
面板数据模型
1.面板数据定义。
时间序列数据或截面数据都是一维数据。例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是同时在时间和截面空间上取得的二维数据。面板数据示意图见图1。面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。
面板数据用双下标变量表示。例如
y i t, i= 1, 2, …, N; t = 1, 2, …, T
N表示面板数据中含有N个个体。T表示时间序列的最大长度。若固定t不变,y i ., ( i= 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t = 1, 2, …, T)是纵剖面上的一个时间序列(个体)。
图1 N=7,T=50的面板数据示意图
例如1990-2000年30个省份的农业总产值数据。固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。面板数据由30个个体组成。共有330个观测值。
对于面板数据y i t, i= 1, 2, …, N; t = 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。
注意:EViwes 3.1、4.1、5.0既允许用平衡面板数据也允许用非平衡面板数据估计模型。
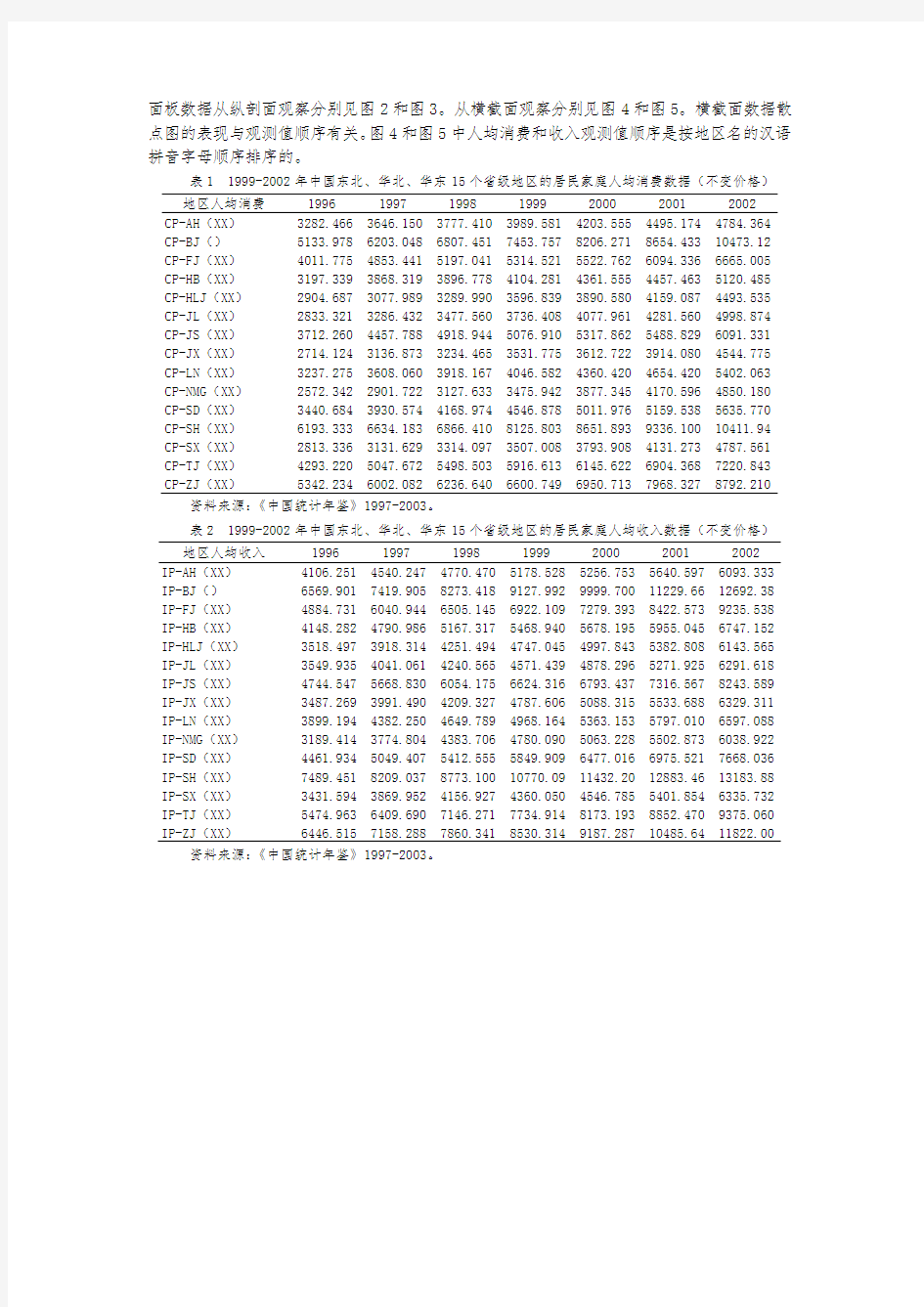
例1(file:panel02):1996-2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(不变价格)和人均收入数据见表1和表2。数据是7年的,每一年都有15个数据,共105组观测值。
人均消费和收入两个面板数据都是平衡面板数据,各有15个个体。人均消费和收入的
面板数据从纵剖面观察分别见图2和图3。从横截面观察分别见图4和图5。横截面数据散点图的表现与观测值顺序有关。图4和图5中人均消费和收入观测值顺序是按地区名的汉语拼音字母顺序排序的。
表1 1999-2002年中国东北、华北、华东15个省级地区的居民家庭人均消费数据(不变价格)地区人均消费1996 1997 1998 1999 2000 2001 2002 CP-AH(XX) 3282.466 3646.150 3777.410 3989.581 4203.555 4495.174 4784.364 CP-BJ() 5133.978 6203.048 6807.451 7453.757 8206.271 8654.433 10473.12 CP-FJ(XX) 4011.775 4853.441 5197.041 5314.521 5522.762 6094.336 6665.005 CP-HB(XX) 3197.339 3868.319 3896.778 4104.281 4361.555 4457.463 5120.485 CP-HLJ(XX) 2904.687 3077.989 3289.990 3596.839 3890.580 4159.087 4493.535 CP-JL(XX) 2833.321 3286.432 3477.560 3736.408 4077.961 4281.560 4998.874 CP-JS(XX) 3712.260 4457.788 4918.944 5076.910 5317.862 5488.829 6091.331 CP-JX(XX) 2714.124 3136.873 3234.465 3531.775 3612.722 3914.080 4544.775 CP-LN(XX) 3237.275 3608.060 3918.167 4046.582 4360.420 4654.420 5402.063 CP-NMG(XX) 2572.342 2901.722 3127.633 3475.942 3877.345 4170.596 4850.180 CP-SD(XX) 3440.684 3930.574 4168.974 4546.878 5011.976 5159.538 5635.770 CP-SH(XX) 6193.333 6634.183 6866.410 8125.803 8651.893 9336.100 10411.94 CP-SX(XX) 2813.336 3131.629 3314.097 3507.008 3793.908 4131.273 4787.561 CP-TJ(XX) 4293.220 5047.672 5498.503 5916.613 6145.622 6904.368 7220.843 CP-ZJ(XX) 5342.234 6002.082 6236.640 6600.749 6950.713 7968.327 8792.210 资料来源:《中国统计年鉴》1997-2003。
表2 1999-2002年中国东北、华北、华东15个省级地区的居民家庭人均收入数据(不变价格)地区人均收入1996 1997 1998 1999 2000 2001 2002
IP-AH(XX) 4106.251 4540.247 4770.470 5178.528 5256.753 5640.597 6093.333 IP-BJ() 6569.901 7419.905 8273.418 9127.992 9999.700 11229.66 12692.38 IP-FJ(XX) 4884.731 6040.944 6505.145 6922.109 7279.393 8422.573 9235.538 IP-HB(XX) 4148.282 4790.986 5167.317 5468.940 5678.195 5955.045 6747.152 IP-HLJ(XX) 3518.497 3918.314 4251.494 4747.045 4997.843 5382.808 6143.565 IP-JL(XX) 3549.935 4041.061 4240.565 4571.439 4878.296 5271.925 6291.618 IP-JS(XX) 4744.547 5668.830 6054.175 6624.316 6793.437 7316.567 8243.589 IP-JX(XX) 3487.269 3991.490 4209.327 4787.606 5088.315 5533.688 6329.311 IP-LN(XX) 3899.194 4382.250 4649.789 4968.164 5363.153 5797.010 6597.088 IP-NMG(XX) 3189.414 3774.804 4383.706 4780.090 5063.228 5502.873 6038.922 IP-SD(XX) 4461.934 5049.407 5412.555 5849.909 6477.016 6975.521 7668.036 IP-SH(XX) 7489.451 8209.037 8773.100 10770.09 11432.20 12883.46 13183.88 IP-SX(XX) 3431.594 3869.952 4156.927 4360.050 4546.785 5401.854 6335.732 IP-TJ(XX) 5474.963 6409.690 7146.271 7734.914 8173.193 8852.470 9375.060 IP-ZJ(XX) 6446.515 7158.288 7860.341 8530.314 9187.287 10485.64 11822.00 资料来源:《中国统计年鉴》1997-2003。
图2 15个省级地区的人均消费序列(纵剖面)图3 15个省级地区的人均收入序列(file:4panel02)
图4 15个省级地区的人均消费散点图图5 15个省级地区的人均收入散点图(7个横截面叠加)(每条连线表示同一年度15个地区的消费值) (每条连线表示同一年度15个地区的收入值)
用CP表示消费,IP表示收入。AH, BJ, FJ, HB, HLJ, JL, JS, JX, LN, NMG, SD, SH, SX, TJ, ZJ分别表示XX省、市、XX省、XX省、XX省、XX省、XX省、XX省、XX省、XX自治区、XX省、XX市、XX省、XX市、XX省。
15个地区7年人均消费对收入的面板数据散点图见图6和图7。图6中每一种符号代表一个省级地区的7个观测点组成的时间序列。相当于观察15个时间序列。图7中每一种符号代表一个年度的截面散点图(共7个截面)。相当于观察7个截面散点图的叠加。
图6 用15个时间序列表示的人均消费对收入的面板数据
2000
4000
6000
8000
10000
12000
2000400060008000100001200014000
IP(1996-2002)
CP1996
CP1997
CP1998
CP1999
CP2000
CP2001
CP2002
图7 用7个截面表示的人均消费对收入的面板数据(7个截面叠加)为了观察得更清楚一些,图8给出和XX1996-2002年消费对收入散点图。从图中可以看出,无论是从收入还是从消费看XX的水平都低于市。XX2002年的收入与消费规模还不如市1996年的大。图9给出该15个省级地区1996和2002年的消费对收入散点图。可见6年之后15个地区的消费和收入都有了相应的提高。
图8 和XX1996-2002年消费对收入时序图图9 1996和2002年15个地区的消费对收入散点图2.面板数据的估计。
用面板数据建立的模型通常有3种。即混合估计模型、固定效应模型和随机效应模型。
2.1 混合估计模型。
如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。
如果从时间和截面看模型截距都不为零,且是一个相同的常数,以二变量模型为例,则建立如下模型,
y it = +1x it +it, i= 1, 2, …, N; t = 1, 2, …, T (1) 和1不随i,t变化。称模型(1)为混合估计模型。
以例1中15个地区1996和2002年数据建立关于消费的混合估计模型,得结果如下:
图10
EViwes估计方法:在打开工作文件窗口的基础上,点击主功能菜单中的Objects键,选New Object功能,从而打开New Object(新对象)选择窗。在Type of Object选择区选择Pool(混合数据库),点击OK键,从而打开Pool(混合数据)窗口。在窗口中输入15个地区标识AH(XX)、BJ()、…、ZJ(XX)。工具栏中点击Sheet键,从而打开Series List (列写序列名)窗口,定义变量CP?和IP?,点击OK键,Pool(混合或合并数据库)窗口显示面板数据。在Pool窗口的工具栏中点击Estimate键,打开Pooled Estimation(混合估计)窗口如下图。
图11
在Dependent Variable(相依变量)选择窗填入CP?;在mon coefficients(系数相同)选择窗填入IP?;Cross section specific coefficients(截面系数不同)选择窗保持空白;在Intercept(截距项)选择窗点击mon;在Weighting(权数)选择窗点击No
weighting 。点击Pooled Estimation (混合估计)窗口中的OK 键。得输出结果如图10。相应表达式是
it CP ∧
= 129.6313+0.7587IP it
(2.0) (79.7) R 2
= 0.98, SSE r = 4824588, t 0.05 (103) = 1.99
15个省级地区的人均支出平均占收入的76%。
如果从时间和截面上看模型截距都为零,就可以建立不含截距项的(= 0)的混合估计模型。以二变量模型为例,建立混合估计模型如下,
y it = 1x it
+
it
, i = 1, 2, …, N ; t = 1, 2, …, T (2)
对于本例,因为上式中的截距项有显著性(t = 2.0 > t 0.05 (103) = 1.99),所以建立截距项为零的混合估计模型是不合适的。
EViwes 估计方法:在Pooled Estimation (混合估计)对话框中Intercept (截距项)选择窗中选None ,其余选项同上。
2.2 固定效应模型。
在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model )。
固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model )、时刻固定效应模型(time fixed effects regression model )和时刻个体固定效应模型(time and entity fixed effects regression model )。下面分别介绍。
(1)个体固定效应模型。
个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型,表示如下,
y it =
1x it
+
1 W 1
+
2W 2
+… +
N W N
+
it
, t = 1, 2, …, T (3)
其中
W i =?
??=其他个个体如果属于第。,,0,...,2,1,1N i i
it
, i = 1, 2, …, N ; t = 1, 2, …, T ,表示随机误差项。y it , x it , i = 1, 2, …, N ; t
= 1, 2, …, T 分别表示被解释变量和解释变量。
模型(3)或者表示为
y 1t =1
+
1x 1t
+
1t
, i = 1(对于第1个个体,或时间序列),t = 1, 2, …, T y 2t =
2
+1x 2t +
2 t
, i = 2(对于第2个个体,或时间序列),t = 1, 2, …, T …
y N t =N +1x N t +
N t
, i = N (对于第N 个个体,或时间序列),t = 1, 2, …, T
写成矩阵形式,
y 1 = (1x 1)??
?
???βγ1+
1
=
1
+x 1 +
1
…
y N = (1x N )??
?
???βγN +
N
=
N
+ x N +
N
上式中y i ,i ,i ,x i 都是N 1阶列向量。为标量。当模型中含有k 个解释变量时,为k 1阶列向量。进一步写成矩阵形式,
121?????????????N N y y y = N N ?????????????100010001 121?????????????N N γγγ +??????
??????N x x x 21+ 1
2
1???????
??????N N εεε 上式中的元素1,0都是T 1阶列向量。
面板数据模型用OLS 方法估计时应满足如下5个假定条件:
(1)E(it |x i 1, x i 2, …, x iT ,i ) = 0。以x i 1, x i 2, …, x iT ,i 为条件的it 的期望等于零。
(2)(x i 1, x i 2, …, x iT ), ( y i 1, y i 2, …, y iT ), i = 1, 2, …, N 分别来自于同一个联合分布总体,并相互独立。
(3)(x it , it )具有非零的有限值4阶矩。 (4)解释变量之间不存在完全共线性。
(5)Cov(it is |x it ,x is , i ) = 0, t s 。在固定效应模型中随机误差项it 在时间上是非自相关的。其中x it 代表一个或多个解释变量。
对模型(1)进行OLS 估计,全部参数估计量都是无偏的和一致的。模型的自由度是NT –1–N 。
当模型含有k 个解释变量,且N 很大,相对较小时,因为模型中含有k + N 个被估参数,一般软件执行OLS 运算很困难。在计量经济学软件中是采用一种特殊处理方式进行OLS 估计。
估计原理是,先用每个变量减其组内均值,把数据中心化(entity-demeaned ),然后用变换的数据先估计个体固定效应模型的回归系数(不包括截距项),然后利用组内均值等式计算截距项。这种方法计算起来速度快。具体分3步如下。 (1)首先把变量中心化(entity-demeaned )。 仍以单解释变量模型(3)为例,则有
i y = i
+
1
i x +i ε, i = 1, 2, …, N (4)
其中i y =
∑
=T
t it y T
1
1
,i x =
∑
=T
t it x T
1
1
,i ε=
∑=T
t it
T
1
1
ε
, i = 1, 2, …, N 。公式(1)、(4)相减得,
(y it -i y ) =1
(x it -i x ) + (it
-i ε) (5)
令(y it -i y ) =it y ~,(x it -i x ) =it x ~,(
it
-i ε) =it
ε~,上式写为 it y ~=
1
it x ~+it
ε~ (6) 用OLS 法估计(1)、(6)式中的1,结果是一样的,但是用(6)式估计,可以减少被估参
数个数。
(2)用OLS 法估计回归参数(不包括截距项,即固定效应)。
在k 个解释变量条件下,把it x ~用向量形式X ~表示,则利用中心化数据,按OLS 法估计
公式计算个体固定效应模型中回归参数估计量的方差协方差矩阵估计式如下,
∧
Var (β
?)=2?σ(X ~'X ~)-1 (7) 其中2
?σ
=k
ΝΝΤ--'εε?~?~,ε
?~是相对于ε~的残差向量。 (3)计算回归模型截距项,即固定效应参数i
。
i γ?=i Y -i X 'β
? (8) 以例1(file:panel02)为例得到的个体固定效应模型估计结果如下:
注意:个体固定效应模型的EViwes 输出结果中没有公共截距项。
图12
EViwes 估计方法:在EViwes 的Pooled Estimation 对话框中Intercept 选项中选Fixed
effects 。其余选项同上。
注意:
(1)个体固定效应模型的EViwes 输出结果中没有公共截距项。
(2)EViwes 输出结果中没有给出描述个体效应的截距项相应的标准差和t 值。不认为截距项是模型中的重要参数。
(3)当对个体固定效应模型选择加权估计时,输出结果将给出加权估计和非加权估计两种统计量评价结果。
(4)输出结果的联立方程组形式可以通过点击View 选Representations 功能获得。 (5)点击View 选Wald Coefficient Tests …功能可以对模型的斜率进行Wald 检验。 (6)点击View 选Residuals/Table, Graphs, Covariance Matrix, Correlation Matrix 功能可以分别得到按个体计算的残差序列表,残差序列图,残差序列的方差协方差矩阵,残差序列的相关系数矩阵。
(7)点击Procs 选Make Model 功能,将会出现估计结果的联立方程形式,进一步点击Solve 键,在随后出现的对话框中可以进行动态和静态预测。
输出结果的方程形式是
t y 1?γ?XX +1
?βx 1t = 479.3 + 0.70x 1t (55.0) t y 2?=γ?+1
?βx 2t = 1053.2 + 0.70x 2t … (55.0)
t y 15?=γ?XX +1
?βx 15t = 714.2 + 0.70x 15t (55.0)
R 2 = 0.99, SSE r = 2270386, t 0.05 (88) = 1.98
从结果看,、XX 、XX 是消费函数截距(自发消费)最大的3个地区。
相对于混合估计模型来说,是否有必要建立个体固定效应模型可以通过F 检验来完成。
原假设H 0:不同个体的模型截距项相同(建立混合估计模型)。 备择假设H 1:不同个体的模型截距项不同(建立个体固定效应模型)。 F 统计量定义为:
F =
)1/()]1()2/[()(-------N NT SSE N NT NT SSE SSE u u r =)
1/()
1/()(----N NT SSE N SSE SSE u u r (9)
其中SSE r ,SSE u 分别表示约束模型(混合估计模型)和非约束模型(个体固定效应模型)的
残差平方和。非约束模型比约束模型多了N -1个被估参数。(混合估计模型给出公共截距项。)
注意:当模型中含有k 个解释变量时,F 统计量的分母自由度是NT -N -k 。 用上例计算,已知SSE r = 4824588,SSE u = 2270386,
F =
)1/()1/()(----N NT SSE N SSE SSE u u r =)115105/(2270386)115/()22703864824588(----=25510
182443
= 7.15
F 0.05(14, 89) = 1.81
因为F = 7.15> F 0.05(14, 89) = 1.81,所以,拒绝原假设。结论是应该建立个体固定效应模型。
(2)时刻固定效应模型。
时刻固定效应模型就是对于不同的截面(时刻点)有不同截距的模型。如果确知对于不同的截面,模型的截距显著不同,但是对于不同的时间序列(个体)截距是相同的,那么应该建立时刻固定效应模型,表示如下,
y it =
1x it
+
1
+
2D 2
+… +
T D T
+
it
, i = 1, 2, …, N (10)
其中
D t =???=)(,
0,...,2,1个截面其他个截面。,t t T t 不属于第如果属于第
it
, i = 1, 2, …, N ; t = 1, 2, …, T ,表示随机误差项。y i t , x it , i = 1, 2, …, N ; t
= 1, 2, …, T 分别表示被解释变量和解释变量。模型(10)也可表示为
y i 1 =1
+
1x i 1
+
i 1
, t = 1,(对于第1个截面),i = 1, 2, …, N
y i 2 = (
1
+2
)+
1x i 2
+i 2
, t = 2,(对于第2个截面),i = 1, 2, …, N …
y iT = (
1
+
T
)+
1x iT +
iT
, t = T ,(对于第T 个截面),i = 1, 2, …, N
如果满足上述模型假定条件,对模型(2)进行OLS 估计,全部参数估计量都具有无偏
性和一致性。模型的自由度是NT –T -1。
图13
EViwes 估计方法:在Pooled Estimation (混合估计)窗口中的Dependent Variable (相依变量)选择窗填入CP?;在mon coefficients (系数相同)选择窗填入IP? 和虚拟变量D1997, D1998, D1999, D2000, D2001, D2002;在Cross section specific coefficients (截面系数不同)选择窗保持空白;在Intercept (截距项)选择窗点击mon ;在Weighting (权数)选择窗点击No weighting 。点击Pooled Estimation (混合估计)窗口中的OK 键。
以例1为例得到的时刻固定效应模型估计结果如下:
1?i y =α?1996+1
?βx i 1 = 108.5057 + 0.7789x i 1 (1.5) (74.6)
2?i y =α?1997+1
?βx i 2 = 108.5057 +28.1273 + 0.7789x i 2 (1.5) (0.4) (74.6)
7?i y =α?2002+1
?βx i 7 = 108.5057 -199.8213 + 0.7789x i 7 (1.5) (0.4) (74.6)
R 2 = 0.9867, SSE r = 4028843, t 0.05 (97) = 1.98
相对于混合估计模型来说,是否有必要建立时刻固定效应模型可以通过F 检验来完成。
H 0:对于不同横截面模型截距项相同(建立混合估计模型)。 H 1:对于不同横截面模型的截距项不同(建立时刻固定效应模型)。 F 统计量定义为:
F =
)1/()]1()2/[()(-------T NT SSE T NT NT SSE SSE u u r =)
1/()
1/()(----T NT SSE T SSE SSE u u r (11)
其中SSE r ,SSE u 分别表示约束模型(混合估计模型的)和非约束模型(时刻固定效应模型的)
的残差平方和。非约束模型比约束模型多了T -1个被估参数。
注意:当模型中含有k 个解释变量时,F 统计量的分母自由度是NT -T - k 。 用上例计算,已知SSE r = 4824588,SSE u = 4028843,
F =
)1/()1/()(----T NT SSE T SSE SSE u u r =)17105/(4028843)17/()40288434824588(----=41534
132624
= 3.19
F 0.05(6, 87) = 2.2
因为F = 3.19> F 0.05(14, 89) = 2.2,拒绝原假设,结论是应该建立时刻固定效应模型。
(3)时刻个体固定效应模型。
时刻个体固定效应模型就是对于不同的截面(时刻点)、不同的时间序列(个体)都有不同截距的模型。如果确知对于不同的截面、不同的时间序列(个体)模型的截距都显著地不相同,那么应该建立时刻个体效应模型,表示如下,
y it =1x it +1+2D 2 +…+T D T +1W 1+2W 2 +…+N W N +it , i =1,2,…,N ,t = 1, 2, …,
T
(12) 其中虚拟变量
D t =???=其他个截面如果属于第。,,0,...,2,1T t t (注意不是从1开始)
W i =?
??=其他个个体如果属于第。,,0,...,2,1,1N i i (注意是从1开始)
it
, i = 1, 2, …, N ; t = 1, 2, …, T ,表示随机误差项。y i t , x it , (i = 1, 2, …, N ; t
= 1, 2, …, T )分别表示被解释变量和解释变量。模型也可表示为
y 11 =1
+
1
+1x 11
+11
, t = 1,i = 1(对于第1个截面、第1个个体) y 21 =
1
+ 2 +1x 21+21
, t = 1,i = 2(对于第1个截面、第2个个体) … y N 1 =1 +
N +1x N 1+
N 1
, t = 1,i =N (对于第1个截面、第N 个个体)
y 12 = (1
+2
)+ 1
+1x 12
+12
, t = 2,i = 1(对于第2个截面、第1个个体) y 22 = (
1+
2)+
2 +
1x 22+
22
, t = 2,i = 2(对于第2个截面、第2个个体)
y N2 = (1+2)+N +1x N2+N2, t = 2,i=N(对于第2个截面、第N个个体)…
y1T = (1+T)+ 1 +1x12+1T, t = T,i= 1(对于第T个截面、第1个个体)y2T = (1+T)+ 2 +1x22+2T, t = T,i= 2(对于第T个截面、第2个个体)…
y NT = (1+T)+N +1x NT+NT, t = T,i=N(对于第T个截面、第N个个体)
如果满足上述模型假定条件,对模型(12)进行OLS估计,全部参数估计量都是无偏的和一致的。模型的自由度是NT– N–T。注意:当模型中含有k个解释变量时,F统计量的分母自由度是NT– N -T- k+1。
以例1为例得到的截面、时刻固定效应模型估计结果如下:
图14
EViwes 估计方法:在Pooled Estimation (混合估计)窗口中的Dependent Variable (相依变量)选择窗填入CP?;在mon coefficients (系数相同)选择窗填入IP? 和虚拟变量D1997, D1998, D1999, D2000, D2001, D2002;在Cross section specific coefficients (截面系数不同)选择窗保持空白;在Intercept (截距项)选择窗中选Fixed effects ;在Weighting (权数)选择窗点击No weighting 。点击Pooled Estimation (混合估计)窗口中的OK 键。
注意:
(1)对于第1个截面(t =1)EViwes 输出结果中把(1 +i ), (i = 1, 2, …, N )估计在一起。
(2)对于第2, …, T 个截面(t =1)EViwes 输出结果中分别把(1 +t ), (t = 2, …, T )估计在一起。
输出结果如下:
11?y =α?1996+1?βx 11 = 537.9627 + 0.6712x 11, (1996年XX 省) 21?y =α?1996+1
?βx 21 = 1223.758 + 0.6712x 21, (1996年市) …
11?y =α?1997+1?βx 11 = 98.91126 + 0.6712x 11, (1997年XX 省) 21?y =α?1997+1
?βx 21 = 98.91126 +1223.758 + 0.6712x 21, (1997年市) …
7,15?y =α?2002+15?γ+1
?βx 15,7 = (183.3882 +870.4197) + 0.6712x 15,1,(2002年XX 省) R 2 = 0.9932, SSE r = 2045670, t 0.05 (83) = 1.98
相对于混合估计模型来说,是否有必要建立时刻个体固定效应模型可以通过F 检验来完
成。
H 0:对于不同横截面,不同序列,模型截距项都相同(建立混合估计模型)。 H 1:不同横截面,不同序列,模型截距项各不相同(建立时刻个体固定效应模型)。 F 统计量定义为:
F =
)/()]()2/[()(T N NT SSE T N NT NT SSE SSE u u r -------=)
/()
2/()(T N NT SSE T N SSE SSE u u r ---+-
(13)
其中SSE r ,SSE u 分别表示约束模型(混合估计模型的)和非约束模型(时刻个体固定效应模型的)的残差平方和。非约束模型比约束模型多了N +T 个被估参数。
注意:当模型中含有k 个解释变量时,F 统计量的分母自由度是NT -N -T - k -1。 用上例计算,已知SSE r = 4824588,SSE u = 2045670,
F =
)/()2/()(T N NT SSE T N SSE SSE u u r ---+-=)715105/(2045670)2715/()20456704824588(---+-=24647
138946
= 5.6
F 0.05(20, 81) = 1.64
因为F = 5.6> F 0.05(14, 89) = 1.64,拒绝原假设,结论是应该建立时刻个体固定效应模型。
(4)随机效应模型
在固定效应模型中采用虚拟变量的原因是解释被解释变量的信息不够完整。也可以通过对误差项的分解来描述这种信息的缺失。
y it = +1x it + it (14) 其中误差项在时间上和截面上都是相关的,用3个分量表示如下。
it = u i +v t +w it (15) 其中u i N(0, u 2
)表示截面随机误差分量;v t N(0, v 2)表示时间随机误差分量;w it N(0, w 2
)表示混和随机误差分量。同时还假定u i ,v t ,
w it 之间互不相关,各自分别不存在截面自相关、时间自相关和混和自相关。上述模型称为随机效应模型。
随机效应模型和固定效应模型比较,相当于把固定效应模型中的截距项看成两个随机变量。一个是截面随机误差项(u i ),一个是时间随机误差项(v t )。如果这两个随机误差项都服从正态分布,对模型估计时就能够节省自由度,因为此条件下只需要估计两个随机误差项的均值和方差。
假定固定效应模型中的截距项包括了截面随机误差项和时间随机误差项的平均效应,而且对均值的离差分别是u i 和v t ,固定效应模型就变成了随机效应模型。
为了容易理解,先假定模型中只存在截面随机误差项u i ,不存在时间随机误差分量(v t ), y it = + 1x it + (w it + u i )= + 1x it +it (16) 截面随机误差项u i 是属于第个个体的随机波动分量,并在整个时间X 围(t = 1,2, …, T )保持不变。随机误差项u i , w it 应满足如下条件:
E(u i ) =0, E(w it ) = 0
E(w it 2) =w 2
,
E(u i 2)=u 2
,
E(w it u j ) =0, 包括所有的i , t , j 。 E(w it w js ) =0, i j , t s E(u i u j ) =0, i j 因为根据上式有
it = w it + u i
所以这种随机效应模型又称为误差分量模型(error ponent model )。有结论,
E(it ) = E(w it +u j ) =0,
(16)式,y it = + 1x it + (w it + u i ),也可以写成y it = (+ u i ) + 1x it + w it 。服从正态分布的截距项的均值效应u 被包含在回归函数的常数项中。
E(it 2) = E(w it +u j )2 =w 2 +u 2
,
E(it is ) = E[(w it + u i )(w is + u i )] = E[(w it w is +u i w is + w it u i +u i 2)] =u 2
, t s 令
i = (i 1, i 2, …iT )'
则
= E(
i
i ') = ?????
?
???????
?+++)()()(2
22
222
222
222u w u u u u w u u u u w σσσσσσσσσσσσ
=w 2
I (T T ) +u 2
1(T 1)1(T 1) '
其中I (T
T )是(T
T )阶单位阵,1(T 1)是(T 1)阶列向量。因为第i 期与j 期观测值是相互独
立的,所以NT 个观测值所对应的随机误差项的方差与协方差矩阵V 是
V = ???????
??
???ΩΩΩ
00000= ??
?
??
?
??????100010001 = I N
N
其中I N N 表示由(T 1)阶列向量为元素构成的单位阵,其中每一个元素1或0都是(T 1)
阶列向量。表示科罗内克积(Kronecker product )。其运算规则是
A N
K
B =?
?
???
??
?????B B B B B
B B B
B NK N N K K a a a a a a a a a 21222
21
11211 检验个体随机效应的原假设与检验统计量是
H 0:u 2
= 0。(混合估计模型)
H 1:u 2
0。(个体随机效应模型)
LM =)1(2-T NT 2
11212
11????????
????????-?
?????∑∑
∑∑
====N i T t it N i T t it u
u =
)1(2-T NT []
2
112
12
1????????
????????-∑∑
∑===?
N i T t it
N i i u u T =
)
1(2-T NT
2
21???
????
?????-''u u u u T 其中u u
??'表示由个体随机效应模型计算的残差平方和。u u ??'表示由混合估计模型计算的残差平方和。统计量LM 服从1个自由度的2
分布。
可以对随机效应模型进行广义最小二乘估计。以观测值方差的倒数为权。为了求权数,必须采用两阶段最小二乘法估计。因为各随机误差分量的方差一般是未知的,第一阶段用普通最小二乘估计法对混合数据进行估计(采用固定效应模型)。用估计的残差计算随机误差分量的方差。第二步用这些估计的方差计算参数的广义最小二乘估计值。如果随机误差分量服从的是正态分布,模型的参数还可以用极大似然法估计。
仍以例1为例给出随机效应模型估计结果如下:
图15
注意:随机效应模型EViwes 输出结果中含有公共截距项。
图16
以例1为例,用个体随机效应模型和混合模型计算的统计量的值是
LM =
)
1(2-T NT
221???????
?????-''u u u u T =62715??2
21482458825016537??????-?=8.75(24.4)2
= 5209 F 0.05 (1) = 3.84
因为F = 5209 > F 0.05 (1) = 3.84,所以拒绝原假设,结论是应该建立个体随机效应模型。
假定截面截距和时间截距都是随机的。分别服从均值为u 和v ,方差为u 2
和v 2
的正态分布。随机误差项将由3部分组成,并有方差。
Var(it ) = Var(u i ) + Var(v t ) + Var(w it ) =u 2 +v 2+w 2
当u 2和v 2
都等于零,随机效应模型退化为固定效应模型。
随机效应模型和固定效应模型哪一个更好些?实际是各有优缺点。随机效应模型的好处是节省自由度。对于从时间序列和截面两方面上看都存在较大变化的数据,随机效应模型能明确地描述出误差来源的特征。固定效应模型的好处是很容易分析任意截面数据所对应的因变量与全部截面数据对应的因变量均值的差异程度。此外,固定效应模型不要求误差项中的个体效应分量与模型中的解释变量不相关。当然,这一假定不成立时,可能会引起模型参数估计的不一致性。
(5)回归系数不同的面板数据模型 当认为对于不同个体,解释变量的回归系数存在显著性差异时,还可以建立回归系数不同的面板数据模型。
EViwes 估计方法:在Pooled Estimation (混合估计)窗口中的Dependent Variable (相依变量)选择窗填入CP?;在mon coefficients (系数相同)选择窗保持空白(如果需要估计时刻固定效应也可输入虚拟变量D1997, D1998, D1999, D2000, D2001, D2002);在Cross section specific coefficients (截面系数不同)选择窗填入IP?;在Intercept (截距项)选择窗中选Fixed effects (也可以做其他选择);在Weighting (权数)选择窗点击No weighting (也可以做其他选择)。点击Pooled Estimation (混合估计)窗口中的OK 键。
图17
t y 1?γ?XX +1
?βx 1t = 161.62 + 0.76x 1t (9.1)
t y 2?=γ?+1
?βx 2t = 36.22 + 0.81x 2t (31.0)
…
t y 15?=γ?XX +1
?βx 15t = 1328.26 + 0.63 x 15t (21.1)
R 2 = 0.995, SSE r = 1409247
用EViwes 建立面板数据估计模型步骤。
利用1996~2002年15个省级地区城镇居民家庭年人均消费性支出和年人均收入数据(不变价格数据)介绍面板数据模型估计步骤。
(1)建立混合数据库(Pool )对象。 首先建立工作文件。在打开工作文件窗口的基础上,点击EViwes 主功能菜单上的Objects 键,选New Object 功能(如图18),从而打开New Object (新对象)选择窗。在Type of Object 选择区选择Pool (合并数据库),并在Name of Object 选择区为混合数据库起名Pool01(初始显示为Untitled )。如图19,点击OK 键,从而打开混合数据库(Pool )窗口。在窗口中输入15个地区的标识AH (XX )、BJ ()、…、ZJ (XX ),如图20。
图18 图19
图20
(2)定义序列名并输入数据。
在新建的混合数据库(Pool)窗口的工具栏中点击Sheet键(第2种路径是,点击View 键,选Spreadsheet (stacked data)功能),从而打开Series List(列写序列名)窗口,定义时间序列变量CP?和IP?(?符号表示与CP和IP相连的15个地区标识名)如图21。点击OK键,从而打开混合数据库(Pool)窗口,(点击Edit+-键,使EViwes处于可编辑状态)输入数据。输入完成后的情形见图22。
图22所示为以截面为序的阵列式排列(stacked data)。点击Order+-键,还可以变换为以时间为序的阵列式排列。
工作文件也可以以合并数据(Pool data)和非合并数据的形式用复制和粘贴的方法建立。
图21 图22
(3)估计模型
MATLAB空间面板数据模型操作简介 MATLAB安装:在民主湖资源站上下载MA TLAB 2009a,或者2010a,按照其中的安装说明安装MATLAB。(MATLAB较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局: 首先我们说一下MA TLAB处理空间面板数据时,数据文件是怎么布局的,熟悉eviews的同学可能知道,eviews中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中“1-94”“1-95”“1-96”“1-97”中,1是省份的代号,94,95,96,97表示年份,eviews是将每个省份的数据放在一起,再将所有省份堆放在一起。 与eviews不同,MATLAB处理空间面板数据时,面板数据的布局是(在excel中说明):先排放一个横截面上的数据(即某年所有省份的数据),再将不同年份的横截面按时间顺序堆放在一起。如图:
这里需要说明的是,MA TLAB中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。 二、数据的输入: MATLAB与excel链接:在excel中点击“工具→加载宏→浏览”,找到MA TLAB的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为:C:\Programfiles\MATLAB\R2009a\toolbox\exlink,点击excllink.xla即可完成excel与MATLAB的链接。这样的话excel中的数据就可以直接导入MATLAB中形成MATLAB的数据文件。操作完成后excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB”即表示我们希望excel 与MATLAB实现链
面板数据的F检验固定 效应检验 标准化工作室编码[XX968T-XX89628-XJ668-XT689N]
面板数据模型(P A N E L D A T A)F检验,固定效应检验1.面板数据定义。 时间序列数据或截面数据都是一维数据。例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是同时在时间和截面空间上取得的二维数据。面板数据示意图见图1。面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。 面板数据用双下标变量表示。例如 y , i= 1, 2, …, N; t= 1, 2, …, T i t N表示面板数据中含有N个个体。T表示时间序列的最大长度。若固定t不变,y , ( i i . = 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t= 1, 2, …, T)是纵剖面上的一个时间序列(个体)。 图1 N=7,T=50的面板数据示意图 例如1990-2000年30个省份的农业总产值数据。固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。面板数据由30个个体组成。共有330个观测值。 对于面板数据y i t, i = 1, 2, …, N; t= 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。 注意:EViwes 、、既允许用平衡面板数据也允许用非平衡面板数据估计模型。
上课材料之二: 第二章 数学基础 (Mathematics) 第一节 矩阵(Matrix)及其二次型(Quadratic Forms) 第二节 分布函数(Distribution Function),数学期望(Expectation)及方差(Variance) 第三节 数理统计(Mathematical Statistics ) 第一节 矩阵及其二次型(Matrix and its Quadratic Forms) 2.1 矩阵的基本概念与运算 一个m ×n 矩阵可表示为: 矩阵的加法较为简单,若C=A +B ,c ij =a ij +b ij 但矩阵的乘法的定义比较特殊,若A 是一个m ×n 1的矩阵,B 是一个n 1×n 的矩阵,则C =AB 是一个m ×n 的矩阵,而且∑== n k kj ik ij b a c 1,一般来讲,AB ≠BA ,但如下运算是成立 的: ● 结合律(Associative Law ) (AB )C =A (BC ) ● 分配律(Distributive Law ) A (B +C )=AB +AC 问题:(A+B)2=A 2+2AB+B 2是否成立? 向量(Vector )是一个有序的数组,既可以按行,也可以按列排列。 行向量(row ve ctor)是只有一行的向量,列向量(column vector)只有一列的向量。 如果α是一个标量,则αA =[αa ij ]。 矩阵A 的转置矩阵(transpose matrix)记为A ',是通过把A 的行向量变成相应的列向量而得到。 显然(A ')′=A ,而且(A +B )′=A '+B ', ● 乘积的转置(Transpose of a production ) A B AB ''=')(,A B C ABC '''=')(。 ● 可逆矩阵(inverse matrix ),如果n 级方阵(square matrix)A 和B ,满足AB=BA=I 。 则称A 、B 是可逆矩阵,显然1-=B A ,1-=A B 。如下结果是成立的: 1111111)()()()(-------='='=A B AB A A A A 。 2.2 特殊矩阵 1)恒等矩阵(identity matrix)
计量经济学是经济科学领域内的一门应用科学,以一定的经济理论和实际统计资料为基础,运用数学、统计方法与计算机技术,以建立经济计量模型为主要手段,定量分析研究具有随机特性的经济变量关系。 2、数理经济模型与计量经济模型的区别。 数理:揭示经济活动中各个因素之间的理论关系,用确定性的数学方程加以描述。 计量:揭示经济活动中各个因素之间的定量关系,用随机性的数学方程加以描述。 3、经典计量经济学模型的一般形式。 4、计量经济学的数据类型。 时间序列数据:按时间先后排列的统计数据。 截面数据:一个或多个变量在某一时点上的数据集合。 合并数据(平行数据):既包含时间序列数据又有截面 数据。 5、建立计量经济学模型的步骤。 1) 模型的数学形式。③拟定模型中待估计参数的理论期望 值。 2)样本数据的收集: 差项产生序列相关。②截面数据易引起模型随机误差项 产生异方差。③样本数据的质量:完整性、准确性、可 比性、一致性。 3)模型参数的估计。 4 度检验、变量的显着性检验、方程的显着性检验。③计 量经济学检验:序列相关、异方差法(随机误差项)、 多重共线性(解释变量)④模型预测检验。 6、计量经济学模型的应用。 1)结构分析;2)经济预测;3)政策评价;4)检验与发展经济理论。 7、如何正确选择解释变量。 作为“变量”的原因:1 2)考虑数据的可得性;3)考虑入选变量之间的关系。 8、回归分析的目的。 1)根据自变量的取值,估计应变量的均值;2)检验建立在经济理论基础上的假设;3) 值,预测应变量的均值。 9、总体回归函数(PRF)和样本回归函数(SRF)各变量系数名称及函数方程。 10、随机误差项(Ui)的性质或主要内容。
面板数据模型 1.面板数据定义。 时间序列数据或截面数据都是一维数据。例如时间序列数据是变量按时间得到的数据;截面数据是变量在截面空间上的数据。面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是同时在时间和截面空间上取得的二维数据。面板数据示意图见图1。面板数据从横截面(cross section)上看,是由若干个体(entity, unit, individual)在某一时刻构成的截面观测值,从纵剖面(longitudinal section)上看是一个时间序列。 面板数据用双下标变量表示。例如 y i t, i= 1, 2, …, N; t = 1, 2, …, T N表示面板数据中含有N个个体。T表示时间序列的最大长度。若固定t不变,y i ., ( i= 1, 2, …, N)是横截面上的N个随机变量;若固定i不变,y. t, (t = 1, 2, …, T)是纵剖面上的一个时间序列(个体)。 图1 N=7,T=50的面板数据示意图 例如1990-2000年30个省份的农业总产值数据。固定在某一年份上,它是由30个农业总产总值数字组成的截面数据;固定在某一省份上,它是由11年农业总产值数据组成的一个时间序列。面板数据由30个个体组成。共有330个观测值。 对于面板数据y i t, i= 1, 2, …, N; t = 1, 2, …, T来说,如果从横截面上看,每个变量都有观测值,从纵剖面上看,每一期都有观测值,则称此面板数据为平衡面板数据(balanced panel data)。若在面板数据中丢失若干个观测值,则称此面板数据为非平衡面板数据(unbalanced panel data)。 注意:EViwes 3.1、4.1、5.0既允许用平衡面板数据也允许用非平衡面板数据估计模型。 例1(file:panel02):1996-2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(不变价格)和人均收入数据见表1和表2。数据是7年的,每一年都有15个数据,共105组观测值。 人均消费和收入两个面板数据都是平衡面板数据,各有15个个体。人均消费和收入的
第五章经典单方程计量经济学模型:专门问题 一、内容提要 本章主要讨论了经典单方程回归模型的几个专门题。 第一个专题是虚拟解释变量问题。虚拟变量将经济现象中的一些定性因素引入到可以进行定量分析的回归模型,拓展了回归模型的功能。本专题的重点是如何引入不同类型的虚拟变量来解决相关的定性因素影响的分析问题,主要介绍了引入虚拟变量的加法方式、乘法方式以及二者的组合方式。在引入虚拟变量时有两点需要注意,一是明确虚拟变量的对比基准,二是避免出现“虚拟变量陷阱”。 第二个专题是滞后变量问题。滞后变量包括滞后解释变量与滞后被解释变量,根据模型中所包含滞后变量的类别又可将模型划分为自回归分布滞后模型与分布滞后模型、自回归模型等三类。本专题重点阐述了产生滞后效应的原因、分布滞后模型估计时遇到的主要困难、分布滞后模型的修正估计方法以及自回归模型的估计方法。如对分布滞后模型可采用经验加权法、Almon多项式法、Koyck方法来减少滞项的数目以使估计变得更为可行。而对自回归模型,则根据作为解释变量的滞后被解释变量与模型随机扰动项的相关性的不同,采用工具变量法或OLS法进行估计。由于滞后变量的引入,回归模型可将静态分析动态化,因此,可通过模型参数来分析解释变量对被解释变量影响的短期乘数和长期乘数。 第三个专题是模型设定偏误问题。主要讨论当放宽“模型的设定是正确的”这一基本假定后所产生的问题及如何解决这些问题。模型设定偏误的类型包括解释变量选取偏误与模型函数形式选取取偏误两种类型,前者又可分为漏选相关变量与多选无关变量两种情况。在漏选相关变量的情况下,OLS估计量在小样本下有偏,在大样本下非一致;当多选了无关变量时,OLS估计量是无偏且一致的,但却是无效的;而当函数形式选取有问题时,OLS估计量的偏误是全方位的,不仅有偏、非一致、无效率,而且参数的经济含义也发生了改变。在模型设定的检验方面,检验是否含有无关变量,可用传统的t检验与F检验进行;检验是否遗漏了相关变量或函数模型选取有错误,则通常用一般性设定偏误检验(RESET检验)进行。本专题最后介绍了一个关于选取线性模型还是双对数线性模型的一个实用方法。 第四个专题是关于建模一般方法论的问题。重点讨论了传统建模理论的缺陷以及为避免这种缺陷而由Hendry提出的“从一般到简单”的建模理论。传统建模方法对变量选取的
1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输出结果中没有公共截距项。 (2)时刻固定效应模型。 时刻固定效应模型就是对于不同的截面(时刻点)有不同截距的模型。如果确知
一分钟看完计量经济学!!!------开学后的计量笔记 建模是计量的灵魂,所以就从建模开始。 一、 建模步骤:A,理论模型的设计: a,选择变量b,确定变量关系c,拟定参数范围 B,样本数据的收集: a,数据的类型b,数据的质量 C,样本参数的估计: a,模型的识别b,估价方法选择 D,模型的检验 a,经济意义的检验1正相关 2反相关等等 b,统计检验:1检验样本回归函数和样本的拟合优度,R的平方即其修正检验 2样本回归函数和总体回归函数的接近程度:单个解释变量显著性即t检验,函数显著性即F检验,接近程度的区间检验 c,模型预测检验1解释变量条件条件均值与个值的预测
2预测置信空间变化 d,参数的线性约束检验:1参数线性约束的检验 2模型增加或减少变量的检验 3参数的稳定性检验:邹氏参数稳定性检验,邹氏预测检验----------主要方法是以 F检验受约束前后模型的差异 e,参数的非线性约束检验:1最大似然比检验 2沃尔德检验 3拉格朗日乘数检验---------主要方法使用 X平方分布检验统计量分布特征 f,计量经济学检验 1,异方差性问题:特征:无偏,一致但标准差偏误。检测方法:图示法,Park与Gleiser检验法,Goldfeld-Quandt检验法,White检验法-------用WLS修正异方差 2,序列相关性问题:特征:无偏,一致,但检验不可靠,预测无效。检测方法:图示法,回归检验法,Durbin-Waston检验法,Lagrange乘子检验法-------用GLS或广义差分法修正序列相关性 3,多重共线性问题:特征:无偏,一致但标准差过大,t减小,正负号混乱。检测方法:先检验 多重共线性是否存在,再检验多重共线性的范围-------------用逐步回归法,差分法或使用额外信息,增大样本容量可以修正。
第5章 分布滞后与动态模型 §5.1 分布滞后模型 很多经济模型在回归方程中有滞后项,例如,因为修建桥和高速公路需要很多时间,所以公共投资对GDP 的影响有一个滞后期,而且这个影响可能会持续数年;研发新产品需要时间,而后把这个新产品投入生产也需要时间;在研究消费行为时,一个工资的变化可能影响好几期的消费。在消费的恒久收入理论中,消费者会用若干期去决定真实可支配收入的变化是暂时的还是永久的。例如,今年额外的咨询费收入明年是否还会继续?同样,真实可支配收入的滞后值会在回归方程中出现,是因为消费者在平滑其消费行为时十分重视他自身的终身收入。一个人的终身收入可以用他过去和现在的收入来推测。换句话说,回归关系可以写为: T t X X X Y t s t s t t t ,,2,1110 =+++++=--εβββα (5.1) 其中,t Y 代表被解释变量Y 在第t 期的观测值,t s X -代表解释变量X 第t s -期的观测值,α为截距项,0β,1β,…,s β是t X 当期和滞后期的系数。方程(5.1)式就是分布滞后模型因为它把收入增长对消费的影响分为s 期。X 的一个单位变化对Y 的短期影响由0β来表示,而X 的一个单位变化对Y 的长期影响由 (s βββ+++ 10)来表示。 假设我们观察从1955年到1995年的t X ,1t X -为相同的变量,但是提前一期的,也就是1954-1994。因为1954年的数据观察不到,我们就从1955年开始观察 1t X -,到1994年结束。这意味着当我们滞后一期时,t X 序列将从1956年开始到 1995年结束。对于实际的应用来说,也就是当我们滞后一期时,我们将从样本中
MATLAB 空间面板数据模型操作简介 MATLAB 安装: 在民主湖资源站上下载 MA TLAB 2009a ,或者 2010a ,按照其中的安装说明 安装 MATLAB 。( MATLAB 较大,占用内存较大,安装的话可能也要花费一定的时间) 一、数据布局 首先我们说一下 MA TLAB 处理空间面板数据时,数据文件是怎么布局的,熟悉 eviews 的同学 可能知道, eviews 中面板数据布局是:一个省份所有年份的数据作为一个单元(纵截面:一个时间 序列),然后再排放另一个省份所有年份的数据,依次将所有省份的数据排放完,如下图,红框中 “1-94”“1-95” “1-96” “ 1-97”中, 1是省份的代号, 94,95,96,97 表示年份, eviews 是将每个省 份的数据放在一起,再将所有省份堆放在一起。 与 eviews 不同, MATLAB 处理空间面板数据时,面板数据的布局是(在 excel 中说明): 先排 放一个横截面上的数据(即某年所有省份的数据) ,再将不同年份的横截面按时间顺序堆放在一起。 如图:
这里需要说明的是, MA TLAB 中省份的序号需要与空间权重矩阵中省份一一对应,我们一般就采用《中国统计年鉴》分地区数据中省份的排列顺序。(二阶空间权重矩阵我会在附件中给出)。二、数据的输入: MATLAB 与 excel链接:在 excel中点击“工具→加载宏→浏览” ,找到 MA TLAB 的安装目录,一般来说,如果安装时没有修改安装路径,此安装目录为: C:\Programfiles\MATLAB\R2009a\toolbox\exlink ,点击 excllink.xla 即可完成 excel 与 MATLAB 的链接。这样的话 excel 中的数据就可以直接导入 MATLAB 中形成 MATLAB 的数据文件。操作完成后 excel 的加载宏界面如图: 选中“Spreadsheet Link EX3.0.3 for use with MATLAB ”即表示我们希望 excel 与
面板数据的计量方法 1.什么是面板数据? 面板数据(panel data)也称时间序列截面数据(time series and cross section data)或混合数据(pool data)。面板数据是截面数据与时间序列综合起来的一种数据资源,是同时在时间和截面空间上取得的二维数据。 如:城市名:北京、上海、重庆、天津的GDP分别为10、11、9、8(单位亿元)。这就是截面数据,在一个时间点处切开,看各个城市的不同就是截面数据。如:2000、2001、2002、2003、2004各年的北京市GDP分别为8、9、10、11、12(单位亿元)。这就是时间序列,选一个城市,看各个样本时间点的不同就是时间序列。 如:2000、2001、2002、2003、2004各年中国所有直辖市的GDP分别为: 北京市分别为8、9、10、11、12; 上海市分别为9、10、11、12、13; 天津市分别为5、6、7、8、9; 重庆市分别为7、8、9、10、11(单位亿元)。 这就是面板数据。 2.面板数据的计量方法 利用面板数据建立模型的好处是:(1)由于观测值的增多,可以增加估计量的抽样精度。(2)对于固定效应模型能得到参数的一致估计量,甚至有效估计量。(3)面板数据建模比单截面数据建模可以获得更多的动态信息。例如1990-2000 年30 个省份的农业总产值数据。固定在某一年份上,它是由30 个农业总产值数字组成的截面数据;固定在某一省份上,它是由11 年农业总产值数据组成的一个时间序列。面板数据由30 个个体组成。共有330 个观测值。 面板数据模型的选择通常有三种形式:混合估计模型、固定效应模型和随机效应模型 第一种是混合估计模型(Pooled Regression Model)。如果从时间上看,不同个体之间不存在显著性差异;从截面上看,不同截面之间也不存在显著性差异,那么就可以直接把面板数据混合在一起用普通最小二乘法(OLS)估计参数。 第二种是固定效应模型(Fixed Effects Regression Model)。在面板数据散点图中,如果对于不同的截面或不同的时间序列,模型的截距是不同的,则可以采用在模型中加虚拟变量的方法估计回归参数,称此种模型为固定效应模型(fixed effects regression model)。 固定效应模型分为3种类型,即个体固定效应模型(entity fixed effects regression model)、时刻固定效应模型(time fixed effects regression model)和时刻个体固定效应模型(time and entity fixed effects regression model)。(1)个体固定效应模型。 个体固定效应模型就是对于不同的个体有不同截距的模型。如果对于不同的时间序列(个体)截距是不同的,但是对于不同的横截面,模型的截距没有显著性变化,那么就应该建立个体固定效应模型。注意:个体固定效应模型的EViwes输
计量经济学数据分析 学院:管理与经济学院 专业:技术经济及管理 姓名:葛文 学号:20808172
分析中国经济发展对中国股票市场的影响本文通过分析2000年到2007年各月股票市场流通市值(value),成交金额(turnover),GDP现价和居民储蓄(saving)的相关数据,试图分析我国经济发展对股票市场的影响。数据来源为CCFR数据库和证监会网站。具体分析如下: 一、绘制四个数据变量的线性图,查看2000年到2007年他们各自的走势。 5000 10000 15000 20000 25000 2000200120022003200420052006 GDP 40000 60000 80000 100000 120000 140000 160000 180000 2000200120022003200420052006 SAVING 0 10000 20000 30000 40000 50000 60000 2000200120022003200420052006 turnover 10000 20000 30000 40000 50000 60000 2000200120022003200420052006 value 二、采用最小二乘法(OLS)进行分析
回归表达式:gdp=10433.48+0.191218*turnover 其中:Prob低于0.05,说明对应系数显著不为零;R2=0.195641,说明拟合程度一般;Prob(F-statistic)=0.000013<0.05,说明至少有一个解释变量的回归系数不为零。 回归表达式:gdp=8470.567+0.196853*value 其中:Prob低于0.05,说明对应系数显著不为零;R2=0.154730,说明拟合程度一般;Prob(F-statistic)=0.000125<0.05,说明至少有一个解释变量的回归系数不为零。
计量经济学分析模型
摘要 改革开放以来,我国经济呈迅速而稳定的增长趋势,由于分配机制和收入水平的变化,城镇居民生活水平在达到稳定小康之后,消费结构和消费水平都出现了一些新的特点。本文旨在对近几年,我国城镇年人均收入变动对年人均各种消费变动的影响进行实证分析。首先,我们综合了几种关于收入和消费的主要理论观点;本文根据相关的数据统计数据,运用一定的计量经济学的研究方法,进而我们建立了理论模型。然后,收集了相关的数据,利用EVIEWS软件对计量模型进行了参数估计和检验,并加以修正。最后,我们对所得的分析结果和影响消费的一些因素作了经济意义的分析,并相应提出一些政策建议。并找到影响居民消费的主要因素。 关键词:居民消费;城镇居民;回归;Eviews
目录 摘要.................................................................. II 前言. (1) 1 问题的提出 (2) 2 经济理论陈述 (3) 2.1西方经济学中有关理论假说 (3) 2.2有关消费结构对居民消费影响的理论 (4) 3 相关数据收集 (6) 4 计量经济模型的建立 (9) 5 模型的求解和检验 (10) 5.1计量经济的检验 (10) 5.1.1模型的回归分析 (10) 5.1.2拟合优度检验: (11) 5.1.3 F检验 (11) 5.1.4 T检验 (12) 5.2 计量修正模型检验: (12) 5.2.1 Y与的一元回归 (13) 5.2.2拟合优度的检验 (13) 5.2.3 F检验 (14) 5.2.4 T检验: (15) 5.3经济意义的分析: (15) 6 政策建议 (16) 结论 (17) 参考文献 (19)
计量经济学试题一 一、判断题(20分) 1.线性回归模型中,解释变量是原因,被解释变量是结果。() 2.多元回归模型统计显著是指模型中每个变量都是统计显著的。() 3.在存在异方差情况下,常用的OLS法总是高估了估计量的标准差。()4.总体回归线是当解释变量取给定值时因变量的条件均值的轨迹。() 5.线性回归是指解释变量和被解释变量之间呈现线性关系。() 6.判定系数的大小不受到回归模型中所包含的解释变量个数的影响。()7.多重共线性是一种随机误差现象。() 8.当存在自相关时,OLS估计量是有偏的并且也是无效的。() 9.在异方差的情况下,OLS估计量误差放大的原因是从属回归的变大。()10.任何两个计量经济模型的都是可以比较的。() 二.简答题(10) 1.计量经济模型分析经济问题的基本步骤。(4分) 2.举例说明如何引进加法模式和乘法模式建立虚拟变量模型。(6分) 三.下面是我国1990-2003年GDP对M1之间回归的结果。(5分) 1.求出空白处的数值,填在括号内。(2分) 2.系数是否显著,给出理由。(3分) 四.试述异方差的后果及其补救措施。(10分)
五.多重共线性的后果及修正措施。(10分) 六.试述D-W检验的适用条件及其检验步骤?(10分) 七.(15分)下面是宏观经济模型 变量分别为货币供给、投资、价格指数和产出。 1.指出模型中哪些是内是变量,哪些是外生变量。(5分) 2.对模型进行识别。(4分) 3.指出恰好识别方程和过度识别方程的估计方法。(6分) 八、(20分)应用题 为了研究我国经济增长和国债之间的关系,建立回归模型。得到的结果如下:Dependent Variable: LOG(GDP) Method: Least Squares Date: 06/04/05 Time: 18:58 Sample: 1985 2003 Included observations: 19 Variable Coefficient Std. Error t-Statistic Prob. LOG(DEBT) 0.65 0.02 32.8 0 Adjusted R-squared 0.983 S.D. dependent var 0.86 S.E. of regression 0.11 Akaike info criterion -1.46 Sum squared resid 0.21 Schwarz criterion -1.36 Log likelihood 15.8 F-statistic 1075.5 Durbin-Watson stat 0.81 Prob(F-statistic) 0 其中,GDP表示国内生产总值,DEBT表示国债发行量。 (1)写出回归方程。(2分) (2)解释系数的经济学含义?(4分) (3)模型可能存在什么问题?如何检验?(7分)
与MATLAB链接: Excel: 选项——加载项——COM加载项——转到——没有勾选项 2. MATLAB安装目录中寻找toolbox——exlink——点击,启用宏 E:\MATLAB\toolbox\exlink 然后,Excel中就出现MATLAB工具
(注意Excel中的数据:) 3.启动matlab (1)点击start MATLAB (2)senddata to matlab ,并对变量矩阵变量进行命名(注意:选取变量为数值,不包括各变量)
