
.=
《管理统计学》实验指导书及
实验报告
王金玉编著
沈阳航空工业学院经济管理学院
班级
学号
姓名
成绩
实验一用Excel对数据的图表描述
实验目的:掌握用EXCEL进行数据的搜集整理和显示
实验步骤:
用Excel进行数据的统计分组描述,可以获得相应数据分组的频数、频率以及向上向下累计频数、频率的情况,并能做出相应的直方图、折线图等描述数据分布特征的统计图形。我们举例介绍一下数据的Excel图表描述的操作方法。
【例1-1】为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下,数据进行适当的
分组,编制频数分布表;(2)制作合适的统计图反映分布特征。
700 716 728 719 685 709 691 684 705 718
706 715 712 722 691 708 690 692 707 701
708 729 694 681 695 685 706 661 735 665
668 710 693 697 674 658 698 666 696 698
706 692 691 747 699 682 698 700 710 722
694 690 736 689 696 651 673 749 708 727
688 689 683 685 702 741 698 713 676 702
701 671 718 707 683 717 733 712 683 692
693 697 664 681 721 720 677 679 695 691
713 699 725 726 704 729 703 696 717 688
一、编制分布数列
在Excel中有两类方法可以实现分布数列的编制:一是使用相关的函数,如Frequency函数;二是使用分析工具中的【直方图】工具。本例中我们采用函数方法。具体步骤如下:
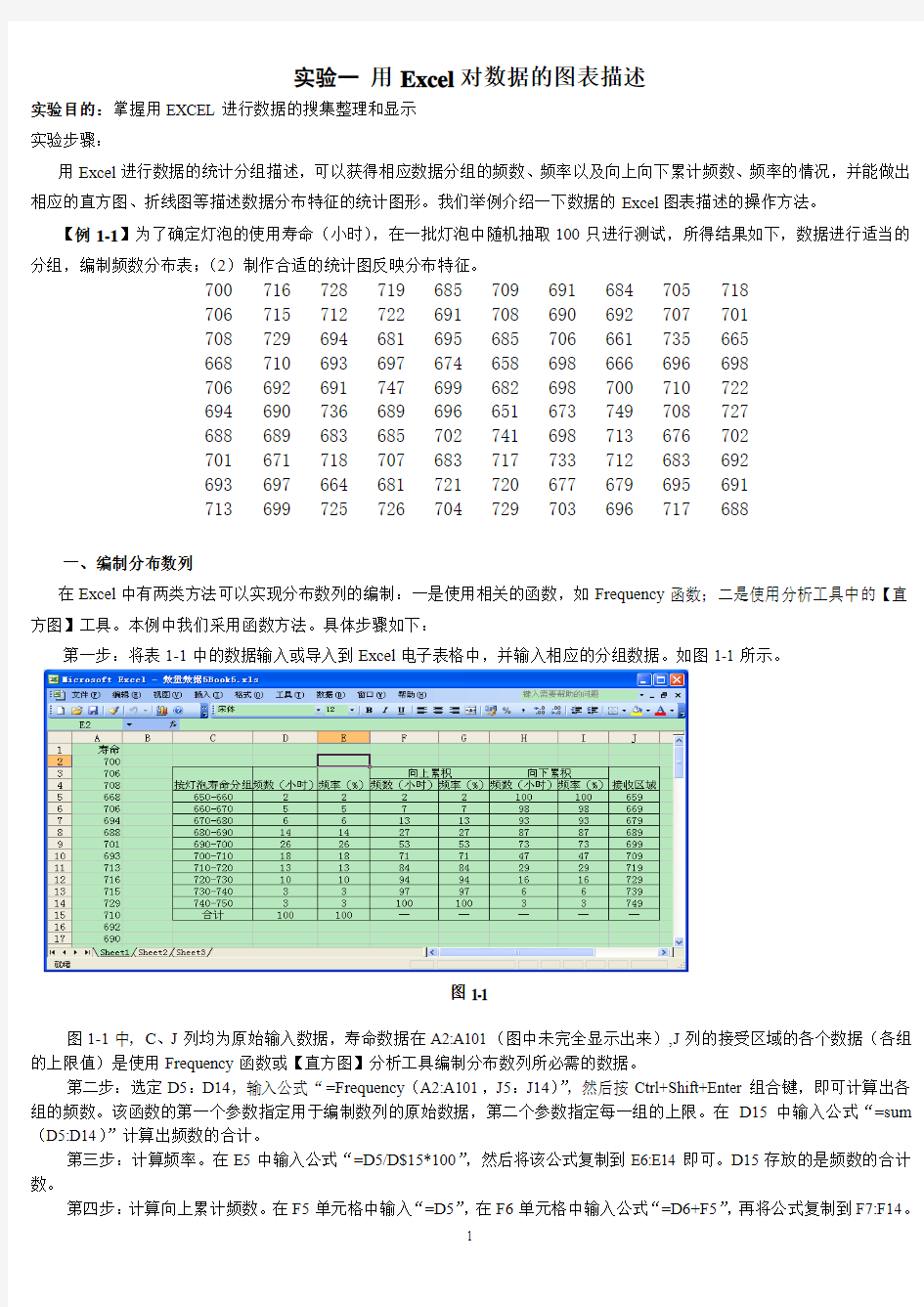
第一步:将表1-1中的数据输入或导入到Excel电子表格中,并输入相应的分组数据。如图1-1所示。
图1-1
图1-1中,C、J列均为原始输入数据,寿命数据在A2:A101(图中未完全显示出来),J列的接受区域的各个数据(各组的上限值)是使用Frequency函数或【直方图】分析工具编制分布数列所必需的数据。
第二步:选定D5:D14,输入公式“=Frequency(A2:A101,J5:J14)”,然后按Ctrl+Shift+Enter组合键,即可计算出各组的频数。该函数的第一个参数指定用于编制数列的原始数据,第二个参数指定每一组的上限。在D15中输入公式“=sum (D5:D14)”计算出频数的合计。
第三步:计算频率。在E5中输入公式“=D5/D$15*100”,然后将该公式复制到E6:E14即可。D15存放的是频数的合计数。
第四步:计算向上累计频数。在F5单元格中输入“=D5”,在F6单元格中输入公式“=D6+F5”,再将公式复制到F7:F14。
第五步:计算向下累计频数。在H14中输入公式“=D14”,在H13单元格中输入公式“=H14+D13”,再将公式复制到H5:H12。可以采用向上填充的方法复制公式,即选中H5:H13单元格区域,然后点击菜单【编辑】→【填充】→【向上填充】。
第六步:参照第三步,可以分别计算出向上累计频率和向下累计频率,如图1-1中G、I列所示。
二、用Excel作统计图
Excel提供的统计图有多种,包括柱形图、条形图、折线图、饼图、散点图、面积图、环形图、雷达图、曲面图、气泡图、股价图、圆柱图、圆锥图等,各种图的作法大同小异。
根据上面所得的频数(频率)以及向上、向下累计频数(频率)表,可以做出相应的统计图来直观描述数据的统计特征。
第一步:做直方图。点击菜单【插入】→【图表】,弹出图表向导对话框,选择图表类型【柱形图】,数据区域选择频数(或频率)所在的区域D5:D14,设定其余参数即可得到频数分布的柱形图,,若要把它变成直方图,可按如下操作:用鼠标左键单击任一直条,然后右键单击,在弹出的快捷菜单中选取数据系列格式,弹出数据系列格式对话框,在对话框中选择选项标签,把间距宽度改为0,按确定后即可得到直方图,如图1-2所示:
图1-2
第二步:做折线图。右键单击直方图,在弹出菜单中选择【图表类型】,将其更改为折线图即可得到频数折线图,如图1-3所示。
图1-3
第三步:做累计频数(频率)图。此图以折线图形式显示为佳。操作步骤与第一步相似,在图表类型中选择【折线图】,数据区域选择向上累计频数(频率)以及向下累计频数(频率)。即可得到向上、向下累计频数(频率)图。见图1-4。
图1-4
根据所得的频数图表,我们可以看出此类灯泡的寿命平均约为700小时,集中趋势比较明显,近似服从于正态分布。
实验二用Excel、SPSS做描述统计
实验目的:用EXCEL计算描述统计量,从而求出有些参数的点估计。
实验步骤:
EXCEL中用于计算描述统计量的方法有两种,函数方法和描述统计工具的方法。
一、用函数计算描述统计量
常用的描述统计量有众数、中位数、算术平均数、调和平均数、几何平均数、极差、四分位差、标准差、方差、平均差、标准差系数、偏斜度和峰度等。一般来说,在Excel中求这些统计量,未分组资料可用函数计算,已分组资料可用公式计算。这里我们仅介绍如何用函数计算。
(一)众数
【例2】:为了解某经济学院新毕业大学生的工资情况,随机抽取30人,月工资如下:
156013401600141015901410161015701710155014901690138016801470 153015601250156013501560151015501460155015701980161015101440 用函数方法求众数,应先将30个人的工资数据输入A1:A30单元格,然后单击任一空单元格,输入“=MODE (A1:A30)”,回车后即可得众数为1560
(二)中位数
仍采用上面的例子,单击任一空单元格,输入“=MEDIAN(A1:A30)”,回车后得中位数为1550。
(三)算术平均数
单击任一单元格,输入“=A VERAGE(A1:A30)”,回车后得算术平均数为1535。
(四)几何平均数
单击任一单元格,输入“=GEOMEAN(A1:A30)”,回车后得几何平均数为1529.425。
(五)调和平均数
单击任一单元格,输入“=HARMEAN(A1:A30)”,回车后得调和平均数为1523.971。
(六)四分位数
在相邻的五个单元格,依次输入“=QUARTILE(A1:A30,0)”、“=QUARTILE(A1:A30,1)”、“=QUARTILE (A1:A30,2)”、“=QUARTILE(A1:A30,3)”、“=QUARTILE(A1:A30,4)”,可得这组数据的最小值、最
大值以及中间的三个四分位点,按照输入公式的顺序得到这五个点为:1250、1462.5、1550、1585、1980。
(七)极差
单击任一单元格,输入“=MAX(A1:A30)-MIN(A1:A30)”,回车后得极差为730。
(八)标准差
单击任一单元格,输入“=STDEV(A1:A30)”,回车后得标准差为135.0287。
(九)平均差
单击任一单元格,输入“=A VEDEV(A1:A30)”,回车后得平均差为93.66667。
(十)方差
单击任一单元格,输入“=V AR(A1:A30)”,回车后得方差为18232.76。
(十一)偏斜度
单击任一单元格,输入“=SKEW(A1:A30)”,回车后得偏斜度为0.832785。
(十二)峰度
单击任一单元格,输入“=KURT(A1:A30)”,回车后得峰度值为3.257451。
二、描述统计工具箱的使用
仍使用上面的例子,我们已经把数据输入到A1:A30单元格,然后按以下步骤操作:
第一步:在工具菜单中选择数据分析选项,从其对话框中选择描述统计,按确定后打开描述统计对话框,如图13-14所示:
第二步:在输入区域中输入$A$1:$A$30,在输出区域中选择$C$1,其他复选框可根据需要选定,选择汇总统计,可给出一系列描述统计量;选择平均数置信度,会给出用样本平均数估计总体平均数的置信区间;第K大值和第K小值会给出样本中第K个大值和第K个小值。
第三步:单击确定,可得输出结果,如图2-1所示:
图2-2描述统计输出结果图2-1描述统计对话框
