
第三章销售和应收帐款管理
前言
Fourth Shift中的销售系统包括销售订单处理、发货、销售分析等模块,它们可以检查客户信用、可签约量,可以对订单、发货情况进行跟踪和支持,随时掌握客户的信息,并且对所跟踪的业务进行分析。
Fourth Shift会将物流转换成现金流、信息流,使销售、应收帐款、总帐等模块相互关联。应收帐款模块用于处理客户发票及回款的准确度和及时性,跟踪应收帐款帐龄情况,按时发出客户对帐单,随时查询客户情况。
在使用销售、应收帐款模块之前需要对系统进行设置。这些设置包括应收帐款模块设置、税金代码的设置。
应收帐款模块设置
应收帐款模块的设置使用两个屏幕: ARCF(应收帐款参数设置)、ARAD(应收帐款帐龄定义)。
ARCF屏幕包括销售、应收帐款、允许折扣、服务费的主帐号;服务费、对帐单、帐龄计算的最后处理日期;发票、贷方凭单是否产生总帐信息的设置。
ARAD屏幕用来设置应收帐款帐龄段,它决定CUID-F9屏幕的显示,此屏幕一经设定不易再改变。
税金代码的设置
除了应收帐款模块设置外,还需对税金进行设置。设置税金使用的屏幕是TXTA(税金代码表)、V ATT(增值税代码表)。
TXTA屏幕用来为不同征税机关设置税金代码、描述、税率和应收、应付主帐号,设置后的税金代码会在V ATT、IVIE等屏幕使用。
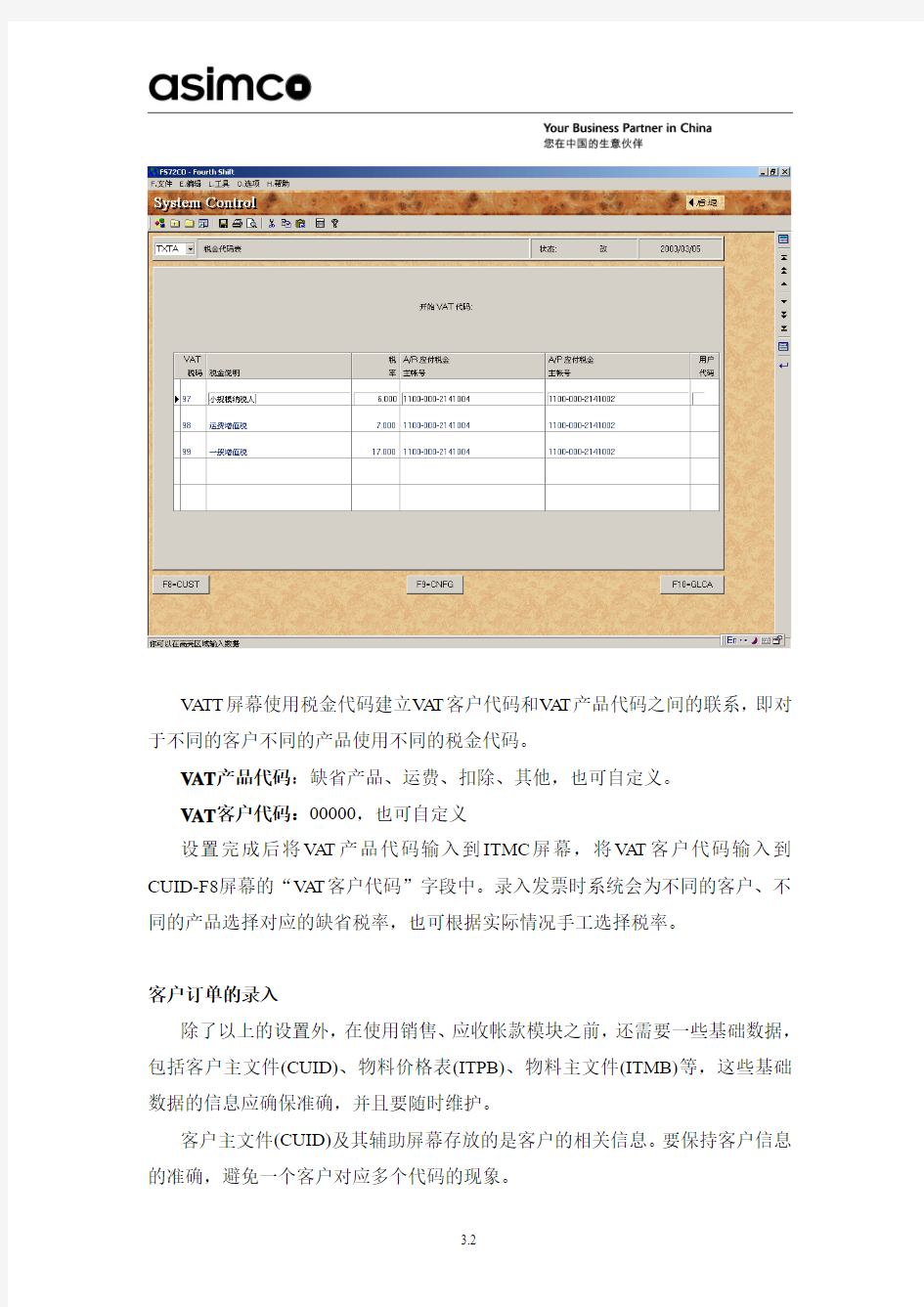
V ATT屏幕使用税金代码建立V AT客户代码和V AT产品代码之间的联系,即对于不同的客户不同的产品使用不同的税金代码。
V AT产品代码:缺省产品、运费、扣除、其他,也可自定义。
V AT客户代码:00000,也可自定义
设置完成后将V AT产品代码输入到ITMC屏幕,将V AT客户代码输入到CUID-F8屏幕的“V AT客户代码”字段中。录入发票时系统会为不同的客户、不同的产品选择对应的缺省税率,也可根据实际情况手工选择税率。
客户订单的录入
除了以上的设置外,在使用销售、应收帐款模块之前,还需要一些基础数据,包括客户主文件(CUID)、物料价格表(ITPB)、物料主文件(ITMB)等,这些基础数据的信息应确保准确,并且要随时维护。
客户主文件(CUID)及其辅助屏幕存放的是客户的相关信息。要保持客户信息的准确,避免一个客户对应多个代码的现象。
客户编码:应有自己公司的编码原则。
客户名称:确保准确,应按客户发票上公章的名称填写。
CUID-F8屏幕存放名称/地址详细信息。
地址/市/省/邮编/国:客户的详细地址。
收货地:收货地代码,可存在多个收货地。
收货人名称地址:收货地的详细信息。
V AT客户代码:确定客户使用的缺省税率。
免税:销售是否计税。
价格调整策略:S-附加费;D-折扣
CUID-F9屏幕记录该客户的财务信息,包括本年销售、本年发货、应收款帐龄等,这些信息会自动更新。另外,赊销限额的设置会对发货进行控制,与”A/R 客户”字段配合使用。当某一客户的应收帐款金额超过了赊销限额时,如果将“A/R客户”设为“H”(软封存),在输入销售订单后系统会提示“客户封存”,
但不限制发货;如果将“A/R客户”设置为“C”(硬封存),输入订单后系统不允许下达订单,并提示“赊销冻结客户-不能下达行物料”,无法进行发货。
物料价格表(ITPB)用于记录物料的标准销售价格。系统可以根据折扣/附加费策略和标准售价计算出客户订单上物料的价格。
定义了这些基础数据之后,就可以录入的订单。订单录入屏幕为COMT(销售订单)。
订单主部信息
客户订单号:要有统一的标准,C-YYMMDDXXX001。
收货地代码:输入正确发货地的代码。
订单明细行信息
承诺交货日:如果订单过期没有发货,应按实际情况修订承诺交货日期。
行状态:3-待下达;4-下达,可以发货;5-关闭,发货完毕或订单被取消。
单价:不含税价格,如果使用ITPB和折扣/附加费,在单价处按F4系统会计算出销售价格。还可以在客户订单主部明细、标准产品明细屏幕设置折扣/附加费的条件。
可签约量的应用
Fourth Shift系统可以计算一个称之为可签约量(ATP)的值。可签约量是指能够向客户承诺的数量,销售人员可根据ATP来确定能否按时满足客户的要求及何时才能满足客户的要求。
BATP(可签约量更新)任务更新订单可签约量。计算可签约量时,考虑当前库存,计划到货和客户订单,每天执行一次。如果已安装MRP模块并且每天运行PLNG(MRP计划)任务,PLNG任务可代替BATP任务。
Fourth Shift系统中有三处可以查询ATP的信息。
-供应/需求情况分析屏幕和供应反查明细窗口。
-主生产计划汇总(MPSS)屏幕
-COMT屏幕,在订货数量处按F4,会出现“订货量有货日期xxxxxx”。
产成品库存管理
对产成品库存的操作包括产成品的发货和完产入库。产成品的发货是通过PICK(提料单)或SHIP(发货),在使用这两个屏幕时必须输入销售订单号,所以销售订单号、行号必须记录到出库单上。按出库单的实际数量对相关物料进行出库操作。
产成品的完产入库通过MORV(生产订单接收/冲减),使用这个屏幕也需要输入生产订单号,生产订单号、行号应在入库单上注明。按实际入库数量进行操作。由此可见订单号是非常重要的,应有自己的编码原则。
系统中通讯操作将物流信息转换成财务信息。销售发货的物流信息会转换到总帐、应收模块。产成品完产入库的物流信息会转换到总帐模块。在总帐模块产生的财务凭证,在GLSS/GLJE屏幕查看,应收模块中产生的是发票原型,IVRV/IVIE屏幕可查看。
发票的产生与维护
经过通讯产生的发票原型可显示在IVRV(发票审核)屏幕中,在IVRV屏幕只能查询到发票原型的汇总信息,包括客户代码、参考号、货款金额、税金、发票金额、发票状态。
发票原型的详细信息可在IVIE(发票录入和维护)屏幕显示,此屏幕包括发票首部、发票明细行两部分。发票首部显示客户代码、发票状态、付款条件、总金;发票明细行显示物料代码、主帐号、发货数量、单价、是否免税,还可以针对每一个物料选择税金代码,在“发票行物料明细”屏幕进行。发票审核需要查看主帐号、单价是否正确,完全正确后将发票状态改为“A”。这样就可以打印发票了,发票的打印使用IVPR或IVEX,他们产生的结果是相同的,只不过生成文件记录的信息格式不同。打印发票后,生成来源代码是IVPR或IVEX的凭证,可以通过GLSS或GLJE屏幕来查询。同时,相关的明细信息也会记录在客户主文件的辅助屏幕上。
