
第 12 章相对数和指数练习参考答案
班级:姓名:学号:得分
一、单项选择题:
1、编制单位成本指数时,同度量因素一般应采用:( A )
( A)报告期销售量( B)基期销售量( C)基期销售价格( D)报告期销售价格2、最常用的加权调和平均数是:( D )
( A)k q k q p0 q0
( B)k p
p0 q0 p0q01p
0 q0
k q
(C)
k p
p0 q0
(D)
k p
p1 q1 1
p0 q0
1
p1q1 k p k p
3、q1 p0q0 p0表示:( D)
(A)由于价格变动引起的产值增减数
(B)由于价格变动引起的产量增减数
(C)由于产量变动引起的价格增减数
(D)由于产量变动引起的产值增减数
4、某企业销售额增长了5%,销售价格下降了 3%,则销售量:( C )
( A)增长 8%( B)增长 % ( C)增长 %( D)增长 %
5、下列各项中属于指数的是:( C)
( A)人均粮食产量( B)平均价格( C)发展速度(D)人口数
二、计算题:
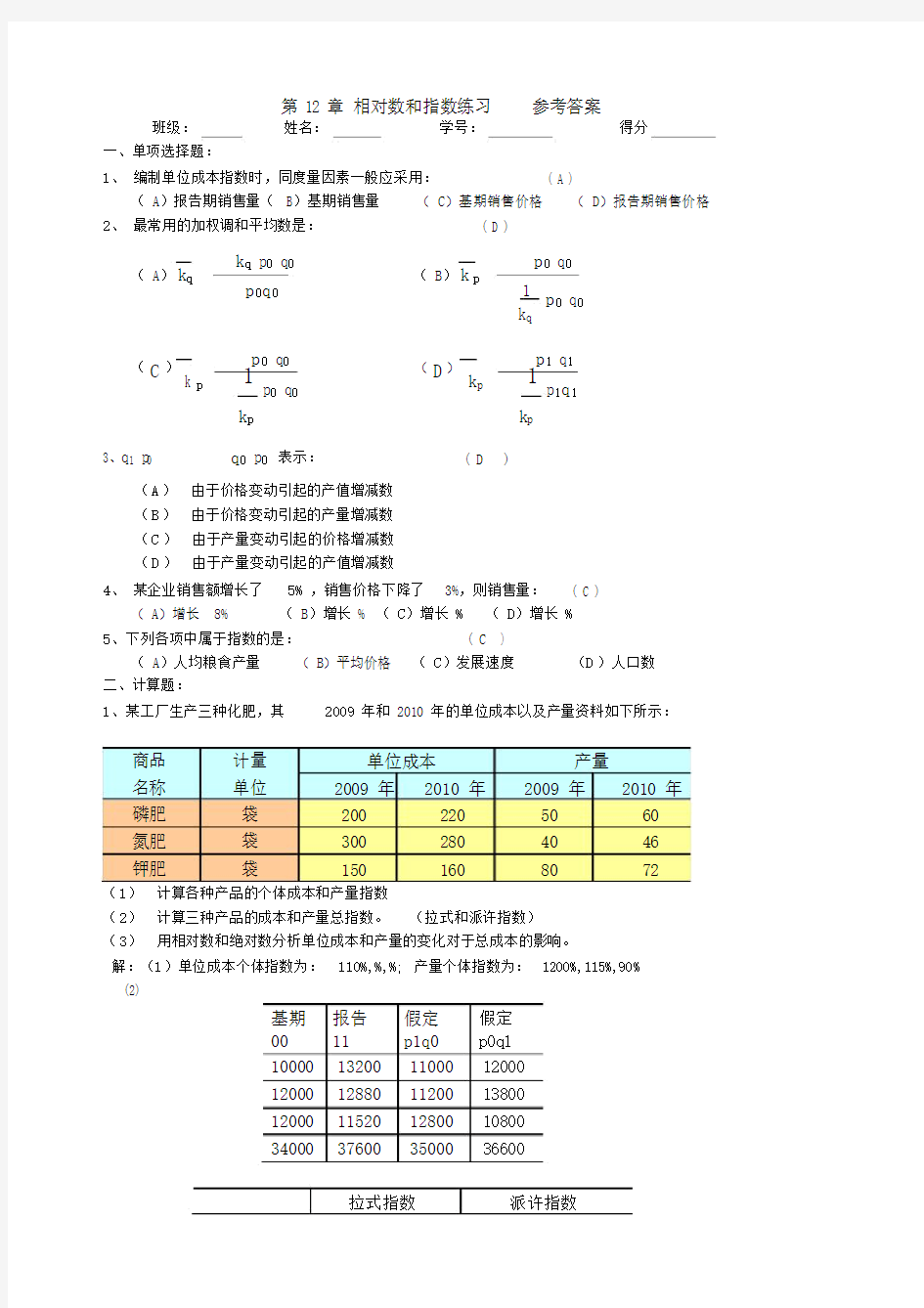
1、某工厂生产三种化肥,其2009 年和 2010 年的单位成本以及产量资料如下所示:
商品计量单位成本产量
名称单位2009 年2010 年2009 年2010 年磷肥袋2002205060氮肥袋3002804046钾肥袋1501608072(1)计算各种产品的个体成本和产量指数
(2)计算三种产品的成本和产量总指数。(拉式和派许指数)
(3)用相对数和绝对数分析单位成本和产量的变化对于总成本的影响。
解:(1)单位成本个体指数为:110%,%,%;产量个体指数为:1200%,115%,90%
(2)
基期报告假定假定
0011p1q0p0q1
10000 13200 1100012000
12000 12880 1120013800
12000 11520 1280010800
34000 37600 3500036600
拉式指数派许指数
产量%%
单位成本%%
(3)一般地,产量用拉式指数分析,因此相对数为%,绝对数 36600-34000=2600 元。
单位成本用派许指数分析,相对数为%,绝对数37600-36600=1000 元。
2、某商店的报告期销售额以及各种商品的销售价格报告期比基期升降幅度资料如下:
商品名称报告期销售额 ( 万元 )销售价格的升降 (%)
螺纹钢568上升
不锈钢464上升
圆钢336下降
特种钢788下降
请计算该四种钢材的物价总指数。
解: k p
p1q1568 464336 788100.94% 1
p q568464336788
11
1.095 1.0730.9550.946
k p
3、已知某百货商场销售的五种家电产品的个体物价指数以及基期销售额资料如下:
商品名称个体物价指数基期销售额(万元)
电冰箱50
洗衣机30
电风扇3
空调40
热水器10
( 1)请计算五种商品的物价总指数(2)计算由于物价变动导致的销售额的变动数额。
50 1.04300.973 1.1400.98101.02133.8解: k p
503034010100.6%
133变动额为: =万元。
4.某市肉蛋类商品调价前后的零售价格以及比重权数资料如下。试计算该市肉蛋类商品零售物价指数
商品计量平均零售价(元)比重权数
名称单位基期报告期( %)
猪肉千克202270
牛肉千克30326
羊肉千克40382
鸡千克323010
鸡蛋千克8712
合计------100
解:这是食品大类中的肉禽蛋种类物价指数的编制,利用固定权数法。
k q kw 22
* 0.7
32
* 0.06
38
* 0.02
30
* 0.1
7
* 0.12 203040328
《统计学原理》作业一 一、判断题 1.社会经济统计的研究对象是社会经济现象总体的各个方面。(×) 2.统计调查过程中采用的大量观察法,是指必须对研究对象的所有单位进行调查。(×) 3.总体的同质性是指总体中的各个单位在所有标志上都相同。(×)4.个人的工资水平和全部职工的工资水平,都可以称为统计指标。(×)5.对某市工程技术人员进行普查,该市工程技术人员的工资收入水平是数量标志。(√) 6.社会经济统计学的研究对象是社会经济现象的数量方面,但它在具体研究时也离不开对现象质的认识。(√) 7.品质标志表明单位属性方面的特征,其标志表现只能用文字表现,所以品质标志不能直接转化为统计指标。(√) 8.品质标志说明总体单位的属性特征,质量指标反映现象的相对水平或工作质量,二者都不能用数值表示。(×) 9.某一职工的文化程度在标志的分类上属于品质标志,职工的平均工资在指标的分类上属于质量指标。(√) 10.总体单位是标志的承担者,标志是依附于总体单位的。(√) 二、单项选择 1.社会经济统计的研究对象是(C )。 A、抽象的数量特征和数量关系 B、社会经济现象的规律性 C、社会经济现象的数量特征和数量关系 D、社会经济统计认识过程的规律和方法
2.构成统计总体的各个单位称为(A )。 A、调查单位 B、标志值 C、品质标志 D、总体单位 3.对某城市工业企业未安装设备状况进行普查,总体单位是(B )。 A、工业企业全部未安装设备 B、工业企业每一台未安装设备 C、每个工业企业的未安装设备 D、每一个工业企业 4.标志是说明总体单位特征的名称(C)。 A、它有品质标志值和数量标志值两类 B、品质标志具有标志值 C、数量标志具有标志值 D、品质标志和数量标志都具有标志值5.总体的变异性是指( B )。 A.总体之间有差异B、总体单位之间在某一标志表现上有差异 C.总体随时间变化而变化D、总体单位之间有差异 6.工业企业的设备台数、产品产值是(D )。 A、连续变量 B、离散变量 C.前者是连续变量,后者是离散变量 D、前者是离散变量,后者是连续变量 7.几位学生的某门课成绩分别是57分、68分、78分、89分、96分,“学生成绩”是(B )。 A、品质标志 B、数量标志 C、标志值 D、数量指标 8.在全国人口普查中(B )。 A、男性是品质标志 B、人的年龄是变量 C、人口的平均寿命是数量标志 D、全国人口是统计指标 9.下列指标中属于质量指标的是(B )。 A、社会总产值 B、产品合格率 C、产品总成本 D、人口总数
