专业的相片扫描软件VueScan v9.4.26中文版用户指南
2014.5.15整理
老式扫描仪在win8系统下通常无法使用扫描功能,如EPSON Perfection1260扫描仪就是如此。当在win8下安装通用扫描驱动软件VueScan v9.4.26后就可以使用。
专业的相片扫描软件VueScan v9.4.26是现在世界上最著名的第三方扫描软件,持续更新好多年了,老牌经典软件,而且官方完全支持全中文,界面虽嫌简陋,并发现,同一台扫描仪,用Vuescan扫描出来的效果要比用原厂驱动扫描出来的效果要好很多,控制也非常精细,于是Vuescan流行起来。
内容
一、开始使用VueScan
二、常见任务
三、快速设置
四、提示和技巧
五、附录A:先进的工具和技术
六、附录B:按钮,菜单和选项参考
一、开始使用VueScan
VueScan是的,旨在帮助您得到最出你的扫描仪和制作从扫描的照片惊人的业绩有强大的扫描工具。
它是挤满了有用和强大的功能负荷,目前支持超过2300扫描仪35扫描仪制造商。
下面的教程旨在帮助您熟悉的软件,其用户界面,并帮助您扫描您的第一个照片和幻灯片。
你会发现有用的提示和技巧,在这里就如何开展共同的任务,例如批量扫描和扫描至PDF文件。
㈠结识VueScan
如果您以前使用过一台扫描仪,你可能已经遇到过的东西,看起来有点类似于VueScan。但它仍然是值得花一点时间来适应这里的一切是前跳水英寸
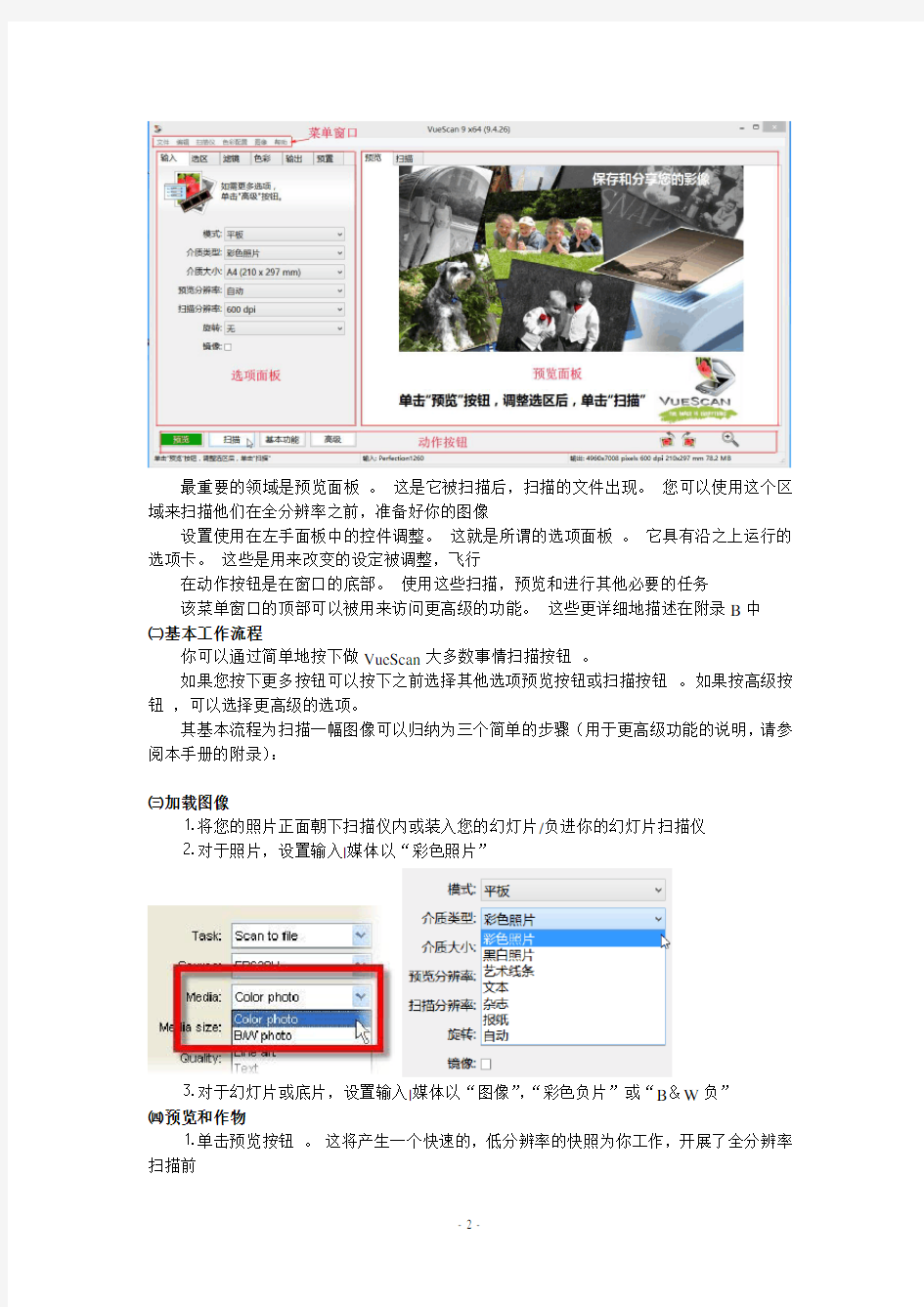
最重要的领域是预览面板。这是它被扫描后,扫描的文件出现。您可以使用这个区域来扫描他们在全分辨率之前,准备好你的图像
设置使用在左手面板中的控件调整。这就是所谓的选项面板。它具有沿之上运行的选项卡。这些是用来改变的设定被调整,飞行
在动作按钮是在窗口的底部。使用这些扫描,预览和进行其他必要的任务
该菜单窗口的顶部可以被用来访问更高级的功能。这些更详细地描述在附录B中
㈡基本工作流程
你可以通过简单地按下做VueScan大多数事情扫描按钮。
如果您按下更多按钮可以按下之前选择其他选项预览按钮或扫描按钮。如果按高级按钮,可以选择更高级的选项。
其基本流程为扫描一幅图像可以归纳为三个简单的步骤(用于更高级功能的说明,请参阅本手册的附录):
㈢加载图像
⒈将您的照片正面朝下扫描仪内或装入您的幻灯片/负进你的幻灯片扫描仪
⒉对于照片,设置输入|媒体以“彩色照片”
⒊对于幻灯片或底片,设置输入|媒体以“图像”,“彩色负片”或“B&W负”
㈣预览和作物
⒈单击预览按钮。这将产生一个快速的,低分辨率的快照为你工作,开展了全分辨率
扫描前
⒉当预览已经完成了你的图像将显示在预览面板
⒊单击并拖动鼠标绘制一个框图像周围。这确保了扫描仪不浪费时间扫描的空白区域
㈤扫描和保存
⒈点击扫描按钮
⒉等待扫描完成。这取决于您的扫描仪,电脑和您要扫描的解析速度
⒊一旦扫描完成后它会自动命名并保存在VueScan目录
二、常见任务
扫描许多照片在一个批处理
扫描多页PDF文件
转VueScan成“复印机”
保存文件
选择不同的分辨率
㈠扫描许多照片在一个批处理
如果你有一大堆,你要扫描的相同尺寸的打印,可以减少所花费的时间量。所有你必须是遵循这些简单的步骤:
⒈负载和预览图像第一
⒈按照步骤1和2中的基本工作流程部分预览您的第一张照片
⒉将照片与对扫描仪的短,底边长边- 这缩短了扫描每张照片的时间
⒉扫描和重复
⒈点击扫描按钮
⒉删除照片
⒊放置在扫描仪的另一照片在完全相同的位置
⒋点击扫描按钮再次
⒌重复,直到任务完成
⒊或...使用VueScan的自动重复设施
⒈这完全自动化的批量扫描过程中,这样你就不必继续点击扫描按钮
⒉在选项面板选择输入选项卡
⒊点击更多按钮
⒋选择自动重复> 5秒延迟
⒌点击扫描按钮。一旦VueScan已经完成了第一次扫描时,将下一个图像中的完全相同的位置。
⒍等待- VueScan将开始下一次扫描在五秒钟
⒎重复,直到你完成,然后单击取消按钮
在每种情况下,VueScan将开展图像进行完全扫描,自动保存,因为它是处理每一个。㈡扫描多页PDF文件
曾经想过能够扫描并发送多页文件给同事,或长杂志文章给朋友海外?利用VueScan 的多页的PDF功能,你将不必送他们作为单独的图像文件了。
以下是如何做到这一点:
调整输出设置
⒈选择输出选项卡在顶部选项面板
⒉单击两个勾选框:PDF文件和PDF多页
负载和预览第一页
⒈按照步骤1和2在本教程的基本工作流程部分以预览文档的第一页
⒉点击扫描按钮
扫描每个页面在继承
⒈将下一页在相同的位置和相同的方向与第一
⒉点击扫描按钮
⒊重复,直到文件完成扫描
⒋提示:您可以自动完成这一过程-只需按照在批处理部分扫描许多照片第3步中的说明
完成这项工作
⒈单击文件菜单窗口的顶部,然后选择文件|尾页
⒉自动VueScan名的文件,并启动PDF格式的Adobe Acrobat Reader软件给你,让你可以检查它。
㈢转VueScan成“复印机”
VueScan可以用来直接发送图片和文件到您的打印机,有效地把它变成一台复印机。
以下是如何做到这一点:
更改输入模式
⒈选择输入选项卡上的选项面板
⒉设置输入|任务为“复制到打印机”
预览,作物和扫描
⒈按照步骤本教程预览和扫描图像的基本工作流程部分的1,2和3
⒉VueScan将直接发送生成的映像文件到您的打印机
⒊点击打印来完成工作
或...使用打印按钮
⒈按照步骤1,2和3本教程以预览的基本工作流程的一部分,并扫描图像
⒉点击打印按钮的下方的预览面板
⒊点击打印来完成工作
㈣保存文件
VueScan自动保存每次自动扫描影像或文件,并把它放在一个默认文件夹。
但是,您可以更改此,如果你想以不同的方式组织您的图像。
这是很容易设置:
选择文件夹
⒈选择输出选项卡上的选项面板
⒉点击旁边的按钮@ 输出|默认文件夹选项
⒊要保存图像使用浏览文件夹窗口中选择。单击OK(确定)
为图片
⒈在文件名框中,删除那里的东西已经并键入一个名称为图像
⒉添加后的一些数字的名称的末尾加号- VueScan然后将保存每个后续扫描,自动编号的每一个序列中
⒊例如image01 +会产生:image01.jpg,image02.jpg,image03.jpg ...等等
㈤选择不同的分辨率
这取决于你想与你的文档和图片什么的,你可能需要扫描它们在不同的分辨率。
决定的分辨率来扫描影像的最佳方式是利用VueScan的预设。这使您可以快速选择正确的分辨率为手头的任务:
选择输出介质
⒈选择输入选项卡上的选项面板
⒉如果你要输出的图像发送至打印机去到下一个步骤,否则点击扫描按钮现在
选择输出尺寸
⒈选择输出选项卡上的选项面板
⒉选择您想在从打印尺寸输出|打印尺寸的选择
三、快速设置
