
Oracle RMAN 恢复机制
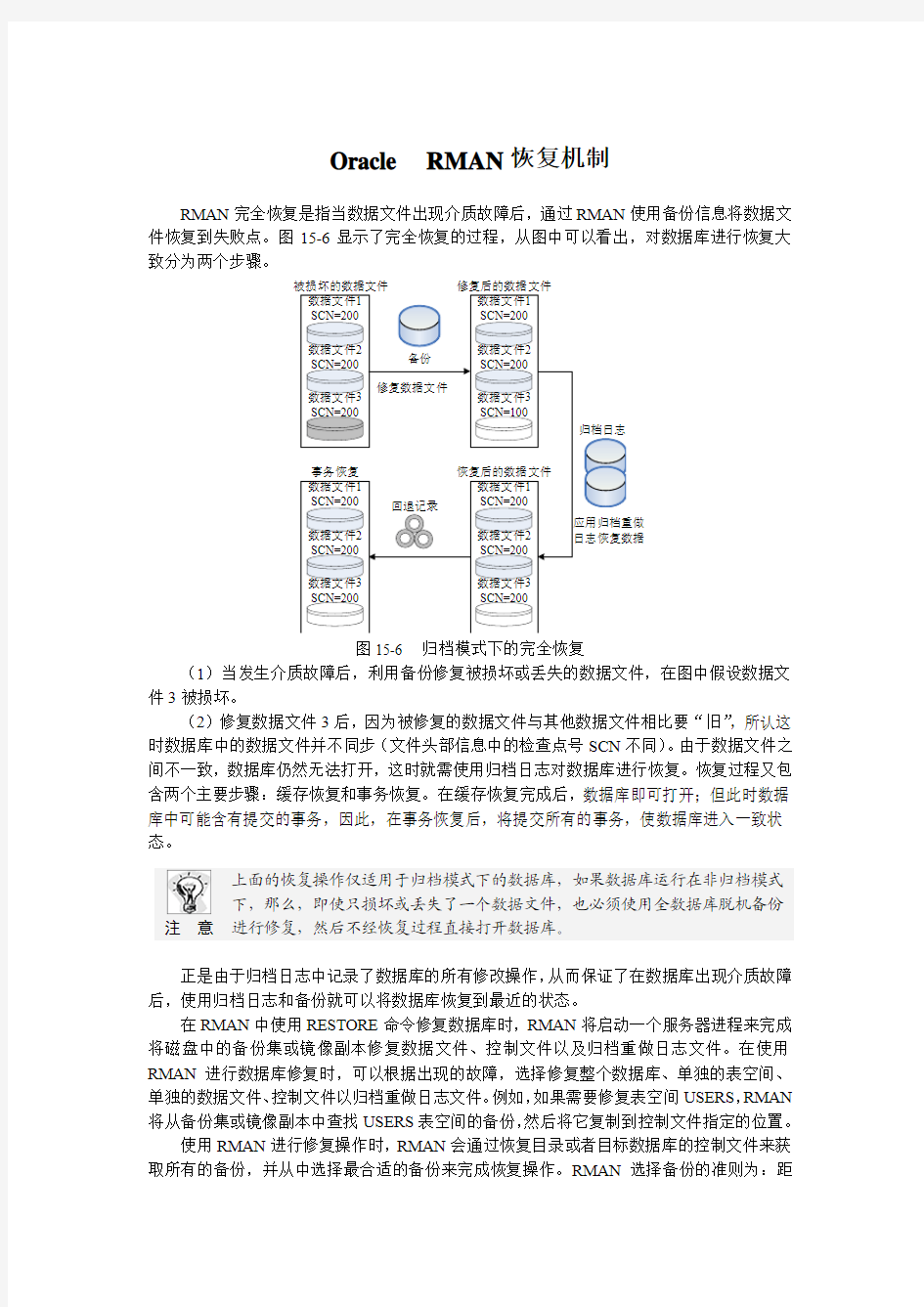
RMAN 完全恢复是指当数据文件出现介质故障后,通过RMAN 使用备份信息将数据文件恢复到失败点。图15-6显示了完全恢复的过程,从图中可以看出,对数据库进行恢复大致分为两个步骤。
备份数据文件1SCN=200数据文件2SCN=200数据文件3SCN=200
数据文件1SCN=200
数据文件2SCN=200数据文件3SCN=100
数据文件1SCN=200数据文件2SCN=200数据文件3SCN=200
数据文件1SCN=200
数据文件2SCN=200数据文件3
SCN=200
归档日志
修复数据文件
应用归档重做日志恢复数据
被损坏的数据文件修复后的数据文件
恢复后的数据文件
事务恢复回退记录
图15-6 归档模式下的完全恢复
(1)当发生介质故障后,利用备份修复被损坏或丢失的数据文件,在图中假设数据文件3被损坏。
(2)修复数据文件3后,因为被修复的数据文件与其他数据文件相比要“旧”,所认这时数据库中的数据文件并不同步(文件头部信息中的检查点号SCN 不同)。由于数据文件之间不一致,数据库仍然无法打开,这时就需使用归档日志对数据库进行恢复。恢复过程又包含两个主要步骤:缓存恢复和事务恢复。在缓存恢复完成后,数据库即可打开;但此时数据库中可能含有提交的事务,因此,在事务恢复后,将提交所有的事务,使数据库进入一致状态。
正是由于归档日志中记录了数据库的所有修改操作,从而保证了在数据库出现介质故障后,使用归档日志和备份就可以将数据库恢复到最近的状态。
在RMAN 中使用RESTORE 命令修复数据库时,RMAN 将启动一个服务器进程来完成将磁盘中的备份集或镜像副本修复数据文件、控制文件以及归档重做日志文件。在使用RMAN 进行数据库修复时,可以根据出现的故障,选择修复整个数据库、单独的表空间、单独的数据文件、控制文件以归档重做日志文件。例如,如果需要修复表空间USERS ,RMAN 将从备份集或镜像副本中查找USERS 表空间的备份,然后将它复制到控制文件指定的位置。
使用RMAN 进行修复操作时,RMAN 会通过恢复目录或者目标数据库的控制文件来获取所有的备份,并从中选择最合适的备份来完成恢复操作。RMAN 选择备份的准则为:距
注 意 上面的恢复操作仅适用于归档模式下的数据库,如果数据库运行在非归档模式下,那么,即使只损坏或丢失了一个数据文件,也必须使用全数据库脱机备份进行修复,然后不经恢复过程直接打开数据库。
Oracle备份恢复场景总结 一、数据文件、表空间恢复 1、数据库文件恢复 1>场景一: 问题描述: test.dbf丢失,有RMAN备份。 重启报错: Startup; ORA-01157: cannot identify/lock data file 5 - see DBWR trace file ORA-01110: data file 5: '/oracle/app/oracle/oradata/orcl/test01.dbf' run{ startup mount; allocate channel ch00 type 'SBT_TAPE'; restore datafile 5; recoverdatafile 5; alter database open; release channel ch00; }
2>场景二 问题描述: 模拟test表空间损坏,删除数据文件(恢复到新目录) 旧目录:/oracle/app/oracle/oradata 新目录: /home/oracle run{ allocate channel ch00 type 'SBT_TAPE'; sql 'alter database datafile 5 offline'; setnewname for datafile 5 to '/home/oracle/test01.dbf'; restoredatafile 5; switchdatafile 5; recoverdatafile 5; sql 'alter database datafile 4 online'; release channel ch00; } 说明: set newname for 告诉RMAN 还原数据文件的新位置在哪里。这个命令在restore 前出现。 switch datafile更新controlfile,记录这个新位置。这个命令要在recover 前出现
jsoup 简介 Java 程序在解析 HTML 文档时,相信大家都接触过 htmlparser 这个开源项目,我曾经在 IBM DW 上发表过两篇关于 htmlparser 的文章,分别是:从 HTML 中攫取你所需的信息和扩展 HTMLParser 对自定义标签的处理能力。但现在我已经不再使用 htmlparser 了,原因是 htmlparser 很少更新,但最重要的是有了jsoup 。 jsoup 是一款 Java 的 HTML 解析器,可直接解析某个 URL 地址、HTML 文本内容。它提供了一套非常省力的 API,可通过 DOM,CSS 以及类似于 jQuery 的操作方法来取出和操作数据。 jsoup 的主要功能如下: 1. 从一个 URL,文件或字符串中解析 HTML; 2. 使用 DOM 或 CSS 选择器来查找、取出数据; 3. 可操作 HTML 元素、属性、文本; jsoup 是基于 MIT 协议发布的,可放心使用于商业项目。 jsoup 的主要类层次结构如图 1 所示: 图 1. jsoup 的类层次结构 接下来我们专门针对几种常见的应用场景举例说明 jsoup 是如何优雅的进行HTML 文档处理的。 回页首
