
预测方法的分类
郑XX
预测方法的分类
由于预测的对象、目标、内容和期限不同,形成了多种多样的预测方法。据不完全统计,目前世界上共有近千种预测方法,其中较为成熟的有150多种,常用的有30多种,用得最为普遍的有10多种。
1-1预测方法的分类体系
1)按预测技术的差异性分类
可分为定性预测技术、定量预测技术、定时预测技术、定比预测技术和评价预测
技术,共五类。
2)按预测方法的客观性分类
可分为主观预测方法和客观预测方法两类。前者主要依靠经验判断,后者主要借
助数学模型。
3)按预测分析的途径分类
可分为直观型预测方法、时间序列预测方法、计量经济模型预测方法、因果分析
预测方法等。
4)按采用模型的特点分类
可分为经验预测模型和正规的预测模型。后者包括时间关系模型、因果关系模
型、结构关系模型等。
1-2 常用的方法分类
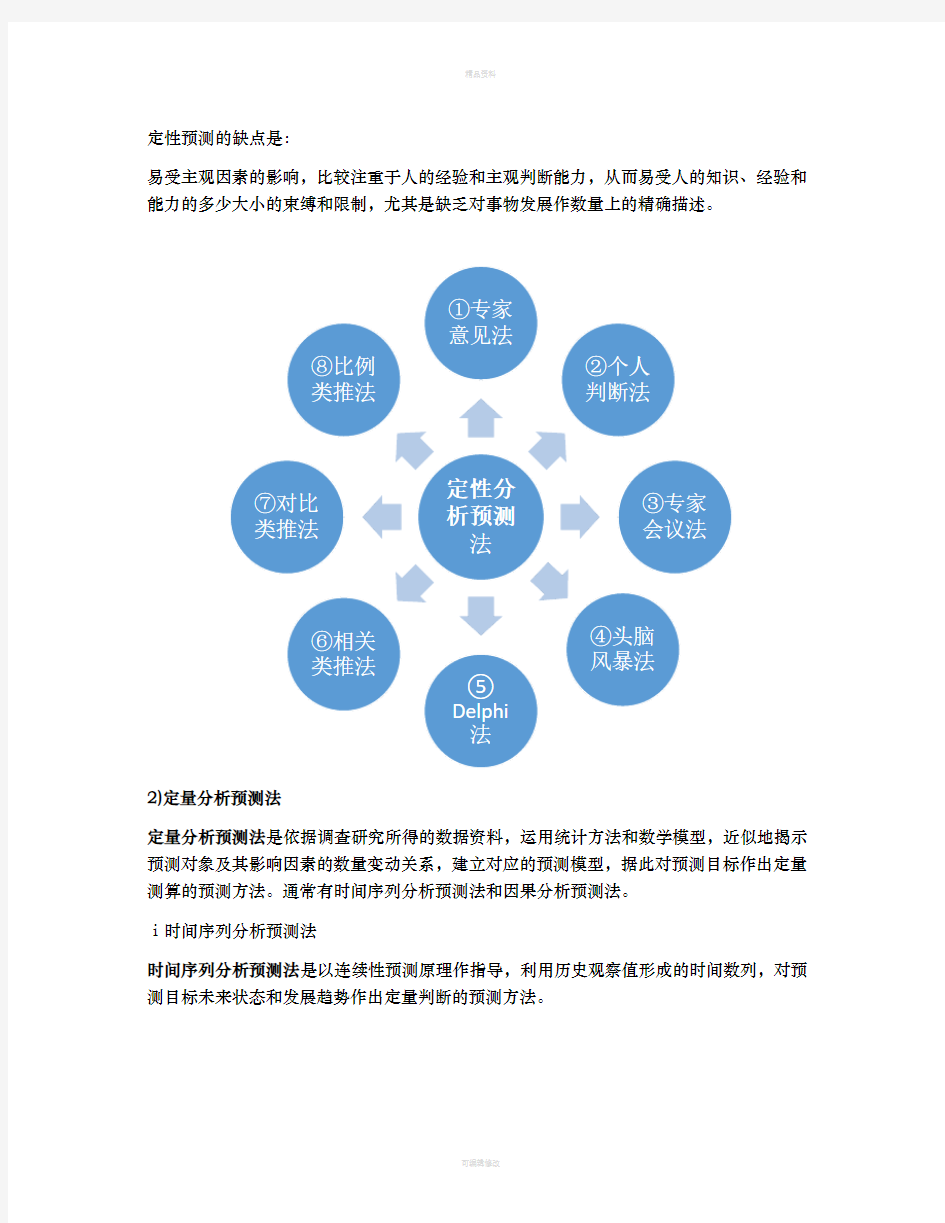
1)定性分析预测法
定性分析预测法是指预测者根据历史与现实的观察资料,依赖个人或集体的经验与智慧,对未来的发展状态和变化趋势作出判断的预测方法。
定性预测优缺点
定性预测的优点在于:
注重于事物发展在性质方面的预测,具有较大的灵活性,易于充分发挥人的主观能动作用,且简单的迅速,省时省费用。
定性预测的缺点是:
易受主观因素的影响,比较注重于人的经验和主观判断能力,从而易受人的知识、经验和能力的多少大小的束缚和限制,尤其是缺乏对事物发展作数量上的精确描述。
2)定量分析预测法
定量分析预测法是依据调查研究所得的数据资料,运用统计方法和数学模型,近似地揭示预测对象及其影响因素的数量变动关系,建立对应的预测模型,据此对预测目标作出定量测算的预测方法。通常有时间序列分析预测法和因果分析预测法。
ⅰ时间序列分析预测法
时间序列分析预测法是以连续性预测原理作指导,利用历史观察值形成的时间数列,对预测目标未来状态和发展趋势作出定量判断的预测方法。
ⅱ因果分析预测法
因果分析预测法是以因果性预测原理作指导,以分析预测目标同其他相关事件及现象之间的因果联系,对市场未来状态与发展趋势作出预测的定量分析方法
定量预测优缺点
定量预测的优点在于:
注重于事物发展在数量方面的分析,重视对事物发展变化的程度作数量上的描述,更多地依据历史统计资料,较少受主观因素的影响。
定量预测的缺点在于:
比较机械,不易处理有较大波动的资料,更难于事物预测的变化。
预测方法选择的影响因素
意义:选择合适的预测方法,对于提高预测精度,保证预测质量,有十分重要的意义。影响预测方法选择的因素很多,在选择预测方法时应综合考虑。
2-1 预测的目标特性
*用于战略性决策,要求采用适于中长期预测的方法,但对其精度要求较低。
*用于战术性决策,要求适于中期和近期预测的方法,对其精度要求较高。
*用于业务性决策,要求采用适于近期和短期预测的方法,且要求预测精度高。
了解……
*战略决策
是解决全局性、长远性、战略性的重大决策问题的决策。一般多由高层次决策者作出。战略决策是企业经营成败的关键,它关系到企业生存和发展。
*战术决策
是为了实现战略决策、解决某一问题做出的决策,以战略决策规定的目标为决策标准。
*业务决策
是企业内部在执行计划过程中,为提高生产效率和日常工作效率的决策。其中包括:作业计划的制定,生产、质量、成本,以及日常性控制等方面的决策。
2-2 预测的时间期限
适用于近期与短期的预测方法:有移动平均法、指数平滑法、季节指数预测法、直观判断法等。
适用于1年以上的短期与中期的预测方法有:趋势外推法、回归分析法、经济计量模型预测法。
适用于5年以上长期预测的方法有:经验判断预测法、趋势分析预测法。
2-3 预测的精度要求
精度要求较高的预测方法有:
回归分析预测法、经济计量模型预测法等。
精度要求较低的预测方法有:
经验判断预测法、移动平均预测法、趋势外推预测法等。
2-4 预测的费用预算
预测方法的选择,既要达到精度的要求,满足预测的目标需要,还要尽可能节省费用。即:既要有高的经济效率,也要实现高的经济效益。用于预测的费用包括调研费用、数据处理费用、程序编制费用、专家咨询费用等。
费用预算较低的方法有:
经验判断预测法、时间序列分析预测法有及其他较简单的预测模型法。
费用预算较高的方法有:
经济计量模型预测法及大型的复杂的预测模型方法。
2-5 资料的完备程度与模型的难易程度
1)资料的完备程度
在诸多预测方法中,凡是需要建立数学模型的方法,对资料的完备程度要求较高,当资料不够完备时,可采用专家调查法等经验判断类预测方法。
2)模型的难易程度
在预测方法中,因果分析方法都需建立模型,其中有些方法的建模要求预测者有较坚实的预测基础理论和娴熟的数学应用技巧。因此,预测人员的水平难以胜任复杂模型的预测方法时,则应选择较为简易的方法。
2-6 历史数据的变动趋势
在定量预测方法的选择中,必须以历史数据的变动趋势为依据。在实际的应用中,通常使用的曲线预测模型有指数曲线(修正指数曲线)、线性模型、抛物曲线、龚珀兹曲线等。
一、请描述根据不同分类方法的评估类型。 公共政策评估可以按不同的类型进行分类。从评估的实际出发可以对公共政策评估分成三类:正式评估与非正式评估;对象评估,自我评估,专业评估;方案评估,执行评估和终结评估等。 这类评估是从评估活动的方式来划分的。 正式评估是指事先制定完整的评估方案,由专门的机构与人员按严格的程序和规范所进行的政策评估。这种评估由于评估机构与人员具有专门的知识与素养,评估的资料详尽真实,评估方法手段先进,因而评估的结果比较客观、可信。非正式评估是指那种对评估者、评估程序、评估方法、评估资料都未作严格要求而进行的局部的、分散的政策评估。非正式评估虽然结论不一定非常可靠、完整,但其形式灵活、简单易行,有广泛的适用性。这两种评估活动方式可以有机结合起来运用。以正式评估为主,将非正式评估作为正式评估的事先准备和必要的补充。对象评估、社会评估、自我评估这类评估是以不同的评估者来划分的。对象评估是指由政策目标集团成员进行的评估。由于政策目标集团成员是政策的承受者,他们对政策制定与实施的利弊得失有最真切的感受,对政策的成果最有发言权。因此,这种政策评估可以获取第一手资料,可以对政策的成效有真实的估计,其结论具体、真切。但这种评估也有不足之处,目标集团成员只是社会的一部分,提供的资料虽然真实,但有较大的局限性。社会评估是指在政策系统之外所进行的评估。通常有两类:一类是政府等公共部门委托的专业评估;一类是社会成员自行组织的评估。对象评估与社会评估可以统称为外部评估。政府委托评估是政府部门委托专业性的咨询公司、盈利或非盈利性的研究机构、大专院校的专家学者所进行的政策评估。这种评估的优点在于评估者在一定程度上能置身于政策系统之外,从而使评估具有较大的客观性;实施评估的机构与人员一般都具有专门的评估理论与知识、方法与手段、实践与经验,从而使评估具有较高的可靠性。但这种评估也有其局限性,主要是评估机构与人员容易受委托者在经费和资料两方面的限制,从而有可能削弱评估的客观性与公正性。自我评估是由政策系统内部进行的评估。这种评估的优点在于,评估者中有政策的制定者与执行者,对整个政策过程有全面的了解,掌握大量的第一手资料,从而评估的结论较为可靠。另外,从评估的实用性来看,政策系统内部评估的结论可以直接被用于政策调整,容易产生效用。但这种评估也有其缺点,由于评估者是政策的制定者与执行者,可能会因为顾及政绩而夸大成绩、回避失误;可能会从部门的局部利益考虑而产生片面性;可能会受到机构内部利益和人际关系影响而失去公正性。 方案评估、执行评估、终结评估这类评估是以评估实施的阶段来划分的。方案评估是在政策实施前进行的评估,因此又称预评估。执行评估是在政策实施过程中进行的评估。虽然这时的政策执行还未结束,但政策推行的效果、效率、效益已经表现出来,特别是政策方案中存在的缺陷、政策资源配置中的问题、政策环境中某些条件的改变等,已经暴露出来。终结评估是指政策执行完成后的评估,这是对一项政策的最终评估。由于政策已经执行完毕;政策的最终效果、效率、效益已经成为客观存在,评估的结论是对政策全过程的总结。二、政策终结都存在哪些障碍?结合我国政策实践论述政策终结可采取的策略。 1、政策终止的心理障碍。政策终止会对政策过程中不同群体成员的心理产生影响。首先是对政策受益者心理的影响。政策实施时,这一群体的成员从现行政策中得到好处,一旦现行政策终止,就意味着原来的既得利益丧失了,因此,会产生心理上的抵触。其次是对政策执行者心理的影响。政策执行了一段时间以后,政策执行者在工作上已经习惯,在心理上已经适应,如果该政策宣布终止,反而会出现新的不习惯和不适应,严重的会出现心理抵触。第三是对政策制定者心理的影响
预测方法的分类 郑XX 预测方法的分类 由于预测的对象、目标、内容和期限不同,形成了多种多样的预测方法。据不完全统计,目前世界上共有近千种预测方法,其中较为成熟的有150多种,常用的有30多种,用得最为普遍的有10多种。 1-1预测方法的分类体系 1)按预测技术的差异性分类 可分为定性预测技术、定量预测技术、定时预测技术、定比预测技术和评价预测 技术,共五类。 2)按预测方法的客观性分类 可分为主观预测方法和客观预测方法两类。前者主要依靠经验判断,后者主要借 助数学模型。 3)按预测分析的途径分类 可分为直观型预测方法、时间序列预测方法、计量经济模型预测方法、因果分析 预测方法等。 4)按采用模型的特点分类 可分为经验预测模型和正规的预测模型。后者包括时间关系模型、因果关系模 型、结构关系模型等。 1-2 常用的方法分类 1)定性分析预测法 定性分析预测法是指预测者根据历史与现实的观察资料,依赖个人或集体的经验与智慧,对未来的发展状态和变化趋势作出判断的预测方法。 定性预测优缺点 定性预测的优点在于: 注重于事物发展在性质方面的预测,具有较大的灵活性,易于充分发挥人的主观能动作用,且简单的迅速,省时省费用。
定性预测的缺点是: 易受主观因素的影响,比较注重于人的经验和主观判断能力,从而易受人的知识、经验和能力的多少大小的束缚和限制,尤其是缺乏对事物发展作数量上的精确描述。 2)定量分析预测法 定量分析预测法是依据调查研究所得的数据资料,运用统计方法和数学模型,近似地揭示预测对象及其影响因素的数量变动关系,建立对应的预测模型,据此对预测目标作出定量测算的预测方法。通常有时间序列分析预测法和因果分析预测法。 ⅰ时间序列分析预测法 时间序列分析预测法是以连续性预测原理作指导,利用历史观察值形成的时间数列,对预测目标未来状态和发展趋势作出定量判断的预测方法。
信息检索与分析能力训练3报告课题名称:分类方法 专业软件工程(NIIT) 学生学号(姓名) B12040914 吴凡 学生学号(姓名) B12040920 沈一州 指导教师成小惠 指导单位计算机学院 日期2014.9.9
目录(一号宋体,居中)目录自动生成(小四号宋体,左对齐,单倍行距)
摘要 模式识别(英语:Pattern Recognition),就是通过计算机用数学技术方法来研究模式的自动处理和判读。模式识别的目标往往是识别,即分析出待测试的样本所属的模式类别。分类方法即通过比较事物之间的相似性,把具有某些共同点或相似特征的事物归属于一个不确定集合的逻辑方法,是模式识别中常采用的方法,包括近邻法、Bayes方法、决策树与SVM等方法。分类的目的是学会一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的类别中。分类可用于预测。从利用历史数据记录中自动推导出对给定数据的推广描述,从而能对未来数据进行类推测。 关键词: 1.近邻法 2.Bayes法 3.决策树法 4.SVM法
Abstract 模式识别(英语:Pattern Recognition),就是通过计算机用数学技术方法来研究模式的自动处理和判读。模式识别的目标往往是识别,即分析出待测试的样本所属的模式类别。分类方法即通过比较事物之间的相似性,把具有某些共同点或相似特征的事物归属于一个不确定集合的逻辑方法,是模式识别中常采用的方法,包括近邻法、Bayes方法、决策树与SVM等方法。分类的目的是学会一个分类器(分类函数或模型),该分类器能把待分类的数据映射到给定的类别中。分类可用于预测。从利用历史数据记录中自动推导出对给定数据的推广描述,从而能对未来数据进行类推测。 Key Words: 1.近邻法 2.Bayes法 3.决策树法 4.SVM法
一、一般购买者分析和应对 1、按消费者购买目标的选定程度区分 1)全确定型 此类消费者在进入商场前,已有明确的购买目标,包括产品的名称、商标、型号、规格、样式、颜色以至价格的幅度都有明确的要求,他们进入商场后,可以毫不犹豫的买下商品中。 应对方法:不需做过多的干扰,只需给其提供简短准确的答复即可,更多使用肯定简短的语气,在交易后期可征询对方的需要,如:什么时候要?等。 2)半确定型 此类消费者进商场前,已有大致的购买目标,但具体要求还不明确,这类消费者进入商场后,一般不能向营业员明确清晰地提出对所需产品的各项要求,实现购买目的,需要经过长时间的比较和评定阶段。 应对方法:一般要给予较多的跟进,向其提出更多的问题,根据其需要,给予详细的解答,以肯定和专业的语言帮助其下决心,并就顾客所担心的问题,如售后服务问题等,作出必要的附加说明。 3)不确定型 此类消费者在进商场前没有明确的或坚定的购买目标,进入商场一般是漫无目的地看商品或随便了解一些商品的销售情况,碰到感兴趣的商品也会购买。 应对方法:不要进行干扰,保持距离,当其提出问题时,在提供亲切的解释。 2、按消费者态度与要求区分 1)习惯型 消费者对某种产品的态度,常取决于对产品的信念,信念可以建立在知识的基础上,也可以建立在见解可信任的基础上,属于此类型的消费者,往往根据过去的购买经验和使用习惯获取购买行为,或长期惠顾商店,或长期使用某个厂牌、商标的商品。 应对方法:首先应尊重对方的专业水平,提供选择,特别是新的产品信息,让对方作出判断。 2)慎重型 此类消费者购买行为以理智为主,感情为辅,他们喜欢收集产品的有关信息并了解市场行情,在经过周密的分析和思考后,在决定是否购买。在购买过程中,
传统的基于像素的遥感影像处理方法都是基于遥感影像光谱信息极其丰富,地物间光谱差异较为明显的基础上进行的。对于只含有较少波段的高分辨率遥感影像,传统的分类方法,就会造成分类精度降低,空间数据的大量冗余,并且其分类结果常常是椒盐图像,不利于进行空间分析。为解决这一传统难题,模糊分类技术应运而生。模糊分类是一种图像分类技术,它是把任意范围的特征值转换为0 到1 之间的模糊值,这个模糊值表明了隶属于一个指定类的程度。通过把特征值翻译为模糊值,即使对于不同的范围和维数的特征值组合,模糊分类能够标准化特征值。模糊分类也提供了一个清晰的和可调整的特征描述。 对于影像分类来说,基于像元的信息提取是根据地表一个像元范围内辐射平均值对每一个像元进行分类,这种分类原理使得高分辨率数据或具有明显纹理特征的数据中的单一像元没有很大的价值。影像中地物类别特征不仅由光谱信息来刻画的,很多情况下(高分辨率或纹理影像数据)通过纹理特征来表示。此外背景信息在影像分析中很重要,举例来说,城市绿地与某些湿地在光谱信息上十分相似,在面向对象的影像分析中只要 明确城市绿地的背景为城市地区,就可以轻松地区分绿地与湿地,而在基于像元的分类中这种背景信息几乎不可利用。面向对象的影像分析技术是在空间信息技术长期发展的过程中产生的,在遥感影像分析中具有巨大的潜力,要建立与现实世界真正相匹配的地表模型,面向对象的方法是目前为止较为理想的方法。 面向对象的处理方法中最重要的一部分是图像分割。 图像分割是一种重要的图像技术,在理论研究和实际应用中都得到了人们的广泛重视。图像分割的方法和种类有很多,有些分割运算可直接应用于任何图像,而另一些只能适用于特殊类别的图像。有些算法需要先对图像进行粗分割,因为他们需要从图像中提取出来的信息。例如,可以对图像的灰度级设置门限的方法分割。值得提出的是,没有唯一的标准的分割方法。许多不同种类的图像或景物都可作为待分割的图像数据,不同类型的图像,已经有相对应的分割方法对其分割,同时,某些分割方法也只是适合于某些特殊类型的图像分割。分割结果的好坏需要根据具体的场合及要求衡量。图像分割是从图像处理到图像分析的关键步骤,可以说,图像分割结果的好坏直接影响对图像的理解。 为后续工作有效进行而将图像划分为若干个有意义的区域的技术称为图像分割(Image Segmentation),早期的图像分割方法可以分为两大类。一类是边界方法,这种方法假设图像分割结果的某个子区域在原来图像中一定会有边缘存在;一类是区域方法,这种方法假设图像分割结果的某个子区域一定会有相同的性质,而不同区域的像素则没有共同的性质。这两种方法都有优点和缺点,有的学者考虑把两者结合起来进行研究。现在,随着计算机处理能力的提高,很多方法不断涌现,如基于彩色分量分割、纹理图像分割。所使用的数学工具和分析手段也是不断的扩展,从时域信号到频域信号处理,小波变换等等。 目前,有许多的图像分割方法,从分割操作策略上讲,可以分为基于区域生成的分割方法,基于边界检测的分割方法和区域生成与边界检测的混合方法.图像分割主要包括4种技术:并行边界分割技术、串行边界分割技术、并行区域分割技术和串行区域分割技术。