(data表中数据进行命名) (空间权重进行命名) (3)导入MATLAB中的两个矩阵变量就可以看见
4.将elhorst和jplv7两个程序文件夹复制到MATLAB安装目录的toolbox文件夹 5.设置路径:
6.输入程序,得出结果 T=30; N=46; W=normw(W1); y=A(:,3);
x=A(:,[4,6]); xconstant=ones(N*T,1); [nobs K]=size(x); results=ols(y,[xconstant x]); vnames=strvcat('logcit','intercept','logp','logy'); prt_reg(results,vnames,1); sige=*((nobs-K)/nobs); loglikols=-nobs/2*log(2*pi*sige)-1/(2*sige)*'* % The (robust)LM tests developed by Elhorst LMsarsem_panel(results,W,y,[xconstant x]); % (Robust) LM tests 解释 每一行分别表示:
注意:实验报告的题可以从以下题目中选择,也可以自己命题,自己命题要与金融专业知识相关。 第一部分多元线性回归 1、经研究发现,家庭书刊消费受家庭收入及户主受教育年数的影响,表中为对某地区部分家庭抽样调查得到样本数据: 家庭书刊年消费支出(元)Y 家庭月平 均收入 (元)X 户主受教 育年数 (年)T 家庭书 刊年消 费支出 (元)Y 家庭月平 均收入 (元)X 户主受教 育年数 (年)T 450 1027.2 8 793.2 1998.6 14 507.7 1045.2 9 660.8 2196 10 613.9 1225.8 12 792.7 2105.4 12 563.4 1312.2 9 580.8 2147.4 8 501.5 1316.4 7 612.7 2154 10 781.5 1442.4 15 890.8 2231.4 14 541.8 1641 9 1121 2611.8 18 611.1 1768.8 10 1094.2 3143.4 16 1222.1 1981.2 18 1253 3624.6 20 (1) 建立家庭书刊消费的计量经济模型; (2)利用样本数据估计模型的参数; (3)检验户主受教育年数对家庭书刊消费是否有显著影响; (4)分析所估计模型的经济意义和作用 2某地区城镇居民人均全年耐用消费品支出、人均年可支配收入及耐用消费品价格指数的统计资料如表所示: 年份人均耐用消费 品支出 Y(元)人均年可支配 收入 X1(元) 耐用消费品价 格指数 X2(1990年 =100) 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 137.16 124.56 107.91 102.96 125.24 162.45 217.43 253.42 251.07 285.85 327.26 1181.4 1375.7 1501.2 1700.6 2026.6 2577.4 3496.2 4283.0 4838.9 5160.3 5425.1 115.96 133.35 128.21 124.85 122.49 129.86 139.52 140.44 139.12 133.35 126.39 利用表中数据,建立该地区城镇居民人均全年耐用消费品支出关于人均年可支配收入和耐用消费品价格指数的回归模型,进行回归分析,并检验人均年可支配收入及耐用消费品价格指数对城镇居民人均全年耐用消费品支出是否有显著影响。
空间面板数据计量经济分析 空间面板数据计量经济分析 *以上分别介绍了区域创新过程中空间效应(依赖性和异质性)的空间计量检测,以及纳入空间效应的计量模型的估计方法——空间常系数回归模型(空间滞后模型,SLM 和空间误差模型,SEM )和空间变系数回归模型(地理加权回归模型,GWR );同时还介绍和分析了面板数据(Panel Data )计量经济学方法的估计和检验。 *可以看出,目前的空间计量经济学模型使用的数据集主要是截面数据,只考虑了空间单元之间的相关性,而忽略具有时空演变特征的时间尺度之间的相关性,这显然是一个美中不足。 *Anselin (1988)也认识到这一点。当然,大多学者通过将多个时期截面数据变量计算多年平均值的办法来综合消除时间波动的影响和干扰,但是这种做法仍然造成大量具有时间演变特征的创新行为信息的损失,从而无法科学和客观地认识和揭示具有时空二维特征的研发与创新过程的真实机制。*面板数据(Panel Data )计量经济模型作为目前一种前沿的计量经济估计技术,由于其可以综合创新行为变量时间尺度的信息和截面(地域空间)单元的信息,同时集成考虑了时间相关性和空间(截面)相关性,因而能够科学而客观地反映受到时空交互相关性作用的创新行为的特征和规律,是定量揭示研发、知识溢出与区域创新相互作用关系的有效方法。但是,限于在所有时刻对所有个体(空间)均相等的假定(即不考虑空间效应),面板数据计量经济学理论也有其美中不足之处,具有很大的改进余地。 *鉴于空间计量经济学理论方法和面板数据计量经济学理论方法各有所长,把面板数据模型的优点和空间计量经济学模型的特点有机结合起来,构建一个综合考虑了变量时空二维特征和信息的空间面板数据计量经济模型,则是一种新颖的研究思路。以下根据空间计量经济模型和标准的面板数据模型[1]的建模思路,提出空间面板数据(Spatial Panel Data Model ,SPDM )模型的建模思路和过程。 [1]与动态面板数据模型的建模思路类似,只要施加一些假定,引入因变量的滞后项,则为空间动态面板数据模型。 空间滞后面板数据计量分析 *考虑一个标准的面板数据模型: it it it it it y αx βμ=++*如果将变量的真实的区域空间自相关性(依赖性)(Anselin &Florax ,1995)考虑到创新行为中来,这种创新行为的空间自相关性可以视为区域创新过程中的一种外部溢出形式,这样则可以设定如下模型: it it it it it it y αWy x βμρ=+++*上式为空间滞后面板数据(Spatial Lag Panel Data Model ,SLPDM )计量经济模型。其中,是创新的空间滞后变量,主要度量在地理空间上邻近地区的外部知识溢出,是一个区域在地理上邻近的区域在时期创新行为变量的加权求和。 空间误差面板数据计量分析 *如果在创新行为的空间依赖性存在误差扰动项中来测度邻近地区创新因变量的误差冲击对本地区创新行为的影响程度,则可以通过空间误差模型的空间依赖性原理可得: it it it it it y αx βμ=++it it it W μλμε=+*上式即为空间误差面板数据(Spatial Error Panel Data Model ,SEPDM )计量经济模型。其中,参数衡量了样本观察值的误差项引进的一个区域间溢出成分。 *因为已经在面板数据模型中考虑了创新行为变量的空间依赖性,因此采用一般面板数据模型的估计技术如OLS 或GLS 等将具有良好的估计效果。如果能够综合考虑面板数据模型中的一些假定,如时间加权(Period Weights )或截面加权(Cross-section Weights ),则可获得更加符合创新现实的估计结果。
#学术探讨# 现代计量经济学模型体系解析* 李子奈刘亚清 内容提要:本文对现代计量经济学模型体系进行了系统的解析,指出了现代计量经济学的各个分支是以问题为导向,在经典计量经济学模型理论的基础上,发展成为相对独立的模型理论体系,包括基于研究对象和数据特征而发展的微观计量经济学、基于充分利用数据信息而发展的面板数据计量经济学、基于计量经济学模型的数学基础而发展的现代时间序列计量经济学、基于非设定的模型结构而发展的非参数计量经济学,并对每个分支进行了扼要的描述。最后在/交叉与综合0的方向上提出了现代计量经济学模型理论的研究前沿领域。 关键词:经典计量经济学时间序列计量经济学微观计量经济学 一、引言 计量经济学自20世纪20年代末30年代初诞生以来,已经形成了十分丰富的内容体系。一般认为,可以以20世纪70年代为界将计量经济学分为经典计量经济学(Classical Econometrics)和现代计量经济学(Mo dern Eco no metr ics),而现代计量经济学又可以分为四个分支:时间序列计量经济学(Tim e Ser ies Econo metrics)、微观计量经济学(M-i cro-econometrics)、非参数计量经济学(Nonpara-m etric Econometrics)以及面板数据计量经济学(Panel Data Eco nom etrics)。这些分支作为独立的课程已经被列入经济学研究生的课程表,独立的教科书也已陆续出版,应用研究已十分广泛,标志着它们作为计量经济学的分支学科已经成熟。 据此提出三个问题:一是经典计量经济学的地位问题。既然现代计量经济学模型体系已经成熟,而且它们都是在经典模型理论的基础上发展的,那么经典模型还有应用价值吗?是不是凡是采用经典模型的研究都是低水平和落后的?二是现代计量经济学的各个分支的发展导向问题。即它们是如何发展起来的?三是现代计量经济学进一步创新和发展的基点在哪里?回答这些问题,对于正确理解计量经济学的学科体系,对于计量经济学的课程设计和教学内容安排,对于正确评价计量经济学理论和应用研究的水平,对于进一步推动中国的计量经济学理论研究,都是十分有益的。 现代计量经济学的各个分支是以问题为导向,以经典计量经济学模型理论为基础而发展起来的。所谓/问题0,包括研究对象和表征研究对象状态和变化的数据。研究对象不同,表征研究对象状态和变化的数据具有不同的特征,用以进行经验实证研究的计量经济学模型既然不同,已有的模型理论方法不适用了,就需要发展新的模型理论方法。按照这个思路,就可以用图1简单地描述经典计量经济学模型与现代计量经济学模型各个分支之间的关系。 本文试图从方法论的角度对现代计量经济学模型的发展,特别是现代计量经济学模型与经典计量经济学模型之间的关系进行较为系统的讨论,以期对未来我国计量经济学的发展研究提供借鉴和启示。本文的内容安排如下:首先分析经典计量经济学模型的基础地位,明确它在现代的应用价值,同时对发生于20世纪70年代的/卢卡斯批判0的实质进行讨论;然后依次讨论时间序列计量经济学、微观计量经济学、非参数计量经济学以及面板数据计量经济学的发展,回答它们是以什么问题为导向,以什么为目的而发展的;最后以/现代计量经济学模型体系的分解与综合0为题,讨论现代计量经济学的前沿研究领域以及从对我国计量经济学理论的创新和发展 ) 22 ) *本文受国家社会科学基金重点项目(08AJY001,计量经济学模型方法论基础研究)的资助。