数据结构综合练习题
1填空题
1.数据结构包含三个方面的内容,分别是数据的逻辑结构、数据的存储结构和数据的运算。
2.实现数据结构的四种存储方法有顺序存储方法、链接存储方法、索引存储方法和散列存储方法。
3.数据结构的逻辑结构有线性结构和非线性结构两大类。
4.一种抽象数据类型包括抽象数据的组织和与之相关的操作两个部分。
5.算法的五个重要特性是输入、输出、确定性、可行性和有穷性。
6.栈顶的位置是随进栈和出栈操作而变化的。
7.在链队列只有一个元素的情况下,对其做删除操作时,应当把对头指针和队尾指针都置为null。
8.操作系统中先来先服务是数据结构中的队列应用的典型例子。
9.在解决计算机主机与打印机之间速度不匹配问题时,通常设置一个打印数据缓冲区,主机将要输
出的数据依次写入该缓冲区,而打印机从该缓冲区中取出数据打印。该缓冲区应该是一个队列结构。
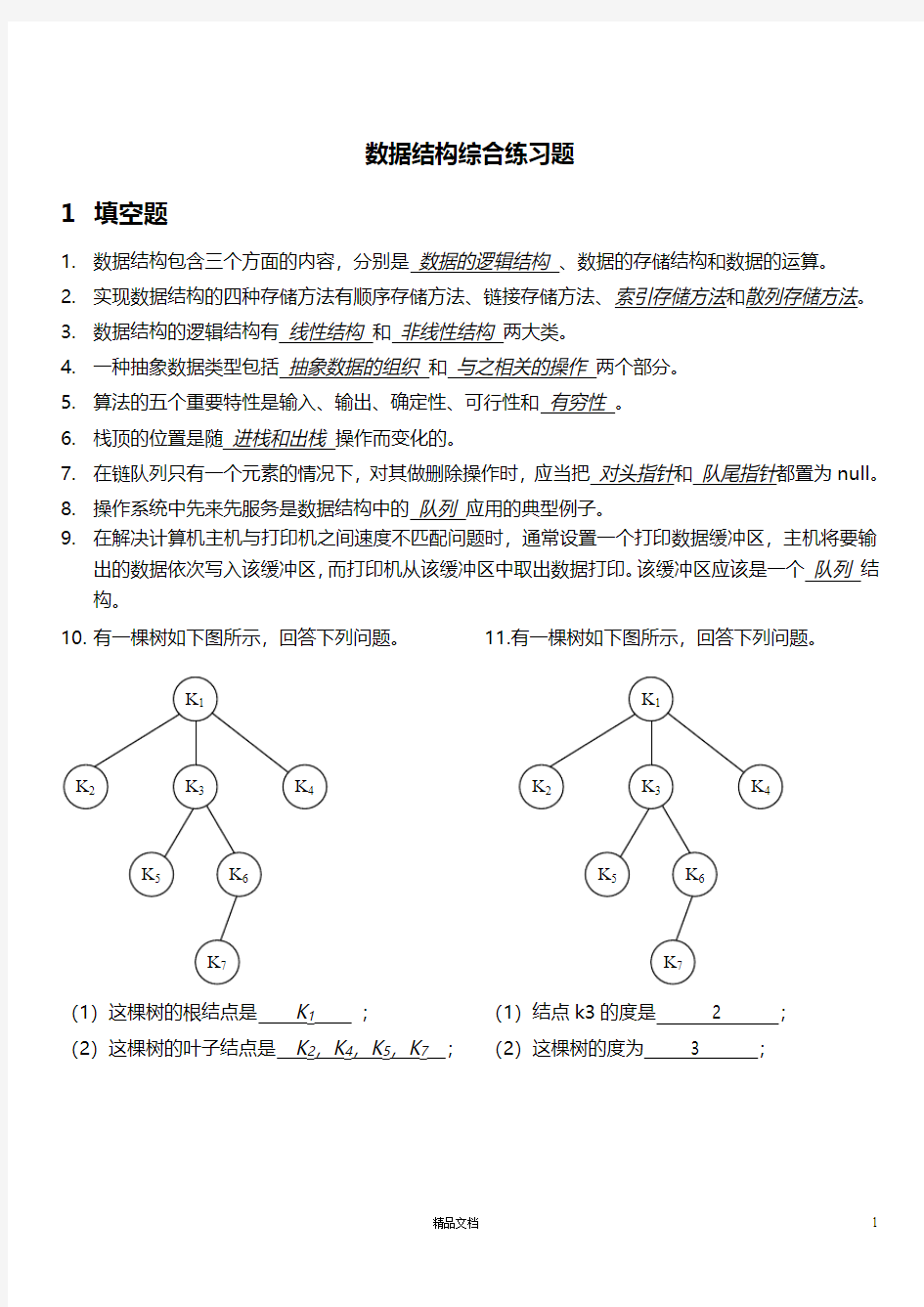
10.有一棵树如下图所示,回答下列问题。11.有一棵树如下图所示,回答下列问题。
(1)这棵树的根结点是K1;(1)结点k3的度是 2 ;
(2)这棵树的叶子结点是K2,K4,K5,K7;(2)这棵树的度为 3 ;
12.有一棵树如下图所示,回答下列问题。
13有一棵树如下图所示,回答下列问题。
这棵树的深度为 4 ;
(1)结点K3的子女是 K5 ,K6 ; (2)结点K3的双亲结点是 K1 。
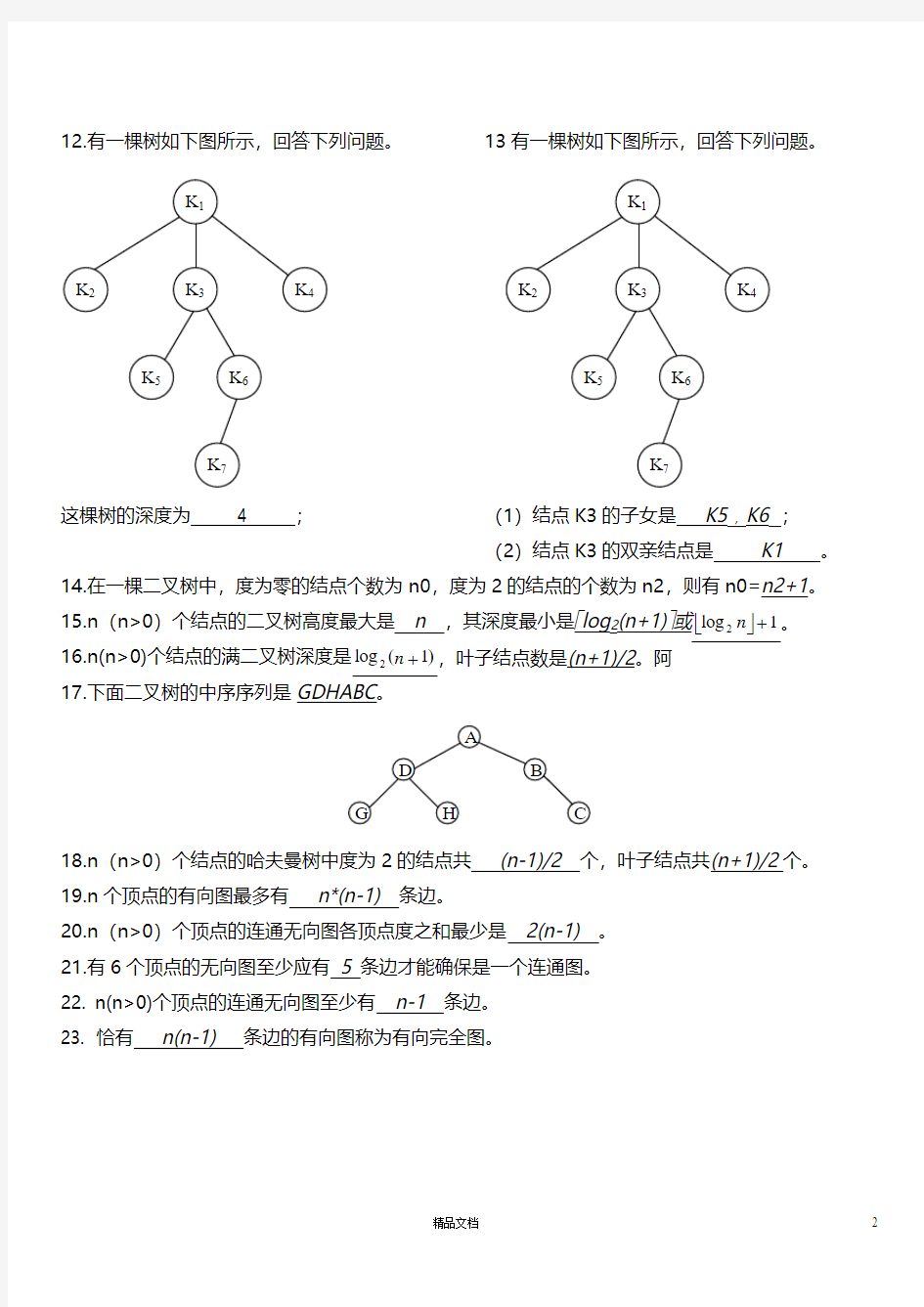
14.在一棵二叉树中,度为零的结点个数为n0,度为2的结点的个数为n2,则有n0=n2+1。 15.n (n>0)个结点的二叉树高度最大是 n ,其深度最小是?log 2(n+1)?或??1log 2+n 。 16.n(n>0)个结点的满二叉树深度是)1(log 2+n ,叶子结点数是
(n+1)/2。阿 17.下面二叉树的中序序列是GDHABC 。
18.n (n>0)个结点的哈夫曼树中度为2的结点共 (n-1)/2 个,叶子结点共(n+1)/2个。 19.n 个顶点的有向图最多有 n*(n-1) 条边。
20.n (n>0)个顶点的连通无向图各顶点度之和最少是 2(n-1) 。 21.有6个顶点的无向图至少应有 5 条边才能确保是一个连通图。 22. n(n>0)个顶点的连通无向图至少有 n-1 条边。 23. 恰有 n(n-1) 条边的有向图称为有向完全图。
2单项选择题
1.下列说法正确的是( B )
A.数据元素是具有独立意义的最小标识单位
B.原子类型的值不可再分解
C.原子类型的值由若干个数据段组成
D.结构类型的值不可再分解
2.一个存储结点存放一个(B )
A.数据项
B.数据元素
C.数据结构
D.数据类型
3.在数据结构中,从逻辑上可以把数据结构分成(C )
A.动态结构和静态结构
B.紧凑结构和非紧凑结构
C.线性结构和非线性结构
D.内部结构和外部结构
4.线性结构是数据元素之间存在一种(D )
A.一对多关系
B.多对多关系
C.多对一关系
D.一对一关系
5.算法分析的目的是(B )
A.正确性和简明性
B.时间复杂性和空间复杂性
C.可读性和文档性
D.数据复杂性和程序复杂性
6.算法必须具备输入输出和(C )
A.计算方法
B.排序方法
C.解决问题的有限运算步骤
D.程序设计方法
7.线性表中正确的说法是(D )
A.每个元素都有一个直接前驱和一个直接后继
B.线性表至少要求一个元素
C.表中的元素必须按由小到大或由大到小排序
D.除了第一个和最后一个元素外,其余每个元素都有且仅有一个直接前驱和一个直接后继
8.线性表是具有n个(C )的有限序列
A.整数
B.字符
C.数据元素
D.数据项
9.线性表采用链式存储结构时,结点的存储地址(C )
A.必须是不连续的
B.必须是连续的C是否连续都可以
D.和头结点的存储地址相连续
10.在带有头结点的单链表中插入一个新结点时不可能修改(A )
A.头指针
B.头结点指针域
C.开始结点指针域D其它结点指针域
11.相对于顺序存储结构而言,链接存储的优点是(C )
A.随机存取
B.节约空间
C.增、删操作方便
D.结点关系简单
12.设线性表有n个元素,下面算法中在顺序表上实现比在链表上实现效率更高的是(A )
A.输出第i(1≤i<≤n)个元素值
B.交换第0个元素与第1个元素的值
C. 顺序输出这n 个元素的值
D. 输出与给定值x 相等的元素在线性表中的序号 13. 下列说法正确的是( A )
A. 栈是一种线性表
B. 栈具有先进先出特性
C. 栈删除运算会引起其它元素的移动
D. 栈插入运算会引起其它元素的移动
14. 一个栈的入栈序列是:a,b,c,d,e, 则栈的不可能的输出序列是( C )
A. Edcba
