SQL SERVER 带事务存储过程
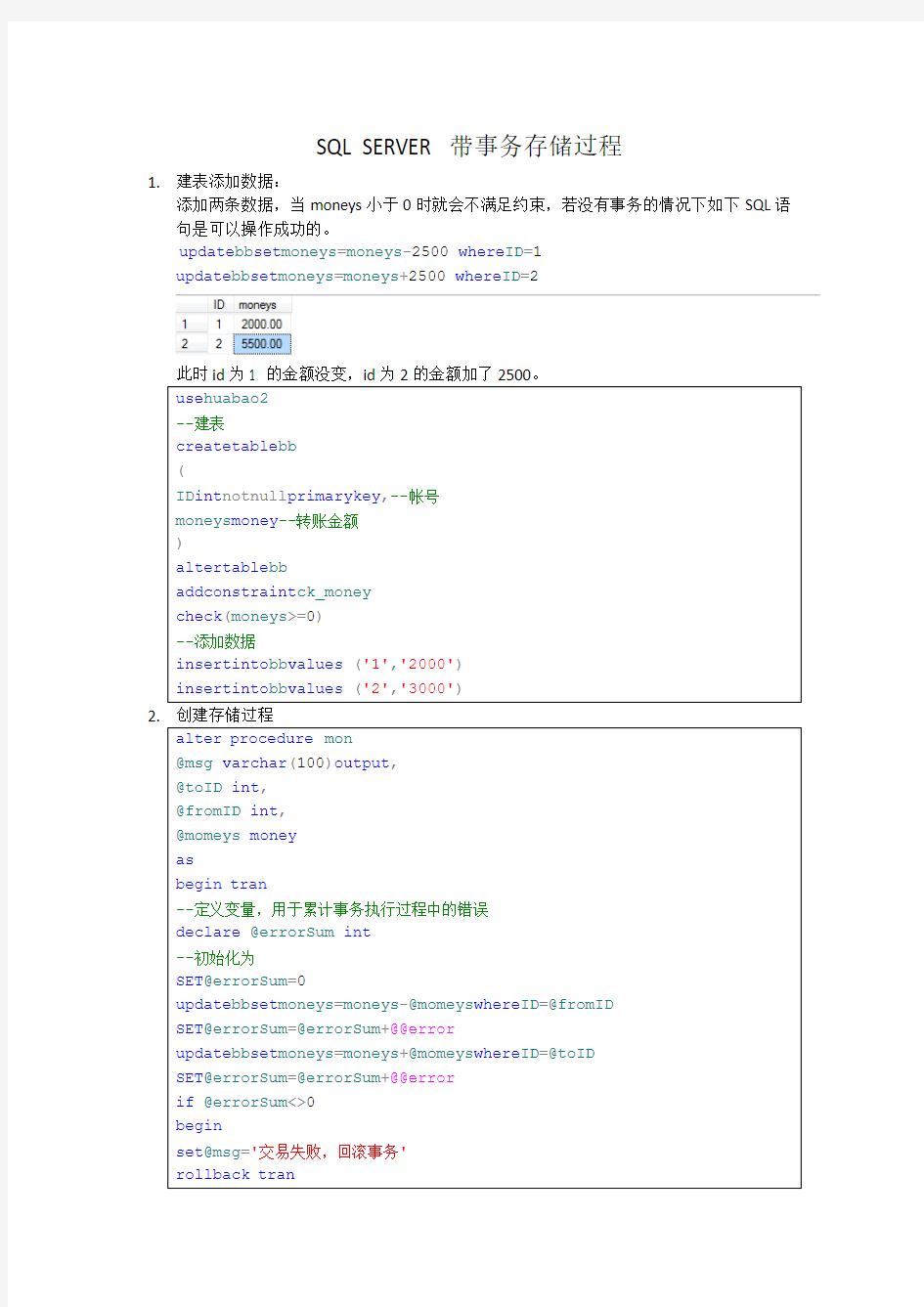
1.建表添加数据:
添加两条数据,当moneys小于0时就会不满足约束,若没有事务的情况下如下SQL语句是可以操作成功的。
update bb set moneys=moneys-2500 where ID=1
update bb set moneys=moneys+2500 where ID=2
此时id为1 的金额没变,id为2的金额加了2500。
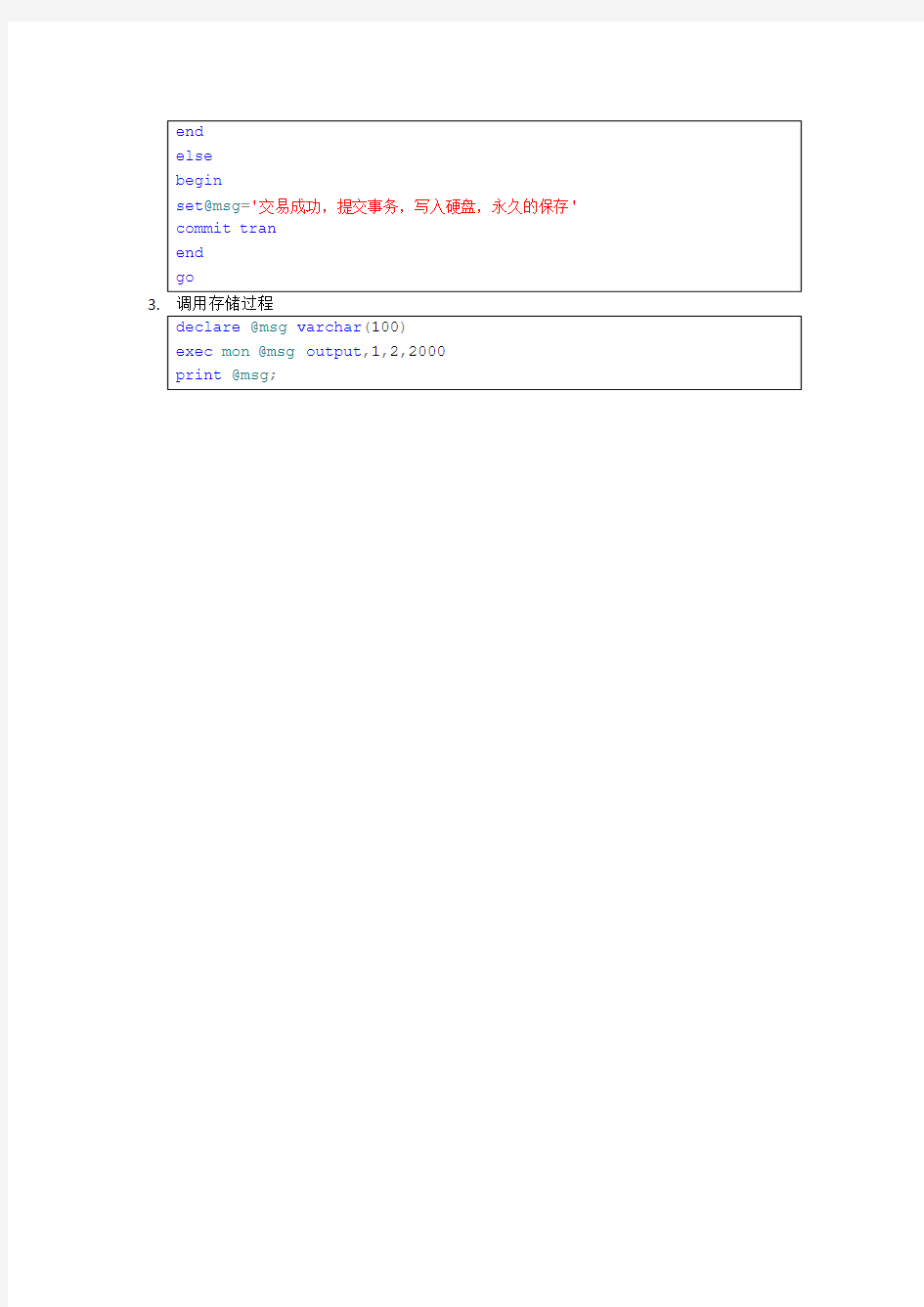
2.
3.
1.存储过程中的commit与rollback create table A ( A VARCHAR2(46) not null, primary key (A) ) create table B ( A VARCHAR2(46) ) create table C ( A VARCHAR2(46) ) 表B中插入值 Insert into B(A) valus(‘a’); Insert into B(A) valus(‘b’); Insert into B(A) valus(‘b’); Insert into B(A) valus(‘c’); 1. create or replace procedure test as begin for v_cur in (select a from b) loop insert into c(a)values(v_cur.a) ; insert into a(a)values(v_cur.a) ; end loop; end; 执行结果:A、C表中均无记录。系统启动隐式事务,在遇到异常时自动回滚。 2. create or replace procedure test as begin for v_cur in (select a from b) loop insert into C(a)values(v_cur.a) ; end loop; end; 执行结果:C表中无记录。系统启动隐式事务,但等待提交或回滚。Commit后C表中可查询到插入的4条数据。 3 create or replace procedure test as
SQLServer 存储过程返回值总结 1. 存储过程没有返回值的情况 (即存储过程语句中没有 return 之类的语句用方法 int count = ExecuteNonQuery(..执行存储过程其返回值只有两种情况 (1假如通过查询分析器执行该存储过程,在显示栏中假如有影响的行数,则影响几行 count 就是几 (2假如通过查询分析器执行该存储过程, 在显示栏中假如显示 ' 命令已成功完成。 ' 则 count = -1;在显示栏中假如有查询结果,则 count = -1 总结:A.ExecuteNonQuery(该方法只返回影响的行数,假如没有影响行数,则该方法的返回值只能是 -1,不会为 0。 B.不论 ExecuteNonQuery(方法是按照 CommandType.StoredProcedure 或者 CommandType.Text 执行, 其效果和 A 一样。 --------------------------------------------------------------------------------------------------------------------------------------------------- 2. 获得存储过程的返回值 --通过查询分析器获得 (1不带任何参数的存储过程 (存储过程语句中含有 return ---创建存储过程 CREATE PROCEDURE testReturn AS return 145 GO ---执行存储过程
DECLARE @RC int exec @RC=testReturn select @RC ---说明 查询结果为 145 (2带输入参数的存储过程 (存储过程语句中含有 return ---创建存储过程 create procedure sp_add_table1 @in_name varchar(100, @in_addr varchar(100, @in_tel varchar(100 as if(@in_name = '' or @in_name is null return 1 else begin insert into table1(name,addr,tel values(@in_name,@in_addr,@in_tel return 0
动态语句基本语法 1 :普通SQL语句可以用exec执行 Select * from tableName exec('select * from tableName') exec sp_executesqlN'select * from tableName' -- 请注意字符串前一定要加N 2:字段名,表名,数据库名之类作为变量时,必须用动态SQL declare @fnamevarchar(20) set @fname = 'FiledName' Select @fname from tableName -- 错误,不会提示错误,但结果为固定值FiledName,并非所要。exec('select ' + @fname + ' from tableName') -- 请注意加号前后的单引号的边上加空格 当然将字符串改成变量的形式也可 declare @fnamevarchar(20) set @fname = 'FiledName' --设置字段名 declare @s varchar(1000) set @s = 'select ' + @fname + ' from tableName' exec(@s) -- 成功 exec sp_executesql @s -- 此句会报错 declare @s Nvarchar(1000) -- 注意此处改为nvarchar(1000) set @s = 'select ' + @fname + ' from tableName' exec(@s) -- 成功 exec sp_executesql @s -- 此句正确 3. 输出参数 declare @numint, @sqlsnvarchar(4000) set @sqls='select count(*) from tableName' exec(@sqls) --如何将exec执行结果放入变量中? declare @numint, @sqlsnvarchar(4000) set @sqls='select @a=count(*) from tableName ' execsp_executesql @sqls,N'@aint output',@num output select @num 1 :普通SQL语句可以用Exec执行例: Select * from tableName Exec('select * from tableName')
存储过程的作用和意义 随着唐山公司开发部的成立,针对各项生产经营活动的系统支撑逐步到位,在开发过程中,数据库存储过程应用逐渐广泛,这里我来简要介绍下存储过程。 一、什么是存储过程: 存储过程(Stored Procedure)是在大型数据库系统中,一组为了完成特定功能的SQL 语句集,存储在数据库中,经过第一次编译后再次调用不需要再次编译,用户通过指定存储过程的名字并给出参数(如果该存储过程带有参数)来执行它。存储过程是数据库中的一个重要对象,任何一个设计良好的数据库应用程序都应该用到存储过程。 二、为什么要用存储过程呢? 存储过程真的那么重要吗,它到底有什么好处呢?存储过程说白了就是一堆SQL 的合并。中间加了点逻辑控制。 1.存储过程处理比较复杂的业务时比较实用。具体分为两个方面:(一)、响应时间上来说有优势:如果你在前台处理的话。可能会涉及到多次数据库连接。但如果你用存储过程的话,就只有一次。存储过程可以给我们带来运行效率提高的好处;(二)、从安全上使用了存储过程的系统更加稳定:程序容易出现BUG 不稳定,而存储过程,只要数据库不出现问题,基本上是不会出现什么问题的。 2.数据量小的项目不用存储过程也可以正常运作。 三、那么什么时候才需要用存储过程? 存储过程不仅仅适用于大型项目,对于中小型项目,使用存储过程也是非常有必要的。其优势主要体现在: 1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL 语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。 2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete 时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。这些操作,如果用程序来完成,就变成了一条条的SQL 语句,可能要多次连接数据库。而换成存储,只需要连接一次数据库就可以了。 3.存储过程可以重复使用,可减少数据库开发人员的工作量。 4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权。 5.更强的适应性:由于存储过程对数据库的访问是通过存储过程来进行的,因此数据库开发人员可以在不改动存储过程接口的情况下对数据库进行任何改动,而这些改动不会对应用程序造成影响。 6.分布式工作:应用程序和数据库的编码工作可以分别独立进行,而不会相互压制。 一般来说,存储过程的编写比基本SQL语句复杂,编写存储过程需要更高的技能,更丰富的经验。 四、系统开发中存储过程使用的优势和劣势 优点如下: 1.执行效率高。 2.安全性能好。 3.对于一些场合非常容易实现需求。 缺点如下: 1.可维护性比较差。 2.可读性也差。
SQL Server在存储过程中编写事务处理代码的三种方法 SQL Server中数据库事务处理是相当有用的,鉴于很多SQL初学者编写的事务处理代码存往往存在漏洞,本文我们介绍了三种不同的方法,举例说明了如何在存储过程事务处理中编写正确的代码。希望能够对您有所帮助。 在编写SQL Server 事务相关的存储过程代码时,经常看到下面这样的写法: begin tran update statement 1 ... update statement 2 ... delete statement 3 ... commit tran 这样编写的SQL存在很大隐患。请看下面的例子: create table demo(id int not null) go begin tran insert into demo values (null) insert into demo values (2) commit tran go 执行时会出现一个违反not null 约束的错误信息,但随后又提示(1 row(s) affected)。我们执行select * from demo 后发现insert into demo values(2) 却执行成功了。这是什么原因呢? 原来SQL Server在发生runtime 错误时,默认会rollback引起错误的语句,而继续执行后续语句。 如何避免这样的问题呢? 有三种方法:
1. 在事务语句最前面加上set xact_abort on set xact_abort on begin tran update statement 1 ... update statement 2 ... delete statement 3 ... commit tran go 当xact_abort 选项为on 时,SQL Server在遇到错误时会终止执行并rollback 整个事务。 2. 在每个单独的DML语句执行后,立即判断执行状态,并做相应处理。 begin tran update statement 1 ... if@@error<>0 begin rollback tran goto labend end delete statement 2 ... if@@error<>0 begin rollback tran goto labend end commit tran labend: go 3. 在SQL Server 2005中,可利用try...catch 异常处理机制。
https://www.doczj.com/doc/6517462719.html,事务处理 一事务处理介绍 事务是这样一种机制,它确保多个SQL语句被当作单个工作单元来处理。事务具有以下的作用: * 一致性:同时进行的查询和更新彼此不会发生冲突,其他 用户不会看到发生了变化但尚未提交的数据。 * 可恢复性:一旦系统故障,数据库会自动地完全恢复未完 成的事务。 二事务与一致性 事务是完整性的单位,一个事务的执行是把数据库从一个一 致的状态转换成另一个一致的状态。因此,如果事务孤立执行时是正确的,但如果多个事务并发交错地执行,就可能相互干扰,造成数据库状态的不一致。在多用户环境中,数据库必须避免同时进行的查询和更新发生冲突。这一点是很重要的,如果正在被处理的数据能够在该处理正在运行时被另一用户的修改所改变,那么该处理结果是不明确的。 不加控制的并发存取会产生以下几种错误: 1 丢失修改(lost updates) 当多个事务并发修改一个数据时,不加控制会得出错误的结 果,一个修改会覆盖掉另一个修改。 2 读的不可重复性 当多个事务按某种时间顺序存取若干数据时,如果对并发存 取不加控制,也会产生错误。 3 脏读(DIRDY DATA),读的不一致性 4 光标带来的当前值的混乱 事务在执行过程中它在某个表上的当前查找位置是由光标表 示的。光标指向当前正处理的记录。当处理完该条记录后,则指向下一条记录。在多个事务并发执行时,某一事务的修改可能产生负作用,使与这些光标有关的事务出错。 5 未释放修改造成连锁退出 一个事务在进行修改操作的过程中可能会发生故障,这时需 要将已做的修改回退(Rollback)。如果在已进行过或已发现错误尚未复原之前允许其它事务读已做过修改(脏读),则会导致连锁退出。 6 一事务在对一表更新时,另外的事务却修改或删除此表的 定义。 数据库会为每个事务自动地设置适当级别的锁定。对于前面 讲述的问题:脏读、未释放修改造成的连锁退出、一事务在对一表更新时另外的事务却修改或删除此表的定义,数据库都会自动解决。而另外的三个问题则需要在编程过程中人为地定义事务或加锁来解决。 三事务和恢复 数据库本身肩负着管理事务的责任。事务是最小的逻辑工作
SqlServer 使用存储过程导出为Excel 一个脱离office组件的可以将语句结果导出到Excel的过程 --1.执行时所连接的服务器决定文件存放在哪个服务器 [sql]view plain copy print? 1.CREATE PROC ExportFile 2. @QuerySql VARCHAR(max) 3. ,@Server VARCHAR(20) 4. ,@User VARCHAR(20) = 'sa' 5. ,@Password VARCHAR(20) 6. ,@FilePath NVARCHAR(100) = 'c:\ExportFile.csv' 7.AS 8.DECLARE @tmp VARCHAR(50) = '[##Table' + CONVERT(VARCHAR(36),NEWID())+']' 9.BEGIN TRY 10.DECLARE @Sql VARCHAR(max),@DataSource VARCHAR(max)=''; 11.--判断是否为远程服务器 12. IF @Server <> '.'AND @Server <> '127.0.0.1' 13.SET @DataSource = 'OPENDATASOURCE(''SQLOLEDB'',''Data Source='+@Server+';User ID='+@Us er+';Password='+@Password+''').' 14.--将结果集导出到指定的数据库 15.SET @Sql = REPLACE(@QuerySql,' from ',' into '+@tmp+ ' from ' + @DataSource) 16. PRINT @Sql 17.EXEC(@Sql) 18. 