每个任务到目前为止已经进行了使用基本的,缺省设置。这些都是罚款扫描照片上平板扫描仪。
如果您要扫描的文件,杂志文章幻灯片或底片,但是,你需要使用不同的设置。
这里有一个快速指导,建立VueScan对不同类型的媒体:
㈠彩色幻灯片
⒈选择文件|缺省选择从文件菜单中重置VueScan
⒉选择输入选项卡上的选项面板
⒊设置输入|来源到您的扫描仪
⒋设置输入|模式,以“透明”
⒌设置输入|媒体以“图像”
㈡黑白商业文档
⒈选择文件|缺省选择从文件菜单中重置VueScan
⒉选择输入选项卡上的选项面板
⒊设置输入|来源到您的扫描仪
⒋设置输入|模式,以“平板”(可选-取决于扫描仪)
⒌设置输入|媒体为“文本”
㈢彩色杂志文章
⒈选择文件|缺省选择从文件菜单中重置VueScan
⒉选择输入选项卡上的选项面板
⒊设置输入|来源到您的扫描仪
⒋设置输入|模式,以“平板”(可选-取决于扫描仪)
⒌设置输入|媒体为“杂志”
㈣黑白胶片
⒈传统的黑色和白色(卤化银)
⒈选择文件|缺省选择从文件菜单中重置VueScan
⒉选择输入选项卡上的选项面板
⒊设置输入|来源到您的扫描仪
⒋设置输入|模式,以“透明”
⒌设置输入|媒体以“B / W负”
⒉显色黑色和白色(或C-41彩色处理)
⒈选择文件|缺省选择从文件菜单中重置VueScan
⒉选择输入选项卡上的选项面板
⒊设置输入|来源到您的扫描仪
⒋设置输入|模式,以“透明”
⒌设置输入|媒体以“彩色负片”
㈤黑白反转片
⒈选择文件|缺省选择从文件菜单中重置VueScan
⒉选择输入选项卡上的选项面板
⒊设置输入|来源到您的扫描仪
⒋设置输入|模式,以“透明”
⒌设置输入|媒体以“图像”
四、提示和技巧
㈠扫描图像只有一次
如果你想尝试处理负片或幻灯片的方式不同,你并不需要扫描一次以上。原始扫描数据,预览和扫描保存在内存中。刚刚调整设置,并使用文件|保存图像的命令上文件菜单保存图像一次。
㈡被歧视
在很多照片扫描时节省时间的最好方法是,先什么,你扫描了一些艰难的决定。一个好的经验法则是,你应该只从一卷胶卷扫描五分之一的照片。大多数人都可以通过一组36张照片或幻灯片,并快速查看7或8,他们希望进行扫描。
当然,如果这是唯一现存的照片你父母的婚礼,那么你可能要扫描他们所有。否则,是鉴别- 没有人需要从10年前(笑)扫描出来的一个表姐的朋友的后花园焦点图片。
㈢使用JPEG文件
通过扫描所有照片和幻灯片使用JPEG文件格式保存的磁盘空间。很少有人会看到的JPEG文件和文件类型如TIFF和BMP之间没有太大的区别,但JPEG文件只占用10%的这些其他文件类型的磁盘空间美分。随着VueScan,设置输出| JPEG文件做到这一点。
㈣备份到CD
每一天的工作后,每次烧你已经扫描到CD,标记光盘,然后确保你可以阅读从CD影像图像。刻录两套CD的,保持一组用于自己,并单独存放的主副本。
只使用主副本,如果你的主副本有问题,否则不要再碰它。如果朋友或亲戚想要一个副本,使他们成为一个副本从主副本。
光盘可以失败,磨损,划伤,迷路,得到了狗吃- 所以始终保持两个副本!
㈤使用默认选项
默认选项已被设计为与大多数的图像和在大多数系统上运行良好。如果您有任何问题扫描,通过选择重置所有选项到默认值默认选项|文件在命令文件菜单。现在试着改变一个选项的时间和重新做扫描。
这也是一个好主意,重置为默认值,每当你开始新的工作。这意味着你可以用一块干
净的石板,每次启动。
㈥使用TIFF格式,如果从VueScan存档或编辑文件
每一次的图像保存为JPEG格式,关于图像的一些信息丢失,即使在最高画质(和最低的压缩)的水平。这种效应加剧,如果你保存一个文件,然后进行一些更改并再次保存。所以,如果你打算编辑或者修改你的图片在以后的日子,JPEG是不是理想的选择相反,使用TIFF格式,其存储所有的图像的数据的无损失压缩时也是如此。TIFF是归档文件的一个不错的选择,并且在像Photoshop(TM)的图像编辑应用图像操作。TIFF 格式的缺点是文件大小。压缩甚至当文件比JPEG格式大很多。
刻录TIFF文件,以高品质的CD-R或DVD光盘永久存档
㈦减少作物|预览区上的平板扫描仪,以提高扫描时间
很多参与了扫描时间是采取与扫描头的移动(用于平板式扫描仪)或媒体持有人(电影扫描仪)。下面的技巧会产生更快的扫描。
放置在扫描仪的横向传媒(放置照片的长边,例如,对扫描仪的短,底边)。这减少了需要被覆盖的扫描头的区域。
㈧从纸与OCR软件使用扫描文本
在扫描打印文档时获得最佳效果,请在输入|媒体为“文本”。这将确保结果限制为黑色和白色,这将降低噪音。通常情况下的OCR软件包希望TIFF文件格式; 设置输出| TIFF 文件。您还可以找到输出| TIFF多页,并输出| PDF多页选项很有用,因为多个页面将被保存在一个文件中。
㈨关闭旋转扫描,如果内存有限
如果保存比的内存量显著放大你的电脑上的影像,设定输入|旋转到无.。这将使得裁剪快得多。
五、附录A:先进的工具和技术
最常见的任务已被覆盖上一节中。下一节将介绍如何利用一些VueScan的更先进的功能。
调整色彩平衡
直方图
计算每英寸点数为阴性
使用原始扫描文件
先进的工作流程建议
扫描仪评测与IT8目标
打印机设置与IT8目标
电影剖析与IT8目标
如何VueScan工程
扫描彩色负片
扫描黑/白负片
最大限度地提高图像质量
文件格式
电影类型
㈠调整色彩平衡
正确的色彩平衡是至关重要的任何图像看起来令人信服。中性的颜色应该保持中立,其他颜色逼真。
VueScan的默认设置为颜色|颜色平衡(“白平衡”)能够对扫描的绝大多数自动执行此操作。我们说对于绝大多数因为如果你已经采取了一枪不寻常的照明,它可以混淆白平衡算法。
从日落的光,例如,可被调节以使地面呈灰色,而不是橙色和鲜花扫描可能会较不强烈。
为了解决这个问题:
更改颜色|颜色平衡的“白平衡”至“中性”
如果你扫描幻灯片,然后确保你设置输入|媒体以“图像”
您可以设定中性色自己的价值通过使用手动设置,但是要注意这似乎违反直觉的降低红色的中性色,比如,会增加图像的整体红色。
它更容易使用鼠标右键,单击一个中性色(灰色的即阴影)来更新色彩平衡(与Mac OS X使用的控制键)。您可以通过双击用鼠标右键(Mac OS X中使用的控制键)在图像上重设色彩平衡,白平衡。
㈡直方图
直方图是显示色调和色彩的扫描图像中的分布图。暗色调显示在x轴的曲线图,光的色调在右端的左端,并且中间色调是在中间。
有在VueScan提供四种不同的直方图的图形,这些可以显示在选项面板中通过选择一个图片|图表...从选择图像菜单。
以下是对每个人做一个说明:
图表原料:显示从已作出任何调整前的色调和色彩直方图
图形图像:在你使用下面的两个图进行了调整显示的色调和色彩直方图..
图 B / W:允许您设置黑点和白点的阈值。此作品以类似的方式在图像编辑器(如Photoshop)(TM)水平的工具。拖动箭头在图中的底部进行调整
图形曲线:类似于图像编辑器,如Photoshop的曲线工具,这可以让你微调高光,中间色调和阴影。拖动箭头在图中的底部进行调整
㈢计算每英寸点数为阴性
下面显示了一个基本公式为扩大负最多打印尺寸。要注意的是一个35mm的帧将正确地按比例缩放到一个4x6in和8x12in打印是重要的。**
比例公式:(最终图像宽度X打印机DPI)/原始大小=扫描仪的分辨率
例如,如果你想以300 dpi的打印机上打印从一个4x6in打印一个35mm底片,首先计算宽度:
4英寸×300打印机的DPI = 1200,然后按原来的0.9448英寸= 1270(自定义扫描dpi)的划分
然后,只是要确定,计算高度:
6英寸×300 dpi的= 1800,然后按原来的1.417英寸= 1270(自定义扫描dpi)的划分扩展到任何的5x7英寸或8×10英寸,你应该计算使用较大尺寸,以避免裁剪的照片(例如:7 5×7和10 8×10)。如果你想要确切的5x7英寸或8×10英寸,但打算种植在你的照片编辑器使用较低的值。
* 35mm的帧是24X36毫米。这大约相当于0.9448x1.417英寸。
㈣使用原始扫描文件
如果您扫描几个图像一气呵成,扫描每个图像一次,并保存原始CCD数据文件。然后,可以重新处理这些扫描在各种不同的方式,而无需再次扫描图像。这最大限度地减少胶片处理,并以最快的方式重新处理所有的扫描,如果你想尝试不同的选择。
对于批量扫描:
设置选项上输入选项卡中的选项面板中的源和媒体你使用
选择文件|缺省选择从文件菜单,然后按下更多按钮,然后按下高级按钮以显示高级选项
设置裁剪|预览区域为“默认”,作物|裁剪大小为“最大”
在输出选项卡中取消选中所有的选项除了输出|原始文件
为每个图像被扫描时,将创建具有顺序编号的文件,如“scan0001.tif,scan0002.tif”等。
您可以通过更改更改文件夹和文件名的RAW文件|输出name选项。
重新处理这些原始文件:
设置输入|来源选择“文件”,并设置输入|文件以指向在该系列的启动文件(如scan0001.tif)
使用文件|默认选项命令来设置所有其他选项,它们的默认值,然后设置其它选项,如果你是扫描的图像
设置输入|批量扫描到“全部”扫描所有文件,或者将其设置为“列表”和手动设置帧数。例如,如果您将其设置为1-3,5,7,然后scan0001.tif,scan0002.tif,scan0003.tif,scan0005.tif 和scan0007.tif会当您按下扫描按钮处理。
您可能还需要遵循的程序在本使用说明书的高级工作流程的建议部分锁定曝光和片基颜色的膜整卷。这将提供最佳的扫描质量。
㈤先进的工作流程建议
如果您扫描几个帧从电影的同一卷,下面的程序将优化设置的CCD曝光和胶片基色(即面膜的颜色):
按下高级按钮
⒈设置输入|媒体
⒉插入膜与透明区域
⒊如果输入|锁定曝光是可见的,明确的输入|锁定曝光
⒋按下预览按钮
⒌如有必要,调整种植
⒍如果输入|锁定曝光是可见的,设置输入|锁定曝光
⒎按下预览按钮,再次
⒏如果输入|锁片基的颜色是可见的,设置输入|锁片基的颜色
对于上面的步骤#2,使用具有将打印为纯黑色为负极,或纯白色的滑梯的区域在电影画面。
无论每一帧的光照条件,快门速度和光圈的,你应该曝光和扫描所有帧上的电影胶卷基色使用这些固定的值。一旦你有了固定曝光和片基的颜色,你可以扫描使用这些值膜整卷。
如果您使用的是相同的照明对辊(或帧的子集)的所有帧,可以通过扫描亮框系列中,然后设置锁定的色彩平衡锁定图像色彩|输入选项。这将锁定黑白点的场景,并会产生一致的色彩系列中的所有帧。这也是有用的,如果你要扫描的已经全部采取了相同的光线,快门速度和光圈的全景场景,或者如果你扫描系列提供相同的光线,快门速度和光圈拍摄的工作室拍摄的。
要优化工作流程,扫描到原始文件,后来与色彩校正试验。请确保你第一次设置输入|锁定曝光扫描一卷胶卷之前。
如果要保存原始扫描文件,你可以关闭输出| TIFF文件和输出| JPEG文件。您也可以通过清除捕捉整个预览区域而不是自动裁剪区域作物|自动偏移和作物|自动旋转和设置裁剪|裁剪大小为“最大”。
为了更快的批量扫描,设置输入|锁定曝光和清晰的作物|自动偏移和作物|自动旋转。这将从创建一个预览停止扫描按钮。
㈥扫描仪评测与IT8目标
扫描器分析是确定扫描仪或数码相机的精确颜色特征的过程。VueScan使用IT8目标(也称为Q60目标)来做到这一点。
IT8目标所包含的许多扫描仪。您还可以获取IT8目标,从这个来源:
狼浮士德:http://www.targets.coloraid.de/
要配置您的扫描仪或数码相机与IT8目标:
⒈设置输入|任务为“个人扫描仪”
⒉点击'@'按钮旁边的颜色|扫描IT8数据,并选择随IT8目标的IT8描述文件
⒊按下预览按钮
⒋如果必要,可旋转预览图像,以使灰度级是在底部与字母和数字可以正常读
⒌调整VueScan裁剪面具的大小,直到它IT8目标图像匹配
⒍您可能需要重新调整目标在扫描仪上压台,并按下预览按钮,再如果图像是在一个角度
⒎选择公司简介|个人资料扫描仪从下拉菜单
⒏ICC配置文件将被保存在同一个文件夹“scanner.icc”为“vuescan.ini”
如果您以前提出您的扫描仪的ICC配置文件,你只需要做到以下几点:
⒈设置颜色|扫描仪色彩空间,以“ICC配置文件”
⒉设置颜色|扫描仪ICC配置文件到文件的ICC文件的名称
VueScan正常读取和写入的ICC配置文件,使用该文件scanner.icc扫描仪。或者,您也可以输入ICC配置文件的文件名变为彩色|扫描仪ICC配置文件。
每一个IT8目标具有描述目标中的每个正方形的确切颜色相关联的数据文件。您可以通过点击'@'按钮旁边的选择该文件扫描IT8数据|颜色。
同时,ICC和。IT8文件通常位于同一文件夹中vuescan.ini。
需要注意的是在颜色选项卡中的设置不影响分析。看是否剖析工作正常,你应该设置颜色|颜色平衡至“中性”。
㈦打印机设置与IT8目标
打印机配置文件是用于确定打印机的精确颜色特征的过程。此配置文件是唯一的每个纸张类型和每次更改打印机设置选项。
要与IT8目标配置您的打印机:
⒈简介您的扫描仪(见上文)
⒉设置输入|任务“交IT8目标”
⒊按下扫描按钮,这将创建与你的打印机的打印
⒋将打印输出到扫描仪
⒌设置输入|任务为“个人打印机”
⒍按下预览按钮
⒎如果必要,可旋转预览图像,以使灰度级是在底部与字母和数字可以正常读
⒏调整VueScan裁剪面具的大小,直到它IT8目标图像匹配
⒐您可能需要重新调整目标在扫描仪上压台,并按下预览按钮,再如果图像是在一个角度
⒑选择个人资料|简介打印机从下拉菜单
⒒ICC配置文件将被写在VueScan目录printer.icc
如果您以前作出的打印机的ICC配置文件,你只需要做到以下几点:
⒈设置颜色|打印机色彩空间,以“ICC配置文件”
⒉一套彩色|打印机ICC配置文件的ICC文件的文件名
VueScan正常读取和写入的ICC配置文件,使用该文件printer.icc打印机。或者,您也可以输入ICC配置文件的文件名变为彩色|打印机ICC配置文件。
㈧电影剖析与IT8目标
膜分析是确定彩色负片的精确颜色特征的过程。要做到这一点,你需要采取一个IT8目标的图像和扫描这个框架。确保图像是矩形的薄膜。
您可以从获得一张A4大小的相机目标:
狼浮士德:http://www.targets.coloraid.de/
要与IT8目标配置您的电影:
⒈简介您的扫描仪(见上文)
⒉设置输入|任务为“个人电影”
⒊复制与您的目标走进同一个文件夹vuescan.ini的IT8描述文件,并重新命名副本film.it8
⒋按下预览按钮
⒌如果必要,可旋转预览图像,以使灰度级是在底部与字母和数字可以正常读
⒍调整VueScan裁剪面具的大小,直到它IT8目标图像相匹配。你可能需要再次调整扫描仪上的台板,按预览目标如果图像是在一个角度
⒎选择个人资料|电影简介从下拉菜单
⒏ICC配置文件将被保存在同一文件夹vuescan.ini到film.icc
如果您以前做的一卷胶卷的ICC配置文件,你只需要做到以下几点:
⒈设置颜色|电影色彩空间,以“ICC配置文件”
⒉一套彩色|电影ICC配置文件的ICC文件的文件名
VueScan正常读取并使用该文件film.icc写电影的ICC配置文件。或者,您也可以输入ICC配置文件的文件名变为彩色|电影ICC配置文件。
每一个IT8目标具有描述目标中的每个正方形的确切颜色相关联的数据文件。您可以通过点击'@'按钮旁边的选择该文件电影IT8数据|颜色。
同时,ICC和。IT8文件通常位于同一文件夹中vuescan.ini。
㈨如何VueScan工程
VueScan做两件事情:它扫描的图像,然后将其从扫描仪处理原始数据,以产生色彩校正的图像。这两件事情都做了步骤,它扫描和处理时,要了解每个步骤是非常有用的。
该预览按钮和扫描按钮同时执行扫描和处理步骤。在保存按钮开始从内存中的原始CCD数据,只执行处理步骤。
扫描
扫描图像包括:选择性地聚焦扫描仪,设置曝光时间为CCD扫描区,数每个样品位,每个像素的样本,扫描分辨率,然后读取原始CCD数据到VueScan的内存缓冲区的数目。
如果单通多路扫描使能时,从CCD数据的每一行被读取多次,并结合(平均值),而被存储在存储缓冲器中。如果多通多路扫描使能时,在整个扫描区域被读取多次,并结合(平均值)在存储器缓冲区。
还有就是在扫描步骤中的原始CCD数据不结垢或色彩校正。有些扫描仪无论是经常或有时转换10位或12位CCD数据为8位,将其传输到VueScan之前,然后VueScan转换回10位或12位CCD数据。这是通过使用由sRGB标准中指定的相同的伽马校正表。