B.decba
C.dceab
D.abcde
15. 一个链栈的栈顶指针是topNode ,则执行出栈操作时(栈非空),用topElement 保存被删除结
点的数据元素,则执行( D )
A. topElement = top; top = topNode.next;
B. topElement = topNode.element;
C. topNode = topNode.next; topElement = topNode.element;
D. topElement = topNode.element; topNode = topNode.next; 16. 一个队列的入队序列是a,b,c,d, 则队列的输出序列是( B )
A. d,c,b,a
B.a,b,c,d
C.a,d,c,b
D.c,b,a,d 17. 将递归过程转化为非递归过程需要用到( A )
A.栈
B.队列
C.树
D.图 18. 栈和队列的共同点是( C )
A. 都是先进后出
B.都是先进先出
C.只允许在端点处插入和删除元素
D.没有共同点 19. 树最适合用来表示( D )
A. 有序数据元素
B.无序数据元素
C.元素之间无联系的数据
D.元素之间具有分支层次关系的数据
20. 一棵深度为9的满二叉树的叶结点数是( B )
A. 255
B.256
C.511
D.512
21. n 个结点的满二叉树的高度是( B )
A.n/2
B.)1(log 2+n
C.)1(log 2-n
D.n 2l og 22. 按照二叉树的定义,具有3个结点的二叉树有( C )种
A. 3
B.4
C.5
D.6
23. 深度为5的二叉树至多有( C )个结点
A. 16 B32 C.31 D.10
24. 由结点A 、B 、C 构成不同的二叉树共( D )棵
A. 6
B.18
C.36
D.30
25.下列说法正确的是(D )
A.二叉树是度为2的无序树
B.二叉树中结点只有一个孩子时无左右之分
C.二叉树中必有度为2的结点
D.二叉树中的一个结点最多只有两棵子树,并且有左右之分
26.一棵二叉树的先序序列是ABCDEF,它可能的中序序列是(A )
A.CBDAFE
B.CABDEF
C.DABCEF
D.FCABED
27.要唯一地确定一棵二叉树,只需要知道该二叉树的(C )
A.前序序列
B.中序序列
C.中序和后序序列
D.前序和后序序列
28.任何一棵二叉树的叶结点在先序、中序和后序遍历中的相对次序(A )
A.不发生改变
B.发生改变
C.不能确定
D.以上都不对
29.在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的(B )倍
A.1/2
B.1
C.2
D.4
30.用邻接矩阵存储图所需的存储空间大小仅与(A )有关
A.图的顶点数
B.图的边数
C.图的顶点数与边数之和
D.图的各顶点度之和
31.若存储图G的邻接矩阵是对称矩阵,则G(C )
A.一定是无向图
B.一定是连通无向图
C.可能是无向图
D.一定是有向图
32.下列说法正确的是(B )
A.有向图的邻接矩阵一定是非对称矩阵
B.无向图的邻接矩阵一定是对称矩阵
C.若图G的邻接矩阵是对称的,则G一定是无向图
D.有向图的邻接矩阵一定是下三角矩阵
33.已知一个图如下所示。若从顶点a出发按深度优先搜索算法进行遍历,则可能得到的一种顶点序
列为(D )
A.abecdf
B.acfebd
C.aebfcd
D.aedfcb
3.解答题
1.简述数据结构的逻辑结构和存储结构的区别和联系。它们如何影响算法的设计与实现?
若用结点表示某个数据元素,则结点和结点之间的逻辑关系就称为数据的逻辑结构。数据在计算机中的存储表示称为数据的存储结构。可见,数据的逻辑结构是反映数据之间的固有联系,而数据的存储结构是数据在计算机中的存储表示。尽管因采用的存储结构不同,逻辑上相邻的结点,其物理地址未必相邻,但可通过结点的内部信息,找到其相邻的结点,从而保留了逻辑结构的特点。由于采用的存储结构不同,该数据结构上的操作灵活性、算法复杂度等区别较大。
2.简述数据的运算与数据逻辑结构和存储结构之间的关系。
数据的运算定义在逻辑结构上,也就是说,一旦数据的逻辑结构确定了,就可以定义在这种逻辑结构上可以进行何种运算了。但是,数据的运算的具体实现时依赖于数据的存储结构的。同样的逻辑结构,可能有不同的存储结构。那么,在不同的存储结构上实现同一个数据运算的方法也不一样。所以,要具体实现某个运算,还要根据数据的存储结构来定。
3.试举一个应用数据结构的例子,叙述其逻辑结构、存储结构、运算这三方面的内容。
要点:说明逻辑结构、存储结构的概念,同时用自然语言例子中的逻辑结构和存储结构和运算的基本规则
4.何时选用顺序表、何时选用链表作为线性表的存储结构为宜?
