数据分析期末试题及答案
一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分)
解:
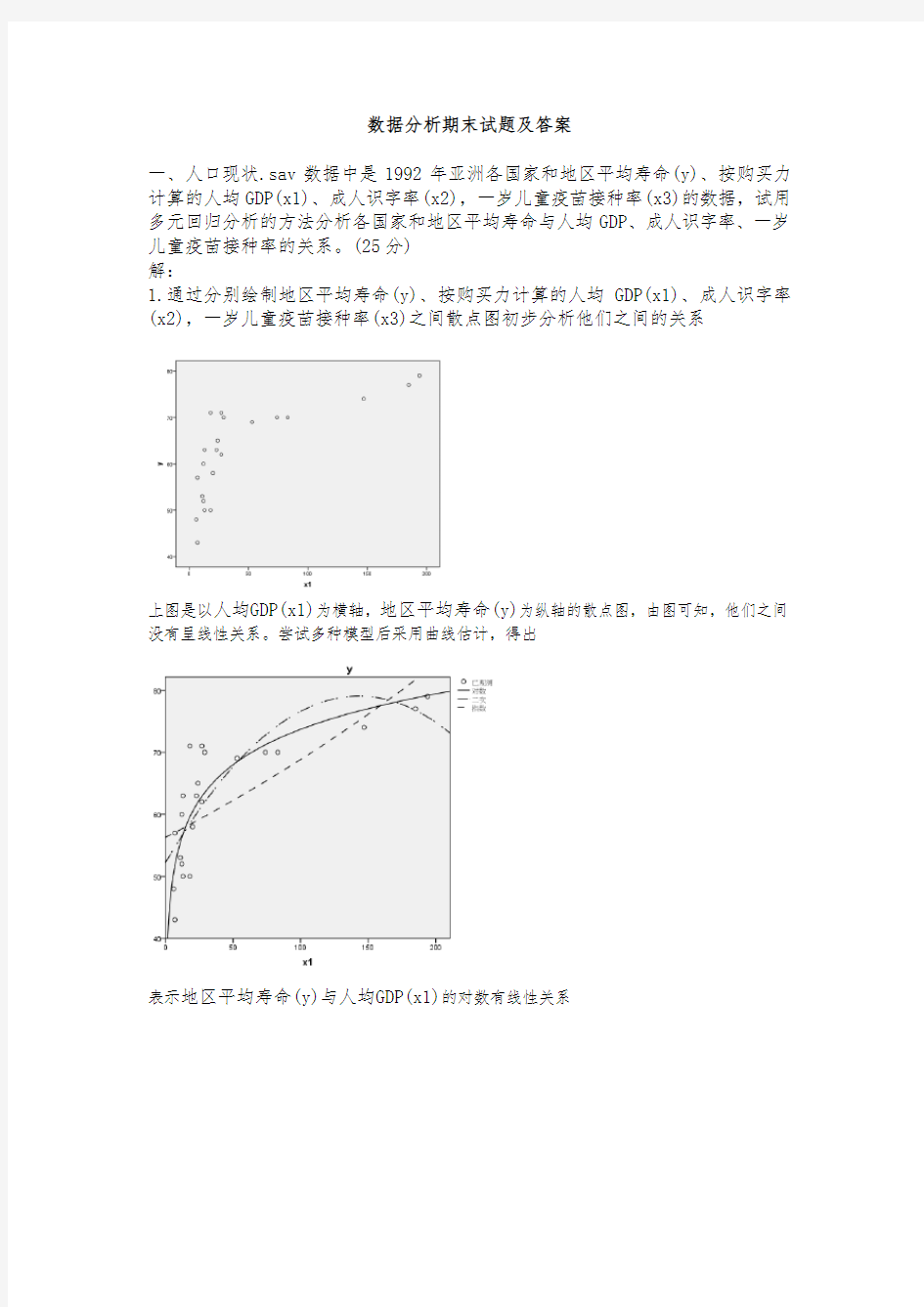
1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系
上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出
表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
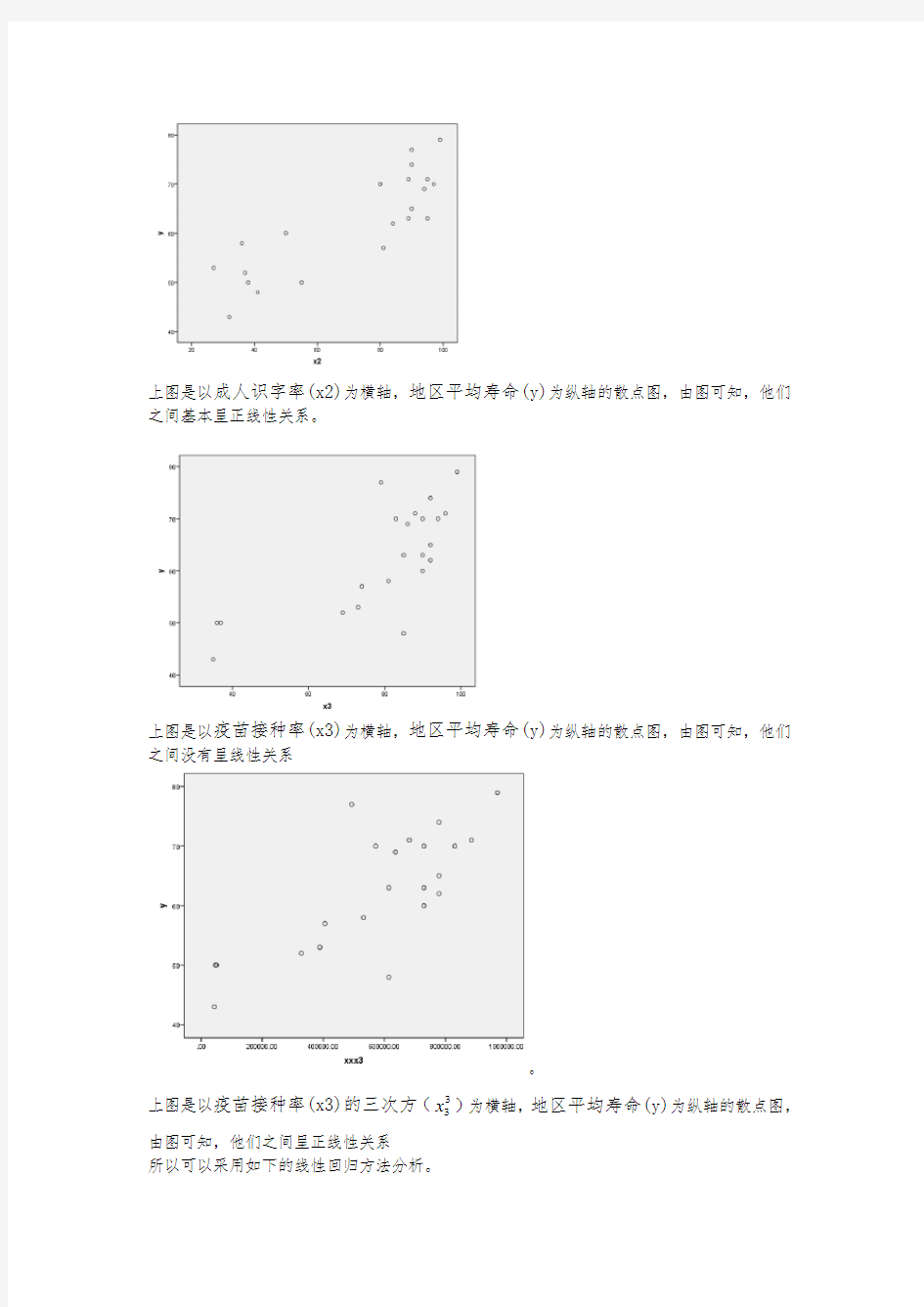
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。
上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系
。
x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3
3
由图可知,他们之间呈正线性关系
所以可以采用如下的线性回归方法分析。
2.线性回归
先用强行进入的方式建立如下线性方程
设Y=β0+β1*(Xi1)+β2*Xi2+β3*
X+εi i=1.2 (24)
3i
其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差
R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。
建立总体性的假设检验
提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零
得如下方差分析表
上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
做独立性的假设检验得出参数估计表
2=β3=0: H1:β1、β2、β3不全为零
由表知,
β1=33.014,β1=0.072,β2=0.169,β3=0.178,以β1=0.072为例,表示当
成人识字率(x2),一岁儿童疫苗接种率(x3)不变时,,人均GDP(x1)每增加一个单
位,平均寿命(y)就增加0.072个单位。
基于以上结果得出年平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫
苗接种率(x3)之间有显著性的线性关系有回归方程
Y=33.014+0.072*X1+ 0.169*X2+ 0.178*X3
β1、β2、β3对应得p值分别为0.000,0.000,0.002,对应的概率p值都小于0.05,
表示它们的单独性的假设检验没通过,即该模型是最优的,所以不用采用逐步回
归的方式分析。
对原始数据进行残差分析
未标准化的残差RES_1
-7.53964
-3.57019
-3.42221
-2.89835
-2.30455
-2.17263
-2.05862
-1.37142
-1.17048
-.43890
-.17260
-.03190
.94655
1.42896
1.61252
1.61590
2.10139
3.01856
3.02571
3.49808
4.60737
5.29645
以X1为横轴,RES_1为纵轴画出如下散点图
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
同理可以得出RES_1与X2、X3的散点图,
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
由上图可以看出,该残差图中各点分布近似长条矩形,所以模型拟合较好,即该线性回归模型比较合理。
误差项的正态性检验
数据(RES_1)标准化残差ZRES_1
由图可以看出,散点图近似的在一条直线附近,则可以认为数据来自正太分布总体
二、诊断发现运营不良的金融企业是审计核查的一项重要功能,审计核查的分类失败会导致灾难性的后果。下表列出了66家公司的部分运营财务比率,其中33家在2年后破产Y=0,另外33家在同期保持偿付能力(Y=1)。请用变量X1(未分
配利润/总资产),X2(税前利润/总资产)和X3(销售额/总资产)拟合一个Logistic 回归模型,并根据模型给出实际意义的分析,数据见财务比率.sav(25分)。 解:
整体性的假设检验 提出假设性检验
H0:回归系数i β=0(i=1,2,3),H1:不都为0 建立logistic 模型:
)}
0{1}
0{ln(
=-=Y p Y p =3
213210X X X ββββ+++
上表显示了logistic 分析的初始阶段方程中只有常数项时的错判矩阵,其中33家在2年后破产(y=0),但模型均预测为错误,正确率为0%,另外33家在同期保持偿付能力(Y=1),正确率为100%,所以模型总的预测正确率为50%。
由上表得知,如果变量X1(未分配利润/总资产),X2(税前利润/总资产)进入方程,概率p 值都为0.000,小于显著性水平0.05,本应该是拒绝原假设,X1,X2是可以进入方程的。而X3(销售额/总资产)进入方程,概率p 值为0.094,大于显著性
《海量数据挖掘技术及工程实践》题目 一、单选题(共80题) 1)( D )的目的缩小数据的取值范围,使其更适合于数据挖掘算法的需要,并且能够得到 和原始数据相同的分析结果。 A.数据清洗 B.数据集成 C.数据变换 D.数据归约 2)某超市研究销售纪录数据后发现,买啤酒的人很大概率也会购买尿布,这种属于数据挖 掘的哪类问题?(A) A. 关联规则发现 B. 聚类 C. 分类 D. 自然语言处理 3)以下两种描述分别对应哪两种对分类算法的评价标准? (A) (a)警察抓小偷,描述警察抓的人中有多少个是小偷的标准。 (b)描述有多少比例的小偷给警察抓了的标准。 A. Precision,Recall B. Recall,Precision A. Precision,ROC D. Recall,ROC 4)将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B. 分类和预测 C. 数据预处理 D. 数据流挖掘 5)当不知道数据所带标签时,可以使用哪种技术促使带同类标签的数据与带其他标签的数 据相分离?(B) A. 分类 B. 聚类 C. 关联分析 D. 隐马尔可夫链 6)建立一个模型,通过这个模型根据已知的变量值来预测其他某个变量值属于数据挖掘的 哪一类任务?(C) A. 根据内容检索 B. 建模描述 C. 预测建模 D. 寻找模式和规则 7)下面哪种不属于数据预处理的方法? (D) A.变量代换 B.离散化
C.聚集 D.估计遗漏值 8)假设12个销售价格记录组已经排序如下:5, 10, 11, 13, 15, 35, 50, 55, 72, 92, 204, 215 使用如下每种方法将它们划分成四个箱。等频(等深)划分时,15在第几个箱子内? (B) A.第一个 B.第二个 C.第三个 D.第四个 9)下面哪个不属于数据的属性类型:(D) A.标称 B.序数 C.区间 D.相异 10)只有非零值才重要的二元属性被称作:( C ) A.计数属性 B.离散属性 C.非对称的二元属性 D.对称属性 11)以下哪种方法不属于特征选择的标准方法: (D) A.嵌入 B.过滤 C.包装 D.抽样 12)下面不属于创建新属性的相关方法的是: (B) A.特征提取 B.特征修改 C.映射数据到新的空间 D.特征构造 13)下面哪个属于映射数据到新的空间的方法? (A) A.傅立叶变换 B.特征加权 C.渐进抽样 D.维归约 14)假设属性income的最大最小值分别是12000元和98000元。利用最大最小规范化的方 法将属性的值映射到0至1的范围内。对属性income的73600元将被转化为:(D) A.0.821 B.1.224 C.1.458 D.0.716 15)一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年 级110人。则年级属性的众数是: (A) A.一年级 B.二年级 C.三年级 D.四年级
1、当前大数据技术的基础是由( C)首先提出的。(单选题,本题2分) A:微软 B:百度 C:谷歌 D:阿里巴巴 2、大数据的起源是(C )。(单选题,本题2分) A:金融 B:电信 C:互联网 D:公共管理 3、根据不同的业务需求来建立数据模型,抽取最有意义的向量,决定选取哪种方法的数据分析角色人员是 ( C)。(单选题,本题2分) A:数据管理人员 B:数据分析员 C:研究科学家 D:软件开发工程师 4、(D )反映数据的精细化程度,越细化的数据,价值越高。(单选题,本题2分) A:规模 B:活性 C:关联度 D:颗粒度 5、数据清洗的方法不包括( D)。(单,本题2分)
A:缺失值处理 B:噪声数据清除 C:一致性检查 D:重复数据记录处理 6、智能健康手环的应用开发,体现了( D)的数据采集技术的应用。(单选题,本题2分) A:统计报表 B:网络爬虫 C:API接口 D:传感器 7、下列关于数据重组的说法中,错误的是( A)。(单选题,本题2分) A:数据重组是数据的重新生产和重新采集 B:数据重组能够使数据焕发新的光芒 C:数据重组实现的关键在于多源数据融合和数据集成 D:数据重组有利于实现新颖的数据模式创新 8、智慧城市的构建,不包含( C)。(单选题,本题2分) A:数字城市 B:物联网 C:联网监控 D:云计算 大数据的最显著特征是( A)。(单选题,本题2分) A:数据规模大 B:数据类型多样
C:数据处理速度快 D:数据价值密度高 10、美国海军军官莫里通过对前人航海日志的分析,绘制了新的航海路线图,标明了大风与洋流可能发生的地 点。这体现了大数据分析理念中的(B )。(单选题,本题2分) A:在数据基础上倾向于全体数据而不是抽样数据 B:在分析方法上更注重相关分析而不是因果分析 C:在分析效果上更追究效率而不是绝对精确 D:在数据规模上强调相对数据而不是绝对数据 11、下列关于舍恩伯格对大数据特点的说法中,错误的是(D )。(单选题,本题2分) A:数据规模大 B:数据类型多样 C:数据处理速度快 D:数据价值密度高 12、当前社会中,最为突出的大数据环境是(A )。(单选题,本题2分) A:互联网 B:物联网 C:综合国力 D:自然资源 13、在数据生命周期管理实践中,( B)是(单选题,本题2分) A:数据存储和备份规 B:数据管理和维护 C:数据价值发觉和利用
大数据时代的数据挖掘 大数据是2012的时髦词汇,正受到越来越多人的关注和谈论。大数据之所以受到人们的关注和谈论,是因为隐藏在大数据后面超千亿美元的市场机会。 大数据时代,数据挖掘是最关键的工作。以下内容供个人学习用,感兴趣的朋友可以看一下。 智库百科是这样描述数据挖掘的“数据挖掘又称数据库中的知识发现,是目前人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。数据挖掘是一种决策支持过程,它主要基于人工智能、机器学习、模式识别、统计学、数据库、可视化技术等,高度自动化地分析企业的数据,做出归纳性的推理,从中挖掘出潜在的模式,帮助决策者调整市场策略,减少风险,做出正确的决策。 数据挖掘的定义 技术上的定义及含义 数据挖掘(Data Mining )就是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。这个定义包括好几层含义:数据源必须是真实的、大量的、含噪声的;发现的是用户感兴趣的知识;发现的知识要可接受、可理解、可运用;并不要求发现放之四海皆准的知识,仅支持特定的发现问题。 与数据挖掘相近的同义词有数据融合、人工智能、商务智能、模式识别、机器学习、知识发现、数据分析和决策支持等。 ----何为知识从广义上理解,数据、信息也是知识的表现形式,但是人们更把概念、规则、模式、规律和约束等看作知识。人们把数据看作是形成知识的源泉,好像从矿石中采矿或淘金一样。原始数据可以是结构化的,如关系数据库中的数据;也可以是半结构化的,如文本、图形和图像数据;甚至是分布在网络上的异构型数据。发现知识的方法可以是数学的,也可以是非数学的;可以是演绎的,也可以是归纳的。发现的知识可以被用于信息管理,查询优化,决策支持和过程控制等,还可以用于数据自身的维护。因此,数据挖掘是一门交叉学科,它把人们对数据的应用从低层次的简单查询,提升到从数据中挖掘知识,提供决策支持。在这种需求牵引下,汇聚了不同领域的研究者,尤其是数据库技术、人工智能技术、数理统计、可视化技术、并行计算等方面的学者和工程技术人员,投身到数据挖掘这一新兴的研究领域,形成新的技术热点。 这里所说的知识发现,不是要求发现放之四海而皆准的真理,也不是要去发现崭新的自然科学定理和纯数学公式,更不是什么机器定理证明。实际上,所有发现的知识都是相对的,是有特定前提和约束条件,面向特定领域的,同时还要能够易于被用户理解。最好能用自然语言表达所发现的结果。n x _s u x i a n g n i n g
《大数据分析与挖掘》课程教学大纲 一、课程基本信息 课程代码:16054103 课程名称:大数据分析与挖掘 英文名称:Big data analysis and mining 课程类别:专业选修课 学时:48(理论课:32, 实验课:16) 学 分:3 适用对象: 软件工程专业、计算机科学与技术 考核方式:考查 先修课程:多媒体技术、程序设计、软件工程 二、课程简介 本课程从大数据挖掘分析技术实战的角度,结合理论和实践,全方位地介绍基于Python语言的大数据挖掘算法的原理与使用。本课程涉及的主题包括基础篇和实战篇两部分, 其中基础篇包括:数据挖掘基础,Python数据分析简介,数据探索,数据预处理和挖掘建模;实战篇包括:电力窃漏电用户自动识别,航空公司客户价值分析,中医证型关联规则挖掘,基于水色图像的水质评价,家用电器用户行为分析与事件识别,应用系统负载分析与磁盘容量预测和电子商务网站用户行为分析及服务推荐。 本课程不是一个泛泛的理论性、概念性的介绍课程,而是针对问题讨论基于Python语言机器学习模型解决方案的深入课程。教师对于上述领域有深入的理论研究与实践经验,在课程中将会针对这些问题与学员一起进行研究,在关键点上还会搭建实验环境进行实践研究,以加深对于这些解决方案的理解。通过本课程学习,目的是让学生能够扎实地掌握大数据分析挖掘的理论与应用。 This course introduces the principle and application of big data mining algorithm based on Python language comprehensively from the perspective of big data mining analysis technology practice, combining theory and practice. This course covers two parts, the basic part and the practical part. The basic part includes: basic data mining, introduction to Python data analysis, data exploration, data preprocessing and mining modeling. Practical article included: electric power leakage automatic identification of the user, airlines customer value analysis, TCM syndrome association rule mining, based on water quality evaluation of color image, household electrical appliances
数据分析师常见的7道笔试题目及答案 导读:探索性数据分析侧重于在数据之中发现新的特征,而验证性数据分析则侧 重于已有假设的证实或证伪。以下是由小编J.L为您整理推荐的实用的应聘笔试题目和经验,欢迎参考阅读。 1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把 整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用 hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000 个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日 志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也 就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是: 第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一 个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N) + N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10 个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000 个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到 分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树 /hash_map等),并取出出现频率最大的100个词(可以用含100 个结点的最小堆),并把
龙源期刊网 https://www.doczj.com/doc/5614946377.html, 浅谈大数据时代的数据分析与挖掘 作者:单海波 来源:《科技创新与应用》2016年第24期 摘要:随着改革开放的进一步深化,以及经济全球化的快速发展,我国各行各业都有了 质的飞跃,发展方向更加全面。特别是近年来科学技术的发展和普及,更是促进了各领域的不断发展,各学科均出现了科技交融。在这种社会背景下,数据形式和规模不断向着更加快速、精准的方向发展,促使经济社会发生了翻天覆地的变化,同时也意味着大数据时代即将来临。就目前而言,数据已经改变传统的结构模式,在时代的发展推动下积极向着结构化、半结构化,以及非结构化的数据模式方向转换,改变了以往的只是单一地作为简单的工具的现象,逐渐发展成为具有基础性质的资源。文章主要针对大数据时代下的数据分析与挖掘进行了分析和讨论,并论述了建设数据分析与挖掘体系的原则,希望可以为从事数据挖掘技术的分析人员提供一定的帮助和理论启示,仅供参考。 关键词:大数据;数据分析;数据挖掘;体系建设 引言 进入21世纪以来,随着高新科技的迅猛发展和经济全球化发展的趋势,我国国民经济迅速增长,各行业、领域的发展也颇为迅猛,人们生活水平与日俱增,在物质生活得到极大满足的前提下,更加追求精神层面以及视觉上的享受,这就涉及到数据信息方面的内容。在经济全球化、科技一体化、文化多元化的时代,数据信息的作用和地位是不可小觑的,处理和归类数据信息是达到信息传递的基础条件,是发展各学科科技交融的前提。 然而,世界上的一切事物都包含着两个方面,这两个方面既相互对立,又相互统一。矛盾即对立统一。矛盾具有斗争性和同一性两种基本属性,我们必须用一分为二的观点、全面的观点看问题。同时要积极创造条件,促进矛盾双方的相互转变。数据信息在带给人们生产生活极大便利的同时,还会被诸多社会数据信息所困扰。为了使广大人民群众的日常生活更加便捷,需要其客观、正确地使用、处理数据信息,完善和健全数据分析技术和数据挖掘手段,通过各种切实可行的数据分析方法科学合理地分析大数据时代下的数据,做好数据挖掘技术工作。 1 实施数据分析的方法 在经济社会快速发展的背景下,我国在科学信息技术领域取得长足进步。科技信息的发展在极大程度上促进了各行各业的繁荣发展和长久进步,使其发展更加全面化、科学化、专业化,切实提升了我国经济的迅猛发展,从而形成了一个最佳的良性循环,我国也由此进入了大数据时代。对于大数据时代而言,数据分析环节是必不可少的组成部分,只有科学准确地对信息量极大的数据进行处理、筛选,才能使其更好地服务于社会,服务于广大人民群众。正确处理数据进行分析过程是大数据时代下数据分析的至关重要的环节。众所周知,大数据具有明显
数据分析期末试题及答案 一、人口现状.sav数据中是1992年亚洲各国家和地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)的数据,试用多元回归分析的方法分析各国家和地区平均寿命与人均GDP、成人识字率、一岁儿童疫苗接种率的关系。(25分) 解: 1.通过分别绘制地区平均寿命(y)、按购买力计算的人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间散点图初步分析他们之间的关系 上图是以人均GDP(x1)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系。尝试多种模型后采用曲线估计,得出 表示地区平均寿命(y)与人均GDP(x1)的对数有线性关系
上图是以成人识字率(x2)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间基本呈正线性关系。 上图是以疫苗接种率(x3)为横轴,地区平均寿命(y)为纵轴的散点图,由图可知,他们之间没有呈线性关系 。 x)为横轴,地区平均寿命(y)为纵轴的散点图,上图是以疫苗接种率(x3)的三次方(3 3 由图可知,他们之间呈正线性关系 所以可以采用如下的线性回归方法分析。
2.线性回归 先用强行进入的方式建立如下线性方程 设Y=β0+β1*(Xi1)+β2*Xi2+β3* X+εi i=1.2 (24) 3i 其中εi(i=1.2……22)相互独立,都服从正态分布N(0,σ^2)且假设其等于方差 R值为0.952,大于0.8,表示两变量间有较强的线性关系。且表示平均寿命(y)的95.2%的信息能由人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)一起表示出来。 建立总体性的假设检验 提出假设检验H0:β1=β2=β3=0,H1,:其中至少有一个非零 得如下方差分析表 上表是方差分析SAS输出结果。由表知,采用的是F分布,F=58.190,对应的检验概率P值是0.000.,小于显著性水平0.05,拒绝原假设,表示总体性假设检验通过了,平均寿命(y)与人均GDP(x1)、成人识字率(x2),一岁儿童疫苗接种率(x3)之间有高度显著的的线性回归关系。
数据分析处理需求分类 1 事务型处理 在我们实际生活中,事务型数据处理需求非常常见,例如:淘宝网站交易系统、12306网站火车票交易系统、超市POS系统等都属于事务型数据处理系统。这类系统数据处理特点包括以下几点: 一就是事务处理型操作都就是细粒度操作,每次事务处理涉及数据量都很小。 二就是计算相对简单,一般只有少数几步操作组成,比如修改某行得某列; 三就是事务型处理操作涉及数据得增、删、改、查,对事务完整性与数据一致性要求非常高。 四就是事务性操作都就是实时交互式操作,至少能在几秒内执行完成; 五就是基于以上特点,索引就是支撑事务型处理一个非常重要得技术. 在数据量与并发交易量不大情况下,一般依托单机版关系型数据库,例如ORACLE、MYSQL、SQLSERVER,再加数据复制(DataGurad、RMAN、MySQL数据复制等)等高可用措施即可满足业务需求。 在数据量与并发交易量增加情况下,一般可以采用ORALCERAC集群方式或者就是通过硬件升级(采用小型机、大型机等,如银行系统、运营商计费系统、证卷系统)来支撑. 事务型操作在淘宝、12306等互联网企业中,由于数据量大、访问并发量高,必然采用分布式技术来应对,这样就带来了分布式事务处理问题,而分布式事务处理很难做到高效,因此一般采用根据业务应用特点来开发专用得系统来解决本问题。
2数据统计分析 数据统计主要就是被各类企业通过分析自己得销售记录等企业日常得运营数据,以辅助企业管理层来进行运营决策。典型得使用场景有:周报表、月报表等固定时间提供给领导得各类统计报表;市场营销部门,通过各种维度组合进行统计分析,以制定相应得营销策略等. 数据统计分析特点包括以下几点: 一就是数据统计一般涉及大量数据得聚合运算,每次统计涉及数据量会比较大。二就是数据统计分析计算相对复杂,例如会涉及大量goupby、子查询、嵌套查询、窗口函数、聚合函数、排序等;有些复杂统计可能需要编写SQL脚本才能实现. 三就是数据统计分析实时性相对没有事务型操作要求高。但除固定报表外,目前越来越多得用户希望能做做到交互式实时统计; 传统得数据统计分析主要采用基于MPP并行数据库得数据仓库技术.主要采用维度模型,通过预计算等方法,把数据整理成适合统计分析得结构来实现高性能得数据统计分析,以支持可以通过下钻与上卷操作,实现各种维度组合以及各种粒度得统计分析。 另外目前在数据统计分析领域,为了满足交互式统计分析需求,基于内存计算得数据库仓库系统也成为一个发展趋势,例如SAP得HANA平台。 3 数据挖掘 数据挖掘主要就是根据商业目标,采用数据挖掘算法自动从海量数据中发现隐含在海量数据中得规律与知识。
数据分析笔试题 一、编程题(每小题20分)(四道题任意选择其中三道) 有一个计费表表名jifei 字段如下:phone(8位的电话号码),month(月份),expenses (月消费,费用为0表明该月没有产生费用) 下面是该表的一条记录:64262631,201011,30.6 这条记录的含义就是64262631的号码在2010年11月份产生了30.6元的话费。 按照要求写出满足下列条件的sql语句: 1、查找2010年6、7、8月有话费产生但9、10月没有使用并(6、7、8月话费均在51-100 元之间的用户。 2、查找2010年以来(截止到10月31日)所有后四位尾数符合AABB或者ABAB或者AAAA 的电话号码。(A、B 分别代表1—9中任意的一个数字) 3、删除jifei表中所有10月份出现的两条相同记录中的其中一条记录。
4、查询所有9月份、10月份月均使用金额在30元以上的用户号码(结果不能出现重复) 二、逻辑思维题(每小题10分)须写出简要计算过程和结果。 1、某人卖掉了两张面值为60元的电话卡,均是60元的价格成交的。其中一张赚了20%, 另一张赔了20%,问他总体是盈利还是亏损,盈/亏多少? 2、有个农场主雇了两个小工为他种小麦,其中A是一个耕地能手,但不擅长播种;而B 耕地很不熟练,但却是播种的能手。农场主决定种10亩地的小麦,让他俩各包一半,于是A从东头开始耕地,B从西头开始耕。A耕地一亩用20分钟,B却用40分钟,可是B播种的速度却比A快3倍。耕播结束后,庄园主根据他们的工作量给了他俩600元工钱。他俩怎样分才合理呢? 3、1 11 21 1211 111221 下一行是什么? 4、烧一根不均匀的绳,从头烧到尾总共需要1个小时。现在有若干条材质相同的绳子,问如何用烧绳的方法来计时一个小时十五分钟呢?(绳子分别为A 、B、C、D、E、F 。。。。。来代替)
从互联网巨头数据挖掘类招聘笔试题目看我们还差多少知识 1 从阿里数据分析师笔试看职业要求 以下试题是来自阿里巴巴招募实习生的一次笔试题,从笔试题的几个要求我们一起来看看数据分析的职业要求。 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’ test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差(标准差)作为标准测度
信息工程学院“计算机技术工程”专业硕士点论证 《大数据分析与挖掘》方向: --团队 --近5年发表论文 --近5年获得的代表性科研项目、课题情况 --本研究方向的特色、定位、作用和意义 --培养方案 --人才需求与培养目标 --实践基地与培养模式 1.团队: 2.近5年发表论文: 研究方向 姓 名 出生年月 职 称 学历/学位 备 注 大数据分析与挖掘 邵艳华 1975.03 教授 研究生/博士 学科带头人 张儒良 1963.06 教授 研究生/硕士 学术带头人 曹俊英 1981.05 教授 研究生/博士 学术骨干 夏大文 1982.09 副教授 研究生/博士生 学术骨干 李小武 1966.11 副教授 研究生/博士 学术后备人才 龙 飞 1978.03 副教授 研究生/硕士 学术后备人才 吴有富 1966.04 教授 研究生/博士 兼职 吴茂念 1974.02 教授 研究生/博士 兼职 刘运强 1984.07 高级工程师 研究生/硕士 兼职
本学科方向近5年发表论文情况 序 号 论文名称作者(*)发表时间发表刊物、会议名称或ISSN、检索号 1 Research about Model and Simulation of Enterprise Evolution Based on Agent 邵艳华 (1/?) 2012.10, 3114-3117 ICECC 2012 2 一类复杂适应系统的建模研究 邵艳华 (1/?) 2012, 38(1), 253-255 计算机工程 3 Modeling and simulation of agent decision based on prospect theory. 邵艳华 (1/?) 2014.12 ICFEEE 2014 4 Application of Modeling and Simulation Based on Agent 邵艳华 (1/?) 2014.11, 939-942 ICMECS 2014 5 A Method of Slant Correction of Vehicle License Plate Based on Watershed Algorithm 张儒良 (1/2) 2010.02 Robotics and Automation,2010 (2) 95-98 6 A Method of Slant Correction of Vehicle License Plate Based on Watershed Algorithm 张儒良 (1/2) 2010.02 Robotics and Automation,2010 (2) 95-98 7 Car Number Plate Detection Using https://www.doczj.com/doc/5614946377.html,yer Weak Filter 张儒良 (1/2) 2009.07 Business Intelligence (EI收录) IEEE Computer Society, ISBN: 978-0-7695-3705-4 检索号:20094712459305 8 A high order schema for the numerical solution of the fractional ordinary differential equations 曹俊英 (1/2) 2013(4):15 4-168 J. Comput. Physics 9 A high order schema for the numerical solution of ordinary fractional differential equations 曹俊英 (1/2) 2013(586):9 3-103 Contemporary Mathematics 10 Hadoop关键技术的研究与应用 夏大文 (1/?) 2013计算机与现代化 11 A Novel Parallel Algorithm for Frequent Itemsets Mining in Massive Small Files Datasets 夏大文 (1/?) 2014 ICIC Express Letters, Part B: Applications 12 Discovery and Analysis of Usage Data Based on Hadoop for Personalized Information Access 夏大文 (1/?) 2013BDSE’13 13 A geometric strategy for computing intersections of two spatial parametric curves(SCI) 李小武 (1/?) 2013The Visual Computer,29,1151-1158 14 On a family of trimodal distributions, Communications in Statistics - Theory and Methods(SCI) 李小武 (1/?) 2014 Communications in Statistics - Theory and Methods, 43(14),2886–2896. 15 基于开源少民信息资源保存系统设计 研究 龙飞 (1/?) 2011 计算机技术与发展 3. 近5年获得的代表性科研项目、课题情况
1、海量日志数据,提取出某日访问百度次数最多的那个IP。 首先是这一天,并且是访问百度的日志中的IP取出来,逐个写入到一个大文件中。注意到IP是32位的,最多有个2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件,再找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率。然后再在这1000个最大的IP中,找出那个频率最大的IP,即为所求。 或者如下阐述: 算法思想:分而治之+Hash 1.IP地址最多有2^32=4G种取值情况,所以不能完全加载到内存中处理; 2.可以考虑采用“分而治之”的思想,按照IP地址的Hash(IP)24值,把海量IP日志分别存储到1024个小文件中。这样,每个小文件最多包含4MB个IP地址; 3.对于每一个小文件,可以构建一个IP为key,出现次数为value的Hash map,同时记录当前出现次数最多的那个IP地址; 4.可以得到1024个小文件中的出现次数最多的IP,再依据常规的排序算法得到总体上出现次数最多的IP; 2、搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 典型的Top K算法,还是在这篇文章里头有所阐述, 文中,给出的最终算法是:
第一步、先对这批海量数据预处理,在O(N)的时间内用Hash表完成统计(之前写成了排序,特此订正。July、2011.04.27); 第二步、借助堆这个数据结构,找出Top K,时间复杂度为N‘logK。 即,借助堆结构,我们可以在log量级的时间内查找和调整/移动。因此,维护一个K(该题目中是10)大小的小根堆,然后遍历300万的Query,分别和根元素进行对比所以,我们最终的时间复杂度是:O(N)+ N’*O(logK),(N为1000万,N’为300万)。ok,更多,详情,请参考原文。 或者:采用trie树,关键字域存该查询串出现的次数,没有出现为0。最后用10个元素的最小推来对出现频率进行排序。 3、有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M。返回频数最高的100个词。 方案:顺序读文件中,对于每个词x,取hash(x)P00,然后按照该值存到5000个小文件(记为x0,x1,…x4999)中。这样每个文件大概是200k左右。 如果其中的有的文件超过了1M大小,还可以按照类似的方法继续往下分,直到分解得到的小文件的大小都不超过1M。 对每个小文件,统计每个文件中出现的词以及相应的频率(可以采用trie树/hash_map 等),并取出出现频率最大的100个词(可以用含100个结点的最小堆),并把100个词及相应的频率存入文件,这样又得到了5000个文件。下一步就是把这5000个文件进行归并(类似与归并排序)的过程了。 4、有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个
大数据、数据分析和数据挖掘的区别 大数据、数据分析、数据挖掘的区别是,大数据是互联网的海量数据挖掘,而数据挖掘更多是针对内部企业行业小众化的数据挖掘,数据分析就是进行做出针对性的分析和诊断,大数据需要分析的是趋势和发展,数据挖掘主要发现的是问题和诊断。具体分析如下: 1、大数据(big data): 指无法在可承受的时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产; 在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)Veracity(真实性) 。 2、数据分析:
是指用适当的统计分析方法对收集来的大量数据进行分析,提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。这一过程也是质量管理体系的支持过程。在实用中,数据分析可帮助人们作出判断,以便采取适当行动。 数据分析的数学基础在20世纪早期就已确立,但直到计算机的出现才使得实际操作成为可能,并使得数据分析得以推广。数据分析是数学与计算机科学相结合的产物。 3、数据挖掘(英语:Data mining): 又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。 简而言之: 大数据是范围比较广的数据分析和数据挖掘。 按照数据分析的流程来说,数据挖掘工作较数据分析工作靠前些,二者又有重合的地方,数据挖掘侧重数据的清洗和梳理。 数据分析处于数据处理的末端,是最后阶段。 数据分析和数据挖掘的分界、概念比较模糊,模糊的意思是二者很难区分。 大数据概念更为广泛,是把创新的思维、信息技术、统计学等等技术的综合体,每个人限于学术背景、技术背景,概述的都不一样。
大数据时代的数据挖掘 技术 Document serial number【UU89WT-UU98YT-UU8CB-UUUT-UUT108】