当输入|来源选项设置为“文件”,原始CCD数据从一个TIFF或JPEG文件读取并存储在内存缓冲区,就好像它已经直接从扫描仪读取。
当在预览图像被扫描时,曝光时间固定为1.0时,被扫描区域为满预览区域,扫描分辨率设置为能产生约100万个像素的值。
当全扫描操作完成时,曝光时间或从预览或从手动设定计算和要扫描的区域是预览区域(通过裁剪来确定)的一个子集。如果扫描分辨率是自动,扫描分辨率选择,产生约400万像素。
当预览或扫描被执行时,原始数据被放入存储器缓冲区。如果输出|原始文件选项被启用,并输出|与原料输出设置为“预览”或“扫描”,原始数据被写入到,因为它的投入到内存缓冲区的同时TIFF文件。
处理
正在执行用于预览和全扫描的处理步骤。
第一步使用红外数据在除尘(如果已启用)第一次尝试。这从内存缓冲区读取整个图像的颜色通道和红外通道之间的关系特征。然后它读取每行一次,校正它的尘点,并通过在每行以做进一步处理的后续步骤。
接下来的步骤是施加在清洁过滤器。该过滤器利用红外线数据识别和清除尘点,然后填写点与相邻的尘点的图像数据删除尘点。该过滤器还可以减少胶片颗粒的使用西格玛过滤器的外观。
注:红外数据只能从具有一个红外通道的扫描仪。如果通道不存在红外线清洗选项将被跳过。
如果在保存文件时,输出|原始文件选项被启用,并输出|与原料输出设置为“保存”,在这个阶段的数据被写入到一个TIFF文件。这个原始数据可以随后被重新处理通过设置输入|来源选择“文件”。
注意:从红外信道的数据,如果存在,被保存为原始文件的一部分。
接下来,色彩还原和恢复褪色过滤器的应用(如果已启用)。此读取整个图像一次,以检测原始颜色的图像,然后读取每行一次以校正颜色偏移和染料的褪色。
下一步是进行更正电影媒体。此读取整个图像一次来计算薄膜基材的强度,然后读取每一行,纠正它基于薄膜的特性,并且通过在每一行,以供进一步处理的后续步骤。
在这一点锐化与锐化掩模如果进行锐化|过滤器选项已启用。
最后一步是色彩校正。整个图像被读取一次,并且从颜色选项卡中选择用于转换到保存图像的最终颜色。输入到这一步是16位线性光的样品,并从该步骤中,输出伽马校正后的样本。
一旦图像数据已得到纠正,预览图像数据显示在预览选项卡或扫描的图像数据可以选择显示在扫描标签或写入TIFF文件,JPEG文件,PDF文件,一个OCR文本文件,并/或一个索引文件。
㈩扫描彩色负片
彩色负片是能够捕捉到更广泛的范围内强度比反转片及扫描底片时,这就会造成问题。
反转片的0:2.7的密度范围映射到1:500的强度范围,但底片0:2.4较小的密度范围映射到1:4000更大的强度范围。
想象一下,一个典型的户外场景的图像的明亮的蓝色天空与蓬松的云彩随着一个人站在树荫下的一棵树。此外,服用想象这个画面既反转片和负片。
当使用反转片拍摄这张照片,摄影师必须设置曝光要么捕捉到天空和云彩的细节,或将曝光捕捉到站在树荫下树下的人的详细资料。一旦拍摄照片两个强度范围之一的,有没有办法开发电影后,回到另一个强度范围。但是,使用负片拍摄这张照片使用自动相机时,相机通常会设定曝光让双方在云和阴影的细节被捕获。
是否捕捉阴影云或该人的强度范围的决定是由摄影师使用反转片时所作,但它通常是由
计算机打印负时所作的电影彩扩机。大多数微型实验室将打印该类型的场景与细节在阴影和天空夹在白色的没有任何云或天空的细节。
解决这个问题的方法之一是使用来控制图像的亮度颜色|亮度或颜色|白点(%)选项,这样既扫描时,图像显示细节的亮暗部分操纵的负面形象。
(十一)扫描黑/白负片
如果您要扫描的黑/白负片,首先检查,看是否漆膜外观灰色或橙色的肉眼。如果它看起来灰色,设置输入|媒体以“B / W负”,如果它看起来橙色,将其设置为“彩色负片”。然后转到颜色选项卡,然后选择一个黑色/ 白色薄膜型。如果你不能找到确切您使用的胶片,实验与柯达的T最大设定相匹配一种电影类型。
在大多数扫描仪,设置输入|媒体以“彩色负片”,将增加绿化曝光时间由2.5倍和蓝色曝光时间由3.5倍。这导致通过该膜的橙色掩模调整为绿色和蓝色的吸收。如果膜不具有橙色掩膜,然后利用“彩色负”将导致原始扫描文件,看起来很青色。
(十二)最大限度地提高图像质量
当你决定了你的最终图像(或你完成图像的交替的像素尺寸)的分辨率,你如何最大限度地提高图像的质量?有一件事可以做,它涉及较长的扫描时间,但在最终图像捕捉更多的原始数据对每一个像素。
其基本思想是扫描每个像素一次以上,平均的像素。像素的数目每增加一倍,由1增加的数据的有用比特的有效数量。举例来说,如果你有一个10位的扫描仪像尼康LS-30和你读了CCD 4次在每个像素位置,你有效地得到12位的有用的图像数据。
有实现多种图像样本的几种方法。首先是单通多次扫描。一些扫描器是能够读取各像素位置前进扫描头到一个新的位置之前多次。第二种技术是多通道多扫描,其中大多数扫描仪能够(不过,有些不能准确定位每一个扫描传球,所以这可能并不总是很好地工作)。
获得多个图像样本的另一个有用的方法是扫描以较高的分辨率和随后的像素平均相邻块。例如,扫描在2700 dpi的和平均的像素的每一2x2的块,将导致比仅仅扫描在1350 dpi 的高品质的1350 dpi的扫描。在这个例子中扫描在1350 dpi的丢掉每隔一个像素,每一个其它的扫描线,同时扫描在2700 dpi的设置输出| TIFF尺寸减小到“2”,将导致平均的像素的2x2块,并增加有效比特数由2位的分辨率。
请注意,多扫描是提高质量的最高分辨率的唯一方法,而使用输出| TIFF尺寸的减小或输出| jpeg文件大小减少为生产高质量的扫描,以较低的分辨率更好的办法。
(十三)文件格式
VueScan读取扫描仪的原始CCD传感器的数据,能写这为以后再处理原始TIFF文件。最终裁剪的数据可以被存储在TIFF格式的任意组合,JPEG,PDF和OCR文本文件。索引打印存储为Windows BMP文件。
原料和裁剪的TIFF文件可以有六种不同的格式,每一个不同的数字每个像素的样本,每个样本的比特。一个灰度级图像具有每象素一个样品,一个正常的彩色图像3(红色,绿色,蓝色),并从同一个红外信道的扫描仪扫描的每像素具有4个样本(红,绿,蓝,红外)。
VueScan内部保存的所有样本中16位线性格式,即使在扫描仪只支持10位采样,但要尽量减少磁盘使用情况,不同的TIFF文件格式的支持:
每个样本8每像素每像素1样品8位每位灰度1个字节
每像素采样16位格雷每像素2个字节1个样品16 bits每
每个像素的每个像素3个样品每个采样8位24位RGB 3个字节
每像素采样48位RGB 6个字节每像素3个样品16 bits每
每像素采样64位RGBI 8个字节每像素4个样品16 bits每
图片文字识别软件怎么复制或修改pdf内的 文字 pdf文件是一种最常见的文件存储方式,特别是当我们要发布一些资料或者是对资料进行扫描时,一般都会采取这种格式,同时它还有文件体积小,不易再编辑和修改等优点,所以公司经常用到公司各种文档资料的存储和传送,因为这种方式可以有效的减少其他人对公司文件的修改,最常见的就是公司文件的扫描件了; 1、俗话说,一个事物它有利就肯定有弊,pdf文件j虽说有很多优点,但是也是一样存在着自己的缺点,不易被编辑即是它的优点同时,在某些时候也成为它的缺点了,就好比当我们拿着一份扫描文件时,不管这个文件是pdf还是图片,我们需要对这个文件进行修改,而当我们没有这个文件的电子版本时,这时候我们需要借助于捷速ocr文字识别软件了; 2、当我们选择文字识别软件时,可能很多朋友第一反应就是必须是要免费的,因为我们工新一族本来也没有那么多的闲钱来花在这个上面,同时也应该找到一款文字识别能力强的,我们不能一味的强调免费而不管施工质量了,如果软件的文字识别能力太弱会让我们做很多无用功的,最后,这
款软件应该是运行稳定迅速的,选择对的软件后,你只需要下载到你电脑内然后进行安装就可以了; 3、打开这个软件后,这个软件的上面就是菜单工具栏,你要实现文字的提取就必须从这上面做足文章,从这菜单栏的按钮名字我们就清楚的知道这些功能都是做什么用的,一个是软件的添加文件功能,一个是文字提取的功能;
4、你只需要两步就可以顺利的实现文字提取了,第一步是在捷速ocr文字识别软件添加文件,这也是我们的前期准备工作,如果你不添加文件,再历害的软件都没有用,你可以直拉把文件拉到软件上面来,也可以在软件的左上触上点添加文件的按钮;
超简单从图片中读取文字的方法(使用word自带软件) (全文原创,转载请注明版权。本文下载免费,如果对您有一定帮助,请在右边给予评价,这样有利于将本文档位于百度搜索结果的靠前位置,方便本方法的推广) 【本文将介绍读取图片中的文字、读取书中文字、读取PDF格式文件中的文字的方法】一、背景 看到图片中满是文字,而你又想把这些文字保存下来,怎么办? 日常读书,某篇文章写的极好,想把它分享到网络上,怎么办? 一个字一个字敲进电脑?太麻烦了。是不是希望有一种东西能自动识别读取这些文字? 是的,科技就是拿来偷懒的。 其实你们电脑中安装的word早就为你考虑过这些问题了,只是你还不知道。 二、方法 1、图片格式转换 只有特定格式的图片才能读取文字,所以要转换。大家常见的图片格式都是jpg,或者png,bmp等,用电脑自带的画图软件打开你要获取文字的图片(画图软件在开始——所有程序——附件中,win7用户直接右击图片,选择编辑,就默认使用画图软件打开图片),然后把图片另存为tiff格式。 (以我的win7画图为例。另存为tiff格式如下图) 2、打开读取文字的工具 开始——所有程序——Microsoft Office ——Microsoft Office工具——Microsoft Office Document Imaging(本文全部以office2003为例。另外,有些人
