
实验三、最优路径分析
一、背景
随着社会经济发展需求,公路的重要性日益提高。在一些交通欠发达的地区,公路建设迫在眉睫。如何根据实际地形情况设计出比较合理的公路规划,是一个值得研究的问题。
二、实验目的
通过练习,熟悉ArcGIS栅格数据距离制图、表面分析、成本权重距离、数据重分类、最短路径等空间分析功能,熟练掌握利用ArcGIS上述空间分析功能分析解决实际应用问题的基本流程和操作过程。
三、实验要求
(1) 新建路径成本较少;
(2) 新建路径为较短路径;
(3) 新建路径的选择应该避开主干河流,以减少成本;
(4) 新建路径的成本数据计算时,考虑到河流成本(Reclass_river)是路径成本中较关键因素,先将坡度数据(reclass_slope)和起伏度数据(reclass_QFD)按照0.6:0.4权重合并,然后与河流成本作等权重的加和合并,公式描述如下:
cost = Reclass_river + ( reclass_slope*0.6+reclass_QFD*0.4)
(5) 寻找最短路径的实现需要运用ArcGIS的空间分析(Spatial Analyst)中距离制图中的成本路径及最短路径、表面分析中的坡度计算及起伏度计算、重分类及栅格计算器等功能完成
(6) 最后提交寻找到的最短路径路线图
四、实验数据
(1) dem(高程数据)
(2) startPot (路径源点数据)
(3) endPot (路径终点数据)
(4) river (小流域数据)
所有原始数据存放于随书光盘的..\Chp8\Ex2\目录下
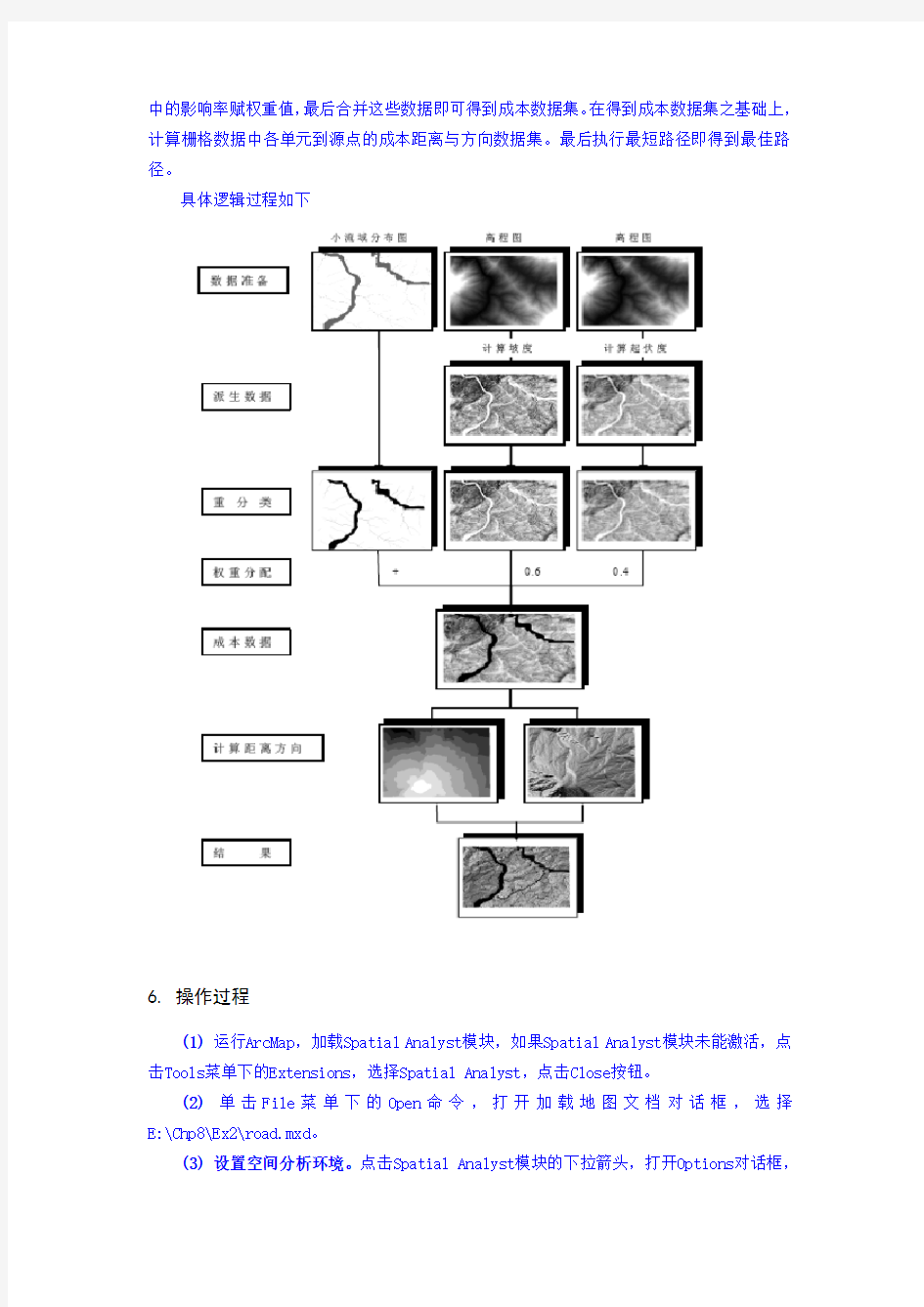
五、实现流程图
ArcGIS中实现最佳路径分析,首先利用高程数据派生出坡度数据以及起伏度数据集。然后重分类流域数据、坡度、起伏度数据集到相同的等级范围,再按照上述数据集在路径选择
中的影响率赋权重值,最后合并这些数据即可得到成本数据集。在得到成本数据集之基础上,计算栅格数据中各单元到源点的成本距离与方向数据集。最后执行最短路径即得到最佳路径。
具体逻辑过程如下
6. 操作过程
(1) 运行ArcMap,加载Spatial Analyst模块,如果Spatial Analyst模块未能激活,点击Tools菜单下的Extensions,选择Spatial Analyst,点击Close按钮。
(2) 单击File菜单下的Open命令,打开加载地图文档对话框,选择E:\Chp8\Ex2\road.mxd。
(3) 设置空间分析环境。点击Spatial Analyst模块的下拉箭头,打开Options对话框,
设置相关参数:
1) 打开Options对话框中的General选项卡,设置默认工作路径为:“E:\Chp8\Ex2\result\”。
2) 打开Options对话框中的Extent选项卡,在Analysis Extent下拉框中选择“Same as Layer landuse”。
3) 打开Options对话框中的Cell Size 选项卡,在Analyst Cell Size下拉框中选择“Same as Layer landuse”。
(4) 创建成本数据集
要找到到学校的最佳路径,首先需要从适宜性地图创建源数据输入及成本数据集,把它们作为成本加权函数输入。
考虑到山地坡度、起伏度对修建公路的成本影响比较大,其中尤其山地坡度更是人们首先关注的对象,则在创建成本数据集时,可考虑分配其权重比为:0.6:0.4。但是在有流域分布的情况下,河流对成本影响不可低估。在此情形下,成本数据集考虑为合并山地坡度和起伏度之后的成本,加上河流对成本之影响即可。
1) 坡度成本数据集
选择DEM数据层,点击Spatial Analyst下拉列表框,选择Surface Analysis并点击slope,生成坡度数据集,记为Slope。
选择Slope数据层,点击Spatial Analyst下拉键头,选择Reclassify命令实施重分类。对坡度数据集实施重分类的基本原则是:采用等间距分为10级,坡度最小一级赋值为1,最大一级赋值为10 ,得到图11所示坡度成本数据(reclass_slope)。
2) 起伏度成本数据集
选择DEM数据层,点击Spatial Analyst下拉列表框,选择Neighborhood Statistics,设置如图12所示参数设置,点击Ok按钮,生成起伏度数据层,记为QFD。
选择QFD数据层,点击Spatial Analyst下拉键头,选择Reclassify命令,按10级等间距实施重分类,地形越起伏,级数赋值越高,即最小一级赋值为1,最大一级赋值为10 ,得到图13所示地形起伏成本数据(reclass_QFD)。
3) 河流成本数据集
选择River数据层,点击Spatial Analyst下拉键头,选择Reclassify命令,按照河流等级如下进行分类:4级为10;如此依次为8,5,2,1,生成图14所示河流成本(reclass_river)。
(5) 加权合并单因素成本数据,生成最终成本数据集。
点击Spatial Analyst下拉箭头,选择Raster Calculator命令合并数据集,计算公式如下:
cost = reclass_river(重分类流域数据)+ ( reclass_slope(重分类坡度数据)*0.6 + reclass_rough(重分类起伏度数据)* 0.4)
得到图15所示最终成本数据集(cost),其中深色表示成本高的部分。
(6) 计算成本权重距离函数
在工具Spatial Analyst 选择Distance下的Cost Weighted,设置参数如图16,点击OK 按钮。生成图17所示成本距离图(其中浅色为源点),图18所示成本方向图。
(7) 求取最短路径:点击Spatial Analist选择Distance下的Shortest Path,设置参数如图19,点击OK按钮,生成最佳路径图(图20)
《数据分析实务与案例实验报告》 曲线估计 学号:2013111104000614 班级:2013 应用统计 姓名: 日期: 2 0 1 4 – 12 – 7 数学与统计学学院
一、实验目的 1. 准确理解曲线回归分析的方法原理。 2. 了解如何将本质线性关系模型转化为线性关系模型进行回归分析。 3. 熟练掌握曲线估计的SPSS 操作。 4. 掌握建立合适曲线模型的判断依据。 5. 掌握如何利用曲线回归方程进行预测。 6. 培养运用多曲线估计解决身边实际问题的能力。 二、准备知识 1. 非线性模型的基本内容 变量之间的非线性关系可以划分为 本质线性关系和本质非线性关系。所谓本质线性关系是指变量关系形式上虽然呈非线性关系,但可以通过变量转化为线性关系,并可最终进行线性回归分析,建立线性模型。本质非线性关系是指变量之间不仅形式上呈现非线性关系,而且也无法通过变量转化为线性关系,最终无法进行线性回归分析,建立线性模型。本实验针对本质线性模型进行。 下面介绍本次实验涉及到的可线性化的非线性模型,所用的变换既有自变量的变换,也有因变量的变换。 乘法模型: 123y x x x βγδαε= 其中α,β,γ,δ 都是未知参数,ε是乘积随机误差。对上式两边取自然对数得到 123ln ln ln ln ln ln y x x x αβγδε=++++
上式具有一般线性回归方程的形式,因而用多元线性回归的方法来处理。然而,必须强调指出的是,在求置信区间和做有关试验时,必须是2ln (0,)n N I εδ: , 而不是2n N I εδ:(0,) ,因此检验之前,要先检验ln ε 是否满足这个假设。 三、实验内容 已有很多学者验证了能源消费与经济增长的因果关系,证明了能源消费是促进经济增长的原因之一。也有众多学者利用C-D 生产函数验证了劳动和资本对经济增长的影响机理。所有这些研究都极少将劳动、资本、和能源建立在一个模型中来研究三个因素对经济增长的作用方向和作用大小。 现从我国能源消费、全社会固定资产投资和就业人员的实际出发,假定生产技术水平在短期能不会发生较大变化,经济增长、全社会固定资产投资、就业人员、能源消费可以分别采用国内生产总值、全社会固定资产投资总量、就业总人数、能源消费总量进行衡量,并假定经济增长与能源消费、资本和劳动力的关系均满足C-D 生产函数。 问题中的C-D 生产函数为: Y AK L E αβγ= 式中:Y 为GDP ,衡量总产出;K 为全社会固定资产投资,衡量资本投入量;L 为就业人数,衡量劳动投入量;E 为能源消费总量,衡量能源投入量;A,α,β, γ 为未知参数。根据C-D 函数的假定,一般情形α,β,γ均在0和1之间,但当α,β,γ中有负数时,说明这种投入量的增长,反而会引起GDP 的下降,当α,β,γ中出现大于1的值时,说明这种投入量的增加会引起GDP 成倍增加,这在经济学现象中都是存在的。 以我国1985—2004年的有关数据建立了SPSS 数据集,参见
算法设计与分析实验报告 贪心算法 班级:2013156 学号:201315614 姓名:张春阳哈夫曼编码 代码 #include printf("\n"); for(i=0;i 统计学数学实验报告 单因素方差分析 姓名 专业 学号 单因素方差分析 摘要统计学是关于数据的科学,它所提供的是一套有关数据收集、处理、分析、解释数据并从数据中得出结论的方法,统计研究的是来自各个领域的数据。单因素方差分析也是统计学分析的一种。单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响。关键字单因素、方差、数据统计 方差分析(analysis of variance,ANOVA)就是通过检验各总体的均值是否相等来判断分类型自变量对数值型因变量是否有显著影响。当方差分析中之涉及一个分类型自变量时称为单因素方差分析(one-way analysis of variance). 单因素方差分析研究的是一个分类型自变量对一个数值型因变量的影响。例如要检验汽车市场销售汽车时汽车颜色对销售数据的影响,这里只涉及汽车颜色一个因素,因而属于单因素方差分析。 为了更好的理解单因素方差分析,下面举个例子来具体说明单因素方差所要解决的问题。从3个总体中各抽取容量不同的样本数据,结果如下表1所示。检验3个总体的均值之间是否有显著差异(α=0.01)P29210.1 样本1 样本2 样本3 158 153 169 148 142 158 161 156 180 154 149 169 如果要进行单因素方差分析时,就需要得到一些相关的数据结构,从而对那些数据结构进行分析,如下表2所示: 分析步骤 1.提出假设 与通常的统计推断问题一样,方差分析的任务也是先根据实际情况提出原假设H0与备择假设H1,然后寻找适当的检验统计量进行假设检验。本节将借用上面的实例来讨论单因素试验的方差分析问题。 回归分析基本分析: 将毕业生人数移入因变量,其他解释变量移入自变量。在统计量中选择估计和模型拟合度,得到如图 注解:模型的拟合优度检验: 第二列:两变量(被解释变量和解释变量)的复相关系数R=0.999。 第三列:被解释向量(毕业人数)和解释向量的判定系数R2=0.998。 第四列:被解释向量(毕业人数)和解释向量的调整判定系数R2=0.971。在多个解释变量的时候,需要参考调整的判定系数,越接近1,说明回归方程对样本数据的拟合优度越高,被解释向量可以被模型解释的部分越多。 第五列:回归方程的估计标准误差=9.822 回归方程的显著性检验-回归分析的方差分析表 F检验统计量的值=776.216,对应的概率p值=0.000,小于显著性水平0.05,应拒绝回归方程显著性检验原假设(回归系数与0不存在显著性差异),认为:回归系数不为0,被解释变量(毕业生人数)和解释变量的线性关系显著,可以建立线性模型。 注解:回归系数的显著性检验以及回归方程的偏回归系数和常数项的估计值第二列:常数项估计值=-544.366;其余是偏回归系数估计值。 第三列:偏回归系数的标准误差。 第四列:标准化偏回归系数。 第五列:偏回归系数T检验的t统计量。 第六列:t统计量对应的概率p值;小于显著性水平0.05,拒接原假设(回归系数与0不存在显著性差异),认为回归系数部位0,被解释变量与解释变量的线性关系是显著的;大于显著性水平0.05,接受原假设(回归系数与0不存在显著性差异),认为回归系数为0被解释变量与解释变量的线性关系不显著的。 于是,多元线性回归方程为: y=-544.366+0.032x1+0.009x2+0.001x3-0.1x5+3.046x6 回归分析的进一步分析: 1.多重共线性检验 从容差和方差膨胀因子来看,在校学生数和教职工总数与其他解释变量的多重共线性很严重。在重新建模中可以考虑剔除该变量 一元线性回归模型案例分析 一、研究的目的要求 居民消费在社会经济的持续发展中有着重要的作用。居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。为了研究全国居民消费水平及其变动的原因,需要作具体的分析。影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。 二、模型设定 我们研究的对象是各地区居民消费的差异。居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。 因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。因此建立的是2002年截面数据模型。 影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。为了与“城市居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。 从2002年《中国统计年鉴》中得到表2.5的数据: 表2.52002年中国各地区城市居民人均年消费支出和可支配收入 兰州交通大学 《算法设计与分析》 实验报告3 题目03-动态规划 专业计算机科学与技术 班级计算机科学与技术2016-02班学号201610333 姓名石博洋 第3章动态规划 1. 实验题目与环境 1.1实验题目及要求 (1) 用代码实现矩阵连乘问题。 给定n个矩阵{A1,A2,…,A n},其中A i与A i+1是可乘的,i=1,2,…,n-1。考察这n 个矩阵的连乘积A1A2…A n。由于矩阵乘法满足结合律,故计算矩阵的连乘积可以有许多不同的计算次序,这种计算次序可以用加括号的方式来确定。若一个矩阵连乘积的计算次序完全确定,则可以依此次序反复调用2个矩阵相乘的标准算法(有改进的方法,这里不考虑)计算出矩阵连乘积。 确定一个计算顺序,使得需要的乘的次数最少。 (2) 用代码实现最长公共子序列问题。 一个给定序列的子序列是在该序列中删去若干元素后得到的序列。确切地说,若给定序列X= < x1, x2,…, xm>,则另一序列Z= < z1, z2,…, zk>是X的子序列是指存在一个严格递增的下标序列< i1, i2,…, ik>,使得对于所有j=1,2,…,k有Xij=Zj 。例如,序列Z=是序列X=的子序列,相应的递增下标序列为<2,3,5,7>。给定两个序列X和Y,当另一序列Z既是X的子序列又是Y的子序列时,称Z是序列X和Y的公共子序列。例如,若X= < A, B, C, B, D, A, B>和Y= < B, D, C, A, B, A>,则序列是X和Y的一个公共子序列,序列也是X和Y的一个公共子序列。而且,后者是X和Y的一个最长公共子序列,因为X和Y没有长度大于4的公共子序列。 (3) 0-1背包问题。 现有n种物品,对1<=i<=n,已知第i种物品的重量为正整数W i,价值为正整数V i,背包能承受的最大载重量为正整数W,现要求找出这n种物品的一个子集,使得子集中物品的总重量不超过W且总价值尽量大。(注意:这里对每种物品或者全取或者一点都不取,不允许只取一部分) 使用动态规划使得装入背包的物品价值之和最大。 1.2实验环境: CPU:Intel(R) Core(TM) i3-2120 3.3GHZ 内存:12GB 操作系统:Windows 7.1 X64 编译环境:Mircosoft Visual C++ 6 2. 问题分析 (1) 分析。 统 计 分 析 综 合 实 验 报 告 专业:班级: 姓名:学号: 规定题目 一.问题提出及分析目的 (一)问题提出 夏春同学打算毕业后去上海创办一家属于自己的投资咨询服务公司,以便利用在学校里学到的经济学知识,去为广大的货币市场从业人员提供必要的投资指导。为了能顺利地实现自己的创业计划,他着手编辑了一份投资信息简报、分发给一些投资商,希望这些人能提供各方面的建议,进而了解投资商们感兴趣的东西。(二)分析目的 (1)、对货币市场的交易规模和收益情况进行描述分析。 (2)在95%的置信水平下,对整个货币市场的投资规模、每周收益率和每月收益率进行区间估计,并作出解释。 (3)对周收益率和月收益率进行比较。 (4)资产规模大小对收益率影响是否显著? 二.数据收集及录入 1.打开SPSS 应用程序,在“变量视图”编辑框中录入以下数据: 2.在“数据视图”编辑框中依据收集的数据录入以下数据:(因版面需要在此呈现前5行数据,后面27行按前5行方式录入) 三.数据分析 (一)描述性分析 1.在SPSS 中依次选取“分析”—“描述统计”—“描述”,将资产规模和过去一周、一月的平均收益率全部选取转至右侧方框: 2.在描述性对话框中点击右侧“选项”,进入选项属性设置对话框,选中“均值”、“标准差”、“最大值”、“最小值”、“峰度”、“偏度”、“变量列表”选项: (二)区间估计 1.在SPSS中依次选取“分析”—“描述统计”—“探索过程”,将资产规模和过去一周、一月的平均收益率全部选取转至右侧方框: 2. .在“探索”对话框中点击右侧“统计量”,进入统计量设置对话框,设置均值置信区间为95%: (三)周月收益率分析 1.在SPSS中依次选取“分析”——“比较均值”——“配对样本T检验”,将过去一周、一月的平均收益率选取转至右侧方框: 2. .在“配对样本T检验”对话框中点击右侧“选项”,进入选项属性设置对话框,设置置信区间为95%: 实验报告 1. 实验目的随着中国经济的发展,居民的常住收入水平不断提高,粮食销售量也不断增长。研究粮食年销售量与人均收入之间的关系,对于探讨粮食年销售量的增长的规律性有重要的意义。 2. 模型设定 为了分析粮食年销售量与人均收入之间的关系,选择“粮食年销售量” 为被解释变量(用Y 表示),选择“人均收入”为解释变量(用X 表 示)。本次实验报告数据取自某市从1974 年到1987 年的数据(教材书上101页表3.11),数据如下图所示: 1粮食年销售量Y/万吨人均收入X/ rF1974[ 9& 45153.2 1975100.7190 pl1976102.8240.3 1977133. 95301.12 [61978140.13361 71979143.11420 8—1980146.15491.76「91981144.6501 101982148. 94529.2 1 11-1983158.55552. 72匸1984169. 68771.16 131985P 162.1481L8 14二1986170. 09988.43 1519871F& 691094.65为分析粮食年销售量与人均收入的关系,做下图所谓的散点图 从散点图可以看出粮食年销售量与人均收入大体呈现为线性关 系,可以建立如下简单现行回归模型: 3?估计参数 Y t = ■? 1 2 X t ——I t 假定所建模型及其中的随机扰动项叫满足各项古典假定,可以 用OLS法估计其参数。 通过利用EViews对以上数据作简单线性回归分析,得出回归结果如下表所示: Dependent Variable Y Method: Least Squares Date 10/15/11 Time 14 49 Sample- 1 14 Included observations: 14 Variable Coefficient Std Error t-Statistic Prob C99 61349 6 431242 15 489000 0000 X0.0814700.010738 7.5071190.0000 R-squared0 827493Mean dependent var142 7129 Adjusted R-squared0 813123S.D. dependent var26.09805 S E of regression11 28200Akaike info criterion7 915858 Sum squared resid1527 403Schwarz criterion7 907152 Log likelihood-52.71101F-statisti c5756437 Durbin-V/atson stat0 638969Prob(尸-statistic)0 000006 可用规范的形式将参数估计和检验的结果写为: A Y t =99.61349+0.08147 X t (6.431242)(0.10738) t= (15.48900) (7.587119) R2=0.827498 F=57.56437 n=14 4?模型检验 (1).经济意义检验 A A 所估计的参数1=99.61349, 1 2=0.08147,说明人均收入每增加 1元,平均说来可导致粮食年销售量提高0.08147元。这与经济学中 《算法设计与分析》实验报告 分治策略 姓名:XXX 专业班级:XXX 学号:XXX 指导教师:XXX 完成日期:XXX 一、试验名称:分治策略 (1)写出源程序,并编译运行 (2)详细记录程序调试及运行结果 二、实验目的 (1)了解分治策略算法思想 (2)掌握快速排序、归并排序算法 (3)了解其他分治问题典型算法 三、实验内容 (1)编写一个简单的程序,实现归并排序。 (2)编写一段程序,实现快速排序。 (3)编写程序实现循环赛日程表。设有n=2k个运动员要进行网球循环赛。现 要设计一个满足以下要求的比赛日程表:(1)每个选手必须与其它n-1个选手各赛一次(2)每个选手一天只能赛一场(3)循环赛进行n-1天 四、算法思想分析 (1)编写一个简单的程序,实现归并排序。 将待排序元素分成大小大致相同的2个子集合,分别对2个子集合进行 排序,最终将排好序的子集合合并成为所要求的排好序的集合。 (2)编写一段程序,实现快速排序。 通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有 数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数 据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据 变成有序序列。 (3)编写程序实现循环日赛表。 按分治策略,将所有的选手分为两组,n个选手的比赛日程表就可以通 过为n/2个选手设计的比赛日程表来决定。递归地用对选手进行分割, 直到只剩下2个选手时,比赛日程表的制定就变得很简单。这时只要让 这2个选手进行比赛就可以了。 五、算法源代码及用户程序 (1)编写一个简单的程序,实现归并排序。 #include 实验一 一、实验目的及要求 对应分析是你也降维的思想以达到减化数据结构的目的,凤的研究广泛用于定义属性变量构成的列联表利用对应分析方法分析问卷中教育程度与网上购物支付方式之间的相互关系。 二、实验环境 SPSS 19.0 window 7系统 三、实验内容及实验步骤(实践内容、设计思想与实现步骤) 实验题目: 通过分析问卷数据,绘制如下的教育程度与网上购物支付方式的交叉表,运用对应分析方法研究教育程度与网上购物所选择的支付方式之间的相关性,及揭示不同人群网上购物的特征等问题。 设计思想:原假设:H1:χ2>χα2[(n?1)(p?1)] 实现步骤: 1.在变量视窗中录入3个变量,用edu表示【教育程度】,用fangshi表示【在网上购物时采用什么样的支付方式】,用pinshu表示【频数】;如图所示: 2.先对数据进行预处理。执行【数据】→【加权个案】命令,弹出【加权个案】对话框。选中【加权个案】按钮,把【频数】放入【频率变量】框中,点击【确定】按钮完成。 3.打开主窗口,选择菜单栏中的【分析】→【降维】→【对应分析】命令,弹出【对应分析】对话框。 4.将【教育程度】导入【行】,将【在网上购物时采用什么样的支付方式】导入【列】。 5. 单击【定义范围(D)】,打开【对应分析:定义行范围】对话框; 定义行变量分类全距最小值为1,最大值为4,单击【更新】;点击【继续】,返回【对应分析】对话框;同方法打开【对应分析:定义列范围】对话框; 定义列变量全距最小值为1,最大值为5,单击【更新】; 6. 单击【统计量】打开【对应分析:统计量】对话框;选择【行轮廓表】,【列轮廓表】;单击【继续】,返回【对应分析】对话框, 7.选择【绘制】→【对应分析:图】对话框,选择【散点图】中的【行点】、【列点】选择【线图】中的【已转换的行类别】、【已转换的列类别】,单击【继续】,返回【对应分析】对话框。 8.单击【确定】按钮,完成设置并执行列联表分析。 四、调试过程及实验结果(详细记录实验在调试过程中出现的问题及解决方法。记录实验的结果) SPSS实验结果及分析: 上表显示了在32155名被调查者中,大多数消费者在网上购物时选择第三方支付和网上银行支付,在网上购物的消费人群以大学本科生相对最多。 回归分析 实验内容:基于居民消费性支出与居民可支配收入的简单线性回归分析 【研究目的】 居民消费在社会经济的持续发展中有着重要的作用。影响各地区居民消费支出的因素很多,例如居民的收入水平、商品价格水平、收入分配状况、消费者偏好、家庭财产状况、消费信贷状况、消费者年龄构成、社会保障制度、风俗习惯等等。为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的经济模型去研究。 【模型设定】 我们研究的对象是各地区居民消费的差异。由于各地区的城市与农村人口比例及经济结构有较大差异,现选用城镇居民消费进行比较。模型中被解释变量Y选定为“城市居民每人每年的平均消费支出”。从理论和经验分析,影响居民消费水平的最主要因素是居民的可支配收入,故可以选用“城市居民每人每年可支配收入”作为解释变量X,选取2010年截面数据。 1、实验数据 表1: ( 2010年中国各地区城市居民人均年消费支出和可支配收入 } 数据来源:《中国统计年鉴》2010年 2、实验过程 作城市居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图1: 表2 模型汇总b 模型… R R方调整R方标准估计的误差 1.965a.93 2.930 a.预测变量:(常量),可支配收入X(元)。 b.因变量:消费性支出Y(元) ~ 表3 相关性 消费性支出Y (元) 可支配收入X(元) Pearson相关 性消费性支出 Y(元) .965 从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立如下线性模型:Y=a+bX 学生实验报告书 实验课程名称算法设计与分析开课学院计算机科学与技术学院 指导教师姓名李晓红 学生姓名 学生专业班级软件工程zy1302班2015-- 2016学年第一学期 实验课程名称:算法设计与分析 同组者实验日期2015年10月20日第一部分:实验分析与设计 一.实验内容描述(问题域描述) 1、利用分治法,写一个快速排序的递归算法,并利用任何一种语言,在计算机上实现,同时 进行时间复杂性分析; 2、要求用递归的方法实现。 二.实验基本原理与设计(包括实验方案设计,实验手段的确定,试验步骤等,用硬件逻辑或者算法描述) 本次的解法使用的是“三向切分的快速排序”,它是快速排序的一种优化版本。不仅利用了分治法和递归实现,而且对于存在大量重复元素的数组,它的效率比快速排序基本版高得多。 它从左到右遍历数组一次,维护一个指针lt使得a[lo..lt-1]中的元素都小于v,一个指针gt 使得a[gt+1..hi]中的元素都大于v,一个指针i使得a[lt..i-1]中的元素都等于v,a[i..gt]中的元素都还未确定,如下图所示: public class Quick3way { public static void sort(Comparable[] a, int lo, int hi) { if (lo >= hi) return; int lt = lo, i = lo + 1, gt = hi; Comparable pivot = a[lo]; 第二部分:实验调试与结果分析 一、调试过程(包括调试方法描述、实验数据记录,实验现象记录,实验过程发现的问题等) 1、调试方法描述: 对程序入口进行断点,随着程序的运行,一步一步的调试,得到运行轨迹; 2、实验数据: "R", "B", "W", "W", "R", "W", "B", "R", "R", "W", "B", "R"; 3、实验现象: 4、实验过程中发现的问题: (1)边界问题: 在设计快速排序的代码时要非常小心,因为其中包含非常关键的边界问题,例如: 什么时候跳出while循环,递归什么时候结束,是对指针的左半部分还是右半部分 排序等等; (2)程序的调试跳转: 在调试过程中要时刻记住程序是对那一部分进行排序,当完成了这部分的排序后, 会跳到哪里又去对另外的那一部分进行排序,这些都是要了然于心的,这样才能准 确的定位程序。 二、实验结果分析(包括结果描述、实验现象分析、影响因素讨论、综合分析和结论等) 1、实验结果: 一、实验类型 验证型实验。分析1991-2013年中国1年期实际储蓄存款利率的变化特点,运用名义利率、通货膨胀率和物价指数的数据用两种方法来计算并分析哪种方法更科学。 二、实验目的 1、掌握实际利率的两种计算方法,并分析1991-2013年中国1年期实际储蓄存款利率的变化特点。 2、比较两种实际利率测算方法的差异性及科学性。 三、实验背景 利率是国家调控经济的重要杠杆之一,特定的宏观经济目标和微观经济目标可以通过利率调整实现。利率调整是在一定的经济运行环境下进行的,它的调整对经济增长、居民消费、居民储蓄、市场投资等都会产生直接或是简洁的影响。 实际利率(Effective Interest Rate/Real interest rate) 是指剔除通货膨胀率后储户或投资者得到利息回报的真实利率。研究实际利率对经济发展有很大的作用,本实验就1991年至2013年中国1年期实际储蓄利率的变化特点进行探讨,并比较分析实际利率的计算方法。 四、实验环境 本实验属于自主实验,由学员课后自主完成,主要使用Excel软件。 数据来源:通过国家统计局网站、中国人民银行网站获取数据。 五、实验原理 1、实际利率=名义利率-通货膨胀率。 2、实际利率=(名义利率-通货膨胀率)/(1+通货膨胀率)。 六、实验步骤 1、采集实验基础数据。通过网上登录国家统计局网站查看中国统计年鉴,以及登录中国人民银行网站获取相应数据。数据样本区间为1991-2013年。 2、利用Excel软件分别按照两种方法计算实际利率。 3、做出实际储蓄存款利率的变化以及两种不同算法下实际利率变化的折线图。 4、分析图表,考察实际存款利率变化特点并比较两种计算方法的科学性。 七、实验结果分析 (一)实验结果 经过整理和测算的结果如图所示 计量经济学多元线性回归、多重共线性、异方差实验报告记录 ————————————————————————————————作者:————————————————————————————————日期: 计量经济学实验报告 多元线性回归、多重共线性、异方差实验报告 一、研究目的和要求: 随着经济的发展,人们生活水平的提高,旅游业已经成为中国社会新的经济增长点。旅游产业是一个关联性很强的综合产业,一次完整的旅游活动包括吃、住、行、游、购、娱六大要素,旅游产业的发展可以直接或者间接推动第三产业、第二产业和第一产业的发展。尤其是假日旅游,有力刺激了居民消费而拉动内需。2012年,我国全年国内旅游人数达到亿人次,同比增长%,国内旅游收入万亿元,同比增长%。旅游业的发展不仅对增加就业和扩大内需起到重要的推动作用,优化产业结构,而且可以增加国家外汇收入,促进国际收支平衡,加强国家、地区间的文化交流。为了研究影响旅游景区收入增长的主要原因,分析旅游收入增长规律,需要建立计量经济模型。 影响旅游业发展的因素很多,但据分析主要因素可能有国内和国际两个方面,因此在进行旅游景区收入分析模型设定时,引入城镇居民可支配收入和旅游外汇收入为解释变量。旅游业很大程度上受其产业本身的发展水平和从业人数影响,固定资产和从业人数体现了旅游产业发展规模的内在影响因素,因此引入旅游景区固定资产和旅游业从业人数作为解释变量。因此选取我国31个省市地区的旅游业相关数据进行定量分析我国旅游业发展的影响因素。 二、模型设定 根据以上的分析,建立以下模型 Y=β 0+β 1 X 1 +β 2 X 2 +β 3 X 3 +β 4 X 4 +Ut 参数说明: Y ——旅游景区营业收入/万元 X 1 ——旅游业从业人员/人 X 2 ——旅游景区固定资产/万元 X 3 ——旅游外汇收入/万美元 X 4 ——城镇居民可支配收入/元 本科实验报告 课程名称:算法设计与分析 实验项目:递归与分治算法 实验地点:计算机系实验楼110 专业班级:物联网1601 学号:2016002105 学生:俞梦真 指导教师:郝晓丽 2018年05月04 日 实验一递归与分治算法 1.1 实验目的与要求 1.进一步熟悉C/C++语言的集成开发环境; 2.通过本实验加深对递归与分治策略的理解和运用。 1.2 实验课时 2学时 1.3 实验原理 分治(Divide-and-Conquer)的思想:一个规模为n的复杂问题的求解,可以划分成若干个规模小于n的子问题,再将子问题的解合并成原问题的解。 需要注意的是,分治法使用递归的思想。划分后的每一个子问题与原问题的性质相同,可用相同的求解方法。最后,当子问题规模足够小时,可以直接求解,然后逆求原问题的解。 1.4 实验题目 1.上机题目:格雷码构造问题 Gray码是一个长度为2n的序列。序列无相同元素,每个元素都是长度为n的串,相邻元素恰好只有一位不同。试设计一个算法对任意n构造相应的Gray码(分治、减治、变治皆可)。 对于给定的正整数n,格雷码为满足如下条件的一个编码序列。 (1)序列由2n个编码组成,每个编码都是长度为n的二进制位串。 (2)序列中无相同的编码。 (3)序列中位置相邻的两个编码恰有一位不同。 2.设计思想: 根据格雷码的性质,找到他的规律,可发现,1位是0 1。两位是00 01 11 10。三位是000 001 011 010 110 111 101 100。n位是前n-1位的2倍个。N-1个位前面加0,N-2为倒转再前面再加1。 3.代码设计: 多元线性回归模型实验报告 13级财务管理 101012013101 蔡珊珊 【摘要】首先做出多元回归模型,对于解释变量作出logx等变换,选择拟合程度最高的模型,然后判断出解释变量之间存在相关性,然后从检验多重线性性入手,由于解释变量之间有的存在严重的线性性,因此采用逐步回归法,将解释变量进行筛选,保留对模型解释能力较强的解释变量,进而得出一个初步的回归模型,最后对模型进行异方差和自相关检验。 【操作步骤】1.输入解释变量与被解释变量的数据 2.作出回归模型 R^2=0.966951 DW=0.626584 F-statictis=241.3763 ②我们令y1=log(consumption),x4=log(people),x5=log(price),x6=log(retained),x7= log(gdp), 作出回归模型 ② 发现拟合程度很高,也通过了F检验与T检验。但是我们首先检查模型的共线性 发现x4与x6,x4与x7,x6与x7存在很强的共线性,对模型会造成严重影响。 目前暂用模型y1=10.55028-3.038439x4-0.236518x5+2.647396x6-0.557805x7,我们将陆续进行调整。 3.分别作出各解释变量与被解释变量之间的线性模型 ①作出汽车消费量与汽车保有量之间的线性回归模型 R^2=0.956231 DW=0.147867 F-statistic=786.4967 因为prob小于α置信度,则可说明β1不明显为零。经济意义存在 Y1^=4.142917 + 0.761197x6 (8.283960) (28.04455) 我国农民收入影响因素的回归分析 本文力图应用适当的多元线性回归模型,对有关农民收入的历史数据和现状进行分析,探讨影响农民收入的主要因素,并在此基础上对如何增加农民收入提出相应的政策建议。?农民收入水平的度量常采用人均纯收入指标。影响农民收入增长的因素是多方面的,既有结构性矛盾因素,又有体制性障碍因素。但可以归纳为以下几个方面:一是农产品收购价格水平。二是农业剩余劳动力转移水平。三是城市化、工业化水平。四是农业产业结构状况。五是农业投入水平。考虑到复杂性和可行性,所以对农业投入与农民收入,本文暂不作讨论。因此,以全国为例,把农民收入与各影响因素关系进行线性回归分析,并建立数学模型。 一、计量经济模型分析 (一)、数据搜集 根据以上分析,我们在影响农民收入因素中引入7个解释变量。即:2x -财政用于农业的支出的比重,3x -第二、三产业从业人数占全社会从业人数的比重,4x -非农村人口比重,5x -乡村从业人员占农村人口的比重,6x -农业总产值占农林牧总产值的比重,7x -农作物播种面积,8x —农村用电量。 资料来源《中国统计年鉴2006》。 (二)、计量经济学模型建立 我们设定模型为下面所示的形式: 利用Eviews 软件进行最小二乘估计,估计结果如下表所示: DependentVariable:Y Method:LeastSquares Sample: Includedobservations:19 Variable Coefficient t-Statistic Prob. C X1 X3 X4 X5 X6 X7 X8 R-squared Meandependentvar AdjustedR-squared 表1最小二乘估计结果 回归分析报告为: () ()()()()()()()()()()()()()()() 2345678 2? -1102.373-6.6354X +18.2294X +2.4300X -16.2374X -2.1552X +0.0100X +0.0634X 375.83 3.7813 2.066618.37034 5.8941 2.77080.002330.02128 -2.933 1.7558.820900.20316 2.7550.778 4.27881 2.97930.99582i Y SE t R ===---=230.99316519 1.99327374.66 R Df DW F ====二、计量经济学检验 (一)、多重共线性的检验及修正 ①、检验多重共线性 (a)、直观法 从“表1最小二乘估计结果”中可以看出,虽然模型的整体拟合的很好,但是x4x6 实验报告 课程名称统计学学号 11学生姓名辅导教师 系别经济与管理系实验室名称实验时间 1.实验名称 统计指数分析 2.实验目的 掌握各项指数的计算及因素分析法的运用。 在 Excel 中完成各项指数及有关数值的计算,主要用到的是公式和公式复制 3.实验内容 甲乙丙三种商品基期和报告期各项数据如下: 价格(元) P销量 q 商品计量单位 基期 p0报告期 p1基期 q0报告期 q1 甲个302810001200 乙双202120001600 丙公斤232515001500 合计 1)计算三种商品的个体销售量指数和个体价格指数。 2)三种商品的销售额总指数。 3)三种商品的销售量总指数和价格总指数。 4)分析销售量变动和价格变动对销售额影响的绝对额。(这一问分析要手写完成) 4.实验原理 在 Excel 中实现综合指数及其相关数值的计算,主要用到的是公式和公式的复制功 能 5.实验过程及步骤 (1)在工作表中输入已知数据的名称和数值(包括商品名称,计量单位,基期价格,报告 期价格,基期销售量和报告期销售量) (2)计算综合指标的各个综合总量在单元格G4中输入公式“ =C4*E4”,在H4中输入“=D4*F4”, 在 I4 中输入“ =C4*F4”, 在 J4 中输入“ =D4*E4”, 公式复制 在 A7 中输入合计,在单元格中输入“=SuM(G4:G6),再将单元格 G7的公式向右复制到 J7 (3)分别计算各个综合指标及其分子分母之差额 在单元格 A10 中输入“销售额总额指数” ,在单元格 F10 中输入公式“ =H7/G7*100” , 在单元格 H10 中输入公式” =H7-G7” 一元线性回归在公司加班制度中的应用 院(系): 专业班级: 学号姓名: 指导老师: 成绩: 完成时间: 一元线性回归在公司加班制度中的应用 一、实验目的 掌握一元线性回归分析的基本思想和操作,可以读懂分析结果,并写出回归方程,对回归方程进行方差分析、显著性检验等的各种统计检验 二、实验环境 SPSS21.0 windows10.0 三、实验题目 一家保险公司十分关心其总公司营业部加班的程度,决定认真调查一下现状。经10周时间,收集了每周加班数据和签发的新保单数目,x 为每周签发的新保单数目,y 为每周加班时间(小时),数据如表所示 y 3.5 1.0 4.0 2.0 1.0 3.0 4.5 1.5 3.0 5.0 2. x 与y 之间大致呈线性关系? 3. 用最小二乘法估计求出回归方程。 4. 求出回归标准误差σ∧ 。 5. 给出0 β∧与1 β∧ 的置信度95%的区间估计。 6. 计算x 与y 的决定系数。 7. 对回归方程作方差分析。 8. 作回归系数1 β∧ 的显著性检验。 9. 作回归系数的显著性检验。 10.对回归方程做残差图并作相应的分析。 11.该公司预测下一周签发新保单01000 x=张,需要的加班时间是多少? 12.给出0y的置信度为95%的精确预测区间。 13.给出 () E y的置信度为95%的区间估计。 四、实验过程及分析 1.画散点图 如图是以每周加班时间为纵坐标,每周签发的新保单为横坐标绘制的散点图,从图中可以看出,数据均匀分布在对角线的两侧,说明x和y之间线性关系良好。 2.最小二乘估计求回归方程 用SPSS 求得回归方程的系数01,ββ分别为0.118,0.004,故我们可以写出其回归方程如下: 0.1180.004y x =+ 3.求回归标准误差σ∧ 由方差分析表可以得到回归标准误差:SSE=1.843 故回归标准误差: 2= 2SSE n σ∧-,2σ∧=0.48。 4.给出回归系数的置信度为95%的置信区间估计。 由回归系数显著性检验表可以看出,当置信度为95%时: 一般线性回归分析案例 1、案例 为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康的影响,随机抽取了30个观测数据,基于多员线性回归分析的理论方法,对儿童体内几种必需元素与血红蛋白浓度的关系进行分析研究。这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu)。 表一血红蛋白与钙、铁、铜必需元素含量 (血红蛋白单位为g;钙、铁、铜元素单位为ug) case y(g)ca fe cu 17.0076.90295.300.840 27.2573.99313.00 1.154 37.7566.50350.400.700 48.0055.99284.00 1.400 58.2565.49313.00 1.034 68.2550.40293.00 1.044 78.5053.76293.10 1.322 88.7560.99260.00 1.197 98.7550.00331.210.900 109.2552.34388.60 1.023 119.5052.30326.400.823 129.7549.15343.000.926 1310.0063.43384.480.869 1410.2570.16410.00 1.190 1510.5055.33446.00 1.192 1610.7572.46440.01 1.210 1711.0069.76420.06 1.361 1811.2560.34383.310.915 1911.5061.45449.01 1.380 2011.7555.10406.02 1.300 2112.0061.42395.68 1.142 2212.2587.35454.26 1.771 2312.5055.08450.06 1.012 2412.7545.02410.630.899 2513.0073.52470.12 1.652 2613.2563.43446.58 1.230统计学实验报告
多元线性回归SPSS实验报告
一元线性回归模型案例分析
算法分析_实验报告3
统计分析综合实验报告
计量经济学简单线性回归实验报告精编
算法分析实验报告--分治策略
多元统计分析实验报告
SPSS线性回归分析案例
武汉理工大学算法分析实验报告
金融统计学实验报告
计量经济学多元线性回归、多重共线性、异方差实验报告记录
算法设计与分析实验报告
多元线性回归模型实验报告
多元线性回归模型案例
统计学实验报告7.统计指数分析.docx
一元线性回归分析实验报告
一般线性回归分析案例
相关主题
文本预览