不同类型数学知识的有效教学方式 不同学科的知识具有不同的特征,某一学科的知识也可以划分为不同的类型。不同类型的知识在形成、发展、迁移等过程中具有不同的特点,如果用单一的方式来指导多种类型知识的学习,便会混洧各类知识的特征,遮蔽各类知识间的差异,阻碍知识价值的实现。为了提高教学成效,实现知识价值的最大化发展,教师需要在教学中对知识进行分类,依据不同类型的性质、特征来选取合理的教学方式。 一、数学知识的类型 哲学家、心理学家已根据不同的的标准对知识进行不同类型的划分,哲学家更多地关注知识的客观形态,心理学家更多地关注主体对知识的表征,数学教学是以知识内容为中介,师生共同参与的过程,既有客观性的知识内容,又有师生主体的参与,因而教学方式的建构既要根据数学学科知识的形态,又要考虑学生学习的认识规律,这就促使我们从学科知识和人的认识特征两个方面来思考对数学知识类型的划分。 课程标准把数学内容分为四个部分,分别是“数与代数”“图形与几何”“统计与概率”“综合与实践”。“数与代数”主要包括各类数的概念、式的概念、量的概念;各类数与式的性质、数量关系、运算规律、运算率;各类数、式、量的运算;运用数、式量进行问题解决等。“图形与几何”主要包含各类图形的概念与特征;各类图形之间的关系、性质、公式、定理等;图形的作图、测量、相关量的运算;进行
相关问题的解决。“统计与概率”主要包含各类数据的平均数、中位数、众数、方差等的概念;不同的图表如条形统计图、扇形统计图等概念;数据的收集、整理,图表的设计、绘制等;利用数据进行简单的推断、通过简单随机事件判断概率的发生;对数据、图表进行分析并解决实际问题。“综合与实践”部分不涉及新的知识,主要是要求学生综合运用所学知识与方法进行实际问题的分析与解决。不同领域虽然有各自的特点,包含体现各自特色的知识,但它们之间也有共性,都包含基本的概念,相关的公式、法则、定理、定律等进行操作的程序性知识,运用相应的知识进行实际问题的解决。因此,根据不同领域知识的存在形态,数学知识又可以概括为数学概念、数学命题、程序性知识、数学问题四大类。 现代萃知心理学把知识分为陈述性知识和程序性知识两大类,莫雷教授在借鉴、吸收这两种分类的同时也指出该分类的主要是依据不同类型的知识在大脑中形成、表征、激活等不同的特点及性质来划分的,他认为,仅从这一维度来考虑知识的分类是不够的,还需要关注“知识内容方面的心理特征”在莫雷教授看来,人类学习机制有两类,一类是联联结性学习机制,即“个体奖同时出现在工作记忆的若干客体的激活点联系起来而获得经验的心理机制”;一类是运算性学习机制,即“有机体进行复杂的认知操作(即运算)而获得经验的心理机制”。从获得知识的过程来看,有些知识可通过联结性学习机制来获得,依据这一维度,知识又可分为联结性知识和运算性知识。莫雷教授的这种分类观对我们进行数学知识类型的划分具有直接的指导意
[深基础和浅基础的划分]深基础与浅基础的不同 在一些教材中,一般认为埋置深度小于某个数值,或埋置深度与基础宽度比值超过某个数值,如表所示。但这种划分的方法没有反映浅基础与深基础的本质区别,特别在当代工程规模的条件下,由于高层建筑的大量兴建,地下空间的开发利用,地下室的埋置深度越来越深,这种分类思路的缺陷是十分明显的。 关于深基础和浅基础的区别,有两种考虑,一种的是按基础的埋置深度或者是相对的深度D/B划分,另一种是按施工方法的不同来划分。 史佩栋在《深基础工程特殊技术问题》[2]一书中,归纳了各种著作中关于深基础定义的论点,见表。 浅基础的定义 序号定义出处 1 D≤4B或D 2 D≤2B 文献3([美] J.E.Bowles,1975) 3 D≤B 文献4,5(高大钊,1998,1999) 4 D≤B 文献6([澳大利亚] I.K.Lee等,1983) 5 D≤B 文献7([美] J.E.Bowles,1978;1993) 6 D 7 D=3~5m 文献10(杨位洸,1981) 8 明挖基础文献11(刘成宇,1981) 9 D 10 D 注:D—基础埋置深度;B—基础底面宽度或最小宽度。 按照埋置深度的绝对值来划分是常用的一种方法,但是这种方法没有反映基础宽度的影响,例如5m的埋置深度对10m宽的筏形基础来说是“不深”的,但对2m的条形基础来说,已经很“深”了。 于是就有用相对深度来划分的方法,考虑了基础宽度的影响,这当然是比较好的一种思路,如认为当D/B1时是深基础。但这种方法仍然没有反映深基础和浅基础的本质区别,也没有说明这两种基础的设计计算方法有什么差别,承载性状有什么根本的不同。 在当代工程规模的条件下,表12-1的分类方法都不适用了。多层地下室的兴建,已经打破了上述界限,基础的埋置深度已经深达20余米,但仍然是按照浅基础的原则设计的,说明上述分类方法并没有反映浅基础和深基础的根本区别。 郑大同在《地基极限承载力的计算》一书中论述了梅耶霍夫对深基础地基承载力的贡献:“50年代,梅耶霍夫进一步考虑了基础底面以上,土体发生抗剪强度的影响,从而提出了浅基础和深基础的极限承载力公式。”“梅耶霍夫在1951年曾经指出,地基承载力取决于地基土的物理力学性质(密度、抗剪强度和变形性质),取决于地基中的原始应力和地下水的情况,取决于基础的物理性质(基础尺寸、埋置深度和基底的粗糙程度),而且也取决于建造基础的方法。” [3] 梅耶霍夫指出了深基础和浅基础的建造方法的差别对承载机理的影响。施工方法的差别对基础的承载性状有重要的影响,浅基础采用敞开开挖基坑的方法,浇筑基础后再回填侧面的土,因此不能考虑侧向原状土层对基础侧面的摩阻力,不考虑对地基承载力的贡献。而深基础采用挤压成孔或成槽的方法,然后浇筑混凝土或者采用挤压的方法将深基础直接置入土中,即使采用人工挖土的方法,也是在形成的孔中直接浇筑混凝土这种施工方法使桩(墙) 壁与侧面天然土体直接接触,侧向土层的制约作用非常明显。深基础周围的土体可视为原状的土体或者比原状土的强度更强一些的土体,可以发挥对承载力的贡献。而浅基础周围填筑
