
范式
就关系数据库而言,一贯认为:从其他元素中消除数据冗余问题,去除重复往往以减少冗余, 从特定的表中最小化冗余意味着摆脱不必要的数据。
商业上来讲,主要目标是通常保存空间和组织的数据可用性和可管理性,而不牺牲性能。此外,要求强烈繁忙的应用程序和最终用户的需要往往需要以多种方式打破规则的范式,以满足性能要求。第三范式以外的范式常常被忽视和有时甚至是第三范式本身就是多余的。
范式是一个升级的过程,每个上层的模式都是建立在下一级范式之上的。
消除数据冗余的影响如下:
?物理空间需要存储的数据减少。
?数据变得更有组织。
?范式化允许修改少量的数据(即单记录)。换言之,一个表的具体字段记录更新时,会影响其他引用他的表。
首先我们对一些概念性的东西来进行一个总结,通过对这些概念的理解,从来从根本上做到合理的数据库设计:
异常
●添加异常:当我们添加一条记录的时候,他依赖的主表记录还没有记录,而该记录
已经插入成功。
●删除异常:当我们的主表记录删除,而依赖他的子表没有清空对应的记录。
●更新异常:当我们的主表记录有更新草组,而已来他的子表没有相应的更新记录。依赖,决定因子
●函数依赖:当Y的值由X决定的时候,我们就说Y函数依赖于X,这就类似于一个
线性方程:Y=X+1;类似的ERD图中,我们这样表示,很清楚的看
到表Category,中的主键是CategoryID,他决定着其他字段的值Name和Pic,
我们就说Name或者Pic 函数依赖于CategoryID,他们之间就是一个函数依赖关
系。
●决定因素:如上例中,CategoryID就是一个决定因素,他决定其他字段的值,Y=X
+1中,X就决定着Y的值,虽然加了一个常量。
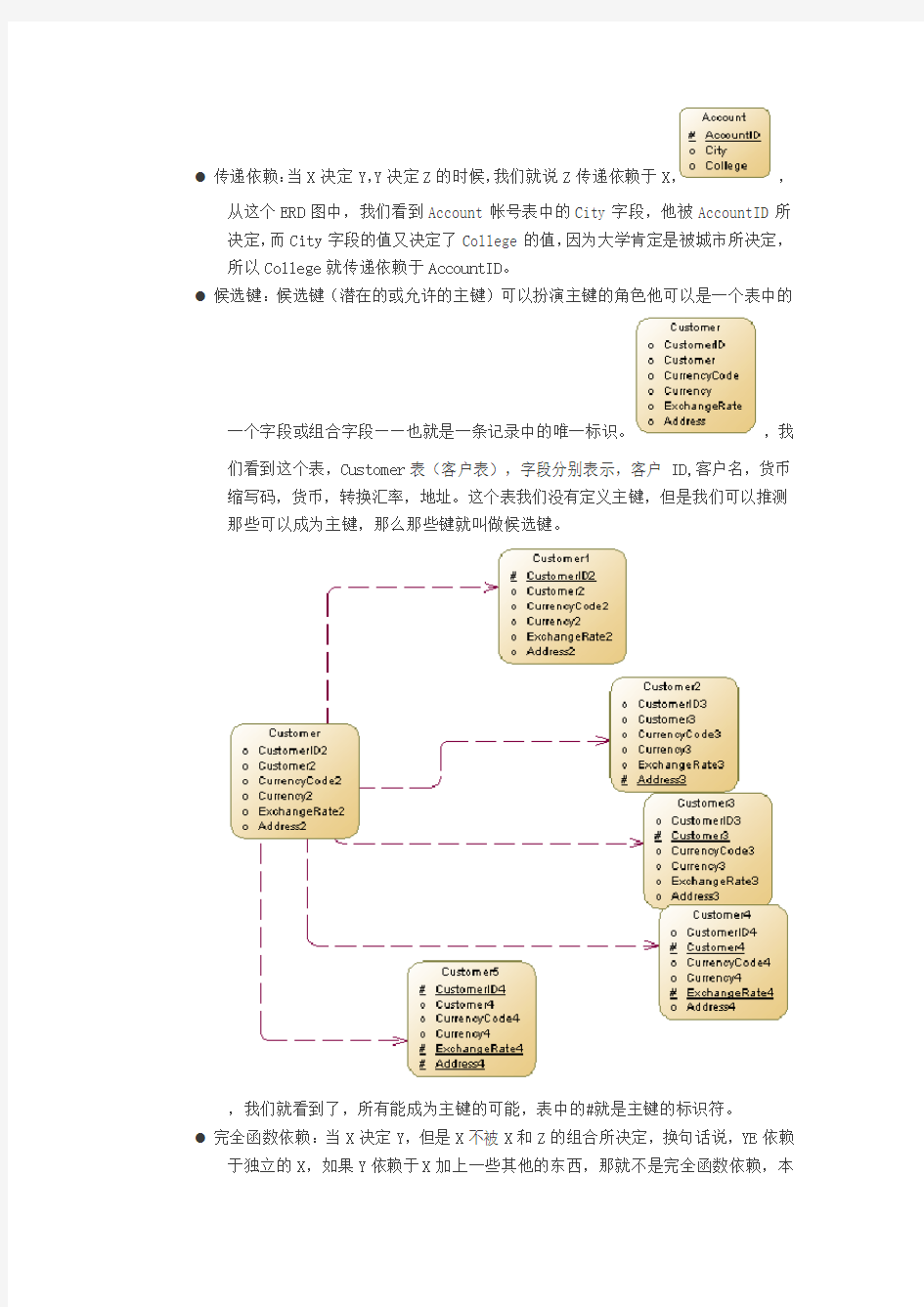
●传递依赖:当X决定Y,Y决定Z的时候,我们就说Z传递依赖于X,,
从这个ERD图中,我们看到Account帐号表中的City字段,他被AccountID所决定,而City字段的值又决定了College的值,因为大学肯定是被城市所决定,所以College就传递依赖于AccountID。
●候选键:候选键(潜在的或允许的主键)可以扮演主键的角色他可以是一个表中的
一个字段或组合字段——也就是一条记录中的唯一标识。,我们看到这个表,Customer表(客户表),字段分别表示,客户ID,客户名,货币缩写码,货币,转换汇率,地址。这个表我们没有定义主键,但是我们可以推测那些可以成为主键,那么那些键就叫做候选键。
,我们就看到了,所有能成为主键的可能,表中的#就是主键的标识符。
●完全函数依赖:当X决定Y,但是X不被X和Z的组合所决定,换句话说,YE依赖
于独立的X,如果Y依赖于X加上一些其他的东西,那就不是完全函数依赖,本
质上,决定因素X不能是一个组合键。,我们来看到旅游表Tra
vel,Country是旅游的国家,Populication是旅游的城市,同时TravelID和C
ountryID是主键,可以看出来只有CountryID决定着Populcation人口,但是
这里有两个主键,所以Populication并没有完全函数依赖于主键组合,只部分
依赖于CountryID
●多值依赖:某个字段中的值之一个集合,或者是用某种分隔符分割开来的元素集合,
我们就称为多值依赖。很经典的,Path保存的这个递归表的所
有上司的级别,比如老大的ID是1,老2是2,Path 就保存1,2,像这样的字
段,我们就称为多值依赖。
●循环依赖:循环依赖就如其名,是一个个闭环的依赖系统。A依赖于B,B依赖于C,
C依赖于A。
范式(学术定义)
●第一范式(1NF):消除表中所有重复的记录,除了主键以外的所有其他字段全部依
赖于主键。
●第二范式(2NF):所有非键值字段必须全部完全函数依赖于主键,当一个字段完
全函数依赖于一组组合主键的部分函数依赖是不允许的。
●第三范式(3NF):消除传递依赖,意味着一个字段必须非间接的依赖于主键
●正规化范式(BCDF):所有表中的决定因素必须是一个候选键,如果只有一个候选
键,那么就和第三范式是一样的。
●第四范式(4NF):消除多值依赖。
●第五范式(5NF):消除循环依赖。
我们从一个比较容易的位置来理解范式,通过上述的理解,加上实际的操作范式,让我们对数据库的设计有一个比较深的认识,以决定什么情况下用范式。
●第一范式(1NF):通过创建一个新表来移除重复的元素,使他们成为一个主从关系
或者是one to many的关系,类似下图:
。
●第二范式(2NF):建立在1NF的基础上,就是移除重复的值到一个新表中去,新
表有唯一的主键,而主表有一个对新表的外键的引用,排除存在的部分依赖。
如下图:
Boo kid 是book表的主键,而author是author1的主键,在book表中建立author,主表有一个对子表的外键引用,而不是把author也定义为主键,那样就存在部分函数依赖,因为bookid就已经确定了title,page,isbn等等信息。
●第三范式:消除传递依赖,如下图:
我们把多对多的关系变化成上图的关系。这是一种简单的形式,下面展示一个另外一种情况:
这里的表分别是客户(客户名,货币号,货币,货币,汇率,地址),提供商(客户名,货币号,货币,汇率,地址)。首先他们的地址决定了他们的货币情况,而地址又是由客户或者提供商决定的,所以他们之间存在一个传递依赖关系,而且最好是把相同的存在于不同的数据移植到一个新表中去。前面我们提到了
这个关系,也是一个不满足第三范式的表,City和College以及主键存在传递关系,所以可以把College移植到一个新表中去,
还有一些存在订单的表中,有类似(qty(数量),price(单价),total(总价))的结构,qty和price决定了total,而订单号决定了qty和,price,所以也存在一中依赖关系,我们要删除total字段,但是不是都遵循范式的表都是好的结构,我们还是要根据实际情况,比如在一个数据仓库的设计中,汇总字段就是必须的。
●超三范式(Beyond 3NF)中的one to one关系,这个主要用户当我们表中一些字
