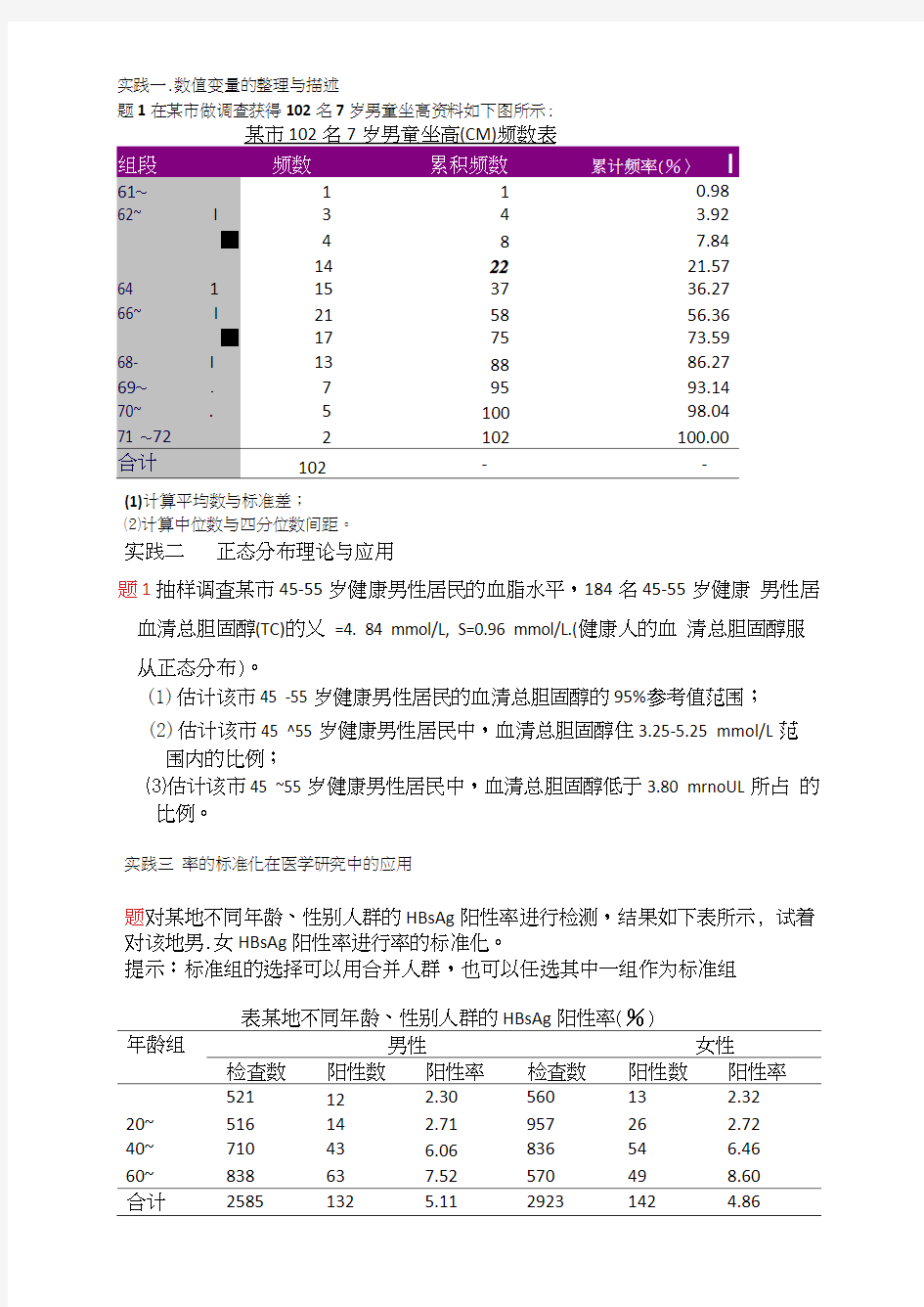

实践一.数值变量的整理与描述
题1在某市做调查获得102名7岁男童坐高资料如下图所示:
(1)计算平均数与标准差;
⑵计算中位数与四分位数间距。
实践二正态分布理论与应用
题1抽样调査某市45-55岁健康男性居民的血脂水平,184名45-55岁健康男性居血清总胆固醇(TC)的乂=4. 84 mmol/L, S=0.96 mmol/L.(健康人的血清总胆固醇服
从正态分布)。
(1)估计该市45 -55岁健康男性居民的血清总胆固醇的95%参考值范围;
(2)估计该市45 ^55岁健康男性居民中,血清总胆固醇住3.25-5.25 mmol/L范
围内的比例;
⑶估计该市45 ~55岁健康男性居民中,血清总胆固醇低于3.80 mrnoUL所占的
比例。
实践三率的标准化在医学研究中的应用
题对某地不同年龄、性别人群的HBsAg阳性率进行检测,结果如下表所示, 试着对该地男.女HBsAg阳性率进行率的标准化。
提示:标准组的选择可以用合并人群,也可以任选其中一组作为标准组
表某地不同年龄、性别人群的HBsAg阳性率(%)
实验四总体均数估计在医学研究中的运用
题1从某疾病患者中随机抽取25例,其红细胞沉降率(mm/h)的均数为9.15, 标准差为2.13.假定该类患者的红细胞沉降率服从正态分布,试估计该总体均数的95%的置信区间。
题2某实验随机测定了100名正常人血浆内皮素(ET)含豎(ng/L), 得均数X = 81.0标准差S = 18.2,
(1)计算抽样误差指标
(2)估计正常人血浆内皮素的95%总体均数可信区间。
实验五假设检验与t检验
1经研究显示,汉族成年男子的环指长度的总体均数为10.1cm.某医生记录
了某地区12名汉族正常成年男子的环指长度(cm)分别为:10.05 10.33 10.49 10.00 9.89 10.15 9.52 10.33 10.16 10.37 10.11 10.27
问:该地区正常成年男子的环指长度是否大于一般成年男子?