按不同的标准分类 教学内容: 苏教版二年级下册第90~92页的例1和“想想做做”的第1~3题。 教学目标: 1.基于解决问题的需要收集和整理数据,从现实情景中发现一些需要借助数据才能回答的问题,同时体会只有借助数据才能了解更多的信息。 2.学习收集数据、记录和呈现数据的方法,并对方法进行一定的优化。 3.能够有感受到分类收集数据的作用:不同的问题要按不同的标准分类,通过不同标准的分类可以获得不同的信息,解决不同的问题。 教学重点: 按不同标准分类收集和整理数据的方法。 教学难点: 分类标准和记录方法。 教具准备: 教学课件、可移动板书、作业纸。 教学过程: 一、提出问题 1.提问:(出示情境图)小朋友们,仔细观察,你看到童心园里有哪些人?学生说有老师,有学生。教师在黑板上相机贴写有“老师”和“学生”的纸条。 提问:再好好看一看,他们分别在做什么呢? 学生说有的在下棋,有的在看书,有的在做游戏。教师继续贴写有“看书”“下棋”和“做游戏”的纸条。 追问:从这幅图中你还想知道些什么,还有什么疑问吗?同桌两个小朋友先商量商量。 2.提出问题。 预设学生可能提出以下问题: (1)图中有多少位老师?学生呢? (2)参加每种活动的分别有多少人? (3)一共有多少人? ……
过渡:小朋友们真了不起,提出了这么多的问题,今天这节课,咱们就重点来解决这几个问题。 在黑板上贴出问题: (1)学生比老师多多少人? (2)参加哪种活动的人最多? 3.激发分类的需要。 引导:要解决第一个问题,应该将图中的人怎样分类呢?你会上来移动卡片吗?可以按老师和学生分成两类,也可以像这样横着用线隔开来。 画线。 引导:要解决第二个问题,你有什么好建议?可以按他们参加的活动分成三类。 移动卡片,画线。 小结:请小朋友们仔细观察这二种分类的方法,你觉得它们的分类标准一样吗?应该根据不同的问题来选择合适的分类标准。 二、收集数据 过渡:要解决刚才提出的问题,分类以后还要想办法知道每一类各有多少人,这就是收集数据。 引导:要知道老师和学生各有多少人,怎么办?(数一数)这边数一个,那边数一个,好不好?可以怎样数? 根据学生的交流提示:可以按照从上往下,从左往右的顺序数一个就记录一个,这样就不会漏掉了。如果图中的人特别多,特别乱,怎么知道这个人我已经记录过了呢? 示范:可以像这样,做一个记号就记录一个,这样就不会重复记录了。 三、记录数据 谈话:现在,我在图中找到的第一个是男的,怎样把他在表中记录下来呢? 学生可能会说画勾的方法。 追问:一个勾就表示?(图中的一个人),除了画勾,还可以怎样表示?小朋友们可以用自己喜欢的符号来表示图中的一个人。 对比优化记录方法:
预测模型分类及优缺点分析 灰色(系统)预测模型 神经网络预测模型 趋势平均预测法 1 微分方程模型 当我们描述实际对象的某些特性随时间(或空间)而演变的过程、分析它的变化规律、预测它的未来性态、研究它的控制手段时,通常要建立对象的动态微分方程模型。微分方程大多是物理或几何方面的典型.问题,假设条件已经给出,只需用数学符号将已知规律表示出来,即可列出方程,求解的结果就是问题的答案,答案是唯一的,但是有些问题是非物理领域的实际问题,要分析具体情况或进行类比才能给出假设条件。作出不同的假设,就得到不同的方程。比较典型的有:传染病的预测模型、经济增长预测模型、正规战与游击战的预测模型、药物在体内的分布与排除预测模型、人口的预测模型、烟雾的扩散与消失预测模型以及相应的同类型的预测模型。其基本规律随着时间的增长趋势是指数的形式,根据变量的个数建立初等微分模型。微分方程模型的建立基于相关原理的因果预测法。该法的优点:短、中、长期的预测都适合,而.既能反映内部规律,反映事物的内在关系,也能分析两个因素的相关关系,精度相应的比较高,另外对初等模型的改进也比较容易理解和实现。该法的缺点:虽然反映的是内部规律,但是由于方程的建立是以局部规律:的独立性假定为基础,故做中长期预测时,偏差有点大,而且微分方程的解比较难以得到。 2 时间序列法 将预测对象按照时问顺序排列起来,构成一个所谓的时间序列,从所构成的这一组时间序列过去的变化规律,推断今后变化的可能性及变化趋势、变化规律,就是时间序列预测法。时间序列预测一般反映三种实际变化规律:趋势变化、周期性变
化、随机性变化。考虑一组给定的随时间变化的观察值,t=1,2,3,?,n},如何选取合适模型预报,t=n+1,n+3, n+k}的值。 上面的模型统称ARMA模型,是时间序列建模中最重要和最常用的预测手段。 事实上,对实际中发生的平稳时间序列做恰当的描述,往往能够得到自回归、滑动平均或混合的模型,其阶数通常不超过2。时间序列模型其实也是一种回归模型,属于定量预测,其基于的原理是,一方面承认事物发展的延续性,运用过去时间序列的数据进行统计分析就能推测事物的发展趋势;另一方面又充分考虑到偶然因素影响而产生的随机性,为了消除随机波动的影响,利用历史数据,进行统计分析,并对数据进行适当的处理,进行趋势预测。优点是简单易行,便于掌握,能够充分运用原时间序列的各项数据,计算速度快,对模型参数有动态确定的能力,精度较好,采用组合的时间序列或者把时间序列和其他模型组合效果更好。缺点是不能反映事物的内在联系,不能分析两个因素的相关关系,常数的选择对数据修匀程度影响较大,不宜取得太小,只适用于短期预测 3 灰色预测理论模型 灰色预测的基本思路是将已知的数据序列按照某种规则构成动态或非动态的 白色模块,再按照某种变化、解法来求解未来的灰色模型。它的主要特点是模型使用的不是原始数据序列,而是生成的数据序列。其核心体系是灰色模型(GM),即对原始数据作累加生成(或其他方法生成)得到近似的指数规律再进行建模的模型方法。优点是不需要很多的数据,一般只需要4个数据就够,能解决历史数据少、序列的完整性及可靠性低的问题;能利用微分方程来充分挖掘系统的本质,精度高;能将无规律的原始数据进行生成得到规律性较强的生成数列,运算简便,易于检验,具有不考虑分布规律,不考虑变化趋势。缺点是只适用于中长期的预测,只适合指数增长的预测,对波动性不好的时间序列预测结果较差。 4 BP神经网络模型
监督分类和面向对象分类流程 高分一号城市绿地现状调查与分析实现教程将介绍基于高分一号影像数据的城市绿地信息提取的实现步骤,下图是主要的操作流程图一首先对高分影像进行预处理,其次使用监督分类法和面向对象分类法对城市绿地进行分类,然后对分类出来的影像进行矢量化处理,最后另其在arcGIS中进行统计分析,得出武汉市城市绿地的现状,下面是具体步骤。第一章数据预处理因为处理数据是高分一号影像,处理软件为,因为以下版本不能对高分一号直接进行处理,所以需要安装r6补丁,将下面两个文件直接粘贴到软件所在位置,然后就可以打开高分影像了图二图三为了加快数据处理的速度,是选择先进行辐射定标然后将图像裁剪在进行后续的操作,预处理流程如下图:
图四辐射校正分为辐射定标和大气校正打开数据:ENVI-Open As-CRESDA-GF-1,选择处理的影像,打开XML后缀文件;辐射定标:选择Toolbox->Radiometric Correction-> Radiometric Calibration,选择待处理的高分数据弹出Radiometric Calibration对话框,进行如图设置。对于多光谱影像,点击Apply FLAASH Setting 设置成默认值;如果是对全色影像进行辐射定标,那么Calibration则是Reflectance,Out Put Type 为UInt,Scale Factor为1000,如下图:高分一号多光谱影像参数设置高分一号全色影像参数设置大气校正:选择Toolbox->Radiometric Correction->Atmospheric Correction Module->FLAASH Atmospheric Correction,弹出FLAASH Atmospheric Correction Model Input Parameters对话框。要注意,全色影像不做大气校正,多光谱影像则需要做大气校正处理。
现代六爻预测的十种分类预测方法 预测求财做生意 在市场经济中,每个人的经济活动都离不开经济效益。广义上讲,看我们自己所做的一切工作有没有经济效益。这就是求财。 在求财预测中,必须先搞清楚各个卦爻在预测财运中各自代表什么人什么物,然后依据人和物的旺衰、相生相克、空亡入墓等等情况,才可做出综合判断,看能否得到财。因而,知道卦爻在求财中代表什么,能派上什么用场,是积极因素还是消极因素,才能最后达到预测准确的目的。所以,取准用神是至关重要的第一步,然后再去考虑忌原仇及各自的旺衰。 财爻代表所求的经济效益,是求财中的主用神,因而,财爻的旺与衰,直接关系到能否得到财。 首先,财爻必须与世爻(代表求财人)构成一种关系,这种关系就是财爻持世并合关系,财爻生世克世的关系,财爻被世爻生和克的关系。这几种关系,在卦中是相生相克的关系,在实际求财中,是求财人与经济效益的关系。因而,测求财时,如果卦中无财(财爻不上卦),或伏藏不得出,或子孙爻也不上卦,一般情况下是求财无望。这是因为,卦中无财,无法与世爻构成这种关系,既无这种人与经济效益的关系,或财无来源,又怎能谈发财呢! 按五行论,无论世爻是何种五行,必然与其他五行构成并列、相生、相克三种关系。有了这三种关系,不等于说世爻同财爻就构成了这种联系。因为在实际断卦中,虽然财爻可以生世爻,但财爻衰弱,或空亡,或入墓或因合忘生等等情况,实际上财爻并不能生世爻。这种实际不能生的情况,就等于财爻与世爻暂时无必然联系,无相互关系。既然无联系和无关系,又怎能谈发财呢!财爻可以因种种原因不能生世爻,世爻也可以因其衰弱或入墓空而不受生。这种不受生的表现形式,也等于割断了财爻与世爻的联系。至于世爻克财爻,世爻生财爻,都可以因自己或对方旺衰强弱的具体情况,而不能克对方生对方,或不受生不受克,因而暂时都没有了联系。没有了联系,就不会得财。 财爻生世克世,或世爻生财爻克财爻,都是得财之象。在遇到暂时不能生克对方而被切断这种联系的情况时,也可以因为年月日令即旺衰的来源的改变而又恢复这种联系,使财爻可以生世克世,世爻可以克财生财的时候,也就是求财的应期到了。 不论你是为公私营企业求利,或以自己技能求利,以及得奖、接受馈赠、借贷、继承遗产等等,都是求财求利,希望自己能得到财力。在预测时,均以财爻为用来代表。
蝈蝈不同种类的划分方法_蝈蝈不同种类怎么划分 蝈蝈的分类有多种多样,你知道蝈蝈是怎么分类的吗?今天小编就来教大家蝈蝈不同 种类的划分方法。 优雅蝈螽体型粗壮,中等偏大,体长约35~40毫米,野生蝈螽的体色通常为草绿或褐 绿色。头大,前胸背板宽大,似马鞍形,侧板下缘和后缘镶以白边。叫声如:"极-极,极-极"。 暗褐蝈螽体形同于优体形同于优蝈螽,翅面具草绿色,条纹并布满褐色斑点,呈花翅状,故也有"花叫"叫声:"吱拉,吱拉"。,翅面具草绿色,条纹并布满褐色斑点,呈花翅状,故也有"花叫"叫声:"吱拉,吱拉"。 鼓翅鸣螽体型偏小且娟秀,翅薄呈半透明,翅脉清晰可见,如妇人纱裙,故"姐儿"之 尊称。叫声:"甲、甲、甲"素色似织螽,体形中等,体大部分为草绿,头部背面黄褐,叫声"丝扎-丝扎"纺织娘接近,故有"小故娘"之美名。 斑翅草螽是一种常见种,体型小,体色为绿色和褐色两种。叫声:"丝-丝"中间有小停 顿 悦鸣草螽体型与草螽相似,体色艳丽,深绿或黄绿色。叫声:"齐-齐-"可连续鸣叫。 京蝈蝈又叫燕蝈蝈。主要指北京山区和郊区的蝈蝈,北京人爱讲究大山的蝈蝈。北京 以产黑色大铁蝈蝈著称。 冀蝈蝈河北山区,每年蝈蝈产量大。多为铁皮蝈蝈,紫蓝脸,红牙,粉肚皮膀大翅长 蛤蟆音。间或有少量草白蝈蝈与山青蝈蝈。河北省蝈蝈以保定市易县西山北乡的为主,名 气最大。 鲁蝈蝈主要指山东北部为主的地区,鲁蝈蝈又以绿蝈蝈为主,但头项部局部泛红褐色 的边纹,但也有个头大点的。也有少量的草白和山青等中等身量的蝈蝈。 晋蝈蝈山西作为主产小蝈蝈的地区,气候有些干旱,多产中小身量蝈蝈,以小个为主 的山青、草白蝈蝈以及少量的铁蝈蝈。晋蝈蝈的优点皮实好养,皮粗翅厚,叫声响,但不 美观罢了,尤其以宣化蝈蝈最为出名,它耐干旱,生命力特别强。 南蝈蝈生长在中国南方各省的蝈蝈都统称为南蝈蝈。西南四川成都包括长江流域等地 的蝈蝈个头较小,比札嘴略大,鸣声也小而尖。总的来说南蝈蝈没有北蝈蝈筋粗皮厚,皮 实耐旱,鸣声也不如北蝈蝈那样强劲有力。在南方很难见到北方的大铁蝈蝈。 从观赏的角度按体色分类,蝈蝈可分为五类:绿蝈蝈、黑蝈蝈、山青蝈蝈、草白蝈蝈、异色蝈蝈。如易县西山北的蝈蝈多为铁皮蝈蝈,所以说欲捉,欲买极品名优蝈蝈就到蝈蝈
绿茶的各种分类方法 茶学上将茶叶分为基本茶类和再加工茶类两大类,绿茶属于基本茶类,也可以分为基本绿茶和再加工绿茶。按照绿茶加工工艺生产的绿茶毛茶及精制茶为基本绿茶,如着名的龙井茶、碧螺春、黄山毛峰等;以绿茶为茶坯进行再加工、深加工而成的茶为再加工绿茶,主要有花茶、紧压绿茶、萃取绿茶、果味绿茶、袋泡绿茶、含绿茶的饮料和食品,以及提取绿茶中的有效物质制成的茶多酚制剂等。绿茶的各种分类方法按照产地不同绿茶可以分为浙江绿茶、安徽绿茶、四川绿茶、江苏绿茶、江西绿茶等。 按照季节不同 绿茶一般分为春茶、夏茶、秋茶,其中春茶的品质最好,秋茶次之,夏茶一般不采摘。春茶按照节气不同又有明前茶、雨前茶之分,同一个地方采摘的绿茶,明前绿茶为上品。 按照级别不同 绿茶一般分为特级、一级、二级、三级、四级、五级等,有的特级茶还细分为特一、特二、特三等级别。 按照外形不同 绿茶注重外形,不同的绿茶其外形也各不相同,有针形茶,如安化松针等;扁形茶,如龙井茶、千岛玉叶等;曲螺形茶,如碧螺春、蒙顶甘露等;片形茶,如六安瓜片等;兰花形茶,如舒城兰花、太平猴魁等;单芽形茶,如蒙顶黄芽等;直条形茶,如南京雨花茶、信阳毛尖等;曲条形茶,如婺源茗眉、径山茶等;珠形茶,如平水珠茶等。
按照出现的时间不同 绿茶分为历史名茶和现代名茶,历史名茶如顾渚紫笋,现代名茶如南京雨花茶等。 按照加工方式不同 绿茶分为机制绿茶和手工炒制绿茶,高档名优绿茶大多数是全手工制作,也有中高档茶采用机械或半机械半手工制作。 按照品质特征不同 绿茶分为名优绿茶和大宗绿茶两大类。 按照杀青和干燥方式不同 绿茶大致分为蒸青绿茶、炒青绿茶、烘青绿茶、晒青绿茶四大类。
【ENVI入门系列】24. 面向对象图像分类 目录 1.概述 2.基于规则的面向对象信息提取 第一步:准备工作 第二步:发现对象 第三步:根据规则进行特征提取 3.基于样本的面向对象的分类 第一步:选择数据 第二步:分割对象 第三步:基于样本的图像分类 4.基于规则的单波段影像提取河流信息 1.概述 面向对象分类技术集合临近像元为对象用来识别感兴趣的光谱要素,充分利用高分辨率的全色和多光谱数据的空间,纹理,和光谱信息来分割和分类的特点,以高精度的分类结果或者矢量输出。它主要分成两部分过程:影像对象构建和对象的分类。ENVI FX的操作可分为两个部分:发现对象(Find Object)和特征提取(Extract features),如下图所示。
图1.1 FX操作流程示意图(*项为可选操作步骤) 这个工具分为三种独立的流程化工具:基于规则、基于样本、图像分割。 本课程分别学习基于规则的面向对象分类和基于样本的面向对象分类,以及基于规则的方法从单波段灰度影像中提取河流信息。 注:本课程需要面向对象空间特征提取模块(ENVI Feature Extraction-FX)使用许可。
2.基于规则的面向对象信息提取 该工具位置在:Toolbox /Feature Extraction/ Rule Based Feature Extraction Workflow。 数据位置:"24-面向对象图像分类\1-基于规则"。 第一步:准备工作 根据数据源和特征提取类型等情况,可以有选择地对数据做一些预处理工作。 ?空间分辨率的调整 如果您的数据空间分辨率非常高,覆盖范围非常大,而提取的特征地物面积较大(如云、大片林地等)。可以降低分辨率,提供精度和运算速度。可利用Toolbox/Raster Management/Resize Data工具实现。 ?光谱分辨率的调整 如果您处理的是高光谱数据,可以将不用的波段除去。可利用Toolbox/Raster Management/Layer Stacking工具实现。 ?多源数据组合 当您有其他辅助数据时候,可以将这些数据和待处理数据组合成新的多波段数据文件,这些辅助数据可以是DEM, lidar 影像, 和SAR 影像。当计算对象属性时候,会生成这些辅助数据的属性信息,可以提高信息提取精度。可利用Toolbox/Raster Management/Layer Stacking工具实现。
蛋白质功能预测方法概述 摘要: 蛋白质是生物体内最必需也是最通用的大分子,对它们功能的认识对于科学领域和农业领域的发展有着至关重要的作用。随着后基因组时代的发展,NCBI 数据库中迅速涌现出大量不明结构与功能的蛋白质序列,这些蛋白质序列甚至一跃成了研究的热点。近几十年来蛋白质功能预测的方法不断被完善。由最初的仅基于蛋白质序列或3D 结构信息的方法衍生出更多的基于序列相似性、基于结构基序、基于相互作用网络等新方法,这些新型方法采用新的算法、新的研究思路和技术手段,力求得到准确性与普遍性并存,能够被广泛应用的蛋白质功能预测方法。本文综述了近年来蛋白质功能预测的方法,并将这些研究方法分类归纳,各自阐明了每类方法的优缺点。 关键词: 蛋白质功能预测方法,结构基序,相互作用网络,ESG An Overview protein function prediction methods Abstract: Protein is the most necessary and versatile macromolecules in vivo,researches on their functions are very important to the fields of science and the development of the agriculture. With the development of the post - genomic era,the NCBI database quickly emerges a large number of protein sequences of unknown structure and functions, which even become hot research Points. In the recent decades,protein function prediction methods have been more and more improved and developed. This article reviews the protein function prediction methods occured in recent years,All these methods were inducted and classicicated,and their advantages and disadvantages of each methods were illustrates respectively. Keywords: Protein Function Prediction Methods,Structal Motif,Interaction Networks,ESG 1 引言 基因组学和蛋白质组学在过去十年的发展过程中产生了大规模的新的蛋白质序列和试 验数据,科学家为了确定这些新序列的功能借助计算机手段进行了大量的研究[1 - 2]。在过去的二十年里,人们利用计算机技术对蛋白质功能进行预测的文章发表了上千篇之多( http: / /www.ncbi.nlm.nih.gov /pubmed) ,大部分是基于序列相似性、基于结构域、基于相互作用网络等方法预测,再利用生物学知识来进行解析。本文综合阐述了迄今为止蛋白质功能预测的分类,大致可分为四类: ( 1) 基于序列相似性预测方法; ( 2) 基于蛋白质相互作用网络预测方法;( 3) 基于结构相似性预测方法; ( 4) 其他预测方法。 2 蛋白质功能 蛋白质功能对于客观环境很敏感: 给定的发挥作用的空间环境不同、规定的作用时间不同都可以使蛋白质所表现出来的功能是有差异性的。为了使功能预测的结果更加准确,Bork 等提出了一种蛋白质功能类型的分类[3],按蛋白质发挥作用的平台不同将蛋白质功能分为分子功能,细胞功能和生理功能。很明显,这三个类型不是独立存在的,而是如图2 那样等级相关的。现如今在蛋白质功能预测中最常用的是GO 分类,Gene Ontology 分类从细胞组
不同的天气状况怎样划分呢?答:一种简单的方法是,把天空当做一个圆,平均分成4份,把看到的云量填充到这个圆里,按照云天空中所占的多少进行区分 3、怎样把盐水中的盐和水分离开来?(4分)(写出两种办法,并选择一种方法写出操作过程)。 酒精和食盐都能溶解于水,请根据你做过的实验结果判断:它们都能无限地溶解在水中吗?答:它们都不能无限地溶解在水中,成了饱和溶液,就不能在溶解了。 1、搅拌能加快某种物质的溶解吗?请设计实验证明。 我的猜想:搅拌能加快食盐的溶解 实验所需材料及数量:烧杯2个,搅拌棒1个实验过程: 2、写出实验计划: 研究的问题:50毫升水能溶解多少克小苏打? 实验所需材料:烧杯、搅拌棒、量筒、筷子、天平、记录纸 实验方法: 七、简答: 1、请举例说明,物质在水中是否溶解,我们应该怎样观察和区别? 答:物质是否在水中化成了肉眼看不见的微粒,均匀分布在水中,且不能用过滤或沉降的方法分离出来。 2、某种物质在水中的溶解快与慢与哪些因素有关?答: 八、课外实践 观察在日常生活和生产中,哪些地方应用水能溶解一些物质的特 1、为什么人们在月球上互相通话必须借助无线电?答:、空气是传播声音的重要物质,在 真空中声音不能传播。所以在月球上,由于没有空气,即没有可以传播振动的物质,两个人即使相隔不远,也不能互相通话,必须要使用无线电设备。 2、我们是怎样听到声音的?答:一个振动的物体会使它周围的空气发生振动,振动的空 气到达我们的耳朵,敲打鼓膜并使它振动。耳朵中的听小骨再将振动传到充满液体的内耳,引起液体的振动,液体的振动导致听觉神经的移动——产生了信号,大脑接受了听觉神经传过来的信号,我们便感受到了声音。
高分一号城市绿地现状调查与分析实现教程 本文将介绍基于高分一号影像数据的城市绿地信息提取的实现步骤,下图是主要的操作流程(图一) 图一 首先对高分影像进行预处理,其次使用监督分类法和面向对象分类法对城市绿地进行分类,然后对分类出来的影像进行矢量化处理,最后另其在arcGIS中进行统计分析,得出武汉市城市绿地的现状,下面是具体步骤。 第一章数据预处理 因为处理数据是高分一号影像,本文处理软件为ENVI5.1,因为ENVI5.2以下版本不能对高分一号直接进行处理,所以需要安装r6补丁,将下面两个文件直接粘贴到软件所在位置(图二),然后就可以打开高分影像了(图三)
图二 图三 为了加快数据处理的速度,本文是选择先进行辐射定标然后将图像裁剪在进行后续的操作,预处理流程如下图(图四): 图四 1.1 辐射校正 分为辐射定标和大气校正
(1)打开数据:ENVI-Open As-CRESDA-GF-1,选择处理的影像,打开XML后缀文件; (2)辐射定标:选择Toolbox->Radiometric Correction-> Radiometric Calibration,选择待处理的高分数据 弹出Radiometric Calibration对话框,进行如图设置。对于多光谱影像,点击Apply FLAASH Setting 设置成默认值;如果是对全色影像进行辐射定标,那么Calibration则是Reflectance,Out Put Type 为UInt,Scale Factor为1000,如下图:
高分一号多光谱影像参数设置 高分一号全色影像参数设置 (3)大气校正:选择Toolbox->Radiometric Correction->Atmospheric Correction Module->FLAASH Atmospheric Correction,弹出FLAASH Atmospheric Correction Model Input Parameters对话框。要注意,全色影像不做大气校正,多光谱影像则需要做大气校正处理。