(1)基于空间的考虑:当线性表的长度变化较大,难以估计其存储规模时,采用动态链表作为存储结构为好。当线性表的长度变化不大,易于事先确定其大小时,为了节省存储空间,采用顺序表为好。(2)基于时间的考虑:若线性表的操作主要是进行查找,很少做插入和删除操作时,采用顺序表做存储结构为好。反之,对于频繁进行插入和删除的线性表,采用链表为好。
5.设二叉树如下所示,试采用顺序存储方法和链接存储方法画出它的存储结构。
b
c
d
链式存储结构如下:
6.设二叉树如下所示,试采用顺序存储方法和链式存储方法画出它的存储结构。
顺序存储结构如下:
链式存储结构如下:
7.设树形结构如下,请画出该树的双亲孩子链表表示。
A
B
D
E
F
解:
01234
5
8.现有权值:7,16,5,28,2。试构造这组权值的哈夫曼(Huvvman )树。用树形表示法画出这个哈夫曼(Huvvman )树。
28
9.以下面数据作为叶子结点的权值构造一棵哈夫曼(Huvvman )树。用树形表示法画出这个哈夫曼
(Huvvman )树。
17,3,7,8,24,10,16,9,6
10.设图G=(V ,E ),V={ v0,v1,v2,v3,v4},E={
邻接矩阵如下
0 1 1 0 0
0 0 0 0 1 0 0 0 1 0 0 0 0 0 1
0 0 0 0 0
邻接表如下
0214
311.已知一个有向图G 的顶点集合为{A,B,C,D,E},其邻接表为
01234顶点表
出边表
(1)画出G 的图形
(2)分别给出G 从A 开始的深度优先和广度优先遍历序列 (1)
(2)从A 开始的深度优先序列:ABCDE
从A 开始的广度优先序列:ABDEC
12.设无向图G 的顶点集合为{a,b,c,d,e,f},其邻接表如下:
01234
顶点表
边表
5
(1)画出G 的图形
(2)分别给出G 从a 开始的深度优先和广度优先遍历序列 (1)该图的图形
(2)从a 开始的深度优先序列:abdcfe
从a 开始的广度优先序列:abcdef
4.算法设计题
1.设顺序表类型定义如下:
public class AList implements ListInterface {
private Object[] entry; // 线性表元素数组
private int length; // 线性表当前元素的个数
private static final int MAX_SIZE = 50; // 默认的线性表的最大长度
public AList() {
length = 0;
entry = new Object[MAX_SIZE];
}
}
请写出从顺序表中删除指定位置的元素的算法。
public Object remove(int givenPosition) {
Object result = null;
if ((givenPosition >= 1) && (givenPosition <= length)) {
result = entry[givenPosition - 1];
if (givenPosition < length)
removeGap(givenPosition);
length--;
}
return result;
}
private void removeGap(int givenPosition) {
for (int index = givenPosition; index < length; index++)
entry[index - 1] = entry[index];
}
2.设顺序表类型定义如下:
public class AList implements ListInterface {
private Object[] entry; // 线性表元素数组
private int length; // 线性表当前元素的个数
private static final int MAX_SIZE = 50; // 默认的线性表的最大长度
public AList() {
length = 0;
entry = new Object[MAX_SIZE];
}
}
请写出往顺序表中的指定位置插入一个新元素的算法。
public boolean add(int newPosition, Object newEntry) {
boolean isSuccessful = true;
if (!isFull() && (newPosition >= 1) && (newPosition <= length + 1)) { makeRoom(newPosition);
entry[length] = newEntry;
length++;
}
else
isSuccessful = false;
return isSuccessful;
}
private void makeRoom(int newPosition) {
for (int index = length; index >= newPosition; index--)
entry[index] = entry[index - 1];
}
3.设单链表结点类型和单链表类型定义如下:
public class ChainNode {
Object element; // 结点的数据域
ChainNode next; // 结点的链接域
ChainNode(Object element) {
this.element = element;
}
ChainNode(Object element, ChainNode next) {
this.element = element;
this.next = next;
}
}
public class Chain implements ListInterface {
private ChainNode firstNode; // 指向链表第1个结点的引用
private int length; // 链表中元素个数
public Chain() { // 初始时链表为空
firstNode = null;
length = 0;
}
}
请写出返回链表中指定位置的结点的引用的算法。
/**
*Task:返回链表中指定位置的结点的引用
*Precondition:链表不空;1<= givenPosition <= length
*/
private ChainNode getNodeAt(int givenPosition) {
ChainNode currentNode = firstNode;
// traverse the chain to locate the desired node
for (int counter = 1; counter < givenPosition; counter++)
currentNode = currentNode.next;
return currentNode;
} // end getNodeAt
4.单链表结点类型和单链表类型定义如下:
public class ChainNode {
Object element; // 结点的数据域
ChainNode next; // 结点的链接域
ChainNode(Object element) {
this.element = element;
}
ChainNode(Object element, ChainNode next) {
this.element = element;
this.next = next;
}
}
public class Chain implements ListInterface {
private ChainNode firstNode; // 指向链表第1个结点的引用
private int length; // 链表中元素个数
public Chain() { // 初始时链表为空
firstNode = null;
length = 0;
}
}
请写出检索线性表中指定位置的元素的算法。
public Object getEntry(int givenPosition) {
Object result = null;
if ((!isEmpty()) && (givenPosition >= 1) && (givenPosition <= length))
result = getNodeAt(givenPosition).element;
return result;
}
5.设链栈结点类型和链栈类型定义如下:
public class StackNode {
Object element; // 结点的数据域
StackNode next; // 结点的链接域
StackNode(Object element) {
this.element = element;
}
StackNode(Object element, StackNode next) {
this.element = element;
this.next = next;
}
}
public class LinkedStack implements StackInterface {
private StackNode topNode; // 引用栈顶结点对象
public LinkedStack() {
topNode = null;
}
}
请写出入栈算法和出栈算法。
public void push(Object newEntry) {
StackNode newNode = new StackNode(newEntry, topNode);