题2将18名某疾病患者随机分成两组,分别用A/B两种药物治疗,
观察前后的血红蛋白含量如下表:
表疾病患者经A、B两种药物治疗前后的血红蛋白的变化结果(g/L)
患者编号123456789
治疗前364453566258454326
治疗后476268877358694950
B患者编号1011128
药治疗前564967587340483629
物治疗后8584960
问(1) A药物是否有效?
(2)B药物是否有效?
(3) A. B药物之间疗效有无差别?
实验六方差分析在医学研究中的实践
题1:某医生将36名缺铁性贫血患者随机分成三组用A、B、C三种不同治疗方案治疗缺铁性贫血,测量一个月后的红细胞升高数(1012/L),结果如下表,问三种治疗方案疗效有无差别,若有差别做进一步的两两比较。
编号A方案B方案C方案
10.81 1.32 2.35
20.75 1.41 2.50
30.74 1.35 2.43
40.86 1.38 2.36
50.82 1.40 2.44
60.87 1.33 2.46
70.75 1.43 2.40
80.74 1.38 2.43
90.72 1.40 2.21
100.82 1.40 2.45
110.80 1.34 2.38
120.75 1.46 2.40
实验七卡方检验在医学实践中的运用
题1 某研究欲比较A. B两种抗生素治疗单纯尿路感染,将84例患者随机等分成两组,一组A药物治疗,另一组B药物治疗。7天后观察疗效,A组37例有效,B组29例有效。
(1)将资料整理成合格的四格表形式
(2)比较两组药物的疗效有无差别。
题2某研究欲探讨螺旋CT和髙分辨率HRCT在煤工尘埃沉着病肺气肿检出方面的差异,选择96例1期煤工尘埃沉着病肺气肿患者,进行64排螺旋CT和HRCT 扫描检査,结果两种CT均检出73例,均未检出14例,螺旋CT检出而HRCT未检出者2例。
(1)将资料整理成合格的配对四格表形式。
(2)螺旋CT和高分辨率HRCT在煤工尘埃沉着病肺气肿检出结果有无差异。
题3欲比较甲乙丙三种方案治疗单纯性肥胖的有效率,将120例思者随机等分
成三组,分别采用三种方案,结果见表如下:
三种方案治疗单纯性肥胖的效果
问三种方案下的有效率有无差别?实验八秩和检验
题1测得某工厂铅作业与非铅作业工人的血铅值(Pinol/L)如下表:表铅作业与非铅作业工人的血铅值测定值(u mol/L)
铅作业组0.82 0.87 0.97 1.21 1.64 2.08 2.13
非铅作业组0.24 0.24 0.29 0.33 0.44 0.58 0.63 0.72 0.87 1.01 请问该厂非铅作业组工人的血铅值是否高于铅作业组工人?
题2某医生研究盐酸地儿硫桌缓释片治疗心绞痛的效果,采用该普通片做为
对照,服药后观察疗效,结果如下表:
问缓释片组与普通片组之间疗效有无差别?
实验九SPSS统计实践
1.圆图绘制
2.线图绘制
3.t检验的SPSS操作(第三版书本的例题8.2
4.方差分析的SPSS操作(例题9.1)
5.卡方检验的SPSS操作(例题11.3)
第二单元 计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指 标 性 别 例 数 均 数 标准差 标准值* 红细胞数/1012 ·L -1 男 360 4.66 0.58 4.84 女 255 4.18 0.29 4.33 血红蛋白/g ·L -1 男 360 134.5 7.1 140.2 女 255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV )比较二者的变异程度。 女性红细胞数的变异系数0.29 100%100% 6.94%4.18 S CV X = ?=?= 女性血红蛋白含量的变异系数10.2 100%100%8.67%117.6 S CV X =?=?= 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误X S 来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误0.031 X S = ==(1210/L ) 男性血红蛋白含量的标准误0.374 X S = ==(g/L )
女性红细胞数的标准误0.018X S = ==(1210/L ) 女性血红蛋白含量的标准误0.639X S = ==(g/L ) (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100,可视为大样本。σ未知,但n 足够大 ,故总体均数的区间估计按 (/2/2X X X u S X u S αα-+ , )计算。 该地男性红细胞数总体均数的95%可信区间为: (4.66-1.96×0.031 , 4.66+1.96×0.031),即(4.60 , 4.72)1210/L 。 该地女性红细胞数总体均数的95%可信区间为: (4.18-1.96×0.018 , 4.18+1.96×0.018),即(4.14 , 4.22)1210/L 。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准 H 0:12μμ=,即该地健康成年男、女血红蛋白含量均数无差别 H 1:12μμ≠,即该地健康成年男、女血红蛋白含量均数有差别 0.05α= 2) 计算检验统计量 22.829X X u === 3) 确定P 值,作出统计推断 查t 界值表(ν=∞时)得P <0.001,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同,男性高于女性。 (5) 样本均数与已知总体均数的比较,因样本含量较大,均作近似u 检验。 1) 男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准 H 0:0μμ=,即该地男性红细胞数的均数等于标准值
1、总体(population):是根据研究目的确定的同质研究对象的全体。 2、样本(sample):从总体中抽取的一部分有代表性的个体。 3、同质(homogeneity):是指所研究的观察对象具有某些相同的性质或特征。 4、变异(variation):指同质个体的某项指标之间的差异。 5、参数(parameter):反映总体特征的指标称为参数。 6、统计量(statistic):通过样本资料计算出来的相应指标称为统计量。 7、抽样误差(sampling error):由随机抽样造成的样本指标与总体指标之间、样本指标与样本指标之间的差异。 8、概率(probability):某事件发生的可能性大小。 9、正态分布(normal distribution):高峰位于均数处,中间高两边低,左右完全对称地下降,但永远不与横轴相交的钟形曲线。 10、平均数(average):是描述一组同质变量值的平均水平或集中趋势的指标。 11、中位数(median):将一组数据由小到大排列,位于中间位置的观测值。 12、医学参考值范围(medical reference range):又称正常值范围,医学上常将包括绝大多数正常人的某项指标的波动范围称为该指标的正常值范围。 13、方差(variance):是各个数据与平均数之差的平方的平均数。 14、标准差(standard deviation):是各数据偏离平均数的距离的平均数,它是离均差平方和平均后的方根,用σ表示。 15、标准误(standard error):样本均数的标准差,等于原变量总体标准差除以例数的平方根,用以说明均数抽样误差的大小。 16、均数的抽样误差(sampling error of mean):由个体差异和抽样所导致的样本均数与样本均数之间,样本均数与总体均数之间的差异。 17、假设检验(hypothesis testing):先对总体做出某种假设,然后根据样本信息来推断其是否成立的一类统计方法的总称。 18、统计推断(statistical inference):是根据已知的样本信息来推断未知的总体,是统计分析的目的,包括参数估计和假设检验。 19、Ⅰ型错误(type Ⅰ error):拒绝了实际上成立的H0,这类弃真错误,发生的概率为α,为已知。 20、Ⅱ型错误(type Ⅱ error):不拒绝实际上不成立的H0,这类存伪错误,发生的概率为β,未知。 21、检验效能(power of test):又称把握度,为1-β,其意义是两总体确有差别,按α水准能发现它们有差别的能力。 22、可信区间(confidence interval):指总体参数可能所在的范围。 23、率(rate):说明某现象发生的频率或强度。 24、构成比(constituent ratio):表示某事物内部各组成部分所占的比重或分布,常以百分数表示。 25、相对比(relative ratio):表示两个有关事物指标之比,常以百分数和倍数表示,用以说明一个指标是另一个指标的几倍或百分之几。 26、标准化率(standardized rate):亦称调整率,是采用统一的标准对内部构成不同的各组频率进行调整和对比的方法。 27、参数检验(parametric test):一类依赖于总体分布的具体形式的统计推断方法。 28、非参数检验(non parametric test):一类不依赖总体分布类型的检验,在应用中可以不考虑被研究对象为何种分布以及分布是否已知,检验假设中没有包括总体参数的统计方法。
一、是非题 1.单个自变量的线性回归就是直线回归。 2.直线回归就是指自变量和应变量的观察值落在在一条直线上。 3.直线回归中预测值Y 是固定某个X 值,Y 的总体均数估计值。 4.用逐步回归的方法评价自变量与应变量之间的关联性,只能推断某个自变量与应变量有关联性,不能推断无它们之间无关联性。 二、选择题 1.用最小二乘法确定直线回归方程的原则是各观察点() A . 距直线的纵向距离相等 B . 距直线的纵向距离的平方和最小 C . 与直线的垂直距离相等 D . 与直线的垂直距离的平方和最小 2.直线回归的系数假设检验() E . 只能利用相关系数r 的检验方法进行检验 F . 只能用t 检验 G . 只能用F 检验 H . 三者均可 3.Y ?=7+2X 是1~7岁儿童以年龄(岁)估计体重(公斤)的回归方程,若把体重的单位换成市斤, 则此方程( ) A .截矩改变 B .回归系数改变 C . 截矩与回归系数都改变 D .回归系数不变 E .截矩不变 4.直线回归系数的假设检验,其自由度为( ) A .n B .n-1 C .n-2 D .2n-1 E .2n-2 5.对应变量Y 的离均差平方和,下列哪个分解是正确的?( ) A .SS 剩=SS 回 B .SS 总=SS 剩 C .SS 总=SS 回 D .SS 总+SS 剩=SS 回 E .SS 总+SS 回=SS 剩 三、计算分析题
1.15名儿童的身高与肺死腔容积的观察值如表15-3所示。 表15-3 儿童身高与肺死腔容积的观测数据 对象号 身高(cm) X 肺死腔容积(ml) Y 对象号 身高(cm) X 肺死腔容积(ml) Y 1 110 45 9 175 102 2 116 32 10 167 111 3 123 41 11 165 88 4 130 45 12 160 65 5 129 43 13 157 79 6 142 67 14 156 92 7 147 58 15 149 58 8 153 57 试用该资料进行回归分析: (1)计算样本回归方程的截矩与回归系数; (2)进行回归系数等于0的假设检验; (3)验证是否存在F t b =的关系; (4)估计回归系数β的95%置信区间。 2.一名产科医生收集的12名产妇24h 的尿,测量其中雌三醇的含量,同时记录了产儿的体重,见表15-4。 表15-4 待产妇尿中雌三醇含量与新生儿体重 编号 尿雌三醇(mg/24h) X 新生儿体重(kg) Y 编号 尿雌三醇(mg/24h) X 新生儿体重(kg) Y 1 7 2.5 7 19 3.1 2 9 2.5 8 21 3.0 3 12 2.7 9 22 3.5 4 14 2.7 10 24 3.4 5 16 3.7 11 25 3.9 6 17 3.0 12 27 3.4 (1)试用该数据进行回归分析; (2)求回归系数的95%置信区间; (3)试求当待产妇尿中雌三醇含量为18(mg/24h)时,新生儿体重个体值的95%预测区间。
