搜集文献情报与资料过程中,不仅对所需要的材料进行定性鉴别,而且有助于揭示一些较专深的不易明察的资料信息,在进行教育调查和教育实验时,也需要运用比较方法对实验结果进行定性与
模糊层次分析法理论基础 FAHP及计算过程层次分析法(AHP)是20世纪70年代美国运筹学家T.L. Saaty教授提出的一种定性与定量相结合的系统分析方法,该方法对于量化评价指标,选择最优方案提供了依据,并得到了广泛的应用。然而, AHP存在如下方面的缺陷:检验判断矩阵是否一致非常困难,且检验判断矩阵是否具有一致性的标准CR < 0. 1缺乏科学依据;判断矩阵的一致性与人类思维的一致性有显著差异。为此,本文结合模糊数学理论,首先介绍了模糊层次分析法(Fuzzy - AHP) FAHP ,然后用FAHP对公共场所安全性指标权重进行了处理。 1. 1 模糊一致矩阵及有关概念[4 ,5 ] 1. 1. 1 定义1. 1 设矩阵R = ( rij) n×n ,若满足: 0 ≤( rij) ≤ 1 , ( i = 1 ,2 , ……n , j = 1 ,2 , ……n),则称R 为模糊矩阵 1. 1. 2 定义1. 2 若模糊矩阵R = ( rij) n×n ,若满足: Πi , j , k 有rij= rik - rij + 0. 5 ,则称模糊矩阵R 为模糊一致矩阵。 1. 1. 3 定理1. 1 设模糊矩阵R = ( rij) n×n是模糊一致矩阵,则有 (1) Πi ( i = 1 ,2 , …n) ,则rij = 0. 5 ; (2) Πi , j ( i = 1 ,2 , …n , j = 1 ,2 , …n) ,有rij + rji= 1 ; (3) R 的第i 行和第i 列元素之和为n ; (4)从R 中划掉任一行及其对应列所得的矩阵仍然是模糊一致矩阵; (5) R 满足中分传递性,即当λ≥0. 5 时,若rij≥λ, rjk ≥λ,则rij ≥λ;当λ≤0. 5 时,若rij ≤λ, rjk ≤λ,则rij ≤λ。(证明见文献1) 。 1. 1. 4 定理1. 2 模糊矩阵R = ( rij) n×n是模糊一致矩阵的充要条件是任意指定行和其余各行对应元素之差是一个常数。 1. 1. 5 定理1. 3 如果对模糊互补矩阵 F = ( f ij) n×n按行求和,记为ri = 6nk = 1f ik ( i = 1 ,2 , …, n) ,并施之如下数学变换:rij =ri - rj2 m + 0. 5 (1),则由此建立的矩阵是模糊一致的。 1. 2 模糊一致判断矩阵的建立 模糊一致判断矩阵的建立R 表是针对上一层某元素,本层次与之有关元素之间相对重要性的比较,假定上一层次元素T 同下一层次元素a1 , a2 ,…, an 有关系,则模糊一致判断矩阵可表示为: rij的实际意义是:元素ai 和元素aj 相对于元素T 进行比较时, ai 和aj 具有模糊关系“…比…重要得多”的隶属度,表1采用0. 1~0. 9 数量标度来说明其模糊关系。
大庆石油学院学报第32卷第2期2008年4月JOURNAL OF DAQING PET ROLEU M INS TIT UT E V o l.32No.2A pr.2008 基于模糊层次分析法的环境综合评价 王 怡1,2 (1.大庆石油学院经济管理学院,黑龙江大庆 163318; 2.西南财经大学工商管理学院,四川成都 610074) 摘 要:分析环境综合评价的影响因素,建立环境综合评价指标体系,包括社会生活系统、环境经济系统、环境资源 系统、环境技术系统和环境管理系统.运用模糊层次分析方法对我国2006年的环境状况进行综合评价.该方法同普通 层次分析法的区别在于判断矩阵的模糊性,能够简化人们判断目标相对重要性的复杂程度,借助模糊判断矩阵实现由定 性向定量的转换,评价结果可信度较高. 关 键 词:模糊层次分析法;环境综合评价;影响因素;指标体系 中图分类号:X508 文献标识码:A 文章编号:10001891(2008)02010003 0 引言 环境评价是对环境系统状况的价值的评定、判断和提出对策[1].通过环境评价可以掌握环境规制手段对社会经济的影响,利用评价结果的反馈,不断调整规制措施,促进区域经济、社会、资源与环境的协调发展.在环境评价中,层次分析法是运用较多的评价方法.