由于小数位的取舍会发生系统发票与手工发票金额不符的情况。这时要对系统的发票进行调整,调整的方法有以下几种:
货款不正确:
金额比手工发票多,按F6增加一明细行,物料代码处输入“LESS:”,主帐号使用销售收入,发票数量输入“1”,单价为所差金额,免税处输入“Y”,不计税。
金额比手工发票少,按F6增加一明细行,物料代码处输入“ADD:”,主帐号使用销售输入,发货数量输入“1”,单价为所差金额,免税处输入“Y”,不计税。
税金不正确:
金额比手工凭证多,按F6增加一明细行,物料代码处“LESS:”,主帐号使用销项税,发货数量输入“1”,单价为所差金额,免税处为“Y”。
金额比手工凭证少,按F6增加一明细行,物料代码处“ADD:”,主帐号使用销项税,发货数量输入“1”,单价为所差金额,免税处为“Y”。
如果客户对产品不满意,就要使用PICK或SHIP屏幕进行退货,通讯之后会产生贷方凭单-红票。贷方凭单的信息也可以通过IVRV/IVIE屏幕查询。贷方凭单除在“发票类型”处显示“R”,其它内容与发票相同。审核贷方凭单准确无误后,将“状态”改为“A”后,就可以使用IVPR/IVEX执行贷方凭单的打印,生成来源代码是IVPR/IVEX的凭证。贷方凭单要与相应的发票核销。
现金回款及核销
客户支付货款时,应将信息及时输入系统并与发票信息进行核销。
回款的录入是在ARCD(应收款现金存款)屏幕执行的,选定需要使用的现金集和银行号,确定记入会计期间的正确性,再将涉及到的每个供应商的明细信息输入到明细行内,包括客户代码、回款参考号、回款日期、回款金额、回款说明。确定输入正确后,进入辅助屏幕生成来源代码是ARCD的总帐凭证,同时系统也会记录明细信息。如果没有生成凭证就退出会造成应收帐款总帐/明细帐不符。此外,回款的类型一定为30,若修改也会造成总帐和明细帐不符。
如果回款需要记入的会计期间已经关闭,可以使用ARPD(前期应收帐款现金存款)来完成回款的操作,除会计期间应特别注意外,其他操作与ARCD相同。
贷方凭单、回款与发票的核销在ARCR进行。输入客户代码、回款参考号或贷方凭单号,核销相应的发票。发票的核销方法可以采用逐票核销也可以采用余额承前,核销后不生成凭证。
应收帐款分析
应收帐款是各个企业都比较关心的问题,Fourth Shift系统可以帮助企业完成应收帐款的分析工作。
ARAD-(应收帐款帐龄定义),定义应收帐款的三个帐龄段,同时影响CUID-F9屏幕显示的帐龄段。
ARAG-(应收帐款帐龄计算),根据ARAD屏幕定义的帐龄期间计算帐龄,提供汇总信息的报告,对CUID-F9屏幕进行更新。
ARTB(应收帐款帐龄试算平衡表),可以自行定义帐龄段,但帐龄段也只限三段,提供每个客户的明细报告。
应定期核对应收帐款总帐和明细帐:
GLDQ屏幕获得应收帐款当前期间已过帐的本期余额和未过帐的净发生额,结果相加得到总帐的金额。使用ARAG打印报告,得出明细帐金额。查看总帐和明细帐金额是否相等。
ARST-(应收帐款对帐单打印),打印客户的对帐单。客户选定的核销方式会影响对帐单的内容:
余额承前方法,对帐单上列出自上次打印对帐单后的发票、贷方凭单和现金收款。
逐票核销方法,对帐单上列出截止到指定日期的所有现金收款、贷方凭单和有到期余额的发票。
ARBS-(应收帐款对帐单数据输出),和ARST报告的内容相同,只是文件的格式不同,生成文件中的每个字段是以逗号间隔。
ARBS和ARST不能同时使用,否则后执行的一个任务输出文件无内容。
ARST报告
ARCJ-(应收款贷方凭单日记帐),按客户代码的贷方凭单号打印所选日期和主帐号范围内的贷方凭单日记帐,按号码、日期、金额、已核销和未核销金额标识每个贷方凭单,还可列出与每个贷方凭单核销的发票的信息。
ARCJ报告
ARIR-(应收帐款发票登记簿),打印在所选时段或发票号码范围内的发票、贷方凭单信息,包括号码、日期、类型、客户代码、客户订单、总金额等。
ARIR报告
ARRJ-(应收帐款现金收入日记帐),按客户代码的付款号打印所选定日期和主帐号范围内的现金收入日记帐,按号码、日期、金额、准予折扣、已分配和未分配金额。打印出某天的报告可以用来与银行存款对帐。还可以列出所核销的发票的信息。
ARTX-(应收帐款税金登记簿),按税金代码打印选定时段内的税金汇总。
ARTX报告
应收帐款会计期间的关闭
当一个会计期间结束后,应该进行会计期间的关闭。以前版本会计期间的关闭使用GLPC屏幕即可,但在新版本中会计期间的关闭分为三部分:应收、应付、总帐。如果使用了现金模块,在执行GLPC前还需要对现金集进行关闭。
应收帐款会计期间的关闭使用ARCP屏幕,将本期的应收现金集状态由4变为6,将已有发生额但状态仍为3的现金集列示在报告中。当本期所有的现金集状态全部大于6时才能进行总帐会计期间的关闭。
查询和报告
为了方便地获得信息,系统提供的一些报告和查询屏幕。
发票信息的查询:
IVCO-发票查询(客户订单)
用此屏幕查询特定客户订单发货或退货生成的发票货贷方凭单。
IVIA-(发票调整),跟踪客户发票和贷方凭单所做的修改。
IVPP-(预打印发票报告),生成的报告按客户代码列出未打印的发票原型,包括贷方凭单。也就是IVRV屏幕显示的内容。
ARIC-(应收帐款发票查询(客户)),显示特定客户的所有发票及贷方凭单。
付款信息查询:
ARAH-(应收帐款付款核销历史),查看与指定现金收款或贷方凭单核销的发票,包括原始金额、已核销金额、未核销金额、发票号、日期等。
ARIH-(应收帐款发票历史),查看所有已经与指定发票核销的现金回款/贷方凭单,包括日期、付款参考号、合计金额、发票号等。
ARIP-(应收帐款发票/付款审计),跟踪发票打印、现金收款、发票调整和兑换率浮动的信息。