第一章绪论 1.下列关于概率的说法,错误的是 A. 通常用P表示 B. 大小在0%与100%之间 C. 某事件发生的频率即概率 D. 在实际工作中,概率是难以获得的 E. 某事件发生的概率很小,在单次研究或观察中时,称为小概率事件 [参考答案] C. 某事件发生的频率即概率 2.下列有关个人基本信息的指标中,属于有序分类变量的是 A. 学历 B. 民族 C. 血型 D. 职业 E. 身高 [参考答案] A. 学历3.下列有关个人基本信息的指标,其中属于定量变量的是 A. 性别 B. 民族 C. 职业 D. 血型 E. 身高 [参考答案] E. 身高 4.下列关于总体和样本的说法,不正确的是 A. 个体间的同质性是构成总体的必备条件 B. 总体是根据研究目的所确定的观察单位的集合 C. 总体通常有无限总体和有限总体之分 D. 一般而言,参数难以测定,仅能根据样本估计 E. 从总体中抽取的样本一定能代表该总体
[参考答案] E. 从总体中抽取的样本一定能代表该总体 5.在有关2007年成都市居民糖尿病患病率的调查研究中,总体是 A. 所有糖尿病患者 B. 所有成都市居民 C. 2007年所有成都市居民 D. 2007年成都市居民中的糖尿病患者 E. 2007年成都市居民中的非糖尿病患者[参考答案] C. 2007年所有成都市居民 6.简述小概率事件原理。 答:当某事件发生的概率很小,习惯上认为小于或等于0.05时,统计学上称该事件为小概率事件,其含义是该事件发生的可能性很小,进而认为它在一次抽样中不可能发生,这就是所谓小概率事件原理,它是进行统计推断的重要基础。 7.举例说明参数和统计量的概念答:某项研究通常想知道关于总体的某些数值特征,这些数值特征称为参数,如整个城市的高血压患病率。根据样本算得的某些数值特征称为统计量,如根据几百人的抽样调查数据所算得的样本人群高血压患病率。统计量是研究人员能够知道的,而参数是他们想知道的。一般情况下,这些参数是难以测定的,仅能根据样本估计。显然,只有当样本代表了总体时,根据样本统计量估计的总体参数才是合理的 8.举例说明总体和样本的概念 答:研究人员通常需要了解和研究某一类个体,这个类就是总体。总体是根据研究目的所确定的观察单位的集合,通常有无限总体和有限总体之分,前者指总体中的个体数是无限的,如研究药物疗效,某病患者就是无限总体,后者指总体中的个体数是有限的,它是指特定时间、空间中有限个研究个体。但是,研究整个总体一般并不实际,通常能研究的只是它的一部分,这个部分就是样本。例如在一项关于2007
一、单向选择题 1. 医学统计学研究的对象是 E.有变异的医学事件 2. 用样本推论总体,具有代表性的样本指的是E.依照随机原则抽取总体中的部分个体 3. 下列观测结果属于等级资料的是 D.病情程度 4. 随机误差指的是 E. 由偶然因素引起的误差 5. 收集资料不可避免的误差是 A.随机误差 1.某医学资料数据大的一端没有确定数值,描述其集中趋势适用的统计指标是 A. 中位数 2. 算术均数与中位数相比,其特点是 B.能充分利用数据的信息 3. 一组原始数据呈正偏态分布,其数据的特点是 D.数值分布偏向较小一侧 4. 将一组计量资料整理成频数表的主要目的是E.提供数据和描述数据的分布特征 1. 变异系数主要用于 A .比较不同计量指标的变异程度 2. 对于近似正态分布的资料,描述其变异程度应选用的指标是E. 标准差 3.某项指标95%医学参考值范围表示的是D.在“正常”总体中有95%的人在此范围 4.应用百分位数法估计参考值范围的条件是B .数据服从偏态分布 5.已知动脉硬化患者载脂蛋白B 的含量(mg/dl)呈明显偏态分布,描述其个体差异的统计指标应使用 E .四分位数间距 1.样本均数的标准误越小说明 E.由样本均数估计总体均数的可靠性越大 2. 抽样误差产生的原因是D.个体差异 3.对于正偏态分布的的总体,当样本含量足够大时,样本均数的分布近似为C.正态分布 4. 假设检验的目的是 D.检验总体参数是否不同 5. 根据样本资料算得健康成人白细胞计数的95%可信区间为7.2×109 /L ~9.1×109 /L ,其含义是 E.该区间包含总体均数的可能性为95% 1. 两样本均数比较,检验结果05.0 P 说明 D.不支持两总体有差别的结论 2. 由两样本均数的差别推断两总体均数的差别, 其差别有统计学意义是指 E. 有理由认为两总体均数有差别 3. 两样本均数比较,差别具有统计学意义时,P 值越小说明 D.越有理由认为两总体均数不同 4. 减少假设检验的Ⅱ类误差,应该使用的方法是 E.增加样本含量 5.两样本均数比较的t 检验和u 检验的主要差别是B.u 检验要求大样本资料
医学统计学 1、应用相对数时应注意的事项 ①计算相对数时分母不能太小; ②分析时不能以构成比代替率; ③当各分组的观察单位数不等时,总率(平均率)的计算不能直接将各分组的率相加求其平均; ④对比时应注意资料的可比性:两个率要在相同的条件下进行,即要求研究方法相同、研究对象同质、观察时间相等以及地区、民族、年龄、性别等客观条件一致,其他影响因素在各组的内部构成应相近; ⑤进行假设检验时,要遵循随机抽样原则,以进行差别的显著性检验。 2、正态分布的特点及其应用 性质:①两头低中间高,略呈钟形; ②只有一个高峰,在X=μ,总体中位数亦为μ; ③以均数为中心,左右对称; ④μ为位置参数,当σ恒定时,μ越大,曲线沿横轴越向右移动; σ为变异度参数,当μ恒定时,σ越大,表示数据越分散,曲线越矮胖,反之,曲线越瘦高; ⑤对于任何服从正态分布N(μ,σ2)的随机变量X作的线性变换,都会变换成u 服从于均数为0,方差为1的正态分布,即标准正态分布。 应用:①概括估计变量值的频数分布; ②制定参考值范围; ③质量控制; ④是许多统计方法的理论基础。 3、确定参考值范围的一般原则和步骤、方法 一般原则和步骤:①抽取足够例数的正常人样本作为观察对象; ②对选定的正常人进行准确而统一的测定,以控制系统误差; ③判断是否需要分组测定; ④决定取单侧范围值还是双侧范围值; ⑤选定适当的百分范围; ⑥选用适当的计算方法来确定或估计界值。 方法:①正态分布法:②百分位数法(偏态分布) 4、总体均数的可信区间与参考值范围的区别 概念:可信区间是按预先给定的概率来确定的未知参数μ的可能范围。 参考值范围是绝大多数正常人的某指标范围。所谓正常人,是指排除了影响所研究指标的疾病和有关因素的人;所谓绝大多数,是指范围,习惯上指正常人的95%。 计算公式:可信区间① ② ③ 参考值范围①正态分布 ②偏态分布 用途:可信区间用于总体均数的区间估计 参考值范围用于表示绝大多数观察对象某项指标的分布范围
第二单元 计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指 标 性 别 例 数 均 数 标准差 标准值* 红细胞数/1012·L -1 男 360 4.66 0.58 4.84 女 255 4.18 0.29 4.33 血红蛋白/g ·L -1 男 360 134.5 7.1 140.2 女 255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV )比较二者的变异程度。 女性红细胞数的变异系数0.29 100%100% 6.94%4.18 S CV X = ?=?= 女性血红蛋白含量的变异系数10.2 100%100%8.67%117.6 S CV X =?=?= 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误X S 来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误0.031 X S = ==(1210/L ) 男性血红蛋白含量的标准误0.374 X S = ==(g/L )
女性红细胞数的标准误0.018X S = ==(1210/L ) 女性血红蛋白含量的标准误0.639X S = ==(g/L ) (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100,可视为大样本。σ未知,但n 足够大 ,故总体均数的区间估计按 (/2/2X X X u S X u S αα-+ , )计算。 该地男性红细胞数总体均数的95%可信区间为: (4.66-1.96×0.031 , 4.66+1.96×0.031),即(4.60 , 4.72)1210/L 。 该地女性红细胞数总体均数的95%可信区间为: (4.18-1.96×0.018 , 4.18+1.96×0.018),即(4.14 , 4.22)1210/L 。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准 H 0:12μμ=,即该地健康成年男、女血红蛋白含量均数无差别 H 1:12μμ≠,即该地健康成年男、女血红蛋白含量均数有差别 0.05α= 2) 计算检验统计量 22.829X X u === 3) 确定P 值,作出统计推断 查t 界值表(ν=∞时)得P <0.001,按0.05α=水准,拒绝H 0,接受H 1,差别有统计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同,男性高于女性。 (5) 样本均数与已知总体均数的比较,因样本含量较大,均作近似u 检验。 1) 男性红细胞数与标准值的比较 ① 建立检验假设,确定检验水准 H 0:0μμ=,即该地男性红细胞数的均数等于标准值
WORD 文档下载可编辑 第二单元计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指标性别例数均数标准差标准值* 红细胞数/1012·L -1男360 4.66 0.58 4.84 女255 4.18 0.29 4.33 血红蛋白/g·L -1男360 134.5 7.1 140.2 女255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1 解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一 致,应采用变异系数(CV )比较二者的变异程度。 女性红细胞数的变异系数CV S 100% X S 0.29 4.18 100% 6.94% 10.2 女性血红蛋白含量的变异系数CV 100% 100% 8.67% X 117.6
由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误S X 来表示,由表 4 计算各项指标的标准误。 男性红细胞数的标准误S X S 0.58 0.031 ( 1012 /L ) n 360 S 男性血红蛋白含量的标准误S X n 7.1 360 0.374 (g/L ) 女性红细胞数的标准误S X S 0.29 0.018 ( 1012 /L) n 255 女性血红蛋白含量的标准误S X S 10.2 0.639 (g/L ) n 255 (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100 ,可视为大样本。未知,但n 足够大,故总体均数的区间估计按( X u / 2S X, X u / 2 S X)计算。 该地男性红细胞数总体均数的95% 可信区间为: (4.66 -1.96 ×0.031 , 4.66 +1.96 ×0.031) ,即(4.60 , 4.72) 1012 /L。 该地女性红细胞数总体均数的95% 可信区间为: (4.18 -1.96 ×0.018 , 4.18 +1.96 ×0.018) ,即(4.14 , 4.22) 1012 /L。 (4) 两成组大样本均数的比较,用u 检验。 1) 建立检验假设,确定检验水准 H0: 1 2 ,即该地健康成年男、女血红蛋白含量均数无差别 H1: 1 2 ,即该地健康成年男、女血红蛋白含量均数有差别 0.05 2) 计算检验统计量
统计学(Statistics):运用概率论、数理统计的原理与方法,研究数据的搜集;分析;解释;表达的科学。 总体(population):大同小异的研究对象全体。更确切的说,总体是指根据研究目的确定的、同质的全部研究单位的观测值。 样本(sample):来自总体的部分个体,更确切的说,应该是部分个体的观察值。样本应该具有代表性,能反映总体的特征。利用样本信息可以对总体特征进行推断。 抽样误差(sampling error)在抽样过程中由于抽样的偶然性而出现的误差。表现为总体参数与样本统计量的差异,以及多个样本统计量之间的差异。可用标准误描述其大小。 标准误(Standard Error) 样本统计量的标准差,反映样本统计量的离散程度,也间接反映了抽样误差的大小。样本均数的标准差称为均数的标准误。均数标准误大小与标准差呈正比,与样本例数的平方根呈反比,故欲降低抽样误差,可增加样本例数 区间估计(interval estimation):将样本统计量与标准误结合起来,确定一个具有较大置信度的包含总体参数的范围,该范围称为置信区间(confidence interval,CI),又称可信区间。 参考值范围描述绝大多数正常人的某项指标所在范围;正态分布法(标准差)、百分位数法,参考值范围用于判断某项指标是否正常 置信区间揭示的是按一定置信度估计总体参数所在的范围。t分布法、正态分布法(标准误)、二项分布法。置信区间估计总体参数所在范围 可信区间:按预先给定的概率确定的包含未知总体参数的可能范围。该范围称为总体参数的可信区间(confidence interval,CI)。它的确切含义是:可信区间包含总体参数的可 能性是1- α ,而不是总体参数落在该范围的可能性为1-α 。 参数统计(parametric statistics) 非参数统计(nonparametric statistics)是指在统计检验中不需要假定总体分布形式和计算参数估计量,直接对比较数据(x)的分布进行统计检验的方法。 变异(variation):对于同质的各观察单位,其某变量值之间的差异 同质(homogeneity):研究对象具有的相同的状况或属性等共性。 回归系数有单位,而相关系数无单位 β为回归直线的斜率(slope)参数,又称回归系数(regression coefficient)。 线性相关系数(linear correlation coefficient):又称Pearson积差相关系数(Pearson product moment coefficient),是定量描述两个变量间线性关系的密切程度与相关方向的统计指标。 参数(parameter):描述总体特征的统计指标。 统计量(statistic):描述样本特征的统计指标。实验设计的基本原则 对照 (control) 对受试对象不施加处理因素的状态。在确定接受处理因素的实验组时,要同时设立对照组 重复 (replication)相同实验条件下进行多次实验或多次观察。整个实验的重复;观察多个受试对象(样本量);同一受试对象重复观察。作用是估计变异大小和降低变异 随机化(randomization) 采用随机的方式,使每个受试对象都有同等的机会被抽取或分配到试验组和对照组。 I类错误(假阳性错误)真实情况为H0是成立的,但检验结果为H0不成立,这样的错误称为I类错误。其发生的概率用α表示。在假设检验中作为检验水准。一般取0.05或0.01。 II类错误(假阴性错误)真实情况为H1是成立的,但检验结果为H1不成立,这样的错误称为II类错误。其发生的概率用β表示。由于其取值取决于H1 ,因此在假设检验中无法确定。 变异指标是用于描述一组观察值围绕中心位置散布的范围,即描述离散趋势的统计指标。数值越大,说明数据越离散,反之越集中。极差 (range);四分位数间距(quartile range);方差(variance);标准差(standard deviation);变异系数(coefficient of variation 平均数指标用于描述一组同质观察值的集中趋势,反映一组观察值的平均水平。算术均数(arithmetic mean);几何均数(geometric mean);中位数(median);众数(mode) 单纯抽样将调查总体的全部观察单位编号,从而形成抽样框架,在抽样框架中随机抽取部分观察单位组成样本。每个观察对象都有相同的机会被抽中系统抽样又称机械抽样。按照某种顺序给总体中的个体编号,然后随机地抽取一个号码作为第一个调查个体,其他的调查个体则按照某种确定的规则“系统”地抽取。最常用的方法是等距抽样 分层抽样先将总体中全部个体按某种特征分成若干“层”,再从每一层内随机抽取一定数量的个体组成样本。分层特征与研究目的有关。按各层比例抽样。为减少抽样误差,要求层内误差最小,层间误 差最大。 整群抽样先将总体分成若干“群”,从中随机抽取 几个群,抽取群内的所有观察单位组成调查样本。 “群”的确定与研究目的无关。为减少抽样误差, 需多抽几个“群”。 方差分析:又称变异数分析或 F检验,适用于对多 个平均值进行总体的假设检验,以检验实验所得的 多个平均值是否来自相同总体。 析因设计(factorial design)实验:凡同时配置两个 或两个以上处理因素,这些因素的各水平又具有完 全组合的实验,统称为析因设计(factorial design) 实验。 随机区组设计(randomized block design)是事先 将全部受试对象按某种可能与实验因素有关的特征 分为若干个区组(block),使每一区组内的受试对 象例数与处理因素的分组数相等,使每个实验组从 每一区组得到一例受试对象。 单向方差分析(one way analysis of variance)是指 处理因素只有一个。这个处理因素包含有多个离散 的水平,分析在不同处理水平上应变量的平均值是 否来自相同总体。 (2)计数资料:将观察单位按某种属性或类别分组, 所得的观察单位数称为计数资料 (count data)。计数资料亦称定性资料或分类资料。 其观察值是定性的,表现为互不相容的类别或属性。 如调查某地某时的男、女性人口数;治疗一批患者, 其治疗效果为有效、无效的人数;调查一批少数民 族居民的A、B、AB、O 四种血型的人数等。 (3)等级资料:将观察单位按测量结果的某种属性 的不同程度分组,所得各组的观察单位数,称为等 级资料(ordinal data)。等级资料又称有序变量。如 患者的治疗结果可分为治愈、好转、有效、无效或 死亡,各种结果既是分类结果,又有顺序和等级差 别,但这种差别却不能准确测量;一批肾病患者尿 蛋白含量的测定结果分为+、++、+++等。 随机变量(random variable)是指取指不能事先确 定的观察结果。随机变量的具体内容虽然是各式各 样的,但共同的特点是不能用一个常数来表示,而 且,理论上讲,每个变量的取值服从特定的概率分 布。 变异系数(coefficient of variation)用于观察指标单 位不同或均数相差较大时两组资料变异程度的比 较。用CV 表示。计算:标准差/均数*100% 直线回归(linear regression)建立一个描述应变量 依自变量变化而变化的直线方程, 并要求各点与该直线纵向距离的平方和为最小。直 线回归是回归分析中最基本、最简单的一种,故又 称简单回归(simple regression)。 回归系数(regression coefficient )即直线的斜率 (slope),在直线回归方程中用b 表示,b 的统计意 义为X每增(减)一个单位时,Y平均改变b 个单 位。 相关系数r:用以描述两个随机变量之间线性相关 关系的密切程度与相关方向的统计指标。 秩次:变量值按照从小到大顺序所编的秩序号称为 秩次(rank)。 秩和:各组秩次的合计称为秩和(rank sum),是非 参数检验的基本统计量。 方差(variance):方差表示一组数据的平均离散情 况,由离均差的平方和除以样本个数得到。 检验效能:1- β称为检验效能(power of test),它是 指当两总体确有差别,按规定的检验水准a 所能发 现该差异的能力。 百分位数(percentile)是将n 个观察值从小到大依 次排列,再把它们的位次 依次转化为百分位。百分位数的另一个重要用途是 确定医学参考值范围 随机误差(random error)又称偶然误差,是指排 除了系统误差后尚存的误差。它受多种因素的影响, 使观察值不按方向性和系统性而随机的变化。误差 变量一般服从正态分布。随机误差可以通过统计处 理来估计。 一、统计表有哪些要素构成的?制表的注意事项有 哪些? 一般来说,统计表由标题、标目、线条和数字、备 注五部分组成。但备注并不是必需的内容,可以根 据需要出现。 1简明扼要,重点突出:最好一张表突出一个中心, 不易太多中心,如果需要说明多个中心,可分成多 张统计表。 2合理安排主语和谓语的位置:对于表中任意一行, 从左至右,通过简短的连接词,可连成成一句通顺 的句子。 3表中数据要认真核对,保证准确可靠 二、为什么不宜用t 检验对多组均数进行比较? 如果用t检验进行多个样本均数的两两比较,则会 增加犯I 类错误的概率。 经检验得到拒绝H0 ,认为两组之间有差别的结论 可能犯I类错误的概率为α,不犯I类错误的概率为 1- α.每次判断均不犯I类错误的概率为(1- α)k, k为比较的次数,上例α=0.05, k=3,则均不犯错误 的概率为( 1- 0.05)3 =0.86. 至少有一次判断犯I 类错误的概率为1-(1- α)k 三、方差分析的基本思想是什么? 按实验设计的类型,将全部观察值间的变异分解成 两个或多个组成部分,然后将各部分的变异与随机 误差进行比较(每个部分的变异可由某因素的作用 来解释),以判断各部分的变异是否具有统计学意 义,从而推断不同样本所代表的总体均数是否相同。 五、简述直线相关与回归的区别与联系 区别:1.回归说明依存关系,直线回归用于说明两 变量间数量依存变化的关系,描述y如何依赖于x 而变化;相关说明相关关系,直线相关用于说明两 变量间的直线相关关系,此时两变量的关系是平等 的 2.r与b有区别:r说明具有直线关系的两个 变量间相关的密切程度与相关方向; b表示x每改 变一个单位,y平均增(减)多少个单位; 3.资料要求不同:直线回归要求应变量 y是来自正态总体的随机变量,而x可以是来自正 态总体的随机变量,也可以是严密控制、精确测量 的变量,相关分析则要求x,y是来自双变量正态分 布总体的随机变量。 4.取值范围:-∞ 卫生统计学试题1 注:因原件较模糊,所以试题中可能有错字或答案错漏,有的请指出,仅供参考;复习主要看书本。 一、选择题(每题只有一个正确答案,共40分) 1、随机事件的概率p 等于( ) A p=0 B p=1 C p= D 0 第二单元计量资料的统计推断 分析计算题 2.1 某地随机抽样调查了部分健康成人的红细胞数和血红蛋白量,结果见表4: 表4 某年某地健康成年人的红细胞数和血红蛋白含量 指标性别例数均数标准差标准值* 红细胞数/1012·L-1男360 4.66 0.58 4.84 女255 4.18 0.29 4.33 血红蛋白/g·L-1男360 134.5 7.1 140.2 女255 117.6 10.2 124.7 请就上表资料: (1) 说明女性的红细胞数与血红蛋白的变异程度何者为大? (2) 分别计算男、女两项指标的抽样误差。 (3) 试估计该地健康成年男、女红细胞数的均数。 (4) 该地健康成年男、女血红蛋白含量有无差别? (5) 该地男、女两项血液指标是否均低于上表的标准值(若测定方法相同)? 2.1解: (1) 红细胞数和血红蛋白含量的分布一般为正态分布,但二者的单位不一致,应采用变异系数(CV)比较二者的变异程度。 女性红细胞数的变异系数 女性血红蛋白含量的变异系数 由此可见,女性血红蛋白含量的变异程度较红细胞数的变异程度大。 (2) 抽样误差的大小用标准误来表示,由表4计算各项指标的标准误。 男性红细胞数的标准误(/L) 男性血红蛋白含量的标准误(g/L) 女性红细胞数的标准误(/L) 女性血红蛋白含量的标准误(g/L) (3) 本题采用区间估计法估计男、女红细胞数的均数。样本含量均超过100,可视为大样本。未知,但足够大,故总体均数的区间估计按()计算。 该地男性红细胞数总体均数的95%可信区间为: (4.66-1.96×0.031 , 4.66+1.96×0.031),即(4.60 , 4.72)/L。 该地女性红细胞数总体均数的95%可信区间为: (4.18-1.96×0.018 , 4.18+1.96×0.018),即(4.14 , 4.22)/L。 (4) 两成组大样本均数的比较,用u检验。 1) 建立检验假设,确定检验水准 H0:,即该地健康成年男、女血红蛋白含量均数无差别 H1:,即该地健康成年男、女血红蛋白含量均数有差别 2) 计算检验统计量 3) 确定P值,作出统计推断 查t界值表(ν=∞时)得P<0.001,按水准,拒绝H0,接受H1,差别有统计学意义,可以认为该地健康成年男、女的血红蛋白含量均数不同,男性高于女性。 (5) 样本均数与已知总体均数的比较,因样本含量较大,均作近似u检验。 1) 男性红细胞数与标准值的比较 ①建立检验假设,确定检验水准 H0:,即该地男性红细胞数的均数等于标准值 医学统计学期末复习题 一、单项选择题 1 下面的变量中是分类变量的是 A.身高 B.体重 C.年龄 D.血型 2 下面的变量中是是数值变量的是 A.性别 B.年龄 C.血型 D.职业 3.随机事件的概率 P 为 =0 B. P=1 C. P= D. 0 1、 总^(population):就是根据研究目得确泄得同质研究对象得全体。 2、 样本(sample):从总体中抽取得一部分有代表性得个体。 3、 同质(homogeneity):就是指所研究得观察对象具有某些相同得性质或特征。 4、 变异(variation):指同质个体得某项指标之间得差异。 5、 参数(parameter):反映总体特征得指标称为参数。 6、 统计量(statistic):通过样本资料il ?算出来得相应指标称为统计量。 7、 抽样误差(sampling error):由随机抽样造成得样本指标与总体指标之间、样本指标与样本指标 Z 间得差异。 8、 概率(probability):某事件发生得可能性大小。 9、 正态分布(normal distribution):高帐位于均数处冲间高两边低,左右完全对称地下降,但永远不与 横轴相交得钟形曲线。 10、 平均数(average):就是描述一组同质变量值得平均水平或集中趋势得指标。 11、 中位数(median):将一组数据由小到大排列,位于中间位置得观测值。 12、 医学参考值范@(medical reference range):X 称正常值范饥医学上常将包括绝大多数正常人得 某项指标得波动范围称为该指标得正常值范鬧。 13、 方差他I 伽CC):就是徉个数据与平均数之差得平方得平均数。 14、 标准差(standard deviation):就是各数据偏离平均数得距离得平均数,它就是离均差平方与平均 后得方根,用0表示。 15、 标准i^tstandard error):样本均数得标准差,等于原变量总体标准差除以例数得平方根,用以说明 均数抽样误差得大小。 16、 均数得抽样误差(sampling error of mean):由个体差异与抽样所导致得样本均数与样本均数之 间,样本均数与总体均数之间得差异。 17、 假设检验(hypothesistesting):先对总体做出某种假设,然后根据样本信息来推断其就是否成立 得一类统计方法得总称。 18、 统计推断(statistical inference):就是根据已知得样本信息来推断未知得总体,就是统计分析得目 得,包括参数估计与假设检验。 19、 I 型错误(type I error):拒绝了实际上成立得Hu.这类弃真错误,发生得槪率为Q,为已知。 20、 II 型错误(type II error):不拒绝实际上不成立得Ho,这类存伪错误,发生得概率为B ,未知。 21、 检验效能(power of test):又称把握度,为意义就是两总体确有差别,按a 水准能发现它们 有差别得能力。 可信区间(confidence interval):指总体参数可能所在得范围。 率(血⑹:说明某现象发生得频率或强度。 构成比(constituent ratio):^示某事物内韶^$组成部分所占得比重或分布,常以百分数表示。 相对比(relative ratio):表示两个有关事物指标之比,常以百分数与倍数表示,用以说明一个指标 就是另一个指标得几倍或百分之几。 26、 标准化率(standardized 臥C):亦称调整率,就是采用统一得标准对内部构成不同得各组频率进行 调整与对比得方法。 27、 参数检验(paramchic test):—类依赖于总体分布得具体形式得统计推断方法。 28、 非参数检验(non parametric test):-类不依赖总体分布类型得检验,在应用中可以不考虑被研究 对象为何种分布以及分布就是否已知,检验假设中没有包括总体参数得统计方法。 22 、 23、 24卫生统计学试题1
医学统计学分析计算题答案
医学统计学复习习题2018
医学统计学名词解释及问答题
相关主题
文本预览