一、判断题 ( 对 ) 1 X ( X 1 , X 2 ,L , X p ) 的协差阵一定是对称的半正定阵 ( 对 ( ) 2 标准化随机向量的协差阵与原变量的相关系数阵相同。 对) 3 典型相关分析是识别并量化两组变量间的关系,将两组变量的相关关系 的研究转化为一组变量的线性组合与另一组变量的线性组合间的相关关系的研究。 ( 对 )4 多维标度法是以空间分布的形式在低维空间中再现研究对象间关系的数据 分析方法。 ( 错)5 X (X 1 , X 2 , , X p ) ~ N p ( , ) , X , S 分别是样本均值和样本离 差阵,则 X , S 分别是 , 的无偏估计。 n ( 对) 6 X ( X 1 , X 2 , , X p ) ~ N p ( , ) , X 作为样本均值 的估计,是 无偏的、有效的、一致的。 ( 错) 7 因子载荷经正交旋转后,各变量的共性方差和各因子的贡献都发生了变化 ( 对) 8 因子载荷阵 A ( ij ) ij 表示第 i 个变量在第 j 个公因子上 a 中的 a 的相对重要性。 ( 对 )9 判别分析中, 若两个总体的协差阵相等, 则 Fisher 判别与距离判别等价。 (对) 10 距离判别法要求两总体分布的协差阵相等, Fisher 判别法对总体的分布无特 定的要求。 二、填空题 1、多元统计中常用的统计量有:样本均值向量、样本协差阵、样本离差阵、 样本相关系数矩阵. 2、 设 是总体 的协方差阵, 的特征根 ( 1, , ) 与相应的单 X ( X 1,L , X m ) i i L m 位 正 交 化 特 征 向 量 i ( a i1, a i 2 ,L ,a im ) , 则 第 一 主 成 分 的 表 达 式 是 y 1 a 11 X 1 a 12 X 2 L a 1m X m ,方差为 1 。 3 设 是总体 X ( X 1, X 2 , X 3, X 4 ) 的协方差阵, 的特征根和标准正交特征向量分别 为: 1 2.920 U 1' (0.1485, 0.5735, 0.5577, 0.5814) 2 1.024 U 2' (0.9544, 0.0984,0.2695,0.0824) 3 0.049 U 3' (0.2516,0.7733, 0.5589, 0.1624) 4 0.007 U 4' ( 0.0612,0.2519,0.5513, 0.7930) ,则其第二个主成分的表达式是
第七章统计指数 一、判断题 1.分析复杂现象总体的数量变动,只能采用综合指数的方法。() 2.在特定的权数条件下,综合指数与平均指数有变形关系。() 3.算术平均数指数是通过数量指标个体指数,以基期的价值量指标为权数,进行 加权平均得到的。() 4.在简单现象总量指标的因素分析中,相对量分析一定要用同度量因素,绝对量 分析可以不用同度量因素。() 5.设p表示单位成本,q表示产量,则∑p1q1-∑p0q1表示由于产品单位成本 的变动对总产量的影响。() 6.设p表示价格,q表示销售量,则∑p0q1-∑p0q0表示由于商品价格的变动对 商品总销售额的影响。() 7.从指数化指标的性质来看,单位成本指数是数量指标指数。() 8.如果各种商品价格平均上涨5%,销售量平均下降5%,则销售额指数不变。() 1、× 2、√ 3、√ 4、× 5、× 6、× 7、× 8、×。 二、单项选择题 1.广义上的指数是指()。 A.价格变动的相对数 B.物量变动的相对数 C.社会经济现象数量变动的相对数 D.简单现象总体数量变动的相对数 2.编制总指数的两种形式是()。 A.数量指标指数和质量指标指数 B.综合指数和平均数指数 C.算术平均数指数和调和平均数指数 D.定基指数和环比指数 3.综合指数是()。 A.用非全面资料编制的指数 B.平均数指数的变形应用 C.总指数的基本形式 D.编制总指数的唯一方法 4.当数量指标的加权算术平均数指数采用特定权数时,计算结果与综合指数相同, 其特定权数是()。 A.q1p1 B.q0p1 C.q1p0 D.q0p0 5.当质量指标的加权调和平均数指数采用特定权数时,计算结果与综合指数相同, 其特定权数是()。 A.q1p1 B.q0p1 C.q1p0 D.q0p0 6.在由三个指数所组成的指数体系中,两个因素指数的同度量因素通常()。 A.都固定在基期 B.都固定在报告期 C.一个固定在基期,一个固定在报告期 D.采用基期和报告期交叉 7.某市1995年社会商业零售额为12000万元,1999年增至15600万元,这四年物 价上涨了4%,则商业零售量指数为()。 A.130% B.104% C.80% D.125% 8.某造纸厂1999年的产量比98年增长了13.6%,总成本增长了12.9%,则该厂1999 年产品单位成本()。 A.减少0.62% B.减少5.15% C.增加12.9% D. 增加1.75% 9.已知某工厂生产三种产品,在掌握其基期、报告期生产费用和个体产量指数时, 编制三种产品的产量总指数应采用()。
《多元统计分析思考题》 第一章 回归分析 1、回归分析是怎样的一种统计方法,用来解决什么问题 答:回归分析作为统计学的一个重要分支,基于观测数据建立变量之间的某种依赖关系,用来分析数据的内在规律,解决预报、控制方面的问题。 2、线性回归模型中线性关系指的是什么变量之间的关系自变量与因变量之间一定是线性关系形式才能做线性回归吗为什么 答:线性关系是用来描述自变量x 与因变量y 的关系;但是反过来如果自变量与因变量不一定要满足线性关系才能做回归,原因是回归方程只是一种拟合方法,如果自变量和因变量存在近似线性关系也可以做线性回归分析。 3、实际应用中,如何设定回归方程的形式 答:通常分为一元线性回归和多元线性回归,随机变量y 受到p 个非随机因素x1、x2、x3……xp 和随机因素?的影响,形式为: 01p βββ???是p+1个未知参数,ε是随机误差,这就是回归方程的设定形 式。 4、多元线性回归理论模型中,每个系数(偏回归系数)的含义是什么 答:偏回归系数01p βββ???是p+1个未知参数,反映的是各个自变量对随机变 量的影响程度。 5、经验回归模型中,参数是如何确定的有哪些评判参数估计的统计标准最小二乘估计法有哪些统计性质要想获得理想的参数估计值,需要注意一些什
么问题 答:经验回归方程中参数是由最小二乘法来来估计的; 评判标准有:普通最小二乘法、岭回归、主成分分析、偏最小二乘法等; 最小二乘法估计的统计性质:其选择参数满足正规方程组, (1)选择参数01 ??ββ分别是模型参数01ββ的无偏估计,期望等于模型参数; (2)选择参数是随机变量y 的线性函数 要想获得理想的参数估计,必须注意由于方差的大小表示随机变量取值 的波动性大小,因此自变量的波动性能够影响回归系数的波动性,要想使参数估计稳定性好,必须尽量分散地取自变量并使样本个数尽可能大。 6、理论回归模型中的随机误差项的实际意义是什么为什么要在回归模型中加入随机误差项建立回归模型时,对随机误差项作了哪些假定这些假定的实际意义是什么 答:随机误差项?的引入使得变量之间的关系描述为一个随机方程,由于因变 量y 很难用有限个因素进行准确描述说明,故其代表了人们的认识局限而没有考虑到的偶然因素。 7、建立自变量与因变量的回归模型,是否意味着他们之间存在因果关系为什么 答:不是,因果关系是由变量之间的内在联系决定的,回归模型的建立只是 一种定量分析手段,无法判断变量之间的内在联系,更不能判断变量之间的因果关系。 8、回归分析中,为什么要作假设检验检验依据的统计原理是什么检验的过程
统计学作业2 单项选择题 第1题某地区有10万人口,共有80个医院。平均每个医院要服务1250人,这个指标是()。 A、平均指标 B、强度相对指标 C、总量指标 D、发展水平指标 答案:B 第2题某企业2002年工业总产值比1992年增长了3倍,则该公司1992-2002年间工业总产值平均增长速度为() A、11.61% B、14.87% C、13.43% D、16.65% 答案:A 第3题某工业企业的某种产品成本,第一季度是连续下降的。1月份产量750件,单位成本20元;2月份产量1000件,单位成本18元;3月份产量1500件,单位成本15元。则第一季度的平均成本为()。 A、17.67 B、17.54 C、17.08 D、16.83 答案:C 第4题已知4个水果商店苹果的单价和销售额,要求计算4个商店苹果的平均单价,应该采用()。 A、简单算术平均数 B、加权算术平均数 C、加权调和平均数 D、几何平均数 答案:C
第5题如果分配数列把频数换成频率,那么方差()。 A、不变 B、增大 C、减小 D、无法预期变化 答案:A 第6题某厂5年的销售收入如下:200万、220万、250万、300万、320万,则平均增长量为()。 A、120/5 B、120/4 C、320/200的开5次方 D、320/200的开4次方 答案:B 第7题直接反映总体规模大小的指标是()。 A、平均指标 B、相对指标 C、总量指标 D、变异指标 答案:C 第8题计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和()。 A、小于100% B、大于100% C、等于100% D、小于或大于100% 答案:C 多项选择题 第9题下列统计指标属于总量指标的是()。 A、工资总额
第一章: 多元统计分析研究的内容(5点) 1、简化数据结构(主成分分析) 2、分类与判别(聚类分析、判别分析) 3、变量间的相互关系(典型相关分析、多元回归分析) 4、多维数据的统计推断 5、多元统计分析的理论基础 第二三章: 二、多维随机变量的数字特征 1、随机向量的数字特征 随机向量X 均值向量: 随机向量X 与Y 的协方差矩阵: 当X=Y 时Cov (X ,Y )=D (X );当Cov (X ,Y )=0 ,称X ,Y 不相关。 随机向量X 与Y 的相关系数矩阵: )',...,,(),,,(2121P p EX EX EX EX μμμ='=Λ)')((),cov(EY Y EX X E Y X --=q p ij r Y X ?=)(),(ρ
2、均值向量协方差矩阵的性质 (1).设X ,Y 为随机向量,A ,B 为常数矩阵 E (AX )=AE (X ); E (AXB )=AE (X )B; D(AX)=AD(X)A ’; Cov(AX,BY)=ACov(X,Y)B ’; (2).若X ,Y 独立,则Cov(X,Y)=0,反之不成立. (3).X 的协方差阵D(X)是对称非负定矩阵。例2.见黑板 三、多元正态分布的参数估计 2、多元正态分布的性质 (1).若 ,则E(X)= ,D(X)= . 特别地,当 为对角阵时, 相互独立。 (2).若 ,A为sxp 阶常数矩阵,d 为s 阶向量, AX+d ~ . 即正态分布的线性函数仍是正态分布. (3).多元正态分布的边缘分布是正态分布,反之不成立. (4).多元正态分布的不相关与独立等价. 例3.见黑板. 三、多元正态分布的参数估计 (1)“ 为来自p 元总体X 的(简单)样本”的理解---独立同截面. (2)多元分布样本的数字特征---常见多元统计量 样本均值向量 = 样本离差阵S= 样本协方差阵V= S ;样本相关阵R (3) ,V分别是 和 的最大似然估计; (4)估计的性质 是 的无偏估计; ,V分别是 和 的有效和一致估计; ; S~ , 与S相互独立; 第五章 聚类分析: 一、什么是聚类分析 :聚类分析是根据“物以类聚”的道理,对样品或指标进行分类的一种多元统计分析方法。用于对事物类别不清楚,甚至事物总共可能有几类都不能确定的情况下进行事物分类的场合。聚类方法:系统聚类法(直观易懂)、动态聚类法(快)、有序聚类法(保序)...... Q-型聚类分析(样品)R-型聚类分析(变量) 变量按照测量它们的尺度不同,可以分为三类:间隔尺度、有序尺度、名义尺度。 二、常用数据的变换方法:中心化变换、标准化变换、极差正规化变换、对数变换(优缺点) 1、中心化变换(平移变换):中心化变换是一种坐标轴平移处理方法,它是先求出每个变量的样本平均值,再从原始数据中减去该变量的均值,就得到中心化变换后的数据。不改变样本间的相互位置,也不改变变量间的相关性。 2、标准化变换:首先对每个变量进行中心化变换,然后用该变量的标准差进行标准化。 经过标准化变换处理后,每个变量即数据矩阵中每列数据的平均值为0,方差为1,且也不再具有量纲,同样也便于不同变量之间的比较。 3、极差正规化变换(规格化变换):规格化变换是从数据矩阵的每一个变量中找出其最大值和最小值,这两者之差称为极差,然后从每个变量的每个原始数据中减去该变量中的最小值,再除以极差。经过规格化变换后,数据矩阵中每列即每个变量的最大数值为1,最小数值为0,其余数据取值均在0-1之间;且变换后的数据都不再具有量纲,便于不同的变),(~∑μP N X μ∑μ p X X X ,,,21Λ),(~∑μP N X ) ,('A A d A N s ∑+μ)()1(,, n X X ΛX )',,,(21p X X X Λ)')(()()(1X X X X i i n i --∑=n 1 X μ∑μX )1,(~∑n N X P μ),1(∑-n W p X X
第12章 相对数和指数练习 参考答案 班级: 姓名: 学号: 得分 一、单项选择题: 1、 编制单位成本指数时,同度量因素一般应采用: ( A ) (A )报告期销售量(B )基期销售量 (C )基期销售价格 (D )报告期销售价格 2、 最常用的加权调和平均数是: ( D ) (A )∑∑= 00 0q p q p k k q q (B )∑∑= 0001q p k q p k q p (C )∑∑= 0001q p k q p k p p (D )∑∑= 1 11 11q p k q p k p p 3、 ∑∑-0 1 p q p q 表示: ( D ) (A ) 由于价格变动引起的产值增减数 (B ) 由于价格变动引起的产量增减数 (C ) 由于产量变动引起的价格增减数 (D ) 由于产量变动引起的产值增减数 4、 某企业销售额增长了5%,销售价格下降了3%,则销售量: ( C ) (A )增长8% (B )增长% (C )增长% (D )增长% 5、下列各项中属于指数的是: ( C ) (A )人均粮食产量 (B )平均价格 (C )发展速度 (D )人口数 二、计算题: 1、某工厂生产三种化肥,其2009年和2010年的单位成本以及产量资料如下所示: (1) 计算各种产品的个体成本和产量指数 (2) 计算三种产品的成本和产量总指数。(拉式和派许指数) (3) 用相对数和绝对数分析单位成本和产量的变化对于总成本的影响。 解:(1)单位成本个体指数为:110%,%,%;产量个体指数为:1200%,115%,90% (2)
(3) 一般地,产量用拉式指数分析,因此相对数为%,绝对数36600-34000=2600元。 单位成本用派许指数分析,相对数为%,绝对数37600-36600=1000元。 2、某商店的报告期销售额以及各种商品的销售价格报告期比基期升降幅度资料如下: 商品名称 报告期销售额(万元) 销售价格的升降(%) 螺纹钢 568 上升 不锈钢 464 上升 圆钢 336 下降 特种钢 788 下降 请计算该四种钢材的物价总指数。 解:1111 1p p p q k p q k = ∑∑568464336788 100.94%568464336788 1.095 1.0730.9550.946 +++= =+++ 3、已知某百货商场销售的五种家电产品的个体物价指数以及基期销售额资料如下: 商品名称 个体物价指数 基期销售额(万元) 电冰箱 50 洗衣机 30 电风扇 3 空调 40 热水器 10 (1)请计算五种商品的物价总指数(2)计算由于物价变动导致的销售额的变动数额。 解:50 1.04300.973 1.1400.9810 1.02133.8 100.6%503034010133 p k ?+?+?+?+?= ==++++ 变动额为:=万元。 4.某市肉蛋类商品调价前后的零售价格以及比重权数资料如下。试计算该市肉蛋类商品零售物价指数 解:这是食品大类中的肉禽蛋种类物价指数的编制,利用固定权数法。
一、填空题: 1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法. 2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著. 3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。通常聚类分析分为 Q型聚类和 R型聚类。 4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。 5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。 6、若 () (,), P x N αμα ∑=1,2,3….n且相互独立,则样本均值向量x服从的分布 为_x~N(μ,Σ/n)_。 二、简答 1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。 在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。 2、简述相应分析的基本思想。 相应分析,是指对两个定性变量的多种水平进行分析。设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。相应分析即是通过列联表的转换,使得因素A
和因素B 具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A 、B 的联系。 3、简述费希尔判别法的基本思想。 从k 个总体中抽取具有p 个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数 系数: 确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。 5、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设 和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2 /21exp 2np n e tr n λ???? =-?? ? ???? S S 00p H =≠ΣΣI : /2 /2**1exp 2np n e tr n λ???? =-?? ? ???? S S
练习题 一、填空题 1.人们通过各种实践,发现变量之间的相互关系可以分成(相关)和(不相关)两种类型。多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相关系数。 2.总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。3.回归方程显著性检验时通常采用的统计量是(S R/p)/[S E/(n-p-1)]。 4.偏相关系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的)的相关系数。 5.Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。 6.主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求(降维)的一种方法。 7.主成分分析的基本思想是(设法将原来众多具有一定相关性(比如P个指标),重新组合成一组新的互相无关的综合指标来替代原来的指标)。 8.主成分表达式的系数向量是(相关系数矩阵)的特征向量。 9.样本主成分的总方差等于(1)。 10.在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。主成分的协方差矩阵为(对称)矩阵。主成分表达式的系数向量是(相关矩阵特征值)的特征向量。 11.SPSS中主成分分析采用(analyze—data reduction—facyor)命令过程。 12.因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部分为(特殊因子)。 13.变量共同度是指因子载荷矩阵中(第i行元素的平方和)。 14.公共因子方差与特殊因子方差之和为(1)。 15.聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏程度)进行科学的分类。 16.Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。 17.Q型聚类统计量是(距离),而R型聚类统计量通常采用(相关系数)。 18.六种Q型聚类方法分别为(最长距离法)、(最短距离法)、(中间距离法)、(类平均法)、(重心法)、(离差平方和法)。 19.快速聚类在SPSS中由(k-均值聚类(analyze—classify—k means cluster))过程实现。 20.判别分析是要解决在研究对象已(已分成若干类)的情况下,确定新的观测数据属于已知类别中哪一类的多元统计方法。 21.用判别分析方法处理问题时,通常以(判别函数)作为衡量新样本点与各已知组别接近程度的指标。 22.进行判别分析时,通常指定一种判别规则,用来判定新样本的归属,常见的判别准则有(Fisher准则)、(贝叶斯准则)。 23.类内样本点接近,类间样本点疏远的性质,可以通过(类与类之间的距离)与(类内样本的距离)的大小差异表现出来,而两者的比值能把不同的类区别开来。这个比值越大,说明类与类间的差异越(类与类之间的距离越大),分类效果越(好)。24.Fisher判别法就是要找一个由p个变量组成的(线性判别函数),使得各自组内点的
实用多元统计分析相 尖习题 练习题 一、填空题 1?人们通过各种实践,发现变量之间的相互矢系可以分成(相尖)和(不相尖)两种 类型。多元统计中常用的统计量有:样本均值、样本方差、样本协方差和样本相尖系数。 2?总离差平方和可以分解为(回归离差平方和)和(剩余离差平方和)两个部分,其中(回归离差平方和)在总离差平方和中所占比重越大,则线性回归效果越显著。 3 ?回归方程显著性检验时通常采用的统计量是(S R/P)/[S E/ (n-p-1) ]O 4?偏相尖系数是指多元回归分析中,(当其他变量固定时,给定的两个变量之间的) 的相尖系数。 5. Spss中回归方程的建模方法有(一元线性回归、多元线性回归、岭回归、多对多线性回归)等。
6 ?主成分分析是通过适当的变量替换,使新变量成为原变量的(线性组合),并寻求 (降维)的一种方法。 7 ?主成分分析的基本思想是(设法将原来众多具有一定相尖性(比如P个指标),重 新组合成一组新的互相无矢的综合指标来替代原来的指标)。 8 ?主成分表达式的系数向量是(相尖系数矩阵)的特征向量。 9 ?样本主成分的总方差等于(1)。 10 ?在经济指标综合评价中,应用主成分分析法,则评价函数中的权数为(方差贡献度)。主成分的协方差矩阵为(对称)矩阵。主成分表达式的系数向量是(相尖矩阵特征值)的特征向量。 11. SPSS 中主成分分析采用(analyze—data reduction — facyor)命令过程。 12?因子分析是把每个原始变量分解为两部分因素,一部分是(公共因子),另一部
分为(特殊因子)。 13 ?变量共同度是指因子载荷矩阵中(第i行元素的平方和)。 14 ?公共因子方差与特殊因子方差之和为(1) o 15 ?聚类分析是建立一种分类方法,它将一批样品或变量按照它们在性质上的(亲疏 程度)进行科学的分类。 16. Q型聚类法是按(样品)进行聚类,R型聚类法是按(变量)进行聚类。 17. Q型聚类统计量是(距离),而R型聚类统计量通常采用(相尖系数)。 18. 六种Q型聚类方法分别为(最长距离法)、(最短距离法)、(中间距离法)、(类平均法)、(重心法)、(离差平方和法)。 19?快速聚类在SPSS中由(k■均值聚类(analyze— classify— k means cluste))过程实 现。 20. 判别分析是要解决在研究对象已(已分成若干类)的情况下,确定新的观测数据属于已知类别中哪一类的多元统计方法。 21. 用判别分析方法处理问题时,通常以(判别函数)作为衡量新样本点与各已知组别接近程度的指标。 22. 进行判别分析时,通常指定一种判别规则,用来判定新样本的归属,常见的判别准则有 (Fisher准则)、(贝叶斯准则)。 23. 类内样本点接近,类间样本点疏
多元统计分析有哪些应用? 比较 关系 预测 分类 评价 各种应用对应的多元统计分析方法 比较:多元方差分析 关系:回归模型 预测:回归模型 分类:聚类分析与判别分析、回归模型 评价:主成分分析与因子分析 ?多元回归、logisitic回归、Cox回归、Poisson回归 多元统计分析方法主要内容 多元T检验、多元方差分析 ?Hotelling T2 ?multivariate analysis of variance (MANOV A) 多元线性回归(multivariate linear regression) logistic回归(logistic regression) Cox比例风险模型(Cox model) Poisson回归(Poisson regression) 聚类分析(cluster analysis) 判别分析(discriminant analysis) 主成分分析和因子分析 生存分析 本课程的要求 上机做练习,分析实际资料 学会看文献,判断统计分析的应用是否正确 统计软件SAS,或Stata, SPSS10.01 考试: 理论占30%,实验占70% 二、多元统计分析的基本概念 研究因素从广义的角度看,所有可以测量的变量都可以成为研究因素,比如:年 龄、性别、文化程度、人体的各种生物学特征和生理生化指标环境因素、心理因素等。狭义来看,研究因素是指可能与研究目的有关的影响因素 多元统计分析对多变量样本的要求 ①分布:多元正态分布、相互独立、多元方差齐 ②样本含量 目前尚没有多元分析的样本含量估计方法,一般认为样本含量应超过研究因素5-10倍以上即可。 数值变量→分类成有序分类变量 哑变量的数量=K-1(K为分类数)
《统计学原理》作业(二) (第四章) 一、判断题 1、总体单位总量和总体标志总量是固定不变的,不能互相变换。(×) 2、相对指标都是用无名数形式表现出来的。(×) 3、能计算总量指标的总体必须是有限总体。(×) 4、按人口平均的粮食产量是一个平均数。(×) 5、在特定条件下,加权算术平均数等于简单算术平均数。(√) 6、用总体部分数值与总体全部数值对比求得的相对指标。说明总体内部的组成状况,这个相对指标是比例相对指标。(×) 7、国民收入中积累额与消费额之比为1:3,这是一个比较相对指标。(×) 8、总量指标和平均指标反映了现象总体的规模和一般水平。但掩盖了总体各单位的差异情况,因此通过这两个指标不能全面认识总体的特征。(√) 9、用相对指标分子资料作权数计算平均数应采用加权算术平均法。(×) 10、标志变异指标数值越大,说明总体中各单位标志值的变异程度就越大,则平均指标的代表性就越小。(√) 二、单项选择 1、总量指标数值大小(A) A、随总体范围扩大而增大 B、随总体范围扩大而减小 C、随总体范围缩小而增大 D、与总体范围大小无关
2、直接反映总体规模大小的指标是(C) A、平均指标 B、相对指标 C、总量指标 D、变异指标 3、总量指标按其反映的时间状况不同可以分为(D) A、数量指标和质量指标 B、实物指标和价值指标 C、总体单位总量和总体标志总量 D、时期指标和时点指标 4、不同时点的指标数值(B) A、具有可加性 B、不具有可加性 C、可加或可减 D、都不对 5、由反映总体各单位数量特征的标志值汇总得出的指标是(B) A、总体单位总量 B、总体标志总量 C、质量指标 D、相对指标 6、计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和(C) A、小于100% B、大于100% C、等于100% D、小于或大于100% 7、相对指标数值的表现形式有( D ) A、无名数 B、实物单位与货币单位 C、有名数 D、无名数与有名数 8、下列相对数中,属于不同时期对比的指标有(B) A、结构相对数 B、动态相对数 C、比较相对数 D、强度相对数
实验报告 一、实验名称 多元统计分析作业题。 二、实验目的 (一)了解并掌握主成分分析与因子分析的基本原理和简单解法。 (二)学会使用matlab编写程序进行因子分析,求得特征值、特征向量、载荷矩阵等值。(三)学会使用排序、元胞数组、图像表示最后的结果,使结果更加直观。 三、实验内容与要求
四、实验原理与步骤 (一)第一题: 1、实验原理: 因子分析简介: (1) 1.1 基本因子分析模型 设p维总体x=(x1,x2,....,xp)'的均值为u=(u1,u2,....,u3)',因子分析的一般模型为 x1=u1+a11f1+a12f2+........+a1mfm+ε 1 x2=u2+a21f1+a22f2+........+a2mfm+ε 2 ......... xp=up+ap1f1+fp2f2+..........+apmfm+εp 其中,f1,f2,.....,fm为m个公共因子;εi是变量xi(i=1,2,.....,p)所独有的特殊因子,他们都是不可观测的隐变量。称aij(i=1,2,.....,p;j=1,2,.....,m)为变量xi的公共因子fi上的载荷,它反映了公共因子对变量的重要程度,对解释公共因子具有重要的作用。上式可以写为矩阵形式 x=u+Af+ε
其中A=(aij)pxm 称为因子载荷矩阵;f=(f1,f2,....,fm)'为公共因子向量;ε=(ε1,ε2,.....εp)称为特殊因子向量 (2) 1.2 共性方差与特殊方差 xi的方差var(xi)由两部分组成,一个是公共因子对xi方差的贡献,称为共性方差;一个是特殊因子对xi方差的贡献,称为特殊方差。每个原始变量的方差都被分成了共性方差和特殊方差两部分。 (3) 1.3 因子旋转 因子分析的主要目的是对公共因子给出符合实际意义的合理解释,解释的依据就是因子载荷阵的个列元素的取值。当因子载荷阵某一列上各元素的绝对值差距较大时,并且绝对值大的元素较少时,则该公共因子就易于解释,反之,公共因子的解释就比较困难。此时可以考虑对因子和因子载荷进行旋转(例如正交旋转),使得旋转后的因子载荷阵的各列元素的绝对值尽可能量两极分化,这样就使得因子的解释变得容易。 因子旋转方法有正交旋转和斜交旋转两种,这里只介绍一种普遍使用的正交旋转法:最大方差旋转。这种旋转方法的目的是使因子载荷阵每列上的各元素的绝对值(或平方值)尽可能地向两极分化,即少数元素的绝对值(或平方值)取尽可能大的值,而其他元素尽量接近于0. (4) 1.4 因子得分 在对公共因子做出合理解释后,有时还需要求出各观测所对应的各个公共因子的得分,就比如我们知道某个女孩是一个美女,可能很多人更关心该给她的脸蛋、身材等各打多少分,常用的求因子得分的方法有加权最小二乘法和回归法。 注意:因子载荷矩阵和得分矩阵的区别: 因子载荷矩阵是各个原始变量的因子表达式的系数,表达提取的公因子对原始变量的影响程度。因子得分矩阵表示各项指标变量与提取的公因子之间的关系,在某一公因子上得分高,表明该指标与该公因子之间关系越密切。简单说,通过因子载荷矩阵可以得到原始指标变量的线性组合,如X1=a11*F1+a12*F2+a13*F3,其中X1为指标变量1,a11、a12、a13分别为与变量X1在同一行的因子载荷,F1、F2、F3分别为提取的公因子;通过因子得分矩阵可以得到公因子的线性组合,如F1=a11*X1+a21*X2+a31*X3,字母代表的意义同上。 (5) 1.5 因子分析中的Heywood(海伍德)现象 如果x的各个分量都已经标准化了,则其方差=1。即共性方差与特殊方差的和为1。也就是说共性方差与特殊方差均大于0,并且小于1。但在实际进行参数估计的时候,共性方差
解答:首先将6个样品的各自看成一类,即: G i =(i ),i=1,2,3,4,5,6 将相关系数矩阵记为R 0,则: {}{}{}{}{}{}{} {} {}{}{} 012345620.92130.840.68 1 40.790.770.811 50.690.760.710.82 1 60.65 0.780.860.740.89 1 D = 从这个矩阵可以看出,G 1,G 2的相关性最大,因此将G 1,G 2在水平0.92上合成一个新类G 7={1,2},计算G 7与G 3, G 4, G 5, G 6之间的最长距离,得到: {}{}{}{}731323741424751525761626max ,0.84max ,0.79max ,0.76max ,0.78 D d d D d d D d d D d d ======== 在第一个相关矩阵中将划去{1},{2}所对应的行和列,并加上新类G 7={1,2}到其他类的距离作为新的一行一列,得到: {} {}{}{}{} 11,23456 30.84140.790.81 1 50.760.710.821 60.78 0.860.740.891 D = 从这个矩阵可以看出,G 5,G 6的相关性最大,因此将G 5,G 6在水平0.89上合成一个新类G 8={5,6},计算G 8与G 7, G 3, G 4,之间的最长距离,得到:
{}{}{}8751526162835363845464max ,,,0.78max ,0.86max ,0.82 D d d d d D d d D d d ====== 在第二个相关矩阵中将划去{5},{6}所对应的行和列,并加上新类G 8={5,6}到其他类的距离作为新的一行一列,得到: {}{} {}{} {}{}{} 21,2345,630.84140.790.811 5,60.78 0.860.82 1 D = 从这个矩阵可以看出,G 3,G 8的相关性最大,因此将G 3,G 8在水平0.86上合成一个新类G 9={3,5,6},计算G 9与G 7, G 4,之间的最长距离,得到: {}{}9773757694345464max ,,0.84max ,,0.82 D d d d D d d d ==== 在第三个相关矩阵中将划去{3},{8}所对应的行和列,并加上新类G 9={3,5,6}到其他类的距离作为新的一行一列,得到: {}{}{} {} {} 33,5,61,241,20.84140.82 0.79 1 D = 从这个矩阵可以看出,G 9,G 7的相关性最大,因此将G 9,G 7在水平0.84上合成一个新类G 10={1,2,3,5,6},计算G 10与G 4之间的最长距离,得到: {}1049474max ,0.82D d d == 从而得到{}{}{} 41,2,3,5,6440.82 1 D = 最后在0.82的水平上,将G 10,G 4合为一个包含所有样品的大类. 最长距离的聚类谱系图为: 1 2 3 5 6 4 1 0.9 2 0.89 0.86 0.84 0.82
1、简述多元统计分析中协差阵检验的步骤 第一,提出待检验的假设H0和H1; 第二,给出检验的统计量及其服从的分布; 第三,给定检验水平,查统计量的分布表,确定相应的临界值,从而得到否定域; 第四,根据样本观测值计算出统计量的值,看是否落入否定域中,以便对待判假设做出决策(拒绝或接受)。 协差阵的检验 检验0=ΣΣ 0p H =ΣI : /2/21exp 2np n e tr n λ????=-?? ?????S S 00p H =≠ΣΣI : /2/2**1exp 2np n e tr n λ????=-?? ????? S S 检验12k ===ΣΣΣ012k H ===ΣΣΣ: 统计量/2/2/2/211i i k k n n pn np k i i i i n n λ===∏∏S S 2. 针对一个总体均值向量的检验而言,在协差阵已知和未知的两种情形下,如何分别构造的统计量? 3. 作多元线性回归分析时,自变量与因变量之间的影响关系一定是线性形式的吗?多元线性回归分析中的线性关系是指什么变量之间存在线性关系? 答:作多元线性回归分析时,自变量与因变量之间的影响关系不一定是线性形式。当自变量与因变量是非线性关系时可以通过某种变量代换,将其变为线性关系,然后再做回归分析。 多元线性回归分析的线性关系指的是随机变量间的关系,因变量y 与回归系数βi 间存在线性关系。 多元线性回归的条件是: (1)各自变量间不存在多重共线性; (2)各自变量与残差独立; (3)各残差间相互独立并服从正态分布; (4)Y 与每一自变量X 有线性关系。 4.回归分析的基本思想与步骤 基本思想:
《多元统计分析》思考题答案 记得老师课堂上说过考试内容不会超出这九道思考题, 如下九道题题目中有错误的或不清楚 的地方,欢迎大家指出、更改、补充。 1、 简述信度分析 答题提示:要答可靠度概念,可靠度度量,克朗巴哈 系数、拆半系数、单项 与总体相 关系数、稀释相关系数等(至少要答四个系数,至少要给出两个指标的公式) 答: 信度( Reliability )即可靠性,它是指采用同样的方法对同一对象重复测量时所得结果 的一致性程度。 信度指标多以相关系数表示, 大致可分为三类: 稳定系数 (跨时间的一致性) 等值系数(跨形式的一致性)和内在一致性系数(跨项目的一致性) 。信度分析的方法主要 有以下四种: 1)、重测信度法 这一方法是用同样的问卷对同一组被调查者间隔一定时间重复施测, 计算两次施测结果 的相关系数。 重测信度属于稳定系数。 重测信度法特别适用于事实式问卷, 如果没有突发事 件导致被调查者的态度、 意见突变, 这种方法也适用于态度、 意见式问卷。 由于重测信度法 需要对同一样本试测两次, 被调查者容易受到各种事件、 活动和他人的影响, 而且间隔时间 长短也有一定限制,因此在实施中有一定困难。 2)、复本信度法 复本信度法是让同一组被调查者一次填答两份问卷复本,计算两个复本的相关系数。复 本信度属于等值系数。复本信度法要求两个复本除表述方式不同外,在内容、格式、难度和 对应题项的提问方向等方面要完全一致,而在实际调查中,很难使调查问卷达到这种要求, 因此采用这种方法者较少。 3)、折半信度法 折半信度法是将调查项目分为两半,计算两半得分的相关系数,进而估计整个量表的信 度。折半信度属于内在一致性系数, 测量的是两半题项得分间的一致性。 这种方法一般不适 用于事实式问卷(如年龄与性别无法相比) ,常用于态度、意见式问卷的信度分析。在问卷 调查中,态度测量最常见的形式是 5 级李克特( Likert )量表。进行折半信度分析时,如果 量表中含有反意题项, 应先将反意题项的得分作逆向处理, 以保证各题项得分方向的一致性, 然后将全部题项按奇偶或前后分为尽可能相等的两半,计算二者的相关系数。 为了校正差异,两半测验的方差相等时,常运用斯皮尔曼 - 布朗公式( Spearman- Brown Formula ):rxx=2rhh/(1+rhh ) ,其中, rhh :两半测验的相关系数; rxx :估计或修正后的信度。 该公式可以估计增长或缩短一个测验对其信度系数的影响。 当两半测验的方差不同时, 应采 用卢伦公式( Rulon Formula )或弗拉纳根公式( Flanagan Formula )进行修正。 4)、α信度系数法 Cronbach α信度系数是目前最常用的信度系数,其公式为: S i 从公式中可以看出,α系数评价的是量表中各题项得分间的一致性,属于内在一致性系数。其中, n n1 i1 S X S i 2 为每一项目的方差; S X 2 为测验总分方差。