topNode = newNode;
}
public Object pop() {
Object topElement = null;
if (!isEmpty()) {
topElement = topNode.element;
topNode = topNode.next;
}
return topElement;
}
6.设循环队列型定义如下:
public class ArrayQueue implements QueueInterface {
private Object[] queue; // 存放队列元素的循环数组
private int frontIndex; // 队头索引,标记队头元素在数组中的位置
private int rearIndex; // 队尾索引,标记队尾元素之后的下一个位置
private static final int DEFAULT_MAX_SIZE = 50; // 默认的队列的最大长度
public ArrayQueue() {
queue = new Object[DEFAULT_MAX_SIZE + 1]; // 创建比默认的队列的最大长度大1的数组
frontIndex = 0;
rearIndex = 0;
}
}
请写出入队算法和出队算法。
public void enqueue(Object newEntry) {
if (!isFull()) {
queue[rearIndex] = newEntry;
rearIndex = (rearIndex + 1) % queue.length;
}
else
System.out.println("Queue overflow.");
}
public Object dequeue() {
Object frontElement = null;
if (!isEmpty())
{
frontElement = queue[frontIndex];
queue[frontIndex] = null;
frontIndex = (frontIndex + 1) % queue.length;
} // end if
return frontElement;
}
7.设二叉树结点类型和二叉树类型定义如下:
public class BinaryNode {
Object element; //数据元素
public BinaryNode leftChild, rightChild; //分别指向左、右孩子结点public BinaryNode(Object theElement,
BinaryNode theleftChild,
BinaryNode therightChild)
{
element = theElement;
leftChild = theleftChild;
rightChild = therightChild;
}
}
public class BinaryTree implements BinaryTreeInterface {
BinaryNode root; //根结点
public BinaryTree() { //构造空二叉树
root = null;
}
}
请写出求一棵二叉树中所有结点个数的算法。
public int count() //求一棵二叉树中所有结点个数{
return count(root);
}
public int count(BinaryNode p) //求以p结点为根的子树的结点个数{
if (p!=null)
return 1+count(p.leftChild)+count(p.rightChild);
else
return 0;
}
8.设二叉树结点类型和二叉树类型定义如下:
public class BinaryNode {
Object element; //数据元素
public BinaryNode leftChild, rightChild; //分别指向左、右孩子结点public BinaryNode(Object theElement,
BinaryNode theleftChild,
BinaryNode therightChild)
{
element = theElement;
leftChild = theleftChild;
rightChild = therightChild;
}
}
public class BinaryTree implements BinaryTreeInterface {
BinaryNode root; //根结点
public BinaryTree() { //构造空二叉树
root = null;
}
}
请写出求一棵二叉树的深度的算法。
public int depth() //求二叉树的深度
{
return depth(root);
}
public int depth(BinaryNode p) //求以p结点为根的子树的深度,后根次序遍历{
if (p!=null)
{
int ld = depth(p.leftChild); //求左子树的深度
int rd = depth(p.rightChild);
return (ld>=rd) ? ld+1 : rd+1;
}
return 0;
}
4、比较类试题
比较类试题 一、题型特征 比较是确定事物之间相同点和不同点的思维方法,它为客观、全面地认识事物提供了一个重要途径。高考题中比较类试题的设问方式主要有:比较图中……和……的差异(不同或异同),分析……和……的共同特点(问题),说明图示××和××的自然条件和类型的差异等。 二、应试策略(四步审题、三项联系、二定要点及格式是正确解答比较类试题的秘诀所在。) “四步审题”是关键:第一步审比较对象,审准对象可以在很大程度上避免答题时张冠李戴;第二步审比较要求,即审准题意要求找相同点还是不同点,还是异同点都找,或者要求通过比较进一步找原因;第三步审比较考点,如比较A、B 两地的气候类型及特征的异同点,其比较的考点是气候类型及特征,此步骤可避免跑题;第四步审比较角度,审准题目从什么角度、几个角度去比较,此步骤可避免漏掉答题的要点。 “三项联系”是答题依据:首先,联系题中图表和材料,它们是解决比较类问题最直接的依据;其次,联系所学教材知识点,即能迅速地理解题目设置的情境和需要解决的问题,与所学知识建立准确的联系,并从中提取出需要的知识点;最后,联系生活经验和常识,当学生实在想不起所学的教材知识点时,根据题意联系自己的生活经验和常识来答题往往也是很有效的。 “二定”是指根据分值定要点、根据内容定格式。根据分值定要点,要求学生养成要点化答题的习惯,看分给点,只有给足正确的要点,才有可能得足分;根据内容定格式是指采取要点纵列化或者采取列表比较,这要根据答题的内容来定。一般来说,比较异同时列表比较更直观些。 1、图a是世界某区域示意图,图b和图c分别是对应区域的景观和气候资料,据此完成下列问题。
数据结构简答题 1.1 简述下列术语:数据,数据元素、数据对象、数据结构、存储结构、数据类型和抽象数据类型。 解:数据是对客观事物的符号表示。在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。 数据元素是数据的基本单位,在计算机程序常作为一个整体进行考虑和处理。 数据对象是性质相同的数据元素的集合,是数据的一个子集。 数据结构是相互之间存在一种或多种特定关系的数据元素的集合。 存储结构是数据结构在计算机中的表示。 数据类型是一个值的集合和定义在这个值集上的一组操作的总称。 抽象数据类型是指一个数学模型以及定义在该模型上的一组操作。是对一般数据类型的扩展。 1.2 试描述数据结构和抽象数据类型的概念与程序设计语言中数据类型概念的区别。 解:抽象数据类型包含一般数据类型的概念,但含义比一般数据类型更广、更抽象。一般数据类型由具体语言系统部定义,直接提供给编程者定义用户数据,因此称它们为预定义数据类型。抽象数据类型通常由编程者定义,包括定义它所使用的数据和在这些数据上所进行的操作。在定义抽象数据类型中的数据部分和操作部分时,要求只定义到数据的逻辑结构和操作说明,不考虑数据的存储结构和操作的具体实现,这样抽象层次更高,更能为其他用户提供良好的使用接口。 1.7 在程序设计中,可采用下列三种方法实现输出和输入: (1) 通过scanf和printf语句; (2) 通过函数的参数显式传递; (3) 通过全局变量隐式传递。 试讨论这三种方法的优缺点。 解:(1)用scanf和printf直接进行输入输出的好处是形象、直观,但缺点是需要对其进行格式控制,较为烦琐,如果出现错误,则会引起整个系统的崩溃。 (2)通过函数的参数传递进行输入输出,便于实现信息的隐蔽,减少出错的可能。 (3)通过全局变量的隐式传递进行输入输出最为方便,只需修改变量的值即可,但过多的全局变量使程序的维护较为困难。 2.1 描述以下三个概念的区别:头指针,头结点,首元结点(第一个元素结点)。 解:头指针是指向链表中第一个结点的指针。首元结点是指链表中存储第一个数据元素的结点。头结点是在首元结点之前附设的一个结点,该结点不存储数据元素,其指针域指向首元结点,其作用主要是为了方便对链表的操作。它可以对空表、非空表以及首元结点的操作进行统一处理。 2.2 填空题。 解:(1) 在顺序表中插入或删除一个元素,需要平均移动表中一半元素,具体移动的元素个数与元素在表中的位置有关。 (2) 顺序表中逻辑上相邻的元素的物理位置必定紧邻。单链表中逻辑上相邻的元素的物理位置不一定紧邻。 (3) 在单链表中,除了首元结点外,任一结点的存储位置由其前驱结点的链域的值指示。 (4) 在单链表中设置头结点的作用是插入和删除首元结点时不用进行特殊处理。 2.3 在什么情况下用顺序表比链表好?
1、有一课程管理系统,有如下特点:一个系可开设多门课程,但一门课只在一个系部开设,一个学生可选修多门课程,每门课可供若干学生选修,一名教师只教一门课程,但一门课程可有几名教师讲授,每个系聘用多名教师,但一个教师只能被一个系所聘用,要求这个课程管理系统能查到任何一个学生某门课程的成绩,以及这个学生的这门课是哪个老师所教的。 (1)请根据以上描述,绘制相应的E-R图,并直接在E-R图上注明实体名、属性、联系类型; (2)将E-R图转换成关系模型,画出相应的数据库模型图,并说明主键和外键。 (3)分析这些关系模式中所包含的函数依赖,根据这些函数依赖,分析相应的关系模式达到了第几范式。对这些关系模式进行规范化。 1、参考答案:
2、设某汽车运输公司数据库中有三个实体集。一是“车队”实体集,属性有车队号、车队名等;二是“车辆”实体集,属性有牌照号、厂家、出厂日期等;三是“司机”实体集,属性有司机编号、姓名、电话等。 车队与司机之间存在“聘用”联系,每个车队可聘用若干司机,但每个司机只能应聘于一个车队,车队聘用司机有“聘用开始时间”和“聘期”两个属性; 车队与车辆之间存在“拥有”联系,每个车队可拥有若干车辆,但每辆车只能属于一个车队; 司机与车辆之间存在着“使用”联系,司机使用车辆有“使用日期”和“公里数”两个属性,每个司机可使用多辆汽车,每辆汽车可被多个司机使用。 (1)请根据以上描述,绘制相应的E-R图,并直接在E-R图上注明实体名、属性、联系类型; (2)将E-R图转换成关系模型,画出相应的数据库模型图,并说明主键和外键。 (3)分析这些关系模式中所包含的函数依赖,根据这些函数依赖,分析相应的关系模式达到了第几范式。对这些关系模式进行规范化。 2、参考答案:
数据结构练习题(含答案)
数据结构练习题 习题1 绪论 1.1 单项选择题 1. 数据结构是一门研究非数值计算的程序设计问题中,数据元素的①、数据信息在计算机中的②以及一组相关的运算等的课程。 ① A.操作对象B.计算方法C.逻辑结构D.数据映象 ②A.存储结构B.关系C.运算D.算法 2. 数据结构DS(Data Struct)可以被形式地定义为DS=(D,R),其中D是①的有限集合,R是D上的②有限集合。 ① A.算法B.数据元素C.数据操作D.数据对象 ② A.操作B.映象C.存储D.关系 3. 在数据结构中,从逻辑上可以把数据结构分成。 A.动态结构和静态结构B.紧凑结构和非紧凑结构 C.线性结构和非线性结构D.内部结构和外部结构 4. 算法分析的目的是①,算法分析的两个主要方面是②。 ① A. 找出数据结构的合理性 B. 研究算法中的输 入和输出的关系 C. 分析算法的效率以求改进 D. 分析算法的易懂
性和文档性 ② A. 空间复杂性和时间复杂性 B. 正确性和简明性 C. 可读性和文档性 D. 数据复杂性和程序 复杂性 5. 计算机算法指的是①,它必具备输入、输出和②等五个特性。 ① A. 计算方法 B. 排序方法 C. 解决问题的有限运算序列 D. 调度方法 ② A. 可行性、可移植性和可扩充性 B. 可行性、确定性和有穷性 C. 确定性、有穷性和稳定性 D. 易读性、稳定性和安全性 1.2 填空题(将正确的答案填在相应的空中) 1. 数据逻辑结构包括、和三种类型,树形结构和图形结构合称为。 2. 在线性结构中,第一个结点前驱结点,其余每个结点有且只有个前驱结点;最后一个结点后续结点,其余每个结点有且只有个后续结点。 3. 在树形结构中,树根结点没有结点,其余每个结点有且只有个直接前驱结点,叶子结点没有结点,其余每个结点的直接后续结点可以。 4. 在图形结构中,每个结点的前驱结点数和后续结点数可以。 5. 线性结构中元素之间存在关系,树形结构中元素之间存在关系,图形结构中元素之间存在关系。 6. 算法的五个重要特性是__ __ , __ __ , ___ _ ,
第九章相似比较 第一节结构比较 结构比较题型是从推理的形式或推理的方法上比较题干和选项之间的相同或不同,在做该类型题目时,不考虑内容的对错也不考虑题干本身的结构是否正确,只要抽象出题干与选项的推理结构和形式,并对其进行比较就能找到正确答案。 考题的典型问法有:“下面哪项与上述推理结构最相似?”;“哪一项与上文的论证方式是相同的?”;“以下哪项与上述推理的逻辑结构一致?” 1.【2016年真题】 注重对孩子的自然教育,让孩子亲身感受大自然的神奇与美妙,可促进孩子释放天性,激发自身潜能;而缺乏这方面教育的孩子容易变得孤独,道德、情感与认知能力的发展都会受到一定的影响。 以下哪项与以上陈述方式最为类似?() A.脱离环境保护搞经济发展是“涸泽而渔”,离开经济发展抓环境保护是“缘木求鱼”。 B.只说一种语言的人,首次被诊断出患阿尔茨默症的平均年龄为76岁;说三种语言的人首次被诊断出患阿尔茨海默症的平均年龄约为78岁。 C.老百姓过去“盼温饱”,现在“盼环保”,过去“求生存”,现在“求生态”。 D.注重调查研究,可以让我们掌握第一手资料,闭门造车只能让我们脱离实际。 E.如果孩子完全依赖电子设备来进行学习和生活,将会对环境越来越漠视。 【答案】D 【解析】题干中的陈述方式是先陈述自然教育的优点,再补充陈述缺少自然教育的缺点,
即正面会得到一种结果,反面会得到另外一种结果。D项,先陈述注重调查研究的优点,再陈述不注重调查研究的缺点,与题干最为类似。 2.【2015年真题】 研究人员将角膜感觉神经断裂的兔子分为两组:实验组和对照组。他们给实验组兔子注射一种从土壤霉菌中提取的化合物。3周后检查发现,实验组兔子的角膜感觉神经已经复合;而对照组兔子未注射这种化合物,其角膜感觉神经都没有复合。研究人员由此得出结论:该化合物可以使兔子断裂的角膜感觉神经复合。 以下哪项与上述研究人员得出结论的方式最为类似?() A.科学家在北极冰川地区的黄雪中发现了细菌,而该地区的寒冷气候与木卫二的冰冷环境有着惊人的相似。所以,木卫二可能存在生命。 B.绿色植物在光照充足的环境下能茁壮成长,而在光照不足的环境下只能缓慢生长。所以,光照有助于绿色植物的生长。 C.一个整数或者是偶数,或者是奇数。0不是奇数,所以,0是偶数。 D.昆虫都有三对足,蜘蛛并非三对足。所以,蜘蛛不是昆虫。 E.年逾花甲的老王戴上老花眼镜可以读书看报,不戴则视力模糊。所以,年龄大的人都要戴老花眼镜。 【答案】B 【解析】题干所用的方法是求异法,B项也是求异法,故答案为B项。A项为类比;C 项为选言证法;D项为演绎推理;E项为例证法。 3.【2011年真题】
形考作业一 题目1 把数据存储到计算机中,并具体体现数据元素间的逻辑结构称为()。 选择一项: A. 逻辑结构 B. 给相关变量分配存储单元 C. 算法的具体实现 D. 物理结构 题目2 下列说法中,不正确的是()。 选择一项: A. 数据可有若干个数据元素构成 B. 数据元素是数据的基本单位 诃C.数据项是数据中不可分割的最小可标识单位 产_D.数据项可由若干个数据元素构成 题目3 一个存储结点存储一个()。 选择一项: A. 数据结构 B. 数据类型 C. 数据项 i_D.数据元素 题目4 数据结构中,与所使用的计算机无关的是数据的()。 选择一项: 题目5
下列的叙述中,不属于算法特性的是(选 )°择一项: A. 有穷性 B. 可行性
* C.可读性 D. 输入性 题目6 正确 获得2.00分中的2.00分 ◎ A.研究算法中的输入和输出的关系 B. 分析算法的易懂性和文档性 I 圏 C.分析算法的效率以求改进 D.找出数据结构的合理性 题目7 算法指的是( )。 选择一项: A. 排序方法 B. 解决问题的计算方法 C. 计算机程序 * D.解决问题的有限运算序列 题目8 算法的时间复杂度与( 选择一项: A. 所使用的计算机 因B.数据结构 D. i 题目10 设有一个长度为n 的顺序表,要删除第i 个元素移动元素的个数为( )。 选择一项: )有关。 D. 计算机的操作系统 题目9 设有一个长度为n 的顺序表,要在第i 个元素之前(也就是插入元素作为新表的第 i 个元 素),插入一个元素,则移动元素个数为( )。 选择一项: A. n-i+1 3 B. n-i-1 rj C. n-i C.算法本身
一、选择题 1设有关系模式W(C,P,S,G,T,R),其中各属性的含义是:C 课程,P 教师, S 学生,G 成绩,T 时间,R 教室,根据语义有如下数据依赖集: D={C->P ,( S,C )->G , ( T , R)->C , (T , P)-> R,( T,S )->R} 关系模式W的一个关键字是( ) A (S ,C ) B ( T, R) C) (T ,P ) D) (T ,S ) 2 设有关系模式W(C,P,S,G,T,R),其中中各属性的 含义是:C课程,P教师,S学生。G成绩,T时间,R教室,根据主义有如下依据赖集:K={C→P,(S,C)→G,(T,R )→C,(T,P)→R,(T,S)→R} 关系模式W的规范化程序最高达到() A 1NF B 2NF C 3NF D BCNF 3规范化理论中分解()主要消除其中多余的数据相关性。A关系运算 B 内模式 C外模式 D 视图 4现有职工关系W(工号,姓名,工程,定额),其中每一个工号(职工可能有同名), 每个职工有一个工程,每个工程有一个定额,则关系W已达到() A 1NF B2NF C3NF D4NF 5现有职工关系W(工号,姓名,工程,定额),其中每一
