
统计分析模型
(1)信度分析文献[558]
操作步骤:分析—度量—可靠性分析(R)—移动变量到项目(I)框内—统计量—描述性(项+度量+如果。)—项之间(相关性)—继续—确定
信度系数界限值:0.60—0.65认为不可信;0.65—0.70认为是最小可接受值:0.70~0.80认为相当好;0.80—0.90就是非常好。因此,—份信度系数好的量表或问卷最好在0.80以上,0.70—0.80之间还算是可以接受的范围;分量表最好在0.70以上:0.60—0.70之间可以接受。若分量表的内部一致性系数在0.60以下或者总量表的信度系数在0.80以下,应该考虑重新修订量表或增删题目。
删除任何题项后的Cronbach’s α系数也无显著提高。可见核心知识性员工激励组合量表的内部一致性高,信度较好。信度分析说明该问卷的整体结构设计具有较高的可信度。由此可以认为,该问卷具有较好的内在信度,依此调查得到的数据是可信的,基于该问卷进行的数据统计分析结果也是比较可靠的。
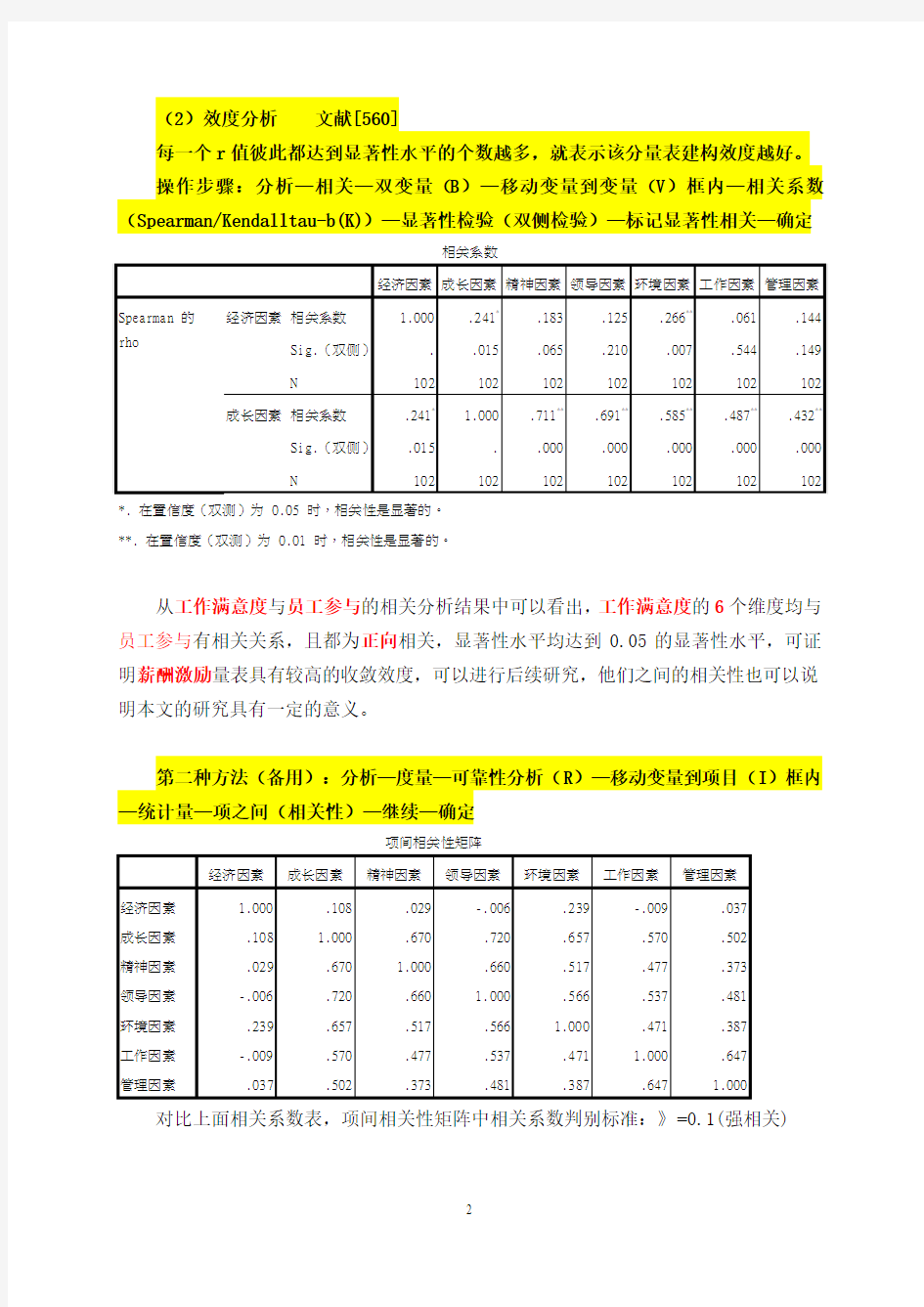
从工作满意度与员工参与的相关分析结果中可以看出,工作满意度的6个维度均与员工参与有相关关系,且都为正向相关,显著性水平均达到0.05的显著性水平,可证明薪酬激励量表具有较高的收敛效度,可以进行后续研究,他们之间的相关性也可以说明本文的研究具有一定的意义。
对比上面相关系数表,项间相关性矩阵中相关系数判别标准:》=0.1(强相关)
(3)频数分析 P66 文献[558]
操作步骤:分析—描述统计—(123)频率(F)—移动变量到变量(V)框内—显示频率表格√—统计量—分布(偏度+峰度)—继续—确定
频率也称频数,就是一个变量在各个变量值上取值的个案数。SPSS中的频数分析过程可以方便地产生详细的频数分布表,即对数据按组进行归类整理,形成各变量的不同水平的频数分布表和常用的图形,以便对各变量的数据特征和观测量分布状况有一个概括的认识。描述总体分布形态的统计量主要有偏度和峰度两种。偏度(Skewness)是描述取值分布形态对称性的统计量,由Pearson在1895年提出。偏度由样本的3阶中心矩与样本方差的3/2次方的比值而得,偏度的绝对值越大,表示数据分布的偏斜程度越高。来自正态总体的样本偏度近似为0。偏度系数有两种测量方式,分别为皮尔逊偏度系数1和皮尔逊偏度系数2。偏度系数等于0的时候属于正态分布;偏度系数大于0的时候是右偏分布,表明较低的值占多数;偏度系数小于0的时候为左偏分布,表明较高的值占多数。峰度(Kutosis)是描述变量取值分布形态扁平程度的统计量,由Pearson 在1905年提出。峰度等于0的时候表示数据分布的扁平程度适中,即正态分布;峰度大于0的时候表示数据呈扁平分布;峰度小于0表明数据呈尖峰分布。
(4)描述性统计分析 P71 文献[558]
操作步骤:分析—描述统计—描述(D)—移动变量到变量(V)框内—选项—均值、样本方差、样本标准差—继续—确定离散系数另行计算
描述性统计量是研究随机变量变化综合特征(参数)的重要工具,它们集中描述了变量变化的特征。SPSS提供的基本统计量大致可以分为3类:描述集中趋势的统计量、描述离散程度的统计量和描述总体分布形态的统计量。
统计学中的集中趋势统计量是由样本值确定的量,样本值有向这个数据集中的趋势。测度集中趋势就是寻找数据一般水平的代表值或中心值,不同类型的数据用不同的集中趋势测度值,选择哪种测度值取决于数据的类型。描述集中趋势的统计量有样本均值、中位数等。均值(Mean)又称为“算术平均值”,指一组数的平均值。样本均值反映了变量取值的集中趋势,或者平均水平,是最常用的基本统计量。
统计学中描述离散趋势的统计量是样本值远离集中趋势统计量程度的定量化描述,说明了集中趋势测度值的代表程度,不同的数据有不同的离散趋势测度值。比较重要的离散趋势统计量有样本方差、样本标准差、离散系数等。样本方差(Variance)是刻画样本数据关于均值的平均偏差平方的一个量,是描述样本离散趋势的最常用的统计量。样本方差越大,表明样本值偏离样本平均值的可能性就越大。由于样本方差的计算单位是样本值的平方,将样本方差开方后可以得到和样本值相同量纲的统计量,称为样本标准差(Std.deviation)。样本标准差和样本方差一样,也是度量样本离散程度的重要统计量。离散系数也称标准差系数,即标准差与相应均值之比,主要用于测量相对离散程度,对不同组别离散数据进行比较。离散系数消除了数据水平高低和计量单位的影响。
均值、样本方差、样本标准差、离散系数
(5)均值比较
操作步骤:分析—比较均值—均值(M)—移动变量到因变量列表(D)框内—移动分组变量到自变量列表(I)框内—选项—均值从统计量(S)框移动到单元格统计量(C)—继续—确定
Means过程倾向于对样本进行描述,它可以对需要比较的各组计算描述指针,进行检验前的预先分析。Means过程的优势在于所有的描述性统计变量均按因变量的取值分组计算,无须先进行文件拆分过程,输出结果中各组的描述指标放在一起,便于相互比较分析。Means过程计算指定变量的综合描述统计量,包括均值、标准差、总和、观测量数、方差等一系列单变量描述统计量,当观测量按一个分类变量分组时,Means过程可以进行分组计算。Means过程还可给出方差分析表和线性检验结果。使用Means过程求若干组的描述统计量,目的在于比较,因此必须分组求均值。
(6)单因素方差分析文献[558]
操作步骤:分析—比较均值—单因素ANOVA—移动变量到因变量列表(E)框内—移动分组变量到因子(F)框内(注意:一次只能移动一个)—两两比较(H)—LSD√+ Tamhane”s T2—继续—选项—方差同质性检验(H)—继续—确定
假设检验是对给定的总体参数值,利用样本数据对其推断,并给出接受或者拒绝的过程。对正态总体参数的检验过程一般包括参数的假设检验和参数估计。在总体已知的情况下对总体包含的参数进行推断的问题称为参数检验问题。参数检验不仅可以针对一个总体的检验,也可以针对两个或更多个总体的比较问题。当总体分布未知时,根据样本推断总体的分布类型和参数值的大小的过程称为非参数检验文献[558]。假设检验的基本原则是依据统计推断原理,即小概率事件在一次特定的抽样中一般是不会发生的,如果发生了小概率事件,就有理由怀疑假设的正确性,从而拒绝检验该问题时做出的假设文献[561]。
任何领域的研究者要检验一个新理论或新观点时,可以首先陈述自己认为正确的假设,这个试图确立的假设作为备择假设H1,与备择假设相配的是原假设H0。然后,通过收集有关样本数据和采用相应的检验方法来检验。这种方法不是设法证明备择假设成立,而是努力收集证据来证明原假设不成立文献[559]。检验的基本步骤: 1)给出检验问题的零假设
根据检验问题的要求,将需要检验的最终结果作为零假设(原假设),通常表述为H0:u1=u2=u3=u4=u5(因素影响无显著差异);备择假设H1:u1、u2、u3,u4、u5不全相等(因素影响有显著差异)。
2)选择检验统计量
在统计推断中,总是通过构造样本的统计量并计算该统计量的概率值进行推断,一般构造的统计量应服从或近似服从常用的已知分布,例如均值检验中最常用的t分布和F分布等。
3)计算检验统计量的观测值及其发生的概率值
在给定零假设前提下,计算统计量的观测值和相应概率p值。概率p值就是在零假设H0成立时检验统计量的观测值发生的概率,该概率值间接地给出了样本值在零假设成立的前提下的概率,对此可以依据一定的标准来判定其发生的概率是否为小概率。
4)在给定显著性水平条件下,做出统计推断结果
显著性水平指当假设正确时被拒绝的概率,即弃真概率,一般取0.01或0.05。当检验统计量的概率p值小于显著性水平时,则认为此时拒绝零假设而犯弃真错误的概率小于显著性水平,即低于预先给定的水平,也就是说犯错误的概率小到我们能容忍的范围,这时可以拒绝零假设,认为控制变量不同水平下观测变量各总体的均值存在显著差异,当控制变量的各个效应不同时为0时,控制变量的不同水平对观测变量产牛了显著影响;反之,如果检验统计量的概率p值大于显著性水平,如果拒绝零假设,犯弃真错误的概率大于预先给定的容忍水平,这时不应该拒绝零假设,认为控制变量不同水平下观测变量各总体的均值无显著差异,控制变量的各个效应同时为0时,控制变量的不同水平对观测变量没有产生显著影响。
方差分析是统计学的一个重要范畴,是对观察结果的数据做分析的一种常用的统计方法,目的是检验两个或多个样本均数间差异的显著性意义。方差分析是通过对数据误差来源的分析判断不同总体之间的均值是否相等,进而分析自变量是否有影响文献[561]。方差分析是—种假设检验,它是对全部样本观测值的变动进行分解,将某种控制因素下各组样本观测值之间可能存在的由该因素导致的系统性误差和随机误差加以比较,据此推断各组样本之间是否存在显著差异。若存在显著差异,则说明该因素对各总体的影响是显著的。方差分析主要用于:均数差别的显著性检验、分离各有关因素并估计其对总变异的作用、分析因素间的交互作用和方差齐性检验。根据观测变量的个数,可以将方差分析分为单变量方差分析和多变量方差分析;根据因素的个数,可以将方差分析分为单因素方差分析和多因素方差分析。
单因素方差分析用来研究—个控制变量的不同水平是否对观测量产生了显著影响。单因素方差分析是检验由单—因素影响的多组样本某因变量的均值是否有显著差异的问题,如果各组之间有显著差异,说明这个因素(分类变量)对因变量是有显著影响的,
因素的不同水平会影响到因变量的取值。方差分析基本假定:对于因素的每一个水平,要求观测值是来自服从正态分布总体的简单随机样本:对于各组观察数据,要从具有等方差的总体中抽取的,即要求各个总体的方差必须相同(方差具有齐性);要求独立试验(观测)。
当方差分析F检验否定了原假设,即认为至少有两个总体的均值存在显著性差异时,须进一步确定是哪两个或哪几个均值显著的不同,则需要进行多重比较来检验。多重比较是指在因变量的三个或三个以上水平下均值之间进行的两两比较检验。SPSS提供了各种不同的多重比较方法,包括最小显著差异LSD法、Bonferroni法、Tukey法、Scheff 法等。
根据方差齐次性检验表的结果显示,经验开放性这一因素的显著性系数为0.012,小于0.05,不具有方差齐次性(各个总体的方差相同),因此读取Tamhane”s T2的两两t检验结果;责任意识因素的显著性系数大于0.05,具有方差齐次性,因此读取LSD (Least一signifieantdifferenee)的两两t检验结果,结果如表??所示。
(7)相关分析文献[558]
操作步骤:分析—相关—双变量(B)—移动一个个人变量到变量(V)框内—移动全部分析变量到变量(V)框内—相关系数(√Spearman/Kendall)—显著性检验(双侧检验√)—√标记显著性相关—确定
变量间的关系分为确定性关系和非确定性关系两类:确定性关系即通常所说的函数关系;非确定性关系即相关关系。相关分析(Correlate)是研究变量之间关系紧密度的一种统计方法,应用广泛,是专业统计分析的基础。在统计分析中,常利用相关系数定量地描述两个变量之间线性关系的紧密程度。相关分析的主要目的是研究变量之间关系的密切程度,以及根据样本的资料推断总体是否相关。在统计分析中,常利用相关系数定量地描述两个变量之间线性关系的紧密程度。数据度量尺度不同,相关分析的方法也不同。连续变量之间的相关性常用Pearson简单相关系数来测定;定序变量的相关性常用Spearman秩相关系数或Kendall秩相关系数来测定:而定类变量的相关分析则要使用列联表分析方法。针对不同的变量类型,相关系数的计算方法不尽相同,但它们的含义和取值范围是相同的,即相关系数的取值范围都在-1和+1之间;如果r>0,则表示两变量存在正相关;反之,则存在负相关。一般认为,当相关系数的绝对值大于0.8时,两个变量之间具有较强的线性关系;而相关系数的绝对值小于0.3时,两个变量之间的线性关系较弱文献[561]。
由于存在抽样的随机性和样本数量较少等原因,通常样本相关系数不能直接用来说明样本来自的两总体是否具有显著的线性相关性,需要通过假设检验的方式对样本来自的总体是否存在显著的线性相关关系进行统计推断。基本步骤如下:文献[558][561]
1)提出原假设,即两总体无显著的线性关系。
2)构造检验统计量。由于不同的相关系数采用不同的检验统计量,因此在相关分析时,不同的过程需要构造不同的检验统计量。
3)计算检验统计量的观测值及对应的概率p值(双尾显著性概率,Sig.(2-railed))。
4)根据计算结果得出结论。如果检验统计量的概率P值小于给定的显著性水平a(—般取0.05或0.01),应拒绝原假设,认为两总体之间存在显著的线性关系;反之,如果检验统计量的概率p值大于给定的显著性水平a,则应接受原假设,认为两总体之间无显著的线性关系。
本文的研究模型假设个人特征决定了个体对激励因素的选择行为,个体不同的个性特征决定了个体在激励因素选择上的偏好差异。为了探讨个性特征对知识型员工激励性
因素的影响作用,我们将个性特征的6个维度和激励因素的??项维度进行相关性分析,结果如表??所示。我们发现,在0.01的显著性水平上,工作任务激励因素和个体外向性、责任意识、宜人性显著正相关;个人成长激励因素与个体的经验开放性、外向性、责任意识、宜人性以及神经质这4个维度显著正相关,并与神经质这一维度显著负相关;工作氛围激励因素与经验开放性、外向胜和宜人性这3项因子显著相关;同时,企业条件激励因素与外向性、责任意识以及宜人性这3个维度显著相关。
SPSS统计软件使用指导 管理统计学课程设计是在学习了《管理统计学》课程之后,进行此课程设计,是对这门课程的全面复习。是整个教学工作的重要环节。 一、目的和任务 通过管理统计学课程设计教学所要达到的目的是:以管理统计学课程和理论知识为基础,通过课程设计的实践,培养学生理论联系实际的思想,加强学生对所修相关课程的理解、掌握,训练并提高其在SPSS软件的使用、统计分析的方法、独立解决问题的思路和计算机应用等方面的能力。 管理统计学课程设计的任务是:依据所提供的SPSS软件功能及相关资料,完成SPSS实现操作并选择有现实意义的课题进行计算与分析,递交统计分析报告。 二、设计要求 1.时间要求:本课程设计安排在《管理统计学》课程教学之后进行,设计时间为(30学时)。其中: 2学时:对所研究的问题进行课堂分析。 2学时:熟悉SPSS界面:①SPSS的启动,②SPSS的主窗口,③SPSS的菜单,④SPSS录入数据,⑤SPSS的退出,⑥SPSS的求助系统。 10学时:根据《管理统计学》课程设计指导书实地操作SPSS软件的主要功能:①SPSS的数据管理功能,②SPSS文本文件的编辑,③摘要性分析,即对原始数据进行描述性分析。④平均水平的比较:Means(平均数)过程、Indendent-Samples T Test(两组资料样本T检验)过程、Paired-Samples T Test (配对样本T检验)过程、One-Way-ANOV A(单因素方差分析)过程。⑤方差分析。⑥相关分析。⑦回归分析。 2学时:SPSS制图功能:主要练习SPSS中条形图、线图、控制图、散点图和直方图的绘制。 12学时:根据案例提供的样本数据,登陆国家统计局网站:https://www.doczj.com/doc/d12665740.html,/(或其他网站)选择有意义课题,选取4个自变量,即T、Y、X1、X2、X3、X4,进行多元线性回归分析。 2学时:总结设计过程,整理课程设计的书面材料,撰写并提交一份统计分析报告。 2.设计资料要求:尽可能选用具有说服力的,反映社会经济现象发展趋势的数据作为该课程设计的基础内容。 3.工作量要求:学生3-5人分为一组,以小组为单位共同完成本课程设计。小组成员明确独立完成的工作量,使每名学生工作量均饱满。 4.成果要求:学生以小组为单位完成课程设计的全部任务,撰写课程设计说明书,累计字数不少于8000字。并按时、按质、按量提交规范格式的设计成果。交计算机打印稿及电子版。 5.设计步骤:首先运用SPSS软件,按着指导书的内容将SPSS的基本功能逐个练习掌握。其次登陆《国家统计局网站:https://www.doczj.com/doc/d12665740.html,/》或其他网站,选择有意义课题,选取不少于4个自变量,即T、Y、X1、X2、X3、X4,进行多元线性回归分析,并提交一份统计分析报告。提交设计成果及装订顺序如下: (1)封面 使用统一封面,具体格式按给定的模版,不允许修改。 注意①“指导教师”一项为空;②“班级”一项统一规范,尤其是专业名称,如:05工商管理1班、05信息管理2班、05电子商务1班、05市场营销2班;③“日期”一项统一规范,统一为2007年6月10日。
实验一S P S S简介及 统计整理
实验一SPSS简介及统计整理 一、实验目的和要求 1掌握SPSS安装、启动、主界面和退出; 2掌握SPSS的变量定义信息; 3掌握SPSS的数据录入与保存方法; 4掌握在SPSS中的实现各种统计描述参数的计算。引到学生利用正确的统计方法对数据进行适当的整理和显示,描述并探索出数据内在的数量规律性,掌握统计思想,培养学生学习统计学的兴趣,为继续学习推断统计方法及应用各种统计方法解决实际问题打下必要而坚实的基础。 5理解并掌握SPSS软件包有关数据文件创建和整理的基本操作 6学习如何将收集到的数据输入计算机,建成一个正确的SPSS数据文件 7掌握如何对原始数据文件进行整理,包括数据查询,数据修改、删除,数据的排序8 实验类型:验证型;实验时间:2学时 二、实验主要仪器和设备 计算机一台,Windows XP操作系统,SPSS环境。 三、实验原理 SPSS数据文件是一种结构性数据文件,由数据的结构和数据的内容两部分构成,也可以说由变量和观测两部分构成。一个典型的SPSS数据文件如表2.1 所示。 SPSS变量的属性
SPSS中的变量共有10个属性,分别是变量名(Name)、变量类型(Type)、长度(Width)、小数点位置(Decimals)、变量名标签(Label)、变量名值标签(Value)、缺失值(Missing)、数据列的显示宽度(Columns)、对其方式(Align)和度量尺度(Measure)。定义一个变量至少要定义它的两个属性,即变量名和变量类型,其他属性可以暂时采用系统默认值,待以后分析过程中如果有需要再对其进行设置。在spss数据编辑窗口中单击“变量视窗”标签,进入变量视窗界面(如图2.1所示)即可对变量的各个属性进行设置。 四、实验内容与步骤 实验1.1数据文件管理 1.创建一个数据文件 数据文件的创建分成三个步骤: (1)选择菜单【文件】→【新建】→【数据】新建一个数据文件,进入数据编辑窗口。窗口顶部标题为“PASW Statistics数据编辑器”。 (2)单击左下角【变量视窗】标签进入变量视图界面,根据实验的设计定义每个变量类型。 (3)变量定义完成以后,单击【数据视窗】标签进入数据视窗界面,将每个具体的变量值录入数据库单元格内。 2.读取外部数据
1、在spss中打开你要处理的数据,在菜单栏上执行:analyse-compare means--one-way anova,打开单因素方差分析对话框。 2、在这个对话框中,将因变量放到dependent list中,将自变量放到factor中,这个 研究中有两个因变量,所以把两个因变量都放到上面的列表里。 3、点击post hoc,打开一个对话框,设置事后检验的方法。 4、在这个对话框中,我们在上面的方差齐性的方法中选择tukey和REGWQ,在方差
不齐性的方法中选择dunnetts,点击continue继续。 5、回到了anova的对话框,点击options按钮,设置要输出的基本结果。 6、这里选择描述统计结果和方差齐性检验,点击continue按钮。
7、点击ok按钮,开始处理数据。 8、我们看到的结果中,第一个输出的表格就是描述统计,从这个表格里我们可以看到 均值和标准差,在研究报告中,通常要报告这两个参数。
9、接着看方差齐性检验,方差不齐性的话是不能够用方差齐性的方法来检验的,还好, 这里显示,显著性都没有达到最小值0.05,所以是不显著的,这证明方差是齐性的 。 10、接着看单因素方差分析表,反应时sig值不显著,而错误率达到了显著的水平,这 说明实验处理对错误率产生了影响,但是对反应时没有影响。 11、接着看事后检验,因为反应时是没有显著差异的,所以就不必再看反应时的事后检 验,直接看错误率的事后检验,从图中标注的红色方框可以看到,第一组和二三组都有显著的差异,而第二组和第三组没有显著差异。关于dunnet方法,它适合在方差不齐性的时候使用,因为方差齐性,不必去看这个方法的检验结果了。
目录 一、SPSS界面介绍 (2) 1、如何打开文件 (2) 2、如何在SPSS中打开excel表 (3) 3、数据视图界面 (3) 4、变量视图界面 (4) 二、如何用SPSS进行频数分析 (11) 三、如何用SPSS进行多变量分析 (15) 四、如何对多选题进行数据分析 (18) 1、对多选题进行变量集定义 (18) 2、对多选题进行频数分析 (21) 3、对多选题进行多变量交互分析 (24) 五、如何就SPSS得出的表在excel中作图 (27)
一、SPSS界面介绍 提前说明:第一,我这里用的是SPSS 20.0 中文汉化版。第二,我教的是傻瓜操作,并不涉及理论讲解,具体的为什么和用什么理论公式来解释请认真去听《社会统计学》的课程。第三,因为是根据我自己的操作和理解来写的,所以可能有些地方显的不那么科学,仍然要说请大家认真去听《社会统计学》的课程,那个才是权威的。 1、如何打开文件 这个东西打开之后界面是这样的: 我们打开一个文件:
要提的一点就是,SPSS保存的数据拓展名是.sav: 2、如何在SPSS中打开excel表 在上图的下拉箭头里找到excel这个选项: 然后你就能找到你要打开的excel表了。 3、数据视图界面 我现在打开了一个数据库。 可以看到左下角这个地方有两个框,两个是可以互相切换的,跟excel切换表一样,跟excel切换表一样: 现在的页面是数据视图,也就是说这一页都是原始数据,这里的一行就是一张问卷,一列就是一个问题,白框里的1234代表的是选项。这个表当时录数据的时候为了方便看,是把ABCD都转换成了1234,所以显示的是1234,当然直接录ABCD也可以,根据具体情况看怎么录,只要能看懂。 多选题的录入全部都是细化到每个选项,比如第四题,选项A选了就是“是”,没选就是
SPSS25.0新功能介绍: 1、高级统计模块中贝叶斯统计 执行新的贝叶斯统计函数,包括回归、方差分析和t检验。 贝叶斯统计数据正变得非常流行,因为它绕过了标准统计数据带来的许多误解。贝叶斯没有使用p值拒绝或不拒绝零假设,而是对参数设置了不确定性,并从所观察到的数据中获取所有相关信息。我们对贝叶斯统计数据的方法是独一无二的,因为我们的贝叶斯程序和我们的标准统计测试一样容易运行。只需几次点击,你就可以运行线性回归,ANOVA,一个样本,pair - sample,独立样本t检验,二项比例推理,泊松分布分析,Pairwise Pearson相关,和log线性模型来测试两个分类变量的独立性。 新图表模板,可实现word等微软家族中编辑 这个新功能,通俗的说,就是SPSS输出的图表,你可以不用在原始的输出界面进行编辑修改,可以直接保存到word等里面,在进行修改。想想都比较高大上! 建造现代化、吸引人的、详细的图表从来都不容易。 你可以把大多数图表复制成微软的图形对象,这样你就可以在Microsoft Word、PowerPoint 或Excel中编辑标题、颜色、样式,甚至图表类型。 另外,SPSS还提供了图表构建器,也就是图表的模板,可以选择模板点击创建发布质量图表。 还可以在构建图表时指定图表颜色、标题和模板。而且,默认的模板即使没有修改,也确保了一个漂亮的图表。 在SPSS的图表从来都不是这么容易的。所有这些图表功能都在基本版本中找到。 将高级统计分析扩展到混合、genlin混合、GLM和UNIANOVA。 新版软件增加了最受欢迎的高级统计功能的大部分增强功能。在混合线性模型(混合)和广义
第一章 SPSS10.0 for Windows简介 SPSS软件是由美国SPSS公司研制的。SPSS的全称为Statistical Program for Social Sciences,即“社会科学统计程序”。SPSS10.0 for Windows是在Windows操作系统下运行的社会科学统计软件包,该软件是国际上公认的最优秀的统计分析软件包之一。它在经济、工业、管理、心理、教育、医学等许多领域应用广泛,在科研工作中发挥了巨大的作用。SPSS 最初的版本是建立在D0S基础上的,但在80年代末,Microsoft推出Windows后,SPSS迅速向Windows移植。并不断推出SPSS软件的新版本。SPSS for Windows版本从6.0、7.0、8.0、9.0,至1999年底,正式推出SPSS10.0 for Windows版本。该版本相对于一些早期的版本而言,不仅改写了一些模块,使运行速度大大提高,而且根据统计理论与技术的发展,增加了许多新的统计分析方法,使之功能日趋完善。近年由推出11.0和12.0 版本,这两新版本主要提高运行速度和增加了一些新统计学方法,其余与10.0 版本基本相同。本书以10.0版本介绍SPSS for Windows的使用方法。 第一节 SPSS10.0 for Windows的特点 SPSS软件风靡世界并为各个领域的广大科研工作者及其他用户所钟爱,原因在于它有以下的特点; 1、多种实用分析力法。SPSS提供了多种分析方法,包括了从基本的统计特征描述到诸如非参数检验、生存分析等各种高层次的分析。除此之外,SPSS还具有强大的绘制图形、编辑图形的能力。 2、易于学习,易于使用。对于SPSS for Windows而言,除了数据输入工作要使用键盘之外,其他的大部分操作均可以通过“菜单”、“对话框”来完成,使用户不必记忆大量的命令,操作更简单。 3、文件易于转换。与其他软件有数据转换接口。 Excel文件、文本文件等均可以转换成相应的SPSS数据文件。 4、操作方法多种多样。不仅有灵活的菜单对话框式操作,而且用户也可以自已编写SPSS 语句来进行数据统计分析工作。 第二节 SPSSl0.0 for Windows对环境的要求 一、对硬件的要求 由于SPSS主要用途是面向大型数据库的,它的运算一般涉及的数据量比较多。故而用户一般需要有较大的内存,而且如果用户还要进行多因素分析、生存分析之类的大运算量的分析,计算机至少要有16M的内存。 二、对软件的要求 SPSS for W1ndows目前没有汉化版本。一般用户可以在以下环境中运行SPSS。 1、中文Windows95、Windows98、Windows me、Windows2000 SPSS for W1ndows在此环境下运行,对话框中的按钮功能能以中文显示。可以使用中文设置变量标签和值标签。在要点表中显示中文标签。打印的时候,只能把正排汉字正常打印,图形中被旋转了的汉字打印的结果是乱码。 2、英文Windows95、Windows98、Windows me、Windows2000加中文平台,以便定义和输出中文标签。
第四章:SPSS结果窗口用法详解 §4.1结果窗口元素介绍 SPSS实际上提供了两个结果窗口--结果浏览窗口和结果草稿浏览窗口。前者最为常用,显示美观,但非常消耗系统资源;后者实际上是一个RTF格式文档,显示简单朴素,但节省资源。我们可以根据所用计算机的情况选择使用哪一种窗口。 结果草稿浏览窗口的内容虽然是RTF格式,但由于中、英文兼容性的问题, 其中的表格读入WORD以后会变的面目全非,因此对我们不是很适用。 4.1.1 结果浏览窗口 SPSS的输出结果美观大方,是该软件的一大特色,下面是一个典型的结果浏览窗口。 相信99%的人都用过资源管理器,SPSS的结果浏览窗口和Windows资源管理器的结构完全相同,操作也几乎相同。除了上面的菜单栏、工具栏以外,绝大部分窗口被纵向一分为二!左侧是大纲视图(Outline view),又称结构视图,右侧则
显示详细的统计结果(统计表、统计图和文本结果),两侧的元素是完全一一对应的,即选中一侧的某元素,在另一侧该元素也会被选中。例如左侧的Title 图标旁有一个红色的箭头,表明该内容为结果窗口当前所在位置,相应的,右侧的标题Descriptives旁也出现一个红色三角,表明这就是Title图标所代表的内容。下面解释一下大纲视图的各个元素。 大纲视图顾名思义,大纲视图用于概略显示结果的结构,用于在宏观上对结果进行管理,如移动,删除等。里面采取和资源管理器类似的层次方式排列元素,每个元素用一个小图标来表示。常见的图标有: 大纲图标,代表一段或整个输出结果,含下级元素,单击左侧的减号就可以 将下级元素折叠,折叠后减号变为加号,图标则变为。 运行记录图标,代表系统操作产生的一段运行记录。 警告图标,代表输出结果中的系统警告。 注解图标,代表系统自动产生的注解,默认情况下注解内容在输出结果中是隐藏的。 标题图标,代表输出标题。 页标题图标,代表输出标题,较少出现。 表格图标,代表输出结果中的统计表(Pivot table,字面意思为数据透视表)。 统计图图标,代表统计图。 文本图标,代表文本输出结果。 交互式统计图图标,代表交互式统计图。 统计地图图标,代表统计地图。 单击图标会选中所代表的一块或一段输出结果,双击图标可以让对应输出在显示、隐藏间切换,选中后单击图标的名称则可以对图标改名。 4.1.2 结果草稿浏览窗口 和它漂亮的兄弟相比,结果草稿浏览窗口就朴素的多了,什么花样也没有。当然,系统资源也要少占用许多,前面的输出结果在结果草稿浏览窗口中的显示如下:
实习一SPSS基本操作 第1题:请把下面的频数表资料录入到SPSS数据库中,并划出直方图,同时计算均数和标准差。 身高组段频数 110~ 1 112~ 3 114~ 9 116~ 9 118~ 15 120~ 18 122~ 21 124~ 14 126~ 10 128~ 4 130~ 3 132~ 2 134~136 1 解答:1、输入中位数(小数位0):111,113,115,117,....135;和频数1,3,. (1) 2、对频数进行加权:DATA━Weigh Cases━Weigh Cases by━频数━OK 3、Analyze━Descriptive Statistics━Frequences━将组中值加 入Variable框━点击Statistics按钮━选中Mean和 Std.devision━Continue━点击Charts按钮━选中HIstograms ━Continue━OK 第2题某医生收集了81例30-49岁健康男子血清中的总胆固醇值(mg/dL)测定结果如下,试编制频数分布表,并计算这81名男性血清胆 固醇含量的样本均数。 219.7 184.0 130.0 237.0 152.5 137.4 163.2 166.3 181.7 176.0 168.8 208.0 243.1 201.0 278.8 214.0 131.7 201.0 199.9 222.6 184.9 197.8 200.6 197.0 181.4 183.1 135.2 169.0 188.6 241.2 205.5 133.6 178.8 139.4 131.6 171.0 155.7 225.7 137.9 129.2 157.5 188.1 204.8 191.7 109.7 199.1 196.7 226.3 185.0 206.2 163.8 166.9 184.0 245.6 188.5 214.3 97.5 175.7 129.3 188.0 160.9 225.7 199.2 174.6 168.9 166.3 176.7 220.7 252.9 183.6 177.9 160.8 117.9 159.2 251.4 181.1 164.0 153.4 246.4 196.6 155.4 解答:1、输入数据:单列,81行。
SPSS 回顾: 1描述性统计分析 1.1基本描述性统计量的概念 (1)操作步骤:Analyze→Descriptive Statistics→Descriptives (2)概念 集中趋势的统计量:平均值、中位数、众数、求和 离散趋势的统计量:方差、标准差、极差、最小值、最大值、均值标准误差 分布形态的统计量:偏度、峰度 1.2频数分析 (1)操作步骤:Analyze → Descriptive Statistics→Frequencies (2)概念 频数(Frenquency):变量值落在某个区间或者某个取值点的个数。 百分比(Percent):各频数占总样本数的百分比。 有效百分比(Valid Percent):各频数占有效样本数的百分比。 累计百分比(Cumulative Percent):各百分比逐级累加起来的结果,最终取值是100。1.3探索性分析 (1)操作步骤:Analyze → Descriptive Statistics→Explore
(2)看得懂以下图形:箱图、茎叶图、QQ图 特别注意:以下内容都与假设检验有关。 不同的检验有不同的零假设,但基本上对检验结果的判断都遵循以下判别规则,不再赘述。 (1)如果相伴概率值(P值或Sig.值)小于或等于显著性水平α,则拒绝H0。 (2)相伴概率值(P值或Sig.值)大于显著性水平α,则接受H0。 (3)相伴概率值在spss运行结果中查找。显著性水平可由用户自行设定,如没有特别要求可取默认值。2两总体均值比较 2.1单样本T检验 (1)基本原理:检验样本均值与已知总体均值之间是否存在差异。 (2)操作步骤:Analyze→Compare Means→One Sample T Test (3)原假设H0:样本均值和总体均值之间不存在显著差异。 (4)关键结果标题和统计量:One Sample Test表和其中的t统计量和sig值。 2.2独立样本T检验 (1)基本原理:检验两个独立正态样本的总体均值之间是否存在显著差异 (2)应用的条件:两个样本相互独立且满足正态分布,样本数量可以不同 (3)操作步骤:Analyze → Compare Means→Independent Samples T Test (4)原假设H0:两个独立样本的总体均值不存在显著差异。
SPSS使用方法: 1、录入数据 A.在变量视图设变量名称(一般建议用a/b/c等,变量总分及其各因子分名称可用x0,x1,x2;y0,y1,y2等),并改相应的标签和值。 B.在数据视图输入数据(除了变量总分及其各因子分) 2、数据整理 A. 反向计分:转换----重新编码为相同变量----选择需反向计分 的题目转入变量窗口----旧值和新值----接下来就该会了 B. 计算变量总分及其各因子分:转换----计算变量----目标变量 (输入所计算因子分的名称,如x1),右边函数组中找统计量----在下面的方框里选sum----转入上面的方框----在括号里写所要计算的因子所包括的题目名称,如b1,中间用英文逗号隔开----确定---确定(先算各因子分,再算总分) 3、各变量的总体状况:用单样本T检验 分析----比较均值----单样本t检验----将所需要的因子分和总分分别转入检验变量窗口----检验值为所检验因子的常模值或中间值(意义就是比较我们所测变量的实际值与理论值或中间值谁大谁小,差异是否显著,如果实际值显著高于理论值或中间值,则可认为所测变量的总体水平比较高) 4、人口统计学变量与各变量的差异检验 A.如果人口学变量为两个维度(如性别),可用独立样本T检验: 分析----比较均值-----独立样本T检验----检验变量为变量总分及
其各因子分,分组变量为人口学变量,如性别,定义组写0,1或1,2,(根据性别变量所赋的值)。 B.若人口学变量为两个以上维度(如年级),可用单因素方差分 析:分析----比较均值----单因素ANOVA----因变量为检验变量,因子为年级----在选项中选择描述性 5、相关分析 分析----相关----双变量----将需要做相关的两个变量的所有因子和总分都转入变量窗口----确定 6、回归分析 我也不会。。。 注:对于所计算的结果要有取舍,可借鉴相关硕士论文。 麻烦点的是独立样本T检验的结果:在独立样本检验下面的表中,先看F后面的Sig,若其大于0.05,则选择第一栏的t和sig(双侧),即方差相等;若其小于等于0.05,则选择第二栏的t和sig(双侧),即方差不相等。
Spss基础入门 1. 个案排序:对数据视图中的某个个案进行排序,具体排序规则可以点进去选择 2. 变量排序:对变量视图中某个变量进行排序,具体规则可以点进去选择 3. 转置:行列互转 4. 合并文件:有两种文件的合并,添加个案可以实现两个文件的纵向合并,添加变量可以两个文件的横向合并 5. 重构:实现把一个表格的若干个变量变为同一个变量等进行表格的合适转换 6. 汇总:对数据按照类别进行汇总,比如三个班级的学生成绩表格,可以按照班级把学生成绩的平均值等等汇总到另外一个表格,该表格就会显示比如按班级显示各个班级的成绩平均值等 7. 拆分文件:实现输出图形表格的合理拆分,比如一个公司有8个部门,现要求分男女比较各个部门的人员工资情况,理论上我们用选择个案(见下条),逐个选择男女与部门需要操作2*8次,由此画出2*8张图表。利用拆分文件,这个时候可以选择 比较组或者按组来组织输出,然后分组依据就是部门与性别,在利用下面会讲到的数据描述就可以实现预期效果。 8. 选择个案:实现选择表格中符合条件的个案然后对其进行相应操作,点击进去后会有各种选择方式,比如如果满足什么条件才选择,随机选择百分之多少等等 一.转换 1. 重新编码为不同变量:可以把原来的变量或者变量的范围重新定义为新的变量,比如现有一个班级的学生成绩,要求分心50-70分,70-90分90-100分的同学所占比例,平均值等,现在就可以利用重新编码为不同变量,把上述范围重新编码为新的变量(名字可以自己任意选取),具体操作点击进去之后比较清楚。 2. 计算变量:实现对原来变量的重新计算从而产生新的变量,比如对原来变量进行乘以10操作产生新的变量等等,产生的变量名都是可以自己选择的 一.分析 1.描述统计:实现对表格中变量的各种类型的描述统计
SPSS基本操作步骤详解 本文采用SPSS21.0版本,其它版本操作步骤大体相同 一、基本步骤 (一)检查数据 在进行项目分析或统计分析之前,要检核输入的数据文件有无错误,即检核missing。 例,“XX量表”采用Likert scale五点量表式填答,每个题项的数据只有五个水平:1,2,3,4,5。 1.执行次数分布表的程序 Analyze(分析)→Descriptive statistics(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Frequencies(频率)→Statistics(统计量)→Minimum (最小值)、Maximum(最大值)→Continue(继续)→OK(确定) 2.执行描述统计量的程序 Analyze(分析)→(描述统计)→将题项变量【例,a1—a10】键入至Variables(变量)框中→Descriptives(描述)→Options(选项)→Minimum(最小值)、Maximum(最大值)【此处一般为默认状态即可】→Continue(继续)→OK(确定) (二)反项计分 若是分析的预试量表中没有反向题,则此操作步骤可以省略; 量表或问卷题中如果有反向题,则在进行题项加总之前将反向题反向计分,否则测量分数所表示的意义刚好相反。 例,“XX量表”采用Likert scale五点量表式填答,反向题重向编码计分:1→5,2→4,3→3【可不写】,4→2,5→1。 Transform(转换)→Recode into same Variables(重新编码为相同变量)→将要反向的题目键入至Variables(变量)框中【例,a1,a3,a5】→Old and new values(旧值和新值)→在左边Old value—value中键入1,在右边New value—value中键入5,Add (添加)→……依次进行此步骤……在左边Old value—value中键入5,在右边New value —value中键入1,Add(添加)→Continue(继续)→OK(确定)【注意不同量表计分方式不同,因而反向编码计分也不同,常见的有四点量表、五点量表和六点量表等】 (三)题项加总 量表题项加总的目的在于便于进行观察值得高低分组。 例,“XX量表”采用Likert scale五点量表式填答,题项为:a1,a2……a10,记总分为:az。 Transform(转换)→Computer Variable(计算变量)→在左边Target Variable(目标变量)中键入az,在右边Numeric Expression(数字表达式)中键入a1+a2+……+a10
统计分析软件SPSS操作方法 SPSS for Windows的启动和退出 图2 软件启动 在鼠标顺序单击“开始”——“程序”——“SPSS 10.0 for Windows”——“SPSS 10.0 for Windows”启动条之后,SPSS启动界面如图2所示。
图3 启动界面 如需要退出程序可单击右上角的“×”或左上角“File”下的“Exit”即可退出。如果在本次SPSS期间激活的窗口如DATA窗口、OUTPUT窗口的有关内容已经作为文件存盘,则系统直接退出SPSS系统。否则系统会对各窗口一一提问:是否保存×××窗口的内容。用户可按自己的意愿一一给以回答。随后,结束本次SPSS期间,退出SPSS系统。 菜单及窗口介绍 由图3所示,SPSS软件的主菜单主要包括10项: ①File:文件操作;②Edit:文件编辑;③View:视图;④Data:数据文件建立与编辑;⑤Transform:数据转换;⑥Analyze:统计分析;⑦Graphs:统计图表的建立与编辑;⑧Utilities:实用程序;⑨Window:窗口控制;⑩Help:帮助。 而数据窗口主要包括两部分内容,data view和variable view两个表格,这一点与EXCEL 软件极为相似,data view主要用来显示需要处理的数据,而variable view则用来为数据不同的变量的性质进行设置,如名字name、类型type、宽度width、小数点位数Decimals等。以下为下一级子菜单的介绍。 1 File 鼠标单击“File”后即打开下一级下拉子菜单。共计包括16项。现主要介绍常用的命令。 图4 File子菜单 “New”与“Open”命令分别为新建和打开一个文件(包括数据文件data、程序文件syntax、结果文件output、脚本文件script、其他文件other)。需要注意的是SPSS10.0可以直接打开EXCEL2000和数据库的文件(其他还有systat、文本、Lotus等格式的文件)。
基本统计图表的制作 1 P-P图和Q-Q图 P-P图是根据变量的累积比例与指定分布的累积比例之间的关系所绘制的图形。通过P-P图可以检验数据是否符合指定的分布。当数据符合指定分布时,P-P图中各点近似呈一条直线。如果P-P图中各点不呈直线,但有一定规律,可以对变量数据进行转换,使转换后的数据更接近指定分布。 Q-Q图同样可以用于检验数据的分布,所不同的是,Q-Q图是用变量数据分布的分位数与所指定分布的分位数之间的关系曲线来进行检验的。 由于P-P图和Q-Q图的用途完全相同,只是检验方法存在差异,SPSS17.0中用于做出P-P图的对话框和用于做出Q-Q图的对话框完全一致,下面将对两者统一加以说明。 具体操作步骤如下: 打开数据文件,选择【分析】(Analyze)菜单,单击【描述统计】(Descript ive Statistics)命令下的【P-P图】(P-P Plots)或【Q-Q图】(Q-Q Plots)命令。“P-P图”(P-P Plots)、“Q-Q图”(Q-Q Plots)的对话框分别如图3-20和图3-21所示。 图3-20 “P-P图”对话框
图3-21 “Q-Q图”对话框 在“P-P图”(P-P Plots)或“Q-Q图”(Q-Q Plots)对话框中,最左边的变量列表为原变量列表,通过单击按钮可选择一个或者几个变量进入位于对话框中间的“变量”(Variables)列表框中。根据这些变量数据可创建P-P图或Q-Q图,并进行分布检验。 “P-P图”或“Q-Q图”对话框的中下方和右方有5个选项栏,选项栏中各选项的意义如下: (1)转换(Transform)栏(复选项): l 自然对数转换(Natural log transform):选择此项,对当前变量的数据取自然对数,即将原有变量转换成以自然数e为底的对数变 量。 l 标准值(Standardize values):选择此项,将当前变量的数据转换为标准值,即转换后变量数据的均值为0,方差为1。 l 差分(Difference):选择此项,对当前变量的数据进行差分转换,即利用变量中连续数据之间的差值来转换数据。选择此项以后,后面 的文本框变为可用,在其中输入一个正整数,以确定转换的差分度, 默认值为1。
实验三-IBM-SPSS软件的基本操作
云南大学软件学院 实验报告 课程:大数据分析及应用任课教师:蔡莉实验指导教师(签名): 学号: 20131170142 姓名:郭昱专业:软件工程日期: 2015/11/01 成绩: 实验三 IBM SPSS软件的基本操作 一、实验目的 1.熟悉SPSS的菜单和窗口界面,熟悉SPSS 各种参数的设置; 2.掌握SPSS的数据管理功能。 二、实验内容及步骤 (一)数据的输入和保存 1. SPSS界面 当打开SPSS后,展现在我们面前的界面如下: 菜单栏 工具栏
注意:窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。该界面和EXCEL极为相似,很多操 作也与EXCEL类似。 2.定义变量 选择菜单Data==>Define Variable。系统弹出定义变量对话框如下: 对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下: GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 先来建立分组变量GROUP。请将变量名改为GROUP,然后单击OK按钮。 现在SPSS的数据管理窗口如下所示: 第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。 现在我们来建立变量X。单击第一行第二列的单元格,然后选择菜单Data==>Define Variable,同样,将变量名改为X,然后确认。此时SPSS的数据管理窗口如下所示: 现在,第一、第二列的名称均为深色显示,表明这两列已经被定义为变量,其余各列的名称仍为灰色的“var”,表示尚未使用。同样地,各行的标号也为灰色,表明现在还未输入过数据,即该数据集内没有记录。 3.输入数据 我们先来输入变量X的值,请确认一行二列单元格为当前单元格,弃鼠标而用键盘,输入第一
经管实验中心实验报告 学院:管理学院 课程名称:市场调研 专业班级: 姓名: 学号: 实验项目实验 一 实验 二 实验 三 实验 四 实验 五 实验 六 实验 七 实验 八 实验 九 实验 十 总评 成绩 评分
学生实验报告 实验项目图表的制作 □必修□选修□演示性实验□验证性实验□操作性实验□综合性实验实验地点文管实验中心实验仪器台号30 指导教师实验日期及节次2013-6-5 一、实验目的及要求: 1、目的 要求学生能够进行基本的统计分析;能够对频数分析、描述分析和探索分析 的结果进行解读;完成基本的统计图表的绘制;并能够对统计图表进行编辑美化 及结果分析;能够理解多元统计分析的操作(聚类分析和因子分析) 2、内容及要求 2.1 基本的统计分析 打开“分析/描述统计”菜单,可以看到以下几种常用的基本描述统计分析 方法: 1.Frequencies过程(频数分析) 频数分析可以考察不同的数据出现的频数及频率,并且可以计算一系列的统 计指标,包括百分位值、均值、中位数、众数、合计、偏度、峰度、标准差、方差、全距、最大值、最小值、均值的标准误等。 2.Descriptives过程(描述分析) 调用此过程可对变量进行描述性统计分析,计算并列出一系列相应的统计指标,包括:均值、合计、标准差、方差、全距、最大值、最小值、均值的标准误、峰度、偏度等。 3.Explore过程(探索分析) 调用此过程可对变量进行更为深入详尽的描述性统计分析,故称之为探索性 统计。它在一般描述性统计指标的基础上,增加有关数据其他特征的文字与图形 描述,显得更加细致与全面,有助于用户思考对数据进行进一步分析的方案。 4.Crosstabs过程(列联表分析) 调用此过程可进行计数资料和某些等级资料的列联表分析,在分析中,可对 二维至n维列联表(RC表)资料进行统计描述和χ2 检验,并计算相应的百分 数指标。此外,还可计算四格表确切概率(Fisher’s Exact Test)且有单双侧(One-Tail、Two-Tail),对数似然比检验(Likelihood Ratio)以及线性关系 的Mantel-Haenszelχ2 检验。 2.2 基本统计分析结果解读 1.频率分析的结果解读 2.描述分析的结果解读 3.探索分析的结果解读 4.列联表分析的结果解读