ARPH-(应收帐款客户付款历史),查看客户的所有的收款和贷方凭单。
总帐通讯
总帐凭证审核/录入
销售订单
销售出库
发票通讯
发票审核
发票录入/维护
打印发票
A/R现金存款
应收帐款现金/贷方凭单
核销
客户主文件
物料主文件
物料价格表物料/工作中心成本数据
销售/应收帐款流程
传统meanshift 跟踪算法实现流程 一、 Meanshift 算法流程图 视频流 手动选定跟踪目标 提取目标灰度加权直方图特征hist1 提取候选目 标区域 提取候选目标的灰度加权直方图特征hist2 均值漂移得到均值漂移向量及新的候选区域位 置 是否满足迭代结束条件 第二帧之后图像 第一帧图像 得到当前帧目标位置 是 否 图1 meanshift 流程图 二、 各模块概述 1、 手动选定目标区域:手动框出目标区域,并把该区域提取出来作为目标模板 区域; 2、 提取目标灰度加权直方图特征hist1; 2.1构造距离权值矩阵m_wei ; 使用Epanechnikov 核函数构造距离加权直方图矩阵:设目标区域中像素
点(,)i j 到该区域中心的距离为dist ,则 _(,)1/m wei i j dist h =-,这里h 是核函数窗宽,h 为目标区域中离区域中心 最远的像素点到中心的距离:若所选目标区域为矩形区域,区域的半宽度为 x h ,半高度为y h ,则22()x y h sqrt h h =+; 2.2得到归一化系数C ; 1/C M =,其中M 是m_wei 中所有元素值之和; 2.3计算目标的加权直方图特征向量hist1; 若图像为彩色图像,则把图像的,,r g b 分量归一化到[0,15]之间(分量值与16取余,余数即为归化后的分量值),然后为不同的分量值赋予不同的权值得到每个像素点的特征值_q temp : _256*16*q t e m p r g b = ++ 对于像素点(,)i j ,设其特征值为_q temp ,则另 1(_1)1(_1)_(,)hist q temp hist q temp m wei i j +=++; 若图像是灰度图像,则直接利用每个像素的灰度值作为每个像素的特征值,然后统计得到hist1; 把一维数组hist1归一化:11*hist hist C =;归一化后的数组hist1即为目标的加权直方图特征向量; 3、 从第二帧开始的图像,通过迭代的方式找到该帧图像中目标的位置; 3.1提取候选目标区域:以上一帧图像中目标的位置或上一次迭代得到的目标位置为中心提取出目标模板区域大小的区域; 3.2提取候选目标区域的加权直方图特征向量hist2:提取方法同步骤2.3; 计算候选目标区域的特征值矩阵_1q temp : _1 (,)256*(,) 16*(,)q t e m p i j r i j g i j b i j =++; 3.3均值漂移到新的目标区域; 3.3.1计算候选目标区域相对于目标区域的均值漂移权值w : ( 1()/2()),2(2w s q r t h i s t i h i s t i h i s t =≠ 2() 0h i s t i =时,()0;w i = 3.3.2 根据每个像素点所占的均值漂移权值计算漂移矩阵xw : 11(_1(,)1)*[(1),(2)]a b i j xw xw w q temp i j i y j y ===++--∑∑ 3.3.2得到权值归一化后的均值漂移向量Y :
基于Mean Shift的目标跟踪算法研究 指导教师:
摘要:该文把Itti视觉注意力模型融入到Mean Shift跟踪方法,提出了一种基于视觉显著图的Mean Shift跟踪方法。首先利用Itti视觉注意力模型,提取多种特征,得到显著图,在此基础上建立目标模型的直方图,然后运用Mean Shift方法进行跟踪。实验证明,该方法可适用于复杂背景目标的跟踪,跟踪结果稳定。 关键词:显著图目标跟踪Mean Shift Mean Shift Tracking Based on Saliency Map Abstract:In this paper, an improved Mean Shift tracking algorithm based on saliency map is proposed. Firstly, Itti visual attention model is used to extract multiple features, then to generate a saliency map,The histogram of the target based on the saliency map, can have a better description of objectives, and then use Mean Shift algorithm to tracking. Experimental results show that improved Mean Shift algorithm is able to be applied in complex background to tracking target and tracking results are stability. 1 引言 Mean Shift方法采用核概率密度来描述目标的特征,然后利用Mean Shift搜寻目标位置。这种方法具有很高的稳定行,能够适应目标的形状、大小的连续变化,而且计算速度很快,抗干扰能力强,能够保证系统的实时性和稳定性[1]。近年来在目标跟踪领域得到了广泛应用[2-3]。但是,核函数直方图对目标特征的描述比较弱,在目标周围存在与目标颜色分布相似的物体时,跟踪算法容易跟丢目标。目前对目标特征描述的改进只限于选择单一的特征,如文献[4]通过选择跟踪区域中表示目标主要特征的Harris点建立目标模型;文献[5]将初始帧的目标模型和前一帧的模型即两者的直方图分布都考虑进来,建立混合模型;文献[6]提出了以代表图像的梯度方向信息的方向直方图为目标模型;文献[7-8]提出二阶直方图,是对颜色直方图一种改进,是以颜色直方图为基础,颜色直方图只包含了颜色分布信息,二阶直方图在包含颜色信息的前提下包含了像素的均值向量和协方差。文献[9]提出目标中心加权距离,为离目标中心近的点赋予较大的权值,离目标中心远的点赋予较小的权值。文献[4-9]都是关注于目标和目标的某一种特征。但是使用单一特征的目标模型不能适应光线及背景的变化,而且当有遮挡和相似物体靠近时,容易丢失目标;若只是考虑改进目标模型,不考虑减弱背景的干扰,得到的效果毕竟是有限的。 针对上述问题,文本结合Itti 提出的视觉注意模型[5],将自底向上的视觉注意机制引入到Mean Shift跟踪中,提出了基于视觉显著图的Mean Shift跟踪方法。此方法在显著图基础上建立目标模型,由此得到的目标模型是用多种特征来描述的,同时可以降低背景对目标的干扰。 2 基于视觉显著图的Mean Shift跟踪方法