如金菊良[2]将基于加速遗传算法的层次分析法应用在水环境系统工程中,用以实行快速自适应全局优化搜索;胡秀芳、钱鹏[3]采用模糊数学中的多层次综合评价方法对环境质量进行评价,建立了切实可行的综合评价数学模型;邓燕雯[4]探讨了环境价值的集中评价方法,包括收益资本化法、边际机会成本法、总经济价值评估法等.在实际的环境评价中,由环境问题导致的经济效果定量分析比较容易,而社会效果通常采用定性分析.对于那些局部的、间接的和相对的指标,难以用综合的定量指标分析.运用层次分析法处理不肯定、不明确、带有模糊性的评价指标时,往往发生环境评价结果与环境的实际状况不一致的现象.笔者在建立环境综合评价指标体系的基础上,采用模糊判断矩阵评价环境指标,利用层次分析法[5]确定上层指标的综合判断权值,并确保该权值的一致性,得到环境评价的综合发展指数值. 1 评价指标体系 1.1 影响因素 环境 社会和经济系统是一个复合系统,具有系统性和动态性的特点.因此,构建的环境综合评价指标体系是一个包含多因素、全方位的评价指标体系框架.社会生活系统、环境经济系统、环境资源系统、环境技术系统及环境管理系统等因素对环境综合评价的效果产生直接的影响[3].社会生活系统主要考察城市居民的生活质量及环境因素对生活质量的影响;环境经济系统反映在一定的环境规制政策下,用于环境保护的投入和环保产业的发展水平;环境资源系统是构建综合评价指标体系的重要组成部分,环境质量的提高不仅有赖于废弃排放的减低,还要充分利用排放和废弃来创造经济效益,实现经济和生态效益的双赢;技术对环境保护具有推动作用,通过对环境科技成果转化和应用,能够有效地促进 三废 的达标排放和总量控制,加快环保产业的发展,提高地区的竞争力;环境管理系统是环境综合评价重中之重,反映了环境规制的效率,包括环境政策本身的效率及环境规制带来的社会效率.这些影响因素之间相互关联、相互作用,具有较强的耦合性. 收稿日期:20070917;审稿人:肖艳玲;编辑:王文礼 作者简介:王 怡(1975-),女,博士生,主要从事产业经济、规制方面的研究.
23. 模糊聚类分析原理及实现 聚类分析,就是用数学方法研究和处理所给定对象,按照事物间的相似性进行区分和分类的过程。 传统的聚类分析是一种硬划分,它把每个待识别的对象严格地划分到某个类中,具有非此即彼的性质,这种分类的类别界限是分明的。 随着模糊理论的建立,人们开始用模糊的方法来处理聚类问题,称为模糊聚类分析。由于模糊聚类得到了样本数与各个类别的不确定性程度,表达了样本类属的中介性,即建立起了样本对于类别的不确定性的描述,能更客观地反映现实世界。 本篇先介绍传统的两种(适合数据量较小情形,及理解模糊聚类原理):基于择近原则、模糊等价关系的模糊聚类方法。 (一)预备知识 一、模糊等价矩阵 定义1 设R=(r ij )n ×n 为模糊矩阵,I 为n 阶单位矩阵,若R 满足 i) 自反性:I ≤R (等价于r ii =1); ii) 对称性:R T =R; 则称R 为模糊相似矩阵,若再满足 iii) 传递性:R 2 ≤R (等价于1 ()n ik kj ij k r r r =∨∧≤) 则称R 为模糊等价矩阵。 定理1 设R 为n 阶模糊相似矩阵,则存在一个最小的自然数k
(k 模糊聚类分析法及其应用 (汽车学院钟锐 2011122071) 摘要模糊聚类分析方法是一种多元统计分析方法, 它通过多个指标将样本划分为若干类, 这种分类方法能很好地应用于交通规划、交通流分析、安全评价等多个方面。文章以交通调查的选择为例说明了模糊聚类分析在规划过程中的具体应用, 并分析了模糊聚类分析在交通规划其他方面的应用。在交通调查中, 可利用模糊聚类分析将交通分区按工业、居住、公建、道路绿化广场等各项用途来进行分类。可相应减少同类交通分区的相似调查工作量。 关键词模糊聚类分析; 交通规划; 交通调查 1 问题的提出 交通规划旨在确定公路和城市道路交通建设的发展目标, 设计达到这些目 标的策略、过程与方案。交通规划包括目标确定、组织工作、数据调查、相关基本模型分析、分析预测、方案设计、方案评价、方案实施过程中的信息反馈和修改等工作阶段。在交通规划的很多阶段, 需要进行分类。例如可将众多的交通小区划分成几大类, 将具有相似特性的交通小区归于一类, 可以减少调查的工作量; 对线路网络进行分析评价时, 也需要进行分类。单一的指标往往不能全面反映交通分区之间的关系, 需要用多个指标来进行。在分类方法中,聚类分析是一种应用很广泛的方法, 它在交通规划领域应用较多。 