段经常存在空值的时候,我们将存在的NULL字段移到一个新表中去,然后建立1对1的关系。
●BCNF范式:BCNF划分成多个表的表格,以确保没有一个单一的表有更多不止一个
潜在的主键。这是我的理解BCNF 。在我看来,是BCNF 用于商业环境是“过度设计“的。从本质上讲,从数学的角度上它的漂亮,但在商业环境中它不是很酷。
下面的例子是一个BCNF转换:
●第四范式:消除多值依赖,很经典的一个环境就是,我们的递归表问题
,一个Manager有多个Employee,然后每条记录都有一个Path 老表示这种关系,所以path和EmployeeId就存在一个多对多的关系。我们就应该重新建立一个新表,用来消除Path字段,新表中就保留一个EmployeeId作为外键,另外一个EmployeeId用来表示他的下属。
●消除循环依赖,如下图:
在这个实例中Solution表中的键都是主键,他们存在这样的关系,每两个组合的主键决定另外一个主键。比方项目1和经理1就决定了有哪些下属属于项目1和经理1关系,而
一个经理1和他的下属员工又决定了他们参与了那些项目。所以他们之间其实是一个循环的依赖。
反范式:
●这种类型的应用在商业正常化环境将导致业绩不佳,更精确的数学的必要性比
商业要低的多。因此:
●同样的,对于第4范式,我们很多时候都没有必要去消除他们里面多值的依赖,
那样对性能来说简直是个噩梦。所以很多情况下,我们都是用类似的处理
CSDN上的,显示自己的技术就是这样的反范式化转换。
●在商业环境中,绝大多数超越第3范式的设计都是不切实际的。因为应用程序
在3NF级别就能变现的相当出色。我们上述的很多例子,将指向箭头反过来
就是先了反范式化。所以我们要对整体的结构有个比较深的认识,才确定我
们是否范式话或者反范式化,范式化越深的东西越导致表的增多,也就意味
着查询的join开销。
●总结一下反范式化的一些准则:
?分离活动和静态的数据,数据可分为独立的物理表,即
?活动和静态表。那些累计的历史数据导致我们占据了绝大多数的空间。这
是影响性能的最经常的数据,在数据仓库设计中,我们经常将无效的静
态的数据移植到数据仓库中,由于OLAP和数据挖掘。
?在表之间复制字段,在那些不是直接有链接表的之间复制字段,使得我们
不必每次进行查询都要通过第3方表,越少的join操作,使得性能的
大幅度提升。
?在夫表中建立统计字段,这样可以减去消耗大的聚合操作,但是实时更新
会给我们带来另外的麻烦。
?分离繁重和轻松的字段,就像把活动和静态的数据数据表分离一样,这个
避免持续物理扫描很少使用的数据字段,尤其是当这些字段不包含空值。
这是一个潜在的合理利用4NF在分离表格分为两个表格,相关的一对一
关系。
数据库三大范式说明 数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。 实质上,设计范式用很形象、很简洁的话语就能说清楚,道明白。本节课将对范式进行通俗地说明,以一个简单论坛的数据库为例来讲解怎样将这些范式应用于实际项目中。 范式说明: 第一范式(1NF): 数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。 很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。 第二范式(2NF): 数据库表中不存在非关键字段对任一候选关键字段的部分函数依赖(部分函数依赖指的是存在组合关键字中的某些字段决定非关键字段的情况),也即所有非关键字段都完全依赖
于任意一组候选关键字。 假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系: (学号, 课程名称) →(姓名, 年龄, 成绩, 学分) 这个数据库表不满足第二范式,因为存在如下决定关系: (课程名称) →(学分) (学号) →(姓名, 年龄) 即存在组合关键字中的字段决定非关键字的情况。 由于不符合2NF,这个选课关系表会存在如下问题: (1) 数据冗余: 同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。 (2) 更新异常: 若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。 (3) 插入异常: 假设要开设一门新的课程,暂时还没有人选修。这样,由于还没有"学号"关键字,课程名称和学分也无法记录入数据库。 (4) 删除异常: 假设一批学生已经完成课程的选修,这些选修记录就应该从数据库表中删除。但是,与此同时,课程名称和学分信息也被删除了。很显然,这也会导致插入异常。 把选课关系表SelectCourse改为如下三个表: 学生:Student(学号, 姓名, 年龄); 课程:Course(课程名称, 学分); 选课关系:SelectCourse(学号, 课程名称, 成绩)。 这样的数据库表是符合第二范式的,消除了数据冗余、更新异常、插入异常和删除异常。 另外,所有单关键字的数据库表都符合第二范式,因为不可能存在组合关键字。
范式 就关系数据库而言,一贯认为:从其他元素中消除数据冗余问题,去除重复往往以减少冗余, 从特定的表中最小化冗余意味着摆脱不必要的数据。 商业上来讲,主要目标是通常保存空间和组织的数据可用性和可管理性,而不牺牲性能。此外,要求强烈繁忙的应用程序和最终用户的需要往往需要以多种方式打破规则的范式,以满足性能要求。第三范式以外的范式常常被忽视和有时甚至是第三范式本身就是多余的。 范式是一个升级的过程,每个上层的模式都是建立在下一级范式之上的。 消除数据冗余的影响如下: ?物理空间需要存储的数据减少。 ?数据变得更有组织。 ?范式化允许修改少量的数据(即单记录)。换言之,一个表的具体字段记录更新时,会影响其他引用他的表。 首先我们对一些概念性的东西来进行一个总结,通过对这些概念的理解,从来从根本上做到合理的数据库设计: 异常 ●添加异常:当我们添加一条记录的时候,他依赖的主表记录还没有记录,而该记录 已经插入成功。 ●删除异常:当我们的主表记录删除,而依赖他的子表没有清空对应的记录。 ●更新异常:当我们的主表记录有更新草组,而已来他的子表没有相应的更新记录。依赖,决定因子 ●函数依赖:当Y的值由X决定的时候,我们就说Y函数依赖于X,这就类似于一个 线性方程:Y=X+1;类似的ERD图中,我们这样表示,很清楚的看 到表Category,中的主键是CategoryID,他决定着其他字段的值Name和Pic, 我们就说Name或者Pic 函数依赖于CategoryID,他们之间就是一个函数依赖关 系。 ●决定因素:如上例中,CategoryID就是一个决定因素,他决定其他字段的值,Y=X +1中,X就决定着Y的值,虽然加了一个常量。