大数据时代的数据挖掘技术 【摘要】随着大数据时代的到来,在大数据观念不断提出的今天,加强数据大数据挖掘及时的应用已成为大势所趋。那么在这一过程中,我们必须掌握大数据与数据挖掘的内涵,并对数据挖掘技术进行分析,从而明确大数据时代下数据挖掘技术的应用领域,促进各项数据的处理,提高大数据处理能力。 【关键词】大数据时代;数据挖掘技术;应用 大数据时代下的数据处理技术要求更高,所以要想确保数据处理成效得到提升,就必须切实加强数据挖掘技术的应用,才能更好地促进数据处理职能的转变,提高数据处理效率,以下就大数据时代下的数据挖掘技术做出如下分析。 1.大数据与数据挖掘的内涵分析 近年来,随着云计算和物联网概念的提出,信息技术得到了前所未有的发展,而大数据则是在此基础上对现代信息技术革命的又一次颠覆,所以大数据技术主要是从多种巨量的数据中快速的挖掘和获取有价值的信息技术,因而在云时代的今天,大数据技术已经被我们所关注,所以数据挖掘技术成为最为关键的技术。尤其是在当前在日常信息关联和处理中越来越离不开数据挖掘技术和信息技术的支持。大数据,而主要是对全球的数据量较大的一个概括,且每年的数据增长速度较快。而数据挖掘,主要是从多种模糊而又随机、大量而又复杂且不规则的数据中,获得有用的信息知识,从数据库中抽丝剥茧、转换分析,从而掌握其潜在价值与规律[1]。
2.大数据时代下数据挖掘技术的核心-分析方法 数据挖掘的过程实际就是对数据进行分析和处理,所以其核心就在于数据的分析方法。要想确保分析方法的科学性,就必须确保所采用算法的科学性和可靠性,获取数据潜在规律,并采取多元化的分析方法促进问题的解决和优化。以下就几种常见的数据分析方法做出简要的说明。 一是归类法,主要是将没有指向和不确定且抽象的数据信息予以集中,并对集中后的数据实施分类整理和编辑处理,从而确保所形成的数据源具有特征一致、表现相同的特点,从而为加强对其的研究提供便利。所以这一分析方法能有效的满足各种数据信息处理。 二是关联法,由于不同数据间存在的关联性较为隐蔽,采取人力往往难以找出其信息特征,所以需要预先结合信息关联的表现,对数据关联管理方案进行制定,从而完成基于某种目的的前提下对信息进行处理,所以其主要是在一些信息处理要求高和任务较为复杂的信息处理工作之中。 三是特征法,由于数据资源的应用范围较广,所以需要对其特征进行挖掘。也就是采用某一种技术,将具有相同特征的数据进行集中。例如采用人工神经网络技术时,主要是对大批量复杂的数据分析,对非常复杂的模式进行抽取或者对其趋势进行分析。而采取遗传算法,则主要是对其他评估算法的适合度进行评估,并结合生物进化的原理,对信息数据的成长过程进行虚拟和假设,从而组建出半虚拟、半真实的信息资源。再如可视化技术则是为数据挖掘提供辅助,采取多种方式对数据的
XXX公司数据分析专员笔试试题 姓名:日期: 一、异常值是指什么?请列举1种识别连续型变量异常值的方法? 异常值(Outlier)是指样本中的个别值,其数值明显偏离所属样本的其余观测值。在数理统计里一般是指一组观测值中与平均值的偏差超过两倍标准差的测定值。 Grubbs’ test(是以Frank E. Grubbs命名的),又叫maximum normed residual test,是一种用于单变量数据集异常值识别的统计检测,它假定数据集来自正态分布的总体。 未知总体标准差σ,在五种检验法中,优劣次序为:t检验法、格拉布斯检验法、峰度检验法、狄克逊检验法、偏度检验法。 点评:考察的内容是统计学基础功底。 二、什么是聚类分析?聚类算法有哪几种?请选择一种详细描述其计算原理和步骤。 聚类分析(cluster analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术。聚类分析也叫分类分析(classification analysis)或数值分类(numerical taxonomy)。聚类与分类的不同在于,聚类所要求划分的类是未知的。 聚类分析计算方法主要有:层次的方法(hierarchical method)、划分方法(partitioning method)、基于密度的方法(density-based method)、基于网格的方法(grid-based method)、基于模型的方法(model-based method)等。其中,前两种算法是利用统计学定义的距离进行度量。 k-means 算法的工作过程说明如下:首先从n个数据对象任意选择 k 个对象作为初始聚类中心;而对于所剩下其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类;然后再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值);不断重复这一过程直到标准测度函数开始收敛为止。一般都采用均方差作为标准测度函数. k个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。 其流程如下: (1)从 n个数据对象任意选择 k 个对象作为初始聚类中心; (2)根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离;并根据最小距离重新对相应对象进行划分; (3)重新计算每个(有变化)聚类的均值(中心对象); (4)循环(2)、(3)直到每个聚类不再发生变化为止(标准测量函数收敛)。 优点:本算法确定的K 个划分到达平方误差最小。当聚类是密集的,且类与类之间区别明显时,效果较好。对于处理大数据集,这个算法是相对可伸缩和高效的,计算的复杂度为 O(NKt),其中N是数据对象的数目,t是迭代的次数。一般来说,K<
相关主题
文本预览