19.DECLARE @Columns VARCHAR(max) = '',@Data NVARCHAR(max)='' 20.SELECT @Columns = @Columns + ',''' + name +''''--获取列名(xp_cmdshell导出文件没有列名) 21. ,@Data = @Data + ',Convert(Nvarchar,[' + name +'])'--将结果集所在的字段更新为nvarchar(避 免在列名和数据union的时候类型冲突) 22.FROM tempdb.sys.columns WHERE object_id = OBJECT_ID('tempdb..'+@tmp) 23.SELECT @Data = 'SELECT ' + SUBSTRING(@Data,2,LEN(@Data)) + ' FROM ' + @tmp 24.SELECT @Columns = 'Select ' + SUBSTRING(@Columns,2,LEN(@Columns)) 25.--使用xp_cmdshell的bcp命令将数据导出 26.EXEC sp_configure 'xp_cmdshell',1 27. RECONFIGURE 28.DECLARE @cmd NVARCHAR(4000) = 'bcp "' + @Columns+' Union All ' + @Data+'" queryout ' + @Fi lePath + ' -c' + CASE WHEN RIGHT(@FilePath,4) = '.csv'THEN' -t,'ELSE''END + ' -T' 29. PRINT @cmd 30.exec sys.xp_cmdshell @cmd 31.EXEC sp_configure 'xp_cmdshell',0 32. RECONFIGURE 33.EXEC('DROP TABLE ' + @tmp) 34.END TRY 35.BEGIN CATCH
Oracle存储过程中的事务处理 当在SQL*Plus中进行操作时,用户可以使用COMMIT语句将在事务中的所有操作“保存”到数据库中。如果用户需要撤销所有的操作,则可以使用ROLLBACK语句回退事务中未提交的操作,使数据库返回到事务处理开始前的状态。在PL/SQL过程中,不仅可以包括插入和更新这类的DML操作,还可以包括事务处理语句COMMIT和ROLLBACK。 Oracle支持事务的嵌套,即在事务处理中进行事务处理。在嵌套的事务处理过程中,子事务可以独立于父事务处理进行提交和回滚。对于过程而言,每个过程就相当于一个子事务,用户可以在自己事务处理的任何地方调用该过程,并且无论父事务是提交还是回滚,用户都可以确保过程中的子事务被执行。 下面通过一个示例演示过程中的事务处理。 (1)以用户SCOTT身份连接到数据库,并建立两个表TEMP和LOG_TABLE。 SQL> create table temp(n number); 表已创建。 SQL> create table log_table( 2 username varchar2(20), 3 message varchar2(4000)); 表已创建。 (2)建立一个存储过程INSERT_INTO_LOG,用于向表LOG_TABLE添加记录。 SQL> create or replace procedure insert_into_log(msg_param varchar2) is 2 pragma autonomous_transaction; 3 begin 4 insert into log_table(username,message) 5 values(user,msg_param); 6 commit; 7 end insert_into_log; 8 / 过程已创建。 其中,PRAGMA AUTONOMOUS_TRANSACTION语句表示自动开始一个自治事务,实际上该语句也可以省略。 (3)在匿名程序块中调用INSERT_INTO_LOG过程向LOG_TABLE表中添加数据,并使用INSERT语句向表TEMP添加数据。 SQL> begin 2 insert_into_log('添加数据到TEMP表之前调用'); 3 insert into temp 4 values(1); 5 insert_into_log('添加数据到TEMP表之后调用'); 6 rollback;
列出SQLServer数据库中所有的存储过程 Dim cn As rdoConnection Dim ps As rdoPreparedStatement Dim rs As rdoResultset Dim strConnect As String Dim strSQL As String '利用 DSNless 连接到 pubs 数据库 '改变参数以适合你自己的 SQL Server strConnect = "Driver={SQL Server}; Server=myserver; " & "Database=pubs; Uid=sa; Pwd=" Set cn = rdoEnvironments(0).OpenConnection(dsName:="", Prompt:=rdDriverNoPrompt, ReadOnly:=False, Connect:=strConnect) strSQL = "Select