Mean Shift 概述 Mean Shift 简介 Mean Shift 这个概念最早是由Fukunaga 等人[1]于1975年在一篇关于概率密度梯度函数的估计中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift 是一个名词,它指代的是一个向量,但随着Mean Shift 理论的发展,Mean Shift 的含义也发生了变化,如果我们说Mean Shift 算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束. 然而在以后的很长一段时间内Mean Shift 并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift 的重要文献[2]才发表.在这篇重要的文献中,Yizong Cheng 对基本的Mean Shift 算法在以下两个方面做了推广,首先Yizong Cheng 定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng 还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift 的适用范围.另外Yizong Cheng 指出了Mean Shift 可能应用的领域,并给出了具体的例子. Comaniciu 等人[3][4]把Mean Shift 成功的运用的特征空间的分析,在图像平滑和图像分割中Mean Shift 都得到了很好的应用. Comaniciu 等在文章中证明了,Mean Shift 算法在满足一定条件下,一定可以收敛到最近的一个概率密度函数的稳态点,因此Mean Shift 算法可以用来检测概率密度函数中存在的模态. Comaniciu 等人[5]还把非刚体的跟踪问题近似为一个Mean Shift 最优化问题,使得跟踪可以实时的进行. 在后面的几节,本文将详细的说明Mean Shift 的基本思想及其扩展,其背后的物理含义,以及算法步骤,并给出理论证明.最后本文还将给出Mean Shift 在聚类,图像平滑,图像分割,物体实时跟踪这几个方面的具体应用. Mean Shift 的基本思想及其扩展 基本Mean Shift 给定d 维空间d R 中的n 个样本点i x ,i=1,…,n,在x 点的Mean Shift 向量的基本形式定义为: ()()1 i h h i x S M x x x k ∈≡ -∑ (1) 其中,h S 是一个半径为h 的高维球区域,满足以下关系的y 点的集合,
mean shift及其改进算法图像跟踪原理和应用Mean Shift 简介 Mean Shift 这个概念最早是由Fukunaga等人[1]于1975年在一篇关于概率密度梯度函数的估计中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift是一个名词,它指代的是一个向量,但随着Mean Shift理论的发展,Mean Shift的含义也发生了变化,如果我们说Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束. 然而在以后的很长一段时间内Mean Shift并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift的重要文献才发表.在这篇重要的文献中,Yizong Cheng对基本的Mean Shift算法在以下两个方面做了推广,首先Yizong Cheng定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift的适用范围.另外Yizong Cheng 指出了Mean Shift可能应用的领域,并给出了具体的例子. Comaniciu等人把Mean Shift成功的运用的特征空间的分析,在图
像平滑和图像分割中Mean Shift 都得到了很好的应用. Comaniciu 等在文章中证明了,Mean Shift 算法在满足一定条件下,一定可以收敛到最近的一个概率密度函数的稳态点,因此Mean Shift 算法可以用来检测概率密度函数中存在的模态. Comaniciu 等人还把非刚体的跟踪问题近似为一个Mean Shift 最优化问题,使得跟踪可以实时的进行. 在后面的几节,本文将详细的说明Mean Shift 的基本思想及其扩展,其背后的物理含义,以及算法步骤,并给出理论证明.最后本文还将给出Mean Shift 在聚类,图像平滑,图像分割,物体实时跟踪这几个方面的具体应用. Mean Shift 的基本思想及其扩展 基本Mean Shift 给定d 维空间d R 中的n 个样本点i x ,i=1,…,n,在x 点的Mean Shift 向量的基本形式定义为: ()()1 i h h i x S M x x x k ∈≡ -∑ (1) 其中,h S 是一个半径为h 的高维球区域,满足以下关系的y 点的集合, ()() (){ } 2:T h S x y y x y x h ≡--≤ (2) k 表示在这n 个样本点i x 中,有k 个点落入h S 区域中.
