
河 北 工 业 科 技
第19卷 第5期 第54页H EBE I JOU RNAL O F I NDU STR I AL V o l.19 N o.5 P.54总第75期 2002年SC IEN CE&T ECHNOLO GY Sum75 2002
文章编号:100821534(2002)0520054203
Excel统计函数在数据分析方面的应用技巧
刘君妹,赵其明,姚桂芬,马 军,吕悦慈
(河北科技大学纺织服装学院,河北石家庄 050031)
摘 要:Excel97 2000是一较优秀的数据分析软件,利用其统计函数可很方便地进行常用的数据统计分析工作。在简要介绍了其常用统计函数的功能的基础上,首先介绍其在学生成绩分析和数据统计分析方面的应用实例,如计算平均分和各科平均成绩、查找最高和最低分、统计各分数段人数、计算总体方差和标准偏差、按成绩排序等;其次介绍其在实验数据的线性回归和相关性分析方面的应用实例,如求回归直线斜率、Y轴截距和求X、Y 两组数据的相关系数等;详细研究了其应用技巧。
关键词:Excel统计函数;数据分析;应用技巧
中图分类号:T P391114 文献标识码:A
在对学生成绩分析时,常需计算每个学生的平均分及各科平均成绩、总体方差和标准偏差,统计各分数段人数等数据统计分析工作;在对实验数据进行处理时,常需进行线性回归和相关性分析等数据统计分析工作。目前,大多数人使用计算器、工具软件或编程进行这些数据统计工作。使用计算器进行数据统计不仅速度慢,且易出错;使用工具软件进行数据统计,受软件功能的限制;通过编程进行数据统计,不仅烦琐,而且一些人员受编程方面知识的限制,不会使用该方法。实际上,被广泛使用的Excel97或2000,是一优秀的数据分析软件,完全可利用其统计函数进行常用的数据统计分析工作。但在相关书籍和材料中,仅介绍了Excel的几个常用函数的使用方法,使广大用户没能充分利用其具备的数据统计分析能力。为此,简要介
收稿日期:2001209210;修回日期:2002203208
责任编辑:李 穆
作者简介:刘君妹(19672),女,河北行唐县人,副教授,在职硕士研究生。研究方向:计算机在纺织上的应用。
绍Excel常用统计函数的功能,并探讨其在数据统计分析方面的应用技巧,是非常必要的。
1 常用统计函数简介
1)AV ERA GE工作表函数 该工作表函数返回参数的算术平均值。其语法格式为“AV2 ERA GE(n1,n2,…,n30)”。2)CO RR EL工作表函数 该工作表函数返回两个数值单元格区域之间的相关系数。其语法格式为“CO RR EL(ar2 ray1,array2)”,参数A rray1和A rray2分别表示第一和第二个单元格区域。3)COU N T IF工作表函数 该工作表函数返回给定区域内满足给定条件的单元格的数目。其语法格式为“COU N T IF(range,criteria)”,参数R ange是单元格区域,C riteria是给定条件。4)L I N EST 工作表函数 该工作表函数的功能是使用最小二乘法对已知数据进行最佳直线拟合,并返回描述此直线的数组。其语法格式为“L I N EST (y’s,x’s,con st,stats)”,参数y’s和x’s分别
是y值和x值集合,参数Con st为一逻辑值(若为TRU E或省略,b将被正常计算;若为FAL SE,b将被设为0,并同时调整m值使y= m x),参数Stats为一逻辑值(若为TRU E,函数返回附加回归统计值;若为FAL SE或省略,函数只返回系数m和常数项b)。5)M A X、M I N 工作表函数 前者返回数据集中的最大值,后者返回数据集中的最小值。其语法格式分别为“M A X(n1,n2,…,n30)”和M I N(n1,n2,…, n30)”。6)RAN K工作表函数 该函数返回一个数值在一组数值中的排位。其语法格式为“RAN K(num ber,ref,o rder)”,参数N um ber 为需要找到排位的数字,参数R ef为包含一组数字的数组或引用,参数O rder为一数字(若为0或省略,按降序排位;若不为零,按升序排位)。7)STD EV、STD EV P工作表函数 前者返回样本的标准偏差,后者返回整个样本总体的标准偏差。其语法格式分别为“STD EV(n1, n2,…)”和STD EV P(n1,n2,…)”,N um ber1, N um ber2,…为1到30个样本值。8)VA R、VA R P工作表函数 前者返回样本方差,后者返回总体的方差。其语法格式分别为“VA R
(n1,n2,…,n30)”和VA R P(n1,n2,…,n30)”。2 应用技巧实例
211 学生成绩分析
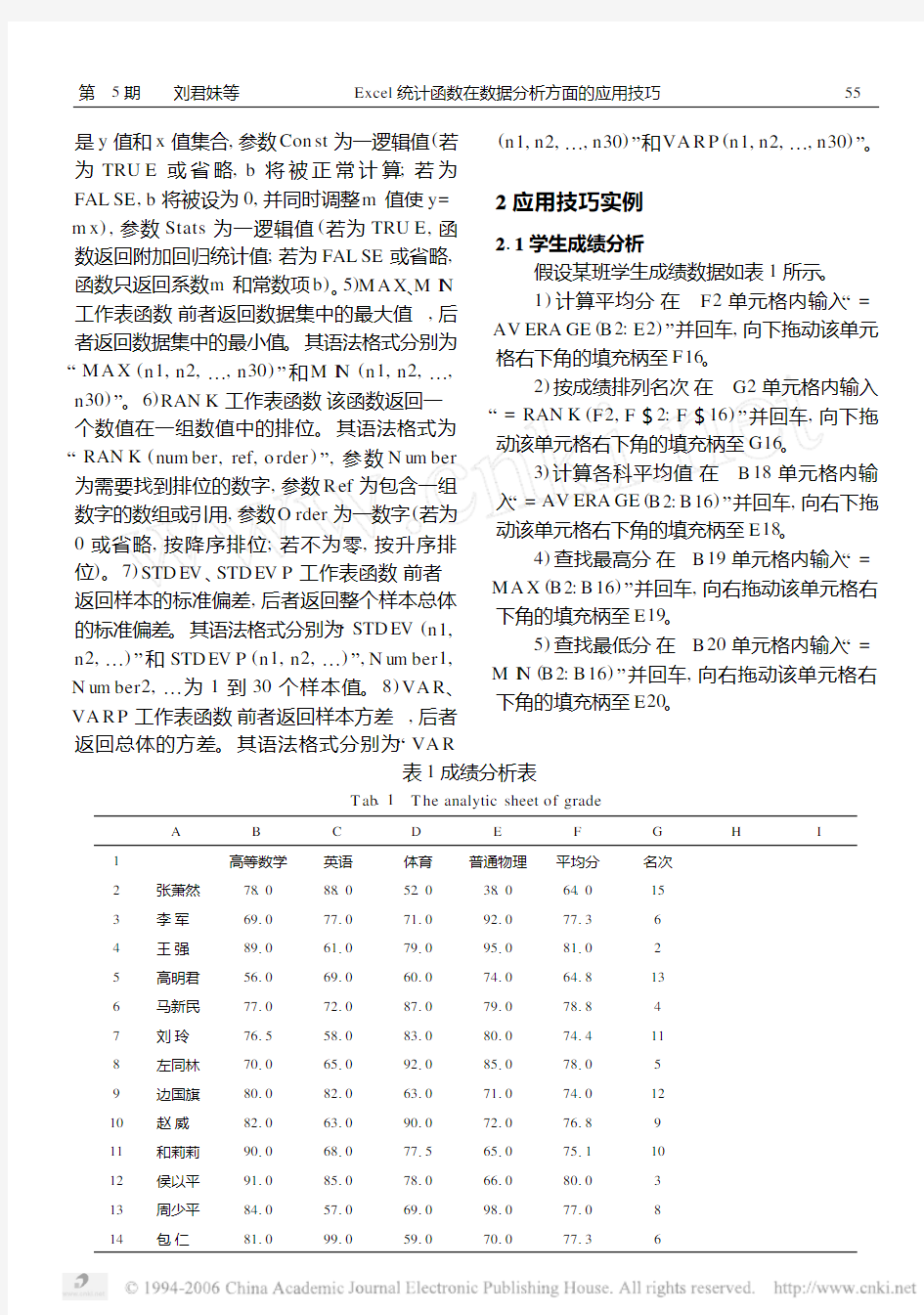
假设某班学生成绩数据如表1所示。
1)计算平均分 在F2单元格内输入“= AV ERA GE(B2:E2)”并回车,向下拖动该单元格右下角的填充柄至F16。
2)按成绩排列名次 在G2单元格内输入“=RAN K(F2,F$2:F$16)”并回车,向下拖动该单元格右下角的填充柄至G16。
3)计算各科平均值 在B18单元格内输入“=AV ERA GE(B2:B16)”并回车,向右下拖动该单元格右下角的填充柄至E18。
4)查找最高分 在B19单元格内输入“= M A X(B2:B16)”并回车,向右拖动该单元格右下角的填充柄至E19。
5)查找最低分 在B20单元格内输入“= M I N(B2:B16)”并回车,向右拖动该单元格右下角的填充柄至E20。
表1 成绩分析表
T ab.1 T he analytic sheet of grade
A B C D E F G H I 1高等数学英语体育普通物理平均分名次
2张萧然78.088.052.038.064.015
3李 军691077107110921077136
4王 强891061107910951081102
5高明君5610691060107410641813
6马新民771072108710791078184
7刘 玲7615581083108010741411
8左同林701065109210851078105
9边国旗8010821063107110741012
10赵 威821063109010721076189
11和莉莉9010681077156510751110
12侯以平911085107810661080103
13周少平841057106910981077108
14包 仁81109910591070107713655
第5期 刘君妹等 Excel统计函数在数据分析方面的应用技巧
A B C D E F G H I 15庞 龙6610811093101001085101
16卫一帆8010781045105510641014
17
18各科成绩7810731573127610
19最高分91109910931010010
20最低分5610571045103810
21>=90(人)2134
2280~89(人)6422
2370~79(人)4345
2460269(人)2532
25<60(人)1232
26总体方差8513137122091126417
27标准偏差912111714151613
6)统计“>=90”人数 在B21单元格内输入“=COU N T IF(B2:B16,">=90")”并回车,向右拖动该单元格右下角的填充柄至E21。
7)统计“80290”人数 在B22单元格内输入“=COU N T IF(B2:B16,">=80")-B21”并回车,向右拖动该单元格右下角的填充柄至E22。
8)统计“70279”人数 在B23单元格内输入“=COU N T IF(B2:B16,">=70")-B21-B22”并回车,向右拖动该单元格右下角的填充柄至E23。
9)统计“60269”人数 在B24单元格内输入“=COU N T IF(B2:B16,">=60")-B21-B22-B23”并回车,向右拖动该单元格右下角的填充柄至E24。
10)统计“<60”人数 在B25单元格内输入“=COU N T IF(B2:B16,"<60")”并回车,向右拖动该单元格右下角的填充柄至E25。
11)计算总体方差 在B26单元格内输入“=VA R P(B2:B16)”并回车,向右拖动该单元格右下角的填充柄至E26。
12)计算标准偏差 在B27单元格内输入“=STD EV P(B2:B16)”并回车,向右拖动该单元格右下角的填充柄至E27。
212 实验数据的线性回归和相关性分析假设某实验测得数据如表2所示。
表2 实验数据工作表
T ab.2 T he sheet of experi m en tal data
A B C D E F G H I J K L
1X值:129257142021301610
2Y值:38146211455055804717
3
4直线斜率2188
5Y轴截距-5.25
6相关系数0196
7
(下转第70页)
T he Study of Inh ib ito rs on
Zine2m anganese Cell
W AN G Chun2fang,L I U H u i2ru,XU Zh i2ce,ZHAO D i2shun
(Co llege of Chem istry and Pharm aceu tical Engineering,H ebei U n iversity of Science and T echno logy,Sh ijiazhuang H ebei050018,Ch ina)
Abstract:T h is paper review s the statu s of inh ib ito rs on zine2m anganese cell.It also describes the inh ib iting m ech2 an is m s2physical adso rp ti on and chem ical adso rp ti on and concen ted m echan is m.T he type and and selecti on w ere also in troduced.It show s that to u se is u rgen t.
Key words:zine2m anganese cell;inh ib ito r;inh iting m echan is m;selecti on p rinci p le
(上接第56页)
1)求回归直线斜率和Y轴截距
斜率:在B4单元格内输入“=I ND EX (L I N EST(B2:K2,B1:K1),1”并回车。
截距:在B5单元格内输入“=I ND EX (L I N EST(B2:K2,B1;K1),2)”并回车。
2)求X、Y两组数据的相关系数
在B6单元格内输入“=CO RR EL(B1: K1,B2:K2)”并回车。
3 结 语
笔者在介绍Excel常用统计函数的功能的基础上,通过介绍其在学生成绩分析和实验数据统计分析等方面的实例,详细研究了其应用技巧,对提高学生成绩或实验数据分析的工作效率和准确度具有一定的现实意义。
参考文献:
[1] 朱燕堂1应用概率统计方法[M]1西安:西北工业大学
出版社,1986114821961
[2] 浙江大学高数教研组1概率论与数理统计[M]1北京:
高等教育出版社,1984128423201
[3] 李志敏1侯 斌1Excel2000即学即用[M]1北京:科学
出版社,19991
A pp licati on of Excel Statistical Functi on in D ata A nalysis
L I U Jun2m ei,ZHAO Q i2m ing,YAO Gu i2fen,M A Jun,L u Yue2ci
(Co llege of T ex tile and Garm en t,H ebei U n iversity of Science and T echno logy,Sh ijiazhuang H ebei050031,Ch ina)
Abstract:Excel97 2000is a first2class data analyzing softw are.U sing statistical functi on,w e can conven ien tly p rocess common w o rk of data statistical analyzing.T he paper b riefly in troduced the statistical functi on in common u se.F irst of all,it in troduced the actual app licati on s in studen ts’ach ievem en t analysis and data statistical analysis. Fo r examp le,calcu lating average sco re,research ing the h ighest and the low est sco re,etc.T hen,it in troduced the ac2 tual app licati on s in linear regressi on and relati on analysis of experi m en t data.Such as calcu lating slop of line,co rre2 lati on coefficien t,and so on.To sum up,the m ethods and sk ill of statistical functi on in common u se have been dis2 cu ssed in detail.
Key words:Excel statistic functi on;data;analysis;app lcati on techn ique
使用Excel可以完成很多专业软件才能完成的数据统计、分析工作,比如:直方图、相关系数、协方差、各种概率分布、抽样与动态模拟、总体均值判断,均值推断、线性、非线性回归、多元回归分析、时间序列等。本专题将教您完成几种最常用的专业数据分析工作。 注意:所有操作将通过Excel“分析数据库”工具完成,如果您没有安装这项功能,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项。 直方图 某班进行期中考试后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。 以往手工分析的步骤是先将各分数段的人数分别统计出来制成一张新的表格,再以此表格为基础建立数据统计直方图。使用Excel可以直接完成此任务。 [具体方法] 描述统计 某班进行期中考试后,需要统计成绩的平均值、区间,并给出班级内部学生成绩差异的量化标准,借此来作为解决班与班之间学生成绩的参差不齐的依据。要求得到标准差等统计数值。 样本数据分布区间、标准差等都是描述样本数据范围及波动大小的统计量,统计标准差需要得到样本均值,计算较为繁琐。这些都是描述样本数据的常用变量,使用Excel 数据分析中的“描述统计”即可一次完成。[具体方法] 排位与百分比排位 某班级期中考试进行后,按照要求仅公布成绩,但学生及家长要求知道排名。故欲公布成绩排名,学生可以通过成绩查询到自己的排名,并同时得到该成绩位于班级百分比排名(即该同学是排名位于前“X%”的学生)。 排序操作是Excel的基本操作, Excel“数据分析”中的“排位与百分比排位”可以使这个工作简化,直接输出报表。[具体方法]
Excel之统计函数(doc 14页)
Excel函数应用之统计函数 编者语:Excel是办公室自动化中非常重要的一款软件,很多巨型国际企业都是依靠Excel进行数据管理。它不仅仅能够方便的处理表格和进行图形分析,其更强大的功能体现在对数据的自动处理和计算,然而很 多缺少理工科背景或是对Excel强大数据处理功能不了解的人却难以进一步深入。编者以为,对Excel函 数应用的不了解正是阻挡普通用户完全掌握Excel的拦路虎,然而目前这一部份内容的教学文章却又很少见,所以特别组织了这一个《Excel函数应用》系列,希望能够对Excel进阶者有所帮助。《Excel函数应用》系列,将每周更新,逐步系统的介绍Excel各类函数及其应用,敬请关注! Excel的统计工作表函数用于对数据区域进行统计分析。例如,统计工作表函数可以用来统计样本的方差、数据区间的频率分布等。是不是觉得好像是很专业范畴的东西?是的,统计工作表函数中提供了很多属于统计学范畴的函数,但也有些函数其实在你我的日常生活中是很常用的,比如求班级平均成绩,排名等。在本文中,主要介绍一些常见的统计函数,而属于统计学范畴的函数不在此赘述,详细的使用方法可以参考Excel 帮助及相关的书籍。 在介绍统计函数之前,请大家先看一下附表中的函数名称。是不是发现有些函数是很类似的,只是在名称中多了一个字母A?比如,A VERAGE 与A VERAGEA;COUNT与COUNTA。基本上,名称中带A的函数在统计时不仅统计数字,而且文本和逻辑值(如TRUE 和FALSE)也将计
算在内。在下文中笔者将主要介绍不带A的几种常见函数的用法。 一、用于求平均值的统计函数A VERAGE、TRIMMEAN 1、求参数的算术平均值函数A VERAGE 语法形式为A VERAGE(number1,number2, ...) 其中Number1, number2, ...为要计算平均值的1~30 个参数。这些参数可以是数字,或者是涉及数字的名称、数组或引用。如果数组或单元格引用参数中有文字、逻辑值或空单元格,则忽略其值。但是,如果单元格包含零值则计算在内。 2、求数据集的内部平均值TRIMMEAN 函数TRIMMEAN先从数据集的头部和尾部除去一定百分比的数据点,然后再求平均值。当希望在分析中剔除一部分数据的计算时,可以使用此函数。比如,我们在计算选手平均分数中常用去掉一个最高分,去掉一个最低分,XX号选手的最后得分,就可以使用该函数来计算。 语法形式为TRIMMEAN(array,percent)
Excel工作表数据汇总 一、复制一张工作表并清空数据,作为汇总统计表,在要统计的第一个单元格内输入: =SUM('路径1[工作簿名1]工作表名1'!单元格名1+'路径1[工作簿名1]工作表名1'!单元格名1+……) 有多少张表,就得输入多少个'路径[工作簿名]工作表名'!单元格名。第一个单元格输好后,其它单元格用填充柄拉一下就可。 二、将所有要统计的工作表都使用“编辑”中的“移动或复制工作表”的命令复制到一个工作簿中,复制一张工作表并清空数据,作为汇总统计表,选中汇总统计表中要汇总的第一个单元格并点一下工具栏上的自动求和图标,选择要统计的第一张工作表,按住Shift键选择最后一张工作表,然后选择要统计的最后一张工作表中的第一个单元格并回车,怎么样,一个单元格的汇总数据出来了吧,其它单元格用填充柄拉一下就可。 三、把所有要统计的工作簿都打开,如果你用WINXP的话,最好右键点一下最下面的任务栏,在属性中选择“分组相似任务栏按钮”,以免工作簿太多找不到。复制一张工作表并清空数据,作为汇总统计表,选中汇总统计表中要统计的区块,在数据菜单中选择“合并计算”,点引用位置右边的那个小方框图标,选择表一的数据区域,点添加,然后再点应用位置右边的那个小方框图标,选择表二的数据区域,点添加,重复以上过程,最后点确定即可统计出结果。引用位置添加时
可用快捷键ALT+A来加快添加速度,如果选中“创建连至源数据的链接”则源数据更新,汇总数据也更新。 四、在网上搜寻EXCEL文件累加器或Excel报表汇总助手等小工具,利用它进行汇总。 比较一下: 第一种方法适合输入速度较快的人,优点是不打开所有工作表也能汇总,缺点是容易输错,且烦琐; 第二种方法适合于在同一工作簿的多工作表统计,如不在同一工作表内,需要复制到同一工作簿中,复制的过程比较麻烦; 第三种方法比较方便,汇总的速度也比较快,要鼠标就能完成,除进行相同格式的工作表汇总外,还可以通过分类来合并计算数据(方法和通过位置来合并计算数据类似,但要连分类一起选择并标志分类标签位置),推荐这一方法,缺点是所有工作簿都要打开,当工作簿有几百张时容易影响速度; 第四种方法优点是速度快且不用打开所有的工作表,不过要借用工具,很多工具都要注册才能使用,而且要先制作一个统计模板,适合工作表数量特别多时的统计。
1Excel 统计函数一览表 函数名称函数功能 AVEDEV 返回一组数据与其均值的绝对偏差的平均值,用于评测这组数据的离散度。 AVERAGE 返回指定序列算术平均值。 AVERAGEA 计算参数清单中数值的算数平均值。不仅数字,而且文本和逻辑值(如TRUE 和FALSE)也将计算在内。 BETADIST 返回Beta 分布累积函数的函数值。Beta 分布累积函数通常用于研究样本集合中某些事物的发生和变化情况。 BETAINV 返回beta 分布累积函数的逆函数值。即,如果probability = BETADIST(x,...) ,则BETAINV(probability,...) = x。beta 分布累积函数可用于项目设计,在给定期望的完成时间和变化参数后,模拟可能的完成时间。 BINOMDIST 返回一元二项式分布的概率值。函数BINOMDIST 适用于固定次数的独立实验,实验的结果只包含成功或失败二种情况,且成功的概率在实验期间固定不变。 例如,函数BINOMDIST 可以计算三个婴儿中两个是男孩的概率CHIDIST 返回X2 分布的单尾概率。X2 分布与X2 检验相关。使用X2 检验可以比较观察值和期望值。例如,某项遗传学实验假设下一代植物将呈现出某一组颜色。使用此函数比较观测结果和期望值,可以确定初始假设是否有效。
CHIINV 返回X2 分布单尾概率的逆函数。如果probability =CHIDIST(x,?),则CHIINV(probability,?)= x。使用此函数比较观测结果和期望值,可以确定初始假设是否有效。 CHITEST 返回独立性检验值。函数CHITEST 返回X2 分布的统计值及相应的自由度。可以使用X2 检验确定假设值是否被实验所证实。CONFIDENCE 返回总体平均值的置信区间。置信区间是样本平均值任意一侧的区域。例如,如果通过邮购的方式订购产品,依照给定的置信度,可以确定最早及最晚到货的时间。 CORREL 返回单元格区域array1 和array2 之间的相关系数。使用相关系数可以确定两种属性之间的关系。例如,可以检测某地的平均温度和空调使用情况之间的关系。 COUNT 返回参数的个数。利用函数COUNT 可以计算数组或单元格区域中数字项的个数。 COUNTA 回参数组中非空值的数目。利用函数COUNTA 可以计算数组或单元格区域中数据项的个数。 COVAR 返回协方差,即每对数据点的偏差乘积的平均数,利用协方差可以决定两个数据集之间的关系。例如,可利用它来检验教育程度与收入档次之间的关系。 CRITBINOM 返回使累积二项式分布大于等于临界值的最小值。此函数可以用于质量检验。例如,使用函数CRITBINOM来决定最多允许出现多少个有缺陷的部件,才可以保证当整个产品在离开装配线时检验合格。DEVSQ 返回数据点与各自样本均值偏差的平方和。
EXCEL分析工具库教程 第一节:分析工具库概述 “分析工具库”实际上是一个外部宏(程序)模块,它专门为用户提供一些高级统计函数和实用的数据分析工具。利用数据分析工具库可以构造反映数据分布的直方图;可以从数据集合中随机抽样,获得样本的统计测度;可以进行时间数列分析和回归分析;可以对数据进行傅立叶变换和其他变换等。本讲义均在Excel2007环境下进行操作。 1.1. 分析工具库的加载与调用 打开一张Excel表单,选择“数据”选项卡,看最右边的“分析”选项中是 否有“数据分析”,若没有,单击左上角的图标,单击最下面的“E xcel选项”,弹出“Excel选项”对话框,在左侧列表中选择“加载项”,在下方有“管理:Excel加载项转到”,单击“转到”,勾选“分析工具库”(加载数据分析工具)和“分析工具库-VBA”(加载分析工具库所需要的VBA函数)(图 1-1),单击确定,则“数据分析”出现在“数据|分析”中。 图 1-1 加载分析工具库
1.2. 分析工具库的功能分类 分析工具库内置了19个模块,可以分为以下几大类: 表 1-1 随机发生器功能列表 第二节.随机数发生器 重庆三峡学院关文忠 1.随机数发生器主要功能 “随机数发生器”分析工具可用几个分布之一产生的独立随机数来填充某个区域。可以通过概率分布来表示总体中的主体特征。例如,可以使用正态分布来表示人体身高的总体特征,或者使用双值输出的伯努利分布来表示掷币实验结果的总体特征。 2.随机数发生器对话框简介
执行如下命令:“数据|分析|数据分析|随机数发生器”,弹出随机数发生器对话框(图2-1)。 图2-1随机数发生器对话框 该对话框中的参数随分布的选择而有所不同,其余均相同。 变量个数:在此输入输出表中数值列的个数。 随机数个数:在此输入要查看的数据点个数。每一个数据点出现在输出表的一行中。 分布:在此单击用于创建随机数的分布方法。包括以下几种:均匀分布、正态分布、伯努利分布、二项式、泊松、模式、离散。具体应用将在第3部分举例介绍。 随机数基数:在此输入用来产生随机数的可选数值。可在以后重新使用该数值来生成相同的随机数。 输出区域:在此输入对输出表左上角单元格的引用。如果输出表将替换现有数据,Excel 会自动确定输出区域的大小并显示一条消息。 新工作表:单击此选项可在当前工作簿中插入新工作表,并从新工作表的A1单元格开始粘贴计算结果。若要为新工作表命名,请在框中键入名称。 新工作簿:单击此选项可创建新工作簿并将结果添加到其中的新工作表中。 3.随机数发生器应用举例
Excel统计分析报告优秀2篇大家知道,在Microsoft Office的系列组件中,Word 以文字处理见长,而Excel则以表格数据处理见长。虽然说Word本身也有简单的表格数据功能,而Excel单元格本身也支持文字处理,但是,如果报告本身对文字和数据处理均有特别高的要求或复杂的需求时,“联手”才是好办法。 报告写作中的必要“嫁接” 在制作报告时,有时会在文本中涉及到一些简单表格,我们往往顺手通过Word中的表格制作功能制作一些简单的表格。但如果表格稍微复杂,尤其是涉及到单元格之间的数据运算,我们就会觉得在Word里难以完成。于是,有人挖掘在Word中通过函数、公式甚至VBA代码来实现表格计算的功能。这些方法的确可以实现在Word中进行表格数据的计算,但普通电脑用户要掌握有一定门槛,因此不建议使用这种深挖技巧式的“死抠”法。在MS Office软件设计之初,微软就考虑到组件间相互利用的技术问题。用户只需通过简单引用,即可将一个组件中擅长制作的内容轻松引用到另一个组件中。如用早已熟悉的Excel表格软件将需要的表格做好后在Word中引用即可。 Word“嫁接”Excel方法多 Word与Excel的联合使用,既可以先在Excel中做好表格然后复制到Word编辑页面中,也可以直接在Word编辑页
面中插入Excel新表格后填写数据,还可以以超链接的方式将表格引入到文档中。 1. 同样的复制不同的使用效果 先在Excel中制作Word报告需要的数据表格,然后全选表格并复制,返回到Word报告的编辑页面中执行鼠标右键粘贴命令。这时,我们会发现,在“粘贴选项”中出现了6个粘贴按钮,分别是“保留源格式”、“使用目标样式”、“链接与保留源格式”、“链接与使用目标格式”、“图片”、“只保留文本”。那么,在引用表格时到底用哪种方式最好呢?这要看表格在今后的使用情况而定。 如果确定表格的数据完全正确,不会有任何变动,且希望保留Excel软件中的表格样式,那么选择“保留源格式”;如果确定不会变动,但还担心表格排版会出现兼容问题而造成版面混乱,那么可以选择“图片”模式,将表格以图片的形式插入到Word文档中;如果对表格及其中的数据是否会有所变动心里没底或难以预测,那么就选择“链接与保留源格式”,这样将来Excel表格中的数据有所更改时,Word报告中的表格会跟着变动,无需人为重新编辑。 2. 不离Word环境制作Excel新表 如果在起草Word报告的过程中,需要当下建立一个新的Excel表格,而不是引用已有的现成Excel表格,那么,可以在Word中制作Excel表格,根本不用去手动启动Excel
2006年11月第22卷 第6期 四川外语学院学报 Journal of Sichuan I nternati onal Studies University Nov.,2006 Vol.22 No.6 解读语言形成的认知过程 ———七论语言的体验性:详解基于体验的认知过程 王 寅 (四川外语学院外国语文研究中心,重庆 400031) 提 要:人类语言形成的认知过程是一个十分复杂的过程,包括多个步骤。本文尝试以体验哲学和认知语言学核心思想“现实—认知—语言”为基线,将心理学、哲学、逻辑学等学科以及国外主要认知语言学家的观点贯通起来,
图1 从图1可见,体验哲学和C L认为人们的认知过程起始于互动性的感知体验(如感知环境、移动身体、发出动力、感受力量等),逐步形成了意象图式(I m age Sche ma),在此基础上结合隐喻模型、换喻模型、命题模型,建构出抽象的认知模型(Cognitive Model,简称C M),若干个相关C M整合起来进而形成了理想化认知模型(I dealized Cognitive Model,简称I C M),基于此自然就可形成一个范畴原型,进而可进行范畴化和概念化,同时形成意义。将范畴、概念和意义用语言形式固定下来就形成了词语和构造。人们在长期的生活实践中形成了很多基本概念,又逐步将其组合和整合成复杂概念,进而逐步形成了我们今天所掌握的复杂概念结构。 2.感觉、知觉和表象 从体验到意象图式的过程可根据普通心理学讨论的感觉(Sensati on)、知觉(Percep ti on)和表象(I m2 age)来解释,这三个过程的递进关系就表示了人们认识客观事物初始阶段的一般规律。 2.1感觉 客观世界是我们感觉的源泉,其中的事物在当前情况下作用于我们的感觉器官时,它的个别属性就会在我们头脑中形成某种反映,这就是我们对该事物的初步“感觉”,它是认识的最简单形式,人们一开始就是依靠它来认识世界中的客观事物。 2.2知觉 “感”是初步的、简单的认识,而“知”则意味着较为全面的、复杂的认识,因此“知觉”是一种比“感觉”更为复杂的认识形式,是各种感觉的总和,指客观外物当前作用于我们感觉器官的各种属性在头脑中的综合反映。例如,我们起初可以感觉到梨子的颜色、形状、味道、硬度等等,我们在综合这些感觉的基础上就可构成对梨子这一整体的总体印象,也就是说,此时就可获得对梨子的“知觉”。 2.3表象 “感觉”和“知觉”都是以存在当前事物为前提的,即为一种“在线(On2line)”认知加工,而“表象”则指客观事物不在场时依旧能够留在人们头脑中的印象,人们依旧能够通过想像“唤起”或“回忆”起该事物的表象,它是感觉和知觉的抽象性心智表征,当属一种“下线(Off2line)”认知加工。很多学者认为,其他动物可能不具备这一本领,那么,这就是人与其他动物的区别之所在:下线加工的灵活性①。 3.意象图式 “表象”和“意象”、“心象”常作为心理学术语,它们都指人类特有的、下线的心理表征。有学者认为它们基本相同,也有学者认为意象或心象比表象更为抽象和概括,其实对这三个术语没有必要再加严格区分。 图式(Sche me,Sche ma)是指人们在感觉、知觉和表象的基础上,把有关经验和信息加工组织成某种常规性的认知结构,能够较为长期地储存于记忆之中,具有概括性和抽象性。古希腊哲学家、Kant(康德)、巴特莱特(Bartlett)、Piaget(皮亚杰)、菲尔墨(Fill2 more)等学者都对其作出了论述,当代C L接受并发展了图式理论。Lakoff&Johns on于1980年在《我们赖以生存的隐喻》一书中首次将“意象”和“图式”这两个概念结合而成“意象图式”,并将其应用到隐喻分析之中。他们又分别于1987年基于体验哲学再次详细论述了“意象图式”,认为图式是我们日常的感知互动和运动程序中反复出现的比较简单的、动态的样式,可为我们的经验提供连贯性和结构性。 正如术语本身所示,它既有“意象”的含义,又兼有“图式”的含义。作为“意象”,它是特定的、体验性 ①人与其他动物的本质性区分除了“下线加工的灵活性”之外还有:理性思维的程度性、认知方式的复杂性、交流渠道的多样性、语言表达的丰富性、文化知识的百科性等。
excel统计分析工具 Microsoft Excel 提供了一组数据分析工具,称为“分析工具库”,在建立复杂统计或工程分析时可节省步骤。只需为每一个分析工具提供必要的数据和参数,该工具就会使用适当的统计或工程宏函数,在输出表格中显示相应的结果。其中有些工具在生成输出表格时还能同时生成图表。 相关的工作表函数 Excel 还提供了许多其他统计、财务和工程工作表函数。某些统计函数是内置函数,而其他函数只有在安装了“分析工具库”之后才能使用。 访问数据分析工具“分析工具库”包括下述工具。要使用这些工具,请单击“工具”菜单上的“数据分析”。如果没有显示“数据分析”命令,则需要加载“分析工具库”加载项(加载项:为 Microsoft Office 提供自定义命令或自定义功能的补充程序。)程序。 方差分析 方差分析工具提供了几种方差分析工具。具体使用哪一种工具则根据因素的个数以及待检验样本总体中所含样本的个数而定。 方差分析:单因素此工具可对两个或更多样本的数据执行简单的方差分析。此分析可提供一种假设测试,该假设的内容是:每个样本都取自相同基础概率分布,而不是对所有样本来说基础概率分布都不相同。如果只有两个样本,则工作表函数 TTEST 可被平等使用。如果有两个以上样本,则没有合适的 TTEST 归纳和“单因素方差分析”模型可被调用。 方差分析:包含重复的双因素此分析工具可用于当数据按照二维进行分类时的情况。例如,在测量植物高度的实验中,植物可能使用不同品牌的化肥(例如 A、B 和 C),并且也可能放在不同温度的环境中(例如高和低)。对于这 6 对可能的组合 {化肥,温度},我们有相同数量的植物高度观察值。使用此方差分析工具,我们可检验: 1.使用不同品牌化肥的植物的高度是否取自相同的基础总体;在此分析中, 温度可以被忽略。 2.不同温度下的植物的高度是否取自相同的基础总体;在此分析中,化肥可 以被忽略。 3.是否考虑到在第 1 步中发现的不同品牌化肥之间的差异以及第 2 步中 不同温度之间差异的影响,代表所有 {化肥,温度} 值的 6 个样本取自 相同的样本总体。另一种假设是仅基于化肥或温度来说,这些差异会对特 定的 {化肥,温度} 值有影响。
Excel统计分析报告 ——护士对于工作的满意度 物流工程112 1110640050 叶尔强
前言 国家医护协会(National Health Care Association)对于医护专业未来护士的缺乏十分关注。为了了解现阶段护士们对于工作的满意程度,该协会发起了一项对全国的医院护士的调查研究。作为研究的一部分,一个由50名护士组成的样本被要求写出她们对工作、工资和升职机会的满意程度。这三个方面的评分都是从0到100,分值越大表明满意程度越高。 另外,调查数据还根据该护士所在的医院的类型,划分为3类。它们包括私人医院、公立医院和学院医院。具体数据详见附录一、附录二、附录三、附录四。 调查数据的分析 本次调查对象为50名护士,评分皆实行百分制,附录一中的数据为50位护士对于工作、工资和升职机会的调查数据,附录二、附录三和附录四中的数据分别为在私人医院、公立医院和学院医院当中工作的护士对于工作、工资和升职机会的调查数据。 1、三方面的满意程度分析 运用excel中的函数average、median、mode工具对附录一中的数据进行统计分析,可得到以下结果: 从以上图表中可以看出无论是平均数、中位数还是众数,工作的满意度都是最高的,而工作和升职机会的满意度都低于整体的满意程度水平。就工资与升职机会
的满意程度相比较,升职机会的平均值和中位数都比工资的高,且工资满意度呈现出左偏,而升职机会的满意度呈现出右偏。 就以上分析可以得到结论:在工作这一方面护士们的满意度最高,而在工资这一方面护士们的满意度最低。以上结论说明了护士们对于护士之一职业还是比较满意的,喜欢干这一行,但对于这一职业的工资待遇和升职机会还是有所不满。因此就有必要对护士这一职业的工资待遇和升职机会有所改进。以下是几种改进方案: 1)应该适当提高护士的工资水平,对于一些在工作中有突出表现或是对医院有 所贡献的护士可以通过增加工资以作为奖励。 2)对护士平时的工作设立一套评估方案,在年末对所有护士的工作表现进行评 估,对于那些符合评估要求的护士可以给予年终奖或是提高下一年的工资水平,这样不仅可以鼓励护士在平时能够认真工作还可以提高护士对工资的满意度。 3)要合理的实行人才选拔制度,例如将升职机会与平时工作表现、对医院的贡 献等相结合,让每一个护士都有平等的升职机会。这样不仅可以促使护士们能够积极表现还可以提高他们对于升职机会的满意度。 2、三方面的差异度分析 运用excel中的函数min、max、quartile、stdev、skew、kvrt工具对附录一中数据进行统计分析,可得到以下数据结果:
Excel的统计分析功能 Excel是办公自动化中非常重要的一款软件,很多巨型国际企业和国内行政、企事业单位都用Excel 进行数据管理。它不仅能够方便地进行图形分析和表格处理,其更强大的功能还体现在数据的统计分析研究方面。然而很多缺少数理统计基础知识而对Excel强大统计分析功能不够了解的人却难以更加深入、更高层次地运用Excel。笔者认为,对Excel统计分析功能的不了解正是阻挡普通用户完全掌握Excel的拦路虎,但目前这方面的教学文章却又很少见。下面笔者对Excel的统计分析功能进行简单的介绍,希望能够对Excel进阶者有所帮助。 Microsoft Excel提供了一组数据分析工具,称为“分析工具库”,在建立复杂统计或工程分析时,只需为每一个分析工具提供必要的数据和参数,该工具就会使用适宜的统计或工程函数,在输出表格中显示相应的结果。其中有些工具在生成输出表格时还能同时生成图表。 在使用Excel的“分析工具库”时,如果“工具”菜单中没有“数据分析”命令,则需要安装“分析工具库”。步骤如下:在“工具”菜单中,单击“加载宏”命令,选中“分析工具库”复选框完成安装。如果“加载宏”对话框中没有“分析工具库”,请单击“浏览”按钮,定位到“分析工具库”加载宏文件“Analys32.xll”所在的驱动器和文件夹(通常位于“Microsoft Office\Office\Library\Analysis”文件夹中)(Microsoft OfficeXP:插入光盘,即可) ;如果没有找到该文件,应运行“安装”程序。 安装完“分析工具库”后,要查看可用的分析工具,请单击“工具”菜单中的“数据分析”命令,Excel提供了以下15种分析工具。 1、方差分析(anova) 本工具提供了三种工具,可用来分析方差。具体使用哪一工具则根据因素的个数以及待检验样本总体中所含样本的个数而定。 (1)“Anova:单因素方差分析”分析工具 此分析工具通过简单的方差分析(anova),对两个以上样本均值进行相等性假设检验(抽样取自具有相同均值的样本空间)。此方法是对双均值检验(如t-检验)的扩充。 (2)“Anova:可重复双因素分析”分析工具 此分析工具是对单因素anova分析的扩展,即每一组数据包含不止一个样本。 (3)“Anova:无重复双因素分析”分析工具 此分析工具通过双因素anova分析(但每组数据只包含一个样本),对两个以上样本均值进行相等性假设检验(抽样取自具有相同均值的样本空间)。此方法是对双均值检验(如t-检验)的扩充。 2、相关系数分析工具 此分析工具及其公式可用于判断两组数据集(可以使用不同的度量单位)之间的关系。总体相关性计算的返回值为两组数据集的协方差除以它们标准偏差的乘积: 可以使用“相关系数”分析工具来确定两个区域中数据的变化是否相关,即,一个集合的较大数据是否与另一个集合的较大数据相对应(正相关);或者一个集合的较小数据是否与另一个集合的较小数据相对应(负相关);还是两个集合中的数据互不相关(相关性为零)。 3、协方差分析工具 此分析工具及其公式用于返回各数据点的一对均值偏差之间的乘积的平均值。协方差是测量两组数据相关性的量度。(公式略) 可以使用协方差工具来确定两个区域中数据的变化是否相关,即,一个集合的较大数据是否与另一个
Excel函数应用教程:统计函数 1.AVEDEV 用途:返回一组数据与其平均值的绝对偏差的平均值,该函数可以评测数据(例如学生的某科考试成绩)的离散度。 语法:AVEDEV(number1,number2,...) 参数:Number1、number2、...是用来计算绝对偏差平均值的一组参数,其个数可以在1~30个之间。 实例:如果A1=79、A2=62、A3=45、A4=90、A5=25,则公式“=AVEDEV(A1:A5)”返回20.16。 2.AVERAGE 用途:计算所有参数的算术平均值。 语法:AVERAGE(number1,number2,...)。 参数:Number1、number2、...是要计算平均值的1~30个参数。 实例:如果A1:A5区域命名为分数,其中的数值分别为100、70、92、47和82,则公式“=AVERAGE(分数)”返回78.2。 3.AVERAGEA 用途:计算参数清单中数值的平均值。它与AVERAGE函数的区别在于不仅数字,而且文本和逻辑值(如TRUE和FALSE)也参与计算。 语法:AVERAGEA(value1,value2,...) 参数:value1、value2、...为需要计算平均值的1至30个单元格、单元格区域或数值。 实例:如果A1=76、A2=85、A3=TRUE,则公式“=AVERAGEA(A1:A3)”返回54(即76+85+1/3=54)。 4.BETADIST
用途:返回Beta分布累积函数的函数值。Beta分布累积函数通常用于研究样本集合中某些事物的发生和变化情况。例如,人们一天中看电视的时间比率。 语法:BETADIST(x,alpha,beta,A,B) 参数:X用来进行函数计算的值,须居于可选性上下界(A和B)之间。Alpha分布的参数。Beta分布的参数。A是数值x所属区间的可选下界,B是数值x所属区间的可选上界。 实例:公式“=BETADIST(2,8,10,1,3)”返回0.685470581。 5.BETAINV 用途:返回beta分布累积函数的逆函数值。即,如果probability=BETADIST(x,...),则BETAINV(probability,...)=x。beta分布累积函数可用于项目设计,在给出期望的完成时间和变化参数后,模拟可能的完成时间。 语法:BETAINV(probability,alpha,beta,A,B) 参数:Probability为Beta分布的概率值,Alpha分布的参数,Beta分布的参数,A数值x所属区间的可选下界,B数值x所属区间的可选上界。 实例:公式“=BETAINV(0.685470581,8,10,1,3)”返回2。 6.BINOMDIST 用途:返回一元二项式分布的概率值。BINOMDIST函数适用于固定次数的独立实验,实验的结果只包含成功或失败二种情况,且成功的概率在实验期间固定不变。例如,它可以计算掷10次硬币时正面朝上6次的概率。 语法:BINOMDIST(number_s,trials,probability_s,cumulative) 参数:Number_s为实验成功的次数,Trials为独立实验的次数,Probability_s为一次实验中成功的概率,Cumulative是一个逻辑值,用于确定函数的形式。如果cumulative 为TRUE,则BINOMDIST函数返回累积分布函数,即至多number_s次成功的概率;如果为FALSE,返回概率密度函数,即number_s次成功的概率。 实例:抛硬币的结果不是正面就是反面,第一次抛硬币为正面的概率是0.5。则掷硬币10次中6次的计算公式为“=BINOMDIST(6,10,0.5,FALSE)”,计算的结果等于0.205078
认知体验性与等效翻译的关系 摘要:体验是认知的本源。人以“体认”的方式认识世界,而语言的结构和意义受制于来源于客观世界的经验结构。世界范围内人类的生理结构以及所处环境的大致相似,这决定了经验结构的相似性,这是翻译成为可能的认知基础。经验结构是一个丰富的意象图式网络。意象图式是人在认识世界的主客观互动中,外部世界的物理能量转换而成的心理事件,是我们经验和知识的抽象模式。因此思维带有具象性,这决定了信息的意码和形码的双重编码结构。翻译的过程即是以意象图式为媒介的、原文与译语文化意象之间的辨识和匹配。翻译中的“等效”即经验结构的相似性。 关键词:认知体验等效翻译 1.引言 关于翻译的定义,可谓见仁见智,可以说至今还没有一种完全令人满意的、为学界所公认的说法。现代认知语言学已经揭示,语言是心智的表征,语言结构映照了人类经验结构。翻译活动中的语码转换,就是对心智的解读和编码,翻译活动必定反映心智活动的规律,因此翻译研究决不可忽视对心智的研究。 2.体验是认知的本源 莱考夫(1987)的著作Women,Fire,and Dangerous Things: What Categories Reveal about the Mind 标志着现代认知语言学的诞生。 莱考夫等人认为,人以“体认” 的方式认知世界,心智离不开身体经验,作为心智的表征和对世界进行范畴化的工具的语言就具有体验性,这就是体验哲学的思想。语言的结构和意义受制于来源于客观世界的经验结构,因此,语言是有形的。“从根本上讲,思维产生于人的肉体经验”(Lakoff&Johnson1987)。 人认识客观世界是从自己的身体感知开始的。客观世界是由各种实体和他们之间的关系构成的。在主客观互动中,各种关系反复作用于我们的身体,在记忆中形成丰富的意象。大脑从这些意象中抽象出同类意向的的共同本质,从而形成意象图式。在这个过程中,外部世界的物质能量转换成了心理事件,也就是由经验结构抽象成概念结构。马克·约翰逊(1987)说:“意象图式使我们经验和知识的抽象模式”。人类的生理结构式相同的,又由于同居于一个地球,其所处的自然环境也大致相同,所以,对于外部世界的感知也必然大致相同。因此,以体验为本源的认知模式就具有普世性,由此决定语言本质的普世性,这就是使语际转换—翻译成为可能的认知理据。 3.信息的双重编码 认知语言学揭示,脱离了人对客观世界的一般认知和对经验进行组织的机
用Excel进行统计趋势预测分析 在统计工作中运用电脑技术,不仅仅需要使用专门的统计软件,还应当使用一些其他软件为我们的统计工作服务,excel以强大的处理表格、图表和数据的功能被广泛地应用于统计领域。预测分析是统计数据分析工作中的重要组成部分之一,Excel中不仅可以用函数,也可以用“趋势线”来进行趋势预测分析。下面介绍一下具体使用方法。 一、函数法 1、简单平均法 简单平均法非常简单,以往若干时期的简单平均数就是对未来的预测数。 例如,某企业今年1-6月份的各月实际销售额资料如图1。在c9中输入公式average(b3:b8)即可预测出7月份的销售额。 图1 2、简单移动平均法
简单移动平均法预测所用的历史资料要随预测期的推移而顺延。仍用上例,我们假设预测时用前面3个月的资料,我们可以用两种方法实现用该法预测销售额:一是在d6输入公式averag e(b3:b5),拖曳d6到d9,这样就可以预测出4-7月的销售额;二是运用excel的数据分析功能,选取工具菜单中的数据分析项(如没有此项,则选择加载宏来加载此项),然后选择移动平均,在输入区域输入b3:b8,输出区域输入d4:d9,也可以得到相同的结果。 3、加权移动平均法 加权移动平均法在简单移动平均法的基础上对所用的资料分别确定一定的权数,算出加权平均数即为预测数。还是用上例,在e6输入公式sum(b3*1+b4*2+b5*3)/6,把e6拖曳到e 9即可预测出4-7月的销售额。 4、指数平滑法 指数平滑法是通过导入平滑系数对本期的实际数和本期的预测数进行加权平均计算后作为下期预测数的一种方法。仍用上例(b2,f3的数据都为1月份的预测销售额),假设平滑系数为0. 3,我们也可以用两种方法实现。用该法预测销售额:一是在f4输入公式0.3*b3+0.7*f3,把f4拖曳到f9即可;二是运用数据分析功能,在工具菜单中选取数据分析项后,选择指数平滑,在输入区域输入b2:b9,阻尼系数输入0.7,输出区域输入f2:f11,也可得到2-7月份的预测销售额。 5、直线回归分析法
心理科学进展 2007,15(2):275~281 Advances in Psychological Science 语言理解的体验观* 鲁忠义1 高志华2 段晓丽1 刘学华 1 (1河北师范大学教育学院,石家庄050091)(2华北煤炭医学院心理学系,唐山063000) 摘要随着体验哲学和体验认知的蓬勃发展,在语言理解中出现了强调经验作用的新观点,这就是语言理解的体验观。其基本观点是语言根植于知觉和运动,语言理解就是对语言所描述的情境建构心理模拟。这种模拟是以理解者的身体的、情绪的和社会的经验为基础的,因此语言理解实质上是对语言所指代的情境的心理上的经验重演。在语言理解的体验观中,索引假设、浸入式经历者框架和语言的神经理论具有一定的代表性。 关键词体验哲学,体验认知,索引假设,浸入式经历者框架,语言的神经理论。 分类号B842 1 引言 语言理解的体验观的哲学基础是体验哲学(Embodied Philosophy)或称新经验主义(Experientialism)[1,2]。体验哲学是从上世纪80年代开始为解决身心二元对立问题而出现的。体验哲学的提出者Lakoff认为“体验”可以包括个体或社团的各种实际的或潜在的经历,是具有遗传结构的个体与物理和社会的互动。体验哲学认为人类的范畴、概念、推理和心理是基于身体经验而形成的,是身体与环境交互作用的结果。体验哲学的基本内容是:(1)心智本来就是基于身体的;(2)思维大都是无意识的;(3)抽象概念大部分是隐喻性的。并以此为依据,将认知科学划分为第一代和第二代认知科学[1,2]。 第一代认知科学,即传统的认知科学把心理视作是抽象信息的加工器,认为其与外部世界的联系是随意的。知觉运动系统与诸如范畴、概念、推理等高级认知加工没有关系;思维和语言是人类所特有的心理机制。以往大多数思维理论多用来处理命题形式的知识,知识被定义为抽象的语义性知识,用结点(nodes)、命题(propositions)、规则(rules)和图式(schemas)等术语来表达。相反,第二代认知科学,即体验认知的理论前提是,认知是一种生物 收稿日期:2006-03-04 ﹡国家社会科学基金资助项目(04BYY008)。 通讯作者:鲁忠义,E-mail:zhongyilu@https://www.doczj.com/doc/a23695893.html, 高志华,E-mail:victoria_gzh@https://www.doczj.com/doc/a23695893.html, 学现象,它与身体的其它系统共同进化,源于人类与环境的交互作用方式。有机体的生物特性,包括大脑和身体的其它部位,以及有机体所在的物理和社会环境对认知具有重要意义。认知、思维和语言根植于感觉运动系统,而这种机制并不是人类所独有的,也存在于非人类的哺乳动物中。 在认知心理学中,Barsalou把命题符号理论称之为非模态理论(amodal theories),并与之相对立提出了知觉符号系统(Perceptual Symbols System)[3]。知觉符号系统理论认为认知、思维和语言根植于感觉运动系统,知觉符号是对知觉过程中产生的神经元兴奋的记录,它与其指代物存在着类比的关系。知觉符号是图式化的和多感觉通道的,彼此间能够进行整合形成模拟器(simulator),即概念,而这个模拟器会对一个知觉成份进行无限的模拟(simulation)使概念具体化。这样传统认知心理学中的以概念为基础的认知计算就成为以知觉符号为基础的认知行为。当事物不在感知范围内,人们却能进行想象或模拟,这种能力构成了智力的基础。知觉符号的理论基础既为概念的稳定性、思维的多产性提供了解释,同时为心理与外部世界的关系问题提出了新的解决方案,成为心理学中体验认知的代表理论。 在体验认知理论的推动下,语言理解的研究形成了一种注重语言理解的感觉运动基础、强调经验作用的理论观点,它们将心理语言学的技术与认知语言学的体验视角相结合,取得了许多理论和实证
Excel函数应用之统计函数 Excel的统计工作表函数用于对数据区域进行统计分析。例如,统计工作表函数可以用来统计样本的方差、数据区间的频率分布等。是不是觉得好像是很专业范畴的东西?是的,统计工作表函数中提供了很多属于统计学范畴的函数,但也有些函数其实在你我的日常生活中是很常用的,比如求班级平均成绩,排名等。在本文中,主要介绍一些常见的统计函数,而属于统计学范畴的函数不在此赘述,详细的使用方法可以参考Excel帮助及相关的书籍。 在介绍统计函数之前,请大家先看一下附表中的函数名称。是不是发现有些函数是很类似的,只是在名称中多了一个字母A?比如,AVERAGE与AVERAGEA;COUNT与COUNTA。基本上,名称中带A的函数在统计时不仅统计数字,而且文本和逻辑值(如TRUE 和 FALSE)也将计算在内。在下文中笔者将主要介绍不带A的几种常见函数的用法。 一、用于求平均值的统计函数AVERAGE、TRIMMEAN 1、求参数的算术平均值函数AVERAGE 语法形式为AVERAGE(number1,number2, ...) 其中Number1, number2, ...为要计算平均值的 1~30 个参数。这些参数可以是数字,或者是涉及数字的名称、数组或引用。如果数组或单元格引用参数中有文字、逻辑值或空单元格,则忽略其值。但是,如果单元格包含零值则计算在内。 2、求数据集的内部平均值TRIMMEAN 函数TRIMMEAN先从数据集的头部和尾部除去一定百分比的数据点,然后再求平均值。当希望在分析中剔除一部分数据的计算时,可以使用此函数。比如,我们在计算选手平均分数中常用去掉一个最高分,去掉一个最低分,XX号选手的最后得分,就可以使用该函数来计算。语法形式为TRIMMEAN(array,percent) 其中Array为需要进行筛选并求平均值的数组或数据区域。Percent为计算时所要除去的数据点的比例,例如,如果 percent = 0.2,在 20 个数据点的集合中,就要除去 4 个数据点(20 x 0.2),头部除去 2 个,尾部除去 2 个。函数 TRIMMEAN 将除去的数据点数目向下舍为最接近的 2 的倍数。 3、举例说明:示例中也列举了带A的函数AVERAGEA的求解方法。 求选手Annie的参赛分数。在这里,我们先假定已经将该选手的分数进行了从高到底的排序,在后面的介绍中我们将详细了解排序的方法。 图1
从语言符号学角度谈语言学习的体验性 语文课程的根本任务就是指导学生“正确理解和运用祖国的语言文字”。但目前的语文教学依然如吕叔湘先生在1978年所批评的那样“到头来却是大多数人过不了关”。其根本原因在于,我们对语言的体验性特点认识不足,重视不够,从而造成语言体验性学习的缺失和疏漏,这应当引起我们的警觉。 一、语言学习需要“体验” 尽管语言的起源有“感叹说”“劳动喊声说”“摹声说”“唱歌说”等不同说法,但不管是哪一种说法,都与人们的生活体验密不可分。这就告诉我们,语言不是独立于人的生活、生命之外的,而是糅合了思维认识、情感体验、现实世界等诸多因素的结果。就汉语言文字来说,其最大特点就是以形表义、以象见意,它是有形象、有画面的,不仅描摹了自然万物的真实状态,更融合了人对自然万物的理解和想象,表现出一种蕴含情感、情绪的生命“意象”。这种“意象”的把握,是“理解”难以承受的。倘若只有“理解”,我们获得的仅是文字意义,触摸不到语言的律动,感受不到语言的音韵,欣赏不到语言的色彩,享受不到语言的情趣,语言学习也就成了一句空话。所以,语言学习仅靠“理解”是远远不够的,还得借助“体验”,唤醒学生的主体意识,调动他们已有的经验和情感,进而感悟蕴含于字里行间的鲜活的情绪联想和引申意义。 二、语言体验的课堂操作 1.重视表象的生成,在想象中体验。汉语言文字虽然只是一种抽象的符号,但却像一支熊熊燃烧的火把,能够照亮人们心中的想象之路。因此重视发挥想象对促进学生语言体验的独特功能,显得非常重要。尤其是当学习内容远离学生的生活或学生从没有过相应的经验的时候,更要重视表象的生成,引导学生通过看图、播放视频、现场模拟、调动生活背景等途径,把语言想象成画面,感受到语言的具体、形象、生动。比如唐代诗人王维的《鸟鸣涧》可谓是“诗中有画,画中有诗”的杰作。其中“月出惊山鸟”一句,虽字数寥寥,且又通俗易懂,平白如话,却意象生动,内涵丰富,耐人寻味,充满着迷人的画面美、意境美和动态美:一钩弯弯的月儿不甘寂寞地游走在蓝蓝的天幕之上,把如水的月光泻在沟沟壑壑、坡坡峰峰,一下子把早就栖息窝巢静待入眠的鸟鹊给搅得躁动不安起来。这样的场景学生当然不可能有生活经验,诗歌的凝练性也造成了理解上的难度。所以,我们必须启发学生对“鸟惊”的原因进行合理的想象,再结合朗读,使语言文字转化为形象可感的画面,这样,学生对语言蕴含的感受和体验更鲜明、更深刻。 2.强化角色转换,在移情中体验。就是让学生将自己的情绪、情感位移到文本中的人或物上,站在其位置或角度设身处地地考虑问题,表达自己的所思所感所悟,从而强化形象的构筑和情感的体验。哲理性、情景交融的散文教学时常用此法。比如教学《生命的壮歌》之《生命桥》时,学生总是很难走进老羚羊和年轻羚羊的内心世界,此时可采取角色转换、换位体验,让学生把自己当作那只用厚实的肩背托起年轻羚羊的老羚羊,或者是那只脚蹬老羚羊,跃过山涧的年轻羚羊。进入角色的学生,果然获得了与先前不同的阅读体验和感受。“年轻羚羊”说,我“猛蹬”在老羚羊的背上时,感觉到我的双腿好像踩在坚实的土地上,一下子有了力气,借着这股力量,我就轻巧地落到悬崖边上;“老羚羊”却说年轻羚羊的这一“猛蹬”,我虽然很疼,身体下坠得更快,可是一想到年轻一代能脱离危险,心里是甜的,死了也