文档输入 jsoup 可以从包括字符串、URL 地址以及本地文件来加载 HTML 文档,并生成Document 对象实例。 下面是相关代码: 清单1 // 直接从字符串中输入 HTML 文档 String html = "
O R A C L E数据备份与数据恢 复方案 Prepared on 24 November 2020
摘要 结合金华电信IT系统目前正在实施的备份与恢复策略,重点介绍电信业务计算机管理系统(简称97系统)和营销支撑系统的ORALCE数据库备份和恢复方案。 Oracle数据库有三种标准的备份方法,它们分别是导出/导入 (EXP/IMP)、热备份和冷备份。要实现简单导出数据(Export)和导入数据(Import),增量导出/导入的按设定日期自动备份,可考虑,将该部分功能开发成可执行程序,然后结合操作系统整合的任务计划,实现特定时间符合备份规划的备份应用程序的运行,实现数据库的本级备份,结合ftp简单开发,实现多服务器的数据更新同步,实现数据备份的异地自动备份。 关键字:数据库远程异地集中备份 目录
一、前言 目前,数据已成为信息系统的基础核心和重要资源,同时也是各单位的宝贵财富,数据的丢失将导致直接经济损失和用户数据的丢失,严重影响对社会提供正常的服务。另一方面,随着信息技术的迅猛发展和广泛应用,业务数据还将会随业务的开展而快速增加。但由于系统故障,数据库有时可能遭到破坏,这时如何尽快恢复数据就成为当务之急。如做了备份,恢复数据就显得很容易。由此可见,做好数据库的备份至关重要。因此,建立一个满足当前和将来的数据备份需求的备份系统是必不可少的。传统的数据备份方式主要采用主机内置或外置的磁带机对数据进行冷备份,这种方式在数据量不大、操作系统种类单一、服务器数量有限的情况下,不失为一种既经济又简明的备份手段。但随着计算机规模的扩大,数据量几何级的增长以及分布式网络环境的兴起,将越来越多的业务分布在不同的机器、不同的操作平台上,这种单机的人工冷备份方式越来越不适应当今分布式网络环境。 因此迫切需要建立一个集中的、自动在线的企业级备份系统。备份的内容应当包括基于业务的业务数据,又包括IT系统中重要的日志文件、参数文件、配置文件、控制文件等。本文以ORACLE数据库为例,结合金华电信的几个相关业务系统目前正在实施的备份方案,介绍ORACLE数据库的备份与恢复。 二、金华电信ORACLE数据库的备份与恢复方案 由于金华电信IT系统以前只采用逻辑备份方式进行数据库备份,速度较慢并且数据存储管理都很分散,甚至出现备份数据不完整的现象。为了提高备份数据的效率,提供可靠的数据备份,完善备份系统,保证备份数据的完整性,降低数据备份对网络和服务器的影响,对每个IT系统的备份数据进行集中管理,我们对备份工作进行了改进,将逻辑备份与物理备份相结合,在远程建立了一个异地集中、自动在线的备份系统即网络存储管理系统。(这里用到的物理备份指热备份)其具备的主要功能如下:(1)集中式管理 :网络存储备份管理系统对整个网络的数据进行管理。利用集中式管理工具的帮助,系统管理员可对全网的备份策略进行统一管理,备份服务器可以监控所有机器的备份作业,也可以修改备份策略,并可即时浏览所有目录。所有数据可以备份到同备份服
ORACLE11G RMAN备份恢复到异机数据库 1. 主数据库环境 操作系统版本 : Centos6.7 x64 数据库版本 : Oracle 11.2.0.4 x64 数据库名 : prb 数据库SID : prb db_unique_name : prb instance_name : prb IP : 10.0.8.100 2. 备库环境 操作系统版本 : Centos6.7 x64 数据库版本 : Oracle 11.2.0.4 x64 (只安装oracle数据库软件,no netca dbca) 数据库名 : prb 数据库SID : prb db_unique_name: prb instance_name : prb IP:10.0.8.101 将参数文件备份、控制文件备份、数据文件备份、以及归档备份到目标主机 1 此处实验环境为同平台,同字节序,同版本,源机器和目标机器相同的目录结构。 2 目标机器只需要安装oracle只安装oracle数据库软件,no netca dbca 3 第一次利用备份恢复测试环境,之后从源机器拷贝备份到目标机器并在控制文件中注册,再见行恢复测试。 备份数据库 backup format '/u01/prb/rmanbk/fulldb_%d_%U' database include current controlfile plus archivelog delete input; orapwd file='/u01/app/oracle/product/11.2.0.4/db_1/dbs/orapwprb' password=oracle entries=10 force=y 1rman 连接到源数据库 prd-db1-> rman target / Recovery Manager: Release 11.2.0.4.0 - Production on Wed Aug 17 19:23:27 2016 Copyright (c) 1982, 2011, Oracle and/or its affiliates. All rights reserved. connected to target database: PRB (DBID=1906641159) RMAN> 2 分别列出参数文件备份,控制文件备份,数据文件备份,以及归档备份的名字 参数文件备份如下: RMAN> list backup of spfile; using target database control file instead of recovery catalog List of Backup Sets ===================
实验8 Oracle数据库备份与恢复 1 实验目的 (1)掌握Oracle数据库各种物理备份方法。 (2)掌握Oracle数据库各种物理恢复方法。 (3)掌握利用RMAN工具进行数据库的备份与恢复。 (4)掌握数据的导入与导出操作。 2 实验要求 (1)对BOOKSALES数据库进行一次冷备份。 (2)对BOOKSALES数据库进行一次热备份。 (3)利用RMAN工具对BOOKSALES数据库的数据文件、表空间、控制文件、初始化参数 文件、归档日志文件进行备份。 (4)利用热备份恢复数据库。 (5)利用RMAN备份恢复数据库。 (6)利用备份进行数据库的不完全恢复。 3 实验步骤 (1)关闭BOOKSALES数据库,进行一次完全冷备份。 select file_name from dba_data_files; select member from v$logfile; select value from v$parameter where name='control_files';
(2)启动数据库后,在数据库中创建一个名为cold表,并插入数据,以改变数据库的状态。 CREATE TABLE COLD( ID NUMBER PRIMARY KEY, NAME VARCHAR2(25) ); (3)利用数据库冷备份恢复BOOKSALES数据库到备份时刻的状态并查看恢复后是否
存在cold表。 (4)将BOOKSALES数据库设置为归档模式。 1.1 shutdown immediate 正常关闭数据 1.2 startup mount;将数据库启动到mount状态 3)、关闭flash闪回数据库模式,如果不关闭的话,在后面关闭归档日志的时候就会出现讨厌的ora-38774错误。 alter database flashback off 1.3 alter database archivelog;发出设置归档模式的命令 1.4 alter database open;打开数据库 1.5 再次正常关闭数据库,并备份所有的数据文件和控制文件 1.6archive log list;在将数据库设置为归档模式后,可以执行此命令进行确认 1.6.1 Database log mode 为Archive Mode说明当前的数据库为归档模式 1.6.2 Automatic archival为Enable说明启动了自动归档。
1、抓取网页数据通过指定的URL,获得页面信息,进而对页面用DOM进行 NODE分析, 处理得到原始HTML数据,这样做的优势在于,处理某段数据的灵活性高,难点在节算法 需要优化,在页面HTML信息大时,算法不好,会影响处理效率。 2、htmlparser框架,对html页面处理的数据结构,HtmlParser采用了经典的Composite 模式,通过RemarkNode、TextNode、TagNode、AbstractNode和Tag来描述HTML页面 各元素。Htmlparser基本上能够满足垂直搜索引擎页面处理分析的需求,映射HTML标签,可方便获取标签内的HTML CODE。 Htmlparser官方介绍: htmlparser是一个纯的java写的html解析的库,它不依赖于其它的java库文件,主要用于改造或提取html。它能超高速解析html,而且不会出错。现在htmlparser最新版本为2.0。毫不夸张地说,htmlparser就是目前最好的html解析和分析 的工具。 3、nekohtml框架,nekohtml在容错性、性能等方面的口碑上比htmlparser好(包括htmlunit也用的是nekohtml),nokehtml类似XML解析原理,把html标签确析为dom, 对它们对应于DOM树中相应的元素进行处理。 NekoHTML官方介绍:NekoHTML是一个Java语言的HTML扫描器和标签补全器(tag balancer) ,使得程序能解析HTML文档并用标准的XML接口来访问其中的信息。这个解析 器能够扫描HTML文件并“修正”许多作者(人或机器)在编写HTML文档过程中常犯的错误。 NekoHTML能增补缺失的父元素、自动用结束标签关闭相应的元素,以及不匹配的内嵌元 素标签。NekoHTML的开发使用了Xerces Native Interface (XNI),后者是Xerces2的实现基础。由https://www.doczj.com/doc/d43197338.html,/整理
oracle数据库备份与恢复方案
目录 一、编写目的 (1) 二、备份工具及备份方式 (1) 三、软件备份 (1) 四、软件恢复 (2) 五、数据备份 (2) 六、备份的存储 (2) 七、备份数据的保存规定 (3) 八、备份介质的格式 (3) 九、数据恢复 (4)
一、编写目的 本文档主要说明公司项目在实施现场的软件及数据的备份和恢复方案。 二、备份工具及备份方式 1.备份工具 Oracle RMAN(Recovery Manager):是一种用于备份(backup)、还原 (restore)和恢复(recover)数据库的Oracle 工具。RMAN只能用于ORACLE8 或更高的版本中。它能够备份整个数据库或数据库部件,如表空间、数据文件、控制文件、归档文件以及Spfile参数文件。RMAN也允许您进行增量数据块级 别的备份,增量RMAN备份是时间和空间有效的,因为他们只备份自上次备 份以来有变化的那些数据块。 2.备份方式 (1)自动备份:由Windows 计划任务调度完成; (2)手工备份:完成特殊情况下的备份,分热备份和冷备份,热备份是指在不 关闭数据库情况下进行备份,冷备份则需要停止Oracle实例服务。 三、软件备份 1.以七天为一个周期每天23:00将所有软件拷贝到其他存储介质上 2.超出七天的备份依次删除 3.每月一号将上月最后7天的备份文件刻录到光盘上
四、软件恢复 1.找出最近的备份程序覆盖到正式运行环境的相应目录中 五、数据备份 1.业务系统或数据库在打重要补丁或升级的前后,必须按要求对业务系统进行停 机备份或非停机备份,备份需包含应用和数据库的文件系统及数据,备份方式为手工备份,使用RMAN执行备份; 2.系统日常备份:作为7*24运行的重要系统,必须最小化数据丢失的同时,还 需要尽可能缩短恢复时间,数据库的日常备份策略如下: (1)确保数据库处于ArchiliveLog模式; (2)每日凌晨01:00执行数据库全备份,含控制文件备份; (3)每四小时间隔执行数据库归档日志备份,含控制文件备份; (4)每间隔两周执行数据库与应用系统文件备份,执行时间:数据库服务器在第一周的周六05:00,应用服务器在第一周的周六7:00。 3.每周一将上周的备份文件拷贝到其它存储介质上; 4.每月一号将上月最后一周的备份文件刻录到光盘上。 六、备份的存储 1.在确保成功备份数据的同时,必须严格保证存储结构的完整性,在备份服务器 或备份带库上需要保留足够的剩余空间,以存储需要保存的多份备份文件; 2.如项目上采用了专门的备份软件,有专用的备份存储,应提前规划好备份的存
Oracle数据库备份恢复测试报告
目录 1.背景概述 (1) 1.1恢复测试目的 (1) 1.2恢复测试方法 (1) 1.3数据库备份架构 (1) 2.恢复所需资源 (2) 2.1主机资源 (2) 2.2实施环境 (2) 3.数据库恢复测试步骤 (3) 3.1安装配置测试主机 (3) 3.2全库恢复 (3) 3.3测试主机-TSM恢复配置 (3) 3.4测试主机-设定数据库环境变量 (4) 3.5测试主机-启动数据库到NOMOUNT状态 (4) 3.6测试主机-恢复控制文件 (4) 3.7测试主机-更改数据库到MOUNT状态 (5) 3.8测试主机-恢复数据文件 (5) 3.9测试主机-恢复归档日志 (9) 3.10测试主机-以RESETLOGS方法打开数据库 (11) 3.11测试主机-重启数据库 (11) 4.恢复结果 (12)
1.背景概述 1.1恢复测试目的 为了验证数据库的备份有效性,我们进行了此次的数据库恢复测试,用来确保 数据库备份的正确性,可恢复性。 1.2恢复测试方法 异机恢复 因为生产数据库已经在使用,我们不能在生产数据库上进行本机恢复测试,为 了不影响生产数据库的正常使用,我们将在测试机上进行恢复测试。 1.3数据库备份架构 1.备份系统采用IBM Tivoli备份软件; 2.带库使用ADIC磁带库。
2.恢复所需资源 2.1主机资源 需要准备恢复的测试主机,最佳做法是恢复测试主机的硬件架构、操作系统版本和生产主机一致。 2.2实施环境
3.数据库恢复测试 步骤 3.1安装配置测试主机 因为测试机完全拷贝备份主机,故测试机与生产机环境一致,确保测试主机已经正常 运行,并能于要恢复的生产主机,备份主机网络连通。 3.2全库恢复 利用TSM软件界面,调用原来所备份的数据库,以及相应的数据库恢复工具RMAN的 脚本,进行ORACLE 数据库系统的全库恢复。 3.3测试主机-TSM恢复配置 因为测试主机与生产主机架构相同,故只需在TSM SERVER上定义SAN server。 如下:
目录 数据库恢复方案 (1) 文档控制 (1) 一、相关概念 (3) 1,恢复的两个阶段 (3) 2,Oracle实例启动的三个阶段 (3) 3,RMAN信息的保存位置 (3) 二、完全恢复 (3) (一) 控制文件 (3) 1) 丢失部分控制文件: (3) 2) 丢失全部控制文件 (3) (二) 重做日志文件 (4) 1) 非当前使用的重做日志文件: (4)
2) 当前使用的重做日志文件(未归档): (4) (三) 数据文件 (4) 1) 无归档模式下的完全恢复 (4) 2) 归档模式下的完全恢复 (5) 三、不完全恢复 (6) (一) 基于SCN的不完全恢复 (6) 1) 准备工作 (6) 2) 使用RMAN进行恢复 (7) (二) 基于时间点的不完全恢复 (8) 1) 准备工作 (8) 2) 使用RMAN进行恢复 (8) 四、高级篇 (9)
(一) 使用RMAN进行异机同目录 (9) 1) 准备工作 (9) 2) 通过RMAN进行异机恢复 (10) (二)使用RMAN进行异机异目录 (11) 1) 准备工作 (11) 2) 通过RMAN进行异机恢复 (11) (三)使用RMAN进行在线数据块恢复 (14) 一、相关概念 1,恢复的两个阶段 数据库无论采取哪种方式进行恢复都分为Restore和Recover两个步骤。Restore(还原):把控制文件、重做日志文件和数据文件还原到正确位置。Recover(恢复):恢复还原后的数据文件,使数据库达到一致状态。
2,Oracle实例启动的三个阶段 Oracle实例启动经过三个阶段: l NOMOUNT(未装载):读入参数文件,验证参数文件中的目录是否存在。 l MOUNT(装载):读入参数文件指定位置的控制文件。 l OPEN(打开):验证控制文件中指定的重做日志文件和数据文件是否正确、数据文件是否一致,然后读入数据文件中的数据。 所以按照如下顺序使数据库正确打开。 1) SHUTDOWN(关闭)状态下,确保参数文件指定的文件夹存在,启动到NOMMUNT 状态。 2) NOMOUNT状态下,保证控制文件的位置和命名与参数文件中相同,控制文件中指定的重做日志文件和数据文件存在,然后启动到MOUNT状态。 3) MOUNT状态下,执行RMAN还原和恢复操作。
ORACLE 11G AIX HA ----NBU异机恢复过程 恢复前提 1.两台机器上NUB软件都已经安装好 2.指定Master SERVER 上的/usr/openv/netbackup/bp.conf恢复源 FORCE_RESTORE_MEDIA_SERVER = 生产库hostname 测试库hostname 从生产库恢复到测试库。 操作目的 节点POTLDB01 数据库恢复到POTLDB02 即在节点POTLDB01上运行,并在节点POTLDB01上备份,恢复到POTLDB02上 节点POTLDB01机器检查过程 1.检查环境变量检查 root@POTLDB01:/usr/openv/rmanscript#ps -ef |grep smon root 385272 467274 0 10:40:22 pts/2 0:00 grep smon oracle 655484 1 0 Jul 25 - 0:06 ora_smon_portaldb 机器名字 root@POTLDB01:/usr/openv/rmanscript#hostname POTLDB01 root@POTLDB01:/usr/openv/rmanscript#pwd ---rman脚本位置 /usr/openv/rmanscript root@POTLDB01:/usr/openv/rmanscript#ls hot_database_portaldb.sh hot_database_portaldb.sh.out hot_database_portaldb.sh_bak /etc/hosts文件 172.16.3.115 POTLDB01_boot 172.16.3.116 POTLDB02_boot 172.16.3.116 POTLDB02 172.16.3.115 POTLDB01 1.1.3.115 POTLDB01_stby 1.1.3.116 POTLDB02_stby
SQL> conn / as sysdba 已连接。 SQL> create directory mydump as 'd:\oracle\mydump'; SQL> Grant read,write on directory mydump to test; 授权成功。 创建目录d:\oracle\mydump。 C:\Users\David>expdp test/test directory=mydump dumpfile=test.dmp logfile=test.l og tables=t1 Export: Release 11.2.0.1.0 - Production on 星期三7月16 22:52:58 2014 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. 连接到: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Produc tion With the Partitioning, OLAP, Data Mining and Real Application Testing options 启动"TEST"."SYS_EXPORT_TABLE_01": test/******** directory=mydump dumpfile=test .dmp logfile=test.log tables=t1 正在使用BLOCKS 方法进行估计... 处理对象类型TABLE_EXPORT/TABLE/TABLE_DATA 使用BLOCKS 方法的总估计: 64 KB 处理对象类型TABLE_EXPORT/TABLE/TABLE 处理对象类型TABLE_EXPORT/TABLE/STATISTICS/TABLE_STATISTICS . . 导出了"TEST"."T1" 5.507 KB 5 行 已成功加载/卸载了主表"TEST"."SYS_EXPORT_TABLE_01" ****************************************************************************** TEST.SYS_EXPORT_TABLE_01 的转储文件集为: D:\ORACLE\MYDUMP\TEST.DMP 作业"TEST"."SYS_EXPORT_TABLE_01" 已于22:53:09 成功完成 需要将原表删除。 C:\Users\David>impdp test/test directory=mydump dumpfile=test.dmp tables=t1 Import: Release 11.2.0.1.0 - Production on 星期三7月16 23:00:28 2014 Copyright (c) 1982, 2009, Oracle and/or its affiliates. All rights reserved. 连接到: Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Produc
—102 — 基于内容相似度的网页正文提取 王 利1,刘宗田1,王燕华2,廖 涛1 (1. 上海大学计算机科学与工程学院,上海 200072;2. 上海海洋大学信息学院,上海 201306) 摘 要:提出一种将复杂的网页脚本进行简化并映射成一棵易于操作的树型结构的方法。该方法不依赖于DOM 树,无须用HTMLparser 包进行解析,而是利用文本相似度计算方法,通过计算树节点中文本内容与各级标题的相似度判定小块文本信息的有用性,由此进行网页清洗与正文抽取,获得网页文本信息,实验结果表明,该方法对正文抽取具有较高的通用性与准确率。 关键词:网页正文抽取;网页映射;网页清洗;文本相似度 Web Page Main Text Extraction Based on Content Similarity WANG Li 1, LIU Zong-tian 1, WANG Yan-hua 2, LIAO Tao 1 (1. School of Computer Science and Engineering, Shanghai University, Shanghai 200072; 2. School of Information Technology, Shanghai Fisheries University, Shanghai 201306) 【Abstract 】This paper proposes a method of simplifying complex Web page script and mapping it into tree structure easy to operate. It does not depend on DOM tree, and does not need utilize htmlparser bag to parse. By calculating text similarity, it calculates the similarity between the content of tree node and headings of different levels to determine the usefulness of the text information, cleans the Web page and extracts the content information. Experimental results show that the method has better universal property and accuracy rate in main text extraction. 【Key words 】Web page main text extraction; Web page mapping; Web page cleaning; text similarity 计 算 机 工 程 Computer Engineering 第36卷 第6期 Vol.36 No.6 2010年3月 March 2010 ·软件技术与数据库· 文章编号:1000—3428(2010)06—0102—03 文献标识码:A 中图分类号:TP393 1 概述 随着Internet 的飞速发展,网络上的信息呈爆炸式增长。 网页己经成为Internet 上最重要的信息资源。各种网页为人们提供了大量可供借鉴或参考的信息,成为人们日常工作和生活必不可少的一部分。然而,网页上的信息经常包含大量的噪声,如广告链接、导航条、版权信息等非网页主题信息的内容,页面所要表达的主要信息经常被隐藏在无关的内容和结构中,限制了Web 信息的可利用性。本文主要对网页上的这些噪声进行滤除,并抽取网页正文信息,即网页清洗。它是Web 文本分类、聚类、文本摘要等文本信息处理的基础,网页正文抽取的效果直接影响到文本信息处理的效果。 本文的方法首先抽取出HTML 页面中的title 及各级标题,再对网页进行标准化预处理,然后建立一种新的树型结构,HTML 中的所有正文信息都包含在这棵树的节点中。利用这种树型结构可以方便地清洗网页中的噪声、抽取出网页中的正文信息。在抽取网页正文信息时,较大的文本块根据文本的长度极易抽取出,而对于只有小文本块的节点,由于页面中的title 及各级标题高度概括了该网页的主要内容,因此可以根据各节点内容与title 、各级标题的相似度来判定该节点的信息文本是否为有用文本,只要该小块文本与title 或某个子标题的相似度大于设定阈值,就判定其为有用信息。 2 相关工作 虽然网页正文提取是Web 文本挖掘中的一个重要问题, 但相关研究并不多。目前对网页进行噪声过滤与信息自动抽取的方法主要有两大类:(1)针对单一页面进行处理。根据所处理页面的内容特征、可视信息等应用一些启发性规则去除页面的噪音,抽取出页面内容。这类方法对每一个待处理的网页进行同样的处理,对于抽取通过模板产生的网页集效率较低。(2)针对同一站点中页面的一般模式进行处理。这种方法是基于一个或多个网站中的页面集进行模板检测的,但局限于由同一个模板生成的网页集,直接影响清洗的自适应性。 文献[1]的研究仅限于某些特定站点,在这些站点中根据合并不同页面生成的DOM 树来标记页面中哪些是有用信息哪些是噪声,并通过这些标记达到页面清洗的目的。文献[2]根据HTML 标签生成树,通过分析同一网站下网页之间模板的相似性来识别数据区域。文献[3]基于DOM 规范,提出了基于语义信息的STU-DOM 树模型,将HTML 文档转换为STU-DOM 树,并对其进行基于结构的过滤和基于语义的剪枝,完成了对网页主题信息的抽取。文献[4]采用基于标记窗的方法并利用Levenshtein Distance 公式计算标记窗中字符串与标题词之间的距离,从而判断该字符串是否为正文信息,该方法容易导致很多噪声无法滤除。 通过分析可知,现有的网页清洗方法大多基于DOM 树并用HTMLparser 程序包[5]对其进行解析,这种方法效率不高,而且依赖于第三方包。对此本文提出了一种简单的树型结构,在这棵树中保存了正文信息,同时消除了一些无用信息,并对各节点进行了简化,带来了操作上极大的便利。另外,在这棵树中可以通过深度搜索子节点来消除传统方法中不能处理网页正文部分被存放在多个td 中的情况以及不能处 基金项目:国家自然科学基金资助项目(60575035, 60975033);上海市重点学科建设基金资助项目(J50103);上海大学研究生创新基金资助项目(SHUCX092162) 作者简介:王 利(1984-),男,硕士研究生,主研方向:文本挖掘,事件本体;刘宗田,教授、博士生导师;王燕华,硕士研究生;廖 涛,博士研究生 收稿日期:2009-08-10 E-mail :wonglee07@https://www.doczj.com/doc/d43197338.html,
Oracle数据库备份与恢复的三种方法 当我们使用一个数据库时,总希望数据库的内容是可靠的、正确的,但由于计算机系统的故障(包括机器故障、介质故障、误操作等),数据库有时也可能遭到破坏,这时如何尽快恢复数据就成为当务之急。如果平时对数据库做了备份,那么此时恢复数据就显得很容易。由此可见,做好数据库的备份是多么的重要,下面笔者就以ORACLE7 为例,来讲述一下数据库的备份和恢复。ORACLE 数据库有三种标准的备份方法,它们分别为导出/导入(EXPORT/IMPORT)、冷备份、热备份。导出备份是一种逻辑备份,冷备份和热备份是物理备份。 Oracle数据库有三种标准的备份方法,它们分别是导出/导入(EXP/IMP)、热备份和冷备份。导出备件是一种逻辑备份,冷备份和热备份是物理备份。 一、导出/导入(Export/Import) 利用Export可将数据从数据库中提取出来,利用Import则可将提取出来的数据送回到Oracle数据库中去。 1、简单导出数据(Export)和导入数据(Import) Oracle支持三种方式类型的输出: (1)、表方式(T方式),将指定表的数据导出。 (2)、用户方式(U方式),将指定用户的所有对象及数据导出。
(3)、全库方式(Full方式),瘵数据库中的所有对象导出。 数据导入(Import)的过程是数据导出(Export)的逆过程,分别将数据文件导入数据库和将数据库数据导出到数据文件。 2、增量导出/导入 增量导出是一种常用的数据备份方法,它只能对整个数据库来实施,并且必须作为SYSTEM来导出。在进行此种导出时,系统不要求回答任何问题。导出文件名缺省为export.dmp,如果不希望自己的输出文件定名为export.dmp,必须在命令行中指出要用的文件名。 增量导出包括三种类型: (1)、“完全”增量导出(Complete) 即备份三个数据库,比如: exp system/manager inctype=complete file=040731.dmp (2)、“增量型”增量导出 备份上一次备份后改变的数据,比如: exp system/manager inctype=incremental file=040731.dmp (3)、“累积型”增量导出 累计型导出方式是导出自上次“完全”导出之后数据库中变化了的信息。比如: exp system/manager inctype=cumulative file=040731.dmp 数据库管理员可以排定一个备份日程表,用数据导出的三个不同方式合理高效的完成。
https://www.doczj.com/doc/d43197338.html, python抓取网页数据的常见方法 很多时候爬虫去抓取数据,其实更多是模拟的人操作,只不过面向网页,我们看到的是html在CSS样式辅助下呈现的样子,但爬虫面对的是带着各类标签的html。下面介绍python抓取网页数据的常见方法。 一、Urllib抓取网页数据 Urllib是python内置的HTTP请求库 包括以下模块:urllib.request 请求模块、urllib.error 异常处理模块、urllib.parse url解析模块、urllib.robotparser robots.txt解析模块urlopen 关于urllib.request.urlopen参数的介绍: urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None) url参数的使用 先写一个简单的例子:
https://www.doczj.com/doc/d43197338.html, import urllib.request response = urllib.request.urlopen(' print(response.read().decode('utf-8')) urlopen一般常用的有三个参数,它的参数如下: urllib.requeset.urlopen(url,data,timeout) response.read()可以获取到网页的内容,如果没有read(),将返回如下内容 data参数的使用 上述的例子是通过请求百度的get请求获得百度,下面使用urllib的post请求 这里通过https://www.doczj.com/doc/d43197338.html,/post网站演示(该网站可以作为练习使用urllib的一个站点使用,可以 模拟各种请求操作)。 import urllib.parse import urllib.request data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
Oracle数据库10g备份和恢复:RMAN和闪回技术 Oracle 白皮书 2004 年 6 月
发展和革命 (3) 恢复管理器 (3) 快速恢复区 (4) 自动存储管理 (6) 更改跟踪文件 (6) 增量更新备份 (7) Oracle 建议的策略 (7) 备份管理 (9) 跨平台的传输 (10) 革命还未结束 (11) RMAN 比对用户管理的恢复 (11) 网格集群 (13) 人为错误的挑战 (13) 人为错误纠正—闪回技术 (13) 人为错误的传统恢复 (14) 恢复时间目标 (14) 何时使用闪回与传统恢复的对比 (14) 闪回数据库 (15) 闪回表 (17) 闪回删除 (18) 什么是回收站? (18) 闪回查询 (18) 闪回版本查询 (20) 闪回事务查询 (20) 实例 (21) 结论 (22)
发展和革命 数据库备份可能是防止 Oracle 数据库发生介质故障的唯一方式。使用提供给 DBA 的大量工具和方法来恢复关键数据的重要性是毋庸置疑的。保护 Oracle 数据的成本和复杂性包括,从简单的每周备份到磁带,到记录更加繁复的文件快照或备用数据库。Oracle Data Guard1.的体系结构有助于企业恢复对 Oracle 数据库造成不利影响的灾难、人为错误和损坏。每个工具和选项都有其自己的持续可用性优势,并且可以快速备份和/或恢复 Oracle 数据库。 为了保护和恢复数据所采纳的方法或工具应该具有: 可靠性。所有需要恢复的文件都进行了备份,且通过恢复操作能够方便地恢复文件。 灵活性。Oracle 数据库可以在数据库、表空间、数据文件和块级上备份或恢复。 可管理性组织和管理备份文件以便用于恢复操作。 可用性。备份操作不应该干扰数据库事务处理过程同时恢复操作应该快速、有效。 Oracle 恢复管理器通过新的版本和 Oracle 数据库 10g 包含的革命性技 术进步继续得以完善,并提供您一直期待的简单、可靠和自动的恢复工具。此白皮书列出了 Oracle 数据库 10g 用于备份和恢复文件管理的新功能,增强的增量备份和异构平台上相同表空间数据的共享。让革命开始吧! 恢复管理器 恢复管理器 (RMAN) 是管理备份和更重要的数据库恢复的 Oracle 公用程序。提供数据库高级的性能和可用性的同时消除了操作的复杂性。从 Oracle8 开始,恢复管理器为 DBA 提供了集成的备份和恢复解决方案。 1有关 Data Guard 的详细信息,请访问 https://www.doczj.com/doc/d43197338.html,/deploy/availability/htdocs/odg_overview.html。