个职工有一个工号(职工可能有同名),每个职工有一个工程,每个工程有一个定额,则关系W已达到() A1NF B2NF C3NF D4NF 6规范化理论是关系数据库进行逻辑设计的理论依据,根据这个理论,关系数据库中的关系必须满足:其每一属性都是() A、互不相关的 B、不可分解的 C、长度可变的 D、互相关联的 7、在一个关系R中,若每个数据项都是不可再分割的,那 么关系R 一定属于() A、1NF B、2NF C、3NF D、BCNF 8、根所关系数据库规范化理论,关系数据库的关系要满足 1NF,下面“部门”关系中,因()属性而使它不满足1NF。 A、部门号 B、部门名 C、部门成员 D、 部门总经理 9、设有关系模式R(S,D,M)。其函数依赖集F={S->D, D->M},则关系R的规范化程序至多达到() A、1NF B、2NF C、3NF D、BCNF 10、下列关于函数依赖的叙述中,()是不正确的 A、由X->Y,X->Z,有X->YZ B\由XY->Z,有 X->Z,Y->Z C、由X->Y,WY->Z,有xw->z D、由X->Y,Y->Z,有
书面作业练习题 李英龙 湖南科技大学数学与计算科学学院
内容简介 在习题部分,既有选择题、判断题,也有用图表解答的练习题、算法设计题或综合解答分析题。并且配有部分练习题的答案供学生自学、练习、参考。 目录 书面作业练习题 习题一绪论 -------------------------------------------------------------3 习题二顺序表示(线性表、栈和队列)-----------------------------------------6 习题三链表(线性表、栈和队列)---------------------------------------------9 习题四串-----------------------------------------------------------------12 习题五数组 --------------------------------------------------------------13 习题六树与二叉树 -------------------------------------------------------15 习题七图-----------------------------------------------------------------24 习题八查找---------------------------------------------------------------30 习题九排序---------------------------------------------------------------33
2.读成渝经济开发区发展规划图和美国东北部地区示意图,回答下列问题。 (1)成渝经济开发区发展规划中,与北部产业发展带相比,南部产业发展带的城市分布特点和优势分别是什么?(6分) (2)成渝经济开发区和美国东北部地区都具有发展工业优势,试分析共同的区位条件。(6分) (3)试比较成都平原与美国东北部农业生产的差别。(6分)
答题思路 1.“四步审题、三项联系、二定要点及格式”是正确解答对比型试题的秘诀所在 “四步审题”是关键:第一步审比较对象,审准对象可以在很大程度上避免答题时张冠李戴;第二步审比较要求,即审准题意要求找相同点还是不同点,还是异同点都找,或者要求通过比较进一步找原因;第三步审比较考点,如比较A、B两地的气候类型及特征的异同点,其比较的考点是气候类型及特征,此步骤可避免跑题;第四步审比较角度,审准题目从什么角度、几个角度去比较,此步骤可避免漏掉答题的要点。 “三项联系”是答题依据:首先,联系题中图表和材料,它们是解决对比型问题最直接的依据;其次,联系所学教材知识点,即能迅速地理解题目设置的情境和需要解决的问题,与所学知识建立准确的联系,并从中提取出需要的知识点;最后,联系生活经验和常识,当考生实在
对点练习 1.阅读图文资料,回答下列问题。 材料一匹兹堡位于美国五大湖工业区,曾有美国“钢都”之称;武汉位于中国长江中游工业区,钢铁工业发达。两城市所在的工业区人口密集、制造业发达。图甲为两城市所在区域图。 材料二二战后的匹兹堡钢铁工业由于受市场和环境等因素影响,逐渐从辉煌陷入困境。为振兴经济,匹兹堡开始实施“复兴计划” (1)据图说出两城市地理位置的相似性。 (2)依据图文信息,简述两城市发展钢铁工业的相同区位条件。 (3)读图乙概括武汉在发展过程中可从匹兹堡借鉴的成功经验。
练习题及答案 第一部分:选择题 一、单项选择题 1.DBS是采用了数据库技术的计算机系统。DBS是一个集合体,包含数据库、计算机硬件、软件和 A.系统分析员 B.程序员 C.数据库管理员 D.操作员 2.模型是对现实世界的抽象,在数据库技术中,用模型的概念描述数据库的结构与语义,对现实世界进行抽象。表示实体类型及实体间联系的模型称为 A.数据模型 B.实体模型 C.逻辑模型 D.物理模型 3.关系模型概念中,不含有多余属性的超键称为 A.候选键 B.对键 C.内键 D.主键 4.设R、S为两个关系,R的元数为4,S的元数为5,则与R S等价的操作是 A.σ3<6(R×S) B.σ3<2(R×S) C.σ3>6(R×S) D.σ7<2(R×S) 5.分布式数据库存储概念中,数据分配是指数据在计算机网络各场地上的分配策略,一般有四种,分别是集中式、分割式、全复制式和 A. 任意方式 B.混合式 C.间隔方式 D.主题方式 6.数据库系统中,类是指具有相同的消息,使用相同的方法,具有相同的变量名和 A. 变量值 B. 特征 C. 定义 D. 类型
7.随着计算机应用领域的扩大,第一代、第二代DBS不能适应处理大量的 A.格式化数据 B.网络数据 C.非格式数据 D.海量数据 9.数据库并发控制概念中,使用X封锁的规则称为 A.PS协议 B.PX协议 C.PSC协议 D.两段封锁协议 10.在数据库操作过程中事务处理是一个操作序列,必须具有以下性质:原子性、一致性、隔离性和 A.共享性 B.继承性 C.持久性 D.封装性 11.面向对像模型概念中,类可以有嵌套结构。系统中所有的类组成一个有根的 A.有向无环图 B.有向有环图 C.无向有环图 D.无向无环图 12.在教学管理系统中,有教师关系T(T#,NAME),学生关系S(S#,NAME),学生成绩关系S(S#,NU)。其中T#表示
题型卷08 判断比较类综合题 考点定位:判断是什么、属于什么、怎么样。名词比较。特征比较。 1. (2015·经典模拟·浙江嘉兴)根据下列材料,完成问题。 西辽河流域地处我国农牧交错带,年降水量约375 mm,灌溉农业较为发达,素有“北方粮仓”之称。 指出该地区农牧界线的空间变化,并据此判断该地区农业土地利用类型面积的变化。 2.(2015·经典模拟·辽宁五校协作体期中考试)阅读甲、乙两座山脉的自然带垂直分布示意图,回答(1)~(3)题。 不同地区的气候、土壤、生物等地理要素,随着地理位置和地势的变化呈现出规律性的演变,从而形成纷繁复杂而又有规律的自然景观。
(1)比较甲图和乙图山脉自然带带谱的主要差异,并判断哪幅图的山脉所处纬度位置较低。 (2)概述甲图中各自然带在山脉南、北坡出现的高度的差异,并说明原因。 (3)乙图中,山脉在海拔4 000以上的南、北坡,坡度基本相同,气温大致相当,但南坡的雪线却低于北坡,说明其原因。
3.(2015·经典模拟·四川遂宁)读英国地形图,完成下列问题。 判断图中A、B两地哪一地区小麦种植业比较发达,并分析原因。 4.(2015·经典模拟·浙江嘉兴)读世界某区域简图,比较该国西部地区降水的南北差异,并从地形、大气环流角度分析其原因。 5.(2014·江苏南京市、盐城市一模)满洲里是中俄最大的贸易口岸。读满洲里口岸贸易产品构成图,回答下列问题。
比较该口岸进出口贸易产品构成的差异,并从产业结构、资源状况方面分析形成差异的原因。 6.(2015·经典模拟·浙江省六校)读我国局部地区≥10℃等积温线分布图,比较包头、唐山两地积温差异。 7.(2015·经典模拟·黑龙江双鸭山)阅读材料,回答问题。 材料一甲河是我国东南沿海的河流,流域内拥有较丰富的水、土地、矿产、生物、旅游等资源。流域内的东南部以三角洲平原、台地、丘陵为主,中部以台地、丘陵为主,西北部则为山地、丘陵。 材料二下图是甲河流域示意图。
数据库原理与应用练习题及参考答案 一、选择题 1.一下关于关系的说法正确的是( A ) A.一个关系就是一张二维表 B.在关系所对应的二维表中,行对应属性,列对应元组。 C.关系中各属性不允许有相同的域。 D.关系的各属性名必须与对应的域同名。 2.关系数据表的关键字可由( D )属性组成。 A.一个 B.两个 C.多个 D.一个或多个 3.进行自然连接运算的两个关系( A ) A.至少存在一个相同的属性名 B.可不存在任何相同的属性名 C.不可存在个相同的属性名 D.所有属性名必须完全相同 4.概念结构设计是整个数据库设计的关键,它通过对用户需求进行综合、归纳与抽象,形成一个独立于具体DBMS的( B )。 A.数据模型 B.概念模型 C.层次模型 D.关系模型 5.Access 2010 数据库具有很多特点,下列叙述中,正确的是( B )。 A. Access 2010数据表可以保存多种数据类型,但是不包括多媒体数 B. Access 2010可以通过编写应用程序来操作数据库中的数据 C. Access 不能支持 Internet/Intranet 应用 D. Access 2010 使用切换面板窗体管理数据库对象 6.数据表的基本对象是( A ) A.表 B.查询 C.报表 D.窗体 7.利用Access 2010 创建数据库文件,其扩展名是( B ) A.mdb B.accdb C.xlsx D. acc 8.启动Access 2010 后,最先显示的是什么界面( C ) A.数据库工作界面 B.“打开”窗口 C. Backstage D导航窗格 9.在 Access 数据库对象中,不包括的是( B ) A.表 B.向导 C.窗体 D.模块 10.表的组成内容包括( C ) A.查询和字段 B.报表和字段 C.字段和记录 D.记录和窗体 11.在 Access 2010 数据库的表设计视图中,不能进行的操作是( A ) A.修改字段类型 B.设置索引 C.增加字段 D.删除记录
