
第25卷第6期
微计算机应用Vol .25,N o .62004年11月M ICROCO M PU T ER AP PL ICA T ION S N ov .,2004
本文于2004-03-24收到。
一种在线中文搜索引擎模型的研究
郭施(山东科技大学工程学院 泰安 271021)
摘要:本文从汉语言由字、词、句构成,同义词、缩略词大量使用,且表达意义的最小单位
词与词之间没有空格这一有别于西文书写方法的特点出发,提出了一个基于I nternet 环境下应用
数据仓库技术的适合中文条件输入的引擎模型,给出了输入字串转化为搜索词的划分方法。描
述了其数据组织结构的内容和实现原理,构建出符合中文输入的搜索策略,并对实现算法进行
了论述,从而达到搜索结果快捷、有效的目的。
关键词:数据仓库 搜索策略 数据转换 搜索引擎
The Research About A Chinese Searching -Engine Model In Online
GUO Shiyi
(College of Engineering ,Shandong university o f Science &T echnology ,T aian ,271021,China )
Abstract :In this tex t ,authors gave out a kind of the engine model according to characteristics of the
Chinese lang uage ,w hich w as different from English and o ther western -sty le languag es ;fo r example ,it was composed of some w ordages ,vocables and sentences ,a lo t of syno nyms and abbreviations w ere used in it ,and there w as not a space between the least unit of vocables and ano ther .T hey also gave out a parti -tio ned -means that a inputting -string translated into a searching -vocables .T hen they described its data structure and realization principle ,established a searching strateg y to match inputting Chinese ,and dis -cussed the arithmetic .T hereby ,they achieved a shortcut ,effective goal to search .
Key words :Data Warehouse ,Searching Strateg y ,Da ta Conversion ,Searching Eng ine
把汉语语言文字本身的特点和网络、人工智能等技术结合起来,介入数据仓库(data w arehouse )技术,探寻一个真正适合网民使用、符合汉语言特点、具有一定智能性的搜索引擎模型,从而进一步提高基于中文条件搜索结果的正确性和全面性,减少结果数据的冗余度。1
数据组织结构1.1构建目标数据
需要构造一个用于搜索的素材库,采用目前流行的数据仓库技术能够满足基于大数量文本的搜索需要,也适合于中文信息的组织。
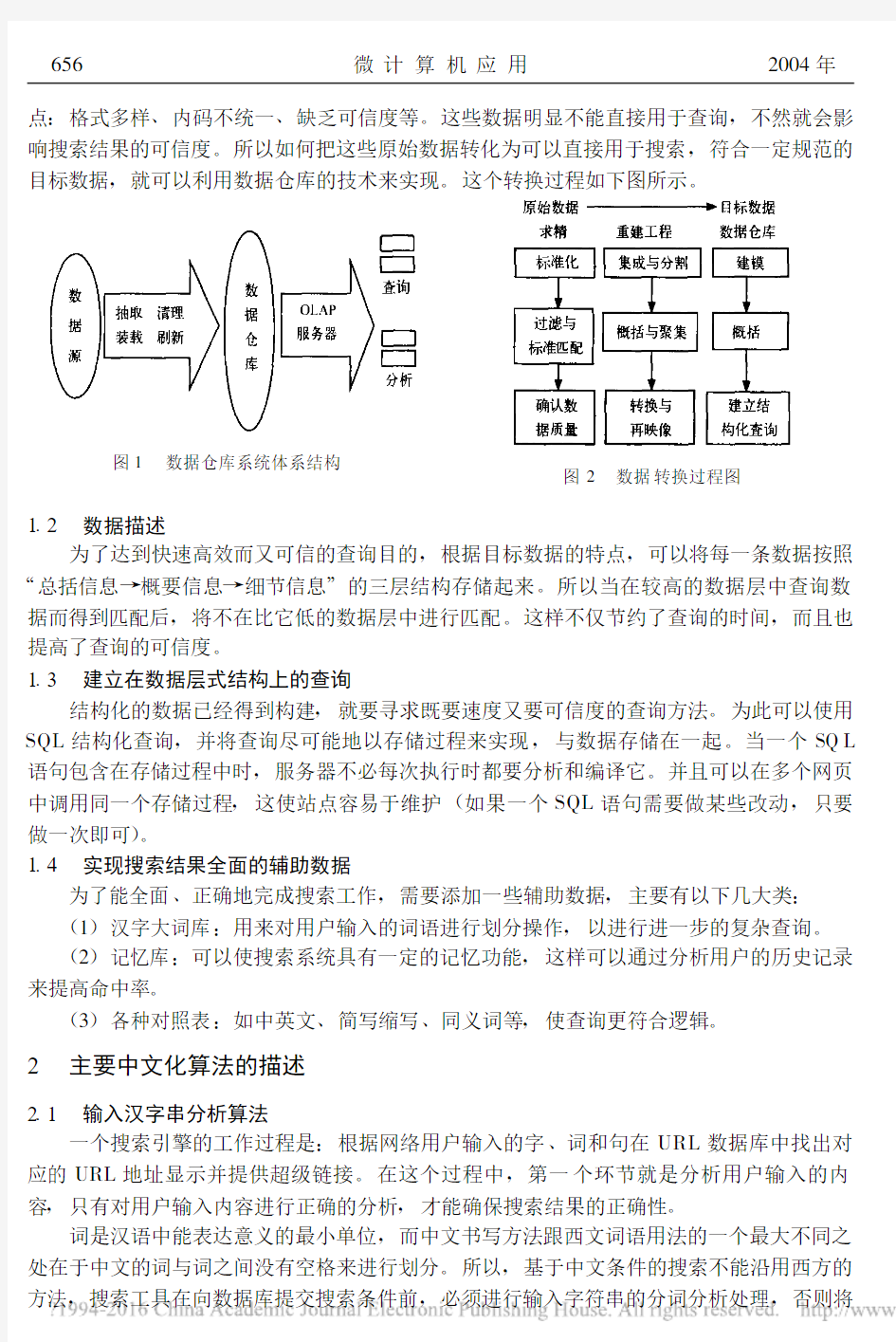
利用数据仓库中数据的收集和存放功能,可以为搜索工具提供一个便于查询、结果正确全面、冗余度小的数据结构。从网络上得到的数据称之为原始数据,它必然存在以下的特
点:格式多样、内码不统一、缺乏可信度等。这些数据明显不能直接用于查询,不然就会影响搜索结果的可信度。所以如何把这些原始数据转化为可以直接用于搜索,符合一定规范的
目标数据,就可以利用数据仓库的技术来实现。这个转换过程如下图所示
。
图1
数据仓库系统体系结构
图2数据转换过程图
1.2数据描述
为了达到快速高效而又可信的查询目的,根据目标数据的特点,可以将每一条数据按照“总括信息※概要信息※细节信息”的三层结构存储起来。所以当在较高的数据层中查询数据而得到匹配后,将不在比它低的数据层中进行匹配。这样不仅节约了查询的时间,而且也提高了查询的可信度。
1.3建立在数据层式结构上的查询
结构化的数据已经得到构建,就要寻求既要速度又要可信度的查询方法。为此可以使用SQL结构化查询,并将查询尽可能地以存储过程来实现,与数据存储在一起。当一个SQ L 语句包含在存储过程中时,服务器不必每次执行时都要分析和编译它。并且可以在多个网页中调用同一个存储过程,这使站点容易于维护(如果一个SQL语句需要做某些改动,只要做一次即可)。
1.4实现搜索结果全面的辅助数据
为了能全面、正确地完成搜索工作,需要添加一些辅助数据,主要有以下几大类:
(1)汉字大词库:用来对用户输入的词语进行划分操作,以进行进一步的复杂查询。
(2)记忆库:可以使搜索系统具有一定的记忆功能,这样可以通过分析用户的历史记录来提高命中率。
(3)各种对照表:如中英文、简写缩写、同义词等,使查询更符合逻辑。
2主要中文化算法的描述
2.1输入汉字串分析算法
一个搜索引擎的工作过程是:根据网络用户输入的字、词和句在URL数据库中找出对应的URL地址显示并提供超级链接。在这个过程中,第一个环节就是分析用户输入的内容,只有对用户输入内容进行正确的分析,才能确保搜索结果的正确性。
词是汉语中能表达意义的最小单位,而中文书写方法跟西文词语用法的一个最大不同之处在于中文的词与词之间没有空格来进行划分。所以,基于中文条件的搜索不能沿用西方的方法,搜索工具在向数据库提交搜索条件前,必须进行输入字符串的分词分析处理,否则将656 微计算机应用2004年
得不到全面、正确的结果。如用户输入“计算机中文信息处理”这个搜索条件,如果我们把它作为一个整体来进行搜索的话,就无法搜索到“计算机的中文信息处理”、“中文信息处理的计算机化”等条目。如果把它分成“计算机”、“中文”、“信息”、“处理”四个词组,由于在“计算机的中文信息处理”、“中文信息处理的计算机化”中分别有这四个词组,所以就能找到这些条目了。
为了能更好地完成对输入字符串的分析工作,系统必须具备以下几个条件:
(1)一个庞大的汉词库,是进行分词的基础。由于语言具有明显的时代性和社会性,每年都会出现近千个新的词,所以这个词库还需要不断的更新。
(2)一个较成功的分词算法。在选择分词算法时,主要考虑的是分词的速度、正确性。
(3)在进行分词时,选择的是短词优先的原则。如上例中,“中文信息处理”本身就是一个词,如采用短词优先的原则,就应该分成如上述的“中文”、“信息”、“处理”三个词,而不是“中文信息处理”一个词。
(4)在输入的字符串中,进行分词后,会出现一些特殊的词。即单字。对这些特殊的词必须进行处理。主要是舍弃没有意义的单字词(主要是助词、量词、感叹词等),如“的”、“是”、“地”等。这些无意义的单字可以收集起来,存放在数据库中,在搜索时通过这个数据库可以简化搜索结果,提高正确率。
2.2总体查询流程
制定查询策略的原则有两条:全而准。全是指找到尽可能多的相关条目;准是指找到的条目与用户的需求是相关的。
对“全”,考虑到与用户提供查询字串相关的条目不一定含有用户提供的完整查询字串,但极有可能含有用户提供查询字串中的部分。由此,可以对拥护提供的查询字串进行划分,把它划分为几个粒度更小的词语,再在还未被命名中的数据上进行匹配。
对“准”,首先应该考虑数据存放的特点。数据按三层层式结构存储,层次越高,与主题的相关度就越高,而且数据量越少,所以,进行匹配时应高层数据优先。用户提供的查询字串或查询字串的划分结果命中的层次越高,则说明被命中的这条数据越可信。
匹配的总体顺序应是“总括信息※概要信息※全文”,如此处理有两点效果:其一,越先查到的数据,它的相关性越高;其二,层越高,信息量越少,查询所需的时间也越少,效率越高。
另外,当查询流程开始时,先扫描一下记忆库,挑选出以前相同查询字串被访问的条目,加到结果集中去。
2.3划分策略
一般用于机器翻译的汉词库都需要几万甚至是几十万的容量,以包容机器翻译过程中用词覆盖面。而作为以数据库检索为目的的汉语查询时,在用词、语法、语义及语用目的等各方面都有一定的限制,这就为提高分词效率,加快分词速度提供了可能。
首先,数据库汉语检索的用词范围相对有限。其次,对汉语查询字串的分词、语法分析和语义分析等目的都是为了生成SQ L 语句。再者数据库查询字串的针对性强,不同的查询领域,需要选择不同的词库进行检索,并可根据查询领域决定某类词语是否有必要去搜索。
划分策略有多种,一个重要的衡量就是划分的粒度。一般来说,划分的粒度越小,划分结果越不能体现原词的意义。对于查询而言,为了找到尽可能多的结果,可以考虑按划分粒657第6期微计算机应用
度的不同,进行多次的划分和查询,而划分粒度应该逐渐减小,这样可以先找出可信度较高的条目。
在本模型分析、研究中使用了三种划分策略:
(1)对用户输入的查询字串进行直接划分,即用户输入的查询字串是几个词语的组合,在这种情况下,划分结果可以比较完整地反映用户输入的查询字串的意义。如:中华人民共和国。
下面是正向单扫描的划分方法:
输入:待处理词串和汉词库(次序按机内码由小到大的顺序排序)。
输出:分词后得到的分词表。
(2)对拥护输入的查询字串不能进行直接的划分,在划分的时候有些字词会被重复使用。在这种情况下,有可能会产生歧义,从而得到的文章可能是与用户输入的查询字串的中心思想不同,可信度降低。如:部分词语※部分、分词、词语。
(3)把字串划分为单个的字,在这种情况下可信度更低。要说明的是,划分结果集中的字词之间是“与”的关系,只有当文章中包含结果集中的所有的字词时才可以被选中。对于不同的划分策略得到的结果集,有它得到的查询结果的可信度也是不同的。
2.4可信度
如前所述,影响可信度的因素主要有两个:数据层次和划分策略。应从两个方面考虑:
(1)从数据的层式存储方式而言,层次越高,该层中的数据与主题相关性越高。若检索时输入关键词命中的层次越高,则可信度就越高;
(2)采用不同的划分策略得到的划分结果越能表达查询字串的含义,则使用该划分结果得到的查询结果的可信度越高。
例如对一个在搜索中被选中的条目,它当时的状态为处于K 层,使用的是第1种划分策略,则可信度trust 为
trust (filename ,searchstr )=Facto r1(K )×Facctor2(L )
其中searchstr 为搜索字串,filename 为搜索字串命中的U RL 。
另外还有一个影响可信度的因素,即对于被用户访问过的内容,它相应于对应的查询字图3多文种匹配实现方法图
串的可信度应该增加。设boo t 为每被击中一次增加的可信度,则
trust (filename ,searchstr )=trust (filename ,searchstr )+boot
2.5多种文种匹配算法
为了把尽可能全面的相关条目搜索出来,仅仅采用
把查询字串划分后再查询的方法是远远不够的。中文
的同义词、缩略词是相当多的,根据中文的这一特点,
必须使查询能处理这些对应关系。同时,对于同一词
语,有中文、英文或其他语言的不同的表达,这也需
要有一种对应关系。这样就把一个查询字或词扩展成
为多个,显然可以找到更多符合要求的条目。字串的
多文种匹配见图3。本研究模型中借助了对照表这样
一个数据结构来记录以下几种词语的对应关系:①同义词;②缩写词;③中文、英文等多文种对照表。658 微计算机应用2004年
建立对照表实际上可以分成两个步骤来实现:≠在系统设计时根据英汉字典,汉语同义词词典等构造这张表,表中数据主要是通过分析一些在线词典得到的,现有几十万条。另外,为了简化对照表,根据输入字串的特点,在表中只存放名词;≡在使用阶段,根据和用户的交互动作进一步完善这张表。
3结束语
基于中文条件的、具有一定智能性的搜索工具模型的创建,必须符合汉语自身的特点,并在此基础上设计中文数据的存放策略、组织严谨的数据结构,构建符合汉语特点的分析算法,以实现搜索结果的快捷、可靠和全面。
参 考 文 献
1 M icrosoft Corporation .Databas e Creation Warehousing and Optimization ,M icrosoft Corporation 著,东方人华译.北京:清华大学出版社,2001.
2 Josang A .Alogic uncertain probabities [J ].Internationnal Journal of Uncertainty ,Fuzziness andKnow ledge ,2001,9(3).3 Principles of Data M ining David Hand .著,张银奎等译.北京:机械工业出版社,2003.
4 宋宏等.基于数据仓库的EIS 在CIM S 中的研究与实现[J ].信息与控制,1999,28(4)
作者简介
郭施,男,1963生,讲师,教学与研究方向:面向对象语言与网络应用
。659第6期微计算机应用
自主访问控制综述 摘要:访问控制是安全操作系统必备的功能之一,它的作用主要是决定谁能够访问系统,能访问系统的何种资源以及如何使用这些资源。而自主访问控制(Discretionary Access Control, DAC)则是最早的访问控制策略之一,至今已发展出多种改进的访问控制策略。本文首先从一般访问控制技术入手,介绍访问控制的基本要素和模型,以及自主访问控制的主要过程;然后介绍了包括传统DAC 策略在内的多种自主访问控制策略;接下来列举了四种自主访问控制的实现技术和他们的优劣之处;最后对自主访问控制的现状进行总结并简略介绍其发展趋势。 1自主访问控制基本概念 访问控制是指控制系统中主体(例如进程)对客体(例如文件目录等)的访问(例如读、写和执行等)。自主访问控制中主体对客体的访问权限是由客体的属主决定的,也就是说系统允许主体(客体的拥有者)可以按照自己的意愿去制定谁以何种访问模式去访问该客体。 1.1访问控制基本要素 访问控制由最基本的三要素组成: ●主体(Subject):可以对其他实体施加动作的主动实体,如用户、进程、 I/O设备等。 ●客体(Object):接受其他实体访问的被动实体,如文件、共享内存、管 道等。 ●控制策略(Control Strategy):主体对客体的操作行为集和约束条件集, 如访问矩阵、访问控制表等。 1.2访问控制基本模型 自从1969年,B. W. Lampson通过形式化表示方法运用主体、客体和访问矩阵(Access Matrix)的思想第一次对访问控制问题进行了抽象,经过多年的扩充和改造,现在已有多种访问控制模型及其变种。本文介绍的是访问控制研究中的两个基本理论模型:一是引用监控器,这是安全操作系统的基本模型,进而介绍了访问控制在安全操作系统中的地位及其与其他安全技术的关系;二是访问矩阵,这是访问控制技术最基本的抽象模型。
几大常用中文搜索引擎的对比 随着互联网的不断发展扩大,网络上中文信息资源和上网的中文用户也大量增加,各类中文搜索引擎更是层出不穷。以下我选取了Google中文,百度,搜狗,必应这几个常用的中文搜索引擎进行较为粗浅的比较。 先比较一下各搜索引擎的特点。Google中文:包括网页、图片、新闻搜索,支持个性化搜索及本地搜索,提供论坛、邮箱、日历服务和桌面搜索工具,是万维网上最大的搜索引擎,但Google中文在中国却一直受到百度搜索的压制,最终由于黑客攻击和敏感词过滤问题退出中国内地转至香港。百度:是全球最大的中文搜索引擎,除网页搜索外,还提供MP3、文档、地图、传情、影视等多样化的搜索服务,率先创造了以贴吧、知道为代表的搜索社区,是目前国内最大的商业化全文搜索引擎。搜狗:搜狗是全球首个百亿规模中文搜索引擎,收录100亿网页,创造了全球中文网页收录量新高,搜狗以网页搜索为核心,在音乐、新闻、图片、地图等方面提供了垂直搜索服务,通过说吧建立用户间的搜索社区,2010年8月搜狐与阿里巴巴宣布将分拆搜狗成立独立公司,引入战略投资,注资后的搜狗有望成为仅次于百度的中文搜索工具。必应(bing):必应是微软公司09年新推出的中文搜索引擎。主打快乐搜索体验。
接着从各方面对比:1.外观排版:Google、百度、搜狗的外观都是以简单的白色背景为主,而必应的背景是一副定期更换的图片,乍看比较新鲜,可是用习惯后我发现搜索引擎还是简洁一点好。不同于其他3家“相关搜索”出现在搜索结果的底部,必应在网页左侧和底部都出现了“相关搜索”,虽然略显重复,但在一定程度上为用户提供了方便。2.搜索结果:在这4家引擎同时输入“集美大学诚毅学院”,可以看到Google用时0.10 秒获得约62,900 条结果,百度用时0.018秒找到相关网页约55,000篇,必应没有显示用时找到共50,900 条,搜狗用时0.027 秒只有30,636条。可见在Google的搜索量大,而百度的时间最短,速度和数量比最好,搜狗略逊一筹3.搜索内容:四家网站的内容更新都比较及时,百度的优势在于很中国化很生活化,符合中国人的习惯。但它的内容的匹配度不如Google高,而且很商业化,广告和垃圾网站很多,适合搜索一般问题。Google专业搜索比较好,适合技术人员,学生教师,搜索范围较广。特别是Google的地图和翻译是其他搜索引擎无法比拟的。但是Google由于版权问题无法搜索MP3,这是个硬伤,因为搜索MP3在中国已经成为流行。Google的死链率也比较高,中文网站检索的更新频率不够快,“网页快照”功能在国内经常出现不可访问的问题。搜狗较多的被用在搜索新闻,音乐,电影上,娱乐性强,商机搜索和说吧也很有特色。必应搜索与传统搜索引擎只是单独列出一个搜索列表不同,微软还会对返回的结果加以分类。但必应默认搜索结果只显示5页,其他搜索引擎都是10页,在点击到第五页的时候,会自动出现9页结果,这显然
Java开源搜索引擎分类列表 Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。文档通过Http利用XML加到一个搜索集合中。查询该集合也是通过http收到一个XML/JSON响应来实现。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面等。 Egothor是一个用Java编写的开源而高效的全文本搜索引擎。借助Java的跨平台特性,Egothor能应用于任何环境的应用,既可配置为单独的搜索引擎,又能用于你的应用作为全文检索之用。 更多Egothor信息 Nutch Nutch 是一个开源Java 实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 更多Nutch信息 Lucene Apache Lucene是一个基于Java全文搜索引擎,利用它可以轻易地为Java软件加入全文搜寻功能。Lucene的最主要工作是替文件的每一个字作索引,索引让搜寻的效率比传统的逐字比较大大提高,Lucen提供一组解读,过滤,分析文件,编排和使用索引的API,它的强大之处除了高效和简单外,是最重要的是使使用者可以随时应自已需要自订其功能。 更多Lucene信息 Oxyus 是一个纯java写的web搜索引擎。 更多Oxyus信息 BDDBot BDDBot是一个简单的易于理解和使用的搜索引擎。它目前在一个文本文件(urls.txt)列出的URL中爬行,将结果保存在一个数据库中。它也支持一个简单的Web服务器,这个服务器接受来自浏览器的查询并返回响应结果。它可以方便地集成到你的Web站点中。 更多BDDBot信息 Zilverline Zilverline是一个搜索引擎,它通过web方式搜索本地硬盘或intranet上的内容。Zilverline 可以从PDF, Word, Excel, Powerpoint, RTF, txt, java, CHM,zip, rar等文档中抓取它们的内容来建立摘要和索引。从本地硬盘或intranet中查找到的结果可重新再进行检索。Zilverline支持多种语言其中包括中文。 更多Zilverline信息 XQEngine
创新教案《身边那些有特点的人》 第二课时:展示修改 一、欣赏佳作 1.出示学生的一篇优秀作品: 请作者朗读,其他同学边看、边听、边思考: (1)写谁?人物有什么特点? (2)什么事表现了这一特点和品质? (3)哪些细节描写生动地体现来这一特点? 2.交流归纳: 作文就是这样简单、快乐,只要你仔细观察生活,就会发现身边有很多有趣的人、事、物,记录下来,就是一篇作文。写好一个人,只要写一件能够表现他特点的事情,并且抓住人物的动作、语言、心理来写,你写的这个人就会活灵活现地站在文中了。 3.展示作品: (1)孩子们,每个同学的作文都有自己的优点,说说这次作文中,哪些地方你认为写的不错?可以是一段话、可以是一句话、可以是一个词语、可以是一个标点,只要你认为写得精彩,用得恰当的,都可以起来展示给其他小伙伴听听。 (2)学生展示自己作品中的得意处。 二、修改问题较多的习作一篇 1.投影展示习作。 2.评议: (1)什么地方需要修改? 如:格式、标点、词语的运用、句子是否通顺、选择的事例是否典型、事情的叙述是否清楚…… (2)师生共同修改,体验修改的好处和乐趣。 三、再次修改自己的习作,并将修改后的自豪地读给伙伴听听 四、将自己的作文配上美丽的插图,张贴在教室里,和大家一起分享作文的快乐 〖板书设计〗 写自己熟悉的一个人 语句通顺
抓住人物的特点 写出人物的神情、动作、语言、心理 第六单元教学初探 一、单元内容总述 1.本单元主题:本单元主题是“童年生活”,全单元主要包括《童年的水墨画》、《一只窝囊的大老虎》、《肥皂泡》和《我不能失信》四篇课文,目的是引导学生学会用多种方法理解难懂的句子,感受童年生活的丰富多彩。 2.本单元重点: (1)运用多种方法理解难懂的句子。学习《童年的水墨画》时要注意联系上下文来理解诗句的意思。《剃头大师》前后充满趣味和无奈,结合生活经验理解小沙“怕剃头”的感受。《肥皂泡》全文质朴优美,阅读时要联系上下文,并查找资料理解“五色的浮光,在那轻清透明的球面上乱转”。《我不能失信》讲述了很常见的故事,记得结合课文内容来联系生活实际,理解句子“一个人在家,是很没劲。可是,我并不后悔,因为我并没有失信”。教学时,教师要引导学生运用多种方法理解难懂的句子,理解课文内容,感受童年生活的美好。 (2)写一个熟悉的人,尝试写出他的特点。本单元安排了习作《身边那些有特点的人》,找出关键词,抓住人物的主要特点练习写作。 3.单元教学建议:学会运用联系上下文、查找资料、联系生活实际等多种方法理解难懂的句子,理解和感悟童年生活。
英文十大搜索引擎十大搜索引擎排名 中文搜索引擎 Google搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) 目前最优秀的支持多语种的搜索引擎之一,约搜索3,083,324,652 张网页。提供网站、图像、新闻组等多种资源的查询。包括中文简体、繁体、英语等35个国家和地区的语言的资源。 百度(baidu)中文搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) 全球最大中文搜索引擎。提供网页快照、网页预览/预览全部网页、相关搜索词、错别字纠正提示、新闻搜索、Flash搜索、信息快递搜索、百度搜霸、搜索援助中心。 北大天网中英文搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) 由北京大学开发,简体中文、繁体中文和英文三个版本。提供全文检索、新闻组检索、FTP 检索(北京大学、中科院等FTP站点)。目前大约收集了100万个WWW页面(国内)和14万篇Newsgroup(新闻组)文章。支持简体中文、繁体中文、英文关键词搜索,不支持数字关键词和URL名检索。 新浪搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) 互联网上规模最大的中文搜索引擎之一。设大类目录18个,子目1万多个,收录网站20余万。提供网站、中文网页、英文网页、新闻、汉英辞典、软件、沪深行情、游戏等多种资源的查询。 雅虎中国搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) Yahoo!是世界上最著名的目录搜索引擎。雅虎中国于1999年9月正式开通,是雅虎在全球的第20个网站。Yahoo!目录是一个Web资源的导航指南,包括14个主题大类的内容。 搜狐搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) 搜狐于1998年推出中国首家大型分类查询搜索引擎,到现在已经发展成为中国影响力最大的分类搜索引擎。每日页面浏览量超过800万,可以查找网站、网页、新闻、网址、软件、黄页等信息。 网易搜索引擎(https://www.doczj.com/doc/ab16335793.html,/) 网易新一代开放式目录管理系统(ODP)。拥有近万名义务目录管理员。为广大网民创建了一个拥有超过一万个类目,超过25万条活跃站点信息,日增加新站点信息500~1000条,日访问量超过500万次的专业权威的目录查询体系。 3721网络实名/智能搜索(https://www.doczj.com/doc/ab16335793.html,/) 3721公司提供的中文上网服务――3721"网络实名",使用户无须记忆复杂的网址,直接输入中文名称,即可直达网站。3721智能搜索系统不仅含有精确的网络实名搜索结果,同时集成多家搜索引擎。
访问控制模型研究综述 沈海波1,2,洪帆1 (1.华中科技大学计算机学院,湖北武汉430074; 2.湖北教育学院计算机科学系,湖北武汉430205) 摘要:访问控制是一种重要的信息安全技术。为了提高效益和增强竞争力,许多现代企业采用了此技术来保障其信息管理系统的安全。对传统的访问控制模型、基于角色的访问控制模型、基于任务和工作流的访问控制模型、基于任务和角色的访问控制模型等几种主流模型进行了比较详尽地论述和比较,并简介了有望成为下一代访问控制模型的UCON模型。 关键词:角色;任务;访问控制;工作流 中图法分类号:TP309 文献标识码: A 文章编号:1001-3695(2005)06-0009-03 Su rvey of Resea rch on Access Con tr ol M odel S HE N Hai-bo1,2,HONG Fa n1 (1.C ollege of Computer,H uazhong Univer sity of Science&Technology,W uhan H ubei430074,China;2.Dept.of C omputer Science,H ubei College of Education,Wuhan H ubei430205,China) Abst ract:Access control is an im port ant inform a tion s ecurity t echnolog y.T o enha nce benefit s and increa se com petitive pow er,m a ny m odern enterprises hav e used this t echnology t o secure their inform ation m ana ge s yst em s.In t his paper,s ev eral m a in acces s cont rol m odels,such as tra dit iona l access control m odels,role-bas ed acces s cont rol m odels,ta sk-ba sed acces s control m odels,t as k-role-based access cont rol m odels,a nd s o on,are discus sed a nd com pa red in deta il.In addit ion,we introduce a new m odel called U CON,w hich m ay be a prom ising m odel for the nex t generation of a ccess control. Key words:Role;Ta sk;Access Cont rol;Workflow 访问控制是通过某种途径显式地准许或限制主体对客体访问能力及范围的一种方法。它是针对越权使用系统资源的防御措施,通过限制对关键资源的访问,防止非法用户的侵入或因为合法用户的不慎操作而造成的破坏,从而保证系统资源受控地、合法地使用。访问控制的目的在于限制系统内用户的行为和操作,包括用户能做什么和系统程序根据用户的行为应该做什么两个方面。 访问控制的核心是授权策略。授权策略是用于确定一个主体是否能对客体拥有访问能力的一套规则。在统一的授权策略下,得到授权的用户就是合法用户,否则就是非法用户。访问控制模型定义了主体、客体、访问是如何表示和操作的,它决定了授权策略的表达能力和灵活性。 若以授权策略来划分,访问控制模型可分为:传统的访问控制模型、基于角色的访问控制(RBAC)模型、基于任务和工作流的访问控制(TBAC)模型、基于任务和角色的访问控制(T-RBAC)模型等。 1 传统的访问控制模型 传统的访问控制一般被分为两类[1]:自主访问控制DAC (Discret iona ry Acces s Control)和强制访问控制MAC(Mandat ory Acces s C ontrol)。 自主访问控制DAC是在确认主体身份以及它们所属组的基础上对访问进行限制的一种方法。自主访问的含义是指访问许可的主体能够向其他主体转让访问权。在基于DAC的系统中,主体的拥有者负责设置访问权限。而作为许多操作系统的副作用,一个或多个特权用户也可以改变主体的控制权限。自主访问控制的一个最大问题是主体的权限太大,无意间就可能泄露信息,而且不能防备特洛伊木马的攻击。访问控制表(ACL)是DAC中常用的一种安全机制,系统安全管理员通过维护AC L来控制用户访问有关数据。ACL的优点在于它的表述直观、易于理解,而且比较容易查出对某一特定资源拥有访问权限的所有用户,有效地实施授权管理。但当用户数量多、管理数据量大时,AC L就会很庞大。当组织内的人员发生变化、工作职能发生变化时,AC L的维护就变得非常困难。另外,对分布式网络系统,DAC不利于实现统一的全局访问控制。 强制访问控制MAC是一种强加给访问主体(即系统强制主体服从访问控制策略)的一种访问方式,它利用上读/下写来保证数据的完整性,利用下读/上写来保证数据的保密性。MAC主要用于多层次安全级别的军事系统中,它通过梯度安全标签实现信息的单向流通,可以有效地阻止特洛伊木马的泄露;其缺陷主要在于实现工作量较大,管理不便,不够灵活,而且它过重强调保密性,对系统连续工作能力、授权的可管理性方面考虑不足。 2基于角色的访问控制模型RBAC 为了克服标准矩阵模型中将访问权直接分配给主体,引起管理困难的缺陷,在访问控制中引进了聚合体(Agg rega tion)概念,如组、角色等。在RBAC(Role-Ba sed Access C ontrol)模型[2]中,就引进了“角色”概念。所谓角色,就是一个或一群用户在组织内可执行的操作的集合。角色意味着用户在组织内的责 ? 9 ? 第6期沈海波等:访问控制模型研究综述 收稿日期:2004-04-17;修返日期:2004-06-28
来源Windows8论坛:https://www.doczj.com/doc/ab16335793.html, 中文搜索引擎与国外搜索引擎的区别 因特网上的科学信息和电子杂志的总量在持续增长,整个网络可看作是一个可以检索的150亿单词的大电子百科全书。但是这些信息是极其无序的,如何获取和利用因特网上的信息已经成了一个大问题。目前解决这一问题的最佳途径是利用搜索引擎。 因特网上的信息呈几何级数增长,快速有效地查询一项艰巨的任务,这个需求直接导致了广域网信息检索技术的快速发展,各类搜索引擎层出不穷。 所谓搜索引擎,是指因特网上的在万维网(WWW)中主动搜索信息并能起自动索引、提供查询服务的一类网站,这些网站通过网络搜索软件(又称为网络搜索机器人)或网站登录等方式,将因特网上大量网站的页面收集到本地,经过加工处理而建成数据库,从而能够对用户提出的各种查询作出响应,提供用户所需的信息。科学家很早就梦想能够快速检索所有的科技文献,现在,搜索引擎使得在数秒钟内取得大量的文献成为可能。 中文搜索引擎概述 中文搜索引擎的出现是最近几年的事情,但发展很快。它的性能究竟如何,能检索到的信息有多少,因特网上的中文信息或网页知多少,这些都是值得关心的问题。 目前中文引擎共有约80多个,可以分为两类,一类是自由词或关键词检索搜索引擎,另一类是分类搜索引擎。由于语言、文化上的差异,中文搜索引擎必然与国外的搜索引擎有所不同。中文搜索引擎有两个特点。1.内码:由于历史原因,目前世界上使用中文的国家与地区在中文语言的使用上有较大差别,体现在计算机处理上也有很大不同,其中最重要的区别是采用不同的字符集及内码体系,例如祖国大陆用的是GB码,而中国台湾地区则用BIG5码,字符集的大小也不尽相同。
Sphinx 全文搜索引擎 1:索引与全文索引的概念 数据库中,表中的行特别多,如何快速的查询某一行,或者某一个文章中的单词, 索引--->查询速度快 全文索引-->针对文章内容中的单词各做索引 2:mysql支不支持全文索引? 答:支持, 但是 A:innoDB引擎在5.5,及之前的版本不支持(5.7实测可以在innodb上建fulltext),只能在myisam 引擎上用fulltext B: mysql的全文索引功能不够强大 C: 无法对中文进行合理的全文索引----- mysql.无法进行中文分词. 注意: 全文索引的停止词 停止词是指出现频率极高的单词, 不予索引. 如果某单词出现频率50%以上,列为停止词 或者是经过统计的常用词,也列为停止词---如is, are , she, he, this 等等 就像中文中: “的”,”是”,”呵呵” 总结: 我们要对中文做全文搜索引擎,需要解决2个问题 1: 性能提高,用第3方的全文搜索引擎工具,如sphinx, solr等 2: 中文分词! (如mmseg)
编译安装sphinx+mmseg == coreseek 官网: https://www.doczj.com/doc/ab16335793.html, 0: 安装工具包 yum install make gcc gcc-c++ libtool autoconf automake imake libxml2-devel expat-devel 1: 下载解压源码,ls查看 csft-4.1 mmseg-3.2.14 README.txt testpack 其中-- csft-4.1是修改适应了中文环境后的sphinx Mmseg 是中文分词插件 Testpack是测试用的软件包 2: 先安装mmseg 2.1: cd mmseg 2.2: 执行bootstrap脚本 2.3: ./configure --prefix=/usr/local/mmseg 2.4: make && make install 3: 再安装sphinx(coreseek) 3.1: 到其目录下执行buildconf.sh 3.2: ./configure --prefix=/usr/local/sphinx --with-mysql=/usr/local/mysql --with-mmseg --with-mmseg-includes=/usr/local/mmseg/include/mmseg/ --with-mmseg-libs=/usr/local/mmseg/lib/ 3.3: make install Sphinx的使用 分三个部分: 1: 数据源---要让sphinx知道,查哪些数据,即针对哪些数据做索引(可以定义多个源) 2: 索引配置--针对哪个源做索引, 索引文件放在哪个目录?? 等等 3: 搜索服务器----sphinx可以在某个端口(默认9312),以其自身的协议,与外部程序做交互. 具体的步骤: 1: 数据源典型配置 source test { type = mysql sql_host = localhost sql_user = root
网络访问控制技术综述 摘要:随着科学的不断进步,计算机技术在各个行业中的运用更加普遍。在计算机技术运用过程中信息安全问题越发重要,网络访问控制技术是保证信息安全的常用方式。本文介绍了研究网络访问控制技术的意义,主流的访问控制技术以及在网络访问控制技术在网络安全中的应用。 关键字:信息安全网络访问控制技术 0.引言 近年来,计算机网络技术在全球范围内应用愈加广泛。计算机网络技术正在深入地渗透到社会的各个领域,并深刻地影响着整个社会。当今社会生活中,随着电子商务、电子政务及网络的普及,信息安全变得越来越重要。在商业、金融和国防等领域的网络应用中,安全问题必须有效得到解决,否则会影响整个网络的发展。一般而言信息安全探讨的课题包括了:入侵检测(Intrusion Deteetion)、加密(Encryption)、认证(Authentieation)、访问控制(Aeeess Control)以及审核(Auditing)等等。作为五大服务之一的访问控制服务,在网络安全体系的结构中具有不可替代的作用。所谓访问控制(Access Control),即为判断使用者是否有权限使用、或更动某一项资源,并防止非授权的使用者滥用资源。网络访问控制技术是通过对访问主体的身份进行限制,对访问的对象进行保护,并且通过技术限制,禁止访问对象受到入侵和破坏。 1.研究访问控制技术的意义 全球互联网的建立以及信息技术飞快的发展,正式宣告了信息时代的到来。信息网络依然成为信息时代信息传播的神经中枢,网络的诞生和大规模应用使一个国家的领域不仅包含传统的领土、领海和领空,而且还包括看不见、摸不着的网络空间。随着现代社会中交流的加强以及网络技术的发展,各个领域和部门间的协作日益增多。资源共享和信息互访的过程逐越来越多,人们对信息资源的安全问题也越发担忧。因此,如何保证网络中信息资源的安全共享与互相操作,已日益成为人们关注的重要问题。信息要获得更大范围的传播才会更能体现出它的价值,而更多更高效的利用信息是信息时代的主要特征,谁掌握的信息资源更多,
中文智能搜索引擎 龙其 072349
摘要 飞速发展的Internet给用户提供了海量的信息资源,导致用户从爆炸性增长的信息中迅速获得需要的信息变得越来越困难。为了帮助用户快速准确地检索到所需的网络信息,网络搜索引擎的研究与开发已经成为当今网络信息检索的热点。本文通过搜索引擎概述及原理介绍中文智能搜索引擎,从中文分词技术;词性标注及词义分析;分类器设计检索模型;PageRank排序技术;研究现状和发展趋势等内容对中文智能搜索引擎进行介绍。 搜索引擎概述及原理 搜索引擎是以Web页面为检索文档的信息检索系统,它的核心就是信息检索技术。广义地说,搜索引擎就是指在指互联网上能够响应用户提交的搜索请求,返回相应的查询结果信息的技术和系统。 搜索引擎以一定的策略在互联网中搜集、发现信息,对信息进行理解、提取、组织和处理,并为用户提供检索服务,从而起到信息导航的目的。 搜索引擎并不是真正地搜索互联网,它搜索的是预先整理好的网页索引数据库。一般来说,搜索引擎得原理可以看做三步:从互联网中抓取网页;建立索引数据库;在索引数据库中进行搜索排序。 (1)互联网中抓取网页:通过网页搜索工具Spider(蜘蛛)或Robot(机器人)等自动访问互联网,沿着URL搜索,并把搜索到的信息带回搜索引擎。 (2)建立索引数据库:通过对收集的网页信息进行分析,把这些相关信息进行分类索引建立索引数据库。 (3)在索引数据库中进行搜索排序:通过Web服务端软件,获得用户输入关键词后,有搜索程序从网页数据库中找到符合该关键词的相关网页。为用户提供浏览界 面下的查询信息。 搜索引擎结构图
中文智能搜索引擎 1.中文搜索引擎 中文搜索引擎是指以Interent网络上的中文信息为主要对象,提供信息的自动收集、自动过滤、自动索引中和检索导航等服务的搜索引擎。中文Internet搜索引擎的最关键组件是能够在海量中英文数据上进行高效全文检索的信息管理系统。中文搜索引擎的机制同英文搜索引擎大致相同,不同的是多了中文语言的处理技术,这主要是中文分词技术和汉化技术。 逻辑上,中文信息搜索引擎与与一般搜索引擎一样分为三个部分:网页搜索引擎,索引引擎和查询引擎。 2.智能搜索引擎 传统搜索引擎局限:传统搜索引擎主要采用网站分类技术和全文检索技术来实现信息查询,前者成本高,对网站描述也比较简单,不能升入网站内部细节。而后者效率比较低且返回信息过多。 传统搜索引擎所使用的技术都难以解决用户“找信息难”的问题,造成这种困难的实质在于搜索引擎缺乏知识处理能力和理解能力。因此要把信息检索从基于关键词层面提高到基于知识层面。 智能搜索引擎,它突破传统搜索引擎基于要求较精确的关键词层面信息检索的局限,发展到基于以不规范、不精确的自然形式出现的知识(或概念)层面来分析和处理用户的查询提问,具有良好的自然语言理解、知识处理能力,在信息检索过程中体现出很强的智能化与人性化优势。 3.中文智能搜索引擎 采用智能搜索引擎得方法实现对中文信息的检索。中文智能搜索引擎可以自动分析中文网页,进行自动分词处理,并自动提取关键词,建立一关键词为基础的查询数据库,降低了系统开销,大大提高了查询效率。它通过充分考虑中文语句的表达结构以及“口语化的提问,智能化的结果”来满足用户的各种查询需求。 中文智能搜索引擎功能结构图大致如下:
习作·身边那些有特点的人 教学目标: 1.理解什么是人物特点。 2.初步领会描写人物的基本要领:抓住人物的外貌,性格、兴趣爱好等方面的特点,按一定顺序写下来。 3.加一个精彩的题目。 教学重点:学会抓住人物的外貌、性格、兴趣爱好等特点,准确真实的描写人物形象。 教学难点:抓住人物的外貌、性格、兴趣爱好等特点,准确而真实的描写人物形象。教学准备:教师:准备范文。学生:观察自己身边有特点的人。 教学时数:1课时。 教学过程: 一、猜谜导入,揭示课题。 同学们,今天咱们来玩一个猜谜游戏。看谁能根据大屏幕上的词语猜出人物形象。看谁的反应最快,猜出来的同学请举手。(大屏幕出示) 【设计意图:游戏导入,用耳熟能详的人物形象激发学生兴趣,揭题。】1.火眼金睛尖嘴猴腮头戴紧箍咒——孙悟空 同学们,眼睛,嘴巴,脸,这些都是孙悟空的外貌。所以咱们可以通过外貌猜出人物。(板书:外貌) 好,同样是《西游记》中的人物,再猜(大屏幕出示) 2.好吃懒做好色——猪八戒 好吃懒做是猪八戒的?性格。好色,就是喜欢女子。也就是爱好、兴趣。所以咱们还可以通过性格爱好来猜出人物。(板书:性格爱好兴趣)
小结:外貌,性格,爱好兴趣,这些都可以称之为人物特点。 二、深入理解“人物特点” 1.出示例文。 我们可以根据外貌猜出人物,大家看这段文字写的是谁? (出示例文)我有一头乌黑的头发,圆圆的脸上长着一双黑色的眼睛,鼻子下面有一张小小的嘴巴。 师:这是谁?生答不知。因为他的外貌没什么特别的地方。没特点。 好多人都长的是这个样子,这是一张大众化的脸谱,放在人堆里看没什么特别的。所以猜不出来。 师:那什么是特点呢?生:特殊的地方。 师:对特别之处。生:和别人不一样的地方。 2.理解什么是特点。 特点就是指的人或者物所具有的独特的地方。这个独特的地方,可以是外貌,也可以是性格爱好兴趣等。这都是特点。 (举例:)比如说:小红左侧脸颊上长了一颗美人痣,这就是她外貌的独特之处。小明特别爱看书,连上厕所的时候都拿着书,这是他的兴趣爱好,也是他的特点。再比如说我们班的郭辰嘉同学,平时非常喜欢帮助别人,一副热心肠,这也是他的特点。 同学们,你们有什么特点呢? 正是有了这些特点,才使得我们与众不同。著名的哲学家布莱尼茨曾说过,:“世界上没有两片完全相同的树叶,也没有性格完全相同的人。”所以咱们在介绍人物时,想让人一下子记住,就必须抓住最鲜明的特点。(板书:抓特点) 三、如何抓住特点来描写人物。
中文搜索引擎大全及简介 作者: https://www.doczj.com/doc/ab16335793.html, 来源: 搜索快报https://www.doczj.com/doc/ab16335793.html, 日期: 2006-7-15,3:32 主要搜索引擎(独立的搜索技术) Google简体中文 https://www.doczj.com/doc/ab16335793.html, Google 的使命是整合全球范围的信息,使人人皆可访问并从中受益。完成该使命的第一步就是Google 的创始人Larry Page 和Sergey Brin 共同开发的全新的在线搜索引擎。该技术诞生于斯坦福大学的一个学生宿舍里,然后迅速传播到全球的信息搜索者。Google 目前被公认为全球最大的搜索引擎,它提供了简单易用的免费服务,用户可以在瞬间返回相关的搜索结果。在访问Google 主页时,您可以使用多种语言查找信息、查看新闻标题、搜索超过10 亿幅的图片,并能够细读全球最大的Usenet 消息存档,其中提供的帖子超过10 亿个,时间可以追溯到1981 年。 2005年,Google高调进军中国市场,推出Google搜索中国版,命名为:谷歌搜索https://www.doczj.com/doc/ab16335793.html, 百度搜索 https://www.doczj.com/doc/ab16335793.html,
百度搜索引擎拥有目前世界上最大的中文搜索引擎,总量超过3亿页以上,并且还在保持快速的增长。百度搜索引擎具有高准确性、高查全率、更新快以及服务稳定的特点,能够帮助广大网民快速的在浩如烟海的互联网信息中找到自己需要的信息,因此深受网民的喜爱。 雅虎中国 https://www.doczj.com/doc/ab16335793.html,/ 2005年11月9日阿里巴巴公司在完成对雅虎中国的收购与整合之后,重新发布了进入中国市场7年之久的雅虎网站, 未来雅虎在中国的业务重点方向将全面转向搜索领域,这也是自8月11日阿里巴巴宣布收购雅虎中国时就从没改变的方向。阿里巴巴CEO马云表示: 阿里巴巴在搜索领域既有决心更有信心,在中国,雅虎就是搜索,搜索就是雅虎。 2006年8月,雅虎中国推出独立搜索引擎网站入口 https://www.doczj.com/doc/ab16335793.html, 中国搜索 https://www.doczj.com/doc/ab16335793.html,/ 中国搜索(原慧聪搜索)2002年正式进入中文搜索引擎市场,2003年8月24日慧聪搜索(现中国搜索)正式推出第三代智能中文搜索引擎.2003年12月23日慧聪搜索正式独立运作,成立中国搜
我首选的中文搜索引擎 1 中文搜索引擎有很多,例如:百度、新浪、搜狗、Google、雅虎、中国搜索、和讯等等,而我首选的是Google. Google的功能有搜索、手气不错、高级搜索、使用偏好、语言工具、更多、网页类型。而百度只有百度一下、帮助、高级检索、空间、更多,少了许多功能。Google 里的更多有搜索服务、探索与创新、分享与沟通等。搜索服务包含大学搜索、地图、快讯、图书搜索、网页目录、学术搜索、资讯。资讯的搜索和浏览的范围是1000多个资讯源的最新消息。资讯分为焦点、财经、科技、体育、娱乐、社会。它收集了各个网站的最近几个小时的相关资讯,它来自新华网、东方网、腾讯网等。例如,来自腾讯网的“2007年高考考生心态调查‘平和’成为最大关键词”。在完成指定检索实习题、记录检索结果的基础上,我了解了搜索引擎的一些特殊功能。Google的特殊功能;查找Flash 文件、网页快照、货币转换、计算器、相关搜索、类似网页、按链接搜索、指定网域、手气不错、错别字改正、天气查询、金融信息、邮编区号、手机号码、定义等。其中查找Flash 文件,只需搜索“关键词filetype:swf”。Google 在访问网站时,会将看过的网页复制一份网页快照,以备在找不到原来的网页时使用。单击“网页快照”时,您将看到Google 将该网页编入索引时的页面。Google 依据这些快照来分析网页是否符合您的需求。Google 相关搜索将帮助您更快地找到更有价值的结果。按下“手气不错”按钮将自动进入Google 查询到的第一个网页。您将完全看不到其它的搜索结果。使用“手气不错”进行搜索表示用于搜索网页的时间较少而用于检查网页的时间较多。用Google 查询中国城市地区的天气和天气预报,只需输入一个关键词(“天气”,“tq”或“TQ”任选其一)和您要查询的城市地区名称即可。Google 返回的网站链接会带给您最新的当地天气状况和天气预报。例如,要查找福州地区的天气状况,可以输入“天气”或“tq”命令,再点击《福州天气预报》,查出五月二十六最高气温是32摄氏度。Google返回的网页链接会给您最新的当地天气状况。利用特殊检索我查出5公顷等于74.9999963市亩,它的输入有两种方法,其中之一是5 公顷等于多少市亩,另一种是5 公顷=?市亩。一般检索有用逻辑与、使用Site(在特定的域或站点中进行搜索)、使用intitle(在网页标题中进行搜索)、使用filetype(限定文献类型搜索)、利用图像检索功能。用高级检索,查出人民网网站([HTTP]https://www.doczj.com/doc/ab16335793.html,[/HTTP]) 最近3个月以内搜索到的标题含有“亚洲金融危机”的网页,有37项,其中有第一网页“亚洲:金融危机卷土重来?”。学术检索是通过“更多”点击后才出现的,点击“学术高级搜索”,通过查找我院曾韶华老师2002以后在《发展研究》上发表的论文,查获篇数2篇。第一篇是《企业可持续发展的战略误区及财务反思》,第二篇是《我国上市公司股权融资偏好原因及危害》。“高级检索”可以节省我们查阅的时间,是一种很好的检索功能。百度的“常用检索”能提供“万年历”和“火车车次”等特殊型信息检索服务,而Google却没有,这是百度的一个优点。通过百度的“更多”点击“常用检索”,再点击“万年历”,查看万年历,查出1945年9月12日对应的农历日期:1945年8月初七。通过“火车车次”查出福州到黄山可乘坐的列车车次和始发时间,它的步骤是点击“更多”、“常用检索”、“火车车次”,再输入出发地以及目的地,再点击“查询车次”,得到车次K68/K69以及开车时间为14:29和K46以及19:19发车的“火车车次”。通过包含特殊符,并使该操作符合您需要的。依网页主旨分别归类,Google可分为休闲、体育、健康、参考、商业、地区、家庭、新闻、游戏、社会、科学、艺术、计算机、购物。通过点击这些,我们可以知道我们所需要查找的内容。通过上课的学习,以及课后的实践,我了解了许多中文搜索引擎,让我更懂得怎么使用网络,学习我课堂上不能学习到的知识。
人教部编版三年级下册第六单元作文写作指导 导语:三年级下册第六单元写作指导《身边那些有特点的人》人教部编版。下面是马老师为你收集整理的写作方法,希望对您有所帮助。
【习作内容】 本次作文是写一个自己身边有特点的人,通过一两件具体的事来突显人物的特点。可以围绕课本所给的表示人物特点的词语来写,也可以抓住人物的其他特点来写。题目自拟。 【写法指导】 第一步:审题 本次作文是写一个有特点的人,要抓住人物的某一个特点来写。 第二步:主题 通过具体事例实现人物的某个性格特征。 第三步:思维导图 校园人物:爱拖堂的老师,“小书虫同学”,“智多星”同桌,班上的“迷”、、、、、、家庭人物:偷懒的爸爸,爱唠叨的妈妈,时尚的爷爷,爱跳广场舞的奶奶、、、、、 社会人物:乐天派的小店老板,热心肠的保安、、、、、、 邻居、亲戚:“手机控”表格,“故事大王”叔叔,对门的“幽默王子”,爱臭美的表 妹、、、、、、 身边啊还有那些有特点的人呢? 第四步:方法(以例文为例)抓住人物的语言、动作进行描写,突出人物的性格特征。 【审题要求】 说说本次习作对我们提出了哪些要求? “边那些有特点的人”要求我们选择一个熟悉的人,也可以是偶尔见到的陌生人,运用本单元学到的描写人物的方法,写出人物的典型特点。同学们选择的这些典型事例,可要把这个人物的某一方面特点突显出来,给人留下深刻的印象,还需要把这个事例写好,尤其是要把事例中最体现人物特点的地方写好。 本次习作的重点是抓住人物典型特点来习作,属于写人的记叙文。 【写作指导】 (1)聚焦“特点”,选定人物。所谓“有特点的人”就是有着鲜明的个性的人。要从平时与自己经常打交道的人中,选择具有鲜明的个性特点的一个人,作为写作的对象。 (2)打开思路,选择事情。这次习作有一个很重要的要求,就是这件事必须是能够体现出这个人物的“特点”的。我们应该从自己认真观察过的、有感受的事情中选择一件来写,体现出这个人某一方面鲜明的品质特点。 (3)一人一事,内容具体。写事就是为了体现出所写人的性格、品质。我们在写作文的时候要把事情发生的时间、地点、人物,事情的起因、经过、结果写清楚,写具体。在记叙事情的过程中,着重刻画人物的言语和内心活动,这样才能做到内容具体,在记事中体现人的“特点”。 (4)围绕中心,选取有代表性的、真实的、有说服力的材料。可以是一件事,也可以是几件事。
中文搜索引擎的自动分词算法 !"#$%&’#(#($)!*+$’(#,-.$/#,01,()0.01,&’&2#0’30&’2,4)+()0 蒋 微5 西南财经大学成都 67889:; <摘要=提出了基于关键词搜索的两种自动分词算法>均以双词及三词作为搜索的最小单位5或基本单位;> 一种以栈实现?一种不借助栈且动态匹配实现>通过此两种算法均可进行发布网站@网页前网名入数据库的关键词标识提取及实现匹配后有效性的确认?以提高中文搜索引擎的搜索准确率及获得由网名入数据库前后同步性决定的快速响应>< 关键词=中文搜索引擎?自动分词?栈?非栈?关键词搜索 !A 3B C !1B D E FG H I F J G K I L I L F MG N O F K L I P Q RS G R T UF MV T W E F K UR T G K X P L M OG K TO L Y T ML MI P L RG K I L X N T ?L ME P L X PI E FE F K U RF K I P K T T E F K U R G K T H R T U G R I P T Q L M L Q H Q H M L I 5F K S G R L X H M L I ;L MR T G K X P L M O ?F M T L R L Q J N T Q T M I T U S W H R T F Z R I G X V ?G M U I P T F I P T K L R M F I S H I S W I P T E G W F Z U W M G Q L X Q G I X P L M O [\F I PG N O F K L I P Q R X G MT ]I K G X I I P T V T W E F K U L U T M I L Z L X G I L F MZ K F Q G M T I E F K VM G Q T T M I T K L M O I P T U G I G S G R T S T Z F K T S K F G U X G R I M T I M F U ?Z K F M I J G O T ?G M U X F M Z L K Q I P T Y G N L U L I W G Z I T K Q G I X P L M O R F G R I F L Q J K F Y T I P T P L O PG X X H K G X W F Z ^P L M T R T X P G K G X I T K R T G K X P T M O L M OG M UG X P L T Y T _H L X VK T R J F M R T U T I T K Q L M T US WR W M X P K F M L R Q S T Z F K T G M UG Z I T K M T I E F K VM G Q T T M I T K L M OI P T U G I G S G R T [‘4a bc C d 3^P L M T R T X P G K G X I T K R T G K X PT M O L M O ?G H I F J G K I L I L F M ?R I G X V ?M F M R I G X V ?V T W E F K UR T G K X P 自动分词系统是为中文搜索做预期和基础性的工作>通过常用词库的支持?它能在一定程度上智能地根据用户需要搜索到相关网站@网页及内容>本文将以类^语言描述两种不同的分词算法> e 算法的支撑 e [e 操作对象 定义75双词;f 存在于词库中以两个字构成的常用词> 定义g 5三词;f 存在于词库中以三个字构成的常用词> 算法的操作对象?即基本单位为双词或三词>范围缩小的依据为f h 单字词应以直接匹配的方式实现i j 四字或五字构成的词可用直接匹配的方式实现?其中可分解成若干双词或三词的词也可用逻辑组合的方式实现搜索> e [k 基本词词性针对网名?l 自动分词m 的分词范围缩小在动词和名词上? 其余为非重要成分>e [n 词库 作为自动分词系统的基础和载体?词库是必然的>要求对汉语常用词作穷举式的逐一调整录入?并以名词和动词进行分类得到词库>词库是本文算法的前提> k 算法的实现 k [e 算法 k [e [e 算法框架 此算法从左至右?以双词为基准?向右扩展>若发 现同一个字或一个词包含在左右相邻的两常用词内?则经判断分析?筛选出合乎逻辑的关键词入关键词组? 防止了l 断章取义m 的可能>特点为实现了无回溯的确定性算法> 注意f 此算法以双词为研究起点?同时进行关键词为三个字的词即三词的提取>前两字不为词?三个字才 为词的情况由子程序X P G K o p T ]I qF K U 5X F M R I X P G K o ;解决> k [e [k 算法的实现 变量说明f R H Q rr 关键词计数器> s \ rr 作为当前基准的双词对象>V T W t u rr 关键词组>v D r 当前双词向右扩展一位所得为三词> \ r 当前双词的右两个字组成双词>w r 当前双词的右字向右扩展一位成双词> D r 当前双词的右三个字组成三词> o g 88g 8789收到?g 88g 8x g y 改回 oo 蒋微?女?7y z 7年生?y y 级在读本科生? 攻读方向f 信息工程?信息管理>{6g {5 总g z z ;中文搜索引擎的自动分词算法 g 88g 年