https://www.doczj.com/doc/6517462719.html,,https://www.doczj.com/doc/6517462719.html,,https://www.doczj.com/doc/6517462719.html,,sc.length " & "FROM syscolumns sc,master..systypes st,sysobjects so " & "WHERE sc.id in (select id from sysobjects where type ='P')" & " AND so.type ='P' " & "AND sc.id = so.id " & "AND sc.type = st.type " & "AND sc.type <> 39" Set ps = cn.CreatePreparedStatement("MyPs", strSQL) Set rs = ps.OpenResultset(rdOpenStatic) list1.AddItem "SP Name,Param Name,Data Type,Length" While Not rs.EOF list1.AddItem rs(0) & " , " & rs(1) & " , " & rs(2) & " , " & rs(3) rs.MoveNext Wend rs.Close Set rs = Nothing cn.Close Set cn = Nothing 【
什么时候使用存储过程比较适合? 当一个事务涉及到多个SQL语句时或者涉及到对多个表的操作时就要考虑用存储过程;当在一个事务的完成需要很复杂的商业逻辑时(比如,对多个数据的操作,对多个状态的判断更改等)要考虑;还有就是比较复杂的统计和汇总也要考虑,但是过多的使用存储过程会降低系统的移植性。为了系统的控制方便,例如当系统进行调整时,这是只需要将后台存储过程进行更改,而不需要更改客户端程序。也无需重新安装客户端应用程序。存储过程不仅仅适用于大型项目,对于中小型项目,使用存储过程也是非常有必要的。其威力和优势主要体现在: 1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL 语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。 2.当对数据库进行复杂操作时(如对多个表进行 Update,Insert,Query,Delete 时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。这些操作,如果用程序来完成,就变成了一条条的SQL 语句,可能要多次连接数据库。而换成存储,只需要连接一次数据库就可以了。 3.存储过程可以重复使用,可减少数据库开发人员的工作
量。 4.安全性高,可设定只有某此用户才具有对指定存储过程 的使用权。优点: 1.速度快。尤其对于较为复杂的逻辑,减少了网络流量之间的消耗 我有的过程和函数达到了几百行,一个微型编译器,相信用程序就更麻烦了。 2.写程序简单,采用存储过程调用类,调用任何存储过程都只要1-2行代码。 (我不知道别人怎么调用,我是深受其益) 3.升级、维护方便 4.调试其实也并不麻烦,可以用查询分析器 5.如果把所有的数据逻辑都放在存储过程中,那么https://www.doczj.com/doc/6517462719.html, 只需要负责界面的显示阿什么的,出错的可能性最大就是在存储过程。我碰到的就一般是这种情况。缺点: 1.可移植性差,我一直采用sql server开发,可是如果想卖 自己的东西,发现自己简直就是在帮ms卖东西,呵呵。想换成mysql,确实移植麻烦。 2.采用存储过程调用类,需要进行两次调用操作,一次是从sql server中取到过程的参数信息,并且建立参数;第二次 才是调用这个过程。多了一次消耗。 不过这个缺点可以在项目开发完成,过程参数完全确定之后,
Java调用SQL Server存储过程 Java调用SQL Server的存储过程详解,主要内容: ●使用不带参数的存储过程 ●使用带有输入参数的存储过程 ●使用带有输出参数的存储过程 ●使用带有返回状态的存储过程 ●使用带有更新计数的存储过程 1.使用不带参数的存储过程 使用JDBC 驱动程序调用不带参数的存储过程时,必须使用call SQL 转义序列。不带参数的call 转义序列的语法如下所示: 实例:在SQL Server 2005 AdventureWorks示例数据库中创建以下存储过程: 此存储过程返回单个结果集,其中包含一列数据(由Person.Contact 表中前十个联系人的称呼、名称和姓氏组成)。 在下面的实例中,将向函数传递AdventureWorks示例数据库的打开连接,然后使用executeQuery方法调用GetContactFormalNames存储过程。
2.使用带有输入参数的存储过程 使用JDBC 驱动程序调用带参数的存储过程时,必须结合SQLServerConnection 类的prepareCall方法使用call SQL转义序列。带有IN参数的call转义序列的语法如下所示: 构造call转义序列时,请使用?(问号)字符来指定IN参数。此字符充当要传递给该存储过程的参数值的占位符。可以使用SQLServerPreparedStatement类的setter方法之一为参数指定值。可使用的setter方法由IN参数的数据类型决定。 向setter方法传递值时,不仅需要指定要在参数中使用的实际值,还必须指定参数在存储过程中的序数位置。例如,如果存储过程包含单个IN参数,则其序数值为1。如果存储过程包含两个参数,则第一个序数值为1,第二个序数值为2。 作为调用包含IN参数的存储过程的实例,使用SQL Server 2005 AdventureWorks示例数据库中的uspGetEmployeeManagers存储过程。此存储过程接受名为EmployeeID的单个输入参数(它是一个整数值),然后基于指定的EmployeeID返回雇员及其经理的递归列表。下面是调用此存储过程的Java代码:
USE[zhuhaioa7-4] GO /****** Object: StoredProcedure [dbo].[proc_records] Script Date: 12/26/2014 20:31:09 ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO ALTER procedure[dbo].[proc_records] as DECLARE@map_table table(r_key varchar(100),r_value varchar(50)) DECLARE@type_id varchar(40) DECLARE@type_name varchar(50) DECLARE@project_id varchar(40) DECLARE@project_name varchar(50) DECLARE@payTypeMoney numeric(16, 2) DECLARE@sumPayTypeMoney numeric(16, 2) BEGIN set@payTypeMoney= 0 set@sumPayTypeMoney= 0 --查询项目列表 DECLARE project_cursor CURSOR for select ep_id,ep_name from AB_engineeringPhase where account_id='2' open project_cursor fetch next from project_cursor into@project_id,@project_name while@@FETCH_STATUS= 0 begin
存储过程和函数的区别 存储过程是用户定义的一系列sql语句的集合,涉及特定表或其它对象的任务,用户可以调用存储过程,而函数通常是数据库已定义的方法,它接收参数并返回某种类型的值并且不涉及特定用户表。 . l 视图的优点?建立视图的基本语法结构? 视图的优点: 1. 视图对于数据库的重构造提供了一定程度的逻辑独立性。数据的逻辑独立性是指数据库重构造时,如数据库扩大(增加了新字段,新关系等),用户和用户程序不会受影响。 2. 简化了用户观点。视图的机制使用户把注意力集中在他所关心的数据上。若这些数据不是直接来自基本表,则可以定义视图,从而使用户眼中的数据结构简单而直接了当,并可大大简化用户的数据查询操作,特别是把若干表连接在一起的视图,把从表到表所需要的连接操作向用户隐蔽了起来。 3. 视图机制使不同的用户能以不同的方式看待同一数据。 4. 视图机制对机密数据提供了自动的安全保护功能。可以把机密数据从公共的数据视图(基本表)中分离出去,即针对不同用户定义不同的视图,在用户视图中不包括机密数据的字段。这样,这类数据便不能经由视图被用户存取,从而自动地提供了对机密数据的保护。 视图的基本语法结构: CREATE VIEW view_name [(column ][,...n])] AS select_statement 其中view_name为要建立的视图的名称,而AS子句后面的就是建立视图的查询语句。而此语句有以下限制:不能包含ORDER BY、COMPUTE和COMPUTE BY等子句;不能包含INTO 关键字;不能涉及临时表。 . l 事务是什么? 事务是作为一个逻辑单元执行的一系列操作,一个逻辑工作单元必须有四个属性,称为ACID (原子性、一致性、隔离性和持久性)属性,只有这样才能成为一个事务: 1、原子性:事务必须是原子工作单元;对于其数据修改,要么全都执行,要么全都不执行。 2、一致性:事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规
SQLSERVER存储过程使用说明书 引言 首先介绍一下什么是存储过程:存储过程就是将常用的或很复杂的工作,预先用SQL语句写好并用一个指定的名称存储起来,并且这样的语句是放在数据库中的,还可以根据条件执行不同SQL语句,那么以后要叫数据库提供与已定义好的存储过程的功能相同的服务时,只需调用execute,即可自动完成命令。 请大家先看一个小例子: create proc query_book as select * from book go --调用存储过程 exec query_book 请大家来了解一下存储过程的语法。 Create PROC [ EDURE ] procedure_name [ ; number ] [ { @parameter data_type } [ VARYING ] [ = default ] [ OUTPUT ] ] [ ,...n ] [ WITH { RECOMPILE | ENCRYPTION | RECOMPILE , ENCRYPTION } ] [ FOR REPLICATION ] AS sql_statement [ ...n ] 一、参数简介 1、procedure_name 新存储过程的名称。过程名必须符合标识符规则,且对于数据库及其所有者必须唯一。 要创建局部临时过程,可以在 procedure_name 前面加一个编号 符 (#procedure_name),要创建全局临时过程,可以在 procedure_name 前面加两