数据结构习题集 一、选择题 1.数据结构中所定义的数据元素,是用于表示数据的。( C ) A.最小单位 B.最大单位 C.基本单位 D.不可分割的单位 2.从逻辑上可以把数据结构分为( C ) A.动态结构、静态结构 B.顺序结构、链式结构 C.线性结构、非线性结构 D.初等结构、构造型结构 3.当待排序序列中记录数较少或基本有序时,最适合的排序方法为(A) A.直接插入排序法 B.快速排序法 C.堆排序法 D.归并排序法 4.关于串的的叙述,不正确的是( B) A.串是字符的有限序列 B.空串是由空格构成的串 C.替换是串的一种重要运算 D.串既可以采用顺序存储,也可以采用链式存储 5.带表头结点链队列的队头和队尾指针分别为front和rear,则判断队空的条件为(A )A.front==rear B.front!=NULL C.rear!=NULL D.front==NULL 6.若构造一棵具有n个结点的二叉排序树,最坏的情况下其深度不会超过(B ) A.n/2 B.n C.(n+1)/2 D.n+1 7.将两个各有n个元素的有序表合并成一个有序表,其最少的比较次数为(A) A.n B.2n-1 C.2n D.n2 8.设顺序表有19个元素,第一个元素的地址为200,且每个元素占3个字节,则第14个元素的存储地址为(B ) A.236 B.239 C.242 D.245 9.一个栈的入栈序列是a,b,c,d,e,则栈的输出序列不可能是(A ) A.dceab B.decba C.edcba D.abcde 10.元素大小为1个单元,容量为n个单元的非空顺序栈中,以地址高端为栈底,以top 作为栈顶指针,则出栈处理后,top的值应修改为(D ) A.top=top B.top=n-1 C.top=top-1 D.top=top+1 11.设有一个10阶的对称矩阵A,采用压缩存储方式以行序为主序存储,a00为第一个元素,其存储地址为0,每个元素占有1个存储地址空间,则a45的地址为( B ) A.13 B.35 C.17 D.36 12.栈和队列(C) A.共同之处在于二者都是先进先出的特殊的线性表 B.共同之处在于二者都是先进后出的特殊的线性表 C.共同之处在于二者都只允许在顶端执行删除操作
【通用版】高考地理综合题区域比较类答题模板 考查方式 以两个或两个以上的区域地理环境要素分布图或材料为命题切入点,考查不同区域之间的地理差异、地理特征差异形成的原因、区域可持续发展中的问题及治理措施等。 二、设问形式 常见设问形式有“比较图中……和……的差异(异同)”“分析……和……的共同特点(问题)”“说明图示……和……的自然条件和类型的差异”等。 三、答题思路 “三步比较”回答区域比较类试题 1、细致审题确定比较对象 审比较对象,避免答题时张冠李戴;审比较考点,如比较AB两地气候特征的异同,可避免跑题;审比较要求,即审准题意要求找相同点还是不同点,还是异同点都找,或者要求通过比较找原因;审比较角度,审准题目从什么角度、几个角度去回答,可避免漏掉答题的要点;注意设问的分值,养成要点化答题的习惯,看分给点。 2、确立比较的类型与思维模式
(1)名词比较类:应先搞清名词的含义,包括的内容,针对内容进行分析比较。如:比较两地的气候特征,须知道比较气候类型,气温和降水特点 (2)区域特征比较类:应先对区域进行综合分析,然后根据要求对分析内容有选择性地列举比较。这类试题重在分析,次在比较。所以,区域的综合分析显得尤为重要,区域的综合分析主要从自然地理和人文地理两个方面进行。 3、巧妙比较,简洁作答 三项联系是答题的依据: A、联系题中图表和材料,他们是解决比较类问题最直接的依据 B、联系所学教材知识点,即能迅速理解题目设置的情景和需要解决的问题,与所学知识建立准确的联系,并从中提取需要的知识点 C、联系生活经验和常识,当学生实在想不起来所学教材知识点时,根据题意联系自己的生活经验和常识来答题往往也是有效的 答题模板
数据结构(本)形考作业1参考答案: 一、单项选择题 1.C 2.D 3.C 4.C 5.D 6.C 7.C 8.C 9.A 10.B 二、填空题 1.n-i+1 2.n-i 3.集合、线性表、树、图 4. 存储结构、物理结构 5.线性表图 6. 有穷性、确定性、可行性、有输入、有输出 7. 图 8.树 9. 线性表 10. n-1 O(n) 11.s->next=p->next; 12.head 13.q->next=p->next; 14.p->next=head; 15.单链表 16.顺序存储链式存储 17.存储结构 18.两个后继结点前驱结点尾结点头结点 19.指向头结点的指针指向第一个结点的指针 20.链式链表 三、问答题 1.简述数据的逻辑结构和存储结构的区别与联系,它们如何影响算法的设计与实现? 答:若用结点表示某个数据元素,则结点与结点之间的逻辑关系就称为数据的逻辑结构。数据在计算机中的存储表示称为数据的存储结构。可见,数据的逻辑结构是反映数据之间的固有关系,而数据的存储结构是数据在计算机中的存储表示。尽管因采用的存储结构不同,逻辑上相邻的结点,其物理地址未必相同,但可通过结点的内部信息,找到其相邻的结点,从而保留了逻辑结构的特点。采用的存储结构不同,对数据的操作在灵活性,算法复杂度等方面差别较大。 2.解释顺序存储结构和链式存储结构的特点,并比较顺序存储结构和链式存储结构的优缺点。 答:顺序结构存储时,相邻数据元素的存放地址也相邻,即逻辑结构和存储结构是统一的,,要求内存中存储单元的地址必须是连续的。 优点:一般情况下,存储密度大,存储空间利用率高。 缺点:(1)在做插入和删除操作时,需移动大量元素;(2)由于难以估计,必须预先分配较大的空间,往往使存储空间不能得到充分利用;(3)表的容量难以扩充。 链式结构存储时,相邻数据元素可随意存放,所占空间分为两部分,一部分存放结点值,另一部分存放表示结点间关系的指针。 优点:插入和删除元素时很方便,使用灵活。
1.设有关系模式 R(A, B, C, D,E),其上的函数依赖集 F={A→BC, CD→E, B→D, E→A} 试计算 ①A+、B+; ②求出 R的所有候选码(3分) 2. 要建立关于系、学生、班级等信息的一个关系数据库。规定:一个系有若干专业、每个专业每年只招一个班,每个班有若干学生,一个系的学生住在同一个宿舍区,一个系只有一个系名,一个系名也只给一个系用。 描述学生的属性有:学号、姓名、出生年月、系名、班号、宿舍区。 描述班级的属性有:班号、专业名、系名、人数、入校年份。 描述系的属性有:系号、系名、系办公室地点、人数。 试给出上述数据库的关系模式;写出每个关系的最小依赖集(即基本的函数依赖集,不是导出的函数依赖);指出是否存在传递函数依赖;对于函数依赖左部是多属性的情况,讨论其函数依赖是完全函数依赖还是部分函数依赖,指出各关系的候选键、外部关系键,进行范式判断。 3.某医院病房计算机管理中需要如下信息: 科室:科名,科地址,科电话,医生姓名 病房:病房号,床位号,所属科室名 医生:姓名,职称,所属科室名,年龄,工作证号 病人:病历号,姓名,性别,诊断,主管医生,病房号 其中,一个科室有多个病房、多个医生,一个病房只能属于一个科室,一个医生只属于一个科室,但是可以负责多个病人的诊治,一个病人的主管医生只有一个。 完成如下设计 (1)请根据需求信息设计该系统的E-R图; (2)请将E-R图转换为关系模式; (3)指出转换结果中每个关系模式的主码(用直下划线)和外码(用曲下划线)。 4. 商品销售系统 假定一个销售公司的业务涉及如下基本实体: (1)职工:职工号、姓名、性别电话、住址; (2)商品:商品编号、商品名称、型号、供货商、进货单价、库存数量、销售 单价; (3)供货商:制造商编号、制造商名称、联系电话、通信地址; (4)客户:客户编号、客户名称、联系电话、通信地址。
数据结构综合练习题
数据结构(一) 一、选择题 1.组成数据的基本单位是( C )。 (A) 数据项(B) 数据类型(C) 数据元素(D) 数据变量 2.设数据结构A=(D,R),其中D={1,2,3,4},R={r},r={<1,2>,<2,3>,<3,4>,<4,1>},则数据结构A 是( C )。 (A) 线性结构(B) 树型结构(C) 图型结构(D) 集合 3.数组的逻辑结构不同于下列( D )的逻辑结构。(A) 线性表(B) 栈(C) 队列(D) 树 4.二叉树中第i(i≥1)层上的结点数最多有(C )个。 (A) 2i (B) 2i(C) 2i-1(D) 2i-1 5.设指针变量p指向单链表结点A,则删除结点A的后继结点B需要的操作为(A )。 (A) p->next=p->next->next (B) p=p->next (C) p=p->next->next (D) p->next=p 6.设栈S和队列Q的初始状态为空,元素E1、E2、E3、E4、E5和E6依次通过栈S,一个元素出栈后即进入队列Q,若6个元素出列的顺序为E2、E4、E3、E6、E5和E1,则栈S的容量至少应该是( C )。 (A) 6 (B) 4 (C) 3 (D) 2