上面的结果中,平均指样本均值;标准误差指样本平均数的标准差;中值即中位数;模式指众数;标准偏差指样本标准差,自由度为n-1;峰值即峰度系数;偏斜度即偏度系数;区域实际上是极差,或全距。(可见中文版的翻译有问题)利用频数分布过程可以方便地对数据按组进行归类整理,形成各变量的不同水平(分组)的频数分布表和图形,以便对各变量的数据的特征和记录分布状况有一个概括的认识。
三、SPSS描述性统计分析
描述统计分析过程通过平均值、算术和、标准差、最大值、最小值、方差、极值和均值标准误等统计量变量进行描述。
操作步骤
(1)在数据窗中建好或打开一个数据文件。
(2)按Analyze→Descriptive Statistics→Descriptives打开Descriptives对话框。
(3)在左侧的源变量中选择一个或多个变量作为待分析变量移入Variable(s).框中。
(4)选中Save standardized values as variables 复选项,对所选择的每一个变量进行标准化产生相应的Z得分,作为新变量保存在数据窗中。其变量名为相应变量名加前缀Z。
(5)单击Options 按钮,展开Options对话框,在对话框中可以指定其他统计量与输出结果显示的顺序基本统计量与Display order输出顺序栏的具体操作,参见5.1中Statisticst 和Format对话框中的选项。
(6)单击OK按钮提交系统执行。
四、SPSS作统计图
与Excel比较而言,SPSS提供了更多的统计图。例如,可以利用SPSS软件迅速做出箱形图。使用SPSS做箱形图的操作步骤如下:
(1)建立或打开了数据文件。
(2)按照Graphs→Boxplot的顺序打开【Boxplot】箱线图作图对话框。
(3)在对话框下侧的数据类型中选择待分析数据的类型—分组数据或者单组数据,单击右上侧的Define按钮,进入下一界面。
(4)若是单组变量,在左侧的源变量框中选择待描述的变量,单击向右箭头按钮使其进入右侧的Boxes Represent框中。如是分组变量,比如是两组数据则选择第一列上连续输入第一组及第二组数,然后在第二列上输入1(第一列第一组数据的相应位置)或2(第一列第二组数据的相应位置),然后在左侧的源变量框中选择相应的变量(第一列),单击向右箭头按钮使其进入右侧的Variable框中,并从源变量框中选择对应的分组变量(第二列)移至Category Axis框中。
(5)单击OK按钮,软件在输出对话框中给出相应数据的箱线图。
实验三用EXCEL计算各种随机变量的概率
实验目的:用EXCEL进行计算正态分布、卡方分布、T分布、F分布等概率分布。
实验步骤:
一、以正态分布为例,计算正态分布函数值的函数为:NOEMDIST(x, mean, standard_dev, cumulative),其中:x为需要计算其分布的数值,mean为分布的算数平均值,standard_dev为分布的标准偏差,c umulative为一逻辑值,指明函数的形式,如果其值为TRUE(=1),则该函数返回累积分布函数,若其值为FALSE(=0),则函数返回相应的概率密度函数。例如单击任一单元格,输入“=NORMDIST(15,14,1.5,0)”,回车返回上述条件下的概率密度函数值0.212965;输入“=NORMDIST(15,14,1.5,1)”回车返回上述条件下的累积分布函数值
0.747507。
【例3-1】随机变量X服从标准正态分布N(0,1),计算P(0.2 二、类似地,使用CHINDIST、TDIST、FDIST等函数并给出相应的参数值,即可返回卡方分布、T分布和F分布的概率分布函数值。 【例3-2】若随机变量X服从自由度为6的卡方分布,求P(2 在任一单元格中输入公式“=CHIDIST(2,6)-CHIDIST(10,6)”,回车即可得出近似概率值0.795047;类似可得自由度为9时概率的近似值为0.688586。 【例3-3】若随机变量X服从自由度为(5,6)的F分布,求P(X>10),P(X<5)的近似值。 在任一单元格中输入公式“=FDIST(10,5,6)”回车即得P(X>10)的近似值0.00712;在任一单元格中输入公式“=1-FDIST(5,5,6)”回车得P(X<5)的近似值0.962366。 【例3-4】若随机变量X服从自由度为9的t分布,求P(X>2.619);若随机变量X服从自由度为4的t分布,求P(X<1.982)。 在任一单元格中输入公式“=TDIST(2.619,9,1)”回车即得P(X>2.619)近似值0.013928;在任一单元格中输入公式“=1-TDIST(1.982,4,1)”回车得P(X<1.982)的近似值0.940735。 实验四用EXCEL做参数的区间估计 实验目的:用EXCEL计算总体均值、总体方差、总体标准差、等参数的区间估计。 实验步骤:在EXCEL中,进行参数估计只能使用公式和函数的方法。 【例4】某大学为了解学生每天上网的时间,在全校7500名学生中采取不重复抽样方法随机抽取36人,调查他们每天上网的时间(单位:小时),得到的数据见excel表。 3.3 1.9 5.8 4.3 5.4 0.8 4.4 1.4 2.6 3.5 3.5 3.6 2.1 6.2 5.1 4.1 3.6 3.2 4.7 5.4 2.9 1.8 0.5 2.3 3.1 1.2 2.3 4.2 4.5 1.5 2 1.2 6.4 2.4 5.7 2.5 求该校大学生平均上网时间的置信区间,置信水平为95% 图4-1参数估计数据及结果 计算方法如下: 第一步:把数据输入到A2:A37单元格。 第二步:在C2中输入公式“=COUNT(A2:A37)”,C3中输入“=A VERAGE(A2:A37)”,在C4中输入“STDEV(A2:A37)”,在C5中输入“=C4/SQRT(C2)”,在C6中输入0.90,在C7中输入“=C2-1”,在C8中输入“=TINV(1-C6,C7)”,在C9中输入“=C8*C5”,在C10中输入“=C3-C9”,在C11中输入“=C3+C9”。在输入每一个公式回车后,便可得到上面的结果,从上面的结果我们可以知道,顾客平均消费额的置信下限为2.77214175,置信上限为3.86119158。 关于总体方差的估计、总体比例的估计等可按类似方法进行。 实验五 使用EXCEL 进行假设检验 实验目的:用EXCEL 、SPSS 作出一个正态总体的参数假设检验,如Z 检验和T 检验。 实验步骤: 在EXCEL 中,假设检验工具主要有四个,如图13-43所示: 图13-43数据分析对话框 平均值的成对二样本分析实际上指的是在总体方差已知的条件下两个样本均值之差的检验,准确的说应该是Z 检验,双样本等方差检验是总体方差未知,但假定其相等的条件下进行的t 检验,双样本异方差检验指的是总体方差未知,但假定其不等的条件下进行的t 检验,双样本平均差检验指的是配对样本的t 检验。 如Z 检验。 【例5】:在平炉上进行一项试验以确定改变操作方法的建议是否会增加钢的得率,实验是在同一只平炉上进行的。每炼一炉钢时除操作方法外,其它条件都尽可能做到相同。先用标准方法炼一炉,然后用建议的新方法炼一炉以后交替进行,各炼了10炉,其得率分别为 (1)标准方法:78.1 72.4 76.2 74.3 77.4 78.4 76.0 75.5 76.7 77.3 (2)新方法: 79.1 81.0 77.3 79.1 80.0 79.1 79.1 77.3 80.2 82.1 设这两个样本相互独立且来自正态总体( )2 11,~σμN X 和( )22 2,~σ μN Y ,总体方差相等(但未知) 。试问:在α=0.01水平下,新操作方法能否提高钢的得率? 计算步骤如下: 第一步:输入数据到工作表。 第二步:单击工具菜单,选择数据分析选项,弹出对话框后,在其中选择t —检验:双样本等方差假设,弹出对话框如图5-1所示: 图5-1双样本平均差分析对话框 第三步:按上图所示输入后,按确定按钮,得输出结果如图5-2: 图5-2双样本平均差分析结果 在上面的结果中,我们可以根据P 值进行判断,也可以根据统计量和临界值比较进行判断。如本例采用的是单尾检验,其单尾P 值为0.00021,小于给定的显著性水平0.01,所以应该拒绝原假设,即新操作方法没有提高钢的得率;若用临界值判断,得出的结论是一样的,如本例t 值为4.29574277,大于临界值2.552379618,由于是右尾检验,所以也是拒绝原假设。 实验六 用EXCEL 作方差分析 实验目的:用EXCEL 作出方差分析。 实验步骤:可以见教材147页方差分析的实现过程。下面给出一个例题。 