2 聚类分析方法 聚类分析取意于“人以群分, 物以类聚”的俗语, 即将一组事物根据其性质上亲疏远近的程度进行分类, 把性质相近的个体归为一类, 使得同一类中的个体具有高度的同质性, 不同类之间的个体具有高度的异质性。为使分类合理, 必须描述个体之间的亲疏程度。对此, 通常有距离法、相关系数法等方法。距离法是将每个样本看成m( m 为统计指标的个数) 维空间的一个点, 在m 维空间中定义点与点之间的某种距离; 相关系数法是用某种相似系数来描述样本之间的关系, 如相关系数。聚类的方法有很多, 如系统聚类法、模糊聚类法、分裂法、 第一章概述 1.1 质性研究与量化研究 一.方法论背景 实证主义和人文主义作为两种不同的方法论在经验研究中也代表着两种不同的探求知识的方法,前者是科学主义的,后者是自然主义的。量化研究方法和质性研究方法则是这两种方法论最集中的体现。长期以来,随着科学技术的发在而形成的实证研究范式在社会学研究中占主流地位。由于受自然科学量化研究范式的影响,实证主义者认为只有客观的、实证的和量化的研究才是科学的,有价值的。社会学的发展也离不开量化的测量和分析。法国社会学家迪尔凯姆则受到实证主义思想和统计规律性思想的影响,在其著作《自杀论》中,通过分析犯罪统计学提供的统计资料,最终展示了自杀现象中类似于自然科学的规律性。 然而,由于社会科学不仅研究可观察的现实(客观事件),而且也研究主观现实,因此,社会研究的客观性和确质性远远不如自然科学。正是由于社会研究受到其特定研究对象和研究内容的制约,再加上实证研究范式本身的缺陷,社会研究者不可能完全依赖这种研究范式来达到对社会的全面理解。20世纪70年代以来,社会研究者开始对实证研究范式的缺陷进行批评,并逐步发展出更具人文主义色彩的解释范式。 解释范式就是一种质性研究范式,其发展主要受到西方现象学、诠释学、批判理论、民俗方法论、符号互动论等思想和理论的影响,同时也部分吸取了文化人类学的研究方法。 从本体论上看,质性研究范式假定人类行为是一种有.意义的行动,它可以通过人的意识和情感作用来完成一切认知.。同时,人的行动也是社会取向的,“我”毕竟要走向“他人”。因此,人不仅通过自我来追求意义,同时也必须通过他人来赋予世界意义。换句话说,主体不是封闭性的自我系统,而是走向社会的“存在”,是以“相互主体性”来构建这个世界。从认识论上看,它强调知识的形成和发展并非只受知识内在理性原则的限制或是纯粹由理性推论而来,它是由主体的意识作用在日常生活世界不断与其他的人或事物的接触中,来建立可供沟通的知识。即知识的形成是经由“协商”的过程而来。 模糊聚类分析方法 对所研究的事物按一定标准进行分类的数学方法称为聚类分析,它是多元统计“物以类聚”的一种分类方法。载科学技术、经济管理中常常要按一定的标准(相似程度或亲疏关系)进行分类。例如,根据生物的某些性状可对生物分类,根据土壤的性质可对土壤分类等。由于科学技术、经济管理中的分类界限往往不分明,因此采用模糊聚类方法通常比较符合实际。 一、模糊聚类分析的一般步骤 1、第一步:数据标准化[9] (1) 数据矩阵 设论域12{,,,}n U x x x =为被分类对象,每个对象又有m 个指标表示其性状, 即 12{,, ,}i i i im x x x x = (1,2, ,)i n =, 于是,得到原始数据矩阵为 11 121212221 2 m m n n nm x x x x x x x x x ?? ? ? ? ??? 。 其中nm x 表示第n 个分类对象的第m 个指标的原始数据。 (2) 数据标准化 在实际问题中,不同的数据一般有不同的量纲,为了使不同的量纲也能进行比较,通常需要对数据做适当的变换。但是,即使这样,得到的数据也不一定在区间[0,1]上。因此,这里说的数据标准化,就是要根据模糊矩阵的要求,将数据压缩到区间[0,1]上。通常有以下几种变换: ① 平移·标准差变换 ik k ik k x x x s -'= (1,2,,;1,2,,)i n k m == 其中 11n k ik i x x n ==∑, k s = 经过变换后,每个变量的均值为0,标准差为1,且消除了量纲的影响。但 是,再用得到的ik x '还不一定在区间[0,1]上。 ② 平移·极差变换 111min{}max{}min{}ik ik i n ik ik ik i n i n x x x x x ≤≤≤≤≤≤''-''=''-,(1,2,,)k m = 显然有01ik x ''≤≤,而且也消除了量纲的影响。 ③ 对数变换 lg ik ik x x '= (1,2,,;1,2,,)i n k m == 取对数以缩小变量间的数量级。 2、第二步:标定(建立模糊相似矩阵) 设论域12{,, ,}n U x x x =,12{,, ,}i i i im x x x x =,依照传统聚类方法确定相似 系数,建立模糊相似矩阵,i x 与j x 的相似程度(,)ij i j r R x x =。确定(,)ij i j r R x x =的方法主要借用传统聚类的相似系数法、距离法以及其他方法。具体用什么方法,可根据问题的性质,选取下列公式之一计算。 (1) 相似系数法 ① 夹角余弦法 21 m ik jk ij m ik jk k x x r x == ∑∑。 ② 最大最小法 11() () m ik jk k ij m ik jk k x x r x x ==∧= ∨∑∑。 ③ 算术平均最小法 校园环境质量的模糊综合评价方法 信息与计算科学2003级马文彬 指导教师杜世平副教授 摘要:本文应用模糊数学理论,把模糊综合评价方法具体应用到校园环境质量综合评价研究中,结合校园的实际情况将环境评价系统根据需要分成若干个指标,建立了因子集、评价集、隶属函数和权重集,实现对校园环境的质量等级综合评判。采用层次分析法计算评价的权重集,并对取大取小算法和评价结果的最大隶属度原则进行了改进,取得较好的效果。实例表明:模糊综合评价方法可操作性强、效果较好,可在一般环境的质量评价中广泛应用。 关键词:校园环境质量,模糊综合评价,层次分析法,权重 Fuzzy Comprehensive Evaluation Method for the Environment Quality of university Campus MA Wen-bin Information and Computational Science , Grade 2003 Directed by Du Shi-ping (Associate Prof ) Abstract: In this paper,based on fuzzy mathematics theory, the fuzzy comprehensive evaluation is applied in the environment quality evaluation of university campus,combining the actual situation list to evaluate the general level of university campus by fuzzy comprehensive evaluation. By setting up the factor sets, the evaluation sets, subjection functions and the weighting sets. Implementation of the Campus Environment Quality Level comprehensive evaluation. The evaluation of the weighting sets are made by AHP. The choosing big or small algorithm and the maximal subjection degree of the evaluation result is improved, and the effect is very good.The applying example indicates: the researched method is feasible and effective, it can be used widely in the environment quality assessment. Keywords:Environment quality of university campus,Fuzzy Comprehensive Evaluation,Analytical Hierarchy Process,Weighting模糊聚类法
(完整版)所有定性研究方法整理
模糊聚类分析方法汇总
基于.层次分析法的模糊综合评价
相关主题
文本预览