安装的是Office精简版,可能没有附带这个功能,那就需要添加安装一下,安装步骤见文末注释①) 3、导入tiff格式的图片 在Microsoft Office Document Imaging软件界面中,选择文件——导入,然后选择你刚才存放的tiff格式的图片,导入。
Ocr技术如何将扫描图片上的文字变成word文档以前好像弄过,记不太清. 我扫下来的图格式是jpg,然后双击打开,打开后点击"编辑"——“全选”(也可以直接按住鼠标左键选出你要的部分图和字)——复制——打开一个word文档——粘贴(出来的既有图又有字)——删去图就只有字了(如果旁边出现一个智能标记,还可以将鼠标移到标记上点一下,看见出现几个选择,选“仅保留文本”就行)。 还弄过从网页上复制的,不过前提好像要该网页允许复制内容才行,那更简单一点,直接用鼠标选出要复制的东东,再建一个文本文档,先粘贴在文本文档上,再建一个word文档,再从文本文档上复制粘贴到word上就行了,下来的好像直接就是只有字了。 好像当时就是这样的,具体的你可以试一下。 扫描文字,结果以图片格式(.bmp)存入电脑。然后使用ORC识别系统进行转换,最终用WORD进行修改编辑。下面教你如何使用ORC: OCR是英文OpticalCharacterRecognition的缩写,翻译成中文就是通过光学技术对文字进行识别的意思,是自动识别技术研究和应用领域中的一个重要方面。它是一种能够将文字自动识别录入到电脑中的软件技术,是与扫描仪配套的主要软件,属于非键盘输入范畴,需要图像输入设备主要是扫描仪相配合。现在OCR主要是指文字识别软件,在1996年清华紫光开始搭配中文识别软件之前,市场上的扫描仪和OCR软件一直是分开销售的,专业的OCR软件谠缧┦焙蚵舻帽壬枰腔挂蟆K孀派枰欠直媛实奶嵘琌CR软件也在不断升级,扫描仪厂商现在已把专业的OCR软件搭配自己生产的扫描仪出售。OCR技术的迅速发展与扫描仪的广泛使用是密不可分的,近两年随着扫描仪逐渐普及和OCR 技术的日臻完善,OCR己成为绝大多数扫描仪用户的得力助手 二、OCR的基本原理 简单地说,OCR的基本原理就是通过扫描仪将一份文稿的图像输入给计算机,然后由计算机取出每个文字的图像,并将其转换成汉字的编码。其具体工
细心看吧希望能帮助你 要下载安装文字识别软件,你可以试试尚书七号,或者汉王等等 下面教你如何使用ORC: OCR是英文Optical Character Recognition的缩写,翻译成中文就是通过光学技术对文字进行识别的意思, 是自动识别技术研究和应用领域中的一个重要方面。它是一种能够将文字自动识别录入到电脑中的软件技术,是与扫描仪配套的主要软件,属于非键盘输入范畴,需要图像输入设备主要是扫描仪相配合。现在OCR主要是指文字识别软件,在1996年清华紫光开始搭配中文识别软件之前,市场上的扫描仪和OCR软件一直是分开销售的,扫描仪厂商现在已把专业的OCR软件搭配自己生产的扫描仪出售。OCR技术的迅速发展与扫描仪的广泛使用是密不可分的,近两年随着扫描仪逐渐普及和OCR技术的日臻完善,OCR 己成为绝大多数扫描仪用户的得力助手。 一、OCR技术的发展历程 自20世纪60年代初期出现第一代OCR产品开始,经过30多年的不断发展改进,包括手写体的各种OCR技术的研究取得了令人瞩目的成果,人们对OCR 产品的功能要求也从原来的单纯注重识别率,发展到对整个OCR系统的识别速度、用户界面的友好性、操作的简便性、产品的稳定性、适应性、可靠性和易升级性、售前售后服务质量等各方面提出更高的要求。 IBM公司最早开发了OCR产品,1965年在纽约世界博览会上展出了IBM公司的OCR产品——IBMl287。当时的这款产品只能识别印刷体的数字、英文字母及部分符号,并且必须是指定的字体。20世纪60年代末,日立公司和富士通公司也分别研制出各自的OCR产品。全世界第一个实现手写体邮政编码识别的信函自动分拣系统是由日本东芝公司研制的,两年后NEC公司也推出了同样的系统。到了1974年,信函的自动分拣率达到92%左右,并且广泛地应用在邮政系统中,发挥着较好的作用。1983年日本东芝公司发布了其识别印刷体日文汉字的OCR系统OCRV595,其识别速度为每秒70~100个汉字,识别率为99.5%。其后东芝公司又开始了手写体日文汉字识别的研究工作。 中国在OCR技术方面的研究工作相对起步较晚,在20世纪70年代才开始对数字、英文字母及符号的识别技术进行研究,20世纪70年代末开始进行汉字识别的研究。1986年,国家863计划信息领域课题组织了清华大学、北京信息工程学院、沈阳自动化所三家单位联合进行中文OCR软件的开发工作。至1989年,清华大学率先推出了国内第一套中文OCR软件--清华文通TH-OCR1.0版,至此中文OCR正式从实验室走向了市场。清华OCR印刷体汉字识别软件其后又推出了TH-OCR 92高性能实用简/繁体、多字体、多功能印刷汉字识别系统,使印刷体汉字识别技术又取得重大进展。到1994年推出的TH-OCR 94高性能汉英混排印刷文本识别系统,则被专家鉴定为“是国内外首次推出的汉英混排印刷文本识别系统,总体上居国际领先水平”。上个世纪90年代中后期,清华大学电子工程系提出并进行了汉字识别综合研究,使汉字识别技术在印刷体文本、联机手写汉字识别、脱机手写汉字识别和脱机手写数字符号识别等领域全面地取得了重要成果。具有代表性的成果是TH-OCR 97综合集成汉字识别系统,它可以完成多文种(汉、英、日)印刷文本、联机手写汉字、脱机手写汉字和手写数字的
文字扫描识别软件怎么使用-捷速OCR文字识别 智能手机在改变人们生活的同时,也带来了信息安全隐患。在30日的第四届上海信息安全周活动上,安全信息专家演示的APP应用变身“密探”,手机充电宝成敲诈帮凶,这些事例还真是不看不知道,一看吓一跳。但是人们在日常的工作和生活中还是会为了方便使用手机的很多功能,上次老板给一份机密文件给小刘看,这份文件只有一份不好流传,所以小刘当即拿起手机进行拍照,想到手机可能不安全,于是存到电脑中。但是存在电脑中发现这些文字不能使用,也就是说文件中的信息都不能使用,那这份文件就没有什么意义了。 为了找到图片文字提取的方法,小刘尝试了很多种办法,最后选定了ocr文字识别软。因为该软件不仅识别效果好,操作也非常的简单。 第一步:打开软件,直接进入到软件的操作主界面; 第二步:选择左上角的“添加文件”按钮,找到扫描文件所在的位置,点击打开就完成了添加工作; 第三步:软件的右下角有一个“输出路径”的选择,就是识别好之后的word文档保存在什么地方,这个根据自身的要求进行选择,也可以选择存放在原有文件夹内; 第四步:点击上方正中的“开始转换”按钮,短暂的时间过后转换就会结束,就可以得到你想要的word文档。 图片文字提取要怎么样实现?ocr文字识别软件只要上面几步就可以轻轻松松帮你实现。小编在此还是提醒,如果用手机记录一些有用的信息文字,应该尽快的转换成文字保存在电脑中加密,不然文字的安全得不到保证,就像这样的机密文件一旦泄漏后果是不堪设想的。千万不要轻信那些在线转换,那样泄漏的机率更大,还是应该找ocr文字识别软件这样操作简单的,自己就能实现文字提取,而且识别效果非常的好,能够达到98%左右。
不需要扫描仪就可以把书上的字快速弄到word的方法~图片也行哦! 在工作中,常常在想,要是能把纸上有用的文字快速输入到电脑中,不用打字录入便可以大大提高工作效率该有多好呀!随着科技的发展,这个问题在不断的解决,例如,现在市场上的扫描仪就带有OCR软件,可以把扫描的文字转换到电脑中进行编辑。但是,对于我们平常人来说,大多数人都是即不想多花钱购买不常用的设备,又不想费力气打字录入,那我就给大家提供一个我刚刚发现的方法吧!现在数码相机很普遍,也很常用,我们就从这里下手吧。 工具准备: 硬件:电脑一台数码相机 软件:word2003(其它的版本我没有实验) doPDF (百度可以搜索下载,是一款免费的PDF制作软件) CAJViewer软件(在百度可以搜索下载,是一款免费的阅读器) 步骤: 1、在电脑中安装doPDF和CAJViewer 2、用数码相机把需要的文字拍下来(相机和照像水平就不多谈了。照片效果越好,可以大大缩小转换文字的误差率) 例如: 3、在word中插入你用数码相机照的书上的文字(打开word——插入菜单——图片——来自文件——选择照片——插入) 4、在word中选择文件菜单——打印——在打印机选项中选择doPDF——确定
——点击“浏览”选项——选择文件保存的位置和填写文件名称——保存——确定 5、按照上面的步骤,电脑会自动打开CAJViewer软件,若没有自动打开该软件,可以自己打开CAJViewer软件,然后在CAJViewer中打开刚刚转换的PDF文件。 6、选择CAJViewer中的,然后在需要的文字部分拖动鼠标画出虚线。 7、点击发送到word按钮,就可以转换成word文件了。可以编辑了。 第6、7步骤图片如下:
如何将扫描图片上的文字变成word文档 以前好像弄过,记不太清. 我扫下来的图格式是jpg,然后双击打开,打开后点击"编辑"——“全选”(也可以直接按住鼠标左键选出你要的部分图和字)——复制——打开一个word文档——粘贴(出来的既有图又有字)——删去图就只有字了(如果旁边出现一个智能标记,还可以将鼠标移到标记上点一下,看见出现几个选择,选“仅保留文本”就行)。 还弄过从网页上复制的,不过前提好像要该网页允许复制内容才行,那更简单一点,直接用鼠标选出要复制的东东,再建一个文本文档,先粘贴在文本文档上,再建一个word文档,再从文本文档上复制粘贴到word上就行了,下来的好像直接就是只有字了。 好像当时就是这样的,具体的你可以试一下。 扫描文字,结果以图片格式(.bmp)存入电脑。然后使用ORC识别系统进行转换,最终用WORD进行修改编辑。下面教你如何使用ORC: OCR是英文Optical Character Recognition的缩写,翻译成中文就是通过光学技术对文字进行识别的意思, 是自动识别技术研究和应用领域中的一个重要方面。它是一种能够将文字自动识别录入到电脑中的软件技术,是与扫描仪配套的主要软件,属于非键盘输入范畴,需要图像输入设备主要是扫描仪相配合。现在OCR主要是指文字识别软件,在1996年清华紫光开始搭配中文识别软件之前,市场上的扫描仪和OCR软件一直是分开销售的,专业的OCR软件谠缧┦焙蚵舻帽壬 枰腔挂 蟆K孀派 枰欠直媛实奶嵘 琌CR软件也在不断升级,扫描仪厂商现在已把专业的OCR软件搭配自己生产的扫描仪出售。OCR技术的迅速发展与扫描仪的广泛使用是密不可分的,近两年随着扫描仪逐渐普及和OCR技术的日臻完善,OCR己成为绝大多数扫描仪用户的得力助手 二、OCR的基本原理 简单地说,OCR的基本原理就是通过扫描仪将一份文稿的图像输入给计算机,然后由计算机取出每个文字的图像,并将其转换成汉字的编码。其具体工作过程是,扫描仪将汉字文稿通过电荷耦合器件CCD将文稿的光信号转换为电信号,经过模拟/数字转换器转化为数字信号传输给计算机。计算机接受的是文稿的数字图像,其图像上的汉字可能是印刷汉字,也可能是手写汉字,然后对这些图像中的汉字进行识别。对于印刷体字符,首先采用光学的方式将文档资料转换成原始黑白点阵的图像文件,再通过识别软件将图像中的文字转换成文本格式,以便文字处理软件的进一步加工。其中文字识别是OCR的重要技术。 1.OCR识别的两种方式 与其它信息数据一样,在计算机中所有扫描仪捕捉到的图文信息都是用0、1这两个数字来记录和进行识别的,所有信息都只是以0、1保存的一串串点或样本点。OCR识别程序识别页面上的字符信息,主要通过单元模式匹配法和特征提取法两种方式进行字符识别。 单元模式匹配识别法(Pattern Matching)是将每一个字符与保存有标准字体和字号位图的文件进行不严格的比较。如果应用程序中有一个已保存字符的大数据库,则应用程序会选取合适的字符进行正确的匹配。软件必须使用一些处理技术,找出最相似的匹配,通常是不断试验同一个字符的不同版本来比较。有些软件可以扫描一页文本,并鉴别出定义新字体的每一个字符。有些软件则使用自己的识别技术,尽其所能鉴别页面上的字符,然后将不可识别的字符进行人工选择或直接录入。 特征提取识别法(Feature Extraction)是将每个字符分解为很多个不同的字符特征,包括斜线、水平线和曲线等。然后,又将这些特征与理解(识别)的字符进行匹配。举个简单的例子,应用程序识别到两条水平横线,它就会“认为”该字符可能是“二”。特征提取法的优点是可以识别多种字体,例如中文书法体就是采用特征提取法实现字符识别的。
如何将图片上的文字转换成WORD格式 安装OCR软件,给您提一点小技巧,在使用OCR软件识别前,可用用图片处理软件(例如:photoshop)处理一下,转换成黑白模式,并适当加大对比度,可以大大提高识别率。 图片文字提取(OCR)图解教程 或 Microsoft Office Document Imaging(office2003中内含) OFFICE中有一个组件document image,功能一样的强大。不仅扫描的文字图片,连数码相机拍的墙上的宣传告示上的字都能提取出来。 第一步打开带有文字的图片或电子书籍等,找到你希望提取的页面,按下键盘上的"ALT+打印屏幕键(PrintScreen)"进行屏幕取图,或者用其他抓图软件。保存成tif格式。 第二步我们需要安装"Microsoft Office Document Imaging"的组件,点"开始程序Microsoft OfficeMicrosoft Office 工具",在"Microsoft Office 工具" 里点" Microsoft Office Document Imaging" 然后打开图片,找到OCR识别工具(像眼睛),点击此工具,开始安装,这个时候就需要你把光盘(或虚拟光驱)的office安装文件。 第三步用Microsoft Office Document Imaging打开图片,用OCR工具(图中红色筐圈部分)选取你要提取的文字,然后点右键,选择-复制到word或者记事本。 或用摄像头作扫描仪输入文字: 我们平时使用的摄像头大家好象只用作聊天了吧
其实它的作用也是很广泛的.好多的朋友在写论文,资料的时候总是要用一些书上的资料.总 是到打印社进行扫描打印,其实我们的摄像头就可以解决这个问题. 一,安装Microsoft office 2003(仅以office 2003为例。其它版本office均可) 二,打开"开始Microsoft officeMicrosoft office工具Microsoft office Document scannging",如果该项未安装,系统则会自动安装。此时会弹出扫描新文件对话框,单击[扫描仪]按钮,在弹出的对话框中选中摄像头,并选中"在扫描前显示扫描仪驱动"复选框,再选中"黑白模式",并选中"换页提示"和"扫描后查看文件"两项。 三,再单击[扫描]按钮即可进行扫描,在扫描过程中会弹出一个对话框,选中[格式]按钮,在"输出大小"中选择600×480分辨率,然后将文稿放平,反复调节摄像头的焦距和位置,使画面达到最佳效果,点击[捕获]按钮即可得到图片画面,该图片会显示在"图例"框中, 四,选中该图片,点击[发送]按钮会开始扫描该图片中的文字,扫描完成后点[完成]按钮,然后系统会自动打开识别程序Microsoft Office Document Imaging,用该文件就可以识别了。完成后可以选中全文,鼠标右击后选中"将文本发送到Word"项,则所选内容便会被Word 打开并可以进行编辑了 但,识别效果与摄像头扫描质量有关。自己多测试一下!
提取图片中(或扫描版PDF)的文字 如果在书上看到一篇好文章用相机拍下来,或是纸质文章需要输入到电脑时,如果数量比较大,手动输入会很慢,下面介绍几中方法将图片中的文字转化为文本,同样适用于影印版PDF。 1 ABBYY FineReader 11软件 泰比(ABBYY)FineReader提供直观的文件扫描和转换成可编辑、可搜索的电子格式工具。泰比(ABBYY)FineReader可以识别和转换几乎所有打印的文档类型,包括书籍、志上的文章与复杂的布局、表格和电子表格、图片,甚至以准确的精度发传真。 下载地址:网上随便一搜就很多例如: https://www.doczj.com/doc/7238140.html,/soft/Application/Processing/15768.html 破解补丁: https://www.doczj.com/doc/7238140.html,/space/file/l513980209/share/2011/11/2/ABBYY_F ineReader_11_Professional_Edition_-514d-5e8f-5217-53f7-65e0-9650-5236 -7834-89e3-7248-7834-89e3-6587-4ef6.rar/.page# 破解方法:将下载的文件替换安装文件即可。
2 Office200 3 自带组件Microsoft Office Document Imaging 如果Office装的是精简版,那么在就没装这个组件,可以自己装一下或是下载完整版。装完后如下图。 第一步:转换文件格式。用ACDSee打开你的.jpg文件,单击界面上的“浏览器”按钮(或者双击当前图片都可以进入到浏览器界面),在打开的浏览器中,右键这个文件,在右键菜单中选择“工具/转换文件格式”;在转换文件格式对话框中,选择TIFF格式,两次下一步后,就开始转换,结果是将你当前的.jpg 文件转换成了.tif文件。 第二步:将图片转换为文字。选择:开始/所有程序/Microsoft Office/Microsoft Office工具/Microsoft Office Document Imaging,打开这个工具后,菜单:文件/打开,找到你保存的那个.tif文件,打开它。然后选择菜单:工具/使用OCR识别文本;梢等一会儿,继续菜单:工具/将文本发送到Word。这样,这幅图片就到了Word中成了可以编辑的文字内容了。因为OCR识别并非百分之百成功,所以有些位置可能需要你进行手动修改。 界面如下:
扫描图片变文字的软件--文档识别 作为秘书的小王接到一个任务,把去年的单位管理规章制度材料再提交一份出来。可她却忘了放在哪儿了,在电脑里搜索,但是没找到,心想可能是误删除了吧。于是就从档案袋中找到一份原来的打印稿,心想,拿给领导吧!如果以后让我再提一份,怎么办?再打一份。那可足足30多页啊。 如果你遇到这样子的一种情况,你会怎么办?不部分人要么拿去打印店录入,要么自己手工去录入。接下来,让我们一起去了解除此之外的一种方法,使用OCR文档识别软件--云脉文档识别。云脉文档识别软件是指利用手机照相功能或者电脑摄像头检查纸上打印的字符,然后用字符识别方法将形状翻译成计算机文字的过程;即,对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程。 使用云脉文档识别,可以随时随地用数码相机、手机自由采集书籍、报刊、标牌、展板、名片及网页等各类文字图像,上传到电脑或者手机上后就可以轻松的转成文本文字问题。 云脉文档识别软件的三大特色: 精确识别纸质文档:拍文档并上传到云端自动识别和校对,文档的各种字符都能被精确识别。 实时备份文档信息:经过识别的文档会存储在云端,无论何时何地都可以查看全部已识别的文档。 识别十几种语言:可以直接识别中文(简体、繁体),英文和其
余15种欧洲语言(法文、德文、意大利文、西班牙文、荷兰文、瑞典文、土耳其文等),可以大大方便用户,让用户无需进行文字转换。 云脉文档识别,支持从手机相册中选取现成的文档图像进行扫描、横向竖向文档扫描。这些细节上的设计和功能支持,显示出了云脉文档识别为国内用户提供了很好的应用功能服务。 文档识别软件日益成为大部分人生活中不可或缺的一款软件,运用文档识别软件,我们不必手工去录入文档,省时省力,有这方便需求的人士可以安装一个云脉文档识别软件试用。
把书上的字快速弄到电脑上 在工作中,我常常在想,要是能把纸上有用的文字快速输入到电脑中,不用打字录入便可以大大提高工作效率该有多好呀!随着科技的发展,这个问题在不断的解决,例如,现在市场上的扫描仪就带有OCR软件,可以把扫描的文字转换到电脑中进行编辑。但是,对于我们平常人来说,大多数人都是即不想多花钱购买不常用的设备,又不想费力气打字录入,那我就给大家提供一个我刚刚发现的方法吧!现在数码相机很普遍,也很常用,我们就从这里下手吧。 工具准备: 硬件:电脑一台数码相机 软件: word2003(其它的版本我没有实验) doPDF (百度可以搜索下载,是一款免费的PDF制作软件) CAJViewer软件(在百度可以搜索下载,是一款免费的阅读器) 步骤: 1、在电脑中安装doPDF和CAJViewer 2、用数码相机把需要的文字拍下来(相机和照像水平就不多谈了。照片效果越好,可以大大缩小转换文字的误差率) 例如: 3、在word中插入你用数码相机照的书上的文字(打开word——插入菜单——图片——来自文件——选择照片——插入) 4、在word中选择文件菜单——打印——在打印机选项中选择doPDF——确定——点击“浏览”选项——选择文件保存的位置和填写文件名称——保存——确定 5、按照上面的步骤,电脑会自动打开CAJViewer软件,若没有自动打开该软件,可以自己打开CAJViewer软件,然后在CAJViewer中打开刚刚转换的PDF文件。 6、选择CAJViewer中的,然后在需要的文字部分拖动鼠标画出虚线。 7、点击发送到word按钮,就可以转换成word文件了。可以编辑了。 第6、7步骤图片如下:
图片文字识别如何实现 工作中难免会遇到各种各样,奇葩的问题,就像图片文字识别的问题,乍一听,大家肯定都不知道如何操作吧,其实方法很简单的,但前提是我们要借助图片文字识别软件来进行操作,那么今天我们就一起来看一下借助图片文字识别软件,是如何实现图片文字识别的吧。需要用到的工具:捷速OCR文字识别软件 软件介绍:该软件具备改进图片处理算法功能:软件进一步改进图像处理算法,提高扫描文档显示质量,更好地识别拍摄文本。所以要想实现图片转换为其它格式、PDF文件和caj文件转换,或者是票证识别,捷速OCR文字识别https://www.doczj.com/doc/7238140.html,都是不错的选择。 方法讲解: 步骤一:我们要先将需要用到的工具安装到电脑上,打开电脑浏览器搜索并下载捷速OCR文字识别软件。 步骤二:软件安装好后,打开该软件,同时会跳出一个插入图片的选
项,点击“退出”按钮,退出该选项。 步骤三:然后在软件的左上方,选择“图片局部识别”的选项。 步骤四:进入图片局部识别的页面后,点击软件左上角“添加图片”的选项,将需要识别的图片添加进来。
步骤五:图片添加进来后,先不用急着开始识别,我们可在软件的左下角,修改图片识别后的文件的储存位置。 步骤六:储存位置修改好后,按住鼠标左键,将需要识别的文字用文字框框出来,然后软件就会对被框选出来的文字进行自动识别了。
步骤七:等待图片识别好后,点击右下角“保存为TXT的按钮”,将其识别内容进行保存,这样图片文字识别的操作就完成了。 图片文字识别如何实现的操作已经为大家分享结束了,操作简单。工作中再遇到图片文字识别的问题,只需要按照上面的操作步骤进行即可。
扫描图片文字怎么转换成word 快开学的,所以去找堂弟玩,可是没想到他一反常态,开端还忧虑他不在家,进到他家门却发如今电脑前认认真真的做这些啥。本来表弟快开学了,教师给他们布置了一篇调研陈述的作业,开学要交的。我这个表弟即是典型的延迟症病人,不到最终一刻就不知道要努力的。所以这几天都在张狂的寻觅材料,预备撰写调研陈述。我走近一看,发现表弟正十分的费劲把一张扫描图像上的文字敲入电脑中,十分的费事。看在表弟那么辛苦的份上,我就决议通知他一个好办法,能够疾速把扫描图像变换成Word。 堂弟听后十分的快乐,要我立刻的教他。这个办法也很简略,即是运用如今最领先的OCR文字辨认技能就能够了。OCR文字辨认技能是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,然后用字符辨认办法将形状翻译成计算机文字的进程;即,对文本材料进行扫描,然后对图像文件进行剖析处理,获取文字及版面信息的进程。我帮堂弟下载了一个最好用的捷速扫描文字识别软件,帮他进行了操作。 翻开现已下载好的软件,直接进入到软件的操作界面,左上角摆放着软件的操作按钮,首要点击“读取”按钮,读取需求辨认的文件。直接点击“辨认”按钮,软件会主动对添加好的文件进行辨认作业,通常都是刹那间完结,当然批量辨认在外。在同一页面同一版面临其进行核对,核对完结依据自个的需求保留格局,通常都是Word格局,这么全部辨认作业就完结了,十分的简略。 堂弟表明不可思议,他辛辛苦苦那么久才输入进入那么点,而捷速扫描文字识别软件在那么短的时间内竟把整张扫描图像都变换成了Word,真的是太好用了。他十分开心,今后有了捷速扫描文字识别软件,能够轻松把图像变换成Word了,不必自个再费事手动输入了。
我们在使用电脑打字时,最喜欢复制粘贴了,但是如果遇到图片中的文字,就不能复制了,你还在对照着图片手动输入吗? 这样就太浪费时间了,其实电脑中就自带扫描功能,可以将图片转换成文字,下面一起来学习一下吧。 一、笔记本提取 如果你的电脑上安装了office,那么你一定不知道,其实还隐藏着【一站式笔记管理平台】,我们可以通过这个应用,将图片上的文字提取出来。
如何进入一站式笔记管理平台? 方法1:点击屏幕左下角的【开始】,在全部应用列表中,鼠标往下滑动,找到“OneNote2016”,点击进入。(2016代表当前office版本是2016版)
方法2:直接按下快捷键【Win+S】,在下方搜索框中输入“OneNote”,将自动匹配出这个应用,单击就能打开。 如何使用图片文字提取功能? 1、首先我们点击【+】创建一个新分区;然后在顶部菜单栏中找到【插入】-【图片】;从电脑中选择图片并点击【打开】,支持批量添加图片。
2、可以看到图片添加到笔记本中了,接下来选中一张图片,鼠标右击选择【复制图片中的文本】,然后在空白处按下【Ctrl+V】,文本就提取出来了。
二、在线网站识别 上面我们看到电脑中的扫描功能,其实来自于office,用来提取单张图片上的文字,是非常方便的。那么如果有200张图片需要提取文字,手动操作就很浪费时间了。 在精挑细选下,终于找到了一个自动识别图片文字的工具,可以一键将200张图片转成文字,就是这个迅捷在线PDF转换器,打开任意浏览器都能找到。 如何实现图片转换成文字? 1、首先我们找到【图片文字识别】功能;然后在右侧设置转换格式为【txt】,识别效果为【识别优先】;接着在上方点击选择文件,从电脑中批量选择图片。
如何把打印稿变成电子稿 办公室——教你如何把打印稿变成电子稿(太牛啦!!你打一天的字都比不上她2分钟!!人手一份,留着以后用哈!) 注意: 教你如何将打印稿变成电子稿最近,我的一个刚刚走上工作岗位上的朋友老是向我报怨,说老板真的是不把我们这些新来工作的人不当人看啊,什么粗活都是让我们做,这不,昨天又拿了10几页的文件拿来,叫他打成电子稿,他说都快变成打字工具了,我听之后既为他感到同情,同时教给他一个简单的方法,可以轻松将打印稿变成电子稿,我想以后对大家也有用吧,拿出来给大家分享一下。 首先你得先把这些打印稿或文件通过扫描仪扫到电脑上去,一般单位都有扫描仪,如果没有也没关系,用数码相机拍也行,拍成图片放到WORD里面去,不过在些之前,你还得装一下WORD自带的组件,03和07的都行。点开始-程序-控制面板-添加/删除程序,找到Office-修改找到Microsoft Office Document Imaging 这个组件,Microsoft Office Document Imaging Writer 点在本机上运行,安装就可以了。 首先将扫描仪安装好,接下来从开始菜单启动“Microsoft Office/ Microsoft Office 工具/Microsoft Office Document Scanning”即可开始扫描。 提示:Office 2003默认安装中并没有这个组件,如果你第一次使用这个功能可 能会要求你插入Office2003的光盘进行安装。由于是文字扫描通常我们选择“黑白模式”,点击扫描,开始调用扫描仪自带的驱动进行扫描。这里也要设置为“黑白模式”,建议分辨率为300dpi。扫描完毕后回将图片自动调入Office 2003种另外一个组件“Microsoft Office Document Imaging”中。 点击工具栏中的“使用OCR识别文字”按键,就开始对刚才扫描的文件进行识别了。按下“将文本发送到Word”按键即可将识别出来的文字转换到 Word中去了。如果你要获取部分文字,只需要用鼠标框选所需文字,然后点击鼠标右键选择“将文本发送到Word”就将选中区域的文字发送到Word中了。 此软件还有一小技巧:通过改变选项里的OCR语言,可以更准确的提取文字。例如图片里为全英文,把OCR语言改为“英语”可以确保其准确率,而如果是“默认”则最终出现的可能是乱码~ 还有: 应该说,PDF文档的规范性使得浏览者在阅读上方便了许多,但倘若要从里面提取些资料,实在是麻烦的可以。回忆起当初做毕业设计时规定的英文翻译,痛苦的要命,竟然傻到用Print Screen截取画面到画图板,再回粘到word中,够白了:(最近连做几份商务标书,从Honeywell本部获取的业绩资料全部是英文版
用扫描仪和OCR软件实现扫描录入文字 将书本文字录入电脑,成为可排版的文字,有多种方法可实现,我这里介绍的是用扫描仪和OCR识别软件来实现。在扫描仪所附送的光盘内,就有OCR识别软件,此外,在office组件里也有OCR识别软件。当然,不同的识别软件操作方法不同,但都大同小异。 下面就以office2003OCR识别软件为例作一些介绍。 1、单击“开始→程序→Microsoft office→Microsoft office工具→Microsoft Office Document Imaging”运行OCR识别软件。第一次使用可能会提示你安装此组件。有些人的电脑可能在“开始→程序”里根本找不到该组件,那就是没有安装此组件,只能自己重新把它安装上。 2、程序运行后,单击“扫描新文档”按键(图一①)开始扫描,弹出“扫描新文档”对话框,第一次扫描要单击“扫描仪”按键(图二③),选择能正常使用的扫描仪。如果原稿超过一页纸,可先选定“换页提示”(图二②),这样在扫描时,每扫描完一页后,会提示放入第二页,节省一点时间。接着单击“扫描”按键(图二①),会弹出扫描控制面版,这一面版与用其它程序进行扫描是一样的,不再多说,但有一点必须要做,就是将输出目的设置为“OCR识别”,或直
接将扫描分辨率自定义为300dpi,这样才能保证转换准确率。 3、扫描完成后,会自动识别,并自动创建一个新文件(*.tif文件)。单击“将文本发送到Word”按键,会将识别后的文字以另一文件存放,但不是*.doc 文件,而是*.him文件。如果要的不是全部,而只是其中的一部分文字,可用选择工具(图一②)选定图片内的文字,复制(快捷键“Ctrl”+“c”)后,到Word文件内粘贴(快捷键“Ctrl”+“v”),将选定的文字复制到Word内进行编辑。 4、如果识别准确率不高时,可单击“工具”→“选项”进行设置,提高准确率,如原稿为全英文时,可在选项卡里单击“OCR”选项卡,将“OCR语言”设置成“英语”,确定后,单击“使用OCR识别文本”键(图一③)重新识别。 原稿的质量是识别准确率的关键,怎样的原稿才能有较高的识别准确率呢?原稿的纸张平整,没有在上面涂画,文字字迹清晰,笔画没有间断,文字底下没有图画或花纹,这样识别准确率会较高。另外纸张灰色(如报纸)和文字有底色对识别准确率影响不大。
文字扫描识别该怎么做呢 文字扫描识别相信很多人并不陌生,因为在日常的工作中经常会接触到扫描的文字或是纸质文字,这类的文字是不能被计算机读取的,如果需要进行编辑或是修改,就需要进行文字扫描识别。虽然现在市面上一些扫描仪是带有文字识别功能的,但是这类的扫描仪价格比较贵,如果为了这点工作让公司换一台扫描仪或是购买一台扫描仪,显然花费的成本太高是不划算的,那文字扫描识别该怎么做?其实,只需要下载一款小的捷速ocr扫描文字识别软件就能够轻松的解决这一问题。 文字扫描识别该怎么做?下面就给大家详细的介绍一下捷速ocr扫描文字识别软件的操作流程。 首先,我们需要找到软件的正规下载渠道,在百度搜索“捷速ocr文字识别软件”就能轻松的找到,这个没有什么难度,找到之后根据提示进行下载安装,就像安装一般的软件一样。安装完成之后接下来就进入到真正的运用部分。 1、双击快捷方式打开软件,直接进入到软件的主界面,在这个界面的上方有一排大的功能键,这在下面是要用上的。 2、点击左起第一个“添加文件”键,找到需要转换的扫描文件添加到软件中等到转换,如果是纸质文件的话先进行扫描没有扫描仪用手机或是相机进行拍照亦可。
3、扫描文件添加完成就可以进行输出路径的选择,根据自身的需求,在软件的右下方选择输出路径。 4、最后,也是最为关键的转换步骤来了,轻击“开始转换”按钮就能完成转换了。不需要多余的任何操作,等待转换结果就可以了。 文字扫描识别该怎么做?说起来是有四个步骤,实际操作起来非常的简单,数秒时间就能完成整个操作流程。不仅操作简单,捷速ocr扫描文字软件的识别率也是非常高的能够达到95%以上,因为软件自身具备强大的识别技术,对文字进行深层次的分析,以达到文字的识别效果。
史上最强伪原创工具!图像转文字软件,告别伪原创时代 效率就是金钱! 效果就是硬道理! 为了网站的排名费尽心思、绞尽脑汁写原创~ 还试过去偷、去抢、去盗、去采别人的文章,十八般武艺通通用上.... 在我快要崩溃的时候,感谢老天爷,感谢CCTV,感谢广大群众,终于让我遇到了它----它就是传说中
的专为广大站长、SEOer而打造的图文ORC原创利器!能把图像转化为文字的神器!! 买本书,轻轻松松的网站就可以更新好几个月,一不小心就把竞争对手甩到了后面,再也不用为原创烦恼!告别伪原创的时代来了!鼠标轻点打造高质量绝对原创文章! 用了他,我才知道,什么叫做效率!什么叫做绝对原创!什么叫做浮云!! 为了再次感谢广大读者,广大群众,广大支持海多的朋友,我做了一个果断的决定,决定把这个重金收购过来的神器出售给广大需要它的SEOer,站长朋友们!
在软件推广期间,只需要10元就可以拥有这个传说中的神器! 是的,你没有听错,只需要10元就可以永久拥有,永久告别伪原创!以后每月上升1元,直到恢复原价168元~ 虽然,我说的是有些夸张,但软件确实是物超所值的。也经过本人再三测试,可以完美运行在XP系统和WIN7系统(本人也是WIN7系统),除了注册的时候有点麻烦,其他是没有问题的。 您不用再为将纸质文字资料输入电脑需要耗费大量时间精力而烦恼;您不再需要对seo原创内容面烦恼,不用在对图片上的字用键盘一个一个字的敲打;您可以随时随地的采集您感兴趣的资料...更多的功能您可以凭自己的想象力去自由的发挥。 可以识别的内容 软件可对当前屏幕的文字或表格内容进行屏幕识别并得到结果,例如用数码相机拍下来的文字图像、当前所浏览的网页、扫描后所得到的文字图像等等,并可识别竖排的文本。也可以对摄像头拍下的镜头进行文
可以识别屏幕文字的软件 屏幕文字大家会联想到电视屏幕或是电脑屏幕,没错今天就是要讲讲屏幕文字怎么识别。电视屏幕上的文字我们是不能直接输入电脑的,由于现在电视技术的发展,很多电视都有回放录制功能,拿着电脑对照着输入里面的文字也是方法之一但是不是唯一。电脑网页文字虽然也在电脑中,但是一些网页进行设置,里面的文字不能进行复制。这些屏幕文字想要使用就必须要进行识别,那么屏幕文字识别软件哪个好? 在这里小编给大家推荐捷速ocr文字识别软件,小编在日常的工作中对一些图片文字、扫描文字、pdf文字都是用它进行识别的,效果非常的好。所以当遇到屏幕文字识别的时候第一个就是想到它,经过亲自试验发现效果非常好,所以在此推荐给大家。 首先需要截取屏幕上的文字,可以使用拍照或是截图的方法,电视上的文字可以使用拍照的方式、电脑网页中的文字直接截图就可以了非常的方便。将整理好的这些屏幕文字存放在电脑中,就可以开始识别工作了。打开捷速ocr文字识别软件直接进入到软件的操作主界面,下面就开始操作了: 第一步,添加文件:打开软件后看到左上角有一个“添加文件”按钮,点击之后找到需要识别的扫描文件进行添加,当然也可以拖拽文件到界面 第二步,输出选项:软件的右下角有一个“浏览”按钮点击之后可以自定义选择。还可以省略此步骤,这样结果就会存放在原文件夹内。 第三步,点击“开始转化”,转换完成后,识别过程中会有数秒的等待时间,等识别完成系统会自动在桌面生成一个txt文件。 使用捷速ocr文字识别软件识别后的屏幕文字可以自由的进行编辑,因为软件使用的是先进的光学识别技术,所以不需要担心识别正确率的问题,软件的识别正确率一直保持在98%,远远领先于行业水平。
先用橡皮擦把你不要的文字擦掉。 这样你擦掉的部分就是白色的。如果要求不高。就直接打字上去就好了。如果要求高的话,那么就的用其他工具了。 选择仿复章工具,先按ALT在颜色差不多的地方取色,然后就直接往白色部分涂过去。慢慢来,这样可以使得你擦掉的白色部分跟背景色几乎一样。。 然后在打字上去。就完了。· 如何用photoshop修改扫描图片中的文字 1、拼字;从扫描文档里找到你需要的文字然后选择后粘贴,这样的方便 性不说了,局限就是可能没有需要的字; 2、写字;在ps里按照原来文档的字体写出要修改的文字,然后模糊、对比度、 阴影等调节,然后差不多了然周围的字也变得模糊,之后合并图层,整体调节对比度,黑白状态下,强对比,直接把效果打得差不多; 3、我不知道还有其他什么方法,如果有电子档当然直接修改电子档了,用识别 软件可以转化部分文档。 整理思路:修改文字,一方面需要解决添加的文字效果;另一方面是解决原有扫描的效果;两者差不多了,就可以了 =============== 扫描图片处理方法: 在photoshop里打开你扫描的图片,然后ctrl+L打开色阶调整,在右下角有三个貌似吸管的按钮,鼠标移动上去之后会分别提示:设置黑场、设置白场、设置灰场。选择设置黑场按钮,在画面中的黑色文字上单击,然后选择设置白场按钮,在画面上白色背景部分单击。然后确定。这样基本上背景就是纯白的了。如果文字带有颜色的话。在执行图像——调整——去色。即可!! 先用刷子加模糊工具,把原来的字迹用背景色覆盖掉,然后你就直接 打字好了 "把文字字号那个72拖蓝后打入你想要的数字大小就可以了,可是这样也很难掌握其大小,所以,你可以把打入字号的涂层(用鼠标右键点击涂层面板中字号那个图层,然后选..)栅格化涂层,这时的文字和数字就变成图像了,你就可以对它直接操作了:你可以按住ctrl键的同时用鼠标点它,所有的文字便被选中了,你可以再按住ctrl键按“T”键就可以自由变换了,这时你想要多大就可拖多大,只到你认为合适为止,按回车键确认即可。如果不想文字(数字)变形的话,在拖动时你要按住“shift”键可以保持比例不变的...... "