数据库三范式 1.1 第一范式(1NF)无重复的列 所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。 说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 1.2 第二范式(2NF)属性完全依赖于主键[消除部分子函数依赖] 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是属性完全依赖于主键。 1.3 第三范式(3NF)属性不依赖于其它非主属性[消除传递依赖] 满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主关键字信息。例如,存在一个部门信息表,其中每个部门有部门编号(dept_id)、部门名称、部门简介等信息。那么在的员工信息表中列出部门编号后就不能再将部门名称、部门简介等与部门有关的信息再加入员工信息表中。如果不存在部门信息表,则根据第三范式(3NF)也应该构建它,否则就会有大量的数据冗余。简而言之,第三范式就是属性不依赖于其它非主属性。 II、范式应用实例剖析 下面以一个学校的学生系统为例分析说明,这几个范式的应用。首先第一范式(1NF):数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS 中设计出不符合第一范式的数据库都是不可能的。 首先我们确定一下要设计的内容包括那些。学号、学生姓名、年龄、性别、课程、
范式分解 主属性:包含在任一候选关键字中的属性称主属性。 非主属性:不包含在主码中的属性称为非主属性。 函数依赖: 是指关系中一个或一组属性的值可以决定其它属性的值。函数依赖正象一个函数 y = f(x) 一样,x的值给定后,y的值也就唯一地确定了。 如果属性集合Y中每个属性的值构成的集合唯一地决定了属性集合X中每个属性的值构成的集合,则属性集合X函数依赖于属性集合Y,计为:Y→X。属性集合Y中的属性有时也称作函数依赖Y→X的决定因素(determinant)。例:身份证号→姓名。部分函数依赖: 设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。 完全函数依赖: 在R(U)中,如果Y函数依赖于X,并且对于X的任何一个真子集X',都有Y不函数依赖于X',则称Y对X完全函数依赖。否则称Y对X部分函数依赖。
【例】; 举个例子就明白了。假设一个学生有几个属性 SNO 学号 SNAME 姓名 SDEPT系 SAGE 年龄 CNO 班级号 G 成绩 对于(SNO,SNAME,SDEPT,SAGE,CNO,G)来说,G完全依赖于(SNO, CNO), 因为(SNO,CNO)可以决定G,而SNO和CNO都不能单独决定G。 而SAGE部分函数依赖于(SNO,CNO),因为(SNO,CNO)可以决定SAGE,而单独的SNO也可以决定SAGE。 传递函数依赖: 设R(U)是属性集U上的关系,x、y、z是U的子集,在R(U)中,若x→y,但y→x,若y→z,则x→z,称z传递函数依赖于x,记作X→TZ。 如果X->Y, Y->Z, 则称Z对X传递函数依赖。 计算X+ (属性的闭包)算法: a.初始化,令X+ = X; b.在F中依次查找每个没有被标记的函数依赖,若“左边属性集”包含于X+ ,则令X+ = X+∪“右边属性集”, 并为访问过的函数依赖设置标记。
设计数据表: a)发现领域中的概念,理清领域中概念之间的关系,将其映射成表 b)尽量遵循数据库设计范式 1. 第一范式:有主键,具有原子性,列不可分割 2. 第二范式:完全依赖,没有部分依赖 3. 第三范式:没有传递依赖 c)主键设计最好采用单一主键,最好不要采用复合主键,尽量使用没有业务语段作为主键(如:Oracle的Sequence来维护一个主键),主键一般建议使用数值型,提高检索效率 d)最好假如外键约束(在开发阶段最好不要设置外键约束,运行阶段加上外键约束) e)关于冗余字段的问题,应该根据需求的具体情况是否加入 f)如果做通用性产品,最好不是使用数据库特性的功能,除非特殊情况。 g)如果数据量非常大,并且频繁的根据相关字段查询,最好建立索引。 范式标准: 基本表及字段之间的关系,应尽量满足第三范式。但是,满足第三范式的数据库设计,往往不是最好的设计。为了提高数据库的运行效率,常常需要降低范式标准:适当增加冗余,达到空间换时间的目的。 实例:有一张存放商品的基本表,如表1所示。“金额”这个字段的存在,表明该表的设计不满足第三范式,因为“金额”可以由“单价”乘以“数量”得到,说明“金额”是冗余字段。但是,增加“金额”这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。 在Rose 2002中,规定列有两种类型:数据列和计算列。“金额”这样的列被称为“计算列”,而“单价”和“数量”这样的列被称为“数据列”。 表1 商品表的表结构 商品名称商品型号单价数量金额 电视机29吋2,500 40 100,000 主键与外键: 当全局数据库的设计完成以后,有个美国数据库设计专家说:“键,到处都是键,除了键之外,什么也没有”,这就是他的数据库设计经验之谈,也反映了他对信息系统核心(数据模型)的高度抽象思想。因为:主键是实体的高度抽象,主键与外键的配对,表示实体之间的连接。
1:Redundancy(冗余),可能带来的问题:冗余存储(redundant storage),插入/删除/更新异常(insert/delete/update anomalies) 冗余来源于完整性约束(Integrity constraints), 特别是函数依赖(functional dependencies) 2:函数依赖(functional dependency简写为FD)的定义:在一个关系模式R的所有关系实例中任取两个元组,如果他们的X属性的投影完全相同,则Y一定相同,则有X决定Y,或称Y依赖于X,用关系代数表示为: for every allowable instance r of R: 例:Hourly_Emps (ssn, name, lot, rating, hrly_wages, hrs_worked),以下简写为Hourly_Emps(SNLRWH),的一个函数依赖为:S--> SNLRWH 3:关于函数依赖的三个定理及两个推论: Armstrong’s Axioms: 自反律: 如果Y X,则有X—>Y 增广律: 如果X→Y,则对于任意的Z有XZ→YZ 传递律: 如果X→Y and Y→Z,则X→Z 推论: 两个推论的证明: (1):Union:可以直接使用定义证明。设r是R的任意一个关系,s,t是r的任意两个元组,若s[X]=t[X],由X→Y可得s[Y]=t[Y],
由X→Z可得s[Z]=t[Z],则有s[YZ]=t[YZ],即当s[X]=t[X]时一定可以得到s[YZ]=t[YZ],则根据函数依赖的定义可以有X→YZ。 (2):Decomposition: Y?YZ,由自反律得YZ→Y,又X→YZ,由传递律得X→Y 同理可证X→Z。 4:函数依赖集的闭包: 5:属性闭包的定义: X的属性闭包记为+X,是一个属性集合,集合中的元素A要求 X→A 在函数依赖F的属性闭包中(求属性闭包要注意是在哪个函数依赖的基础上求的)。 6:计算属性闭包的算法: 为什么需要属性闭包:对于函数依赖闭包的求解是一个NP难度问题,经常不需要求一个函数依赖的属性闭包,而只需要判断一个函数依赖
数据库-部分函数依赖,传递函数依赖,完全函数依赖, 三种范式的区别 要讲清楚范式,就先讲讲几个名词的含义吧: 部分函数依赖:设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。 举个例子:学生基本信息表R中(学号,身份证号,姓名)当然学号属性取值是唯一的,在R关系中,(学号,身份证号)->(姓名),(学号)->(姓名),(身份证号)->(姓名);所以姓名部分函数依赖与(学号,身份证号); 完全函数依赖:设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。例子:学生基本信息表R(学号,班级,姓名)假设不同的班级学号有相同的,班级内学号不能相同,在R关系中,(学号,班级)->(姓名),但是(学号)->(姓名)不成立,(班级)->(姓名)不成立,所以姓名完全函数依赖与(学号,班级); 传递函数依赖:设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。 例子:在关系R(学号 ,宿舍, 费用)中,(学号)->(宿舍),宿舍!=学号,(宿舍)->(费用),费用!=宿舍,所以符合传递函数的要求;
在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 所谓第一范式(1NF)是指数据库表的每一列(即每个属性)都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。简而言之,第一范式就是无重复的列。 2、第二范式(2NF) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被唯一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是唯一的,因此每个员工可以被唯一区分。这个唯一属性列被称为主关键字或主键、主码。 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的唯一标识。简而言之,第二范式就是非主属性依赖于主关键字。
1、请简述满足1NF、2NF和3NF的基本条件。并完成下题:某信息一览表如下, 第一范式的关系应满足的基本条件是元组中的每一个分量都必须是不可分割的数据项。 第二范式,指的是这种关系不仅满足第一范式,而且所有非主属性完全依赖于其主码。 第三范式,指的是这种关系不仅满足第二范式,而且它的任何一个非主属性都不传递依赖于任何主关键字。 考生情况(考生编号,姓名,性别,考生学校) 考场情况(考场号,考场地点) 考场分配(考生编号,考场号) 成绩(考生编号,考试成绩,学分) 2、某信息一览表如下,其是否满足3NF,若不满足请将其化为符合3NF的关系。 配件关系:(配件编号,配件名称,型号规格) 供应商关系(供应商名称,供应商地址) 配件库存关系(配件编号,供应商名称,单价,库存量) 3、简述满足1NF、2NF和3NF的基本条件。并完成下题:已知教学关系, 教学(学号,姓名,年龄,性别,系名,系主任,课程名,成绩),试问该关系的主键是什么,属于第几范式,为什么?如果它不属于3NF,请把它规范到3NF。 4、请确定下列关系的关键字、范式等级;若不属于3NF,则将其化为3NF 。 例1.仓库(仓库号,面积,电话号码,零件号,零件名称,规格,库存数量)例1答案: 仓库号+零件号;1NF; 仓库(仓库号,面积,电话号码)
零件(零件号,零件名称,规格) 保存(仓库号,零件号,库存数量) 例2. 报名(学员编号,学员姓名,培训编号,培训名称,培训费,报名日期),每项培训有多个学员报名,每位学员可参加多项培训。 例2答案: 学员编号+培训编号;1NF; 学员(学员编号,学员姓名) 培训(培训编号,培训名称,培训费) 报名(学员编号,培训编号,报名日期) 5、请确定下列关系的关键字、范式等级;若不属于3NF,则将其化为3NF,要求每个关系写一条记录。 (部门编号,部门名称,所在城市,员工编号,员工姓名,项目编号,项目名称,预算,职务,加入项目的日期) [注]职务指某员工在某项目中的职务。 部门(部门编号,部门名称,所在城市) 员工(员工编号,员工姓名,部门编号) 项目(项目编号,项目名称,预算) 工作(员工编号,项目编号,职务,加入项目的日期)
什么是范式 简单的说,范式是为了消除重复数据减少冗余数据,从而让数据库内的数据更好的组织,让磁盘空间得到更有效利用的一种标准化标准,满足高等级的范式的先决条件是满足低等级范式。(比如满足2nf一定满足1nf) DEMO 让我们先从一个未经范式化的表看起,表如下: 先对表做一个简单说明,employeeId是员工id,departmentName是部门名称,job代表岗位,jobDescription是岗位说明,skill是员工技能,departmentDescription是部门说明,address是员工住址 对表进行第一范式(1NF) 如果一个关系模式R的所有属性都是不可分的基本数据项,则R∈1NF。 简单的说,第一范式就是每一个属性都不可再分。不符合第一范式则不能称为关系数据库。对于上表,不难看出Address是可以再分的,比如”北京市XX路XX小区XX号”,着显然不符合第一范式,对其应用第一范式则需要将此属性分解到另一个表,如下:
对表进行第二范式(2NF) 若关系模式R∈1NF,并且每一个非主属性都完全函数依赖于R的码,则R∈2NF 简单的说,是表中的属性必须完全依赖于全部主键,所以只有一个主键的表如果符合第一范式,那一定是第二范式,而不是部分主键。这样做的目的是进一步减少插入异常和更新异常。在上表中,departmentDescription是由DepartmentName所决定,但却不能由EmployeeID 决定,故要departmentDescription对主键是部分依赖,对其应用第二范式如下表: 对表进行第三范式(3NF)
关系模式R
数据库规范化三个范式应用实例 5. 通俗地理解三个范式 通俗地理解三个范式,对于数据库设计大有好处。在数据库设计中,为了更好地应用三个范式,就必须通俗地理解三个范式(通俗地理解是够用的理解,并不是最科学最准确的理解): 第一范式:1NF是对属性的原子性约束,要求属性具有原子性,不可再分解; 第二范式:2NF是对记录的惟一性约束,要求记录有惟一标识,即实体的惟一性; 第三范式:3NF是对字段冗余性的约束,即任何字段不能由其他字段派生出来,它要求字段没有冗余. 没有冗余的数据库设计可以做到。但是,没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是:在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。 规范化为什么重要?目前很多的数据库由于种种原因还没有被规范化。本文中解释了其中一些原因,并用不同形式的范式(normal form)规范化了一个保险公司的理赔表。在这个过程中表的改变以及添加的一些附加表使数据库效率更高、错误更少、更容易维护。 数据库的规范化是优化表的结构和把数据组织到表中的实践,这样做数据才能更明确。规范化使你能够改变业务规则、需求和数据而不需要重新构造整个系统。 通过改变存储数据的方式--仅仅改变一丁点--并改变访问这些信息的程序,你就可以消除很多错误或垃圾数据出现的机会并减轻更新信息所必要的工作量。 公司现实存在的一个问题可以用一句话概括"我们一般都这样做"。我们一般像采用那种方式存储信息;我们一般允许人们把任何信息写入
数据库范式(1NF 2NF 3NF BCNF)详解 数据结构设计模式编程制造 数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。 范式说明 1.1 第一范式(1NF)无重复的列 所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。 说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 包括整型、实数、字符型、逻辑型、日期型等。很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS 中设计出不符合第一范式的数据库都是不可能的。 1.2 第二范式(2NF)属性完全依赖于主键 [ 消除部分子函数依赖 ] 如果关系模式R为第一范式,并且R中每一个非主属性完全函数依赖于R 的某个候选键,则称为第二范式模式。 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键、主码。 例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。 简而言之,第二范式(2NF)就是非主属性完全依赖于主关键字。 所谓完全依赖是指不能存在仅依赖主关键字一部分的属性(设有函数依赖 W→A,若存在XW,有X→A成立,那么称W→A是局部依赖,否则就称W→A是完全函数依赖)。如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。 假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系: (学号, 课程名称) → (姓名, 年龄, 成绩, 学分)
第七章补充讲义一、式举例 例1:已知R,请问R为几式? BCNF。(25改成15还是BCNF.如:课程号与学号) 例2:已知R,请问R为几式? 2NF。有部分依赖。
例3:已知R,请问R为几式? BCNF。 例4:R(X,Y,Z),F={XY->Z},R为几式? BCNF。 例5:R(X,Y,Z),F={Y->Z,XZ->Y},R为几式? 3NF。R的候选码为{XZ,XY},(R中所有属性都是主属性,无传递依赖) 二、求闭包 数据库设计人员在对实际应用问题调查中,得到的结论往往是零散的、不规的(直观问题好办,复杂问题难办了),所以,这对分析数据模型,达到规化设计要求,还有差距,为此,从规数据依赖集合的角度入手,找到正确分析数据模型的方法,以确定关系模式的规化程度。 例1.已知关系模式R(U、F),其中,U={A,B,C,D,E}; F={AB→ C, B→ D, EC → B , AC→B} ,
求(AB)+F. 解:设X(0)=AB ○1计算X(1),在F中找出左边为AB子集的FD,其结果是:AB→C,B→D ∴X(1)=X(0)UB=ABUCD=ABCD 显然,X(1)≠X(0) ○2计算X(2),在F中找出左边为ABCD子集的FD,其结果是:C→E,AC→B ∴X(2)=X(1)UB=ABCDUBE=ABCDE 显然,X(2)=U 所以,(AB)+ F=ABCDE.(等于U,所以AB是唯一候选关键字) 例2.设有关系模式R(U、F),其中U={A,B,C,D,E,I};F={A→D,AB→E,B→E,CD→I,E→C},计算(AE)+ 解:令X={AE},X(0)=AE ○1在F中找出左边是AE子集的FD,其结果是:A→D,E→C ∴X(1)=X(0)UB=X(0)UDC=ACDE 显然,X(1)≠X(0) ○2在F中找出左边是ACDE子集的FD,其结果是:CD→I ∴X(2)=X(1)UI=ACDEI 显然,X(2)≠X(1),但F中未用过的函数依赖的左边属性已含有X(2)的子集,所以不必再计算下去,即(AE)+=ACDEI. 因为,X(3)=X(2),所以,算法结束。 三、求最小依赖集 最小依赖集是对函数依赖集合进行规的结果,这样才能对一般关系模式进行准确分析。 例1.设函数依赖集F={AB→CE,A→C,GP→B,EP→A,CDE→P,HB→P,D→HG,ABC→PG},求与F等价的最小函数依赖集。 解:○1将F中依赖右部属性单一化:
数据库三大范式详解 设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。 目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴德斯科范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。 第一范式(1NF)无重复的列 所谓第一范式(1NF)是指在关系模型中,对域添加的一个规范要求,所有的域都应该是原子性的,即数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。即实体中的某个属性有多个值时,必须拆分为不同的属性。在符合第一范式(1NF)表中的每个域值只能是实体的一个属性或一个属性的一部分。简而言之,第一范式就是无重复的域。 说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的设计基本要求,一般设计中都必须满足第一范式(1NF)。不过有些关系模型中突破了1NF的限制,这种称为非1NF的关系模型。换句话说,是否必须满足1NF的最低要求,主要依赖于所使用的关系模型。 第二范式(2NF)属性 在1NF的基础上,非码属性必须完全依赖于主键[在1NF基础上消除非主属性对主码的部分函数依赖] 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或记录必须可以被唯一地区分。选取一个能区分每个实体的属性或属性组,作为实体的唯一标识。例如在员工表中的身份证号码即可实现每个一员工的区分,该身份证号码即为候选键,任何一个候选键都可以被选作主键。在找不到候选键时,可额外增加属性以实现区分,如果在员工关系中,没有对其身份证号进行存储,而姓名可能会在数据库运行的某个时间重复,无法区分出实体时,设计辟如ID等不重复的编号以实现区分,被添加的编号或ID选作主键。(该主键的添加时在ER设计时添加,不是建库是随意添加) 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之
数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。反之则是乱七八糟,不仅给数据库的编程人员制造麻烦,而且面目可憎,可能存储了大量不需要的冗余信息。 范式说明 1.1 第一范式(1NF)无重复的列 所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。简而言之,第一范式就是无重复的列。 说明:在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 例如,如下的数据库表是符合第一范式的: 字段1 字段2 字段3 字段4 而这样的数据库表是不符合第一范式的: 字段1 字段2 字段3 字段4 字段3.1 字段3.2 数据库表中的字段都是单一属性的,不可再分。这个单一属性由基本类型构成,包括整型、实数、字符型、逻辑型、日期型等。很显然,在当前的任何关系数据库管理系统(DBMS)中,傻瓜也不可能做出不符合第一范式的数据库,因为这些DBMS不允许你把数据库表的一列再分成二列或多列。因此,你想在现有的DBMS中设计出不符合第一范式的数据库都是不可能的。
1.2 第二范式(2NF)属性完全依赖于主键[ 消除部分子函数依赖] 如果关系模式R为第一范式,并且R中每一个非主属性完全函数依赖于R的某个候选键,则称为第二范式模式。 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。这个惟一属性列被称为主关键字或主键、主码。 例如员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。 简而言之,第二范式(2NF)就是非主属性完全依赖于主关键字。 所谓完全依赖是指不能存在仅依赖主关键字一部分的属性(设有函数依赖W→A,若存在XW,有X→A成立,那么称W→A是局部依赖,否则就称W→A是完全函数依赖)。如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。 假定选课关系表为SelectCourse(学号, 姓名, 年龄, 课程名称, 成绩, 学分),关键字为组合关键字(学号, 课程名称),因为存在如下决定关系: (学号, 课程名称) →(姓名, 年龄, 成绩, 学分) 这个数据库表不满足第二范式,因为存在如下决定关系: (课程名称) →(学分) (学号) →(姓名, 年龄) 即存在组合关键字中的字段决定非关键字的情况。 由于不符合2NF,这个选课关系表会存在如下问题: (1) 数据冗余: 同一门课程由n个学生选修,"学分"就重复n-1次;同一个学生选修了m门课程,姓名和年龄就重复了m-1次。 (2) 更新异常: 若调整了某门课程的学分,数据表中所有行的"学分"值都要更新,否则会出现同一门课程学分不同的情况。
第三范式具有如下性质: 1.如果R3NF,则R也是2NF。 证明:3NF的另一种等价描述是:对于关系模式R,不存在如下条件的函数依赖,X→Y (Y X),Y→Z,其中X是键属性,Y是任意属性组,Z是非主属性,Z Y。在此定义下,令Y X,Y是X的真子集,则以上条件X→Y,Y→Z就变成了非主属性对键X的部分函数依赖,X Z。但由于3NF中不存在这样的函数依赖,所以R中不可能存在非主属性对键X的部分函数依赖,R必定是2NF。 2.如果R2NF,则R不一定是3NF。 例如,我们前面由关系模式SCD分解而得到的SD和SC都为2NF,其中,SC3NF,但在SD中存在着非主属性MN对主键SNO传递依赖,SD3NF。对于SD,应该进一步进行分解,使其转换成3NF。 BCNF具有如下性质: 1.满足BCNF的关系将消除任何属性(主属性或非主属性)对键的部分函数依赖和传递函数依赖。也就是说,如果R BCNF,则R也是3NF。 证明:采用反证法。设R不是3NF。则必然存在如下条件的函数依赖,X→Y(Y X),Y→Z,其中X是键属性,Y是任意属性组,Z是非主属性,Z Y,这样Y→Z函数依赖的决定因素Y不包含候选键,这与BCNF范式的定义相矛盾,所以如果R BCNF,则R也是3NF。 2.如果R3NF,则R不一定是BCNF。 现举例说明。设关系模式SNC(SNO,SN,CN0,SCORE),其中SNO代表学号,SN代表学生姓名并假设没有重名,CNO代表课程号,SCORE代表成绩。可以判定,SNC 有两个候选键(SNO,CNO)和(SN,CNO),其函数依赖如下: SNO SN (SNO,CNO)→SCORE (SN,CNO)→SCORE 唯一的非主属性SCORE对键不存在部分函数依赖,也不存在传递函数依赖。所以SNC 3NF。 但是,因为SNO SN,即决定因素SNO或SN不包含候选键,从另一个角度说,存在着主属性对键的部分函数依赖:(SNO,CNO)SN,(SN,CNO)SNO,所以SNC不是BCNF。 正是存在着这种主属性对键的部分函数依赖关系,造成了关系SNC中存在着较大的数据冗余,学生姓名的存储次数等于该生所选的课程数。从而会引起修改异常。 比如,当要更改某个学生的姓名时,则必须搜索出现该姓名的每个学生记录,并对其姓名逐一修改,这样容易造成数据的不一致问题。 解决这一问题的办法仍然是通过投影分解进一步提高SNC的范式等级,将SNC规范到BCNF。
设计范式(范式,数据库设计范式,数据库的设计范式)是符合某一种级别的关系模式的集合。构造数据库必须遵循一定的规则。在关系数据库中,这种规则就是范式。关系数据库中的关系必须满足一定的要求,即满足不同的范式。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、第四范式(4NF)、第五范式(5NF)和第六范式(6NF)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。下面我们举例介绍第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。 在创建一个数据库的过程中,范化是将其转化为一些表的过程,这种方法可以使从数据库得到的结果更加明确。这样可能使数据库产生重复数据,从而导致创建多余的表。范化是在识别数据库中的数据元素、关系,以及定义所需的表和各表中的项目这些初始工作之后的一个细化的过程。 下面是范化的一个例子Customer Item purchased Purchase price Thomas Shirt $40 Maria Tennis shoes $35 Evelyn Shirt $40 Pajaro Trousers $25 如果上面这个表用于保存物品的价格,而你想要删除其中的一个顾客,这时你就必须同时删除一个价格。范化就是要解决这个问题,你可以将这个表化为两个表,一个用于存储每个顾客和他所买物品的信息,另一个用于存储每件产品和其价格的信息,这样对其中一个表做添加或删除操作就不会影响另一个表。 关系数据库的几种设计范式介绍 1 第一范式(1NF) 在任何一个关系数据库中,第一范式(1NF)是对关系模式的基本要求,不满足第一范式(1NF)的数据库就不是关系数据库。 所谓第一范式(1NF)是指数据库表的每一列都是不可分割的基本数据项,同一列中不能有多个值,即实体中的某个属性不能有多个值或者不能有重复的属性。如果出现重复的属性,就可能需要定义一个新的实体,新的实体由重复的属性构成,新实体与原实体之间为一对多关系。在第一范式(1NF)中表的每一行只包含一个实例的信息。例如,对于图3-2 中的员工信息表,不能将员工信息都放在一列中显示,也不能将其中的两列或多列在一列中显示;员工信息表的每一行只表示一个员工的信息,一个员工的信息在表中只出现一次。简而言之,第一范式就是无重复的列。 2 第二范式(2NF) 第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。如图3-2 员工信息表中加上了员工编号(emp_id)列,因为每个员工的员工编号是惟一的,因此每个员工可以被惟一区分。这个惟一属性列被称为主关键字或主键、主码。 第二范式(2NF)要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性,如果存在,那么这个属性和主关键字的这一部分应该分离出来形成一个新的实体,新实体与原实体之间是一对多的关系。为实现区分通常需要为表加上一个列,以存储各个实例的惟一标识。简而言之,第二范式就是非主属性非部分依赖于主关键字。 3 第三范式(3NF)