7.将10阶对称矩阵压缩存储到一维数组A中,则数组A 的长度最少为( C )。 (A) 100 (B) 40 (C) 55 (D) 80 8.设结点A有3个兄弟结点且结点B为结点A的双亲结点,则结点B的度数数为( B )。 (A) 3 (B) 4 (C) 5 (D) 1 9.根据二叉树的定义可知二叉树共有( B )种不同的形态。 (A) 4 (B) 5 (C) 6 (D) 7 10.设有以下四种排序方法,则( B )的空间复 杂度最大。 (A) 冒泡排序(B) 快速排序(C) 堆排序(D) 希尔排序 11、以下说法正确的是( A ) A.连通图的生成树,是该连通图的一个极小连通子图。 B.无向图的邻接矩阵是对称的,有向图的邻接矩阵一定是不对称的。 C.任何一个有向图,其全部顶点可以排成一个拓扑序列。 D.有回路的图不能进行拓扑排序。 12、以下说法错误的是 ( D ) A.一般在哈夫曼树中,权值越大的叶子离根结点越近 B.哈夫曼树中没有度数为1的分支结点 C.若初始森林中共有n裸二叉树,最终求得的哈夫曼树
《比较文学》练习测试题库 一、填空题: 1、比较文学的研究范围,一是;二是 2、真正意义上的比较文学产生于世纪末。它的出现与当时整个社会的经济、文化环境有着密切关系。 3、从比较文学的眼光看,我国文学的发展历史是一个不断与世界各国文学、、、的历史。 4、法国学者基亚认为比较文学实际上是史。 5、季羡林先生说过,从全世界文学艺术的历史来看,文艺理论真能持之有故,言之成理,确有创见而又能自成体系的只有三个地方,一个是,一个是,一个是从古代希腊、罗马一直到今天欧洲国家所在的广大地区。 6、在《长篇诗在中国何以不发达》一文中以一种宏观的视野,从传统文化、民族性格等方面探讨了缺类问题。 7、比较文学就是要突破各种学术研究的界限,“打通”整个文化领域,使文学研究进入了性研究的新阶段。 8、从积极的意义上看,东西方文化的沟通常常是在中实现的。 9、置身于接受者的立场,探讨作家作品的源流,分析它们所受到的各国文学的影响,这一研究被称为。 10、比较诗学是一门从跨文化的角度对、的比较研究。 11、比较文学是一门跨越民族,,文化和的文学研究。 12、比较文学要求在研究中国文学时,应以为背景,以为参照系统,认识和评价自己。 13、丹纳《艺术哲学》中提出的制约文学发展的三大要素中与达尔文进化论的“外界条件”相对应的是和。 14、文学理论对音乐的借鉴体现在对音乐和的吸收上。 15、在西方历史上,古希腊哲学家首创的哲学专题论文引起了哲学和文学的分化。 16、钱钟书先生曾倡导法,它不仅表现在文学范围内地域、时代、文类诸界限的打破,而且推向整个文化领域,体现为各个学科门类的汇通。 17、是比较文学研究的重点之一。 18、1848年,马克思、恩格斯在一书中使用了“世界文学”这个概念。 19、18世纪下半叶和19世纪初叶席卷全欧的文学思潮为比较文学的诞生准备了文学土壤。
试题(一) 一、填空题 1.在关系模式R中,能函数决定所有属性的的属性组,称为模式R的候选码。2.当合并局部E-R图时可能出现的冲突有属性冲突,命名冲突和结构冲突。3.设计概念模型通常采用自底向上的方法。 4.事务是数据库操作的逻辑工作单位,事务中的操作要么都做,要么都不做,是指它的原子性特性。 5.恢复技术的基本原理是建立数据冗余,最常用的技术是数据转储和登记日志文件。6.数据库的并发操作引发的问题包括丢失修改、读脏数据和不可重复读。常用的并发控制的方法是封锁。 二、综合题 1.设有关系模型R(U,F),其中U={ABCDEG},F={BG→C,BD→E,DG→C,DAG→CB,AG→B,B→D} (1)求出关系模式的候选码。 (2)此关系模式最高属于哪级范式。 答案:(1)AG AG={AGBDCE} (2)2NF 3.学校有若干个系,每个系有各自的系号、系名和系主任;每个系有若干名教师和学生,教师有教师号、教师名和职称属性,每个教师可以担任若干门课程,一门课程只能由一位教师讲授,课程有课程号、课程名和学分,并参加多项项目,一个项目有多人合作,且责任轻重有个排名,项目有项目号、名称和负责人;学生有学号、姓名、年龄、性别,每个学生可以同时选修多门课程,选修有分数。 (1)请设计此学校的教学管理的E-R模型。(第一章试题中已做) (2)将E-R模型转换为关系模型。 答案: (1)
(2)系(系号,系名,系主任) 教师(教师号,教师名,职称,系号) 学生(学号,姓名,年龄,性别,系号) 项目(项目号,名称,负责人) 课程(课号,课程名,学分,教师号) 选修(课号,学号,分数) 负责(教师号,项目号,排名) 试题(二) 一、填空题 1.数据库的三级模式是指内模式、___________________、外模式。(模式) 2.____________________是现实世界在人们头脑中的反映,是对客观事物及其联系的一种抽象描述。(概念世界) 3.数据模型由三部分组成:模型结构、数据操作、__________________。(完整性规则)4.一种数据模型的特点是:有且仅有一个根结点,根结点没有父结点;其它结点有且仅有一个父结点。则这种数据模型是__________________________。(层次模型) 5.能唯一标识一个元组的属性或属性组成为________________。(候选码) 7. SQL语言一种标准的数据库语言, 包括数据查询、数据定义、数据操纵、___________四部分功能。(数据控制) 8. 视图是从其它________________________或视图导出的表。(基本表)
选择一项: 1. 108 2. 110 3. 100 4. 120 2.在n个结点的顺序表中,算法的时间复杂度是O(1)的操作是( b) 选择一项: a. 删除第i个结点(1≤i≤n) b. 访问第i个结点(1≤i≤n)和求第i个结点的直接前驱(2≤i≤n) c. 将n个结点从小到大排序 d. 在第i个结点后插入一个新结点(1≤i≤n) 3.以下说法错误的是( d)。 选择一项: a. 由于顺序存储要求连续的存储区域,所以在存储管理上不够灵活 b. 顺序存储的线性表可以随机存取 c. 求表长、定位这两种运算在采用顺序存储结构时实现的效率不比采用链式存储结构时实现的效率低 d. 线性表的链式存储结构优于顺序存储结构 4.单链表的存储密度( b)。 选择一项: a. 不能确定 b. 小于1 c. 大于1 d. 等于1 5.向一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动的元素个数为( c)。 选择一项: a. 63 b. 7 c. d. 8 6.在一个长度为n的顺序表中,在第i个元素(1≤i≤n+1)之前插入一个新元素时须向后移动( b)个元素。 选择一项: a. n-i b. n-i+1 c. i d. n-i-1 7.在单链表中,要将s所指结点插入到p所指结点之后,其语句应为(a )。 选择一项: a. s->next=p->next; p->next=s; b. (*p).next=s; (*s).next=(*p).next; c. s->next=p->next; p->next=s->next;
d. s->next=p+1; p->next=s; 8.在双向循环链表中,在p指针所指的结点后插入q所指向的新结点,其修改指针的操作是(b )。 选择一项: a. p->next=q; q->prior=p; p->next->prior=q; q->next=q; b. q->prior=p; q->next=p->next; p->next->prior=q; p->next=q; c. p->next=q; p->next->prior=q; q->prior=p; q->next=p->next; d. q->prior=p; q->next=p->next; p->next=q; p->next->prior=q; 9.在双向链表存储结构中,删除p所指的结点时须修改指针(c )。 选择一项: a. p->prior=p->next->next; p->next=p->prior->prior; b. p->next=p->next->next; p->next->prior=p; c. p->next->prior=p->prior; p->prior->next=p->next; d. p->prior->next=p; p->prior=p->prior->prior; 10.将两个各有n个元素的有序表归并成一个有序表,其最少的比较次数是(c )。 选择一项: a. 2n b. n-1 c. n d. 2n-1 11.线性表L=(a1,a2,……an),下列说法正确的是( b)。 选择一项: a. 表中诸元素的排列必须是由小到大或由大到小 b. 除第一个和最后一个元素外,其余每个元素都有一个且仅有一个直接前驱和直接后继。 c. 每个元素都有一个直接前驱和一个直接后继 d. 线性表中至少有一个元素 12.线性表若采用链式存储结构时,要求内存中可用存储单元的地址(d )。 选择一项: a. 部分地址必须是连续的 b. 一定是不连续的 c. 必须是连续的 d. 连续或不连续都可以 13.线性表L在(d )情况下适用于使用链式结构实现。 选择一项: a. L中结点结构复杂 b. L中含有大量的结点 c. 需经常修改L中的结点值 d. 需不断对L进行删除插入 14.若指定有n个元素的向量,则建立一个有序单链表的时间复杂性的量级是( b)。 选择一项: