
实验报告一
课程___统计软件分析与应用学生姓名___ ______
学号___________
学院__数学与统计学院______ 专业_____ 统计学__________ 指导教师___________
二O一四年三月十日
1、打开帮助文档首页,并查阅其中的“introduction to R”
> help.start()
2、看一下你的软件中有哪些程序包
> search()
[1] ".GlobalEnv" "package:stats" "package:graphics"
[4] "package:grDevices" "package:utils" "package:datasets"
[7] "package:methods" "Autoloads" "package:base"
3、载入程序包“emplik”
> install.packages("emplik")
然后选择镜像
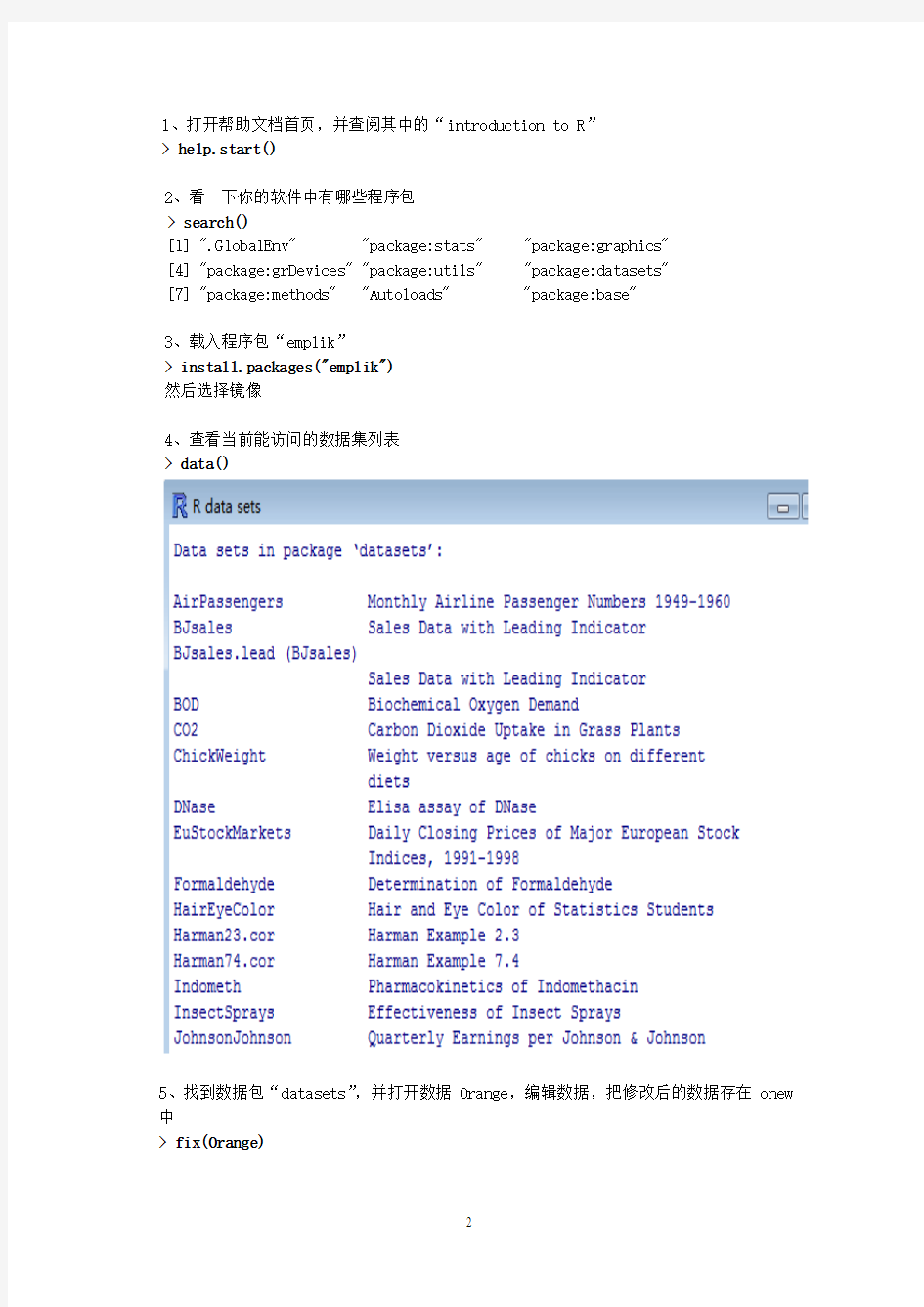
4、查看当前能访问的数据集列表
> data()
5、找到数据包“datasets”,并打开数据Orange,编辑数据,把修改后的数据存在onew 中
> fix(Orange)
> sink("D:/R/onew")
> Orange
> sink()
6、显示数据集Orange的内容> Orange
Tree age circumference
1 1 118 30
2 1 484 58
3 1 66
4 87
4 1 1004 115
5 1 1231 120
6 1 1372 142
7 1 1582 145
8 2 118 33
9 2 484 69
10 2 664 111
11 2 1004 156
12 2 1231 172
13 2 1372 203
14 2 1582 203
15 3 118 30
16 3 484 51
17 3 664 75
18 3 1004 108
19 3 1231 115
20 3 1372 139
21 3 1582 140
22 4 118 32
23 4 484 62
24 4 664 112
25 4 1004 167
26 4 1231 179
27 4 1372 209
28 4 1582 214
29 5 118 30
30 5 484 49
31 5 664 81
32 5 1004 125
33 5 1231 142
34 5 1372 174
35 5 1582 177
7、运行Orange 自带的示例
> ?Orange starting httpd help server ... done
> require(stats); require(graphics)
> coplot(circumference ~ age | Tree, data = Orange, show.given = FALSE) > fm1 <- nls(circumference ~ SSlogis(age, Asym, xmid, scal),
+ data = Orange, subset = Tree == 3)
> plot(circumference ~ age, data = Orange, subset = Tree == 3,
+ xlab = "Tree age (days since 1968/12/31)",
+ ylab = "Tree circumference (mm)", las = 1,
+ main = "Orange tree data and fitted model (Tree 3 only)")
> age <- seq(0, 1600, length.out = 101)
> lines(age, predict(fm1, list(age =age)))
5001000150040
60
80100120
140
Orange tree data and fitted model (Tree 3 only)
Tree age (days since 1968/12/31)
T r e e c i r c u m f e r e n c e (m m )
8、显示命令”lm”自带的示例
> ?Lm
9、建立一个变量X,赋值为向量分量为1到10
> x<-1:10
> x
[1] 1 2 3 4 5 6 7 8 9 10
10、建立一个变量Y,赋值为向量2-20,且全为偶数。
y<-seq(2,20,2)
> y
[1] 2 4 6 8 10 12 14 16 18 20
11、求向量X中所有数据的均值
> mean(x)
[1] 5.5
12、求向量Y中所有数据的均值
> mean(y)
[1] 11
13、求这个向量X,Y中所有数据的均值
> a<-c(x,y)
> a
[1] 1 2 3 4 5 6 7 8 9 10 2 4 6 8 10 12 14 16 18 20 > mean(a)
[1] 8.25
14、画关于数据X,Y的散点图,并在当前图上加上连接线
> plot(x,y)
> plot(x,y,type="l")
24
6810
510152
x y
24
6810510152
x y
15、显示你所定义的变量
> ls()
[1] "a" "ctl" "group" "lm.D9" "lm.D90" "opar" "trt" "weight"
[9] "x" "y" "a"
16、删除变量Y
> rm(y)
17、建立一个变量Z ,赋值为向量3.2,4.2,5.2,6.2
> z<-c(3.2,4.2,5.2,6.2)
> z
[1] 3.2 4.2 5.2 6.2
18、定义z为X的前四个数即在z=(1,2,,3,4)
>z<-x[1:4]
> z
[1] 1 2 3 4
19、Z中每个元素的以e为底的对数值
> log(z)
[1] 0.0000000 0.6931472 1.0986123 1.3862944
21、Z中各元素的正弦值
> sin(z)
[1] 0.8414710 0.9092974 0.1411200 -0.7568025
22、求值使得它的平方等于-17
> sqrt(-17)
[1] NaN
23、变量r<-rnorm(20),显示r,,求r的最大值,最小值,以及取值范围
> r<-rnorm(20)
> r
[1] -1.0692477 0.9105421 -1.1211643 1.9187331 -0.3197184 -1.1331422 -0.1297310
[8] -0.2526089 0.9941777 -0.5259946 0.1131596 1.4280643 0.4560638 -1.1988377
[15] 1.3622017 -0.9726582 -1.7936976 1.6542267 1.2437757 0.4747459
> max(r)
[1] 1.918733
> min(r)
[1] -1.793698
> range(r)
[1] -1.793698 1.918733
24、t<-rnorm(40), 显示t,对t 变量排序,从大到小
> t<-rnorm(40)
> t
[1] -0.2670832 -1.0401581 0.5706880 1.5695349 -1.5690820 2.2925257
2.9650736
[8] 0.6301941 -0.4208117 -0.5037243 1.0455926 0.5702032 0.4042575 0.4859722
[15] -0.7256744 1.0271393 2.5225848 -0.4791973 -0.3687917 -0.1824528 -0.3619730
[22] 0.2427025 -1.3023220 -2.4195959 0.9214635 0.4371514 0.0941338 -1.2573875
[29] -0.0391432 -0.1379714 1.1886162 -0.7219681 0.7326512 -0.6338557 1.0715916
[36] -0.8621995 1.2685845 0.5469610 -1.0772754 0.8161401
> sort(t,decreasing=T)
[1] 2.02142530 1.91562838 1.53469685 1.43885574 0.79778720 0.78902117
[7] 0.58228504 0.56960206 0.46576359 0.45366005 0.40453543 0.37763874 [13] 0.34104963 0.33813041 0.25838519 0.18191518 0.05703162 -0.01967698 [19] -0.02151746 -0.03326609 -0.05493251 -0.06631020 -0.08530721 -0.17452125 [25] -0.19679555 -0.23479574 -0.33598317 -0.37910012 -0.38721287 -0.40621203 [31] -0.46855478 -0.47084477 -0.57244759 -0.62724050 -0.64578447 -0.76105801 [37] -1.05574427 -1.30903186 -1.49405612 -1.71880206
25、建立变量A,它是一个矩阵4阶方阵,元素按行排列为1333,3233,3333,3334,求此矩阵的行列式的值,显示矩阵A的行数和列数,并得到它的转置矩阵B,求A和B的积,> d<-c(1,3,3,3,3,2,3,3,3,3,3,3,3,3,3,4)
> A<-matrix(d,nrow=4,ncol=4,byrow=T)
> A
[,1] [,2] [,3] [,4]
[1,] 1 3 3 3
[2,] 3 2 3 3
[3,] 3 3 3 3
[4,] 3 3 3 4
> det(A)
[1] 6
> t(A)
[,1] [,2] [,3] [,4]
[1,] 1 3 3 3
[2,] 3 2 3 3
[3,] 3 3 3 3
[4,] 3 3 3 4
> nrow(A)
[1] 4
> ncol(A)
[1] 4
> B<-A
> B
[,1] [,2] [,3] [,4]
[1,] 1 3 3 3
[2,] 3 2 3 3
[3,] 3 3 3 3
[4,] 3 3 3 4
> A*B
[,1] [,2] [,3] [,4]
[1,] 1 9 9 9
[2,] 9 4 9 9
[3,] 9 9 9 9
[4,] 9 9 9 16
26、定义一个矩阵C对角元素依次为1,2,3,4其它全为0的四阶对角阵,并显示出来
> C<-c(1,2,3,3)
> diag(C)
[,1] [,2] [,3] [,4]
[1,] 1 0 0 0
[2,] 0 2 0 0
[3,] 0 0 3 0
[4,] 0 0 0 3
27、b 为(1,2,3,4)组成的向量,求Ax=b 的解x ,并显示出来 > b<-c(1,2,3,4)
> solve(A,b)
[1] 1 1 -2 1
28、画出(-3.14,3.14)内余弦函数的大致图像
> g<-seq(-3.14,3.14,0.01)
> h<-cos(g)
>
plot(g,h,type=”1”
-3-2-10123
-
1.0
-
0.5
.0
.5
1
.
g
h )
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
城镇居民家庭收入的逐步回归分析 07级数学1班盛平0707021012 摘要:用多元统计中逐步回归分析的方法和SAS软件解决了可支配收入与其他收入之间的关系,并用此模型预测在以后几年里居民平均每人全年家庭可支配收入。 关键词:逐步回归分析多元统计SAS软件 正文 1 模型分析 各地区城镇居民平均每人全年家庭可支配收入y与工薪收入x1、经营净收入x2、财产性收入x3和转移性收入x4有关,共观测了15组数据,试用逐步回归法求‘最优’回归方程。 各地区城镇居民平均每人全年家庭收入来源(2007年) 单位:元 2模型的理论 (1)基本思想:逐个引入自变量,每次引入对y影响最显著的自变量,并对方程中的老变量逐个进行检验,把变为不显著的变量逐个从方程中剔除掉,最终得到的方程中既不漏掉对Y影响显著的变量,又不包含对Y影响不显著的变量。 (2)逐步筛选的步骤:首先给出引入变量的显著性水平 和剔除变量的显著性 in
水平 ;然后按图4.1的框图筛选变量。 out 3模型的求解 (1)源程序: data ch; input x1 x2 x3 x4 x5 y @@; cards; 28.2 47.9 44.1 3.8 23.9 100.0 31.3 47.1 43.6 3.5 21.6 100.0 30.2 48.2 43.9 4.3 21.6 100.0 ?? 31.9 46.1 41.9 4.2 22.0 100.0 33.4 44.8 40.6 4.1 21.8 100.0 33.2 44.4 39.9 4.5 22.4 100.0 32.1 43.1 38.7 4.4 24.8 100.0 28.4 42.9 38.3 4.6 28.7 100.0 ?? 27.2 43.7 38.6 5.1 29.1 100.0
回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验:
第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。
第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量
软件工程实验报告 姓名:冯巧 学号 实验题目:实验室设备管理系统 1、系统简介: 每天对实验室设备使用情况进行统计,对于已彻底损坏的作报废处理,同时详细记录有关信息。对于有严重问题(故障)的要即时修理,并记录修理日期、设备名、修理厂家、修理费用、责任人等。对于急需但又缺少的设备需以“申请表”的形式送交上级领导请求批准购买。新设备购入后立即对新设备登记(包括类别、设备名、型号、规格、单价、数量、购置日期、生产厂家、购买人等),同时更新申请表的内容。 2、技术要求及限定条件: 采用C#语言设计桌面应用程序,同时与数据库MySql进行交互。系统对硬件的要求低,不需要网络支持,在单机环境下也能运行,在局域网环境下也能使用。方案实施相对容易,成本低,工期短。 一:可行性分析 1、技术可行性分析 计算机硬件设备,数据库,实验室设备管理软件与实验室设备管理系统的操作人员组成,能够实现实验室设备管理的信息化,提高工作效率,实现现代化的实验室设备管理。系统需要满足实验室设备管理(包括对实验设备的报废、维修和新设备的购买)、实验室设备信息查询(包括按类别进行查询和按时间进行查询)、实验室设备信息统计报表(包括对已报废设备的统计、申请新设备购买的统计和现有设备的统计)。这些功能框图如下图所示: 2、经济可行性分析 依据用户的现实需求、技术现状、经济条件、工期以及其他局限性因素等等因素,考虑到工期的长短、技术的成熟可靠、操作方便等因素,本方案具备经济可行性。
3、系统可选择的开发方案 ①方案A用C#开发系统的特点是:开发工具与数据库集成一体,可视化,开发速度较快,但数据库能够管理的数据规模相对较小。系统对硬件的要求低,不需要网络支持,在单机环境下也能运行,在局域网环境下也能使用。方案的实施相对容易,成本低,工期短。 ②方案B:以小型数据库管理系统为后台数据库,该前台操作与数据库分离,也能够实现多层应用系统。系统对硬件的要求居中,特别适合在网络环境下使用,操作方便。但系统得实现最复杂,成本最高,工期也较长。 二:软件需求分析 1.软件系统需求基本描述: 实验室设备管理系统是现代企业资源管理中的一个重要内容,也是资源开发利用的基础性工作。实验室设备在信息化之前,在用户系统管理、设备维修管理、设备的增删改查管理等方面存在诸多不利于管理的地方,不适应现代的企业管理形势和资源的开发利用。 2.软件系统数据流图(由加工、数据流、文件、源点和终点四种元素组成): 1)顶层数据流图 2)二层流程图 3)总数据流图
陕西科技大学实验报告 课 程: 数理金融 实验日期: 2014 年 5 月 22 日 班 级: 数学112 交报告日期: 2013 年 5 月 23 日 姓 名: 常海琴 报告退发: (订正、重做) 学 号: 201112010101 教 师: 刘利明 实验名称: 多元回归分析 一、实验预习: 1.多元回归模型。 2.多元回归模型参数的检验。 3.多元回归模型整体的检验。 二、实验的目的和要求: 通过案例分析掌握多元回归模型的建立方法和检验的标准;并掌握分析解决实际金融问题的能力。 三、实验过程:(实验步骤、原理和实验数据记录等) 软件:Eviews3.1 数据:给定美国机动车汽油消费量研究数据。 实验原理:最小二乘法拟合多元线性回归方程 数据记录: 实例中1950年到1987年机动汽车的消费量、汽车保有量、汽油价格、人口数、国民生产总值 图1各个量之间的关系
陕西科技大学理学院实验报告 - 2 - 1、录入数据 图2录入数据 2、回归分析 443322110X X X X Y βββββ++++= 图3运行结果 Y=24553723+1.418520x1-27995762x2-59.87480x3-30540.88x4 S (25079670) (0.266) (5027085) (198.5517) (9557.981) T (0.979) (5.314) (-5.568) (-0.301) (-3.195) 2R =0.966951 F=241.3764 - R =0.9629 dw=0.6265 四、实验总结:(实验数据处理和实验结果讨论等) 用残差和最小确定直线位置是一个途径。计算残差和有相互抵消的问题。用残差绝对值和最小确定直线位置也是一个途径绝对值计算起来比较麻烦。最小二乘法用绝对值平方和最小确定直线位置。0β、1β、2β、3β、4β具有线性特性,无偏特性,有效性。-R =0.9629基本上接近于1,拟合效果较好。
实验报告 1. 实验目的随着中国经济的发展,居民的常住收入水平不断提高,粮食销售量也不断增长。研究粮食年销售量与人均收入之间的关系,对于探讨粮食年销售量的增长的规律性有重要的意义。 2. 模型设定 为了分析粮食年销售量与人均收入之间的关系,选择“粮食年销售量” 为被解释变量(用Y 表示),选择“人均收入”为解释变量(用X 表 示)。本次实验报告数据取自某市从1974 年到1987 年的数据(教材书上101页表3.11),数据如下图所示:
1粮食年销售量Y/万吨人均收入X/ rF1974[ 9& 45153.2 1975100.7190 pl1976102.8240.3 1977133. 95301.12 [61978140.13361 71979143.11420 8—1980146.15491.76「91981144.6501 101982148. 94529.2 1 11-1983158.55552. 72匸1984169. 68771.16 131985P 162.1481L8 14二1986170. 09988.43 1519871F& 691094.65为分析粮食年销售量与人均收入的关系,做下图所谓的散点图 从散点图可以看出粮食年销售量与人均收入大体呈现为线性关 系,可以建立如下简单现行回归模型: 3?估计参数
Y t = ■? 1 2 X t ——I t 假定所建模型及其中的随机扰动项叫满足各项古典假定,可以 用OLS法估计其参数。 通过利用EViews对以上数据作简单线性回归分析,得出回归结果如下表所示: Dependent Variable Y Method: Least Squares Date 10/15/11 Time 14 49 Sample- 1 14 Included observations: 14 Variable Coefficient Std Error t-Statistic Prob C99 61349 6 431242 15 489000 0000 X0.0814700.010738 7.5071190.0000 R-squared0 827493Mean dependent var142 7129 Adjusted R-squared0 813123S.D. dependent var26.09805 S E of regression11 28200Akaike info criterion7 915858 Sum squared resid1527 403Schwarz criterion7 907152 Log likelihood-52.71101F-statisti c5756437 Durbin-V/atson stat0 638969Prob(尸-statistic)0 000006 可用规范的形式将参数估计和检验的结果写为: A Y t =99.61349+0.08147 X t (6.431242)(0.10738) t= (15.48900) (7.587119) R2=0.827498 F=57.56437 n=14 4?模型检验 (1).经济意义检验 A A 所估计的参数1=99.61349, 1 2=0.08147,说明人均收入每增加 1元,平均说来可导致粮食年销售量提高0.08147元。这与经济学中
四个常用统计软件SAS,STATA,SPSS,R语言分析比较及其他统计软件概述 一、SAS,STATA,SPSS,R语言简介 (一)SAS简介 SAS(全称Statistical Analysis System,简称SAS,翻译成汉语是统计分析系统)是全球最大的软件公司之一,是由美国NORTH CAROLINA州立大学1966年开发的统计分析软件。1976年SAS软件研究所(SAS INSTITUTE INC)成立,开始进行SAS系统的维护、开发、销售和培训工作。期间经历了许多版本,并经过多年来的完善和发展,SAS系统在国际上已被誉为统计分析的标准软件,在各个领域得到广泛应用。 其网址是:https://www.doczj.com/doc/5a2396262.html,/ (二)STSTA简介 STATA统计软件由美国计算机资源中心(Computer Resource Center)1985年研制。STATA 是一套提供其使用者数据分析、数据管理以及绘制专业图表的完整及整合性统计软件。它提供许许多多功能,包含线性混合模型、均衡重复反复及多项式普罗比模式。 新版本的STATA采用最具亲和力的窗口接口,使用者自行建立程序时,软件能提供具有直接命令式的语法。STATA提供完整的使用手册,包含统计样本建立、解释、模型与语法、文献等超过一万余页的出版品。 除此之外,STATA软件可以透过网络实时更新每天的最新功能,更可以得知世界各地的使用者对于STATA公司提出的问题与解决之道。使用者也可以透过STATA Journal 获得许许多多的相关讯息以及书籍介绍等。另外一个获取庞大资源的管道就是STATAlist,它是一个独立的listserver,每月交替提供使用者超过1000个讯息以及50个程序。 其网址是:https://www.doczj.com/doc/5a2396262.html,/ (三)SPSS简介 SPSS(Statistical Product and Service Solutions),“统计产品与服务解决方案”软件。最初软件全称为“社会科学统计软件包”(Statistical Package for the Social Sciences),但是随着SPSS产品服务领域的扩大和服务深度的增加,SPSS公司已于2000年正式将英文全称更改为“统计产品与服务解决方案”,标志着SPSS 的战略方向正在做出重大调整。为IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称SPSS,有Windows和Mac OS X等版本。 1984年SPSS总部首先推出了世界上第一个统计分析软件微机版本SPSS/PC+,开创了SPSS微机系列产品的开发方向,极大地扩充了它的应用范围,并使其能很快地应用于自然科学、技术科学、社会科学的各个领域。世界上许多有影响的报刊杂志纷纷就SPSS的自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予了高度的评价。 SPSS是世界上最早的统计分析软件,由美国斯坦福大学的三位研究生Norman H. Nie、C. Hadlai (Tex) Hull 和Dale H. Bent于1968年研究开发成功,同时成立了SPSS公司,并于1975年成立法人组织、在芝加哥组建了SPSS总部。
一元线性回归在公司加班 制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成 绩: 完成时间 :
一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想与操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21、0 windows10、0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据与签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3、5 1、0 4、0 2、0 1、0 3、0 4、5 1、5 3、0 5、0 1. 画散点图。 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧ 与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10. 对回归方程做残差图并作相应的分析。 11. 该公司预测下一周签发新保单01000x =张,需要的加班时间就是多少?
12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1、画散点图 如图就是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以瞧出,数据均匀分布在对角线的两侧,说明x与y之间线性关系良好。 2、最小二乘估计求回归方程 系数a 模型非标准化系数标准系数t Sig、 B 的 95、0% 置信区间 B 标准误差试用版下限上限
什么软件可以统计数据 【篇一:什么软件可以统计数据】 用replace pioneer,简单极了。注意是英文版,但是处理中文文档没有任何问题。 1. 按ctrl-o打开要统计的文件 2. 按ctrl-h打开replace对话框,设置如下: 1) 把replace unit设置成 line ,表示按行处理 2)在 search for pattern 下面填.*(注 .* 表示所有行): 3)在 replace with pattern 下 面填: $match count($match, [12345] ) n 注:$match表示匹配的原文,count($match, [12345] )表示 计算12345出现的次数, n表示回车符 3. 点击 replace ,完成!处理结果如下: 14793685 4 2586973 3 369258 4 4 7894563 3 replace pioneer下载:注意安装时不要装在中文路径下参考资料: 【篇二:什么软件可以统计数据】 《概率论与数理统计》是一门实践性很强的课程。但是,目前在国内, 大多侧重基本方法的介绍,而忽视了统计实验的教学。这样既不利于 提高学生创新精神和实践能力,也使得这门课程的教学显得枯燥无味。为此,我们介绍一些常用的统计软件,以使学生对统计软件有初步的 认识,为以后应用统计方法解决实际问题奠定初步的基础。 一、统计软件的种类 1.sas 是目前国际上最为流行的一种大型统计分析系统,被誉为统计分析 的标准软件。尽管价格不菲,sas已被广泛应用于政府行政管理,科研,教育,生产和金融等不同领域,并且发挥着愈来愈重要的作用。目前sas已在全球100多个国家和地区拥有29000多个客户群,直 接用户超过300万人。在我国,国家信息中心,国家统计局,卫生部,中国科学院等都是sas系统的大用户。尽管现在已经尽量“傻瓜化”,但是仍然需要一定的训练才可以使用。因此,该统计软件主要适 合于统计工作者和科研工作者使用。 2.spss spss作为仅次于sas的统计软件工具包,在社会科学领域有着广泛 的应用。spss是世界上最早的统计分析软件,由美国斯坦福大学的 三位研究生于20世纪60年代末研制。由于spss容易操作,输出漂亮,功能齐全,价格合理,所以很快地应用于自然科学、技术科学、 社会科学的各个领域,世界上许多有影响的报刊杂志纷纷就spss的 自动统计绘图、数据的深入分析、使用方便、功能齐全等方面给予 了高度的评价与称赞。迄今spss软件已有30余年的成长历史。全 球约有25万家产品用户,它们分布于通讯、医疗、银行、证券、保险、制造、商业、市场研究、科研教育等多个领域和行业,是世界
实践报告书写要求 实践报告原则上要求学生手写,要求书写工整。若因课程特点需打印的,要遵照以下字体、字号、间距等的具体要求。纸张一律采用A4的纸张。 实践报告书写说明 实践报告中一至四项内容为必填项,包括实践目的和要求;实践环境与条件;实践内容;实践报告。各院部可根据学科特点和实践具体要求增加项目。 填写注意事项 (1)细致观察,及时、准确、如实记录。 (2)准确说明,层次清晰。 (3)尽量采用专用术语来说明事物。 (4)外文、符号、公式要准确,应使用统一规定的名词和符号。 (5)应独立完成实践报告的书写,严禁抄袭、复印,一经发现,以零分论处。 实践报告批改说明 实践报告的批改要及时、认真、仔细,一律用红色笔批改。实践报告的批改成绩采用百分制,具体评分标准由各院部自行制定。 实践报告装订要求 实践报告批改完毕后,任课老师将每门课程的每个实践项目的实践报告以自然班为单位、按学号升序排列,装订成册,并附上一份该门课程的实践大纲。
实践项目名称:统计软件应用实践学时: 同组学生姓名:实践地点: 实践日期:实践成绩: 批改教师:批改时间: 指导教师评阅: 一、实践目的和要求 统计软件应用是具有较强应用性的课程,实验教学对于完成本课程教学目标具有重要地位。通过实验教学,训练学生熟练使用统计软件,掌握数据统计分析的基本步骤,为实际工作奠定基础。在训练学生熟练使用统计软件的基础上,培养学生能够运用实际的统计数据和统计方法分析经济、金融问题,研究常见的金融活动中表现出的数量关系,提高学生运用经济、金融信息分析问题和解决问题的能力。 二、实践环境与条件 课程所需要的软件《SPSS 18.0》、EXCEL等及运行软件所需要的计算机设备。
吉林财经大学2014-2015学年第一学期 《SPSS统计软件应用》期末综合实验学分:2学分 院别:亚泰工商管理学院 专业班级:物流管理1112 学号:0804111236 姓名:朱俊辉
一、实验项目 运用分组数据资料频数分析,单因素方差分析,相关回归分析等方法对我国2010年到2012年各规模以上港口的吞吐量进行分析。 二、实验数据 本次实验参考数据是2010年、2011年、2012年我国主要规模以上港口吞吐量,数据源自于《2013年统计年鉴》,其具体数据如下表: 表1 我国主要规模以上港口城市吞吐量及经济生产总值单位:万吨 数据来源:中国国家统计局三、实验目的 港口货运是国际物流产业的重要组成部分,港口货运吞吐量是反映区域海运物流的重要指标。港口货物吞吐量指经由水路进、出港区范围,并经过装卸的货物数量。按货物流向分为进港吞吐量和出港吞吐量,按货物的贸易性质分为内贸和外贸吞吐量。货物类别根据现行的交通行业《运输货物分类和代码》标准分类。 选取沿海规模以上港口货物吞吐量当期值数据(2010年-2012年)。借鉴已有数据,建立统计分析模型,进行检验和修正,以分析经济生产总值和港口货运吞吐量之间的关系,基于此对未来港口货运吞吐量的相关关系进行判断,为相关决策人员提供决策依据。 通过本次实验学会利用SPSS软件中的描述统计,方差分析、相关与回归的只是。对收集到的数据进行处理。并对结果能进行解读。同时提高本软件在企业经营管理活动中的应用。
四、实验步骤与实验结果 (一)描述统计:频数分析 利用描述统计中学到的频数分析方法对2012年各省市自治区的数据进行分析。 1.对资料进行分组 表2 2012年我国主要规模以上港口城市吞吐量分组情况表 2.分组数据频数分析 15。均值为29840.47,中位数为27099,标准差为19561.03,方差为382633889.64,偏度系数为0. 838>0,故数据呈现出右偏态,即右偏分布,此时数据位于均值右边的比位于左边的少。说明港口货物吞吐量和经济生产总值之间可能存在正比例关系。峰度系数为-0. 426<0说明,数据的分布比正态分布平缓。全距73306。
实验报告 实验课程:[信息分析] 专业:[信息管理与信息系统] 班级:[ ] 学生姓名:[ ] 指导教师:[请输入姓名] 完成时间:2013年6月28日
一.实验目的 多元线性回归简单地说是涉及多个自变量的回归分析,主要功能是处理两个变量之间的线性关系,建立线性数学模型并进行评价预测。本实验要求掌握附带残差分析的多元线性回归理论与方法。 二.实验环境 实验室308教室 三.实验步骤与内容 1打开应用统计学实验指导书,新建excel表 2.打开SPSS,将数据输入。 3.调用SPSS主菜单的分析——>回归——>线性命令,打开线性回归对话框,指定因变量(工业GDP比重)和自变量(工业劳动者比重、固定资产比重、定额资金流动比重),以及回归方式;逐步回归(图1)
图1 线性对话框 4.在统计栏中,选择估计以输出回归系数B的估计值、t统计量等,选择Duribin-watson以进行DW检验;选择模型拟合度输出拟合优度统计量值,如R^2、F统计量值等(图2)。 图2 统计量栏
5.在线性回归栏中选择直方图和正态概率图以绘制标准化残差的直方图和残差分析与正态概率比较图,以标准化预测值为纵坐标,标准化残差值为横坐标,绘制残差与Y的预测值的散点图,检验误差变量的方差是否为常数(图3)。 图3 绘制栏 6.提交分析,并在输出窗口中查看结果,以及对结果进行分析。 系统在进行逐步分析的过程中产生了两个回归模型,模型1先将与因变量(销售收入)线性关系的自变量地区人口引入模型,建立他们之间的一元线性关系。而后逐步引入其他变量,表1中模型2表明将自变量人均收入引入,建立二元线性回归模型,可见地区人口和人均收入对销售收入的影响同等重要。
计量经济学多元线性回归、多重共线性、异方差实验报告记录
————————————————————————————————作者:————————————————————————————————日期:
计量经济学实验报告
多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元
统计分析方法常用的(功能)函数(包括统计处理、统计分布) 一、加载分析工具库,工具—>数据分析 抽样 随机数发生器 z-检验---双样本均值差检验 t-检验---双样本等方差检验 t-检验--双样本异方差检验 t-检验—平均值得成对二样本检验 F-检验—双样本方差 方差分析:单因素方差分析 方差分析:可重复双因素方差分析 方差分析:无重复双因素方差分析 相关系数 协方差 回归 移动平均 指数平滑 二、统计函数 算术平均AVERAGE (number1,number2,…) 求和SUM(number) 几何平均GEOMEAN (number1,number2,…) 调和平均HARMEAN(number1,number2,…) 计算众数MODE (number1,number2,…) 中位数MEDIAN (number1,number2,…) 方差V AR (number1,number2,…) 标准差STDEV (number1,number2,…) 计算数据的偏度SKEW (number1,number2,…) 计算数据的峰度KURT (number1,number2,…) 频数统计COUNTIF(range,criteria) 组距式分组的频数统计FREQUENCY(data_array,bins_array) 随机实数RAND() 区间的随机整数RANDBETWEEN (a,b) 二项分布的概率值BINOMDIST(number_s,trials,probability_s,cumulative) 泊松分布的概率值POISSON(x,mean,cumulative) 正态分布的概率值NORMDIST(x,mean,standard_dev,cumulative) 计算正态分布的P值NORMSDIST(z)
实验报告 实验目的: 1.构建一元及多元回归模型,并作出估计 2.熟练掌握假设检验 3.对构建的模型进行回归预测 实验内容: 对1970——1982年某国实际通货膨胀率、失业率和预期通货膨胀率进行分析,根据下表(表一)提供的数据进行模型设定,假设检验及回归预测。 表一 年份Y X2 X3 1970 5.92 4.90 4.78 1971 4.30 5.90 3.84 1972 3.30 5.60 3.31 1973 6.23 4.90 3.44 1974 10.97 5.60 6.84 1975 9.14 8.50 9.47 1976 5.77 7.70 6.51 1977 6.45 7.10 5.92 1978 7.60 6.10 6.08 1979 11.47 5.80 8.09 1980 13.46 7.10 10.01 1981 10.24 7.60 10.81 1982 5.99 9.70 8.00 实验步骤: 1.模型设定: 为分析实际通货膨胀率(Y)分别和失业率(X2)、预期通货膨胀率(X3)之间的关系,作出如下图所示的散点图。 图一
从上示散点图可以看出实际通货膨胀率(Y)分别和失业率(X2)不呈线性关系,与预期通货膨胀率(X3)大体呈现为线性关系,为分析实际通货膨胀率(Y)分别和失业率(X2)、预期通货膨胀率(X3)之间的数量关系,可以建立单线性回归模型和多元线性回归模型:
1231 Y X ββμ=++ 123322Y X X βββμ=+++ 2.估计参数 在Eviews 命令框中输入 “ls y c x2”,按回车,对所给数据做简单的一元线性回归分析。分析结果见表二。 表二 Dependent Variable: Y Method: Least Squares Date: 10/09/11 Time: 17:23 Sample: 1970 1982 Included observations: 13 Variable Coefficient Std. Error t-Statistic Prob. C 1.323831 1.626284 0.814022 0.4329 X3 0.960163 0.228633 4.199588 0.0015 R-squared 0.615875 Mean dependent var 7.756923 Adjusted R-squared 0.580955 S.D. dependent var 3.041892 S.E. of regression 1.969129 Akaike info criterion 4.333698 Sum squared resid 42.65216 Schwarz criterion 4.420613 Log likelihood -26.16904 F-statistic 17.63654 Durbin-Watson stat 1.282331 Prob(F-statistic) 0.001487 由回归分析结果可估计出参数1β、2β 即^ 31.3238310.960163Y X =+ (1.626284)(0.228633) ()()0.814022 4.199588 t = 2 0.615875R = F=17.63654 n=13
多元线性回归模型实验报告 13级财务管理 101012013101 蔡珊珊 【摘要】首先做出多元回归模型,对于解释变量作出logx等变换,选择拟合程度最高的模型,然后判断出解释变量之间存在相关性,然后从检验多重线性性入手,由于解释变量之间有的存在严重的线性性,因此采用逐步回归法,将解释变量进行筛选,保留对模型解释能力较强的解释变量,进而得出一个初步的回归模型,最后对模型进行异方差和自相关检验。 【操作步骤】1.输入解释变量与被解释变量的数据 2.作出回归模型
R^2=0.966951 DW=0.626584 F-statictis=241.3763 ②我们令y1=log(consumption),x4=log(people),x5=log(price),x6=log(retained),x7= log(gdp), 作出回归模型
② 发现拟合程度很高,也通过了F检验与T检验。但是我们首先检查模型的共线性 发现x4与x6,x4与x7,x6与x7存在很强的共线性,对模型会造成严重影响。
目前暂用模型y1=10.55028-3.038439x4-0.236518x5+2.647396x6-0.557805x7,我们将陆续进行调整。 3.分别作出各解释变量与被解释变量之间的线性模型
①作出汽车消费量与汽车保有量之间的线性回归模型 R^2=0.956231 DW=0.147867 F-statistic=786.4967
因为prob小于α置信度,则可说明β1不明显为零。经济意义存在 Y1^=4.142917 + 0.761197x6 (8.283960) (28.04455)