第七章补充讲义一、范式举例 例1:已知R,请问R为几范式? BCNF。(25改成15还是BCNF.如:课程号与学号) 例2:已知R,请问R为几范式? 2NF。有部分依赖。
例3:已知R,请问R为几范式? BCNF。 例4:R(X,Y,Z),F={XY->Z},R为几范式? BCNF。 例5:R(X,Y,Z),F={Y->Z,XZ->Y},R为几范式? 3NF。R的候选码为{XZ,XY},(R中所有属性都是主属性,无传递依赖) 二、求闭包 数据库设计人员在对实际应用问题调查中,得到的结论往往是零散的、不规范的(直观问题好办,复杂问题难办了),所以,这对分析数据模型,达到规范化设计要求,还有差距,为此,从规范数据依赖集合的角度入手,找到正确分析数据模型的方法,以确定关系模式的
规范化程度。 例1.已知关系模式R(U、F),其中,U={A,B,C,D,E}; F={AB→ C, B→ D, EC → B , AC→B} ,求(AB)+F. 解:设X(0)=AB ○1计算X(1),在F中找出左边为AB子集的FD,其结果是:AB→C,B→D ∴X(1)=X(0)UB=ABUCD=ABCD 显然,X(1)≠X(0) ○2计算X(2),在F中找出左边为ABCD子集的FD,其结果是:C→E,AC→B ∴X(2)=X(1)UB=ABCDUBE=ABCDE 显然,X(2)=U 所以,(AB)+ F=ABCDE.(等于U,所以AB是唯一候选关键字) 例2.设有关系模式R(U、F),其中U={A,B,C,D,E,I};F={A→D,AB→E,B→E,CD→I,E→C},计算(AE)+ 解:令X={AE},X(0)=AE ○1在F中找出左边是AE子集的FD,其结果是:A→D,E→C ∴X(1)=X(0)UB=X(0)UDC=ACDE 显然,X(1)≠X(0) ○2在F中找出左边是ACDE子集的FD,其结果是:CD→I ∴X(2)=X(1)UI=ACDEI 显然,X(2)≠X(1),但F中未用过的函数依赖的左边属性已含有X(2)的子集,所以不必再计算下去,即(AE)+=ACDEI. 因为,X(3)=X(2),所以,算法结束。
数据库的三个范式 第一范式:关系模式中,每个属性不可再分。属性原子性 第二范式:非主属性完全依赖于主属性,即消除非主属性对主属性的部分函数依赖关系。第三范式:非主属性对主属性不存在传递函数依赖关系。 BNCF范式:在第三范式的基础上,消除主属性之间的部分函数依赖 关系数据库设计之时是要遵守一定的规则的。尤其是数据库设计范式现简单介绍1NF(第一范式),2NF(第二范式),3NF(第三范式)和BCNF,另有第四范式和第五范式留到以后再介绍。在你设计数据库之时,若能符合这几个范式,你就是数据库设计的高手。 第一范式(1NF):在关系模式R中的每一个具体关系r中,如果每个属性值都是不可再分的最小数据单位,则称R是第一范式的关系。例:如职工号,姓名,电话号码组成一个表(一个人可能有一个办公室电话和一个家里电话号码)规范成为1NF有三种方法: 一是重复存储职工号和姓名。这样,关键字只能是电话号码。 二是职工号为关键字,电话号码分为单位电话和住宅电话两个属性 三是职工号为关键字,但强制每条记录只能有一个电话号码。 以上三个方法,第一种方法最不可取,按实际情况选取后两种情况。 第二范式(2NF):如果关系模式R(U,F)中的所有非主属性都完全依赖于任意一个候选关键字,则称关系R 是属于第二范式的。 例:选课关系SCI(SNO,CNO,GRADE,CREDIT)其中SNO为学号,CNO为课程号,GRADEGE 为成绩,CREDIT 为学分。由以上条件,关键字为组合关键字(SNO,CNO) 在应用中使用以上关系模式有以下问题: a.数据冗余,假设同一门课由40个学生选修,学分就重复40次。 b.更新异常,若调整了某课程的学分,相应的元组CREDIT值都要更新,有可能会出现同一门课学分不同。 c.插入异常,如计划开新课,由于没人选修,没有学号关键字,只能等有人选修才能把课程和学分存入。 d.删除异常,若学生已经结业,从当前数据库删除选修记录。某些门课程新生尚未选修,则此门课程及学分记录无法保存。 原因:非关键字属性CREDIT仅函数依赖于CNO,也就是CREDIT部分依赖组合关键字(SNO,CNO)而不是完全依赖。 解决方法:分成两个关系模式SC1(SNO,CNO,GRADE),C2(CNO,CREDIT)。新关系包括两个关系模式,它们之间通过SC1中的外关键字CNO相联系,需要时再进行自然联接,恢复了原来的关系 第三范式(3NF):如果关系模式R(U,F)中的所有非主属性对任何候选关键字都不存在传递信赖,则称关系R是属于第三范式的。 例:如S1(SNO,SNAME,DNO,DNAME,LOCATION)各属性分别代表学号, 姓名,所在系,系名称,系地址。 关键字SNO决定各个属性。由于是单个关键字,没有部分依赖的问题,肯定是2NF。但这关系肯定有大量的冗余,有关学生所在的几个属性DNO,DNAME,LOCATION将重复存储,插入,删除和修改时也将产生类似以上例的情况。 原因:关系中存在传递依赖造成的。即SNO -> DNO。而DNO -> SNO却不存在,DNO -> LOCATION, 因此关键辽SNO 对LOCATION 函数决定是通过传递依赖SNO -> LOCATION 实现的。也就是说,SNO不直接决定非主属性LOCATION。