
SPSS统计软件实验
指导书
大庆师范学院生命科学学院
徐太海
2013年11月
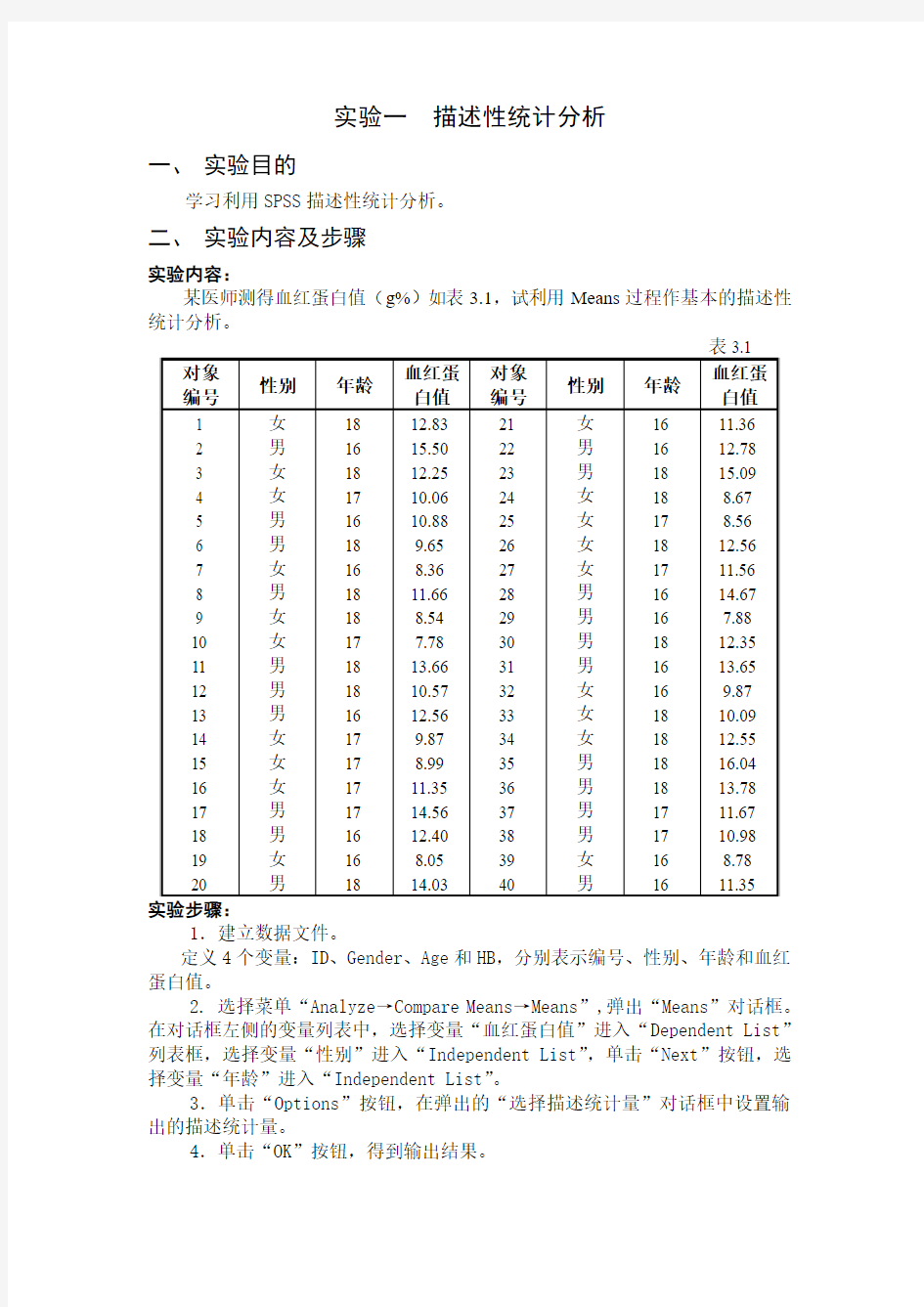
实验一描述性统计分析
一、实验目的
学习利用SPSS描述性统计分析。
二、实验内容及步骤
实验内容:
某医师测得血红蛋白值(g%)如表3.1,试利用Means过程作基本的描述性统计分析。
1.建立数据文件。
定义4个变量:ID、Gender、Age和HB,分别表示编号、性别、年龄和血红蛋白值。
2. 选择菜单“Analyze→Compare Means→Means”,弹出“Means”对话框。在对话框左侧的变量列表中,选择变量“血红蛋白值”进入“Dependent List”列表框,选择变量“性别”进入“Independent List”,单击“Next”按钮,选择变量“年龄”进入“Independent List”。
3.单击“Options”按钮,在弹出的“选择描述统计量”对话框中设置输出的描述统计量。
4.单击“OK”按钮,得到输出结果。
实验二均值检验
一、实验目的
学习利用SPSS进行单样本、两独立样本以及成对样本的均值检验。
二、实验内容及步骤
(一)单样本T检验(One-Sample T Test过程)
实验内容:
某地区10年测得16-18岁人口的平均血红蛋白值为10.25。现在抽查测量了该地区40个16-18岁人口的血红蛋白如表1,试分析该地区现在16-18岁人口的血红蛋白与10年前相比,是否有显著的差异?
实验步骤:
1.打开数据文件。
2. 选择菜单“Analyze→Compare Means→One-Sample T Test”。弹出“One-Sample T Test”对话框。
3.在对话框左侧的变量列表中选择变量“血红蛋白”进入“Test Variable(s)”框;在“Test Value”编辑框中输入过去的平均血红蛋白值10.25.
4.单击“OK”按钮,得到输出结果。
(二)双样本T检验(Independent-Samples T Test过程)
实验内容:
分别测得14例老年性慢性支气管炎病人及11例健康人的尿中17酮类固醇
1.建立数据文件。
定义变量名:把实际观察值定义为x,再定义一个变量group来区分病人与健康人。输入原始数据,在变量group中,病人输入1,健康人输入2。
2. 选择菜单“Analyz e→Compare Means→Independent-samples T Test”项,弹出“Independent- samples T Test”对话框。从对话框左侧的变量列表中选x,进入“Test Variable(s)”框,选择变量“group”,进入“Grouping Variable”框,点击“Define Groups”钮弹出“Define Groups”定义框,在Group 1中输入1,在Group 2中输入2。
3.单击“OK”按钮,得到输出结果。
(三)成对样本T检验(Paired-Samples T Test过程)
实验内容:
某单位研究饲料中缺乏维生素E与肝中维生素A含量的关系,将大白鼠按性别、体重等配为8对,每对中两只大白鼠分别喂给正常饲料和维生素E缺乏饲
料,一段时期后将之宰杀,测定其肝中维生素A含量(μmol/L)如下,问饲料中缺乏维生素E对鼠肝中维生素A含量有无影响?
实验步骤:
1.建立数据文件。
定义变量名:正常饲料组测定值为x1,维生素E缺乏饲料组测定值为x2,输入原始数据。
2.选择菜单“Analyz e→Compare Means→Paired-samples T Test”项,弹出“Paired - samples T Test”对话框。从对话框左侧的变量列表中选择变量x1、x2进入Variables框。
3.单击“OK”按钮,得到输出结果。
实验三方差分析
一、实验目的
学习利用SPSS进行单因素方差分析、多因素方差分析和协方差分析。二、实验内容及步骤
(一)单因素方差分析(One-Way ANOVA过程)
实验内容:
某城市从4个排污口取水,进行某种处理后检测大肠杆菌数量,单位面积内
1.建立数据文件。
定义变量名:编号、大肠杆菌数量和排污口的变量名分别为x1、x2、x3,之后输入原始数据。
2. 选择菜单“Analyz e→Compare Means→One-way ANOV A”,弹出单因素方差分析对话框。从对话框左侧的变量列表中选择变量”大肠杆菌数量”,使之进入“Dependent List”列表框;选择“排污口”进入“Factor”框。
3.选择进行各组间两两比较的方法。
单击“Post Hoc”,弹出“One-Way ANOVA: Post Hoc Multiple Comparisons”。在“Equal Variances Assumed”复选框组中选择LSD.
4.定义相关统计选项以及缺失值处理方法。
单击“Options”按钮,弹出“One-Way ANOV A: Options”对话框。在“Statistics”复选框组选择Descriptive 和Homogeneity-of-variance.同时选中“Means plot”复选框。
5.单击“OK”按钮,执行单因素方差分析,得到输出结果。
(二)多因素方差分析(Univariate过程)
实验内容:
某城市从4个排污口取水,经两种不同方法处理后,检测大肠杆菌数量,单
1.建立数据文件。
定义变量名:编号、大肠杆菌数量、处理方法和排污口的变量名分别为x1、x2、x3和x4,之后输入原始数据。
2. 选择菜单“Analyze→General Linear Model→ Univariate”,弹出“多因素方差分析”对话框。在对话框左侧的变量列表中选择变量“大肠杆菌数量”进入“Dependent Variable”框,选择“排污口”和“处理方法”进入“Fixed Factor(s)
”框。
3.选择建立多因素方差分析的模型。
单击“Univariate”对话框中的“Model”按钮,弹出“Univariate: Model”对话框。选中“Full Factorial”单选纽即饱和模型。
4.设置多因素变量的各组差异比较。
单击“Contrasts”按钮,弹出“Univariate: Contrasts”对话框,在“Contrasts”下拉框中选择Simple;单击“Change”按钮可改变多因素变量的各组差异比较类型。
5.设置以图形方式展现多因素之间是否存在交互作用。
单击“Plots”按钮,弹出“Univariate:Profile Plots”对话框。选择变量“排污口”进入“Horizontal Axis”编辑框,单击“ADD”进入“Plots”框后,选择变量“处理方法”进入“Horizontal Axis”编辑框, 单击“ADD”进入“Plots”框。
6.设置均值多重比较类型。
单击“Post Hoc”按钮,弹出“Univariate: Post Hoc Multiple Comparisons for Observed Means”对话框。将因素“排污口”选入“Post Hoc Test for”列表框,进行多重比较分析。在“Equal Variances Assumed”复选框组中,选择LSD法进行方差齐时两两均值的比较。
7.设置输出到结果窗口的选项。
单击“Options”按钮,弹出“Univariate:Options”对话框,在“Display”复选框中选择Descriptive statistics和Homogeneity tests.
8.单击“OK”按钮,执行多因素方差分析,得到输出结果。
实验四相关及回归分析
一、实验目的
学习利用SPSS进行相关分析、偏相关分析、距离分析、线性回归分析和曲线回归。
二、实验内容及实验步骤
(一)两变量的相关分析(Bivariate过程)
实验内容:
某地区10名健康儿童头发和全血中的硒含量(1000ppm)如下,试作发硒与血硒的相关分析。
编号发硒血硒
1 2 3 4 5 6 7 8 9 1074
66
88
69
91
73
66
96
58
73
13
10
13
11
16
9
7
14
5
10
实验步骤:
1.建立数据文件。
定义变量名:发硒为x,血硒为y,按顺序输入相应数值。
2.选择菜单“Analyze→Correlate→Bivariate”,弹出“Bivariate Correlation”对话框。在对话框左侧的变量列表中选x、y,使之进入“Variables”框;再在“Correlation Coefficients”框中选择Pearson相关系数(r);在“Test of Significance”框中选相关系数的“Two-tailed”(双侧)检验。选中复选框“Flag significant correlations”设置是否突出显示显著相关。
3.单击“Options”按钮,弹出“Bivariate Correlation: Options”对话框,选择“Means and standard deviations”,输出X、Y的均数与标准差。
4.单击“OK”按钮,得到输出结果。
5.做散点图。
(二)偏相关分析(Partial 过程)
实验内容:
某地29名13岁男童身高(cm)、体重(kg)和肺活量(ml)的数据如下表, 试对该资料作控制体重影响作用的身高与肺活量相关分析。
1.建立数据文件。
定义变量名:身高为height,体重为weight,肺活量为vc,按顺序输入相应数据。
2.选择菜单“Analyze→Correlate→Partial”,弹出“Partial Correlations”对话框。在对话框左侧的变量列表中选变量height、vc 进入Variables框,选择要控制的变量weight进入“Controlling for”框中,以在控制体重的影响下对变量身高与肺活量进行偏相关分析;在“Test of Significance”框中选双侧检验。
3.单击“Options”按钮,弹出“Partial Correlations: Options”对话框。在“Statistics”复选框组中选择要输出的统计量。
4.单击“OK”按钮,得到输出结果。
(三)线性回归分析(Linear过程)
实验内容:
某医师测得10名3岁儿童的身高(cm)、体重(kg)和体表面积(cm2)资料如下。试用多元回归方法确定以身高、体重为自变量,体表面积为应变量的回
1.建立数据文件。
定义变量名:体表面积为Y,保留3位小数;身高、体重分别为X1、X2,1位小数。输入原始数据。
2.选择菜单“Analyz e→Regression→Linear”,弹出“Linear Regression”对话框。从对话框左侧的变量列表中选择变量y,使之进入“Dependent”框,选择变量x1、x2,进入“Indepentdent(s)”框;在“Method”处下拉菜单,选用Enter 法。
3.单击“Statistics”按钮选择是否作变量的描述性统计、回归方程应变量的可信区间估计等分析;单击“Plots”按钮选择对标准化Y预测值作变量分布图;单击“Save”按钮选择对根据所确定的回归方程求得的未校正Y预测值和标准化Y预测值作保存;单击“Options”按钮选择变量入选与剔除的α、β值和缺失值的处理方法。
4.单击“OK”完成设置,得到输出结果。
(四)曲线回归(Curve Estimation过程)
实验内容:
某地1963年调查得儿童年龄(岁)X与锡克试验阴性率(%)Y的资料如下,试拟合对数曲线。
年龄(岁)
X 锡克试验阴性率(%)
Y
1 2 3 4 5 6 7 57.1 76.0 90.9 93.0 96.7
95.6
96.2
实验步骤:
1.建立数据文件。
定义变量名:锡克试验阴性率为Y,年龄为X,输入原始数据。
2.选择菜单“Analyz e→Regression→Curve Estimation”,弹出“Curve Estimation”对话框。从对话框左侧的变量列表中选择变量y,进入“Dependent”框,选择变量x,进入“Indepentdent(s)”框;在“Model”框内选择所需的曲线模型,本例选择Logarithmic模型(即对数曲线);选中“Plot models”复选框,输出曲线拟合图。
3.单击“Save”按钮,弹出“Curve Estimation: Save”对话框,选中“Predicted value”复选框,在原始数据文件中保存根据对数方程求出的Y预测值。
4.单击“OK”按钮完成设置,得到输出结果。
实验五绘制统计图
一、实验目的
学会利用SPSS绘制各种统计图形
二、实验内容及步骤
(一)直条图
实验内容:
研究血压状态与冠心病各临床型发生情况的关系,分析资料如下所示,试
1.建立数据文件。
定义变量名:年龄标化发生率为RATE,冠心病临床型为DISEASE,血压状态为BP。RATE按原数据输入,DISEASE按冠状动脉机能不全=1、猝死=2、心绞痛=3、心肌梗塞=4输入,BP按正常=1、临界=2、异常=3输入。
2.选择菜单“Graphs→Bar”过程,弹出“Bar Chart”定义选项框。在定义选项框的上方选择复式直条图“Clustered”。
3.单击“Define”钮,弹出“Define Clustered Bar: Summaries for Groups of Cases”对话框,在左侧的变量列表中选择变量rate,使之进入“Bars Represent”栏的“Other summary function”选项的“Variable”框,选择变量disease,使之进入“Category Axis”框,并选择变量bp进入“Define Clusters by”框。
4.单击“Titles”钮,弹出“Titles”对话框,在“Title”栏内输入“血压状态与冠心病各临床型年龄标化发生率的关系”,单击“Continue”按钮返回“Define Clustered Chart: Summaries for Groups of Cases对话框。
5.单击“OK“按钮,得到输出结果。
(二)线图
实验内容:
某地调查居民心理问题的存在现状,资料如下表所示,试绘制线图比较不同性别和年龄组的居民心理问题检出情况。
年龄分组心理问题检出率(%)男性女性
15- 25- 35- 10.57
11.57
9.57
19.73
11.98
15.50
45- 55- 65- 75- 11.71
13.51
15.02
16.00
13.85
12.91
16.77
21.04
实验步骤:
1.建立数据文件。
定义变量名:心理问题检出率为RATE,年龄分组为AGE,性别为SEX,AGE 与SEX可定义为字符变量。RATE按原数据输入,AGE按分组情况分别输入15-、25-、35-、45-、55-、65-、75-,SEX是男的输入M、女的输入F。
2.选择菜单“Graphs→Line”,弹出Line Chart定义选项框,选择”Multiple“绘制多条线图。
3.单击“Define”按钮,弹出“Define Multiple Line: Summaries for Groups of Cases”对话框,在左侧的变量列表中选择变量rate,使之进入“Lines Represent”栏的“Other summary function”选项的“Variable”框,选择变量age,使之进入“Category Axis”框,选择变量sex,使之进入“Define Lines by”框。
4.单击“Titles”按钮,弹出“Titles”对话框,在“Title”栏内输入“某地男女性年龄别心理问题检出率比较”,单击“Continue”按钮返回“Define Multiple Line: Summaries for Groups of Cases”对话框。
5.单击“OK”按钮,得到输出结果。
(三)区域图
实验内容:
在某城市抽样研究20-49岁已婚育龄妇女的避孕现状,频数分布资料参见下表,试绘制区域图。
年龄分组
避孕现状
有无
20- 25- 30- 35- 40- 45-
63
939
1860
1277
1141
987
68
184
273
91
173
399
实验步骤:
1.建立数据文件。
定义变量名:避孕有无的人数为NUMBER,年龄分组为AGE,避孕现状为CONTRA,AGE与CONTRA可定义为字符变量。NUMBER按实际人数输入(有无避孕的人数全部输入变量NUMBER中),AGE按分组情况分别输入20-、25-、30-、35-、40-、45-,CONTRA有的输入Y、无的输入N。
2.选择菜单“Graphs→Area”,弹出“Area Chart”定义选项框,选择堆积区域图“Stacked”。
3.单击“Define”钮,弹出“Define Stacked Area: Summaries for Groups of Cases”对话框。在左侧的变量列表中选择变量number,使之进入“Areas Represent”栏的“Other summary function”选项的“Variable”框,选择变
量age,使之进入“Category Axis”框,选择变量contra,使之进入”Define Areas by”框。
4.单击“Titles”按钮,弹出“Titles”对话框,在“Title”栏内输入“某市已婚育龄妇女避孕状况分析”,单击“Continue”按钮返回“Define Stacked Area: Summaries for Groups of Cases”对话框。
5.单击“OK”按钮,得到输出结果。
(四)构成图(Pie Chart过程)
实验内容:
某年某医院用中草药治疗182例慢性支气管炎患者,其疗效如下所示,试绘制构成图。
疗效病例数百分构成(%)
控制显效好转无效37
71
60
14
20.3
39.0
33.0
7.7
合计182 100.0
实验步骤:
1.建立数据文件。
定义变量名:百分构成资料为DATA,构成部分的名称为TEXT,TEXT定义为字符变量。DATA按实际百分数输入,TEXT依次输入1、2、3、4。
2.选择菜单“Graphs→Pie”,弹出“Pie Chart”定义选项框。单击“Define”按钮,弹出“Define Pie: Summaries for Groups of Cases”对话框,在左侧的变量列表中选择变量data进入“Slices Represent”栏的“Other summary function”选项的“Variable”框,选择变量text进入“Define Slices by”框。
3.单击“Titles”按钮,弹出Titles对话框,在“Title”栏内输入“中草药治疗慢性支气管炎效果构成图”,单击“Continue”按钮返回“Define Pie: Summaries for Groups of Cases”对话框。
4.单击“OK”按钮,得到输出结果。
(五)高低区域图(High-Low过程)
实验内容:
为了解水体污染情况,某市测定三种水源中放射性元素锶(90Sr)的含量(10-2Bq· L-1),资料如下,试绘制高低区域图。
水源点范围均值
自来水湖水水库水0.65~0.93
1.31~
2.11
1.01~
2.16
0.79
1.71
1.58
实验步骤:
1.建立数据文件。
定义变量名:变量DATA将范围的低值与高值以及均值一并输入;变量CAT 用于定义低值、高值和均值,低值为1、高值为2、均值为3;水源点变量名为GROUP,依次输入1、2、3。
2. 选择菜单“Graphs→High-Low”,弹出“High-Low Chart”定义选项框,选择“Simple High-Low-Close”(简单线型高低区域图)。
3.单击“Define”按钮,弹出“Define Simple High-Low-Close: Summaries for Groups of Cases”对话框。在左侧的变量列表中选择变量data进入“Bars Represent”栏的“Other summary function”选项的“Variable”框;选择变量cat进入“Category Axis”框, 选择变量group进入“Define High-Low-Close by”框。
4.单击“Titles”按钮,弹出“Titles”对话框,在“Title”栏内输入“某市测定不同水体放射性元素锶的含量比较”,单击“Continue”按钮返回“Define Simple High-Low-Close: Summaries for Groups of Cases”对话框。
5.单击“OK”按钮,得到输出结果。
(六)直条构成线图(Pareto过程)
实验内容:
随访1000名20-25岁的男性一年,分季节考察其感冒发生情况,结果如下,试绘制直条构成线图。
季节病例数百分构成(%)
春夏秋冬443
104
379
187
39.80
9.35
34.05
16.80
合计1113 100.00
实验步骤:
1.建立数据文件。
定义变量名:各季节病例数的变量名为DATA,输入具体数字;季节的变量名为SEASON,依次输入1、2、3、4;系统自动生成百分构成。
2.选择菜单“Graphs→Pareto”,弹出“Pareto Chart”定义选项框,选择“Simple”(单一直条构成线图),
3.单击“Define”按钮,弹出“Define Simple Pareto: Summaries for Groups of Cases”对话框,在左侧的变量列表中选择变量data进入“Sums of variable”框,选择变量season进入“Category Axis”框。
4.单击“Titles”按钮,弹出“Titles”对话框,在“Title”栏内输入“1000名20-25岁男性各季节感冒发生人数分析”,单击“Continue”按钮返回“Define Simple Pareto: Summaries for Groups of Cases”对话框。
5.单击“OK”按钮,得到输出结果。
(七)质量控制图(Control过程)
实验内容:
对一种标准试液中某物质含量测平行样5次,结果如下,试绘制质量控制图以便对准确度与精确度进行评价。
测定次序
平行样
均数极差第一次第二次
1 10.4 10.1 10.25 0.3
2 3 4 5 10.8
9.8
9.4
10.1
11.0
10.4
11.0
11.3
10.90
10.10
10.20
10.70
0.2
0.6
1.6
1.2
实验步骤:
1.建立数据文件。
定义变量名:平行样数据的变量名为DATA,将测定数据一并输入;变量GROUP,用于定义测定次序,依次输入1、2、3、4、5。系统自动生成均数和极差的数据。
2.选择菜单“Graphs→Control”,弹出“Control Chart”定义选项框,选用“X-Bar, R, s”控制图。
3.单击“Define”按钮,弹出“X-Bar, R, s: Cases Are Units”对话框,在左侧的变量列表中选择变量data,使之进入“Process Measurement”框,选择变量group,使之进入“Subgroups Defined by”框。在“Charts”栏中选“X-Bar and range”项,输出均数控制图和极差控制图。
4.单击“Titles”按钮,弹出“Titles”对话框,在“Title”栏内输入“样品测定的质量控制图”。单击“Continue”按钮返回“X-Bar, R, s: Cases Are Units”对话框。
5.单击“OK”按钮,得到输出结果。
(八)箱图(Boxplot过程)
实验内容:
研究甲基汞对肝脏脂质过氧化的毒性作用,选用25只大白鼠,随机分成五组,按不同剂量染毒一段时期后测定肝脏LPO含量(n mol/L),资料如下表,试绘制箱图。
编号
染毒剂量(mg/kg体重)
5.0 10.0 20.0 30.0 40.0
1 2 3 4 5 184.30
268.20
222.64
127.52
291.50
391.50
487.25
345.69
574.12
526.78
1025.40
1289.24
1463.55
1168.47
1356.70
1897.21
1705.33
1532.46
2015.46
2100.40
1821.33
2897.53
2001.40
2748.97
4539.75
数据准备
激活数据管理窗口,定义变量名:所测定肝脏LPO含量数据的变量名为DATA,输入原始数据;再设一变量为GROUP,用于定义不同染毒剂量组,依次输入1、2、3、4、5。
操作步骤
选Graphs菜单的Boxplot...过程,弹出Boxplot Chart定义选项框,有2种箱图可选:Simple为简单箱图,Clustered为复式箱图,本例选用简单箱图。然后点击Define钮,弹出Define Simple Boxplot:Summaries for Groups of Cases 对话框(图15.10),在左侧的变量列表中选data点击 钮使之进入Variable 框,选group点击 钮使之进入Category Axis框。点击OK钮即完成。
实验六非参数检验
一、实验目的
学习利用SPSS进行卡方检验、分布检验等非参数检验。
二、实验内容及实验步骤
(一)卡方检验(Chi-Square过程)
实验内容:
某地一周内各日死亡数的分布如下表,请检验一周内各日的死亡危险性是否相同?
实验步骤:
1.建立数据文件。
定义变量名:周日为day,死亡数为death。按顺序输入数据。
2.选择菜单“Data→Weight Case s”,弹出Weight Cases对话框,选择变量death进入“Frequency Variable”框,定义死亡数为权数。
3.选择菜单“Analyze→Nonparametric Tests→Chi-Square”,弹出Chi-Square Test对话框。在对话框左侧的变量列表中选择变量day,使之进入“Test Variable List”框,对一周内各日的死亡数进行分布分析。
4.单击“OK”按钮,得到输出结果。
(二)二项分布(Binomial过程)
实验内容:
某地某一时期内出生40名婴儿,其中女性12名(定Sex=0),男性28名(定Sex=1)。问这个地方出生婴儿的性比例与通常的男女性比例(总体概率约为0.5)是否不同?
实验步骤:
1.建立数据文件。
定义性别变量为sex。按出生顺序输入数据,男性为1 ,女性为0。
2.选择菜单“Analyze→Nonparametric Tests→Binomial Test”,弹出Binomial Test对话框。在对话框左侧的变量列表中选择变量sex,进入“Test Variable List”框,“在Test Proportion”框中键入0.50。
3.单击“OK”按钮,得到输出结果。
(三)游程检验(Runs过程)
实验内容:
某村发生一种地方病,其住户沿一条河排列,调查时对发病的住户标记为“1”,对非发病的住户标记为“0”,共17户:
0 1 1 0 0 0 1 0 0 1 0 0 0 0 1 1 0 0
1 0 0 0 0 1 0 1
问病户的分布排列是呈聚集趋势,还是随机分布?
实验步骤:
1.建立数据文件。
定义住户变量为epi。按住户顺序输入数据,发病的住户为1 ,非发病的住户为0。
2.选择菜单“Analyze→Nonparametric Tests→Runs Test”,弹出“Runs Test”对话框。在对话框左侧的变量列表中选择变量epi,使之进入Test Variable List框。在临界割点“Cut Point”框中选“Custom”项,在其方框中键入1(根据需要选项,本例是0、1二分变量,故临界割点值用1)。
3.单击“OK”按钮,得到输出结果。
(四)单样本Kolmogorov-Smirnov检验(1-Sample K-S过程)
实验内容:
某地正常成年男子144人红细胞计数(万/立方毫米)的频数资料如下,问
实验步骤:
1.建立数据文件。
定义频数变量名为f,并输入相应数据。
2.选择菜单“Analyze→Nonparametric Tests→1-Sample K-S”,弹出“One-Sample Kolmogorov-Smirnov Test”对话框。在对话框左侧的变量列表中选择变量f进入“Test Variable List”框,在“Test Distribution”框中选“Normal”项,表明与正态分布形式相比较。
3.单击“OK”按钮,得到输出结果。
(五)两独立样本比较(2 Independent Samples过程)
实验内容:
调查某厂的铅作业工人7人和非铅作业工人10人的血铅值(μg / 100g)
实验步骤:
1.建立数据文件。
定义分组变量为group(非铅作业组为1,铅作业组为2),血铅值为Pb。按顺序输入数据。
2.选择菜单“Analyze→Nonparametric Tests→2 Independent Samples”,弹出Two-Independent-Samples-Test对话框。在对话框左侧的变量列表中选择Pb,进入“Test Variable List框”;选择变量group,进入“Grouping Variable”框,点击“Define Groups”钮,在弹出的“Two Independent Samples: Define Groups”对话框内定义Group 1为1,Group 2为2,单击“Continue”按钮返回;在“Test Type”框中选择“Mann-Whitney U”检验方法。
3.单击“OK”按钮,得到输出结果。
(六)K独立样本比较(K Independent Samples过程)
实验内容:
随机抽样得以下三组人的血桨总皮质醇测定值(μg / L),试比较有无差异?
1
定义分组变量为 group(正常人为1,单纯性肥胖为2,皮质醇增多症为3),总皮质醇测定值为pzc。按顺序输入数据。
2.选择菜单“Analyze→Nonparametric Tests→k Independent Samples”,弹出“Tests for Several Independent Samples”对话框。在对话框左侧的变量列表中选择变量pzc,进入“Test Variable List”框。选择变量group,进入“Grouping Variable”框,单击“Define Range”钮,在弹出的“K Independent Samples: Define Range”对话框内定义Mininum为1,Maxinum为2,单击“Continue”钮返回。在Test Type框中选择“Kruskal-Wallis H”检验方法。
3.单击“OK”按钮,得到输出结果。
(七)2相关样本比较(2 Related Samples过程)
实验内容:
研究饲料中缺乏Vit E对大鼠肝中Vit A含量的关系,将大鼠按性别相同、体重相近的原则配成8对,并将每对大鼠随机分为2组(正常饲料组、Vit E缺乏饲料组),一定时间后杀死大鼠,测定肝中Vit A含量,结果如下表,问:饲料中缺乏Vit E对大鼠肝中Vit A含量有无影响?
大鼠对别正常饲料组Vit E 缺乏饲料组
1 2 3 4 5 6 7 8 37.2
20.9
31.4
41.4
39.8
39.3
36.1
31.9
25.7
25.1
18.8
33.5
34.0
28.3
26.2
18.3
1.建立数据文件。
定义正常饲料组变量名为va1, Vit E 缺乏饲料组变量名为va2, 按顺序输入数据。
2.选择菜单“Analyze→Nonparametric Tests→2 Related Samples”,弹出“Two-Related-Samples Tests”对话框。在对话框左侧的变量列表中选择变量va1,在“Current Selections”栏的“Variable 1”处出现va1,选择变量va2,在“Current Selections”栏的“Variable 2”处出现va2,然后使va1 -va2进入“Test Pair(s) List”框。在“Test Type”框中选择“Wilcoxon”和“Sign”两项。单击“Options”按钮,弹出“Two-Related-Samples: Options”对话框,在“Statistics”栏中选“Decriptives”,计算均数、标准差等指标.
3.单击“OK”按钮,得到输出结果。
(八)K相关样本比较(K Related Samples过程)
实验内容:
用某药治疗血吸虫病患者,在治疗前和治疗后一周、二周和四周各测定7名患者血清SGPT值的变化,以观察该药对肝功能的影响,结果如下表,问:患
1.建立数据文件。
定义变量名:治疗前为before、治疗后一周为w1、二周为w2、四周为w4,按顺序输入各组SGPT数据。
2.选择菜单“Analyze→Nonparametric Tests→k Related Samples”,弹出“Tests for Serveral Related Samples”对话框。在对话框左侧的变量列表中选择变量before、w1、w2和w4,进入“Test Variables”框。在“Test Type”框中选择“Friedman”和“Kendall’s W”两种检验方法。再单击“Statistics”
按钮,弹出“K Related-Samples: Statistics”对话框,在“Statistics”栏中选中“Decriptives”,计算均数、标准差等指标,单击“Continue”按钮返回。
3.单击OK钮,得到输出结果。
实验七聚类分析和判别分析
一、实验目的
学习利用SPSS进行聚类分析和判别分析。
二、实验内容及实验步骤
(一)系统聚类法(Hierarchical Cluster过程)
实验内容:
29名儿童的血红蛋白(g/100ml)与微量元素(μg/100ml)测定结果如下表。由于微量元素的测定成本高、耗时长,故希望通过聚类分析(即R型指标聚类)筛选代表性指标,以便更经济快捷地评价儿童的营养状态。
编号N0. 钙
X1
镁
X2
铁
X3
锰
X4
铜
X5
血红蛋
白
X6
1 2 3 4 5 6 7 8 9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28 54.89
72.49
53.81
64.74
58.80
43.67
54.89
86.12
60.35
54.04
61.23
60.17
69.69
72.28
55.13
70.08
63.05
48.75
52.28
52.21
49.71
61.02
53.68
50.22
65.34
56.39
66.12
73.89
30.86
42.61
52.86
39.18
37.67
26.18
30.86
43.79
38.20
34.23
37.35
33.67
40.01
40.12
33.02
36.81
35.07
30.53
27.14
36.18
25.43
29.27
28.79
29.17
29.99
29.29
31.93
32.94
448.70
467.30
425.61
469.80
456.55
395.78
448.70
440.13
394.40
405.60
446.00
383.20
416.70
430.80
445.80
409.80
384.10
342.90
326.29
388.54
331.10
258.94
292.80
292.60
312.80
283.00
344.20
312.50
0.012
0.008
0.004
0.005
0.012
0.001
0.012
0.017
0.001
0.008
0.022
0.001
0.012
0.000
0.012
0.012
0.000
0.018
0.004
0.024
0.012
0.016
0.048
0.006
0.006
0.016
0.000
0.064
1.010
1.640
1.220
1.220
1.010
0.594
1.010
1.770
1.140
1.300
1.380
0.914
1.350
1.200
0.918
1.190
0.853
0.924
0.817
1.020
0.897
1.190
1.320
1.040
1.030
1.350
0.689
1.150
13.50
13.00
13.75
14.00
14.25
12.75
12.50
12.25
12.00
11.75
11.50
11.25
11.00
10.75
10.50
10.25
10.00
9.75
9.50
9.25
9.00
8.75
8.50
8.25
8.00
7.80
7.50
7.25
实验一S P S S简介及 统计整理
实验一SPSS简介及统计整理 一、实验目的和要求 1掌握SPSS安装、启动、主界面和退出; 2掌握SPSS的变量定义信息; 3掌握SPSS的数据录入与保存方法; 4掌握在SPSS中的实现各种统计描述参数的计算。引到学生利用正确的统计方法对数据进行适当的整理和显示,描述并探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。 5理解并掌握SPSS软件包有关数据文件创建和整理的基本操作 6学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件 7掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序8 实验类型:验证型;实验时间:2学时 二、实验主要仪器和设备 计算机一台,Windows XP操作系统,SPSS环境。 三、实验原理 SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。一个典型的SPSS数据文件如表2.1 所示。 SPSS变量的属性
SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面(如图2.1所示)即可对变量的各个属性进行设置。 四、实验内容与步骤 实验1.1数据文件管理 1.创建一个数据文件 数据文件的创建分成三个步骤: (1)选择菜单【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。窗口顶部标题为“PASW Statistics数据编辑器”。 (2)单击左下角【变量视窗】标签进入变量视图界面,根据实验的设计定义每个变量类型。 (3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。 2.读取外部数据
1、在spss中打开你要处理的数据,在菜单栏上执行:analyse-compare means--one-way anova,打开单因素方差分析对话框。 2、在这个对话框中,将因变量放到dependent list中,将自变量放到factor中,这个 研究中有两个因变量,所以把两个因变量都放到上面的列表里。 3、点击post hoc,打开一个对话框,设置事后检验的方法。 4、在这个对话框中,我们在上面的方差齐性的方法中选择tukey和REGWQ,在方差
不齐性的方法中选择dunnetts,点击continue继续。 5、回到了anova的对话框,点击options按钮,设置要输出的基本结果。 6、这里选择描述统计结果和方差齐性检验,点击continue按钮。
7、点击ok按钮,开始处理数据。 8、我们看到的结果中,第一个输出的表格就是描述统计,从这个表格里我们可以看到 均值和标准差,在研究报告中,通常要报告这两个参数。
9、接着看方差齐性检验,方差不齐性的话是不能够用方差齐性的方法来检验的,还好, 这里显示,显著性都没有达到最小值0.05,所以是不显著的,这证明方差是齐性的 。 10、接着看单因素方差分析表,反应时sig值不显著,而错误率达到了显著的水平,这 说明实验处理对错误率产生了影响,但是对反应时没有影响。 11、接着看事后检验,因为反应时是没有显著差异的,所以就不必再看反应时的事后检 验,直接看错误率的事后检验,从图中标注的红色方框可以看到,第一组和二三组都有显著的差异,而第二组和第三组没有显著差异。关于dunnet方法,它适合在方差不齐性的时候使用,因为方差齐性,不必去看这个方法的检验结果了。
目录 一、SPSS界面介绍 (2) 1、如何打开文件 (2) 2、如何在SPSS中打开excel表 (3) 3、数据视图界面 (3) 4、变量视图界面 (4) 二、如何用SPSS进行频数分析 (11) 三、如何用SPSS进行多变量分析 (15) 四、如何对多选题进行数据分析 (18) 1、对多选题进行变量集定义 (18) 2、对多选题进行频数分析 (21) 3、对多选题进行多变量交互分析 (24) 五、如何就SPSS得出的表在excel中作图 (27)
一、SPSS界面介绍 提前说明:第一,我这里用的是SPSS 20.0 中文汉化版。第二,我教的是傻瓜操作,并不涉及理论讲解,具体的为什么和用什么理论公式来解释请认真去听《社会统计学》的课程。第三,因为是根据我自己的操作和理解来写的,所以可能有些地方显的不那么科学,仍然要说请大家认真去听《社会统计学》的课程,那个才是权威的。 1、如何打开文件 这个东西打开之后界面是这样的: 我们打开一个文件:
要提的一点就是,SPSS保存的数据拓展名是.sav: 2、如何在SPSS中打开excel表 在上图的下拉箭头里找到excel这个选项: 然后你就能找到你要打开的excel表了。 3、数据视图界面 我现在打开了一个数据库。 可以看到左下角这个地方有两个框,两个是可以互相切换的,跟excel切换表一样,跟excel切换表一样: 现在的页面是数据视图,也就是说这一页都是原始数据,这里的一行就是一张问卷,一列就是一个问题,白框里的1234代表的是选项。这个表当时录数据的时候为了方便看,是把ABCD都转换成了1234,所以显示的是1234,当然直接录ABCD也可以,根据具体情况看怎么录,只要能看懂。 多选题的录入全部都是细化到每个选项,比如第四题,选项A选了就是“是”,没选就是
精品文档 SPSS学习 第一章数据文件的建立 数据编码 Type:Numeric:数值型string:字符串型 Missing: Measure:scale定量变量nominal定性变量 根据已有的变量建立新变量 1、对于数据进行重新编码 Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue 2、通过SPSS函数建立新变量 Transform—compute variable –从function group中选择公式范围下面选择具体的公式—if中设置要改变—continue—OK(可以对变量进行各种计算) 第二章清除数据与基本统计分析 1、对不合理的数据检查并清理 检查:analysis-description statistic-frequencies—选入要检查的数据—OK 结果:频数统计表—看是否有错误—missing system 清理: 1.对系统缺失值的清理 Data—select case—if condition is satisfied—if—function group(missing)--下面选(missing) --continue—output(delete unselected cases)--OK—对num为哪一位的进行修改 2.对sex=3的清理(直接就清除了) Data—select case—if condition is satisfied—if—sex调入再输入=3—continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 2. 对相关变量间逻辑性检查和清理 Data—select case—if condition is satisfied—if—输入表达式(前后逻辑不相符合的表达式)--continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 精品文档. 精品文档3.统计描述正态分布统计描述one-sample —1-sample K-SAnalysis—nonparametric tests—legacy dialogs—1、正态性检验:ok/ —–normalKolomogorov Smirnov test ok ——options2、统计描述:Analysis—descriptives--time选入ok 调入—data—split file –compare group –sex3、按照男女统计描述:OK——time 调入—options 选择–Analysis-descriptive statistic descriptive 非正态分布资料统计描述nonparametric 正态性检验1、 OK ——frequencies 选入-- statistics选择2、Analysis—descriptive statistics
SPSS因子分析实例操作步骤 实验目的: 引入2003~2013年全国的农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业7个产业的投资值作为变量,来研究其对全国总固定投资的影响。 实验变量: 以年份,合计(单位:千亿元),农、林、牧、渔业,采矿业,制造业电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业作为变量。 实验方法:因子分析法 软件: 操作过程: 第一步:导入Excel数据文件 1.open data document——open data——open; 2. Opening excel data source——OK.
第二步: 1.数据标准化:在最上面菜单里面选中Analyze——Descriptive Statistics——OK (变量选择除年份、合计以外的所有变量). 2.降维:在最上面菜单里面选中Analyze——Dimension Reduction——Factor ,变量选择标准化后的数据.
3.点击右侧Descriptive,勾选Correlation Matrix选项组中的Coefficients和 KMO and Bartlett’s text of sphericity,点击Continue. 4.点击右侧Extraction,勾选Scree Plot和fixed number with factors,默认3个,点击Continue.
5.点击右侧Rotation,勾选Method选项组中的Varimax;勾选Display选项组中的Loding Plot(s);点击Continue. 6.点击右侧Scores,勾选Method选项组中的Regression;勾选Display factor score coefficient matrix;点击Continue.
第一章 SPSS10.0 for Windows简介 SPSS软件是由美国SPSS公司研制的。SPSS的全称为Statistical Program for Social Sciences,即“社会科学统计程序”。SPSS10.0 for Windows是在Windows操作系统下运行的社会科学统计软件包,该软件是国际上公认的最优秀的统计分析软件包之一。它在经济、工业、管理、心理、教育、医学等许多领域应用广泛,在科研工作中发挥了巨大的作用。SPSS 最初的版本是建立在D0S基础上的,但在80年代末,Microsoft推出Windows后,SPSS迅速向Windows移植。并不断推出SPSS软件的新版本。SPSS for Windows版本从6.0、7.0、8.0、9.0,至1999年底,正式推出SPSS10.0 for Windows版本。该版本相对于一些早期的版本而言,不仅改写了一些模块,使运行速度大大提高,而且根据统计理论与技术的发展,增加了许多新的统计分析方法,使之功能日趋完善。近年由推出11.0和12.0 版本,这两新版本主要提高运行速度和增加了一些新统计学方法,其余与10.0 版本基本相同。本书以10.0版本介绍SPSS for Windows的使用方法。 第一节 SPSS10.0 for Windows的特点 SPSS软件风靡世界并为各个领域的广大科研工作者及其他用户所钟爱,原因在于它有以下的特点; 1、多种实用分析力法。SPSS提供了多种分析方法,包括了从基本的统计特征描述到诸如非参数检验、生存分析等各种高层次的分析。除此之外,SPSS还具有强大的绘制图形、编辑图形的能力。 2、易于学习,易于使用。对于SPSS for Windows而言,除了数据输入工作要使用键盘之外,其他的大部分操作均可以通过“菜单”、“对话框”来完成,使用户不必记忆大量的命令,操作更简单。 3、文件易于转换。与其他软件有数据转换接口。 Excel文件、文本文件等均可以转换成相应的SPSS数据文件。 4、操作方法多种多样。不仅有灵活的菜单对话框式操作,而且用户也可以自已编写SPSS 语句来进行数据统计分析工作。 第二节 SPSSl0.0 for Windows对环境的要求 一、对硬件的要求 由于SPSS主要用途是面向大型数据库的,它的运算一般涉及的数据量比较多。故而用户一般需要有较大的内存,而且如果用户还要进行多因素分析、生存分析之类的大运算量的分析,计算机至少要有16M的内存。 二、对软件的要求 SPSS for W1ndows目前没有汉化版本。一般用户可以在以下环境中运行SPSS。 1、中文Windows95、Windows98、Windows me、Windows2000 SPSS for W1ndows在此环境下运行,对话框中的按钮功能能以中文显示。可以使用中文设置变量标签和值标签。在要点表中显示中文标签。打印的时候,只能把正排汉字正常打印,图形中被旋转了的汉字打印的结果是乱码。 2、英文Windows95、Windows98、Windows me、Windows2000加中文平台,以便定义和输出中文标签。
S P S S操作步骤汇总 Company Document number:WUUT-WUUY-WBBGB-BWYTT-1982GT
SPSS学习 第一章数据文件的建立 数据编码 Type:Numeric:数值型 string:字符串型 Missing: Measure:scale定量变量 nominal定性变量 根据已有的变量建立新变量 1、对于数据进行重新编码 Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue 2、通过SPSS函数建立新变量 Transform—compute variable –从function group中选择公式范围下面选择具体的公式—if 中设置要改变—continue—OK(可以对变量进行各种计算) 第二章清除数据与基本统计分析 1、对不合理的数据检查并清理 检查:analysis-description statistic-frequencies—选入要检查的数据—OK 结果:频数统计表—看是否有错误—missing system 清理: 1.对系统缺失值的清理
Data—select case—if condition is satisfied—if—function group(missing)--下面选 (missing)--continue—output(delete unselected cases)--OK—对num为哪一位的进行修改 2.对sex=3的清理(直接就清除了) Data—select case—if condition is satisfied—if—sex调入再输入=3—continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 2. 对相关变量间逻辑性检查和清理 Data—select case—if condition is satisfied—if—输入表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改 3.统计描述 正态分布统计描述 1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/ 2、统计描述:Analysis—descriptives--time选入—options—ok 3、按照男女统计描述:data—split file –compare group –sex调入—ok Analysis-descriptive statistic – descriptive—time 调入—options选择—OK非正态分布资料统计描述 1、正态性检验nonparametric 2、Analysis—descriptive statistics—frequencies 选入-- statistics选择—OK 第三章T检验
第四章:SPSS结果窗口用法详解 §4.1结果窗口元素介绍 SPSS实际上提供了两个结果窗口--结果浏览窗口和结果草稿浏览窗口。前者最为常用,显示美观,但非常消耗系统资源;后者实际上是一个RTF格式文档,显示简单朴素,但节省资源。我们可以根据所用计算机的情况选择使用哪一种窗口。 结果草稿浏览窗口的内容虽然是RTF格式,但由于中、英文兼容性的问题, 其中的表格读入WORD以后会变的面目全非,因此对我们不是很适用。 4.1.1 结果浏览窗口 SPSS的输出结果美观大方,是该软件的一大特色,下面是一个典型的结果浏览窗口。 相信99%的人都用过资源管理器,SPSS的结果浏览窗口和Windows资源管理器的结构完全相同,操作也几乎相同。除了上面的菜单栏、工具栏以外,绝大部分窗口被纵向一分为二!左侧是大纲视图(Outline view),又称结构视图,右侧则
显示详细的统计结果(统计表、统计图和文本结果),两侧的元素是完全一一对应的,即选中一侧的某元素,在另一侧该元素也会被选中。例如左侧的Title 图标旁有一个红色的箭头,表明该内容为结果窗口当前所在位置,相应的,右侧的标题Descriptives旁也出现一个红色三角,表明这就是Title图标所代表的内容。下面解释一下大纲视图的各个元素。 大纲视图顾名思义,大纲视图用于概略显示结果的结构,用于在宏观上对结果进行管理,如移动,删除等。里面采取和资源管理器类似的层次方式排列元素,每个元素用一个小图标来表示。常见的图标有: 大纲图标,代表一段或整个输出结果,含下级元素,单击左侧的减号就可以 将下级元素折叠,折叠后减号变为加号,图标则变为。 运行记录图标,代表系统操作产生的一段运行记录。 警告图标,代表输出结果中的系统警告。 注解图标,代表系统自动产生的注解,默认情况下注解内容在输出结果中是隐藏的。 标题图标,代表输出标题。 页标题图标,代表输出标题,较少出现。 表格图标,代表输出结果中的统计表(Pivot table,字面意思为数据透视表)。 统计图图标,代表统计图。 文本图标,代表文本输出结果。 交互式统计图图标,代表交互式统计图。 统计地图图标,代表统计地图。 单击图标会选中所代表的一块或一段输出结果,双击图标可以让对应输出在显示、隐藏间切换,选中后单击图标的名称则可以对图标改名。 4.1.2 结果草稿浏览窗口 和它漂亮的兄弟相比,结果草稿浏览窗口就朴素的多了,什么花样也没有。当然,系统资源也要少占用许多,前面的输出结果在结果草稿浏览窗口中的显示如下:
实习一SPSS基本操作 第1题:请把下面的频数表资料录入到SPSS数据库中,并划出直方图,同时计算均数和标准差。 身高组段频数 110~ 1 112~ 3 114~ 9 116~ 9 118~ 15 120~ 18 122~ 21 124~ 14 126~ 10 128~ 4 130~ 3 132~ 2 134~136 1 解答:1、输入中位数(小数位0):111,113,115,117,....135;和频数1,3,. (1) 2、对频数进行加权:DATA━Weigh Cases━Weigh Cases by━频数━OK 3、Analyze━Descriptive Statistics━Frequences━将组中值加 入Variable框━点击Statistics按钮━选中Mean和 Std.devision━Continue━点击Charts按钮━选中HIstograms ━Continue━OK 第2题某医生收集了81例30-49岁健康男子血清中的总胆固醇值(mg/dL)测定结果如下,试编制频数分布表,并计算这81名男性血清胆 固醇含量的样本均数。 219.7 184.0 130.0 237.0 152.5 137.4 163.2 166.3 181.7 176.0 168.8 208.0 243.1 201.0 278.8 214.0 131.7 201.0 199.9 222.6 184.9 197.8 200.6 197.0 181.4 183.1 135.2 169.0 188.6 241.2 205.5 133.6 178.8 139.4 131.6 171.0 155.7 225.7 137.9 129.2 157.5 188.1 204.8 191.7 109.7 199.1 196.7 226.3 185.0 206.2 163.8 166.9 184.0 245.6 188.5 214.3 97.5 175.7 129.3 188.0 160.9 225.7 199.2 174.6 168.9 166.3 176.7 220.7 252.9 183.6 177.9 160.8 117.9 159.2 251.4 181.1 164.0 153.4 246.4 196.6 155.4 解答:1、输入数据:单列,81行。
目录 第四章统计描述 (2) 4.2 频数分析 (2) 4.3描述性统计量 (2) 4.4.1(探索性数据分析)操作步骤 (4) 第五章统计推断 (6) 5.2单样本t检验 (6) 5.3 两独立样本t检验 (7) 5.4 配对样本t检验 (8) 第六章方差分析 (9) 6.2.2 单因素单变量方差分析(One-way ANOVA)(操作步骤) (10) 6.3.3 多因素单变量方差分析操作步骤 (14) 6.3.5 不考虑交互效应的多因素方差分析 (17) 6.3.6 引入协变量的多因素方差分析 (18) 第八章相关分析 (19) 8.2 连续变量相关分析实例 (20) 8.3 离散变量相关分析的实例(列联表) (22) 第九章回归分析 (24) 9.1.3 线性回归(操作步骤) (26) 1.多重共线性检验 (26) 2.使用变量筛选的方法克服多重共线性 (29) 二、曲线估计(操作步骤) (32) 9.2.5二项Logistic回归(操作步骤) (35) 第十章聚类分析 (39) 10.3.1 K-均值操作步骤: (39) 10.4.1 系统聚类法操作步骤 (43) 第十一章判别分析 (47) 11.3.1 操作步骤 (48) 第十二章因子分析 (53) 12.2.2操作步骤 (56) 第十三章主成分分析 (64) 13.2 操作步骤 (65) 第十四章相应分析 (69) 14.2相应分析实例(操作步骤) (70) 第十五章典型相关分析 (75) 15.2操作步骤: (75)
第四章统计描述 统计描述是指如何搜集、整理、分析、研究并提供统计资料的理论和方法,用于说明总体的情况和特征。 4.1 基本概念和原理 4.1.1 频数分布 4.1.2 集中趋势指标 算数平均值:适用于定比数据、定距数据 中位数:适用于定比数据、定距数据和定序数据 众数:适用于定比数据、定距数据、定序数据和定类数据 4.1.3离散程度指标 作用:(1)它可以表明现象的平衡程度和稳定程度;(2)离散性指标可以表明平均指标的代表性,数据离散程度越大,则该分布的平均指标的代表性就越小。方差、标准差、均值标准误差、极差。 均值标准误差:也叫抽样标准误差,是样本均值的标准差,反映了样本均值与总体均值之间的差异程度。 4.1.4反映分布形态的描述性指标 偏度、峰度 4.2 频数分析 Analyze——Descriptive Statistics——Frequencies 4.3描述性统计量 Analyze——Descriptive Statistics——Frequencies
Spss基础入门 1. 个案排序:对数据视图中的某个个案进行排序,具体排序规则可以点进去选择 2. 变量排序:对变量视图中某个变量进行排序,具体规则可以点进去选择 3. 转置:行列互转 4. 合并文件:有两种文件的合并,添加个案可以实现两个文件的纵向合并,添加变量可以两个文件的横向合并 5. 重构:实现把一个表格的若干个变量变为同一个变量等进行表格的合适转换 6. 汇总:对数据按照类别进行汇总,比如三个班级的学生成绩表格,可以按照班级把学生成绩的平均值等等汇总到另外一个表格,该表格就会显示比如按班级显示各个班级的成绩平均值等 7. 拆分文件:实现输出图形表格的合理拆分,比如一个公司有8个部门,现要求分男女比较各个部门的人员工资情况,理论上我们用选择个案(见下条),逐个选择男女与部门需要操作2*8次,由此画出2*8张图表。利用拆分文件,这个时候可以选择 比较组或者按组来组织输出,然后分组依据就是部门与性别,在利用下面会讲到的数据描述就可以实现预期效果。 8. 选择个案:实现选择表格中符合条件的个案然后对其进行相应操作,点击进去后会有各种选择方式,比如如果满足什么条件才选择,随机选择百分之多少等等 一.转换 1. 重新编码为不同变量:可以把原来的变量或者变量的范围重新定义为新的变量,比如现有一个班级的学生成绩,要求分心50-70分,70-90分90-100分的同学所占比例,平均值等,现在就可以利用重新编码为不同变量,把上述范围重新编码为新的变量(名字可以自己任意选取),具体操作点击进去之后比较清楚。 2. 计算变量:实现对原来变量的重新计算从而产生新的变量,比如对原来变量进行乘以10操作产生新的变量等等,产生的变量名都是可以自己选择的 一.分析 1.描述统计:实现对表格中变量的各种类型的描述统计
SPSS学习 第一章数据文件的建立 数据编码 Type:Numeric :数值型string :字符串型 Missing: Measure : scale定量变量nominal定性变量 根据已有的变量建立新变量 1、对于数据进行重新编码 Tran sform—recode into differe nt variables —选择in put variable output variable -定义新变量的 名称一change—开始定义新旧变量一continue 2、通过SPSS函数建立新变量 Transform—compute variable -从function group 中选择公式范围下面选择具体的公式—if中 设置要改变一continue—OK(可以对变量进行各种计算) 第二章清除数据与基本统计分析 1、对不合理的数据检查并清理 检查:analysis-description statistic-frequencies —选入要检查的数据—OK 结果:频数统计表—看是否有错误—missing system 清理: 1. 对系统缺失值的清理 Data—select case— if condition is satisfied —if —function group (missing)--下面选 (missing) --continue —output (delete unselected cases) --OK—对num 为哪一位的进行修改 2. 对sex=3 的清理(直接就清除了) Data—select case—if condition is satisfied —if—sex 调入再输入=3—continue-- output (delete unselected cases) --OK—对num 为哪一位的进行修改 2. 对相关变量间逻辑性检查和清理 Data—select case—if condition is satisfied —if —输入表达式(前后逻辑不相符合的表达式)--
基本统计图表的制作 1 P-P图和Q-Q图 P-P图是根据变量的累积比例与指定分布的累积比例之间的关系所绘制的图形。通过P-P图可以检验数据是否符合指定的分布。当数据符合指定分布时,P-P图中各点近似呈一条直线。如果P-P图中各点不呈直线,但有一定规律,可以对变量数据进行转换,使转换后的数据更接近指定分布。 Q-Q图同样可以用于检验数据的分布,所不同的是,Q-Q图是用变量数据分布的分位数与所指定分布的分位数之间的关系曲线来进行检验的。 由于P-P图和Q-Q图的用途完全相同,只是检验方法存在差异,SPSS17.0中用于做出P-P图的对话框和用于做出Q-Q图的对话框完全一致,下面将对两者统一加以说明。 具体操作步骤如下: 打开数据文件,选择【分析】(Analyze)菜单,单击【描述统计】(Descript ive Statistics)命令下的【P-P图】(P-P Plots)或【Q-Q图】(Q-Q Plots)命令。“P-P图”(P-P Plots)、“Q-Q图”(Q-Q Plots)的对话框分别如图3-20和图3-21所示。 图3-20 “P-P图”对话框
图3-21 “Q-Q图”对话框 在“P-P图”(P-P Plots)或“Q-Q图”(Q-Q Plots)对话框中,最左边的变量列表为原变量列表,通过单击按钮可选择一个或者几个变量进入位于对话框中间的“变量”(Variables)列表框中。根据这些变量数据可创建P-P图或Q-Q图,并进行分布检验。 “P-P图”或“Q-Q图”对话框的中下方和右方有5个选项栏,选项栏中各选项的意义如下: (1)转换(Transform)栏(复选项): l 自然对数转换(Natural log transform):选择此项,对当前变量的数据取自然对数,即将原有变量转换成以自然数e为底的对数变 量。 l 标准值(Standardize values):选择此项,将当前变量的数据转换为标准值,即转换后变量数据的均值为0,方差为1。 l 差分(Difference):选择此项,对当前变量的数据进行差分转换,即利用变量中连续数据之间的差值来转换数据。选择此项以后,后面 的文本框变为可用,在其中输入一个正整数,以确定转换的差分度, 默认值为1。
SPSS基本操作步骤详解 本文采用SPSS21.0版本,其它版本操作步骤大体相同 一、基本步骤 (一)检查数据 在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。 例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。 1.执行次数分布表的程序 Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定) 2.执行描述统计量的程序 Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定) (二)反项计分 若是分析的预试量表中没有反向题,则此操作步骤可以省略; 量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。 例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。 Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】 (三)题项加总 量表题项加总的目的在于便于进行观察值得高低分组。 例,“XX量表”采用Likert scale五点量表式填答,题项为:a1,a2……a10,记总分为:az。 Transform(转换)→Computer Variable(计算变量)→在左边Target Variable(目标变量)中键入az,在右边Numeric Expression(数字表达式)中键入a1+a2+……+a10
主成分分析在SPSS中的操作应用 SPSS在调用Factor Analyze过程进行分析时,SPSS会自动对原始数据进行标准化处理,所以在得到计算结果后指的变量都是指经过标准化处理后的变量,但SPSS不会直接给出标准化后的数据,如需要得到标准化数据,则需调用Descriptives过程进行计算。 图表 3 相关系数矩阵
图表 4 方差分解主成分提取分析表 主成分分析在SPSS中的操作应用(3) 图表 5 初始因子载荷矩阵
从图表3可知GDP与工业增加值,第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、地方财政收入这几个指标存在着极其显著的关系,与海关出口总额存在着显著关系。可见许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。 主成分个数提取原则为主成分对应的特征值大于1的前m个主成分。注:特征值在某种程度上可以被看成是表示主成分影响力度大小的指标,如果特征值小于1,说明该主成分的解释力度还不如直接引入一个原变量的平均解释力度大,因此一般可以用特征值大于1作为纳入标准。通过图表4(方差分解主成分提取分析)可知,提取2个主成分,即m=2,从图表5(初始因子载荷矩阵)可知GDP、工业增加值、第三产业增加值、固定资产投资、基本建设投资、社会消费品零售总额、海关出口总额、地方财政收入在第一主成分上有较高载荷,说明第一主成分基本反映了这些指标的信息;人均GDP和农业增加值指标在第二主成分上有较高载荷,说明第二主成分基本反映了人均GDP和农业增加值两个指标的信息。所以提取两个主成分是可以基本反映全部指标的信息,所以决定用两个新变量来代替原来的十个变量。但这两个新变量的表达还不能从输出窗口中直接得到,因为“Component Matrix”是指初始因子载荷矩阵,每一个载荷量表示主成分与对应变量的相关系数。用图表5(主成分载荷矩阵)中的数据除以主成分相对应的特征值开平方根便得到两个主成分中每个指标所对应的系数[2]。将初始因子载荷矩阵中的两列数据输入(可用复制粘贴的方法)到数据编辑窗口(为变量B1、B2),然后利用“TransformàCompute Variable”,在Compute Variable对话框中输入“A1=B1/SQR(7.22)” [注:第二主成分SQR后的括号中填1.235],即可得到特征向量A1(见图表6)。同理,可得到特征向量A2。将得到的特征向量与标准化后的数据相乘,然后就可以得出主成分表达式[注:因本例只是为了说明如何在SPSS进行主成分分析,故在此不对提取的主成分进行命名,有兴趣的读者可自行命名]: F1=0.353ZX1+0.042ZX2-0.041ZX3+0.364ZX4+0.367ZX5+0.366ZX6+0.352ZX7+0.364ZX 8+0.298ZX9+0.355ZX10
经管实验中心实验报告 学院:管理学院 课程名称:市场调研 专业班级: 姓名: 学号: 实验项目实验 一 实验 二 实验 三 实验 四 实验 五 实验 六 实验 七 实验 八 实验 九 实验 十 总评 成绩 评分
学生实验报告 实验项目图表的制作 □必修□选修□演示性实验□验证性实验□操作性实验□综合性实验实验地点文管实验中心实验仪器台号30 指导教师实验日期及节次2013-6-5 一、实验目的及要求: 1、目的 要求学生能够进行基本的统计分析;能够对频数分析、描述分析和探索分析 的结果进行解读;完成基本的统计图表的绘制;并能够对统计图表进行编辑美化 及结果分析;能够理解多元统计分析的操作(聚类分析和因子分析) 2、内容及要求 2.1 基本的统计分析 打开“分析/描述统计”菜单,可以看到以下几种常用的基本描述统计分析 方法: 1.Frequencies过程(频数分析) 频数分析可以考察不同的数据出现的频数及频率,并且可以计算一系列的统 计指标,包括百分位值、均值、中位数、众数、合计、偏度、峰度、标准差、方差、全距、最大值、最小值、均值的标准误等。 2.Descriptives过程(描述分析) 调用此过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,包括:均值、合计、标准差、方差、全距、最大值、最小值、均值的标准误、峰度、偏度等。 3.Explore过程(探索分析) 调用此过程可对变量进行更为深入详尽的描述性统计分析,故称之为探索性 统计。它在一般描述性统计指标的基础上,增加有关数据其他特征的文字与图形 描述,显得更加细致与全面,有助于用户思考对数据进行进一步分析的方案。 4.Crosstabs过程(列联表分析) 调用此过程可进行计数资料和某些等级资料的列联表分析,在分析中,可对 二维至n维列联表(RC表)资料进行统计描述和χ2 检验,并计算相应的百分 数指标。此外,还可计算四格表确切概率(Fisher’s Exact Test)且有单双侧(One-Tail、Two-Tail),对数似然比检验(Likelihood Ratio)以及线性关系 的Mantel-Haenszelχ2 检验。 2.2 基本统计分析结果解读 1.频率分析的结果解读 2.描述分析的结果解读 3.探索分析的结果解读 4.列联表分析的结果解读
实验三-IBM-SPSS软件的基本操作
云南大学软件学院 实验报告 课程:大数据分析及应用任课教师:蔡莉实验指导教师(签名): 学号: 20131170142 姓名:郭昱专业:软件工程日期: 2015/11/01 成绩: 实验三 IBM SPSS软件的基本操作 一、实验目的 1.熟悉SPSS的菜单和窗口界面,熟悉SPSS 各种参数的设置; 2.掌握SPSS的数据管理功能。 二、实验内容及步骤 (一)数据的输入和保存 1. SPSS界面 当打开SPSS后,展现在我们面前的界面如下: 菜单栏 工具栏
注意:窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。该界面和EXCEL极为相似,很多操 作也与EXCEL类似。 2.定义变量 选择菜单Data==>Define Variable。系统弹出定义变量对话框如下: 对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下: GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 先来建立分组变量GROUP。请将变量名改为GROUP,然后单击OK按钮。 现在SPSS的数据管理窗口如下所示: 第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。 现在我们来建立变量X。单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。此时SPSS的数据管理窗口如下所示: 现在,第一、第二列的名称均为深色显示,表明这两列已经被定义为变量,其余各列的名称仍为灰色的“var”,表示尚未使用。同样地,各行的标号也为灰色,表明现在还未输入过数据,即该数据集内没有记录。 3.输入数据 我们先来输入变量X的值,请确认一行二列单元格为当前单元格,弃鼠标而用键盘,输入第一
SPSS基本概述与介绍 在教育技术学研究中,常常需要对大量的数据进行统计处理,这是一项细致而繁琐的工作,如果完全依靠手工来进行,工作量较大,且难以保证准确性,也得不到高的精度。为了减轻整理和计算大量数据的负担,提高工作效率,我们必须充分利用现代化的技术手段。随着计算机软件技术的发展,计算机在分析数据方面发挥了相当大的作用,它功能多、速度快、计算精确、较易利用,并且计算机统计软件可以完成更为精确系统的数据分析与统计计算。 在教育技术研究资料统计处理中常采用的统计软件有SPSS INC公司的SPSS统计软件系统、SAS统计分析系统和Microsoft公司的Excel软件等。SPSS是Statistics Package for Social Sciences(社会科学统计软件包)的缩写,它是社会科学研究人员首选的统计软件,也是目前世界上最流行的统计软件之一。因而被广泛应用于社会科学和自然科学的各个领域中。 一、SPSS统计软件概况 SPSS是专业的通用统计软件包,它是一个组合式软件包,兼有数据管理、统计分析、统计绘图和统计报表功能,界面友好,使用简单,广泛用于教育、心理、医学、市场、
人口、保险等研究领域,也用于产品质量控制、人事档案管理和日常统计报表等。 SPSS对硬件系统的要求较低,普通配置的计算机都可以运行该软件;对运行的软件环境要求宽松,有各种版本可运行在WINDOWS 3X、9X、2000环境下,现在较新的10.0版可运行在WINDOWS 2000中(SPSS早期版本运行于DOS下,这里不再进行介绍,本节以SPSS 10.0版本为例介绍的该软件的使用)。SPSS 10.0有英文版和汉化版两种版本,可运行在中英文平台上。 SPSS统计软件采用电子表格的方式输入与管理数据,能方便地从其他数据库中读入数据(如Dbase,Excel,Lotus 等)。它的统计过程包括描述性统计、平均值比较、相关分析、回归分析、聚类分析、数据简化、生存分析、多重响应等几大类,每类中又下含同类多种统计过程,比如回归分析中又分线形回归分析、非线性回归分析、曲线估计等多个统计过程,而且每个过程中允许用户选择不同的方法及参数进行统计分析,因此除可以实现常规的各种统计外,还可用来做一些不常用的分析处理。 SPSS采用Sax Basic引擎,允许用户使用类Basic的语