摘要 在图像处理和计算机视觉里,图像分割是一个十分基础而且很重要的部分,决定了最终分析结果的好坏。图像分割问题的典型定义就是如何在图像处理过程中将图像中的一致性区域和感兴趣对象提取出来。 MeanShift 图像分割方法是一种统计迭代的核密度估计方法。MeanShift算法以其简单有效而被广泛应用,但该方法在多特征组合方面和数据量较大的图像处理上仍存在不足之处,本文针对这些问题对该算法的结构进行了优化。本文利用图像上下文信息对图像进行了区域合并以此来对输入数据进行了压缩;并实现特征空间中所有特征量的优化组合。 最后,总结了本文的研究成果。下一步需要深入的研究工作有:(1)考虑分割的多尺度性,实现基于Mean Shift算法的多尺度遥感图像分割;(2)考虑利用Gabor滤波器来提取纹理特征,或将更多的特征如形状等特征用于MeanShift遥感图像分割中。 关键词: Mean Shift, 图像分割, 遥感图像, 带宽
ABSTRACT mage segmentation is very essential and critical to image processing and computer vision, which is one of the most difficult tasks in image processing, and determines the quality of the final result of analysis. In image segmentation problem, the typical goal is to extract continuous regions and interest objects in the case of image processing. The Mean Shift algorithm for segmentation is a statistical iterative algorithm based on kernel density estimation. Mean Shift algorithm has been widely applied for its simplicity and efficiency. But the algorithm has some deficiencies in feature combination and image processing for large data. According to the deficiencies of the Mean Shift algorithm, this paper optimizes the structure of the algorithm for segmentation. Firstly, this paper introduces a method of data compressing by merging the nearest points with similar properties into consistency regions. Secondly, We optimize the combination of features. At last, after concluding all research work in this paper, further work need to be in-depth studied: (1) Consider multi-scale factors of remote sensing, and realize multi-scale remote sensing image segmentation based on Mean Shift algorithm. (2) Consider extracting textures features by using Gabor filter, or use more features such as shape features to segment remote sensing images based on Mean Shift algorithm. KEY WORDS: Mean Shift, image segmentation, remote sensing images, bandwidth,
经典Mean Shift算法介绍 1无参数密度估计 (1) 2核密度梯度估计过程 (3) 3算法收敛性分析 (4) 均值漂移(Mean Shift)是Fukunaga等提出的一种非参数概率密度梯度估计算法,在统计相似性计算与连续优化方法之间建立了一座桥梁,尽管它效率非常高,但最初并未得到人们的关注。直到1995年,Cheng改进了Mean Shift算法中的核函数和权重函数,并将其应用于聚类和全局优化,才扩大了该算法的适用范围。1997年到2003年,Comaniciu等将该方法应用到图像特征空间的分析,对图像进行平滑和分割处理,随后他又将非刚体的跟踪问题近似为一个Mean Shift最优化问题,使得跟踪可以实时进行。由于Mean Shift算法完全依靠特征空间中的样本点进行分析,不需要任何先验知识,收敛速度快,近年来被广泛应用于模式分类、图像分割、以及目标跟踪等诸多计算机视觉研究领域。 均值漂移方法[4]是一种最优的寻找概率密度极大值的梯度上升法,提供了一种新的目标描述与定位的框架,其基本思想是:通过反复迭代搜索特征空间中样本点最密集的区域,搜索点沿着样本点密度增加的方向“漂移”到局部密度极大点。基于Mean Shift方法的目标跟踪技术采用核概率密度来描述目标的特征,由于目标的直方图具有特征稳定、抗部分遮挡、计算方法简单和计算量小的特点,因此基于Mean Shift的跟踪一般采用直方图对目标进行建模;然后通过相似性度量,利用Mean Shift搜寻目标位置,最终实现目标的匹配和跟踪。均值漂移方法将目标特征与空间信息有效地结合起来,避免了使用复杂模型描述目标的形状、外观及其运动,具有很高的稳定性,能够适应目标的形状、大小的连续变换,而且计算速度很快,抗干扰能力强,在解决计算机视觉底层任务过程中表现出了良好的鲁棒性和较高的实时处理能力。 1无参数密度估计 目标检测与跟踪过程中,必须用到一定的手段对检测与跟踪的方法进行优化,将目标的表象信息映射到一个特征空间,其中的特征值就是特征空间的随机变量。假定特征值服从已知函数类型的概率密度函数,由目标区域内的数据估计密度函数的参数,通过估计的参数得到整个特征空间的概率密度分布。参数密度估计通过这个方法得到视觉处理中的某些参数,但要求特征空间服从已知的概率
MeanShift聚类 分类:计算机视觉2012-03-23 14:021423人阅读评论(0)收藏举报算法优化存储c Mean shift主要用在图像平滑和图像分割(那个跟踪我现在还不清楚),先介绍一下平滑的原理: 输入是一个5维的空间,2维的(x,y)地理坐标,3维的(L,u,v)的颜色空间坐标,当然你原理也可以改写成rgb色彩空间或者是纹理特征空间。 先介绍一下核函数,有uniform的,也有高斯的核函数,不管是哪个的,其基本思想如下:简单的平滑算法用一个模板平均一下,对所有的像素,利用周围的像素平均一下就完事了,这个mean shift的是基于概率密度分布来的,而且是一种无参的取样。有参的取样就是假设所有的样本服从一个有参数的概率分布函数,比如说泊松分布,正态分布等等,高中生都知道概率公式里面是有参数的,在说一下特征空间是一个5维的空间,距离用欧几里德空间就可以了,至少代码里就是这样实现的,而本文的无参取样是这样的:在特征空间里有3维的窗口(想象一下2维空间的窗口),对于一个特征空间的点,对应一个5维的向量,可以计算该点的一个密度函数,如果是有参的直接带入该点的坐标就可以求出概率密度了,基于窗函数的思想就是考虑它邻近窗口里的点对它的贡献,它假设密度会往密集一点的地方转移,算出移动之后的一个5维坐标,该坐标并会稳定,迭代了几次之后,稳定的地方是modes。这样每一个像素点都对应一个这么一个modes,用该点的后3维的值就是平滑的结果了,当然在算每个点的时候,有些地方可能重复计算了,有兴趣的化你可以参考一下源代码,确实是可以优化的。总结一下mean shift的平滑原理就是在特征空间中向密度更高的地方shift(转移)。 其次是怎么利用mean shift分割图像.先对图像进行平滑,第2步利用平滑结果建立区域邻接矩阵或者区域邻接链表,就是在特征空间比较近的二间在2维的图像平面也比较接近的像素算成一个区域,这样就对应一个区域的邻接链表,记录每个像素点的label值。当然代码中有一个传递凸胞的计算,合并2个表面张力很接近的相邻区域,这个我还没想怎么明白,希望比较清楚的朋友讲一讲。最后还有一个合并面积较小的区域的操作,一个区域不是对应一个modes值嘛,在待合并的较小的那个区域中,寻找所有的邻接区域,找到距离最小的那个区域,合并到那个区域就ok了。 Mean-Shift分割原理 Mean-Shift是一种非参数化的多模型分割方法,它的基本计算模块采用的是传统的模式识别程序,即通过分析图像的特征空间和聚类的方法来达到分割的目的。它是通过直接估计特征空间概率密度函数的局部极大值来获得未知类别的密度模式,并确定这个模式的位置,然后使之聚类到和这个模式有关的类别当中。下面对Mean-Shift算法进行简介。 设S是n维空间X中的一个有限集合,K表示X空间中λ球体的一个特征函数,则其表达式为:
核函数也称“窗口函数”。一维空间用到的核函数有高斯(Gaussian)、余弦弧(Cosinus arch)、双指数(Double Exponential)、均匀(Uniform)、三角(Trangle)、依潘涅契科夫(Epanechikov)、双依潘涅契科夫(DoubleEpanechnikov)、及双权(Biweight)函数。图2.1给出了最常用的几个核函数
给定一组一维空间的n个数据点集合令该数据集合 的概率密度函数假设为f (x),核函数取值为,那么在数据点x处的密度估计可以按下式计算: 上式就是核密度估计的定义。其中,x为核函数要处理的数据的中心点,即数据集合相对于点x几何图形对称。核密度估计的含义可以理解为:核估计器在被估计点为中心的窗口内计算数据点加权的局部平均。或者:将在每个采样点为中心的局部函数的平均效果作为该采样点概率密度函数的估计值。
MeanShift实现: 1.选择窗的大小和初始位置. 2.计算此时窗口内的Mass Center. 3.调整窗口的中心到Mass Center. 4.重复2和3,直到窗口中心"会聚",即每次窗口移动的距离小于一定的阈值,或者迭代次数达到设定值。 meanshift算法思想其实很简单:利用概率密度的梯度爬升来寻找局部最优。它要做的就是输入一个在图像的范围,然后一直迭代(朝着重心迭代)直到满足你的要求为止。但是他是怎么用于做图像跟踪的呢?这是我自从学习meanshift以来,一直的困惑。而且网上也没有合理的解释。经过这几天的思考,和对反向投影的理解使得我对它的原理有了大致的认识。 在opencv中,进行meanshift其实很简单,输入一张图像(imgProb),再输入一个开始迭代的方框(windowIn)和一个迭代条件(criteria),输出的是迭代完成的位置(comp )。 这是函数原型: int cvMeanShift( const void* imgProb, CvRect windowIn,CvTermCriteria criteria, CvConnectedComp* comp ) 但是当它用于跟踪时,这张输入的图像就必须是反向投影图了。 为什么必须是反向投影图呢?首先我们要理解什么是反向投影图。 简单理解它其实实际上是一张概率密度图。经过反向投影时的输入是一个目标图像的直方图(也可以认为是目标图像),还一个输入是当前图像就是你要跟踪的全图,输出大小与全图一样大,它上像素点表征着一种概率,就是全图上这个点是目标图像一部分的概率。如果这个点越亮,就说明这个点属于物体的概率越大。现在我们明白了这原来是一张概率图了。当用meanshift跟踪时,输入的原来是这样一幅图像,那也不难怪它可以进行跟踪了。 半自动跟踪思路:输入视频,用画笔圈出要跟踪的目标,然后对物体跟踪。用过opencv的都知道,这其实是camshiftdemo的工作过程。 第一步:选中物体,记录你输入的方框和物体。 第二步:求出视频中有关物体的反向投影图。
Kmeans与Meanshift、EM算法的关系 Kmeans算法是一种经典的聚类算法,在模式识别中得到了广泛的应用,基于Kmeans的变种算法也有很多,模糊Kmeans、分层Kmeans等。 Kmeans和应用于混合高斯模型的受限EM算法是一致的。高斯混合模型广泛用于数据挖掘、模式识别、机器学习、统计分析。Kmeans的迭代步骤可以看成E步和M步,E:固定参数类别中心向量重新标记样本,M:固定标记样本调整类别中心向量。K均值只考虑(估计)了均值,而没有估计类别的方差,所以聚类的结构比较适合于特征协方差相等的类别。 Kmeans在某种程度也可以看成Meanshitf的特殊版本,Meanshift是一种概率密度梯度估计方法(优点:无需求解出具体的概率密度,直接求解概率密度梯度。),所以Meanshift可以用于寻找数据的多个模态(类别),利用的是梯度上升法。在06年的一篇CVPR文章上,证明了Meanshift方法是牛顿拉夫逊算法的变种。Kmeans和EM算法相似是指混合密度的形式已知(参数形式已知)情况下,利用迭代方法,在参数空间中搜索解。而Kmeans和Meanshift相似是指都是一种概率密度梯度估计的方法,不过是Kmean 选用的是特殊的核函数(uniform kernel),而与混合概率密度形式是否已知无关,是一种梯度求解方式。PS:两种Kmeans的计算方法是不同的。 Vector quantization也称矢量量化:指一个向量用一个符号K来代替。比如有10000个数据,用Kmeans 聚成100类即最有表征数据意义的向量,使得数据得到了压缩,以后加入的数据都是用数据的类别来表示存储,节约了空间,这是有损数据压缩。数据压缩是数据聚类的一个重要应用,也是数据挖掘的主要方法。 混合高斯模型是一系列不同的高斯模型分量的线性组合。在最大似然函数求极值时,直接求导存在奇异点的问题,即有时一个分量只有一个样本点,无法估计其协方差,导致其似然函数趋于无穷,无法求解。另一个问题是,用代数法求得的解是不闭合的,即求解的参数依赖于参数本身的值,变成一个鸡生蛋,蛋生鸡的问题。这些问题看似无解,但是可以使用迭代的方法如EM,k均值等,预先设置一些参数,然后迭代求解。PS:也有用基于梯度的方法求解的。在求解混合模型时,有一个重要的概念即模型的可辨识性(如果无论样本的数量为多少都无法求出模型参数的唯一解,则称模型是不可辨识的),这是EM算法的前提。在实际应用时,由于EM算法的复杂度比K均值高,所以一般先用K均值大致收敛到一些点,然后用EM算法。EM算法求解混合模型的固然有效,但不能保证找到最大使然函数的最大值。 EM算法是求解具有隐变量的概率模型的最大似然函数的解的常用方法。当样本集是样本与隐变量一一对应时,数据集称为完整数据集,可以直接求解模型参数,但很多时候只知道样本,不知道其对应的隐变量,这是非完整数据集。所以求解模型参数的关键是隐变量的后验概率,由后验概率可以推出完整数据集用于求解参数。增量式的EM算法,每次只更新一个点,收敛速度更快。上述方法可以看成是无监督学习。 PS:EM是一个似然函数下界最大化解法,保证了解法的收敛性。 Opencv之KMEANS篇 Opencv中的K-means适用于数据预处理,但图像分割的消耗的时间太长并且效果不怎么好,使用空间信息后,图像的分割后受空间的影响很大(同一类的数据如果分布较远,不是高斯型的,就会错分),
MeanShiftCluster.m %testDistCluters clear clc profile on nPtsPerClust = 250; nClust = 3; totalNumPts = nPtsPerClust*nClust; m(:,1) = [1 1]'; m(:,2) = [-1 -1]'; m(:,3) = [1 -1]'; var = .6; bandwidth = .75; clustMed = []; %clustCent; x = var*randn(2,nPtsPerClust*nClust); %*** build the point set for i = 1:nClust x(:,1+(i-1)*nPtsPerClust:(i)*nPtsPerClust) = x(:,1+(i- 1)*nPtsPerClust:(i)*nPtsPerClust) + repmat(m(:,i),1,nPtsPerClust); end tic [clustCent,point2cluster,clustMembsCell] = MeanShiftCluster(x,bandwidth); toc
numClust = length(clustMembsCell); figure(10),clf,hold on cVec = 'bgrcmykbgrcmykbgrcmykbgrcmyk';%, cVec = [cVec cVec]; for k = 1:min(numClust,length(cVec)) myMembers = clustMembsCell{k}; myClustCen = clustCent(:,k); plot(x(1,myMembers),x(2,myMembers),[cVec(k) '.']) plot(myClustCen(1),myClustCen(2),'o','MarkerEdgeColor','k','MarkerFaceColor',cVec(k ), 'MarkerSize',10) end title(['no shifting, numClust:' int2str(numClust)]) testMeanShift.m %testDistCluters clear clc profile on nPtsPerClust = 250; nClust = 3; totalNumPts = nPtsPerClust*nClust; m(:,1) = [1 1]'; m(:,2) = [-1 -1]'; m(:,3) = [1 -1]'; var = .6; bandwidth = .75;
meanshift 公式 第一步:rect (含有四个参数:矩形框的左上点坐标,矩形框的宽和高) 矩形框的中心坐标: _(1)(3)/2 _(2)(4)/2 tic x rect rect tic y rect rect =+=+ 第二步:矩形框的高为a ,宽为b (a 为行数,b 为列数) (1)/2 (2)/2 y a y b == 带宽 (1)^2(2)^2(/2)^2(/2)^2h y y a b =+=+ 计算矩形区域每一点的权重矩阵(模板帧) 111212122 21211...111...1_............11...1b b a a ab a a a a a a m wei a a a ------= --- m_wei 是一个axb 的矩阵其中 11(1/2)^2(1/2)^2 11(/2)^2(/2)^2 a b a a b -+--=- + 即 (/2)^2(/2)^2 11(/2)^2(/2)^2 ij i a j b a a b -+--=- + ((1,),(1,))i a j b ∈∈ 归一化系数C 为矩阵m_wei 中每个元素相加的和的倒数 11 1 (/2)^2(/2)^21(/2)^2(/2)^2a b i j C i a j b a b === -+--+∑∑ 第三步:rgb 颜色空间量化为16x16x16bins 矩形框区域内每个像素点中的RGB 分量为q_R,q_B,q_G ____*256*16161616 q R q G q B q temp = ++ 求出的q_temp 用来作为的是hist1矩阵的列向量下标形式为 1(_1)1q temp hist + 第四步:计算权重矩阵 111213141516140961......hist h h h h h h h =
基于MeanShift的目标跟踪算法及实现 这次将介绍基于MeanShift的目标跟踪算法,首先谈谈简介,然后给出算法实现流程,最后实现了一个单目标跟踪的MeanShift算法【matlab/c两个版本】 csdn贴公式比较烦,原谅我直接截图了… 一、简介 首先扯扯无参密度估计理论,无参密度估计也叫做非参数估计,属于数理统计的一个分支,和参数密度估计共同构成了概率密度估计方法。参数密度估计方法要求特征空间服从一个已知的概率密度函数,在实际的应用中这个条件很难达到。而无参数密度估计方法对先验知识要求最少,完全依靠训练数据进行估计,并且可以用于任意形状的密度估计。所以依靠无参密度估计方法,即不事先规定概率密度函数的结构形式,在某一连续点处的密度函数值可由该点邻域中的若干样本点估计得出。常用的无参密度估计方法有:直方图法、最近邻域法和核密度估计法。 MeanShift算法正是属于核密度估计法,它不需要任何先验知识而完全依靠特征空间中样本点的计算其密度函数值。对于一组采样数据,直方图法通常把数据的值域分成若干相等的区间,数据按区间分成若干组,每组数据的个数与
总参数个数的比率就是每个单元的概率值;核密度估计法的原理相似于直方图法,只是多了一个用于平滑数据的核函数。采用核函数估计法,在采样充分的情况下,能够渐进地收敛于任意的密度函数,即可以对服从任何分布的数据进行密度估计。 然后谈谈MeanShift的基本思想及物理含义:此外,从公式1中可以看到,只要是落入Sh的采样点,无论其离中心x的远近,对最终的Mh(x)计算的贡献是一样的。然而在现实跟踪过程中,当跟踪目标出现遮挡等影响时,由于外层的像素值容易受遮挡或背景的影响,所以目标模型中心附近的像素比靠外的像素更可靠。因此,对于所有采样点,每个样本点的重要性应该是不同的,离中心点越远,其权值应该越小。故引入核函数和权重系数来提高跟踪算法的鲁棒性并增加搜索跟踪能力。 接下来,谈谈核函数: 核函数也叫窗口函数,在核估计中起到平滑的作用。常用的核函数有:Uniform,Epannechnikov,Gaussian等。本文算法只用到了Epannechnikov,它数序定义如下: 二、基于MeanShift的目标跟踪算法
基于MeanShift算法的目标跟踪 1 算法描述 1.1 meanshift算法背景 meanShift这个概念最早是由Fukunage在1975年提出的,Fukunage等人在一篇关于概率密度梯度函数的估计中提出这一概念。其最初的含义正如其名:偏移的均值向量;但随着理论的发展,meanShift的含义已经发生了很多变化。如今,我们说的meanShift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,然后以此为新的起始点,继续移动,直到满足一定的结束条件。 在很长一段时间内,meanShift算法都没有得到足够的重视,直到1995年另一篇重要论文的发表。该论文的作者Yizong Cheng定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同。其次,他还设定了一个权重系数,使得不同样本点的重要性不一样,这大大扩展了meanShift的应用范围。此外,还有研究人员将非刚体的跟踪问题近似为一个meanShift的最优化问题,使得跟踪可以实时进行。目前,利用meanShift进行跟踪已经相当成熟。 1.2 meanshift算法原理 Meanshift可以应用在很多领域,比如聚类,图像平滑,图像分割,还在目标跟踪领域有重要的应用。Meanshift跟踪算法是通过计算候选目标与目标模板之间相似度的概率密度分布,然后利用概率密度梯度下降的方向来获取匹配搜索的最佳路径,加速运动目标的定位和降低搜索的时间,因此其在目标实时跟踪领域有着很高的应用价值。 该算法由于采用了统计特征,因此对噪声具有很好的鲁棒性;由于是一个蛋参数算法,容易作为一个模块和其他算法集成;采用核函数直方图建模,对边缘阻挡、目标的旋转、变形以及背景运动都不敏感;同时该算法构造了一个可以用meanshift算法进行寻优的相似度函数。Meanshift本质上是最陡下降法,因此其求解过程收敛速度快,使得该算法具有很好的实用性。 Meanshift算法的思想是利用概率密度的梯度爬升来寻找局部最优。它要做的就是输入一个在图像的范围,然后一直朝着重心迭代,直到满足你的要求或者达到迭代最大次数结束。在opencv中,进行meanshift其实很简单,输入一张图像(imgProb),再输入一个开始迭代的方框(windowIn)和一个迭代条件(criteria),输出的是迭代完成的位置(comp )。这是函数原型: int cvMeanShift( const void* imgProb, CvRect windowIn, CvTermCriteria criteria, CvConnectedComp* comp ) 参数介绍: imgProb:目标直方图的反向投影 windowIn:初试的搜索框 Criteria:确定搜索窗口的终止条件 Comp:生成的结构,包含收敛的搜索窗口坐标(comp->rect 字段) 与窗口内部所有像素的和(comp->area 字段)
function [] = select() close all; clear all; %%%%%%%%%%%%%%%%%%根据一f幅目标全可见的图像圈定跟踪目标%%%%%%%%%%%%%%%%%%%%%%% I=imread('0201.jpg');%读取第1帧图像 figure(1); imshow(I); [temp,rect]=imcrop(I); [a,b,c]=size(temp); %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%计算目标图像的权值矩阵%%%%%%%%%%%%%%%%%%%%%%% y(1)=a/2; y(2)=b/2; tic_x=rect(1)+rect(3)/2; tic_y=rect(2)+rect(4)/2; m_wei=zeros(a,b);%权值矩阵 h=y(1)^2+y(2)^2 ;%带宽 for i=1:a for j=1:b dist=(i-y(1))^2+(j-y(2))^2; m_wei(i,j)=1-dist/h; %epanechnikov profile end end C=1/sum(sum(m_wei));%归一化系数 %计算目标权值直方图qu %hist1=C*wei_hist(temp,m_wei,a,b);%target model hist1=zeros(1,4096); for i=1:a for j=1:b %rgb颜色空间量化为16*16*16 bins q_r=fix(double(temp(i,j,1))/16); %fix为趋近0取整函数 q_g=fix(double(temp(i,j,2))/16); q_b=fix(double(temp(i,j,3))/16); q_temp=q_r*256+q_g*16+q_b; %设置每个像素点红色、绿色、蓝色分量所占比重
meanshift 做跟踪的优缺点及其代码 (2012-03-28 12:45:16) 转载▼ 标签: 转载 原文地址:meanshift 做跟踪的优缺点及其代码作者:千里8848 meanShift算法用于视频目标跟踪时,采用目标的颜色直方图作为搜索特征,通过不断迭代meanShift向量使得算法收敛于目标的真实位置,从而达到跟踪的目的。 传统的meanShift算法在跟踪中有几个优势: (1)算法计算量不大,在目标区域已知的情况下完全可以做到实时跟踪; (2)采用核函数直方图模型,对边缘遮挡、目标旋转、变形和背景运动不敏感。 同时,meanShift算法也存在着以下一些缺点: (1)缺乏必要的模板更新; (2)跟踪过程中由于窗口宽度大小保持不变,当目标尺度有所变化时,跟踪就会失败;(3)当目标速度较快时,跟踪效果不好; (4)直方图特征在目标颜色特征描述方面略显匮乏,缺少空间信息; 由于其计算速度快,对目标变形和遮挡有一定的鲁棒性,所以,在目标跟踪领域,meanShift 算法目前依然受到大家的重视。但考虑到其缺点,在工程实际中也可以对其作出一些改进和调整;例如: (1)引入一定的目标位置变化的预测机制,从而更进一步减少meanShift跟踪的搜索时间,降低计算量; (2)可以采用一定的方式来增加用于目标匹配的“特征”; (3)将传统meanShift算法中的核函数固定带宽改为动态变化的带宽; (4)采用一定的方式对整体模板进行学习和更新; 代码如下,使用方法:先圈出要跟踪对象的初始位置,然后双击。输入为图片序列。
/////////////////////////////////////////////////////////////////////////////////////////// close all; clear all; rgb = imread('0015.jpeg'); figure(1); imshow(rgb); [temp,rect] = imcrop(rgb);%交互式切图 [a,b,c] = size(temp); %中心点位置 y(1) = a/2; y(2) = b/2; %带宽 h = y(1)^2 + y(2)^2; %用epanechnikov计算权值矩阵 t_weight = zeros(a,b); for i = 1:a for j = 1:b dist = (i - y(1))^2 + (j - y(2))^2; t_weight(i,j) = 1 - dist/h; end
Mean Shift,我们翻译为“均值飘移”。其在聚类,图像平滑。图像分割和跟踪方面得到了比较广泛的应用。由于本人目前研究跟踪方面的东西,故此主要介绍利用Mean Shift方法进行目标跟踪,从而对MeanShift有一个比较全面的介绍。 (以下某些部分转载常峰学长的“Mean Shift概述”)Mean Shift 这个概念最早是由Fukunaga等人于1975年在一篇关于概率密度梯度函数的估计(The Estimation of the Gradient of a Density Function, with Applications in Pattern Recognition )中提出来的,其最初含义正如其名,就是偏移的均值向量,在这里Mean Shift是一个名词,它指代的是一个向量,但随着Mean Shift理论的发展,Mean Shift的含义也发生了变化,如果我们说Mean Shift算法,一般是指一个迭代的步骤,即先算出当前点的偏移均值,移动该点到其偏移均值,然后以此为新的起始点,继续移动,直到满足一定的条件结束. 然而在以后的很长一段时间内Mean Shift并没有引起人们的注意,直到20年以后,也就是1995年,另外一篇关于Mean Shift的重要文献(Mean shift, mode seeking, and clustering )才发表.在这篇重要的文献中,Yizong Cheng对基本的Mean Shift算法在以下两个方面做了推广,首先Yizong Cheng定义了一族核函数,使得随着样本与被偏移点的距离不同,其偏移量对均值偏移向量的贡献也不同,其次Yizong Cheng还设定了一个权重系数,使得不同的样本点重要性不一样,这大大扩大了Mean Shift的适用范围.另外Yizong Cheng指出了Mean Shift可能应用的领域,并给出了具体的例子。 Comaniciu等人在还(Mean-shift Blob Tracking through Scale Space)中把非刚体的跟踪问题近似为一个Mean Shift最优化问题,使得跟踪可以实时的进行。目前,利用Mean Shift进行跟踪已经相当成熟。 目标跟踪不是一个新的问题,目前在计算机视觉领域内有不少人在研究。所谓跟踪,就是通过已知的图像帧中的目标位置找到目标在下一帧中的位置。 下面主要以代码形式展现Mean Shift在跟踪中的应用。 void CObjectTracker::ObjeckTrackerHandlerByUser(IplImage *frame)//跟踪函数{ m_cActiveObject = 0; if (m_sTrackingObjectTable[m_cActiveObject].Status) { if (!m_sTrackingObjectTable[m_cActiveObject].assignedAnObject) { FindHistogram(frame,m_sTrackingObjectTable[m_cActiveObject].initHistogram); m_sTrackingObjectTable[m_cActiveObject].assignedAnObject = true;