【例6】某饮料生产企业研制出一种新型饮料。饮料的颜色共有四种,分别为橘黄色、粉色、绿色和无色透明。这四种饮料的营养含量、味道、价格、包装等可能影响销售量的因素全部相同。现从地理位置相似、经营规模相仿的五家超级市场上收集了前一时期该饮料的销售情况,见下表。试分析饮料的颜色是否对销售量产生影响。 计算步骤如下: 第一步:输入数据到工作表。见图5-2. 第二步:单击工具菜单,选择数据分析选项,弹出对话框后,在其中方差分析:单因素方差分析,弹出对话框如图6-1所示: 图5-1单因素方差分析对话框 第三步:按上图所示输入后,按确定按钮,得输出结果如图5-2中灰色部分所示。 图5-2单因素方差分析结果 结果分析: P-值规则:根据算得得检验统计量的样本值算出P-值为0.000466(见图5-2),由于P-值=0.000466<显著水平标准α=0.05,所以拒绝原假设,即饮料的颜色对销售量产生了影响。也可以通过临界值规则:F=10.4862>F =3.238872,检验统计量的样 0.05 本值落入接受域,结论,即饮料的颜色对销售量产生了影响。 实验七用EXCEL进行相关与回归分析 实验目的:用EXCEL进行相关与回归分析 实验步骤: 我们用下面的例子进行相关和回归分析: 【例7】:随机抽取7家超市,得到其广告费支出和销售额数据见excel表。用广告费支出作自变量,销售额为因变量,求出估计的回归方程。检验广告费支出与销售额之间的线性关系是否显著( =0.05)。 超市广告费支出/万元销售额/万元 A 1 19 B 2 32 C 4 44 D 6 40 E 10 52 F 14 53 G 20 54 一、用EXCEL进行相关分析 首先把有关数据输入EXCEL的单元格中,如图7-1 图7-1 EXCEL数据集 用EXCEL进行相关分析有两种方法,一是利用相关系数函数,另一种是利用相关分析宏。 1.利用函数计算相关系数 在EXCEL中,提供了两个计算两个变量之间相关系数的方法,CORREL函数和PERSON函数,这两个函数是等价的,这里我们介绍用CORREL函数计算相关系数: 第一步:单击任一个空白单元格,单击插入菜单,选择函数选项,打开粘贴函数对话框,在函数分类中选择统计,在函数名中选择CORREL,单击确定后,出现CORREL对话框。 第二步:在array1中输入B2:B8,在array2中输入C2:C8,即可在对话框下方显示出计算结果为0.831。如图7-2所示: 图7-2CORREL对话框及输入结果 2.用相关系数宏计算相关系数 第一步:单击工具菜单,选择数据分析选项,在数据分析选项中选择相关系数,弹出相关系数对话框,如图7-3所示: 图7-3相关系数对话框 第二步:在输入区域输入$B$1:$C$8,分组方式选择逐列,选择标志位于第一行,在输出区域中输入$E$1,单击确定,得输出结果如图7-4 图7-4相关分析输出结果 在上面的输出结果中,身高和体重的自相关系数均为1,身高和体重的相关系数为0.831,和用函数计算的结果完全相同。 二、用EXCEL进行回归分析 EXCEL进行回归分析同样分函数和回归分析宏两种形式,其提供了9个函数用于建立回归模型和预测。这9个函数分别是: INTERCEPT 返回线性回归模型的截距、SLOPE 返回线性回归模型的斜率 、RSQ 返回线性回归模型的判定系数、FORECAST 返回一元线性回归模型的预测值、STEYX 计算估计的标准误、TREND 计算线性回归线的趋势值、GROWTH 返回指数曲线的趋势值、LINEST 返回线性回归模型的参数、LOGEST 返回指数曲线模型的参数 用函数进行回归分析比较麻烦,我们这里介绍使用回归分析宏进行回归分析。 第一步:单击工具菜单,选择数据分析选项,出现数据分析对话框,在分析工具中选择回归,如图7-5 图7-5数据分析对话框 第二步:单击确定按钮,弹出回归对话框,在Y值输入区域输入$B$2:$B$11,在X值输入区域输入$C$2:$C$11,在输出选项选择新工作表组,如图7-6所示: 图7-6回归对话框 第四步:单击确定按钮,得回归分析结果如图7-7所示 图7-7EXCEL回归分析结果 在上面的输出结果中,第一部分为汇总统计,MultipleR指复相关系数,R Square指判定系数,Adjusted指调整的判定系数,标准误差指估计的标准误,观测值指样本容量;第二部分为方差分析,df指自由度,SS指平方和,MS指均方,F指F统计量,Significance of F指p值;第三部分包括:Intercept指截距,Coefficient指系数,t stat指t统计量。 使用SPSS操作步骤如下: (1)按Analyze→Regression→Linear Regression对话框。 (2)在左侧的源变量框中选择一个变量作为因变量,将其送入Depndent框中;选择一个或多个变量作为自变量,将其送入Independent(s)框中。 (3)在Method框中选择回归分析方法。(4)根据变量值选择参与回归分析的记录,将作为参照的变量进入Selection Variable 框中,单击Rule按钮,打开Set Rule对话框确定运算法则与数值。(5)在Case Label下面输入变量名,用其值作为记录标签。 (6)单击WLS按钮,选择一个作为权重的变量进入WLS Weight框中 (7)单击Statistics按钮,打开Statistics对话框选择输出的统计量。 实验八Excel在时间序列分析中的应用 实验目的:用EXCEL 做出时间序列的分析中模型预测。 实验步骤: 一家旅馆过去9个月的营业额数据见下表。 2 283 3 322 4 355 5 286 6 379 7 381 8 431 9 424 10 473 11 470 12 481 13 449 14 544 15 601 16 587 17 644 18 660 根据上表的数据,利用指数平滑法预测该企业产品第19个月和第20个月的营业额 操作步骤如下: 1、准备工作表,如图13-30。图中方框之内的数据是通过计算得到的,方框外边的是原始输入数据。 2、计算E(1)、E(2)、a t、b t 在C3、D3、E3、F3这4个单元格中分别输入如下公式: =0.45*B3+0.55*C2 =0.45*C3+.55*D2 =2*C3-D3 =0.45/0.55*(C3-D3) 然后选定C3:F19单元格区域,按Ctrl+D组合键,即可计算出第2个月~第18个月的E(1)、E(2)、a t、b t 3、计算预测值y t (1)在G4中输入公式“=E3+F3”,并将公式复制到G5:G20单元格G20中的单元格区域。单元格G20中的公式计算结果便是第19个月营业额的预测值。 (2)在G21中输入公式“=G19+G20”,边可以得到第20个月的营业额预测值。 回弹模量试验作业指导书 1 承载板法 1.1 目的和适用范围本试验适用于不同湿度和密度的细粒土。 1.2 仪器设备 1.2.1 杠杆压力仪:最大压力1500N 1-调平砝码;2-千分表3-立柱4-加压杆5-水平杠杆6-水平气泡7-加压球座8-底座气泡9-调平脚螺丝10-加载架 1.2.2 承载板:直径50 毫米,高80 毫米,如图19.1.2-2 所示。欠图 1.2.3 试筒:内径152 毫米、高170 毫米的金属圆筒;套环,高50 毫米;筒内垫块,直径151 毫米,高50 毫米;夯击 底板与击实仪相同。 1.2.4 量表:千分表两块。 1.2.5 秒表一只。 1.3 试样 按击实试验(T0131-93)方法制备试样,根据工程要求选择轻型或重型法,视最大粒径用小筒或大筒进行击实试验,得出最佳含水量和最大干密度,然后按最佳含水量用上述试筒击实制备试件。 1.4 试验步骤 1.4.1 安装试样:将试件和试筒的底面放在杠杆压力仪的底盘上,将承载板放在试件中央(位置)并与杠杆压力仪的加压球座对正;将 千分表固定在立柱上,将表的测头安放在承载板的表架上。 1.4.2 预压:在杠杆仪的加载架上施加砝码,用预定的最大单位压力p 进行预压。含水量大于塑限的土,p=50--100k Pa,含水量小于塑限的土,p=100--200kPa。预压进行1--2 次,每次预压1min。预压后调正承载板位置,并将千分表调到接近満量程的位置,准备试验。 1.4.3 测定回弹量:将预定最大单位压力分成4--6 份,作为每级加载的压力。每级加载时间为1min 时,记录千分表读数,同时卸载,让试件恢复变形,卸载1min 时,再次记录千分表读数,同时施加下一级荷载。如此逐级进行加载卸 载,并记录千分表读数,直至最后一级荷载。