常用统计软件下载 1. SAS 8e(下载) SAS(statistical analysis system)是美国SAS软件研究所研制的一套大型集成应用软件系统,具有完备的数据存取、数据管理、数据分析和数据展现功能。尤其是创业产品—统计分析系统部分,由于其具有强大的数据分析能力,一直为业界著名软件,在数据处理和统计分析领域,被誉为国际上的标准软件和最权威、最优秀的统计软件包,广泛应用于政府行政管理、科研、教育、生产和金融等不同领域,发挥着重要的作用。SAS系统中提供的主要分析功能包括统计分析、经济计量分析、时间序列分析、决策分析、财务分析和全面质量管理工具等。 SAS系统是一个组合软件系统,由多个功能模块组合而成,其基本部分是BASE SAS模块。BASE SAS模块是SAS系统的核心,承担着主要的数据管理任务,管理用户使用环境,进行用户语言的处理,调用其它SAS模块和产品。也就是说,SAS系统的运行,首先必须启动BASE SAS 模块,它除了本身具有的数据管理、程序设计及描述统计计算功能外,还是SAS系统的中央调度室。它既可单独存在,也可与其它产品或模块共同构成一个完整的系统。各模块的安装与更新都可通过其安装程序非常方便地进行。SAS系统具有灵活的功能扩展接口和强大的功能模块,在BASE SAS的基础上,还可以增加如下不同的功能模块:SAS/STAT(统计分析模块)、SAS/GRAPH(绘图模块)、SAS/QC(质量控制模块)、SAS/ETS(经济计量学和时间序列分析模块)、SAS/OR(运筹学模块)、SAS/IML(交互式矩阵程序设计语言模块)、SAS/FSP(快速数据处理的交互式菜单系统模块)、SAS/AF(交互式全屏幕软件应用系统模块)等。SAS有一个智能型绘图系统,不仅能绘各种统计图,还能绘制地图。SAS提供多个统计过程,每个过程均含有极丰富的功能选项。用户还可以通过对数据集的一连串加工,实现更为复杂的统计分析。此外,SAS还提供了各类概率分析函数、分位数函数、样本统计函数和随机数生成函数,使用户能方便地实现特殊的统计分析。 虽然近几年SAS才在我国得到广泛应用,但是随着计算机应用的普及和信息事业的不断发展,越来越多的单位采用了SAS软件。尤其在教育和科研领域,SAS软件已成为专业研究人员实用的标准统计分析软件。SAS作为专业统计软件中的巨无霸,目前还没有其它统计软件包能与之抗衡。 2. MiniTab 14.0(下载) Minitab是美国宾州大学研制的国际上流行的一个统计软件包,其特点是简单易懂,在国外大学统计学系开设的统计软件课程中,Minitab与SAS、BMDP相互并列,有的学术研究机构甚至专门教授Minitab之概念及其使用。Minitab for Windows统计软件比SAS、SPSS等小得多,但功能并不弱,特别是它的试验设计与质量控制等功能。 MiniTab目前的最高版本为V14.1,它提供了对二维工作表中的数据进行分析的多种功能,包括:基本统计分析、回归分析、方差分析、多元分析、非参数分析、时间序列分析、试验设计、质量控制、模拟、绘制高质量三维图形等,从功能来看,Minitab除各种统计模型外,还具有许多统计软件不具备的功能——矩阵运算。 3. Statistica 6.0(下载) Statistica是一套完整的统计资料分析、图表绘制、资料管理、应用程序开发的系统,还提供
实验报告三课程应用回归分析 学生姓名陆莹 学号20121315021 学院数学与统计学院 专业统计学 任课教师宋凤丽 二O一四年四月十七日
(1) shuju<-read.table("E:/4.14.txt") namesdata<-c("y",paste("x",1:2,sep="")) colnames(shuju)<-namesdata lm.shuju<-lm(y~.,data=shuju) summary(lm.shuju) Call: lm(formula = y ~ ., data = shuju) Residuals: Min 1Q Median 3Q Max -747.71 -229.80 -2.15 267.23 547.68 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -574.0624 349.2707 -1.644 0.1067 x1 191.0985 73.3092 2.607 0.0121 * x2 2.0451 0.9107 2.246 0.0293 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘’ 1 Residual standard error: 329.7 on 49 degrees of freedom Multiple R-squared: 0.2928, Adjusted R-squared: 0.264 F-statistic: 10.15 on 2 and 49 DF, p-value: 0.0002057 >plot(lm.shuju,2) 由上图可知,残差通过正态性检验,原假设成立。
一元线性回归在公司加班制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成绩: 完成时间:
一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想和操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21.0 windows10.0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3.5 1.0 4.0 2.0 1.0 3.0 4.5 1.5 3.0 5.0 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10.对回归方程做残差图并作相应的分析。
11.该公司预测下一周签发新保单01000 x=张,需要的加班时间是多少? 12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1.画散点图 如图是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以看出,数据均匀分布在对角线的两侧,说明x和y之间线性关系良好。 2.最小二乘估计求回归方程
用SPSS 求得回归方程的系数01,ββ分别为0.118,0.004,故我们可以写出其回归方程如下: 0.1180.004y x =+ 3.求回归标准误差σ∧ 由方差分析表可以得到回归标准误差:SSE=1.843 故回归标准误差: 2= 2SSE n σ∧-,2σ∧=0.48。 4.给出回归系数的置信度为95%的置信区间估计。 由回归系数显著性检验表可以看出,当置信度为95%时: