
不知道大家有没有听说过OCR文字识别技术?OCR文字识别技术就是一种图片文字识别,语音识别等识别方面的技术。今天小编给大家分享是在OCR文字识别技术的基础上怎样的进行身份证识别的。
第一步:关于身份证识别,我们需要借助一款OCR文字识别软件的辅助,我们可以在百度里搜索OCR文字识别软件,下载并安装到我们的电脑里。
第二步:完成下载安装,即可打开文字识别软件,点击票证识别。
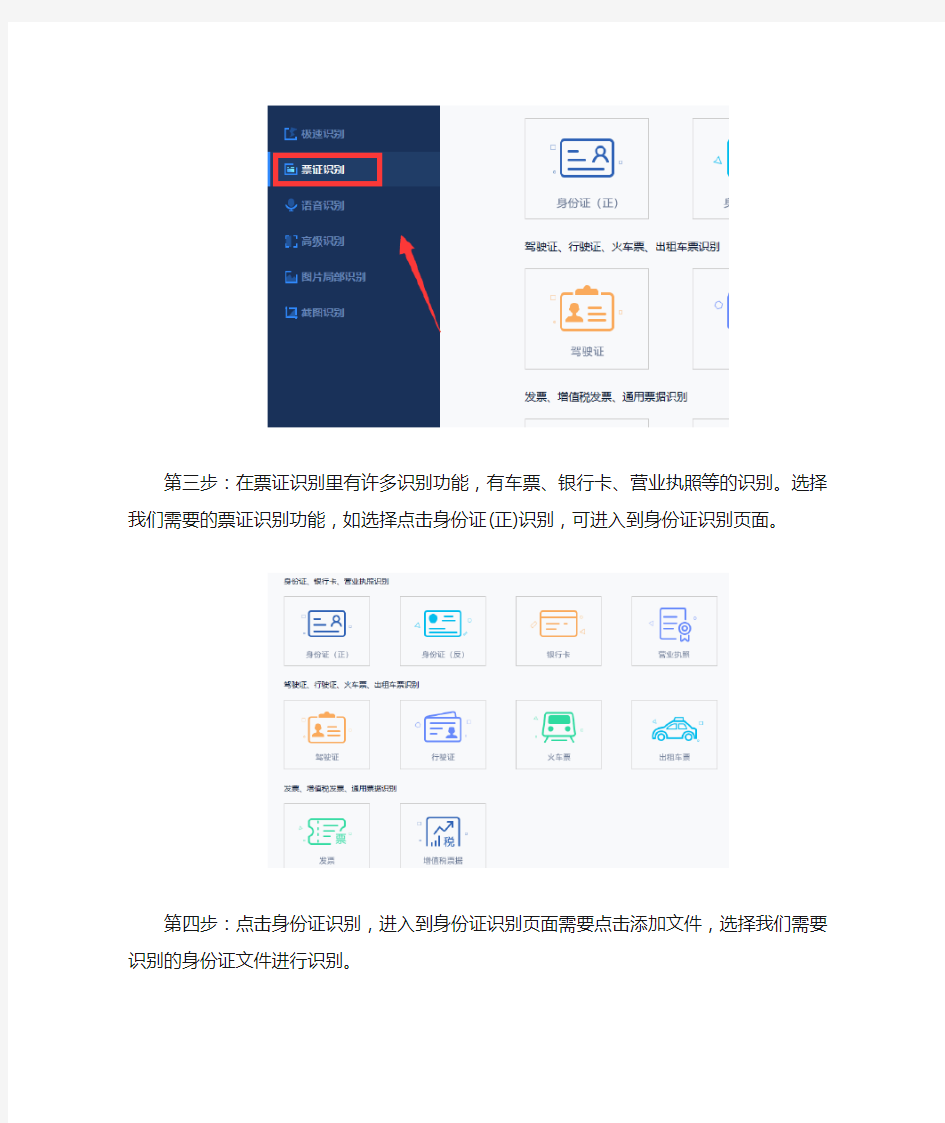
第三步:在票证识别里有许多识别功能,有车票、银行卡、营业执照等的识别。选择我们需要的票证识别功能,如选择点击身份证(正)识别,可进入到身份证识别页面。
第四步:点击身份证识别,进入到身份证识别页面需要点击添加文件,选择我们需要识别的身份证文件进行识别。
第五步:添加文件成功后,可以在设置保存路径处,选择我们要保存的位置。
第六步:选择好输出位置,就需要点击一键识别了,这样我们就是完成身份证识别的操作啦。
以上就是在OCR文字识别技术的基础上完成的身份证识别的操作了,有兴趣的小伙伴可以试着操作一下哟。
自动识别技术 1. 条码 5. 电子信息交换 2. 生物测量 6. 机器视觉 3. 卡片技术7. 光学字符识别 3.1磁条卡8. 射频信息通讯 3.2光学卡片9. 射频识别 3.3智能卡10.语音识别 4. 接触记忆 自动识别技术概述 条形码是主要的自动收集技术,用来收集有关任何人物、地点或物品的资料.它的应用范围是无限的。条码被用来进行物品追踪、控制库存、记录时间和出勤、监视生产过程、质量控制、检进检出、分类、订单输入、文件追踪、进出控制、个人识别、送货与收货、仓库管理、路线管理、售货点作业以及包括追踪药物使用和病人收款等在内的医疗保健方面的应用。 条码本身不是一套系统,而是一种十分有效的识别工具它提供准确及时的信息来支持成熟的管理系统。条码使用能够逐渐地提高准确性和效率,节省开支并改进业务操作。 条码是由不同宽度的浅色和深色的部分(通常是条形)组成的图形,这些部分代表数字、字母或标点符号。将由条与空代表的信息编码的方法被称作符号法。符号法有许多种。下面列举的是一些最常使用的符号法。 通用产品码(UPC码)和它在世界范围的相似物国际物品码(EAN码)在零售业被非常广泛地使用,它们正在工业和贸易领域中被广泛地接受。UPC/EAN码是一种全数字的符号法(它只能表示数字)。 在工业、药物和政府应用中最多的是39码,它是一种字母与数字混合符号法,它具有自我检验功能,能够提供不同的长度和较高的信息安全性。它被一些工业贸易组织所接受,包括汽车工业活动组织(AIAG)、保健工业贸易通讯委员会(HIBCC)和美国国防部(DOD)。工业应用包括追踪生产过程、仓库库存,还有识别影印领域这样的特别应用。作为一种字母与数字混合符号法,39码除有数字外,还能够支持大写字母并有一些标点符号。 与39码相比,128码是一种更便捷的符号法,它能够代表整个ASCII字母系列。它提供一种特殊的“双重密度”的全数字模式并有高信息安全性能。128码正在逐渐代替39码。HIBCC 和统一编码委员会(UCC)已接受一种特殊版本的128码(UCC/EAN-128)用来进行送货箱的标记。在ANSI的送货箱标记标准中也承认UCC/EAN-128码。在需要将序号、批量号和其它有关信息输入到产品标签上的应用中使用UCC/EAN-128码的趋势有进一步的发展。两维码符号法正在跟进 两维码符号法是条码发展的下一步骤。它们比传统的条形码的密度高得多,所以能提供较高的信息完整程度。因为它们能够将更多的信息放入更小的面积内,所以它们为许多不同的应用所接受。 有两种不同的两维码符号法:重叠式条码(条码的细条重叠在一起)和矩阵式符号法(它是统一规格的黑白方块的组合,而不是不同宽度的条与空的组合)。 重叠式条码(如PDF417码、Codablock、Supercode)包括附加的版式排列信息,这样信息会总处于正确的位置中。信息量可达到1K的字母(如果计算进“连接”的符号会更高)。例如,PDF417码被用来为送货/收货标签信息编码,甚至ANSI使用它来为送货箱的标签编码,作为“纸张电子信息交换”的一部分。这种符号法被多个工业组织和许多工业公司所采
光学字符识别 OCR是英文Optical Character Recognition的缩写,意思是光学字符识别,也可简单地称为文字识别,是文字自动输入的一种方法。它通过扫描和摄像等光学输入方式获取纸张上的文字图像信息,利用各种模式识别算法分析文字形态特征,判断出汉字的标准编码,并按通用格式存储在文本文件中,从根本上改变了人们对计算机汉字人工编码录入的概念。使人们从繁重的键盘录入汉字的劳动中解脱出来。只要用扫描仪将整页文本图像输入到计算机,就能通过OCR软件自动产生汉字文本文件,这与人手工键入的汉字效果是一样的,但速度比手工快几十倍。比如用手机给名片拍照,名片中的姓名、电话号码等信息就会自动识别进入到手机中,从此查询、拨打轻而易举。目前支持该功能的手机主要有摩托罗拉A1200、索爱P990和LG G832等。所以,OCR是一种非常快捷、省力的文字输入方式,也是在文字量比较大的今天,很受人们欢迎的一种输入方式。 由于OCR是一门与识别率拔河的技术,因此如何除错或利用辅助信息提高识别正确率,是OCR最重要的课题,ICR(Intelligent Character Recognition)的名词也因此而产生。而根据文字资料存在的媒体介质不同,及取得这些资料的方式不同,就衍生出各式各样、各种不同的应用。 在此对OCR作一基本介绍,包括其技术简介以及其应用介绍。 OCR的发展 要谈OCR的发展,早在60、70年代,世界各国就开始有OCR的研究,而研究的初期,多以文字的识别方法研究为主,且识别的文字仅为0至9的数字。以同样拥有方块文字的日本为例,1960年左右开始研究OCR的基本识别理论,初期以数字为对象,直至1965至1970年之间开始有一些简单的产品,如印刷文字的邮政编码识别系统,识别邮件上的邮政编码,帮助邮局作区域分信的作业;也因此至今邮政编码一直是各国所倡导的地址书写方式。 OCR可以说是一种不确定的技术研究,正确率就像是一个无穷趋近函数,知道其趋近值,却只能靠近而无法达到,永远在与100%作拉锯战。因为其牵扯的因素太多了,书写者的习惯或文件印刷品质、扫描仪的扫瞄品质、识别的方法、学习及测试的样本……等等,多少都会影响其正确率,也因此,OCR的产品除了需有一个强有力的识别核心外,产品的操作使用方便性、所提供的除错功能及方法,亦是决定产品好坏的重要因素。 一个OCR识别系统,其目的很简单,只是要把影像作一个转换,使影像内的图形继续保存、有表格则表格内资料及影像内的文字,一律变成计算机文字,使能达到影像资料的储存量减少、识别出的文字可再使用及分析,当然也可节省因键盘输入的人力与时间。其处理流程如下图:
印刷行业中的机器视觉技术 北京兰德梅克科技开发公司 王庆国 机器视觉就是用利用机器代替人眼来做判断、测量和识别。根据印刷生产线的要求,其特点是高速、非接触式、客观和精确。在现代工业向着高度自动化、智能化发展的今天,机器视觉技术在各行各业的应用越来越广泛。同样在印刷行业的各种全自动设备中也能见到它的影子。 机器视觉开始于上世纪80年代初,首先兴起于电子行业,90年代初进入印刷行业。 自动定位 基于机器视觉的平面自动定位系统是通过两个摄像头获取目标位置信息,然后获取待对位对象的当前位置,通过计算获得两个位置间的相对距离,将计算结果反馈给控制系统,控制系统驱动电机自动地将待对位对象移到目标位置。目前,同过机器视觉技术达到的自动定位可以达到微米级精度。 其工作流程如下: 1、获取目标位置:首先要求目标位置(如图1)和待对位对象附带两个靶标(如图1蓝色所示)。摄像头获取目标位置靶标(如图2)。 2、获取待对位对象位置:通过摄像头获取待对位的对象的两个靶标。 3、计算相对距离:通过计算两组靶标的相对距离,从而控制驱动电机将待对位对象移到目标位置上。 在国外一些全自动印刷设备上,自动定位系统正逐渐被应用。如全自动打孔机,对于彩附带靶标的目标位置 图3待对位对象位置 图5待对位对象和目标位置相对位置 图6 对位后图像
色印刷而言,PS版在印刷及滚筒上是否正确对位是决定印刷品质重要因素,而保证正确对位的一个关键是PS版上的孔打的位置精确与否。采用机器视觉定位系统的全自动打孔机只要将PS版放在工作台上,摄像头将自动搜索位置,并将其移到目标位置并完成打孔,其打孔精度可保证在10微米以内。在印刷电路板行业,曝光机、平面丝印机是不可或缺的设备,对于全自动曝光机,为了实现基板和底片的高精度的对位,有些生产厂家采用4个摄像头,从而可以避免由于操作者不同引起的质量差异。在全自动平面丝印机上,每块印制版的基准孔(印制版上的靶标)首先通过摄像头被检出、定位,然后实现高精度印刷。 印刷品缺陷检测 基于机器视觉的印刷品缺陷检测技术是采用高速、高清晰度摄像头和自动可调专业光源来获取标准图像,根据印品的特征和客户的需求来设置检测区域和检测等级。然后在相同的采集条件下获取待检测图像,在图像处理装置中与标准样张进行比较,对于与标准样张存在差异的地方,根据其差异程度,按预先设定的等级进行分类,并作出相应的反馈。从而实现对刀丝、飞墨、针孔、异物等缺陷和颜色偏差的在线全幅检测。图7是基于PRS-LB130视觉检查系统的印刷品缺陷检测示意图。 图7 PRS-LB130视觉检查系统的印刷品缺陷检测示意 基于机器视觉的印刷品缺陷检测技术从原理分析不难,但它对硬件、软件要求比较高。首先是摄像头,必须颜色再现性要好,能够真实获取样张的色彩,再则,曝光速度要足够快,这两项指标使得摄像头的成本就比较高。其次,对于光源的要求,由于印刷速度不恒定,那么随着印刷速度的变化,光源的亮度应该实时可变,从而可以保证采集的图像质量。第三,图像处理算法应该具有较强的鲁棒性来克服在印刷过程中产生的一些随机因素导致图像采集不稳定,同时一些生产厂商开发特殊的图像处理引擎来满足高速印刷发展的要求。 目前基于机器视觉的印刷品缺陷检测技术已逐渐在一些高精度、高附加值的印刷行业的设备中得到应用。首先是票证印刷行业,由于它的印刷对象大都是有价证券,对印刷质量有特殊要求。其次是烟包印刷,烟草包装不同于其他产品的包装,有着其自身的特点,烟包印刷所需的技术工艺是仅次于钞票和有价证券的印刷,是目前要求精度最高的包装产品之一。同时烟草包装也是附加值最高的包装产品之一,因而其也是全自动印刷品质量检测设备应用最广的领域。由于标签印刷其印刷幅面相对来说较小,因而其所需的全自动印刷品质量检测的硬件成本相对来说较少,因此欧洲和日本的设备制造商争相将印刷质量检测系统引入到标签印刷上。为获得稳定的印刷质量提供了有力保障。 自动套色控制 基于机器视觉的自动套色控制系统采用高清晰彩色摄像头获取样张上的辅助色标,通过图像处理算法识别出各色标颜色,并计算他们的位置。如果各色的位置及其相对位置与预先设定的不一致,则说明套印出现偏差。例如假设色标线水平长10 mm , 宽1 mm , 每个相邻颜色的标志线在套印精确时应相互平行, 垂直(纵向) 相距20 mm (如图8), 通过采集分析得出各色标间距,如果相邻两色色标间隔大于或小于20 mm ,则说明套印出现了偏差。然后将偏差信号反馈给系统作出相应修正。 图8 色标示意图
提取图片中的文字Office也能行 微软在Microsoft Office 2003中的工具组件中有一个“Microsoft Office Document Imaging”的组件包,它可以直接执行光学字符识别(OCR),下面笔者就为大家介绍利用Office 2003新增的OCR功能从图片中提取文字的方法。 第一步我们需要安装“Microsoft Office Document Imaging”的组件,点“开始→程序”,在“Microsoft Office 工具” 里点“ Microsoft Office Document Imaging” 即可安装运行(如图1所示)。 图1 安装组件 第二步打开带有文字的图片或电子书籍等,找到你希望提取的页面,按下键盘上的打印屏幕键(PrintScreen)进行屏幕取图。 第三步打开Microsoft Office Word 2003 ,将刚才的屏幕截图粘贴进去;点击“文件”菜单中的“打印”,在安装Microsoft Office Document Imaging组件后,系统会自动安装一个名为“Microsoft Office Document Imaging Writer”的打印机。如图2所示,在“打印机”下拉列表框中选择“Microsoft Office Document Imaging Writer”打印机,其他选项无须额外设置,点击“确定”按钮后,设定好文件输出的路径及文件名(缺省使用源文件名),然后很快就可以自动生成一个MDI格式的文档了。 图2 选择打印机
打开刚才保存的MDI类型文件(如图3所示),根据你的需要用鼠标选择文字内容(被选中的内容在红色的框内),然后单击鼠标右键,在弹出的快捷菜单中选择“将文本发送到Word”,即可将图片内容自动转换为一个新的Word文档,然后你就可以在Word文档中随心所欲地进行编辑了。 图3 将文本发送到Word 提示:如果你不想将转换的内容输入到一个新的Word 文档中,而是希望粘贴到一个已经打开的Word 文档,只需在上面的操作中点击右键菜单的“复制”,然后再到指定文档中执行粘贴即可。()
一、名词解释 1.自动识别技术 2.条码 3.射频识别 4.光学字符识别 5.生物识别 二、单项选择题 1.自动识别技术是一门依赖于()的多学科结合的边缘技术。 A.机械技术B.光电技术 C.电磁技术D.信息技术 2.一般来说,自动识别系统由标签、标签生成设备、识读器及计算机等设备组成。其中()是信息的载体。 A.标签B.标签生成设备 C.识读器D.计算机 3.()技术是最早的也是最著名和最成功的自动识别技术。 A.RFID B.条码 C.虹膜识别D.指纹识别 4.条码识读器有光笔识读器、CCD识读器和激光识读器等几类。()一般需与标签接触才能识读条码信息。 A.手持式识读器B.激光识读器 C.CCD识读器D.光笔识读器 5.20世纪60年代初交通部门开始使用磁卡,()年代银行业开始使用,之后磁卡的使用率不断增长,现在已经非常普及。 A.60B.70 C.80D.90
6.条码的研究始于()。 A.美国B.日本 C.德国D.法国 7.我国条码技术的研究始于20世纪70年代末80年代初,条码应用系统是()年代末建立的。 A.60B.70 C.80D.90 8.()系统的概念源于20世纪40年代空战中用雷达识别敌机和友机的技术。 A.条码B.EDI C.SCM D.RFID 9.射频识别技术的核心在()。 A.中间件B.天线 C.电子标签D.阅读器 10.任一RFID系统至少应包含()根天线。 A.1B.2 C.3D.4 11.RFID最大的容量则有()个字符。 A.5B.50 C.5000D.数兆 12.保存有约定格式的电子数据,是射频识别系统真正的数据载体的是()。 A.中间件B.天线 C.电子标签D.阅读器 13.()电子标签系统用于短距离、低成本的应用中。 A.低频B.中频
OCR识别技术 OCR技术是光学字符识别技术的缩写(Optical Character Recognition),是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。可应用于银行票据、大量文字资料、档案卷宗、文案的录入和处理领域。适合于银行、税务等行业大量票据表格的自动扫描识别及长期存储。相对一般文本,通常以最终识别率、识别速度、版面理解正确率及版面还原满意度4个方面作为OCR技术的评测依据;而相对于表格及票据,通常以识别率或整张通过率及识别速度为测定OCR技术的实用标准。 采用OCR识别技术,可以将其应用于银行票据光盘缩微系统,可以自动提取票据要素,可减轻操作员的工作量,减少重复劳动,尤其是在与银行事后且监督系统相结合后,可以替代原先的操作人员完成事后监督工作。由计算机自动识别票据上的日期、帐号、金额等要素,通过银行事后监督系统与业务系统中的数据进行比较,完成传统的事后监督操作;配有印章验证系统后,自动将凭证图像中的印章与系统中预留的印鉴进行比较,完成印章的真伪识别。 OCR识别技术不仅具有可以自动判断、拆分、识别和还原各种通用型印刷体表格,在表格理解上做出了令人满意的实用结果,能够自动分析文稿的版面布局,自动分栏、并判断出标题、横栏、图像、表格等相应属性,并判定识别顺序,能将识别结果还原成与扫描文稿的版面布局一致的新文本。表格自动录入技术,可自动识别特定表格
的印刷或打印汉字、字母、数字,可识别手写体汉字、手写体字母、数字及多种手写符号,并按表格格式输出。提高了表格录入效率,可节省大量人力。同时支持将表格识别直接还原成PTF、PDF、HTML 等格式文档;并可以对图像嵌入横排文本和竖排文本、表格文本进行自动排版面分析。 利用目前的高新技术-OCR,直接从凭证影像中提取金额、帐号等重要数据,代替人的手工录入,与条码识别/流水识别紧密结合, 实现建立事后副本帐、完成事后监督的工作。OCR处理一般使用性 能较好的PC机,OCR处理程序一经启动会自动扫描数据库中的凭 证影像,发现有需OCR处理而未处理的,提取到本地进行处理。 OCR手写体、印刷体识别技术,能识别不同人写的千差万别的 手写体汉字和数字,应用于本系统,识别凭证影像中储户填写的信息,如大写金额、小写金额、帐号、存期、日期、证件号等,可以代替手工录入。同时被识别得出的金额还要与流水识别所得的金额进行核对,核对成功,则OCR识别成功。这样处理是为了避免误判。 经过对银行产生的实际凭证进行的大量测试,在实际开发过程中,根据银行的实际需求,OCR技术在票据和表格识别能力和手写体自 动识别能力上不断提升,目前处理速度可达到每分钟60~80张票据,存折识别率已经达到了85%以上,存单、凭条识别率达到90%以上,而85%以上的识别率就能减少80%以上的数据录入员。 在档案领域OCR技术使档案扫描成果达到了全文可识别,将档 案数字化发展提升了到了一个新的阶段,是原本扫描出来的图片变得
光学字符识别系统 摘要:本文设计了一系列的算法,完成了文字特征提取、文字定位等工作,并基于卷积神经网络(CNN)建立了字符识别模型,最后结合统计语言模型来提升效果,构建一个完整的OCR(光学字符识别)系统.在特征提取方面,抛弃了传统的“边缘检测+腐蚀膨胀”的方法,基于一些基本假设,通过灰度聚类、图层分解、去噪等步骤,得到了良好的文字特征,文字特征用于文字定位和模型中进行识别。在文字定位方面,通过邻近搜索的方法先整合特征碎片,得到了单行的文字特征,然后通过前后统计的方法将单行的文字切割为单个字符。在光学识别方面,基于CNN的深度学习模型建立单字识别模型,自行生成了140万的样本进行训练,最终得到了一个良好的单字识别模型,训练正确率为99.7%,测试正确率为92.1%,即便增大图片噪音到15%,也能有90%左右的正确率.最后,为了提升效果,结合了语言模型,通过微信的数十万文本计算常见汉字的转移概率矩阵,由Viterbi算法动态规划,得到最优的识别组合。经过测试,系统对印刷文字的识别有着不错的效果,可以作为电商、微信等平台的图片文字识别工具. 关键字:CNN,特征提取,文字定位,单字识别
1 研究背景和假设 关于光学字符识别(Optical Character Recognition, OCR),是指将图像上的文字转化为计算机可编辑的文字内容,众多的研究人员对相关的技术研究已久,也有不少成熟的OCR技术和产品产生,比如汉王OCR、ABBYY FineReader、Tesseract OCR等. 值得一提的是,ABBYY FineReader 不仅正确率高(包括对中文的识别),而且还能保留大部分的排版效果,是一个非常强大的OCR商业软件. 然而,在诸多的OCR成品中,除了Tesseract OCR外,其他的都是闭源的、甚至是商业的软件,我们既无法将它们嵌入到我们自己的程序中,也无法对其进行改进. 开源的唯一选择是Google的Tesseract OCR,但它的识别效果不算很好,而且中文识别正确率偏低,有待进一步改进. 综上所述,不管是为了学术研究还是实际应用,都有必要对OCR技术进行探究和改进. 将完整的OCR系统分为“特征提取”、“文字定位”、“光学识别”、“语言模型”四个方面,逐步进行解决,最终完成了一个可用的、完整的、用于印刷文字的OCR系统. 该系统可以初步用于电商、微信等平台的图片文字识别,以判断上面信息的真伪.
研究生 《机器视觉》 课程论文 2015 年 6 月 30 日 题目 (中文): 基于HALCON 的喷码光学字符识别 (英文): Based on HALCON equipments of optical character recognition 姓 名 学 号 院 (系) 专业、年级 任 课 老 师
基于HALCON的喷码光学字符识别 湖南理工学院信息与通信工程学院 摘要:大规模自动化流水线生产的化妆品,其批次信息对仓储管理系统至关重要。因此有必要研究一种运行速度快、识别率高和鲁棒性好的瓶底喷码字符识别系统。现有基于机器视觉的智能检测技术是实现其生产质量快速、自动检测与控制的新型重要手段。在此基础上,本文介绍了基于HALCON机器视觉软件的检测系统和针对化妆品瓶底批号的图像处理关键技术,包括灰度值调整、形态学运算、字符分割及识别数字对象。 关键词:机器视觉;HALCON;批号检测;OCR图像处理 1.引言 随着计算机软件、硬件的发展,数字图像处理的理论和方法不断完善,利用机器视觉实现产品质量无接触自动检测的技术已逐渐变得切实可行,因此我们尝试将机器视觉技术应用于包装批号检测中,以实现生产的快速、自动检测与控制。机器视觉又称计算机视觉,是用计算机来实现人的视觉功能,也就是用机器代替人眼来做测量和判断[1-2]。机器视觉技术包含光源照明技术、光成像技术、传感器技术、数字图像处理技术、机械工程技术、检测控制技术、模拟与数字视频技术、计算机技术、人机接口技术等相关技术[3-5],是实现计算机集成系统的基础技术。 机器视觉目前应用极其广泛,例如利用人脸、虹膜、指纹等识别技术来实现安保功能;利用视觉监控系统识别环境中发生的异常事件,如陌生人的侵入、异常行动;利用视频监控技术的智能交通管理系统、视频检索;用于军事目的的自动目标检测等[6],都应用机器视觉技术来解决问题。正如视觉是人类在自然环境与社会环境生存不可缺少的最重要感知器官,机器视觉也是信息技术中一门至关重要的技术。 1.1.HALCON软件简介 德国MVtec公司的图像处理软件HALCON,是世界公认具有最佳效能的机
1 OCR简介 OCR是英文Optical Character Recognition的缩写,意思是光学字符识别,也可简单地称为文字识别,是文字自动输入的一种方法。它通过扫描和摄像等光学输入方式获取纸张上的文字图像信息,利用各种模式识别算法分析文字形态特征,判断出汉字的标准编码,并按通用格式存储在文本文件中,从根本上改变了人们对计算机汉字人工编码录入的概念。使人们从繁重的键盘录入汉字的劳动中解脱出来。只要用扫描仪将整页文本图像输入到计算机,就能通过OCR软件自动产生汉字文本文件,这与人手工键入的汉字效果是一样的,但速度比手工快几十倍。比如用手机给名片拍照,名片中的姓名、电话号码等信息就会自动识别进入到手机中,从此查询、拨打轻而易举。目前支持该功能的手机主要有摩托罗拉A1200、索爱P990和LG G832等。所以,OCR是一种非常快捷、省力的文字输入方式,也是在文字量比较大的今天,很受人们欢迎的一种输入方式。
2 OCR的发展概况 20世纪70年代初,日本的学者开始研究汉字识别,并做了大量的工作。我国研究汉字识别的起步比较晚,20世纪70年代末才开始进行OCR的研究工作。早期的OCR软件,由于识别率及产品化等多方面的因素,未能达到实际要求。同时,由于硬件设备成本高,运行速度慢,也没有达到实用的程度。只有个别部门,如信息部门、新闻出版单位等使用OCR软件。1 986年以后我国的OCR研究有了很大进展,在汉字建模和识别方法上都有所创新,在系统研制和开发应用中都取得了丰硕的成果,不少单位相继推出了中文OCR产品。 进入20世纪90年代以后,随着平台式扫描仪的广泛应用,以及我国信息自动化和办公自动化的普及,大大推动了OCR技术的进一步发展,使OCR的识别正确率、识别速度满足了广大用户的要求。 目前,比较流行的OCR软件很多,英文OCR主要有OmniPage,中文OCR主要有清华紫光OCR、清华文通OCR、汉王OCR、中晶尚书OCR、丹青OCR、蒙恬OCR等。尽管汉字字量大、字形复杂,但OCR技术已经走向成熟。许多OCR软件不仅能识别黑白印刷体汉字,还能识别灰度和彩色印刷体汉字,识别速度很快,识别正确率达到了99%以上;可识别宋体、黑体、楷体等多种字体的简、繁体;可对多种字体、不同字号的混排进行识别;有些OCR软件