
决策支持系统导论期末作业
姓名:
学号:
哈工大
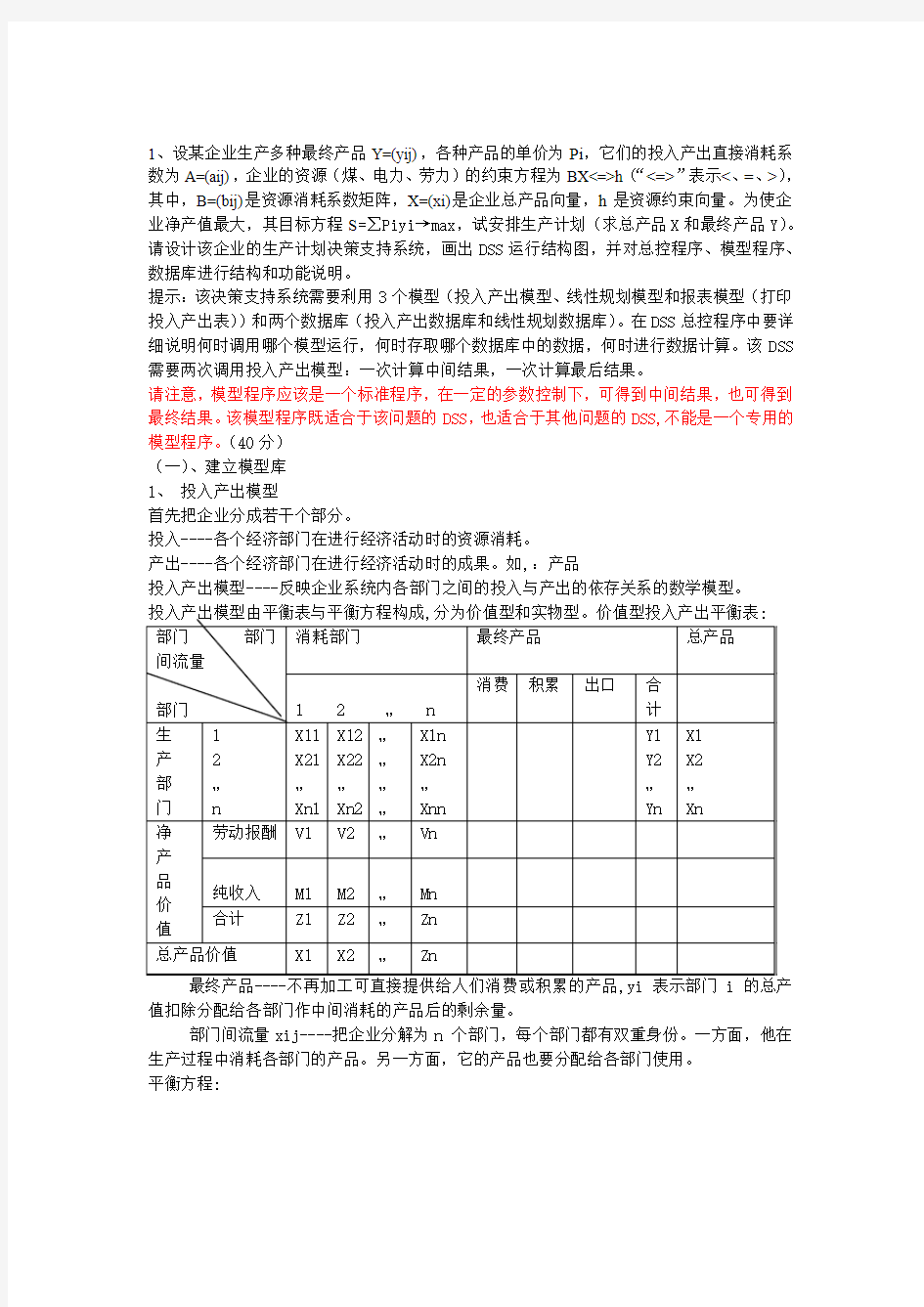
1、设某企业生产多种最终产品Y=(yij),各种产品的单价为Pi,它们的投入产出直接消耗系数为A=(aij),企业的资源(煤、电力、劳力)的约束方程为BX<=>h(“<=>”表示<、=、>),其中,B=(bij)是资源消耗系数矩阵,X=(xi)是企业总产品向量,h是资源约束向量。为使企业净产值最大,其目标方程S=∑Piyi→max,试安排生产计划(求总产品X和最终产品Y)。请设计该企业的生产计划决策支持系统,画出DSS运行结构图,并对总控程序、模型程序、数据库进行结构和功能说明。
提示:该决策支持系统需要利用3个模型(投入产出模型、线性规划模型和报表模型(打印投入产出表))和两个数据库(投入产出数据库和线性规划数据库)。在DSS总控程序中要详细说明何时调用哪个模型运行,何时存取哪个数据库中的数据,何时进行数据计算。该DSS 需要两次调用投入产出模型:一次计算中间结果,一次计算最后结果。
请注意,模型程序应该是一个标准程序,在一定的参数控制下,可得到中间结果,也可得到最终结果。该模型程序既适合于该问题的DSS,也适合于其他问题的DSS,不能是一个专用的模型程序。(40分)
(一)、建立模型库
1、投入产出模型
首先把企业分成若干个部分。
投入----各个经济部门在进行经济活动时的资源消耗。
产出----各个经济部门在进行经济活动时的成果。如,:产品
投入产出模型----反映企业系统内各部门之间的投入与产出的依存关系的数学模型。
值扣除分配给各部门作中间消耗的产品后的剩余量。
部门间流量xij----把企业分解为n 个部门,每个部门都有双重身份。一方面,他在生产过程中消耗各部门的产品。另一方面,它的产品也要分配给各部门使用。
平衡方程:
分配平衡方程
i
i n
j x y x
=+∑=1
ij
,i=1,2,…,n 反映部门i 的分配情况
消耗平衡方程 ∑
==+n
i j
j ij x
z x 1
②,j=1,2,…,n 反映部门j 的消
耗情况
综合平衡方程
∑∑
===
m
i n
i
j j
i z
y 1
,中间使用+最终产品=总产出
直接消耗系数::
为了更深入地研究各部门、生产与消耗的关系,引入直接消耗系数的概念。部门j 所生
产的单位价值的产品对部门i 的产品的直接消耗量为 j
ij x
x =
ij a ,i ,j=1,2,3……,n
④称为部门j 对部门i 的直接消耗系数,
而
n m ij a A ?=)(称为直接消耗系数矩阵,,从④得j ij ij a x x =把它代入①
得⑤∑
==+n
j i
i ij
x y a
1
,i=1,2,3….,n ⑤
设
T
T
n Y x x x )
,...,y ,y (y ,,...,,X n 2121==)(,AX+Y=X 即(I-A)X=Y
⑥。
可见ij a 具有性质:①10
<≤ij a ② 11
<∑=n
i ij a (j=1,2,..,n)
通过上述公式可推得:Y
X -1
A)-(I = ⑦
完全消耗系数:
完全消耗系数是指第j 产品部门每提供一个单位最终使用时,对第i 产品部门货物或服务
的直接消耗和间接消耗之和。将各产品部门的完全消耗系数用表的形式表现出来,就是完全消耗系数表或完全消耗系数矩阵,通常用字母B 表示。完全消耗系数的计算公式为
n)
1,2,...,j ...(i,a b 111
n 11
-ij ij =++
+=∑∑∑∑∑====n
t n s n
k kj sk it
s n k kj sk si
a a a
a a a
:
式中的第一项aij 表示第j 产品部门对第i 产品部门的直接消耗量;式中的第二项
∑=n
k kj
ik
a a
1
表示第j 产品部门对第i 产品部门的第一轮间接消耗量;依此类推,第n+1
项为第n 轮间接消耗量。按照公式所示,将直接消耗量和各轮间接消耗量相加就是完全消耗系数。
完全消耗系数矩阵可以在直接消耗系数矩阵的基础上计算得到的,利用直接消耗系数矩阵计算完全消耗系数矩阵的公式为:I -A -I B -1
)(= 式中的A 为直接消耗系数矩阵,I 为
单位矩阵,为完全消耗系数矩阵。
标准程序描述:
该模型的输入参数主要有A 、Y,当Y==0 时,即为初始化状态时,输出中间结果,根据模 型内部的数学公式Y
A -I X -1
)(=,输出-1
A -I )
((或者输入参数B,
输出(B+I ));若Y !=0,则输出最终结果X 。
(二)、线性规划模型
选择x1,x2,…,x n 的值,借以使S=ΣPiyi →max 达到最大,约束方程为BX<=>h 中B 、X 、h 均为矩阵或向量)约束条件展开为::
0)
0,...x 0,x (x h b ...b b .......
..........h b ...b b h b ...b b n 21n mn 2m21m12n 2n 2221211n 1n 212111≥≥≥≤+++≤+++≤+++m x x x x x x x x x
输入参数为B 、P 、h,运用模型中的数学公式求解问题,最后输出Y 。
(三)、报表模型
调用投入产出数据库中的数据,根据投入产出模型的分析结果,得到投入产出表,并将 其打印出来。不需要输入参数,可以手动调用,也可以用时间来触发,生成表格。 数据库
(一)、 投入产出数据库
数据库首先对数据进行初始化,其中存入了投入产出相关的数据,包括最终产品Y=(yj),, 各种产品的单价为Pi ,它们的投入产出直接消耗系数A=(aij),资源消耗系数矩阵B=(bij)即完全消耗系数,企业总产品向量X=(xi)等用于投入产出表计算的重要数据,方便模型对数据的提取。数据库本身可以对数据进行维护,如自动初始化,自动更新等操作。 (二)、线性规划数据库
该数据库中存放用于线性规划运算的数据,首先要对数据进行初始化,存储的数据包括 最终产品Y=(yj),各种产品的单价为Pi ,资源消耗系数矩阵B=(bij),企业总产品向量X=(xi)
企业的资源(煤、电力、劳力)的约束方程为BX<=>h(“<=>”表示<、=、>)目标方程S=
ΣPiyi 等线性规划是需要的数据。数据库设计要方便用户与相关模型的数据提取。
人机交互子系统
用友好的界面来提供服务,首先让用户选择需要决策的问题,之后提示用户输入相关的数据,其重要提示用户输入数据的格式及注意事项。之后运行模型库、数据库等解决相关问题并进行必要提示,最后将运行结果返回给用户。
总控程序
1) 据系统提示选择需要的服务,输入提示要求的相关数据,保存到数据库中。
2) 用投入产出模型,提取投入产出数据库中A、Y 作为模型的输入参数。调用模型内部的公式解决问题,根据输入参数判断需要输出的是中间结果还是最终结果,将结果输并存入投入产出数据库中。
3) 用线性模型,提取线性规划数据库中的数据作为输入参数,根据模型内部公式进行数据计算,既要符合约束条件,又要使得目标函数值最大,最终得出Y 向量,将结果输出并存入投入产出数据库。
4) 用投入产出模型,提取投入产出数据库中的A、Y 作为输入参数。调用模型内部公式计算出需要的结果X,根据输入参数判断需要的输出结果,输出结果,并存入投入产出数据库。
5) 用报表模型,提取投入产出数据库中的数据,得出投入产出表并打印。
DSS
控制流:
数据流:2、考虑去卡拉OK厅唱歌的时候,是否要等待包间的问题。规定如下属性可用于描述该领
域内的实例:
(1)Others(其他地点):附近是否有其他卡拉OK厅;
(2)WaitCond(等候条件):供顾客等候的地方是否舒适;
(3)Weekend(周末):若是周六或周日,则为真;
(4)Conssumers(顾客):店中有多少顾客(值为None(没人),Some(一些)或Full(满座));
(5)Price(价格):价格范围(值为Cheep(便宜),Middle(中等),Expensive(较贵));(6)Raining(下雨):外面是否在下雨;
(7)Reservation(预约):是否预约过;
(8)WaitEstimate(等候时间估计):估计的等候时间(值为0—10,10—30,30—60,>60,单位为分钟)。
训练集见表:
解答:
通过对训练集进行训练建立神经网络模型,首先对训练集输入数字化,如下表:
之后建立神经网络,设置输入输出向量,网络层数及网络各层权值阈值。然后进行训练得到神将网络模型。最后进行容错分析,可以训练原训练集的数据,分析网络的准确性,均
方差的误差值等,也可以对原训练集数据稍作修改,看是否会影响所作的决策。
对训练集数据修改后如下表,用来进行容错分析。
Warning: Could not get change notification handle for local C:\Program
Files\MATLAB\R2007b\work.
Performance degradation may occur due to on-disk directory change checking. >> close all
>> clear
>> echo on
>> pause;
>> P=[1 0 0 0 -1 0 1 1; 1 0 0 -1 1 0 0 0;
0 1 0 0 1 0 0 1; 1 0 1 -1 1 1 0 0.5;
1 0 1 -1 -1 0 1 -1; 0 1 0 0 0 1 1 1;
0 1 0 1 1 1 0 1; 0 0 0 0 0 1 1 1;
0 1 1 -1 1 1 0 -1; 1 1 1 -1 -1 0 1 0.5;
0 0 0 1 1 0 0 1; 1 1 1 -1 1 0 0 0;]';
>> T=[1 0 1 1 0 1 0 1 0 0 0 1];
>> pause;
>> net=newff(minmax(P),[3,1],{'tansig','purelin'},'traingdm') Warning: NEWFF used in an obsolete way.
> In nntobsu at 18
In newff at 105
See help for NEWFF to update calls to the new argument list. net =
Neural Network object:
architecture:
numInputs: 1
numLayers: 2
biasConnect: [1; 1]
inputConnect: [1; 0]
layerConnect: [0 0; 1 0]
outputConnect: [0 1]
numOutputs: 1 (read-only)
numInputDelays: 0 (read-only)
numLayerDelays: 0 (read-only)
subobject structures:
inputs: {1x1 cell} of inputs
layers: {2x1 cell} of layers
outputs: {1x2 cell} containing 1 output
biases: {2x1 cell} containing 2 biases
inputWeights: {2x1 cell} containing 1 input weight
layerWeights: {2x2 cell} containing 1 layer weight
functions:
adaptFcn: 'trains'
divideFcn: (none)
gradientFcn: 'calcgrad'
initFcn: 'initlay'
performFcn: 'mse'
trainFcn: 'traingdm'
parameters:
adaptParam: .passes
divideParam: (none)
gradientParam: (none)
initParam: (none)
performParam: (none)
trainParam: .epochs, .goal, .lr, .max_fail,
.mc, .min_grad, .show, .time
weight and bias values:
IW: {2x1 cell} containing 1 input weight matrix
LW: {2x2 cell} containing 1 layer weight matrix
b: {2x1 cell} containing 2 bias vectors
other:
userdata: (user information)
>> inputWeights=net.IW{1,1}
inputWeights =
0.9333 1.2258 -0.6569 0.6893 0.6779 -1.0620 0.8665 -0.6884
1.6281 0.5310 0.1881 -0.6869 -0.0293 -0.3139 1.8436 0.7004
-1.0904 -1.1765 1.3374 0.6878 0.4389 1.2153 0.4553 0.6343
>> inputbias=net.b{1}
inputbias =
-2.2595
-1.9384
-1.9766
>> layerWeights=net.LW{2,1}
layerWeights =
0.3575 0.5155 0.4863
>> layerbias=net.b{2}
layerbias =
-0.2155
>> pause;
>> net.trainParam.show = 50;
>> net.trainParam.lr = 0.05;
>> net.trainParam.mc = 0.9;
>> net.trainParam.epochs = 1000;
>> net.trainParam.goal = 1e-3;
>> pause;
>> [net,tr]=train(net,P,T);
TRAINGDM-calcgrad, Epoch 0/1000, MSE 1.84616/0.001, Gradient 4.0328/1e-010 TRAINGDM-calcgrad, Epoch 50/1000, MSE 0.176539/0.001, Gradient 0.132313/1e-010 TRAINGDM-calcgrad, Epoch 100/1000, MSE 0.149195/0.001, Gradient 0.0876254/1e-010 TRAINGDM-calcgrad, Epoch 150/1000, MSE 0.133347/0.001, Gradient 0.0743841/1e-010 TRAINGDM-calcgrad, Epoch 200/1000, MSE 0.119214/0.001, Gradient 0.0775118/1e-010 TRAINGDM-calcgrad, Epoch 250/1000, MSE 0.103785/0.001, Gradient 0.0790047/1e-010 TRAINGDM-calcgrad, Epoch 300/1000, MSE 0.0890668/0.001, Gradient 0.0722843/1e-010 TRAINGDM-calcgrad, Epoch 350/1000, MSE 0.0776446/0.001, Gradient 0.0603288/1e-010 TRAINGDM-calcgrad, Epoch 400/1000, MSE 0.0699584/0.001, Gradient 0.0487528/1e-010 TRAINGDM-calcgrad, Epoch 450/1000, MSE 0.0647695/0.001, Gradient 0.0417182/1e-010 TRAINGDM-calcgrad, Epoch 500/1000, MSE 0.060674/0.001, Gradient 0.0393769/1e-010 TRAINGDM-calcgrad, Epoch 550/1000, MSE 0.0567327/0.001, Gradient 0.0408581/1e-010 TRAINGDM-calcgrad, Epoch 600/1000, MSE 0.052168/0.001, Gradient 0.0461054/1e-010 TRAINGDM-calcgrad, Epoch 650/1000, MSE 0.04611/0.001, Gradient 0.0537851/1e-010 TRAINGDM-calcgrad, Epoch 700/1000, MSE 0.0383222/0.001, Gradient 0.057384/1e-010 TRAINGDM-calcgrad, Epoch 750/1000, MSE 0.0305656/0.001, Gradient 0.0523951/1e-010 TRAINGDM-calcgrad, Epoch 800/1000, MSE 0.0244536/0.001, Gradient 0.0452673/1e-010 TRAINGDM-calcgrad, Epoch 850/1000, MSE 0.0199063/0.001, Gradient 0.0388748/1e-010 TRAINGDM-calcgrad, Epoch 900/1000, MSE 0.0165633/0.001, Gradient 0.0332512/1e-010 TRAINGDM-calcgrad, Epoch 950/1000, MSE 0.0141134/0.001, Gradient 0.0285427/1e-010 TRAINGDM-calcgrad, Epoch 1000/1000, MSE 0.0122947/0.001, Gradient 0.0247655/1e-010 TRAINGDM, Maximum epoch reached, performance goal was not met.
>> pause
>> A = sim(net,P)
A =
Columns 1 through 11
0.7708 0.0446 1.0086 1.0508 -0.0921 1.1178 0.0647
0.9401 -0.0444 0.2307 -0.0433
Column 12
0.9434
>> E = T - A
E =
Columns 1 through 11
0.2292 -0.0446 -0.0086 -0.0508 0.0921 -0.1178 -0.0647 0.0599 0.0444 -0.2307 0.0433
Column 12
0.0566
>> MSE=mse(E)
MSE =
0.0123
>> test=[1 0 1 0 -1 0 1 0; 1 0 0 -1 1 0 1 0;
0 1 0 1 1 0 0 1; 1 0 1 -1 0 1 0 0.5;
1 1 1 -1 -1 0 1 -1; 0 1 1 0 1 1 1 1;
0 1 0 1 1 0 0 1; 0 0 0 0 0 1 0 1;
1 1 1 0 1 1 0 -1; 1 1 1 -1 -1 0 1 0.5;
0 1 0 1 1 0 0 1; 1 1 1 0 1 0 0 0;]';
>> A1 = sim(net,test)
A1 =
Columns 1 through 11
0.6638 1.1255 0.8135 1.0079 0.1281 1.1872 0.8135 -0.0810 0.6832 0.2307 0.8135
Column 12
1.5866
>> E1 = T - A1
E1 =
Columns 1 through 11
0.3362 -1.1255 0.1865 -0.0079 -0.1281 -0.1872 -0.8135
1.0810 -0.6832 -0.2307 -0.8135
Column 12
-0.5866
>> MSE=mse(E1)
MSE =
0.4018
>> pause
>> echo off
3、编制旅行商路径优化问题的遗传算法程序,并计算一个实例。(30分)
旅行商问题(Traveling Saleman Problem,TSP) 译为旅行推销员问题、货郎担问题,简称为TSP 问题,是最基本的路线问题,该问题是在寻求单一旅行者由起点出发,通过所有给定的需求点之后,最后再回到原点的最小路径成本。TSP 问题最简单的求解方法是枚举法。它的解是多维的、多局部极值的、趋于无穷大的复杂解的空间,搜索空间是n 个点的所有排列的集合,大小为n-1 可以采用遗传算法来搜索解空间,群体搜索易于进行并行化处理,它并不是盲目穷举,而是启发式搜索,由于采用了遗传、变异、突变,丰富了种群的基因,优化了解空间。遗传算法是建立在最优解与较优解的差别小的基础上的,也可以说是建立在父母漂亮,小孩很有可能也漂亮的理论基础上的。遗传算法得出的很有可能是局部最优解,而不是全局最优解。
算法描述:
1)由计算机随机产生N 个城市的坐标,取点操作完成后,绘图显示城市的分布,并计算城市之间的距离,这里定义距离为欧几里德范数,产生城市的距离矩阵dCity。设起始城市为第nCity 个城市。
2)设定种群个体数量,生成种群,每个个体的基因为nCity 个城市的全排列,用函数randperm()随机产生。输入交叉概率、突变概率、交叉部分占整体的百分比、最优个体被保护概率等数据,若未输入数据,则设置默认值。
3)算法终止条件一,迭代代数满足设定迭代次数 法终止条件二,最短路径值连续nR 代不变。用counter1 记录迭代的次数,counter2 记录最短路径连续不变的代数。
4)用选择算子对种群进行选择。选择算子:对种群的每一个个体在路径上相邻的城市的距离累加的值在加上起始点到路径首尾点的距离即为总路径长度。Rlength 记录最短路径长度,R 记录最短路径。使用调整的公式计算个体的适应概率,并计算种群的累积适应概率,采用轮盘赌选择算法对个体进行选择。
5)Record 记录每一次选择的最短路径,rR 记录每一次的路径长度 .并用图表显示。
6)继续对种群进行交叉和突变。
交叉算子:在交叉时,依据随机生成的随机数来选择是否对个体进行交叉。从第j 个双亲中随机产生交叉点,计算交叉宽度,得到一个子串,将子串复制到一个子代种群个体中的相应位置,产生部分原始后代。删去第i 个双亲个体中子串已有的城市,得到原始后代需要的其他城市的顺序,按照这个城市顺序,从左到右将这些城市定位到后代的空缺位置上,产生新的子代种群个体。
突变算子:根据突变的概率,随机选择个体的两位进行互换,我那成子代种群的突变。
7)通过循环进行迭代,直到满足算法停止的两个条件之一。通过图表展示最短路径及
算法在优化过程中最短路径值的变化情况,可以看到算法的优化过程。
用遗传算法求解旅行商问题在MATLAB 中运行的源代码如下:
(1)文件GA_TSP.m中的代码如下:
%----------------------- 遗传算法解决TSP 问题 ----------------------- %.........<主程序.Main>.........
%******************参数及参数说明******************
%-------nCity 市数量 数取值范围>2 整数
%-------xyCity 市二维坐标 例由计算机随机产生 围(0,1) 定起始城市为第nCity个城市
%-------dCity 市间距离矩阵 例考虑城市间往返距离相等 定义距离为欧几里德
范数
%-------nPopulation 群个体数量
%------Population 群nPopulation*(nCity-1)矩阵 行由{1,2,...,nCity-1}某一个全排列构成
%-------generation 法终止条件一 代代数
%-------nR 法终止条件二 短路径值连续nR 代不变
%-------R 短路径
%-------Rlength 短路径长度。
function
[R,Rlength]=GA_TSP(xyCity,dCity,Population,nPopulation,pCrossover,percent,pMuta tion,generation,nR,rr,rangeCity,rR,moffspring,record,pi)
clear ALL
%10 个城市坐标
%xyCity=[0.4 0.4439;0.2439 0.1463;0.1707 0.2293;0.2293 0.761;0.5171 0.9414;
% 0.8732 0.6536;0.6878 0.5219;0.8488 0.3609;0.6683 0.2536;0.6195 0.2634];
%10 cities d'=2.691
%--------------------------------------------------------------------------
%30 个城市坐标
xyCity=[41 94;37 84;54 67;25 62;7 64;2 99;68 58;71 44;54 62;83 69;64 60;18 54;22 60;83 46;91 38;25 38;24 42;58 69;71 71;74 78;87 76;18 40;13 40;82 7;62 32;58 35;45 21;41 26;44 35;4 50];
%30 cities d'=423.741 by D B Fogel
figure(1)
axis([0 10 0 10])
grid on
scatter(xyCity(:,1),xyCity(:,2),'x') %城市的横坐标纵坐标
grid on
nCity=size(xyCity,1);
for i=1:nCity %计算城市间距离 设距离为欧几里德范数
for j=1:nCity
dCity(i,j)=((xyCity(i,1)-xyCity(j,1))^2+(xyCity(i,2)-xyCity(j,2))^2)^0.5;
end
end %计算城市间距离 设距离为欧几里德范数
xyCity %显示城市坐标
dCity %显示城市距离矩阵
%初始种群
k=input('取点操作结束'); %取点时对操作保护
disp('-------------------')
nPopulation=input('种群个体数量'); %输入种群个体数量
if size(nPopulation,1)==0
nPopulation=20; %默认值
end
for i=1:nPopulation
Population(i,:)=randperm(nCity-1); %产生随机个体
end
Population %显示初始种群
%
%添加绘图表示
pCrossover=input('交叉概率'); %输入交叉概率
percent=input('交叉部分占整体的百分比'); %输入交叉比率
pMutation=input('突变概率'); %输入突变概率
nRemain=input('最优个体保留最大数量');
pi(1)=input('选择操作最优个体被保护概率'); %输入最优个体被保护概率
pi(2)=input('交叉操作最优个体被保护概率');
pi(3)=input('突变操作最优个体被保护概率');
if size(pCrossover,1)==0
pCrossover=0.85;
end
if size(percent,1)==0
percent=0.5;
end
if size(pMutation,1)==0
pMutation=0.05;
end
rr=0;
Rlength=0; %最短路径长度
counter1=0; %计算迭代的次数
counter2=0; %计算最短路径不发生变化的次数
R=zeros(1,nCity-1); %初始化最短路径 认均为0
[newPopulation,R,Rlength,counter2,rr]=select(Population,nPopulation,nCity,dCity ,Rlength,R,counter2,pi,nRemain);
R0=R;
record(1,:)=R; %记录每一代选择的最短路径
rR(1)=Rlength; %记录每一次的路径长度
Rlength0=Rlength;
figure(2) %第二个图
subplot(1,3,1)
plotaiwa(xyCity,R,nCity)
generation=input('算法终止条件A.最多迭代次数'); %输入算法终止条件
if size(generation,1)==0
generation=50;
end
nR=input('算法终止条件B.最短路径连续保持不变代数');
if size(nR,1)==0
nR=10;
end
while counter1 counter1 %newPopulation offspring=crossover(newPopulation,nCity,pCrossover,percent,nPopulation,rr,pi,nR emain); %offspring moffspring=Mutation(offspring,nCity,pMutation,nPopulation,rr,pi,nRemain); [newPopulation,R,Rlength,counter2,rr]=select(moffspring,nPopulation,nCity,dCity ,Rlength,R,counter2,pi,nRemain); counter1=counter1+1; rR(counter1+1)=Rlength; record(counter1+1,:)=R; end %R0 %Rlength0 %R %Rlength disp('最短路经长度:') minR=min(rR) disp('最短路经出现代数:') rr=find(rR==minR) %rr 记录最短路径的出现代数 disp('最短路经:') record(rr,:) mR=record(rr(1,1),:); counter1 counter2 subplot(1,3,2) %图像显示最短路径 plotaiwa(xyCity,R,nCity) subplot(1,3,3) plotaiwa(xyCity,mR,nCity) figure(3) %显示第三个图表 i=1:counter1+1; plot(i,rR(i)) grid on (2)文件中的select.m代码如下: %.........<选择算子.select operator>......... %目标函数为路径长度 %******************参数及参数说明****************** %-------newPopulation 择后的新种群 %-------Distance 来存储及计算个体路径长度 %-------Sum 路径长度 %-------Fitness 个个体的适应概率 %-------sFitness 积概率 %-------a 随机数 function [newPopulation,R,Rlength,counter2,rr]=select(Population,nPopulation,nCity,dCity ,Rlength,R,counter2,pi,nRemain); Distance=zeros(nPopulation,1); %零化路径长度 Fitness=zeros(nPopulation,1); %零化适应概率 Sum=0; %路径长度 for i=1:nPopulation %计算个体路径长度 for j=1:nCity-2 Distance(i)=Distance(i)+dCity(Population(i,j),Population(i,j+1)); %每一个个体在路径上的相邻城市的距离累加得到该个体的路径总长度 end %对路径长度调整 加起始点到路径首尾点的距离 Distance(i)=Distance(i)+dCity(Population(i,1),nCity)+dCity(Population(i,nCity-1 ),nCity); Sum=Sum+Distance(i); %累计总路径长度 end %计算个体路径长度 if Rlength==min(Distance) counter2=counter2+1; else counter2=0; end Rlength=min(Distance); %更新最短路径长度 Rlength rr=find(Distance==Rlength); %rr 保存最短路径的代数,类似栈 近的最短路径放在最上面 记录是种群的哪一个个体 R=Population(rr(1,1),:); %更新最短路径 R for i=1:nPopulation Fitness(i)=(max(Distance)-Distance(i)+0.001)/(nPopulation*(max(Distance)+0.001) -Sum); %适应概率=个体/总和。。。已作调整 小作了调换 end %Fitness %显示适应概率 sFitness=zeros(nPopulation,1); %累积概率 sFitness(1)=Fitness(1); for i=2:nPopulation sFitness(i)=sFitness(i-1)+Fitness(i); end %sFitness %显示累积概率 newPopulation=zeros(nPopulation,nCity-1); %零化新种群 for i=1:nPopulation %甩随机数 a=rand; %a %显示甩出的随机数 for j=1:nPopulation if a newPopulation(i,:)=Population(j,:); break end end end %选择出新的种群 随机数a 来选择。轮盘赌算法进行选择 for i=1:size(rr,1) if rand newPopulation(rr(i,1),:)=Population(rr(i,1),:); end end (3)文件中crossover.m的代码如下: %newPopulation %显示被选中的新种群个体 %.........<交叉算子.crossover operator>......... %顺序交叉(OX)算子说明 %--1.从第一双亲中随机选一个子串 %--2.将子串复制到一个空字串的相应位置 生一个原始后代 %--3.删去第二双亲中子串已有的城市 到原始后代需要的其他城市的顺序 %--4.按照这个城市顺序 左到右将这些城市定位到后代的空缺位置上。 %******************参数及参数说明****************** %-------offspring 代种群 %-------pCrossover 叉概率 %-------wCrossover 叉宽度 %-------pointCrossover 叉点 %-------percent 叉比例 function offspring=crossover(newPopulation,nCity,pCrossover,percent,nPopulation,rr,pi,nR emain) offspring=zeros(nPopulation,nCity-1); %初始化后代 ccc=0; for i=1:nPopulation s=find(rr==i); if size(s,1)~=0&rand offspring(i,:)=newPopulation(i,:); ccc=ccc+1; elseif rand j=unidrnd(nPopulation); %选择另一参与交叉的个体 i 个体与第j 个体进行交叉 while i==j j=unidrnd(nPopulation); %unidrnd(n)产生{1,2,...,n}里的随机数 end wCrossover=floor((nCity-1)*percent); %确定交叉宽度 backPopulation=newPopulation(i,:); %第i 个体的基因复制给子代个体 pointCrossover=unidrnd(nCity-1-wCrossover); %随机产生交叉点 差确保不溢出 for m=1:wCrossover %OX 交叉 offspring(i,pointCrossover+m-1)=newPopulation(j,pointCrossover+m-1); %步骤1~2 end for n=1:nCity-1 for m=1:wCrossover if backPopulation(n)==newPopulation(j,pointCrossover+m-1) backPopulation(n)=0; %删去第二字串中相同的城市 end end end for n=1:nCity-1 if backPopulation(n)~=0 for o=1:nCity-1 if offspring(i,o)==0 offspring(i,o)=backPopulation(n); break end end end end else offspring(i,:)=newPopulation(i,:); end end (4)文件中Mutation.m的代码如下: %offspring %显示交叉后子代 %.........<突变算子.mutation operator>......... %两点互换变异 %******************参数及参数说明****************** %-------pMutation 变概率 function moffspring=Mutation(offspring,nCity,pMutation,nPopulation,rr,pi,nRemain) exchange=0; ccc=0; for m=1:nPopulation moffspring(m,:)=offspring(m,:); k=find(rr==m); if size(k,1)~=0&rand m=rr(k(1,1),1); moffspring(m,:)=moffspring(m,:); ccc=ccc+1; 应急指挥调度平台 1.应急指挥调度平台 1.1.概述 应急指挥系统解决方案是一个充分利用现代网络技术、计算机技术和多媒体技术,以资源数据库、方法库和知识库为基础,以地理信息系统、数据分析系统、信息表示系统为手段,实现对突发事件数据的收集、分析、对应急指挥的辅助决策、对应急资源的组织、协调和管理控制等指挥功能。该系统在面对突发事件时,能够为指挥首长和参与指挥的业务人员和专家,提供各种通讯和信息服务,提供决策依据和分析手段以及指挥命令实施部署和监督方法,能及时、有效地调集各种资源,实施灾情控制和医疗救治工作,减轻突发事件对居民健康和生命安全造成威胁,用最有效的控制手段和小的资源投入,将损失控制在最小范围内。 1.1.1.方案实现目标 在数据采集和信息处理方面,实现突发事件信息的采集、传输、存储、处理、分析、预案确定及启动全过程的信息化、自动化和网络化。 在预警方面,建立分布式可逐级监测和处理突发事件信息管理网络,实现对突发事件的评估与预警触发启动; 在会商方面,利用视频接收设备、通讯系统、数据库系统、地理信息系统等设施,为指挥首长、业务人员和专家提供大屏幕显示和信息服务,随时为首长决策提供各种有效而生动的辅助决策信息; 在决策支持方面,形成一套具有实时监测、科学预测、及时有效发布和动态反馈评估等功能的辅助决策系统,实现对突发事件应急处理的决策支持。 在资源调度方面,通过系统对应急资源的科学调度,充分保证对特定突发事件应急处理所需资源的配置。 在公众信息发布方面,能及时向社会公众发布紧急救助信息服务和善后处理工作信息。 1.1. 2.方案特色 在监测、预警和应急领域提供“监测、预警、应急”一体化的应急决策指挥解决方案,实现系统“平战结合”的建设思想。 基于我们丰富的监测系统设计经验,我们提供一套快速的监测系统开发和部署框架;以多样化、可扩展的可靠信息渠道解决应急指挥中必须的信息来源问题; 基于数据仓库和数据挖掘技术,提供多类行业的数据分析和预警模型,实现监测与预警联动; 融合门户技术和关键指标仪表盘设计技术,结合系统中丰富的系统分析模块,实现各种业务数据的显示界面集成,便于决策者快速、直观地了解信息、把握全局; 以业界主流和开放的技术标准和设计模式,提供开放的、平台级的应用编程接口和管理工具,既满足各级政府部门快速拓展和实施系统,又便于保护投资,使系统长期健康发展。 1.2.总体框架 应急决策指挥系统涉及领域广,技术层次深,系统的构架也是比较复杂,总体来讲,其框架图如下: 智能决策支持系统 一、智能决策支持系统的定义 决策支持系统(Decision Support System,简称DSS),就是以管理科学、运筹学、控制论、与行为科学为基础,以计算机技术、仿真技术与信息技术为手段,针对半结构化的决策问题,支持决策活动的具有智能作用的人机系统。该系统能够为决策者提供所需的数据、信息与背景资料,帮助明确决策目标与进行问题的识别,建立或修改决策模型,提供各种备选方案,并且对各种方案进行评价与优选,通过人机交互功能进行分析、比较与判断,为正确的决策提供必要的支持。它通过与决策者的一系列人机对话过程,为决策者提供各种可靠方案,检验决策者的要求与设想,从而达到支持决策的目的。 决策支持系统一般由交互语言系统、问题系统以及数据库、模型库、方法库、知识库管理系统组成。在某些具体的决策支持系统中,也可以没有单独的知识库及其管理系统,但模型库与方法库通常则就是必须的。由于应用领域与研究方法不同,导致决策支持系统的结构有多种形式。 传统DSS 采用各种定量模型,在定量分析与处理中发挥了巨大作用, 它也对半结构化与非结构化决策问题提供支持, 但由于它通过模型来操纵数据,实际上支持的仅仅就是决策过程中结构化与具有明确过程性的部分、随着决策环境日趋复杂,DSS的局限性也日趋突出, 具体表现在:系统在决策支持中的作用就是被动的, 不能根据决策环境的变化提供主动支持, 对决策中普遍存在的非结构化问题无法提供支持,以定量数学模型为基础,对决策中常见的定性问题、模糊问题与不确定性问题缺乏相应的支持手段。[1] DSS应具备以下特征[2]: ●系统的主要功能就是为管理人员提供决策支持,其目的就是帮助管理人员进行决策 而不就是代替她们,就是为了提高决策的效能而不就是组织的管理效率; ●传统数据管理技术与有关的模型技术、分析技术相结合; ●系统应该有很强的灵活性、适应性、便于用户使用。 智能决策支持系统(IDSS)就是决策支持系统与人工智能技术相结合的系统[3],她包括决 策支持系统所拥有的组件,包括数据库系统、模型库系统与人机交互系统,同时集成了最新发展的人工智能技术,如专家系统、多代理以及神经网络与遗传算法等。它就是以信息技术为手段,应用管理科学、计算机科学及有关学科的理论与方法,针对半结构化与非结构化的决策问题,通过提供背景材料、协助明确问题、修改完善模型、列举可能方案、进行分析比较等方式,为管理者做出正确决策提供帮助的智能型人机交互式信息系统。智能决策支持系统的广义结构如下图所示。 院长辅助决策支持系统 院长辅助决策支持系统是为法院高级管理层人员,提供对法院内部各个方面的信息综合管理和监控的系统。院长决策支持系统在最大程度上体现了系统“集成”的能力。它不再仅仅是一些死板的统计报表和一系列令人眼花缭乱的文书题目,而是给法院的高层决策者提供许多形象、直观的“感受”。 院长辅助决策支持系统是一个动态的为法院高层管理者,根据法院现有的管理模式定制的决策支持系统。它根据法院内部所设立的各类标准,对法院内部所有办案人员所办案件的数量、质量和进度等各种指标进行算、分类、排行。通过这样的数据,为法院的中高层领导及时有效的决策,提供法院内部案件办理的第一手资料。 院长辅助决策支持系统主要由案件的查询、统计构件和其他根据院领导要求定制的多模式监控构件组成。 院长辅助决策支持系统根据提供信息的形式分类,主要对院领导的决策提供以下几种类型的决策信息服务: 数据信息服务 数据信息主要是指为法院高级领导提供院内以数字或文字为主的信息,以便为院长做决策提供数据支持。 数据信息服务主要由案件的统计、查询和案件监控构件组成,除此之外系统还提供各种进入其他系统的功能入口,方便院领导进入相关系统办公。 数据信息服务主要包括以下主要功能: ●案件监控 该功能模块主要是实时的对法院内部所有的案件进行监控,为院长提供了全院各类案件的在案件办理的各个阶段的停留情况,院长可以通过这样的监控数据,找到全院整个案件办理的流程的瓶颈,调整相应的工作人员、方法或程序; ●排行榜 该功能模块为院领导提供了院内各个庭室的案件办理情况的排行榜,使得院 长在随时了解到院内各个庭室人员最近的案件办理的进度和情况; ●统计分析 该功能模块是根据要求,专门为院领导定制了一套完整的统计报表,实时的统计法院高级管理者所关心的数据,直接为院领导的决策提供数据支持。 ●审理报告 该功能是将审判系统中的需要上会的审理报告进行调阅的功能模块,以便审委会成员能够通过计算机调阅审理报告,进行案件的讨论。 除了以上栏目外,系统还提供相应和其他系统的相应入口,如“新收公文”、“案件办理”等功能链接,使得院长可以像一般工作人员一样,在院长决策系统中进行日常的案件办理和公文的处理。 除了对院内的数据信息采集之外,院长辅助决策系统可以对其他信息进行采集。 多媒体信息服务 多媒体信息服务是为法院的高级领导提供图象、声音等多媒体信息,为法院领导直接感受现场情况,对工作进行指导提供信息服务。 该功能模块主要是和信息化法院的硬件和网络视频设备进行联动,实现预期的功能。 多媒体信息服务主要包括以下功能: ●庭审录像 该功能模块是系统在排期阶段,系统会根据排期情况,自动打开法庭的监控设备,对挺身情况进行自动录像,院长可以在院长决策系统中调取该案件的庭审录像,在网络上观看,并可以对该案件的审理过程进行批注,并发布在录像中,使得下一次调用该录像的用户,可以看到录像批注,对案件的庭审过程的指导作用意义重大。 ●审委会评议 该功能模块是系统在审委会上提供庭审的实况转播,并通过声像同步技术,使得审委会成员可以直接在异地对案件庭审的过程进行指导。 目录 1 工程背景和依据 (2) 1.1 项目背景 (2) 1.2 编制的依据 (3) 2 决策支持建设现状 (4) 2.1 建设基础 (4) 2.2 需求分析 (4) 3 指导思想、建设原则 (6) 3.1 指导思想 (6) 3.2 建设原则 (6) 4 总体目标 (7) 4.1 总体目标 (7) 5 总体框架和体系 (8) 5.1 总体框架 (8) 5.2 技术路线 (9) 6 主要任务 (11) 6.1 完善信息基础设施 (11) 6.2 建立信息资源中心 (11) 6.3 搭建应用支撑平台 (11) 6.4 建立决策支持应用 (12) 6.5 完善相关支撑体系 (13) 7 重点工程 (15) 7.1 市领导辅助决策支持系统 (15) 7.1.1 市级领导应用 (15) 7.1.2 办公厅及部门应用 (15) 7.2 市领导空间决策支持系统 (16) 7.3 市领导智能决策支持系统 (17) 7.4 市领导多媒体协同办公系统 (18) 7.5 决策分析政务数据交换平台 (19) 7.6 领导决策综合数据库 (20) 8 保障措施 (22) 8.1 加强组织体系建设 (22) 8.2 完善相关政策和制度 (22) 8.3 加强资金保障 (23) 8.4 加强项目培训和咨询 (23) 8.5 强化标准规范建设 (23) 9 计划安排及投资类别 (24) 9.1 总体安排 (24) 9.1.1 工程一期 (24) 9.1.2 工程二期 (24) 9.2 投资类别 (25) 1 工程背景和依据 1.1 项目背景 贯彻党的十六大报告要求“进一步转变政府职能,改进管理方式,推行电子政务,提高行政效率,降低行政成本,形成行为规范、运转协调、公正透明、廉洁高效的行政管理体制”。 贯彻党的十七大报告要求“推进决策科学化、民主化,完善决策信息和智力支持系统”。 《黑龙江省电子政务建设“十一五”规划》:“各级各部门要高度重视电子政务建设工作,切实纳入重要议事日程。主要领导要及时掌握情况,解决问题,加强督促,有计划、有力度地搞好工作推进。”。 《黑龙江省电子政务建设“十一五”规划》:“整合各专业数据系统的关系型数据、非结构化数据,以及多媒体数据,建设全省电子政务数据仓库,利用数据整合、数据分析、数据挖掘技术,建立全省电子政务决策支持系统,为各级领导提供决策支持。” 哈尔滨市已经具备决策支持建设的条件和环境,《哈尔滨市国民经济和社会信息化“十一五”发展规划》指出:“在应用系统建设方面,统一建设了公文传输、信息管理、督办管理、目标管理、议案管理和政务值班管理等6个政务应用系统,在工商、税务等各业务部门分别建设各自业务应用系统的基础上,建设完成了全市企业基础信息共享平台、城市空间地理基础信息共享平台等跨领域、跨部门的应用系统,工商、建委、市政、市长热线和政务呼叫中心等电话呼叫系统,提高了政府为民排忧解难的服务效率”。 1.2 编制的依据《黑龙江省电子政务建设“十一五”规划》《哈尔滨市国民 第1章决策支持系统概述 ▲数据: 记载下来的事实,客观属性的值 ▲信息: 构成一定含义的一组数据 ▲系统: 由若干相互联系相互制约的元素结合在一起,并具有特定功能的有机整体。 ▲系统的组成: 1、系统由各元素或子系统组成 2、至少包含两个以上的元素 3、各元素之间相互联系或相互制约 4、具有目的性 5、适应环境的变化 ▲数据处理系统: 是对大量数据进行收集、组织、存储、加工与传播的总和 ▲数据处理系统的特征: 1、数据量大; 2、没有特别复杂的运算; 3、时效性强 ▲管理信息系统MIS: 运用系统管理的理论方法,以计算机网络和现代通信技术为手段,对信息进行收集、组织、存储、加工、传播和使用的人机系统。 ▲管理信息系统的基本组成: 管理业务应用系统、数据库系统 ▲管理信息系统特点: 1、以数据库系统为基础; 2、数据录入; 3、数据传输; 4、数据存储; 5、数据查询; 6、数据统计; 7、指标计算 ▲决策支持系统: 以管理科学、运筹学、行为科学、控制论为基础,以计算机技术、模拟技术、信息技术为手段,面向半结构化的决策问题,支持决策活动的具有智能作用的人机系统。 ▲决策支持系统主要特征: 1、关注上层管理人员经常遇到的结构化程度不高、规范化不明 确的问题 2、把模拟或分析技术与传统的数据存取和检索技术结合起来 3、易于非计算机专业的人员,以交互会话的方式使用 4、强调对环境及用户决策方法改变的适应性和灵活性 5、提供决策的良好效果 ▲DSS的功能: 1、管理并提供外部信息 2、收集、管理并提供内部信息 3、收集、管理并提供反馈信息 4、存储和管理数学模型 5、修改和添加数据、模型、方法 决策支持系统实例 物资分配调拨问题是根据各单位提出对物资的需求申请,按仓库的库存情况制定分配方案,再根据分配放案以及仓库和单位的距离制定物资运输方案。最后按照物资运输方案制定各仓库的发货表和各单位的接收表,修改各仓库库存数和各单位的物资数。 该决策问题需要设计多个数据库和多个模型共同求解。总的处理流程如图: 图1 物资分配调拨流程图 一、物资申请和库存的计划汇总 1、各单位按自己的需求提出对各物资的申请 申请数据库为: D i={SQ(W1),SQ(W2),… } i=1,2,3…(1.1) 其中D i表示第i各单位,SQ(W j)表示申请物资W j的需要数量。 将各单位的申请数据库汇总成各单位对物资的需求量,形成总申请数据库。 W j={ SQ(D1),SQ(D2),…} j=1,2,3… (1.2) 其中SQ(D i)表示第i个单位对物资W j的申请数量。 该项数据处理需要编制程序,类似于数据库的旋转来完成。 2、 各仓库度物资的可供应情况 K i ={XY(W 1)—KD(W 1),XY(W 2)—KD(W 2),…} i=1,2,… (1.3) 其中K i 表示第i 个仓库;XY(W j ), KD(W j )分别表示该仓库中物资W j 的现有数量和最低储备量;XY(W j )—KD(W j )表示物质W j 的可供量。 各仓库的多物资的可供应情况汇总成某一物资个仓库的可供量,形成总库存数据库。 Wj={XY(K 1)—KD(K 1),XY(K 2)—KD(K 2),…} (1.4) 该项数据处理工作,要在数据库中计算出可供量后,再进行类似于数据库旋转来实现。 该计划汇总工作构成数据处理模型,它与数据库的关系如图: 图2 计划汇总模型与数据库的关系 二、 制定物资的分配方案 物资分配方案是利用物资分配模型来完成的,该分配模型是通过一系列公式实现。 1、 比较分配情况 对同一物资W j 计算总可供量S (各仓库可供量之和)与总申请量Q (各单位申请量之和)的大小。 2、 物资分配方法 (1) 总可供量大于等于总申请量S ≥Q 物资总申请数据库 物资总库存数据库 科技创新辅助决策支持系统STADS ——中国科学技术信息研究所与万方数据重拳出击 联合打造科技创新能力评估新利器 什么是科技创新辅助决策支持系统? 科技创新辅助决策支持系统由中国科学技术信息研究所与北京万方数据股份有限公司联合推出,是面向政府、科研院所、高校、企业等单位的科研管理部门,进行科技信息挖掘、分析,进行科技创新能力评估的工具。利用该工具,用户只需输入关注内容、轻点鼠标,即可轻松了解所关注主题的研究状况、学科领域专家与研究机构、科研项目课题成果与进展、科研机构科研能力统计与分析,并获得相关分析报告,为科技创新决策提供支持与服务。 为什么推出科技创新辅助决策支持系统? “重视科学技术弘扬科技创新”已经成为全民普遍认可的国家发展理念。国家财政对科技投入的增加,通过实施新产品试制鉴定、科技攻关、星火、火炬、自然科学基金、社会科学基金、科技成果推广等一系列科技计划,在面向经济建设主战场、高新技术产业化、基础性研究三个层次上都取得了显著成绩。 在这样的大环境下,不论是政府部门、高校、科研院所,还是企业的科技管理部门,都需要对单位和个人,从科研综合能力、优势领域、人员素质、成果水平等方面,对于科技创新能力进行权威公正的考量。 为解决科研管理部门进行科研项目监控、科研立项查新、学科领域专家搜索、人员科研状况分析、机构科技创新能力评估等问题,辅助科研管理部门进行科学决策,中国科学技术信息研究所与万方数据重拳出击,推出科技创新能力评估新利器,即科技创新辅助决策支持系统(简称:STADS)。 我们需要科技创新辅助决策支持系统吗? 科技创新辅助决策支持系统给您带来的应用价值 学生实验报告书 实验课程名称决策支持系统 开课学院 指导教师姓名 学生姓名 学生专业班级 实验报告填写说明 1.设计性、综合性实验必须填写实验报告,验证、演示性实验可不写实验报告; 2.老师在指导学生实验时,必须按实验大纲的要求,逐项完成各项实验; 3.每项实验依据其实验内容的多少,可安排在一个或多个时间段内完成,但每项实验只须填写一份实验报告;4.教师在每份实验报告后均须给出实验成绩,及简短的评语以说明评分的依据; 5.课程实验的所有实验项目结束后,学生应将每项实验按实验先后次序及封面一起装订成册,交实验指导老师;6.实验指导老师综合学生各项实验的成绩,给出相关课程实验环节的总评分,并记入课程总成绩中。 推的基本假设是未来系过去和现在连续发展的结果。趋势外推法的基本理论是:决定事物过去发展的因素,在很大程度上也决定该事物未来的发展,其变化,不会太大;事物发展过程一般都是渐进式的变化,而不是跳跃式的变化掌握事物的发展规律,依据这种规律推导,就可以预测出它的未来趋势和状态。 a)二次曲线模型预测法。在市场上,某些产品的销售并不一定按同一趋势发展, 有可能出现先上升而后下降的趋势;也有可能出现先下降,当下降到一定程度 后又迅速上升的趋势。二次曲线模型在图形上正好表现出了上述的两种趋势, 利用历史资料,拟合成二次曲线模型,这一模型的应用已经成为市场预测中的 一种普遍方法。 b)在一定时期内,有些产品的销售量往往表现为随着时间的变化按同一增长率不 断增加或不断减少。指数曲线预测法正是针对这种产品的销售变化趋势,利用 其时间序列资料,拟合成指数曲线,建立模型并进行预测的一种方法。 5)季节周期法。 许多产品的市场需求往往有季节性。例如,服装、空调和冷饮等。对于这类产品市场需求的预测,需要考虑季节波动的因素。同季平均法是分析、预测季节波动一种最常用、最简单的方法,主要适用于受季节波动和不规则波动影响、而无明显的趋势变动规律的产品市场需求预测。 2 功能分析 市场预测支持系统的软件结构,应充分考虑市场需求预测所涉及到的市场环境复杂、预测种类繁多及不确定影响因素多等特点,许多影响因素的作用很难用定量的方法确定,需要发挥人的主观能动性和判断力。 市场预测支持系统的功能结构包括几个子系统,如图2-1所示。 图2- 1 市场预测支持系统的功能结构 3 逻辑结构分析 根据产品市场需求预测的一般过程和预测支持系统的功能结构,系统的市场需求预测过程逻辑结构可由预测产品及其相关资料数据调入、预测模型选择、最佳预测模型确定及预测值的分析、修正等模块组成,如图3-1所示。 医院综合管理决策支持系统 背景分析12 3数据分散于各业务系统,无法统一管控数据缺乏积累沉淀, 无法进行挖掘分析 和可视化呈现数据缺少共享机制,无 法进行统一上报和自动 化推送 随着医疗信息化的发展,HIS 、LIS 、药房管理、财务及电子病历等系统正支撑着医院业务正常运转,提高了医院办公效率,但各系统沉积的数据价值并未被较好挖掘,主因如下: 建设目标 基于大数据分析技术进行优质决策的案例不断涌现,而该医院现有的信息系统和联机事务处理并不具备应用的数据分析能力,于是决定开发决策支持系统,功能如下: 决策支持 ?采集业务数据,建设数据仓库 ?建设分析主题进行数据挖掘,为管理决策提供依据 数据展示 ?提供报表、图表、管理驾驶舱等可视化效果 ?支持APP、微信等移动端数据展示 数据服务 ?对各业务系统统一管控,保证数据质量 ?数据共享,实现数据上报和推送 权限控制 ?各层级人员的数据权限 建设成果 八大模块:院长决策分析、门诊分析、住院分析、收入分析资源分析、药品耗材分析、检查手术分析、医疗质量分析 院长决策分析 院长决策分析全面展示医院综合情况,为医院领导提升医院管理、优化资源配置提供科学依据。院长可以从仪表盘获得全院整体情况,包括门诊和住院的主要业务量、业务趋势,以及主营收入的进度和构成。 门诊业务是所有医院最主要的服务类型,自然也是患者人流量最大的部分。从人流量上,可以从挂号、就诊、检查三方面进行分析,比如挂号可以看急诊挂号人次(同比、环比)、挂号人次构成、挂号人次分析(近6个月发展趋势、各科室排名);就诊可以看接诊病人 来源(按地域)、接诊人次、接诊人次分析(人次构成、近6个月发展趋势、科室排名)。从收入方面,也可以分为门急诊费用、药品收入、耗材收入、门急诊医保四方面进行详细分析。 临床决策支持系统前言: 随着时代的发展, 知识爆炸对医疗工作提出了严峻的挑战, 医师们日益感到难以跟上突飞猛进的医学发展步伐。虽然临床分科有助于缓解这一矛盾, 但绝非根本解决方法。因为即使是很专业的医学领域的知识更新和增长, 也超出医师的学习和掌握限度, 大量的信息和数据也让医师们无所适从。而借助电脑的巨大存储能力和处理能力有可能改变这一状况, 于是临床决策支持系统应运而生。临床决策支持系( Clinical Decision- Making “临床决策支持系统”的定义是:“能够根据病人的两项或多项信息针对病情生成具体建议的活性知识系统”。亚马特亚库(Amatayakul)相信,临床决策支持系统可以在诊疗过程中提供的一种实时帮助,而且能够发掘外部的知识资源。作为一种复杂的计算机化的管理系统,它还可以根据现有的知识生成各种可供选择的诊疗和护理建议(Randolph et al)。 那么,临床决策支持系统的基本功能都有哪些?根据兰道夫(Randolph et al)2001年的研究报告,表6.1概述了波莱尔(Pryor)的建议。 表6.1 临床决策支持系统 Bayesian theorem 的方法和Belief networks。另外,近期的已经在国外的临床中具体应用的事件监视器(Event Monitor)也都是基于规则的决策支持系统。这些系统通过事先定义好的规则来实时地监视病人的相关信息,一旦规则中的前提条件得到满足,相关规则将被触发,相应采取规则中规定的行动,或是对诊断或是对治疗提供决策支持。 2) 系统功能 临床决策系统也可以按其设计的所能完成的系统功能来划分。主要有两大类主要的功能:一是帮助决策什么是对的判断,例如临床诊断,早期的Leeds Abdominal Pain、DXplain和QMR等医学诊断系统即属此类。二是帮助医生决策下一步应该做做么事,例如做什么检查,用什么药,要不要手术等,最典型的一个例子就是决策分析树,即根据概率分析医生下一步应该怎样做。 3) 建议方式 临床决策系统的建议方式分为主动和被动两种。主动的方式为系统主动地给医生提 早 例 (Critiquingmodel)顾问式在流程中不断地与医生进行交互获得必要信息,最终生成最后的建议,例如在MYCIN 系统中,需要用户不断地与计算机进行信息交互,最终计算机才能给出最后的决策意见。而批评式的系统事先根据相关信息生成一个决策建议,如果医生的决策与之不符,则给出系统的决策建议,适用于医生愿意自己决策而只是需要系统对自己的决策进行再次确认的情况,前面提到的事件监视器系统即属于批评式的。 6) 决策支持程度 应急专家决策支持系统 1、应急通知及建立应急现场监测数据库 应急事故发生后通过应急短信快速有效的通知相关工作人员到达事故现场; 建立健全应急现场监测数据库,应包现场监测因子、现场实验方法、原始结果快速计算、相关曲线图等,存储相关现场监测结果以及自动产生对应报表,以供其它人员进行分析; 2、现场紧急情况上报 将现场采集监测的数据及应急监测现场视频、声音、图片、文字等多种类型文件通过卫星通讯管理系统上传至本数据库,以供专家领导对现场进行判断做出正确决策; 3、建立地理信息系统 地理信息系统空间管理平台是整个系统的核心和操作平台,通过应用软件可以实现空间数据的管理与访问、空间查询分析、缓冲区分析、专题分析与专题图定制等基本操作。 4、建立危险品管理体系 1、危险品管理应涵盖了国家环境监测总站发布的1361种有毒、有害危险品及其与周围环境水、气或其他产生化学反应的衍生物的信息,应包含危险品与衍生物的名称、CAS号、外观形状、属性类别、应急监测方法、实验室监测方法、应急处置方法等; 2、对有毒、有害危险品的信息应提供综合查询、分类查询等多种不同方式的查询; 3、应涵盖应急事故录入、维护、应急预案、污染事故案例 5、建立应急专家预案库 6、建立健全市属危险源信息 危险源的管理是对属性和空间特征的统一管理,一方面在突发环境事故处理中可以进行多种危险源的信息查询,另一方面针对已知的危险源可以准确定位危险品的属性和空间,所以要建立健全市属危险源信息,对其排放危险污染物、危险化工原料等企业排放情况、生产工艺相关信息进行整理登记;并与“危险品管理子系统”联动,提高应急反应速度。 7、建立大气污染扩散模拟功能 大气点源扩散模拟系统是对点源污染从时间和空间两个角度分别进行数据分析、预报及预警,从时间上可分析任何时间污染到哪些区域、扩散到任何一个区域需要的时间等,从空间上可实现污染区域涵盖空间的数据信息查询市及分析等,可将模拟数据在电子地图上进行渲染,并可对模拟数据进行存储和动态回放演示。 8、建立水体污染扩散模拟功能 水系污染扩散模拟系统可以根据河流上发生污染事故的排放源的源强,结合水文参数(河流流向、流速等),对河流(主要是排放源的下游)的污染状况进行模拟分析和评价,并将模拟分析结果在电子地图上通过各种表现形式进行展现,用户能够直观地了解到河流的污染进度和污染情况,为环境污染事故指挥提供预警决策支持。 实验名称:多维数据分析实验 实验目的:掌握工作表之间的关系及从一个表中查询记录,了解EXCELL知识和VB编程技术。 实验内容:1、用EXCELL做一张产品销售表,记录不少于100条。 2、每条记录使用序号、产品名称、销售网点、销售人员、销售时间、 数量、单价、销售额,除销售额外,每个属性取值不少于4个。 3、用EXCELL做一个使用界面,分别从产品名称、销售网点、销售 人员三个视角查看销售额,将该截面做到单独的一张工作表上。 4、分别用三张工作表表示产品名称销售额、销售网点销售额、销售 人员销售额三的视图。 5、按产品名称求销售额汇总,并用工作表表示。 实验工具:Excel的控件技术、编程技术 问题与解决方法:(1)点击控件时,目标数据能够显示,但必须“手动”切换到相应的界面,而非点击后直接显示。解决方法为:在Sub 销售额汇总表()后,Sheet6.Select(2)在编写程序时容易出现错误,解决方法是通过对宏进行录制实现控件功能。 实验结论: 产品销售表 序号 产品名 称 产地销售网点销售时间销售人员数量单价销售额 1 优盘山西赛格20XX-10-11 李一50 89 4450 2 优盘山西赛格20XX-10-12 李一100 89 8900 3 优盘山西赛格20XX-10-13 李一20 89 1780 4 优盘山西赛格20XX-10-13 李一50 89 4450 5 优盘山西赛格20XX-10-13 李一20 89 1780 6 优盘山西赛格20XX-10-14 李一59 89 5251 7 显示器河北赛格20XX-10-15 李一8 100 800 8 显示器河北赛格20XX-10-16 李一9 100 900 9 显示器河北赛格20XX-10-16 李一20 100 2000 10 显示器河北赛格20XX-10-16 李一10 100 1000 11 显示器河北赛格20XX-10-16 李一13 100 1300 12 显示器河北赛格20XX-10-17 李一 5 100 500 13 显示器河北赛格20XX-10-17 李一16 100 1600 14 显示器河北赛格20XX-10-17 李一16 100 1600 15 显示器河北赛格20XX-10-17 李一18 100 1800 16 显示器河北赛格20XX-10-17 李一13 100 1300 17 显示器河北赛格20XX-10-17 李一12 100 1200 18 光驱陕西青龙20XX-10-18 张红9 110 990 19 电脑陕西青龙20XX-10-18 张红15 5420 81300 临床辅助决策支持系统(CDSS)招标要求及技术参数 一、项目总体方案 1、总体目标 临床辅助决策支持系统是基于我院医疗大数据平台和医院海量真实病历数据,结合医学文献、临床知识库等资源,利用分布式存储和计算、自然语言处理、机器学习等技术构建的,面向临床医生的辅助决策和推荐系统,系统支持自动从医生工作站获取当前就诊的患者信息,并从辅助诊疗、病历分析、知识推荐等角度在医生诊疗过程提供辅助决策。 2、基本功能需求 (1)诊断推荐 根据输入的患者信息和主诉现病史等信息,当医生下诊断时,自动推荐疑似诊断,并提供这些诊断的典型症状以及医院内相似病历,并提供相关推荐依据。 (2)检查检验推荐 根据医生当前初步诊断结合患者基本信息、一诉五史,当医生下处置时,自动推荐合适的检验、检查项,并挖掘展示这些检查检验项在医院的相似病历中开立占比,以及相关文献参考,帮助医生进一步确诊。 (3)治疗方案推荐 根据医生当前诊断及患者基本信息、一诉五史,在医生下医嘱时,推荐最佳的治疗方案,并提供这些治疗方案在医院的相似病历中的占比,以及相关文献参考等推荐依据。 (4)智能提醒 依据患者基本信息、一诉五史,结合医院临床历史数据,在医生下诊断或开具不适合患者病情的医嘱处置时,自动预警提示。 (5)病历分析 根据医生在工作站输入的性别、年龄、主诉、现病史、诊断、检查检验、用药等信息,基于医院历史数据找出相似病历及其各个维度的统计数据。 (6)历史数据实时统计分析 根据条件对医院历史数据进行实时统计分析,包括相关病种数量、性别比例、年龄分布、病因分布、疗效比较、并发症、好转率、不良反应、平均住院日、平均住院费用、平均术前时间、手术率、复诊率等不少于20个相关性指标,将这些数据的统计分析结果实时展示在系统界面上,供医生参考。 收稿日期 :2008-11-04作者简介 :朱伟 (1978- , 男 , 江西南昌人 , 北京城市系统工程研究中心副研究员 , 主要从事城市安全研究。 2008年 12月第 30卷专辑 三峡大学学报 (人文社会科学版 Journal of China Three Gorges University (Hu manities &Social Sciences Dec . 2008 Vol 130 Special sec . 城市公共安全应急决策支持系统框架研究 朱伟 (北京市城市系统工程研究中心 , 北京 100089 摘要 :随着经济的发展 , 突发事故的频率和后果损失都呈现急剧上涨的趋势。针对城市公共安全应急决策需求 , 围绕决策支持系统的定义、功能、系统设计等方面展开探讨 ; 结合灾害事故监测技术、模拟预测技术和 GI S 技术 , 讨论了该系统与城市公共安全体制的融合机制问题 , 并提出了一种快速、支持系统的总体框架 ; 为城市灾害信息的科学管理 , 各种灾害分析模拟 , 技术支持 , , 效的辅助手段。 关键词 :公共安全 ; 应急 ; 决策支持 ; 中图分类号 :X 913. 4:A :1672-6219(2008 专辑 -0014-03 、资源、环境、灾 、相互依赖、相互制约所构成的复杂空间地域系统。随着社会经济体系的发展 , 城市系统复杂性也随之增加 , 其表现之一就是城市灾害事故频频发生。城市突发性事故不仅对个人、群体和组织的正常活动构成了巨大威胁 , 而且使得城 市公共安全面临空前的挑战。例如 , 纽约世贸大厦的坍塌就引发了全球思考。建立城市公共安全应急决策支持系统 , 实现城市公共安全保障 , 对于某一地区乃至整个国家的经济发展与政治稳定都具有重大的现实意义。 在国际上 , 发达国家近年来在公共安全方面做了大量的投入 , 特别注重跨领域、跨部门的一体化应急技术体系的研发。欧美等国已经成功地利用先进的应急技术与装备武装了本国的公共安全保障体系 , 并 有超前的灾害研究和完善事故预防机制方面的研究 , 形成了一整套较为完备的灾害应急防御体系。例如 , 美国政府建立了“ 国家应急反应系统” , 将指挥、响应、救援技术系统整合为国家综合应急联动技术体系 , 确保在危机发生后能迅速提供优化决策与快速救援。我国在公共安全部分领域利用已有技术初步建立了监测预警系统 , 但在计划经济体制影响下形成的分部 门、分灾种的城市应急模式 , 还缺乏统一协调的应急指挥系统。在 2004年制定的国家中长期科技发展规 划 (2006~2020年中 , 建国 50多年来首次将公共安全列为重点研究专题。开展应急技术科技攻关 , 为建立健全公共安全应急技术体系、充分发挥应急预案在预防和应对突发公共事件中的指导作用提供科技支撑 , 是建立我国强大的公共安全保障体系、实现公共安全总体形势根本好转的有效途径。 本论文针对城市公共安全应急决策需求 , 首先围绕决策支持系统的定义、功能、系统设计等方面展开探讨 ; 然后结合灾害事故监测技术、模拟预测技术和GI S 技术 , 探讨了该系统与城市公共安全体制的融合 机制问题 , 并提出了一种快速、高效构建城市应急辅助决策支持系统的总体框架。 一、决策支持系统的理论分析及模型 基于云计算的智能决策发展综述 郜炎峰 (哈尔滨商业大学计算机学院哈尔滨Y1310120306 )摘要:随着计算机和通信技术的快速发展,一些基于不同环境下的智能决策支持系统层出不穷,本文主要简单介绍了智能决策支持系统的发展现状,然后重点介绍了基于云计算的智能决策的研究现状,对云计算环境下的智能决策受到的影响,决策资源管理,决策问题协同求解,智能决策支持系统等进行简单分析,进一步提出今后的智能决策系统的研究思路。 关键词:发展现状;云计算;智能决策; Abstract:With the rapid development of computer andcommunicatio n technology, a number of different environments based intelligent decisionsupport systemafter another,This paper briefly introduces the development status of intelligent decision support system, and then focuses on the research status of cloud-based intelligent decis ion.The impact of cloud computing environments being intelligent decision,decision-making resource management,collaborative deci sion-making problem solving, intelligent decision support system fo r simple analysis.Further research ideas putted forward in the futur e of intelligent decision system. 临床决策支持系统 前言: 随着时代的发展, 知识爆炸对医疗工作提出了严峻的挑战, 医师们日益感到 难以跟上突飞猛进的医学发展步伐。虽然临床分科有助于缓解这一矛盾, 但绝非 根本解决方法。因为即使是很专业的医学领域的知识更新和增长, 也超出医师的 学习和掌握限度, 大量的信息和数据也让医师们无所适从。而借助电脑的巨大存 储能力和处理能力有可能改变这一状况, 于是临床决策支持系统应运而生。临床 决策支持系( Clinical Decision- Making Support System, CDSS) 指能为医生 的诊疗工作提供决策支持和帮助的计算机系统。另一方面, 药物的多样性和患者 信息的不同使药物治疗复杂化, 故此药物治疗需要完善的信息支持系统,临床决 策支持系统(CDSS)是支持药物治疗的有力工具。现已表明, 较好地使用了决策支 持系统(DSS)的机构已经实现了提高质量和降低成本。同样的, 人们将决策支持系统运用到复杂的药物治疗中, 可以很及时、准确、完整地为医师提供相应的信息 资料, 有助于医师做出正确有效的诊断决策, 以提高药物治疗的效率. 很多临床医师熟悉那些处理实验室信息的计算机系统,也熟悉那些用来跟踪药物处方及重复取药的药房计算机系统。鉴于他们已经习惯于按几个键就能够找到或显示所需要的信息,他们不可能愿意回到原来那种乏味地从大堆资料中查找一些零碎信息的情境。 尽管电子健康记录系统能够获取、转换、显示和分析某些信息,但是,如果不能筛选和提炼信息,也将无法满足那些复杂的临床决策。在这一点上,临床决策支持系统有了进一步的发展。将患者个人的详细信息输入计算机程序之后,这些信息就被存储起来,然后,在计算机知识库中进行程序或算法匹配,为临床医师生成针对该患者的健康评估和诊疗建议(Randolph, Haynes, Wyatt, Cook, & Guyatt, 2001)。在1994年约翰斯顿(Johnston)等人的研究报告中,维亚孜(Wyaath)和斯比格尔特(Spiegelhalter)给“临床决策支持系统”的定义是:“能够根据病人的两项或多项信息针对病情 决策支持系统发展现状与趋势分析 信息092 王岩090612271引言 决策是人类社会发展中人们在为实现某一目的而决定策略或办法时,时时存在的一种社会现象。任何行动都是相关决策的一种结果。正是这种需求的普遍性,决策支持系统应运而生。20多年来,DSS已在理论研究、系统开发和实际应用诸方面取得了令人瞩目的进步,并呈现出积极的多元化的发展态势。随着人工智能技术、网络技术、通信技术和信息处理技术的发展和多学科的交叉结合发展,决策支持系统呈现多元化结构发展态势。 决策支持系统,简称DSS(Decision Support System),是以特定形式辅助决策的一种科学工具。它通过人机对话等方式为决策者提供了一个将知识性、主动性、创造性和信息处理能力相结合、定性与定量相结合的工作环境,协助决策者分析问题、探索决策方法,进行评价、预测和选优。 近几年来,从关于决策支持系统基本定义和决策支持系统基本结构出发,演化产生了一系列新的概念、观点和结构。为此,本文从对决策支持系统的发展现状加以概括论述,同时总结了决策支持系统发展的趋势和前景。 决策支持系统的兴起于发展 决策支持系统的大致经历了这样几个发展过程:20世纪60年代后期,面向模型的决策支持系统诞生,标志着决策系统的这门学科的开端,20世纪70年代,决策支持系统的理论得到了长足的发展,80年代的前期和中期,实现了金融规划系统以及群体决策支持系统;20世纪80年代中期,通过将决策支持系统和知识系统相结合,提出了发展智能决策支持系统的设想;此后,开始出现主管信息系统,联机分析处理等。到了20世纪90年代中期,人们开始关注和开发基于Web的决策支持系统,随着Internet的革命性和深入应用,基于分布式的、基于群体网络化和远程化的协同的情报分析与综合决策支持系统逐步浮出水面并开始走向应用;随着人工智能的不断发展,决策支持系统的智能化程度越来越高,对人们的决策的支持能力也越来越大。 DSS的系统结构 尽管DSS在形态上各色各样,但它们在结构上有一个基本特征——集成性,对不同形态的DSS进行分解时,又会发现DSS主要由五个部件组成:人机接口、数据库、模型库、知识库、方法库。每个库又带有各自的管理系统,即对话管理系统、数据库管理系统、模型库管理系统、知识库管理系统、方法库管理系统。因此一般地说,大部分DSS都可以认为是这十个基本部件的不同的集成和组合,即这十个部件可以组成实现支持任何层次和级别的DSS系统。 阻碍决策支持系统发展的关键技术问题 1980年,Sprague就曾提出了决策支持系统的三部件结构,即对话部件、数据部件(数据库Data Base和数据库管理系统DBMS)、模型部件(模型库MB和模型库管理系统MBMS)。该结构明确了DSS的组成,也间接地反映了DSS的关键技术,即模型库管理系统、部件接口、系统综合集成。 1981年,Bonczak等又提出了DSS三系统结构,即语言系统(LS)、问题处理系统(PPS)、知识系统(KS)[13]。从这些系统总体架构的概括与设计思路看,开发一个实际的高性能DSS需要解决如下关键技术问题: (1)模型库系统的设计和实现:它包括模型库的组织结构、模型库管理系统 城市应急预案决策支持系统 城市应急预案决策支持系统框架研究 毛政利朱宝训 (平顶山工学院测绘与国土信息系,河南,平顶山467001) 摘要:城市应急预案决策支持系统是城市各类应急预案的有效综合和具体实施;本 文详细阐述了利用GIS强大的空间数据管理与空间分析能力,建立城市应急预案决 策支持系统的原理、方法、空间数据库设计及空间分析模型建模等;城市应急预案 决策支持系统能有效地缩短城市应对各类紧急事故的时间,提高应对效率,为救援 工作的及时、快速、准确提供决策支持。 关键词:应急预案决策支持系统GIS 城市 Study on The Frame of Decision Support System for Emergency Plan of City MAO Zheng-li ZHU Baoxun (Department of Survey & Soil information, Pingdingshan Institute of Technology, Henan Pingdingshan, 467001) Abstract: The decision support system (DSS) for emergency plan of city is the effectual integration and concrete actualization of every type of emergency plan of city. Making use of the powerful capability of spatial data management and spatial analysis of GIS, the principle, technique, design of spatial database and mode of spatial analysis which the decision应急指挥调度平台
智能决策支持系统
院长辅助决策支持系统
决策支持系统项目解决方案
决策支持系统概述
决策支持系统实例
科技创新辅助决策支持系统
决策支持系统DSS实验报告
医院综合管理决策支持系统
临床决策支持系统
应急专家决策支持系统
决策管理-财务决策支持系统实验 精品
临床辅助决策支持系统参数
城市公共安全应急决策支持系统框架研究.
智能决策支持系统
临床决策支持系统
决策支持系统发展现状与发展趋势(1)
城市应急预案决策支持系统
相关主题
文本预览