个编号符 (##procedure_name)。完整的名称(包括 # 或 ##)不能超过 128 个字符。指定过程所有者的名称是可选的。 2、;number 是可选的整数,用来对同名的过程分组,以便用一条 Drop PROCEDURE 语句即可将同组的过程一起除去。例如,名为 orders 的应用程序使用的过程可以命名为 orderproc;1、orderproc;2 等。Drop PROCEDURE orderproc 语句将除去整个组。如果名称中包含定界标识符,则数字不应包含在标识符中,只应 在 procedure_name 前后使用适当的定界符。 3、@parameter 过程中的参数。在 Create PROCEDURE 语句中可以声明一个或多个参数。用户必须在执行过程时提供每个所声明参数的值(除非定义了该参数的默认值)。存储过程最多可以有 2100 个参数。 使用@符号作为第一个字符来指定参数名称。参数名称必须符合标识符的规则。每个过程的参数仅用于该过程本身;相同的参数名称可以用在其它过程中。默认情况下,参数只能代替常量,而不能用于代替表名、列名或其它数据库对象的名称。 4、data_type 参数的数据类型。所有数据类型(包括 text、ntext 和 image)均可以用作存储过程的参数。不过,cursor 数据类型只能用于 OUTPUT 参数。如果指定的数据类型为 cursor,也必须同时指定 VARYING 和 OUTPUT 关键字。 说明:对于可以是cursor 数据类型的输出参数,没有最大数目的限制。 5、VARYING 指定作为输出参数支持的结果集(由存储过程动态构造,内容可以变化)。仅适用于游标参数。 6、default 参数的默认值。如果定义了默认值,不必指定该参数的值即可执行过程。默认值必须是常量或 NULL。如果过程将对该参数使用 LIKE 关键字,那么默认值中可以包含通配符(%、_、[] 和 [^])。 7、OUTPUT
存储过程的优点 2007-11-02 15:21 1.存储过程只在创造时进行编译即可,以后每次执行存储过程都不需再重新编译,而我们通常使用的SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。 2.经常会遇到复杂的业务逻辑和对数据库的操作,这个时候就会用SP来封装数据库操作。当对数据库进行复杂操作时(如对多个表进行Update, Insert,Query,Delete时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。可以极大的提高数据库的使用效率,减少程序的执行时间,这一点在较大数据量的数据库的操作中是非常重要的。在代码上看,SQL 语句和程序代码语句的分离,可以提高程序代码的可读性。 3.存储过程可以设置参数,可以根据传入参数的不同重复使用同一个存储过程,从而高效的提高代码的优化率和可读性。 4.安全性高,可设定只有某此用户才具有对指定存储过程的使用权存储过程的种类: (1)系统存储过程:以sp_开头,用来进行系统的各项设定.取得信息.相关管理工作,如 sp_help就是取得指定对象的相关信息。 (2)扩展存储过程以XP_开头,用来调用操作系统提供的功能 exec master..xp_cmdshell 'ping 10.8.16.1' (3)用户自定义的存储过程,这是我们所指的存储过程常用格式 模版:Create procedure procedue_name [@parameter data_type][output] [with]{recompile|encryption} as sql_statement 解释:output:表示此参数是可传回的 with {recompile|encryption} recompile:表示每次执行此存储过程时都重新编译一次;encryption:所创建的存储过程的内容会被加密。 SQL存储过程实例 2007-11-02 15:24 实例1:只返回单一记录集的存储过程。 表银行存款表(bankMoney)的内容如下
SqlServer 使用存储过程实现插入或更新语句 存储过程的功能非常强大,在某种程度上甚至可以替代业务逻辑层, 接下来就一个小例子来说明,用存储过程插入或更新语句。 1、数据库表结构 2、创建存储过程 1Create proc[dbo].[sp_Insert_Student] 2@No char(10), 3@Name varchar(20), 4@Sex char(2), 5@Age int, 6@rtn int output 7as 8declare 9@tmpName varchar(20), 10@tmpSex char(2), 11@tmpAge int 12 13if exists(select*from Student where No=@No) 14begin 15select@tmpName=Name,@tmpSex=Sex,@tmpAge=Age from Student where No=@No 16if ((@tmpName=@Name) and (@tmpSex=@Sex) and (@tmpAge=@Age)) 17begin 18set@rtn=0 19end 20else 21begin 22update Student set Name=@Name,Sex=@Sex,Age=@Age
where No=@No 23set@rtn=2 24end 25end 26else 27begin 28insert into Student values(@No,@Name,@Sex,@Age) 29set@rtn=1 30end 3、调用存储过程 1declare@rtn int 2exec sp_Insert_Student '1101','张三','男',23,@rtn output 3 4if@rtn=0 5print'已经存在相同的。' 6else if@rtn=1 7print'插入成功。' 8else 9print'更新成功'
首先介绍一下概念,存储过程(Stored Procedure)是一组为了完成特定功能的SQL语句集,是利用SQL Server所提供的Transact-SQL语言所编写的程序。经编译后存储在数据库中。他可以接收参数,可以返回参数的,当然也可以没有参数。个人理解,他和程序中的函数差不多,只不过他是在数据库中创建的。 存储过程分为系统存储过程和自定义存储过程 存储过程的优点: 1.存储过程只在创造时进行编译,以后每次执行存储过程都不需再重新编译,而一般SQL语句每执行一次就编译一次,所以使用存储过程可提高数据库执行速度。 2.当对数据库进行复杂操作时(如对多个表进行Update,Insert,Query,Delete 时),可将此复杂操作用存储过程封装起来与数据库提供的事务处理结合一起使用。这也是我愿意使用它的一个重要原因。 下面是一个带输入参数的一个存储过程 use LineManager go create procProcRegist @CardNovarchar(10), @StuNovarchar(11), @Sex varchar(10), @Grade varchar(10), @ClassNovarchar(10), @ChargeFeevarchar(10), @Name varchar(10), @Department varchar(10), @Explain varchar(50), @UserNamevarchar(10), @OperateDate date ---------------------输入参数 as begin begin transaction insert into Student(StudentNo ,Name ,Sex ,Department ,Grade ,ClassNo ) values (@StuNo ,@Name ,@Sex ,@Department ,@Grade ,@ClassNo ) insert into Regist (CardNo ,StudentNo ,State ,Explain ,UserName ,OperateDate ) values(@CardNo ,@StuNo ,'使用' ,@Explain,@UserName ,@OperateDate ) insert into Charge (CardNo ,ChargeDateTime ,Charge ,UserName ,LastBalance ,CurrentBalanc e ,OrderState ,PrintState )values (@CardNo ,@OperateDate ,@ChargeFee ,@UserName ,0,@ChargeFee ,'未 结账','未打印') if @@ERROR =0
实验三事务与存储过程 一、实验目的 掌握事务操作、游标操作、存储过程使用。二、实验步骤(一准备数据库 1、创建一个名为“ ERP ” +班号 +学号的数据库; 2、建立如下二维表: 客户表
产品表 订单表 订单明细表 (二事务操作 1、计算订单明细中的金额,等于单价乘以数量。 update T_订单明细 set 金额 =单价 *数量 2、将订单明细的金额在原有基础上加 10元,要求放在事务中执行,执行完毕提交事务 begin transaction update T_订单明细 set 金额 =金额 +10 commit
3、将订单明细的金额在原有基础上减 10元,要求放在事务中执行,执行完毕回滚事务 begin transaction update T_订单明细 set 金额 =金额 -10 rollback 4、在订单表以及订单明细表中将最后一张订单删除,要求使用事务。 begin transaction delete from t_订单 where 订单编号 ='R004' delete from t_订单明细 where 订单编号 ='R004' commit (三游标操作 在订单表中有一个总金额字段, 其值等于该订单中所有产品金额的和, 使用游标计算每一订单的总金额。 计算每笔订单总金额 --计算过程 :定义游标,取出每张订单的订单号 --根据订单号汇总明细,代替订单中的金额 --定义订单号、金额合计内存变量 declare @OrderNO varchar (4 declare @OrderSum numeric (12, 2 --定义游标