为使试验曲线开始部分比较准确,第一、二级荷载可用每份的一半,试验的最大压力也可 略大于预定压力。 1.5 结果整理 1.5.1 计算每级荷载下的回弹变形L: L=加载读数-卸载读数(19.1.5-1) 1.5.2 以单位压力p 为横坐标(向右),回弹变形L 为纵坐标(向下),绘制p--L 曲线 1.5.3 按下式计算每级荷载下的回弹模量: E=πpD/4L(L-μ2) 式中:E--回弹模量,kPa; p--承载板 .= 《管理统计学》实验指导书及 实验报告 王金玉编著 沈阳航空工业学院经济管理学院 班级 学号 姓名 成绩 实验一用Excel对数据的图表描述 实验目的:掌握用EXCEL进行数据的搜集整理和显示 实验步骤: 用Excel进行数据的统计分组描述,可以获得相应数据分组的频数、频率以及向上向下累计频数、频率的情况,并能做出相应的直方图、折线图等描述数据分布特征的统计图形。我们举例介绍一下数据的Excel图表描述的操作方法。 【例1-1】为了确定灯泡的使用寿命(小时),在一批灯泡中随机抽取100只进行测试,所得结果如下,数据进行适当的 分组,编制频数分布表;(2)制作合适的统计图反映分布特征。 700 716 728 719 685 709 691 684 705 718 706 715 712 722 691 708 690 692 707 701 708 729 694 681 695 685 706 661 735 665 668 710 693 697 674 658 698 666 696 698 706 692 691 747 699 682 698 700 710 722 694 690 736 689 696 651 673 749 708 727 688 689 683 685 702 741 698 713 676 702 701 671 718 707 683 717 733 712 683 692 693 697 664 681 721 720 677 679 695 691 713 699 725 726 704 729 703 696 717 688 一、编制分布数列 在Excel中有两类方法可以实现分布数列的编制:一是使用相关的函数,如Frequency函数;二是使用分析工具中的【直方图】工具。本例中我们采用函数方法。具体步骤如下: 第一步:将表1-1中的数据输入或导入到Excel电子表格中,并输入相应的分组数据。如图1-1所示。 图1-1 图1-1中,C、J列均为原始输入数据,寿命数据在A2:A101(图中未完全显示出来),J列的接受区域的各个数据(各组的上限值)是使用Frequency函数或【直方图】分析工具编制分布数列所必需的数据。 第二步:选定D5:D14,输入公式“=Frequency(A2:A101,J5:J14)”,然后按Ctrl+Shift+Enter组合键,即可计算出各组的频数。该函数的第一个参数指定用于编制数列的原始数据,第二个参数指定每一组的上限。在D15中输入公式“=sum (D5:D14)”计算出频数的合计。 第三步:计算频率。在E5中输入公式“=D5/D$15*100”,然后将该公式复制到E6:E14即可。D15存放的是频数的合计数。 第四步:计算向上累计频数。在F5单元格中输入“=D5”,在F6单元格中输入公式“=D6+F5”,再将公式复制到F7:F14。 《管理统计学》 实验二假设检验与方差分析 实验项目名称 案例4.1 谷类食品生产商的投资问题 案例4.2 数控机床的选购问题 案例5.1 运动员团体成绩预测问题 案例5.2 手机电池通话时间测试 案例5.3 月份与CPI的关系 目录 一、实验目的 (3) 二、实验原理 (3) 三、设备 (3) 四、实验内容和实验步骤 (3) 1、案例4.1 谷类食品生产商的投资问题 (3) 2、案例4.2 数控机床的选购问题 (6) 3、案例5.1 运动员团体成绩预测问题 (11) 4、案例5.2 手机电池通话时间测试 (17) 5、案例5.3 月份与CPI的关系整理 (22) 五、实验总结 (29) 一、实验目的 1. 掌握SPSS数据文件的建立 2. 掌握SPSS统计分析中的均值比较和T检验方法 3. 掌握单因素方差分析和多因素方差分析的原理与步骤 4. 学习并将管理统计学课程所学的知识用于解决实际问题 二、实验原理 SPSS软件有数据整理、分析数据的功能,其中包括假设检验及方差分析实验可以用到的工具,如均值比较、参数分析、建立线性模型等。 三、设备 SPSS软件(英文名称Statistical Package for the Social Science) 四、实验内容和实验步骤 1、案例4.1 谷类食品生产商的投资问题 1)启动SPSS,在变量视图里面输入案例变量“食用者类型(字符串)”和“热量摄取量(数值,小数设为0位)” 2)在数据输入窗口输入数据 3)分别对两种食用者类型的热量摄取量均值进行检验(α=0.05),按照”分析-比较均值-独立样本检验”,加入检验变量“热量摄取量”、加入分组变量“食用者类型”,设置组1、2分别为A、B组,点击选项,设置置信区间百分比为95% 《数据库原理及使用》实验指导书 (适用于计算机科学和技术、软件工程专业) 热风器4 计算机科学和技术学院 2011年12月 ⒈本课程的教学目的和要求 数据库系统产生于20世纪60年代末。30多年来,数据库技术得到迅速发展,已形成较为完整的理论体系和一大批实用系统,现已成为计算机软件领域的一个重要分支。数据库原理是计算科学和技术专业重要的专业课程。 本课程实验教学的目的和任务是使学生通过实践环节深入理解和掌握课堂教学内容,使学生得到数据库使用的基本训练,提高其解决实际问题的能力。 ⒉实验教学的主要内容 数据库、基本表、视图、索引的建立和数据的更新;关系数据库的查询,包括单表查询、连接查询、嵌套查询等;数据库系统的实现技术,包括事务的概念及并发控制、恢复、完整性和安全性实现机制;简单数据库使用系统的设计实现。 ⒊实验教学重点 本课程的实验教学重点包括: ⑴数据库、基本表、视图、索引的建立和数据的更新; ⑵SQL的数据查询; ⑶恢复、完整性和安全性实现机制; ⑷简单数据库使用系统的设计实现; 4教材的选用 萨师煊,王珊.数据库系统概论(第四版).北京:高等教育出版社.2006,5 实验1创建数据库(2学时) 实验目的 1.学会数据表的创建; 2.加深对表间关系的理解; 3.理解数据库中数据的简单查询方法和使用。 实验内容 一、给定一个实际问题,实际使用问题的模式设计中至少要包括3个基本表。使用问题是供应商给工程供应零件(课本P74)。 1.按照下面的要求建立数据库: 创建一个数据库,数据库名称可以自己命名,其包含一个主数据文件和一个事务日志文件。注意主数据文件和事务日志文件的逻辑名和操作系统文件名,初始容量大小为5MB, 土工作业指导书击实试验实施细则 文件编号: 版本号: 编制: 批准: 生效日期: 击实试验实施细则 1. 目的 为了规范标准固结试验中的各个环节,特制定本细则。 2. 适用范围 本试验分轻型击实和重型击实。轻型击实试验适用于粒径小于5mm的粘性土,重型击实试验适用于粒径不大于20mm的土。采用三层击实时,最大粒径不大于40mm。 3. 引用文件 GB/T50123-1999 土工试验方法标准。 4. 检测设备 本试验所用的主要仪器设备,应符合下列规定: a、击实仪的击实筒和击锤尺寸应符合下表规定: b、天平:称量200g,最小分度值,0.01g。 c、台秤:称量10kg,最小分度值5g。 d、标准筛:孔径为20mm、40mm和5mm。 e、试样推出器:宜用螺旋式千斤顶颧液压式千斤顶,如无此类装置,亦可用刮刀和修 土刀从击实筒中取出试样。 5.操作步骤进行: 5.1试样的制备: 5.1.1干法试样制备: a .用四分法取代表性土样20kg (重型为50kg ),风干碾碎,过5mm (重型过20mm 或40mm )筛,将筛下土样拌匀,并测定土样的风干含水率。根据土的塑限预估最优含水率,并制备5个不同含水率的一组试样,相邻2个含水率的差值宜为2%。 注:轻型击实中5个含水率中应有2个大于塑限,2个小于塑限,1个接近塑限。 b .湿法制备试样按下列步骤进行:取天然含水率的代表性土样20kg (重型为50kg ),碾碎,过5mm 筛(重型过20mm 或40mm ),将筛下土样拌匀,并测定土样的天然含水率。根据土样的塑限预估最优含水率,并选择至少5个含水率的土样,分别将天然含水率的土样风干或加水进行制备,应使制备好的土样水分均匀分布。 5.2击实试验应按下列步骤进行: a .将击实仪平稳置于刚性基础上,击实筒与底座联接好,安装好护筒,在击实筒内壁均匀涂一薄层润滑油。称取一定量试样,倒入击实筒内,分层击实,轻型击实试样为2~5kg ,分3层,每层25击;重型击实试样为4~10kg ,分5层,每层56击,若分3层,每层94击。每层试样高度宜相等,两层交界处的土面应刨毛。击实完成时,超出击实筒顶的试样高度应小于6mm 。 b.卸下护筒,用直刮刀修平击实筒顶部的试样,拆除底板,试样底部若超出筒外,也应修平,擦净筒外壁,称筒与试样的总质量,准确至1g ,并计算试样的湿密度。 c.用推土器将试样从击实筒中推出,取2个代表性试样测定含水率,2个含水率的差值应不大于1%。 d.对不同含水率的试样依次击实。 6.计算结果: 6.1试样的干密度按下式计算: i d ω01.01ρρ0 += 6.2干密度和含水率的关系曲线,应在直角坐标纸上绘制。并应取曲线峰值点相应的纵坐标为击实试样的最大干密度,相应的横坐标为击实试样的最优含水率。当关系曲线不能绘出峰 《管理统计学》 综合性实验报告 题目:大学生消费情况综合分析 班级:____________姓名:____________学号:____________ 综合实验报告评分标准 评分项目比例得分 所有同学每月生活费的平均值,最大值和最小 10% 值 10% 男生、女生每月生活费的平均值,最大值和最 小值 所有同学每月生活费的茎叶图10% 频数分布表10% 方差分析部分40% 聚类分析部分10% 语言表达与排版10% 实验报告总评(用A,B,C,D和E表示) 1.通过综合性实验检验对SPSS的掌握情况,并作为期末的考核标准之一。 二、实验内容: 1.用SPSS分别计算农村学生的比例,女生比例 2.用SPSS计算出所有同学每月生活费的平均值,最大值和最小值。 3.用SPSS分别计算出男生、女生每月生活费的平均值,最大值和最小值。 4.作出所有同学每月生活费的茎叶图。 5.整理所有同学每月生活费数据,制作一个频数分布表(分成5组)。 6.从每个班中随机抽10人,这10人每月生活费可以看作本班的一个随机样本,试分析信 管1班,2班,3班,4班,工业工程1班,2班之间的每月生活费的方差是否齐性,判 断每个班同学的月均生活费是否有显著差异;分析户口所在地、性别对每月的生活费的 影响是否显著。(显著性水平为0.05) 7.以每月平均生活费、伙食费所占比例、生活费来源中家庭给予所占比例为观测变量,对 本专业学生进行聚类分析。 三、实验详细过程与结果 问题1解:采用频率分布表解答。将户口与性别放入变量中,得到户口与性别的频率统计 答:由上面得到的第二个表格得出农村学生的比例为48.8,女生的比例为37.7。 问题2解:采用频率分布表解答。在统计量选项中勾中均值、最大值和最小值。 数据库系统原理 实验指导书 (本科) 目录 实验一数据定义语言 (1) 实验二SQL Sever中的单表查询 (3) 实验三SQL Serve中的连接查询 (4) 实验四SQL Serve的数据更新、视图 (5) 实验五数据控制(完整性与安全性) (7) 实验六语法元素与流程控制 (9) 实验七存储过程与用户自定义函数 (11) 实验八触发器 (12) 实验一数据定义语言 一、实验目的 1.熟悉SQL Server2000/2005查询分析器。 2.掌握SQL语言的DDL语言,在SQL Server2000/2005环境下采用Transact-SQL实现表 的定义、删除与修改,掌握索引的建立与删除方法。 3.掌握SQL Server2000/2005实现完整性的六种约束。 二、实验内容 1.启动SQL Server2000/2005查询分析器,并连接服务器。 2.创建数据库: (请先在D盘下创建DB文件夹) 1)在SQL Server2000中建立一个StuDB数据库: 有一个数据文件:逻辑名为StuData,文件名为“d:\db\S tuDat.mdf”,文件初始大小为5MB,文件的最大大小不受限制,文件的增长率为2MB; 有一个日志文件,逻辑名为StuLog,文件名为“d:\db\StuLog.ldf”,文件初始大小为5MB,文件的最大大小为10MB,文件的增长率为10% 2)刷新管理器查看是否创建成功,右击StuDB查看它的属性。 3.设置StuDB为当前数据库。 4.在StuDB数据库中作如下操作: 设有如下关系表S:S(CLASS,SNO, NAME, SEX, AGE), 其中:CLASS为班号,char(5) ;SNO为座号,char(2);NAME为姓名,char(10),设姓名的取值唯一;SEX为性别,char(2) ;AGE为年龄,int,表中主码为班号+座号。 写出实现下列功能的SQL语句。 (1)创建表S; (2)刷新管理器查看表是否创建成功; (3)右击表S插入3个记录:95031班25号李明,男性,21岁; 95101班10号王丽,女性,20岁; 95031班座号为30,名为郑和的学生记录; (4)将年龄的数据类型改为smallint; (5)向S表添加“入学时间(comedate)”列,其数据类型为日期型(datetime); (6)对表S,按年龄降序建索引(索引名为inxage); (7)删除S表的inxage索引; (8)删除S表; 5.在StuDB数据库中, (1)按照《数据库系统概论》(第四版)P82页的学生-课程数据库创建STUDENT、COURSE 和SC三张表,每一张表都必须有主码约束,合理使用列级完整性约束和表级完整性。 并输入相关数据。 (2)将StuDB数据库分离,在D盘下创建DB文件夹下找到StuDB数据库的两个文件,进行备份,后面的实验要用到这个数据库。 6.(课外)按照《数据库系统概论》(第四版)P74页习题5的SPJ数据库。创建SPJ数据 库,并在其中创建S、P、J和SPJ四张表。每一张表都必须有主码约束,合理使用列级完整性约束和表级完整性。要作好备份以便后面的实验使用该数据库数据。 三、实验要求: 目录 一无机结合料稳定土击实试验作业指导书 (1) 二无机结合料稳定材料无侧限抗压强度试验作业指导书 (3) 三石灰的有效氧化钙含量试验作业指导书 (5) 四石灰的氧化镁含量试验作业指导 (6) 五水泥稳定土中水泥剂量测定试验作业指导书(EDTA滴定法) (10) 六粉煤灰细度试验作业指导书 (12) 七粉煤灰烧失量试验作业指导书 (13) 八粉煤灰比表面积试验作业指导书 (14) 一、无机结合料稳定土击实试验作业指导书 1.依据标准:《公路工程无机结合料稳定材料试验规程》JTG E51-2009。 2.试验目的及适用范围: 2.1目的:在规定的试筒内,对水泥稳定土(在水泥水化前)、石灰稳定土及石灰(或水泥)粉煤灰稳定土进行击实试验,以绘制稳定土的含水量-干密度关系曲线,从而确定其最佳含水量和最大干密度。 2.2适用范围:试验集料的最大粒径宜控制在37.5mm以内(方孔筛)。 3.试验环境:进入试验室内先检查温湿度仪,并在记录中注明试验时室内的温湿度。 4.试验准备: 4.2试样制备 4.4.1将具有代表性的风干试料(必要时,也可以在50℃烘箱内烘干)用木锤或 木碾捣碎。土团均应捣碎到能通过5mm的筛孔。但应注意不使粒料的单个颗粒破碎或不使其破碎程度超过施工中拌和机械的破碎率。 4.2.2如试料是细粒土,将已捣碎的具有代表性的土过5mm筛备用(用甲法或乙法做试验)。 4.2.3如试料中含有粒径大于5mm的颗粒,则先将试料过25mm的筛,如存留在25mm筛孔的颗粒的含量不超过20%,则过筛料留作备用(用甲法或乙法做试验)。 4.2.4如试料中粒径大于25mm的颗粒含量过多,则将试料过40mm的筛备用(用丙法试验)。 4.2.5每次筛分后,均应记录超尺寸颗粒的百分率。 4.2.6在预定做击实试验的前一天,取有代表性的试料测定其风干含水量。对于细粒土,试样应不少于100g;对于中粒土(粒径小于25mm的各类集料),试样应不少于1000g;对于粗粒土的各种集料,试样应不少于2000g。 5. 试验步骤: 具体试验步骤依据《公路工程无机结合料稳定材料试验规程JTG E51-2009》T 0804-1994的方法进行试验。 6. 试验结果整理: 6.1按下式计算稳定材料的干密度: Pd=P w/1+0.01w 式中P w—试样的含水量。 6.2制图:以干密度为纵坐标、含水量为横坐标,绘制含水量—干密度曲线。将试验各点采用二次曲线方法拟合曲线,曲线的峰值点对应的含水量及干密度即为最佳含水量和最大干密度; 7.