SPSS基本概述与介绍 在教育技术学研究中,常常需要对大量的数据进行统计处理,这是一项细致而繁琐的工作,如果完全依靠手工来进行,工作量较大,且难以保证准确性,也得不到高的精度。为了减轻整理和计算大量数据的负担,提高工作效率,我们必须充分利用现代化的技术手段。随着计算机软件技术的发展,计算机在分析数据方面发挥了相当大的作用,它功能多、速度快、计算精确、较易利用,并且计算机统计软件可以完成更为精确系统的数据分析与统计计算。 在教育技术研究资料统计处理中常采用的统计软件有SPSS INC公司的SPSS统计软件系统、SAS统计分析系统和Microsoft公司的Excel软件等。SPSS是Statistics Package for Social Sciences(社会科学统计软件包)的缩写,它是社会科学研究人员首选的统计软件,也是目前世界上最流行的统计软件之一。因而被广泛应用于社会科学和自然科学的各个领域中。 一、SPSS统计软件概况 SPSS是专业的通用统计软件包,它是一个组合式软件包,兼有数据管理、统计分析、统计绘图和统计报表功能,界面友好,使用简单,广泛用于教育、心理、医学、市场、
人口、保险等研究领域,也用于产品质量控制、人事档案管理和日常统计报表等。 SPSS对硬件系统的要求较低,普通配置的计算机都可以运行该软件;对运行的软件环境要求宽松,有各种版本可运行在WINDOWS 3X、9X、2000环境下,现在较新的10.0版可运行在WINDOWS 2000中(SPSS早期版本运行于DOS下,这里不再进行介绍,本节以SPSS 10.0版本为例介绍的该软件的使用)。SPSS 10.0有英文版和汉化版两种版本,可运行在中英文平台上。 SPSS统计软件采用电子表格的方式输入与管理数据,能方便地从其他数据库中读入数据(如Dbase,Excel,Lotus 等)。它的统计过程包括描述性统计、平均值比较、相关分析、回归分析、聚类分析、数据简化、生存分析、多重响应等几大类,每类中又下含同类多种统计过程,比如回归分析中又分线形回归分析、非线性回归分析、曲线估计等多个统计过程,而且每个过程中允许用户选择不同的方法及参数进行统计分析,因此除可以实现常规的各种统计外,还可用来做一些不常用的分析处理。 SPSS采用Sax Basic引擎,允许用户使用类Basic的语
第一章 SPSS概览--数据分析实例详解 1.1 数据的输入和保存 1.1.1 SPSS的界面 1.1.2 定义变量 1.1.3 输入数据 1.1.4 保存数据 1.2 数据的预分析 1.2.1 数据的简单描述 1.2.2 绘制直方图 1.3 按题目要求进行统计分析 1.4 保存和导出分析结果 1.4.1 保存文件 1.4.2 导出分析结果 希望了解SPSS 10.0版具体情况的朋友请参见本网站的SPSS 10.0版抢鲜报道。 例1.1 某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下, 问该地急性克山病患者与健康人的血磷值是否不同(卫统第三版例4.8)? 患者: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 健康人: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87 解题流程如下: 1. 将数据输入SPSS,并存盘以防断电。 2. 进行必要的预分析(分布图、均数标准差的描述等),以确定应采用的 检验方法。 3. 按题目要求进行统计分析。 4. 保存和导出分析结果。 下面就按这几步依次讲解。 §1.1 数据的输入和保存 1.1.1 SPSS的界面 当打开SPSS后,展现在我们面前的界面如下:
请将鼠标在上图中的各处停留,很快就会弹出相应部位的名称。 请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。这是一个典型的Windows软件界面,有菜单栏、工具栏。特别的,工具栏下方的是数据栏,数据栏下方则是数据管理窗口的主界面。该界面和EXCEL极为相似,由若干行和列组成,每行对应了一条记录,每列则对应了一个变量。由于现在我们没有输入任何数据,所以行、列的标号都是灰色的。请注意第一行第一列的单元格边框为深色,表明该数据单元格为当前单元格。 有的SPSS系统打开时会出现一个导航对话框,请单击右下方的Cancer按钮,即可进入上面的主界面。 1.1.2 定义变量 该资料是定量资料,设计为成组设计,因此我们需要建立两个变量,一个变量代表血磷值,习惯上取名为X,另一个变量代表观察对象是健康人还是克山病人,习惯上取名为GROUP。 对数据的统计分析格式不太熟悉的朋友请先学习统计软件第一课。 选择菜单Data==>Define Variable。系统弹出定义变量对话框如下: 该变量定义对话框在SPSS 10.0版中已被取消,这里的操作只适合9.0~7.0版的用户。
S P S S编程操作入门
第四章 SPSS编程操作入门 4.1程序编辑窗口操作入门 一、进入程序编辑窗口界面 ①创建一个新程序 File——new——syntax ②打开一个旧程序 File——open——syntax 程序文件的扩展名为*.sps 注:syntax窗口的菜单和SPSS窗口的菜单功能基本一致,区别在于RUN菜单。 RUN ALL——运行全部程序 RUN SELECTION——运行所选择的部分程序 二、熟用Paste 按钮 在SPSS所有菜单对话框中均有Paste功能,在所有对话框选择完毕后,不选择 OK,而使用Paste,则程序编辑窗口会自动生成程序。 此功能使得SPSS编程操作变得简单易行,只需要对生成的程序适当加以修改即可。 示例:运用Paste创建一个程序文件。以xuelin.sav.为例,产生P50页的程序语句,并保存在桌面上备用。
该程序文件可以保存,当下次做相同的分析时,无需重新进行复杂的菜单选择,直接在原有程序文件上进行适当的修改,运行即可。 三、编程进行对话框无法完成的工作 示例1:见书 示例2:怎么产生连续自然数1~200 Input program. Loop #i=1 to 200. Compute x=#i. end case. End loop. End file. End input program. Execute. 4.2结构化语句简介 一、分支语句(条件语句) ①IF语句 SPSS程序格式: IF逻辑表达式目标表达式 逻辑表达式用于给出判断条件。
目标比达式表示如果满足逻辑表达式后该如何操作。 注:编程基本小知识: ①每句命令完成后,以点号结束,否则程序不被执行。 ②全部命令编辑完成后,以Execute.结束,否则程序不被执行. ③学会使用help——command syntax reference自学编程。 示例1:打开案例数据brain1.sav,要求将年龄小于20,性别为1(男)的病人归为第一组(group=1). GET FILE='F:\chenghongli\spss\数据集\brain1.sav'. if age<20 & sex=1( 逻辑表达式) group=1.(目标表达式)Execute. 示例2:打开案例数据brain1.sav,要求将年龄小于等于40岁的女性病人归为组2. GET FILE='F:\chenghongli\spss\数据集\brain1.sav'. if age le 40 group=2. execute. 练习1:将血小板大于等于100的列为组1 练习2:打开brain1.sav,创造一个新的字符型变量sex1,当sex 取值为1时,sex1取值为f, 当sex取值为2时,sex1取值为m. GET