试验报告: 试验报告应包括内容:○1.检测项目名称;○2.原材料的品种、规格和产地;○3.试验日期及时间○4.仪器设备名称、型号及编号;○5.试样的最大粒径、超尺寸颗粒的百分率;;○6.无机结合料类型及剂量;所用试验方法类别;最大干密度(g/cm3);最佳含水量(%),并附击实曲线;○7.执行标准;○8.要说明的其他内容。 8. 试验注意事项: 8.1. 2011版中试验仪器和操作步骤与2000版有所不同,应注意区分,勿延用老标准。 河南工业大学管理学院 课程设计(实验)报告书题目统计学实验 专业电子商务 班级1204班 学生姓名伍琴 学号201217050430 指导教师任明利 时间:2012 年 4 月 6 日 实验一:数据整理 一、项目名称:数据整理 二、实验目的 (1)掌握Excel中基本的数据处理方法; (2)学会使用Excel进行统计分组,能以此方式独立完成相关作业。 三、实验要求 1、已学习教材相关内容,理解数据整理中的统计计算问题;已阅读本次实验导引,了解Excel中相关的计算工具。 2、准备好一个统计分组问题及相应数据(可用本实验导引所提供问题与数据)。 3、以Excel文件形式提交实验报告(包括实验过程记录、疑难问题发现与解决记录)。 四、实验内容和操作步骤 (一)问题与数据 某百货公司连续40天的商品销售额如下(单位:万元): 41 25 29 47 38 34 30 38 43 40 46 36 45 37 37 36 45 43 33 44 35 28 46 34 30 37 44 26 38 44 42 36 37 37 49 39 42 32 36 35 根据上面的数据进行适当分组,编制频数分布表,并绘制直方图. (二)操作步骤: 1、在单元区域A1:E9中输入原始数据,如图: 2、并计算原始数据的最大值(在单元格B10中)与最小值(在单元格D10中)。 3、根据经验公式计算经验组距和经验组数。 4、根据步骤3的计算结果,计算并确定各组上限、下限(在单元区域F1:G6),如图所示: 5、绘制频数分布表框架,如图所示: 6、计算各组频数: (1)选定B19:B23作为存放计算结果的区域。 (2)从“公式”菜单中选择“插入函数”项。 (3)在弹出的“插入函数”对话框中选择“统计”函数FREQUENCY. 土的击实试验培训 培训人志良 时间2017.05.30 1 依据标准 《公路土工试验规程》JTG E40-2007 2 目的和适用围 2.1本试验目的是求出土的最佳含水率及最大击实密度,本方法适用于细粒土。(注:细粒土即粒 组划分图中细粒组含量≥50%的土,粗粒土为巨粒组含量≤15%且巨粒组与粗粒组之和>50%的土) 2.2 本试验的若干概念及规定: 2.2.1本试验分轻型击实和重型击实。 轻型击实只适用于粒径≤20mm的土,重型击实试验适用于粒径≤40mm的土。 2.2.2击实试筒有尺寸有径10cm试筒、15.2cm试筒、大尺寸(尺寸由土的最大粒径确定)试筒, 一般试验室常见前两种。 a、径10cm试筒只适用于最大粒径≤20mm土; b、径15.2cm试筒适用于最大粒径≤40mm土; c、当土中最大颗粒粒径≥40mm,并且≥40mm颗粒粒径的质量含量大于5%(前提:土 仍然属于细粒土)时,则应使用大尺寸试筒进行击实试验(注:当≥40mm颗粒含量大 于5%且小于30%时,也可按6.4进行最大密度和最佳含水率校正)。 大尺寸试筒要求其最小尺寸大于土样中最大颗粒粒径的5倍以上,并且击实试验的分层 厚度应大于土样中最大颗粒粒径的3倍以上。单位体积击实功能控制在 2677.2~2687.0kJ/m3围。 2.2.3当细粒土中的粗粒土总含量大于40%或粒径大于0.005mm颗粒的含量大于土总质量的 70%(即d30≤0.005mm)时,还应做粗粒土最大干密度试验(注:有振动台法和表面 震动压实仪法),其结果与重型击实试验结果比较,最大干密度取两种试验结果的最大值。 2.2.4击实试样制备方法分为干土法和湿土法。 干土法:将土样自然风干或晾晒至含水量很小(或绝干)的状态后,测其含水率量,按照预估最佳含水量,通过计算加不同量的水拌和闷土,制备5个或以上含水率以2% 左右递增的土样,其中至少有2个大于和2个小于最佳含水率。 湿土法:采集5个以上的高含水率土,按施工时能进行碾压的最高含水率,分别晾干至不同含水率(不必像干土法一样先风干再加水,而是直接分别风干至预定的不同含 水率),其中至少3个土样小于最高含水率,至少2个土样大于最高含水率。 湿土法适用于高含水率的土,干土法和湿土法土样均不得重复使用。 3 仪器设备 3.1 标准击实仪。击实试验方法和相应设备的主要参数应符合表1的规定。 表1 击实试验方法种类 注:根据规程T 0131-2007 击实试验中轻型击实试验适用于粒径不大于20mm的土的规定,上表中I-2方法中最大粒径应是20mm。 3.2 烘箱及干燥器。 3.3 天平:2000g,感量0.01g;15kg,感量0.1g 3.4圆孔筛:孔径40mm、20mm和5mm各1个。 3.5 拌和工具:400mm×600mm、深70mm的金属盘,土铲。 3.6 其他:喷水设备、碾土器、盛土盘、量筒、推土器、铝盒、修土刀、平直尺等。 4 试样 4.1 本试验可分别采用不同的方法准备试样。各方法可按表2准备试料。 管理学院实验报告 学号201305169063 姓名朱可欣 专业班级市场营销1302班 指导老师李洪斌 实验日期2015.11.05 课程名称管理统计学 实验名称管理统计学上机实验 实验成绩 实验报告具体内容一般应包括:一、实验目的和要求; 二、主要仪器设备(软件); 三、实验内容及实验数据记录; 四、实验体会 实验项目一:假设检验的Excel实现 实验时间:_____2015-11-5____________ 1. 实验目的和要求 巩固熟悉假设检验的相关原理及方法,掌握Excel中进行假设检验的相关计算过程。 2. 实验原理 假设检验的相关原理及方法。 3. 主要仪器设备(软件) 1)硬件配置: 使用综合实验室中现有配置的计算机,无特殊要求。 2)软件环境: Windows XP或以上的操作系统,Excel软件。 4. 实验内容及步骤 假设检验中关于T检验、F检验的相关内容选作2-3个计算实例。 5.实验数据记录 t-检验:双样本等方差假设 某家禽研究所各选8只粤黄鸡进行两种饲料饲养对比试验,试验时间为60天,增重结果如下,假设鸡的增重服从正态分布且两种饲料喂养的鸡增重方差相等,请问两种饲料对粤黄鸡的增重效果有无显著差异?(α=0.05) 饲料A 720 710 735 680 690 705 700 705 饲料B 680 695 700 715 708 685 698 688 解:饲料A和饲料B饲养的粤黄鸡平均增重分别用u 1和u 2 表示,检验无特定方 向,所以为双侧检验。这是两个正态总体,小样本抽样且总体方差未知的情形,采用合并方差的t检验。故: 本检验的假设为: H 0:u 1 -u 2 ≠0, H 1 :u 1 -u 2 =0 《数据库》实训计划 课程名称:数据库原理及应用 一、课程简介 《数据库原理及应用》课程是我院计算机科学与技术专业的一门重要专业课程,是一门理论性和实践性都很强的面向实际应用的课程,它是计算机科学技术中发展最快的领域之一。可以说数据库技术渗透到了工农业生产、商业、行政管理、科学研究、教育、工程技术和国防军事等各行各业。因此本课程的教学既要向学生传授一定的数据库理论基础知识,又要培养学生运用数据库理论知识和数据库技术解决实际应用问题的能力。 二.课程实验 实验题目 1.学籍管理系统 2.图书档案管理系统 3.企业人事管理系统 4.工资管理系统 5.用户和权限管理系统。 6.仓库管理系统。 7.企业进销存管理系统。 8、超市管理系统 10、酒店管理系统 11、旅游管理系统 12、高考成绩信息管理系统 13、医院信息管理系统 14、银行计算机储蓄系统 15、 ICU监护系统 16、可自拟题目 任选一题按照下列实验纲要进行设计。 实验纲要 1、实验目标 本课程实验教学的目的和任务是使学生通过实践环节深入理解和掌握课堂教学内容,使学生得到数据库应用的基本训练,提高其解决实际问题的能力。 2、实验内容 数据库的模式设计;数据库、表、视图、索引的建立与数据的更新;关系数据库的查询,包括嵌套查询、连接查询等;数据库系统的实现技术,包括事务的概念及并发控制、恢复、完整性和安全性实现机制;简单数据库应用系统的设计实现。 给定一实际问题,让学生自己完成数据库模式的设计,包括各表的结构(属性名、类型、约束等)及表之间的关系,在选定的DBMS上建立数据库表。用SQL命令和可视化环境分别建立数据库表,体会两种方式的特点。 3、实验教学重点 本课程的实验教学重点包括:⑴数据库的模式设计;⑵SQL的数据查询; ⑶并发控制、恢复、完整性和安全性实现机制;⑷简单数据库应用系统的设计实现; 实验1:数据库的创建 击实试验作业指导书 7.3.1试验目的:通过轻型击实和重型击实,确定该土最大干密度和最佳含水量。 7.3.2 依据标准:《公路土工试验规程》(JTG E40-2007) 7.3.3 仪器设备 标准击实仪 烘箱及干燥器 天平台秤感量 圆孔筛 拌和工具 金属盘 土铲 喷水设备 碾土器 盛土盘 量筒 推土器 铝盒 修土刀 平直尺等。 7.3.4 本试验可分别采用不同的方法准备试样: 1、干土法(土重复使用)将具有代表性的风干或在50℃温度下烘干的土样放在橡皮板上,用圆木棍碾散,然后过不同孔径的筛(视粒径大小而定)。对于小试筒,按四分法取筛下的土约3kg,对于大试筒,同样按四分法取样约6.5kg。 估计土样风干或天然含水量,如风干含水量低于开始含水量太多时,可将土样铺于一不吸水的盘上,用喷水设备均匀地喷洒适当用量的水,并充分拌和,闷料一夜备用。 2、干土法(土不重复使用)按四分法至少准备5 个试样,分别加入不同水份(按2-3%含水量递增),拌匀后闷一夜备用。 3、湿土法(土不重复使用)对于高含水量土,可省略过筛步骤,用手拣除大于38mm的粗石子即可。保持天然含水量的第一个土样,可立即用于击实试验。其余几个试样,将土分成小土块,分别风干,使含水量按2-3%递减。 7.3.5 试验步骤: 1、根据工程要求,按规定选择轻型或重型试验方法。根据土的性质(含易击碎风化石数量多少,含水量高低),按规定选用干土法(土重复或不重复使用)或湿土法。 2、将击实筒放在坚硬的地面上,取制备好的土样分3-5次倒入筒内。小筒按三层法时,每层约800-900g(其量应使击实后的试样等于或略高于筒高的1/3);按五层法 管理统计学综合训练二统计分析报告(判断男生成绩与女生成绩是否有显著性差异) 专业班级:经济14-2班 指导教师: 王宏新 小组成员:宋佳玉林曼雪 潘香宇刘月 刘晓东刘子楗刘志强 时间:2016 年5月 分数: 一、训练要求与考查内容 1、训练要求:搜集某一个学期某个班级全部学生所学的全部学科的成绩,利用SPSS 软件进行处理,给出一个完整的统计分析报告。 2、考察内容:区间估计和假设检验知识单元 二、涉及的知识点回顾 (一)区间估计 1、两个总体均值差的区间估计 若随机变量)(~),(~2 2222 111σμσμ,,X X , (1)方差已知 经标准化后两个总体平均数之差服从标准正态分布,即 则两个总体平均数之差(μ1-μ2)在(1-α)置信水平下的双侧置信区间为 。 (2)方差未知(教材P 117,,不进行详细说明) ○1σ12=σ22,则两个总体平均数之差经标准化后服从自由度为(n 1+n 2-2)的t 分布; ○ 2σ12 ≠σ22,则两个总体平均数之差经标准化后近似服从自由度为v 的t 分布。 最终得到两个总体均值差的置信区间若是包含“0”,则认为两个总体之间不存在显著性差异,反之,若不包含“0”,则认为两个总体之间存在显著性差异。 2、两个总体方差比的区间估计 在总体均值μ1与μ2未知的情况下,)(~),(~2 2222 111σμσμ,,X X , 两个总体方差比服从 , 所以得到两个总体方差之比在1-α置信水平下的双侧置信区间为 ) 1,0(~) ()(2 2 2 1 2 1 2121N n n x x z σσμμ+ ---= 22 21212 21212221212 21)()()(n n z x x n n z x x σσμμσσαα ++-≤-≤+--)1,1(~//212 2 212 2 21--=n n F S S F σσ 实验报告 ——(关于小麦品种对小麦产量显著性影响的分析研究) 班级:09工商2班组长:tjs学号:09513285成绩: 小组成员姓名: tjs 09513285 wdh 09513286 ww 09513287 wj 09513288 一、实验目的与意义 本文运用单因素方差分析的统计方法对小麦品种对小麦产量是否具有显著性影响进行实证研究,经过数据分析得出了不同小麦品种对小麦产量具有显著性影响的结论。 二、实验内容 1、为了研究不同的小麦品种对小麦的产量是否有显著性影响,我们选取三个小麦品种:品种1、品种 2、品种3并且对每个品种选取四个地块的产量作为观测值。设三个品种总体均值分别为μ1 μ2 μ3 提出假设:H0 :μ1 =μ2 =μ3 总体均值完全相等,自变量对因变量没有显著性影响。 H1 :μ1 μ2 μ3总体均值不完全相等,自变量对因变量有显著性影响 设置显著性水平为0.05 其数据结构如下: 2、运用spss软件进行数据处理,以下是具体操作过程 (1)选择[Analyze]=>[Compare Means]=>[One-Way ANOVA...],打开[One-Way ANOVA]主对 话框(如图所示)。 (2)从主对话框左侧的变量列表中选定小麦产量[var01],单击按钮使之进入[DependentList]框,再选定变量小麦品种[var02],单击按钮使之进入[Factor]框。单击[OK]按钮完成。 (3)生成统计结果如下: 3、结果分析 根据上面的计算结果,SS为离差平方和; df为自由度;MS为均方;F为检验的统计量;Sig=0.009 为P 值。我们直接运用计算出的P值与显著性水平α的进行比较,若P>α则不能拒绝原假设H0;若P<α则拒绝原 假设H0 ;在本题中,P=0.009<α=0.05 所以拒绝原假设H0 即小麦品种对产量有显著性影响。 信息工程学院 数据库原理实验指导书二零一六年五月 目录 实验一SQL SERVER 2005的安装与启动 (1) 实验二数据库的操作 (11) 实验三SQL SERVER2005查询编辑器 (23) 实验四SQL语言的DDL (31) 实验五SQL语言的DML初步 (34) 实验六DML的数据查询 (36) 实验七数据库综合设计 (40) 实验一SQL Server 2005的安装与启动 一、实验目的 SQL Server 2005是Mircosoft公司推出的关系型网络数据库管理系统,是一个逐步成长起来的大型数据库管理系统。 本次实验了解SQL Server 2005的安装过程,了解SQL Server 2005的启动,熟悉SQL Server 2005软件环境。学会安装SQL Server 2005。 二、实验内容 1.安装SQL Server 2005 (1)将SQL Server 2005(中文开发版)安装盘插入光驱后,SQL Server 2005安装盘将自动启动安装程序;或手动执行光盘根 目录下的Autorun.exe文件,这两种方法都可进行SQL Server 2005的安装。出现如下画面。 (2)选中“运行SQL Server Client 安装向导”进行安装,弹出【最终用户许可协议】界面。 (3)选中【我接受许可条款和条件】选项,单击【下一步】按钮,进入【安装必备组件】界面。 (4)组件安装完成后,单击【下一步】按钮,进入【欢迎使用Microsoft SQL Server 安装向导】界面。 (5)单击【下一步】按钮,进入【系统配置检查】界面。检查完毕将显示检查结果。 (6)检查如果没有错误,单击【下一步】按钮,进入【注册信息】界面。 无机结合料稳定土的击实试验方法作业指导书 1 目的和适用范围 1.1本试验法适用于在规定的试筒内,对水泥稳定土(在水泥水化前)、石灰稳定土及石灰(或水泥)粉煤灰稳定土进行击实试验,以绘制稳定土的含水量-干密度关系曲线,从而确定其最佳含水量和最大干密度。 1.2试验集料的最大粒径宜控制在25mm以内,最大不得超过40mm (圆孔筛)。 1.3试验方法类别。本试验方法分三类,各类击实方法的主要参数列于表T0804-1中。 表T0804-1试验方法类别 类别锤的 质量 (kg ) 锤击 面 直径 (cm) 落高 (c m) 试筒尺寸 锤 击 层 数 每层 锤 击次 数 平均 单位 击实 功 容许 最大 粒径 (mm ) 内 径 (c m) 高 (c m) 容积 (cm3 ) 甲 4.5 5.0 45 10 12.7 997 5 27 2.687 25 乙 4.5 5.0 45 15.2 12.0 2177 5 59 2.687 25 丙 4.5 5.0 45 15.2 12.0 2177 3 98 2.687 40 2 仪器设备 2.1击实筒:小型,内径100mm,高127mm的金属圆筒,套环高50mm,底座;中型,内径152mm、高170mm的金属圆筒,套环高50mm,直径151mm和高50mm的筒内垫块,底座; 2.2击锤和导管:击锤的底面直径50mm,总质量为4.5kg。击锤在导管内的总行程为450mm。 2.3天平:感量0.01g。 2.4台秤:称量15kg,感量5g。 2.5圆孔筛:孔径40mm、25mm或20mm以及5mm的筛各一个。 2.6量筒:50mL、100mL和500mL的量筒各1个。 2.7直刮刀:长200~250mm、宽30mm和厚3mm,一侧开口的直刮刀,用以刮平和修饰粒料大试件的表面。 2.8刮土刀:长150~200mm、宽约20mm的刮刀。用以刮平和修饰小试件的表面。 2.9工字型刮平尺:30mm×50mm×310mm,上下两面和侧面均刨平。 2.10拌和工具:约400mm×600mm×70mm,的长方形金属盘,拌和用平头小铲等。 2.11脱模器。 2.12测定含水量用的铝盒、烘箱等其它用具。 3 试料准备 将具有代表性的风干试料(必要时,也可以在50℃烘箱内烘干)用木锤或木碾捣碎。土团均应捣碎到能通过5mm的筛孔。但应注意不使粒料的单个颗粒破碎或不使其破碎程度超过施工中拌和机械的破 数据管理 一、实验目的与要求 1.掌握计算新变量、变量取值重编码的基本操作。 2.掌握记录排序、拆分、筛选、加权以及数据汇总的操作。 3.了解数据字典的定义和使用、数据文件的重新排列、转置、合并的操作。 二、实验内容提要 1.自行练习完成课本中涉及的对CCSS案例数据的数据管理操作 2.针对SPSS自带数据Employee data.sav进行以下练习。 (1)根据变量bdate生成一个新变量“年龄” (2)根据jobcat分组计算salary的秩次 (3)根据雇员的性别变量对salary的平均值进行汇总 (4)生成新变量grade,当salary<20000时取值为d,在20000~50000范围内时取值为c,在50000~100000范围内取值为b,大于等于100000时取值为a 三、实验步骤 1、针对CCSS案例数据的数据管理操作 1.1.计算变量,输入TS3到目标变量,在数字表达式中输入3,把任意年龄段分成三个组20-30设为1组,1-40设为2组41-50设为3组。图1, 图1 1.2.对已有变量的分组合并,在“名称”文本框中输入新变量名TS3单击“更改”按钮,原来的S3->?就会变为S3->TS3,单击“旧值和新值”按钮,系统打开“重新编码到其他变量:旧值和新值”,如下图2, 图2 图3 1.3.可视离散化,选择“转换”->“可视离散化”,打开的对话框要求用户选择希望进行离散化的变量,单击继续,如下图4, 图4 单击“生成分割点”,设定分割点数量为10,宽度为5,第一个分割点位置为18,单击“应用”,如下图, 图5 结果显示如下, 实验报告 课程名称统计学学号 11学生姓名辅导教师 系别经济与管理系实验室名称实验时间 1.实验名称 统计指数分析 2.实验目的 掌握各项指数的计算及因素分析法的运用。 在 Excel 中完成各项指数及有关数值的计算,主要用到的是公式和公式复制 3.实验内容 甲乙丙三种商品基期和报告期各项数据如下: 价格(元) P销量 q 商品计量单位 基期 p0报告期 p1基期 q0报告期 q1 甲个302810001200 乙双202120001600 丙公斤232515001500 合计 1)计算三种商品的个体销售量指数和个体价格指数。 2)三种商品的销售额总指数。 3)三种商品的销售量总指数和价格总指数。 4)分析销售量变动和价格变动对销售额影响的绝对额。(这一问分析要手写完成) 4.实验原理 在 Excel 中实现综合指数及其相关数值的计算,主要用到的是公式和公式的复制功 能 5.实验过程及步骤 (1)在工作表中输入已知数据的名称和数值(包括商品名称,计量单位,基期价格,报告 期价格,基期销售量和报告期销售量) (2)计算综合指标的各个综合总量在单元格G4中输入公式“ =C4*E4”,在H4中输入“=D4*F4”, 在 I4 中输入“ =C4*F4”, 在 J4 中输入“ =D4*E4”, 公式复制 在 A7 中输入合计,在单元格中输入“=SuM(G4:G6),再将单元格 G7的公式向右复制到 J7 (3)分别计算各个综合指标及其分子分母之差额 在单元格 A10 中输入“销售额总额指数” ,在单元格 F10 中输入公式“ =H7/G7*100” , 在单元格 H10 中输入公式” =H7-G7” 数据库实验指导书 (试用版) 二零零六年三月 目录 引言 1 一、课程实验目的和基本要求 1 二、主要实验环境 1 三、实验内容 1 实验1 数据库模式设计和数据库的建立 2 一、教学目的和要求 2 二、实验内容 2 三、实验步骤 2 四、思考与总结 3 实验2 数据库的简单查询和连接查询 4 一、教学目的和要求 4 二、实验内容 4 三、实验步骤 4 四、思考与总结 5 实验3 数据库的嵌套查询和组合统计查询 6 一、教学目的和要求 6 二、实验内容 6 三、实验步骤 6 四、思考与总结 7 实验4 视图与图表的定义及数据完整性和安全性 8 一、教学目的和要求 8 二、实验内容 8 三、实验步骤 8 四、思考与总结 9 实验5 简单应用系统的实现 10 一、教学目的和要求 10 二、实验内容 10 三、实验步骤 10 四、思考与总结 10 附录1:数据库实验报告格式 11 附录2:SQL Server 2000使用指南 12 1 SQL Server 2000简介 12 2 SQL Server 2000的版本 12 3 SQL Server 2000实用工具 12 4 创建数据库 15 5 创建和修改数据表 17 6 创建索引 22 7 存储过程 23 8 触发器 25 9 备份和恢复 27 10 用户和安全性管理 28 引言 数据库技术是一个理论和实际紧密相连的技术,上机实验是数据库课程的重要环节,它贯穿于整个―数据库阶段‖课程教学过程中。 一、课程实验目的和基本要求 上机实验是本课程必不可少的实践环节。学生应在基本掌握各知识点内容的基础上同步进行相关实验,以加深对知识的理解和掌握,达到理论指导实践,实践加深理论的理解与巩固的效果。 数据库课程上机实验的主要目标是: 通过上机操作,加深对数据库系统理论知识的理解。 通过使用具体的DBMS,了解一种实际的数据库管理系统,并掌握操作技术。 通过实际题目的上机实验,提高动手能力,提高分析问题和解决问题的能力。 实验在单人单机的环境下,在规定的时间内,由学生独立完成。出现问题时,教师要引导学生独立分析、解决,不得包办代替。 上机总学时不少于12学时。 二、主要实验环境 操作系统为Microsoft Windows 2000/XP。 数据库管理系统可以选择:(1)Microsoft SQL Server 2000标准版或企业版 (2)Microsoft Access2000 (3)金仓数据库KingbaseES。 三、实验内容 本课程实验主要包括数据库的模式设计,数据库、表、视图、索引的建立与数据的更新;关系数据库的查询,包括连接查询、嵌套查询、组合查询等;数据库系统的实现技术,包括事务的概念及并发控制、完整性和安全性实现机制;简单数据库应用系统的设计与实现。实验1 数据库模式设计和数据库的建立 一、教学目的和要求 根据一个具体应用,独自完成数据库模式的设计。 熟练使用SQL语句创建数据库、表、索引和修改表结构。 熟练使用SQL语句向数据库输入数据、修改数据和删除数据的操作。 二、实验内容 对实际应用进行数据库模式设计(至少三个基本表)。回弹模量试验作业指导书
管理统计学试验指导书和答案
管理统计学--实验二-spss
#(16课时)数据库实验指导书
击实试验实施细则
管理统计学报告
福建工程学院《实验指导书(数据库系统原理及应用)》
试验室资质评审无机结合料稳定材料试验作业指导书
统计学实验报告
土的击实试验培训
管理统计学
数据库实训指导书
击实试验作业指导书 (2)
管理统计学综合训练二分析报告
[管理学]统计学实验报告
2016数据库原理实验指导书
无机结合料稳定土的击实试验方法作业指导书
管理统计学SPSS数据管理 实验报告
统计学实验报告7.统计指数分析.docx
数据库实验指导书
相关主题
文本预览